nvidia官方最近发布了Hybrid-EP,已经开源在DeepEP仓库,整体架构类似DeepEP的normal,相对DeepEP,Hybrid-EP降低了对SM的占用,并且在超节点表现更好。
用法
cpp
buffer = deep_ep.HybridEPBuffer(
group=group,
hidden_dim=HIDDEN_DIM,
max_num_of_tokens_per_rank=MAX_NUM_OF_TOKENS_PER_RANK,
num_local_experts=NUM_LOCAL_EXPERTS,
num_of_hybrid_ep_ranks_per_nvlink_domain=NUM_OF_RANKS_PER_NODE,
use_mnnvl=USE_MNNVL,
use_fp8=use_fp8
)
dispatched_hidden, dispatched_probs, _, handle = (
buffer.dispatch(hidden=hidden, scaling_factor=scaling_factor, topk_idx=topk_idx, topk_weights=topk_weights, num_of_experts=NUM_OF_EXPERTS)用法很简单,创建一个HybridEPBuffer,然后执行buffer.dispatch就可以。
初始化
首先看下buffer的初始化,MAX_NUM_OF_TOKENS_PER_RANK表示所有rank中传入dispatch kernel的token最大值,
cpp
class HybridEPBuffer:
def __init__(...):
self.num_sms_preprocessing_api = num_sms_preprocessing_api
self.num_sms_dispatch_api = num_sms_dispatch_api
self.num_sms_combine_api = num_sms_combine_api
self.num_blocks_permute_api = num_blocks_permute_api
self.config.num_of_experts_per_rank = num_local_experts
self.config.num_of_ranks_per_node = self.num_of_hybrid_ep_ranks_per_nvlink_domain
self.config.num_of_nodes = self.num_of_nodes
self.runtime = hybrid_ep_cpp.HybridEPBuffer(...)首先设置超参,比如num_sms_dispatch_api表示dispatch使用多少个CTA,num_of_ranks_per_node表示一个node有多少个rank,这里的node指的不是OS粒度,而是值一个nvlink domain,比如使用单机八卡的机型,一个node有8个rank,如果对于NVL32,那么一个node有32个rank。
分配buffer
cpp
void HybridEPBuffer::allocate_buffer() {
// Token number at the worst case, all tokens are routed to the same expert.
this->max_num_of_tokens = buffer_config.max_num_of_tokens_per_rank *
buffer_config.num_of_ranks_per_node *
buffer_config.num_of_nodes;
allocate_buffer_for_preprocessing();
allocate_buffer_for_dispatch();
exchange_remote_handle();
}HybridEPBuffer::max_num_of_tokens表示一个rank最多会收到的token数,极端情况就是所有rank的token都会dispatch到当前rank。
cpp
enum scan_state{
EMPTY = 0,
PRIV_SUM = 1
};
struct tmp_state_t{
scan_state state;
int32_t value;
};
void HybridEPBuffer::allocate_buffer_for_preprocessing() {
auto preprocessing_tmp_elts =
buffer_config.num_of_blocks_preprocessing_api * buffer_config.num_of_ranks_per_node;
cudaMalloc((void **)&this->preprocessing_tmp, preprocessing_tmp_elts * sizeof(hybrid_ep::tmp_state_t));
}这里分配预处理阶段所需要的buffer,预处理的时候会计算一个前缀和,前缀和计算过程中,block之间需要通过GMEM进行通信,因此分配了CTA数量个tmp_state_t,tmp_state_t包含value和state,value用于保存前缀和,state为flag,表示value是否ready。
cpp
void HybridEPBuffer::allocate_buffer_for_dispatch() {
auto expert_output_token_elts = max_num_of_tokens * buffer_config.hidden_dim;
remote_allocator.allocate((void**)&dispatch_buffers.expert_output_token, expert_output_token_elts * sizeof_token_data_type);
MemHandle handles[4];
remote_allocator.get_handle(&handles[0], dispatch_buffers.expert_output_token);
// Pack handles into tensor
dispatch_memory_handles = torch::empty({static_cast<int64_t>(sizeof(handles))},
torch::dtype(torch::kUInt8).device(torch::kCPU));
memcpy(dispatch_memory_handles.data_ptr<uint8_t>(), handles, sizeof(handles));
}然后开始分配机内用于dispatch的buffer,每个rank分配用于接收其他rank dispatch过来的数据,如前所述,最差的情况是所有rank的数据都会被dispatch过来,因此这里分配的大小为max_num_of_tokens,然后通过get_handle获取ipc handle,写入到dispatch_memory_handles。然后通过allgather进行机内所有rank ipc handle的交换。
cpp
void HybridEPBuffer::open_handles_from_other_ranks(std::vector<torch::Tensor> dispatch_handles) {
// Malloc the pointer arrays used in the dispatch kernel.
dispatch_buffers.expert_output_token_all_ranks = (void **)malloc(buffer_config.num_of_ranks_per_node * sizeof(void *));
auto global_offset = node_rank * buffer_config.num_of_ranks_per_node;
for (int i = 0; i < buffer_config.num_of_ranks_per_node; i++) {
MemHandle expert_output_token_handle, expert_output_prob_handle,
expert_output_scaling_factor_handle;
auto base_ptr = dispatch_handles[i + global_offset].data_ptr<uint8_t>();
memcpy(&expert_output_token_handle, base_ptr, sizeof(MemHandle));
// Open the handles for export_output
if (i != local_rank) {
remote_allocator.open_handle((void**)(&dispatch_buffers.expert_output_token_all_ranks[i]),
&expert_output_token_handle);
} else {
// For local rank, use direct pointer assignment (more efficient, no IPC overhead)
dispatch_buffers.expert_output_token_all_ranks[i] =
dispatch_buffers.expert_output_token;
}
}
}dispatch_handles是allgather之后的结果,然后分配expert_output_token_all_ranks用于保存机内所有rank的buffer,通过open_handle将ipc handle对应的地址记录到expert_output_token_all_ranks的对应位置。
RDMA初始化
cpp
void RDMACoordinator::init(...) {
hybrid_ep::get_nic(gpu_idx_vec, local_device_idx, &net_name);
ib_context = ibv_open_device(ib_dev);
ibv_query_port(ib_context, IB_PORT, &port_attr);
uint8_t link_layer = port_attr.link_layer;
hybrid_ep::ncclIbGetGidIndex(ib_context, IB_PORT, &port_attr, &gid_index);
ib_pd = ibv_alloc_pd(ib_context);
gpu_handler = (struct doca_gpu *)calloc(1, sizeof(struct doca_gpu));
get_gpu_handler(gpu_handler, ib_context, local_device_idx);
mr_access_flag = IBV_ACCESS_LOCAL_WRITE | IBV_ACCESS_REMOTE_WRITE | IBV_ACCESS_REMOTE_READ |
IBV_ACCESS_REMOTE_ATOMIC | IBV_ACCESS_RELAXED_ORDERING;
}init过程中一个node是指一个OS粒度,这里就是通过get_nic找到最近的网卡,然后初始化,gpu_handler就是记录ibgda相关的信息,比如是否支持dmabuf,是否支持bfuar等。
cpp
void RDMACoordinator::allocate_dispatch_rdma_buffers(DispatchBuffers &dispatch_buffers) {
auto attn_input_token_elts = buffer_config.max_num_of_tokens_per_rank * buffer_config.hidden_dim;
auto rdma_inter_node_group_token_elts = buffer_config.max_num_of_tokens_per_rank *
(buffer_config.num_of_nodes - 1) *
buffer_config.hidden_dim;
auto rdma_inter_node_group_flags_elts = ((buffer_config.max_num_of_tokens_per_rank - 1) /
buffer_config.num_of_tokens_per_chunk_dispatch_api + 1) *
(buffer_config.num_of_nodes - 1);
// Allocate RDMA buffers
CUDA_CHECK(cudaMalloc((void**)&dispatch_buffers.attn_input_token,
attn_input_token_elts * sizeof_token_data_type));
CUDA_CHECK(cudaMalloc((void**)&dispatch_buffers.rdma_inter_node_group_token,
rdma_inter_node_group_token_elts * sizeof_token_data_type));
CUDA_CHECK(cudaMalloc((void**)&dispatch_buffers.rdma_inter_node_group_flags,
rdma_inter_node_group_flags_elts * sizeof(uint64_t)));
CUDA_CHECK(cudaMalloc((void**)&dispatch_buffers.attn_input_flags,
rdma_inter_node_group_flags_elts * sizeof(uint64_t)));
attn_input_token_mr = ibv_reg_mr(ib_pd, dispatch_buffers.attn_input_token,
attn_input_token_elts * sizeof_token_data_type, mr_access_flag);
dispatch_rdma_inter_node_group_token_mr = ibv_reg_mr(ib_pd, dispatch_buffers.rdma_inter_node_group_token,
rdma_inter_node_group_token_elts * sizeof_token_data_type, mr_access_flag);
attn_input_flags_mr = ibv_reg_mr(ib_pd, dispatch_buffers.attn_input_flags,
rdma_inter_node_group_flags_elts * sizeof(uint64_t), mr_access_flag);
dispatch_rdma_inter_node_group_flags_mr = ibv_reg_mr(ib_pd, dispatch_buffers.rdma_inter_node_group_flags,
rdma_inter_node_group_flags_elts * sizeof(uint64_t), mr_access_flag);然后开始分配rdma buffer,由于用户输入的hidden可能没有通过rdma注册过,不能直接用于rdma传输,因此这里通过attn_input_token存储用户传入的hidden,大小为hidden_dim * max_num_of_tokens_per_rank。rdma_inter_node_group_token用于接收其他机器同号卡通过网络转发过来的token,因此大小为单个rank 传入的hidden大小乘以(node_num - 1)。
Hybrid-EP中对token的处理是分chunk粒度的,默认大小为128个token,在机间通信的时候处理一个chunk大小的token,将这个chunk中nodex需要的token发送过去,完成之后再写一个flag给对端,表示完成了这个chunk的发送,所以flag的大小为所有同号卡机器token数的和再除以chunk。flag的发送通过rdma atomic,rdma_inter_node_group_flags为实际的flag,用于接收其他机器同号卡的atomic写入,attn_input_flags为atomic的返回值。最后注册mr。
cpp
void RDMACoordinator::allocate_dispatch_rdma_buffers(DispatchBuffers &dispatch_buffers) {
int num_of_dispatch_qps = (buffer_config.num_of_nodes - 1) * buffer_config.num_of_blocks_dispatch_api;
dispatch_gverbs_ctx.qp_hls = (struct doca_gpu_verbs_qp_hl **)calloc(sizeof(struct doca_gpu_verbs_qp_hl *), num_of_dispatch_qps);
create_and_place_qps(&dispatch_gverbs_ctx, dispatch_gverbs_ctx.qp_init_attr, num_of_dispatch_qps);
}然后开始建链,Hybrid-EP中对于ibgda用的是doca接口,doca接口之前在nccl gin中有做过介绍,这里不再过多赘述。
对于一个peer node,一个CTA使用一个单独的qp和这个peer通信,因此总qp数num_of_dispatch_qps为 CTA数量 * (num_node - 1)。create_and_place_qps就是通过doca_gpu_verbs_create_qp_hl创建所有的qp到qp_hls。
cpp
void RDMACoordinator::allocate_dispatch_rdma_buffers(...) {
for (int qp_idx = 0; qp_idx < buffer_config.num_of_blocks_dispatch_api; ++qp_idx) {
for (int peer_idx = 0; peer_idx < buffer_config.num_of_nodes - 1; ++peer_idx) {
// Fill rkeys and raddrs into remote_info.
int idx = qp_idx * (buffer_config.num_of_nodes - 1) + peer_idx;
struct remote_info *curr_info = my_dispatch_info + idx;
curr_info->lid = port_attr.lid;
curr_info->qpn = doca_verbs_qp_get_qpn(dispatch_gverbs_ctx.qp_hls[idx]->qp);
curr_info->gid_index = gid_index;
curr_info->token_rkey = dispatch_rdma_inter_node_group_token_mr->rkey;
curr_info->token_vaddr = (uintptr_t)((uint16_t *)dispatch_rdma_inter_node_group_token_mr->addr + peer_idx * token_stride);
curr_info->flag_rkey = dispatch_rdma_inter_node_group_flags_mr->rkey;
curr_info->flag_vaddr = (uintptr_t)((uint64_t *)dispatch_rdma_inter_node_group_flags_mr->addr +
peer_idx * flag_stride);
}
}
exchange_remote_rdma_info(dispatch_remote_info_vec, my_dispatch_info, num_of_dispatch_qps);
setup_qp_attr_and_set_qp(&dispatch_gverbs_ctx, ib_context, &port_attr,
dispatch_remote_info_vec, dispatch_gverbs_ctx.qp_attr,
buffer_config.num_of_blocks_dispatch_api, buffer_config.num_of_nodes, node_rank, num_of_dispatch_qps);
}然后开始交换元信息,除了lid,qpn等基本信息外,还需要交换token,flag等mr的信息。将这些信息写入my_dispatch_info,然后通过exchange_remote_rdma_info执行allgather得到dispatch_remote_info_vec。最后通过setup_qp_attr_and_set_qp执行modify qp完成建链。
cpp
void RDMACoordinator::allocate_dispatch_rdma_buffers(...) {
dispatch_mr_info_h = (dispatch_memory_region_info_t *)calloc(sizeof(dispatch_memory_region_info_t), num_of_dispatch_qps);
CUDA_CHECK(cudaMalloc((void**)&dispatch_mr_info_d, num_of_dispatch_qps * sizeof(dispatch_memory_region_info_t)));
for (int qp_idx = 0; qp_idx < buffer_config.num_of_blocks_dispatch_api; ++qp_idx) {
for (int peer_idx = 0; peer_idx < buffer_config.num_of_nodes - 1; ++peer_idx) {
int actual_node_idx = peer_idx < node_rank ? peer_idx : (peer_idx + 1);
int actual_idx_in_node = peer_idx < node_rank ? (node_rank - 1) : node_rank;
int my_idx = qp_idx * (buffer_config.num_of_nodes - 1) + peer_idx;
int rem_idx = actual_node_idx * num_of_dispatch_qps + qp_idx * (buffer_config.num_of_nodes - 1) + actual_idx_in_node;
struct dispatch_memory_region_info_t *data = dispatch_mr_info_h + my_idx;
data->token_laddr = (uint64_t)attn_input_token_mr->addr;
data->token_lkey = htobe32(attn_input_token_mr->lkey);
data->token_raddr = dispatch_remote_info_vec[rem_idx].token_vaddr;
data->token_rkey = htobe32(dispatch_remote_info_vec[rem_idx].token_rkey);
data->flag_laddr = (uint64_t)((uint64_t *)attn_input_flags_mr->addr + peer_idx * flag_stride);
data->flag_lkey = htobe32(attn_input_flags_mr->lkey);
data->flag_raddr = dispatch_remote_info_vec[rem_idx].flag_vaddr;
data->flag_rkey = htobe32(dispatch_remote_info_vec[rem_idx].flag_rkey);
}
}
CUDA_CHECK(cudaMemcpy(dispatch_mr_info_d, dispatch_mr_info_h, num_of_dispatch_qps * sizeof(dispatch_memory_region_info_t), cudaMemcpyHostToDevice));
// Set RDMA attributes to dispatch buffers.
dispatch_buffers.d_qps_gpu = dispatch_gverbs_ctx.d_qps_gpu;
dispatch_buffers.mr_info = dispatch_mr_info_d;
}然后将host端的qp和mr拷贝到device,对于mr,只关注token和flag即可。
dispatch
单测中调用为
cpp
buffer.dispatch(hidden=hidden, scaling_factor=scaling_factor, topk_idx=topk_idx, topk_weights=topk_weights, num_of_experts=NUM_OF_EXPERTS)
cpp
def dispatch(
self,
hidden: torch.Tensor,
scaling_factor: torch.Tensor = None,
topk_idx: torch.Tensor = None,
topk_weights: torch.Tensor = None,
num_of_experts: int = None,
probs: torch.Tensor = None,
routing_map: torch.Tensor = None,
num_dispatched_tokens_tensor: torch.Tensor = None,
num_dispatched_tokens: int = None,
handle: tuple = None,
):
num_of_tokens, hidden_dim = hidden.shape
if routing_map is not None:
...
else:
if topk_idx is not None:
routing_map, probs = indices_to_map(
topk_idx, topk_weights, num_of_tokens, num_of_experts
)
...
def indices_to_map(
topk_idx: torch.Tensor,
topk_weights: torch.Tensor,
num_of_tokens: int,
num_of_experts: int,
):
routing_map = torch.zeros(
num_of_tokens, num_of_experts, device="cuda", dtype=torch.bool
)
routing_map = routing_map.scatter(1, topk_idx.to(torch.int64), 1).bool()
if topk_weights is not None:
probs = torch.zeros(
num_of_tokens, num_of_experts, device="cuda", dtype=torch.float32
)
probs = probs.scatter(1, topk_idx.to(torch.int64), topk_weights)
else:
probs = None
return routing_map, probs由于没有指定routing_map,因此这里会通过indices_to_map创建routing_map和probs,routing_map为bool矩阵,shape为 num_of_tokens, num_of_experts,routing_mapij表示tokeni是否需要到expertj,同理probs。
routing_map如图1所示。
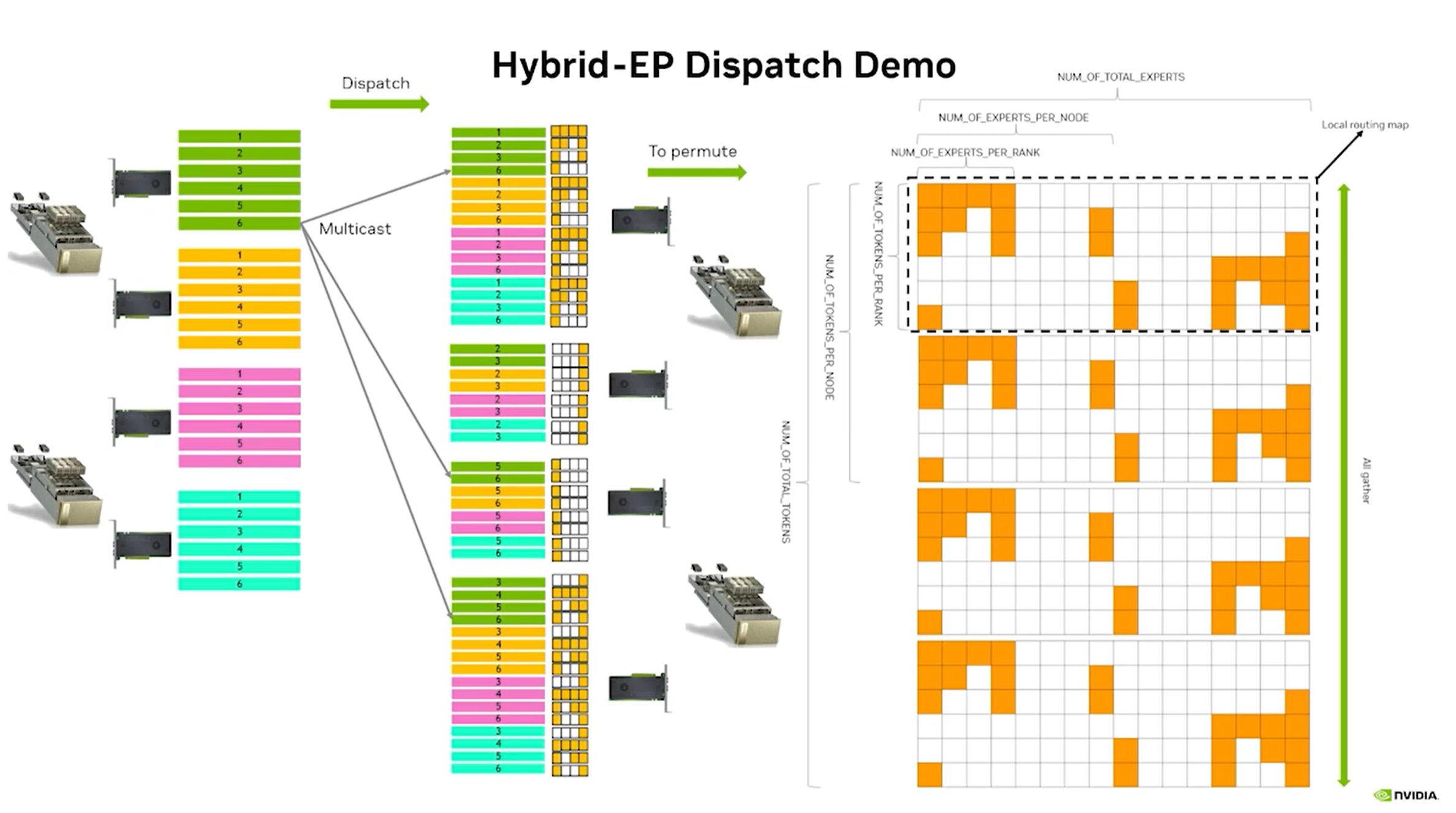
图 1
meta预处理
然后开始预处理
cpp
def dispatch(...):
if handle is None:
# The hybrid-ep kernel requires the routing info from all ranks.
global_routing_map = torch.empty(
num_of_tokens * self.group_size,
num_of_experts,
device="cuda",
dtype=torch.bool,
)
torch.distributed.all_gather_into_tensor(
global_routing_map, routing_map, self.group
)
# Run the metadata preprocessing kernel.
(
sparse_to_dense_map,
rdma_to_attn_map,
attn_to_rdma_map,
num_dispatched_tokens_tensor,
local_expert_routing_map,
) = self.runtime.metadata_preprocessing(
config=config,
routing_map=global_routing_map,
num_of_tokens_per_rank=num_of_tokens,
)
# Create the handle using the data generated by the preprocessing kernel.
handle = (
sparse_to_dense_map,
rdma_to_attn_map,
attn_to_rdma_map,
num_dispatched_tokens_tensor,
local_expert_routing_map,
num_of_tokens,
config,
)首先通过allgather拿到全局的global_routing_map,然后基于global_routing_map执行预处理。预处理的结果如下:
num_dispatched_tokens_tensor
shape为1,类型为int,表示当前rank的所有local expert一共会收到多少个token,如果一个token在当前rank的多个local expert,只会存储一次。
sparse_to_dense_map
shape为NUM_OF_TOKENS_PER_RANK \* NUM_OF_NODES, NUM_OF_RANKS_PER_NODE,类型为int,sparse_to_dense_mapxy表示同号卡所有rank的输入中,第x个token会dispatch到当前节点的local_ranky中输出buffer的位置。
rdma_to_attn_map
shape为(NUM_OF_TOKENS_PER_RANK padded to 16) \* NUM_OF_NODES,类型为bool,表示rdma_to_attn_mapx的意思为同号卡所有rank的输入中,第x个token是否需要发送到当前rank。
attn_to_rdma_map
shape为NUM_OF_TOKENS_PER_RANK, NUM_OF_NODES - 1,类型为bool,每一行表示当前rank的这个token会被路由到哪些node。
这些预处理的过程其实就是在如图1的routing_map中按照列做前缀和,一列的cell大小为一个rank的所有expert。
dispatch_preprocess
cpp
std::tuple<torch::Tensor, torch::Tensor> Executor::dispatch_preprocess(...) {
if(config.num_of_nodes > 1) {
auto sizeof_token_data_type = get_token_data_type_size(config.token_data_type);
CUDA_CHECK(cudaMemcpyAsync(dispatch_buffers.attn_input_token, args.hidden.data_ptr(), args.hidden.numel() * sizeof_token_data_type, cudaMemcpyDeviceToDevice, args.stream));
} else {
// Set the tensor pointers to the dispatch buffers.
dispatch_buffers.attn_input_token = args.hidden.data_ptr();
dispatch_buffers.attn_input_prob = (config.forward_dispatch_api) ? args.probs.data_ptr() : nullptr;
dispatch_buffers.attn_input_scaling_factor = (config.token_data_type == APP_TOKEN_DATA_TYPE::UINT8) ? args.scaling_factor.data_ptr() : nullptr;
}如果多机场景,需要将用户输入的hidden拷贝到attn_input_token,只有注册过的内存才可以执行rdma的操作,单机场景下直接将用户输入的指针设置到dispatch_buffers。
dispatch_core
每个CTA都会启动4个warp,分为如下三个角色,角色之间的pipeline如图2所示
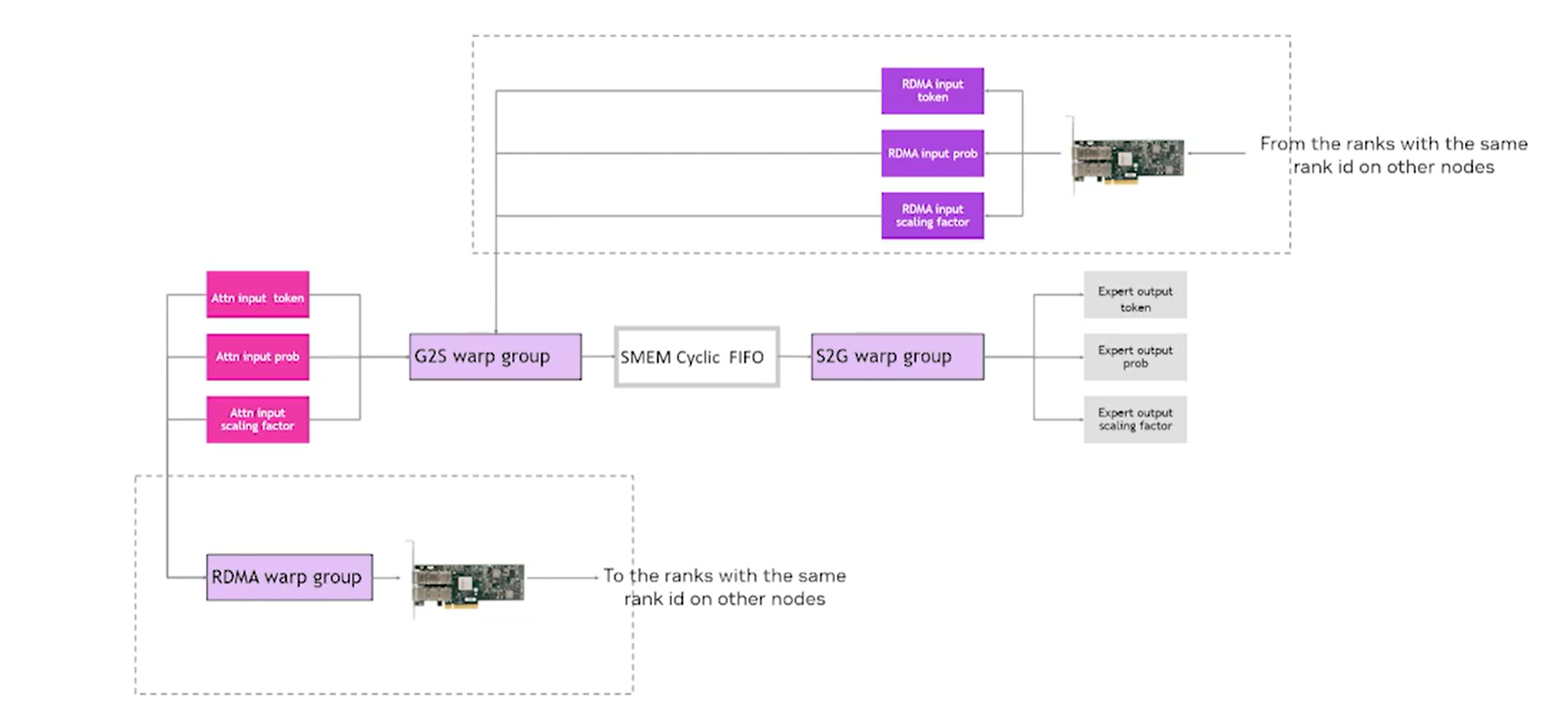
图 2
然后我们具体介绍一下。
inter_node_group
多机才会有,只有一个warp,负责将当前rank的token通过rdma转发到其他机器的同号卡。
cpp
inline __device__ void N2N_warp_group_device_function(...) {
int NUM_OF_CHUNKS_PER_RANK = (num_of_tokens_per_rank - 1) / NUM_OF_TOKENS_PER_CHUNK + 1;
int block_offset = blockIdx.x * (NUM_OF_NODES - 1);
if (INTER_NODE_GROUP::thread_rank() < NUM_OF_NODES - 1) {
smem_mr_info_ptr[INTER_NODE_GROUP::thread_rank()] = mr_info[INTER_NODE_GROUP::thread_rank() + block_offset];
}
__syncwarp();
}NUM_OF_CHUNKS_PER_RANK表示一个rank上的token分成多少个chunk。因为一个block会使用(num_node - 1)个qp和其他所有节点通信,因此通过block_offset就可以定位当前block对应的qp和mr,然后将mr_info写入到共享内存的smem_mr_info_ptr。
cpp
inline __device__ void N2N_warp_group_device_function(...) {
for (int chunk_idx = blockIdx.x; chunk_idx < NUM_OF_CHUNKS_PER_RANK; chunk_idx += NUM_OF_BLOCKS) {
int chunk_base_token_idx = chunk_idx * NUM_OF_TOKENS_PER_CHUNK;
int token_range = NUM_OF_TOKENS_PER_CHUNK;
// Attn_to_rdma_map cached in shared memory.
bool *smem_attn_to_rdma_map_ptr = nullptr;
// Reading one chunk of attn_to_rdma_map into shared memory.
if constexpr(NUM_OF_NODES != 1) {
smem_attn_to_rdma_map_ptr = smem_buffer_ptr->attn_to_rdma_map_buffer;
if (chunk_base_token_idx + token_range > num_of_tokens_per_rank) {
token_range = num_of_tokens_per_rank - chunk_base_token_idx;
}
for (int map_load_idx = INTER_NODE_GROUP::thread_rank();
map_load_idx < token_range * (NUM_OF_NODES - 1);
map_load_idx += INTER_NODE_GROUP::size()) {
smem_attn_to_rdma_map_ptr[map_load_idx] = attn_to_rdma_map[chunk_base_token_idx * (NUM_OF_NODES - 1) + map_load_idx];
}
__syncwarp();
}
}一个CTA一次处理一个chunk,chunk_base_token_idx为这个chunk的第一个token id,token_range为这个chunk的token个数,然后warp粒度将这个chunk的token对应的attn_to_rdma_map load到共享内存smem_attn_to_rdma_map_ptr中,attn_to_rdma_map的每一行记录了该行对应的token需要被路由到哪些node,后续会根据这些信息执行rdma的发送。
cpp
inline __device__ void N2N_warp_group_device_function(...) {
for (int chunk_idx = blockIdx.x; chunk_idx < NUM_OF_CHUNKS_PER_RANK; chunk_idx += NUM_OF_BLOCKS) {
for (int idx = 0; idx < NUM_OF_NODES - 1; ++idx) {
int remote_idx = (idx + node_rank) % (NUM_OF_NODES - 1);
// Queue pair for the current block to the current remote.
struct doca_gpu_dev_verbs_qp *qp = d_qps_gpu[remote_idx + block_offset];
// Real remote node rank.
int remote_node_rank = remote_idx < node_rank ? remote_idx : remote_idx + 1;
// Calculating total num of tokens need to be sent to the current remote.
int num_of_tokens_need_write = 0;
for (int token_idx_in_chunk = INTER_NODE_GROUP::thread_rank();
token_idx_in_chunk < token_range;
token_idx_in_chunk += INTER_NODE_GROUP::size()) {
num_of_tokens_need_write += smem_attn_to_rdma_map_ptr[remote_idx + token_idx_in_chunk * (NUM_OF_NODES - 1)];
}
num_of_tokens_need_write = __reduce_add_sync(0xffffffff, num_of_tokens_need_write);
int total_write_cnt = num_of_tokens_need_write * WQE_NUM_RATIO + 1;
// Getting wqe slots.
uint64_t base_wqe_idx = 0;
if (INTER_NODE_GROUP::thread_rank() == 0) {
base_wqe_idx = doca_gpu_dev_verbs_reserve_wq_slots<DOCA_GPUNETIO_VERBS_RESOURCE_SHARING_MODE_EXCLUSIVE>(qp, total_write_cnt);
smem_inter_node_num_of_write_per_node_ptr[remote_idx] += total_write_cnt;
}
base_wqe_idx = __shfl_sync(0xffffffff, base_wqe_idx, 0);
uint64_t curr_wqe_idx = base_wqe_idx;
}
}warp粒度遍历所有其他的节点remote_rank(后续不区分remote_rank和remote_idx的关系),获取对应的qp。
然后统计这个chunk中有多少个token需要发送到remote_rank,每个线程负责chunk中的一部分token,通过attn_to_rdma_map可以得到该token是否需要发送到remote_rank,最后通过__reduce_add_sync得到chunk的一共需要发送的token数num_of_tokens_need_write。
然后计算总的wqe数total_write_cnt,一个token对应了WQE_NUM_RATIO个wqe,发送token的hidden需要一个wqe,如果是量化的话scale还需要一个,prob需要一个,一共3个,最后这个chunk还需要通过rdma atomic写一个flag,因此还需要+1。
tid0通过doca_gpu_dev_verbs_reserve_wq_slots在qp中预留total_write_cnt个wqe,通过shfl_sync广播给所有线程。
cpp
inline __device__ void N2N_warp_group_device_function(...) {
for (int chunk_idx = blockIdx.x; chunk_idx < NUM_OF_CHUNKS_PER_RANK; chunk_idx += NUM_OF_BLOCKS) {
for (int idx = 0; idx < NUM_OF_NODES - 1; ++idx) {
for (int token_idx_in_chunk = INTER_NODE_GROUP::thread_rank();
token_idx_in_chunk < NUM_OF_TOKENS_PER_CHUNK;
token_idx_in_chunk += INTER_NODE_GROUP::size()) {
int64_t token_idx = token_idx_in_chunk + chunk_base_token_idx;
bool need_write = false;
if (token_idx_in_chunk < token_range) {
need_write = smem_attn_to_rdma_map_ptr[remote_idx + token_idx_in_chunk * (NUM_OF_NODES - 1)];
}
uint32_t write_map = __ballot_sync(0xffffffff, need_write);
uint32_t partial_write_map = ((1 << INTER_NODE_GROUP::thread_rank()) - 1) & write_map;
int write_cnt = __popc(write_map);
int write_idx = __popc(partial_write_map);
if (need_write) {
// Constructing wqes for tokens.
uint64_t my_wqe_idx = curr_wqe_idx + write_idx;
struct doca_gpu_dev_verbs_wqe *token_wqe_ptr = doca_gpu_dev_verbs_get_wqe_ptr(qp, my_wqe_idx);
doca_gpu_dev_verbs_wqe_prepare_write(qp, token_wqe_ptr, my_wqe_idx,
DOCA_GPUNETIO_IB_MLX5_OPCODE_RDMA_WRITE,
DOCA_GPUNETIO_IB_MLX5_WQE_CTRL_CQ_UPDATE, 0,
smem_mr_info_ptr[remote_idx].token_raddr + token_idx * HIDDEN_DIM * sizeof(TOKEN_DATA_TYPE),
smem_mr_info_ptr[remote_idx].token_rkey,
smem_mr_info_ptr[remote_idx].token_laddr + token_idx * HIDDEN_DIM * sizeof(TOKEN_DATA_TYPE),
smem_mr_info_ptr[remote_idx].token_lkey,
HIDDEN_DIM * sizeof(TOKEN_DATA_TYPE));
}
curr_wqe_idx += write_cnt * WQE_NUM_RATIO;
__syncwarp(0xffffffff);
...
}最后开始写wqe,一个warp一次处理连续的32 token,每个线程对应一个token,通过attn_to_rdma_map判断当前token是否需要发送,即need_write,然后通过__ballot_sync得到32线程对应token的全局信息write_map,write_cnt为这32个token中一共要发送的token数,write_idx为当前线程这个token在write_map中的前缀和,即写入到qp中的位置,然后通过doca_gpu_dev_verbs_wqe_prepare_write写wqe,token_laddr即attn_input_token,token_raddr即dispatch_rdma_inter_node_group_token中当前node对应的位置。
cpp
inline __device__ void N2N_warp_group_device_function(...) {
for (int chunk_idx = blockIdx.x; chunk_idx < NUM_OF_CHUNKS_PER_RANK; chunk_idx += NUM_OF_BLOCKS) {
for (int idx = 0; idx < NUM_OF_NODES - 1; ++idx) {
...
if (INTER_NODE_GROUP::thread_rank() == 0) {
// Construct wqe for flag.
struct doca_gpu_dev_verbs_wqe *flag_wqe_ptr = doca_gpu_dev_verbs_get_wqe_ptr(qp, curr_wqe_idx);
doca_gpu_dev_verbs_wqe_prepare_atomic(qp, flag_wqe_ptr, curr_wqe_idx,
DOCA_GPUNETIO_IB_MLX5_OPCODE_ATOMIC_FA,
DOCA_GPUNETIO_IB_MLX5_WQE_CTRL_CQ_UPDATE,
smem_mr_info_ptr[remote_idx].flag_raddr + chunk_idx * sizeof(uint64_t),
smem_mr_info_ptr[remote_idx].flag_rkey,
smem_mr_info_ptr[remote_idx].flag_laddr + chunk_idx * sizeof(uint64_t),
smem_mr_info_ptr[remote_idx].flag_lkey,
sizeof(uint64_t), 1, 0);
// Post send and poll cqs.
doca_gpu_dev_verbs_mark_wqes_ready<DOCA_GPUNETIO_VERBS_RESOURCE_SHARING_MODE_CTA>(qp, base_wqe_idx, curr_wqe_idx);
doca_gpu_dev_verbs_submit_db<DOCA_GPUNETIO_VERBS_RESOURCE_SHARING_MODE_CTA,
DOCA_GPUNETIO_VERBS_SYNC_SCOPE_GPU,
DOCA_GPUNETIO_VERBS_GPU_CODE_OPT_DEFAULT,
DOCA_GPUNETIO_VERBS_QP_SQ>(qp, (curr_wqe_idx + 1));
}
__syncwarp();
...
}最后tid0执行rdma atomic,flag_raddr为remote_rank的rdma_inter_node_group_flags中当前node对应的区间,每个chunk在这个区间中有一个单独的flag,因此为flag_raddr + chunk_idx * sizeof(uint64_t),同理flag_laddr 。然后写db发送。
intra_node_g2s_group
intra_node_g2s_group和intra_node_s2g_group形成生产者消费者,intra_node_g2s_group负责将其他节点通过rdma发送过来的token从GMEM拷贝到SMEM,intra_node_s2g_group负责将intra_node_g2s_group生产的token从SMEM拷贝到当前机器的其他rank。
这相当于在SMEM这层有一个fifo,g2s负责写入,s2g负责写出,不过和DeepEP不同的是,Hybrid-EP通过mbarrier实现fifo的同步,可以避免轮询flag从而减小对GMEM的带宽消耗。
g2s只有一个warp,执行过程为根据rdma_to_attn_map,遍历所有同号卡的输入token,如果这个token需要被发送到当前rank,那么就从对应的rdma输出buffer中TMA到SMEM。
cpp
inline __device__ void G2S_warp_group_device_function(...) {
int stage = 0;
uint32_t consumer_parity = 1;
if(elect_sync(~0)){
for(int i = blockIdx.x; i < num_of_chunks_per_rank; i += NUM_OF_BLOCKS){
...
for(int j = 0; j < NUM_OF_NODES; j++){
int node_id = node_rank >= j ? node_rank - j : node_rank + NUM_OF_NODES - j;
int rdma_buffer_tile_id = node_id > node_rank ? node_id - 1 : node_id;
if(node_id != node_rank){
const uint64_t* flag_location = rdma_inter_node_group_flags + (rdma_buffer_tile_id * max_num_of_chunks_per_rank + i);
uint64_t rdma_flag = 0;
do{
rdma_flag = 0;
// Need a strong system-scope load to observe external RDMA Atomic result.
asm volatile("ld.relaxed.sys.global.b64 %0, [%1];"
: "=l"(rdma_flag)
: "l"(__cvta_generic_to_global(flag_location))
: "memory");
}while(rdma_flag != *expected_flag_value);
...
}stage表示在fifo中的哪个slot,consumer_parity记录mbarrier的奇偶,一个CTA处理一个chunk,当执行chunkx时,遍历所有的node,当执行nodey的hidden时,轮询rdma_inter_node_group_flags中nodey的chunkx位置,直到flag到了。
cpp
inline __device__ void G2S_warp_group_device_function(...) {
if(elect_sync(~0)){
for(int i = blockIdx.x; i < num_of_chunks_per_rank; i += NUM_OF_BLOCKS){
for(int j = 0; j < NUM_OF_NODES; j++){
const rdma_to_attn_map_load_t* rdma_to_attn_map_load_base_addr = reinterpret_cast<const rdma_to_attn_map_load_t*>(rdma_to_attn_map +
(node_id * rdma_to_attn_map_size_per_node + i * NUM_OF_TOKENS_PER_CHUNK));
int chunk_first_token_id = rdma_buffer_tile_id * MAX_NUM_OF_TOKENS_PER_RANK + i * NUM_OF_TOKENS_PER_CHUNK;
token_load_base_addr = rdma_inter_node_group_token + chunk_first_token_id * HIDDEN_DIM;
for(int k = 0; k < num_of_routing_info_load_iter_for_current_chunk; k++){
rdma_to_attn_map_load_t rdma_to_attn_map_data = rdma_to_attn_map_load_base_addr[k];
for(int n = 0; n < NUM_OF_TOKENS_PER_LOAD_ITER; n++){
int current_token_id = k * NUM_OF_TOKENS_PER_LOAD_ITER + n;
...
}rdma_to_attn_map_load_base_addr为nodey的chunkx开始的位置,chunk_first_token_id是这个chunk开始的tokenid,然后找到rdma接收buffer的位置,即token_load_base_addr。
一个chunk需要load rdma_to_attn_map中大小为NUM_OF_TOKENS_PER_CHUNK字节的数据,由于rdma_to_attn_map为bool数组,为了访存友好,这里才用uint4的类型进行load,NUM_OF_TOKENS_PER_LOAD_ITER表示一个uint4对应了几个token,NUM_OF_ROUTING_INFO_LOAD_ITER_PER_CHUNK表示需要几个uint4才能load完成一个chunk,所以这里是两重循环。
cpp
alignas(8) uint64_t intra_node_mbarrier_buffer[NUM_OF_STAGES][2];
for(int i = 0; i < NUM_OF_STAGES; i++){
// Initialize mbarrier
cuda::ptx::mbarrier_init(&smem_buffer_ptr->intra_node_mbarrier_buffer[i][0], 1);
cuda::ptx::mbarrier_init(&smem_buffer_ptr->intra_node_mbarrier_buffer[i][1], INTRA_NODE_S2G_GROUP::warp_size());
}然后先看下用于fifo同步的mbarrier,一个stage就是一个slot,每个slot对应两个mbarrier,mbarrier0表示是否有数据,mbarrier1表示是否为空。过程如图3所示(图片来自这里)
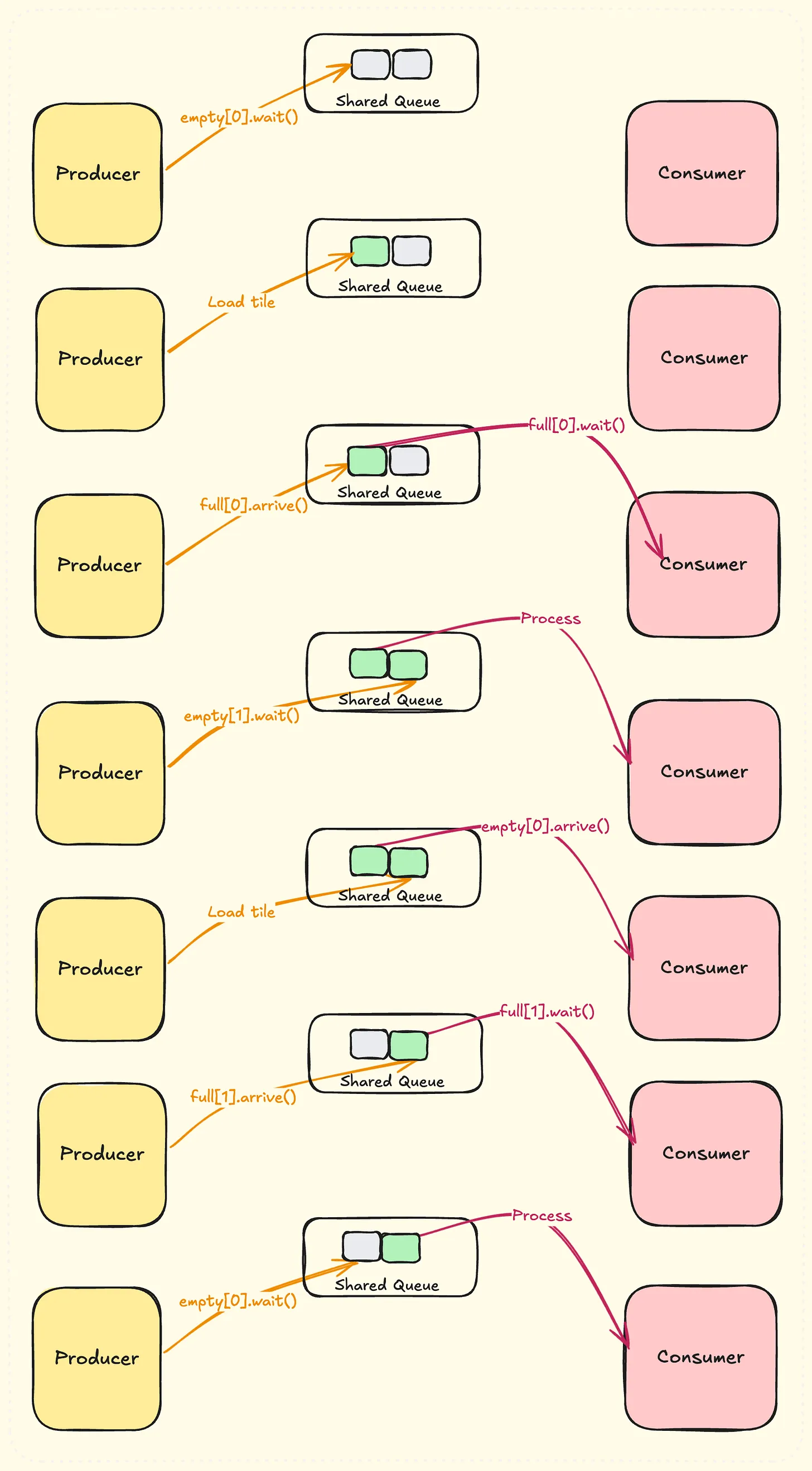
图 3
cpp
inline __device__ void G2S_warp_group_device_function(...) {
if(elect_sync(~0)){
for(int i = blockIdx.x; i < num_of_chunks_per_rank; i += NUM_OF_BLOCKS){
for(int j = 0; j < NUM_OF_NODES; j++){
for(int n = 0; n < NUM_OF_TOKENS_PER_LOAD_ITER; n++){
int current_token_id = k * NUM_OF_TOKENS_PER_LOAD_ITER + n;
bool token_needed_by_this_node = *(reinterpret_cast<bool*>(&rdma_to_attn_map_data) + n);
if(token_needed_by_this_node){
while(!cuda::ptx::mbarrier_try_wait_parity(&smem_buffer_ptr->intra_node_mbarrier_buffer[stage][1], consumer_parity)){}
uint32_t total_tx_size = 0;
// Load token.
cuda::ptx::cp_async_bulk(cuda::ptx::space_shared,
cuda::ptx::space_global,
reinterpret_cast<void*>(&smem_buffer_ptr->intra_node_token_buffer[stage][0]),
reinterpret_cast<const void*>(token_load_base_addr + (current_token_id * HIDDEN_DIM)),
(uint32_t)(HIDDEN_DIM * sizeof(TOKEN_DATA_TYPE)),
&smem_buffer_ptr->intra_node_mbarrier_buffer[stage][0]);
total_tx_size += (uint32_t)(HIDDEN_DIM * sizeof(TOKEN_DATA_TYPE));
cuda::ptx::mbarrier_arrive_expect_tx(cuda::ptx::sem_release,
cuda::ptx::scope_cta,
cuda::ptx::space_shared,
&smem_buffer_ptr->intra_node_mbarrier_buffer[stage][0],
total_tx_size);
stage += 1;
if(stage == NUM_OF_STAGES){
stage = 0;
consumer_parity ^= 1;
...
}对于current_token_id,通过rdma_to_attn_map_data得到这个token是否被当前node需要,如果需要的话就要拷贝到SMEM。首先通过wait intra_node_mbarrier_bufferstage1直到这个slot为空,然后将数据从rdma接收buffer,即token_load_base_addr中TMA到这个slot,即intra_node_token_buffer,完成后通知intra_node_mbarrier_bufferstage0。
最后通过mbarrier_arrive_expect_tx设置mbarrier的tx-count,并执行arrive。
intra_node_s2g_group
如果是单机场景,s2g_group为3个warp,多机场景这是2个warp。核心思路是每个block每次处理一个chunk的token,对于指定的chunk,load对应的rdma_to_attn_map和sparse_to_dense_map,遍历rdma_to_attn_map,对于当前node需要的token,一个warp一次处理这个token对应当前node的一个dst rank,将这个token TMA到对应的dst rank。因为sparse_to_dense_map需要在warp间共享,所以sparse_to_dense_map也拷贝到SMEM,同样通过mbarrier + fifo隐藏load的开销。
cpp
inline __device__ void S2G_warp_group_device_function(...) {
using sparse_to_dense_map_load_t = Copy_t<NUM_OF_RANKS_PER_NODE * sizeof(int32_t)>;
constexpr int NUM_OF_SPARSE_TO_DENSE_MAP_LOAD_ITER_PER_INPUT_TOKEN = (NUM_OF_RANKS_PER_NODE * sizeof(int32_t)) / sizeof(sparse_to_dense_map_load_t);
constexpr int NUM_OF_OUTPUT_TOKENS_PER_LOAD_ITER = sizeof(sparse_to_dense_map_load_t) / sizeof(int32_t);
if(elect_sync(~0)){
if(INTRA_NODE_S2G_GROUP::warp_rank() == 0){
// 预取第一个chunk的sparse_to_dense_map
}
for(int i = blockIdx.x; i < num_of_chunks_per_rank; i += NUM_OF_BLOCKS) {
for(int j = 0; j < NUM_OF_NODES; j++){
uint64_t state_token = cuda::ptx::mbarrier_arrive(&smem_buffer_ptr->S2G_group_mbarrier_buffer);
while(!cuda::ptx::mbarrier_try_wait(&smem_buffer_ptr->S2G_group_mbarrier_buffer, state_token)){}
...
}和rdma_to_attn_map的load一样,sparse_to_dense_map也是尽可能的使用大的读写,sparse_to_dense_map类型为int,一行有NUM_OF_RANKS_PER_NODE个int,假设第x行为tmpNUM_OF_RANKS_PER_NODE,tmpz表示tokenx需要被转发到当前机器local_rankz的哪个位置,-1表示local_rankz不需要这个token。
NUM_OF_OUTPUT_TOKENS_PER_LOAD_ITER表示一次可以load tmp数组中多少个int,NUM_OF_SPARSE_TO_DENSE_MAP_LOAD_ITER_PER_INPUT_TOKEN表示需要多少次load才能完成tmp的load。
每个warp只有一个线程执行s2g,第一个warp通过TMA预取第一个chunk的sparse_to_dense_map。每个block一次处理一个chunk,对于一个chunk_id,处理每个node的chunk_id。
cpp
cuda::ptx::mbarrier_init(&smem_buffer_ptr->S2G_group_mbarrier_buffer, INTRA_NODE_S2G_GROUP::warp_size());S2G_group_mbarrier_buffer初始化的arrive count为warp的个数,因为SMEM中共享了sparse_to_dense_map,因此在load下一个chunk的sparse_to_dense_map之前,需要同步一下所有warp,保证对上一个sparse_to_dense_map的访存都已经完成。
cpp
inline __device__ void S2G_warp_group_device_function(...) {
for(int n = 0; n < NUM_OF_TOKENS_PER_LOAD_ITER; n++){
int current_token_id = k * NUM_OF_TOKENS_PER_LOAD_ITER + n;
bool token_needed_by_this_node = *(reinterpret_cast<bool*>(&rdma_to_attn_map_data) + n);
if(token_needed_by_this_node){
const sparse_to_dense_map_load_t* sparse_to_dense_map_load_addr = ...
while(!cuda::ptx::mbarrier_try_wait_parity(&smem_buffer_ptr->intra_node_mbarrier_buffer[stage][0], producer_parity)){}
for(int m = INTRA_NODE_S2G_GROUP::warp_rank(); m < NUM_OF_SPARSE_TO_DENSE_MAP_LOAD_ITER_PER_INPUT_TOKEN; m += INTRA_NODE_S2G_GROUP::warp_size()){
sparse_to_dense_map_load_t sparse_to_dense_map_data = sparse_to_dense_map_load_addr[m];
for(int t = 0; t < NUM_OF_OUTPUT_TOKENS_PER_LOAD_ITER; t++){
int32_t output_buffer_index = *(reinterpret_cast<int32_t*>(&sparse_to_dense_map_data) + t);
if(output_buffer_index != -1){
int remote_rank_id = m * NUM_OF_OUTPUT_TOKENS_PER_LOAD_ITER + t;
TOKEN_DATA_TYPE* remote_token_addr = remote_expert_output_token[remote_rank_id] + (output_buffer_index * HIDDEN_DIM);
cuda::ptx::cp_async_bulk(...,reinterpret_cast<void*>(remote_token_addr), reinterpret_cast<const void*>(&smem_buffer_ptr->intra_node_token_buffer[stage][0]), ...);
}
}
}
cuda::ptx::cp_async_bulk_commit_group();
in_flight_s2g += 1;
if(in_flight_s2g > NUM_OF_IN_FLIGHT_S2G){
cuda::ptx::cp_async_bulk_wait_group_read(cuda::ptx::n32_t<NUM_OF_IN_FLIGHT_S2G>{});
in_flight_s2g -= 1;
int notify_stage = (stage - NUM_OF_IN_FLIGHT_S2G) >= 0 ? (stage - NUM_OF_IN_FLIGHT_S2G) : (stage - NUM_OF_IN_FLIGHT_S2G + NUM_OF_STAGES);
cuda::ptx::mbarrier_arrive(&smem_buffer_ptr->intra_node_mbarrier_buffer[notify_stage][1]);
}
stage += 1;
...
}对于current_token_id,首先通过rdma_to_attn_map判断当前node是否需要,如果需要的话则wait intra_node_mbarrier_bufferstage0,等到这个stage的数据非空,然后每个warp每次执行一个dst_rank的数据发送,通过读取对应dst_rank的sparse_to_dense_map,如果非-1,说明需要被路由到dst_rank,并且值就是dst_rank输出buffer的位置,那么通过TMA将数据从intra_node_token_buffer拷贝到remote_expert_output_token,即expert_output_token。然后commit_group,如果未完成的group数超过了NUM_OF_IN_FLIGHT_S2G,则通过wait group保证未完成的数量不超过NUM_OF_IN_FLIGHT_S2G。
dispatch_postprocess
完成dispatch之后,还需要执行后处理,将数据从expert_output_token拷贝到torch tensor返回给用户。
cpp
Executor::dispatch_postprocess(HybridEpConfigInstance config, DispatchBuffers& dispatch_buffers, DispatchArgs& args) {
int num_dispatched_tokens = 0;
if (args.num_dispatched_tokens >= 0) {
num_dispatched_tokens = args.num_dispatched_tokens;
} else {
num_dispatched_tokens = args.num_dispatched_tokens_tensor.value().item<int>();
}
size_t sizeof_token_data_type = get_token_data_type_size(dispatch_buffers.data_type);
dispatched_tokens = torch::empty(
{num_dispatched_tokens, config.hidden_dim},
torch::dtype(args.hidden.dtype()).device(torch::kCUDA)
);
auto res_sz = num_dispatched_tokens * config.hidden_dim * sizeof_token_data_type;
CUDA_CHECK(cudaMemcpyAsync(dispatched_tokens.data_ptr(), dispatch_buffers.expert_output_token, res_sz, cudaMemcpyDeviceToDevice, args.stream));
}总结
整体上讲Hybrid-EP思路和DeepEP的normal版本一致,Hybrid-EP的重点是降低SM占用,提高超节点的表现,因此Hybrid-EP几乎全部使用了TMA,进一步的通过以显存换SM的方式,省掉了DeepEP中的kRDMASender和kNVLReceivers的warp。
显存
Hybrid-EP额外申请了一些buffer:
额外申请了大小为hidden_dim * max_num_of_tokens_per_rank的attn_input_token的rdma输入buffer,会一次性将用户的输入hidden通过cudaMemcpy拷贝到rdma注册内存attn_input_token,好处是消除了SM的占用,不足是显存占用较多,另外导致copy和rdma发送串行,无法流水线。
额外申请了大小为hidden_dim * max_num_of_tokens_per_rank * (num_node - 1)的rdma输出buffer rdma_inter_node_group_token,rdma发送线程可以直接将token发送过来,避免了DeepEP中复杂的同步机制,不足是显存占用较多,发送的数据也做不到像DeepEP一样可以聚合,一次只能发一个token的信息。
对于机内,额外申请了大小为的max_num_of_tokens_per_rank * num_of_ranks_per_node * num_of_nodes;
的expert_output_token,这样转发线程可以直接发送到dst rank,不再需要dst rank的recv warp,不足是显存占用较多,转发和最后的cudaMemcpy无法流水线(不过这个官方引入了permute的fuse,可以省掉这个cudaMemcpy)。
notify
Hybrid-EP的meta预处理相当于DeepEP的notify阶段,这里就allgather所有rank的route info,通信量相对大一些。
同步机制
相对于DeepEP的基于轮询GMEM中head tail的fifo机制,Hybrid-EP通过mbarrier进行fifo同步,mbarrier位于SMEM,并且有硬件做缓存,因此可以降低对GMEM的带宽需求。
nvlink读
在combine中(下次介绍),机内通过nvlink读的方法消除了NVLSender warp,因此额外要求nvlink读的性能不能比写差太多。
padding
Hybrid-EP要求输入的最大值为MAX_NUM_OF_TOKENS_PER_RANK,在易用性和性能上可能有一些影响。