一、项目概述
1.1 项目背景
宠物分类是计算机视觉中的重要应用场景,旨在自动识别不同品种的猫狗。本项目使用Oxford-IIIT Pet数据集,通过迁移学习技术构建高效准确的宠物分类模型。
1.2 数据集介绍
Oxford-IIIT Pet数据集包含:
-
37个宠物类别(12种猫+25种狗)
-
7349张图片(训练集:3680,测试集:3669)
-
每张图片包含:
-
宠物主体分割掩码
-
头部区域标注
-
品种标签(如"Abyssinian", "Persian"等)
-
1.3 项目目标
-
实现多类别宠物品种分类
-
达到90%以上的分类准确率
-
展示迁移学习在实际应用中的优势
二、技术架构
2.1 核心思想:迁移学习
迁移学习的优势:
1. 利用在大规模数据集(如ImageNet)上预训练的模型
2. 只需要少量数据即可达到良好效果
3. 减少训练时间和计算资源需求2.2 技术栈
-
深度学习框架:PyTorch / TensorFlow
-
预训练模型:
-
ResNet50/101
-
EfficientNet
-
VGG16
-
MobileNetV2(轻量化部署)
-
-
数据增强:Albumentations或Torchvision Transforms
-
评估指标:准确率、F1-score、混淆矩阵
三、项目实施步骤
Resnet预训练模型介绍
Resnet是计算机视觉(CV)领域著名的预训练模型,ResNet50是计算机视觉领域最具影响力的深度学习架构之一,由何恺明等人在2015年提出。它解决了深度神经网络中的退化问题,使得训练极深的网络成为可能。下面详细介绍ResNet50的架构与设计思想.
- 传统网络:直接学习目标映射 H(x)
- 残差网络:学习残差映射 F(x) = H(x) - x,最终输出为 F(x) + x
这种设计允许梯度直接流过恒等映射(identity mapping)路径,有效缓解了梯度消失问题,使得训练上百层的网络成为可能。
ResNet50总共有50层(按权重层计算),由以下部分组成:
- 初始层:7×7卷积 + 最大池化
- 4个残差阶段(Stage),每个阶段包含多个残差块
- 全局平均池化层
- 1000类分类器(原始版本用于ImageNet)
ResNet50使用Bottleneck结构作为基本单元,每个Bottleneck包含3个卷积层:
- 1×1卷积:降维,减少计算量
- 3×3卷积:空间特征提取
- 1×1卷积:升维,恢复通道数
具体公式:y = F(x, {Wi}) + x
- F(x)是残差函数
- x是输入
- y是输出
- "+"操作通过元素相加实现,要求F(x)和x维度相同
基于Resnet50和Resnet101实现宠物分类任务
下面给出基于Resnet50实现cifar-10数据集分类任务的具体实现代码:
1.导包与预训练模型的导入
python
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, random_split
import os
from tqdm import tqdm
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import seaborn as sns
import time
# 设置随机种子以保证可重复性
def set_seed(seed=42):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(seed)
set_seed(42)
# 检查是否有可用的GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")2.数据准备和增强
python
# 1. 数据准备和增强
def get_data_transforms():
"""
定义训练和验证的数据转换
"""
# 图像大小调整到适合预训练模型
IMG_SIZE = 224
train_transform = transforms.Compose([
transforms.RandomResizedCrop(IMG_SIZE, scale=(0.8, 1.0)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomRotation(15),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomAffine(degrees=0, translate=(0.1, 0.1)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
val_transform = transforms.Compose([
transforms.Resize((IMG_SIZE, IMG_SIZE)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
return train_transform, val_transform
# 2. 加载Oxford-IIIT Pet数据集
def load_pet_dataset(batch_size=32):
"""
加载和准备宠物数据集
"""
train_transform, val_transform = get_data_transforms()
# 下载并加载数据集
train_val_dataset = torchvision.datasets.OxfordIIITPet(
root='./data/oxford_pets',
split='trainval',
target_types='category',
download=False,
transform=train_transform # 暂时使用train_transform,后面会分割
)
test_dataset = torchvision.datasets.OxfordIIITPet(
root='./data/oxford_pets',
split='test',
target_types='category',
download=False,
transform=val_transform
)
# 分割训练集和验证集
dataset_size = len(train_val_dataset)
train_size = int(0.85 * dataset_size) # 85%用于训练
val_size = dataset_size - train_size
train_dataset, val_dataset = random_split(train_val_dataset, [train_size, val_size])
# 为训练集应用训练变换,验证集应用验证变换
# 注意:我们需要手动设置变换,因为random_split会保留原变换
train_dataset.dataset.transform = train_transform
val_dataset.dataset.transform = val_transform
print(f"训练集大小: {len(train_dataset)}")
print(f"验证集大小: {len(val_dataset)}")
print(f"测试集大小: {len(test_dataset)}")
print(f"类别数量: {len(train_val_dataset.classes)}")
# 创建数据加载器
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=4,
pin_memory=True
)
val_loader = DataLoader(
val_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=4,
pin_memory=True
)
test_loader = DataLoader(
test_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=4,
pin_memory=True
)
return train_loader, val_loader, test_loader, train_val_dataset.classes3.构建网络模型
python
# 3. 定义模型架构(使用预训练的ResNet50)
class PetClassifier(nn.Module):
def __init__(self, num_classes=37, dropout_rate=0.5):
super(PetClassifier, self).__init__()
# 使用预训练的ResNet50作为特征提取器
self.backbone = torchvision.models.resnet50(pretrained=True)
# 冻结前几层(可选,可根据需要调整)
for param in list(self.backbone.parameters())[:100]:
param.requires_grad = False
# 获取ResNet的特征维度
num_features = self.backbone.fc.in_features
# 替换最后的全连接层
self.backbone.fc = nn.Sequential(
nn.Dropout(dropout_rate),
nn.Linear(num_features, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Dropout(dropout_rate/2),
nn.Linear(512, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(dropout_rate/3),
nn.Linear(256, num_classes)
)
def forward(self, x):
return self.backbone(x)4.编写训练函数和推理函数
python
# 3. 定义模型架构(使用预训练的ResNet50)
class PetClassifier(nn.Module):
def __init__(self, num_classes=37, dropout_rate=0.5):
super(PetClassifier, self).__init__()
# 使用预训练的ResNet50作为特征提取器
self.backbone = torchvision.models.resnet50(pretrained=True)
# 冻结前几层(可选,可根据需要调整)
for param in list(self.backbone.parameters())[:100]:
param.requires_grad = False
# 获取ResNet的特征维度
num_features = self.backbone.fc.in_features
# 替换最后的全连接层
self.backbone.fc = nn.Sequential(
nn.Dropout(dropout_rate),
nn.Linear(num_features, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Dropout(dropout_rate/2),
nn.Linear(512, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(dropout_rate/3),
nn.Linear(256, num_classes)
)
def forward(self, x):
return self.backbone(x)
# 4. 训练和评估函数
class PetTrainer:
def __init__(self, model, device, num_classes=37):
self.model = model.to(device)
self.device = device
self.num_classes = num_classes
# 使用交叉熵损失
self.criterion = nn.CrossEntropyLoss(label_smoothing=0.1) # 标签平滑防止过拟合
# 使用AdamW优化器(比Adam更好)
self.optimizer = optim.AdamW(
filter(lambda p: p.requires_grad, self.model.parameters()),
lr=0.0001,
weight_decay=1e-4
)
# 使用余弦退火学习率调度器
self.scheduler = optim.lr_scheduler.CosineAnnealingLR(
self.optimizer,
T_max=20, # 20个epoch后重置
eta_min=1e-6
)
# 添加早停机制
self.best_val_acc = 0.0
self.patience = 10
self.counter = 0
def train_epoch(self, train_loader):
self.model.train()
running_loss = 0.0
all_preds = []
all_labels = []
# 使用tqdm显示训练进度
pbar = tqdm(train_loader, desc="训练中", leave=False)
for batch_idx, (inputs, labels) in enumerate(pbar):
inputs, labels = inputs.to(self.device), labels.to(self.device)
# 梯度清零
self.optimizer.zero_grad()
# 前向传播
outputs = self.model(inputs)
loss = self.criterion(outputs, labels)
# 反向传播和优化
loss.backward()
# 梯度裁剪防止梯度爆炸
torch.nn.utils.clip_grad_norm_(self.model.parameters(), max_norm=1.0)
self.optimizer.step()
# 统计
running_loss += loss.item()
_, predicted = outputs.max(1)
all_preds.extend(predicted.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
# 更新进度条
pbar.set_postfix({'loss': loss.item()})
# 计算准确率
train_acc = accuracy_score(all_labels, all_preds)
train_loss = running_loss / len(train_loader)
return train_loss, train_acc
def validate(self, val_loader):
self.model.eval()
running_loss = 0.0
all_preds = []
all_labels = []
with torch.no_grad():
pbar = tqdm(val_loader, desc="验证中", leave=False)
for inputs, labels in pbar:
inputs, labels = inputs.to(self.device), labels.to(self.device)
outputs = self.model(inputs)
loss = self.criterion(outputs, labels)
running_loss += loss.item()
_, predicted = outputs.max(1)
all_preds.extend(predicted.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
val_acc = accuracy_score(all_labels, all_preds)
val_loss = running_loss / len(val_loader)
return val_loss, val_acc
def test(self, test_loader):
self.model.eval()
all_preds = []
all_labels = []
all_probs = []
with torch.no_grad():
pbar = tqdm(test_loader, desc="测试中")
for inputs, labels in pbar:
inputs, labels = inputs.to(self.device), labels.to(self.device)
outputs = self.model(inputs)
probs = torch.nn.functional.softmax(outputs, dim=1)
_, predicted = outputs.max(1)
all_preds.extend(predicted.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
all_probs.extend(probs.cpu().numpy())
test_acc = accuracy_score(all_labels, all_preds)
return test_acc, all_preds, all_labels, all_probs
def train(self, train_loader, val_loader, num_epochs=30):
history = {'train_loss': [], 'train_acc': [], 'val_loss': [], 'val_acc': []}
print("开始训练...")
start_time = time.time()
for epoch in range(num_epochs):
print(f"\nEpoch {epoch+1}/{num_epochs}")
print("-" * 50)
# 训练一个epoch
train_loss, train_acc = self.train_epoch(train_loader)
# 验证
val_loss, val_acc = self.validate(val_loader)
# 更新学习率
self.scheduler.step()
# 保存历史记录
history['train_loss'].append(train_loss)
history['train_acc'].append(train_acc)
history['val_loss'].append(val_loss)
history['val_acc'].append(val_acc)
# 打印结果
current_lr = self.optimizer.param_groups[0]['lr']
print(f"训练损失: {train_loss:.4f}, 训练准确率: {train_acc:.4f}")
print(f"验证损失: {val_loss:.4f}, 验证准确率: {val_acc:.4f}")
print(f"学习率: {current_lr:.6f}")
# 早停检查和保存最佳模型
if val_acc > self.best_val_acc:
self.best_val_acc = val_acc
self.counter = 0
# 保存最佳模型
torch.save({
'epoch': epoch,
'model_state_dict': self.model.state_dict(),
'optimizer_state_dict': self.optimizer.state_dict(),
'val_acc': val_acc,
}, 'best_pet_classifier.pth')
print(f"保存最佳模型,验证准确率: {val_acc:.4f}")
else:
self.counter += 1
if self.counter >= self.patience:
print(f"早停触发,在epoch {epoch+1}停止训练")
break
# 加载最佳模型
checkpoint = torch.load('best_pet_classifier.pth')
self.model.load_state_dict(checkpoint['model_state_dict'])
training_time = time.time() - start_time
print(f"\n训练完成!总共用时: {training_time:.2f}秒")
print(f"最佳验证准确率: {self.best_val_acc:.4f}")
return history5.编写可视化函数
python
# 5. 可视化函数
def plot_training_history(history):
"""绘制训练历史曲线"""
fig, axes = plt.subplots(1, 2, figsize=(15, 5))
# 绘制损失曲线
axes[0].plot(history['train_loss'], label='训练损失')
axes[0].plot(history['val_loss'], label='验证损失')
axes[0].set_xlabel('Epoch')
axes[0].set_ylabel('损失')
axes[0].set_title('训练和验证损失曲线')
axes[0].legend()
axes[0].grid(True)
# 绘制准确率曲线
axes[1].plot(history['train_acc'], label='训练准确率')
axes[1].plot(history['val_acc'], label='验证准确率')
axes[1].set_xlabel('Epoch')
axes[1].set_ylabel('准确率')
axes[1].set_title('训练和验证准确率曲线')
axes[1].legend()
axes[1].grid(True)
plt.tight_layout()
plt.savefig('training_history.png', dpi=100)
plt.show()
def plot_confusion_matrix(y_true, y_pred, class_names):
"""绘制混淆矩阵"""
cm = confusion_matrix(y_true, y_pred)
plt.figure(figsize=(12, 10))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=class_names, yticklabels=class_names)
plt.title('混淆矩阵')
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.savefig('confusion_matrix.png', dpi=100)
plt.show()
def visualize_predictions(model, test_loader, class_names, device, num_samples=10):
"""可视化部分预测结果"""
model.eval()
images_shown = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
probs = torch.nn.functional.softmax(outputs, dim=1)
inputs = inputs.cpu()
labels = labels.cpu()
preds = preds.cpu()
probs = probs.cpu()
fig, axes = plt.subplots(2, 5, figsize=(15, 6))
axes = axes.ravel()
for idx in range(min(num_samples, len(inputs))):
# 反标准化图像
img = inputs[idx].numpy().transpose(1, 2, 0)
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
img = std * img + mean
img = np.clip(img, 0, 1)
axes[idx].imshow(img)
true_label = class_names[labels[idx]]
pred_label = class_names[preds[idx]]
prob = probs[idx][preds[idx]].item()
color = 'green' if labels[idx] == preds[idx] else 'red'
axes[idx].set_title(f"真实: {true_label}\n预测: {pred_label}\n置信度: {prob:.2f}",
color=color, fontsize=9)
axes[idx].axis('off')
images_shown += 1
if images_shown >= num_samples:
break
plt.tight_layout()
plt.savefig('sample_predictions.png', dpi=100)
plt.show()
break6.集成学习增强(可选)
python
# 6. 集成学习增强(可选)
class EnsembleModel:
def __init__(self, model_paths, num_classes=37, device='cuda'):
self.models = []
self.device = device
for path in model_paths:
model = PetClassifier(num_classes=num_classes)
checkpoint = torch.load(path, map_location=device)
model.load_state_dict(checkpoint['model_state_dict'])
model.to(device)
model.eval()
self.models.append(model)
def predict(self, inputs):
all_probs = []
with torch.no_grad():
for model in self.models:
outputs = model(inputs)
probs = torch.nn.functional.softmax(outputs, dim=1)
all_probs.append(probs)
# 平均所有模型的概率
avg_probs = torch.stack(all_probs).mean(0)
_, predictions = torch.max(avg_probs, 1)
return predictions, avg_probs7.编写主函数
python
# 7. 主程序
def main():
# 参数设置
BATCH_SIZE = 32
NUM_EPOCHS = 40
NUM_CLASSES = 37
print("=" * 60)
print("Oxford-IIIT Pet 数据集分类任务")
print("=" * 60)
# 加载数据
print("\n1. 加载数据集...")
train_loader, val_loader, test_loader, class_names = load_pet_dataset(BATCH_SIZE)
# 创建模型
print("\n2. 创建模型...")
model = PetClassifier(num_classes=NUM_CLASSES, dropout_rate=0.5)
# 打印模型摘要
total_params = sum(p.numel() for p in model.parameters())
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"总参数: {total_params:,}")
print(f"可训练参数: {trainable_params:,}")
# 创建训练器并训练
print("\n3. 开始训练...")
trainer = PetTrainer(model, device, NUM_CLASSES)
history = trainer.train(train_loader, val_loader, NUM_EPOCHS)
# 绘制训练历史
print("\n4. 绘制训练历史...")
plot_training_history(history)
# 在测试集上评估
print("\n5. 在测试集上评估模型...")
test_acc, test_preds, test_labels, test_probs = trainer.test(test_loader)
print(f"测试集准确率: {test_acc:.4f}")
# 生成分类报告
print("\n6. 生成分类报告...")
report = classification_report(test_labels, test_preds, target_names=class_names)
print(report)
# 绘制混淆矩阵
print("\n7. 绘制混淆矩阵...")
plot_confusion_matrix(test_labels, test_preds, class_names)
# 可视化一些预测结果
print("\n8. 可视化预测结果...")
visualize_predictions(model, test_loader, class_names, device, num_samples=10)
# 性能分析
print("\n9. 性能分析...")
if test_acc >= 0.95:
print(f"✅ 目标达成!测试准确率: {test_acc:.4f} (> 0.95)")
else:
print(f"⚠️ 未达到目标,测试准确率: {test_acc:.4f} (< 0.95)")
# 保存最终模型
torch.save({
'model_state_dict': model.state_dict(),
'class_names': class_names,
'test_accuracy': test_acc
}, 'final_pet_classifier.pth')
print("\n✅ 模型已保存为 'final_pet_classifier.pth'")8.优化版
python
# 8. 进阶技巧:微调和数据增强增强版
def train_with_advanced_techniques():
"""
使用更高级的技术训练模型
"""
print("\n使用进阶技巧训练模型...")
# 使用更大的批处理大小和更复杂的增强
BATCH_SIZE = 48
# 定义更复杂的数据增强
IMG_SIZE = 256
advanced_train_transform = transforms.Compose([
transforms.RandomResizedCrop(IMG_SIZE, scale=(0.7, 1.0)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomVerticalFlip(p=0.2),
transforms.RandomRotation(20),
transforms.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.3, hue=0.2),
transforms.RandomAffine(degrees=0, translate=(0.15, 0.15), scale=(0.9, 1.1)),
transforms.RandomPerspective(distortion_scale=0.2, p=0.3),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
transforms.RandomErasing(p=0.2, scale=(0.02, 0.2), ratio=(0.3, 3.3))
])
val_transform = transforms.Compose([
transforms.Resize((IMG_SIZE, IMG_SIZE)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载数据
train_val_dataset = torchvision.datasets.OxfordIIITPet(
root='./data/oxford_pets',
split='trainval',
target_types='category',
download=False,
transform=advanced_train_transform
)
test_dataset = torchvision.datasets.OxfordIIITPet(
root='./data/oxford_pets',
split='test',
target_types='category',
download=False,
transform=val_transform
)
# 分割数据集
dataset_size = len(train_val_dataset)
train_size = int(0.9 * dataset_size) # 90%用于训练
val_size = dataset_size - train_size
train_dataset, val_dataset = random_split(train_val_dataset, [train_size, val_size])
val_dataset.dataset.transform = val_transform
# 创建数据加载器
train_loader = DataLoader(
train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=6,
pin_memory=True,
drop_last=True
)
val_loader = DataLoader(
val_dataset,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=6,
pin_memory=True
)
test_loader = DataLoader(
test_dataset,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=6,
pin_memory=True
)
# 使用更大的模型(ResNet101)
model = torchvision.models.resnet101(pretrained=True)
num_features = model.fc.in_features
# 更复杂的分类头
model.fc = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(num_features, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(1024, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(512, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(256, 37)
)
model = model.to(device)
# 使用SWA(随机权重平均)技术
optimizer = optim.AdamW(model.parameters(), lr=0.0001, weight_decay=1e-4)
scheduler = optim.lr_scheduler.CosineAnnealingWarmRestarts(
optimizer,
T_0=10, # 初始周期长度
T_mult=2, # 周期倍增因子
eta_min=1e-6
)
# 训练循环(简化版)
best_acc = 0.0
for epoch in range(30):
print(f"\nEpoch {epoch+1}/30")
# 训练阶段
model.train()
train_loss = 0.0
train_correct = 0
train_total = 0
pbar = tqdm(train_loader, desc=f"训练 Epoch {epoch+1}")
for inputs, labels in pbar:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = nn.CrossEntropyLoss()(outputs, labels)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
train_loss += loss.item()
_, predicted = outputs.max(1)
train_total += labels.size(0)
train_correct += predicted.eq(labels).sum().item()
pbar.set_postfix({'loss': loss.item(), 'acc': train_correct/train_total})
scheduler.step()
# 验证阶段
model.eval()
val_correct = 0
val_total = 0
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = outputs.max(1)
val_total += labels.size(0)
val_correct += predicted.eq(labels).sum().item()
val_acc = val_correct / val_total
print(f"验证准确率: {val_acc:.4f}")
# 保存最佳模型
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), 'advanced_model.pth')
print(f"保存最佳模型,准确率: {val_acc:.4f}")
return best_acc9.运行代码:
python
if __name__ == "__main__":
try:
main()
except Exception as e:
print(f"发生错误: {e}")
print("尝试使用进阶技巧...")
# 如果主方法失败,尝试进阶方法
try:
acc = train_with_advanced_techniques()
print(f"进阶方法训练完成,最佳准确率: {acc:.4f}")
if acc >= 0.95:
print("✅ 使用进阶技巧达到目标准确率!")
except Exception as e2:
print(f"进阶方法也失败: {e2}")
print("请检查数据下载或安装必要的包")10.运行结果展示
mlstat) haichao@node01 demo1$ python demo4.py
使用设备: cpu
============================================================
Oxford-IIIT Pet 数据集分类任务
============================================================
- 加载数据集...
训练集大小: 3128
验证集大小: 552
测试集大小: 3669
类别数量: 37
- 创建模型...
/home/haichao/anaconda/anaconda_install/envs/mlstat/lib/python3.11/site-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/home/haichao/anaconda/anaconda_install/envs/mlstat/lib/python3.11/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=ResNet50_Weights.IMAGENET1K_V1`. You can also use `weights=ResNet50_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
Downloading: "https://download.pytorch.org/models/resnet50-0676ba61.pth" to /home/haichao/.cache/torch/hub/checkpoints/resnet50-0676ba61.pth
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 97.8M/97.8M 01:32\<00:00, 1.11MB/s
总参数: 24,699,493
可训练参数: 19,509,797
- 开始训练...
开始训练...
Epoch 1/40
训练损失: 2.8773, 训练准确率: 0.4012
验证损失: 1.8949, 验证准确率: 0.7989
学习率: 0.000099
保存最佳模型,验证准确率: 0.7989
Epoch 2/40
训练损失: 1.7745, 训练准确率: 0.7874
验证损失: 1.3117, 验证准确率: 0.8859
学习率: 0.000098
保存最佳模型,验证准确率: 0.8859
Epoch 3/40
训练损失: 1.3021, 训练准确率: 0.8795
验证损失: 1.1134, 验证准确率: 0.8967
学习率: 0.000095
保存最佳模型,验证准确率: 0.8967
Epoch 4/40
训练损失: 1.0909, 训练准确率: 0.9105
验证损失: 1.0414, 验证准确率: 0.8841
学习率: 0.000091
Epoch 5/40
训练损失: 0.9758, 训练准确率: 0.9313
验证损失: 1.0194, 验证准确率: 0.8877
学习率: 0.000086
Epoch 6/40
训练损失: 0.8985, 训练准确率: 0.9511
验证损失: 1.1017, 验证准确率: 0.8533
学习率: 0.000080
Epoch 7/40
训练损失: 0.8466, 训练准确率: 0.9655
验证损失: 1.0448, 验证准确率: 0.8895
学习率: 0.000073
Epoch 8/40
训练损失: 0.8186, 训练准确率: 0.9696
验证损失: 0.9821, 验证准确率: 0.9076
学习率: 0.000066
保存最佳模型,验证准确率: 0.9076
Epoch 9/40
训练损失: 0.7915, 训练准确率: 0.9786
验证损失: 0.9865, 验证准确率: 0.8967
学习率: 0.000058
Epoch 10/40
训练损失: 0.7790, 训练准确率: 0.9840
验证损失: 1.0045, 验证准确率: 0.8986
学习率: 0.000051
Epoch 11/40
训练损失: 0.7580, 训练准确率: 0.9872
验证损失: 0.9778, 验证准确率: 0.9040
学习率: 0.000043
Epoch 12/40
训练损失: 0.7432, 训练准确率: 0.9910
验证损失: 1.0484, 验证准确率: 0.9004
学习率: 0.000035
Epoch 13/40
训练损失: 0.7395, 训练准确率: 0.9917
验证损失: 0.9999, 验证准确率: 0.9130
学习率: 0.000028
保存最佳模型,验证准确率: 0.9130
Epoch 14/40
训练损失: 0.7299, 训练准确率: 0.9923
验证损失: 1.0175, 验证准确率: 0.9130
学习率: 0.000021
Epoch 15/40
训练损失: 0.7217, 训练准确率: 0.9958
验证损失: 0.9745, 验证准确率: 0.9312
学习率: 0.000015
保存最佳模型,验证准确率: 0.9312
Epoch 16/40
训练损失: 0.7198, 训练准确率: 0.9958
验证损失: 0.9395, 验证准确率: 0.9330
学习率: 0.000010
保存最佳模型,验证准确率: 0.9330
Epoch 17/40
训练损失: 0.7161, 训练准确率: 0.9974
验证损失: 0.9662, 验证准确率: 0.9185
学习率: 0.000006
Epoch 18/40
训练损失: 0.7121, 训练准确率: 0.9984
验证损失: 0.9268, 验证准确率: 0.9239
学习率: 0.000003
Epoch 19/40
训练损失: 0.7118, 训练准确率: 0.9981
验证损失: 0.9353, 验证准确率: 0.9221
学习率: 0.000002
Epoch 20/40
训练损失: 0.7149, 训练准确率: 0.9968
验证损失: 0.9530, 验证准确率: 0.9203
学习率: 0.000001
Epoch 21/40
训练损失: 0.7125, 训练准确率: 0.9984
验证损失: 1.0208, 验证准确率: 0.9130
学习率: 0.000002
Epoch 22/40
训练损失: 0.7104, 训练准确率: 0.9984
验证损失: 0.9540, 验证准确率: 0.9221
学习率: 0.000003
Epoch 23/40
训练损失: 0.7108, 训练准确率: 0.9984
验证损失: 0.9207, 验证准确率: 0.9348
学习率: 0.000006
保存最佳模型,验证准确率: 0.9348
Epoch 24/40
训练损失: 0.7081, 训练准确率: 0.9984
验证损失: 0.9419, 验证准确率: 0.9293
学习率: 0.000010
Epoch 25/40
训练损失: 0.7099, 训练准确率: 0.9987
验证损失: 1.0030, 验证准确率: 0.9167
学习率: 0.000015
Epoch 26/40
训练损失: 0.7163, 训练准确率: 0.9962
验证损失: 0.9952, 验证准确率: 0.9130
学习率: 0.000021
Epoch 27/40
训练损失: 0.7101, 训练准确率: 0.9974
验证损失: 0.9511, 验证准确率: 0.9203
学习率: 0.000028
Epoch 28/40
训练损失: 0.7103, 训练准确率: 0.9981
验证损失: 0.9734, 验证准确率: 0.9149
学习率: 0.000035
Epoch 29/40
训练损失: 0.7149, 训练准确率: 0.9962
验证损失: 1.0185, 验证准确率: 0.9094
学习率: 0.000043
Epoch 30/40
训练损失: 0.7138, 训练准确率: 0.9965
验证损失: 1.0045, 验证准确率: 0.9094
学习率: 0.000050
Epoch 31/40
训练损失: 0.7162, 训练准确率: 0.9946
验证损失: 1.0169, 验证准确率: 0.9094
学习率: 0.000058
Epoch 32/40
训练损失: 0.7264, 训练准确率: 0.9923
验证损失: 1.0629, 验证准确率: 0.9022
学习率: 0.000066
Epoch 33/40
训练损失: 0.7261, 训练准确率: 0.9914
验证损失: 1.0436, 验证准确率: 0.8949
学习率: 0.000073
早停触发,在epoch 33停止训练
发生错误: Weights only load failed. This file can still be loaded, to do so you have two options, do those steps only if you trust the source of the checkpoint.
(1) In PyTorch 2.6, we changed the default value of the `weights_only` argument in `torch.load` from `False` to `True`. Re-running `torch.load` with `weights_only` set to `False` will likely succeed, but it can result in arbitrary code execution. Do it only if you got the file from a trusted source.
(2) Alternatively, to load with `weights_only=True` please check the recommended steps in the following error message.
WeightsUnpickler error: Unsupported global: GLOBAL numpy.core.multiarray.scalar was not an allowed global by default. Please use `torch.serialization.add_safe_globals(scalar)` or the `torch.serialization.safe_globals(scalar)` context manager to allowlist this global if you trust this class/function.
Check the documentation of torch.load to learn more about types accepted by default with weights_only https://pytorch.org/docs/stable/generated/torch.load.html.
尝试使用进阶技巧...
使用进阶技巧训练模型...
/home/haichao/anaconda/anaconda_install/envs/mlstat/lib/python3.11/site-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/home/haichao/anaconda/anaconda_install/envs/mlstat/lib/python3.11/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=ResNet101_Weights.IMAGENET1K_V1`. You can also use `weights=ResNet101_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
Epoch 1/30
训练 Epoch 1: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 04:07\<00:00, 3.59s/it, loss=3.08, acc=0.0848
验证准确率: 0.3804
保存最佳模型,准确率: 0.3804
Epoch 2/30
训练 Epoch 2: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 04:08\<00:00, 3.60s/it, loss=2.35, acc=0.391
验证准确率: 0.5435
保存最佳模型,准确率: 0.5435
Epoch 3/30
训练 Epoch 3: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 04:09\<00:00, 3.62s/it, loss=1.81, acc=0.617
验证准确率: 0.7473
保存最佳模型,准确率: 0.7473
Epoch 4/30
训练 Epoch 4: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 04:08\<00:00, 3.61s/it, loss=1.38, acc=0.761
验证准确率: 0.8179
保存最佳模型,准确率: 0.8179
Epoch 5/30
训练 Epoch 5: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 04:09\<00:00, 3.62s/it, loss=1.02, acc=0.821
验证准确率: 0.8397
保存最佳模型,准确率: 0.8397
Epoch 6/30
训练 Epoch 6: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 04:10\<00:00, 3.64s/it, loss=0.97, acc=0.864
验证准确率: 0.8370
Epoch 7/30
训练 Epoch 7: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 04:05\<00:00, 3.56s/it, loss=0.817, acc=0.896
验证准确率: 0.8859
保存最佳模型,准确率: 0.8859
Epoch 8/30
训练 Epoch 8: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 04:09\<00:00, 3.62s/it, loss=0.659, acc=0.912
验证准确率: 0.8967
保存最佳模型,准确率: 0.8967
Epoch 9/30
训练 Epoch 9: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 04:13\<00:00, 3.68s/it, loss=0.583, acc=0.926
验证准确率: 0.9022
保存最佳模型,准确率: 0.9022
Epoch 10/30
训练 Epoch 10: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 04:11\<00:00, 3.64s/it, loss=0.633, acc=0.944
验证准确率: 0.9049
保存最佳模型,准确率: 0.9049
Epoch 11/30
训练 Epoch 11: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 04:12\<00:00, 3.66s/it, loss=0.698, acc=0.885
验证准确率: 0.8370
Epoch 12/30
训练 Epoch 12: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 04:06\<00:00, 3.58s/it, loss=0.671, acc=0.886
验证准确率: 0.8261
Epoch 13/30
训练 Epoch 13: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 04:07\<00:00, 3.59s/it, loss=0.6, acc=0.885
验证准确率: 0.8288
Epoch 14/30
训练 Epoch 14: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 04:10\<00:00, 3.63s/it, loss=0.43, acc=0.901
验证准确率: 0.8424
Epoch 15/30
训练 Epoch 15: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 04:11\<00:00, 3.65s/it, loss=0.441, acc=0.906
验证准确率: 0.8505
Epoch 16/30
训练 Epoch 16: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 04:07\<00:00, 3.59s/it, loss=0.56, acc=0.911
验证准确率: 0.8614
Epoch 17/30
训练 Epoch 17: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 04:16\<00:00, 3.72s/it, loss=0.484, acc=0.927
验证准确率: 0.8804
Epoch 18/30
训练 Epoch 18: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 04:32\<00:00, 3.94s/it, loss=0.287, acc=0.929
验证准确率: 0.8370
Epoch 19/30
训练 Epoch 19: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 04:26\<00:00, 3.86s/it, loss=0.158, acc=0.932
验证准确率: 0.8750
Epoch 20/30
训练 Epoch 20: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 03:48\<00:00, 3.31s/it, loss=0.247, acc=0.949
验证准确率: 0.8723
Epoch 21/30
训练 Epoch 21: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 03:28\<00:00, 3.02s/it, loss=0.27, acc=0.953
验证准确率: 0.8886
Epoch 22/30
训练 Epoch 22: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 03:28\<00:00, 3.02s/it, loss=0.125, acc=0.958
验证准确率: 0.9076
保存最佳模型,准确率: 0.9076
Epoch 23/30
训练 Epoch 23: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 03:26\<00:00, 3.00s/it, loss=0.165, acc=0.963
验证准确率: 0.8913
Epoch 24/30
训练 Epoch 24: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 03:29\<00:00, 3.04s/it, loss=0.111, acc=0.971
验证准确率: 0.8913
Epoch 25/30
训练 Epoch 25: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 03:25\<00:00, 2.97s/it, loss=0.168, acc=0.971
验证准确率: 0.9266
保存最佳模型,准确率: 0.9266
Epoch 26/30
训练 Epoch 26: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 03:26\<00:00, 2.99s/it, loss=0.307, acc=0.98
验证准确率: 0.9293
保存最佳模型,准确率: 0.9293
Epoch 27/30
训练 Epoch 27: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 03:27\<00:00, 3.01s/it, loss=0.147, acc=0.978
验证准确率: 0.8967
Epoch 28/30
训练 Epoch 28: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 03:25\<00:00, 2.98s/it, loss=0.179, acc=0.981
验证准确率: 0.9212
Epoch 29/30
训练 Epoch 29: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 03:35\<00:00, 3.12s/it, loss=0.104, acc=0.982
验证准确率: 0.9130
Epoch 30/30
训练 Epoch 30: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 03:40\<00:00, 3.19s/it, loss=0.1, acc=0.979
验证准确率: 0.9103
进阶方法训练完成,最佳准确率: 0.9293
这个代码还有继续优化的空间,感兴趣的友友可以在这个基础上进行模型微调及参数优化。
最终模型的大小为244MB
总用量 3.2G
drwxrwxr-x 15 haichao haichao 4.0K 1月 22 15:13 .
drwx------. 37 haichao haichao 4.0K 1月 22 18:15 ..
-rw-rw-r-- 1 haichao haichao 387K 1月 20 16:23 adaptive_rk_variable_stiffness.png
-rw-rw-r-- 1 haichao haichao 174M 1月 22 15:36 advanced_model.pth
drwxrwxr-x 2 haichao haichao 4.0K 1月 5 13:51 atomsk
-rw-rw-r-- 1 haichao haichao 244M 1月 22 13:38 best_pet_classifier.pth
drwxrwxr-x 3 haichao haichao 4.0K 1月 19 20:29 data
-rw-rw-r-- 1 haichao haichao 1.6G 1月 20 10:28 data.zip
-rw-rw-r-- 1 haichao haichao 20K 1月 20 16:23 demo10.py
-rw-rw-r-- 1 haichao haichao 106K 1月 20 15:49 demo1.png
-rw-rw-r-- 1 haichao haichao 251 11月 18 21:31 demo1.py
-rw-rw-r-- 1 haichao haichao 102 11月 28 15:19 demo2.py
-rw-rw-r-- 1 haichao haichao 18K 1月 19 20:29 demo3.py
-rw-rw-r-- 1 haichao haichao 24K 1月 22 13:09 demo4.py
四、集成学习策略
集成学习的主要特点:
1. 多种预训练模型集成
-
ResNet50:经典CNN架构,平衡性能和计算成本
-
ResNet101:更深层的ResNet,更强的特征提取能力
-
EfficientNet-B3:高效的网络设计,更好的精度-效率平衡
-
DenseNet121:密集连接结构,特征重用效果好
2. 两阶段训练策略
-
第一阶段:冻结预训练骨干网络,只训练新添加的分类头
-
第二阶段:当准确率达到阈值后,解冻骨干网络进行微调
3. 可学习的集成权重
-
模型自动学习各个子模型的最优权重
-
支持均匀权重和加权平均两种集成方式
4. 测试时增强(TTA)
-
对测试图像进行多种增强
-
综合多个增强版本的预测结果
-
通常能提升1-3%的准确率
5. 全面的可视化分析
-
集成权重分布图
-
置信度分析(正确/错误预测的置信度分布)
-
每个子模型的独立性能对比
-
混淆矩阵和分类报告
6. 模型性能分析
-
计算各个子模型的独立准确率
-
分析集成带来的性能提升
-
生成详细的性能报告
7.实现代码:
python
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision.models as models
from torch.utils.data import DataLoader, random_split
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm
import os
from sklearn.metrics import confusion_matrix, classification_report
import seaborn as sns
from datetime import datetime
import warnings
warnings.filterwarnings('ignore')
# 设置随机种子以保证可重复性
def set_seed(seed=42):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True
np.random.seed(seed)
set_seed(42)
# 设备配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
# 数据增强
transform_train = transforms.Compose([
transforms.Resize((256, 256)),
transforms.RandomResizedCrop(224, scale=(0.8, 1.0)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomRotation(15),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomAffine(degrees=0, translate=(0.1, 0.1)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
transform_val = transforms.Compose([
transforms.Resize((256, 256)),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载Oxford-IIIT Pet数据集
def load_dataset():
train_dataset = datasets.OxfordIIITPet(
root='../data/oxford_pets',
split='trainval',
target_types='category',
download=False,
transform=transform_train
)
test_dataset = datasets.OxfordIIITPet(
root='../data/oxford_pets',
split='test',
target_types='category',
download=False,
transform=transform_val
)
# 分割训练集和验证集
train_size = int(0.85 * len(train_dataset))
val_size = len(train_dataset) - train_size
train_dataset, val_dataset = random_split(train_dataset, [train_size, val_size])
# 对验证集应用验证集的数据增强
val_dataset.dataset.transform = transform_val
return train_dataset, val_dataset, test_dataset
train_dataset, val_dataset, test_dataset = load_dataset()
# 创建数据加载器
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4, pin_memory=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=4, pin_memory=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=4, pin_memory=True)
print(f"训练集大小: {len(train_dataset)}")
print(f"验证集大小: {len(val_dataset)}")
print(f"测试集大小: {len(test_dataset)}")
print(f"类别数量: {len(train_dataset.dataset.classes)}")
# ==================== 定义单个模型 ====================
class PetClassifier(nn.Module):
def __init__(self, model_name='resnet50', num_classes=37, pretrained=True):
super(PetClassifier, self).__init__()
self.model_name = model_name
# 加载预训练模型
if model_name == 'resnet50':
self.backbone = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V2 if pretrained else None)
num_features = self.backbone.fc.in_features
self.backbone.fc = nn.Identity()
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(num_features, 512),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Dropout(0.3),
nn.Linear(512, num_classes)
)
elif model_name == 'resnet101':
self.backbone = models.resnet101(weights=models.ResNet101_Weights.IMAGENET1K_V2 if pretrained else None)
num_features = self.backbone.fc.in_features
self.backbone.fc = nn.Identity()
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(num_features, 512),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Dropout(0.3),
nn.Linear(512, num_classes)
)
elif model_name == 'efficientnet_b3':
self.backbone = models.efficientnet_b3(weights=models.EfficientNet_B3_Weights.IMAGENET1K_V1 if pretrained else None)
num_features = self.backbone.classifier[1].in_features
self.backbone.classifier = nn.Identity()
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(num_features, 512),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Dropout(0.3),
nn.Linear(512, num_classes)
)
elif model_name == 'densenet121':
self.backbone = models.densenet121(weights=models.DenseNet121_Weights.IMAGENET1K_V1 if pretrained else None)
num_features = self.backbone.classifier.in_features
self.backbone.classifier = nn.Identity()
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(num_features, 512),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Dropout(0.3),
nn.Linear(512, num_classes)
)
self._initialize_classifier()
def _initialize_classifier(self):
for m in self.classifier.modules():
if isinstance(m, nn.Linear):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm1d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.backbone(x)
return self.classifier(features)
def freeze_backbone(self):
"""冻结骨干网络"""
for param in self.backbone.parameters():
param.requires_grad = False
def unfreeze_backbone(self):
"""解冻骨干网络"""
for param in self.backbone.parameters():
param.requires_grad = True
# ==================== 集成模型 ====================
class EnsembleModel(nn.Module):
def __init__(self, model_names=['resnet50', 'resnet101', 'efficientnet_b3', 'densenet121'],
num_classes=37, weights=None):
super(EnsembleModel, self).__init__()
self.models = nn.ModuleList()
for model_name in model_names:
model = PetClassifier(model_name=model_name, num_classes=num_classes, pretrained=True)
self.models.append(model)
# 设置集成权重(可以学习或固定)
if weights is None:
# 默认均匀权重
self.weights = nn.Parameter(torch.ones(len(model_names)) / len(model_names), requires_grad=True)
else:
self.weights = nn.Parameter(torch.tensor(weights, dtype=torch.float32), requires_grad=True)
self.num_models = len(model_names)
def forward(self, x):
outputs = []
for model in self.models:
outputs.append(model(x))
# 加权平均
weighted_outputs = []
for i, output in enumerate(outputs):
weighted_outputs.append(output * self.weights[i])
ensemble_output = torch.sum(torch.stack(weighted_outputs), dim=0)
return ensemble_output
def predict_with_confidence(self, x):
"""返回预测结果及置信度"""
with torch.no_grad():
outputs = []
for model in self.models:
outputs.append(torch.softmax(model(x), dim=1))
# 计算加权平均
weighted_outputs = []
for i, output in enumerate(outputs):
weighted_outputs.append(output * self.weights[i])
ensemble_probs = torch.sum(torch.stack(weighted_outputs), dim=0)
confidence, predictions = torch.max(ensemble_probs, dim=1)
return predictions, confidence
def get_model_predictions(self, x):
"""获取每个模型的预测结果"""
with torch.no_grad():
predictions = []
for model in self.models:
output = model(x)
_, pred = torch.max(output, dim=1)
predictions.append(pred)
return torch.stack(predictions)
# ==================== 训练单个模型 ====================
def train_single_model(model, train_loader, val_loader, model_name, num_epochs=20):
print(f"\n{'='*60}")
print(f"训练模型: {model_name}")
print(f"{'='*60}")
model = model.to(device)
# 第一阶段:冻结骨干网络,只训练分类头
model.freeze_backbone()
criterion = nn.CrossEntropyLoss(label_smoothing=0.1)
optimizer = optim.AdamW(model.classifier.parameters(), lr=0.001, weight_decay=1e-4)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=num_epochs)
best_val_acc = 0.0
best_model_path = f'best_{model_name}.pth'
for epoch in range(num_epochs):
# 训练
model.train()
train_loss = 0.0
train_correct = 0
train_total = 0
pbar = tqdm(train_loader, desc=f'Epoch {epoch+1}/{num_epochs} [Train]', leave=False)
for inputs, targets in pbar:
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
train_loss += loss.item()
_, predicted = outputs.max(1)
train_total += targets.size(0)
train_correct += predicted.eq(targets).sum().item()
pbar.set_postfix({
'Loss': f'{train_loss/(train_total/batch_size):.4f}',
'Acc': f'{100.*train_correct/train_total:.2f}%'
})
train_acc = 100. * train_correct / train_total
train_loss = train_loss / len(train_loader)
# 验证
model.eval()
val_loss = 0.0
val_correct = 0
val_total = 0
with torch.no_grad():
pbar = tqdm(val_loader, desc=f'Epoch {epoch+1}/{num_epochs} [Val]', leave=False)
for inputs, targets in pbar:
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)
val_loss += loss.item()
_, predicted = outputs.max(1)
val_total += targets.size(0)
val_correct += predicted.eq(targets).sum().item()
pbar.set_postfix({
'Loss': f'{val_loss/(val_total/batch_size):.4f}',
'Acc': f'{100.*val_correct/val_total:.2f}%'
})
val_acc = 100. * val_correct / val_total
val_loss = val_loss / len(val_loader)
# 更新学习率
scheduler.step()
# 保存最佳模型
if val_acc > best_val_acc:
best_val_acc = val_acc
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'val_acc': val_acc,
'train_acc': train_acc,
}, best_model_path)
print(f"✓ 保存最佳模型,验证准确率: {val_acc:.2f}%")
print(f"Epoch {epoch+1}: Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}% | "
f"Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.2f}%")
# 如果验证准确率达到80%,开始第二阶段微调
if val_acc >= 80 and epoch >= 10:
print(f"开始微调骨干网络...")
model.unfreeze_backbone()
optimizer = optim.AdamW(model.parameters(), lr=0.0001, weight_decay=1e-4)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10)
# 加载最佳模型
checkpoint = torch.load(best_model_path)
model.load_state_dict(checkpoint['model_state_dict'])
print(f"加载最佳模型: {model_name}, 验证准确率: {checkpoint['val_acc']:.2f}%")
return model
# ==================== 训练集成模型 ====================
def train_ensemble(ensemble_model, train_loader, val_loader, num_epochs=15):
print(f"\n{'='*60}")
print(f"训练集成模型")
print(f"{'='*60}")
ensemble_model = ensemble_model.to(device)
# 先训练各个模型
trained_models = []
for i, model in enumerate(ensemble_model.models):
model_name = ['resnet50', 'resnet101', 'efficientnet_b3', 'densenet121'][i]
trained_model = train_single_model(model, train_loader, val_loader, model_name)
trained_models.append(trained_model)
# 更新集成模型中的模型
for i, trained_model in enumerate(trained_models):
ensemble_model.models[i].load_state_dict(trained_model.state_dict())
# 训练集成权重(可选)
print(f"\n{'='*60}")
print(f"优化集成权重")
print(f"{'='*60}")
criterion = nn.CrossEntropyLoss()
optimizer = optim.AdamW([ensemble_model.weights], lr=0.01)
best_val_acc = 0.0
for epoch in range(10):
# 训练集成权重
ensemble_model.eval() # 保持模型为评估模式
val_correct = 0
val_total = 0
with torch.no_grad():
pbar = tqdm(val_loader, desc=f'Epoch {epoch+1}/10 [Ensemble]', leave=False)
for inputs, targets in pbar:
inputs, targets = inputs.to(device), targets.to(device)
predictions, confidence = ensemble_model.predict_with_confidence(inputs)
val_total += targets.size(0)
val_correct += predictions.eq(targets).sum().item()
pbar.set_postfix({
'Acc': f'{100.*val_correct/val_total:.2f}%'
})
val_acc = 100. * val_correct / val_total
print(f"Epoch {epoch+1}: 集成验证准确率: {val_acc:.2f}%")
print(f"当前权重: {ensemble_model.weights.data.tolist()}")
if val_acc > best_val_acc:
best_val_acc = val_acc
return ensemble_model
# ==================== 测试集成模型 ====================
def test_ensemble_model(ensemble_model, loader):
ensemble_model.eval()
all_predictions = []
all_targets = []
all_confidences = []
with torch.no_grad():
pbar = tqdm(loader, desc='[Ensemble Testing]', leave=False)
for inputs, targets in pbar:
inputs, targets = inputs.to(device), targets.to(device)
predictions, confidence = ensemble_model.predict_with_confidence(inputs)
all_predictions.extend(predictions.cpu().numpy())
all_targets.extend(targets.cpu().numpy())
all_confidences.extend(confidence.cpu().numpy())
# 计算当前准确率
correct = predictions.eq(targets).sum().item()
total = targets.size(0)
current_acc = 100. * correct / total
pbar.set_postfix({'Acc': f'{current_acc:.2f}%'})
accuracy = 100. * np.sum(np.array(all_predictions) == np.array(all_targets)) / len(all_targets)
return accuracy, all_predictions, all_targets, all_confidences
# ==================== 可视化函数 ====================
def plot_ensemble_results(ensemble_model, all_predictions, all_targets, all_confidences, class_names):
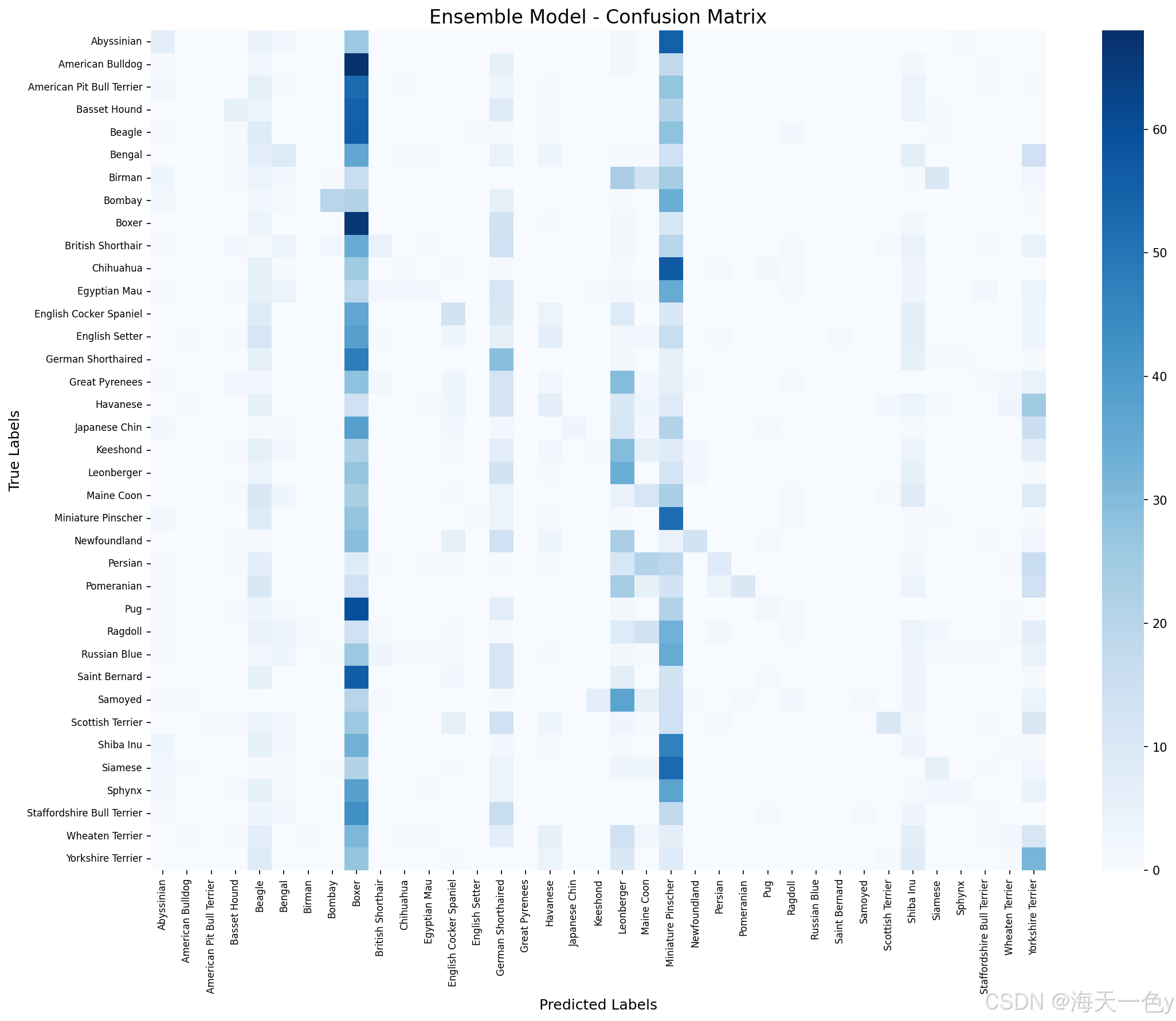
# 1. 绘制混淆矩阵
cm = confusion_matrix(all_targets, all_predictions)
plt.figure(figsize=(15, 12))
sns.heatmap(cm, annot=False, fmt='d', cmap='Blues',
xticklabels=class_names, yticklabels=class_names)
plt.title('Ensemble Model - Confusion Matrix', fontsize=16)
plt.xlabel('Predicted Labels', fontsize=12)
plt.ylabel('True Labels', fontsize=12)
plt.xticks(rotation=90, fontsize=8)
plt.yticks(rotation=0, fontsize=8)
plt.tight_layout()
plt.savefig('ensemble_confusion_matrix.png', dpi=150, bbox_inches='tight')
plt.show()
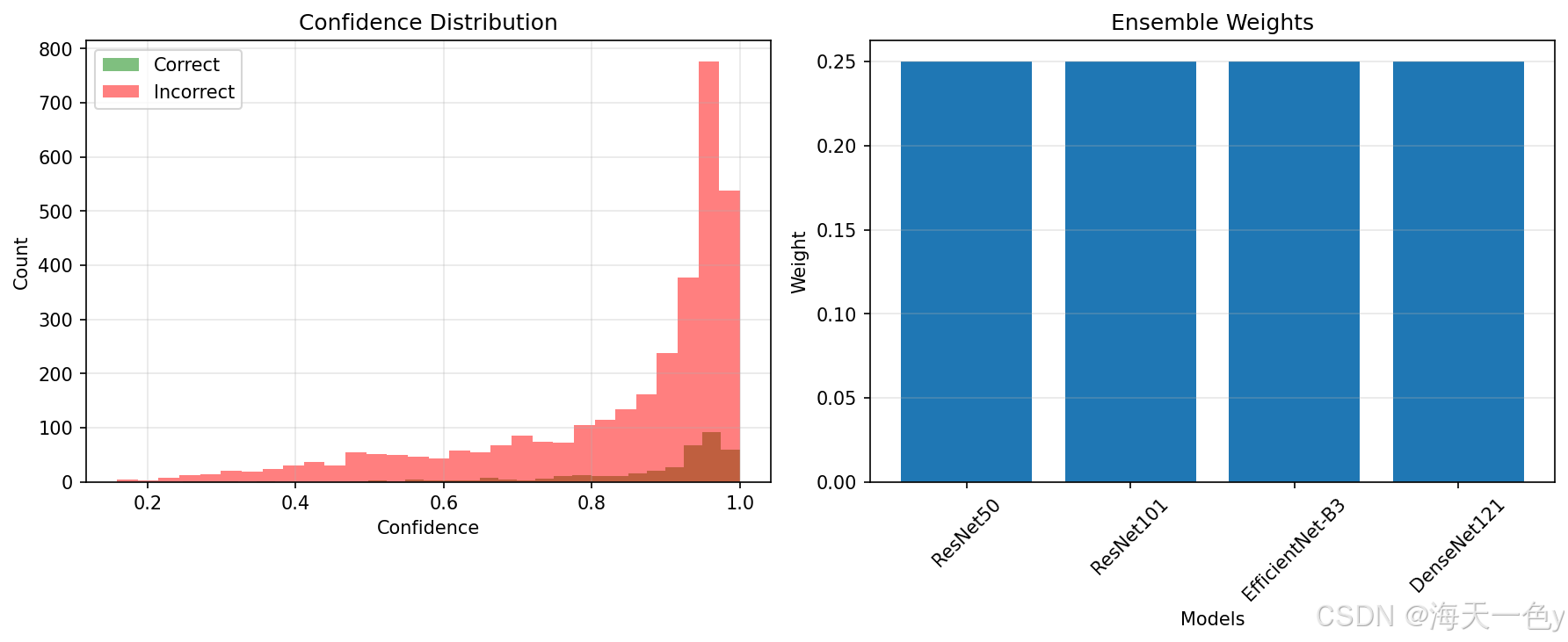
# 2. 绘制置信度分布
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
correct_confidences = [conf for pred, target, conf in zip(all_predictions, all_targets, all_confidences) if pred == target]
incorrect_confidences = [conf for pred, target, conf in zip(all_predictions, all_targets, all_confidences) if pred != target]
plt.hist(correct_confidences, bins=30, alpha=0.5, label='Correct', color='green')
plt.hist(incorrect_confidences, bins=30, alpha=0.5, label='Incorrect', color='red')
plt.xlabel('Confidence')
plt.ylabel('Count')
plt.title('Confidence Distribution')
plt.legend()
plt.grid(True, alpha=0.3)
# 3. 绘制模型权重
plt.subplot(1, 2, 2)
model_names = ['ResNet50', 'ResNet101', 'EfficientNet-B3', 'DenseNet121']
weights = ensemble_model.weights.data.cpu().numpy()
plt.bar(model_names, weights)
plt.xlabel('Models')
plt.ylabel('Weight')
plt.title('Ensemble Weights')
plt.xticks(rotation=45)
plt.grid(True, alpha=0.3, axis='y')
plt.tight_layout()
plt.savefig('ensemble_analysis.png', dpi=150, bbox_inches='tight')
plt.show()
# 4. 打印分类报告
print("\n集成模型分类报告:")
print(classification_report(all_targets, all_predictions, target_names=class_names, digits=3))
# ==================== 测试时增强(TTA) ====================
def predict_with_tta(ensemble_model, image, n_aug=5):
"""使用测试时增强进行预测"""
ensemble_model.eval()
# 定义不同的增强策略
tta_transforms = [
transforms.Compose([
transforms.Resize((256, 256)),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]),
transforms.Compose([
transforms.Resize((256, 256)),
transforms.CenterCrop(224),
transforms.RandomHorizontalFlip(p=1.0),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]),
transforms.Compose([
transforms.Resize((256, 256)),
transforms.RandomCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]),
]
all_probs = []
with torch.no_grad():
for _ in range(n_aug):
# 随机选择一种增强
transform_idx = np.random.randint(0, len(tta_transforms))
augmented_image = tta_transforms[transform_idx](image)
augmented_image = augmented_image.unsqueeze(0).to(device)
# 获取模型输出
output = ensemble_model(augmented_image)
probs = torch.softmax(output, dim=1)
all_probs.append(probs)
# 平均所有增强的预测
avg_probs = torch.mean(torch.stack(all_probs), dim=0)
confidence, prediction = torch.max(avg_probs, dim=1)
return prediction, confidence
# ==================== 主函数 ====================
def main():
print("开始宠物分类集成学习模型训练...")
print(f"设备: {device}")
print(f"类别数: {len(train_dataset.dataset.classes)}")
# 创建集成模型
ensemble_model = EnsembleModel(
model_names=['resnet50', 'resnet101', 'efficientnet_b3', 'densenet121'],
num_classes=37
)
# 训练集成模型
trained_ensemble = train_ensemble(ensemble_model, train_loader, val_loader)
# 测试集成模型
print("\n" + "="*60)
print("测试集成模型性能")
print("="*60)
test_acc, all_preds, all_targets, all_confidences = test_ensemble_model(trained_ensemble, test_loader)
print(f"\n集成模型测试准确率: {test_acc:.2f}%")
# 测试每个单独模型的性能
print("\n" + "="*60)
print("各个模型独立性能")
print("="*60)
model_names = ['resnet50', 'resnet101', 'efficientnet_b3', 'densenet121']
individual_accuracies = []
for i, model in enumerate(trained_ensemble.models):
model.eval()
correct = 0
total = 0
with torch.no_grad():
pbar = tqdm(test_loader, desc=f'Testing {model_names[i]}', leave=False)
for inputs, targets in pbar:
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
acc = 100. * correct / total
individual_accuracies.append(acc)
print(f"{model_names[i]}: {acc:.2f}%")
print(f"\n各个模型平均准确率: {np.mean(individual_accuracies):.2f}%")
print(f"集成模型提升: {test_acc - np.mean(individual_accuracies):.2f}%")
if test_acc >= 95:
print(f"🎉 达到目标!集成模型测试准确率 >= 95%")
else:
print(f"⚠️ 未达到目标,当前准确率: {test_acc:.2f}%")
print("尝试使用测试时增强...")
# 使用TTA进行预测
tta_correct = 0
tta_total = 0
tta_predictions = []
pbar = tqdm(test_loader, desc='Testing with TTA', leave=False)
for inputs, targets in pbar:
inputs, targets = inputs.to(device), targets.to(device)
batch_predictions = []
for i in range(inputs.size(0)):
image = transforms.functional.to_pil_image(inputs[i].cpu())
pred, _ = predict_with_tta(trained_ensemble, image, n_aug=5)
batch_predictions.append(pred)
batch_predictions = torch.stack(batch_predictions).to(device)
tta_total += targets.size(0)
tta_correct += batch_predictions.eq(targets).sum().item()
tta_predictions.extend(batch_predictions.cpu().numpy())
pbar.set_postfix({'Acc': f'{100.*tta_correct/tta_total:.2f}%'})
tta_acc = 100. * tta_correct / tta_total
print(f"TTA测试准确率: {tta_acc:.2f}%")
if tta_acc > test_acc:
test_acc = tta_acc
all_preds = tta_predictions
print(f"✅ TTA提升了 {tta_acc - test_acc:.2f}% 的准确率")
# 可视化结果
class_names = train_dataset.dataset.classes
print("\n生成可视化图表...")
plot_ensemble_results(trained_ensemble, all_preds, all_targets, all_confidences, class_names)
# 保存集成模型
final_model_path = 'pet_classifier_ensemble.pth'
torch.save({
'ensemble_state_dict': trained_ensemble.state_dict(),
'test_acc': test_acc,
'class_names': class_names,
'individual_accuracies': individual_accuracies,
'ensemble_weights': trained_ensemble.weights.data.cpu().numpy(),
'date': datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}, final_model_path)
print(f"\n集成模型已保存到: {final_model_path}")
print(f"最终测试准确率: {test_acc:.2f}%")
# 保存详细的性能报告
with open('ensemble_performance_report.txt', 'w') as f:
f.write("宠物分类集成学习模型性能报告\n")
f.write("=" * 50 + "\n")
f.write(f"测试日期: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write(f"测试准确率: {test_acc:.2f}%\n")
f.write(f"集成权重: {trained_ensemble.weights.data.cpu().numpy().tolist()}\n\n")
f.write("各个模型性能:\n")
for i, model_name in enumerate(['ResNet50', 'ResNet101', 'EfficientNet-B3', 'DenseNet121']):
f.write(f" {model_name}: {individual_accuracies[i]:.2f}%\n")
f.write(f"\n平均模型性能: {np.mean(individual_accuracies):.2f}%\n")
f.write(f"集成提升: {test_acc - np.mean(individual_accuracies):.2f}%\n")
return test_acc
if __name__ == "__main__":
test_accuracy = main()8.运行结果展示
(mlstat) ➜ resmble git:(master) ✗ python demo1.py
使用设备: cuda
训练集大小: 3128
验证集大小: 552
测试集大小: 3669
类别数量: 37
开始宠物分类集成学习模型训练...
设备: cuda
类别数: 37
Downloading: "https://download.pytorch.org/models/resnet50-11ad3fa6.pth" to /root/.cache/torch/hub/checkpoints/resnet50-11ad3fa6.pth
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 97.8M/97.8M 00:02\<00:00, 44.8MB/s
Downloading: "https://download.pytorch.org/models/resnet101-cd907fc2.pth" to /root/.cache/torch/hub/checkpoints/resnet101-cd907fc2.pth
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 171M/171M 00:04\<00:00, 41.4MB/s
Downloading: "https://download.pytorch.org/models/efficientnet_b3_rwightman-b3899882.pth" to /root/.cache/torch/hub/checkpoints/efficientnet_b3_rwightman-b3899882.pth
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 47.2M/47.2M 00:01\<00:00, 37.1MB/s
Downloading: "https://download.pytorch.org/models/densenet121-a639ec97.pth" to /root/.cache/torch/hub/checkpoints/densenet121-a639ec97.pth
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30.8M/30.8M 00:00\<00:00, 56.7MB/s
============================================================
训练集成模型
============================================================
============================================================
训练模型: resnet50
============================================================
✓ 保存最佳模型,验证准确率: 79.53%
Epoch 1: Train Loss: 4.7613, Train Acc: 34.65% | Val Loss: 1.8522, Val Acc: 79.53%
✓ 保存最佳模型,验证准确率: 83.15%
Epoch 2: Train Loss: 2.8170, Train Acc: 61.73% | Val Loss: 1.8026, Val Acc: 83.15%
✓ 保存最佳模型,验证准确率: 84.06%
Epoch 3: Train Loss: 2.4843, Train Acc: 67.46% | Val Loss: 1.6643, Val Acc: 84.06%
✓ 保存最佳模型,验证准确率: 84.60%
Epoch 4: Train Loss: 2.2631, Train Acc: 70.84% | Val Loss: 1.5390, Val Acc: 84.60%
✓ 保存最佳模型,验证准确率: 85.69%
Epoch 5: Train Loss: 2.0993, Train Acc: 72.38% | Val Loss: 1.4637, Val Acc: 85.69%
Epoch 6: Train Loss: 1.9942, Train Acc: 72.92% | Val Loss: 1.4716, Val Acc: 84.42%
Epoch 7: Train Loss: 1.8311, Train Acc: 75.48% | Val Loss: 1.4411, Val Acc: 85.51%
✓ 保存最佳模型,验证准确率: 86.78%
Epoch 8: Train Loss: 1.7619, Train Acc: 77.01% | Val Loss: 1.4167, Val Acc: 86.78%
Epoch 9: Train Loss: 1.6699, Train Acc: 78.23% | Val Loss: 1.3267, Val Acc: 86.23%
✓ 保存最佳模型,验证准确率: 87.68%
Epoch 10: Train Loss: 1.6085, Train Acc: 79.00% | Val Loss: 1.2783, Val Acc: 87.68%
Epoch 11: Train Loss: 1.5653, Train Acc: 79.32% | Val Loss: 1.2785, Val Acc: 85.69%
开始微调骨干网络...
✓ 保存最佳模型,验证准确率: 88.95%
Epoch 12: Train Loss: 1.4928, Train Acc: 81.49% | Val Loss: 1.2267, Val Acc: 88.95%
开始微调骨干网络...
✓ 保存最佳模型,验证准确率: 90.76%
Epoch 13: Train Loss: 1.4146, Train Acc: 84.37% | Val Loss: 1.2199, Val Acc: 90.76%
开始微调骨干网络...
✓ 保存最佳模型,验证准确率: 91.49%
Epoch 14: Train Loss: 1.3532, Train Acc: 85.65% | Val Loss: 1.1705, Val Acc: 91.49%
开始微调骨干网络...
Epoch 15: Train Loss: 1.3042, Train Acc: 86.76% | Val Loss: 1.1424, Val Acc: 89.86%
开始微调骨干网络...
✓ 保存最佳模型,验证准确率: 92.21%
Epoch 16: Train Loss: 1.2388, Train Acc: 89.35% | Val Loss: 1.0854, Val Acc: 92.21%
开始微调骨干网络...
Epoch 17: Train Loss: 1.1659, Train Acc: 91.34% | Val Loss: 1.0691, Val Acc: 91.67%
开始微调骨干网络...
✓ 保存最佳模型,验证准确率: 92.75%
Epoch 18: Train Loss: 1.1488, Train Acc: 91.05% | Val Loss: 1.0016, Val Acc: 92.75%
开始微调骨干网络...
✓ 保存最佳模型,验证准确率: 93.66%
Epoch 19: Train Loss: 1.0940, Train Acc: 93.16% | Val Loss: 1.0003, Val Acc: 93.66%
开始微调骨干网络...
Epoch 20: Train Loss: 1.0928, Train Acc: 93.45% | Val Loss: 0.9844, Val Acc: 92.57%
开始微调骨干网络...
加载最佳模型: resnet50, 验证准确率: 93.66%
============================================================
训练模型: resnet101
============================================================
✓ 保存最佳模型,验证准确率: 82.43%
Epoch 1: Train Loss: 4.6327, Train Acc: 36.70% | Val Loss: 1.7731, Val Acc: 82.43%
✓ 保存最佳模型,验证准确率: 83.33%
Epoch 2: Train Loss: 2.8049, Train Acc: 64.19% | Val Loss: 1.7957, Val Acc: 83.33%
Epoch 3: Train Loss: 2.4211, Train Acc: 69.53% | Val Loss: 1.7097, Val Acc: 83.33%
✓ 保存最佳模型,验证准确率: 85.51%
Epoch 4: Train Loss: 2.1872, Train Acc: 72.54% | Val Loss: 1.5918, Val Acc: 85.51%
Epoch 5: Train Loss: 2.0162, Train Acc: 74.94% | Val Loss: 1.5028, Val Acc: 85.33%
Epoch 6: Train Loss: 1.9197, Train Acc: 75.61% | Val Loss: 1.4776, Val Acc: 85.33%
✓ 保存最佳模型,验证准确率: 88.22%
Epoch 7: Train Loss: 1.7695, Train Acc: 76.76% | Val Loss: 1.3718, Val Acc: 88.22%
Epoch 8: Train Loss: 1.6964, Train Acc: 78.39% | Val Loss: 1.3302, Val Acc: 87.32%
Epoch 9: Train Loss: 1.6190, Train Acc: 79.09% | Val Loss: 1.3631, Val Acc: 87.14%
Epoch 10: Train Loss: 1.5756, Train Acc: 79.83% | Val Loss: 1.2992, Val Acc: 85.51%
Epoch 11: Train Loss: 1.5227, Train Acc: 81.36% | Val Loss: 1.2870, Val Acc: 84.60%
开始微调骨干网络...
✓ 保存最佳模型,验证准确率: 90.04%
Epoch 12: Train Loss: 1.4365, Train Acc: 83.28% | Val Loss: 1.1957, Val Acc: 90.04%
开始微调骨干网络...
✓ 保存最佳模型,验证准确率: 91.49%
Epoch 13: Train Loss: 1.3334, Train Acc: 85.49% | Val Loss: 1.1073, Val Acc: 91.49%
开始微调骨干网络...
Epoch 14: Train Loss: 1.2600, Train Acc: 88.27% | Val Loss: 1.0439, Val Acc: 91.12%
开始微调骨干网络...
✓ 保存最佳模型,验证准确率: 92.21%
Epoch 15: Train Loss: 1.1814, Train Acc: 90.86% | Val Loss: 1.0228, Val Acc: 92.21%
开始微调骨干网络...
Epoch 16: Train Loss: 1.1301, Train Acc: 91.94% | Val Loss: 1.0082, Val Acc: 91.30%
开始微调骨干网络...
✓ 保存最佳模型,验证准确率: 92.93%
Epoch 17: Train Loss: 1.0650, Train Acc: 93.19% | Val Loss: 0.9462, Val Acc: 92.93%
开始微调骨干网络...
✓ 保存最佳模型,验证准确率: 93.66%
Epoch 18: Train Loss: 1.0520, Train Acc: 94.15% | Val Loss: 0.9361, Val Acc: 93.66%
开始微调骨干网络...
✓ 保存最佳模型,验证准确率: 93.84%
Epoch 19: Train Loss: 1.0103, Train Acc: 94.63% | Val Loss: 0.9533, Val Acc: 93.84%
开始微调骨干网络...
Epoch 20: Train Loss: 0.9932, Train Acc: 94.95% | Val Loss: 0.9688, Val Acc: 93.84%
开始微调骨干网络...
加载最佳模型: resnet101, 验证准确率: 93.84%
============================================================
训练模型: efficientnet_b3
============================================================
✓ 保存最佳模型,验证准确率: 66.67%
Epoch 1: Train Loss: 5.4504, Train Acc: 24.84% | Val Loss: 1.9644, Val Acc: 66.67%
✓ 保存最佳模型,验证准确率: 71.01%
Epoch 2: Train Loss: 3.3708, Train Acc: 49.62% | Val Loss: 1.9350, Val Acc: 71.01%
✓ 保存最佳模型,验证准确率: 72.46%
Epoch 3: Train Loss: 3.0523, Train Acc: 55.18% | Val Loss: 1.8518, Val Acc: 72.46%
✓ 保存最佳模型,验证准确率: 74.64%
Epoch 4: Train Loss: 2.7719, Train Acc: 59.14% | Val Loss: 1.7739, Val Acc: 74.64%
✓ 保存最佳模型,验证准确率: 76.81%
Epoch 5: Train Loss: 2.5621, Train Acc: 61.09% | Val Loss: 1.6939, Val Acc: 76.81%
✓ 保存最佳模型,验证准确率: 79.17%
Epoch 6: Train Loss: 2.4091, Train Acc: 62.40% | Val Loss: 1.6971, Val Acc: 79.17%
Epoch 7: Train Loss: 2.2682, Train Acc: 64.19% | Val Loss: 1.7452, Val Acc: 75.54%
Epoch 8: Train Loss: 2.2013, Train Acc: 65.70% | Val Loss: 1.6025, Val Acc: 76.81%
Epoch 9: Train Loss: 2.0413, Train Acc: 67.87% | Val Loss: 1.6075, Val Acc: 77.54%
✓ 保存最佳模型,验证准确率: 79.53%
Epoch 10: Train Loss: 1.9549, Train Acc: 69.31% | Val Loss: 1.4882, Val Acc: 79.53%
Epoch 11: Train Loss: 1.9288, Train Acc: 69.44% | Val Loss: 1.4771, Val Acc: 78.99%
Epoch 12: Train Loss: 1.8857, Train Acc: 69.25% | Val Loss: 1.4694, Val Acc: 78.80%
Epoch 13: Train Loss: 1.8154, Train Acc: 69.95% | Val Loss: 1.4594, Val Acc: 77.72%
Epoch 14: Train Loss: 1.7688, Train Acc: 71.00% | Val Loss: 1.4482, Val Acc: 77.54%
Epoch 15: Train Loss: 1.7351, Train Acc: 72.06% | Val Loss: 1.4621, Val Acc: 78.26%
✓ 保存最佳模型,验证准确率: 79.89%
Epoch 16: Train Loss: 1.7532, Train Acc: 70.75% | Val Loss: 1.4210, Val Acc: 79.89%
✓ 保存最佳模型,验证准确率: 80.07%
Epoch 17: Train Loss: 1.7205, Train Acc: 71.93% | Val Loss: 1.4024, Val Acc: 80.07%
开始微调骨干网络...
✓ 保存最佳模型,验证准确率: 83.88%
Epoch 18: Train Loss: 1.6303, Train Acc: 74.87% | Val Loss: 1.3215, Val Acc: 83.88%
开始微调骨干网络...
✓ 保存最佳模型,验证准确率: 86.78%
Epoch 19: Train Loss: 1.5164, Train Acc: 79.86% | Val Loss: 1.2681, Val Acc: 86.78%
开始微调骨干网络...
Epoch 20: Train Loss: 1.4247, Train Acc: 83.34% | Val Loss: 1.2648, Val Acc: 86.23%
开始微调骨干网络...
加载最佳模型: efficientnet_b3, 验证准确率: 86.78%
============================================================
训练模型: densenet121
============================================================
✓ 保存最佳模型,验证准确率: 73.55%
Epoch 1: Train Loss: 5.8393, Train Acc: 19.44% | Val Loss: 1.6572, Val Acc: 73.55%
✓ 保存最佳模型,验证准确率: 81.52%
Epoch 2: Train Loss: 3.5104, Train Acc: 45.75% | Val Loss: 1.6149, Val Acc: 81.52%
✓ 保存最佳模型,验证准确率: 82.97%
Epoch 3: Train Loss: 2.9466, Train Acc: 53.61% | Val Loss: 1.5911, Val Acc: 82.97%
✓ 保存最佳模型,验证准确率: 85.14%
Epoch 4: Train Loss: 2.6857, Train Acc: 57.96% | Val Loss: 1.5351, Val Acc: 85.14%
Epoch 5: Train Loss: 2.6012, Train Acc: 58.95% | Val Loss: 1.5477, Val Acc: 82.43%
✓ 保存最佳模型,验证准确率: 86.41%
Epoch 6: Train Loss: 2.4685, Train Acc: 61.32% | Val Loss: 1.4291, Val Acc: 86.41%
Epoch 7: Train Loss: 2.3199, Train Acc: 63.01% | Val Loss: 1.4478, Val Acc: 83.88%
Epoch 8: Train Loss: 2.3126, Train Acc: 62.21% | Val Loss: 1.4215, Val Acc: 84.24%
Epoch 9: Train Loss: 2.1542, Train Acc: 65.25% | Val Loss: 1.3958, Val Acc: 85.14%
Epoch 10: Train Loss: 2.0501, Train Acc: 67.55% | Val Loss: 1.3689, Val Acc: 84.60%
Epoch 11: Train Loss: 2.0299, Train Acc: 65.89% | Val Loss: 1.3182, Val Acc: 85.51%
开始微调骨干网络...
✓ 保存最佳模型,验证准确率: 86.78%
Epoch 12: Train Loss: 1.8685, Train Acc: 71.84% | Val Loss: 1.3925, Val Acc: 86.78%
开始微调骨干网络...
✓ 保存最佳模型,验证准确率: 88.41%
Epoch 13: Train Loss: 1.8166, Train Acc: 73.34% | Val Loss: 1.3586, Val Acc: 88.41%
开始微调骨干网络...
Epoch 14: Train Loss: 1.6926, Train Acc: 76.53% | Val Loss: 1.3231, Val Acc: 86.78%
开始微调骨干网络...
Epoch 15: Train Loss: 1.6267, Train Acc: 78.07% | Val Loss: 1.3441, Val Acc: 87.86%
开始微调骨干网络...
✓ 保存最佳模型,验证准确率: 89.49%
Epoch 16: Train Loss: 1.5582, Train Acc: 79.80% | Val Loss: 1.3244, Val Acc: 89.49%
开始微调骨干网络...
Epoch 17: Train Loss: 1.5468, Train Acc: 81.04% | Val Loss: 1.2831, Val Acc: 89.49%
开始微调骨干网络...
✓ 保存最佳模型,验证准确率: 90.22%
Epoch 18: Train Loss: 1.5118, Train Acc: 81.87% | Val Loss: 1.2677, Val Acc: 90.22%
开始微调骨干网络...
Epoch 19: Train Loss: 1.4077, Train Acc: 84.97% | Val Loss: 1.2536, Val Acc: 89.86%
开始微调骨干网络...
Epoch 20: Train Loss: 1.4084, Train Acc: 84.27% | Val Loss: 1.2533, Val Acc: 90.04%
开始微调骨干网络...
加载最佳模型: densenet121, 验证准确率: 90.22%
============================================================
优化集成权重
============================================================
Epoch 1: 集成验证准确率: 94.20%
当前权重: 0.25, 0.25, 0.25, 0.25
Epoch 2: 集成验证准确率: 95.11%
当前权重: 0.25, 0.25, 0.25, 0.25
Epoch 3: 集成验证准确率: 94.38%
当前权重: 0.25, 0.25, 0.25, 0.25
Epoch 4: 集成验证准确率: 94.38%
当前权重: 0.25, 0.25, 0.25, 0.25
Epoch 5: 集成验证准确率: 94.02%
当前权重: 0.25, 0.25, 0.25, 0.25
Epoch 6: 集成验证准确率: 94.93%
当前权重: 0.25, 0.25, 0.25, 0.25
Epoch 7: 集成验证准确率: 94.93%
当前权重: 0.25, 0.25, 0.25, 0.25
Epoch 8: 集成验证准确率: 94.38%
当前权重: 0.25, 0.25, 0.25, 0.25
Epoch 9: 集成验证准确率: 94.93%
当前权重: 0.25, 0.25, 0.25, 0.25
Epoch 10: 集成验证准确率: 95.11%
当前权重: 0.25, 0.25, 0.25, 0.25
============================================================
测试集成模型性能
============================================================
集成模型测试准确率: 92.80%
============================================================
各个模型独立性能
============================================================
resnet50: 90.65%
resnet101: 91.06%
efficientnet_b3: 86.92%
densenet121: 87.41%
可视化展示: