MCP(Model Context Protocol)从入门到精通全教程
本教程聚焦AI领域的Model Context Protocol(模型上下文协议),由Anthropic牵头推出的开放标准,被称为「AI的USB-C接口」。教程从核心原理到生产级落地,循序渐进,所有案例均可直接复制运行,帮你彻底吃透MCP。
前言:先搞懂「MCP到底是什么?为什么非学不可?」
0.1 核心定义
MCP(Model Context Protocol,模型上下文协议)是一套标准化、安全、双向通信的开源协议,为大语言模型(LLM)与外部世界(文件系统、数据库、API、SaaS服务、硬件等)搭建了统一的交互桥梁,彻底解决了大模型工具调用的碎片化难题。
0.2 传统工具调用的核心痛点(MCP解决的问题)
MCP出现前,大模型与外部系统交互完全依赖厂商自定义的Function Calling,存在5个致命痛点:
- 集成爆炸难题:M个模型 × N个工具 = M×N套定制适配代码,开发成本呈指数级增长。
- 碎片化严重:不同厂商的函数调用格式、参数规范完全不统一,模型很难自动发现和使用工具。
- 权限管控缺失:模型直接调用底层API,无统一的权限隔离、审计机制,极易出现越权操作。
- 上下文管理混乱:工具返回数据无标准化裁剪规则,极易超出模型上下文窗口,导致生成质量下降。
- 无状态交互限制 :传统函数调用是单向无状态的,无法实现实时推送、会话级状态管理。
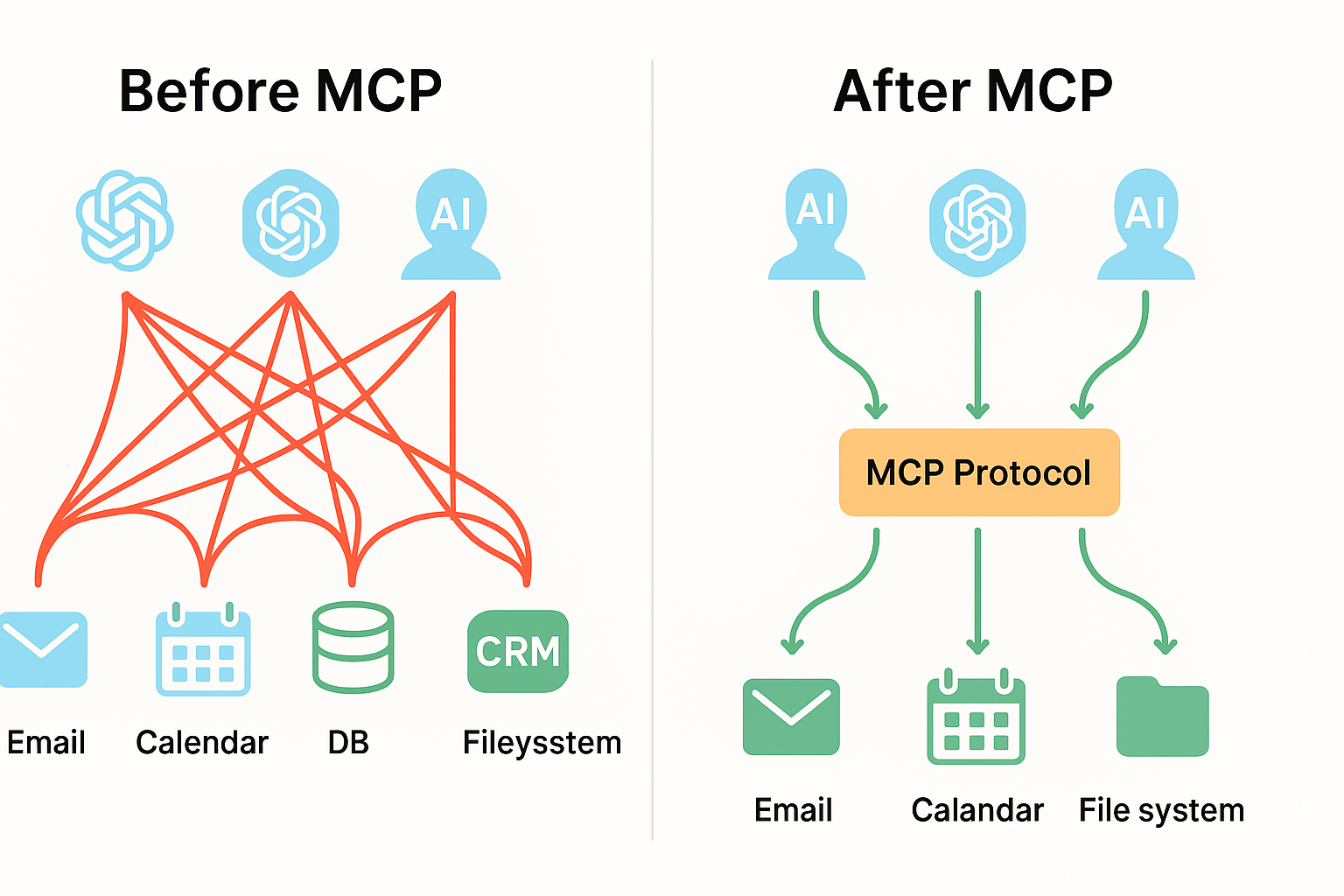
0.3 MCP的核心价值
- 一次开发,全生态兼容:写1套MCP服务,所有支持MCP的客户端(Claude、Cursor、LangChain、Dify等)都能直接调用,无需重复适配。
- 标准化能力声明:模型可自动发现、理解和使用外部能力,无需人工编写大量Prompt调教。
- 企业级安全能力:内置权限模型、审计日志、会话管理,满足生产部署的安全要求。
- 双向通信能力:支持实时推送、进度通知、异步任务处理,覆盖复杂的Agent自动化场景。
第一部分:入门篇 - 彻底吃透MCP核心原理
1.1 MCP的核心架构与角色
MCP采用客户端-服务端(Client-Server) 架构,底层基于JSON-RPC 2.0协议实现双向通信,核心分为3个角色:
| 角色 | 核心定位 | 典型代表 | 核心职责 |
|---|---|---|---|
| MCP Host(宿主) | 大模型运行环境 | Claude Desktop、Cursor IDE、Dify | 接收用户指令,调用大模型推理,管理MCP会话 |
| MCP Client(客户端) | 协议翻译官 | 官方MCP SDK、应用内置MCP模块 | 将模型指令转为标准化JSON-RPC请求,与服务端通信,处理返回结果 |
| MCP Server(服务端) | 能力适配器 | 自定义开发的服务、社区开源服务 | 封装外部系统能力,暴露标准化的工具/资源/提示词,处理客户端请求 |
核心记忆点:Server负责提供能力,Client负责对接模型,Host是用户和模型交互的入口 。我们开发的核心就是MCP Server,一次封装,全生态可用。
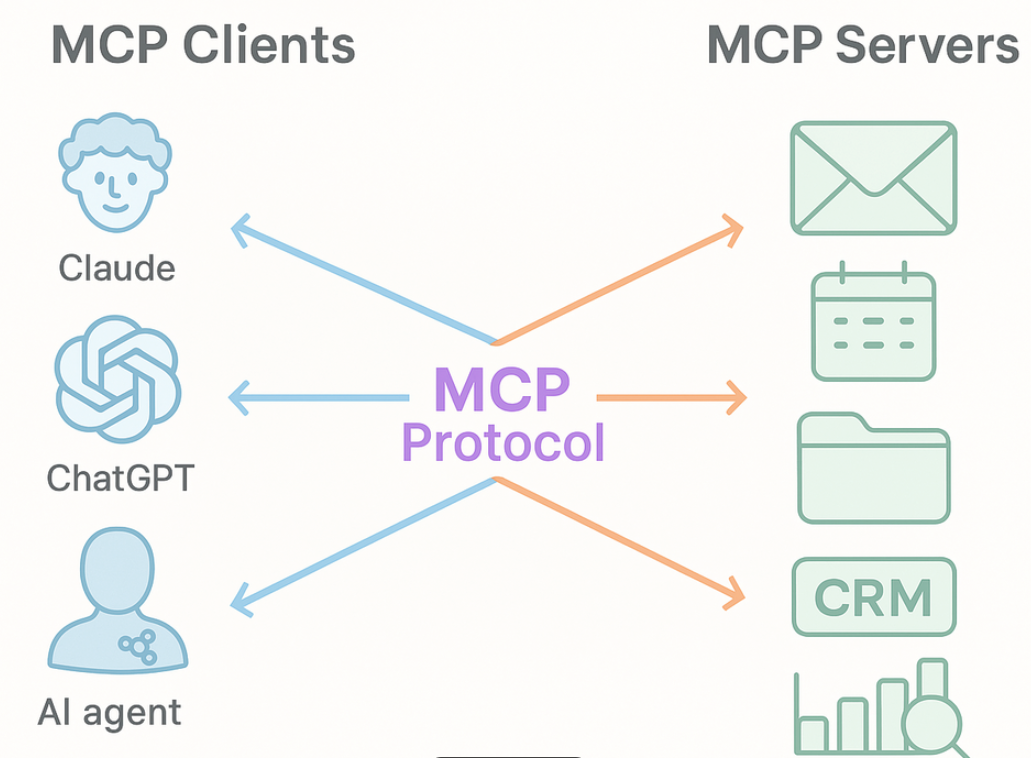
1.2 MCP的三大核心原语(协议灵魂)
MCP定义了3种标准化交互原语,覆盖大模型与外部系统交互的所有场景,这是与传统Function Calling的本质区别:
1.2.1 Tools(工具):模型可控的可执行函数
- 定义:服务端封装的可执行操作,模型可自主决定调用时机和传入参数,服务端执行后返回结果。
- 核心特性:标准化元数据声明、统一参数校验/错误处理、支持同步/异步执行、任务取消。
- 典型场景:发送邮件、执行SQL、运行代码、调用第三方API。
1.2.2 Resources(资源):服务端可控的上下文数据
- 定义 :服务端管理的只读/可写数据,用统一URI格式(
mcp://{scheme}/{path})标识,模型可读取、列表、订阅,无法直接修改。 - 核心特性:统一URI寻址、标准化分页/过滤/订阅、内置权限管控。
- 典型场景:读取本地项目文件、查询数据库表结构、获取知识库文档、订阅系统日志。
1.2.3 Prompts(提示词模板):用户可控的标准化工作流
- 定义:服务端封装的预定义提示词模板,支持参数注入,用户/模型可直接调用,保证交互一致性。
- 核心特性:标准化模板声明、参数类型校验、集中版本管理、可绑定工具/资源实现一体化工作流。
- 典型场景:代码审查模板、SQL生成模板、会议纪要整理模板。
核心区别记忆:
- 工具:模型主动控制,用来「做事情」
- 资源:服务端控制,用来「给信息」
- 提示词:用户控制,用来「定规则」
1.3 MCP的通信原理与协议规范
1.3.1 支持的3种传输方式
| 传输方式 | 适用场景 | 优势 |
|---|---|---|
| STDIO(标准输入输出) | 本地部署(如Claude调用本地服务) | 无需网络、天然安全、配置最简单 |
| WebSocket | 远程部署、多客户端、实时场景 | 双向全双工通信、低延迟、支持实时推送 |
| HTTP SSE | 公网部署、只读数据订阅 | 兼容传统HTTP基础设施、易穿透防火墙 |
1.3.2 核心消息格式
所有MCP消息严格遵循JSON-RPC 2.0规范,分为3类:
- 请求消息:客户端向服务端发送的调用请求,包含唯一id、方法名、参数。
- 响应消息:服务端对请求的返回结果,包含对应请求的id、结果/错误信息。
- 通知消息:无需响应的单向消息(如资源更新、进度通知),无id字段。
1.4 MCP的完整生命周期(一次交互全流程)
理解生命周期是排查问题的核心,一次完整的MCP会话分为4个阶段:
- 连接初始化与版本协商
- 客户端与服务端建立传输连接,发送
initialize请求,声明协议版本(当前稳定版2024-11-05)、支持的能力。 - 服务端返回
initialize响应,完成版本协商;客户端发送initialized通知,进入正常交互阶段。
- 客户端与服务端建立传输连接,发送
- 能力发现
- 客户端发送
tools/list/resources/list/prompts/list请求,自动获取服务端暴露的所有能力元数据。
- 客户端发送
- 核心交互
- 模型根据用户指令,调用工具、读取资源、使用提示词模板;客户端转发请求,服务端执行后返回结果。
- 连接关闭
- 客户端发送
shutdown请求,服务端释放资源后返回确认,关闭连接。
- 客户端发送
1.5 前置环境准备
本教程基于Python SDK开发(受众最广、上手最快),请先准备环境:
- Python版本:3.10+(推荐3.11/3.12)
- 包管理工具:推荐uv(超高速),也可使用pip
- 测试客户端:Claude Desktop(原生支持MCP,推荐)、Cursor IDE、官方MCP CLI
环境安装步骤
- 验证Python版本:
bash
python --version
# 输出 Python 3.10.0 及以上即可- 安装官方MCP Python SDK(最新稳定版1.12.1):
bash
# pip安装
pip install mcp[cli]
# 推荐uv安装(更快)
uv add "mcp[cli]"- 验证安装成功:
bash
mcp --version
# 输出版本号即安装成功第二部分:上手篇 - 零代码&极简代码快速落地
2.1 零代码入门:Claude Desktop + 官方文件系统MCP服务(10分钟跑通)
先通过零代码方式,直观感受MCP的能力。
步骤1:找到Claude Desktop配置文件
Claude原生支持MCP,通过配置文件注册服务,路径如下:
- macOS:
~/Library/Application Support/Claude/claude_desktop_config.json - Windows:
%APPDATA%\Claude\claude_desktop_config.json
步骤2:编辑配置文件,添加文件系统服务
打开配置文件,粘贴以下内容(替换为你要开放的文件夹路径):
json
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": [
"@modelcontextprotocol/server-filesystem",
"/Users/your-name/Projects" // Windows替换为"C:\\Users\\your-name\\Projects"
]
}
}
}步骤3:重启Claude,验证生效
- 完全关闭Claude Desktop,重新打开。
- 输入对话:「列出我Projects文件夹里的所有文件」,Claude会自动调用MCP工具完成操作,无需额外授权。
2.2 极简入门:Python开发你的第一个MCP Server(天气查询工具)
我们使用官方FastMCP框架(类似FastAPI,用装饰器快速开发),从零开发一个完整的天气查询MCP服务。
步骤1:创建项目文件
创建weather_mcp.py,粘贴以下完整代码:
python
from mcp.server.fastmcp import FastMCP
import httpx
import asyncio
# 1. 创建MCP Server实例
mcp = FastMCP("天气查询服务")
# 2. 定义工具:获取指定城市的实时天气
# 装饰器自动将函数注册为MCP工具,文档字符串和类型注解会自动生成元数据
@mcp.tool()
async def get_realtime_weather(city: str, province: str = "") -> str:
"""
获取指定城市的实时天气信息
:param city: 要查询的城市名称,必填,如"成都"、"杭州"
:param province: 省份名称,可选,用于区分重名城市,如"四川"、"浙江"
:return: 格式化的实时天气信息
"""
# 替换为你自己的高德API Key,申请地址:https://lbs.amap.com/
api_key = "你的高德API Key"
if not api_key or api_key == "你的高德API Key":
return "请先配置高德地图API Key,申请地址:https://lbs.amap.com/"
async with httpx.AsyncClient() as client:
try:
# 第一步:获取城市adcode
geo_url = f"https://restapi.amap.com/v3/geocode/geo?address={city}&key={api_key}"
if province:
geo_url += f"®ion={province}"
geo_resp = await client.get(geo_url, timeout=10)
geo_data = geo_resp.json()
if geo_data["status"] != "1" or len(geo_data["geocodes"]) == 0:
return f"未找到城市【{city}】的信息,请检查名称是否正确"
adcode = geo_data["geocodes"][0]["adcode"]
# 第二步:获取实时天气
weather_url = f"https://restapi.amap.com/v3/weather/weatherInfo?city={adcode}&key={api_key}&extensions=base"
weather_resp = await client.get(weather_url, timeout=10)
weather_data = weather_resp.json()
if weather_data["status"] != "1":
return f"查询天气失败:{weather_data.get('info', '未知错误')}"
# 格式化结果
live = weather_data["lives"][0]
return f"""
【{live['province']} {live['city']} 实时天气】
天气状况:{live['weather']}
温度:{live['temperature']}℃
湿度:{live['humidity']}%
风向:{live['winddirection']}风
风力:{live['windpower']}级
更新时间:{live['reporttime']}
""".strip()
except Exception as e:
return f"查询天气失败:{str(e)}"
# 3. 定义资源:热门城市天气榜单
@mcp.resource("weather://hot-cities")
async def get_hot_cities_weather() -> str:
"""获取全国热门城市的实时天气榜单"""
hot_cities = ["北京", "上海", "广州", "深圳", "杭州", "成都", "重庆", "武汉"]
api_key = "你的高德API Key" # 替换为自己的Key
result = "【全国热门城市实时天气榜单】\n"
if not api_key or api_key == "你的高德API Key":
return "请先配置高德地图API Key"
async with httpx.AsyncClient() as client:
for city in hot_cities:
try:
geo_resp = await client.get(f"https://restapi.amap.com/v3/geocode/geo?address={city}&key={api_key}", timeout=5)
geo_data = geo_resp.json()
if geo_data["status"] != "1":
continue
adcode = geo_data["geocodes"][0]["adcode"]
weather_resp = await client.get(f"https://restapi.amap.com/v3/weather/weatherInfo?city={adcode}&key={api_key}&extensions=base", timeout=5)
weather_data = weather_resp.json()
if weather_data["status"] == "1":
live = weather_data["lives"][0]
result += f"- {city}:{live['weather']} {live['temperature']}℃\n"
except:
continue
return result.strip()
# 4. 定义提示词模板:天气出行建议
@mcp.prompt()
def weather_travel_suggestion(city: str, weather_info: str, travel_type: str = "日常出行") -> str:
"""
生成基于天气的出行建议提示词模板
:param city: 出行城市
:param weather_info: 该城市的天气信息
:param travel_type: 出行类型,可选:日常出行、户外登山、自驾旅行、海边游玩
:return: 完整的提示词
"""
return f"""
你是专业的出行建议助手,基于以下天气信息,为用户生成{travel_type}的详细出行建议:
城市:{city}
天气信息:{weather_info}
要求:
1. 针对{travel_type}场景,给出具体的穿搭建议、必备物品、注意事项
2. 语言简洁实用,分点说明
3. 如有极端天气,重点提醒风险和应对措施
"""
# 5. 启动服务
if __name__ == "__main__":
asyncio.run(mcp.run())步骤2:配置API Key
- 访问高德地图开放平台,注册账号,申请Web服务API Key(免费额度足够个人使用)。
- 将代码中的
你的高德API Key替换为申请的Key。
步骤3:在Claude中配置你的服务
编辑claude_desktop_config.json,添加你的天气服务:
json
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": [
"@modelcontextprotocol/server-filesystem",
"/Users/your-name/Projects"
]
},
"weather-server": {
"command": "python",
"args": ["/Users/your-name/Projects/weather_mcp.py"] // 替换为文件绝对路径
}
}
}步骤4:重启Claude,测试服务
- 工具调用测试:输入「查询成都今天的实时天气」,Claude会自动调用你开发的工具。
- 资源调用测试:输入「获取全国热门城市的天气榜单」。
- 提示词模板测试:输入「用天气出行建议模板,生成成都今天的自驾旅行出行建议」。
2.3 本地调试技巧
开发过程中,用官方CLI可快速调试,无需重启Claude:
bash
# 启动调试模式,自动重载代码变更
mcp dev weather_mcp.py进入调试模式后,可直接输入命令调用工具、读取资源,快速验证服务是否正常。
第三部分:进阶篇 - 3个生产级可落地案例
3.1 案例1:MySQL数据库MCP Server - 让大模型安全操作数据库
企业级最常用场景,将MySQL封装为MCP服务,支持表结构查询、数据查询,带严格权限管控。
完整代码(mysql_mcp.py)
python
from mcp.server.fastmcp import FastMCP
import asyncio
import aiomysql
from typing import Optional
# 创建MCP Server实例
mcp = FastMCP("MySQL数据库服务")
# 数据库配置(生产环境建议用环境变量,禁止硬编码)
DB_CONFIG = {
"host": "localhost",
"port": 3306,
"user": "readonly_user", // 强烈建议使用只读用户
"password": "your_password",
"db": "your_database",
"charset": "utf8mb4"
}
# 全局连接池
pool: Optional[aiomysql.Pool] = None
# 服务启动时初始化连接池
@mcp.on_startup
async def on_startup():
global pool
pool = await aiomysql.create_pool(**DB_CONFIG)
print("MySQL连接池初始化成功")
# 服务关闭时释放连接池
@mcp.on_shutdown
async def on_shutdown():
global pool
if pool:
pool.close()
await pool.wait_closed()
print("MySQL连接池已释放")
# 工具1:获取数据库所有表名
@mcp.tool()
async def list_tables() -> str:
"""获取当前数据库中的所有表名和表注释"""
if not pool:
return "数据库连接池未初始化"
async with pool.acquire() as conn:
async with conn.cursor(aiomysql.DictCursor) as cursor:
await cursor.execute("""
SELECT TABLE_NAME, TABLE_COMMENT
FROM information_schema.TABLES
WHERE TABLE_SCHEMA = %s
ORDER BY TABLE_NAME
""", (DB_CONFIG["db"],))
tables = await cursor.fetchall()
if not tables:
return "当前数据库中没有表"
result = "【数据库表列表】\n"
for table in tables:
comment = table["TABLE_COMMENT"] or "无注释"
result += f"- {table['TABLE_NAME']}:{comment}\n"
return result.strip()
# 工具2:获取指定表的结构信息
@mcp.tool()
async def get_table_schema(table_name: str) -> str:
"""
获取指定表的字段结构、类型、主键、注释等信息
:param table_name: 要查询的表名,必填
"""
if not pool:
return "数据库连接池未初始化"
async with pool.acquire() as conn:
async with conn.cursor(aiomysql.DictCursor) as cursor:
await cursor.execute("""
SELECT
COLUMN_NAME, DATA_TYPE, IS_NULLABLE, COLUMN_DEFAULT,
COLUMN_KEY, COLUMN_COMMENT
FROM information_schema.COLUMNS
WHERE TABLE_SCHEMA = %s AND TABLE_NAME = %s
ORDER BY ORDINAL_POSITION
""", (DB_CONFIG["db"], table_name))
columns = await cursor.fetchall()
if not columns:
return f"表【{table_name}】不存在"
# 格式化结果
result = f"【表 {table_name} 结构信息】\n"
for col in columns:
key = "主键" if col["COLUMN_KEY"] == "PRI" else ""
nullable = "允许空" if col["IS_NULLABLE"] == "YES" else "非空"
default = f"默认值:{col['COLUMN_DEFAULT']}" if col["COLUMN_DEFAULT"] is not None else "无默认值"
comment = col["COLUMN_COMMENT"] or "无注释"
result += f"● {col['COLUMN_NAME']} ({col['DATA_TYPE']}):{comment}\n"
result += f" {nullable} | {key} | {default}\n"
return result.strip()
# 工具3:执行只读SQL查询(严格限制SELECT语句)
@mcp.tool()
async def execute_select_sql(sql: str, limit: int = 100) -> str:
"""
执行只读的SELECT SQL查询,返回查询结果,禁止修改数据的操作
:param sql: 要执行的SELECT SQL语句,必填
:param limit: 返回结果的最大行数,默认100,最大1000
"""
# 安全校验:只允许SELECT语句
sql_trim = sql.strip().upper()
if not sql_trim.startswith("SELECT"):
return "安全校验失败:只允许执行SELECT查询语句"
# 限制最大行数
limit = min(limit, 1000)
if not pool:
return "数据库连接池未初始化"
async with pool.acquire() as conn:
async with conn.cursor(aiomysql.DictCursor) as cursor:
try:
await cursor.execute(sql)
if cursor.rowcount == 0:
return "查询结果为空"
# 获取结果
rows = await cursor.fetchmany(limit)
columns = [desc[0] for desc in cursor.description]
# 格式化结果
result = f"【查询结果(共{cursor.rowcount}条,返回前{len(rows)}条)】\n"
result += " | ".join(columns) + "\n"
result += "-" * 50 + "\n"
for row in rows:
row_values = [str(row[col]) for col in columns]
result += " | ".join(row_values) + "\n"
return result.strip()
except Exception as e:
return f"SQL执行失败:{str(e)}"
# 启动服务
if __name__ == "__main__":
asyncio.run(mcp.run())部署与配置
- 安装依赖:
pip install aiomysql - 修改
DB_CONFIG,配置你的MySQL信息,强烈建议使用只读用户。 - 在Claude配置文件中添加该服务,重启后即可用自然语言查询数据库,例如:
- 「列出当前数据库的所有表」
- 「查询user表的结构」
- 「查询user表中2026年注册的前10条用户数据」
3.2 案例2:飞书SaaS MCP Server - 对接企业内部办公系统
将飞书开放平台能力封装为MCP服务,实现文档读取、群消息发送、日程查询,是企业内部AI助手的核心能力。
完整代码(feishu_mcp.py)
python
from mcp.server.fastmcp import FastMCP
import httpx
import asyncio
from datetime import datetime, timezone, timedelta
# 创建MCP Server实例
mcp = FastMCP("飞书办公服务")
# 飞书配置(生产环境建议用环境变量)
FEISHU_CONFIG = {
"app_id": "你的飞书应用App ID",
"app_secret": "你的飞书应用App Secret",
"tenant_access_token": ""
}
# 全局token缓存
TOKEN_EXPIRE_TIME = 0
# 内部工具:获取tenant_access_token
async def get_tenant_access_token() -> str:
global FEISHU_CONFIG, TOKEN_EXPIRE_TIME
current_time = asyncio.get_event_loop().time()
# token未过期直接返回
if FEISHU_CONFIG["tenant_access_token"] and current_time < TOKEN_EXPIRE_TIME:
return FEISHU_CONFIG["tenant_access_token"]
# 申请新token
url = "https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal"
async with httpx.AsyncClient() as client:
resp = await client.post(url, json={
"app_id": FEISHU_CONFIG["app_id"],
"app_secret": FEISHU_CONFIG["app_secret"]
}, timeout=10)
data = resp.json()
if data["code"] != 0:
raise Exception(f"获取飞书token失败:{data['msg']}")
FEISHU_CONFIG["tenant_access_token"] = data["tenant_access_token"]
TOKEN_EXPIRE_TIME = current_time + data["expire"] - 60
return FEISHU_CONFIG["tenant_access_token"]
# 工具1:获取飞书文档内容
@mcp.tool()
async def get_feishu_doc_content(doc_url: str) -> str:
"""
获取飞书文档的纯文本内容
:param doc_url: 飞书文档的链接,必填
"""
try:
token = await get_tenant_access_token()
# 提取文档token
if "docx/" in doc_url:
doc_token = doc_url.split("docx/")[1].split("?")[0]
doc_type = "docx"
elif "wiki/" in doc_url:
doc_token = doc_url.split("wiki/")[1].split("?")[0]
doc_type = "wiki"
else:
return "文档链接格式错误,仅支持飞书docx和wiki文档"
# 调用API获取内容
url = f"https://open.feishu.cn/open-apis/{doc_type}/v1/documents/{doc_token}/raw_content"
headers = {"Authorization": f"Bearer {token}"}
async with httpx.AsyncClient() as client:
resp = await client.get(url, headers=headers, timeout=30)
data = resp.json()
if data["code"] != 0:
return f"获取文档失败:{data['msg']},请检查应用权限"
return data["data"]["content"]
except Exception as e:
return f"获取飞书文档失败:{str(e)}"
# 工具2:发送飞书群消息
@mcp.tool()
async def send_feishu_group_message(chat_id: str, content: str) -> str:
"""
发送文本消息到指定飞书群
:param chat_id: 飞书群的chat_id,必填
:param content: 要发送的消息内容,必填
"""
try:
token = await get_tenant_access_token()
url = "https://open.feishu.cn/open-apis/im/v1/messages"
headers = {"Authorization": f"Bearer {token}"}
params = {"receive_id_type": "chat_id"}
body = {
"receive_id": chat_id,
"content": f'{{"text":"{content}"}}',
"msg_type": "text"
}
async with httpx.AsyncClient() as client:
resp = await client.post(url, headers=headers, params=params, json=body, timeout=10)
data = resp.json()
if data["code"] != 0:
return f"发送消息失败:{data['msg']},请检查应用是否加入群聊"
return f"消息发送成功,消息ID:{data['data']['message_id']}"
except Exception as e:
return f"发送飞书消息失败:{str(e)}"
# 工具3:查询用户今日日程
@mcp.tool()
async def get_today_calendar(user_open_id: str) -> str:
"""
查询指定用户今日的日程列表
:param user_open_id: 飞书用户的open_id,必填
"""
try:
token = await get_tenant_access_token()
tz = timezone(timedelta(hours=8))
today_start = datetime.now(tz).replace(hour=0, minute=0, second=0, microsecond=0)
today_end = today_start + timedelta(days=1)
url = "https://open.feishu.cn/open-apis/calendar/v4/calendars/primary/events"
headers = {"Authorization": f"Bearer {token}"}
params = {
"user_id_type": "open_id",
"start_time": int(today_start.timestamp() * 1000),
"end_time": int(today_end.timestamp() * 1000)
}
async with httpx.AsyncClient() as client:
resp = await client.get(url, headers=headers, params=params, timeout=10)
data = resp.json()
if data["code"] != 0:
return f"查询日程失败:{data['msg']}"
events = data["data"]["items"]
if not events:
return "今日暂无日程"
result = "【今日日程列表】\n"
for event in events:
start = datetime.fromtimestamp(int(event["start_time"])/1000, tz).strftime("%H:%M")
end = datetime.fromtimestamp(int(event["end_time"])/1000, tz).strftime("%H:%M")
result += f"● {start}-{end}:{event['summary']}\n"
if event["location"]:
result += f" 地点:{event['location']}\n"
return result.strip()
except Exception as e:
return f"查询日程失败:{str(e)}"
# 启动服务
if __name__ == "__main__":
asyncio.run(mcp.run())部署与配置
- 安装依赖:
pip install httpx - 飞书应用配置:
- 飞书开放平台创建企业自建应用,获取App ID和App Secret。
- 开启权限:「docx文档:只读权限」、「im:消息:群聊:发送权限」、「calendar:日程:只读权限」。
- 发布应用,企业管理员审核通过。
- 修改代码中的
FEISHU_CONFIG,配置你的App ID和App Secret。 - 在Claude配置文件中添加该服务,重启后即可使用。
3.3 案例3:Agent专属MCP Server - 对接LangChain实现复杂任务自动化
开发支持多工具组合、会话状态管理的MCP Server,对接LangChain Agent,实现爬虫+数据分析+报告生成的全流程自动化。
完整代码(agent_mcp.py)
python
from mcp.server.fastmcp import FastMCP, Context
import asyncio
import httpx
from bs4 import BeautifulSoup
import pandas as pd
from io import StringIO
from typing import Dict, Any
# 创建MCP Server实例,开启会话状态管理
mcp = FastMCP("Agent自动化服务", session_state=True)
# 全局会话状态存储(生产环境建议用Redis)
session_store: Dict[str, Dict[str, Any]] = {}
# 工具1:网页爬虫,获取网页正文内容
@mcp.tool()
async def crawl_webpage(url: str, ctx: Context) -> str:
"""
爬取指定网页的正文内容,去除广告和无关元素
:param url: 要爬取的网页URL,必填
"""
session_id = ctx.session_id
if session_id not in session_store:
session_store[session_id] = {}
try:
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
async with httpx.AsyncClient() as client:
resp = await client.get(url, headers=headers, timeout=30)
resp.raise_for_status()
# 解析网页
soup = BeautifulSoup(resp.text, "html.parser")
for tag in soup(["script", "style", "header", "footer", "nav", "aside"]):
tag.decompose()
# 获取正文
main_content = soup.get_text(separator="\n", strip=True)
# 存储到会话状态
session_store[session_id]["last_crawled_content"] = main_content
session_store[session_id]["last_crawled_url"] = url
return f"网页爬取成功,正文长度:{len(main_content)}字符\n内容预览:\n{main_content[:500]}..."
except Exception as e:
return f"网页爬取失败:{str(e)}"
# 工具2:表格数据解析与分析
@mcp.tool()
async def analyze_table_data(data: str, analysis_type: str = "basic", ctx: Context = None) -> str:
"""
解析表格数据,进行数据分析
:param data: 表格数据,支持CSV格式、Markdown表格格式,必填
:param analysis_type: 分析类型,可选:basic(基础统计)、describe(详细描述)、correlation(相关性分析),默认basic
"""
session_id = ctx.session_id if ctx else "default"
if session_id not in session_store:
session_store[session_id] = {}
try:
# 解析CSV数据
df = pd.read_csv(StringIO(data))
# 存储到会话状态
session_store[session_id]["last_dataframe"] = df.to_json()
# 执行分析
if analysis_type == "basic":
result = f"【基础统计分析】\n数据行数:{len(df)}\n数据列数:{len(df.columns)}\n列名:{', '.join(df.columns)}\n\n数据前5行:\n{df.head().to_string()}"
elif analysis_type == "describe":
result = f"【详细描述统计】\n{df.describe().to_string()}"
elif analysis_type == "correlation":
result = f"【相关性分析】\n{df.corr(numeric_only=True).to_string()}"
else:
result = "不支持的分析类型"
return result
except Exception as e:
return f"数据分析失败:{str(e)}"
# 工具3:生成Markdown格式的分析报告
@mcp.tool()
async def generate_report(title: str, content: str, ctx: Context) -> str:
"""
生成标准化的Markdown格式分析报告
:param title: 报告标题,必填
:param content: 报告正文内容,必填
"""
session_id = ctx.session_id
if session_id not in session_store:
session_store[session_id] = {}
# 生成报告
report = f"""
# {title}
## 报告生成时间
{pd.Timestamp.now().strftime('%Y-%m-%d %H:%M:%S')}
## 核心内容
{content}
## 附录
- 会话ID:{session_id}
- 数据来源:{session_store[session_id].get('last_crawled_url', '未知')}
"""
# 存储到会话状态
session_store[session_id]["last_report"] = report
return f"报告生成成功!\n{report}"
# 资源:获取当前会话的所有数据
@mcp.resource("agent://session/{session_id}/data")
async def get_session_data(session_id: str) -> str:
"""获取指定会话的所有存储数据"""
if session_id not in session_store:
return "会话不存在"
return str(session_store[session_id])
# 启动服务
if __name__ == "__main__":
asyncio.run(mcp.run())部署与配置
- 安装依赖:
pip install httpx beautifulsoup4 pandas - 在Claude配置文件中添加该服务,重启后即可实现复杂自动化任务,例如:
- 「爬取这个商品页面的价格数据,进行分析,生成一份价格趋势分析报告」
第四部分:精通篇 - 生产级架构与高级特性
4.1 MCP高级核心特性详解
4.1.1 会话状态管理
MCP支持会话级状态管理,每个客户端连接对应唯一的session_id,服务端可为每个会话存储独立状态,实现多步复杂操作的上下文保持。在FastMCP中,只需创建实例时开启session_state=True,即可在工具函数中通过ctx参数获取session_id。
4.1.2 资源订阅与实时推送
MCP支持资源订阅,客户端可订阅指定资源,当资源变化时,服务端主动推送更新通知,适用于系统日志监控、数据库变更、实时消息等场景。
示例:可订阅资源
python
@mcp.resource("monitor://system/logs", subscribe=True)
async def get_system_logs() -> str:
"""获取系统实时日志"""
with open("/var/log/syslog", "r") as f:
lines = f.readlines()
return "\n".join(lines[-10:])4.1.3 进度通知与异步任务
对于耗时较长的操作,MCP支持进度通知,服务端可在执行过程中主动推送进度信息,提升用户体验。
示例:进度通知
python
@mcp.tool()
async def process_large_file(file_path: str, ctx: Context) -> str:
"""处理大文件,支持进度通知"""
total_steps = 100
for i in range(total_steps):
await asyncio.sleep(0.1)
# 推送进度通知
await ctx.report_progress(i+1, total_steps, f"处理进度:{i+1}%")
return "文件处理完成"4.1.4 批处理与请求合并
MCP支持批量调用工具,客户端可将多个工具调用合并为一个批量请求,减少网络往返次数,提升性能,降低token消耗。
4.2 生产级MCP架构设计
企业级生产部署推荐采用以下分层架构:
用户层 → MCP Host(Claude/Cursor/Dify) → MCP Client SDK → MCP网关 → 多个MCP Server → 外部系统/数据源核心组件说明:
- MCP网关:核心组件,负责统一接入、认证授权、流量控制、日志审计、服务路由。
- 服务注册与发现:用Consul/Nacos实现MCP Server的注册与发现,客户端自动发现可用服务。
- 负载均衡:对多个MCP Server实例进行负载均衡,提升可用性和性能。
- 监控告警:用Prometheus+Grafana监控调用量、响应时间、错误率,设置告警规则。
- 日志审计:全链路日志采集,记录所有请求的调用方、参数、结果、耗时,满足合规要求。
4.3 跨模型兼容方案:一套MCP适配所有大模型
要实现一套MCP服务适配所有大模型,只需做到3点:
- 严格遵循MCP协议规范:不使用厂商自定义扩展,保证兼容性。
- 标准化元数据声明:工具描述、参数Schema足够清晰,让任何模型都能自动理解。
- 使用适配层:对于不原生支持MCP的模型(如OpenAI、Qwen),用LangChain/LlamaIndex的MCP适配层,自动转换为模型支持的Function Calling格式。
示例:LangChain适配MCP服务,对接OpenAI
python
from langchain_openai import ChatOpenAI
from langchain_mcp import MCPToolkit
from langchain.agents import create_tool_calling_agent, AgentExecutor
from langchain_core.prompts import ChatPromptTemplate
# 初始化MCP工具包,连接你的天气服务
toolkit = MCPToolkit.from_stdio(
command="python",
args=["/path/to/weather_mcp.py"]
)
tools = toolkit.get_tools()
# 初始化大模型
llm = ChatOpenAI(model="gpt-4o", api_key="你的OpenAI API Key")
# 创建Agent
prompt = ChatPromptTemplate.from_messages([
("system", "你是专业的天气助手,使用提供的工具查询天气信息"),
("human", "{input}"),
("agent_scratchpad", "{agent_scratchpad}"),
])
agent = create_tool_calling_agent(llm, tools, prompt)
executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 执行Agent
result = executor.invoke({"input": "查询成都今天的天气"})
print(result["output"])4.4 全链路安全管控体系
生产级部署的安全管控分为5层:
- 传输层安全:本地STDIO传输天然安全;远程WebSocket/HTTP传输必须使用TLS 1.3加密。
- 认证授权:客户端接入用API Key/OAuth2.0认证;基于RBAC模型,为每个客户端分配细粒度权限。
- 输入校验与安全过滤:所有输入参数严格校验,防止SQL注入、命令注入等攻击;高危操作设置白名单。
- 审计与日志:全链路日志记录,敏感操作审计,异常操作实时告警。
- 运行时安全:MCP Server运行在沙箱环境中,限制系统权限;设置超时和限流规则,防止DoS攻击。
第五部分:最佳实践与避坑指南
5.1 开发最佳实践
- 工具设计:每个工具职责单一,描述和参数注释足够详细;严格校验输入参数;统一错误处理,返回清晰的错误信息。
- 资源设计:URI命名语义清晰;大内容必须支持分页;敏感资源设置严格的权限控制。
- 提示词模板设计:通用可复用,明确参数含义,与对应工具/资源绑定实现一体化工作流。
5.2 常见坑与解决方案
| 常见问题 | 原因分析 | 解决方案 |
|---|---|---|
| Claude不识别MCP服务 | 配置路径错误、JSON格式错误、服务启动失败 | 检查配置路径和JSON格式;手动运行服务查看报错 |
| 模型不调用工具,直接回答 | 工具描述不清晰、参数定义不明确 | 优化工具文档字符串,明确参数含义 |
| 服务调用超时 | 工具执行时间过长、网络问题 | 异步执行+进度通知;增加超时重试机制 |
| 上下文溢出 | 工具返回内容过长 | 分页、裁剪、摘要返回内容;限制最大长度 |
| 多客户端调用状态混乱 | 未使用会话状态,全局变量共享 | 开启session_state,用session_id隔离会话数据 |
5.3 调试与排障技巧
- 用
mcp dev your_server.py调试服务,查看完整的请求响应日志。 - 开启FastMCP的DEBUG日志,查看完整的协议交互。
- 分步调试:先验证工具函数逻辑,再接入MCP服务,最后接入客户端。
- 检查客户端和服务端的协议版本是否兼容(当前稳定版
2024-11-05)。
第六部分:MCP生态与学习资源
6.1 主流MCP客户端
- 原生支持:Claude Desktop、Cursor IDE、WindSurf、Roo Code、Dify
- 框架支持:LangChain、LlamaIndex、AutoGen、Haystack
- 开源工具:官方MCP CLI、mcp-inspector
6.2 主流MCP服务端与社区资源
- 官方服务:@modelcontextprotocol/server-filesystem、server-git、server-postgres
- 社区开源服务:飞书MCP、语雀MCP、GitHub MCP、浏览器MCP、数据库万能连接器
- MCP市场:https://mcphub.io/ ,收录大量开箱即用的MCP服务
6.3 官方文档与进阶学习路径
- 官方规范文档:https://modelcontextprotocol.io/
- 官方GitHub组织:https://github.com/modelcontextprotocol
- 中文文档:https://mcp-docs.cn/
- 进阶学习路径 :
- 入门:跑通官方示例,开发简单MCP服务
- 进阶:开发生产级MCP服务,对接企业内部系统
- 精通:设计企业级MCP架构,贡献社区开源服务