MongoDB分片案例
1.实际案例-1
- 按地区和时间分区数据
- 实现就近读取,降低查询延迟,减少网络开销
json
1. 假设我们有一个 电商系统,包含:
2. 数据库:ecommerce
3. 集合:order(订单表)
4. 分片键:{ region: 1, order_date: 1 }(地区 + 订单日期)1.1 对集合进行分片
json
sh.shardCollection("ecommerce.orders", { region: 1, order_date: 1 })1.2 将分片与区域关联
json
db.adminCommand({ addShardToZone: "shard01", zone: "northChina" })
db.adminCommand({ addShardToZone: "shard02", zone: "southChina" })1.3 创建分片键值与区域之间的关联
json
var northChinaRegions = ["北京", "天津", "河北", "河南","山东","山西", "内蒙古","辽宁","吉林","黑龙江"];
northChinaRegions.forEach(function(region) {
db.adminCommand({
updateZoneKeyRange: "ecommerce.orders",
min: { region: region, order_date: MinKey },
max: { region: region, order_date: MaxKey },
zone: "northChina"
})
})
var southChinaRegions = ["上海", "江苏", "浙江", "安徽", "福建", "江西", "广东", "广西", "海南"];
southChinaRegions.forEach(function(region) {
db.adminCommand({
updateZoneKeyRange: "ecommerce.orders",
min: { region: region, order_date: MinKey },
max: { region: region, order_date: MaxKey },
zone: "southChina"
})
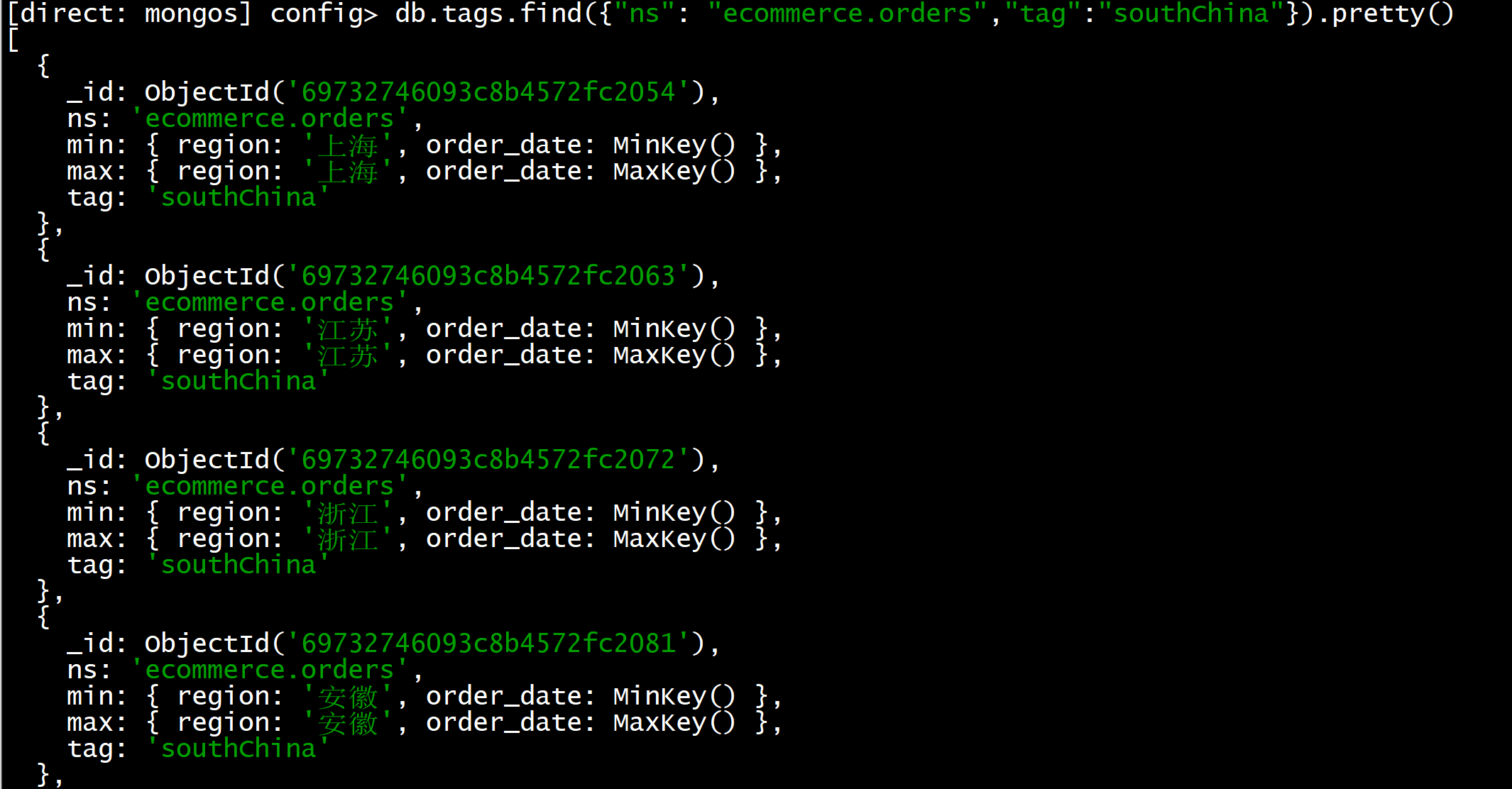
})1.4 查看zone是否设置成功
json
use config
db.tags.find({"ns": "ecommerce.orders","tag":"northChina"}).pretty()
db.tags.find({"ns": "ecommerce.orders","tag":"southChina"}).pretty()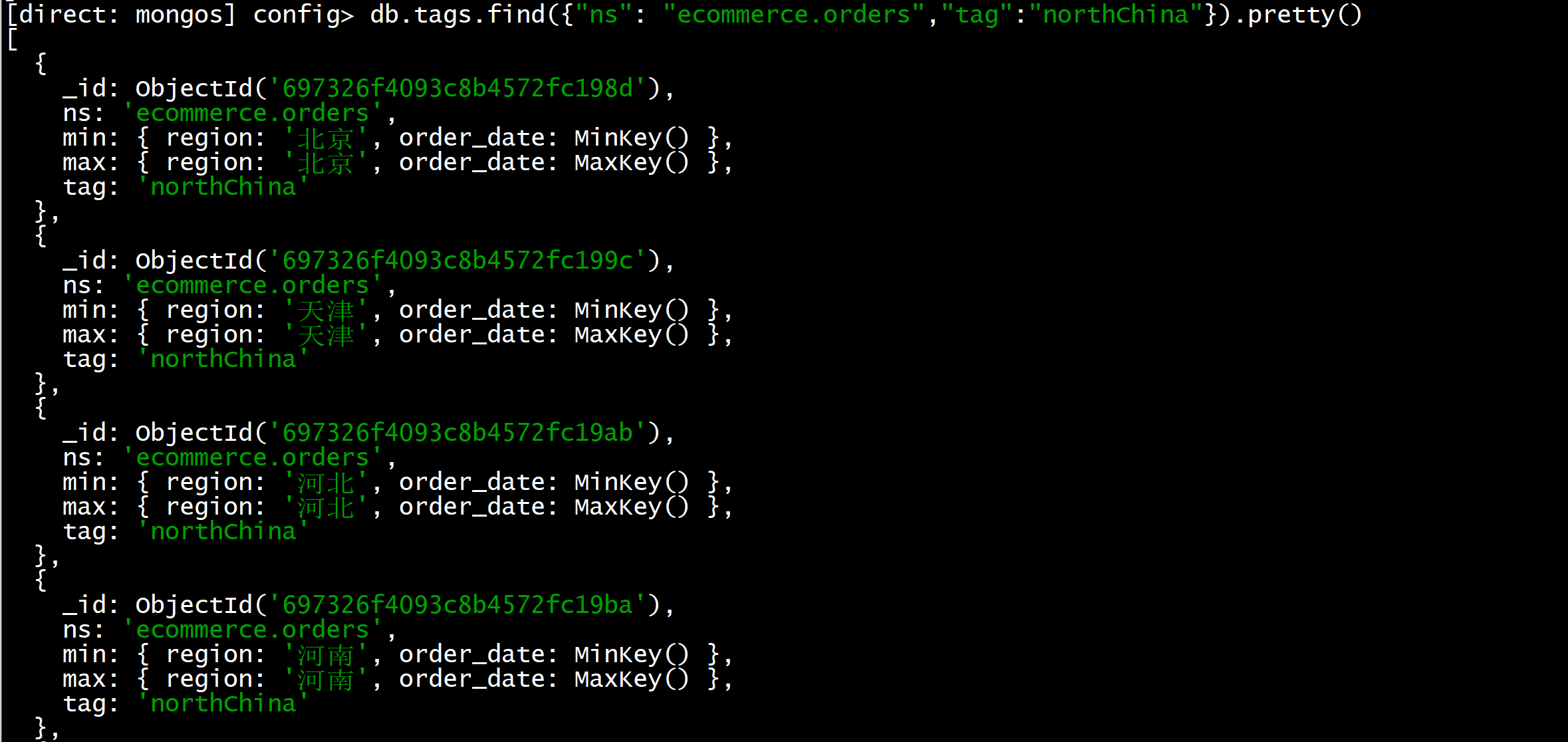
1.5 插入数据
python
# 按地区顺序插入数据,时间严格递增覆盖整个范围
import pymongo
from datetime import datetime, timedelta
import random
import math
# 连接
client = pymongo.MongoClient("mongodb://root:123@127.0.0.1:27019/admin")
db = client.ecommerce
# Zone配置
regions = {
"northChina": ["北京", "天津", "河北", "河南", "山东", "山西", "内蒙古", "辽宁", "吉林", "黑龙江"],
"southChina": ["上海", "江苏", "浙江", "安徽", "福建", "江西", "广东", "广西", "海南"]
}
# 每个地区插入100万行数据
TOTAL_PER_REGION = 1000000
BATCH = 5000 # 减小批次大小,避免内存问题
# 时间范围:2016-01-01 00:00:00 到 2025-12-31 23:59:59
start_date = datetime(2016, 1, 1)
end_date = datetime(2025, 12, 31, 23, 59, 59)
total_seconds = int((end_date - start_date).total_seconds())
print("开始按地区顺序插入数据(时间严格递增)...")
print(f"每个地区插入: {TOTAL_PER_REGION:,} 条数据")
print(f"时间范围: {start_date} 到 {end_date}")
print(f"总秒数: {total_seconds:,} 秒")
total_regions = sum(len(region_list) for region_list in regions.values())
region_data = []
# 为每个地区生成时间序列
for zone, region_list in regions.items():
for region in region_list:
region_data.append({
"region": region,
"zone": zone,
"total_docs": TOTAL_PER_REGION
})
# 按地区顺序插入
for idx, region_info in enumerate(region_data, 1):
region = region_info["region"]
zone = region_info["zone"]
print(f"\n[{idx}/{len(region_data)}] 插入地区: {region} (Zone: {zone})")
# 为该地区生成均匀分布的时间点
inserted = 0
# 方法:将总时间分成 TOTAL_PER_REGION 份
time_increment = total_seconds / TOTAL_PER_REGION
while inserted < TOTAL_PER_REGION:
batch = []
batch_size = min(BATCH, TOTAL_PER_REGION - inserted)
for j in range(batch_size):
# 计算当前文档的时间戳
seconds_offset = int(time_increment * (inserted + j))
doc_date = start_date + timedelta(seconds=seconds_offset)
# 添加微小的随机扰动(0-59秒),避免完全均匀
random_seconds = random.randint(0, 59)
doc_date += timedelta(seconds=random_seconds)
# 确保不超过结束日期
if doc_date > end_date:
doc_date = end_date - timedelta(days=random.randint(0, 7))
batch.append({
"order_id": f"ORD_{region}_{inserted+j+1:08d}_{doc_date.strftime('%Y%m%d_%H%M%S')}",
"region": region,
"order_date": doc_date,
"amount": round(random.uniform(50, 2000), 2),
"status": random.choice(['待付款', '已付款', '已发货']),
"zone": zone,
"insert_sequence": inserted + j + 1
})
try:
db.orders.insert_many(batch, ordered=False)
inserted += batch_size
if inserted % 50000 == 0 or inserted == TOTAL_PER_REGION:
progress_pct = (inserted / TOTAL_PER_REGION) * 100
current_date = batch[0]["order_date"] if batch else start_date
print(f" 进度: {inserted:,}/{TOTAL_PER_REGION:,} ({progress_pct:.1f}%) - 当前时间: {current_date.strftime('%Y-%m-%d %H:%M:%S')}")
except Exception as e:
print(f" 插入出错: {e}")
# 重试当前批次
continue
# 验证该地区的数据
count = db.orders.count_documents({"region": region})
first_doc = db.orders.find_one({"region": region}, sort=[("order_date", 1)])
last_doc = db.orders.find_one({"region": region}, sort=[("order_date", -1)])
if first_doc and last_doc:
print(f"✅ 完成地区: {region}")
print(f" 插入数量: {count:,}")
print(f" 时间范围: {first_doc['order_date'].strftime('%Y-%m-%d %H:%M:%S')} 到 {last_doc['order_date'].strftime('%Y-%m-%d %H:%M:%S')}")
else:
print(f"⚠️ 地区 {region} 数据验证失败")
# 最终统计
print(f"\n{'='*60}")
print("所有地区插入完成!")
print("\n各地区数据统计:")
for zone, region_list in regions.items():
print(f"\nZone: {zone}")
print("-" * 30)
total_zone_count = 0
for region in region_list:
count = db.orders.count_documents({"region": region})
total_zone_count += count
# 获取时间范围
pipeline = [
{"$match": {"region": region}},
{"$group": {
"_id": None,
"min_date": {"$min": "$order_date"},
"max_date": {"$max": "$order_date"},
"count": {"$sum": 1}
}}
]
result = list(db.orders.aggregate(pipeline))
if result:
print(f" {region}: {count:,} 条")
print(f" 时间: {result[0]['min_date'].strftime('%Y-%m-%d')} 到 {result[0]['max_date'].strftime('%Y-%m-%d')}")
print(f" Zone总计: {total_zone_count:,} 条")
total_count = db.orders.count_documents({})
print(f"\n{'='*60}")
print(f"全局统计:")
print(f"总文档数: {total_count:,}")
print(f"总地区数: {len(region_data)}")
print(f"平均每个地区: {total_count/len(region_data):,.0f} 条")
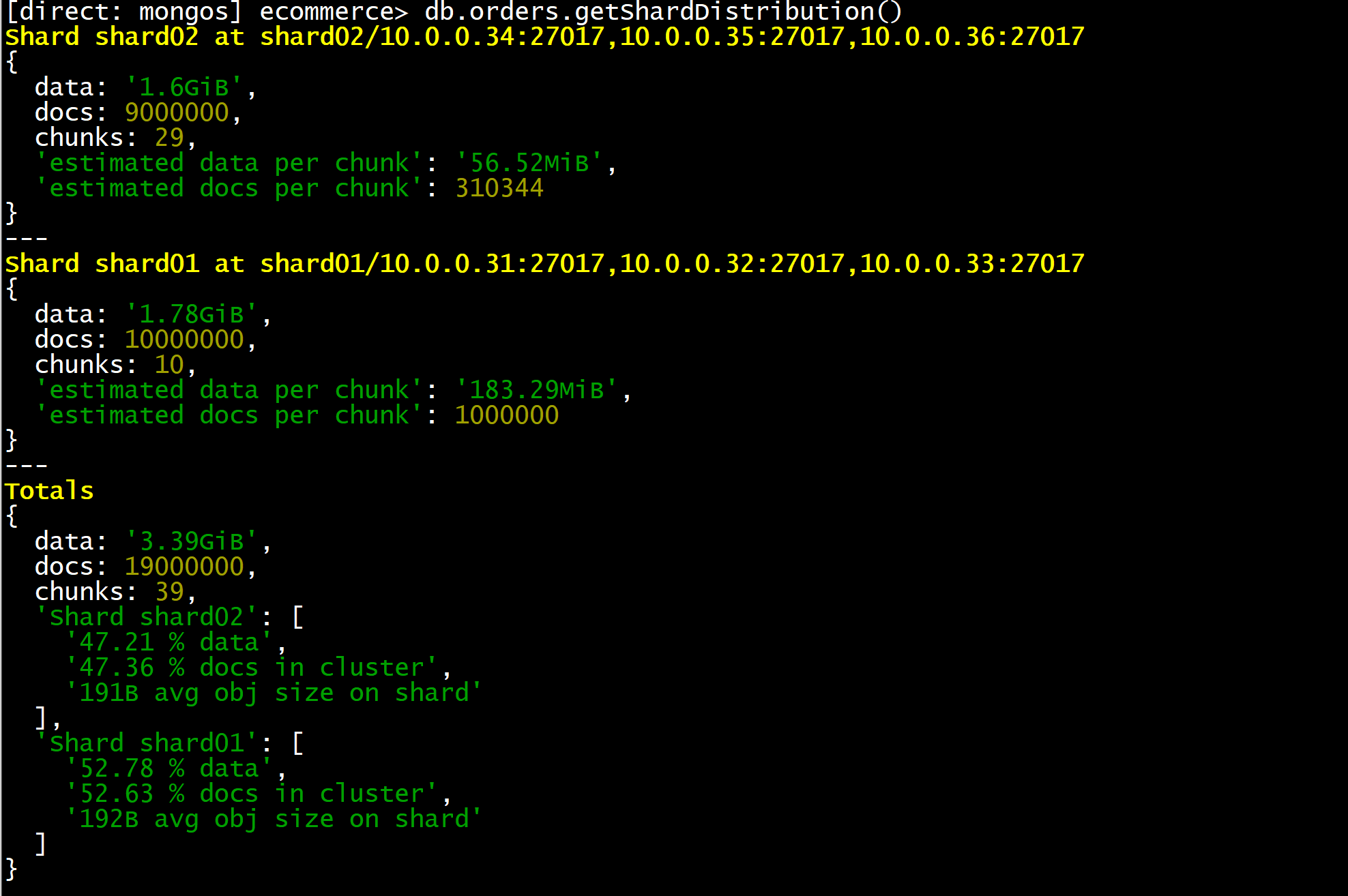
client.close()1.6 查看数据分布
python
use ecommerce
db.orders.getShardDistribution()