前边所讲述的使用PyMySQL进行数据库连接的时候,对数据库进行操作是直接使用SQL语言,而SQLAlchemy 将数据库对象化,实现用 Python 对象和代码来操作数据库,而不是直接编写复杂的 SQL 语句。
一、SQLAlchemy的基础信息
1、介绍及主要组件
SQLAlchemy 本质是 Python 中一个功能强大的 SQL 工具包和对象关系映射器。它使用 pymysql 这类驱动作为底层通信工具,自身是更高级、更完整的抽象层。按照功能清晰分为两部分组件:SQLAlchemy Core (SQL 核心层)和SQLAlchemy ORM (对象关系映射器)
- SQLAlchemy Core:这是数据库抽象的基础层,独立于ORM存在,核心是SQL表达式语言。允许使用Python对象构造SQL语句,之后执行并获取结果。
- SQLAlchemy ORM:这是最常被使用的部分,构建在Core之上,将数据库中的表映射为Python的类,将表中的行映射为类的实例。其主要优点为:可以用面向对象的方式操作数据(自动处理很多底层的SQL操作),极大提升了代码的可读性和可维护性。
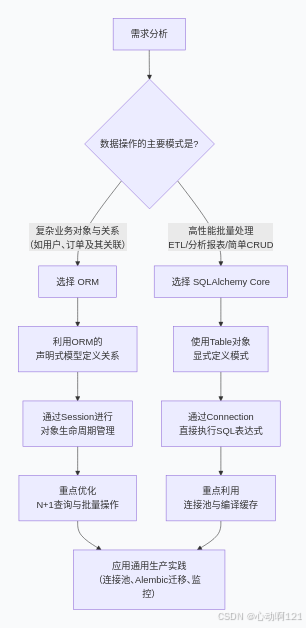
在使用的过程中,如何选择:Core 还是 ORM?
- 选择 SQLAlchemy Core:如果你的应用需要高度定制化、复杂的 SQL 查询,或者你更习惯使用类似 SQL 的声明式风格,并希望完全掌控 SQL 生成。
- 选择 SQLAlchemy ORM:对于大多数应用,尤其是业务逻辑复杂、数据模型以对象为中心的 Web 应用,使用 ORM 可以显著提升开发效率、减少重复代码,并使代码更易于理解和维护。
2、主要特性与优势
-
统一的数据库接口:支持包括 SQLite、PostgreSQL、MySQL、Oracle、MS-SQL Server 在内的多种主流数据库,更换数据库时通常只需修改连接字符串及其配置信息。
-
强大的关系处理:能优雅地定义和操作表之间的一对多、多对一等复杂关系。
-
连接池管理:内置高效的数据库连接池,提升应用性能。
-
事务安全:明确的事务机制确保数据一致性,所有操作在提交 (
commit()) 前不会真正持久化。 -
防范SQL注入:强制使用参数绑定,避免 SQL 注入攻击。
-
异步支持:通过
asyncio扩展支持异步数据库操作,适用于现代高性能 Web 应用。
二、SQLAlchemy的使用
1、创建配置文件config.py和数据库引擎
config文件中有配置数据库连接池的配置信息
python
# config文件
import os
class Config:
# 从环境变量获取,避免硬编码
DB_HOST = os.getenv('DB_HOST', 'localhost')
DB_PORT = os.getenv('DB_PORT', '5432')
DB_NAME = os.getenv('DB_NAME', 'mydb')
DB_USER = os.getenv('DB_USER')
DB_PASSWORD = os.getenv('DB_PASSWORD')
# 生产环境推荐使用连接池
DATABASE_URL = f'postgresql://{DB_USER}:{DB_PASSWORD}@{DB_HOST}:{DB_PORT}/{DB_NAME}'
# 连接池配置
POOL_SIZE = 20
MAX_OVERFLOW = 30
POOL_RECYCLE = 3600 # 1小时回收连接
POOL_PRE_PING = True # 连接前ping测试
# 创建数据库引擎,可以另写一个文件
from sqlalchemy import create_engine
def create_db_engine():
return create_engine(
Config.DATABASE_URL,
pool_size=Config.POOL_SIZE,
max_overflow=Config.MAX_OVERFLOW,
pool_recycle=Config.POOL_RECYCLE,
pool_pre_ping=Config.POOL_PRE_PING,
echo=False # 生产环境设为False,开发时可设为True查看SQL
)2、模型定义与关系映射
(1)创建模型基类base.py,该文件中包含有所数据库表的共同信息。
python
from sqlalchemy.orm import DeclarativeBase, declared_attr
from sqlalchemy import Column, Integer, DateTime
from datetime import datetime
class Base(DeclarativeBase):
"""所有模型的基类"""
@declared_attr.directive
def __tablename__(cls):
# 自动将类名转换为小写复数作为表名
return cls.__name__.lower() + 's'
# 每个表都有的通用字段
id = Column(Integer, primary_key=True, autoincrement=True)
created_at = Column(DateTime, default=datetime.utcnow, nullable=False)
updated_at = Column(DateTime, default=datetime.utcnow,
onupdate=datetime.utcnow, nullable=False)(2)定义业务模型user.py,继承Base类,并添加自身独特的列名
python
from sqlalchemy import String, Text, Boolean, ForeignKey
from sqlalchemy.orm import Mapped, mapped_column, relationship
from .base import Base
class User(Base):
__tablename__ = 'users' # 显式指定表名
# 列定义
username: Mapped[str] = mapped_column(String(50), unique=True, nullable=False)
email: Mapped[str] = mapped_column(String(100), unique=True, nullable=False)
hashed_password: Mapped[str] = mapped_column(String(200), nullable=False)
is_active: Mapped[bool] = mapped_column(Boolean, default=True)
# 关系定义(一对多)
posts: Mapped[list['Post']] = relationship(
'Post', back_populates='author', cascade='all, delete-orphan'
)
class Post(Base):
__tablename__ = 'posts'
title: Mapped[str] = mapped_column(String(200), nullable=False)
content: Mapped[str] = mapped_column(Text, nullable=False)
author_id: Mapped[int] = mapped_column(ForeignKey('users.id'))
# 反向关系
author: Mapped['User'] = relationship('User', back_populates='posts')3、创建会话工厂session.py
创建会话工厂(Session Factory)是SQLAlchemy生产环境中的核心模式,主要为了高效、安全地管理数据库会话的生命周期。
| 作用维度 | 具体机制与优势 |
|---|---|
| 资源复用 | 工厂模式避免每次操作都重新配置会话,复用配置(如绑定引擎、事务设置),减少开销 |
| 统一控制 | 集中设置事务隔离级别、自动刷新、过期策略等,确保所有会话行为一致 |
| 生命周期管理 | 工厂产生的每个会话独立,避免线程间状态污染,便于连接池管理 |
| 依赖注入友好 | 可轻松集成到FastAPI、Flask等框架的依赖注入系统 |
python
from sqlalchemy.orm import sessionmaker
from config import create_db_engine
# 创建引擎
engine = create_db_engine()
# 创建会话工厂
SessionLocal = sessionmaker(
bind=engine,
autocommit=False,
autoflush=False,
expire_on_commit=True # 生产环境推荐True
)
# 依赖注入使用的会话获取器
def get_db():
"""FastAPI等框架中使用的依赖项"""
db = SessionLocal()
try:
yield db
db.commit()
except Exception:
db.rollback()
raise
finally:
db.close()4、业务操作示例
python
from sqlalchemy.orm import Session, selectinload
from sqlalchemy import select
from models.user import User, Post
class UserService:
@staticmethod
def create_user(db: Session, username: str, email: str, password: str):
"""创建用户"""
user = User(
username=username,
email=email,
hashed_password=hash_password(password)
)
db.add(user)
db.commit()
db.refresh(user) # 获取数据库生成的ID
return user
@staticmethod
def get_user_with_posts(db: Session, user_id: int):
"""获取用户及其所有文章(避免N+1查询)"""
stmt = select(User).where(User.id == user_id).options(
selectinload(User.posts) # 使用selectinload预加载
)
result = db.execute(stmt)
return result.scalar_one_or_none()
@staticmethod
def bulk_create_posts(db: Session, user_id: int, posts_data: list):
"""批量创建文章(高性能)"""
posts = [
Post(title=data['title'], content=data['content'], author_id=user_id)
for data in posts_data
]
db.add_all(posts)
db.commit()5、其他操作
(1)数据库迁移管理
初始化Alembic------> 配置Alembic环境------>生成并应用迁移
bash
# 初始化Alembic
alembic init alembic
python
# alembic/env.py 中修改
import sys
import os
sys.path.append(os.path.dirname(os.path.dirname(__file__)))
from models.base import Base
from config import create_db_engine
# 使用生产环境的引擎
engine = create_db_engine()
# 设置目标元数据
target_metadata = Base.metadata生成并迁移
bash
# 生成迁移脚本
alembic revision --autogenerate -m "create user and post tables"
# 应用迁移到数据库
alembic upgrade head
# 查看当前版本
alembic current
# 回滚到上一个版本
alembic downgrade -1(2)docker容器化
bash
# Dockerfile
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
# 启动时运行数据库迁移
CMD ["sh", "-c", "alembic upgrade head && python app/main.py"]