
前言
在人工智能的演进图谱中,大模型训练始终占据着技术金字塔的顶端。它不仅是AI Agent开发的上层建筑,更是当Agent应用发展到一定深度后,不可避免必须跨越的技术鸿沟。唯有掌握底层模型的塑造能力,才能真正突破通用能力的天花板。
正如我在之前的篇章中所强调:
- 面对频繁变动的实时语料,RAG(检索增强生成)是最佳解法;
- 然而,对于规章制度、操作手册等六个月甚至更久都不会变化的固定语料,微调才是唯一的正途。
微调不仅能吞吐远超RAG知识库容量的海量数据,更能让模型将核心知识内化为本能。在处理此类静态高价值信息时,微调带来的性能提升与长期维护成本的降低,其投入产出比远远碾压RAG方案。

市场的反馈最为诚实且敏锐。目前,一线城市对大模型训练工程师的需求迫切度已显著高于AI Agent开发者,且薪资水平几乎是后者的两倍。这一巨大的薪酬剪刀差,足以证明大模型训练已不再是象牙塔里的理论实验,而是当下最炙手可热、最具商业价值的核心竞争力。
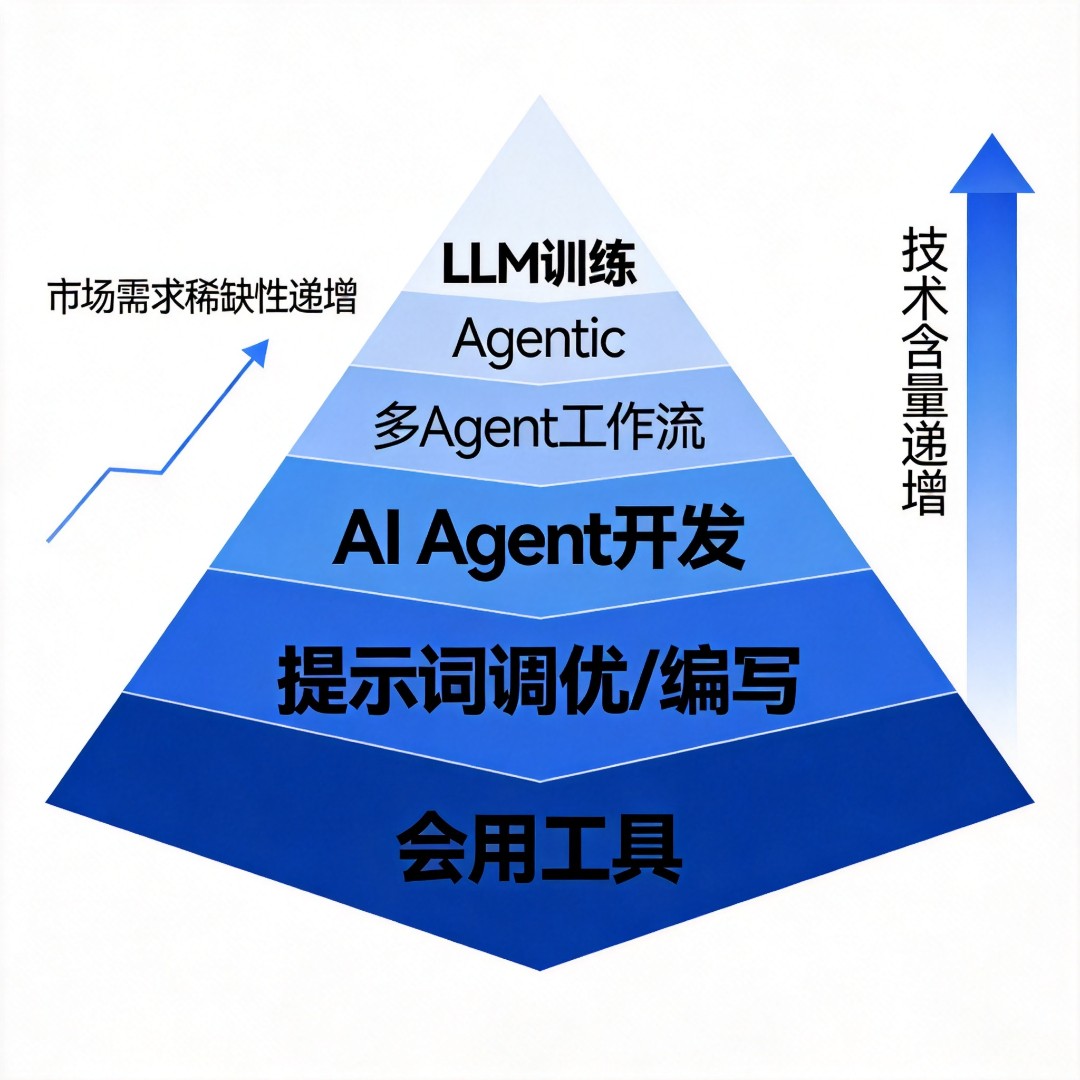
本系列将揭开大模型训练的神秘面纱,带你从更高维度审视AI开发的未来路径,掌握这把开启高阶智能大门的金钥匙。
1. 安装最新版llama-factory
无论是大模型训练小白还是已经用惯了大模型的"老手"或者是在生产环境训练大模型,llama-factory这个东西是少不了的,而且是必用。
它不仅仅提供了图形化界面微调,更可以导出模型、合并模型甚至量化模型。
**比如説:**我们教训好一个模型要把它做成ollama。也会用到llama-factory。
最新版本如此获取:
git clone https://github.com/hiyouga/LlamaFactory.git1.1 最新版llama-factory安装和所有的之前教程不一样行万小心
无论是我之前写的还是网上的llama-factory,最新的是我写的停留在一年前,安装步骤以及相应的坑完完全全已经不一样了,请你仔细阅读这一篇。
因为这一篇涉及到一个连llama-factory的官网的issues里上百条提问都没有解决的一个问题,即:在windows下启动界面正常、训练崩溃且无任何报错的一个无解的坑。
1.2 安装前的环境准备
操作系统与基础软件
- 操作系统:windows10,最新补丁
- 必须安装Miniconda3-latest-Windows-x86_64.exe
虚拟python环境专门用于安装llama-factory
conda create -n llama-factory python=3.11 -y
conda activate llama-factory和所有教程不一样的地方在于,llama-factory的最新版本即:0.9.4,要求必须使用python11起板。这和所有的网上教程不一样。
要不然你安装成功后,启动时会报错。
同时,也正因为了llama-factory要求用python11,同时我们用的是最新的Miniconda3,于是,就引入了这个启动正常、训练时崩溃的"坑"。
安装pytorch三件套
在虚拟了环境后,我们必须安装:pytorch、torchvision、torchaudio。
为了安装它们,你必须安装GPU版本,那么GPU版本安装时会有这样的一种写法
pip install torch==版本号 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu版本号这儿的版本到底怎么填呢?尤其是--index-url后的内容,万分重要。千万不要按照网上的教程直接写个118,121,124,是错的。
- 这儿的--index-url指的是你本地"英卡"上的cuda版本的对照版pytorch三件套的版本是什么。
- 前面的pip install torch==版本号,这儿你可以用2.5.1(最新是2.6.x,但别用)。
为安装正确的pytorch的cuda版本请按下列步骤
启动power shell运行如下命令
nvidia-smi你会得到类似以下这样的输出

看到这儿的cuda版本后,你可以使用:121,124,126即:比nvidia-smi输出的CUDA Version低的pytorch三件套。
这儿我给到大家一个稳定的可支持CUDA Version: 13.0的安装命令(如果CUDA Version>这个值,你必须自己寻找比你的CUDA版本低的pytorch的版本)。
pip install torch==2.5.1 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu1211.3 正式安装llama-factory
在确保conda activate llama-factory的前提下,我们把llama-factory放在D:\LLaMA-Factory。于是键入如下命令。

cd D:\LLaMA-Factory
pip install -e ".[torch,metrics]"安装很顺利,一点出错也没有。
2. 启动llama-factory
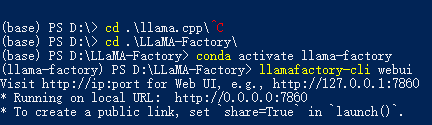
在确保conda activate llama-factory的前提下,我们把llama-factory放在D:\LLaMA-Factory。于是键入如下命令。

llamafactory-cli webui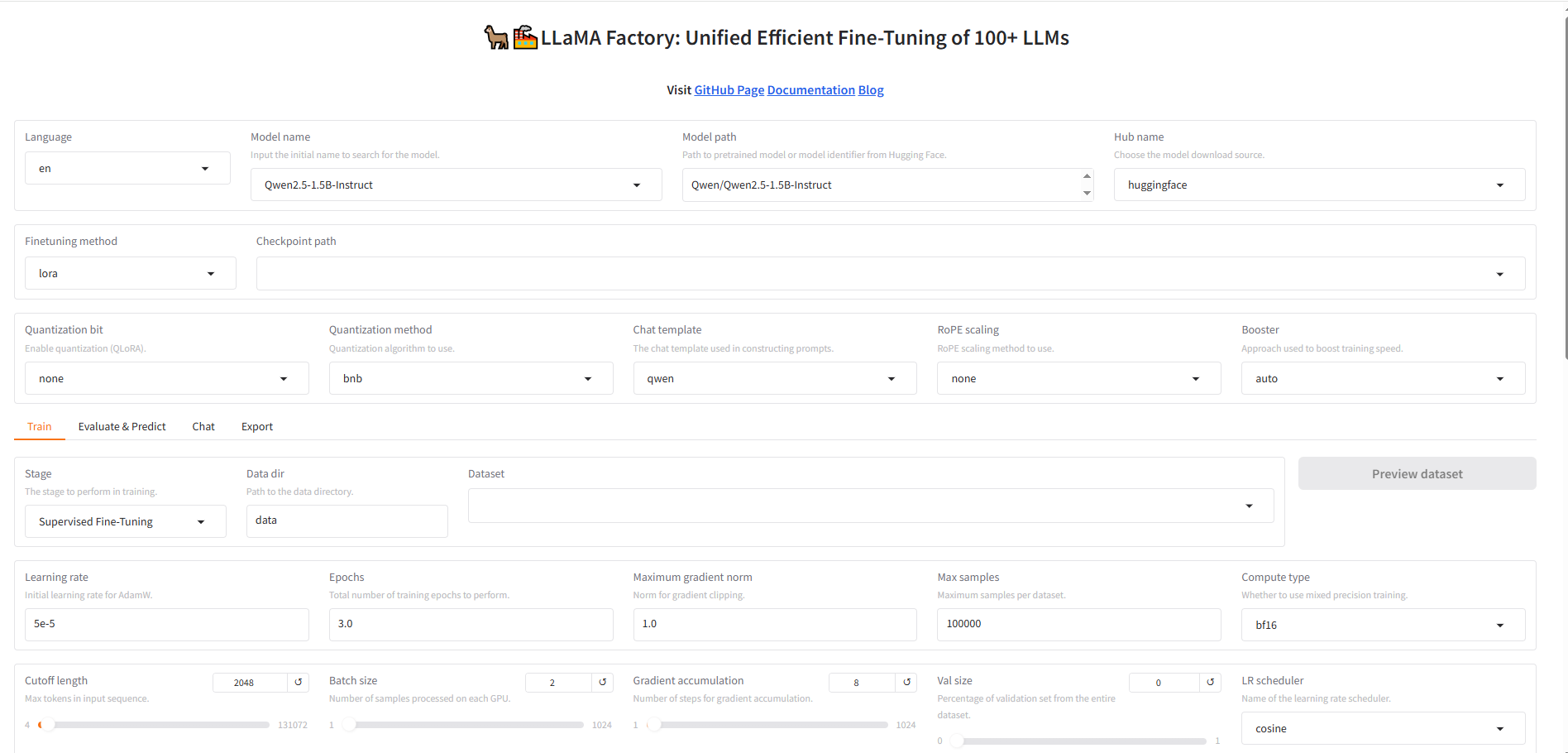
看到此界面,就是启动成功了。
3. 为今后顺利训练-必须做的一些环境上的准备
llama-factory训练时主要是在选用模型、下载模型时会有一个网络很难逾越的梗,即:HuggingFace。

一定要用Instruct模型
一般我们在训练时一定一定要用这种后缀的模型:xxxxx-Instruct。
这种模型又叫:出厂校验模型,即Instruct模型。
事实上我们用的一些SAAS类模型都是Instruct模型。
千万不要按照网上説的,去用Base模型。所谓Base模型就是类似:DeepSeek-LLM-7B-Base这种,或者是:DeepSeek-LLM-7B,后面不带Base。
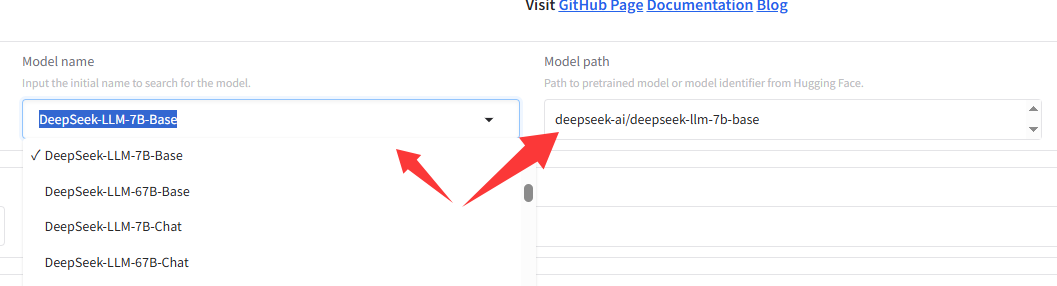
注意这,选了Model name后后面的Model path会联动的。
这是因为Base模型又叫"出厂模型",它没有经过校验也没有被校验过怎么说话、怎么行动。因此在Base模型上经常发生你问一句:你是谁。
然后模型不断的输出回答直到默认Token值(1024)被耗尽才停止回答。
而Instruct模型是指这个模型已经在出厂后经过一轮校验,教会了它如何去理解世界和说话这么一个意思。
微调用Instruct模型,切记,而不是一切从base训练,否则你连1+1=?都要训练模型,你觉得这是一个个人或者哪怕是非模型大厂企业的事吗?
一定要设Hugging Face的默认下载路径
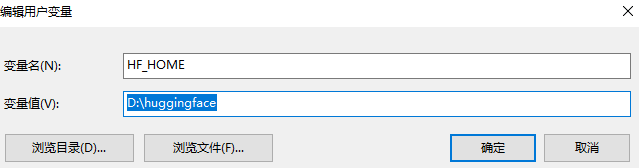
如果不设,因为llama-factory是不带这些模型的,它一发觉要训练的模型没有就会去hugging face上下,下载时默认它把上G的模型放在:C:\Users\你当前登录名\.cache下。
不需要多久,你的C盘就爆了。
这儿给大家多普及一个梗:
你也可以不用设HF_HOME,因为我看到大多在电脑商城买台式机用于训练模型时要求店员把一个4T的硬盘划成C盘2T。。。。。。就是这么来的。

一定要设hugging face的镜像
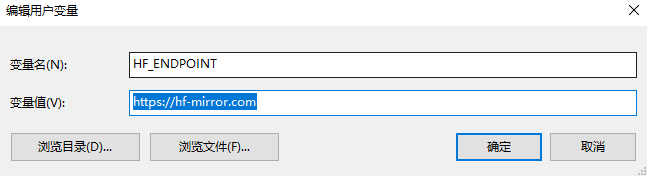
如果不设,那么你的下载要么断线要么始终每秒只有几KB的速度,你到时会真的抓狂的。
4. 第一次试着训练
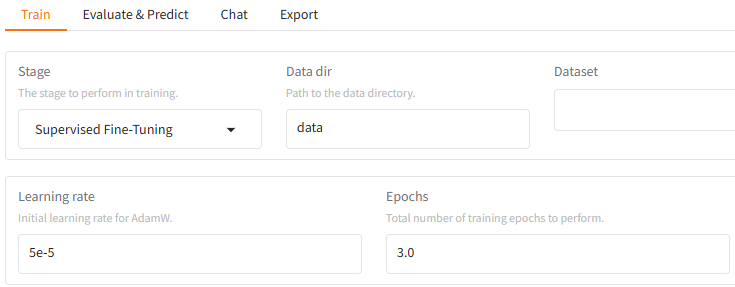
我们按照llama-factory webui中如下设置,尝试第一次快速训练。
- 模型加载用:Qwen2.5-1.5B-Instruct;
- 学习率使用如下的learning rate-5e-5;
- Epochs-学习轮数用3.0;
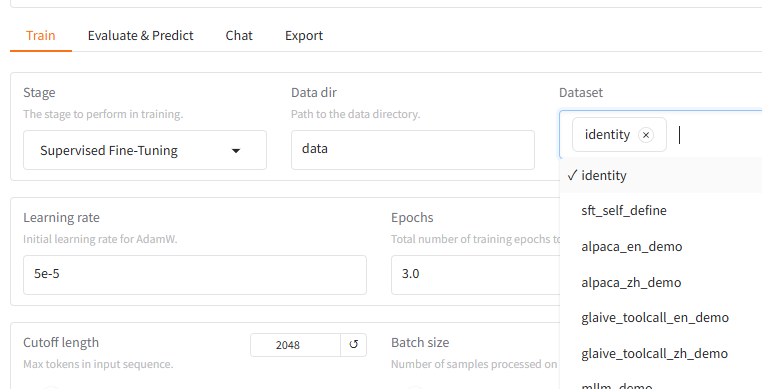
- 训练语料用默认自带的identity(问我是谁,模型个性化回答的语料);
- 点开:Extra configurations选项卡,把Enbable-thinking勾去掉。因为qwen2.5没有thinking模式。
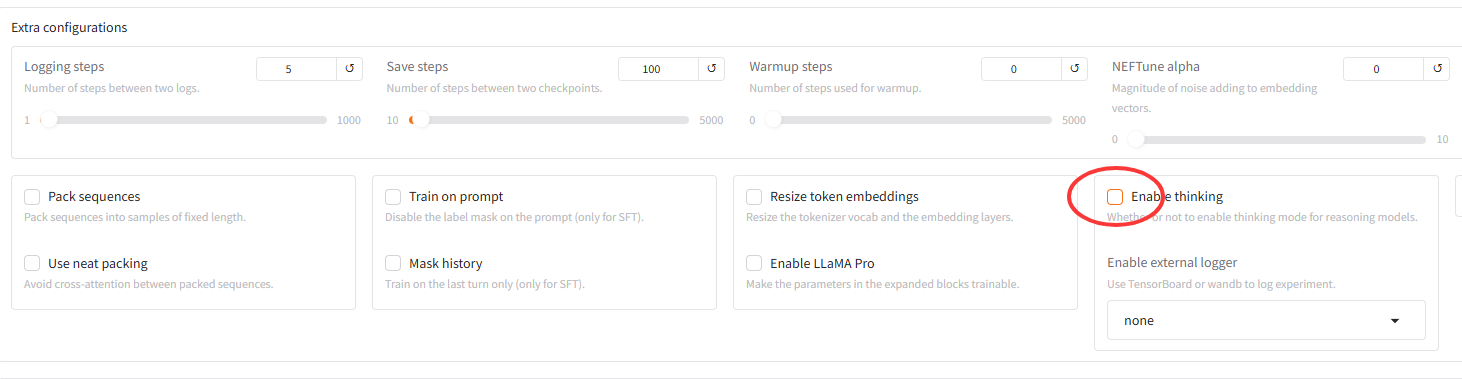
其它都保持原样。点屏幕下方
Start。
1~3秒,界面显示"训练Failed",而启动端无任何报错,连日志都找不到。
界面只会显示一个error code,用这个error code去google, 去官网的github里的issues里去找,上百个类似问题,无回答。
直接抓狂!

5. 解决这个Windows下llama-factory的"坑"
此问题在截止本篇没有发出前为:无解。
经过本人近100小时通过底层代码排查完美解决,直接给出解决手法。
其实这个错不是没有报而是报了,报在了控制面板->管理工具->事件查看器->应用日志里。显示为:nvidia崩溃,有一个崩溃的进程号,其它什么都没有(因此为了排错我还看了nvidia相关支持transformer的c代码。。。)。
记得,以下步骤都必须在conda activate llama-factory 这个虚拟环境的前提下操作!!!
5.1 检查miniconda3安装目录下是否有重复的vcomp140.dll
# 检查环境根目录是否有散落的 vcomp140.dll
Get-ChildItem D:\utility\miniconda3\envs\llama-factory\vcomp140.dll -ErrorAction SilentlyContinue
# 如果存在,删掉(只保留 Library\bin\ 下那一份)
Remove-Item D:\utility\miniconda3\envs\llama-factory\vcomp140.dll -ErrorAction SilentlyContinuewindows系统其实自动这个vcomp140.dll。而miniconda3最新版安装时会把这个.dll通过它自己的源安装进来。
于是,在windows上,web-ui训练时,用的是transformer,一旦用到了nvidia,nvidia用到了vcomp140.dll,这个dll就冲突了。
别急,到此还没有完。
5.2 安装llama-factory时的transformer版本导致了训练时的崩溃
为此,你需要运行以下命令
pip install --force-reinstall --no-deps "transformers==4.57.6" "tokenizers==0.22.0"我是从transformer4.5开始逐步去试一直试到了4.8,而最稳定的就是这个4.57.6了,相应的它需要依赖的tokenizers也需要做对应的降级。
5.3 改动transformers版本号必须对accelerate进行版本校准
根据源码决定的,此时你需要手动改动accelerate。
pip install --force-reinstall --no-deps "accelerate==1.11.0"5.4 改动peft版本
pip install --force-reinstall --no-deps "peft==0.18.1"5.5 改动trl版本
pip install --force-reinstall --no-deps "trl==0.24.0"5.6 Windows ABI 关键修复
pip install --force-reinstall --no-deps "pyarrow==17.0.0"
pip install --force-reinstall --no-deps "numpy==1.26.4"好了,可以进入测试了。
为什么有上述这么多步版本改动?
因为,我在看源码时发觉其实就有这6个点都和版本有关,每个点改了一个后,崩溃的进程号会变,根据每次不同的崩溃的进程号去看代码就又一路发觉了这6个崩溃点,都是python版本导致。
5.7 改完后用手工命令快速验证训练时还会崩溃吗
我已经为大家整理好了,这3条命令必须全部运行通过,如果有一条报python错误,那么根据错误再去排查。
我就是一边看代码一边写命令然后把上面那6个坑全探出来的,一旦这3条命令通过,再在llama-factory web-ui里训练,就一次通过了。
1. ABI 组合 OK
python -X faulthandler -u -c "import torch; torch.cuda.device_count(); import datasets; print('combo ok')"2. LF parser OK
python -X faulthandler -u -c "from llamafactory.train.tuner import run_exp; print('LF ok')"3. 跑一条短训练
python -X faulthandler -u -m llamafactory.cli train --output_dir saves/test_min --model_name_or_path Qwen/Qwen2.5-0.5B --stage kto --finetuning_type lora --template default --dataset kto_self_define --dataset_dir data --fp16 True --pref_beta 0.1 --pref_loss sigmoid --lora_target q_proj --do_train True --max_samples 10 --per_device_train_batch_size 1 --num_train_epochs 1 --logging_steps 1 --learning_rate 5e-53 条都过 = 环境就绪 ✅。
6. llama-factory 0.9.4 windows下训练崩溃结案问题总结
-
✅ pyarrow 17.0.0 修复 access violation
-
✅ transformers 4.57.6 + accelerate 1.11.0 + peft 0.18.1 + trl 0.24.0 兼容
-
✅ vcomp140.dll 散落份要删
-
✅ Web UI 已正常进入训练循环
至此,环境Ready,后面我将为大家介绍生产环境实战训练,包括那些SFT、DPO、KTO、预训练、训练、后训练这些。
全部看完,你可以直接去面试大厂AI Devops或者是训练岗位。