crewai的进一步工具扩展
SerperDevTool
前置环境
今天来测试一下关于网页访问的一些tools的调用,首先就是SerperDevTool,这是一个crewai框架提供的内置搜索工具之一,底层调用的是serper.dev 提供的 Google 搜索 API(SERP API),主要功能:让 AI Agent 能够实时上网搜索,获取最新的网页搜索结果
这个工具的调用方法是使用serper.dev 服务的 API Key。
os.environ"SERPER_API_KEY" = "Your Key" 是什么?从哪里获得?
这是 serper.dev 服务的 API Key。
- Serper.dev 是一个专门提供 Google 搜索结果的第三方 API 服务
- 价格很便宜(号称是 SerpAPI 等竞品的 1/5 ~ 1/10 价格)
- 有免费额度(通常注册送 2500 次查询,够测试和轻度使用)
获取方式(2026 年最新流程基本没变):
-
打开官网:https://serper.dev/
-
用邮箱注册账号(Sign up),不需要信用卡
-
注册/登录后,进入 dashboard(控制台)
-
在左侧菜单或主页明显位置找到 API Key 或 Get API Key
-
复制那一串很长的密钥(类似 sk-abc123...)
-
粘贴到代码里替换 "Your Key":
os.environ["SERPER_API_KEY"] = "你的真实密钥写在这里"
此外还要先下载crewai - tools,方便后面的调用
python
install crewai crewai-tools调用方式
python
import os
from dotenv import load_dotenv # 需安装:pip install python-dotenv
# 加载.env文件中的环境变量(优先读取系统环境变量,本地开发用.env)
load_dotenv()
# 从环境变量读取SERPER API密钥,移除硬编码
os.environ["SERPER_API_KEY"] = os.getenv("SERPER_API_KEY", "your-serper-api-key-here")
from crewai import Agent, Task, Crew, LLM
from crewai_tools import SerperDevTool
LLM_API_KEY = os.getenv("LLM_API_KEY", "your-llm-api-key-here")
LLM_BASE_URL = os.getenv("LLM_BASE_URL", "https://your-llm-base-url-here/api/v1")
LLM_MODEL = os.getenv("LLM_MODEL", "your-llm-model-name-here")
os.environ["OPENAI_API_KEY"] = LLM_API_KEY
os.environ["OPENAI_API_BASE"] = LLM_BASE_URL
my_llm = LLM(
model=f"openai/{LLM_MODEL}",
base_url=LLM_BASE_URL,
api_key=LLM_API_KEY
)
research_agent = Agent(
role='研究员',
goal='查找并总结最新的人工智能新闻',
backstory="""您是一家大公司的研究员。
您负责分析数据并为业务提供见解。""",
llm=my_llm,
verbose=True
)
search_tool = SerperDevTool()
task = Task(
description='查找并总结最新的人工智能新闻',
expected_output='对前 5条最重要的人工智能新闻进行项目符号列表总结',
agent=research_agent,
tools=[search_tool]
)
crew = Crew(
agents=[research_agent],
tasks=[task],
verbose=True
)
result = crew.kickoff()
print(result)结果反馈
但是我们发现这里我们调用的api训练数据是比较老的,他默认当前最新的信息是23年,所以如果我们想去查询实时消息的话,我们需要对时间进行一个定义
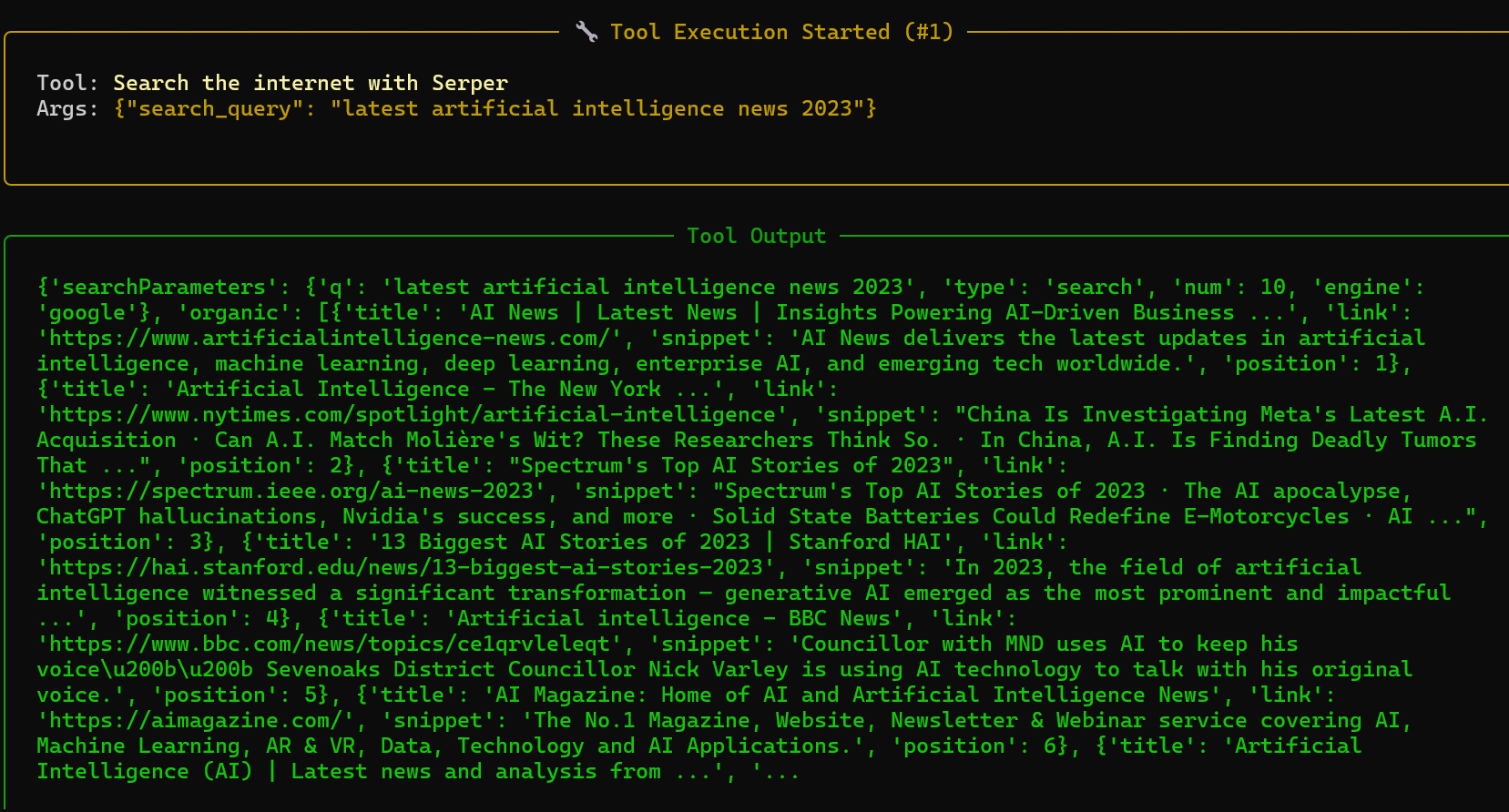
python
from datetime import datetime
#重新定义时间
description=f'查找并总结 {datetime.now().year} 年最新的 AI 新闻',定义玩之后,我们获取的数据就正常了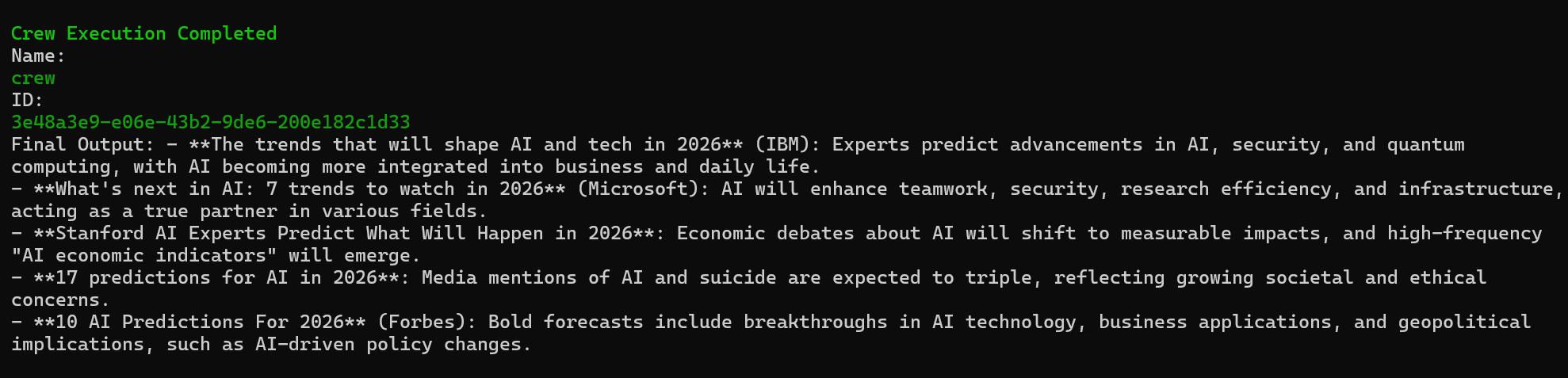
DuckDuckGoSearchRun
前置环境
首先是前置准备,这里我们全部写到requirements.txt里面去,以便于一键安装前置环境
txt
unstructured
langchain
Jinja2>=3.1.2
click>=7.0
langchain-community
duckduckgo-search
bash
pip install requirements.txt这样我们的前置工作就准备好了,工具的调用和之前的是差不多了,也是直接从库里import出来
python
from crewai import Agent, Task, Crew, Process, LLM
from crewai.tools import BaseTool
import os
from langchain_community.tools import DuckDuckGoSearchRun这样我们的ai就具有了去搜查相应网站的实时数据的能力
调用方式
python
from crewai import Agent, Task, Crew, Process, LLM
from crewai.tools import BaseTool
import os
from dotenv import load_dotenv # 需安装:pip install python-dotenv
from langchain_community.tools import DuckDuckGoSearchRun
# 加载.env文件中的环境变量(优先读取系统环境变量)
load_dotenv()
llm = LLM(
model=os.getenv("LLM_MODEL", "openai/deepseek-v3"),
api_key=os.getenv("LLM_API_KEY", "your-llm-api-key-here"),
base_url=os.getenv("LLM_BASE_URL", "https://your-llm-base-url-here/api/v1")
)
class SearchTool(BaseTool):
name: str = "DuckDuckGo Search"
description: str = "Search the web for information using DuckDuckGo"
def _run(self, query: str) -> str:
return DuckDuckGoSearchRun().run(query)
search_tool = SearchTool()
researcher = Agent(
role='Researcher',
goal='Research methods to grow this channel 毕导THU on Bilibili and get more subscribers',
backstory='You are an AI research assistant specializing in Bilibili content ecosystem',
tools=[search_tool],
verbose=True,
llm=llm,
allow_delegation=False
)
writer = Agent(
role='Writer',
goal='Write compelling and engaging reasons as to why someone should join 毕导THU Bilibili channel',
backstory='You are an AI master mind capable of growing any Bilibili channel',
verbose=True,
llm=llm,
allow_delegation=False
)
task1 = Task(
description='Investigate 毕导THU Bilibili channel',
agent=researcher,
expected_output='A detailed report about the channel performance, content style, and current subscriber base.'
)
task2 = Task(
description='Investigate sure fire ways to grow a Bilibili channel',
agent=researcher,
expected_output='A comprehensive list of proven strategies to grow a Bilibili channel including content optimization and engagement techniques.'
)
task3 = Task(
description='Write a list of tasks 毕导THU must do to grow his channel',
agent=writer,
expected_output='A actionable checklist of tasks for the channel owner to implement immediately.'
)
crew = Crew(
agents=[researcher, writer],
tasks=[task1, task2, task3],
verbose=True,
process=Process.sequential
)
result = crew.kickoff()
print(result)结果反馈
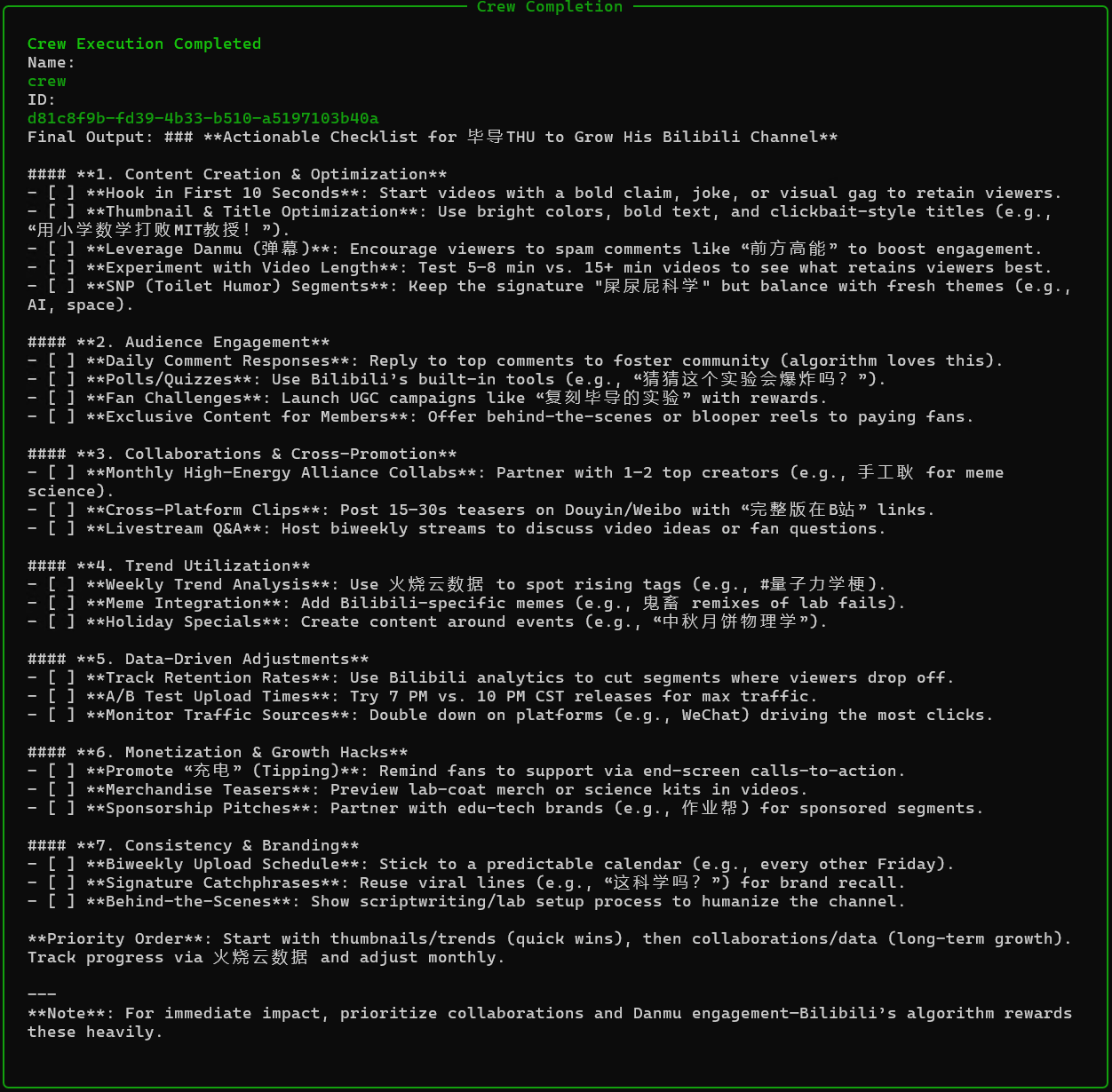
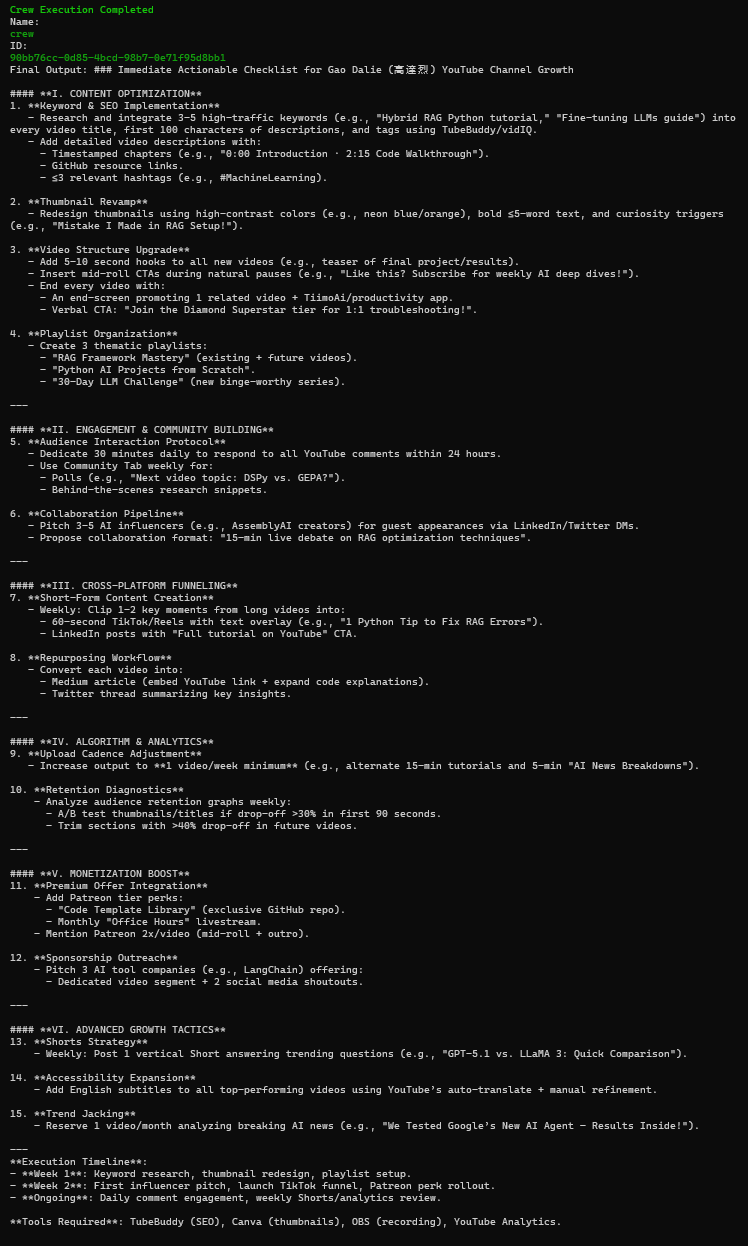
这里我们做了两组实验,第一个用了deep seekv3去调查国内视频平台的以为up主,第二个使用了deep seekr1去调查了了国外视频平台的一位up主。其中发现了一些问题。
1. v3模型------bilibili毕导
首先我们记录一下第一组测试。由于v3是通用文本处理,所以它在工具调用的频率以及深度上是不及于r1的,这里我们从报告的详细度以及丰富度可以看出来。但是因为视频平台是国内的,所以它搜索统计的速度也相对快很多,一共是进行了六次工具的调用。
2. r1模型------YouTube高达烈
其次是r1大模型对国外博主推理结果,因为其是开放式推理,所以处理速度相对要慢很多,当然数据的收集以及统筹就相对详细了,但是由于YouTube是外网的视频平台,国内的api接口在具体访问油管平台进行粉丝数量调查的时候会出现链接超时或者报错的情况。一共调用了19次工具,其中超时失败了4次
共性问题
讲一下两个模型在测试的时候会遇到的共性问题
-
首先是因为deepseek属于基于openai协议的大模型,与crewai本土支持的gpt在内容输出上还是有一定的差异性,所以两者在调用工具的时候,会时不时出现调用工具内容出错的问题
-
其次是可能是由于工具的问题,这个进行调查总结的效率并不高,进程执行的比较缓慢