今日依旧从代码题和c++俩个部分进行记录
代码题
今日的代码题分别为移除链表元素(203) 和 设计链表(707)
今日题为链表题目,所以读者如果不熟悉链表的基础概念可以前往该链接进行学习:关于链表,你该了解这些! | 代码随想录
下面为了方便笔者对该内容进行了ctrl +cv操作,若想看其他版本(如java等请移步)
关于链表,你该了解这些!
什么是链表,链表是一种通过指针串联在一起的线性结构,每一个节点由两部分组成,一个是数据域一个是指针域(存放指向下一个节点的指针),最后一个节点的指针域指向null(空指针的意思)。
链表的入口节点称为链表的头结点也就是head。
如图所示:
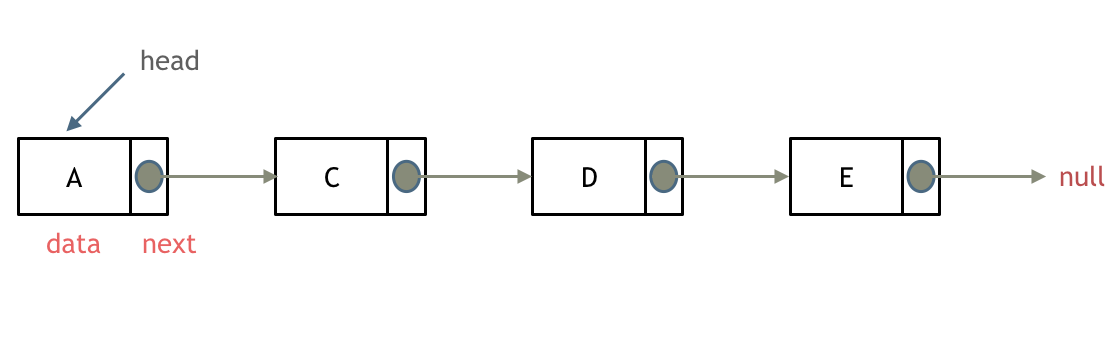
#链表的类型
接下来说一下链表的几种类型:
#单链表
刚刚说的就是单链表。
#双链表
单链表中的指针域只能指向节点的下一个节点。
双链表:每一个节点有两个指针域,一个指向下一个节点,一个指向上一个节点。
双链表 既可以向前查询也可以向后查询。
如图所示:
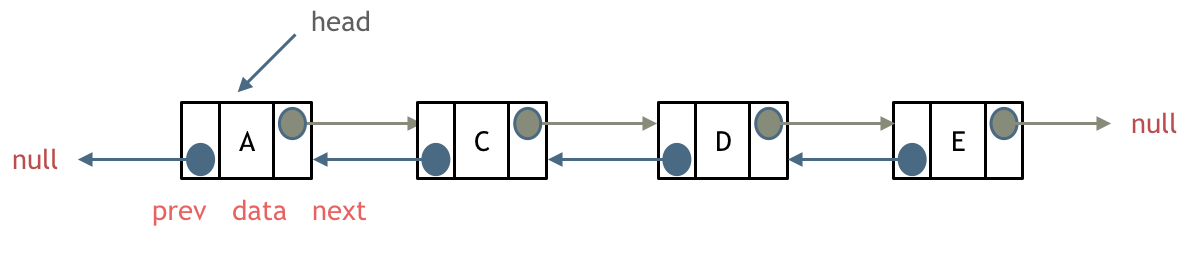
#循环链表
循环链表,顾名思义,就是链表首尾相连。
循环链表可以用来解决约瑟夫环问题。
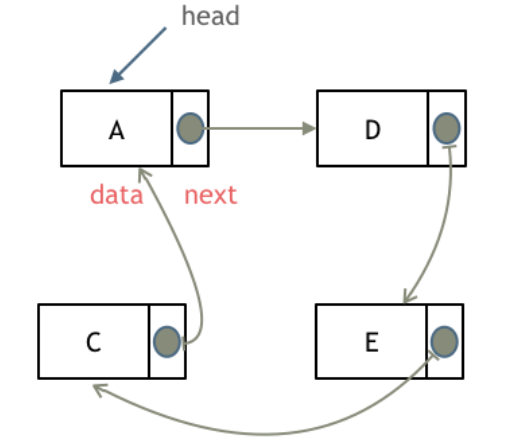
#链表的存储方式
了解完链表的类型,再来说一说链表在内存中的存储方式。
数组是在内存中是连续分布的,但是链表在内存中可不是连续分布的。
链表是通过指针域的指针链接在内存中各个节点。
所以链表中的节点在内存中不是连续分布的 ,而是散乱分布在内存中的某地址上,分配机制取决于操作系统的内存管理。
如图所示:
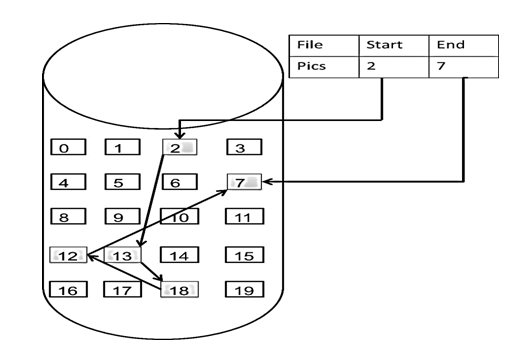
这个链表起始节点为2, 终止节点为7, 各个节点分布在内存的不同地址空间上,通过指针串联在一起。
#链表的定义
接下来说一说链表的定义。
链表节点的定义,很多同学在面试的时候都写不好。
这是因为平时在刷leetcode的时候,链表的节点都默认定义好了,直接用就行了,所以同学们都没有注意到链表的节点是如何定义的。
而在面试的时候,一旦要自己手写链表,就写的错漏百出。
这里我给出C/C++的定义链表节点方式,如下所示:
// 单链表
struct ListNode {
int val; // 节点上存储的元素
ListNode *next; // 指向下一个节点的指针
ListNode(int x) : val(x), next(NULL) {} // 节点的构造函数
};有同学说了,我不定义构造函数行不行,答案是可以的,C++默认生成一个构造函数。
但是这个构造函数不会初始化任何成员变量,下面我来举两个例子:
通过自己定义构造函数初始化节点:
ListNode* head = new ListNode(5);使用默认构造函数初始化节点:
ListNode* head = new ListNode();
head->val = 5;所以如果不定义构造函数使用默认构造函数的话,在初始化的时候就不能直接给变量赋值!
#链表的操作
#删除节点
删除D节点,如图所示:
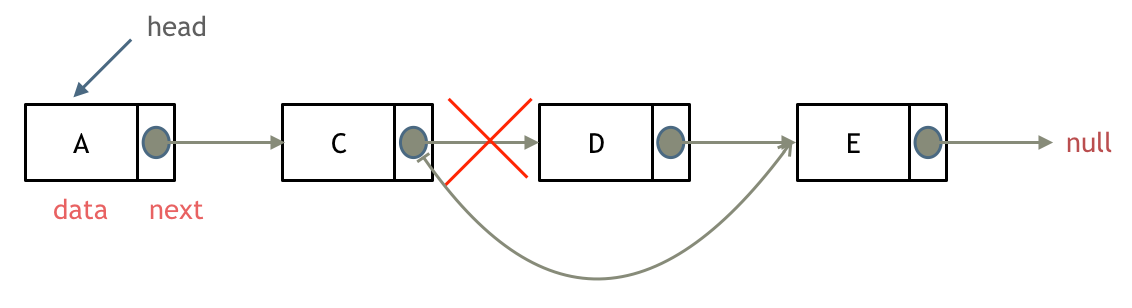
只要将C节点的next指针 指向E节点就可以了。
那有同学说了,D节点不是依然存留在内存里么?只不过是没有在这个链表里而已。
是这样的,所以在C++里最好是再手动释放这个D节点,释放这块内存。
其他语言例如Java、Python,就有自己的内存回收机制,就不用自己手动释放了。
#添加节点
如图所示:
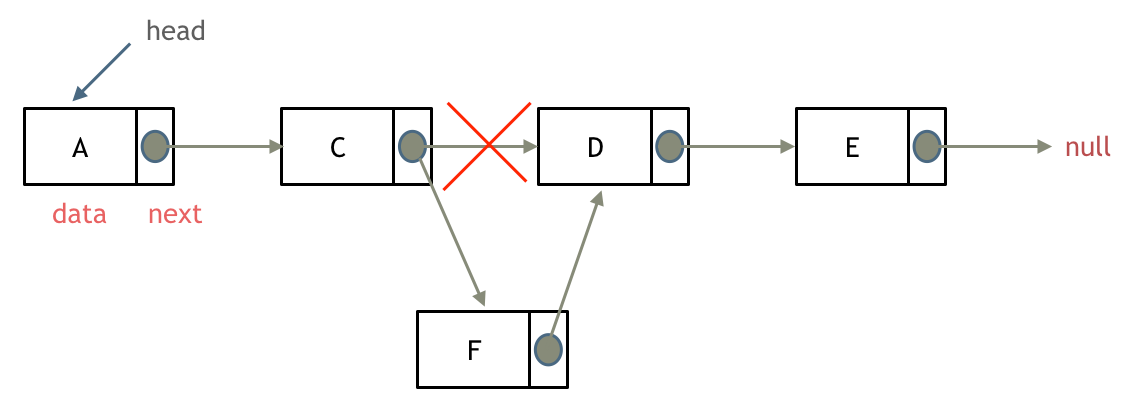
可以看出链表的增添和删除都是O(1)操作,也不会影响到其他节点。
但是要注意,要是删除第五个节点,需要从头节点查找到第四个节点通过next指针进行删除操作,查找的时间复杂度是O(n)。
#性能分析
再把链表的特性和数组的特性进行一个对比,如图所示:
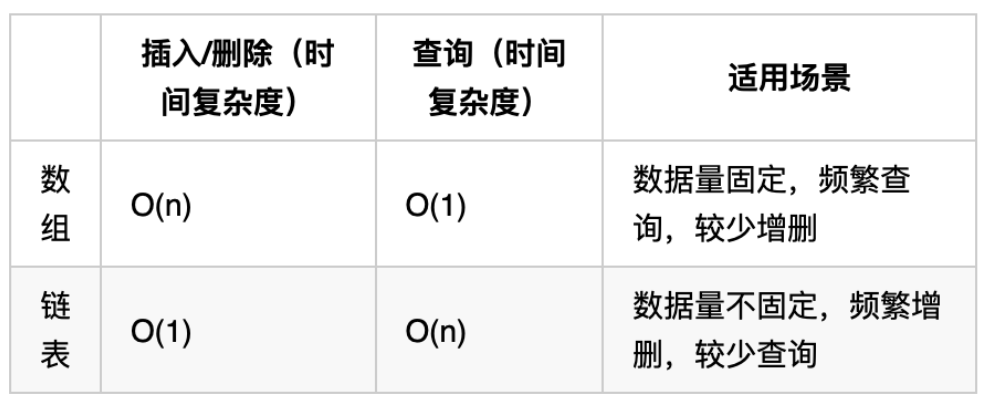
数组在定义的时候,长度就是固定的,如果想改动数组的长度,就需要重新定义一个新的数组。
链表的长度可以是不固定的,并且可以动态增删, 适合数据量不固定,频繁增删,较少查询的场景。
代码题1:203. 移除链表元素 - 力扣(LeetCode)
参考视频:https://www.bilibili.com/video/BV18B4y1s7R9?t=2.7
参考文档:203.移除链表元素 | 代码随想录
该题题目如下
题意:删除链表中等于给定值 val 的所有节点。
示例 1: 输入:head = 1,2,6,3,4,5,6, val = 6 输出:1,2,3,4,5
示例 2: 输入:head = \[\], val = 1 输出:\[\]
示例 3: 输入:head = 7,7,7,7, val = 7 输出:\[\]
思路
这里以链表 1 4 2 4 来举例,移除元素4。
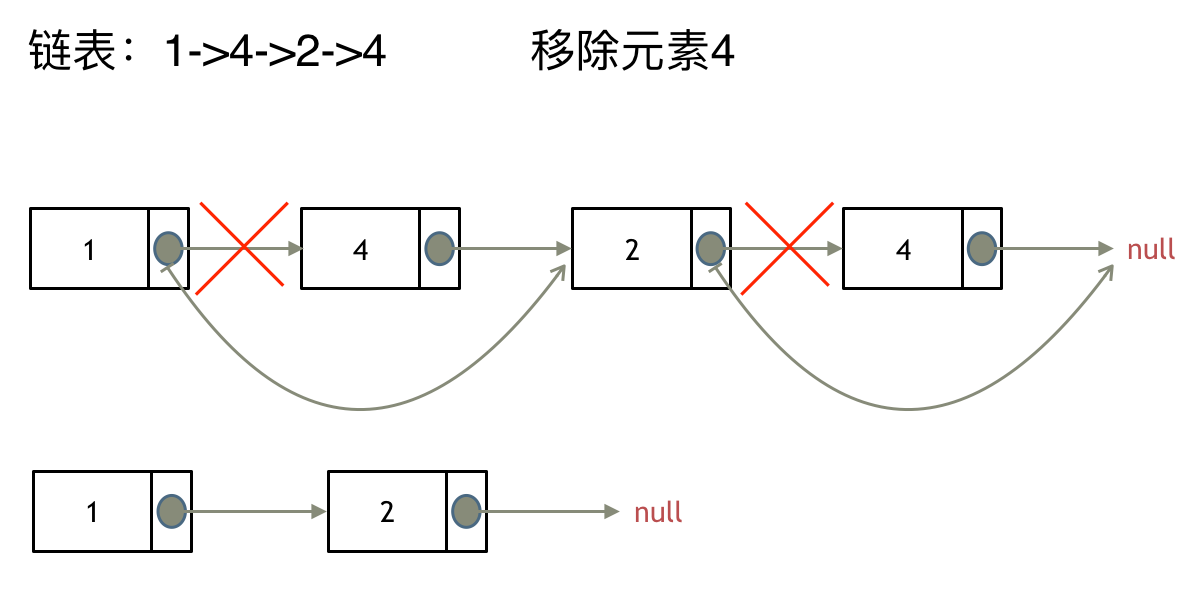
如果使用C,C++编程语言的话,不要忘了还要从内存中删除这两个移除的节点, 清理节点内存之后如图:
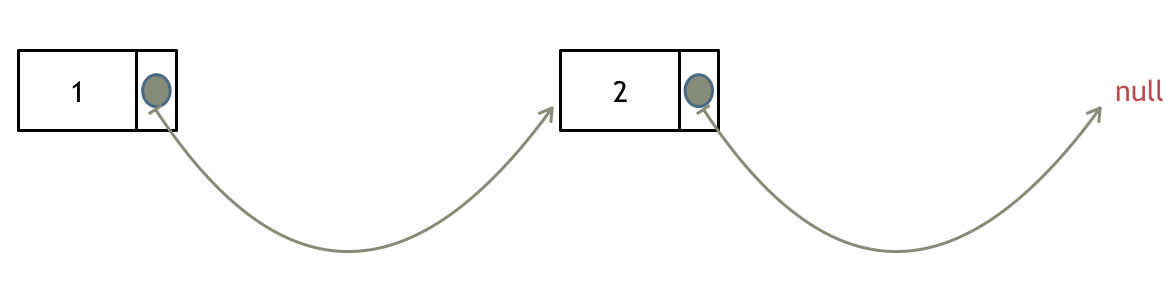
当然如果使用java ,python的话就不用手动管理内存了。
还要说明一下,就算使用C++来做leetcode,如果移除一个节点之后,没有手动在内存中删除这个节点,leetcode依然也是可以通过的,只不过,内存使用的空间大一些而已,但建议依然要养成手动清理内存的习惯。
这种情况下的移除操作,就是让节点next指针直接指向下下一个节点就可以了,
那么因为单链表的特殊性,只能指向下一个节点,刚刚删除的是链表的中第二个,和第四个节点,那么如果删除的是头结点又该怎么办呢?
这里就涉及如下链表操作的两种方式:
- 直接使用原来的链表来进行删除操作。
- 设置一个虚拟头结点在进行删除操作。
来看第一种操作:直接使用原来的链表来进行移除。
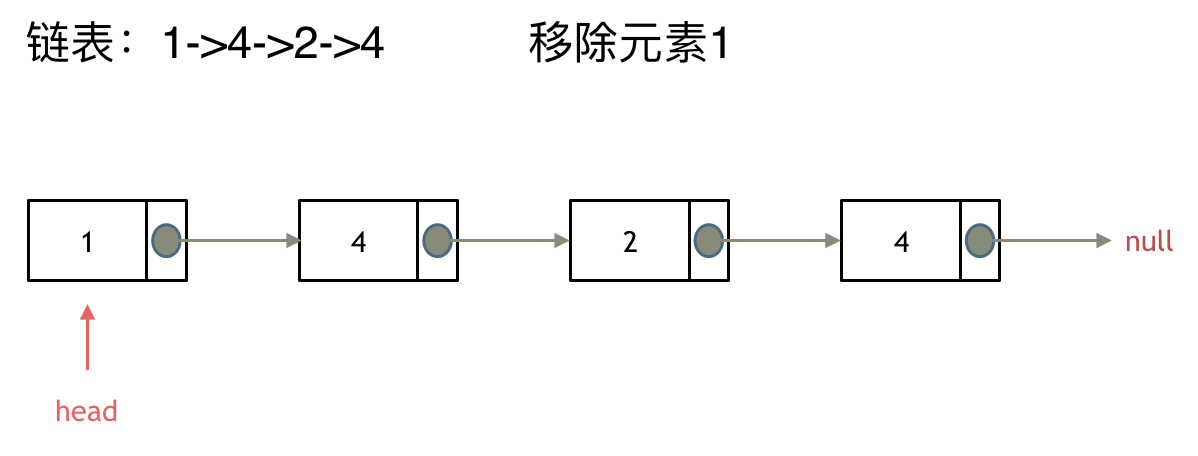
移除头结点和移除其他节点的操作是不一样的,因为链表的其他节点都是通过前一个节点来移除当前节点,而头结点没有前一个节点。
所以头结点如何移除呢,其实只要将头结点向后移动一位就可以,这样就从链表中移除了一个头结点。
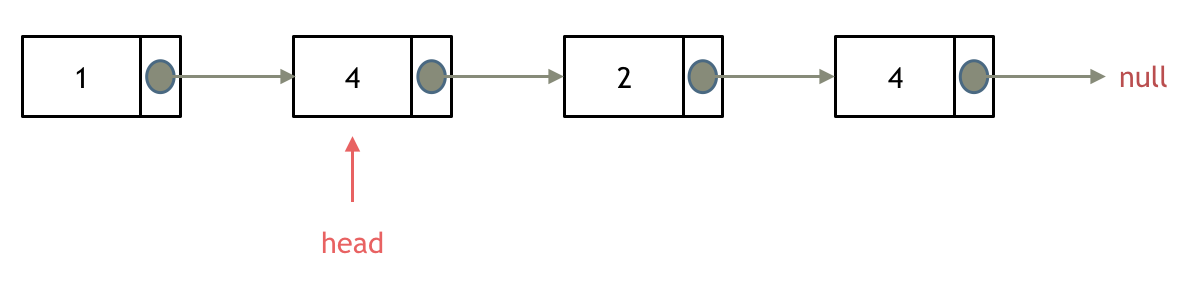
依然别忘将原头结点从内存中删掉。
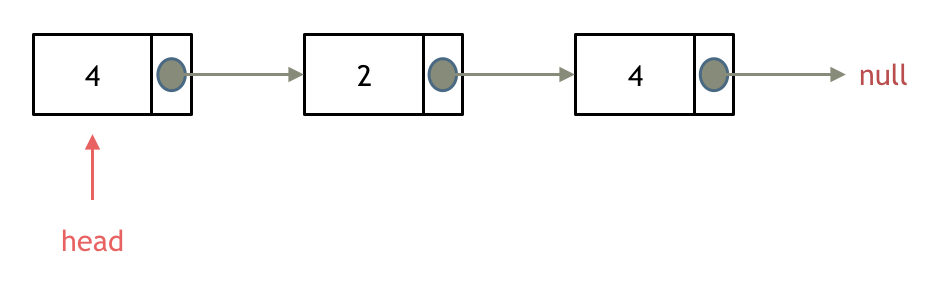
这样移除了一个头结点,是不是发现,在单链表中移除头结点 和 移除其他节点的操作方式是不一样,其实在写代码的时候也会发现,需要单独写一段逻辑来处理移除头结点的情况。
那么可不可以 以一种统一的逻辑来移除 链表的节点呢。
其实可以设置一个虚拟头结点,这样原链表的所有节点就都可以按照统一的方式进行移除了。
来看看如何设置一个虚拟头。依然还是在这个链表中,移除元素1。
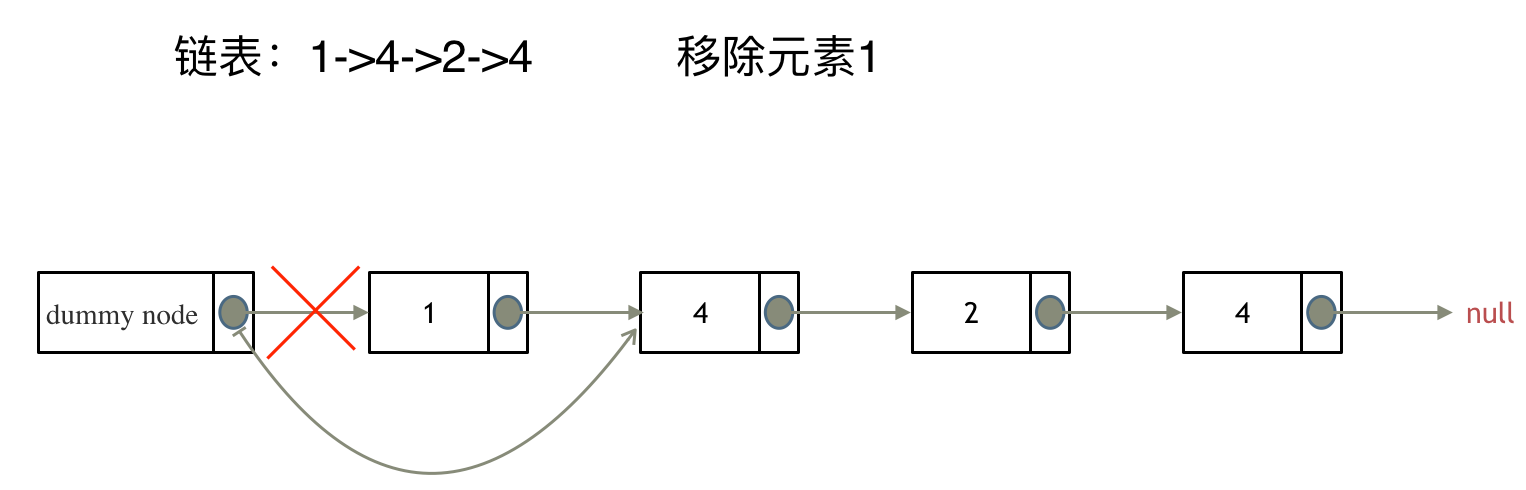
这里来给链表添加一个虚拟头结点为新的头结点,此时要移除这个旧头结点元素1。
这样是不是就可以使用和移除链表其他节点的方式统一了呢?
来看一下,如何移除元素1 呢,还是熟悉的方式,然后从内存中删除元素1。
最后呢在题目中,return 头结点的时候,别忘了 return dummyNode->next;, 这才是新的头结点
直接使用原来的链表来进行移除节点操作:
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
// 删除头结点
while (head != NULL && head->val == val) { // 注意这里不是if
ListNode* tmp = head;
head = head->next;
delete tmp;
}
// 删除非头结点
ListNode* cur = head;
while (cur != NULL && cur->next!= NULL) {
if (cur->next->val == val) {
ListNode* tmp = cur->next;
cur->next = cur->next->next;
delete tmp;
} else {
cur = cur->next;
}
}
return head;
}
};- 时间复杂度: O(n)
- 空间复杂度: O(1)
设置一个虚拟头结点在进行移除节点操作:
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
ListNode* dummyHead = new ListNode(0); // 设置一个虚拟头结点
dummyHead->next = head; // 将虚拟头结点指向head,这样方便后面做删除操作
ListNode* cur = dummyHead;
while (cur->next != NULL) {
if(cur->next->val == val) {
ListNode* tmp = cur->next;
cur->next = cur->next->next;
delete tmp;
} else {
cur = cur->next;
}
}
head = dummyHead->next;
delete dummyHead;
return head;
}
};- 时间复杂度: O(n)
- 空间复杂度: O(1)
也可以通过递归的思路解决本题:
基础情况:对于空链表,不需要移除元素。
递归情况:首先检查头节点的值是否为 val,如果是则移除头节点,答案即为在头节点的后续节点上递归的结果;如果头节点的值不为 val,则答案为头节点与在头节点的后续节点上递归得到的新链表拼接的结果。
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
// 基础情况:空链表
if (head == nullptr) {
return nullptr;
}
// 递归处理
if (head->val == val) {
ListNode* newHead = removeElements(head->next, val);
delete head;
return newHead;
} else {
head->next = removeElements(head->next, val);
return head;
}
}
};- 时间复杂度:O(n)
- 空间复杂度:O(n)
对于上述分析,笔者采用的是虚拟头结点进行操作
因为使用虚拟头结点有以下几个好处
好处1:当进行删除头结点的操作时,方便找到新的头结点
好处2:当我们要删除第n个节点时候,我们实际上需要找到第n个节点的前一个节点的位置,当我们使用虚拟头结点并使用一个临时节点cur->dummynode,我们只需要执行while(n--){cur = cur ->next}操作就可以找到第n-1个节点的位置,方便进行后续操作
笔者代码如下
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
//使用虚拟头结点法
ListNode* dummyHead = new ListNode(0); // 设置一个虚拟头结点
dummyHead -> next = head;
ListNode* cur = dummyHead;
while(cur -> next != NULL ){
if(cur->next->val == val){
cur->next = cur->next->next;
}
else{
cur = cur ->next;
}
}
return dummyHead->next;
}
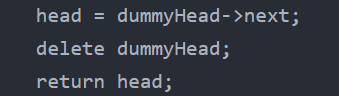
};上述代码中实际未删除创建的虚拟节点,没有手动在内存中删除这个节点,leetcode依然也是可以通过的,只不过,内存使用的空间大一些而已,但建议依然要养成手动清理内存的习惯。
所以最后一步应该执行以下操作删除虚拟头结点
代码题2:707. 设计链表 - 力扣(LeetCode)
参考视频:https://www.bilibili.com/video/BV1FU4y1X7WD?t=1434.0
参考文档:707.设计链表 | 代码随想录
不得不说,这道题是我现在见到的最有力气的一道题,话不多说先看看题
题意:
在链表类中实现这些功能:
- get(index):获取链表中第 index 个节点的值。如果索引无效,则返回-1。
- addAtHead(val):在链表的第一个元素之前添加一个值为 val 的节点。插入后,新节点将成为链表的第一个节点。
- addAtTail(val):将值为 val 的节点追加到链表的最后一个元素。
- addAtIndex(index,val):在链表中的第 index 个节点之前添加值为 val 的节点。如果 index 等于链表的长度,则该节点将附加到链表的末尾。如果 index 大于链表长度,则不会插入节点。如果index小于0,则在头部插入节点。
- deleteAtIndex(index):如果索引 index 有效,则删除链表中的第 index 个节点。

这一道题几乎涵盖了链表的所有基础操作,所以应该格外上心去弄懂这道题,这样链表的基础操作就不会有太大问题
根据上一道题的分析,可以看出使用虚拟头结点的好处,所以这道题我们默认使用虚拟头结点_dummyhead
思路
如果对链表的基础知识还不太懂,可以看这篇文章:关于链表,你该了解这些!(opens new window)
如果对链表的虚拟头结点不清楚,可以看这篇文章:链表:听说用虚拟头节点会方便很多?(opens new window)
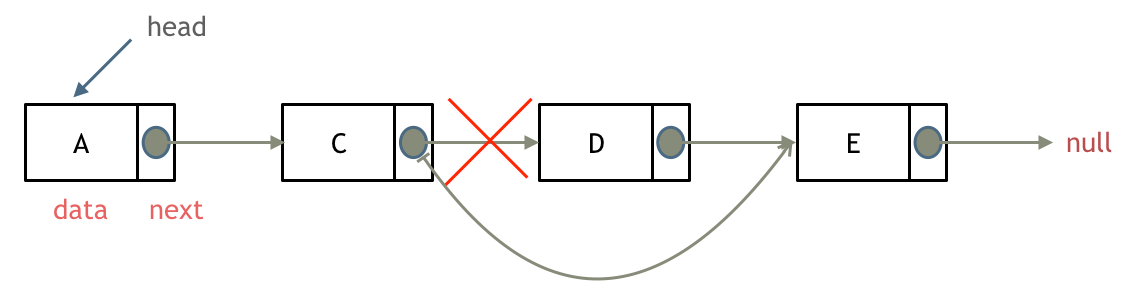
删除链表节点:
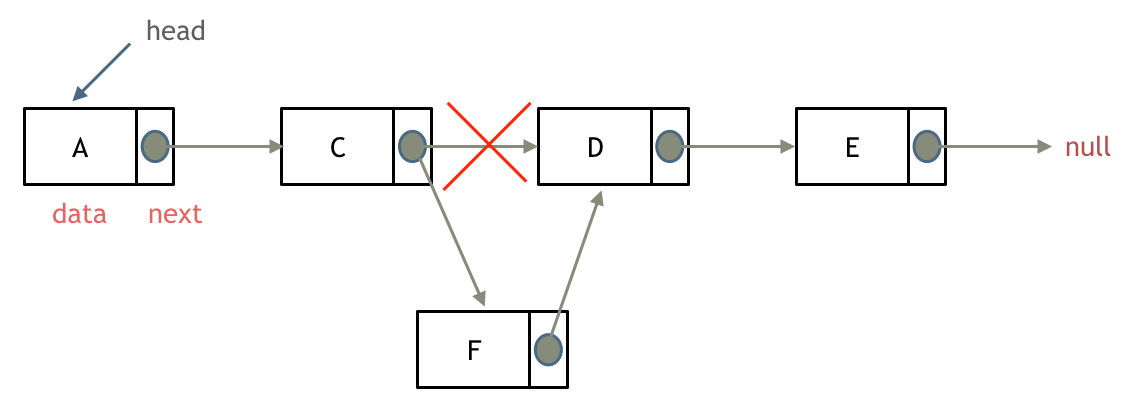
添加链表节点:
这道题目设计链表的五个接口:
- 获取链表第index个节点的数值
- 在链表的最前面插入一个节点
- 在链表的最后面插入一个节点
- 在链表第index个节点前面插入一个节点
- 删除链表的第index个节点
可以说这五个接口,已经覆盖了链表的常见操作,是练习链表操作非常好的一道题目
链表操作的两种方式:
- 直接使用原来的链表来进行操作。
- 设置一个虚拟头结点在进行操作。
下面采用的设置一个虚拟头结点(这样更方便一些,大家看代码就会感受出来)。
class MyLinkedList {
public:
// 定义链表节点结构体
struct LinkedNode {
int val;
LinkedNode* next;
LinkedNode(int val):val(val), next(nullptr){}
};
// 初始化链表
MyLinkedList() {
_dummyHead = new LinkedNode(0); // 这里定义的头结点 是一个虚拟头结点,而不是真正的链表头结点
_size = 0;
}
// 获取到第index个节点数值,如果index是非法数值直接返回-1, 注意index是从0开始的,第0个节点就是头结点
int get(int index) {
if (index > (_size - 1) || index < 0) {
return -1;
}
LinkedNode* cur = _dummyHead->next;
while(index--){ // 如果--index 就会陷入死循环
cur = cur->next;
}
return cur->val;
}
// 在链表最前面插入一个节点,插入完成后,新插入的节点为链表的新的头结点
void addAtHead(int val) {
LinkedNode* newNode = new LinkedNode(val);
newNode->next = _dummyHead->next;
_dummyHead->next = newNode;
_size++;
}
// 在链表最后面添加一个节点
void addAtTail(int val) {
LinkedNode* newNode = new LinkedNode(val);
LinkedNode* cur = _dummyHead;
while(cur->next != nullptr){
cur = cur->next;
}
cur->next = newNode;
_size++;
}
// 在第index个节点之前插入一个新节点,例如index为0,那么新插入的节点为链表的新头节点。
// 如果index 等于链表的长度,则说明是新插入的节点为链表的尾结点
// 如果index大于链表的长度,则返回空
// 如果index小于0,则在头部插入节点
void addAtIndex(int index, int val) {
if(index > _size) return;
if(index < 0) index = 0;
LinkedNode* newNode = new LinkedNode(val);
LinkedNode* cur = _dummyHead;
while(index--) {
cur = cur->next;
}
newNode->next = cur->next;
cur->next = newNode;
_size++;
}
// 删除第index个节点,如果index 大于等于链表的长度,直接return,注意index是从0开始的
void deleteAtIndex(int index) {
if (index >= _size || index < 0) {
return;
}
LinkedNode* cur = _dummyHead;
while(index--) {
cur = cur ->next;
}
LinkedNode* tmp = cur->next;
cur->next = cur->next->next;
delete tmp;
//delete命令指示释放了tmp指针原本所指的那部分内存,
//被delete后的指针tmp的值(地址)并非就是NULL,而是随机值。也就是被delete后,
//如果不再加上一句tmp=nullptr,tmp会成为乱指的野指针
//如果之后的程序不小心使用了tmp,会指向难以预想的内存空间
tmp=nullptr;
_size--;
}
// 打印链表
void printLinkedList() {
LinkedNode* cur = _dummyHead;
while (cur->next != nullptr) {
cout << cur->next->val << " ";
cur = cur->next;
}
cout << endl;
}
private:
int _size;
LinkedNode* _dummyHead;
};- 时间复杂度: 涉及
index的相关操作为 O(index), 其余为 O(1) - 空间复杂度: O(n)
上述操作中均考虑了删除创建的节点释放额外的空间且语法更为公正
下面我将展示笔者的代码并给出注意点
class MyLinkedList {
public:
struct LinkedNode {
int val;
LinkedNode* next;
};
MyLinkedList() {
_dummyHead = new LinkedNode(0); // 这里定义的头结点 是一个虚拟头结点,而不是真正的链表头结点
_size = 0;
}
int get(int index) {
if(index < 0 || index >=_size){
return -1;
}
LinkedNode* cur = _dummyHead->next;
while(index--){
cur = cur->next;
}
return cur ->val;
}
void addAtHead(int val) {
LinkedNode* newNode = new LinkedNode(val);
LinkedNode* cur = _dummyHead;
newNode ->next = cur ->next;
cur ->next = newNode;
_size++;
}
void addAtTail(int val) {
LinkedNode* newNode = new LinkedNode(val);
newNode->next = NULL;
LinkedNode* cur = _dummyHead;
while(cur->next != NULL){
cur = cur->next;
}
cur->next = newNode;
_size++;
}
void addAtIndex(int index, int val) {
if(index < 0 || index >_size)
return ;
LinkedNode* newNode = new LinkedNode(val);
newNode ->next = NULL;
LinkedNode* cur = _dummyHead;
while(index--){
cur = cur->next;
}
newNode -> next = cur ->next;
cur -> next = newNode;
_size++;
}
void deleteAtIndex(int index) {
if(index < 0 || index >=_size)
return ;
LinkedNode* cur = _dummyHead;
while(index--){
cur = cur ->next;
}
cur ->next = cur ->next ->next;
_size--;
}
private:
int _size;
LinkedNode* _dummyHead;
};
/**
* Your MyLinkedList object will be instantiated and called as such:
* MyLinkedList* obj = new MyLinkedList();
* int param_1 = obj->get(index);
* obj->addAtHead(val);
* obj->addAtTail(val);
* obj->addAtIndex(index,val);
* obj->deleteAtIndex(index);
*/首先需要自定义LinkedNode结构体,相信学过408数据结构的同学并不陌生,但是在本题中代码随想录在定义结构体时候多出了
LinkedNode(int val):val(val), next(nullptr){}由于笔者近期正在学习容器并不是很了解该含义,所以只得读者自行查询这句话的作用,不过使用考试时候的定义也是可以通过测试的,即
struct LinkedNode {
int val;
LinkedNode* next;
};在一个就是对类定义不太熟悉的同学,一定要注意public是定义公共成员,private是定义私有成员,所以在MyLinkedList中定义后,一定要在private中声明_size和_dummyHead的类型,否则会报错,俩者的用法和区别见下
c++学习
前言
配套视频:https://www.bilibili.com/video/BV1et411b73Z
只是为方便学习,不做其他用途,在此发布C++基础入门部分配套讲义,原作者为黑马程序
参考文档:《黑马》------C++提高编程_c++ 提高黑马-CSDN博客
今日c++学习了昨天剩下的类模板的内容如下
1.3.7 类模板分文件编写
学习目标:
- 掌握类模板成员函数分文件编写产生的问题以及解决方式
问题:
- 类模板中成员函数创建时机是在调用阶段,导致分文件编写时链接不到
解决:
- 解决方式1:直接包含.cpp源文件
- 解决方式2:将声明和实现写到同一个文件中,并更改后缀名为.hpp,hpp是约定的名称,并不是强制
示例:
person.hpp中代码:
#pragma once
#include <iostream>
using namespace std;
#include <string>
template<class T1, class T2>
class Person {
public:
Person(T1 name, T2 age);
void showPerson();
public:
T1 m_Name;
T2 m_Age;
};
//构造函数 类外实现
template<class T1, class T2>
Person<T1, T2>::Person(T1 name, T2 age) {
this->m_Name = name;
this->m_Age = age;
}
//成员函数 类外实现
template<class T1, class T2>
void Person<T1, T2>::showPerson() {
cout << "姓名: " << this->m_Name << " 年龄:" << this->m_Age << endl;
}类模板分文件编写.cpp中代码
#include<iostream>
using namespace std;
//#include "person.h"
#include "person.cpp" //解决方式1,包含cpp源文件
//解决方式2,将声明和实现写到一起,文件后缀名改为.hpp
#include "person.hpp"
void test01()
{
Person<string, int> p("Tom", 10);
p.showPerson();
}
int main() {
test01();
system("pause");
return 0;
}运行项目并下载源码C++运
总结:主流的解决方式是第二种,将类模板成员函数写到一起,并将后缀名改为.hpp
1.3.8 类模板与友元
学习目标:
- 掌握类模板配合友元函数的类内和类外实现
全局函数类内实现 - 直接在类内声明友元即可
全局函数类外实现 - 需要提前让编译器知道全局函数的存在
示例:
#include <string>
//2、全局函数配合友元 类外实现 - 先做函数模板声明,下方在做函数模板定义,在做友元
template<class T1, class T2> class Person;
//如果声明了函数模板,可以将实现写到后面,否则需要将实现体写到类的前面让编译器提前看到
//template<class T1, class T2> void printPerson2(Person<T1, T2> & p);
template<class T1, class T2>
void printPerson2(Person<T1, T2> & p)
{
cout << "类外实现 ---- 姓名: " << p.m_Name << " 年龄:" << p.m_Age << endl;
}
template<class T1, class T2>
class Person
{
//1、全局函数配合友元 类内实现
friend void printPerson(Person<T1, T2> & p)
{
cout << "姓名: " << p.m_Name << " 年龄:" << p.m_Age << endl;
}
//全局函数配合友元 类外实现
friend void printPerson2<>(Person<T1, T2> & p);
public:
Person(T1 name, T2 age)
{
this->m_Name = name;
this->m_Age = age;
}
private:
T1 m_Name;
T2 m_Age;
};
//1、全局函数在类内实现
void test01()
{
Person <string, int >p("Tom", 20);
printPerson(p);
}
//2、全局函数在类外实现
void test02()
{
Person <string, int >p("Jerry", 30);
printPerson2(p);
}
int main() {
//test01();
test02();
system("pause");
return 0;
}总结:建议全局函数做类内实现,用法简单,而且编译器可以直接识别
类模板案例
案例描述: 实现一个通用的数组类,要求如下:
- 可以对内置数据类型以及自定义数据类型的数据进行存储
- 将数组中的数据存储到堆区
- 构造函数中可以传入数组的容量
- 提供对应的拷贝构造函数以及operator=防止浅拷贝问题
- 提供尾插法和尾删法对数组中的数据进行增加和删除
- 可以通过下标的方式访问数组中的元素
- 可以获取数组中当前元素个数和数组的容量
示例:
myArray.hpp中代码
#pragma once
#include <iostream>
using namespace std;
template<class T>
class MyArray
{
public:
//构造函数
MyArray(int capacity)
{
this->m_Capacity = capacity;
this->m_Size = 0;
pAddress = new T[this->m_Capacity];
}
//拷贝构造
MyArray(const MyArray & arr)
{
this->m_Capacity = arr.m_Capacity;
this->m_Size = arr.m_Size;
this->pAddress = new T[this->m_Capacity];
for (int i = 0; i < this->m_Size; i++)
{
//如果T为对象,而且还包含指针,必须需要重载 = 操作符,因为这个等号不是 构造 而是赋值,
// 普通类型可以直接= 但是指针类型需要深拷贝
this->pAddress[i] = arr.pAddress[i];
}
}
//重载= 操作符 防止浅拷贝问题
MyArray& operator=(const MyArray& myarray) {
if (this->pAddress != NULL) {
delete[] this->pAddress;
this->m_Capacity = 0;
this->m_Size = 0;
}
this->m_Capacity = myarray.m_Capacity;
this->m_Size = myarray.m_Size;
this->pAddress = new T[this->m_Capacity];
for (int i = 0; i < this->m_Size; i++) {
this->pAddress[i] = myarray[i];
}
return *this;
}
//重载[] 操作符 arr[0]
T& operator [](int index)
{
return this->pAddress[index]; //不考虑越界,用户自己去处理
}
//尾插法
void Push_back(const T & val)
{
if (this->m_Capacity == this->m_Size)
{
return;
}
this->pAddress[this->m_Size] = val;
this->m_Size++;
}
//尾删法
void Pop_back()
{
if (this->m_Size == 0)
{
return;
}
this->m_Size--;
}
//获取数组容量
int getCapacity()
{
return this->m_Capacity;
}
//获取数组大小
int getSize()
{
return this->m_Size;
}
//析构
~MyArray()
{
if (this->pAddress != NULL)
{
delete[] this->pAddress;
this->pAddress = NULL;
this->m_Capacity = 0;
this->m_Size = 0;
}
}
private:
T * pAddress; //指向一个堆空间,这个空间存储真正的数据
int m_Capacity; //容量
int m_Size; // 大小
};类模板案例---数组类封装.cpp中
#include "myArray.hpp"
#include <string>
void printIntArray(MyArray<int>& arr) {
for (int i = 0; i < arr.getSize(); i++) {
cout << arr[i] << " ";
}
cout << endl;
}
//测试内置数据类型
void test01()
{
MyArray<int> array1(10);
for (int i = 0; i < 10; i++)
{
array1.Push_back(i);
}
cout << "array1打印输出:" << endl;
printIntArray(array1);
cout << "array1的大小:" << array1.getSize() << endl;
cout << "array1的容量:" << array1.getCapacity() << endl;
cout << "--------------------------" << endl;
MyArray<int> array2(array1);
array2.Pop_back();
cout << "array2打印输出:" << endl;
printIntArray(array2);
cout << "array2的大小:" << array2.getSize() << endl;
cout << "array2的容量:" << array2.getCapacity() << endl;
}
//测试自定义数据类型
class Person {
public:
Person() {}
Person(string name, int age) {
this->m_Name = name;
this->m_Age = age;
}
public:
string m_Name;
int m_Age;
};
void printPersonArray(MyArray<Person>& personArr)
{
for (int i = 0; i < personArr.getSize(); i++) {
cout << "姓名:" << personArr[i].m_Name << " 年龄: " << personArr[i].m_Age << endl;
}
}
void test02()
{
//创建数组
MyArray<Person> pArray(10);
Person p1("孙悟空", 30);
Person p2("韩信", 20);
Person p3("妲己", 18);
Person p4("王昭君", 15);
Person p5("赵云", 24);
//插入数据
pArray.Push_back(p1);
pArray.Push_back(p2);
pArray.Push_back(p3);
pArray.Push_back(p4);
pArray.Push_back(p5);
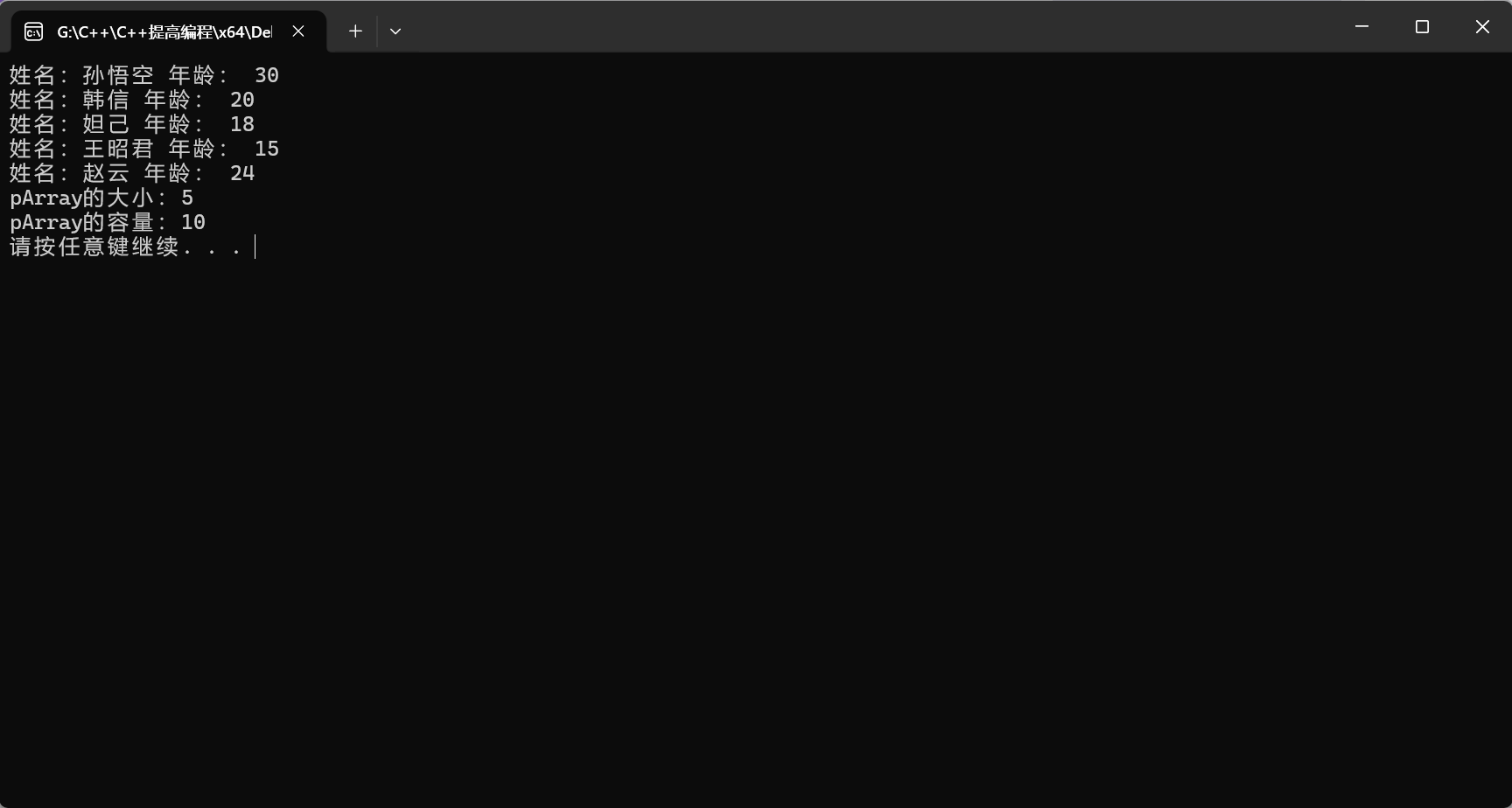
printPersonArray(pArray);
cout << "pArray的大小:" << pArray.getSize() << endl;
cout << "pArray的容量:" << pArray.getCapacity() << endl;
}
int main() {
//test01();
test02();
system("pause");
return 0;
}总结:
能够利用所学知识点实现通用的数组
由于笔者学习c++更多的是偏向于复试,所以并未认真学习该案例,有兴趣的同学可以去哔站观看原视频学习,链接如下https://www.bilibili.com/video/BV1et411b73Z?t=1.0&p=183
运行结果如下
STL初识
2.1 STL的诞生
-
长久以来,软件界一直希望建立一种可重复利用的东西
-
C++的面向对象 和泛型编程 思想,目的就是复用性的提升
-
大多情况下,数据结构和算法都未能有一套标准,导致被迫从事大量重复工作
-
为了建立数据结构和算法的一套标准,诞生了STL
2.2 STL基本概念
- STL(Standard Template Library,标准模板库)
- STL 从广义上分为: 容器(container) 算法(algorithm) 迭代器(iterator)
- 容器 和算法 之间通过迭代器进行无缝连接。
- STL 几乎所有的代码都采用了模板类或者模板函数
2.3 STL六大组件
STL大体分为六大组件,分别是:容器、算法、迭代器、仿函数、适配器(配接器)、空间配置器
- 容器:各种数据结构,如vector、list、deque、set、map等,用来存放数据。
- 算法:各种常用的算法,如sort、find、copy、for_each等
- 迭代器:扮演了容器与算法之间的胶合剂。
- 仿函数:行为类似函数,可作为算法的某种策略。
- 适配器:一种用来修饰容器或者仿函数或迭代器接口的东西。
- 空间配置器:负责空间的配置与管理。
2.4 STL中容器、算法、迭代器
**容器:**置物之所也
STL容器 就是将运用最广泛的一些数据结构实现出来
常用的数据结构:数组, 链表,树, 栈, 队列, 集合, 映射表 等
这些容器分为序列式容器 和关联式容器两种:
序列式容器 :强调值的排序,序列式容器中的每个元素均有固定的位置。
关联式容器:二叉树结构,各元素之间没有严格的物理上的顺序关系
**算法:**问题之解法也
有限的步骤,解决逻辑或数学上的问题,这一门学科我们叫做算法(Algorithms)
算法分为:质变算法 和非质变算法。
质变算法:是指运算过程中会更改区间内的元素的内容。例如拷贝,替换,删除等等
非质变算法:是指运算过程中不会更改区间内的元素内容,例如查找、计数、遍历、寻找极值等等
**迭代器:**容器和算法之间粘合剂
提供一种方法,使之能够依序寻访某个容器所含的各个元素,而又无需暴露该容器的内部表示方式。
每个容器都有自己专属的迭代器
迭代器使用非常类似于指针,初学阶段我们可以先理解迭代器为指针
迭代器种类:
| 种类 | 功能 | 支持运算 |
|---|---|---|
| 输入迭代器 | 对数据的只读访问 | 只读,支持++、==、!= |
| 输出迭代器 | 对数据的只写访问 | 只写,支持++ |
| 前向迭代器 | 读写操作,并能向前推进迭代器 | 读写,支持++、==、!= |
| 双向迭代器 | 读写操作,并能向前和向后操作 | 读写,支持++、--, |
| 随机访问迭代器 | 读写操作,可以以跳跃的方式访问任意数据,功能最强的迭代器 | 读写,支持++、--、n、-n、<、<=、>、>= |
常用的容器中迭代器种类为双向迭代器,和随机访问迭代器
后续就是很重的vector等容器的学习了,但是悲催的是笔记发现看视频好像看跳了,貌似看跳了类的学习,所以明后天应该会先学习类,如果想继续学习的话可以根据哔站视频和参考文档第3阶段-C++核心编程 资料/讲义/C++核心编程.md · 赤伶/Cpp-0-1-Resource - Gitee.com
进行深入学习
++相信看到这的你也很努力,望与诸君共勉!!!++