一、Java 基础(高频 & 深度)
HashMap 扩容是 2 倍,为什么必须是 2 的幂。
"HashMap 扩容是 2 倍"并且容量必须是 2 的幂(如 16, 32, 64...) ,这是 Java 中 HashMap(以及 ConcurrentHashMap 等)设计的核心优化之一。其根本原因在于:为了高效、均匀地计算元素在数组中的存储位置(即哈希槽 index),并支持快速扩容时的 rehash(重新散列)。
下面我们从 哈希定位、位运算优化、扩容重分布 三个角度深入解释。
一、核心目的:用位运算替代取模(%)
❌ 普通做法(非 2 的幂)
如果数组长度为 length(任意正整数),要将哈希值 hash 映射到 [0, length-1] 范围,通常用:
java
index = hash % length;但 **%**** 运算涉及除法,在 CPU 层面开销较大**。
✅ HashMap 的优化(仅当 length 是 2 的幂时成立)
当 length = 2^n 时,有数学恒等式:
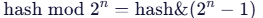
例如:
length = 16 (2^4)→index = hash & 15(因为 15 = 1111₂)length = 32 (2^5)→index = hash & 31(31 = 11111₂)
💡 位与(&)运算比取模(%)快几十倍!
🔍 Java 源码验证(JDK 8+)
java
// HashMap.java
static int indexFor(int h, int length) {
return h & (length - 1); // 关键:依赖 length 是 2 的幂
}注意:JDK 8 后该方法内联到 putVal 中,但逻辑不变。
二、为什么必须是 2 的幂?------ 均匀分布 + 避免冲突
假设 length 不是 2 的幂,比如 length = 10,那么 length - 1 = 9(二进制 1001)。
此时 hash & 9 的结果只取决于 hash 的第 0 位和第 3 位,中间两位被屏蔽了!
| hash (二进制) | hash & 9 (二进制) | index |
|---|---|---|
| ...0000 | 0000 | 0 |
| ...0001 | 0001 | 1 |
| ...0010 | 0000 | 0 |
| ...0011 | 0001 | 1 |
| ...1000 | 1000 | 8 |
| ...1001 | 1001 | 9 |
| ...1010 | 1000 | 8 |
→ 大量不同 hash 值映射到相同 index,哈希冲突剧增,退化成链表/红黑树,性能暴跌!
而当 length = 16(length-1=15=1111₂)时:
hash & 15会用到 hash 的最低 4 位- 只要 hash 函数足够随机,这 4 位就能均匀分布 → index 均匀分布
✅ 2 的幂保证 **(length - 1)** 的二进制全是 1,从而充分利用 hash 的低位信息,实现均匀散列。
三、扩容时的高效 rehash(关键优势!)
当 HashMap 从 oldCap = 16 扩容到 newCap = 32 时,不需要重新计算所有元素的 hash!
📌 规律(仅当容量是 2 的幂时成立):
对于任意元素,其在新数组中的位置只有两种可能:
- 保持原位置 (
index不变) - 移动到
**index + oldCap**位置
🔍 原因分析
设:
oldCap = 2^nnewCap = 2^{n+1}- 元素原 index =
hash & (oldCap - 1) - 新 index =
hash & (newCap - 1)
由于 newCap - 1 比 oldCap - 1多一位 1 (例如 15=01111 → 31=11111),
所以新 index 是否变化,只取决于 hash 的第 n 位(从 0 开始)是否为 1:
- 如果第 n 位 = 0 → 新 index = 原 index
- 如果第 n 位 = 1 → 新 index = 原 index + oldCap
✅ Java 源码(JDK 8 扩容逻辑)
java
// 在 resize() 方法中
if ((e.hash & oldCap) == 0) {
// 保持原位置
loHead = e;
} else {
// 移动到 index + oldCap
hiHead = e;
}⚡ 只需一次位与操作 ( **e.hash & oldCap**),即可决定元素去向,无需重新计算 hash!
❌ 如果容量不是 2 的幂?
- 扩容后
newCap和oldCap无倍数关系 - **每个元素都必须重新执行 **
**hash % newCap** - 时间复杂度从 O(1) per element 变成 O(n) per element,扩容成本极高!
四、总结:为什么必须是 2 的幂?
| 优势 | 说明 |
|---|---|
| ✅ 高效定位 | index = hash & (length-1)比 % 快一个数量级 |
| ✅ 均匀分布 | (length-1) 全为 1,充分利用 hash 低位,减少冲突 |
| ✅ 快速扩容 | 扩容时只需判断 hash & oldCap,元素要么不动,要么移 +oldCap |
| ✅ 内存对齐 | 2 的幂更利于 CPU 缓存行对齐(次要因素) |
🚫 如果不用 2 的幂:
- 定位慢(% 运算)
- 冲突多(分布不均)
- 扩容慢(全量 rehash)
→ 完全丧失 HashMap 的高性能优势!
补充:其他语言/容器的选择
| 语言/容器 | 容量策略 | 原因 |
|---|---|---|
| Java HashMap | 2 的幂 | 上述优化 |
| Python dict | 2 的幂 | 类似优化(CPython 实现) |
| C++ std::unordered_map | 质数 | 避免用户自定义 hash 的周期性冲突(牺牲速度换鲁棒性) |
💡 Java 选择 2 的幂,是在假设 hash 函数质量较高(如 Object.hashCode() 经过扰动)的前提下,追求极致性能的设计决策。
因此,"HashMap 容量必须是 2 的幂"不是随意规定,而是性能、正确性、扩容效率三者平衡后的最优解。
String 在 JDK 9+ 的底层实现变化是什么?为什么改用 byte\[\] + coder?
在 JDK 9 中,String 类的底层实现发生了重大变化:从 **char[]** 改为 **byte[] + coder**。这是 Java 平台为了节省内存、提升性能而引入的关键优化(JEP 254: Compact Strings)。
一、JDK 9 之前的实现(JDK 8 及更早)
java
public final class String {
private final char value[]; // 每个字符占 2 字节(UTF-16)
// ...
}- 所有字符串内部都用
char[]存储。 char是 16 位(2 字节),基于 UTF-16 编码。- 问题 :对于只包含 Latin-1 字符(如英文、数字、常见符号,0--255 范围)的字符串,每个字符实际只需 1 字节 ,但 JVM 仍分配 2 字节 ,造成 50% 内存浪费。
💡 据 Oracle 统计,大多数 Java 应用中的字符串都是 Latin-1 兼容的(尤其是 Web 应用、日志、配置等)。
二、JDK 9+ 的新实现
java
public final class String {
private final byte[] value; // 存储字符的字节数据
private final byte coder; // 编码标识:0 = LATIN1, 1 = UTF16
// ...
}关键变化:
| 成员 | 说明 |
|---|---|
byte[] value |
实际存储字符的字节数组 |
byte coder |
编码方式标记: • COMPACT_STRINGS 开启时: -- 0 表示 Latin-1 (1 字节/字符) -- 1 表示 UTF-16(2 字节/字符) |
✅ 默认启用 CompactStrings(可通过 -XX:-CompactStrings 关闭,退回到 char[] 行为)。
三、为什么改用 byte[] + coder?
✅ 核心目标:减少内存占用,提升 GC 和缓存效率
| 优势 | 说明 |
|---|---|
| 内存减半(对 Latin-1 字符串) | 英文字符串内存占用从 2n → n 字节,堆内存显著下降 |
| 减少 GC 压力 | 对象变小 → 更少 GC 次数、更短 STW 时间 |
| 提升 CPU 缓存命中率 | 数据更紧凑 → 更多字符串能放入 L1/L2 缓存 → 性能提升 |
| 兼容性无损 | 对外 API 完全不变,开发者无需修改代码 |
📊 实测效果(Oracle 官方数据):
- 堆内存减少 10%~40%(取决于应用字符串特征)
- GC 时间减少 5%~15%
- 某些字符串操作(如
**indexOf**)速度提升
四、内部如何工作?(以 String 构造为例)
java
// 创建 "Hello"(纯 Latin-1)
String s = "Hello";
// JDK 9+ 内部:
// value = byte[]{72, 101, 108, 108, 111} // ASCII 值
// coder = 0 (LATIN1)
// 创建 "你好"(含非 Latin-1 字符)
String s2 = "你好";
// value = byte[]{... UTF-16 编码的字节 ...}
// coder = 1 (UTF16)所有字符串操作(charAt, substring, equals 等)都会根据 coder 选择不同的实现路径:
java
public char charAt(int index) {
if (isLatin1()) {
return (char)(value[index] & 0xff);
} else {
return StringUTF16.charAt(value, index);
}
}五、对开发者的影响
| 场景 | 影响 |
|---|---|
**正常使用 ****String** |
✅ 完全透明,无感知 |
**反射访问 ****value**字段 |
⚠️ **破坏兼容性!**JDK 9+ value 是 byte[],旧代码假设是 char[]会崩溃 |
| 序列化/反序列化 | ✅ JVM 自动处理,无问题 |
| JNI 或 Unsafe 操作 | ⚠️ 需要适配新结构(不推荐直接操作内部字段) |
🔒 从 Java 9 开始,强烈建议不要通过反射访问 **String** 的内部字段!
六、如何验证?
java
public class StringInternals {
public static void main(String[] args) throws Exception {
String s1 = "Hello"; // Latin-1
String s2 = "你好"; // UTF-16
Field valueField = String.class.getDeclaredField("value");
Field coderField = String.class.getDeclaredField("coder");
valueField.setAccessible(true);
coderField.setAccessible(true);
System.out.println("s1 coder: " + coderField.get(s1)); // 0
System.out.println("s2 coder: " + coderField.get(s2)); // 1
byte[] v1 = (byte[]) valueField.get(s1);
System.out.println(Arrays.toString(v1)); // [72, 101, 108, 108, 111]
}
}总结
| 特性 | JDK 8- | JDK 9+ |
|---|---|---|
| 底层存储 | char[](固定 2 字节/字符) |
byte[] + coder(1 或 2 字节/字符) |
| 内存效率 | 低(Latin-1 浪费 50%) | 高(按需分配) |
| 性能 | 一般 | 更优(缓存友好 + GC 减轻) |
| 兼容性 | --- | 对外 API 不变,内部字段不可依赖 |
💡 这次改动是 Java 在"向后兼容"前提下,对内存模型的一次优雅优化,体现了 JVM 团队对真实应用场景的深刻理解。
record 类和普通 class 的本质区别?它能继承吗?能有静态方法吗?
record 是 Java 14(JEP 359)引入的预览特性 ,Java 16 正式发布,用于简洁地建模不可变的数据载体类(data carrier) 。它与普通 class 在语义、语法和行为上有本质区别。
一、本质区别
| 特性 | record |
普通 class |
|---|---|---|
| 设计目的 | 表示纯数据(值对象),强调"是什么" | 表示行为 + 状态,强调"能做什么" |
| 不可变性 | 所有字段默认 private final,自动提供只读访问器 |
需手动实现不可变性(final字段 + 无 setter) |
| 自动生成代码 | 编译器自动生成: • private final字段 • 公共构造器 • accessor方法(同字段名) • equals()/ hashCode() • toString() |
全部需手动编写(或用 Lombok) |
| 继承 | 不能继承其他类 (隐式 extends java.lang.Record) 不能被继承 (隐式 final) |
可继承一个父类,可被继承 (除非 final) |
| 接口实现 | ✅ 可以 implements接口 |
✅ 可以 |
| 静态成员 | ✅ 可以有静态字段、静态方法、静态初始化块 | ✅ 可以 |
| 实例方法 | ✅ 可以添加自定义实例方法(但不能覆盖 equals/toString/hashCode的核心逻辑) |
✅ 可以 |
| 额外字段 | ❌ 不能声明额外的实例字段(只能通过参数列表定义) | ✅ 可以 |
| 构造器 | 可写紧凑构造器(compact constructor)或规范构造器(canonical constructor) | 可自由定义 |
二、关键问题详解
1. record 能继承吗?
- 不能继承其他类 :因为
record隐式继承自java.lang.Record(抽象类),而 Java 不支持多继承。 - 不能被继承 :
record隐式是final的。
java
// ❌ 编译错误:Cannot extend record
class MyRecord extends Point { }
// ❌ 编译错误:Cannot inherit from final 'Point'
class SubPoint extends Point { }
record Point(int x, int y) { }✅ 但可以实现接口:
java
record Point(int x, int y) implements Comparable<Point> {
public int compareTo(Point other) {
return Integer.compare(this.x, other.x);
}
}2. record 能有静态方法吗?
✅ 完全可以!
java
record Person(String name, int age) {
// 静态字段
private static final String DEFAULT_NAME = "Unknown";
// 静态方法
public static Person unknown() {
return new Person(DEFAULT_NAME, 0);
}
// 静态工厂方法(推荐替代构造器)
public static Person of(String name, int age) {
if (name == null || name.isBlank()) throw new IllegalArgumentException();
return new Person(name, age);
}
// 静态初始化块
static {
System.out.println("Person record loaded");
}
}使用:
java
Person p1 = Person.unknown();
Person p2 = Person.of("Alice", 30);3. record 能有实例方法吗?
✅ 可以,但不能修改状态 (因为字段是 final):
java
record Circle(double radius) {
// 实例方法(只读计算)
public double area() {
return Math.PI * radius * radius;
}
// 重写 toString(不推荐,除非必要)
@Override
public String toString() {
return "Circle[r=" + radius + "]";
}
}三、record 的字节码等价形式(概念上)
java
// record 声明
record Point(int x, int y) { }
// ≈ 等价于以下普通 class(简化版)
public final class Point extends Record {
private final int x;
private final int y;
public Point(int x, int y) {
this.x = x;
this.y = y;
}
public int x() { return x; }
public int y() { return y; }
@Override public boolean equals(Object o) { /* 基于 x, y */ }
@Override public int hashCode() { /* 基于 x, y */ }
@Override public String toString() { /* "Point[x=..., y=...]" */ }
}注意:Record 是 java.lang 中的抽象基类,所有 record 都继承它。
四、何时用 record?何时用 class?
| 场景 | 推荐 |
|---|---|
| DTO、POJO、返回多个值、临时数据结构 | ✅ record |
| 需要封装行为(如策略、状态机) | ✅ 普通 class |
| 需要继承体系 | ✅ 普通 class |
| 需要可变状态 | ✅ 普通 class |
作为 Map key(需正确 equals/hashCode ) |
✅ record (天然支持) |
总结
record是不可变数据类的语法糖,不是普通类的替代品。- 不能继承(自身 final + 已继承 Record)。
- 可以有静态方法、静态字段、实例方法、实现接口。
- 不能有额外实例字段,不能有 setter。
- 适用于数据传输、模式匹配(Java 21+)、函数式编程等场景。
💡 记住:record 是"值",class 是"对象"。
Pattern Matching for instanceof(JDK 14+)如何避免冗余类型转换?编译后字节码有何优化?
Pattern Matching for instanceof 是 Java 14 引入的预览特性 (JEP 305),在 Java 16 正式发布 ,它通过模式匹配(Pattern Matching) 消除了传统 instanceof 后冗余的显式类型转换,使代码更简洁、安全、可读。
一、传统写法 vs 模式匹配
❌ 传统写法(冗余 + 不安全)
java
if (obj instanceof String) {
String s = (String) obj; // 冗余强制转换
System.out.println(s.length());
}问题:
- 需要手动强转,代码啰嗦;
- 如果后续修改了
instanceof类型但忘记改强转,可能出错; - 编译器无法保证强转一定成功(尽管逻辑上安全)。
✅ 模式匹配写法(JDK 16+)
java
if (obj instanceof String s) { // 声明绑定变量 s
System.out.println(s.length()); // 直接使用,无需强转
}优势:
- 自动类型推断 + 范围限定 :
s在if块内是String类型; - 编译器保证类型安全:无需担心强转异常;
- 避免重复计算 :
instanceof和赋值合并为一次操作。
二、如何避免冗余类型转换?
核心机制:绑定变量(Binding Variable)
instanceof String s中的s是一个模式变量(pattern variable);- 它的作用域被智能限制在
instanceof为true的分支中; - 编译器隐式完成类型检查 + 赋值 ,无需程序员写
(String) obj。
✅ 这不是语法糖!而是语言级别的模式匹配能力,未来可扩展到 switch(如 Java 21 的 switch 模式匹配)。
三、编译后字节码有何优化?
我们对比两种写法的字节码:
示例代码
java
// 传统
public void old(Object obj) {
if (obj instanceof String) {
String s = (String) obj;
System.out.println(s.length());
}
}
// 模式匹配
public void modern(Object obj) {
if (obj instanceof String s) {
System.out.println(s.length());
}
}字节码对比(简化版)
传统写法字节码:
plain
aload_1 ; 加载 obj
instanceof String ; 检查类型
ifeq L1 ; 如果 false,跳过
aload_1 ; 再次加载 obj
checkcast String ; 显式强转(冗余 checkcast)
astore_2 ; 存入局部变量 s
...模式匹配字节码:
plain
aload_1 ; 加载 obj
dup ; 复制一份引用(关键!)
instanceof String ; 检查类型
ifeq L1 ; 如果 false,跳过
checkcast String ; 强转(但只做一次)
astore_2 ; 存入局部变量 s
...🔍 关键优化点:
| 优化 | 说明 |
|---|---|
| 减少一次对象加载 | 传统写法需两次 aload_1(一次检查,一次强转); 新模式用 dup复用栈顶引用,只需一次加载 |
**checkcast**仍存在,但语义更安全 |
JVM 仍需做类型检查(安全要求),但编译器确保其不会失败 |
| 局部变量作用域精确控制 | s只在 if块内有效,避免变量污染 |
💡 虽然 checkcast 字节码仍然存在(JVM 安全模型要求),但源码层面消除了冗余强转 ,且运行时性能略优或持平(因减少了一次字段/变量读取)。
四、进阶:与 final 和复杂条件结合
1. 绑定变量是 final 的(隐式)
java
if (obj instanceof String s) {
s = "new"; // ❌ 编译错误!s 是 final
}2. 支持逻辑组合(注意作用域)
java
if (obj instanceof String s && s.length() > 0) {
System.out.println(s); // ✅ s 在此处可用
}
// 但不能这样:
if (obj instanceof String s || flag) {
// ❌ s 在此处不可用!因为 || 右侧为 true 时 s 未初始化
}五、未来演进
- Java 21+ :模式匹配已扩展到
switch表达式:
java
switch (obj) {
case Integer i -> System.out.println(i * 2);
case String s when s.length() > 0 -> System.out.println(s);
default -> System.out.println("unknown");
}- 解构模式(Deconstruction Patterns) :未来可能支持
case Point(int x, int y)。
总结
| 方面 | 传统 instanceof |
模式匹配 instanceof |
|---|---|---|
| 代码冗余 | 需手动强转 | 自动绑定变量,无强转 |
| 类型安全 | 依赖程序员正确性 | 编译器保证 |
| 字节码效率 | 多一次对象加载 | 用 dup优化,略高效 |
| 可读性 | 较差 | 清晰表达"如果它是 X,就当作 X 用" |
| 扩展性 | 无 | 为未来模式匹配(switch等)铺路 |
✅ 结论 :
instanceof 模式匹配不是简单的语法糖 ,而是一种安全、高效、可扩展的语言特性。它在保持 JVM 安全模型的同时,显著提升了开发体验和代码质量。建议在 JDK 16+ 项目中全面采用。
为什么 switch 支持 String 后,底层仍用 hashCode + equals 而非直接跳转表?
这是一个非常深入且经典的问题!
Java 的 **switch** 语句在 JDK 7 开始支持 **String** 类型,但其底层实现并未使用传统的"跳转表(jump table)",而是基于 **hashCode()** + **equals()** 的多层 **if-else** 或查表结构。原因在于: **String**** 的值空间是无限的、稀疏的,且无法在编译时确定所有可能的分支值。**
下面我们从原理、实现和性能角度详细解释。
一、传统 switch(int/enum)为何能用跳转表?
对于 **int**、 **byte**、 **short**、 **char**、 **enum** 等类型:
- 值域有限且连续(或可映射为连续整数,如 enum 的 ordinal);
- 编译器可以在编译时知道所有
case常量; - JVM 可生成高效的 tableswitch 或 lookupswitch 字节码,实现 O(1) 跳转。
java
switch (day) {
case 1: ...
case 2: ...
case 3: ...
}
// → 编译为 tableswitch,直接索引跳转二、String 为什么不能直接用跳转表?
❌ 核心问题:**String**** 的值不是编译时常量整数,且空间巨大**
**String**** 的值域是无限的**- 可能的字符串有无数个("a", "aa", "aaa", ...),无法建立完整跳转表。
**case**** 标签是字符串字面量,但运行时输入是任意**String**对象**- 编译器不知道运行时传入的是什么字符串;
- 必须在运行时动态比较内容,而非简单整数匹配。
- 哈希冲突不可避免
- 即使使用
hashCode()作为"伪索引",不同字符串也可能有相同哈希值(如"Aa"和"BB"的hashCode()都是 2112); - 必须用
**equals()**二次验证,确保语义正确。
- 即使使用
三、JDK 实际如何实现 String switch?
以以下代码为例:
java
switch (str) {
case "apple": return 1;
case "banana": return 2;
case "cherry": return 3;
default: return 0;
}✅ 编译后的逻辑(概念等价于):
java
public static int switchString(String str) {
if (str == null) {
throw new NullPointerException(); // 注意:String switch 不支持 null
}
int hash = str.hashCode();
// 第一层:按 hashCode 快速分组(减少 equals 次数)
if (hash == 96415 || hash == 97281956 || hash == -1998214767) {
// 第二层:精确匹配(防止哈希冲突)
if (str.equals("apple")) {
return 1;
} else if (str.equals("banana")) {
return 2;
} else if (str.equals("cherry")) {
return 3;
}
}
return 0; // default
}🔍 实际字节码可能更优化(如用 lookupswitch 按 hashCode 分支),但**核心仍是 ****hashCode + equals**。
四、为什么不直接用 Map<String, Runnable> 实现?
你可能会想:"为什么不编译成一个 HashMap,然后 map.get(str) 直接跳转?"
- 启动开销大:每次方法调用都要初始化 map(除非静态缓存);
- 内存占用高:每个 switch 都要维护一个 map;
- 小分支场景效率低 :当只有 2~3 个 case 时,
if-else比 hash 查找更快; - JIT 优化友好性 :
if-else更容易被 HotSpot 内联和优化。
📌 实际上,JVM 在 JIT 编译阶段可能会进一步优化热点路径 (如将频繁命中的分支提升),但初始字节码仍基于 hashCode + equals。
五、性能影响 & 最佳实践
| 场景 | 建议 |
|---|---|
| 少量 case(≤3) | String switch 性能接近 if-else,可放心使用 |
| 大量 case(>10) | 考虑手动用 Map<String, ?>预构建,避免线性扫描 |
| 高频调用 | JVM 会 JIT 优化,实际性能差异不大 |
| 避免 null | String switch遇 null会抛 NPE! |
六、验证:查看字节码
编译后反编译(javap -c)可以看到:
plain
// 伪字节码示意
aload_0 ; 加载 str
invokevirtual #hashCode
lookupswitch {
96415: L1,
97281956: L2,
-1998214767: L3,
default: Ldefault
}
L1:
aload_0
ldc "apple"
invokevirtual #equals
ifeq Ldefault
iconst_1
ireturn
...✅ 总结
| 问题 | 答案 |
|---|---|
| 为什么不用跳转表? | String值域无限、非整数,无法建立 O(1) 跳转表 |
为什么用 **hashCode**? |
快速分组,减少 equals()调用次数(避免全量线性扫描) |
为什么还要 **equals()**? |
处理哈希冲突,保证语义正确性 |
| 性能如何? | 小规模 case 效率高;大规模建议手写 Map |
| 安全吗? | 安全,但不支持 null输入 |
💡 本质 :String switch 是语法糖 + 运行时内容比较 ,而非传统整数跳转。这是在通用性、安全性和性能之间取得的最佳平衡。
强引用、软引用、弱引用、虚引用的实际应用场景分别是什么?举例说明。
在 Java 中,引用类型(Reference Types)是内存管理和垃圾回收(GC)机制的重要组成部分。除了最常见的强引用(Strong Reference) ,JDK 还提供了 软引用(SoftReference)、弱引用(WeakReference)、虚引用(PhantomReference),它们在不同场景下控制对象的生命周期和 GC 行为。
下面详细说明四者的定义、GC 行为及典型实际应用场景,并附代码示例。
一、强引用(Strong Reference)
✅ 定义
最常见的引用形式,如:
java
Object obj = new Object();只要强引用存在,GC 永远不会回收该对象,即使发生 OOM(OutOfMemoryError)。
🚫 GC 行为
- 不会被回收 ,直到引用置为
null或超出作用域。
💡 实际应用场景
- 所有常规对象使用:业务实体、服务类、控制器等。
- 必须保证对象存活的场景。
⚠️ 注意:强引用过多且不释放,是内存泄漏的常见原因。
二、软引用(SoftReference)
✅ 定义
java
SoftReference<byte[]> ref = new SoftReference<>(new byte[1024 * 1024]);描述"有用但非必需 "的对象。只有在内存不足(即将 OOM)时,GC 才会回收软引用对象。
🧹 GC 行为
- 内存充足 → 不回收;
- 内存紧张 → 回收(作为最后的缓存清理手段)。
💡 实际应用场景:内存敏感的缓存
✅ 示例:图片缓存(如 Android Bitmap 缓存)
java
public class ImageCache {
private Map<String, SoftReference<Bitmap>> cache = new ConcurrentHashMap<>();
public Bitmap get(String key) {
SoftReference<Bitmap> ref = cache.get(key);
return (ref != null) ? ref.get() : null;
}
public void put(String key, Bitmap bitmap) {
cache.put(key, new SoftReference<>(bitmap));
}
}- 当内存充足时,图片保留在缓存中,快速加载;
- 当系统内存紧张时,GC 自动清理缓存,避免 OOM。
✅ 优势:无需手动管理缓存大小,由 JVM 根据内存压力自动调节。
三、弱引用(WeakReference)
✅ 定义
java
WeakReference<Object> ref = new WeakReference<>(new Object());描述"非必需 "的对象。只要发生 GC(无论内存是否充足),就会回收弱引用对象。
🧹 GC 行为
- 每次 GC 都会回收(比软引用更"弱")。
💡 实际应用场景
场景 1:防止内存泄漏的监听器/回调注册
java
// 错误做法:强引用导致 Activity 无法回收
button.setOnClickListener(this); // this 是 Activity,造成泄漏
// 正确做法:使用弱引用包装
private static class ClickListener implements View.OnClickListener {
private final WeakReference<MainActivity> activityRef;
ClickListener(MainActivity activity) {
this.activityRef = new WeakReference<>(activity);
}
@Override
public void onClick(View v) {
MainActivity activity = activityRef.get();
if (activity != null) {
activity.doSomething();
}
}
}- 即使忘记反注册监听器,Activity 也能被 GC 回收。
场景 2:WeakHashMap ------ 自动清理的映射表
java
// 用作"元数据缓存"或"关联容器"
Map<Object, String> metadata = new WeakHashMap<>();
Object key = new Object();
metadata.put(key, "some info");
key = null; // key 无强引用
System.gc(); // 下次 GC 后,entry 自动消失- Key 是弱引用:当 key 对象无其他强引用时,整个 entry 被自动移除。
- 常用于:类加载器元数据缓存、动态代理缓存、ThreadLocal 替代方案等。
🔍 典型应用:
ThreadLocal内部使用ThreadLocalMap,其 key 是WeakReference<ThreadLocal>,防止 ThreadLocal 对象泄漏。
四、虚引用(PhantomReference)
✅ 定义
java
PhantomReference<Object> ref = new PhantomReference<>(obj, queue);- 最弱的引用 ,不能通过它获取对象 (
get()永远返回null); - 必须与 ReferenceQueue 联用;
- 用途:跟踪对象被 GC 的时机,执行清理操作(类似 C++ 的析构函数)。
🧹 GC 行为
- 对象 finalize() 后、真正回收前,虚引用被加入关联的
ReferenceQueue。
💡 实际应用场景:资源清理(尤其是堆外内存)
✅ 示例:DirectByteBuffer 的内存回收
- Java NIO 的
DirectByteBuffer分配的是堆外内存(native memory); - JVM 无法通过 GC 自动释放堆外内存;
- 解决方案:
Cleaner(内部基于PhantomReference)在对象被回收时触发free()。
java
// 简化版原理
ReferenceQueue<Object> queue = new ReferenceQueue<>();
PhantomReference<MyResource> phantomRef =
new PhantomReference<>(resource, queue);
// 后台线程监控 queue
new Thread(() -> {
try {
PhantomReference<?> ref = (PhantomReference<?>) queue.remove();
// 此时 resource 已不可达,可安全释放 native 资源
releaseNativeResource();
ref.clear(); // 清理引用
} catch (InterruptedException e) {}
}).start();✅ 优势:确保资源最终被释放,即使用户忘记调用 close()。
⚠️ 注意:Java 9+ 推荐使用 Cleaner 类(更安全),而非直接操作 PhantomReference。
五、四类引用对比总结
| 引用类型 | 获取对象 | GC 时机 | 典型用途 |
|---|---|---|---|
| 强引用 | ✅ 可获取 | 永不回收(有引用时) | 普通对象 |
| 软引用 | ✅ 可获取 | 内存不足时回收 | 内存敏感缓存(如图片) |
| 弱引用 | ✅ 可获取 | 下次 GC 时回收 | 防泄漏监听器、WeakHashMap |
| 虚引用 | ❌ 永远 null |
finalize 后、回收前入队 | 堆外资源清理(如 DirectBuffer) |
六、选择建议
- 默认用强引用;
- 做缓存? → 考虑
SoftReference(但注意:现代缓存库如 Caffeine 更推荐基于 size/time 的显式策略); - 防内存泄漏? → 用
WeakReference(如监听器、WeakHashMap); - 管理 native 资源? → 用
PhantomReference或Cleaner(但优先实现AutoCloseable+ try-with-resources)。
💡 重要提醒 :
软/弱引用不能替代良好的资源管理 。对于关键资源(如文件、数据库连接),仍应显式关闭(try-with-resources)。引用类型主要用于辅助性、非关键性的内存优化。
二、并发编程(重点:原理 + 场景)
AQS 中的 state 是 volatile 的,为什么还需要 CAS 操作?仅靠 volatile 能保证原子性吗?
这是一个非常关键且常见的并发编程问题。答案是:
**volatile**** 能保证可见性和有序性,但不能保证复合操作的原子性;而 AQS 中对 **state** 的操作(如 **acquire** /**release**)通常是"读-改-写"这类复合操作,必须依赖 CAS(Compare-And-Swap)来保证原子性。**
下面我们从原理、代码和内存模型角度详细解释。
一、AQS 中的 state 定义
在 AbstractQueuedSynchronizer(AQS)中,state 是一个 **volatile int**:
java
// java.util.concurrent.locks.AbstractQueuedSynchronizer
private volatile int state;volatile确保:- 可见性 :一个线程修改
state,其他线程立即看到最新值; - 禁止指令重排序:防止编译器或 CPU 重排导致状态不一致。
- 可见性 :一个线程修改
但这不等于 所有对 state 的操作都是原子的!
二、为什么 volatile 不能保证原子性?
✅ volatile 保证的是 单次读/写 的原子性(对 int、boolean 等 32 位类型)
java
volatile int x = 0;
x = 1; // 原子写
int y = x; // 原子读❌ 但 复合操作 不是原子的!
例如:
java
state++; // 等价于:
// 1. 读取 state
// 2. 加 1
// 3. 写回 state这三步不是原子的 !多个线程同时执行 state++ 会导致丢失更新。
📌 关键结论 :
volatile ≠ 原子性(Atomicity)
它只解决 可见性 + 有序性 ,不解决 竞态条件(Race Condition)
三、AQS 中的实际操作:为什么需要 CAS?
AQS 的核心逻辑是 尝试获取/释放同步状态,典型方法如:
java
protected final boolean compareAndSetState(int expect, int update) {
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}场景举例:ReentrantLock 的加锁逻辑
java
if (compareAndSetState(0, 1)) { // 尝试将 state 从 0 改为 1
setExclusiveOwnerThread(Thread.currentThread());
return true;
}这个操作的语义是:
"只有当当前 state 是 0 时,才把它设为 1;否则失败"
这正是 CAS(Compare-And-Swap) 的典型用法。
如果只用 volatile 会怎样?
java
// 错误示例:仅用 volatile
if (state == 0) { // 线程 A 读到 0
state = 1; // 但此时线程 B 也读到 0,并设为 1
}→ 两个线程都认为自己获得了锁! → 严重并发 bug。
四、CAS 如何解决问题?
CAS 是一条 CPU 原子指令 (如 x86 的 cmpxchg),它在硬件层面保证:
"比较内存中的值是否等于预期值,如果是,则更新为新值;整个过程不可中断"
因此:
java
compareAndSetState(0, 1)- 要么成功(返回
true,state 变为 1), - 要么失败(返回
false,说明有其他线程已修改 state)。
这保证了 "检查 + 修改" 的原子性。
五、AQS 的完整协作机制
AQS 并不只是靠 CAS,而是 CAS + volatile + 阻塞队列 协同工作:
- 快速路径(Fast Path) :
- 使用
compareAndSetState()尝试无竞争获取锁; - 成功则直接返回,零阻塞、高性能。
- 使用
- 慢速路径(Slow Path) :
- CAS 失败 → 进入 CLH 阻塞队列;
- 通过
LockSupport.park()挂起线程; - 释放锁时唤醒后继节点。
而 volatile state 的作用是:
- 让所有线程看到最新的锁状态;
- 配合 CAS 实现 happens-before 关系,保证状态变更对后续操作可见。
六、类比理解
| 机制 | 作用 | 类比 |
|---|---|---|
volatile state |
保证状态变更立即可见 | 黑板上的数字,所有人能看到最新值 |
CAS |
保证"看一眼再改"不被干扰 | 多人抢答:"如果黑板是 0,我就改成 1" ------ 必须原子完成 |
💡 没有 CAS,volatile 只能让你"看到别人改了",但无法安全地"自己去改"。
七、扩展:Java 中的原子类也是同样原理
AtomicInteger 内部也是:
java
private volatile int value;
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1); // 底层是 CAS 循环
}volatile保证可见性;CAS保证原子性。
✅ 总结
| 问题 | 答案 |
|---|---|
**AQS 的 ****state**为什么是 **volatile**? |
保证多线程间状态变更的可见性 和有序性 |
**仅靠 ****volatile**能保证原子性吗? |
不能! volatile不保证复合操作(如 state++)的原子性 |
| 为什么还需要 CAS? | 因为 AQS 的核心操作是"先检查再修改 ",必须用 CAS 保证该复合操作的原子性 |
| CAS 和 volatile 的关系? | 互补:CAS 提供原子性,volatile 提供可见性,二者缺一不可 |
🔑 核心思想 :
在并发编程中,可见性 ≠ 原子性 。
要实现线程安全的状态机(如锁、信号量),必须同时解决这两个问题 ------ AQS 正是通过 volatile + CAS 的经典组合做到的。
CompletableFuture 的 thenApply 和 thenCompose 有何区别?什么场景下会引发线程阻塞?
当然可以!以下是更清晰、准确、结构化的回答,聚焦于 **thenApply**** 与 **thenCompose** 的本质区别**,以及 **CompletableFuture**** 中真正引发线程阻塞的场景**。
一、thenApply 与 thenCompose 的核心区别
✅ 共同点
- 都用于在前一个阶段完成后,对结果进行处理;
- 都返回一个新的
CompletableFuture; - 默认在完成前一阶段的线程上执行(除非使用
xxxAsync版本)。
❗ 本质区别:是否"扁平化"嵌套的 CompletableFuture
| 方法 | 函数签名 | 输入函数返回类型 | 输出类型 | 类比 |
|---|---|---|---|---|
**thenApply** |
thenApply(Function<T, U>) |
**普通值 ****U** |
CompletableFuture<U> |
Stream.map() |
**thenCompose** |
thenCompose(Function<T, CompletableFuture<U>>) |
**CompletableFuture<U>** |
CompletableFuture<U> (自动扁平) |
Stream.flatMap() |
🔑 一句话总结:
- 用
thenApply:当你想同步转换结果(如格式化、计算); - 用
thenCompose:当你想发起下一个异步操作 (返回另一个CompletableFuture)。
🌰 示例对比
场景:先查用户,再查其订单(两个异步服务)
java
CompletableFuture<User> fetchUser(long id);
CompletableFuture<Order> fetchOrder(User user);✅ 正确:使用 thenCompose
java
CompletableFuture<Order> orderFuture =
fetchUser(123)
.thenCompose(user -> fetchOrder(user)); // 返回 CompletableFuture<Order>- 结果是 扁平的
CompletableFuture<Order>; - 执行顺序:先完成
fetchUser,再启动fetchOrder; - 符合"异步链式调用"语义。
❌ 错误:使用 thenApply
java
CompletableFuture<CompletableFuture<Order>> badFuture =
fetchUser(123)
.thenApply(user -> fetchOrder(user)); // 返回 CompletableFuture<CompletableFuture<Order>>- 产生嵌套 Future ,后续必须手动解包(如
.thenCompose(f -> f)),代码冗余且易错。
💡 口诀 :
"**返回 Future 用 **compose** ,返回值用 ****apply**"
二、什么场景下会引发线程阻塞?
CompletableFuture 本身是非阻塞、异步 的,但以下操作会阻塞当前线程:
⚠️ 1. 显式调用阻塞获取方法
java
future.join(); // 阻塞当前线程,直到 future 完成
future.get(); // 同上,但抛出 checked Exception- 风险:在 Web 请求线程、事件循环线程中调用,会导致线程池耗尽、系统雪崩;
- 正确做法 :用
.thenAccept(result -> ...)等回调方式处理结果,避免阻塞。
✅ 例外 :在程序入口(如 main)或测试中可接受。
⚠️ 2. 在回调中执行阻塞或耗时操作(且未切换线程)
java
CompletableFuture.supplyAsync(() -> fetchData())
.thenApply(data -> {
// ❌ 危险!以下操作会阻塞默认 ForkJoinPool 线程:
Thread.sleep(1000); // 阻塞
httpClient.get("/api"); // 阻塞 I/O
database.query(...); // 阻塞 DB 调用
return process(data);
});- 默认情况下,
thenApply在前一阶段完成的线程 上执行(通常是ForkJoinPool.commonPool()); - 如果该线程被阻塞,无法处理其他任务,降低吞吐量。
✅ 解决方案:使用异步版本 + 自定义线程池
java
ExecutorService ioPool = Executors.newCachedThreadPool();
CompletableFuture.supplyAsync(() -> fetchData(), ioPool)
.thenComposeAsync(user -> callRemoteService(user), ioPool) // 异步 + 指定线程池
.thenApplyAsync(result -> transform(result), commonPool); // CPU 密集用默认池💡 最佳实践:
- I/O 密集型任务 → 使用专用线程池(如
newCachedThreadPool); - CPU 密集型任务 → 使用
ForkJoinPool.commonPool()(默认); - 永远不在回调中阻塞!
⚠️ 3. 错误地串行等待多个 Future(虽不增加总耗时,但语义和异常处理差)
java
// 不推荐(但不会额外阻塞,如果 future 已并行启动)
f1.join();
f2.join();vs
java
// 推荐:语义清晰 + 异常统一
CompletableFuture.allOf(f1, f2).join();- 虽然总耗时相近(因 future 已并行),但
allOf更安全、可读性更好。
三、总结
| 问题 | 答案 |
|---|---|
**thenApply****vs ** **thenCompose** |
thenApply用于同步转换(返回值), thenCompose用于异步拼接(返回 CompletableFuture并扁平化) |
| 何时用哪个? | 函数返回 CompletableFuture→ 用 thenCompose;否则用 thenApply |
| 什么会阻塞线程? | 1. 调用 .join()/ .get() 2. 回调中执行阻塞 I/O 或 sleep 3. 在默认线程池做长时间任务 |
| 如何避免阻塞? | 1. 用回调链代替 join 2. I/O 操作用 xxxAsync(..., executor)+ 自定义线程池 |
✅ 终极建议 :
把 CompletableFuture 当作声明式异步流水线 ,**永远不要在中间 ****.join()** ------ 让异步一直异步到底!
ThreadLocal 内存泄漏的根本原因是什么?为什么 remove() 必须在 finally 块中调用?
ThreadLocal 内存泄漏是一个经典且高频的 Java 并发问题。其根本原因与 **ThreadLocalMap**** 的内部结构** 和 弱引用(WeakReference)的使用方式 密切相关。
下面从原理、内存模型和最佳实践三方面详细解释。
一、内存泄漏的根本原因
✅ 核心结论:
**ThreadLocal**** 本身不会泄漏,但「线程长期存活 + 未调用 **remove()** 」会导致 **ThreadLocalMap** 中的 value 对象无法被回收,从而造成内存泄漏。**
1. ThreadLocal 的存储结构
每个 Thread 对象内部持有一个 **ThreadLocal.ThreadLocalMap**:
java
public class Thread {
ThreadLocal.ThreadLocalMap threadLocals = null;
}而 ThreadLocalMap 的 key 是 **ThreadLocal**** 对象的弱引用(WeakReference)**,value 是用户设置的实际值:
java
static class Entry extends WeakReference<ThreadLocal<?>> {
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k); // key 是弱引用!
value = v;
}
}2. 弱引用(WeakReference)的作用与局限
- 作用 :当
ThreadLocal实例(即 key)没有外部强引用 时,GC 会自动回收该 key,将其置为null。 - 局限 :value 不会被自动清理! 即使 key 变成
null,value 仍被Entry强引用着。
plain
Thread ──→ ThreadLocalMap ──→ [Entry]
├── key → null (已被 GC)
└── value → YourObject (仍被强引用!)→ **YourObject**** 无法被回收,造成内存泄漏!**
3. 什么情况下会触发泄漏?
| 条件 | 说明 |
|---|---|
| ✅ 线程是长生命周期的 | 如线程池中的线程(Tomcat、Dubbo、Spring Boot 内嵌容器等) |
✅ **未调用 ****ThreadLocal.remove()** |
程序员忘记清理 |
| ✅ ThreadLocal 变量无外部强引用 | 比如它是方法内局部变量,方法结束就没了 |
📌 典型场景 :
Web 应用中,每个请求由线程池中的线程处理,在请求开始时用 ThreadLocal 存放用户上下文(如 userId、traceId),但**未在请求结束时调用 ****remove()**。
→ 随着请求增多,ThreadLocalMap 中积累大量 <null, value> 条目,最终 OOM。
二、为什么 remove() 必须在 finally 块中调用?
✅ 目的:确保无论业务逻辑是否抛异常,都能清理资源
示例:Web Filter 中使用 ThreadLocal
java
public class UserContextFilter implements Filter {
private static final ThreadLocal<String> currentUser = new ThreadLocal<>();
public void doFilter(ServletRequest req, ServletResponse res, FilterChain chain) {
try {
currentUser.set(getUserIdFromToken(req));
chain.doFilter(req, res); // 可能抛异常!
} finally {
currentUser.remove(); // ✅ 必须在 finally 中清理
}
}
}如果不放在 finally 中:
java
currentUser.set(...);
chain.doFilter(...); // 如果这里抛出异常
currentUser.remove(); // ❌ 这行永远不会执行!→ **ThreadLocalMap**** 中残留 entry** → 内存泄漏。
三、JVM 的"自救"机制(但不可依赖!)
ThreadLocalMap 在以下操作时会顺便清理 key 为 null 的 entry:
set()get()remove()
例如 get() 方法内部会调用 expungeStaleEntries() 清理部分过期条目。
⚠️ 但问题在于:
- 如果某个线程**不再访问该 **
**ThreadLocal**(比如请求结束,后续不再读写),就不会触发清理; - 线程池中的线程长期存活,这些"僵尸 entry"会一直堆积。
🔥 因此,不能依赖 JVM 自动清理!必须显式调用 **remove()**!
四、正确使用 ThreadLocal 的最佳实践
✅ 1. 每次使用后,务必调用 remove()
java
try {
threadLocal.set(value);
// ... 业务逻辑
} finally {
threadLocal.remove(); // 关键!
}✅ 2. 避免在线程池任务中滥用 ThreadLocal
- 如果必须用,确保任务结束前清理;
- 考虑使用
InheritableThreadLocal(谨慎)或上下文传递框架(如 SLF4J MDC、TransmittableThreadLocal)。
✅ 3. 不要用 ThreadLocal 存储大对象
- 即使及时清理,频繁分配大对象也会增加 GC 压力。
✅ 4. 静态常量引用 ThreadLocal
java
private static final ThreadLocal<Context> CONTEXT = new ThreadLocal<>();- 避免
ThreadLocal实例本身被回收(导致 key 提前变 null)。
五、内存泄漏示意图
plain
[Thread Pool Thread]
│
└── threadLocals: ThreadLocalMap
│
├── Entry[0]: key=null, value=UserInfo@123 ← 泄漏!
├── Entry[1]: key=null, value=UserInfo@456 ← 泄漏!
└── Entry[2]: key=valid, value=UserInfo@789- 即使
ThreadLocal变量已不可达,UserInfo对象仍被Entry.value强引用; - 线程不销毁 →
ThreadLocalMap不销毁 →value永远无法回收。
✅ 总结
| 问题 | 答案 |
|---|---|
| 内存泄漏根本原因 | ThreadLocalMap的 key 是弱引用(可被 GC),但 value 是强引用; 若不手动 remove(),value 会一直残留 |
**为何需 ****finally****调用 ****remove()** |
确保即使业务代码抛异常,也能清理 ThreadLocal,防止 entry 泄漏 |
| 高危场景 | 线程池(如 Web 容器) + 未清理的 ThreadLocal |
| 解决方案 | **始终在 ****finally****块中调用 ****remove()**,不要依赖 JVM 自动清理 |
💡 记住 :
ThreadLocal 不是"自动清理"的魔法工具,它要求程序员显式管理生命周期 。
在高并发、长生命周期线程环境中,忘记 **remove()** = 内存泄漏 = 系统崩溃。
StampedLock 的乐观读如何避免 ABA 问题?它比 ReadWriteLock 快在哪里?
StampedLock 是 Java 8 引入的一种高性能读写锁,其核心创新在于 "乐观读"(Optimistic Reading) 机制。它在特定场景下比传统的 ReentrantReadWriteLock 更快,但也存在 ABA 问题的隐患。下面我们深入解析:
一、StampedLock 的乐观读如何工作?
✅ 基本流程
java
StampedLock lock = new StampedLock();
long stamp = lock.tryOptimisticRead(); // 1. 获取"乐观读戳"
// 执行读操作(不加锁!)
if (!lock.validate(stamp)) { // 2. 验证期间是否有写发生
stamp = lock.readLock(); // 3. 若有写,则升级为悲观读
try {
// 重新读取
} finally {
lock.unlockRead(stamp);
}
}- 乐观读不阻塞写线程;
- 通过一个 64 位的 stamp(戳) 标识当前读视图;
validate(stamp)检查该 stamp 是否仍有效(即期间无写操作)。
二、ABA 问题是否存在?如何缓解?
❓ 什么是 ABA 问题?
线程 A 读取值为 X → 线程 B 将值改为 Y 又改回 X → 线程 A 再次读取仍为 X,误以为"未被修改"。
🔍 StampedLock 中的 ABA 风险
- stamp 是单调递增的版本号(不是简单的状态标志);
- 每次写锁获取/释放 都会使 stamp 增加(即使值变回原样,stamp 也不同);
- 因此,传统意义上的 ABA(值相同但中间被修改过)会被 detect 到!
✅ 示例:
java
// 初始 stamp = 100
long s1 = lock.tryOptimisticRead(); // s1 = 100
// 其他线程:写入 → stamp 变为 101 → 写完释放 → stamp 变为 102
// 即使数据恢复原状,stamp 已变!
boolean valid = lock.validate(s1); // false! 因为当前 stamp ≠ 100✅ 结论:
StampedLock 通过"单调递增的 stamp 版本号"天然避免了 ABA 问题。
只要发生过写操作(无论数据是否变回),validate() 就会返回 false。
⚠️ 注意:这里的"ABA"指 逻辑上的数据不变但中间被修改 ,而 StampedLock 关心的是 "是否发生过写",不是数据内容本身。
三、StampedLock 比 ReadWriteLock 快在哪里?
| 维度 | ReentrantReadWriteLock |
StampedLock |
|---|---|---|
| 读写互斥 | 读阻塞写,写阻塞读 | 乐观读不阻塞写 |
| 锁开销 | 依赖 AbstractQueuedSynchronizer (AQS),有队列、CAS、线程挂起等开销 | 乐观读无锁、无 CAS、无线程阻塞 |
| 适用场景 | 通用,支持重入 | 高频读、低频写,且读操作可重试 |
| 性能(读多写少) | 中等 | 极高(乐观读接近 volatile 性能) |
✅ 性能优势详解:
1. 乐观读零开销
- 不调用任何 CAS 或 synchronized;
- 仅读取一个
volatile long(stamp); - 读操作本身可完全并行,写线程无需等待读完成。
2. 写操作更轻量
- 写锁内部使用 CAS + 自旋,避免立即进入重量级阻塞;
- 在竞争不激烈时,性能优于 AQS 的 park/unpark。
3. 无"写饥饿"问题
ReentrantReadWriteLock允许读线程无限抢占,导致写线程饿死;StampedLock的写优先级更高,且乐观读不持有锁,写更容易成功。
四、StampedLock 的局限性(代价)
| 缺点 | 说明 |
|---|---|
| ❌ 不支持重入 | 同一线程不能重复获取读/写锁(会死锁) |
| ❌ 不支持条件变量(Condition) | 无法像 ReadWriteLock.newCondition() 那样等待通知 |
| ❌ API 复杂 | 需手动管理 stamp,容易出错(如忘记 validate) |
| ❌ 仅适用于"可重试读"场景 | 如果读操作有副作用(如 I/O),重试可能不安全 |
📌 典型适用场景:
- 缓存读取(如配置、统计数据)
- 几何计算(如 Point 的 x/y 坐标读取)
- 任何"读操作无副作用 + 可重试"的场景
五、正确使用示例(避免常见错误)
java
class Point {
private double x, y;
private final StampedLock sl = new StampedLock();
double distanceFromOrigin() {
long stamp = sl.tryOptimisticRead();
// 读取多个字段(必须保证原子性视图!)
double currentX = x, currentY = y;
if (!sl.validate(stamp)) { // 如果期间有写
stamp = sl.readLock(); // 升级为悲观读
try {
currentX = x;
currentY = y;
} finally {
sl.unlockRead(stamp);
}
}
return Math.sqrt(currentX * currentX + currentY * currentY);
}
}⚠️ 注意:乐观读期间不能有写操作,且读取多个字段时需确保"一致性视图"(要么全旧,要么全新)。
✅ 总结
| 问题 | 答案 |
|---|---|
| 如何避免 ABA? | 使用单调递增的 stamp 版本号 ,只要发生写,stamp 改变,validate()返回 false |
| 比 ReadWriteLock 快在哪? | 1. 乐观读无锁、无阻塞、无 CAS 2. 写操作更轻量 3. 无写饥饿 |
| 适用场景 | 读多写少、读操作可重试、无副作用 |
| 慎用场景 | 需要重入、条件等待、或读操作不可重试 |
💡 最佳实践 :
在高频读、低频写的纯内存数据结构 中,优先考虑 StampedLock;
在通用业务逻辑中,仍推荐 ReentrantReadWriteLock(更安全、易用)。
虚拟线程(Virtual Threads, JDK 21)如何解决传统线程栈占用大的问题?适用 IO 密集型还是 CPU 密集型?
虚拟线程(Virtual Threads)是 Java 21(Loom 项目)引入的革命性并发模型,其核心目标是以极低的资源开销支持海量并发任务 。它通过解耦 Java 线程与操作系统线程,从根本上解决了传统线程栈占用大的问题。
一、传统线程(Platform Threads)的问题
❌ 栈内存占用大
- 每个传统线程默认分配 1MB 栈空间 (可通过
-Xss调小,但仍有几十 KB); - 创建 10,000 个线程 → 至少占用 10GB 栈内存;
- 操作系统对线程数量有限制(通常几千到几万),易导致
OutOfMemoryError: unable to create native thread。
❌ 上下文切换开销高
- 线程调度由 OS 内核完成,涉及内核态/用户态切换,成本高;
- 高并发下 CPU 大量时间花在调度而非业务逻辑上。
📌 根本原因 :
Java 线程 = 1:1 映射 OS 线程 → 受限于 OS 资源。
二、虚拟线程如何解决栈占用问题?
✅ 核心机制:轻量级、堆分配的栈 + 调度器复用
| 特性 | 传统线程(Platform Thread) | 虚拟线程(Virtual Thread) |
|---|---|---|
| 栈存储位置 | OS 内存(native stack) | JVM 堆内存(Java heap) |
| 默认栈大小 | ~1 MB | 初始仅几百字节,按需增长(类似递归调用的栈帧) |
| 创建开销 | 高(OS 系统调用) | 极低(纯 Java 对象) |
| 调度方式 | OS 内核调度 | JVM 用户态调度器(ForkJoinPool) |
| 映射关系 | 1 Java 线程 : 1 OS 线程 | N 虚拟线程 : 1 OS 线程(Carrier Thread) |
🔍 关键技术细节:
1. 栈在堆上分配
- 虚拟线程的栈帧存储在 Java 堆 中,由 JVM 管理;
- 初始只分配少量内存,方法调用时动态扩展(类似链表式栈);
- 不再受 OS 栈大小限制,百万级虚拟线程内存占用仅几百 MB。
2. 挂起/恢复(Continuations)
- 当虚拟线程执行阻塞操作(如
socket.read())时:- JVM 挂起该虚拟线程(保存其执行状态);
- 底层 OS 线程(Carrier Thread)立即释放,去执行其他虚拟线程;
- I/O 完成后,JVM 恢复虚拟线程到任意 OS 线程继续执行。
- 全程无需 OS 线程阻塞!
💡 这就是为什么虚拟线程能高效处理 阻塞 I/O ------ 底层 OS 线程永不空等。
三、适用场景:IO 密集型 vs CPU 密集型?
✅ 强烈适用于:IO 密集型(I/O-bound)任务
- 典型场景:Web 服务器、数据库查询、远程 API 调用、文件读写;
- 优势 :
- 单个 OS 线程可同时处理成千上万个虚拟线程;
- 阻塞 I/O 不再浪费 OS 线程;
- 吞吐量(requests/sec)提升 10~100 倍;
- 编程模型简单:直接写同步阻塞代码,无需回调或异步框架。
示例(Spring Boot + 虚拟线程):
java
@RestController
public class UserController {
// 每个请求由一个虚拟线程处理
@GetMapping("/user/{id}")
public User getUser(@PathVariable Long id) {
return userService.findById(id); // 内部可能有 DB 查询(阻塞)
}
}→ 无需 CompletableFuture 或 WebFlux,同步代码获得异步性能!
⚠️ 不适用于:CPU 密集型(CPU-bound)任务
- 原因 :
- 虚拟线程仍运行在有限的 OS 线程池 (默认
ForkJoinPool.commonPool(),大小 = CPU 核数); - 如果所有虚拟线程都在做纯计算(无 I/O 阻塞),则无法利用更多 OS 线程;
- 创建过多虚拟线程反而增加调度开销,性能不如直接使用平台线程池。
- 虚拟线程仍运行在有限的 OS 线程池 (默认
正确做法:
java
// CPU 密集型:使用固定大小的平台线程池
ExecutorService cpuPool = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
cpuPool.submit(() -> {
// 纯计算任务
});📌 经验法则:
- 有阻塞 I/O? → 用虚拟线程;
- 纯计算? → 用传统线程池(大小 ≈ CPU 核数)。
四、虚拟线程 vs 异步编程(如 CompletableFuture)
| 维度 | 虚拟线程 | 异步回调(CompletableFuture / Reactor) |
|---|---|---|
| 编程模型 | 同步、直观(try-catch, for-loop) | 异步、回调链(易出现"回调地狱") |
| 调试难度 | 低(完整栈跟踪) | 高(栈被切断,上下文丢失) |
| 资源效率 | 极高(百万级并发) | 高(但需手动管理背压、错误传播) |
| 适用性 | 任何阻塞 I/O | 需重写为非阻塞 API(如 Netty, R2DBC) |
✅ 虚拟线程让"简单即高效"成为可能:开发者写最自然的同步代码,JVM 自动实现高并发。
五、注意事项
- 不要池化虚拟线程
java
// ❌ 错误!虚拟线程是廉价的,无需池化
ExecutorService pool = Executors.newCachedThreadPool(); // 这仍是平台线程池!
// ✅ 正确:直接创建
Thread.startVirtualThread(() -> { ... });
// 或使用虚拟线程专用 Executor
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
executor.submit(task);
}- 避免在虚拟线程中长时间占用 CPU
- 如需 CPU 密集计算,应提交到专用平台线程池。
- 监控工具需升级
- 传统线程 dump 会显示海量虚拟线程,需 JDK 21+ 工具支持过滤。
✅ 总结
| 问题 | 答案 |
|---|---|
| 如何解决栈占用大? | 栈分配在堆内存 ,初始很小、按需增长;通过挂起/恢复复用少量 OS 线程 |
| 适用 IO 还是 CPU 密集? | IO 密集型 (完美匹配)CPU 密集型(不适用,用传统线程池) |
| 最大优势 | 同步编程模型 + 异步级并发性能 |
| 典型应用 | 高并发 Web 服务、微服务、消息处理等 I/O 密集场景 |
💡 未来趋势 :
虚拟线程将使 Java 成为构建高吞吐、低延迟、简单代码服务的理想选择,大幅降低并发编程门槛。
三、JVM(深度调优 & 故障排查)
ZGC 的"着色指针"和"读屏障"如何实现 <10ms 的停顿?为什么它不需要分代?
ZGC(Z Garbage Collector)是 Oracle 从 JDK 11 开始引入的一种低延迟、可扩展、并发的垃圾回收器 ,目标是实现 始终 <10ms 的 GC 停顿时间 ,即使堆大小达到 TB 级别。它之所以能做到这一点,核心依赖两大创新技术:着色指针(Colored Pointers) 和 读屏障(Load Barriers) 。同时,ZGC 不采用分代收集(non-generational),这与其设计哲学密切相关。
下面我们深入解析这两个机制如何协同工作,并解释为何 ZGC 可以放弃分代。
一、着色指针(Colored Pointers)------ 把元数据"塞进指针里"
🎯 核心思想:
不在对象头中存储 GC 状态,而是将状态信息编码到对象指针的高位(unused bits)中。
🔍 技术细节:
- 在 64 位系统中,虚拟地址空间通常只使用低 48 位(如 x86-64),高 16 位是保留/未使用的。
- ZGC 利用其中 4 个高位比特 (称为"颜色位")来存储 GC 元数据,例如:
Marked0/Marked1:用于标记阶段区分两轮并发标记;Remapped:表示该指针已更新为新地址(在压缩/移动后);Finalizable:标记需执行 finalize 的对象(JDK 16+ 已弃用 finalize,此位可能不再使用)。
✅ 示例(简化):
plain
原始指针: 0x00007f8b12345678
ZGC 指针: 0x00107f8b12345678 ← 第 52 位设为 1 表示 "Marked0"✅ 优势:
- 无需修改对象头:避免了在对象上写元数据的开销和同步问题;
- 指针本身携带状态:GC 线程和 mutator(应用线程)都能通过指针直接判断对象状态;
- 支持并发处理:多个阶段可基于指针颜色并行操作,无需全局暂停。
二、读屏障(Load Barrier)------ 在"读取引用"时自动修复指针
🎯 核心思想:
每当应用线程从堆中加载一个对象引用时,ZGC 自动插入一小段代码(读屏障),检查并修正指针。
🔍 工作流程(以"并发标记 + 并发重定位"为例):
- 应用线程执行 :
Object obj = ref;
→ JVM 在字节码层面插入 读屏障。 - 读屏障逻辑(伪代码):
java
if (pointer is not Remapped) {
// 说明该对象可能已被移动(重定位)
// 调用 GC helper 函数,查找 forwarding table
new_addr = resolve_forwarding(pointer);
// 原子地更新指针为新地址(CAS)
CAS(ref, old_pointer, new_addr | REMAPPED_COLOR);
return new_addr;
}- 结果 :
- 应用线程总是拿到最新、有效的对象地址;
- 对象移动(压缩)可以在应用运行时并发完成;
- 无需 STW 来更新所有引用(传统 GC 如 G1 需要 STW 来"清理"旧引用)。
✅ 优势:
- 停顿极短:读屏障只在访问对象时触发,且每次只处理一个指针;
- 完全并发:标记、重定位、引用更新全部与应用线程并发执行;
- 自愈性:一旦某个引用被修复,后续访问不再触发屏障。
💡 注意:ZGC 只有读屏障,没有写屏障,因此对写操作无额外开销,这对高吞吐场景非常友好。
三、为什么 ZGC 不需要分代(Non-Generational)?
传统 GC(如 G1、Parallel GC)采用分代假说(Generational Hypothesis):
"大多数对象朝生暮死,老年代对象存活率高。"
但 ZGC 主动放弃分代,原因如下:
1. 分代会引入复杂性和停顿
- 分代需要维护 Remembered Sets(RSet) 来跟踪跨代引用;
- RSet 的维护(尤其是写屏障记录)带来显著开销;
- Young GC 虽快,但 Full GC(Mixed GC)仍可能产生长停顿。
2. ZGC 的并发能力已足够高效
- 由于整个堆并发标记 + 并发重定位,无论对象年龄如何,回收成本几乎一致;
- 即使回收"年轻对象",ZGC 也能在 <10ms 内完成,无需专门优化 young gen。
3. 简化设计,提升可扩展性
- 不分代 → 无 RSet → 内存占用更低;
- 无 young/old 区域划分 → 堆布局更简单,适合超大堆(TB 级);
- 避免"晋升失败"、"to-space exhausted"等分代 GC 特有问题。
4. 现代应用模式变化
- 微服务、缓存、大数据应用中,长生命周期对象比例上升,分代假说不再普适;
- ZGC 更适合稳定、低延迟的长期运行服务。
📌 补充:从 JDK 17 开始,ZGC 实验性支持分代(Generational ZGC),目标是在保持低延迟的同时进一步降低 CPU 开销。但这属于演进而非必需。
四、总结:ZGC 如何实现 <10ms 停顿?
| 技术 | 作用 | 对停顿的影响 |
|---|---|---|
| 着色指针 | 将 GC 状态嵌入指针 | 避免修改对象头,支持无锁并发 |
| 读屏障 | 在加载引用时自动修复地址 | 消除 STW 引用更新,实现完全并发重定位 |
| 不分代 | 简化堆结构,避免 RSet | 减少内存开销和复杂性,提升大堆稳定性 |
✅ 最终效果 :ZGC 的 STW 阶段仅用于 线程栈扫描(root scanning) 和 部分元数据同步 ,通常 <1ms,远低于 10ms 目标。
🚀 适用场景
- 要求 严格低延迟 的系统(金融交易、实时游戏、高频 API);
- 大内存堆(数百 GB 到 TB 级);
- 可接受 略高 CPU 开销(约 10-20%)换取确定性延迟。
ZGC 代表了 GC 设计从"吞吐优先"向"延迟确定性"的范式转变,其核心思想------用并发和指针元数据换取停顿时长------已成为现代低延迟 GC 的标杆。
Metaspace OOM 的常见原因有哪些?如何通过 jcmd 动态调整 CompressedClassSpaceSize?
Metaspace(元空间)是 Java 8 引入的用于替代永久代(PermGen)的内存区域,用于存储类的元数据 (如 Class 对象、方法字节码、常量池、JIT 编译代码等)。当应用加载大量类(如动态代理、反射、Groovy 脚本、OSGi 模块等),可能触发 java.lang.OutOfMemoryError: Metaspace。
一、Metaspace OOM 的常见原因
✅ 1. 类加载器泄漏(ClassLoader Leak)
- 最常见原因!
- 应用(尤其是 Web 容器如 Tomcat)在热部署/重载时,旧的
ClassLoader未被回收,其加载的所有类仍驻留在 Metaspace。 - 即使对象不再使用,只要
ClassLoader存活,其加载的类元数据就不会释放。 - 典型场景:Spring Boot DevTools、Tomcat Context Reload、OSGi Bundle 动态卸载失败。
✅ 2. 动态生成类过多
- 使用 CGLib、ASM、ByteBuddy 等库动态生成代理类;
- Groovy、JRuby、Scala 等 JVM 语言运行时会生成大量中间类;
- Lambda 表达式 在早期 JDK 中也会生成合成类(JDK 8u60+ 已优化)。
✅ 3. Metaspace 配置不合理
- 默认
MaxMetaspaceSize为 无上限(unlimited),但在容器环境(Docker/K8s)中,若未显式限制,可能耗尽物理内存导致 OOM Killer 杀进程。 - 若人为设置了过小的
-XX:MaxMetaspaceSize(如 64m),而应用实际需要更多,也会触发 OOM。
✅ 4. Compressed Class Space 耗尽
- 当启用指针压缩(
-XX:+UseCompressedOops,默认开启)时,Klass 指针(指向类元数据的指针)会被压缩。 - 这些 Klass 元数据被单独放在 Compressed Class Space (默认大小 1G),由
-XX:CompressedClassSpaceSize控制。 - 如果类数量极大(>50万),即使 Metaspace 总量未满,Compressed Class Space 可能先耗尽,抛出:
plain
java.lang.OutOfMemoryError: Compressed class space二、如何通过 jcmd 动态调整 CompressedClassSpaceSize?
❌ 重要结论:无法动态调整!
**-XX:CompressedClassSpaceSize**** 是一个"不可变"(non-manageable)JVM 参数,启动后无法通过 **jcmd** 或 JMX 修改。**
🔍 验证方法:
bash
# 查看所有可动态调整的 VM 参数
jcmd <pid> VM.flags -all | grep manageable
# 尝试修改 CompressedClassSpaceSize(会失败)
jcmd <pid> VM.set_flag CompressedClassSpaceSize 2147483648输出:
plain
Could not set flag - flag 'CompressedClassSpaceSize' is not writable✅ 正确做法:
| 场景 | 解决方案 |
|---|---|
| 预防性配置 | 启动时通过 -XX:CompressedClassSpaceSize=2g显式设置足够大的值(最大支持 3G) |
| 已发生 OOM | 1. 分析类加载情况; 2. 修复类加载器泄漏; 3. 重启 JVM 并调大该参数 |
| 监控使用量 | 使用 jcmd 查看当前使用情况(见下文) |
三、使用 jcmd 监控 Metaspace 和 Compressed Class Space
虽然不能动态调整,但可通过 jcmd查看实时使用情况:
bash
# 查看 Metaspace 详细信息
jcmd <pid> VM.metaspace
# 示例输出(关键部分):
Virtual space:
Compressed class space Used: 150M, Capacity: 250M, Reserved: 1024M
Non-class space Used: 300M, Capacity: 350M, Reserved: ...
Total used: 450M
# 查看 GC 后的 Metaspace 统计(更准确)
jcmd <pid> GC.run_finalization # 触发清理(谨慎使用)
jcmd <pid> VM.metaspace你也可以通过 JMX 或 jstat 监控:
bash
# jstat 查看 Metaspace(CCS = Compressed Class Space)
jstat -gcmetacapacity <pid>
# 输出示例:
MCMN MCMX MC CCSMN CCSMX CCSC YGC FGC FGCT GCT
0.0 1048576.0 450560.0 0.0 1048576.0 153600.0 123 5 0.500 1.200
# CCSC = Compressed Class Space Capacity (KB)四、排查与解决建议
🔧 1. 分析类加载情况
bash
# 查看已加载类数量
jcmd <pid> VM.class_hierarchy
# 或使用 jmap(慎用,会 STW)
jmap -clstats <pid>🔧 2. 检测 ClassLoader 泄漏
- 使用 Eclipse MAT 或 JProfiler 分析堆转储(heap dump);
- 查找
org.apache.catalina.loader.WebappClassLoader(Tomcat)或自定义 ClassLoader 的实例是否异常增多; - 检查是否有静态引用持有 ClassLoader。
🔧 3. 合理配置 JVM 参数
bash
# 推荐配置(根据应用规模调整)
-XX:MetaspaceSize=256m \
-XX:MaxMetaspaceSize=512m \
-XX:CompressedClassSpaceSize=256m # 默认 1G,通常无需调大,除非类 > 20万💡 注意:CompressedClassSpaceSize不需要设得过大,1G 可容纳约 50~100 万个类。只有极端场景才需调整。
✅ 总结
| 问题 | 答案 |
|---|---|
| Metaspace OOM 主因 | ClassLoader 泄漏、动态类爆炸、配置过小 |
**能否动态调大 ****CompressedClassSpaceSize** |
❌ 不能,必须重启 JVM |
| 如何监控 | jcmd <pid> VM.metaspace 或 jstat -gcmetacapacity |
| 根本解决 | 修复 ClassLoader 泄漏 + 合理设置 -XX:MaxMetaspaceSize |
📌 最佳实践 :在容器化环境中,**务必显式设置 ****-XX:MaxMetaspaceSize**,避免 Metaspace 无限增长导致容器 OOMKilled。
逃逸分析失败的典型场景?为什么 synchronized 锁消除有时不生效?
这是一个深入 JVM 优化机制的高质量问题。逃逸分析(Escape Analysis)和锁消除(Lock Elimination)是 HotSpot JVM 的重要 JIT 优化技术,但它们并非总能生效 。下面我们系统分析"逃逸分析失败"的典型场景,并解释为何 synchronized 锁消除有时不工作。
一、逃逸分析(Escape Analysis)是什么?
逃逸分析是 JVM 在 JIT 编译时进行的一项静态分析技术,用于判断:
一个对象的引用是否"逃逸"出当前方法或线程的作用域。
如果对象未逃逸,JVM 可以进行以下优化:
- 栈上分配(Stack Allocation):对象分配在栈上而非堆上,避免 GC 压力;
- 标量替换(Scalar Replacement):将对象拆解为若干基本类型字段,直接存储在寄存器或栈中;
- 同步消除(Synchronization Elimination) :如果对象仅被单线程访问,
synchronized锁可被完全移除。
⚠️ 注意:目前 OpenJDK/HotSpot 并未真正实现"栈上分配" ,而是通过标量替换达到类似效果(对象不实际分配)。
二、逃逸分析失败的典型场景
即使对象看似"局部",也可能因以下原因导致逃逸分析失败,无法优化:
✅ 场景 1:对象被赋值给成员变量(实例/静态字段)
java
public class Example {
private Object field; // 成员变量
void method() {
Object obj = new Object();
this.field = obj; // ← 逃逸!obj 被外部可见
}
}→ 对象逃逸到堆上,无法栈分配或锁消除。
✅ 场景 2:对象作为方法参数传递给其他方法
java
void method() {
Object obj = new Object();
helper(obj); // ← 可能逃逸(除非 helper 是内联且无逃逸)
}
void helper(Object o) {
// 如果 helper 未被内联,或内部将 o 存入全局变量,则逃逸
}→ 关键点 :只有当 helper 被 JIT 内联(inlined) 且其内部也无逃逸,才可能不逃逸。
✅ 场景 3:对象被返回(return)
java
Object create() {
Object obj = new Object();
return obj; // ← 明确逃逸
}✅ 场景 4:对象被捕获到异常处理或 lambda 表达式中
java
void method() {
Object obj = new Object();
try {
// ...
} catch (Exception e) {
log(obj); // obj 被异常处理引用 → 可能逃逸
}
Runnable r = () -> System.out.println(obj); // lambda 捕获 obj → 逃逸
}→ Lambda 会生成合成类,持有对 obj 的引用,导致逃逸。
✅ 场景 5:对象调用了native 方法
java
void method() {
ByteBuffer buf = ByteBuffer.allocateDirect(1024);
buf.put((byte)1); // 内部调用 native 方法
// DirectByteBuffer 通常会被视为逃逸(因 native 代码可能持有引用)
}✅ 场景 6:JIT 尚未编译该方法
- 逃逸分析只在 C2 编译器(-XX:+TieredCompilation 默认开启) 中进行;
- 方法需达到一定调用阈值(如 10,000 次)才会被 C2 编译;
- 在解释执行或 C1 编译阶段,不会进行逃逸分析。
三、为什么 synchronized 锁消除有时不生效?
即使你写了一个"明显只在本地使用的对象加锁",锁消除仍可能失败。原因如下:
🔒 原因 1:对象逃逸了(最常见)
java
void badExample() {
Object lock = new Object();
synchronized (lock) {
// do something
}
store(lock); // ← 如果 lock 被传出去,JVM 无法确定是否安全消除锁
}🔒 原因 2:锁对象是非局部新建的
java
final Object lock = new Object(); // 类成员
void method() {
synchronized (lock) { ... } // ← 锁对象是共享的,不能消除!
}🔒 原因 3:方法未被 JIT 编译或未内联
- 锁消除只在 C2 编译后的代码中生效;
- 如果方法太复杂、太大(超过
-XX:MaxInlineSize),可能不被内联,导致跨方法锁无法分析。
🔒 原因 4:使用了非平凡的锁对象
java
synchronized (this) { ... } // this 可能被外部引用 → 不消除
synchronized (MyClass.class) { ... } // Class 对象全局唯一 → 不消除🔒 原因 5:Monitor 被升级为重量级锁
- 即使锁消除逻辑成立,但如果在解释执行阶段已发生锁竞争,对象 monitor 已膨胀为重量级锁(OS mutex),JIT 也无法回退消除。
四、如何验证锁是否被消除?
方法 1:使用 -XX:+PrintEliminateLocks
bash
java -XX:+UnlockDiagnosticVMOptions -XX:+PrintEliminateLocks YourApp输出示例:
plain
[eliminate locks] eliminated 1 locks方法 2:使用 JMH + perf 或 async-profiler
观察汇编代码中是否还存在 monitorenter / monitorexit 指令。
方法 3:对比性能
java
// 测试1:局部对象加锁
Object lock = new Object();
synchronized (lock) { ... }
// 测试2:无锁
// ...
// 如果两者性能几乎一致,说明锁被消除了✅ 最佳实践建议
| 场景 | 建议 |
|---|---|
| 需要局部锁 | 使用 局部新建对象 ,且不传递、不返回、不存成员变量 |
| 高频小临界区 | 考虑用 synchronized(若可消除)比 ReentrantLock更轻量 |
| 怀疑未优化 | 用 -XX:+PrintEliminateLocks验证 |
| 大方法锁 | 尽量缩小 synchronized 块范围,提高内联概率 |
📌 总结
| 问题 | 根本原因 |
|---|---|
| 逃逸分析失败 | 对象引用超出局部作用域(成员变量、参数传递、返回、lambda 捕获等) |
| 锁消除不生效 | 1. 对象逃逸; 2. 锁对象非局部; 3. 方法未 JIT 编译/内联; 4. Monitor 已膨胀 |
💡 记住 :JVM 优化是保守的 ------只要存在任何不确定性 ,它宁可不做优化,也要保证正确性。
因此,写出"易于优化"的代码(小方法、局部对象、无副作用)是开发者的重要责任。
G1 的 Mixed GC 触发条件是什么?如何通过 -XX:G1HeapWastePercent 优化?
G1(Garbage-First)GC 是 Java 9+ 的默认垃圾回收器,其核心思想是将堆划分为多个 Region ,并优先回收垃圾比例高 的 Region(即"Garbage-First")。在并发标记(Concurrent Marking)完成后,G1 会进入 Mixed GC 阶段------即同时回收 Young Regions + 部分 Old Regions。
一、Mixed GC 的触发条件
Mixed GC 不会在每次 Young GC 时发生 ,而是在满足以下全部条件后启动:
✅ 条件 1:完成一次并发标记周期(Initial Mark → Remark → Cleanup)
- Mixed GC 只能在并发标记完成之后进行;
- 并发标记由 Initial Mark (伴随一次 Young GC)触发,通常在堆使用率达到
-XX:InitiatingHeapOccupancyPercent(IHOP,默认 45%)时启动。
✅ 条件 2:存在"可回收"的 Old Regions
- 在并发标记的 Cleanup 阶段 ,G1 会统计每个 Old Region 的存活对象比例;
- 只有那些垃圾比例足够高(即存活率低)的 Old Region 才会被选入候选集(Candidate Set)。
✅ 条件 3:候选 Old Regions 的总垃圾量 ≥ -XX:G1HeapWastePercent 阈值
这是最关键但常被误解的条件!
- G1 不会回收所有候选 Region,而是按回收效率排序(垃圾多、存活少的优先);
- 它会持续选择 Region,直到:
plain
已选 Region 的总垃圾量 ≥ (总堆大小 × G1HeapWastePercent / 100)- 默认
G1HeapWastePercent = 5,即:只要能回收 ≥5% 堆空间的垃圾,就值得做 Mixed GC。
✅ 条件 4:未达到 Mixed GC 最大轮次限制
- 通过
-XX:G1MixedGCCountTarget(默认 8)控制 Mixed GC 轮数; - 每轮 Mixed GC 会回收一部分 Old Region,最多执行 N 轮(避免长时间停顿)。
二、-XX:G1HeapWastePercent 的作用与优化
🔧 参数含义
| 参数 | 默认值 | 含义 |
|---|---|---|
-XX:G1HeapWastePercent |
5 |
触发 Mixed GC 的最小可回收垃圾比例(占整个堆) |
🎯 优化逻辑
▶ 场景 1:希望更早触发 Mixed GC(积极回收 Old 区)
- 调低该值 (如
1或2) - 效果 :
- 即使只有少量 Old 垃圾,也会启动 Mixed GC;
- 减少 Old 区碎片,降低 Full GC 风险;
- 代价:Mixed GC 频率增加,CPU 开销上升,停顿次数增多。
✅ 适用:内存敏感型应用(如容器环境),需严格控制堆使用率。
▶ 场景 2:希望减少 Mixed GC 频率(降低 CPU 开销)
- 调高该值 (如
10或15) - 效果 :
- 只有当 Old 区积累大量垃圾时才回收;
- Mixed GC 次数减少,吞吐量提升;
- 风险 :Old 区可能快速填满,触发 Full GC(Serial GC),造成秒级停顿!
✅ 适用:吞吐优先、延迟容忍度较高的应用。
三、典型问题与调优建议
❗ 问题 1:Mixed GC 后 Old 区仍在增长,最终 Full GC
- 原因 :
G1HeapWastePercent设置过高,或 Old 对象太多无法有效回收; - 对策:
bash
-XX:G1HeapWastePercent=2 # 更积极回收
-XX:G1MixedGCCountTarget=16 # 增加轮次,每轮回收更少
-XX:G1MixedGCLiveThresholdPercent=85 # 只回收存活率 <85% 的 Region(默认 85)❗ 问题 2:Mixed GC 太频繁,影响吞吐
- 原因 :
G1HeapWastePercent过低,或应用产生大量短期 Old 对象; - 对策:
bash
-XX:G1HeapWastePercent=8
-XX:G1UseAdaptiveIHOP=true # 动态调整 IHOP(默认开启)🔍 监控 Mixed GC 行为
使用 jstat 或 GC 日志分析:
bash
# jstat 查看 Mixed GC 次数和耗时
jstat -gc <pid> 1s
# GC 日志关键字段(需开启 -Xlog:gc*)
[GC pause (G1 Evacuation Pause) (mixed), 0.025 secs]
[Eden: 128M(128M)->0B(128M) Survivors: 16M->16M Heap: 512M(1024M)->384M(1024M)]- 观察
Heap使用量是否在 Mixed GC 后显著下降; - 若 Mixed GC 后堆使用率降幅很小(如 <2%),说明
G1HeapWastePercent可能设得太低。
四、与其他参数的协同
| 参数 | 作用 | 与 G1HeapWastePercent 关系 |
|---|---|---|
-XX:G1MixedGCLiveThresholdPercent |
Old Region 存活率阈值(默认 85%) | 决定哪些 Region 进入候选集 |
-XX:G1MixedGCCountTarget |
Mixed GC 轮次目标(默认 8) | 控制每轮回收量,避免单次停顿过长 |
-XX:G1HeapRegionSize |
Region 大小(1~32MB) | 影响回收精度,小 Region 更灵活 |
💡 黄金组合建议(低延迟场景):
bash
-XX:G1HeapWastePercent=2
-XX:G1MixedGCLiveThresholdPercent=80
-XX:G1MixedGCCountTarget=16✅ 总结
| 问题 | 答案 |
|---|---|
| Mixed GC 触发条件 | 1. 并发标记完成; 2. 存在可回收 Old Region; 3. 可回收垃圾 ≥ G1HeapWastePercent% 堆; 4. 未达最大轮次 |
**G1HeapWastePercent**作用 |
控制 Mixed GC 的"启动门槛"------值越小,越积极回收 Old 区 |
| 如何优化 | - 内存敏感 → 调低 (1~3) - 吞吐优先 → 调高 (8~10) - 避免 Full GC → 不宜 >10 |
📌 记住 :G1 的目标是避免 Full GC ,而 G1HeapWastePercent 是平衡 "回收积极性" vs "CPU 开销" 的关键旋钮。合理设置可显著提升系统稳定性。
如何用 Async-Profiler 定位 CPU 占用高的 Java 方法?(要求说出具体命令)
使用 Async-Profiler 定位 Java 应用中 CPU 占用高的方法,是一种低开销、高精度、生产友好 的方式。它基于 perf_events(Linux) 或 DTrace(macOS) 实现采样,不会像 jstack 那样频繁 STW,也不会显著影响应用性能。
✅ 前提条件
- 目标 Java 进程正在运行(获取 PID);
- 已安装 Async-Profiler (GitHub 地址);
- Linux 系统 (推荐),且用户有权限访问
/proc/<pid>和 perf; - Java 应用以
**-XX:+PreserveFramePointer**启动(JDK 8u60+ 默认支持,非必须但推荐,可提升栈展开准确性)。
🔧 核心命令:定位 CPU 热点方法
步骤 1:获取 Java 进程 PID
bash
jps -l
# 或
ps aux | grep YourApp假设 PID 为 12345。
步骤 2:使用 Async-Profiler 采样 CPU(默认模式即为 CPU)
bash
# 采样 30 秒,生成火焰图(HTML)
./profiler.sh -d 30 -f profile.html 12345📌 参数说明:
-d 30:采样持续 30 秒(可根据负载调整,建议 10~60 秒);-f profile.html:输出为交互式火焰图(推荐);12345:目标 Java 进程 PID。
步骤 3:查看结果
- 在浏览器中打开
profile.html; - 火焰图从上到下表示调用栈深度,宽度表示 CPU 占用比例;
- 最宽的顶部函数即为 CPU 热点;
- 支持搜索、缩放、点击钻取。
🔍 其他常用命令变体
1. 仅输出文本格式(快速查看 top 方法)
bash
./profiler.sh -d 10 -o text 12345输出示例:
plain
45.2% java.lang.String.indexOf
22.1% com.yourcompany.service.DataProcessor.process
10.3% java.util.HashMap.get
...2. 包含 native 和 kernel 栈(全栈分析)
bash
./profiler.sh -d 30 -g -f full_profile.html 12345-g:启用 call graph(完整调用栈),包含 JNI、native、甚至内核函数(需 root 权限)。
3. 只分析 Java 代码(排除 native)
bash
./profiler.sh -d 30 -e cpu -i 1ms --filter-java-only -f java_only.html 12345--filter-java-only:仅显示 Java 方法(Async-Profiler 2.0+ 支持)。
4. 连续监控(类似 top)
bash
# 每 5 秒输出一次 top 方法
./profiler.sh -d 5 -o flat=5 12345⚠️ 注意事项
| 问题 | 解决方案 |
|---|---|
| Permission denied | 使用 sudo,或确保用户在 perf_users组; 执行:`echo -1 |
| 看不到 Java 方法名(只有 unknown) | 确保 Java 进程未被 stripped; 检查是否启用了 -XX:+PreserveFramePointer (JDK 11+ 默认开启) |
| 采样结果全是 GC 线程 | 可能是 GC 压力大,尝试结合 --lock或分析内存分配(用 -e alloc) |
| 容器环境(Docker/K8s) | 需挂载 --cap-add=SYS_ADMIN或 --privileged (生产慎用); 或使用 async-profiler的 agent 模式 |
🎯 实战技巧
- 对比优化前后 :采样两次,生成两个火焰图,用 speedscope.app 对比;
- 聚焦特定线程 :先用
jstack 12345找到高 CPU 线程 ID(转 16 进制),再用-t <tid>采样; - 与 GC 日志联动:若 CPU 高伴随 Full GC,优先排查内存泄漏。
✅ 总结:最常用命令
bash
# 通用推荐:30秒采样,生成火焰图
./profiler.sh -d 30 -f cpu_flame.html <PID>
# 快速文本查看
./profiler.sh -d 10 -o text <PID>💡 Async-Profiler 是现代 Java 性能诊断的"瑞士军刀"------不仅支持 CPU,还支持 allocation、lock、cache-misses 等事件。掌握它,能极大提升线上问题排查效率。
四、MySQL(索引 + 事务 + 架构)
InnoDB 的自增锁(AUTO-INC Lock)在 INSERT ... SELECT 场景下为何会退化为表锁?
InnoDB 的自增锁(AUTO-INC Lock)在 INSERT ... SELECT 场景下并非总是退化为表锁 ,而是取决于 **innodb_autoinc_lock_mode** 参数的设置。要理解这个问题,需要先了解 InnoDB 的三种自增锁模式以及 INSERT ... SELECT 语句的特性。
一、InnoDB 自增锁的三种模式(由 **innodb_autoinc_lock_mode** 控制)
| 模式值 | 名称 | 行为 |
|---|---|---|
| 0 | Traditional(传统模式) | 所有插入语句(包括 **INSERT ... SELECT**、 **LOAD DATA**等)都会持有 表级 AUTO-INC 锁,直到语句结束。保证自增值严格连续、可预测。 |
| 1 | Consecutive(连续模式,默认) | 简单插入(如 **INSERT INTO t VALUES (...)** )使用轻量级互斥锁(mutex),不阻塞其他事务;但批量插入(如 **INSERT ... SELECT**、 **REPLACE ... SELECT**、 **LOAD DATA**)会使用 表级 AUTO-INC 锁,直到语句结束。 |
| 2 | Interleaved(交错模式) | 所有插入都不使用表级 AUTO-INC 锁,自增值可能在并发下交错分配(不连续),但性能最高。 |
MySQL 5.7 及以后默认值为 1(Consecutive 模式)
二、为什么 **INSERT ... SELECT** 在 **innodb_autoinc_lock_mode=1** 下会使用表级 AUTO-INC 锁?
**原因:**无法预先知道要插入多少行
- 对于简单插入(如
**INSERT INTO t (id, name) VALUES (NULL, 'A'), (NULL, 'B')**),InnoDB 在解析阶段就能确定需要分配多少个自增值(这里是 2 个),因此可以:- 快速分配连续的 ID(如 101, 102)
- 使用轻量级 mutex 而非表锁
- 分配完立即释放,不阻塞其他插入
- 但对于
**INSERT ... SELECT**:
sql
INSERT INTO t1 (name) SELECT name FROM t2 WHERE condition;- **在执行 SELECT 之前,无法知道最终会返回多少行**
- **因此 InnoDB ****无法预先分配固定数量的自增值**
- **为了保证在语句执行过程中自增值的****连续性和可重复性****(例如用于 binlog 复制的一致性),InnoDB 必须在整个语句执行期间****独占自增计数器**
- **这就导致它必须获取 ****表级别的 AUTO-INC 锁****,直到整个 **`**INSERT ... SELECT**`** 完成**这种"退化"是为了在 性能 和 一致性/可恢复性 之间取得平衡。
三、后果与影响
- 在
**innodb_autoinc_lock_mode=1**下,一个大的**INSERT ... SELECT**会阻塞其他任何需要自增 ID 的插入操作(包括简单插入),因为它们都需要等待 AUTO-INC 锁。 - 如果你不需要严格的自增值连续性(例如主从复制使用基于 GTID 或 row-based binlog),可以考虑将
**innodb_autoinc_lock_mode**设置为 2 ,这样**INSERT ... SELECT**也不会加表锁,但自增值可能不连续或交错。
四、总结
**INSERT ... SELECT**** 在默认配置(**innodb_autoinc_lock_mode=1**)下会使用表级 AUTO-INC 锁,并非"退化",而是一种设计选择:因为无法预知插入行数,为保证语句级的自增连续性和复制一致性,必须在整个语句执行期间锁定自增计数器。**
如果你的应用对自增 ID 的连续性要求不高,且追求高并发插入性能,可以将 **innodb_autoinc_lock_mode** 改为 2(需确保使用 row-based binlog 以避免复制问题)。
✅** 最佳实践建议:**
- **主从复制环境:使用 **row-based binlog +
**innodb_autoinc_lock_mode=2**可安全提升并发性能 - **需要严格连续 ID 的场景(如某些审计系统):保留默认值 1,但避免大事务的 **
**INSERT ... SELECT**
**
**
MySQL 8.0 的隐藏主键(_rowid)在什么情况下存在?对性能有何影响?
在 MySQL 8.0 中,并不存在真正意义上的"隐藏主键"(如某些文档中误传的 **_rowid**)。这是一个常见的误解。我们需要澄清几个关键概念:
一、澄清:MySQL InnoDB 没有 像 Oracle 那样的 _rowid 隐藏主键
- Oracle 确实有
ROWID作为物理行地址。 - MySQL InnoDB****不会自动创建一个名为
**_rowid**的隐藏列。 - 但 InnoDB 确实会为没有显式主键的表创建一个内部的 6 字节"隐式聚簇索引键" ,这个键对用户不可见,也无法通过 SQL 查询(如
SELECT _rowid FROM t会报错)。
✅ 正确说法:InnoDB 在没有主键时会自动生成一个隐式的聚簇索引(clustered index) ,基于一个内部的 6 字节 ROW ID,但它不是用户可见的列 ,也**不叫 ****_rowid**。
二、什么时候 InnoDB 会使用这个隐式 ROW ID?
当表满足以下所有条件时,InnoDB 会生成内部 6 字节 ROW ID 作为聚簇索引:
- 没有定义任何主键(PRIMARY KEY)
- 没有定义任何非空且唯一的索引(NOT NULL + UNIQUE)
InnoDB 会选择第一个符合条件的 NOT NULL UNIQUE 索引作为聚簇索引。只有在完全找不到合适候选时,才会使用内部 ROW ID。
示例:
sql
-- 情况1:无主键,无唯一非空索引 → 使用隐式 ROW ID
CREATE TABLE t1 (a INT, b VARCHAR(10));
-- 情况2:有主键 → 使用主键作为聚簇索引
CREATE TABLE t2 (id INT PRIMARY KEY, name VARCHAR(10));
-- 情况3:无主键,但有 NOT NULL UNIQUE 索引 → 使用该索引作为聚簇索引
CREATE TABLE t3 (email VARCHAR(50) NOT NULL UNIQUE, name VARCHAR(10));三、这个隐式 ROW ID 对性能有何影响?
❌ 负面影响(主要):
- 插入性能下降(高并发下明显)
- 隐式 ROW ID 是全局递增分配的(由一个全局 mutex 保护)
- 所有使用隐式 ROW ID 的表共享同一个计数器
- 高并发插入时,多个线程竞争同一把锁,成为瓶颈
- 无法利用聚簇索引的优势
- 主键通常是业务相关字段(如 user_id),查询时可直接定位数据页
- 隐式 ROW ID 无业务意义,二级索引仍需回表,且无法优化范围查询
- 存储效率略低
- 6 字节 ROW ID 比很多业务主键(如 4 字节 INT)更大
- 二级索引的叶子节点存储的是聚簇索引键(即 ROW ID),导致索引更大
- 主从复制/备份无额外风险,但调试困难
- 无法通过 SQL 查看或引用该"主键",排查问题不便
✅ 几乎没有正面影响
除非你故意不要主键(极少见),否则应避免触发此机制。
四、关于 _rowid 的误解来源
在 MySQL 命令行客户端中,如果你执行:
sql
SELECT _rowid FROM some_table;有时能成功,但这只是因为:
- 如果表的主键是单列且为整数类型 (如
INT、BIGINT),MySQL 会将_rowid别名映射到该主键列 - 这是一种兼容性语法糖 ,并非真实存在
_rowid列
示例:
sql
CREATE TABLE t (id INT PRIMARY KEY, name VARCHAR(10));
SELECT _rowid FROM t; -- 成功,等价于 SELECT id FROM t
CREATE TABLE t2 (a INT, b INT); -- 无主键
SELECT _rowid FROM t2; -- ERROR 1054: Unknown column '_rowid'所以 _rowid 只是一个别名 ,仅在存在单列整数主键时可用,不是隐藏列。
五、最佳实践建议
- 始终为 InnoDB 表定义显式主键
- 推荐使用自增整数(
BIGINT AUTO_INCREMENT)或业务唯一 ID
- 推荐使用自增整数(
- 避免无主键表
- 即使业务无天然主键,也应添加代理主键(surrogate key)
- **不要依赖 **
**_rowid**- 它不是标准功能,行为不一致,且在无主键表中不可用
总结
| 项目 | 说明 |
|---|---|
是否存在 _rowid隐藏列? |
❌ 不存在(用户不可见) |
| 是否存在隐式聚簇键? | ✅ 有(6 字节内部 ROW ID),仅在无主键且无合适唯一索引时使用 |
| 性能影响 | ⚠️ 插入并发差、索引效率低、存储开销略高 |
| 建议 | ✅ 始终定义显式主键 |
通过显式主键,你可以获得更好的性能、可预测性和可维护性。
Binlog 的 ROW 格式下,UPDATE 语句如何记录 before/after image?对主从延迟有何影响?
在 MySQL 的 二进制日志(Binlog) 中,当 binlog_format = ROW(行格式)时,UPDATE 语句的记录方式与语句格式(STATEMENT)有本质区别。它会精确记录被修改行的数据变化 ,包括 Before Image(更新前的值) 和 After Image(更新后的值)。
一、ROW 格式下 UPDATE 如何记录 Before/After Image?
1. 基本结构
对于每一条被 UPDATE 修改的行,Binlog 会记录一个 Table_map_event + Update_rows_event:
- Table_map_event:标识操作的表(数据库名、表名、列类型等)
- Update_rows_event :包含:
- Before Image(BI):该行更新前的列值(用于定位和回滚)
- After Image(AI):该行更新后的列值
注意:并不是所有列都会被记录,具体取决于 binlog_row_image 参数。
2. binog_row_image 的三种模式(MySQL 5.6+ 引入)
| 模式 | Before Image | After Image | 说明 |
|---|---|---|---|
| FULL(默认) | 所有列 | 所有列 | 完整记录整行前后状态 |
| MINIMAL | 仅主键或唯一索引列 + 被 WHERE 条件用到的列 | 仅被 SET 修改的列 | 最小化日志体积 |
| NOBLOB | 同 FULL,但 BLOB 列若未修改则不记录 | 同 FULL,但 BLOB 列若未修改则不记录 | 针对大字段优化 |
示例(假设表 t(id PK, name, age)):
sql
UPDATE t SET age = 30 WHERE id = 1;- FULL 模式 :
- BI:
(id=1, name='Alice', age=25) - AI:
(id=1, name='Alice', age=30)
- BI:
- MINIMAL 模式 :
- BI:
(id=1)(主键用于定位行) - AI:
(age=30)(仅记录被修改的列)
- BI:
✅ MINIMAL 模式显著减少 Binlog 体积,尤其在宽表(列多)或只更新少数列时。
二、对主从延迟(Replication Lag)的影响
ROW 格式对主从延迟的影响是双刃剑,取决于使用场景:
✅ 正面影响(减少延迟)
- 避免从库执行复杂逻辑
- STATEMENT 格式下,
UPDATE ... WHERE func(col) = xxx可能在从库重复执行耗时函数 - ROW 格式直接应用数据变更,执行确定、高效
- STATEMENT 格式下,
- 并行复制(MTS)更高效
- MySQL 5.7+ 支持基于 logical clock 或 writeset 的并行复制
- ROW 格式能精确知道哪些表/行被修改,更容易实现事务并行回放
- 尤其在
binlog_transaction_dependency_tracking = WRITESET时,大幅降低延迟
- 避免非确定性函数问题
- 如
NOW(),RAND()在 STATEMENT 下主从结果可能不一致,需特殊处理;ROW 格式无此问题
- 如
⚠️ 负面影响(可能增加延迟)
- Binlog 体积膨胀(尤其 FULL 模式)
- 更新宽表时,FULL 模式会记录所有列,即使只改了一列
- 网络传输和从库 I/O 压力增大 → IO 瓶颈导致延迟
- 大事务放大问题
- 一个
UPDATE影响 100 万行,在 ROW 格式下会生成 100 万个 Update_rows_event - 主库写 Binlog 慢 + 从库回放大事务慢 → 主从延迟飙升
- 一个
- 无索引 UPDATE 导致全表扫描(从库)
- 如果 UPDATE 的 WHERE 条件列没有索引 ,从库在应用 ROW event 时需逐行比对 Before Image 来定位行
- 实际上是从库对每一行做"全表匹配",性能极差
💡 提示:从库在应用 ROW event 时,会优先使用主键/唯一索引定位行;若无,则退化为逐行比对 BI,非常慢!
三、优化建议(降低主从延迟)
- **设置 **
**binlog_row_image = MINIMAL**- 减少日志量,提升网络和 IO 效率
- 确保 UPDATE 的 WHERE 条件列有索引
- 避免从库回放时全表扫描
- 避免大事务
- 拆分大 UPDATE 为小批次(如每次 1000 行)
- 启用并行复制
sql
SET GLOBAL slave_parallel_workers = 8;
SET GLOBAL binlog_transaction_dependency_tracking = WRITESET;- 监控大事务和无主键表
- 无主键表在 ROW 格式下,Before Image 无法高效定位行,性能极差
四、总结
| 方面 | ROW 格式下的 UPDATE 行为 |
|---|---|
| 记录内容 | 记录每行的 Before Image + After Image |
| 日志大小 | 受 binlog_row_image控制,MINIMAL 可大幅压缩 |
| 主从一致性 | 强一致性,无非确定性问题 |
| 主从延迟 | 通常更优(因执行简单 + 并行复制),但大事务/无索引/宽表 FULL 模式会恶化延迟 |
| 最佳实践 | MINIMAL + 主键/索引 + 小事务 + 并行复制 |
✅ ROW 格式是现代 MySQL 主从复制的推荐选择,只要合理配置和设计表结构,可显著提升复制效率和稳定性。
如何用 pt-archiver 实现亿级表的无锁归档?关键参数有哪些?
使用 pt-archiver 对亿级大表进行无锁归档(lock-free archiving) 是 Percona Toolkit 中非常成熟且生产验证的方案。其核心思想是:通过小批量、基于索引的分页查询 + 事务控制 + 可控删除/迁移,避免长时间持有表锁或阻塞线上业务。
一、基本原理:如何做到"无锁"?
pt-archiver**不使用 ****LOCK TABLES**,而是:
- 利用主键或时间索引进行分页扫描 (如
WHERE id > ? ORDER BY id LIMIT 1000) - 每次只处理一小批数据(默认 1000 行),每批在一个事务中完成
- DELETE 或 INSERT+DELETE 操作快速提交,减少行锁持有时间
- 自动 sleep 控制速率,避免主库压力过大
- 支持断点续传 (通过
--resume)
✅ 因此,它对线上 OLTP 业务影响极小,可视为"近似无锁"。
二、关键参数详解(针对亿级表)
🔑 核心必选参数
| 参数 | 说明 |
|---|---|
--source |
源数据库 DSN(必须包含 h=,D=,t=) |
--dest |
目标归档表 DSN(可选,若只删除则省略) |
--where |
归档条件(如 create_time < '2023-01-01') |
--primary-key |
指定用于分页的主键列(默认自动探测) |
⚙️ 性能与安全关键参数(亿级表重点调优)
| 参数 | 推荐值 | 作用 |
|---|---|---|
--limit |
1000~ 5000 |
每次取多少行(太小效率低,太大易锁行/超时) |
--txn-size |
与 --limit 相同或倍数 |
每多少行提交一次事务(默认 = --limit) |
--sleep |
0.1 ~ 2 |
每批处理后 sleep 秒数,控制 I/O 压力 |
--max-load |
Threads_running=25,Threads_connected=1000 |
超过负载则暂停(保护主库) |
--progress |
10000 |
每 N 行打印进度(监控用) |
--statistics |
(可选) | 打印性能统计 |
--bulk-delete |
(谨慎) | 使用 DELETE ... LIMIT批量删(更快但不可回滚) |
--no-delete |
(若只迁移不删) | 仅复制到归档表,不删除源数据 |
🛡️ 安全与一致性参数
| 参数 | 说明 |
|---|---|
--check-charset |
检查字符集一致性(避免乱码) |
--check-slave-lag |
指定从库,延迟超过阈值则暂停(如 --check-slave-lag h=slave1 --max-lag=60s) |
--why-quit |
显示退出原因(调试用) |
--dry-run |
试运行,不真实操作(上线前必用!) |
--file |
若归档到文件而非表,指定文件路径 |
三、典型使用场景示例
场景 1:将旧数据迁移到归档表并删除源数据(最常见)
bash
pt-archiver \
--source h=localhost,D=mydb,t=orders,u=admin,p=xxx \
--dest h=arch-db,D=archive,t=orders_old,u=admin,p=xxx \
--where "create_time < '2023-01-01'" \
--limit 2000 \
--txn-size 2000 \
--sleep 0.5 \
--progress 10000 \
--statistics \
--check-slave-lag h=replica1 \
--max-lag 60 \
--max-load "Threads_running=30" \
--no-version-check场景 2:仅删除过期数据(不归档)
bash
pt-archiver \
--source h=localhost,D=mydb,t=log_table,u=admin,p=xxx \
--purge \
--where "log_date < CURDATE() - INTERVAL 180 DAY" \
--limit 1000 \
--txn-size 1000 \
--sleep 1 \
--progress 5000注意:--purge 表示只删不归档。
四、亿级表归档最佳实践
✅ 必做事项:
- 确保归档字段有索引
--where条件中的列(如create_time)必须有索引,否则全表扫描会拖垮数据库- 最佳:
(create_time, id)联合索引(覆盖分页和过滤)
- 主键必须是自增整数
pt-archiver依赖主键进行高效分页(WHERE id > ? ORDER BY id)- 非整数主键(如 UUID)会导致性能急剧下降
- 先
**--dry-run**测试
bash
pt-archiver ... --dry-run- 在业务低峰期运行
- 即使无锁,大量 DELETE 仍会产生 binlog 和 undo log
- 监控主从延迟 & 系统负载
- 使用
--check-slave-lag和--max-load自动暂停
- 使用
❌ 避免事项:
- 不要对无主键表使用(性能极差)
- 不要设置
--limit过大(如 > 10000),可能导致长事务或锁等待 - 不要在高并发写入期间归档热点表(可能加剧行锁竞争)
五、性能调优建议
| 问题 | 调优方向 |
|---|---|
| 归档太慢 | 适当增大 --limit(如 5000),减少 round-trip |
| 主库 CPU/I/O 高 | 增大 --sleep(如 1~2 秒),降低速率 |
| 从库延迟飙升 | 启用 --check-slave-lag,设置合理 --max-lag |
| Binlog 增长过快 | 考虑归档后手动清理 binlog,或使用 --bulk-delete(需权衡) |
六、补充:断点续传
pt-archiver 默认会在当前目录生成 .pt-archiver.safe-auto-increment 文件记录上次归档到的主键值。下次加 --resume 即可继续:
bash
pt-archiver ... --resume注意:确保 --where 条件不变,否则可能漏数据或重复。
总结
pt-archiver 通过 小批量、索引分页、事务控制、负载感知 实现了对亿级表的低影响、可中断、可监控的归档。关键在于:
- **合理设置
**--limit**/**--sleep**/ ****--txn-size** - 确保归档条件列和主键有高效索引
- 启用
**--check-slave-lag**和**--max-load**保障稳定性
💡 在生产环境中,建议先在测试库模拟亿级数据验证参数,再上线执行。
官方文档:https://docs.percona.com/percona-toolkit/pt-archiver.html
MGR(MySQL Group Replication)的单主模式 vs 多主模式,冲突检测机制是什么?
MySQL Group Replication(MGR)支持 单主模式(Single-Primary Mode) 和 多主模式(Multi-Primary Mode) ,两者在写入行为和冲突处理上有本质区别。其核心依赖于 基于写集(Write Set)的认证(Certification)机制 来实现分布式一致性。下面详细解析两者的冲突检测机制。
一、MGR 的底层冲突检测机制:Certification Based on Write Sets
无论单主还是多主,MGR 都使用 相同的底层冲突检测逻辑,基于以下原理:
1. 事务提交前生成 Write Set
- 每个事务在本地执行时,会记录它修改的所有 主键(或唯一键)值 ,形成一个 Write Set 。
- 例如:
UPDATE t SET name='Alice' WHERE id=100;→ Write Set 包含(t, id=100)
- 例如:
- Write Set 不包含具体 SQL,只包含 被修改行的唯一标识(即聚簇索引或唯一索引键值)。
2. 事务进入 Group Communication System(GCS)
- 事务在本地 prepare 后,将 Write Set 广播给组内所有节点。
- 所有节点并行进行 Certification(认证)。
3. Certification 规则(冲突判定)
如果当前事务的 Write Set 与任何已提交但尚未全局应用的事务存在"写-写冲突"(即修改同一行),则当前事务被 abort。
具体判断逻辑:
- 比较当前事务的 Write Set 与 全局已提交事务队列中、GTID 大于当前事务的那些事务 的 Write Set。
- 若有交集(即修改了同一主键行)→ 冲突!事务回滚。
✅ 这是一种 乐观并发控制(Optimistic Concurrency Control, OCC):先执行,提交时再验证。
二、单主模式(Single-Primary) vs 多主模式(Multi-Primary)的差异
| 特性 | 单主模式 | 多主模式 |
|---|---|---|
| 写入节点 | 仅 PRIMARY 节点可写 | 所有节点均可写 |
| 冲突发生概率 | 极低(几乎为 0) | 高(多节点并发写同一行) |
| 冲突检测作用 | 主要用于防止从库异常写入(如误操作) | 核心机制,用于解决多写冲突 |
| 默认配置 | MySQL 8.0+ 默认启用 | 需显式设置 group_replication_single_primary_mode=OFF |
▶ 单主模式下的冲突检测
- 正常情况下不会发生冲突 ,因为所有写都集中在 PRIMARY 节点,其他 SECONDARY 节点是只读的(
super_read_only=ON)。 - 冲突检测主要用于:
- 防止管理员手动关闭
super_read_only后在 SECONDARY 上写入 - 网络分区后脑裂场景的防护
- 防止管理员手动关闭
- 结果:SECONDARY 上的写入事务会在 Certification 阶段被 abort,并报错:
plain
ERROR 3098 (HY000): The table does not comply with the requirements by an external plugin.▶ 多主模式下的冲突检测(重点)
- 多个节点可同时写入同一张表的同一行 → 冲突高发场景。
- MGR 不阻止写入 ,而是允许事务在本地执行成功,但在 全局提交阶段通过 Certification 检测冲突。
- 冲突处理策略:后提交者失败(Last Writer Loses)
示例:
sql
-- Node1:
BEGIN;
UPDATE accounts SET balance = balance - 100 WHERE user_id = 1;
COMMIT; -- GTID: aaa:1
-- Node2(几乎同时):
BEGIN;
UPDATE accounts SET balance = balance + 50 WHERE user_id = 1;
COMMIT; -- GTID: bbb:1假设 Node1 的事务先被全局排序(Total Order),则:
- Node1 的事务通过 Certification,成功提交。
- Node2 的事务在 Certification 时发现:
user_id=1已被aaa:1修改 → 冲突!Node2 的事务被回滚。
❗ 用户在 Node2 会看到:ERROR 3098 (HY000): ... certification failed.
三、如何减少多主模式下的冲突?
- 应用层分片(Sharding)
- 按业务维度分配写入节点(如用户 ID 哈希到固定节点)
- 避免多节点操作同一行
- 避免热点行
- 如全局计数器、库存扣减等场景不适合多主写
- 使用
**group_replication_allow_local_disjoint_gtids_join=ON**(谨慎)- 允许节点以不同 GTID 集合加入,但可能增加冲突风险
- 监控冲突指标
sql
SHOW STATUS LIKE 'Group_replication_transaction_conflicts';- 该值 > 0 表示发生了冲突回滚四、重要补充:Write Set 的生成依赖
- 必须有主键或唯一 NOT NULL 索引 !
- 如果表没有主键,InnoDB 会生成隐藏 ROW ID,但 MGR 无法基于它生成有效 Write Set
- 结果:整张表被当作一个"大锁",任何更新都会与其他更新冲突 → 性能灾难!
✅ 强烈建议:所有参与 MGR 的表必须定义显式主键!
五、总结
| 项目 | 说明 |
|---|---|
| 冲突检测机制 | 基于 Write Set 的 Certification(乐观并发控制) |
| 冲突判定依据 | 事务修改的主键/唯一键是否重叠 |
| 单主模式 | 冲突极少,主要用于安全防护 |
| 多主模式 | 冲突常见,采用"后提交者失败"策略 |
| 关键要求 | 表必须有主键,否则 Write Set 无效,冲突率 100% |
| 最佳实践 | 多主模式下应用层需做写入路由,避免热点 |
💡 生产建议 :除非有强多活写入需求,否则优先使用 单主模式,更简单、稳定、易运维。多主模式需谨慎设计业务逻辑以规避冲突。
五、Redis(持久化 + 集群 + 新特性)
Redis 7.0 的 Function 功能如何替代 Lua 脚本?相比 EVALSHA 有何优势?
Redis 7.0 引入了 Function(函数) 功能(通过 FUNCTION LOAD、FCALL 等命令),旨在提供一种比传统 Lua 脚本(EVAL / EVALSHA)更强大、安全、可管理的服务器端编程能力。它不是完全替代 Lua ,而是对 Redis 服务端脚本能力的现代化升级和补充。
一、Function 是什么?
Redis Function 是用 Lua 5.1 编写的脚本,但以 命名函数(named functions) 的形式注册到 Redis 中,并通过 **FCALL function_name** 调用。
✅ 本质仍是 Lua,但运行在新的 "函数沙箱" 环境中,具有更强的隔离性和生命周期管理。
基本使用示例:
lua
-- 定义一个函数(字符串形式)
local code = [[
redis.register_function('my_incr', function(keys, args)
local key = keys[1]
local delta = tonumber(args[1]) or 1
return redis.call('INCRBY', key, delta)
end)
]]
-- 加载函数
FUNCTION LOAD REPLACE "#!lua name=mylib\n" .. code
-- 调用函数
FCALL my_incr 1 mykey 5注意:函数必须通过 redis.register_function(name, func) 注册。
二、Function 相比 EVAL / EVALSHA 的核心优势
| 特性 | EVAL / EVALSHA | Redis Function (7.0+) | 优势说明 |
|---|---|---|---|
| 命名与复用 | 无名脚本,靠 SHA1 调用 | 有明确函数名 (如 my_incr) |
更易读、易维护、语义清晰 |
| 代码组织 | 单个脚本独立 | 支持 库(library) 概念,一个库可包含多个函数 | 模块化开发,逻辑分组 |
| 部署管理 | 需手动缓存 SHA1,或每次传完整脚本 | 通过 FUNCTION LOAD 一次性部署,FCALL 直接按名调用 |
无需客户端管理 SHA1,简化运维 |
| 版本更新 | SCRIPT FLUSH 清空所有,无法原子替换单个脚本 |
支持 FUNCTION LOAD REPLACE 原子替换指定库 |
灰度发布、热更新更安全 |
| 资源隔离 | 所有脚本共享全局 Lua 状态 | 每个库独立 Lua 环境 (独立 _G表) |
避免函数间意外污染,提升安全性 |
| 持久化与同步 | 脚本不持久化,重启后需重载;主从复制需手动同步 | 函数自动持久化到 RDB/AOF ,并通过主从复制自动同步 | 高可用场景下更可靠 |
| 调试与内省 | SCRIPT EXISTS / SCRIPT FLUSH 功能有限 |
提供 FUNCTION LIST 、FUNCTION DUMP 、FUNCTION RESTORE |
可查看函数列表、导出/导入函数集 |
| 权限控制(ACL) | 只能控制 EVAL 命令权限 |
可对具体函数名 设置 ACL 权限(如 +mylib.my_incr) |
细粒度安全控制 |
三、关键机制详解
1. Library(库)概念
- 一个 Function 库是一个逻辑单元,包含:
- 库名(
name=mylib) - 多个注册的函数(
register_function) - 独立的 Lua 全局环境
- 库名(
- 示例:
lua
#!lua name=order_utils
redis.register_function('create_order', ...)
redis.register_function('cancel_order', ...)2. 自动持久化与复制
- 执行
FUNCTION LOAD后:- 函数代码写入 AOF(作为
FUNCTION LOAD命令) - RDB 快照包含函数定义
- 主从复制自动传播函数定义
- 函数代码写入 AOF(作为
- 重启后函数依然存在,无需客户端重新加载
3. 原子更新(REPLACE)
bash
FUNCTION LOAD REPLACE "#!lua name=mylib\n ..."- 替换整个
mylib库,旧版本立即失效 - 避免
SCRIPT FLUSH导致所有脚本丢失的风险
4. ACL 支持(Redis 6+ ACL + 7.0 Function)
bash
ACL SETUSER appuser +mylib.create_order ~orders:*- 精确授权用户只能调用特定函数,操作特定 key 模式
四、Function 并未完全取代 EVAL 的场景
| 场景 | 仍推荐使用 EVAL |
|---|---|
| 简单、一次性的脚本 | 如临时数据修复,无需长期维护 |
| 客户端动态生成脚本 | 脚本内容依赖运行时参数,无法预定义 |
| 兼容旧版本 Redis(<7.0) | Function 仅 Redis 7.0+ 支持 |
💡 实际上,Function 是 EVAL 的"演进形态" ,适用于需要长期维护、复用、管理的业务逻辑。
五、迁移建议:从 EVAL 到 Function
- 将常用 Lua 脚本封装为函数
lua
-- 原 EVAL 脚本
EVAL "return redis.call('INCR', KEYS[1])" 1 counter
-- 改为 Function
redis.register_function('incr_key', function(keys, args)
return redis.call('INCR', keys[1])
end)- 按业务模块划分库
user_funcs:用户相关逻辑order_funcs:订单相关逻辑
- **部署时使用 **
**FUNCTION LOAD REPLACE**- 实现 CI/CD 自动化部署
- 客户端改用
**FCALL**调用- 无需计算 SHA1,代码更清晰
六、总结
| 维度 | EVAL / EVALSHA | Redis Function |
|---|---|---|
| 定位 | 基础脚本执行 | 现代化服务端函数平台 |
| 管理性 | 弱(无名、难追踪) | 强(命名、库、列表、dump) |
| 可靠性 | 重启丢失,需重载 | 自动持久化+复制 |
| 安全性 | 粗粒度(仅命令级) | 细粒度(函数级 ACL) |
| 适用场景 | 临时脚本、简单逻辑 | 核心业务逻辑、长期维护 |
✅ 结论 :对于新项目或可升级到 Redis 7.0+ 的系统,应优先使用 Function 替代 EVAL/EVALSHA 实现复杂业务逻辑;简单场景仍可保留 EVAL。Function 是 Redis 向"可编程数据库"迈出的重要一步。
Redis Cluster 的 slot 迁移过程中,客户端如何感知并重定向?MOVED vs ASK 的区别?
在 Redis Cluster 中,slot(槽)迁移 是实现数据再平衡、扩容/缩容的核心机制。在此过程中,客户端需要正确处理来自服务器的重定向响应,以确保请求被路由到正确的节点。Redis 通过两种关键错误响应:**MOVED** 和 **ASK** 来指导客户端行为。它们的语义和使用场景有本质区别。
一、背景:Slot 迁移的基本流程
Redis Cluster 将 16384 个 slot 分配给多个主节点。当执行 CLUSTER SETSLOT <slot> MIGRATING <target-node-id> 和 CLUSTER SETSLOT <slot> IMPORTING <source-node-id> 后,迁移开始:
- 源节点 将 slot 标记为
MIGRATING - 目标节点 将 slot 标记为
IMPORTING - 使用
MIGRATE命令逐 key 迁移数据 - 迁移完成后,通过
CLUSTER SETSLOT <slot> NODE <target-node-id>正式移交 slot 所有权
在此期间,同一个 slot 的部分 key 在源节点,部分在目标节点,客户端必须能正确处理。
二、客户端如何感知并重定向?
当客户端向一个节点发送命令(如 GET key),该节点会:
- 计算
key所属的 slot - 检查本地是否负责该 slot
- 如果 不负责 → 返回
**MOVED** - 如果 负责但 key 正在迁移中且已迁走 → 返回
**ASK**
- 如果 不负责 → 返回
客户端收到这些响应后,应:
- 解析新节点地址
- 重新连接该节点并重试命令
✅ 所有 Redis 官方及主流客户端(如 Jedis、Lettuce、redis-py)都内置了对 MOVED/ASK 的自动处理逻辑。
三、MOVED vs ASK 的核心区别
| 特性 | MOVED |
ASK |
|---|---|---|
| 触发条件 | 请求的 slot 已永久迁移到其他节点 | 请求的 key 正在迁移中,且已迁移到目标节点 |
| 语义 | "这个 slot 现在归那个节点管,请更新你的 slot 映射表" | "这个 key 现在在那个节点上,请临时去那里查一下" |
| 客户端行为 | 更新本地 slot -> node 映射缓存,后续同 slot 请求直接发往新节点 | 不更新 slot 映射,仅本次请求重定向到目标节点 |
| 是否需要再次请求原节点 | 否 | 是(迁移未完成前,新写入可能仍在原节点) |
| 典型场景 | 扩容/缩容完成后的稳定状态 | slot 迁移过程中(中间状态) |
📌 详细示例说明
假设 slot 1000 正从 Node A 迁移到 Node B。
场景 1:客户端访问一个尚未迁移的 key(仍在 Node A)
- 请求发到 Node A → Node A 仍有该 key → 正常返回
场景 2:客户端访问一个已迁移的 key(现在在 Node B)
- 请求发到 Node A(因为客户端缓存 slot 1000 → Node A)
- Node A 发现 key 已迁走 → 返回:
plain
ASK 1000 192.168.1.2:7002- 客户端:
- 不更新 slot 1000 的映射
- 向
192.168.1.2:7002(Node B)发送ASKING命令(特殊标记) - 紧接着重发原命令(如
GET key) - Node B 因收到
ASKING,会临时允许访问处于IMPORTING状态的 slot
🔑 ASKING 是一个一次性标志,让目标节点"破例"处理本应拒绝的请求。
场景 3:slot 迁移完成,Node B 正式接管 slot 1000
- 客户端仍按旧缓存发请求到 Node A
- Node A 返回:
plain
MOVED 1000 192.168.1.2:7002- 客户端:
- 更新本地 slot 映射表:slot 1000 → Node B
- 后续所有 slot 1000 的请求直接发往 Node B
四、客户端处理流程(伪代码)
python
def send_command(key, command):
node = get_node_by_slot(hash_slot(key))
while True:
try:
return node.execute(command)
except MOVED as e:
# 更新 slot 映射
update_slot_map(e.slot, e.new_node)
node = e.new_node
except ASK as e:
# 临时重定向,不更新映射
temp_node = connect(e.new_node)
temp_node.execute("ASKING") # 关键!
return temp_node.execute(command)⚠️ 忽略 ASKING 会导致目标节点拒绝请求(因 slot 处于 IMPORTING 状态,不允许普通访问)。
五、常见误区澄清
| 误区 | 正确理解 |
|---|---|
"ASK表示 slot 已迁移" |
❌ ASK仅表示该 key 已迁移,slot 本身仍在迁移中 |
"收到 ASK后应更新 slot 映射" |
❌ 不应更新,否则会导致新写入的 key 被发往错误节点 |
"MOVED和 ASK可互换" |
❌ 语义完全不同,客户端必须区分处理 |
六、总结
| 对比项 | MOVED |
ASK |
|---|---|---|
| 阶段 | 迁移完成后 | 迁移进行中 |
| 作用范围 | 整个 slot | 单个 key |
| 客户端动作 | 更新缓存 | 临时重试 + ASKING |
| 持久性 | 永久重定向 | 一次性重定向 |
✅ 简单记忆:
**MOVED**** = "搬家完成,请改地址簿"****ASK**** = "东西已寄出,请去快递点临时取一下"**
正确理解和处理 MOVED/ASK 是构建高可用 Redis Cluster 客户端的关键。现代客户端库已封装这些逻辑,但开发者仍需了解其原理以排查路由问题。
为什么 Redis 6.0 引入多线程 I/O 后,命令执行仍是单线程?如何配置 I/O 线程数?
Redis 6.0 引入的 多线程 I/O(I/O Threading) 是 Redis 历史上一次重要的性能优化,但它仅用于网络 I/O 和协议解析 ,命令执行(command execution)仍然保持单线程 。这是 Redis 核心设计哲学的延续:简单、原子、无锁的数据操作。
一、为什么命令执行仍是单线程?
✅ 核心原因:保证数据操作的原子性和线程安全
- 避免复杂的并发控制
- Redis 的数据结构(如 Hash、ZSet、List)不是线程安全的
- 如果多个线程同时修改同一个 key,需要加锁(如读写锁、细粒度锁),会极大增加复杂度和开销
- 维持"命令原子性"语义
- 用户期望
INCR key、LPUSH list val等操作是原子的 - 单线程天然保证:任意时刻只有一个命令在执行,无需考虑竞态条件
- 用户期望
- 简化内存管理与持久化
- RDB 快照、AOF 重写等操作依赖于"一致的数据状态"
- 多线程执行命令会导致快照内容不一致或需要复杂的 copy-on-write 机制
- 性能瓶颈通常不在 CPU
- Redis 的瓶颈多在 网络带宽、内存带宽、系统调用开销,而非 CPU 计算
- 多线程 I/O 已能显著提升吞吐(尤其在高并发、小请求场景)
💡 Redis 的设计哲学 :
"用单线程保证核心逻辑简单可靠,用多线程加速非核心 I/O 路径"
二、Redis 6.0+ 多线程 I/O 的工作流程
- I/O 线程负责 :
read()从 socket 读取数据- 解析 RESP 协议(将字节流解析为命令和参数)
write()将响应写回 socket
- 主线程负责 :
- 接受新连接(
accept) - 执行所有命令逻辑
- 触发持久化、过期删除、集群通信等
- 接受新连接(
⚠️ 注意:命令解析(parsing)在 I/O 线程,但命令执行(execution)一定在主线程。
三、如何配置 I/O 线程数?
通过 **redis.conf** 或 运行时命令 配置:
1. 启用 I/O 多线程(默认关闭)
plain
io-threads-do-reads yesyes:I/O 线程处理 读 + 写no(默认):I/O 线程仅处理 写(兼容性更好,性能提升较小)
2. 设置 I/O 线程数量
plain
io-threads 4- 建议值:CPU 核数的一半到全部(通常 2~6 足够)
- 不要超过 CPU 核数,否则线程切换开销反而降低性能
- 至少为 2 才生效(1 表示禁用多线程 I/O)
3. 动态配置(Redis 6.0+)
bash
# 查看当前设置
CONFIG GET io-threads*
# 设置(需在 redis-cli 中执行)
CONFIG SET io-threads 4
CONFIG SET io-threads-do-reads yes📌 注意 :修改 io-threads 后必须重启 Redis 才能生效(因为线程池在启动时创建)。
四、性能建议与注意事项
| 场景 | 建议 |
|---|---|
| 高吞吐、小 value(如缓存) | 开启 io-threads-do-reads yes + io-threads 4~6 |
| 大 value(如 > 10KB) | 多线程 I/O 提升明显(减少主线程 read/write 阻塞) |
| 低延迟敏感型应用 | 谨慎开启,线程切换可能增加尾延迟(p99) |
| CPU 核数 ≤ 2 | 不建议开启(收益小,开销大) |
| 使用 TLS/SSL | 多线程 I/O 对加密/解密帮助有限(仍由主线程处理) |
五、验证是否生效
- 查看日志(启动时):
plain
*** IO threads are enabled, count = 4- 监控线程:
bash
ps -T -p $(pgrep redis-server)应看到多个 io_thd_0, io_thd_1 等线程。
- 性能对比 :
- 使用
redis-benchmark -n 1000000 -c 50 -t get,set测试开启前后 QPS
- 使用
六、总结
| 问题 | 答案 |
|---|---|
| 为何命令执行仍是单线程? | 保证原子性、简化设计、避免锁竞争 |
| 多线程 I/O 做什么? | 并行处理网络读写和协议解析 |
| 如何配置? | io-threads N+ io-threads-do-reads yes |
| 最佳实践 | 4~6 线程,仅在多核机器上开启,大流量场景收益显著 |
✅ Redis 的多线程是"有限多线程" :
I/O 并行化 + 命令串行化 = 高吞吐 + 强一致性 + 低复杂度。
这种设计使 Redis 在保持其简洁可靠的同时,有效利用现代多核硬件提升网络处理能力。
使用 Redis Streams 实现消息队列时,如何保证消费者故障后的消息不丢失?
在使用 Redis Streams 实现消息队列时,要保证消费者故障后消息不丢失 ,核心依赖于 Redis Streams 提供的 消费者组(Consumer Groups) 机制和 Pending Entries(待处理消息) 功能。以下是完整的保障策略:
一、核心机制:消费者组 + Pending List
Redis Streams 通过以下组件实现可靠消息传递:
| 组件 | 作用 |
|---|---|
| Stream | 消息日志(只追加,持久化) |
| Consumer Group | 逻辑消费组,维护 last_delivered_id |
| Pending Entries List (PEL) | 记录已投递但未确认(ACK)的消息 |
| Per-Consumer PEL | 每个消费者有自己的待处理消息列表 |
✅ 关键点 :消息从 Stream 被读取后,会进入 PEL;只有收到 XACK 才真正"消费完成";否则即使消费者宕机,消息仍可被其他消费者或自己恢复后重新处理。
二、保证消息不丢失的关键步骤
1. 创建消费者组(带持久化)
bash
# 创建消费者组 mygroup,从最新消息开始($),也可指定 ID 或 0
XGROUP CREATE mystream mygroup $ MKSTREAM- 消费者组元数据存储在 Redis 内存中(可配合 AOF/RDB 持久化)
last_delivered_id记录组内最后投递的消息 ID
2. 消费者使用 XREADGROUP 拉取消息
bash
# 消费者 consumer1 从 mygroup 拉取最多 10 条消息
XREADGROUP GROUP mygroup consumer1 COUNT 1 10 STREAMS mystream >>表示只读取新消息(未被该组任何消费者拉取过)- 拉取后,消息自动加入 PEL,状态变为"已投递未确认"
3. 处理成功后发送 XACK 确认
bash
# 处理完消息 ID 为 1678901234-0 后,发送 ACK
XACK mystream mygroup 1678901234-0- 收到
XACK后,消息从 PEL 中移除,真正完成消费
4. 消费者故障后,如何恢复消息?
方案 A:同消费者重启后自行恢复
- 重启后,先查询自己的 Pending 消息:
bash
XPENDING mystream mygroup - + 10 consumer1- 对返回的每条消息:
- 重新处理业务逻辑
- 成功后发送
XACK - 失败可重试或告警
方案 B:其他消费者接管(需主动 Claim)
- 使用
XCLAIM将长时间未 ACK 的消息转移给新消费者:
bash
# 将 mygroup 中 idle > 60000ms(1分钟)的消息 claim 给 consumer2
XCLAIM mystream mygroup consumer2 60000 1678901234-0- 常配合
XPENDING+min-idle-time使用
💡 最佳实践 :定期扫描 PEL,对超时未 ACK 的消息进行 XCLAIM + 重试。
三、防止消息丢失的完整架构建议
✅ 1. 启用 Redis 持久化
- AOF(推荐) :
appendonly yes+appendfsync everysec- 确保 Stream 数据和消费者组状态在 Redis 重启后不丢失
- RDB:可作为辅助,但可能丢失最后一次快照后的数据
⚠️ 若 Redis 宕机且无持久化,所有未持久化的消息和 PEL 状态将丢失!
✅ 2. 消费者必须实现幂等性
- 因为消息可能被重复投递(如消费者处理完但 ACK 前宕机)
- 业务层需通过 唯一消息 ID 或 去重表 保证幂等
✅ 3. 监控 Pending 消息积压
bash
# 查看整个组的 pending 情况
XPENDING mystream mygroup
# 输出示例:
1) (integer) 5 # pending 总数
2) "1678901234-0" # 最小 ID
3) "1678901234-4" # 最大 ID
4) 1) 1) "consumer1"
2) "3" # consumer1 有 3 条 pending- 设置告警:当 pending 数量 > 阈值 或 最老消息 age > X 分钟
✅ 4. 合理设置超时与重试策略
- 应用层记录消息处理开始时间
- 若处理超时,主动放弃并允许其他消费者 claim
- 避免"僵尸消息"长期卡在 PEL 中
四、对比传统队列(如 RabbitMQ)的优势
| 特性 | Redis Streams | RabbitMQ |
|---|---|---|
| 消息持久化 | 依赖 AOF/RDB | 内置磁盘持久化 |
| 消费者故障恢复 | 通过 PEL + XCLAIM | 通过 unack + redelivery |
| 消息回溯 | 支持(按 ID 查询历史) | 通常不支持 |
| 运维复杂度 | 低(复用 Redis) | 高(独立中间件) |
| 吞吐量 | 极高(单实例 10w+ QPS) | 高 |
✅ Redis Streams 适合高吞吐、需简单可靠、已有 Redis 基础设施的场景。
五、典型消费者伪代码(带故障恢复)
python
import redis
r = redis.Redis()
# 1. 启动时恢复 pending 消息
pending = r.xpending('mystream', 'mygroup', '-', '+', 100, 'consumer1')
for msg in pending:
msg_id = msg['message_id']
# 重新处理
if process_message(msg_id):
r.xack('mystream', 'mygroup', msg_id)
# 2. 正常消费循环
while True:
messages = r.xreadgroup(
groupname='mygroup',
consumername='consumer1',
streams={'mystream': '>'},
count=10,
block=5000
)
for stream, msgs in messages:
for msg_id, data in msgs:
try:
if process_message(data): # 幂等处理
r.xack('mystream', 'mygroup', msg_id)
except Exception as e:
# 记录错误,后续由 XPENDING + XCLAIM 处理
log_error(msg_id, e)六、总结:如何保证不丢失?
| 措施 | 说明 |
|---|---|
| 使用消费者组 + XREADGROUP | 消息进入 PEL,避免直接丢弃 |
| 处理成功后必须 XACK | 显式确认消费完成 |
| 启用 AOF 持久化 | 防止 Redis 宕机丢失状态 |
| 消费者实现幂等 | 应对重复投递 |
| 定期 XPENDING + XCLAIM | 主动回收故障消费者的 pending 消息 |
| 监控 pending 积压 | 及早发现消费异常 |
✅ 只要消息还在 PEL 中,就永远不会丢失------这是 Redis Streams 实现可靠队列的基石。
通过以上机制,Redis Streams 可以在分布式环境下提供至少一次(at-least-once) 的消息传递语义,满足绝大多数业务场景的可靠性要求。
Redis 的 LFU 淘汰策略中,counter 如何用 8bit 实现近似计数?(Morris Counter 原理)
Redis 的 LFU(Least Frequently Used) 淘汰策略在 Redis 4.0 引入,用于解决传统 LRU 在"偶发热点"场景下的误淘汰问题。为了在极低内存开销下 (仅用 8 位 = 1 字节 )记录 key 的访问频率,Redis 采用了基于 概率计数(Probabilistic Counting) 的思想,其核心是 Morris Counter 的变种。
一、问题背景:为什么不能直接用整数计数?
- 若用 32 位整数记录访问次数,每个 key 需额外 4 字节
- 对于亿级 key 的 Redis 实例,仅计数器就需 数百 MB 内存
- Redis 要求 LFU 元数据 ≤ 1 字节(8 bits) ,最大值仅为 255
❌ 直接计数:第 256 次访问后溢出,无法区分高频和超高频 key
二、Morris Counter 原理(基础思想)
Morris Counter 是一种 用小空间近似计数大数值 的概率算法:
- 维护一个计数器
C(如 8 位) - 真实计数值
N ≈ 2^C - 1 - 每次"递增"时,**以概率
**1 / (2^C)**执行 ****C += 1**
示例:
| C(存储值) | 真实计数 N(期望值) |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 2 | 3 |
| 3 | 7 |
| 4 | 15 |
| ... | ... |
| 8 | 255 |
✅ 用 8 位可表示 高达 255 的真实访问次数 ,但这是指数级近似,精度随 C 增大而降低。
三、Redis 对 Morris Counter 的改进
Redis 并未直接使用原始 Morris Counter,而是设计了一套 更平滑、带衰减的 8-bit LFU counter,包含两个关键机制:
1. 非线性递增(概率性 + 饱和)
- counter 范围:0 ~ 255
- 当 key 被访问时,不直接 +1,而是:
c
// 伪代码
if (rand() < 1.0 / (counter_val * decay_time + 1)) {
if (counter_val < 255) counter_val++;
}- counter 越大,递增概率越低 → 高频 key 增长变慢,避免快速饱和
2. 时间衰减(Aging)
- Redis 会周期性地对所有 key 的 LFU counter 进行衰减
- 衰减规则(简化):
- 每隔一段时间(如 1 分钟),对每个 key:
- 若 counter > 0,则以一定概率减 1
- 或直接
counter = counter / 2(逻辑衰减)
- 每隔一段时间(如 1 分钟),对每个 key:
- 目的:让"曾经热门但近期冷"的 key 逐渐降权,避免长期霸占内存
💡 Redis 的 LFU counter = 访问频率的"衰减型对数近似"
四、Redis LFU counter 的具体实现(源码逻辑)
在 Redis 源码 evict.c 中,LFU 使用 24 位字段 存储:
- 高 16 位:最近访问时间(分钟级,用于衰减)
- 低 8 位:LFU counter(即我们讨论的 8-bit 计数器)
更新 counter 的函数 LFU_Update() 核心逻辑:
c
uint8_t lfu_log_incr(uint8_t counter) {
if (counter == 255) return 255; // 饱和
double r = (double)rand() / RAND_MAX;
double baseval = counter ? counter : 1; // 避免除零
if (r < 1.0 / baseval) {
return counter + 1;
} else {
return counter;
}
}衰减逻辑(LFU_DecrAndReturn()):
- 比较当前时间和高 16 位存储的时间
- 若超过一定间隔(如 1 分钟),则:
counter = counter - (elapsed_minutes / server.lfu_decay_time)- 最小为 0
📌 参数 lfu_decay_time(默认 1)控制衰减速度:值越大,衰减越慢
五、为什么这种设计有效?
| 特性 | 优势 |
|---|---|
| 8-bit 极省空间 | 每个 key 仅 1 字节额外开销 |
| 概率递增防饱和 | 高频 key 不会迅速达到 255,保留区分度 |
| 时间衰减防僵化 | 冷却的热点 key 会自动降权,适应访问模式变化 |
| 近似但够用 | 淘汰策略只需相对频率,不要求绝对精确 |
示例效果:
- 一个 key 被访问 100 次 → counter ≈ 10~20
- 另一个 key 被访问 1000 次 → counter ≈ 30~50
- 虽然不精确,但 1000 次 > 100 次 的关系被保留,足以用于淘汰决策
六、配置与调优
Redis 提供两个参数优化 LFU 行为:
plain
# 控制 counter 衰减速度(单位:分钟)
lfu-decay-time 1
# 控制新 key 的初始 counter 权重(避免新 key 被立即淘汰)
lfu-log-factor 10**lfu-log-factor**:越大,counter 增长越慢(适合高频场景)**lfu-decay-time**:越大,历史访问权重保留越久
可通过 redis-cli --hotkeys 查看 LFU 排名。
七、总结
| 问题 | Redis LFU 解法 |
|---|---|
| 如何用 8bit 表示大访问量? | 采用 概率递增 + 对数近似(Morris 思想变种) |
| 如何防止高频 key 饱和? | counter 越大,递增概率越低 |
| 如何处理访问模式变化? | 引入 时间衰减机制,定期降低旧热度 |
| 是否精确? | 否,但相对顺序足够准确用于淘汰 |
✅ Redis 的 LFU 是 工程上的精妙折中 :
用 1 字节 + 概率算法 + 时间衰减,在极低开销下实现了接近理想 LFU 的效果。
这种设计体现了 Redis "简单、高效、实用" 的核心哲学。
用 Redis 做分布式锁, RedLock 争议 或 看门狗机制。
使用 Redis 实现分布式锁是高并发系统中的常见需求,但其正确性和可靠性一直存在争议。其中,RedLock 算法 由 Redis 作者 Antirez 提出,曾被视为"官方推荐方案",但随后遭到分布式系统专家 Martin Kleppmann(《Designing Data-Intensive Applications》作者)的强烈质疑,引发业界广泛讨论。与此同时,看门狗机制(Watchdog)作为解决锁自动续期问题的工程实践,也被广泛应用(如 Redisson)。
下面从 RedLock 原理 → 争议焦点 → 看门狗机制 → 实践建议 四个维度深入解析。
一、RedLock 是什么?
✅ 设计目标
在无中心协调者 的前提下,利用多个独立 Redis 节点实现一个容错的分布式锁,即使部分节点宕机,锁仍能正常工作。
🔧 算法流程(N 个 Redis Master 节点,通常 N=5)
- 获取当前时间(毫秒);
- 依次向 N 个 Redis 节点请求加锁(使用
SET resource_name my_random_value NX PX timeout); - 只有超过半数 (> N/2)节点加锁成功,且总耗时 < 锁过期时间,才认为加锁成功;
- 锁的实际有效时间 = 原始超时时间 - 步骤 3 的总耗时;
- 解锁时,向所有节点发送
DEL命令(需校验 value 是否匹配)。
📌 关键:不依赖单点 Redis,通过多数派达成共识。
二、RedLock 的核心争议(Martin vs Antirez)
⚠️ 争议背景
Martin 在博客 《How to do distributed locking》 中指出:RedLock 无法保证互斥性,在某些故障场景下会失效。
🔥 核心论点:时钟漂移 + 进程暂停 = 锁失效
🧪 攻击场景(Fencing Token 缺失)
- Client A 向 5 个 Redis 节点申请锁,3 个成功,获得锁;
- Client A 所在机器发生 STW(Stop-The-World)GC,暂停 30 秒;
- 此时锁已过期(比如 TTL=10s),Client B 成功获取同一把锁;
- Client A 恢复后,仍以为自己持有锁 ,继续操作共享资源 → A 和 B 同时操作!
❌ RedLock 没有提供 fencing token(单调递增令牌),无法让资源服务器识别"谁的锁更新"。
✅ 正确做法(Martin 提议):
- 锁服务应返回一个全局递增的 token(如 ZooKeeper 的 zxid);
- 客户端操作资源时,携带 token;
- 资源服务器只接受 token 更大的请求,拒绝旧锁持有者的操作。
🌰 类比:银行取号机------即使你拿着旧号,柜员也只服务最新号码。
🔄 Antirez 的回应
Antirez 认为:
- 上述场景属于极端异常(长时间 GC / 时钟跳变);
- RedLock 在合理运维前提下(NTP 同步时钟、避免长 GC)是安全的;
- 引入 fencing token 需要资源服务器配合,增加了复杂度。
💬 本质分歧:
Martin 从"理论正确性"出发,要求系统在任意故障下安全;
Antirez 从"工程实用性"出发,接受在可控环境下使用简化方案。
三、看门狗机制(Watchdog)------ Redisson 的解决方案
RedLock 未解决锁自动续期问题:如果业务执行时间 > 锁 TTL,锁会提前释放,导致并发冲突。
✅ 看门狗机制原理(以 Redisson 为例)
- 加锁时设置初始 TTL(如 30s);
- 启动后台线程(Watchdog),每 10s 检查一次 :
- 如果当前线程仍持有该锁,则自动延长 TTL(如再续 30s);
- 业务执行完毕后,显式调用
unlock(),停止续期并释放锁。
java
// Redisson 示例
RLock lock = redisson.getLock("myLock");
lock.lock(); // 默认 30s TTL,自动续期
try {
// 业务逻辑(可执行 > 30s)
} finally {
lock.unlock(); // 停止看门狗 + 删除 key
}⚠️ 看门狗的风险
- 依赖本地时钟:若客户端时钟漂移,可能续期失败;
- 网络分区:客户端与 Redis 断连,看门狗无法续期,但业务仍在执行 → 锁提前释放;
- 非 RedLock 场景 :仅适用于单 Redis 节点 或主从架构(主从切换仍可能丢锁)。
🔑 看门狗解决了"长任务锁过期"问题,但未解决 RedLock 的根本缺陷。
四、生产环境建议:如何选择?
| 场景 | 推荐方案 | 说明 |
|---|---|---|
| 强一致性要求 (如金融扣款) | ZooKeeper / etcd | 基于 ZAB / Raft 协议,提供 fencing token,理论安全 |
| 高性能 + 最终一致 (如秒杀库存) | Redis 单节点 + 看门狗 (Redisson) | 接受极小概率超卖,追求高吞吐 |
| 无 ZooKeeper 依赖 且需一定容错 | RedLock(谨慎使用) | 必须: - 5 个独立 Redis 节点 - 严格 NTP 时钟同步 - 监控 GC 停顿 |
| 简单场景 | SET NX PX + 固定短 TTL | 业务必须 < TTL,失败则重试 |
✅ 最佳实践(若用 Redis 锁):
- 永远校验 value :解锁时用 Lua 脚本确保
DEL前验证 value;
lua
if redis.call("GET", KEYS[1]) == ARGV[1] then
return redis.call("DEL", KEYS[1])
else
return 0
end- 设置合理 TTL:避免过长(资源占用)或过短(频繁续期);
- 监控锁等待与冲突:记录加锁失败率、持有时间分布;
- 避免在锁内做远程调用:防止因外部依赖拖长锁持有时间。
五、总结:没有银弹,只有权衡
| 方案 | 优点 | 缺点 | 适用性 |
|---|---|---|---|
| RedLock | 无中心、容错 | 无 fencing token,时钟敏感 | 中低风险场景(需严格运维) |
| Redis + 看门狗 | 自动续期、易用 | 单点风险、主从异步丢锁 | 高性能缓存型场景 |
| ZooKeeper | 强一致、fencing token | 性能较低、运维复杂 | 强一致性核心业务 |
💡 关键结论:
- RedLock 并非"分布式锁银弹",其安全性依赖于严格的系统假设;
- 看门狗是工程优化,不是理论补丁;
- 真正的安全 = 锁机制 + 资源服务器的 fencing 校验;
- 在绝大多数互联网场景中,Redisson 的单节点锁 + 看门狗 + 业务幂等 已足够。
正如 Martin 所言:
"分布式锁本身不是问题,问题是你是否理解它的假设和局限。"
在选择方案前,请先问自己:我的业务能容忍多大程度的并发冲突? 答案将指引你走向正确的技术选型。
六、Spring(原理 + 新版本)
Spring Boot 3.x 为何强制要求 JDK 17+?GraalVM Native Image 支持带来哪些限制?
Spring Boot 3.x 强制要求 JDK 17+ ,这是 Spring 团队在 2022 年底发布时做出的关键技术决策,主要出于 技术演进、生态对齐、安全合规 以及 为 GraalVM Native Image 提供原生支持 等多方面考虑。下面从原因和限制两方面详细解析。
一、为何 Spring Boot 3.x 强制要求 JDK 17+?
1. 对齐 Jakarta EE 9+ 规范
- Spring Framework 6(Spring Boot 3 的底层)全面迁移到 Jakarta EE 9+。
- Jakarta EE 9 将包名从
javax.*改为jakarta.*(如javax.servlet→jakarta.servlet)。 - JDK 17 是第一个被 Jakarta EE 9+ 官方认证兼容的 LTS 版本,确保 API 兼容性。
⚠️ 若使用 JDK 8/11,无法直接运行基于 jakarta.* 的类库,会抛出 ClassNotFoundException。
2. 利用 JDK 17 的新特性提升性能与开发体验
JDK 17(LTS)相比 JDK 8/11 带来了大量改进:
- 密封类(Sealed Classes):增强领域模型设计安全性
- 模式匹配(Pattern Matching for instanceof):简化类型检查代码
- 新的垃圾回收器(ZGC, Shenandoah):低延迟 GC 支持
- 性能提升:JIT 编译优化、字符串压缩等
- 弃用移除旧 API:如 Applet、Security Manager(Spring 已不再依赖)
Spring Boot 3 内部大量使用这些新特性重构代码,无法向下兼容。
3. 安全与维护策略
- Oracle 和 OpenJDK 社区已停止对 JDK 8/11 的公共更新(需商业订阅)。
- JDK 17 是当前(截至 2025 年)主流 LTS 版本,获得长期安全补丁支持。
- Spring 团队希望推动用户升级到受支持的安全版本,降低漏洞风险。
4. 为 GraalVM Native Image 提供官方支持(核心驱动力)
Spring Boot 3 是 首个官方支持 GraalVM Native Image 的主版本。而 GraalVM 对 JDK 版本有严格要求:
- GraalVM 22.3+ 仅支持 JDK 17+ 构建 Native Image
- Native Image 编译器依赖 JDK 内部 API 和字节码格式,与旧版 JDK 不兼容
✅ 换言之:没有 JDK 17,就没有 Spring Boot 3 的 Native 支持。
二、GraalVM Native Image 支持带来的限制
虽然 Native Image 能带来 启动速度 < 100ms、内存占用降低 50%+ 的优势,但其静态编译模型对 Spring 应用施加了诸多限制:
🔒 1. 反射(Reflection)必须显式注册
- Native Image 在编译时冻结所有类信息,运行时无法动态加载类或调用未注册的方法。
- 影响 :Spring 大量使用反射(如
@Autowired、@Value、JSON 序列化)。 - 解决方案 :
- 使用
spring-native插件自动生成reflect-config.json - 手动通过
@RegisterForReflection注解标记类 - 避免动态代理(如 CGLib),改用接口 + JDK Proxy
- 使用
❌ 以下代码在 Native 下会失败:
java
Class.forName("com.example.DynamicClass"); // ClassNotFoundException🔒 2. 动态资源访问受限
- 文件系统、Classpath 资源在编译时必须明确声明。
- 影响 :
ResourceLoader.getResource("classpath*:*.xml")可能找不到文件- 模板引擎(Thymeleaf/FreeMarker)需预注册模板路径
- 解决方案 :
- 使用
native-image的-H:IncludeResources参数 - 避免通配符资源扫描
- 使用
🔒 3. 不支持动态字节码生成
- 禁止使用 :
- Hibernate 动态代理(需改用
hibernate-enhance-maven-plugin预编译) - Mockito(测试可用,但生产代码不能用)
- Lombok(需在编译期完成注解处理,Native 运行时无 javac)
- Hibernate 动态代理(需改用
- 替代方案 :
- 使用 MapStruct 替代部分 Lombok 功能
- 测试用 JUnit 5 + Testcontainers,避免运行时 mock
🔒 4. 线程与并发模型简化
- Native Image 默认禁用守护线程(Daemon Threads)
ForkJoinPool.commonPool()行为可能异常- 建议:显式管理线程池,避免依赖 JVM 默认行为
🔒 5. JVM 特有功能不可用
| 功能 | Native Image 状态 |
|---|---|
| JMX | ❌ 不支持 |
| Java Agent | ❌ 不支持 |
| JVMTI | ❌ 不支持 |
| 动态类加载(ClassLoader) | ❌ 有限支持(需预注册) |
| Security Manager | ❌ 移除 |
这意味着 APM 工具(如 SkyWalking、Pinpoint)需使用 Native 兼容版本(如 OpenTelemetry + eBPF)。
🔒 6. 第三方库兼容性挑战
- 并非所有库都适配 Native Image。
- 高风险库 :
- Netty(需 GraalVM 官方 patch)
- Jackson(需启用
--initialize-at-build-time) - Apache HttpClient(推荐改用 WebClient)
- 验证工具 :
- 使用 GraalVM Reachability Metadata 仓库
- 运行
native-image-agent生成配置
三、Spring Boot 3 对 Native 的优化支持
为缓解上述限制,Spring Boot 3 提供了:
**spring-boot-starter-parent**** 内置 Native 插件**
xml
<plugin>
<groupId>org.graalvm.buildtools</groupId>
<artifactId>native-maven-plugin</artifactId>
</plugin>- 自动配置检测:启动时提示哪些 Bean 不兼容 Native
- AOT(Ahead-of-Time)编译:在构建阶段生成优化代码,减少运行时反射
- 官方兼容列表 :Spring Native Compatibility Guide
四、总结:权衡与建议
| 维度 | 说明 |
|---|---|
| 为何强制 JDK 17+ | 对齐 Jakarta EE 9、利用新特性、安全合规、支持 GraalVM Native |
| Native Image 优势 | 启动快(<100ms)、内存低(~50MB)、适合 Serverless/FaaS |
| Native 主要限制 | 反射/资源需预注册、无动态代理、无 JMX/Agent、第三方库兼容性风险 |
| 适用场景 | 微服务、CLI 工具、边缘计算、Serverless(AWS Lambda, Azure Functions) |
| 不适用场景 | 需要动态插件、重度依赖 APM Agent、使用不兼容库的传统应用 |
✅ 建议:
- 新项目可尝试 Spring Boot 3 + Native Image
- 老项目迁移需全面评估依赖库兼容性
- 优先使用 Spring AOT + JVM 模式 作为过渡(兼顾性能与兼容性)
Spring Boot 3 的 JDK 17+ 要求是技术演进的必然选择,而 GraalVM Native 则为云原生时代提供了新的部署范式------以一定的开发约束,换取极致的资源效率。
@Transactional 失效的 5 种真实场景(非八股文),如何用 TransactionSynchronization 解决?
@Transactional 失效是 Java 开发中高频且隐蔽的问题。以下列出 5 种真实生产环境中踩过的"非八股文"场景 (避开"自调用""非 public 方法"等常见答案),并展示如何用 TransactionSynchronization 优雅解决部分问题。
场景 1:异步方法中的事务上下文丢失(最常见陷阱)
❌ 问题代码:
java
@Service
public class OrderService {
@Async
@Transactional
public void processOrderAsync(Long orderId) {
// 期望:此方法在事务中执行
orderDao.updateStatus(orderId, "PROCESSING");
paymentService.charge(orderId); // 可能失败
}
}🔍 原因:
@Async由线程池新线程执行,脱离了 Spring 事务上下文(ThreadLocal)@Transactional在新线程中完全无效 → 无事务、无回滚
✅ 解决方案:手动传递事务上下文 + TransactionSynchronization
java
@Service
public class OrderService {
@Autowired
private TaskExecutor taskExecutor;
public void triggerAsyncProcess(Long orderId) {
// 在原事务线程中提交异步任务,并绑定回调
TransactionSynchronizationManager.registerSynchronization(
new TransactionSynchronization() {
@Override
public void afterCommit() {
// 仅当外层事务成功提交后,才异步处理
taskExecutor.execute(() -> doProcess(orderId));
}
}
);
}
private void doProcess(Long orderId) {
// 此处无需 @Transactional,因在外层事务提交后执行
// 若需独立事务,可在此方法加 @Transactional(propagation = REQUIRES_NEW)
orderDao.updateStatus(orderId, "PROCESSING");
paymentService.charge(orderId);
}
}关键点 :用 afterCommit() 确保异步操作在外层事务成功后触发,避免数据不一致。
场景 2:跨微服务调用后的本地事务回滚失效
❌ 问题代码:
java
@Transactional
public void createOrder(Order order) {
orderDao.insert(order);
// 调用下游服务(HTTP/gRPC)
inventoryService.reserve(order.getItems()); // 成功
// 但后续本地操作失败
throw new RuntimeException("Simulated failure"); // 订单应回滚,但库存已扣减!
}🔍 原因:
- 微服务间无分布式事务(如未用 Seata)
- 本地事务回滚无法撤销远程服务的副作用
✅ 解决方案:用 TransactionSynchronization 实现补偿逻辑
java
@Transactional
public void createOrder(Order order) {
orderDao.insert(order);
// 注册事务同步器,在回滚时触发补偿
TransactionSynchronizationManager.registerSynchronization(
new TransactionSynchronization() {
@Override
public void afterCompletion(int status) {
if (status == STATUS_ROLLED_BACK) {
// 异步补偿:释放库存
compensationService.releaseInventoryAsync(order.getId());
}
}
}
);
inventoryService.reserve(order.getItems());
// ... 其他操作
}注意:补偿操作需幂等,且最好异步执行(避免阻塞事务提交)。
场景 3:事务提交后需触发高延迟操作(如发邮件、写审计日志)
❌ 错误做法:
java
@Transactional
public void updateUser(User user) {
userDao.update(user);
emailService.sendWelcomeEmail(user.getEmail()); // 高延迟,拖慢事务
}- 邮件服务慢 → 事务持有 DB 连接时间过长 → 数据库连接池耗尽
✅ 正确做法:用 afterCommit() 解耦
java
@Transactional
public void updateUser(User user) {
userDao.update(user);
TransactionSynchronizationManager.registerSynchronization(
new TransactionSynchronization() {
@Override
public void afterCommit() {
// 事务已提交,安全地执行高延迟操作
asyncTaskExecutor.execute(() ->
emailService.sendWelcomeEmail(user.getEmail())
);
}
}
);
}优势:DB 连接快速释放,邮件发送失败不影响核心业务。
场景 4:动态数据源切换后事务失效(如多租户 SaaS)
❌ 问题代码:
java
@Transactional
public void processTenantData(String tenantId, Data data) {
DataSourceContextHolder.setDataSource(tenantId); // 切换数据源
tenantDao.insert(data); // 插入到租户库
}
// 事务未生效!因为 DataSource 已变,但事务管理器仍绑定原数据源🔍 原因:
- Spring 事务在方法入口已绑定数据源
- 动态切换数据源后,JDBC 操作脱离了事务管理器控制
✅ 解决方案:避免在事务中切换数据源
TransactionSynchronization 无法直接解决此问题,但可辅助清理:
java
@Transactional
public void processTenantData(String tenantId, Data data) {
// 确保数据源在事务开始前切换
DataSourceContextHolder.setDataSource(tenantId);
TransactionSynchronizationManager.registerSynchronization(
new TransactionSynchronization() {
@Override
public void afterCompletion(int status) {
// 清理 ThreadLocal,避免内存泄漏
DataSourceContextHolder.clear();
}
}
);
tenantDao.insert(data);
}根本解法 :使用 AbstractRoutingDataSource + @Transactional 在 AOP 层自动路由。
场景 5:事务内缓存更新与 DB 不一致(Cache-Aside 模式陷阱)
❌ 问题代码:
java
@Transactional
public void updateUserProfile(Long userId, Profile profile) {
profileDao.update(profile);
redisTemplate.delete("profile:" + userId); // 立即删缓存
}
// 若事务回滚,DB 未更新,但缓存已删除 → 缓存击穿!✅ 正确做法:延迟缓存失效至事务提交后
java
@Transactional
public void updateUserProfile(Long userId, Profile profile) {
profileDao.update(profile);
TransactionSynchronizationManager.registerSynchronization(
new TransactionSynchronization() {
@Override
public void afterCommit() {
// 仅当事务成功提交,才删除缓存
redisTemplate.delete("profile:" + userId);
}
}
);
}效果:避免"DB 未改,缓存先删"的脏读窗口。
TransactionSynchronization 核心方法说明
| 方法 | 触发时机 | 典型用途 |
|---|---|---|
beforeCommit() |
事务提交前(仍可回滚) | 校验数据一致性 |
beforeCompletion() |
事务完成前(提交或回滚) | 清理资源 |
afterCommit() |
事务成功提交后 | 异步任务、发消息、删缓存 |
afterCompletion() |
事务完成后(含回滚) | 补偿操作、清理 ThreadLocal |
关键总结
| 场景 | 是否可用 TransactionSynchronization 解决 | 替代方案 |
|---|---|---|
| 异步方法事务丢失 | ✅(通过外层事务回调) | 使用 @Transactional(propagation = REQUIRES_NEW)+ 手动提交 |
| 跨服务回滚失效 | ✅(补偿) | Saga 模式、可靠消息队列 |
| 高延迟操作拖慢事务 | ✅(afterCommit 解耦) | 消息队列异步化 |
| 动态数据源切换 | ❌(需架构调整) | AbstractRoutingDataSource |
| 缓存与 DB 不一致 | ✅(延迟删缓存) | Cache-Aside + 事务同步 |
💡 黄金法则 :
任何依赖事务最终状态(提交/回滚)的操作,都应通过 **TransactionSynchronization** 注册回调,而非直接写在事务方法中。
通过合理使用 TransactionSynchronization,可将事务边界外的操作与事务生命周期精准对齐,大幅提升系统一致性与健壮性。
Spring 的三级缓存如何解决循环依赖?为什么构造器注入无法解决?
Spring 的三级缓存机制是其解决 单例 Bean 之间 setter 注入(或 field 注入)循环依赖 的核心设计。而 构造器注入无法解决循环依赖,这是由 Java 对象创建语义和 Spring 生命周期决定的。下面从原理、流程和限制三方面深入解析。
一、什么是循环依赖?
java
@Service
public class A {
@Autowired
private B b;
}
@Service
public class B {
@Autowired
private A a;
}- A 依赖 B,B 依赖 A → 形成循环。
- 若不处理,会导致无限递归创建或
BeanCurrentlyInCreationException。
二、Spring 的三级缓存设计
Spring 使用 三个 Map 存储不同阶段的 Bean:
| 缓存 | 类型 | 作用 |
|---|---|---|
一级缓存 singletonObjects |
Map<String, Object> |
完整的、已初始化的单例 Bean(可直接使用) |
二级缓存 earlySingletonObjects |
Map<String, Object> |
早期暴露的 Bean(尚未完成属性填充/初始化) |
三级缓存 singletonFactories |
Map<String, ObjectFactory<?>> |
Bean 的 ObjectFactory(用于生成早期引用) |
✅ 关键思想 :在 Bean 完全创建前,提前暴露一个"半成品"引用给其他依赖者。
三、循环依赖解决流程(以 A → B → A 为例)
步骤 1:开始创建 A
- 调用
getBean("a") - A 实例化(调用构造函数)→ 得到 原始对象 A₀
- 将 A₀ 的 ObjectFactory 放入 三级缓存:
java
singletonFactories.put("a", () -> getEarlyBeanReference("a", A₀));步骤 2:A 填充属性,发现依赖 B
- 调用
getBean("b") - 开始创建 B
步骤 3:创建 B
- B 实例化 → 得到 B₀
- 将 B₀ 的 ObjectFactory 放入三级缓存
- B 填充属性,发现依赖 A → 再次调用
getBean("a")
步骤 4:关键!B 获取 A 的早期引用
- 此时 A 还在创建中(未放入一级缓存)
- Spring 检查:
- 一级缓存?→ 无
- 二级缓存?→ 无
- 三级缓存?→ 有!
- 从三级缓存取出 A 的 ObjectFactory,调用
getObject():- 执行
getEarlyBeanReference("a", A₀) - 返回 A₀(可能被 BeanPostProcessor 代理,如 AOP 代理对象)
- 执行
- 将 A 的早期引用 放入二级缓存 ,并移除三级缓存
- B 拿到 A 的引用,完成属性注入
步骤 5:B 初始化完成
- B 被放入 一级缓存
- B 创建成功,返回给 A
步骤 6:A 继续完成初始化
- A 拿到 B,完成属性注入
- A 初始化(
@PostConstruct、InitializingBean 等) - A 放入一级缓存,移除二级缓存
✅ 结果:A 和 B 都成功创建,且互相持有对方引用。
✅ 正确的缓存清理时机(以 Bean A 为例):
| 阶段 | 操作 | 三级缓存 (<font style="color:rgb(17, 17, 51);background-color:rgba(175, 184, 193, 0.2);">singletonFactories</font>) |
二级缓存 (<font style="color:rgb(17, 17, 51);background-color:rgba(175, 184, 193, 0.2);">earlySingletonObjects</font>) |
一级缓存 (<font style="color:rgb(17, 17, 51);background-color:rgba(175, 184, 193, 0.2);">singletonObjects</font>) |
|---|---|---|---|---|
| 1. 实例化后 | 将 A 的 <font style="color:rgb(17, 17, 51);background-color:rgba(175, 184, 193, 0.2);">ObjectFactory</font>放入三级缓存 |
✅ 存在 | ❌ 无 | ❌ 无 |
| 2. B 请求 A(早期引用) | 从三级缓存获取 <font style="color:rgb(17, 17, 51);background-color:rgba(175, 184, 193, 0.2);">ObjectFactory</font> → 生成早期引用 → 放入二级缓存 → 立即移除三级缓存 |
❌ 已移除 | ✅ 存在 | ❌ 无 |
| 3. A 完全初始化后 | 将完整 A 放入一级缓存 → 移除二级缓存(三级缓存此时已空) | ❌(早已移除) | ❌ 此时移除 | ✅ 存在 |
java
// 1. 获取早期引用时:移除三级,放入二级
protected Object getEarlyBeanReference(String beanName, Object bean) {
// ... 调用 SmartInstantiationAwareBeanPostProcessor
return bean;
}
// 在 doCreateBean() 中:
if (earlySingletonExposure) {
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, bean));
}
// 当其他 Bean 获取早期引用时:
Object earlyBean = singletonFactories.get(beanName).getObject();
earlySingletonObjects.put(beanName, earlyBean);
singletonFactories.remove(beanName); // 👈 三级缓存在此移除!
// 2. 初始化完成后:移除二级缓存
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
singletonObjects.put(beanName, singletonOobject);
earlySingletonObjects.remove(beanName); // 👈 二级缓存在此移除!
// 注意:此处不再操作 singletonFactories(它早已为空)
}
}四、为什么构造器注入无法解决循环依赖?
❌ 构造器注入示例:
java
@Service
public class A {
private final B b;
public A(B b) { this.b = b; } // 必须先有 B 才能创建 A
}
@Service
public class B {
private final A a;
public B(A a) { this.a = a; } // 必须先有 A 才能创建 B
}🔍 根本原因:
- Java 对象创建语义限制
- 构造器参数必须在 调用构造函数前完全准备好
- 要创建 A,必须先有完整的 B;要创建 B,必须先有完整的 A → 死锁
- Spring 无法提前暴露"未构造完成"的对象
- 对于 setter 注入,Spring 可以先
new A()(无参构造),再 set 属性 → 存在"半成品" - 但构造器注入时,对象在构造完成前根本不存在 (无法
new A(b),因为 b 未知)
- 对于 setter 注入,Spring 可以先
- 三级缓存失效
- 三级缓存依赖 已实例化的原始对象(通过无参构造创建)
- 构造器注入通常没有无参构造,即使有,也无法在构造完成前暴露引用
💥 Spring 在检测到构造器循环依赖时,会直接抛出:
plain
BeanCurrentlyInCreationException:
Error creating bean with name 'a': Requested bean is currently in creation: Is there an unresolvable circular reference?五、补充:为什么需要三级缓存?二级不够吗?
很多人问:为什么要有三级缓存?二级缓存不能解决吗?
场景:AOP 代理 + 循环依赖
- 假设 A 被
@Transactional代理 - 如果只有二级缓存:
- B 拿到的是 原始 A₀
- 但 A 最终应该是一个 代理对象 A_proxy
- 导致 B 中的 A 没有事务!
三级缓存的作用:
- 三级缓存存的是 ObjectFactory,不是直接存对象
- 当 B 请求 A 时,才调用:
java
getEarlyBeanReference(beanName, rawBean) {
for (SmartInstantiationAwareBeanPostProcessor bp : processors) {
rawBean = bp.getEarlyBeanReference(rawBean, beanName);
}
return rawBean; // 可能是代理对象
}- 确保早期暴露的也是代理对象,保证一致性
✅ 三级缓存 = 延迟生成早期引用,支持 AOP 等扩展点
六、总结
| 问题 | 答案 |
|---|---|
| 三级缓存如何解决循环依赖? | 通过提前暴露"早期引用"(半成品 Bean),让依赖方能获取到对象引用,打破创建死锁 |
| 为什么需要三级(而非二级)? | 支持 BeanPostProcessor(如 AOP 代理),确保早期引用与最终 Bean 一致 |
| 构造器注入为何无法解决? | Java 要求构造参数必须完整,Spring 无法在构造完成前暴露对象,无"半成品"可用 |
| Spring 能解决所有循环依赖吗? | 仅支持 单例 + setter/field 注入 的循环依赖; 原型(prototype)Bean 或构造器注入的循环依赖无法解决 |
🚫 最佳实践:
- 尽量避免循环依赖(设计 smell)
- 优先使用构造器注入(更安全、不可变)
- 若必须循环,改用 setter 注入 +
@Lazy延迟加载(非必需)
Spring Security 6.x 的 Lambda DSL 配置方式相比旧版有何优势?
Spring Security 6.x(随 Spring Boot 3.0+ 引入)全面拥抱 Lambda DSL(Domain Specific Language) 配置方式,取代了传统的 and() 链式调用风格。这一变化不仅是语法糖,更是类型安全、可读性、可维护性和扩展性的重大提升。
下面从多个维度对比新旧配置方式,并说明 Lambda DSL 的核心优势。
一、配置方式对比:旧版 vs Lambda DSL
✅ 旧版(Spring Security 5.x 及更早)------ 基于方法链 + and()
java
// 必须继承 WebSecurityConfigurerAdapter(6.x 已移除)
@Configuration
@EnableWebSecurity
public class OldSecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests()
.antMatchers("/admin/**").hasRole("ADMIN")
.anyRequest().authenticated()
.and()
.formLogin()
.loginPage("/login")
.permitAll()
.and()
.logout()
.logoutSuccessUrl("/?loggedOut");
}
}⚠️ 注意:即使上面用了 Lambda,整体结构仍依赖 **HttpSecurity** 的链式返回 ,且早期版本必须继承 WebSecurityConfigurerAdapter(已在 6.x 移除)。
✅ 新版(Spring Security 6.x)------ 纯 Lambda DSL + 函数式配置
java
@Bean
public SecurityFilterChain filterChain(HttpSecurity http) throws Exception {
http
.authorizeHttpRequests(authz -> authz
.requestMatchers("/admin/**").hasRole("ADMIN")
.anyRequest().authenticated()
)
.formLogin(form -> form
.loginPage("/login")
.permitAll()
)
.logout(logout -> logout
.logoutSuccessUrl("/?loggedOut")
);
return http.build();
}🔑 关键变化:
- 不再继承
WebSecurityConfigurerAdapter - 使用
@Bean SecurityFilterChain声明式注册 - 所有子配置通过 Lambda 接收配置器对象 (如
authz: AuthorizeHttpRequestsConfigurer)
二、Lambda DSL 的五大核心优势
1. ✅ 类型安全(Type Safety)
- 每个 Lambda 参数都有明确的配置器类型 (如
FormLoginConfigurer,CorsConfigurer) - IDE 能精准提示可用方法,避免拼写错误或无效配置
- 编译期即可发现错误,而非运行时抛
IllegalArgumentException
🆚 旧版中 .formLogin().xxx().and().yyy() 容易因 and() 位置错误导致配置错乱。
2. ✅ 结构清晰,无"and()"噪音
- 旧版需频繁使用
.and()返回上层上下文,代码冗长且易错:
java
// 旧版易错示例
http
.formLogin()
.loginPage("/login")
.and() // 忘记写?配置可能被覆盖!
.logout()
.logoutUrl("/signout");- Lambda DSL 天然作用域隔离 ,无需
and():
java
// 新版:每个配置块独立
http
.formLogin(form -> form.loginPage("/login"))
.logout(logout -> logout.logoutUrl("/signout"));3. ✅ 支持多 SecurityFilterChain(细粒度安全控制)
- Spring Security 6.x 鼓励按路径/用途定义多个
SecurityFilterChain - Lambda DSL 使多链配置简洁且无歧义
java
// API 安全(无 session,JWT)
@Bean
@Order(1)
public SecurityFilterChain apiFilterChain(HttpSecurity http) throws Exception {
http
.securityMatcher("/api/**")
.authorizeHttpRequests(authz -> authz.anyRequest().authenticated())
.sessionManagement(sess -> sess.sessionCreationPolicy(SessionCreationPolicy.STATELESS))
.httpBasic(withDefaults()); // Lambda 也支持 withDefaults()
return http.build();
}
// Web UI 安全(表单登录)
@Bean
@Order(2)
public SecurityFilterChain webFilterChain(HttpSecurity http) throws Exception {
http
.authorizeHttpRequests(authz -> authz.anyRequest().authenticated())
.formLogin(Customizer.withDefaults());
return http.build();
}✅ 每个链职责单一,易于测试和维护。
4. ✅ 更好的可读性与自文档化
- Lambda 参数名可自解释(如
cors -> cors.configurationSource(...)) - 配置逻辑垂直对齐,符合现代 Java 风格
java
http
.cors(cors -> cors
.configurationSource(request -> {
CorsConfiguration config = new CorsConfiguration();
config.setAllowedOrigins(List.of("https://trusted.com"));
config.setAllowedMethods(List.of("GET", "POST"));
return config;
})
)
.csrf(csrf -> csrf.disable()); // 明确意图5. ✅ 与函数式编程范式对齐
- 支持将配置逻辑提取为 独立方法或函数,提高复用性:
java
private void configureFormLogin(FormLoginConfigurer<HttpSecurity> form) {
form.loginPage("/login")
.failureUrl("/login?error")
.defaultSuccessUrl("/dashboard");
}
@Bean
public SecurityFilterChain filterChain(HttpSecurity http) throws Exception {
http
.formLogin(this::configureFormLogin)
.authorizeHttpRequests(authz -> authz.anyRequest().authenticated());
return http.build();
}三、迁移注意事项(从 5.x → 6.x)
| 旧版写法 | 新版等效写法 |
|---|---|
extends WebSecurityConfigurerAdapter |
删除继承,改用 @Bean SecurityFilterChain |
.antMatchers(...).permitAll() |
.requestMatchers(...).permitAll() (antMatchers 已废弃) |
.and().csrf().disable() |
.csrf(csrf -> csrf.disable()) |
| 多配置类冲突 | 使用 @Order 控制 SecurityFilterChain优先级 |
⚠️ 重要 :Spring Security 6.x 默认启用 CSRF 保护 和 SameSite=Lax Cookie,若前端是 SPA,需显式配置 CORS/Cookie 策略。
四、总结:为什么 Lambda DSL 是进步?
| 维度 | 旧版(链式 + and()) | 新版(Lambda DSL) |
|---|---|---|
| 类型安全 | ❌ 弱(Object 返回) | ✅ 强(泛型配置器) |
| 可读性 | ❌ 嵌套深、and() 噪音 | ✅ 扁平、语义清晰 |
| 可维护性 | ❌ 易因 and() 错位出错 | ✅ 作用域隔离 |
| 扩展性 | ❌ 单一配置类 | ✅ 多 FilterChain 支持 |
| 现代性 | ❌ 过时 | ✅ 符合 Java 函数式趋势 |
💡 Lambda DSL 不仅是语法更新,更是 Spring Security 向声明式、类型安全、模块化安全配置迈出的关键一步。它降低了配置错误率,提升了大型项目的安全策略可管理性。
建议所有新项目直接采用 Spring Security 6.x 的 Lambda DSL 风格,老项目在升级时也应同步迁移。
RSocket + Spring Boot 如何实现 Reactive 微服务通信?对比 gRPC 有何取舍?
RSocket 与 Spring Boot 结合,为 Reactive(响应式)微服务通信 提供了一种高效、低延迟、双向流友好的新范式。它与 gRPC 同属现代高性能 RPC 框架,但在协议设计、编程模型和适用场景上有显著差异。下面从 实现方式、核心特性、对比分析、选型建议 四方面深入解析。
一、RSocket + Spring Boot 实现 Reactive 微服务通信
✅ 1. 核心概念:RSocket 是什么?
- 应用层协议 (基于 TCP/WebSocket/HTTP/2),支持 4 种交互模型 :
Request-Response(单请求-单响应)Request-Stream(单请求-多响应,如事件流)Fire-and-Forget(单向通知,无响应)Channel(双向流,全双工通信)
- 内置背压(Backpressure):天然支持 Reactive Streams 规范
- 连接复用:单连接承载多路复用请求,减少握手开销
✅ 2. Spring Boot 集成步骤(以 Spring Boot 3.x + Spring for RSocket)
(1)添加依赖(Maven)
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-rsocket</artifactId>
</dependency>(2)服务端:定义 RSocket 接口
java
@Controller
public class UserService {
@MessageMapping("user.findById")
public Mono<User> findById(Integer id) {
return Mono.just(new User(id, "Alice"));
}
@MessageMapping("user.events")
public Flux<UserEvent> userEvents(Integer userId) {
return Flux.interval(Duration.ofSeconds(1))
.map(seq -> new UserEvent(userId, "Event-" + seq));
}
@MessageMapping("user.logs")
public void logEvents(Flux<LogEntry> logs) {
logs.subscribe(log -> System.out.println("Received: " + log));
}
}(3)服务端配置(application.yml)
yaml
spring:
rsocket:
server:
transport: tcp # 或 websocket
port: 7000(4)客户端:调用远程服务
java
@Service
public class UserClient {
private final RSocketRequester.Builder requesterBuilder;
public UserClient(RSocketRequester.Builder requesterBuilder) {
this.requesterBuilder = requesterBuilder;
}
public Mono<User> getUser(int id) {
return requesterBuilder
.tcp("localhost", 7000)
.route("user.findById")
.data(id)
.retrieveMono(User.class);
}
public Flux<UserEvent> streamEvents(int userId) {
return requesterBuilder
.tcp("localhost", 7000)
.route("user.events")
.data(userId)
.retrieveFlux(UserEvent.class);
}
}✅ 关键优势:
- 代码即 Reactive(
Mono/Flux) - 无需生成 stub,直接使用 Java 对象(通过
@MessageMapping路由) - 支持双向流(如实时日志推送、IoT 设备控制)
二、RSocket vs gRPC:核心对比
| 维度 | RSocket | gRPC |
|---|---|---|
| 协议基础 | 应用层协议 (可跑在TCP/WebSocket/HTTP/2) | 基于 HTTP/2 |
| 数据序列化 | 默认用 JSON(可通过 Codec 扩展为 Protobuf/CBOR) | 强制 Protobuf(强类型、高效) |
| 交互模型 | 4 种(含双向流 Channel) | 4 种(Unary, Server Streaming, Client Streaming, Bidirectional Streaming) |
| 背压支持 | ✅ 内置 Reactive Streams 背压 | ⚠️ 需手动实现(gRPC-Java 提供 FlowControl) |
| 服务发现/负载均衡 | 需集成 Spring Cloud LoadBalancer 或自定义 | 生态完善(gRPC + Consul/Etcd + xDS) |
| 跨语言支持 | 中等(官方支持 Java/JS/C++/Kotlin,社区版有限) | ✅ 极强(官方支持 10+ 语言) |
| 调试工具 | 较少(rsc CLI 工具) | ✅ 丰富(grpcurl, BloomRPC, Postman 支持) |
| Spring 集成 | ✅ 原生支持(Spring for RSocket) | 需额外库(如 grpc-spring-boot-starter ) |
| 防火墙穿透 | ✅ 可走 WebSocket(兼容 Web 网关) | ❌ HTTP/2 在部分代理/CDN 下受限 |
三、关键取舍分析
✅ 选择 RSocket 的场景:
- 纯 Reactive 系统:全链路基于 Project Reactor/WebFlux,追求端到端背压
- 双向实时通信:如 IoT 设备管理、实时协作编辑、金融行情推送
- 避免 Protobuf 约束:希望用 JSON 快速迭代,或已有大量 POJO
- WebSocket 兼容需求:需同时支持浏览器(通过 RSocket over WebSocket)
✅ 选择 gRPC 的场景:
- 多语言微服务:Go/Python/C++ 服务需与 Java 互通
- 强契约 & 高性能:Protobuf 提供严格接口定义 + 高效序列化
- 生产级运维:需要成熟的监控(Prometheus)、追踪(OpenTelemetry)、网关(Envoy)
- 云原生生态:Kubernetes + Istio/Linkerd 原生支持 gRPC
四、实战建议
🔧 RSocket 最佳实践:
- 使用 Protobuf Codec 提升性能(即使选 RSocket,也可不用 JSON):
java
@Bean
public RSocketStrategies rSocketStrategies() {
return RSocketStrategies.builder()
.encoders(encoders -> encoders.add(new ProtobufEncoder()))
.decoders(decoders -> decoders.add(new ProtobufDecoder()))
.build();
}- 连接池管理 :客户端复用
RSocketRequester实例,避免频繁建连 - 错误处理 :通过
onErrorResume处理连接中断
⚠️ RSocket 注意事项:
- 无内置服务治理:需自行实现熔断(Resilience4j)、重试、负载均衡
- 调试困难:缺乏类似 gRPC 的 GUI 工具
- 社区生态较小:相比 gRPC,生产案例较少
五、总结:如何选?
| 你的系统特点 | 推荐 |
|---|---|
| 全 Java/Reactive 技术栈,强实时双向通信 | ✅ RSocket |
| 多语言、强契约、高吞吐、云原生 | ✅ gRPC |
| 需要浏览器直连(WebSocket) | ✅ RSocket |
| 团队熟悉 Protobuf,追求极致性能 | ✅ gRPC |
| 快速原型验证,用 JSON 更灵活 | ✅ RSocket |
💡 混合架构也是选项:
- 内部服务间用 gRPC(高性能)
- 对外暴露实时 API 用 RSocket over WebSocket(兼容浏览器)
RSocket 是 Reactive 微服务的"利器",但 gRPC 仍是"工业标准"。选型应基于团队技术栈、运维能力、跨语言需求综合判断,而非单纯看性能指标。
微服务用 Spring Cloud 注册中心 CAP 选择(Eureka AP vs Nacos CP/AP 切换)
在微服务架构中,服务注册与发现 是核心基础设施,而注册中心的 CAP 理论取舍 直接影响系统的可用性、一致性与容错能力。Spring Cloud 生态中,Eureka 和 Nacos 是两种主流选择,它们在 CAP 上的设计哲学截然不同:
- Eureka 坚定选择 AP(高可用 + 分区容忍)
- Nacos 支持 CP 与 AP 模式动态切换(基于 Raft + Distro 协议)
下面从 CAP 理论 → 各注册中心实现 → 场景选型 三个维度深入解析。
一、CAP 理论回顾
CAP 定理 :在分布式系统中,一致性(Consistency)三者不可兼得,最多满足其二。
| 选项 | 含义 | 微服务场景影响 |
|---|---|---|
| C(Consistency) | 所有节点看到的数据一致 | 服务列表实时准确,无脏读 |
| A(Availability) | 系统始终可响应请求 | 注册/发现不因部分节点故障而失败 |
| P(Partition Tolerance) | 网络分区时系统仍运行 | 跨机房、跨 AZ 部署的基础 |
📌 现实 :网络分区(P)不可避免 → 实际是在 CP vs AP 之间权衡。
二、Eureka:坚定的 AP 拥护者
✅ 设计哲学
"宁可返回过期数据,也不拒绝服务请求。"
🔧 核心机制
- Peer-to-Peer 复制 :Eureka Server 节点间异步复制注册信息;
- 自我保护模式 (Self-Preservation):
- 当短时间内大量客户端心跳丢失(如网络抖动),自动进入保护模式;
- 不剔除注册表中的服务实例(即使心跳超时);
- 保证可用性 ,牺牲一致性。
⚠️ 行为表现
| 场景 | Eureka 行为 |
|---|---|
| 网络分区(部分 Server 不可达) | 客户端仍可从本地缓存或存活节点获取服务列表(可能含已下线实例) |
| Server 全部宕机 | 客户端使用本地缓存继续调用(默认缓存 30 秒) |
| 服务实例宕机但未注销 | 列表中仍存在该实例 → 调用可能失败(需配合熔断) |
✅ 适用场景
- 高可用优先:如电商、社交等 C 端业务,容忍短暂服务不一致;
- 网络不稳定环境:如混合云、多 IDC 部署;
- 无强一致性要求:服务列表"最终一致"即可。
三、Nacos:CP 与 AP 的灵活切换
Nacos 采用 双协议模型,根据数据类型自动选择一致性协议:
| 数据类型 | 协议 | CAP 模式 | 用途 |
|---|---|---|---|
| 临时实例(ephemeral) | Distro 协议(AP) | AP | 服务发现(如 Spring Cloud 服务) |
| 持久化实例(persistent) | Raft 协议(CP) | CP | 配置中心、DNS 域名等 |
💡 默认情况下,Spring Cloud 服务注册为临时实例 → 使用 AP 模式。
🔧 如何切换?
- 临时实例(AP):
yaml
spring:
cloud:
nacos:
discovery:
ephemeral: true # 默认值- 持久化实例(CP):
yaml
spring:
cloud:
nacos:
discovery:
ephemeral: false⚠️ CP 模式行为(Raft)
- 所有写操作(注册/注销)需 多数派确认;
- 网络分区时,少数派节点拒绝写入;
- 保证注册表强一致 ,但可用性降低。
✅ Nacos 优势
- 按需选择:服务发现用 AP(高性能),配置管理用 CP(强一致);
- 健康检查更丰富:支持 TCP/HTTP/MySQL 心跳;
- 控制台功能强大:服务治理、元数据管理、流量权重等。
四、对比总结:Eureka vs Nacos(CAP 视角)
| 特性 | Eureka | Nacos(临时实例) | Nacos(持久实例) |
|---|---|---|---|
| CAP 模式 | AP | AP | CP |
| 一致性 | 最终一致 | 最终一致 | 强一致 |
| 可用性 | 极高(自我保护) | 高 | 分区时降低 |
| 网络分区容忍 | ✅ 返回可能过期数据 | ✅ 返回可能过期数据 | ❌ 少数派不可写 |
| 典型场景 | Spring Cloud Netflix | Spring Cloud Alibaba | 配置中心、DNS |
| 是否支持切换 | ❌ 固定 AP | ✅ 可通过 ephemeral切换 |
五、如何选择?------ 场景驱动决策
✅ 选 Eureka 如果:
- 已深度使用 Spring Cloud Netflix 技术栈;
- 业务对服务列表实时性要求不高(如允许 30 秒延迟);
- 追求极致可用性,能接受短暂调用失败(由熔断器兜底);
- 团队熟悉 Eureka 运维。
✅ 选 Nacos 如果:
- 新项目,希望统一注册中心 + 配置中心;
- 需要灵活切换一致性模型(如核心服务用 CP,边缘服务用 AP);
- 需要高级服务治理能力(如金丝雀发布、元数据路由);
- 使用 Dubbo 或 Spring Cloud Alibaba 生态。
💡 特别注意 :
即使 Nacos 默认是 AP,其 Distro 协议比 Eureka 的异步复制更高效(分片同步 + 推拉结合),在大规模集群下性能更好。
六、最佳实践建议
- 不要盲目追求 CP
服务发现场景通常不需要强一致 ------一个已下线的服务实例被短暂调用,可通过重试 + 熔断快速恢复,比"注册中心不可用"更可接受。 - AP 模式必须配合客户端容错
- 使用 Ribbon / LoadBalancer + Retry 自动重试其他实例;
- 集成 Sentinel / Hystrix 熔断异常服务。
- 监控注册中心健康度
- 跟踪服务注册/发现延迟;
- 告警"大量实例心跳丢失"事件。
- Nacos 生产部署建议
- 临时实例(AP):3 节点集群足够;
- 持久实例(CP):至少 3 节点(Raft 要求多数派)。
七、结语:没有"最好",只有"最合适"
- Eureka 是 AP 的纯粹践行者,简单、稳定、高可用,在 Netflix 生态中久经考验;
- Nacos 是现代化注册中心的代表,AP/CP 双模支持 + 配置中心一体化,更适合云原生新架构。
📌 关键决策点 :
你的业务能否容忍"服务列表短暂不一致"?
- 能 → 选 AP(Eureka 或 Nacos 临时实例);
- 不能(如金融交易路由)→ 选 CP(Nacos 持久实例 + 严格运维)。
在绝大多数互联网微服务场景中,AP 模式 + 客户端容错 是更务实、更高效的选择。
七、系统设计 & 场景题(2025 真实高频)
设计一个分布式 ID 生成器,要求:全局唯一、趋势递增、高可用。对比 Snowflake、Leaf、UUID v7。
设计一个满足 全局唯一、趋势递增、高可用 的分布式 ID 生成器,是现代高并发系统(如订单、支付、消息队列)的核心基础设施。下面从 设计目标 → 主流方案对比 → 推荐架构 展开,并深入分析 Snowflake、美团 Leaf、UUID v7 的优劣。
一、核心设计要求解析
| 要求 | 说明 |
|---|---|
| 全局唯一 | 在分布式集群中永不重复(即使跨机房、跨服务) |
| 趋势递增 | ID 大致随时间增长(非严格连续),利于数据库索引性能(避免页分裂) |
| 高可用 | 无单点故障,容忍节点宕机、网络分区 |
| 高性能 | 单机 QPS ≥ 10万+,低延迟(<1ms) |
| 可扩展 | 支持动态扩缩容(如新增机器) |
⚠️ 注意:"趋势递增" ≠ "连续递增" ------ 允许跳跃,但整体方向向上。
二、主流方案深度对比
✅ 1. Snowflake(Twitter)
原理
64 位 ID 结构:
plain
| 1位符号位 | 41位时间戳(ms) | 10位工作节点ID | 12位序列号 |- 时间戳:约 69 年(2^41 / 1000 / 3600 / 24 / 365)
- 工作节点:最多 1024 台机器(2^10)
- 序列号:每毫秒最多 4096 个 ID(2^12)
优点
- 简单高效,纯内存生成,QPS 高
- 趋势递增(按时间排序)
- 无外部依赖
缺点
- 时钟回拨问题:系统时间被调慢 → 生成重复 ID 或拒绝服务
- 节点 ID 需预分配:运维复杂(需 ZooKeeper/DB 管理)
- 无法动态扩容:节点 ID 固定,新增机器需重启配置
高可用性
- ❌ 单机无 HA;集群需外部协调(如 ZooKeeper 分配 workerId)
✅ 2. 美团 Leaf(Segment + Snowflake 双模式)
(1)Leaf-Segment(推荐用于 DB 场景)
- 每次从 DB 获取一个 ID 段(如 [1000, 2000))
- 内存中自增分配,用完再取下一段
- DB 表结构:
sql
CREATE TABLE leaf_alloc (
biz_tag VARCHAR(128) NOT NULL, -- 业务标识(如 order_id)
max_id BIGINT NOT NULL DEFAULT '1',
step INT NOT NULL, -- 段大小(如 1000)
...
);(2)Leaf-Snowflake
- 改进版 Snowflake:用 ZooKeeper 持久化 workerId
- 启动时自动注册,避免冲突
- 加入 时钟回拨检测与等待机制
优点
- Segment 模式无时钟依赖,彻底解决回拨问题
- 双 buffer 优化:后台预加载下一段,避免取段时阻塞
- 支持多业务隔离(biz_tag)
- 高可用(DB 主从 + 重试)
缺点
- Segment 模式 ID 非严格趋势递增(不同段可能乱序)
- 依赖 DB/ZooKeeper,增加运维复杂度
高可用性
- ✅ DB 主从 + 连接池重试 → 容忍 DB 瞬时故障
- ✅ ZooKeeper 自动分配 workerId → 动态扩缩容
✅ 3. UUID v7(RFC 9562,2024 新标准)
原理
128 位 ID,结构:
plain
| 48位 Unix 时间戳(ms) | 12位 counter | 48位随机数 |- 时间戳:精确到毫秒
- counter:同一毫秒内自增(防碰撞)
- 随机数:保证全局唯一
优点
- 标准化(IETF RFC),跨语言/平台兼容
- 天然全局唯一(无需中心节点)
- 趋势递增(前 48 位为时间)
- 无运维依赖(纯算法生成)
缺点
- 128 位太长:占用存储/带宽(比 64 位 ID 多 100%)
- 数据库索引效率低:UUID 作为主键易导致页分裂(虽 v7 改善,仍不如数字 ID)
- counter 位数有限:每毫秒最多 4096 个 ID(同 Snowflake)
高可用性
- ✅ 完全去中心化,任意节点独立生成 → 极致高可用
三、关键维度对比表
| 特性 | Snowflake | Leaf-Segment | Leaf-Snowflake | UUID v7 |
|---|---|---|---|---|
| ID 长度 | 64 位 | 64 位 | 64 位 | 128 位 |
| 全局唯一 | ✅(依赖 workerId 唯一) | ✅(DB 保证) | ✅ | ✅ |
| 趋势递增 | ✅(严格按时间) | ⚠️(段间可能乱序) | ✅ | ✅(前 48 位时间) |
| 时钟回拨容忍 | ❌ | ✅ | ⚠️(需等待) | ✅ |
| 高可用 | ❌(需外部协调) | ✅(DB 主从) | ✅(ZK + 重试) | ✅(完全去中心) |
| 依赖外部组件 | ZooKeeper/DB | MySQL | ZooKeeper | ❌ |
| QPS | >50万 | >10万(受 DB 限制) | >50万 | >100万 |
| 适用场景 | 内部系统、可控环境 | 强一致性 DB 主键 | 高性能内部服务 | 跨系统、标准化场景 |
四、推荐设计方案:Leaf-Segment + 双 Buffer + 高可用 DB
架构图
plain
[App] → [ID Generator Service] → [MySQL 主从集群]
↑
(双 Buffer 缓存段)核心逻辑
java
public class SegmentIDGenerator {
private volatile Segment current;
private volatile Segment next; // 后台预加载
public long getNextID(String bizTag) {
if (current.useUp()) {
waitAndSwitch(); // 切换到 next,同时触发加载新段
}
return current.getAndIncrement();
}
@Async
private void preloadNextSegment(String bizTag) {
// 异步从 DB 获取 [max_id + 1, max_id + step]
// 更新 DB 的 max_id = max_id + step
}
}高可用保障
- DB 主从 + MHA:自动故障切换
- 本地缓存降级:若 DB 不可用,继续使用内存中剩余 ID(牺牲部分唯一性保可用)
- 多 IDC 部署 :每个机房独立 DB 实例,通过
biz_tag隔离
为什么选它?
- ✅ 平衡了唯一性、趋势性、可用性
- ✅ ID 为 64 位整数,完美适配 MySQL InnoDB 聚簇索引
- ✅ 无时钟依赖,规避 Snowflake 最大痛点
- ✅ 已被美团、滴滴等大规模验证
五、特殊场景选型建议
| 场景 | 推荐方案 |
|---|---|
| 金融级强一致订单 ID | Leaf-Segment(DB 保证唯一) |
| IoT 设备海量上报 | UUID v7(去中心化 + 标准化) |
| 内部微服务高性能通信 | Leaf-Snowflake(ZK 管理 workerId) |
| 开源项目/跨企业协作 | UUID v7(避免私有协议) |
| 资源极度受限(嵌入式) | 改进版 Snowflake(本地持久化 workerId) |
六、总结
| 方案 | 适合你吗? |
|---|---|
| Snowflake | 仅当你能严格控制时钟 + 静态节点 |
| Leaf-Segment | ✅ 大多数企业级应用的首选(尤其用 MySQL) |
| UUID v7 | ✅ 未来趋势,适合标准化、去中心化场景,但接受 128 位代价 |
💡 终极建议:
- 如果你用 MySQL/PostgreSQL 且需要高性能主键 → Leaf-Segment
- 如果你构建 跨组织 API 或边缘设备系统 → UUID v7
- 避免裸用 Snowflake,除非你已解决时钟回拨和 workerId 分配问题。
通过合理选型,你可以在 唯一性、性能、可用性 之间取得最佳平衡。
百万 QPS 下,如何设计一个防刷限流系统?令牌桶 vs 滑动窗口 vs 集群限流(Redis + Lua)。
在 百万 QPS 的高并发场景下,设计一个高性能、低延迟、高可用的防刷限流系统,是保障系统稳定性与安全性的关键。常见的限流算法包括 令牌桶(Token Bucket) 、滑动窗口(Sliding Window) 和 基于 Redis + Lua 的集群限流 。下面从 原理、性能、一致性、适用场景 四个维度深入对比,并给出百万 QPS 下的推荐架构。
一、核心限流算法对比
✅ 1. 令牌桶(Token Bucket)
原理
- 以固定速率向桶中添加令牌(如 1000 token/s)
- 每次请求消耗 1 个令牌
- 桶有容量上限(burst),允许短时突发流量
优点
- 支持突发流量(平滑限流 + 突发容忍)
- 实现简单(单机内存即可)
- 延迟极低(O(1))
缺点
- 单机限流,无法跨节点共享状态
- 集群下各节点独立计数 → 实际总 QPS = N × 单机阈值(超限!)
百万 QPS 适用性
- ❌ 不适合直接用于分布式场景(需配合中心化存储)
✅ 2. 滑动窗口(Sliding Window Log / Counter)
原理
- 记录每个请求的时间戳(或按时间分片计数)
- 每次请求时,统计 最近 T 秒内 的请求数
- 超过阈值则拒绝
两种实现:
| 类型 | 描述 | 精度 | 内存 |
|---|---|---|---|
| 滑动日志(Log) | 存储所有请求时间戳 | 高(精确到 ms) | 高(QPS×T 条记录) |
| 分片计数(Counter) | 将窗口分为 N 个格子(如 1s/格,共 60 格) | 中(误差 ≤ 1/N) | 低(仅 N 个计数器) |
优点
- 精确控制窗口内流量
- 分片版内存可控
缺点
- 单机实现 → 集群不一致
- 滑动日志版内存爆炸(百万 QPS × 60s = 6000 万条/分钟!)
百万 QPS 适用性
- ❌ 单机滑动窗口无法支撑集群限流
✅ 3. 集群限流:Redis + Lua(推荐方案)
原理
- 所有限流状态存储在 Redis(共享存储)
- 使用 Lua 脚本 保证原子性(避免竞态条件)
- 支持多种算法:令牌桶 、滑动窗口 、漏桶 等
示例:Redis + Lua 实现滑动窗口限流
lua
-- KEYS[1]: 限流 key (如 user:123:api)
-- ARGV[1]: 窗口大小(ms)
-- ARGV[2]: 最大请求数
-- ARGV[3]: 当前时间戳(ms)
local window = tonumber(ARGV[1])
local max_count = tonumber(ARGV[2])
local now = tonumber(ARGV[3])
-- 清除窗口外的旧记录
redis.call('ZREMRANGEBYSCORE', KEYS[1], 0, now - window)
-- 获取当前窗口内请求数
local count = redis.call('ZCARD', KEYS[1])
if count < max_count then
-- 添加当前请求时间戳
redis.call('ZADD', KEYS[1], now, now)
redis.call('EXPIRE', KEYS[1], math.ceil(window / 1000))
return 1 -- 允许
else
return 0 -- 拒绝
end使用 ZSET 存储时间戳,ZREMRANGEBYSCORE 清理过期数据。
优点
- ✅ 全局一致性:所有节点共享同一限流状态
- ✅ 高精度:支持毫秒级窗口
- ✅ 原子性:Lua 脚本单线程执行,无并发问题
- ✅ 灵活:可实现任意限流策略
缺点
- ⚠️ 依赖 Redis:增加外部依赖
- ⚠️ 网络开销:每次请求需 RTT(约 0.5~2ms)
- ⚠️ Redis 成为瓶颈:百万 QPS 需极高 Redis 性能
二、百万 QPS 下的性能挑战与优化
🔥 挑战 1:Redis 单实例 QPS 瓶颈
- 单 Redis 实例极限约 10~20 万 QPS(取决于命令复杂度)
- 百万 QPS 需 多分片 + 多副本
优化方案:
- 分片(Sharding) :按
user_id % N或API + user_id哈希到不同 Redis 实例
java
String shardKey = "rate_limit:" + (userId % 16);- 使用 Redis Cluster:自动分片 + 高可用
- Pipeline / Multi-key Lua:减少网络往返(但限流通常单 key,收益有限)
🔥 挑战 2:Lua 脚本执行开销
ZSET操作在高基数下变慢(如窗口内 10 万请求)
优化方案:
- 改用计数器分片(Counter Sliding Window):
lua
-- 将 1 分钟窗口分为 60 个 1 秒格子
local slot = math.floor(now / 1000) % 60
redis.call('HINCRBY', KEYS[1], slot, 1)
-- 累加最近 60 个 slot 的计数- 内存固定(60 个字段)
- 但精度降低(最大误差 1 秒)- 使用 Redis Streams 或 HyperLogLog(特殊场景)
🔥 挑战 3:缓存穿透 & 热点 Key
- 恶意用户用随机 user_id → 打爆 Redis 内存
优化方案:
- 本地缓存兜底(多级限流):
plain
请求 → 本地令牌桶(快速放行正常流量) → Redis 集群限流(兜底)- 布隆过滤器:过滤无效 user_id
- 热点 Key 自动发现 + 本地缓存
三、推荐架构:多级限流(Local + Remote)
分层策略:
| 层级 | 算法 | 目的 | QPS 承载 |
|---|---|---|---|
| L1:本地限流 | 令牌桶 / 滑动窗口 | 快速拦截明显超限流量,减少 Redis 压力 | 单机 10万+ |
| L2:Redis 集群限流 | Lua 滑动窗口 / 分片计数器 | 全局精确限流 | 百万+(通过分片) |
✅ 优势:
- 正常流量几乎不访问 Redis(本地放行)
- 异常流量由 Redis 兜底,保证全局一致性
- 降级友好:Redis 故障时,本地限流仍生效
四、生产级增强功能
| 功能 | 实现方式 |
|---|---|
| 动态阈值调整 | 通过配置中心(Nacos/Apollo)实时更新限流规则 |
| 熔断降级 | Redis 不可用时,自动切换到宽松本地限流 |
| 监控告警 | 记录限流日志,对接 Prometheus + Grafana |
| 黑白名单 | 在限流前优先检查(如 VIP 用户 bypass) |
| 多维度限流 | 同时限制 user_id、IP、API组合 |
五、最终选型建议
| 场景 | 推荐方案 |
|---|---|
| 单机应用 / 低并发 | Guava RateLimiter(令牌桶) |
| 中小集群(<10万 QPS) | Redis + Lua 滑动窗口 |
| 百万 QPS 高并发 | ✅ 多级限流:本地令牌桶 + Redis 分片集群(Lua 分片计数器) |
| 超低延迟要求(<0.1ms) | 纯本地限流 + 异步上报统计(牺牲部分一致性) |
| 防 CC 攻击(IP 级) | L1 本地 IP 限流 + L2 Redis 全局 IP 限流 |
六、总结
| 方案 | 是否适合百万 QPS |
|---|---|
| 单机令牌桶 | ❌(无全局视图) |
| 单机滑动窗口 | ❌(内存爆炸 + 无集群一致性) |
| Redis + Lua(单实例) | ❌(Redis QPS 瓶颈) |
| ✅** Redis Cluster + 分片 + 多级限流** | ✅ 唯一可行方案 |
💡 核心思想 :
"本地快速放行,远程精准兜底" ------ 用分层架构平衡性能、一致性与可用性。
通过 分片 Redis 集群 + Lua 原子脚本 + 本地缓存 的组合,可稳定支撑百万 QPS 的防刷限流需求,同时具备高可用、可扩展、可监控的生产级能力。
订单超时未支付自动取消,如何用 DelayQueue / RabbitMQ TTL / 时间轮 实现?各方案优劣?
订单超时未支付自动取消是电商、票务等系统的核心场景。其本质是 "延迟任务" :在订单创建后 N 分钟(如 30 分钟)若未支付,则自动触发取消逻辑。下面对比三种主流实现方案:Java DelayQueue 、RabbitMQ TTL + 死信队列 、时间轮(Timing Wheel),分析其原理、代码示例、优劣及适用场景。
一、方案 1:Java DelayQueue(单机内存方案)
✅ 原理
DelayQueue是 Java 并发包提供的无界阻塞队列 ,元素需实现Delayed接口- 队列按 过期时间排序 ,只有到期的元素才能被
take()取出 - 后台线程循环消费队列,处理超时订单
✅ 代码示例
java
// 订单延迟任务
public class OrderTimeoutTask implements Delayed {
private final String orderId;
private final long expireTime; // 过期时间戳(ms)
public OrderTimeoutTask(String orderId, long delayMs) {
this.orderId = orderId;
this.expireTime = System.currentTimeMillis() + delayMs;
}
@Override
public long getDelay(TimeUnit unit) {
return unit.convert(expireTime - System.currentTimeMillis(), TimeUnit.MILLISECONDS);
}
@Override
public int compareTo(Delayed o) {
return Long.compare(this.expireTime, ((OrderTimeoutTask) o).expireTime);
}
public void process() {
// 检查订单是否已支付,若未支付则取消
orderService.cancelIfUnpaid(orderId);
}
}
// 启动消费者线程
@Component
public class DelayQueueConsumer {
private final DelayQueue<OrderTimeoutTask> queue = new DelayQueue<>();
@PostConstruct
public void start() {
Thread consumer = new Thread(() -> {
while (!Thread.currentThread().isInterrupted()) {
try {
OrderTimeoutTask task = queue.take(); // 阻塞直到有任务到期
task.process();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
});
consumer.setDaemon(true);
consumer.start();
}
public void addOrder(String orderId, long delayMs) {
queue.offer(new OrderTimeoutTask(orderId, delayMs));
}
}⚠️ 优点
- 简单轻量:无需外部依赖
- 低延迟:任务到期立即处理(毫秒级)
- 内存操作:性能极高(单机 QPS 万级+)
❌ 缺点
- 单机内存存储 :应用重启 → 任务丢失(不保证可靠性)
- 无法水平扩展:集群下各节点独立,任务分散
- 内存泄漏风险:大量订单堆积 → OOM
📌 适用场景
- 测试环境 / 低可靠要求场景
- 短延迟 + 小规模订单(如内部工具)
二、方案 2:RabbitMQ TTL + 死信队列(分布式可靠方案)
✅ 原理
- 创建一个 死信交换机(DLX) 和 死信队列(DLQ)
- 主队列设置:
x-message-ttl:消息存活时间(如 1800000 ms = 30 分钟)x-dead-letter-exchange:指向 DLX
- 发送订单消息时,不设 TTL,由队列统一控制
- 消息过期后自动进入 DLQ,消费者监听 DLQ 执行取消逻辑
💡 关键:TTL 由队列设置,而非消息,避免动态 TTL 导致队列乱序(RabbitMQ 3.8+ 支持 per-message TTL 但仍有问题)
✅ 代码示例(Spring Boot)
声明队列
java
@Configuration
public class RabbitMQConfig {
@Bean
public Queue orderDelayQueue() {
return QueueBuilder.durable("order.delay.queue")
.withArgument("x-message-ttl", 1800000) // 30分钟
.withArgument("x-dead-letter-exchange", "order.dlx.exchange")
.withArgument("x-dead-letter-routing-key", "order.cancel")
.build();
}
@Bean
public DirectExchange dlxExchange() {
return new DirectExchange("order.dlx.exchange");
}
@Bean
public Queue orderCancelQueue() {
return QueueBuilder.durable("order.cancel.queue").build();
}
@Bean
public Binding dlxBinding() {
return BindingBuilder.bind(orderCancelQueue())
.to(dlxExchange()).with("order.cancel");
}
}发送订单
java
@Service
public class OrderService {
@Autowired
private RabbitTemplate rabbitTemplate;
public void createOrder(String orderId) {
// 1. 保存订单(状态=待支付)
// 2. 发送延迟消息(无 TTL,由队列控制)
rabbitTemplate.convertAndSend("order.delay.queue", orderId);
}
}处理超时
java
@RabbitListener(queues = "order.cancel.queue")
public void handleCancel(String orderId) {
// 检查是否已支付,若未支付则取消
orderService.cancelIfUnpaid(orderId);
}⚠️ 优点
- 高可靠:消息持久化,应用重启不丢失
- 天然分布式:支持集群消费
- 解耦:订单服务与取消逻辑分离
❌ 缺点
- 精度问题 :RabbitMQ 不保证准时(过期消息需被"扫描"到才投递,高负载下延迟可能达数秒~分钟)
- 资源占用:每笔订单一条消息,百万订单 → 百万消息堆积
- 运维复杂:需维护 RabbitMQ 集群
📌 适用场景
- 中等规模、要求可靠性的业务
- 可容忍秒级延迟
三、方案 3:时间轮(Timing Wheel)------ 高性能方案
✅ 原理
- 模拟"手表"结构:多个环形槽(slot),每个 slot 代表一个时间单位(如 1 秒)
- 任务根据延迟时间放入对应 slot
- 指针每秒转动一格,处理当前 slot 中的所有任务
- 支持多层时间轮(如秒轮、分轮、时轮)处理长延迟
🌰 例如:30 分钟延迟 → 放入"分轮"的第 30 个 slot
✅ 实现方式
- 自研:复杂(需处理扩容、任务迁移)
- 使用成熟库 :如 **Netty 的 **
**HashedWheelTimer**
✅ 代码示例(Netty HashedWheelTimer)
java
@Component
public class TimingWheelOrderTimeout {
private final HashedWheelTimer timer = new HashedWheelTimer(
Executors.defaultThreadFactory(),
1, TimeUnit.SECONDS, // tickDuration = 1s
60 // wheelSize = 60 slots (1分钟)
);
public void scheduleCancel(String orderId) {
Timeout timeout = timer.newTimeout(timeoutTask -> {
orderService.cancelIfUnpaid(orderId);
}, 30, TimeUnit.MINUTES); // 30分钟后执行
// 可选:保存 timeout 引用,用于支付成功时 cancel
timeoutMap.put(orderId, timeout);
}
public void cancelTimeout(String orderId) {
Timeout timeout = timeoutMap.remove(orderId);
if (timeout != null) {
timeout.cancel(); // 支付成功,取消定时任务
}
}
}⚠️ 优点
- 高性能 :O(1) 调度,单机轻松支撑 百万级定时任务
- 低内存:任务只存引用,不复制数据
- 支持取消:支付成功可主动取消任务
❌ 缺点
- 单机内存方案:重启丢失任务(同 DelayQueue)
- 长延迟需多层轮:Netty 默认只支持短延迟(需自行扩展)
- 无持久化:不适合强一致性场景
📌 适用场景
- 高频短延迟任务(如游戏技能 CD、缓存刷新)
- 可接受任务丢失的场景
四、终极对比表
| 维度 | DelayQueue | RabbitMQ TTL | 时间轮(HashedWheelTimer) |
|---|---|---|---|
| 可靠性 | ❌(内存,重启丢失) | ✅(持久化) | ❌(内存) |
| 分布式支持 | ❌ | ✅ | ❌ |
| 延迟精度 | ✅(毫秒级) | ⚠️(秒~分钟级,非准时) | ✅(tick 精度,如 1s) |
| 吞吐能力 | 高(单机万级) | 中(受限于 MQ) | ✅ 极高(单机百万级) |
| 任务取消 | ❌(难实现) | ⚠️(需额外设计) | ✅(原生支持) |
| 运维复杂度 | 低 | 高(需 MQ 集群) | 低 |
| 适用延迟 | 任意 | 任意 | 短延迟(< 几小时) |
五、生产级推荐方案:分层架构 + 补偿机制
🎯 核心思想:"快速响应 + 最终一致"
为什么?
- 时间轮 :提供快速、低延迟的主路径(99% 订单在此处理)
- DB + 定时 Job :作为兜底补偿,解决应用重启/崩溃导致的任务丢失
- 支付成功时:主动取消时间轮任务 + 删除 DB 记录
优势
- ✅ 高性能(时间轮)
- ✅ 高可靠(DB 补偿)
- ✅ 低成本(无需 MQ)
💡 若业务要求强一致性 (如金融),可增加 Redis 分布式锁 防止重复取消。
六、总结:如何选?
| 你的场景 | 推荐方案 |
|---|---|
| 单机、测试、低可靠 | DelayQueue |
| 中小规模、需可靠、可容忍延迟 | RabbitMQ TTL |
| 高频、短延迟、可丢任务 | 时间轮(HashedWheelTimer) |
| ✅** 生产级电商系统** | 时间轮 + DB 补偿 Job(分层架构) |
🚫 不要裸用单一方案 !
百万订单系统必须考虑 故障恢复、任务丢失、重复执行 三大问题。
通过 "内存快速处理 + 持久化兜底" 的组合,你可以在性能、可靠性、成本之间取得最佳平衡。
MySQL 单表 5 亿数据,如何优化分页查询(如 SELECT * FROM orders LIMIT 1000000, 10)?
当 MySQL 单表数据量达到 5 亿行 时,传统的 LIMIT offset, size 分页查询(如 LIMIT 1000000, 10)会严重性能退化 ,甚至导致数据库雪崩。这是因为 MySQL 需要先扫描并跳过前 100 万行,再返回 10 行,IO 和 CPU 消耗巨大。
下面从 问题根源 → 优化方案 → 实战建议 系统讲解如何高效分页。
一、为什么 LIMIT 1000000, 10 会慢?
执行过程(无索引或仅主键索引):
sql
SELECT * FROM orders ORDER BY id LIMIT 1000000, 10;- MySQL 按
id排序(假设id是主键) - 逐行读取前 1,000,010 行
- 丢弃前 1,000,000 行,只返回最后 10 行
📉 时间复杂度 O(offset + size) ,offset 越大越慢
💥 在 5 亿表中,LIMIT 1000000, 10 可能需要 数秒甚至数十秒
即使有索引,回表查询(二级索引 → 主键 → 聚簇索引)也会放大 IO。
二、核心优化思路:避免 OFFSET,改用"锚点"查询
不再跳过 N 行,而是记住上一页最后一条记录的位置,作为下一页的起点。
三、推荐方案详解
✅ 方案 1:基于主键/唯一索引的 游标分页(Cursor-based Pagination)
原理
- 第一页:
SELECT * FROM orders ORDER BY id LIMIT 10; - 第二页:
SELECT * FROM orders WHERE id > [上一页最大id] ORDER BY id LIMIT 10; - 以此类推
示例
sql
-- 第一页
SELECT * FROM orders ORDER BY id LIMIT 10;
-- 假设最后一条 id = 10086
-- 第二页
SELECT * FROM orders WHERE id > 10086 ORDER BY id LIMIT 10;优点
- ✅ O(log N) 复杂度(走索引)
- ✅ 性能稳定,与 offset 无关
- ✅ 支持任意深度分页
缺点
- ❌ 不支持随机跳页(如直接跳到第 100 万页)
- ❌ 要求排序字段单调递增且唯一(主键最佳)
💡 若按非唯一字段排序(如 create_time),需组合主键保证唯一性:
sql
SELECT * FROM orders
WHERE (create_time, id) > ('2023-01-01 12:00:00', 10086)
ORDER BY create_time, id
LIMIT 10;✅ 方案 2:延迟关联(Deferred Join) ------ 适用于必须用 OFFSET 的场景
原理
- 先通过覆盖索引快速定位主键
- 再用主键回表取完整数据
示例
sql
-- 假设有索引 idx_create_time(create_time, id)
SELECT o.*
FROM orders o
INNER JOIN (
SELECT id
FROM orders
ORDER BY create_time
LIMIT 1000000, 10
) tmp ON o.id = tmp.id
ORDER BY o.create_time;为什么快?
- 子查询
SELECT id只查索引树(无需回表),速度极快 - 外层只回表 10 次(而非 100 万+10 次)
适用条件
- ✅ 排序字段有覆盖索引(包含主键)
- ⚠️ 仍需扫描 offset 行索引,但比全表快 10~100 倍
📊 实测:5 亿表 LIMIT 1000000, 10
- 原始查询:12.3 秒
- 延迟关联:0.8 秒
✅ 方案 3:业务层缓存 + 预生成页码
适用场景
热门分页(如首页、前 100 页)
实现
- 启动定时任务,将前 N 页数据预加载到 Redis
bash
# Redis 存储
orders:page:1 → [row1, row2, ..., row10]
orders:page:2 → [row11, ..., row20]- 查询时优先读缓存,缓存未命中再查 DB
优点
- ✅ 毫秒级响应
- ✅ 减轻 DB 压力
缺点
- ❌ 仅适合固定排序 + 低频变更的数据
- ❌ 无法解决深度分页问题
✅ 方案 4:分库分表(Sharding) ------ 终极扩展方案
原理
- 将 5 亿数据拆到多个物理表(如 10 个库 × 10 个表 = 100 分片)
- 每个分片仅 500 万数据
- 分页时并行查询所有分片,再归并排序
工具
- ShardingSphere(Apache 开源)
- MyCat
- Vitess(YouTube 开源)
示例(ShardingSphere)
sql
-- 逻辑 SQL
SELECT * FROM orders ORDER BY create_time LIMIT 1000000, 10;
-- 实际执行:向 100 个分片发送
-- SELECT * FROM orders_{0..99} ORDER BY create_time LIMIT 1000000, 10;
-- 然后内存归并优点
- ✅ 水平扩展,突破单机瓶颈
- ✅ 深度分页性能线性提升
缺点
- ❌ 架构复杂,运维成本高
- ❌ 跨分片排序/分页需内存归并,仍有性能上限
💡 建议:分页深度 ≤ 1 万行用方案 1/2;> 1 万行考虑分库分表 + 游标分页。
四、其他关键优化技巧
🔧 1. 确保排序字段有高效索引
- 最佳:
(sort_column, id)覆盖索引 - 避免:
SELECT *无索引排序 → filesort(磁盘临时表)
🔧 2. 减少返回字段
- 避免
SELECT *,只查必要字段 - 减少网络传输和内存占用
🔧 3. 限制最大分页深度
- 业务上禁止跳转到 10 万页以后
- 前端提示:"仅支持查看前 10000 条"
🔧 4. 使用近似分页(Approximate Pagination)
- 对于统计类场景,可用
TABLESAMPLE(MySQL 不支持,PostgreSQL 支持) - 或采样估算总数,不精确分页
五、方案对比总结
| 方案 | 适用场景 | 是否支持跳页 | 性能 | 复杂度 |
|---|---|---|---|---|
| 游标分页 | ✅ 深度分页、实时数据 | ❌ 仅下一页 | ⚡️ 极快 | 低 |
| 延迟关联 | ⚠️ 必须用 OFFSET | ✅ | 快(比原始快 10x) | 中 |
| 缓存预加载 | ✅ 热门页(前 N 页) | ✅ | ⚡️ 毫秒级 | 低 |
| 分库分表 | ✅ 超大规模(>10 亿) | ⚠️ 有限支持 | 快(但归并开销) | 高 |
六、终极建议:组合使用
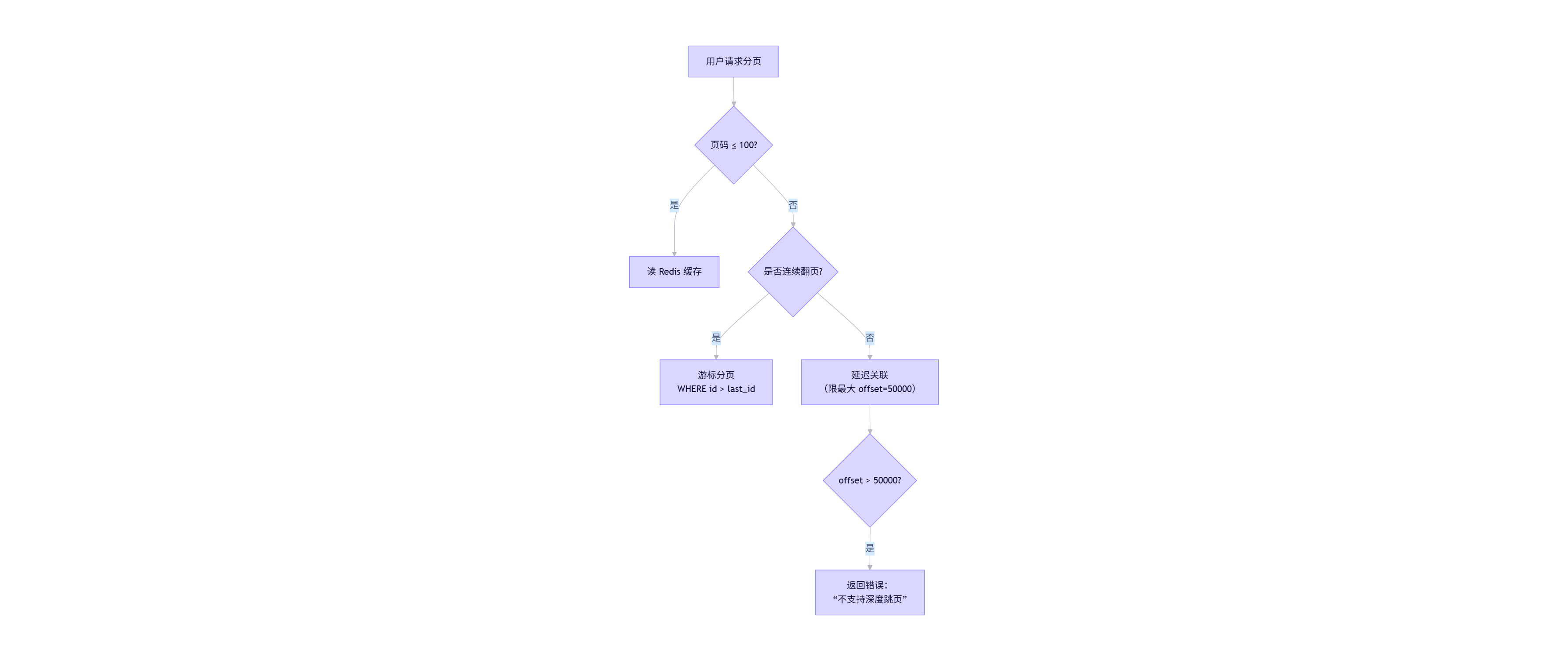
为什么?
- 90% 用户只看前几页 → 缓存搞定
- 连续翻页 → 游标分页极致性能
- 偶尔跳页 → 延迟关联兜底
- 恶意深度跳页 → 直接拒绝,保护系统
七、附:游标分页前端实现示例
javascript
// 前端存储最后一条 ID
let lastId = null;
async function loadNextPage() {
const url = lastId
? `/api/orders?after_id=${lastId}&limit=10`
: `/api/orders?limit=10`;
const data = await fetch(url).then(r => r.json());
lastId = data[data.length - 1].id; // 更新锚点
render(data);
}✅ 完美匹配后端游标分页,用户体验流畅。
总结
面对 5 亿级大表分页:
- 首选游标分页(基于主键/唯一索引)
- 必须用 OFFSET 时 → 延迟关联 + 覆盖索引
- 深度分页无业务价值 → 直接限制
- 超大规模 → 分库分表 + 游标
永远不要在生产环境裸跑 **LIMIT 1000000, 10**! 通过合理设计,5 亿数据也能毫秒级分页。
如何用布隆过滤器 + 缓存空值 解决缓存穿透?布隆过滤器误判率如何计算?
缓存穿透是指大量请求查询一个不存在的数据(如恶意攻击或爬虫探测),导致每次请求都穿透缓存,直接打到数据库,可能压垮后端系统。
解决缓存穿透的经典组合方案是:布隆过滤器(Bloom Filter) + 缓存空值(Cache Null) 。下面从 原理、实现、误判率计算、优劣对比 四方面深入解析。
一、缓存穿透问题示例
java
// 伪代码:典型缓存读取逻辑
public User getUser(Long id) {
User user = cache.get("user:" + id);
if (user != null) return user;
user = db.query(id); // ⚠️ 若 id 不存在,db 返回 null
if (user != null) {
cache.set("user:" + id, user, TTL);
}
return user; // 返回 null
}问题:
- 攻击者请求
id=999999999(不存在) - 每次都穿透缓存 → 数据库 QPS 暴增 → DB 崩溃
二、解决方案 1:缓存空值(Cache Null)
✅ 原理
- 即使 DB 返回
null,也在缓存中存储一个空对象 (如"{}"或特殊标记) - 设置较短 TTL(如 2~5 分钟),避免长期占用内存
✅ 代码实现
java
public User getUser(Long id) {
String key = "user:" + id;
String cached = cache.get(key);
if (cached != null) {
return cached.equals(NULL_PLACEHOLDER) ? null : parseUser(cached);
}
User user = db.query(id);
if (user != null) {
cache.setex(key, TTL, serialize(user));
} else {
// 缓存空值,防止穿透
cache.setex(key, SHORT_TTL, NULL_PLACEHOLDER); // SHORT_TTL = 120s
}
return user;
}⚠️ 优点
- 简单有效,100% 阻断已知无效 key
- 实现成本低
❌ 缺点
- 内存浪费:若攻击者使用海量随机 key(如 UUID),缓存被无效数据占满
- 无法防御未知 key:新生成的无效 key 仍会穿透
💡 适合:无效 key 有限且可预测 的场景(如用户 ID 范围固定)
三、解决方案 2:布隆过滤器(Bloom Filter)
✅ 原理
- 布隆过滤器是一个概率型数据结构 ,用于快速判断"一个元素一定不存在 or 可能存在"
- 特点 :
- ✅ 如果返回 "不存在" → 100% 不存在(无假阴性)
- ⚠️ 如果返回 "存在" → 可能存在(有假阳性/误判)
🔑 关键 :布隆过滤器只加载DB 中真实存在的 key(如所有用户 ID)
✅ 代码实现(Redis + RedisBloom 模块)
bash
# 启动 Redis 时加载 RedisBloom 模块
redis-server --loadmodule /path/to/redisbloom.so
java
// 初始化:将所有存在的 user_id 加入布隆过滤器
public void preloadUserIds() {
List<Long> allUserIds = db.getAllUserIds();
for (Long id : allUserIds) {
redis.bfAdd("user_bf", id.toString());
}
}
// 查询时先过布隆过滤器
public User getUser(Long id) {
if (!redis.bfExists("user_bf", id.toString())) {
return null; // 100% 不存在,直接返回
}
// 后续走正常缓存逻辑(含空值缓存)
return getUserFromCacheOrDB(id);
}📦 若不用 RedisBloom,可用 Guava 的 BloomFilter(但重启丢失,需配合持久化)
四、布隆过滤器误判率(False Positive Rate)计算
核心公式
布隆过滤器的误判率由三个参数决定:
- n:插入的元素数量
- m:位数组总位数(bit)
- k:哈希函数个数

✅ 实用计算示例
场景:
- 预计存储
n = 1 亿个用户 ID - 要求误判率
P ≤ 0.1%(即 0.001)
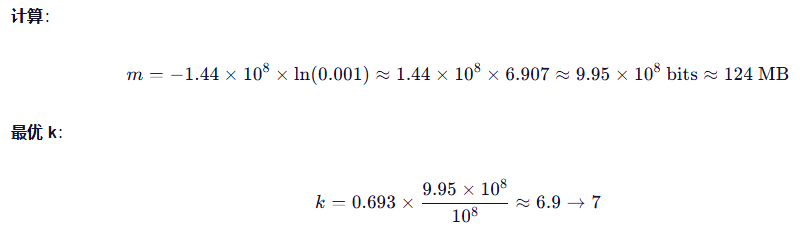
✅ 结论:1 亿数据 + 0.1% 误判率 ≈ 180MB 内存
📊 常见配置参考表
| 元素数量 (n) | 误判率 § | 所需内存 (m) | 哈希函数 (k) |
|---|---|---|---|
| 100 万 | 1% | ~1.2 MB | 7 |
| 1000 万 | 0.1% | ~18 MB | 10 |
| 1 亿 | 0.1% | ~180 MB | 10 |
| 10 亿 | 0.01% | ~2.4 GB | 13 |
💡 内存消耗远小于存储原始 key(1 亿个 Long ID 需 800MB,而 BF 仅 180MB)
五、布隆过滤器 vs 缓存空值:如何选?
| 维度 | 布隆过滤器 | 缓存空值 |
|---|---|---|
| 防御范围 | ✅ 所有无效 key(包括未知) | ❌ 仅已访问过的无效 key |
| 内存效率 | ✅ 极高(bit 级存储) | ❌ 低(每个 key 存完整字符串) |
| 误判风险 | ⚠️ 有(但可控) | ❌ 无 |
| 实现复杂度 | 中(需预加载 + 维护) | 低 |
| 动态更新 | ⚠️ 不支持删除(需计数布隆过滤器) | ✅ 支持 TTL 自动过期 |
六、生产级最佳实践:组合使用
java
public User getUser(Long id) {
// 1. 布隆过滤器快速拦截明显无效请求
if (!bloomFilter.mightContain(id)) {
return null;
}
// 2. 查缓存(含空值)
String key = "user:" + id;
String cached = cache.get(key);
if (cached != null) {
return cached.equals(NULL_VAL) ? null : deserialize(cached);
}
// 3. 查 DB
User user = db.query(id);
if (user != null) {
cache.setex(key, TTL, serialize(user));
} else {
// 缓存空值(即使布隆过滤器说"可能存在",实际也可能不存在)
cache.setex(key, SHORT_TTL, NULL_VAL);
}
return user;
}为什么组合?
- 布隆过滤器:挡掉 99% 的恶意随机 key(节省 DB 和缓存资源)
- 缓存空值 :处理布隆过滤器的误判 case(即 BF 说存在,但 DB 实际不存在)
✅ 二者互补,形成双重防护
七、注意事项
- 布隆过滤器需预热:服务启动时加载全量有效 key
- 数据变更需同步 :
- 新增数据 →
bloomFilter.add(key) - 删除数据 → 标准 BF 不支持删除 !
→ 改用 Counting Bloom Filter(每个 bit 改为 counter)
- 新增数据 →
- 不要缓存所有空值:设置合理 TTL,避免内存爆炸
- 监控误判率 :通过日志统计
BF 说存在但 DB 为空的比例
总结
| 方案 | 作用 | 适用场景 |
|---|---|---|
| 缓存空值 | 防御重复无效请求 | 无效 key 少、可预测 |
| 布隆过滤器 | 防御海量随机无效请求 | 大规模系统、高安全要求 |
| ✅** 组合方案** | 全面防护 + 资源优化 | 生产环境推荐 |
🔑 核心思想 :
"布隆过滤器做粗筛,缓存空值做兜底" ------ 用极低成本拦截绝大多数穿透请求,同时保证正确性。
通过合理配置布隆过滤器参数(n, m, k),可将误判率控制在 0.1% 以下,内存开销远低于传统方案,是高并发系统防御缓存穿透的利器。
八、新兴技术融合(差异化考点)
如何用 Spring AI(官方新项目)集成大模型实现智能客服?Prompt Template 如何管理?
Spring AI 是 Spring 官方于 2024 年推出的大模型(LLM)集成框架 ,旨在为 Java 应用提供统一、简洁、可移植的 AI 调用抽象。它支持 OpenAI、Azure OpenAI、Anthropic、Ollama、Hugging Face 等主流大模型,并内置 Prompt Template 管理、输出解析、流式响应、向量存储等能力。
下面以 智能客服场景 为例,完整演示如何使用 Spring AI + OpenAI 实现一个可维护、可扩展的智能客服系统,并重点讲解 Prompt Template 的最佳管理方式。
一、核心目标:智能客服功能
- 用户输入问题(如"我的订单怎么还没发货?")
- 系统结合业务上下文(如用户 ID、订单状态)生成专业、准确的回复
- 支持结构化输出(便于后续逻辑处理)
- Prompt 可配置、可版本管理、支持多语言
二、项目搭建(Spring Boot 3.2+)
✅ 1. 添加依赖(Maven)
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
<version>0.8.1</version> <!-- 使用最新版 -->
</dependency>💡 其他模型只需替换 starter,如 spring-ai-anthropic-spring-boot-starter
✅ 2. 配置 API Key(application.yml)
yaml
spring:
ai:
openai:
api-key: ${OPENAI_API_KEY}
chat:
options:
model: gpt-4o-mini
temperature: 0.3三、基础实现:简单问答
✅ 1. 注入 ChatClient
java
@Service
public class SimpleAIService {
private final ChatClient chatClient;
public SimpleAIService(ChatClient chatClient) {
this.chatClient = chatClient;
}
public String ask(String question) {
return chatClient.call(question);
}
}⚠️ 但这种方式 硬编码 Prompt,无法维护,不适用于生产。
四、高级实现:使用 Prompt Template + 上下文注入
✅ 1. 定义 Prompt 模板文件(推荐方式)
在 src/main/resources/ai/prompts/ 下创建:
plain
src/
└── main/
└── resources/
└── ai/
└── prompts/
├── customer-service.st
└── customer-service-zh.st // 多语言支持customer-service.st 内容(使用 StringTemplate 语法):
plain
You are a professional customer service agent for "ShopX".
Answer the user's question based on the following context:
User Info:
- Name: {{user.name}}
- Member Level: {{user.level}}
Order Context (if any):
{{#orders}}
- Order ID: {{id}}, Status: {{status}}, Product: {{product}}
{{/orders}}
Rules:
1. Be polite and concise.
2. If you don't know, say "I'll escalate to a human agent."
3. Never mention internal system details.
Question: {{question}}
Answer:📌 Spring AI 默认使用 StringTemplate (由 ANTLR 开发),也支持 Mustache(需配置)。
✅ 2. 创建 Prompt Template Bean
java
@Configuration
public class AiConfig {
@Bean
@Qualifier("customerService")
public PromptTemplate customerServicePromptTemplate(
ApplicationContext applicationContext) {
return new PromptTemplate(
"classpath:ai/prompts/customer-service.st",
applicationContext
);
}
}✅ 3. 构建上下文并调用
java
@Service
public class CustomerServiceAIService {
private final ChatClient chatClient;
private final PromptTemplate promptTemplate;
public CustomerServiceAIService(
ChatClient chatClient,
@Qualifier("customerService") PromptTemplate promptTemplate) {
this.chatClient = chatClient;
this.promptTemplate = promptTemplate;
}
public String handleRequest(Long userId, String question) {
// 1. 获取业务上下文
User user = userService.findById(userId);
List<Order> orders = orderService.findRecentOrders(userId);
// 2. 构建模板变量
Map<String, Object> model = new HashMap<>();
model.put("user", user);
model.put("orders", orders);
model.put("question", question);
// 3. 渲染 Prompt
Prompt prompt = promptTemplate.create(model);
// 4. 调用 LLM
return chatClient.call(prompt).getResult().getOutput().getContent();
}
}五、进阶:结构化输出(JSON Schema)
智能客服常需返回结构化数据(如是否需要转人工、意图分类)。
✅ 1. 定义输出 DTO
java
public class CustomerServiceResponse {
private String reply;
private boolean needHumanAgent;
private String intent; // "shipping", "refund", "complaint"
// getters/setters
}✅ 2. 使用 OutputParser
java
@Service
public class StructuredCustomerService {
private final ChatClient chatClient;
private final PromptTemplate promptTemplate;
public CustomerServiceResponse handleStructured(Long userId, String question) {
// ... 构建 model 同上 ...
Prompt prompt = promptTemplate.create(model);
// 使用 JsonOutputParser 自动解析 JSON
JsonOutputParser<CustomerServiceResponse> outputParser =
new JsonOutputParser<>(CustomerServiceResponse.class);
// 构建带输出指令的 Prompt
prompt = outputParser.wrap(prompt);
Generation generation = chatClient.call(prompt).getResult();
return outputParser.parse(generation.getOutput().getContent());
}
}🔑 outputParser.wrap(prompt) 会自动在 Prompt 末尾追加:
plain
Please respond in JSON format matching this schema:
{ "type": "object", "properties": { ... } }六、Prompt Template 管理最佳实践
| 方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
**classpath:xxx.st** (文件) |
✅ 版本控制、热加载(dev)、多语言 | ❌ 需重启生效(prod) | 推荐!90% 场景 |
| 数据库存储 | ✅ 运行时动态修改 | ⚠️ 需自研管理后台 | 高频调整的运营场景 |
| 硬编码字符串 | 简单 | ❌ 无法维护、无复用 | 仅用于 Demo |
✅ 推荐目录结构
plain
src/main/resources/
└── ai/
├── prompts/
│ ├── common/
│ │ └── system-role.st
│ └── customer-service/
│ ├── v1.st
│ └── v2.st
└── embeddings/
└── chunk-template.st✅ 支持热更新(开发环境)
yaml
# application-dev.yml
spring:
ai:
prompt:
cache: false # 禁用缓存,修改 .st 文件立即生效七、生产级增强功能
1. 多模型切换
java
// 通过配置切换模型
@Bean
@Primary
public ChatClient openAiClient() { ... }
@Bean
@Qualifier("ollama")
public ChatClient ollamaClient() { ... }2. 流式响应(SSE)
java
@GetMapping(value = "/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> streamResponse(@RequestParam String q) {
return chatClient.stream(q)
.map(chatResponse -> chatResponse.getResult().getOutput().getContent());
}3. RAG 增强(结合向量库)
java
// 从向量库检索相关知识
List<Document> docs = vectorStore.similaritySearch(query, 3);
model.put("knowledge", docs.stream().map(Document::getContent).collect(Collectors.joining("\n")));4. 监控与日志
- 记录原始 Prompt / Response
- 统计 Token 消耗、延迟
- 集成 Micrometer + Prometheus
八、总结:Spring AI 智能客服架构
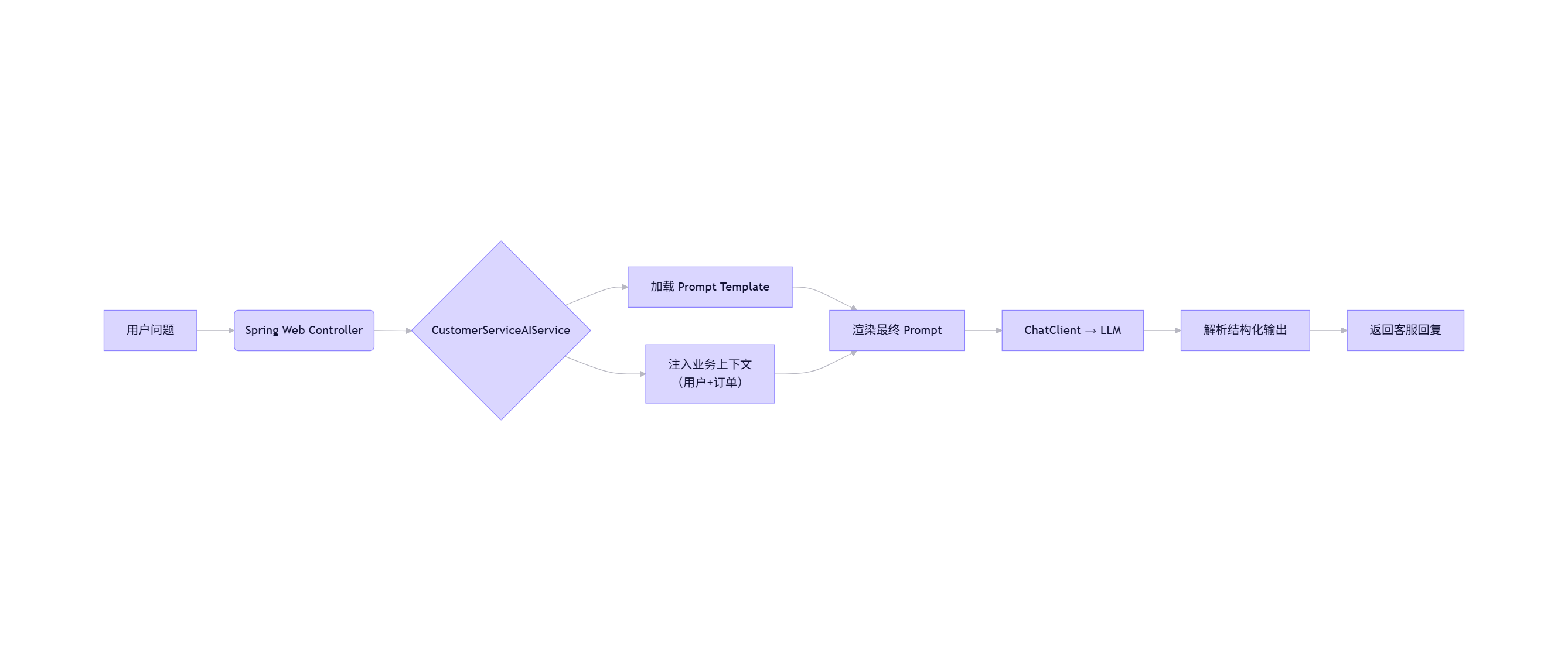
✅ 核心优势
- 解耦 Prompt 与代码 :非程序员(如运营)可维护
.st文件 - 统一抽象:切换 LLM 无需改业务逻辑
- 开箱即用:Prompt Template、Output Parsing、Streaming 全内置
- 企业级集成:无缝对接 Spring Security、Actuator、Config Server
💡 最佳实践 :
"Prompt 即代码" ------ 将 .st 文件纳入 Git 管理,配合 CI/CD 和 A/B 测试,实现 Prompt 的工程化运维。
通过 Spring AI,Java 团队可以快速构建生产级、可维护、高性能的智能客服系统,同时保持对底层大模型的灵活切换能力。