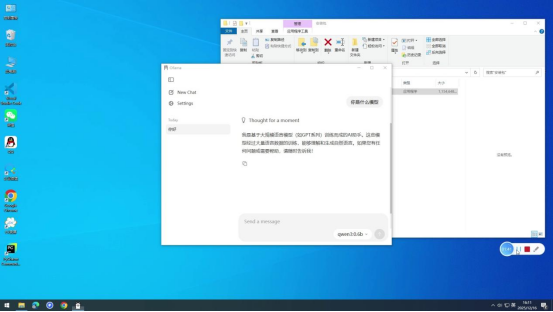
本文档为Ollama软件的独立安装教程,详细记录从安装包获取到软件正常使用的完整流程。Ollama是一款支持本地运行大语言模型的工具,按需安装后可快速部署各类AI模型进行对话交互。
一、安装前期准备
Ollama安装包从指定百度网盘链接获取,确保网络通畅后下载对应安装文件:
百度网盘链接:https://pan.baidu.com/s/1nxWXQsUlLEeNFt5zC6TY3w?pwd=9r1f ,提取码: 9r1f
下载完成后,在本地文件夹中确认安装包已保存完整。
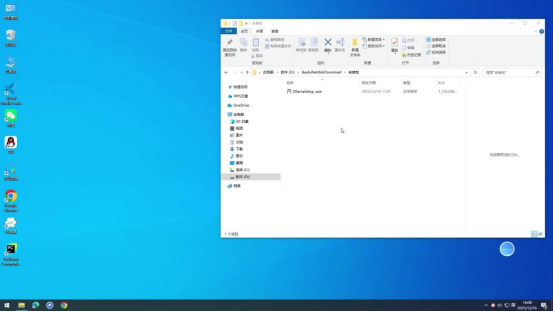
二、Ollama安装步骤(参考"Ollama安装"视频)
步骤1:启动安装程序
从百度网盘下载Ollama安装包(文件名为"OllamaSetup.exe")后,找到该文件所在路径,双击安装包启动安装程序。
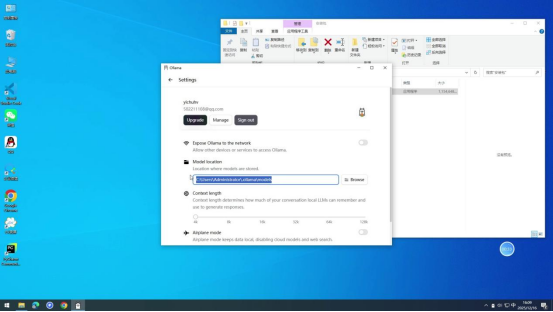
步骤2:完成基础配置
按照安装程序的指引逐步完成安装流程,安装后可根据自身需求自定义模型的下载保存路径。建议选择存储空间充足的磁盘分区(如非系统盘D盘、E盘等),避免占用C盘系统空间。
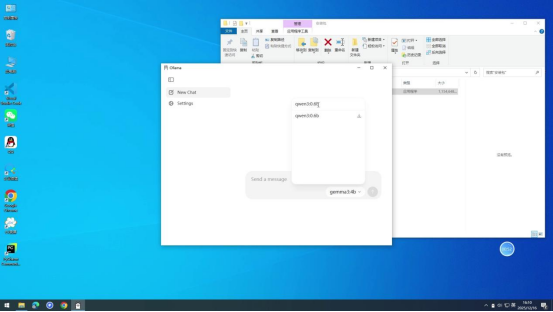
步骤 3 :搜索目标模型
打开Ollama客户端后,在模型搜索区域输入需要的模型名称(如常见的qwen3:0.6b等)进行搜索,搜索结果会实时显示。
步骤 4 :触发模型下载
在搜索结果中选中目标模型,进入模型对话界面。发送任意一条对话内容(如"你好""介绍一下你自己"等),系统会自动识别当前设备未下载该模型,随即启动模型下载流程。
下载过程中,客户端会实时显示下载进度(包括已下载大小、总大小及百分比),可直观了解下载状态。
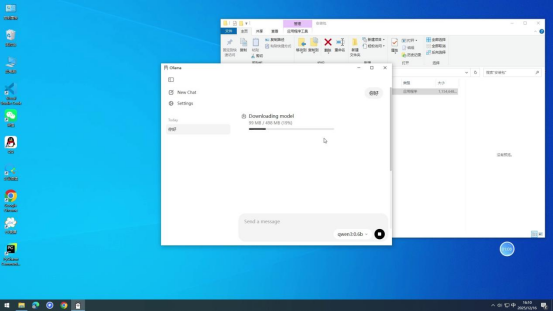
步骤 5 :验证模型可用性
等待模型下载完成(进度达到100%后会自动完成部署),部署完成后,模型会立即响应之前发送的对话内容。此时可继续发送新的对话请求,如"解释什么是大语言模型",若能得到清晰、准确的回复,则说明模型已正常可用。