tiktoken Python 库
介绍
OpenAI 官方推出的用于计算文本 token 数量的工具,也是各类大语言模型(LLM)计算上下文长度、计费的核心工具
tiktoken 是 OpenAI 开源的快速 BPE(字节对编码)token 编码 / 解码库
相比传统 GPT2Tokenizer 等库,它速度更快、内存占用更低
专门适配 OpenAI 全系列模型(如 gpt-3.5-turbo、gpt-4、gpt-4o 等)token 计算规则
Token:可以理解为大模型处理文本的 "最小单位",1 个 token 约等于英文 4 个字符 / 中文 1-2 个汉字
模型的上下文窗口(如 gpt-4o 的 128k)就是按 token 数量计算的
核心作用:计算一段文本会被模型拆分成多少个 token,这直接关系到 API 调用的费用和上下文是否超限
安装与基础使用
bash
pip install tiktoken
python
import tiktoken
# 1. 选择对应模型的编码(不同模型的编码规则不同)
# 常用编码映射:
# gpt-3.5-turbo/gpt-4/gpt-4o → "cl100k_base"
# gpt-3.5-turbo-0301 → "p50k_base"
# text-davinci-003 → "p50k_base"
# gpt-2/gpt-3 → "r50k_base"
# 方式1:直接指定编码名称
encoding = tiktoken.get_encoding("cl100k_base")
# 方式2:根据模型名称自动匹配编码(更推荐,适配模型更新)
def get_encoding_by_model(model_name):
try:
return tiktoken.encoding_for_model(model_name)
except KeyError:
print(f"未找到 {model_name} 的编码,默认使用 cl100k_base")
return tiktoken.get_encoding("cl100k_base")
# 示例:计算 gpt-4o 模型的 token 数量
model_name = "gpt-4o"
encoding = get_encoding_by_model(model_name)
# 2. 编码(文本 → token 列表)
text = "你好,我是使用 tiktoken 计算 token 的示例。Hello, tiktoken!"
tokens = encoding.encode(text)
print(f"文本:{text}")
print(f"Token 列表:{tokens}")
print(f"Token 数量:{len(tokens)}") # 输出:19(不同版本可能略有差异)
# 3. 解码(token 列表 → 文本)
decoded_text = encoding.decode(tokens)
print(f"解码后的文本:{decoded_text}") # 输出原文本
# 4. 批量计算多段文本的 token 数
text_list = ["今天天气很好", "OpenAI tiktoken is fast", "1234567890"]
token_counts = [len(encoding.encode(t)) for t in text_list]
print(f"批量 token 数:{token_counts}") # 输出:[7, 8, 6]tiktoken.get_encoding(encoding_name):根据编码名称获取编码对象(如 cl100k_base)
tiktoken.encoding_for_model(model_name):根据模型名称自动匹配对应的编码(推荐,无需记编码名)
encoding.encode(text):将文本转换为 token 整数列表,返回列表长度即为 token 数
encoding.decode(tokens):将 token 列表还原为文本
encoding.encode_single_token(text):将单个 token 文本转换为对应的整数(如 encoding.encode_single_token("你") 返回 8214)
API 调用前校验:确保输入文本的 token 数不超过模型的上下文窗口(如 gpt-4o 最大 128000 token)
计费预估:OpenAI API 按输入 / 输出 token 数计费,提前计算可预估费用
文本截断:当文本过长时,按 token 数截断(而非字符数),避免模型处理失败
示例:文本截断(保留前 10 个 token)
python
max_tokens = 10
truncated_tokens = tokens[:max_tokens]
truncated_text = encoding.decode(truncated_tokens)
print(f"截断后的文本:{truncated_text}") # 输出:你好,我是使用 tiktoken 计算中文 token 计算:中文每个字 / 标点通常会被拆分为 1-2 个 token,而非按字符数计算(比如 "你好" 是 2 个 token,"," 是 1 个 token)
编码兼容性:不同模型的编码规则不同,必须用对应编码(如 gpt-3.5-turbo 用 cl100k_base,不能用 r50k_base)
速度优势:tiktoken 是用 Rust 实现的核心逻辑,比纯 Python 的 tokenizer 快 10-100 倍,适合批量处理文本
总结
tiktoken 是 OpenAI 官方的高效 token 计算库,核心用于文本与 token 之间的编码 / 解码,是调用 OpenAI API 的必备工具
核心用法:通过 encoding_for_model() 匹配模型编码,用 encode() 计算 token 数,decode() 还原文本
关键注意点:不同模型对应不同编码规则,中文 token 数≠字符数,需按 token 数校验 / 截断文本
核心原理
介绍
BPE(Byte Pair Encoding,字节对编码) 是一种无损数据压缩和子词分词算法
核心思想:从数据中自动学习高频字符/子词对,合并成新符号,反复迭代以减少序列长度
广泛用于 LLM 的 tokenizer(如 GPT、BERT),平衡了词汇表大小和语义完整性
压缩文本序列:减少字符序列的长度,降低存储和计算成本
子词级分词:解决 OOV(未登录词)问题,例如将 unhappiness 拆分为 un + happy + ness,而非单个字符
适配 LLM 需求:让模型既能处理常见词,也能处理罕见词 / 新词
BPE 的执行分为 训练阶段(学习合并规则)和 推理阶段(应用合并规则分词):
训练阶段(学习合并规则)
输入:原始语料库 + 初始词汇表(所有单个字符) + 预设合并次数k
输出:合并规则列表(高频子词对 → 新子词)
步骤详解:
初始化词汇表
将语料中所有文本拆分为单个字符,并在每个词末尾添加结束符(区分词边界,例如low → l o w )
统计每个字符的频率
示例语料(简化):
"low", "low", "newer", "wider", "newer"
拆分后:
l o w , l o w , n e w e r , w i d e r , n e w e r
初始词汇表:{l, o, w, , n, e, r, i, d}
统计字符对频率
遍历所有词,统计相邻字符对的出现次数
示例统计结果:
| 字符对 | 频率 |
|---|---|
| (l,o) | 2 |
| (o,w) | 2 |
| (w,) | 2 |
| (n,e) | 2 |
| (e,w) | 2 |
| (e,r) | 2 |
| (r,) | 3 |
合并最高频字符对
找到频率最高的字符对,将其合并为新子词,并添加到词汇表。
示例:最高频对是(r,)(频率 3),合并为r
用新子词替换所有词中的对应字符对
替换后词序列:
l o w , l o w , n e w e r, w i d e r, n e w e r
重复迭代
重复步骤 2-3,共执行k次合并(k是超参数,决定词汇表大小)
每次合并都会生成一条合并规则(例如r + → r)
生成最终词汇表
合并k次后,词汇表包含初始字符 + k个新子词
推理阶段(分词)
输入:待分词文本 + 训练好的合并规则 + 词汇表
输出:子词序列
步骤:
将输入词拆分为单个字符 +
按合并规则的优先级(训练时的合并顺序),依次检查词中是否存在可合并的子词对,若存在则合并
直到无法再合并为止,最终的子词序列即为分词结果
示例:用训练好的规则分词newest
拆分:n e w e s t
应用规则合并e + w → ew → n ew e s t
继续应用规则合并ew + e → ewe → n ewe s t
最终分词:n ewe s t
BPE 关键特点
优点 缺点
解决 OOV 问题,适配新词 合并次数k需人工调参,影响分词效果
词汇表大小可控 无法处理语义无关的高频字符对
训练速度快,易于实现 对词边界依赖强(需标记)
在大模型作用
无需使用特殊词元 <|unk|> 来替换未知单词,解决 OOV 问题
滑动窗口(Sliding Window)进行数据采样
大模型训练使用滑动窗口(Sliding Window) 进行数据采样:是处理超长文本、适配模型上下文窗口(Context Window)的核心技术
能让模型高效学习长文本中的局部依赖关系,同时避免显存溢出
滑动窗口采样的核心逻辑
大模型的上下文窗口(如 GPT-4o 的 128k、Llama 3 的 8k)是固定的,而训练语料往往是远超窗口长度的超长文本(如整本书、长文档)
滑动窗口采样的核心:
将超长文本切割成多个重叠 / 不重叠的固定长度窗口(窗口长度 = 模型上下文窗口长度)
每个窗口作为一个独立的训练样本,输入模型进行训练
通过步长(Stride) 控制窗口间的重叠程度,平衡数据利用率和训练效率
stride straɪd
n. 大步,阔步;步态,步伐;步距,步幅;步速;进展,进步;<非正式>裤子(strides);钢琴跨越弹奏法
v. 大步走,阔步走;跨越,跨过;<文>跨坐在......上,跨立在......上
关键概念
概念 含义 示例(模型窗口长度 = 10)
窗口长度(Window Size) 单个样本的 token 数,等于模型上下文窗口长度 10 个 token
步长(Stride) 窗口滑动的 token 数 步长 = 5 → 相邻窗口重叠 5 个 token
重叠率 相邻窗口的重叠 token 比例 步长 = 5 → 重叠率 = 50%
重叠token数 = window_size - stride
重叠率 = (window_size - stride) / window_size × 100%
示例:
window_size=1024, stride=512 → 重叠 token 数 = 512 → 重叠率 = 50%
window_size=1024, stride=1024 → 重叠 token 数 = 0 → 重叠率 = 0%
window_size=1024, stride=256 → 重叠 token 数 = 768 → 重叠率 = 75%
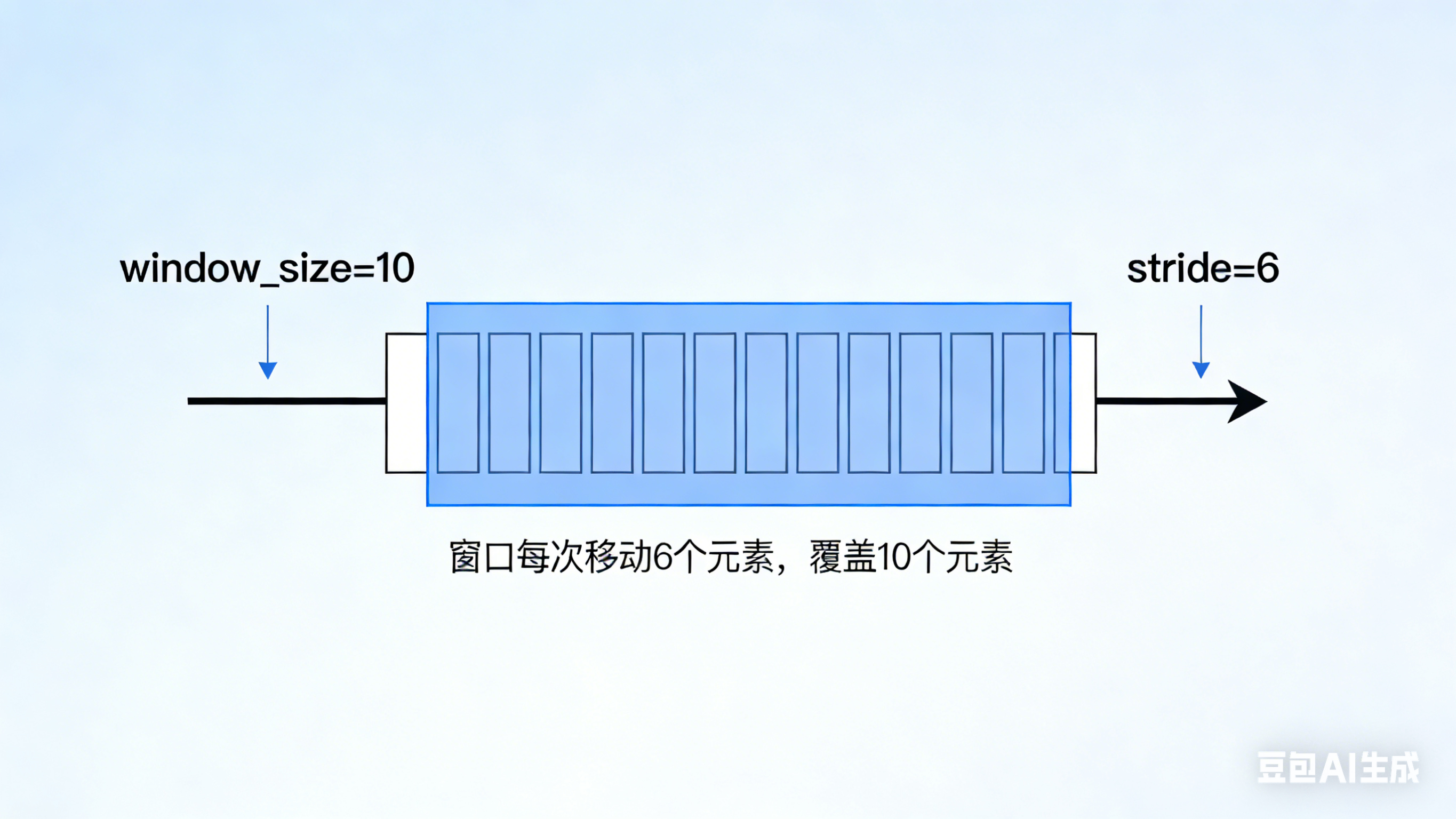
滑动窗口采样的实现
基础版(无重叠) 和进阶版(带重叠),并兼容 tiktoken 计算 token 数:
python
import tiktoken
from typing import List, Tuple
# 初始化tokenizer(适配GPT-4o)
tokenizer = tiktoken.encoding_for_model("gpt-4o")
def sliding_window_sampling(
text: str,
window_size: int = 1024, # 模型上下文窗口长度
stride: int = 512, # 滑动步长
add_eos: bool = True # 是否在每个窗口末尾添加EOS token
) -> List[Tuple[List[int], List[int]]]:
"""
对超长文本进行滑动窗口采样,生成(输入token, 目标token)训练对
:param text: 原始超长文本
:param window_size: 窗口长度(token数)
:param stride: 滑动步长(token数)
:param add_eos: 是否添加EOS token(标记文本结束)
:return: 列表,每个元素是(输入token列表, 目标token列表),目标比输入右移一位(自回归训练)
"""
# 1. 将文本编码为token序列
tokens = tokenizer.encode(text)
if add_eos:
eos_token = tokenizer.encode_single_token("<|endoftext|>") # OpenAI EOS token
tokens.append(eos_token)
# 2. 边界检查
if len(tokens) <= window_size:
# 文本长度≤窗口长度,直接作为单个样本
input_tokens = tokens[:-1] # 输入:最后一个token除外
target_tokens = tokens[1:] # 目标:右移一位(自回归训练)
return [(input_tokens, target_tokens)]
# 3. 滑动窗口切割
train_pairs = []
start_idx = 0
max_idx = len(tokens) - 1 # 预留最后一个token作为目标
while start_idx <= max_idx - window_size:
# 截取当前窗口的token(输入窗口长度=window_size)
end_idx = start_idx + window_size
window_tokens = tokens[start_idx:end_idx + 1] # +1是为了目标右移
# 生成输入-目标对(自回归训练:输入→目标,目标比输入右移一位)
input_tokens = window_tokens[:-1]
target_tokens = window_tokens[1:]
train_pairs.append((input_tokens, target_tokens))
# 滑动窗口
start_idx += stride
# 处理最后一个窗口(避免尾部文本被截断)
if start_idx < max_idx:
window_tokens = tokens[-window_size - 1:] # 取最后window_size+1个token
input_tokens = window_tokens[:-1]
target_tokens = window_tokens[1:]
train_pairs.append((input_tokens, target_tokens))
return train_pairs
# ---------------------- 示例使用 ----------------------
if __name__ == "__main__":
# 超长文本示例(模拟书籍/长文档)
long_text = """
人工智能(AI)是一门旨在使机器模拟人类智能的技术科学。它涵盖了机器学习、自然语言处理、计算机视觉等多个领域。
机器学习是AI的核心分支,通过数据训练模型,让模型自主学习规律。深度学习是机器学习的子集,基于神经网络实现复杂任务。
大语言模型(LLM)是深度学习的应用之一,通过海量文本训练,能够理解和生成人类语言。GPT、Llama、文心一言等都是典型的LLM。
长文本处理是LLM的关键挑战之一,滑动窗口采样是解决该问题的核心方法,能让模型高效学习长文本中的上下文依赖。
模型的上下文窗口长度决定了其能处理的文本长度,滑动窗口则能将超长文本切割为适配窗口的样本,平衡训练效率和效果。
"""
# 滑动窗口采样(窗口长度=20,步长=10,模拟小窗口模型)
train_samples = sliding_window_sampling(
text=long_text,
window_size=20,
stride=10
)
# 打印采样结果
print(f"原始文本token总数:{len(tokenizer.encode(long_text))}")
print(f"采样得到的训练样本数:{len(train_samples)}")
print("\n第一个样本:")
print(f"输入token(前10个):{train_samples[0][0][:10]}")
print(f"输入文本:{tokenizer.decode(train_samples[0][0])}")
print(f"目标token(前10个):{train_samples[0][1][:10]}")
print(f"目标文本:{tokenizer.decode(train_samples[0][1])}")代码关键解释
token 编码:使用tiktoken将文本转为 token 序列,适配 OpenAI 系模型的编码规则
自回归训练对:输入 token 是窗口内前 N 个,目标 token 是后 N 个(右移一位),符合大模型自回归生成的训练逻辑
滑动逻辑:
按stride步长滑动,直到覆盖整个文本
最后一个窗口强制截取尾部文本,避免丢失信息
重叠控制:
步长越小,窗口重叠越多(如步长 = 窗口长度→无重叠,步长 = 窗口长度 / 2→50% 重叠)
滑动窗口采样的进阶优化
动态窗口长度
针对文本中的自然边界(如段落、句子)调整窗口,避免切割语义完整的单元
python
def split_by_sentence(text: str) -> List[str]:
"""按句子分割文本,避免窗口切割句子"""
import re
return re.split(r'[。!?;]', text)
def dynamic_window_sampling(text: str, window_size: int, stride: int):
sentences = split_by_sentence(text)
# 合并句子直到接近窗口长度,再滑动
merged_texts = []
current = ""
for sent in sentences:
if len(tokenizer.encode(current + sent)) < window_size:
current += sent
else:
merged_texts.append(current)
current = sent
merged_texts.append(current)
# 对合并后的文本进行滑动窗口采样
all_samples = []
for merged in merged_texts:
samples = sliding_window_sampling(merged, window_size, stride)
all_samples.extend(samples)
return all_samples随机滑动窗口(增强泛化性)
训练时随机调整窗口起始位置,避免模型过拟合固定窗口边界
python
def random_sliding_window_sampling(
text: str,
window_size: int,
num_samples: int = 5
) -> List[Tuple[List[int], List[int]]]:
"""随机采样窗口,而非顺序滑动"""
tokens = tokenizer.encode(text)
if len(tokens) <= window_size:
return [(tokens[:-1], tokens[1:])]
train_pairs = []
for _ in range(num_samples):
# 随机选择起始位置
start_idx = random.randint(0, len(tokens) - window_size - 1)
end_idx = start_idx + window_size
window_tokens = tokens[start_idx:end_idx + 1]
input_tokens = window_tokens[:-1]
target_tokens = window_tokens[1:]
train_pairs.append((input_tokens, target_tokens))
return train_pairs滑动窗口采样的适用场景与注意事项
适用场景
超长文本训练:如书籍、论文、代码库等远超模型上下文窗口的文本
长上下文模型预训练:提升模型对长文本的依赖关系捕捉能力
低显存训练:单个窗口样本显存占用可控,避免 OOM(显存溢出)
注意事项
步长选择:
步长 = 窗口长度:无重叠,训练效率高,但可能丢失跨窗口依赖
步长 = 窗口长度 / 2:50% 重叠,平衡效率和效果(主流选择)
语义完整性:尽量按自然边界(句子、段落)切割,避免窗口切割核心语义
窗口长度对齐:窗口长度需等于模型的上下文窗口长度,否则需 padding/truncation
总结
滑动窗口采样的核心是将超长文本切割为固定长度、可重叠的窗口样本,适配大模型的上下文窗口限制
核心参数是窗口长度(等于模型上下文长度) 和步长(控制重叠率),步长越小重叠越多,数据利用率越高
进阶优化可通过动态窗口(按语义分割) 和随机窗口(增强泛化) 提升训练效果,同时需注意语义完整性和显存占用
DataLoader中的批次的概念
DataLoader批次为1和4的区别,stride=4,以 in the heart of the city stood the old library, a relic from a bygone era.
DataLoader 加载文本时,通常会先把句子拆分为词 / Token 序列,再按 batch_size(批次大小)和 stride(步长)切分成批量的样本:
batch_size:每一批次加载的样本数量;
stride:滑动窗口每次移动的 Token 数(决定样本间的重叠 / 间隔);
先将例句拆分为 Token 序列(按空格拆分,忽略标点,共 16 个 Token):
plaintext
[0:in, 1:the, 2:heart, 3:of, 4:the, 5:city, 6:stood, 7:the, 8:old, 9:library, 10:a, 11:relic, 12:from, 13:a, 14:bygone, 15:era]场景 1:batch_size=1,stride=4
核心逻辑:每次只加载 1 个样本,滑动窗口每次移动 4 个 Token,样本间无重叠(因为 stride=4 等于窗口长度,这里假设窗口长度 = 4,是 NLP 中常见的 "固定窗口切分")。
具体切分过程(窗口长度 = 4):
批次序号 加载的样本(Token 索引) 样本内容 批次内样本数
1 0,1,2,3 in the heart of 1
2 4,5,6,7 the city stood the 1
3 8,9,10,11 old library a relic 1
4 12,13,14,15 from a bygone era 1
关键特点:
总共生成 4 个批次,每个批次只有 1 个样本;
每个样本是连续的 4 个 Token,且样本间完全不重叠(因为 stride=4 刚好跳过前一个样本的所有 Token);
数据加载次数多(4 次),每次处理的数据量小,适合显存 / 内存极小的场景,但效率低。
场景 2:batch_size=4,stride=4
核心逻辑:每次加载 4 个样本,滑动窗口仍移动 4 个 Token,一次性把所有切分好的样本加载完成(因为总样本数 = 4,刚凑成 1 批次)。
具体切分过程(窗口长度 = 4):
批次序号 加载的样本(Token 索引) 样本内容 批次内样本数
1 0,1,2,3 in the heart of 4
4,5,6,7 the city stood the
8,9,10,11 old library a relic
12,13,14,15 from a bygone era
关键特点:
总共只生成 1 个批次,一次性加载所有 4 个样本;
样本内容和 batch_size=1 时完全一致,但加载次数从 4 次减少到 1 次,效率大幅提升
要求显存 / 内存能容纳 4 个样本的数据量,是深度学习中更常用的配置(批量处理提升计算效率)
延伸:如果窗口长度 > stride(比如窗口长度 = 6,stride=4)
若窗口长度大于步长,样本会出现重叠,两种批次大小的差异会更明显:
batch_size=1:批次 1 加载 0-5,批次 2 加载 4-9(重叠 Token 4-5),批次 3 加载 8-13,批次 4 加载 12-15(补零),共 4 批次;
batch_size=4:1 个批次直接加载 0-5、4-9、8-13、12-15 这 4 个重叠样本,一次性处理。
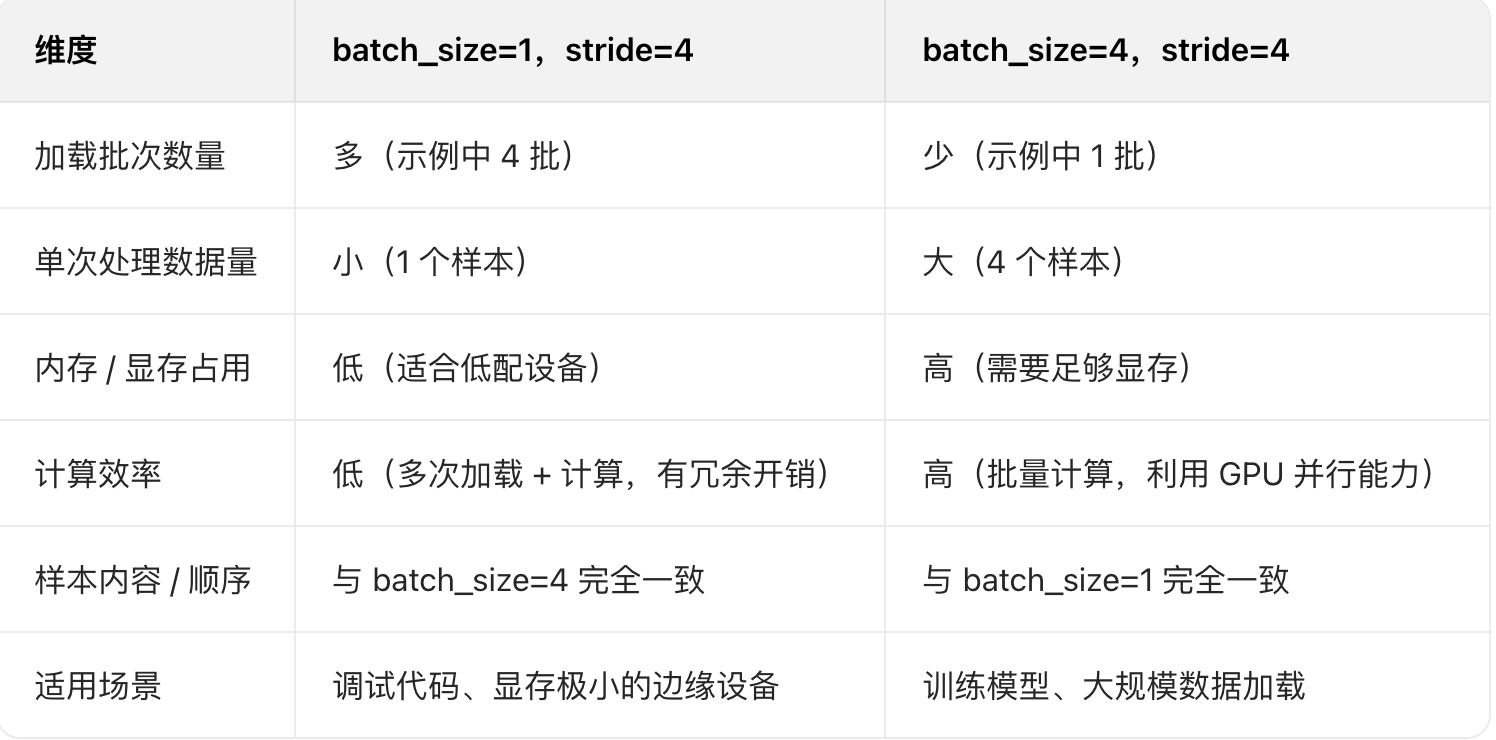
核心区别总结
总结
batch_size 只影响 "每批加载的样本数",不改变样本本身的内容 / 切分逻辑(stride 固定时)
stride=4 决定了样本间的间隔 / 重叠,和 batch_size 无关
实际开发中,batch_size=4 是更高效的选择(充分利用硬件并行能力),而 batch_size=1 仅用于调试或资源极度受限的场景
两者的核心差异是加载效率和资源占用,而非样本本身的内容:batch_size 越大,加载次数越少,计算效率越高,但对硬件的要求也越高
过多重叠的问题
模型过拟合风险