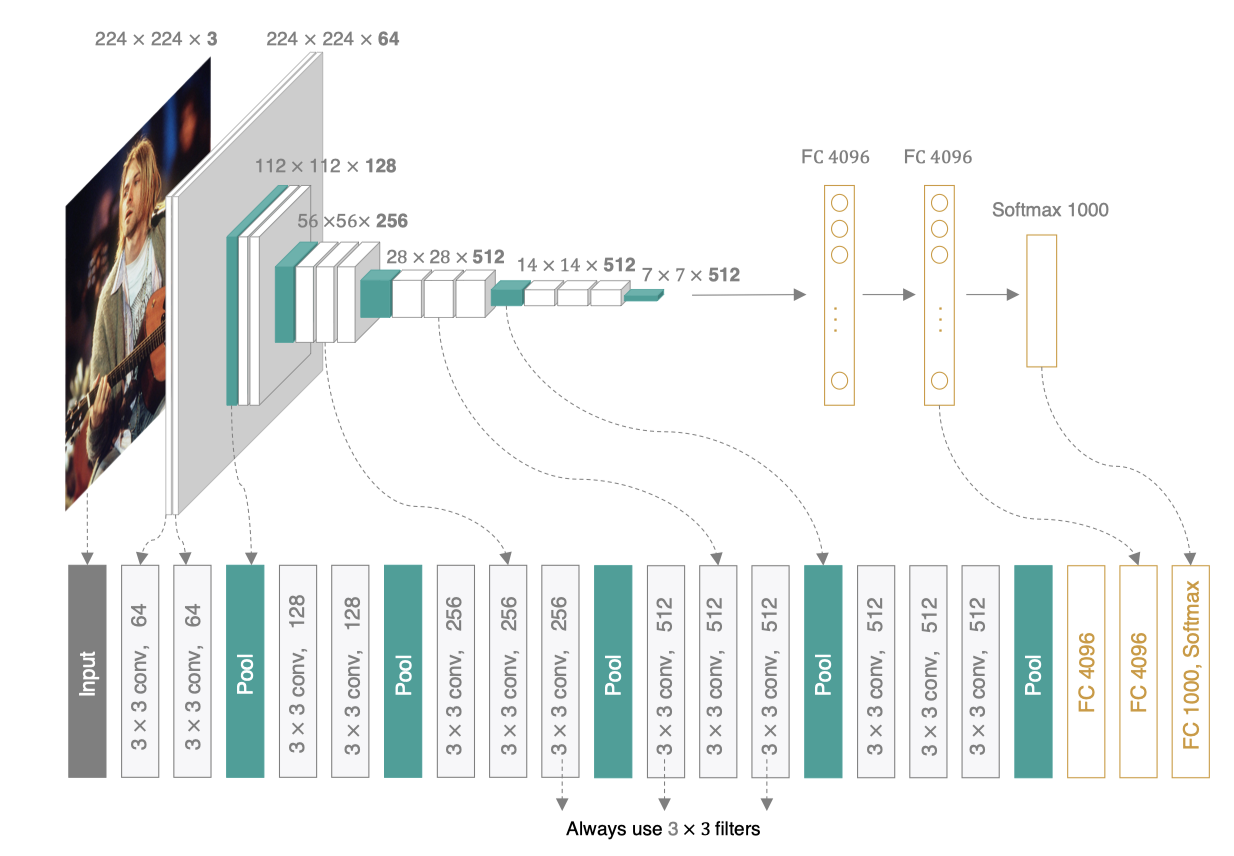
VGG可以看成是加深版的AlexNet,整个网络由卷积层和全连接层叠加而成,和AlexNet不同的是,VGG中使用的都是小尺寸的卷积核(3×3)
学习成果:
bash
2026-02-23 10:37:59,766 - INFO - Using device: cuda
Downloading: "https://download.pytorch.org/models/vgg16-397923af.pth" to C:\Users\story/.cache\torch\hub\checkpoints\vgg16-397923af.pth
100%|██████████| 528M/528M [02:59<00:00, 3.08MB/s]
Epoch 1/5: 100%|██████████| 104/104 [00:21<00:00, 4.74it/s, loss=0.39]
2026-02-23 10:41:25,956 - INFO - Epoch 1/5, Loss: 0.5712, Test Acc: 0.8269
2026-02-23 10:41:26,540 - INFO - Saved best model with accuracy 0.8269
Epoch 2/5: 100%|██████████| 104/104 [00:21<00:00, 4.83it/s, loss=0.13]
2026-02-23 10:41:50,263 - INFO - Epoch 2/5, Loss: 0.3633, Test Acc: 0.8654
2026-02-23 10:41:50,879 - INFO - Saved best model with accuracy 0.8654
Epoch 3/5: 100%|██████████| 104/104 [00:21<00:00, 4.83it/s, loss=0.252]
2026-02-23 10:42:14,623 - INFO - Epoch 3/5, Loss: 0.3388, Test Acc: 0.8544
Epoch 4/5: 100%|██████████| 104/104 [00:21<00:00, 4.84it/s, loss=0.466]
2026-02-23 10:42:38,316 - INFO - Epoch 4/5, Loss: 0.2997, Test Acc: 0.8599
Epoch 5/5: 100%|██████████| 104/104 [00:21<00:00, 4.93it/s, loss=0.524]
2026-02-23 10:43:01,623 - INFO - Epoch 5/5, Loss: 0.3084, Test Acc: 0.8489完整代码:
python
import logging
import os
import torch
from torch import nn
from torchvision import transforms
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
from torchvision.models import vgg16, VGG16_Weights
from tqdm import tqdm # 需要安装: pip install tqdm
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# 使用设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
logging.info(f"Using device: {device}")
def main():
# --- 1. 参数与路径定义 ---
batch_size = 32
epochs = 5
lr = 0.001
this_path = os.path.dirname(os.path.abspath(__file__))
root_path = os.path.dirname(this_path)
train_path = os.path.join(root_path, 'datas', 'flower_datas', 'train', '')
test_path = os.path.join(root_path, 'datas', 'flower_datas', 'val', '')
# --- 2. 数据预处理 (修正:增加归一化) ---
# VGG16 必须使用 ImageNet 的均值和方差进行归一化
transform_method = {
"train": transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(), # 数据增强:随机翻转
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]),
"val": transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
}
# --- 3. 数据集加载 (修正:放入 main 函数内避免多进程问题) ---
try:
train_data = ImageFolder(train_path, transform=transform_method["train"])
test_data = ImageFolder(test_path, transform=transform_method["val"])
except Exception as e:
logging.error(f"Failed to load dataset: {e}")
return
# num_workers 在 Windows 上建议设为 0 或放入 main 保护块内
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, pin_memory=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False, pin_memory=True)
# --- 4. 模型定义 (优化:使用预训练模型) ---
# 加载预训练权重
model = vgg16(weights=VGG16_Weights.IMAGENET1K_V1)
# 冻结特征提取层参数 (迁移学习常用技巧)
for param in model.features.parameters():
param.requires_grad = False
# 修改最后一层分类器
model.classifier[6] = nn.Linear(4096, 5)
model = model.to(device)
# --- 5. 损失函数与优化器 ---
criterion = nn.CrossEntropyLoss()
# 只优化分类层的参数,加快训练速度
optimizer = torch.optim.Adam(model.classifier[6].parameters(), lr=lr)
# optimizer = torch.optim.Adam(model.parameters(), lr=lr) # 如果想训练全模型
# 学习率调度器
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
# --- 6. 训练与评估函数 ---
def evaluate(data_iter, model_input):
total, correct = 0, 0
model_input.eval()
with torch.no_grad():
for image, label in data_iter:
image, label = image.to(device), label.to(device)
output = model_input(image)
_, predicted = torch.max(output.data, dim=1)
total += label.size(0)
correct += (predicted == label).sum().item()
return correct / total if total > 0 else 0
best_acc = 0.0
for epoch in range(epochs):
model.train()
running_loss = 0.0
# 使用 tqdm 显示进度
train_bar = tqdm(train_loader, desc=f'Epoch {epoch + 1}/{epochs}')
for image, label in train_bar:
image, label = image.to(device), label.to(device)
optimizer.zero_grad()
outputs = model(image)
loss_value = criterion(outputs, label)
loss_value.backward()
optimizer.step()
running_loss += loss_value.item() * image.size(0)
train_bar.set_postfix({'loss': loss_value.item()})
lr_scheduler.step()
# 计算平均损失
epoch_loss = running_loss / len(train_data)
test_acc = evaluate(test_loader, model)
logging.info(f"Epoch {epoch + 1}/{epochs}, Loss: {epoch_loss:.4f}, Test Acc: {test_acc:.4f}")
if test_acc > best_acc:
best_acc = test_acc
torch.save(model.state_dict(), 'best_model.pth')
logging.info(f"Saved best model with accuracy {best_acc:.4f}")
if __name__ == '__main__':
main()1. 环境初始化与配置
- 日志配置 :使用
logging模块记录训练过程(时间、等级、信息),便于调试和复盘。- 设备选择 :自动检测是否有 GPU (
cuda),若无则回退到 CPU,确保代码在不同硬件环境下的兼容性。
2. 数据预处理与加载
- 路径管理 :使用
os.path动态构建训练集和验证集的路径,提高了代码的可移植性。- 数据增强与归一化 :
- 训练集 :包含
RandomHorizontalFlip(随机水平翻转)进行数据增强,增加模型泛化能力。- 归一化 :关键点在于使用了 ImageNet 的均值
[0.485, 0.456, 0.406]和方差[0.229, 0.224, 0.225]。这是使用预训练模型的必要步骤,确保输入数据分布与模型预训练时一致。- 数据加载器 :使用
ImageFolder自动根据文件夹结构分类,DataLoader负责批次加载和打乱数据。
3. 模型构建与迁移学习策略
这是代码的核心部分:
- 加载预训练权重 :
VGG16_Weights.IMAGENET1K_V1自动下载并加载 ImageNet 的官方权重。- 冻结参数 :通过
param.requires_grad = False冻结了 VGG16 的特征提取层。这大大减少了计算量,防止在大规模预训练权重上进行微调导致破坏特征。- 修改分类头:将 VGG16 最后一层全连接层输出从 1000 改为 5,适配花卉 5 分类任务。
4. 损失函数与优化器
- 损失函数 :
CrossEntropyLoss,多分类任务的标准选择。- 优化器 :仅将
model.classifier[6].parameters()传入优化器,意味着只更新最后一层的权重,这是迁移学习中 "Feature Extraction" 模式的典型做法。- 学习率调度 :使用
StepLR,每 7 个 Epoch 学习率衰减为原来的 0.1 倍(当前 Epochs=5 未触发,但结构完整)。
5. 训练与评估流程
- 评估函数 (
evaluate) :在torch.no_grad()模式下计算模型在验证集上的准确率,避免计算梯度节省显存。- 训练循环 :
- 标准的 PyTorch 训练步骤:
zero_grad->forward->backward->step。- 模型保存 :采用 "Best Model" 策略,只有当验证集准确率超过历史最高时才保存模型权重 (
best_model.pth)。