
许多团队执行 Oracle 迁移时,并非"能不能迁"这样的大方向问题会真正累垮众人,而是那些表面上不显眼但实际上极具杀伤力的细节:SQL 中蹦出来的"问题词",存储过程怎样适配,脚本工具存在哪些差别,特别是那个让人十分头疼的事情------出了状况之后,逆转需要付出多么大的成本。
本文尝试从Oracle转向金仓数据库的角度出发,针对"问题词","适配性难题"以及"转向成本"这三项人们最为关切的问题展开探讨,并且事先预备了可在Windows本地金仓数据库实例中运行的ksql范例,以利于读者跟随操作予以验证。

文章目录
-
- [1. Oracle 迁移的真实难点:不仅是"换个数据库"](#1. Oracle 迁移的真实难点:不仅是“换个数据库”)
- [2. 先从"问题词"下手:把迁移风险具体化](#2. 先从“问题词”下手:把迁移风险具体化)
- [3. 兼容性挑战拆解:SQL、过程、运维三条线](#3. 兼容性挑战拆解:SQL、过程、运维三条线)
-
- [3.1 SQL 与数据模型层](#3.1 SQL 与数据模型层)
- [3.2 存储过程与触发器层](#3.2 存储过程与触发器层)
- [3.3 运维与工具链层](#3.3 运维与工具链层)
- [4. 迁移成本怎么拆:不只看"改了多少 SQL"](#4. 迁移成本怎么拆:不只看“改了多少 SQL”)
- [5. 示例场景:从 Oracle 订单系统到金仓数据库](#5. 示例场景:从 Oracle 订单系统到金仓数据库)
- [6. 在 Windows 本地用 ksql 跑通示例](#6. 在 Windows 本地用 ksql 跑通示例)
-
- [6.1 Step 1:打开 ksql 并连接到本地实例](#6.1 Step 1:打开 ksql 并连接到本地实例)
- [6.2 Step 2:一键初始化订单示例数据集](#6.2 Step 2:一键初始化订单示例数据集)
- [6.3 Step 3:跑三类典型查询,映射"问题词"场景](#6.3 Step 3:跑三类典型查询,映射“问题词”场景)
-
- [6.3.1 查询每个订单的总金额(聚合场景)](#6.3.1 查询每个订单的总金额(聚合场景))
- [6.3.2 用 CASE 映射订单状态(DECODE 场景的等价改写)](#6.3.2 用 CASE 映射订单状态(DECODE 场景的等价改写))
- [6.3.3 用 COALESCE 处理空备注(NVL 场景的等价改写)](#6.3.3 用 COALESCE 处理空备注(NVL 场景的等价改写))
- [6.4 Step 4:退出 ksql](#6.4 Step 4:退出 ksql)
- [7. 把示例方法推广到真实 Oracle 迁移项目](#7. 把示例方法推广到真实 Oracle 迁移项目)
- 结语:用"工程思维"而不是"蛮力"做迁移
1. Oracle 迁移的真实难点:不仅是"换个数据库"
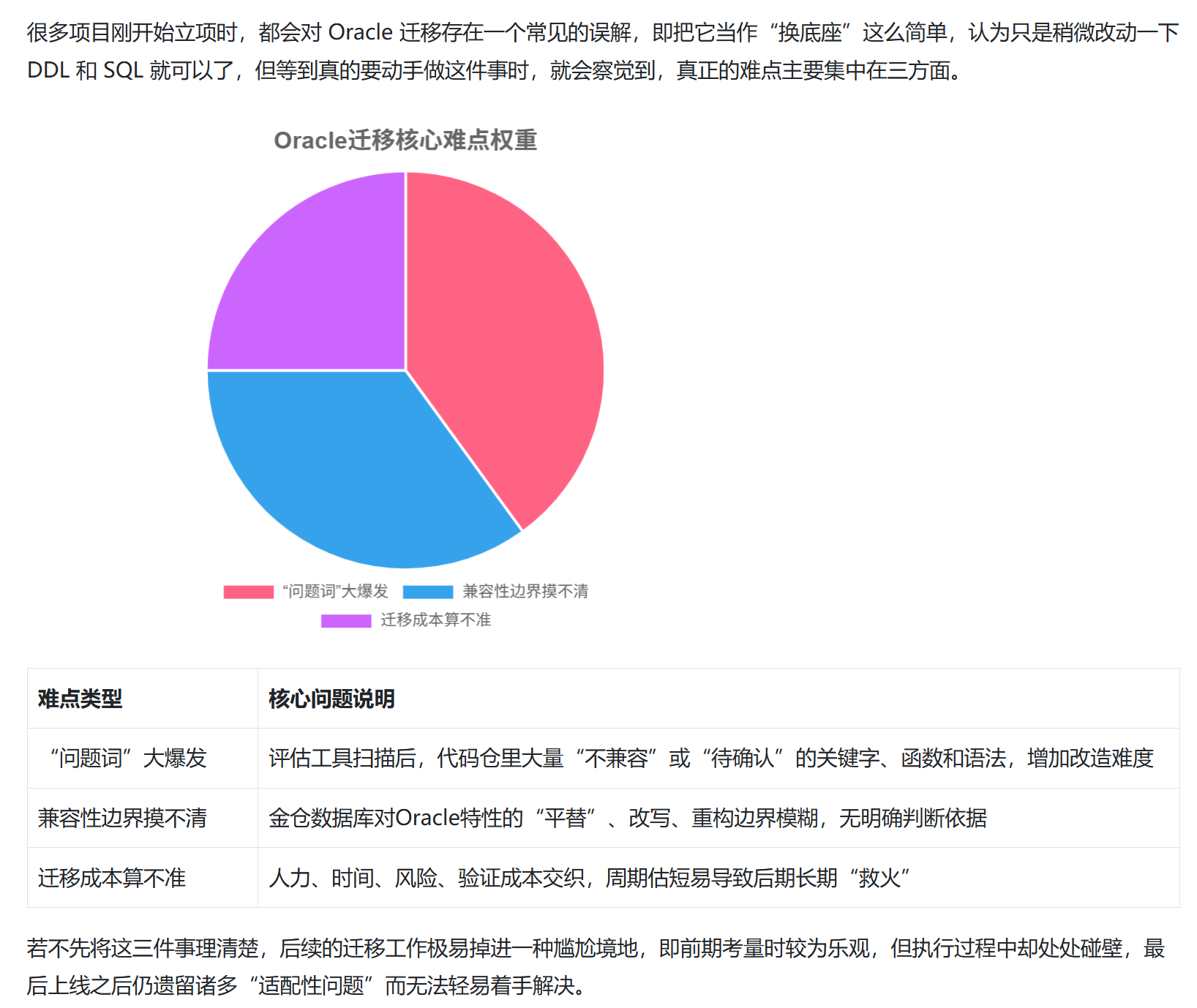
2. 先从"问题词"下手:把迁移风险具体化
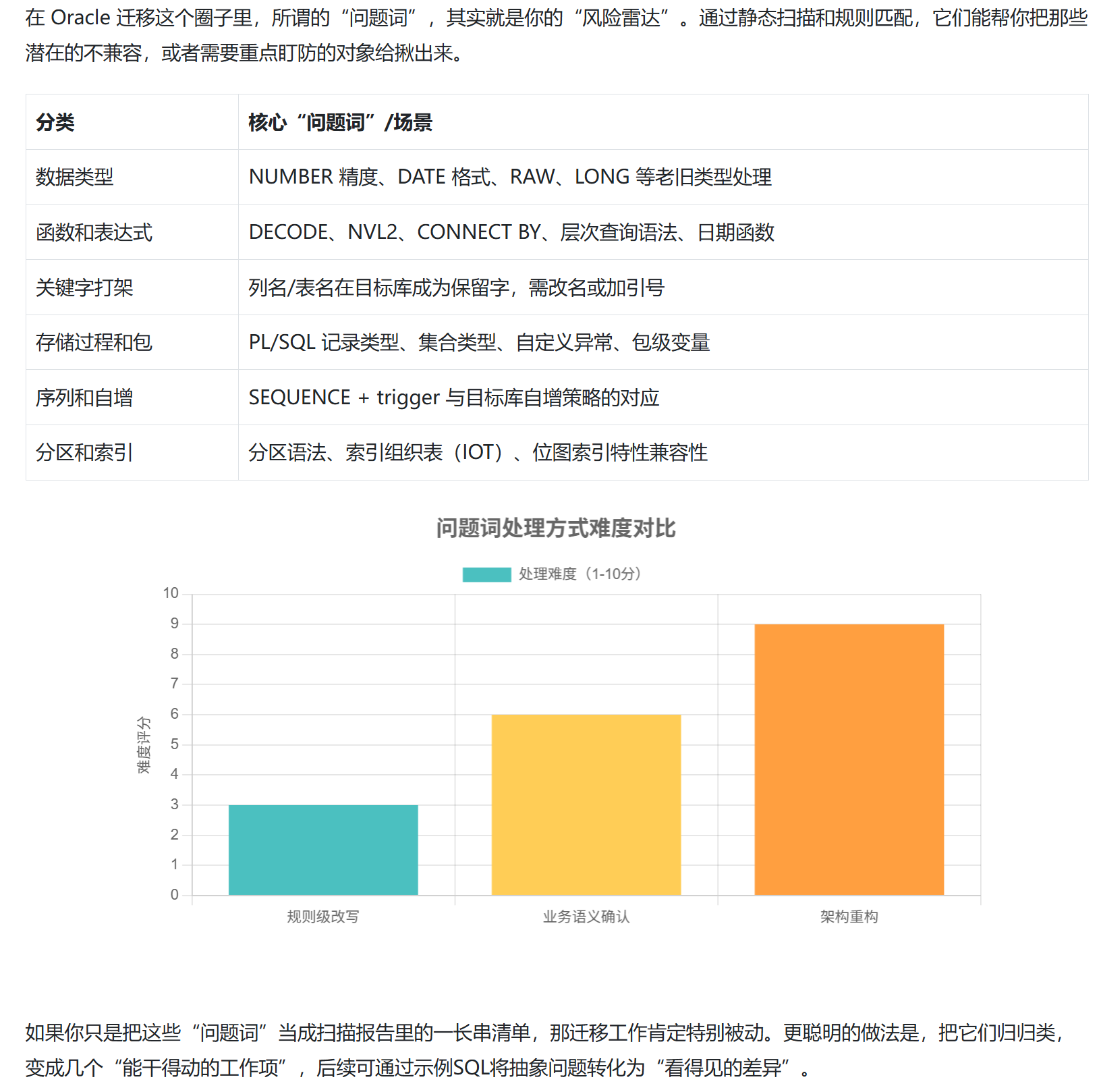
后面我会给出的示例 SQL,也会特意挑几个这种"问题词"的场景,用金仓数据库的写法跑一遍,帮大家把抽象的问题变成"看得见的差异"。
3. 兼容性挑战拆解:SQL、过程、运维三条线
从 Oracle 搬家到金仓数据库,咱们遇到的兼容性挑战,大概可以顺着三条线来拆解:
3.1 SQL 与数据模型层
这一层通常是评估工具最先报警的地方,重点得盯着:
- 数据类型映射 :怎么把
NUMBER(p,s)、DATE、TIMESTAMP、CLOB这些类型,舒舒服服地安顿到金仓数据库的类型体系里。 - 函数与表达式改写 :像
NVL、DECODE、CASE、日期加减、字符串处理这些平时用得最多的,有没有现成的替代品。 - 查询语法差异:层次查询、分页怎么写、外连接怎么连、子查询有啥限制。
这里有个工程上的经验:尽量让模型层和查询层的改动能复用。比如在数据服务或者视图里统一把改写逻辑封装好,别把改法散得到处都是,到时候维护起来想死的心都有。
3.2 存储过程与触发器层
存储过程、触发器、包,这些往往是迁移里的"工作量大户",也是最容易出幺蛾子的地方:
- 控制结构与内置包:PL/SQL 风格的控制语句,还有那一大堆内置包(处理字符串的、日期的、系统工具类的),都得一个一个确认支不支持。
- 复杂业务逻辑的位置:是继续让它们赖在数据库里,还是趁机挪到服务层,通过应用代码重构来解决?
- 触发器与约束:有些触发器其实可以用约束和默认值来替代,这样以后的维护成本能省不少。
3.3 运维与工具链层
工具链这块的差异,经常被人忽略,但它对迁移的交付效率和稳定性影响太大了:
- 脚本工具差异:从原来的脚本环境切换到金仓数据库配套的管理和运维工具,手感肯定不一样。
如何用好官方提供的考量工具与迁移工具,从而提升"问题词"扫描及结构迁移的效率,这是值得我们去探究的地方。
- 监控与诊断手段:性能视图、监控指标、诊断流程,跟原来的系统比有啥不一样。
金仓数据库官网存在诸多资料,其涵盖转录评价,数据转录,开发守护,集中经营这些环节的配套工具,处于 Oracle 转录此种情形时,这些工具能够助力你发挥专业经验,从而规避许多弯路。
4. 迁移成本怎么拆:不只看"改了多少 SQL"
很多团队做迁移方案的时候,习惯盯着"要改多少条 SQL"、"有多少个对象要调整"来算工作量。但从项目负责人的角度看,这么拆成本更有参考价值:
- 评估与梳理成本:光是扫描"问题词"、归类、确认迁移策略,这就得花不少时间。
- 改造与重构成本:简单的语法替换只是热身,真正费劲的是那些牵扯到业务规则的逻辑改写。
- 验证与回归成本:功能回归、性能回归、边界条件测试、数据一致性核对,这些一样都不能少。
- 运维与风险成本:上线窗口怎么定、回滚预案怎么做、灰度策略怎么搞、应急故障怎么处理,这些准备工作都得算进去。
如果能在迁移一开始就把这些成本都摆在明面上,再结合金仓数据库的特性和配套工具来优化路径,整个项目就会显得更"可控",不用一直被动挨打。
下面咱们通过一个简化的业务场景,把兼容性挑战和迁移成本具体化,顺便给一套可以直接在 Windows 本地金仓数据库实例上跑通的示例。
5. 示例场景:从 Oracle 订单系统到金仓数据库
为了方便演示,咱们抽象一个特别常见的场景:订单主表 + 订单明细表。在 Oracle 源系统里,通常会有这些东西:
- 订单主表
ORDERS,存客户信息、下单时间、状态这些。 - 订单明细表
ORDER_ITEMS,存每个订单买了啥。 - 一些典型的写法:用
NVL处理备注,用CASE处理状态映射,聚合统计订单金额等等。
在金仓数据库这边,咱们可以用一样的业务语义,用标准 SQL 写出等价的表结构和查询语句,并在本地通过 ksql 实际跑一遍。
下面的示例脚本,会在金仓数据库里创建:
orders:订单主表order_items:订单明细表- 一组测试数据,用来覆盖常见的空值处理、状态映射、聚合统计场景
6. 在 Windows 本地用 ksql 跑通示例
这里我给大家准备了一套"复制粘贴就能跑"的脚本,在 Windows 本地金仓数据库实例上,通过 ksql 命令行搞定这些事:
- 连接到本地金仓数据库
- 创建示例表结构并插入数据
- 执行三类典型查询(金额汇总、状态映射、空值处理)
- 退出 ksql
6.1 Step 1:打开 ksql 并连接到本地实例
- 打开 PowerShell(或者 Windows Terminal)
- 确认
ksql.exe所在的目录已经在 PATH 环境变量里了(或者你直接进到安装目录的bin目录也行) - 执行连接命令(记得把主机、端口、用户名、数据库名换成你自己的)
bash
ksql -h 127.0.0.1 -p 54322 -U SYSTEM -d TEST
sql
SELECT NOW();
SELECT CURRENT_USER;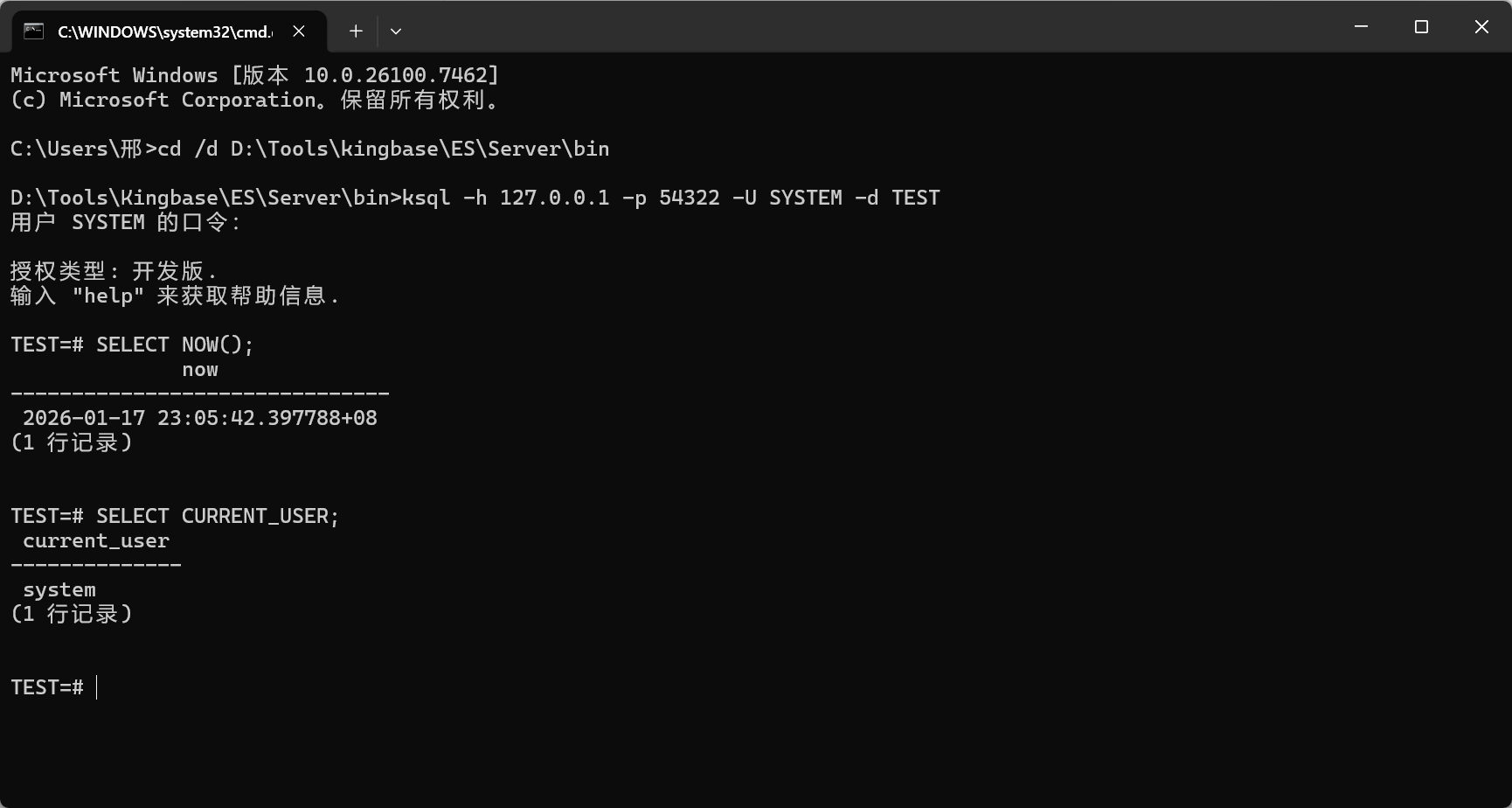
环境准备好了,咱们继续。
6.2 Step 2:一键初始化订单示例数据集
下面这段脚本会帮你清理旧表、创建新表、插入测试数据。你可以一股脑复制到 ksql 里执行。
sql
-- 清理旧表(如存在)
DROP TABLE IF EXISTS order_items;
DROP TABLE IF EXISTS orders;
-- 订单主表
CREATE TABLE orders (
order_id INTEGER NOT NULL,
customer_name VARCHAR(64) NOT NULL,
order_date TIMESTAMP NOT NULL,
status VARCHAR(20) NOT NULL,
remark VARCHAR(200),
PRIMARY KEY (order_id)
);
-- 订单明细表
CREATE TABLE order_items (
item_id INTEGER NOT NULL,
order_id INTEGER NOT NULL,
product_code VARCHAR(32) NOT NULL,
quantity INTEGER NOT NULL,
unit_price NUMERIC(12,2) NOT NULL,
PRIMARY KEY (item_id)
);
-- 常用索引:按订单号查询明细
CREATE INDEX idx_order_items_order_id ON order_items (order_id);
-- 插入订单主表数据
INSERT INTO orders (order_id, customer_name, order_date, status, remark) VALUES
(1001, '企业客户A', '2025-01-01 09:15:00', 'NEW', NULL),
(1002, '企业客户B', '2025-01-01 10:30:00', 'PAID', '年度合同首单'),
(1003, '企业客户C', '2025-01-02 14:05:00', 'CANCEL', NULL),
(1004, '企业客户A', '2025-01-03 11:20:00', 'PAID', '补货订单'),
(1005, '企业客户D', '2025-01-03 16:45:00', 'NEW', '待确认付款方式');
-- 插入订单明细数据
INSERT INTO order_items (item_id, order_id, product_code, quantity, unit_price) VALUES
(1, 1001, 'P-001', 10, 99.00),
(2, 1001, 'P-002', 5, 199.00),
(3, 1002, 'P-003', 2, 499.00),
(4, 1002, 'P-004', 1, 999.00),
(5, 1003, 'P-001', 3, 99.00),
(6, 1004, 'P-005', 20, 49.50),
(7, 1005, 'P-002', 1, 199.00),
(8, 1005, 'P-006', 8, 29.90);
COMMIT;执行完之后,咱们用一条简单的统计语句确认下数据是不是都进去了。
sql
SELECT
COUNT(*) AS order_cnt,
(SELECT COUNT(*) FROM order_items) AS item_cnt
FROM orders;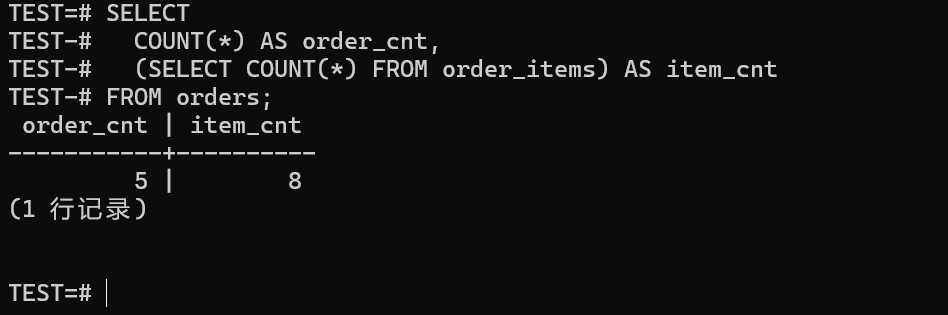
6.3 Step 3:跑三类典型查询,映射"问题词"场景
6.3.1 查询每个订单的总金额(聚合场景)
在 Oracle 源系统里,这种统计通常写在视图或者报表 SQL 里,是迁移的时候最常见的老朋友了。下面是金仓数据库这边的标准写法:
sql
SELECT
o.order_id,
o.customer_name,
SUM(oi.quantity * oi.unit_price) AS total_amount
FROM orders o
JOIN order_items oi ON oi.order_id = o.order_id
GROUP BY o.order_id, o.customer_name
ORDER BY o.order_id;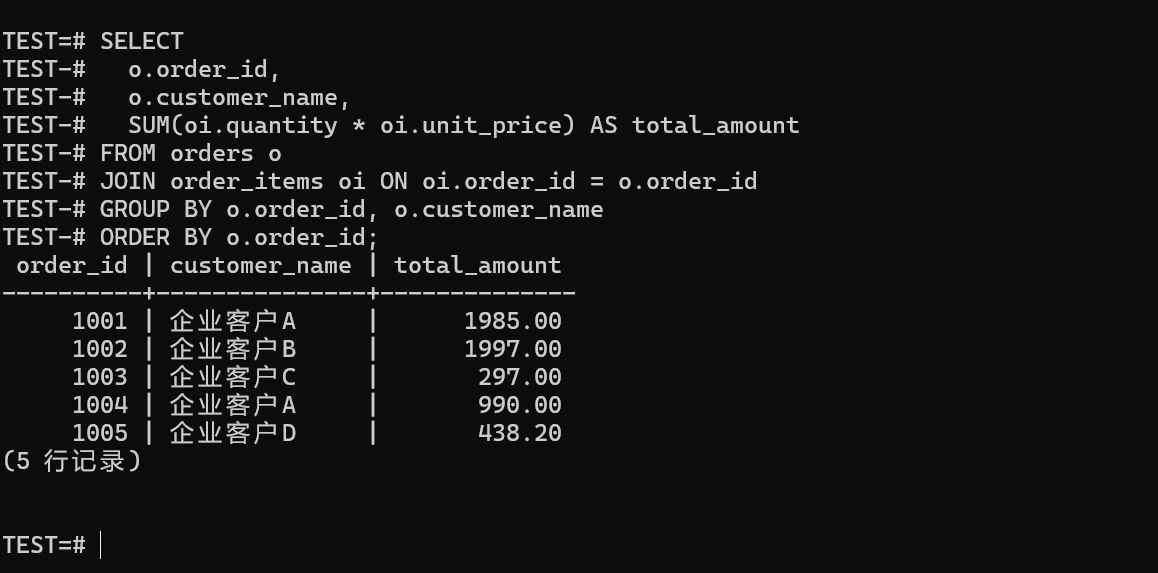
6.3.2 用 CASE 映射订单状态(DECODE 场景的等价改写)
在 Oracle 里,大家习惯用 DECODE 或者 CASE 来给状态做个美化。迁移到金仓数据库的时候,咱们直接用 ANSI 标准的 CASE WHEN 写法,既好读,以后跨库迁移也方便:
sql
SELECT
o.order_id,
o.status,
CASE o.status
WHEN 'NEW' THEN '新建'
WHEN 'PAID' THEN '已支付'
WHEN 'CANCEL' THEN '已取消'
ELSE '其他'
END AS status_label
FROM orders o
ORDER BY o.order_id;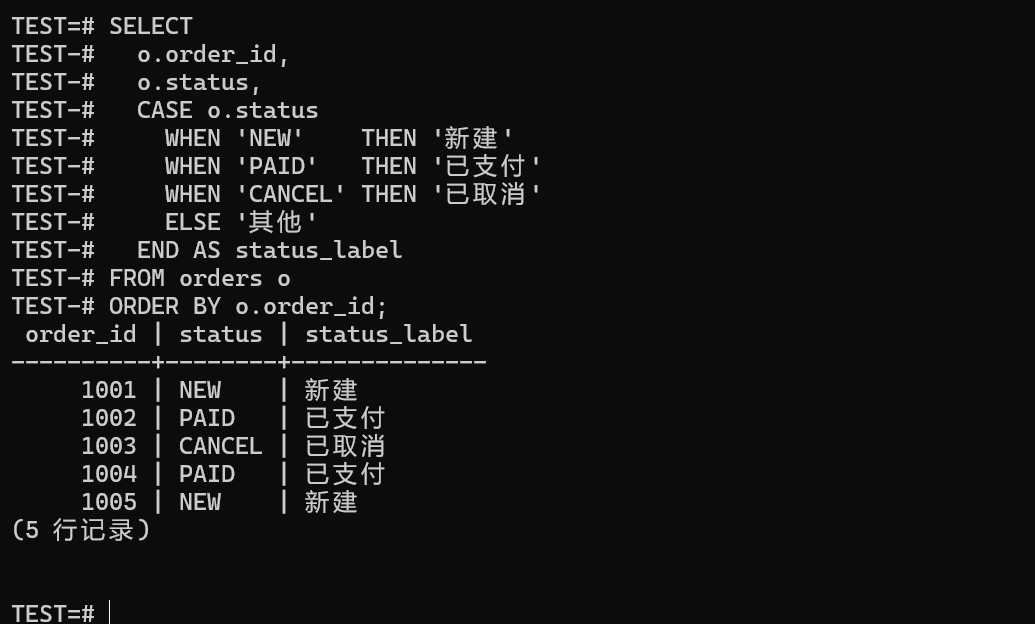
6.3.3 用 COALESCE 处理空备注(NVL 场景的等价改写)
Oracle 里那个抬头不见低头见的 NVL,在金仓数据库里可以用 COALESCE 来完美替代,语义清楚,还符合标准 SQL:
sql
SELECT
o.order_id,
COALESCE(o.remark, '无备注') AS remark_display
FROM orders o
ORDER BY o.order_id;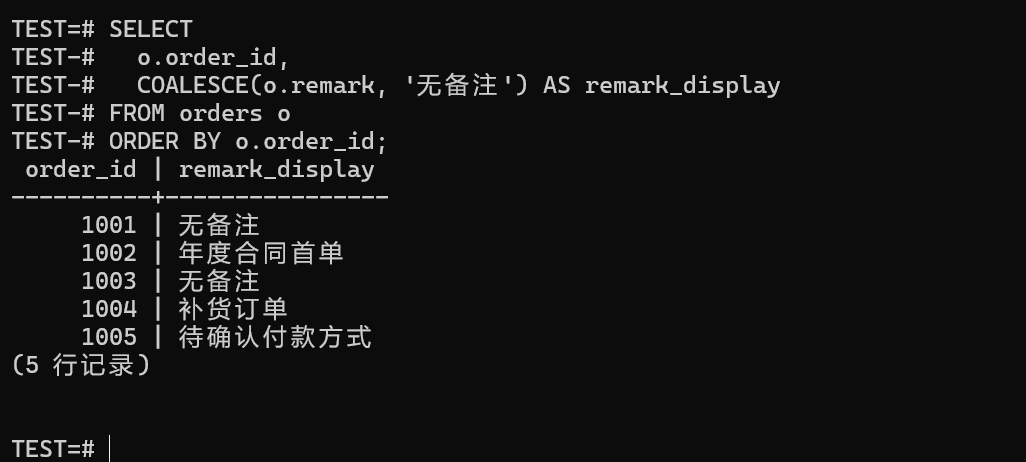
6.4 Step 4:退出 ksql
sql
\q到这儿,这个围绕订单场景的小示例就全都跑通了。你可以在这个基础上自己加点料,验证更复杂的迁移兼容性问题。
7. 把示例方法推广到真实 Oracle 迁移项目
上面的 demo 虽然只是个"袖珍版"的迁移缩影,但真实项目虽然复杂,道理其实是一样的:
- 先用"问题词"扫描,把风险点都摆在明面上,别凭感觉瞎估工作量。
- 再按照 SQL、存储过程、工具链这三条线,把兼容性挑战拆开,一个一个定策略。
- 挑一个或者几个有代表性的子系统,搭个像上面那样的验证环境,在金仓数据库上把关键语句跑通。
- 别忘了用好官方提供的评估和迁移工具,把经验沉淀成规则和脚本,别做成"一锤子买卖"。
一旦你在小范围验证里摸索出了"问题词 → 对应改写模式 → 金仓数据库上的验证脚本"这条路子,后面再放大到整个系统的时候,迁移就变成了一件"心里有谱、进度可查"的工程,而不是一场"硬着头皮上"的豪赌。
结语:用"工程思维"而不是"蛮力"做迁移
把Oracle换成金仓数据库,看似只是个技术活,实际上能否成功往往取决于你是否把它当作一项完整的工程来对待。
- 用"问题词"把风险具体化,别笼统地说"有兼容性问题"。
- 梳理 SQL,过程,工具链这三条线上的适配性策略时,不要仅仅满足于让 SQL 能运行起来就结束了。
- 在迁移成本上,提前把评估、改造、验证、运维这四块账算清楚,让项目从一开始就更可控。
- 充分利用金仓数据库的产品特性和配套工具,把经验固化成模板和脚本,少做重复劳动。
从工程化思维角度看待迁移时,会察觉到之前觉得"很吓人"的Oracle迁移项目,能够被分解成一系列明晰且可行的操作步骤,倘若这种做法运行得当,日后系统升级或者接手新项目的时候,仍然可以采用它。