目录
1.建设框架
首先介绍华为数据工作框架,如图。该框架主要由四大板块组成:数据治理 、数据源 、数据底座及数据消费。
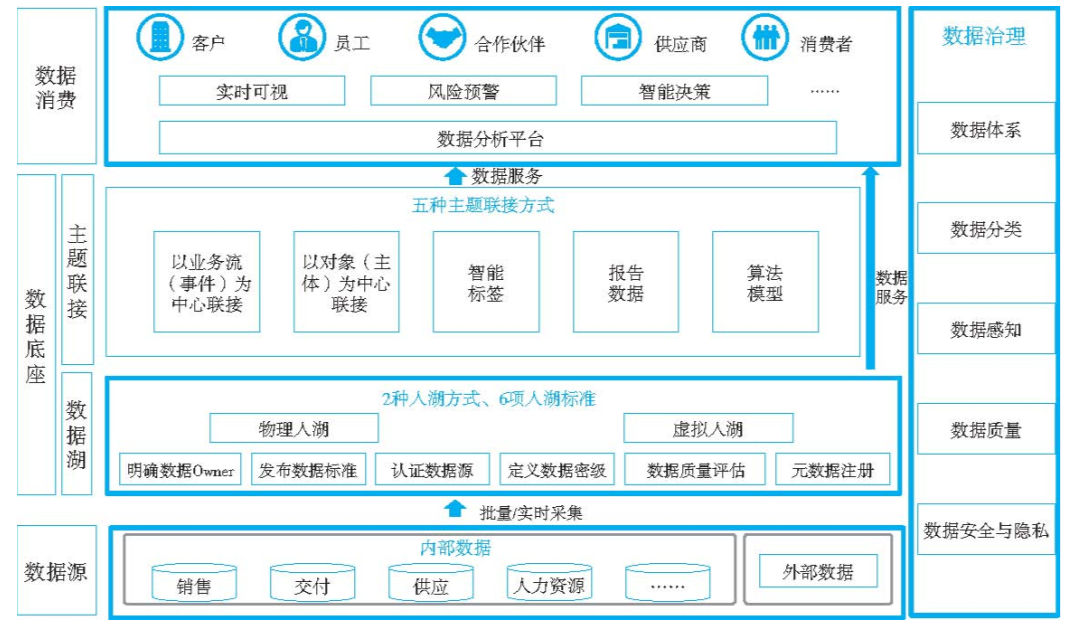
数据源:
业务数字化是数据工作的前提,通过业务对象、规则与过程的数字化,不断提升数据质量,建立清洁、可靠的数据源。
数据底座:
由数据湖和主题联接两部分组成。
数据湖:
基于"统筹推动、以用促建"的建设策略,严格按6项标准,通过物理与虚拟两种入湖方式,汇聚华为内部和外部的海量数据,形成清洁、完整、一致的数据湖。
数据主题联接:
通过5种数据联接方式,从规划和需求出发,建立数据主题联接,并通过服务支撑数据消费。
数据消费:
对准数据消费场景,提供统一的数据分析平台,满足自助式数据消费需求。
数据治理:
为保障各业务领域数据工作的有序开展,需建立统一的数据治理能力,如数据体系、数据分类、数据感知、数据质量、数据安全与隐私等。
2.数据湖
2.1.数据湖特点
华为数据湖主要有3大特点:
| 特点 | 说明 |
|---|---|
| 逻辑统一 | 华为数据湖不是一个单一的物理存储,而是根据数据类型、业务区域等多个不同的物理存储构成,并通过统一的元数据语义层进行定义、拉通和管理。 |
| 类型多样 | 数据湖存放所有不同类型的数据,包括企业内部IT系统产生的结构化数据、业务交易和内部管理的非结构化的文本数据、公司内部园区各种传感器检测到的设备运行数据以及外部的媒体数据等。 |
| 原始记录 | 对原始数据的汇聚,不对数据做任何的转换、清洗、加工等处理,保留数据最原始特征,为数据的加工和消费提供丰富的可能。 |
2.2.数据入湖标准
数据入湖是数据消费的前提条件,需要严格满足入湖的6个条件:
| 入湖标准 | 说明 |
|---|---|
| 明确数据owner | 数据Owner主要由数据产生所对应的流程Owner来担任,是所辖数据端到端管理的责任人,负责对入湖的数据定义数据标准和密级,承接数据消费中的数据质量问题,并制订数据管理工作路标,持续提升数据质量。 |
| 发布数据标准 | 入湖数据要有相应的业务数据标准。业务数据标准描述公司层面需共同遵守的"属性层"数据含义和业务规则,标准明确发布后需在企业内共同遵守。 |
| 认证数据源 | 认证数据源,以确保数据从正确的数据源头入湖。认证数据源需遵循公司数据源管理的要求。认证过的数据源作为唯一数据源头被数据湖调用。 |
| 定义数据密级 | 由数据owner定密,在资产最细粒度属性层级中定义,根据资产不同重要程度定义不同等级。数据管家有责任审视数据密级的完整性,并推动、协调数据定密工作。 |
| 数据质量评估 | 数据质量是数据消费的保证。数据入湖不需要清洗,但需要对数据质量进行评估,让数据消费者了解数据质量情况及了解消费该数据的质量风险。数据owner和管家可以根据数据质量评估情况 。推动数据源头质量质量的提升,满足数据质量要求。 |
| 元数据注册 | 元数据注册是指将入湖数据的业务元数据和技术元数据进行关联,包括逻辑实体与物理表的对应关系,及业务属性和表字段的对应关系。连接业务元数据和技术元数据的关系,能够支撑数据消费人员通过业务语义快速地搜索到数据湖中的数据,降低数据湖中数据消费的门槛,让更多的业务分析人员能理解和消费数据。 |
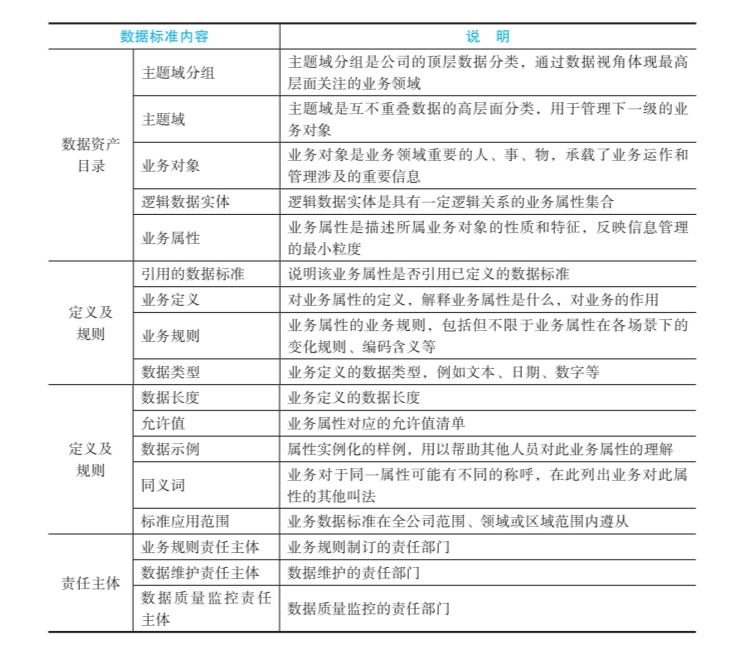
数据标准的相关内容:数据资产目录、属性的业务和技术定义及规则,还有相关的责任主体。
2.3.数据入湖方式
数据入湖遵循华为数据架构,以逻辑数据实体为粒度进行入湖。
|-------|--------|-----------|---|----------|---------|-------------|------------|------------|
| 入湖方式 |||| 数据搬家 | 实时性 | 源系统性能要求 | 批量数据处理 | 历史数据处理 |
| 物理 入湖 | 批量集成 | ETL/ELT工具 | 拉 | √ | × | 低 | 支持(强) | 支持(强) |
| 物理 入湖 | 批量集成 | FTP工具 | 推 | √ | × | 低 | 通常不支持 | 通常不支持 |
| 物理 入湖 | 数据复制同步 | CDC工具 | 拉 | √ | √ | 中 | 通常不支持 | 通常不支持 |
| 物理 入湖 | 消息集成 | MQ工具 | 推 | √ | √ | 中 | 通常不支持 | 通常不支持 |
| 物理 入湖 | 流集成 | Pipeline | 推 | √ | √ | 中 | 通常不支持 | 通常不支持 |
| 虚拟入湖 | 数据 虚拟化 | 虚拟化工具 | 拉 | × | √ | 中 | 支持(弱) | 支持(弱) |
https://blog.csdn.net/qq_35370485/article/details/157254208![]() http://华为数据底座(2)-数据主题联接:多维模型设计
http://华为数据底座(2)-数据主题联接:多维模型设计