一,安装
安装指南如下链接打开:
Claude code 保姆级入门教程,不用学命令行(2025.12 月更新) - 知乎
Claude Code 接入国内大模型(智谱 GLM-4.7)图文教程 - 哔哩哔哩
从零开始安装Claude Code + GLM 4.7------Windows版 - 知乎
上述文章或其他抖音,小红书平台中均有详细的配置安装教学,先自己打开看一看,写的很详细!

二,其他补充😌
1,claude code配置skills(必备)
使用技能扩展 Claude - Claude Code Docs(官网链接)
Claude Code Skills到底怎么用?大家看这篇文章就够了 - 知乎
Claude Code Skills 技能配置完全指南_claude code skill 官方文档-CSDN博客
2026 最新 Claude Skills 保姆级教程及实践! | 人人都是产品经理 (推荐这篇)
上面是官网和国内写的较好的文章指南,请对照着步骤一步一步操作即可完成。
2,claude code其他插件
Claude Code 官方插件汇总_claude-plugins-official-CSDN博客
Claude Code 最新实践:2 个插件让 AI 写代码效率提升300%【完整配置指南】 - 知乎
Claude Code VS Code 插件完整指南:功能、安装与使用 - 博客 - Hrefgo AI
推荐使用vscode或其他集成开发的ide,下载claude code内置插件,开发更加可视化,且内置一套指令,并且可以直接在ide中集成开发代码,更方便
具体可以参考VS Code 集成 -- Claude 中文 - Claude AI 开发技术社区(claude code国内站)
三,使用案例教程
本文使用一个简单的搜索文献,并一件整合成为综述作为案例教学:
背景: 传统阅读文献还在手动搜索文献,而就算我一点代码和爬虫都不会,现在也可以在AI辅助下完成自动化获取大量文献 ,并可以实现一键生成综述,或者在大批量文献基础下进行细化筛选。
打开cmd,输入**/claude** 跟它对话QAQ,就像是跟一个聪明人对话一样,说话的逻辑越严谨,内容和条件越具象,他的回复和动作越接近我想要的状态。

出现问题就一步一步问Claude Code即可,它会自己修复,自我解决问题。
可以自己试着使用提示词跟它对话,让它完成开发,最后项目文件如下
完整的代码如下:
python
"""
AI材料科学文献下载器 - 增强版
支持多种数据源,提高下载成功率
"""
import requests
import scholarly
import pandas as pd
import time
import os
import re
import json
import arxiv
from typing import List, Dict, Optional
from datetime import datetime
from bs4 import BeautifulSoup
class EnhancedAILiteratureDownloader:
def __init__(self, output_dir: str = "./downloaded_papers"):
"""初始化下载器"""
self.output_dir = output_dir
self.papers_info = []
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# arXiv客户端
self.arxiv_client = arxiv.Client(
page_size=100,
delay_seconds=3.0,
num_retries=3
)
def search_arxiv(self, query: str, max_results: int = 20) -> List[Dict]:
"""从arXiv搜索开放获取论文"""
print(f"\n🔍 [arXiv] 搜索: {query}")
papers = []
try:
# 构建搜索查询
search = arxiv.Search(
query=query,
max_results=max_results,
sort_by=arxiv.SortCriterion.SubmittedDate,
sort_order=arxiv.SortOrder.Descending
)
for result in self.arxiv_client.results(search):
paper_info = {
'title': result.title,
'authors': [str(a) for a in result.authors],
'year': result.published.strftime('%Y'),
'venue': f"arXiv:{result.entry_id.split('/')[-1]}",
'abstract': result.summary.replace('\n', ' '),
'url': result.entry_id,
'eprint': result.pdf_url, # 直接PDF链接
'citations': 0, # arXiv没有引用数据
'query': query,
'source': 'arxiv'
}
papers.append(paper_info)
print(f" ✓ 找到: {paper_info['title'][:60]}...")
if len(papers) >= max_results:
break
except Exception as e:
print(f" ⚠ arXiv搜索失败: {e}")
return papers
def search_scholar(self, query: str, num_results: int = 10) -> List[Dict]:
"""从Google Scholar搜索"""
print(f"\n🔍 [Scholar] 搜索: {query}")
papers = []
try:
# 使用新的API: search_pubs
search_query = scholarly.search_pubs(query)
count = 0
for paper in search_query:
if count >= num_results:
break
try:
# 新版scholarly的paper对象结构不同
paper_info = {
'title': paper.bib.get('title', 'Unknown'),
'authors': [str(a) for a in paper.bib.get('author', [])],
'year': paper.bib.get('pub_year', 'Unknown'),
'venue': paper.bib.get('venue', 'Unknown'),
'abstract': paper.bib.get('abstract', ''),
'url': paper.pub_url if hasattr(paper, 'pub_url') else '',
'eprint': paper.eprint_url if hasattr(paper, 'eprint_url') else '',
'citations': paper.citedby if hasattr(paper, 'citedby') else 0,
'query': query,
'source': 'scholar'
}
papers.append(paper_info)
count += 1
print(f" ✓ 找到: {paper_info['title'][:60]}...")
time.sleep(1)
except Exception as e:
continue
except Exception as e:
print(f" ⚠ Scholar搜索失败: {e}")
return papers
def classify_paper(self, paper: Dict) -> str:
"""判断论文类型"""
title = paper['title'].lower()
venue = paper['venue'].lower()
abstract = paper['abstract'].lower()
review_keywords = [
'review', 'survey', 'overview', 'perspective',
'progress', 'advances', 'development', 'trends',
'roadmap', 'challenge', 'opportunity'
]
for keyword in review_keywords:
if keyword in title or keyword in venue:
return 'review'
return 'research'
def download_pdf(self, paper: Dict) -> bool:
"""下载PDF"""
pdf_urls = []
# 1. arXiv直接下载
if paper.get('source') == 'arxiv' and paper.get('eprint'):
pdf_urls.append(paper['eprint'])
# 2. 其他来源
if paper.get('eprint'):
pdf_urls.append(paper['eprint'])
if paper.get('url'):
url = paper['url']
if 'arxiv.org' in url:
arxiv_id = url.split('/')[-1]
pdf_urls.append(f"https://arxiv.org/pdf/{arxiv_id}.pdf")
elif 'nature.com' in url:
pdf_urls.append(url.replace('/article/', '/article/pdf/') + '.pdf')
# 尝试下载
for pdf_url in pdf_urls:
try:
print(f" 📥 尝试: {pdf_url[:80]}...")
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
response = requests.get(pdf_url, headers=headers, timeout=30, stream=True)
if response.status_code == 200:
content_type = response.headers.get('content-type', '').lower()
if 'pdf' in content_type or response.content[:4] == b'%PDF':
filename = self.sanitize_filename(paper['title'])
filepath = os.path.join(self.output_dir, f"{filename}.pdf")
with open(filepath, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
print(f" ✓ 下载成功!")
return True
time.sleep(1)
except Exception as e:
continue
return False
def sanitize_filename(self, filename: str) -> str:
"""清理文件名"""
filename = re.sub(r'[<>:"/\\|?*]', '_', filename)
if len(filename) > 200:
filename = filename[:200]
return filename.strip()
def run(self, num_reviews: int = 5, num_research: int = 15):
"""执行完整的搜索和下载流程"""
print("=" * 60)
print("🚀 AI材料科学文献下载器 - 增强版")
print("=" * 60)
all_papers = []
review_papers = []
research_papers = []
# 第一阶段:从arXiv搜索(确保能下载)
print("\n" + "=" * 60)
print("📚 阶段1: 从arXiv搜索开放获取论文")
print("=" * 60)
arxiv_queries = [
"artificial intelligence materials science",
"machine learning materials discovery",
"deep learning materials properties",
"neural network materials design"
]
for query in arxiv_queries:
papers = self.search_arxiv(query, max_results=10)
for paper in papers:
paper['type'] = self.classify_paper(paper)
all_papers.append(paper)
# 第二阶段:从Google Scholar补充
print("\n" + "=" * 60)
print("📖 阶段2: 从Google Scholar补充高质量论文")
print("=" * 60)
scholar_queries = [
"artificial intelligence materials science review",
"machine learning materials prediction high impact",
"deep learning materials discovery results"
]
for query in scholar_queries:
papers = self.search_scholar(query, num_results=10)
for paper in papers:
# 避免重复
if not any(p['title'] == paper['title'] for p in all_papers):
paper['type'] = self.classify_paper(paper)
all_papers.append(paper)
# 分类并选择
for paper in all_papers:
if paper['type'] == 'review' and len(review_papers) < num_reviews:
review_papers.append(paper)
elif paper['type'] == 'research' and len(research_papers) < num_research:
research_papers.append(paper)
# 如果不够,补充任意类型
selected = review_papers + research_papers
remaining = [p for p in all_papers if p not in selected]
while len(review_papers) < num_reviews and remaining:
review_papers.append(remaining.pop(0))
while len(research_papers) < num_research and remaining:
research_papers.append(remaining.pop(0))
final_papers = review_papers[:num_reviews] + research_papers[:num_research]
print(f"\n✓ 搜索完成!")
print(f" - 综述: {len(review_papers)}篇")
print(f" - 研究: {len(research_papers)}篇")
print(f" - 总计: {len(final_papers)}篇")
# 第三阶段:下载PDF
print("\n" + "=" * 60)
print("📥 阶段3: 下载PDF")
print("=" * 60)
downloaded = 0
for i, paper in enumerate(final_papers, 1):
print(f"\n[{i}/{len(final_papers)}] {paper['title'][:70]}...")
print(f" 类型: {'综述' if paper['type'] == 'review' else '研究'}")
print(f" 来源: {paper.get('source', 'unknown').upper()}")
if self.download_pdf(paper):
downloaded += 1
paper['downloaded'] = True
else:
paper['downloaded'] = False
time.sleep(2)
# 保存信息
self.save_info(final_papers)
# 总结
print("\n" + "=" * 60)
print("📊 下载总结")
print("=" * 60)
print(f"✓ 成功: {downloaded}/{len(final_papers)}篇")
print(f"📁 目录: {os.path.abspath(self.output_dir)}")
def save_info(self, papers: List[Dict]):
"""保存文献信息"""
data = []
for i, paper in enumerate(papers, 1):
data.append({
'序号': i,
'标题': paper['title'],
'作者': ', '.join(paper['authors'][:5]) + '...' if len(paper['authors']) > 5 else ', '.join(paper['authors']),
'年份': paper['year'],
'期刊/来源': paper['venue'],
'类型': '综述' if paper['type'] == 'review' else '研究',
'引用': paper.get('citations', 0),
'URL': paper['url'],
'PDF': paper.get('eprint', ''),
'状态': '✓' if paper.get('downloaded') else '⚠'
})
df = pd.DataFrame(data)
df.to_excel(os.path.join(self.output_dir, 'literature_list.xlsx'), index=False)
with open(os.path.join(self.output_dir, 'literature_list.json'), 'w', encoding='utf-8') as f:
json.dump(papers, f, ensure_ascii=False, indent=2)
print(f"\n✓ 文献列表已保存")
def main():
downloader = EnhancedAILiteratureDownloader(output_dir="./AI_Materials_Papers_Enhanced")
downloader.run(num_reviews=5, num_research=15)
if __name__ == "__main__":
main()上述的代码,逻辑还是比较清楚的,而且本人全程观看,没动手敲一行字。
运行后,发现确实找到了我需要的文献,完成了我交给它的任务(让本人自己写也未必会写QA)
最后,就是让它根据保存到指定目录下的文献,生成综述或其他文献内容总结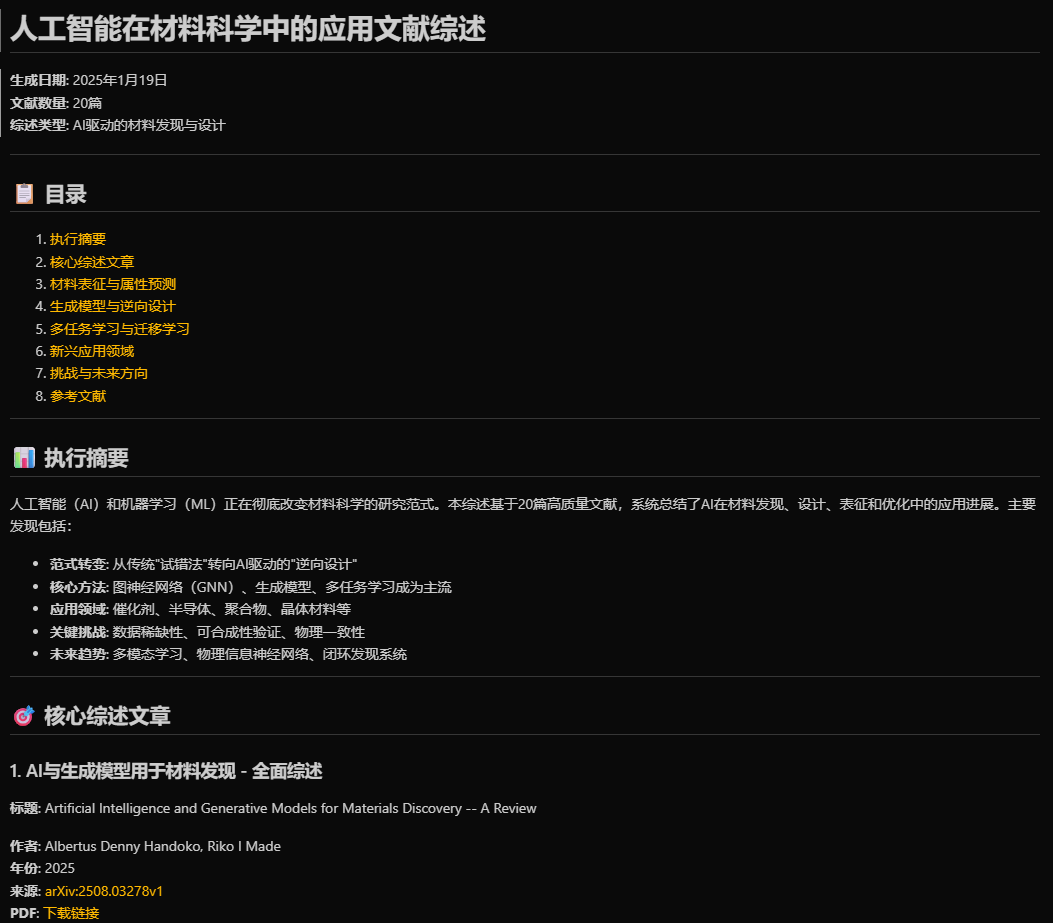
可以看到,写的还是头头是到,并且将链接也附带了!
总结:
可以发现,上述开发根本不需要写一点代码,便将复杂的任务完成(最难的部分可能就是配置安装Claude Code??hhh)