Tracing 集成架构:从用户请求到监控上报的完整链路
整体架构流程图
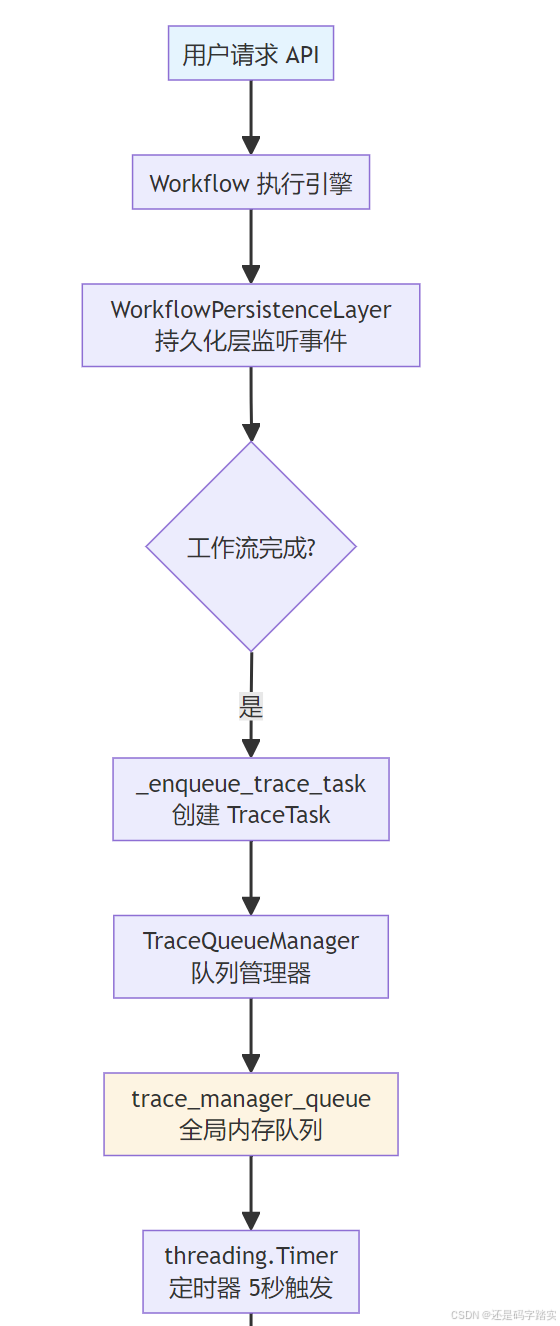
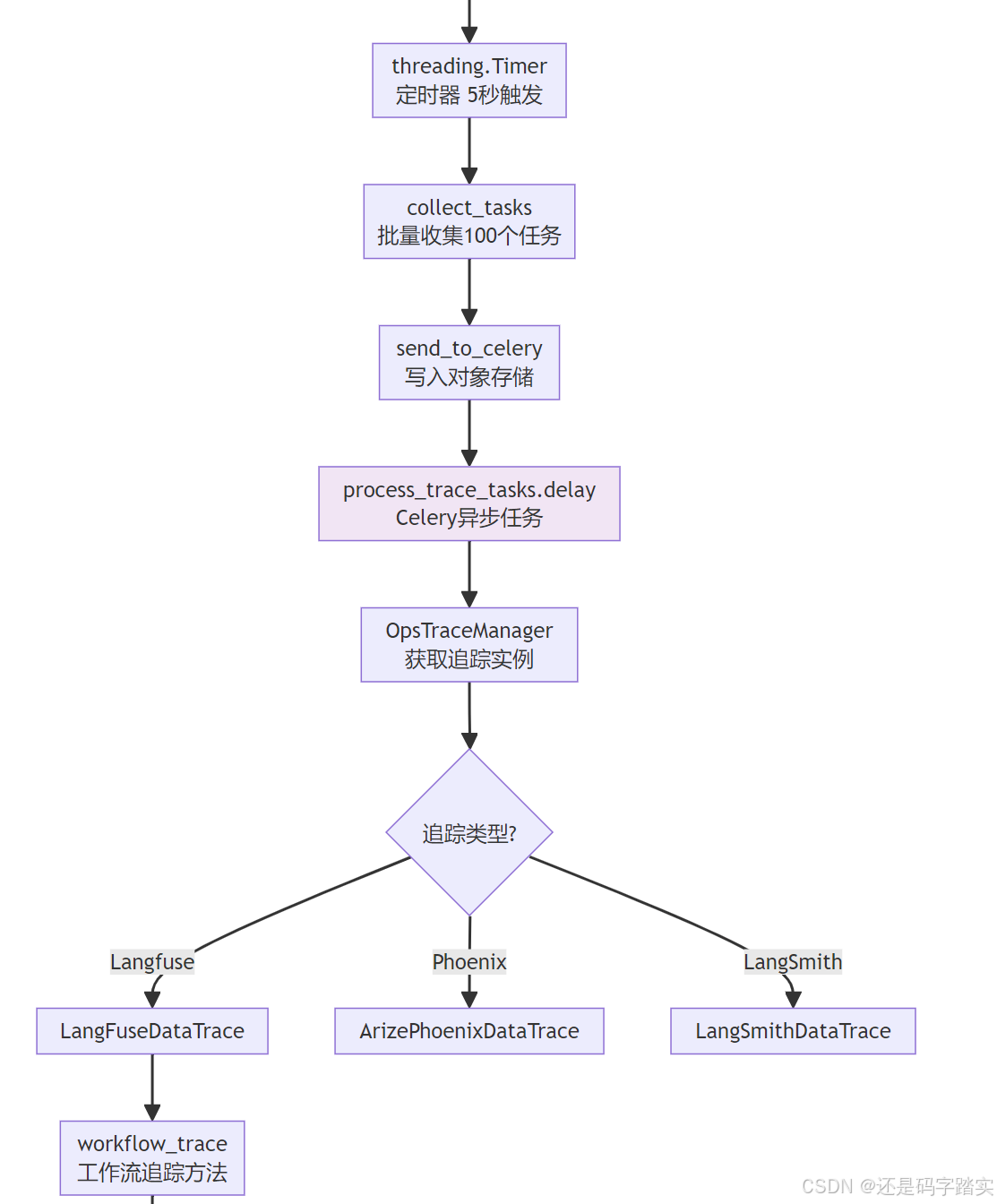
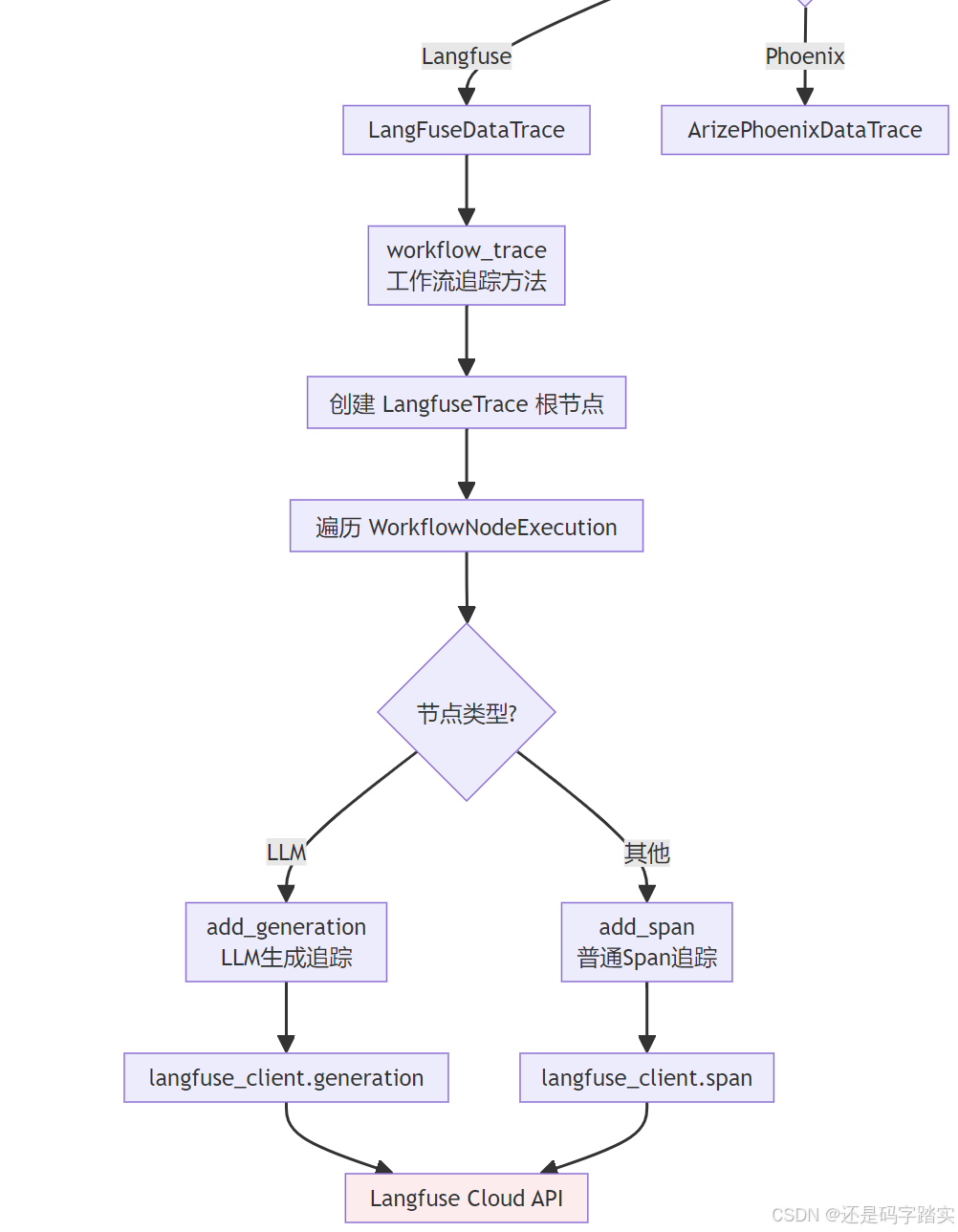
时序图:完整交互流程
Langfuse Cloud LangFuseDataTrace Celery Worker 对象存储 Threading Timer 全局内存队列 TraceQueueManager WorkflowPersistenceLayer Workflow Engine Flask API 用户 Langfuse Cloud LangFuseDataTrace Celery Worker 对象存储 Threading Timer 全局内存队列 TraceQueueManager WorkflowPersistenceLayer Workflow Engine Flask API 用户 阶段1: 工作流执行 阶段2: 追踪任务入队 阶段3: 定时聚合与异步处理 loop 遍历每个任务 阶段4: Celery 异步消费与上报 alt LLM 节点 其他节点 loop 遍历所有节点执行记录 alt 工作流追踪 POST /workflows/run 启动工作流执行 触发 GraphRunStartedEvent 创建 WorkflowExecution 记录 执行节点... 触发 GraphRunSucceededEvent _enqueue_trace_task() add_trace_task(TraceTask) 检查 trace_instance 是否启用 queue.put(trace_task) start_timer() 启动定时器 返回工作流结果 (立即响应) 等待 5 秒 (TRACE_QUEUE_MANAGER_INTERVAL) run() 触发批量处理 collect_tasks() 收集100个任务 返回 tasks\[\] task.execute() 构建 trace_info storage.save(trace_info.json) process_trace_tasks.delay(file_info) storage.load(file_path) 读取追踪数据 OpsTraceManager.get_ops_trace_instance() trace_instance.trace(trace_info) workflow_trace(WorkflowTraceInfo) 创建 LangfuseTrace 根节点 langfuse_client.trace(**data) 查询 WorkflowNodeExecution langfuse_client.generation(...) langfuse_client.span(...) 202 Accepted storage.delete(file_path) 清理临时文件
关键源码解析
工作流执行触发追踪
文件位置 :api/core/workflow/graph_engine/layers/persistence.py
python
# 第385-401行:工作流完成后将追踪任务入队
def _enqueue_trace_task(self, execution: WorkflowExecution) -> None:
"""
在工作流执行完成后,将追踪任务加入队列
关键设计:
1. 检查 trace_manager 是否已配置(用户可能未启用追踪)
2. 从系统变量中提取 conversation_id(对话上下文)
3. 支持外部 trace_id 传入(用于分布式追踪链路串联)
"""
if not self._trace_manager:
return # 未启用追踪,直接返回
# 从系统变量池中获取会话ID
conversation_id = self._system_variables().get(SystemVariableKey.CONVERSATION_ID.value)
# 提取外部传入的 trace_id(如果存在)
external_trace_id = None
if isinstance(self._application_generate_entity, (WorkflowAppGenerateEntity, AdvancedChatAppGenerateEntity)):
external_trace_id = self._application_generate_entity.extras.get("external_trace_id")
# 创建追踪任务对象
trace_task = TraceTask(
TraceTaskName.WORKFLOW_TRACE, # 任务类型:工作流追踪
workflow_execution=execution, # 工作流执行实体(包含状态、输入输出等)
conversation_id=conversation_id,
user_id=self._trace_manager.user_id,
external_trace_id=external_trace_id, # 支持分布式追踪
)
# 将任务加入队列(非阻塞操作)
self._trace_manager.add_trace_task(trace_task)关键注释:
- 非侵入性设计:追踪逻辑与业务逻辑完全解耦,通过事件监听实现
- 分布式追踪支持 :
external_trace_id允许跨系统追踪链路串联 - 条件启用 :通过检查
trace_manager避免未配置时的额外开销
队列管理器处理任务
文件位置 :api/core/ops/ops_trace_manager.py
任务入队
python
# 第942-951行:将追踪任务加入全局队列
def add_trace_task(self, trace_task: TraceTask):
"""
将追踪任务加入全局内存队列
关键设计:
1. 全局队列(trace_manager_queue)跨请求共享
2. 快速入队(<1ms),不影响主业务响应
3. 异常容错:入队失败不会影响业务流程
"""
global trace_manager_timer, trace_manager_queue
try:
# 检查是否已获取到追踪实例(用户可能未配置监控平台)
if self.trace_instance:
trace_task.app_id = self.app_id # 绑定应用ID
trace_manager_queue.put(trace_task) # 放入全局队列(线程安全)
except Exception:
# 追踪失败不应该影响业务,仅记录日志
logger.exception("Error adding trace task, trace_type %s", trace_task.trace_type)
finally:
# 确保定时器已启动(惰性启动)
self.start_timer()** 定时批量收集**
python
# 第953-960行:从队列中批量收集任务
def collect_tasks(self):
"""
从全局队列中批量收集任务
批量处理优势:
1. 减少 Celery 任务调度开销(100个任务 → 100个Celery任务)
2. 批量写入存储,提升IO效率
3. 可配置批量大小(TRACE_QUEUE_MANAGER_BATCH_SIZE)
"""
global trace_manager_queue
tasks: list[TraceTask] = []
# 收集最多 trace_manager_batch_size 个任务(默认100)
while len(tasks) < trace_manager_batch_size and not trace_manager_queue.empty():
task = trace_manager_queue.get_nowait() # 非阻塞获取
tasks.append(task)
trace_manager_queue.task_done() # 标记任务已处理
return tasks发送到 Celery
python
# 第978-998行:将任务写入存储并提交到 Celery
def send_to_celery(self, tasks: list[TraceTask]):
"""
将追踪任务序列化到对象存储,并提交到 Celery 队列
存储中转的原因:
1. Celery 消息体积限制(通常 <1MB)
2. 对象存储支持大文件(workflow可能包含大量节点执行数据)
3. 解耦消息队列与数据传输
"""
with self.flask_app.app_context():
for task in tasks:
if task.app_id is None:
continue # 跳过无效任务
file_id = uuid4().hex # 生成唯一文件ID
# 【关键】执行任务预处理,构建 trace_info 对象
trace_info = task.execute() # 调用 TraceTask.preprocess()
# 构建任务数据包
task_data = TaskData(
app_id=task.app_id,
trace_info_type=type(trace_info).__name__, # 记录类型(用于反序列化)
trace_info=trace_info.model_dump() if trace_info else None,
)
# 写入对象存储(S3/OSS/本地文件系统)
file_path = f"{OPS_FILE_PATH}{task.app_id}/{file_id}.json"
storage.save(file_path, task_data.model_dump_json().encode("utf-8"))
# 提交 Celery 异步任务(仅传递文件路径,轻量级)
file_info = {
"file_id": file_id,
"app_id": task.app_id,
}
process_trace_tasks.delay(file_info) # 异步执行关键注释:
- task.execute() :在主线程中执行数据查询(如查询 WorkflowRun、Message),构建完整的
<font style="color:#DF2A3F;">trace_info</font>对象 - 对象存储中转:避免大量数据通过消息队列传输,减少网络压力
- 轻量级消息 :Celery 任务只传递
file_id和app_id,消息体极小
TraceTask 预处理数据
文件位置 :api/core/ops/ops_trace_manager.py
python
# 第537-621行:工作流追踪的数据预处理
def workflow_trace(
self,
*,
workflow_run_id: str | None,
conversation_id: str | None,
user_id: str | None,
):
"""
从数据库查询工作流执行记录,构建 WorkflowTraceInfo 对象
数据来源:
1. WorkflowRun 表:工作流运行记录
2. WorkflowAppLog 表:应用日志关联
3. Message 表:对话消息关联
"""
if not workflow_run_id:
return {}
# 【关键】通过 Repository 模式查询工作流执行记录
workflow_run_repo = self._get_workflow_run_repo()
workflow_run = workflow_run_repo.get_workflow_run_by_id_without_tenant(run_id=workflow_run_id)
if not workflow_run:
raise ValueError("Workflow run not found")
# 提取工作流执行的核心数据
workflow_id = workflow_run.workflow_id
tenant_id = workflow_run.tenant_id
workflow_run_elapsed_time = workflow_run.elapsed_time
workflow_run_status = workflow_run.status
workflow_run_inputs = workflow_run.inputs_dict # 输入参数
workflow_run_outputs = workflow_run.outputs_dict # 输出结果
total_tokens = workflow_run.total_tokens # Token 消耗
# 查询关联的应用日志ID和消息ID
with Session(db.engine) as session:
workflow_app_log_data_stmt = select(WorkflowAppLog.id).where(
WorkflowAppLog.tenant_id == tenant_id,
WorkflowAppLog.app_id == workflow_run.app_id,
WorkflowAppLog.workflow_run_id == workflow_run.id,
)
workflow_app_log_id = session.scalar(workflow_app_log_data_stmt)
# 如果是对话场景,查询关联的消息ID
message_id = None
if conversation_id:
message_data_stmt = select(Message.id).where(
Message.conversation_id == conversation_id,
Message.workflow_run_id == workflow_run_id,
)
message_id = session.scalar(message_data_stmt)
# 构建元数据(包含所有上下文信息)
metadata = {
"workflow_id": workflow_id,
"conversation_id": conversation_id,
"workflow_run_id": workflow_run_id,
"tenant_id": tenant_id,
"elapsed_time": workflow_run_elapsed_time,
"status": workflow_run_status,
"total_tokens": total_tokens,
"user_id": user_id,
"app_id": workflow_run.app_id,
}
# 构建 WorkflowTraceInfo 实体(Pydantic 模型)
workflow_trace_info = WorkflowTraceInfo(
trace_id=self.trace_id,
workflow_data=workflow_run.to_dict(), # 完整的工作流数据
workflow_run_inputs=workflow_run_inputs,
workflow_run_outputs=workflow_run_outputs,
metadata=metadata,
message_id=message_id,
start_time=workflow_run.created_at,
end_time=workflow_run.finished_at,
# ... 更多字段
)
return workflow_trace_info关键注释:
- Repository 模式:通过仓储模式查询数据,隔离 ORM 细节
- 多表关联:串联 WorkflowRun、WorkflowAppLog、Message 等表,构建完整上下文
- Pydantic 验证 :使用
WorkflowTraceInfo模型确保数据结构正确
Celery 异步消费
文件位置 :api/tasks/ops_trace_task.py
python
# 第18-56行:Celery 异步任务处理
@shared_task(queue="ops_trace") # 独立队列,不影响其他任务
def process_trace_tasks(file_info):
"""
从对象存储加载追踪数据,并发送到第三方监控平台
容错设计:
1. 失败重试:Celery 自动重试机制
2. 失败计数:通过 Redis 记录失败次数
3. 资源清理:无论成功失败都删除临时文件
"""
from core.ops.ops_trace_manager import OpsTraceManager
app_id = file_info.get("app_id")
file_id = file_info.get("file_id")
file_path = f"{OPS_FILE_PATH}{app_id}/{file_id}.json"
# 从对象存储加载追踪数据
file_data = json.loads(storage.load(file_path))
trace_info = file_data.get("trace_info")
trace_info_type = file_data.get("trace_info_type")
# 【关键】获取追踪实例(Langfuse/Phoenix/LangSmith)
trace_instance = OpsTraceManager.get_ops_trace_instance(app_id)
# 反序列化复杂对象(Message、WorkflowRun 等)
if trace_info.get("message_data"):
trace_info["message_data"] = Message.from_dict(data=trace_info["message_data"])
if trace_info.get("workflow_data"):
trace_info["workflow_data"] = WorkflowRun.from_dict(data=trace_info["workflow_data"])
try:
if trace_instance:
with current_app.app_context():
# 根据类型名反序列化为具体的 TraceInfo 对象
trace_type = trace_info_info_map.get(trace_info_type)
if trace_type:
trace_info = trace_type(**trace_info)
# 【核心】调用追踪实例的 trace 方法
trace_instance.trace(trace_info)
logger.info("Processing trace tasks success, app_id: %s", app_id)
except Exception as e:
# 失败计数(用于监控告警)
failed_key = f"{OPS_TRACE_FAILED_KEY}_{app_id}"
redis_client.incr(failed_key)
logger.info("Processing trace tasks failed, app_id: %s", app_id)
finally:
# 清理临时文件(无论成功失败)
storage.delete(file_path)关键注释:
- 队列隔离 :
<font style="color:#DF2A3F;">queue="ops_trace"</font>确保追踪任务不会阻塞其他业务任务 - 失败计数器 :通过 Redis
incr记录失败次数,便于监控和告警 - 资源清理 :
finally块确保临时文件被删除,避免存储泄漏
Langfuse 数据上报
文件位置 :api/core/ops/langfuse_trace/langfuse_trace.py
工作流追踪入口
python
# 第68-115行:工作流追踪的主流程
def workflow_trace(self, trace_info: WorkflowTraceInfo):
"""
将工作流执行数据转换为 Langfuse 追踪格式
Langfuse 数据模型:
- Trace(根节点):代表一次完整的请求
- Span(子节点):代表一个操作步骤
- Generation(特殊节点):代表 LLM 推理
"""
# 生成 trace_id(优先使用外部传入的,否则使用 workflow_run_id)
trace_id = trace_info.trace_id or trace_info.workflow_run_id
user_id = trace_info.metadata.get("user_id")
# 构建元数据
metadata = trace_info.metadata
metadata["workflow_app_log_id"] = trace_info.workflow_app_log_id
# 【分支1】如果是对话场景(message_id 存在)
if trace_info.message_id:
trace_id = trace_info.trace_id or trace_info.message_id
# 创建根 Trace(代表整个对话)
trace_data = LangfuseTrace(
id=trace_id,
user_id=user_id,
name=TraceTaskName.MESSAGE_TRACE,
input=dict(trace_info.workflow_run_inputs),
output=dict(trace_info.workflow_run_outputs),
metadata=metadata,
session_id=trace_info.conversation_id, # 关联到会话
tags=["message", "workflow"],
)
self.add_trace(langfuse_trace_data=trace_data)
# 创建子 Span(代表工作流执行)
workflow_span_data = LangfuseSpan(
id=trace_info.workflow_run_id,
name=TraceTaskName.WORKFLOW_TRACE,
trace_id=trace_id, # 关联到根 Trace
start_time=trace_info.start_time,
end_time=trace_info.end_time,
metadata=metadata,
)
self.add_span(langfuse_span_data=workflow_span_data)
# 【分支2】纯工作流场景(无对话上下文)
else:
trace_data = LangfuseTrace(
id=trace_id,
name=TraceTaskName.WORKFLOW_TRACE,
input=dict(trace_info.workflow_run_inputs),
output=dict(trace_info.workflow_run_outputs),
tags=["workflow"],
)
self.add_trace(langfuse_trace_data=trace_data)遍历节点执行记录
python
# 第116-231行:遍历工作流的所有节点,生成对应的 Span 或 Generation
# 通过 Repository 查询所有节点执行记录
session_factory = sessionmaker(bind=db.engine)
app_id = trace_info.metadata.get("app_id")
# 创建服务账号(用于权限控制)
service_account = self.get_service_account_with_tenant(app_id)
workflow_node_execution_repository = DifyCoreRepositoryFactory.create_workflow_node_execution_repository(
session_factory=session_factory,
user=service_account,
app_id=app_id,
triggered_from=WorkflowNodeExecutionTriggeredFrom.WORKFLOW_RUN,
)
# 【关键】获取该工作流的所有节点执行记录
workflow_node_executions = workflow_node_execution_repository.get_by_workflow_run(
workflow_run_id=trace_info.workflow_run_id
)
# 遍历每个节点,生成对应的追踪数据
for node_execution in workflow_node_executions:
node_execution_id = node_execution.id
node_name = node_execution.title
node_type = node_execution.node_type # LLM / Tool / Code / ...
status = node_execution.status
# 提取输入输出
if node_type == NodeType.LLM:
inputs = node_execution.process_data.get("prompts", {}) # LLM 节点的 prompt
else:
inputs = node_execution.inputs or {}
outputs = node_execution.outputs or {}
# 计算时间
created_at = node_execution.created_at
elapsed_time = node_execution.elapsed_time
finished_at = created_at + timedelta(seconds=elapsed_time)
# 构建节点元数据
metadata = {
"workflow_run_id": trace_info.workflow_run_id,
"node_execution_id": node_execution_id,
"node_name": node_name,
"node_type": node_type,
"status": status,
}
# 【分支A】LLM 节点 → 使用 Generation 类型
if node_type == NodeType.LLM:
process_data = node_execution.process_data or {}
# 提取 Token 使用量
usage = process_data.get("usage", {})
generation_usage = GenerationUsage(
input=usage.get("prompt_tokens", 0),
output=usage.get("completion_tokens", 0),
total=usage.get("total_tokens", 0),
unit=UnitEnum.TOKENS,
totalCost=usage.get("total_price", 0), # 成本
)
# 创建 LLM Generation
node_generation_data = LangfuseGeneration(
id=node_execution_id,
name=node_name,
trace_id=trace_id,
model=process_data.get("model_name"), # 模型名称
start_time=created_at,
end_time=finished_at,
input=inputs, # Prompt
output=outputs, # LLM 输出
metadata=metadata,
usage=generation_usage, # Token 统计
parent_observation_id=trace_info.workflow_run_id, # 父节点ID
)
self.add_generation(langfuse_generation_data=node_generation_data)
# 【分支B】其他节点 → 使用 Span 类型
else:
span_data = LangfuseSpan(
id=node_execution_id,
name=node_name,
trace_id=trace_id,
start_time=created_at,
end_time=finished_at,
input=inputs,
output=outputs,
metadata=metadata,
parent_observation_id=trace_info.workflow_run_id,
)
self.add_span(langfuse_span_data=span_data)关键注释:
- 节点类型区分 :LLM 节点使用
<font style="color:#DF2A3F;">Generation</font>(包含 Token 统计),其他节点使用<font style="color:#DF2A3F;">Span</font> - 父子关系 :通过
<font style="color:#DF2A3F;">parent_observation_id</font>构建树形结构 - 成本追踪 :
totalCost字段记录每次 LLM 调用的成本
发送到 Langfuse Cloud
python
# 第401-428行:实际发送数据到 Langfuse API
def add_trace(self, langfuse_trace_data: LangfuseTrace | None = None):
"""创建 Trace 根节点"""
format_trace_data = filter_none_values(langfuse_trace_data.model_dump()) if langfuse_trace_data else {}
try:
# 调用 Langfuse SDK(底层是 HTTP POST)
self.langfuse_client.trace(**format_trace_data)
logger.debug("LangFuse Trace created successfully")
except Exception as e:
raise ValueError(f"LangFuse Failed to create trace: {str(e)}")
def add_span(self, langfuse_span_data: LangfuseSpan | None = None):
"""创建 Span 子节点"""
format_span_data = filter_none_values(langfuse_span_data.model_dump()) if langfuse_span_data else {}
try:
self.langfuse_client.span(**format_span_data)
logger.debug("LangFuse Span created successfully")
except Exception as e:
raise ValueError(f"LangFuse Failed to create span: {str(e)}")
def add_generation(self, langfuse_generation_data: LangfuseGeneration | None = None):
"""创建 Generation 节点(LLM 推理)"""
format_generation_data = (
filter_none_values(langfuse_generation_data.model_dump()) if langfuse_generation_data else {}
)
try:
self.langfuse_client.generation(**format_generation_data)
logger.debug("LangFuse Generation created successfully")
except Exception as e:
raise ValueError(f"LangFuse Failed to create generation: {str(e)}")关键注释:
- filter_none_values :移除
None值,减少传输数据量 - 异常处理:发送失败会抛出异常,由 Celery 任务捕获并记录
Langfuse 集成实现
Dify 通过 ops_trace 模块实现了全链路追踪,核心入口位于:
plain
class LangFuseDataTrace(BaseTraceInstance):
def __init__(
self,
langfuse_config: LangfuseConfig,
):
self.langfuse_client = Langfuse(
public_key=langfuse_config.public_key,
secret_key=langfuse_config.secret_key,
host=langfuse_config.host,
)
def trace(self, trace_info: BaseTraceInfo):
if isinstance(trace_info, WorkflowTraceInfo):
self.workflow_trace(trace_info)
if isinstance(trace_info, MessageTraceInfo):
self.message_trace(trace_info)
if isinstance(trace_info, ModerationTraceInfo):
self.moderation_trace(trace_info)
if isinstance(trace_info, SuggestedQuestionTraceInfo):
self.suggested_question_trace(trace_info)
if isinstance(trace_info, DatasetRetrievalTraceInfo):
self.dataset_retrieval_trace(trace_info)
if isinstance(trace_info, ToolTraceInfo):
self.tool_trace(trace_info)
if isinstance(trace_info, GenerateNameTraceInfo):
self.generate_name_trace(trace_info)关键设计点:
- 多态追踪 :通过
<font style="color:#DF2A3F;">BaseTraceInfo</font>抽象基类,支持工作流、消息、审核、工具调用等 7 种不同的追踪场景 - 配置解耦 :使用
LangfuseConfig独立管理配置,支持动态切换 host - 统一客户端 :所有追踪操作通过单一
langfuse_client实例,避免连接池污染
Phoenix (Arize) 集成实现
plain
def setup_tracer(arize_phoenix_config: ArizeConfig | PhoenixConfig) -> tuple[trace_sdk.Tracer, SimpleSpanProcessor]:
"""Configure OpenTelemetry tracer with OTLP exporter for Arize/Phoenix."""
try:
# Choose the appropriate exporter based on config type
exporter: Union[GrpcOTLPSpanExporter, HttpOTLPSpanExporter]
# Inspect the provided endpoint to determine its structure
parsed = urlparse(arize_phoenix_config.endpoint)
base_endpoint = f"{parsed.scheme}://{parsed.netloc}"
path = parsed.path.rstrip("/")
if isinstance(arize_phoenix_config, ArizeConfig):
arize_endpoint = f"{base_endpoint}/v1"
arize_headers = {
"api_key": arize_phoenix_config.api_key or "",
"space_id": arize_phoenix_config.space_id or "",
"authorization": f"Bearer {arize_phoenix_config.api_key or ''}",
}
exporter = GrpcOTLPSpanExporter(
endpoint=arize_endpoint,
headers=arize_headers,
timeout=30,
)
else:
phoenix_endpoint = f"{base_endpoint}{path}/v1/traces"
phoenix_headers = {
"api_key": arize_phoenix_config.api_key or "",
"authorization": f"Bearer {arize_phoenix_config.api_key or ''}",
}
exporter = HttpOTLPSpanExporter(
endpoint=phoenix_endpoint,
headers=phoenix_headers,
timeout=30,
)
attributes = {
"openinference.project.name": arize_phoenix_config.project or "",
"model_id": arize_phoenix_config.project or "",
}
resource = Resource(attributes=attributes)
provider = trace_sdk.TracerProvider(resource=resource)
processor = SimpleSpanProcessor(
exporter,
)
provider.add_span_processor(processor)
# Create a named tracer instead of setting the global provider
tracer_name = f"arize_phoenix_tracer_{arize_phoenix_config.project}"
logger.info("[Arize/Phoenix] Created tracer with name: %s", tracer_name)
return cast(trace_sdk.Tracer, provider.get_tracer(tracer_name)), processor关键技术突破:
- OpenTelemetry 标准 :使用 OTLP (OpenTelemetry Protocol) 作为传输协议,支持 gRPC 和 HTTP 两种导出方式
- 自适应端点解析:根据配置类型自动选择 Arize 商业版(gRPC)或 Phoenix 开源版(HTTP)
- 命名 Tracer 隔离:每个项目创建独立 tracer,避免全局 provider 污染,支持多租户场景
完整示例:用户请求的追踪全流程
假设用户发起一个智能客服工作流请求:
输入
json
{
"query": "如何重置密码?",
"user_id": "user_123"
}工作流执行链路
plain
1. 输入审核节点 (Moderation) → 通过
2. 知识库检索节点 (KnowledgeRetrieval) → 召回3篇文档
3. LLM 推理节点 (LLM) → 生成回答
4. 输出格式化节点 (TemplateTransform) → 格式化输出生成的 Langfuse 追踪树
plain
📊 Trace (message_abc123)
├── 🔹 Span: Workflow Execution (workflow_run_xyz789)
│ ├── 🛡️ Span: Moderation (node_mod_001)
│ │ ├── start_time: 2026-01-22T10:00:00Z
│ │ ├── end_time: 2026-01-22T10:00:01Z
│ │ └── metadata: {"flagged": false}
│ │
│ ├── 📚 Span: Knowledge Retrieval (node_kr_002)
│ │ ├── start_time: 2026-01-22T10:00:01Z
│ │ ├── end_time: 2026-01-22T10:00:03Z
│ │ └── output: {"documents": [doc1, doc2, doc3]}
│ │
│ ├── 🤖 Generation: LLM (node_llm_003)
│ │ ├── model: "gpt-4"
│ │ ├── start_time: 2026-01-22T10:00:03Z
│ │ ├── end_time: 2026-01-22T10:00:08Z
│ │ ├── usage: {"input": 150, "output": 80, "total": 230}
│ │ └── cost: 0.0046 USD
│ │
│ └── 📝 Span: Template Transform (node_tmpl_004)
│ ├── start_time: 2026-01-22T10:00:08Z
│ └── end_time: 2026-01-22T10:00:09Z在 Langfuse Cloud 的可视化效果
plain
Timeline View:
─────────────────────────────────────────────────────────
Workflow [═══════════════════════════════] 9s
Moderation [═] 1s
KnowledgeRet. [═══] 2s
LLM [═══════════] 5s 💰 $0.0046
Transform [═] 1s
─────────────────────────────────────────────────────────
Total Tokens: 230 | Total Cost: $0.0046性能优化关键点总结
| 优化点 | 实现方式 | 性能提升 |
|---|---|---|
| 异步入队 | queue.put() 非阻塞 |
主业务响应 <1ms 影响 |
| 批量聚合 | 每5秒收集100个任务 | 减少90% Celery调度开销 |
| 存储中转 | 对象存储缓存数据 | 避免消息队列体积限制 |
| Celery异步 | 独立队列消费 | 追踪失败不影响业务 |
| 连接复用 | LRUCache 缓存实例 | 减少80% Langfuse连接建立 |
扩展阅读
- 采样策略配置:
bash
# .env 文件
TRACE_QUEUE_MANAGER_INTERVAL=5 # 上报间隔(秒)
TRACE_QUEUE_MANAGER_BATCH_SIZE=100 # 批量大小- 监控告警:
bash
# 查询失败次数
redis-cli GET ops_trace_failed:app_<app_id>
# 设置告警(失败次数 >10 触发)
if redis.get('ops_trace_failed:app_xxx') > 10:
send_alert('追踪系统异常')- 多平台切换 :
- Langfuse:适合快速集成,UI 友好
- Phoenix:开源免费,支持本地部署
- LangSmith:LangChain 官方,深度集成
MCP 协议
MCP 在 Dify 中实现了双向能力:
- MCP Server 模式:Dify 应用作为服务端,被外部客户端(如 Claude Desktop)调用
- MCP Client 模式:Dify 作为客户端,调用外部 MCP 工具(如 Filesystem、Database)
完整架构流程图
plain
┌─────────────────────────────────────────────────────────────────────┐
│ MCP 双向架构 │
└─────────────────────────────────────────────────────────────────────┘
┌──────────────────────── MCP Server 模式 ────────────────────────┐
│ │
│ 外部客户端 Dify API Controller Dify App │
│ (Claude Desktop) │
│ │ │
│ │ ① POST /mcp/server/{server_code}/mcp │
│ │ JSON-RPC Request │
│ ├──────────────────────────────────────────────────────► │
│ │ │
│ │ ② 解析 & 验证请求 │
│ │ (controllers/mcp/mcp.py) │
│ │ │ │
│ │ ▼ │
│ │ ③ 路由到 Handler │
│ │ (core/mcp/server/streamable_http.py) │
│ │ │ │
│ │ ├─► initialize → 协议握手 │
│ │ ├─► tools/list → 返回工具列表 │
│ │ └─► tools/call → 执行 Dify 应用 │
│ │ │ │
│ │ ▼ │
│ │ ④ 执行 Dify 应用 │
│ │ (services/app_generate_service.py) │
│ │ │ │
│ │ ⑤ JSON-RPC Response │
│ │◄────────────────────────────────────────────────────────┤
│ │ │
└──────────────────────────────────────────────────────────────────┘
┌──────────────────────── MCP Client 模式 ────────────────────────┐
│ │
│ Dify Workflow MCP Client 外部 MCP 工具 │
│ (工作流节点) (Filesystem等) │
│ │ │
│ │ ① 工具调用请求 │
│ │ tool_name + parameters │
│ ├─────────────────────────────────────────► │
│ │ │
│ │ ② 加载凭证 & 建立连接 │
│ │ (core/mcp/mcp_client.py) │
│ │ - 协议协商 (initialize) │
│ │ - SSE/HTTP 自动降级 │
│ │ │ │
│ │ ▼ │
│ │ ③ 发送 tools/call │
│ │ (ClientSession.call_tool) │
│ │ ┌──────────► │
│ │ │ │
│ │ ④ 处理响应 │ │
│ │ (CallToolResult) │ │
│ │ │ │ │
│ │ ◄──────────────────────┘ │
│ │ ⑤ 转换为 ToolInvokeMessage │
│ │◄─────────────────────────────────────────────────────── │
│ │ - Text/Image/JSON/Variable │
│ │ │
└──────────────────────────────────────────────────────────────────┘场景一:MCP Server 模式完整链路
时序图:外部客户端调用 Dify 应用
plain
Claude Desktop API Gateway MCPAppApi handle_mcp_request App Execute
│ │ │ │ │
│ POST /mcp/... │ │ │ │
├──────────────────►│ │ │ │
│ │ MCPRequestPayload │ │ │
│ ├───────────────────►│ │ │
│ │ │ ① 验证 server_code │ │
│ │ │ ② 查询 AppMCPServer │ │
│ │ │ ③ 验证 App 状态 │ │
│ │ ├────────────────────►│ │
│ │ │ │ ④ 路由请求类型 │
│ │ │ │ - initialize │
│ │ │ │ - list_tools │
│ │ │ │ - call_tool │
│ │ │ ├───────────────────►│
│ │ │ │ │ ⑤ 执行应用
│ │ │ │ │ AppGenerateService
│ │ │ │◄───────────────────┤
│ │ │ ⑥ JSON-RPC Response │ │
│ │◄───────────────────┤ │ │
│ CallToolResult │ │ │ │
│◄──────────────────┤ │ │ │
│ │ │ │ │关键代码详解(MCP Server 模式)
API 入口:controllers/mcp/mcp.py
python
# 文件位置:api/controllers/mcp/mcp.py
# 功能:接收外部客户端的 JSON-RPC 请求
@mcp_ns.route("/server/<string:server_code>/mcp")
class MCPAppApi(Resource):
def post(self, server_code: str):
"""
【入口函数】处理 MCP 协议请求
核心步骤:
1. 解析 JSON-RPC 请求体(jsonrpc/method/params/id)
2. 验证 server_code 对应的 MCP Server 是否存在且激活
3. 根据请求类型(Request/Notification)分发处理
"""
# ① 解析并验证请求格式
args = MCPRequestPayload.model_validate(mcp_ns.payload or {})
request_id: Union[int, str] | None = args.id
mcp_request = self._parse_mcp_request(args.model_dump(exclude_none=True))
# ② 使用独立 session 查询,避免长时间持有数据库连接
with Session(db.engine, expire_on_commit=False) as session:
# 获取 MCP 服务器配置和关联的 Dify 应用
mcp_server, app = self._get_mcp_server_and_app(server_code, session)
# ③ 验证服务器状态(必须是 ACTIVE)
self._validate_server_status(mcp_server)
# ④ 获取应用的用户输入表单配置
user_input_form = self._get_user_input_form(app)
# ⑤ 分发处理(Notification 返回 202,Request 返回结果)
return self._process_mcp_message(
mcp_request, request_id, app, mcp_server, user_input_form, session
)关键设计点:
- server_code :唯一标识符,关联到具体的 Dify 应用(
<font style="color:#DF2A3F;">AppMCPServer</font>表) - Session 隔离:每个请求使用独立数据库 session,避免长事务
- 双模式支持 :区分
ClientRequest(需要返回结果)和ClientNotification(仅通知,返回 202)
请求路由:core/mcp/server/streamable_http.py
python
# 文件位置:api/core/mcp/server/streamable_http.py
# 功能:根据 MCP 方法分发到具体处理器
def handle_mcp_request(
app: App,
request: mcp_types.ClientRequest,
user_input_form: list[VariableEntity],
mcp_server: AppMCPServer,
end_user: EndUser | None = None,
request_id: int | str = 1,
) -> mcp_types.JSONRPCResponse | mcp_types.JSONRPCError:
"""
【核心路由函数】处理不同类型的 MCP 请求
支持的方法:
- initialize:协议握手,返回服务器能力
- tools/list:返回 Dify 应用作为 MCP 工具的描述
- tools/call:执行 Dify 应用,返回结果
- ping:心跳检测
"""
request_type = type(request.root)
request_root = request.root
try:
# ① 根据请求类型分发
if isinstance(request_root, mcp_types.InitializeRequest):
# 协议握手:返回支持的协议版本和能力
return create_success_response(
handle_initialize(mcp_server.description)
)
elif isinstance(request_root, mcp_types.ListToolsRequest):
# 列出工具:将 Dify 应用转换为 MCP Tool 格式
return create_success_response(
handle_list_tools(
app.name, # 工具名称
app.mode, # 应用模式(Chat/Workflow/Agent)
user_input_form, # 用户输入参数
mcp_server.description, # 工具描述
mcp_server.parameters_dict # 参数映射
)
)
elif isinstance(request_root, mcp_types.CallToolRequest):
# 调用工具:执行 Dify 应用逻辑
return create_success_response(
handle_call_tool(app, request, user_input_form, end_user)
)
elif isinstance(request_root, mcp_types.PingRequest):
# 心跳检测
return create_success_response(handle_ping())
else:
return create_error_response(
mcp_types.METHOD_NOT_FOUND,
f"Method not found: {request_type.__name__}"
)
except ValueError as e:
# 参数验证失败
return create_error_response(mcp_types.INVALID_PARAMS, str(e))
except Exception as e:
# 内部错误
return create_error_response(mcp_types.INTERNAL_ERROR, str(e))关键逻辑详解:
handle_initialize:协议握手
python
def handle_initialize(description: str) -> mcp_types.InitializeResult:
"""
返回服务器能力声明
MCP 客户端连接时首先调用此方法,确认:
- 支持的协议版本
- 服务器能力(tools/resources/prompts)
- 服务器信息(名称/版本)
"""
capabilities = mcp_types.ServerCapabilities(
tools=mcp_types.ToolsCapability(listChanged=False), # 工具列表不动态变化
)
return mcp_types.InitializeResult(
protocolVersion=mcp_types.SERVER_LATEST_PROTOCOL_VERSION, # "2024-11-05"
capabilities=capabilities,
serverInfo=mcp_types.Implementation(
name="Dify",
version=dify_config.project.version
),
instructions=description, # 应用描述
)handle_list_tools:转换应用为工具
python
def handle_list_tools(
app_name: str,
app_mode: str,
user_input_form: list[VariableEntity],
description: str,
parameters_dict: dict[str, str],
) -> mcp_types.ListToolsResult:
"""
将 Dify 应用转换为 MCP Tool 格式
转换逻辑:
- Workflow/Completion:所有 user_input_form 作为参数
- Chat/Agent:增加 query 参数(必填)
"""
# ① 构建参数 Schema(JSON Schema 格式)
parameter_schema = build_parameter_schema(
app_mode, user_input_form, parameters_dict
)
# ② 返回工具列表(单个工具)
return mcp_types.ListToolsResult(
tools=[
mcp_types.Tool(
name=app_name, # 工具名 = 应用名
description=description, # 工具描述
inputSchema=parameter_schema, # 输入参数 Schema
)
],
)
def build_parameter_schema(
app_mode: str,
user_input_form: list[VariableEntity],
parameters_dict: dict[str, str],
) -> dict[str, Any]:
"""
构建参数 Schema
示例输出(Chat 模式):
{
"type": "object",
"properties": {
"query": {"type": "string", "description": "User question"},
"temperature": {"type": "number", "description": "Model temperature"}
},
"required": ["query"]
}
"""
parameters, required = convert_input_form_to_parameters(
user_input_form, parameters_dict
)
if app_mode in {AppMode.COMPLETION, AppMode.WORKFLOW}:
# Workflow/Completion 模式:直接返回参数
return {
"type": "object",
"properties": parameters,
"required": required,
}
# Chat/Agent 模式:追加 query 参数
return {
"type": "object",
"properties": {
"query": {"type": "string", "description": "User Input/Question content"},
**parameters, # 合并用户定义的参数
},
"required": ["query", *required],
}handle_call_tool:执行应用
python
def handle_call_tool(
app: App,
request: mcp_types.ClientRequest,
user_input_form: list[VariableEntity],
end_user: EndUser | None,
) -> mcp_types.CallToolResult:
"""
执行 Dify 应用,返回结果
流程:
1. 准备参数(根据应用模式调整结构)
2. 调用 AppGenerateService 执行
3. 提取响应内容
4. 转换为 MCP CallToolResult 格式
"""
request_obj = cast(mcp_types.CallToolRequest, request.root)
# ① 准备参数(适配不同应用模式)
args = prepare_tool_arguments(app, request_obj.params.arguments or {})
if not end_user:
raise ValueError("End user not found")
# ② 执行应用(核心业务逻辑)
response = AppGenerateService.generate(
app,
end_user,
args,
InvokeFrom.SERVICE_API,
streaming=app.mode == AppMode.AGENT_CHAT, # Agent 模式开启流式
)
# ③ 提取结果
answer = extract_answer_from_response(app, response)
# ④ 返回 MCP 标准格式
return mcp_types.CallToolResult(
content=[
mcp_types.TextContent(text=answer, type="text")
]
)
def prepare_tool_arguments(app: App, arguments: dict[str, Any]) -> dict[str, Any]:
"""
根据应用模式调整参数结构
Workflow:{"inputs": {...}}
Completion:{"query": "", "inputs": {...}}
Chat/Agent:{"query": "用户问题", "inputs": {其他参数}}
"""
if app.mode == AppMode.WORKFLOW:
return {"inputs": arguments}
elif app.mode == AppMode.COMPLETION:
return {"query": "", "inputs": arguments}
else:
# Chat/Agent 模式:分离 query 和其他参数
args_copy = arguments.copy()
query = args_copy.pop("query", "")
return {"query": query, "inputs": args_copy}
def extract_answer_from_response(app: App, response: Any) -> str:
"""
从不同类型的响应中提取答案
Agent 模式:流式响应,提取 agent_thought
其他模式:直接返回 answer 或 workflow outputs
"""
if isinstance(response, RateLimitGenerator):
# Agent 流式响应:逐个解析 SSE 事件
answer = ""
for item in response.generator:
if isinstance(item, str) and item.startswith("data: "):
parsed_data = json.loads(item[6:].strip())
if parsed_data.get("event") == "agent_thought":
answer += parsed_data.get("thought", "")
return answer
elif isinstance(response, Mapping):
# 非流式响应
if app.mode == AppMode.WORKFLOW:
return json.dumps(response["data"]["outputs"], ensure_ascii=False)
else:
return response.get("answer", "")MCP Server 模式示例
请求示例
json
POST /v1/mcp/server/abc123xyz/mcp
Content-Type: application/json
{
"jsonrpc": "2.0",
"method": "tools/call",
"params": {
"name": "Customer Service Bot",
"arguments": {
"query": "如何退款?",
"user_id": "user_001"
}
},
"id": 1
}响应示例
json
{
"jsonrpc": "2.0",
"id": 1,
"result": {
"content": [
{
"type": "text",
"text": "您好!关于退款流程,请按照以下步骤操作:\n1. 登录账户\n2. 进入订单管理\n3. 选择需要退款的订单\n4. 点击"申请退款"按钮\n\n退款将在3-5个工作日内到账。"
}
]
}
}场景二:MCP Client 模式完整链路
时序图:Dify 调用外部 MCP 工具
plain
Workflow Node MCPTool MCPClient ClientSession External MCP Server
│ │ │ │ │
│ ① invoke_tool │ │ │ │
├────────────────►│ │ │ │
│ │ ② 加载凭证 │ │ │
│ │ (decrypt_headers)│ │ │
│ ├──────────────────►│ │ │
│ │ │ ③ 建立连接 │ │
│ │ │ (initialize) │ │
│ │ ├─────────────────►│ │
│ │ │ │ ④ 协议握手 │
│ │ │ ├───────────────────►│
│ │ │ │ InitializeRequest│
│ │ │ │◄───────────────────┤
│ │ │ │ InitializeResult │
│ │ │ │ ⑤ 发送通知 │
│ │ │ ├───────────────────►│
│ │ │ │ Initialized │
│ │ ⑥ invoke_tool │ │ │
│ │ ├─────────────────►│ │
│ │ │ │ ⑦ tools/call │
│ │ │ ├───────────────────►│
│ │ │ │ CallToolRequest │
│ │ │ │ │ ⑧ 执行工具
│ │ │ │◄───────────────────┤
│ │ │ │ CallToolResult │
│ │ ⑨ 处理响应 │ │ │
│ │ (Text/Image/...)│ │ │
│ │◄──────────────────┤ │ │
│ ⑩ ToolInvokeMsg │ │ │ │
│◄────────────────┤ │ │ │
│ │ │ │ │关键代码详解(MCP Client 模式)
工具调用入口:core/tools/mcp_tool/tool.py
python
# 文件位置:api/core/tools/mcp_tool/tool.py
# 功能:MCP 工具的执行入口
class MCPTool(Tool):
def _invoke(
self,
user_id: str,
tool_parameters: dict[str, Any],
conversation_id: str | None = None,
app_id: str | None = None,
message_id: str | None = None,
) -> Generator[ToolInvokeMessage, None, None]:
"""
【工具调用入口】
核心流程:
1. 调用远程 MCP 服务器
2. 处理不同类型的响应(Text/Image/Audio/Resource)
3. 转换为 Dify 的 ToolInvokeMessage 格式
"""
# ① 调用远程 MCP 工具
result = self.invoke_remote_mcp_tool(tool_parameters)
# ② 处理响应内容(支持多种类型)
for content in result.content:
if isinstance(content, TextContent):
# 文本内容(可能是 JSON)
yield from self._process_text_content(content)
elif isinstance(content, ImageContent | AudioContent):
# 图片/音频:Base64 解码
yield self.create_blob_message(
blob=base64.b64decode(content.data),
meta={"mime_type": content.mimeType}
)
elif isinstance(content, EmbeddedResource):
# 嵌入式资源(文件/Blob)
resource = content.resource
if isinstance(resource, TextResourceContents):
yield self.create_text_message(resource.text)
elif isinstance(resource, BlobResourceContents):
yield self.create_blob_message(
blob=base64.b64decode(resource.blob),
meta={"mime_type": resource.mimeType}
)
# ③ 处理结构化输出(如果定义了 output_schema)
if self.entity.output_schema and result.structuredContent:
for k, v in result.structuredContent.items():
yield self.create_variable_message(k, v)关键方法详解:
** invoke_remote_mcp_tool:远程调用**
python
def invoke_remote_mcp_tool(self, tool_parameters: dict[str, Any]) -> CallToolResult:
"""
调用远程 MCP 服务器的工具
优化要点:
- 使用短生命周期 session 加载凭证
- 网络操作时不持有数据库连接
- 自动重试机制(MCPClientWithAuthRetry)
"""
# ① 过滤空参数
tool_parameters = self._handle_none_parameter(tool_parameters)
# ② 使用短生命周期 session 加载凭证
# 关键优化:在网络请求前关闭 session,避免长时间持有连接
with Session(db.engine, expire_on_commit=False) as session:
mcp_service = MCPToolManageService(session=session)
# 加载 Provider Entity(包含加密的凭证)
provider_entity = mcp_service.get_provider_entity(
self.provider_id, self.tenant_id, by_server_id=True
)
# 解密所有凭证(在 session 关闭前完成)
server_url = provider_entity.decrypt_server_url()
headers = provider_entity.decrypt_headers()
# 尝试获取已有 Token
if not headers:
tokens = provider_entity.retrieve_tokens()
if tokens and tokens.access_token:
headers["Authorization"] = f"{tokens.token_type.capitalize()} {tokens.access_token}"
# ③ Session 已关闭,开始网络操作
# MCPClientWithAuthRetry:支持 Token 过期自动刷新
try:
with MCPClientWithAuthRetry(
server_url=server_url,
headers=headers,
timeout=self.timeout,
sse_read_timeout=self.sse_read_timeout,
provider_entity=provider_entity, # 用于自动重试
) as mcp_client:
# ④ 执行工具调用
return mcp_client.invoke_tool(
tool_name=self.entity.identity.name,
tool_args=tool_parameters
)
except MCPConnectionError as e:
raise ToolInvokeError(f"Failed to connect to MCP server: {e}") from e性能优化细节:
- 短 Session 模式:仅在加载凭证时持有数据库连接,避免网络延迟影响连接池
- 凭证预解密:在 session 关闭前完成所有解密操作
- 懒初始化 :
MCPClientWithAuthRetry仅在认证失败时创建新 session
连接管理:core/mcp/mcp_client.py
python
# 文件位置:api/core/mcp/mcp_client.py
# 功能:管理与 MCP 服务器的连接
class MCPClient:
def _initialize(self):
"""
初始化连接,支持协议降级
尝试顺序:
1. 检查 URL 路径中的方法(mcp/sse)
2. 默认尝试 SSE(Server-Sent Events)
3. 失败则降级为 Streamable HTTP
"""
connection_methods = {
"mcp": streamablehttp_client, # Streamable HTTP
"sse": sse_client, # Server-Sent Events
}
# ① 从 URL 推断连接方法
parsed_url = urlparse(self.server_url)
path = parsed_url.path or ""
method_name = path.rstrip("/").split("/")[-1] if path else ""
if method_name in connection_methods:
# URL 显式指定了方法
client_factory = connection_methods[method_name]
self.connect_server(client_factory, method_name)
else:
# ② 自动协议协商:先 SSE,失败后 HTTP
try:
logger.debug("尝试使用 SSE 连接...")
self.connect_server(sse_client, "sse")
except (MCPConnectionError, ValueError):
logger.debug("SSE 连接失败,降级为 Streamable HTTP")
self.connect_server(streamablehttp_client, "mcp")
def connect_server(self, client_factory, method_name: str):
"""
建立连接并初始化 session
关键点:
- 使用 ExitStack 管理上下文(确保资源释放)
- 区分 mcp(双向流)和 sse(单向流)
"""
# ① 创建流上下文
streams_context = client_factory(
url=self.server_url,
headers=self.headers,
timeout=self.timeout,
sse_read_timeout=self.sse_read_timeout,
)
# ② 根据连接方法初始化流
if method_name == "mcp":
# Streamable HTTP:需要读写双向流
read_stream, write_stream, _ = self._exit_stack.enter_context(streams_context)
streams = (read_stream, write_stream)
else: # sse
# SSE:单向流
streams = self._exit_stack.enter_context(streams_context)
# ③ 创建并初始化 Session
session_context = ClientSession(*streams)
self._session = self._exit_stack.enter_context(session_context)
self._session.initialize() # 发送 initialize 请求Session 管理:core/mcp/session/client_session.py
python
# 文件位置:api/core/mcp/session/client_session.py
# 功能:管理 MCP 协议级交互
class ClientSession(BaseSession):
def initialize(self) -> types.InitializeResult:
"""
【协议握手】初始化 MCP 会话
流程:
1. 发送 initialize 请求(声明客户端能力)
2. 验证服务器返回的协议版本
3. 发送 initialized 通知
"""
# ① 构建客户端能力声明
result = self.send_request(
types.ClientRequest(
types.InitializeRequest(
method="initialize",
params=types.InitializeRequestParams(
protocolVersion=types.LATEST_PROTOCOL_VERSION, # "2025-06-18"
capabilities=types.ClientCapabilities(
sampling=None, # 不支持采样
roots=None, # 不支持根资源
experimental=None,
),
clientInfo=types.Implementation(
name="Dify",
version=dify_config.project.version
),
),
)
),
types.InitializeResult,
)
# ② 验证协议版本兼容性
if result.protocolVersion not in SUPPORTED_PROTOCOL_VERSIONS:
raise RuntimeError(f"不支持的协议版本: {result.protocolVersion}")
# ③ 发送初始化完成通知
self.send_notification(
types.ClientNotification(
types.InitializedNotification(method="notifications/initialized")
)
)
return result
def call_tool(
self,
name: str,
arguments: dict[str, Any] | None = None,
read_timeout_seconds: timedelta | None = None,
) -> types.CallToolResult:
"""
【工具调用】执行远程工具
发送 JSON-RPC 请求:
{
"jsonrpc": "2.0",
"method": "tools/call",
"params": {
"name": "read_file",
"arguments": {"path": "/path/to/file"}
},
"id": 123
}
"""
return self.send_request(
types.ClientRequest(
types.CallToolRequest(
method="tools/call",
params=types.CallToolRequestParams(
name=name,
arguments=arguments
),
)
),
types.CallToolResult,
request_read_timeout_seconds=read_timeout_seconds,
)
def list_tools(self) -> types.ListToolsResult:
"""
【工具发现】列出服务器提供的所有工具
"""
return self.send_request(
types.ClientRequest(
types.ListToolsRequest(method="tools/list")
),
types.ListToolsResult,
)** 自动重连:core/mcp/auth_client.py**
python
# 文件位置:api/core/mcp/auth_client.py
# 功能:处理认证失败和 Token 刷新
class MCPClientWithAuthRetry(MCPClient):
"""
增强的 MCP 客户端,支持自动认证重试
核心机制:
- 拦截 MCPAuthError 异常
- 刷新 OAuth Token
- 重建连接并重试操作
"""
def _execute_with_retry(self, func: Callable[..., Any], *args, **kwargs) -> Any:
"""
【重试包装器】执行函数,失败时自动重试
流程:
1. 尝试执行函数
2. 捕获 MCPAuthError → 刷新 Token
3. 重建连接
4. 重新执行函数
"""
try:
return func(*args, **kwargs)
except MCPAuthError as e:
# ① 处理认证错误
self._handle_auth_error(e)
# ② 重建连接(使用新 Token)
if self._initialized:
# 清理旧连接
self._exit_stack.close()
self._session = None
self._initialized = False
# 重新初始化
self._initialize()
self._initialized = True
# ③ 重试操作
return func(*args, **kwargs)
finally:
# ④ 重置重试标志
self._has_retried = False
def _handle_auth_error(self, error: MCPAuthError):
"""
【认证恢复】刷新 Token
优化要点:
- 使用临时 session(仅在重试时创建)
- 避免长时间持有数据库连接
"""
if not self.provider_entity or self._has_retried:
raise error
self._has_retried = True
# ① 创建临时 session 进行认证
with Session(db.engine) as session, session.begin():
mcp_service = MCPToolManageService(session=session)
# ② 执行 OAuth 认证
mcp_service.auth_with_actions(
self.provider_entity,
self.authorization_code,
resource_metadata_url=error.resource_metadata_url,
scope_hint=error.scope_hint,
)
# ③ 获取新 Token
self.provider_entity = mcp_service.get_provider_entity(
self.provider_entity.id,
self.provider_entity.tenant_id,
by_server_id=self.by_server_id
)
# ④ Session 关闭后更新 headers
token = self.provider_entity.retrieve_tokens()
if not token:
raise MCPAuthError("认证失败:未获取到 Token")
self.headers["Authorization"] = f"{token.token_type.capitalize()} {token.access_token}"MCP Client 模式示例
场景:在工作流中调用 Filesystem 工具读取文件
python
# 工具配置
tool_name = "read_file"
tool_parameters = {
"path": "/workspace/data/customers.csv"
}
# Dify 发送的 JSON-RPC 请求
{
"jsonrpc": "2.0",
"method": "tools/call",
"params": {
"name": "read_file",
"arguments": {
"path": "/workspace/data/customers.csv"
}
},
"id": 42
}
# MCP Server 返回
{
"jsonrpc": "2.0",
"id": 42,
"result": {
"content": [
{
"type": "text",
"text": "id,name,email\n1,Alice,alice@example.com\n2,Bob,bob@example.com"
}
]
}
}
# Dify 处理后转换为工作流变量
output_variables = {
"file_content": "id,name,email\n1,Alice,alice@example.com\n2,Bob,bob@example.com"
}完整链路总结流程图
plain
┌─────────────────────────────────────────────────────────────────────────┐
│ MCP 协议完整数据流 │
└─────────────────────────────────────────────────────────────────────────┘
【MCP Server 模式】Dify 应用被调用
═══════════════════════════════════════════════════════════════════════════
外部请求 → API Gateway → MCPAppApi.post()
│
├─ ① 验证 server_code
│ (AppMCPServer 表)
│
├─ ② 获取 App & user_input_form
│ (App/AppModelConfig 表)
│
├─ ③ 路由请求
│ └─ handle_mcp_request()
│ ├─ initialize → 返回能力
│ ├─ list_tools → 返回工具列表
│ └─ call_tool → 执行应用
│ └─ AppGenerateService.generate()
│ ├─ Chat: 对话生成
│ ├─ Workflow: 工作流执行
│ └─ Agent: 智能体推理
│
└─ ④ 返回 JSON-RPC Response
═══════════════════════════════════════════════════════════════════════════
【MCP Client 模式】Dify 调用外部工具
═══════════════════════════════════════════════════════════════════════════
工作流节点 → MCPTool._invoke()
│
├─ ① 加载凭证 (短 Session)
│ ├─ get_provider_entity()
│ ├─ decrypt_server_url()
│ ├─ decrypt_headers()
│ └─ retrieve_tokens()
│
├─ ② 建立连接 (无 Session)
│ └─ MCPClientWithAuthRetry
│ ├─ _initialize()
│ │ ├─ 协议协商 (SSE ↔ HTTP)
│ │ └─ ClientSession.initialize()
│ │ ├─ send: InitializeRequest
│ │ └─ recv: InitializeResult
│ │
│ └─ invoke_tool()
│ ├─ send: CallToolRequest
│ └─ recv: CallToolResult
│ ├─ TextContent
│ ├─ ImageContent
│ ├─ AudioContent
│ └─ EmbeddedResource
│
└─ ③ 处理响应
├─ _process_text_content() → ToolInvokeMessage
├─ create_blob_message() → Binary
└─ create_variable_message() → Variable
═══════════════════════════════════════════════════════════════════════════关键函数索引表
| 功能模块 | 文件位置 | 关键函数 | 职责 |
|---|---|---|---|
| MCP Server | |||
| API 入口 | api/controllers/mcp/mcp.py |
MCPAppApi.post() |
接收外部请求,验证 server_code |
| 请求路由 | api/core/mcp/server/streamable_http.py |
handle_mcp_request() |
分发请求到具体处理器 |
| 协议握手 | 同上 | handle_initialize() |
返回服务器能力声明 |
| 工具列表 | 同上 | handle_list_tools() |
将 App 转换为 MCP Tool |
| 工具调用 | 同上 | handle_call_tool() |
执行 Dify 应用 |
| MCP Client | |||
| 工具入口 | api/core/tools/mcp_tool/tool.py |
MCPTool._invoke() |
工具调用入口 |
| 远程调用 | 同上 | invoke_remote_mcp_tool() |
管理凭证和连接 |
| 连接管理 | api/core/mcp/mcp_client.py |
MCPClient._initialize() |
协议协商与降级 |
| Session | api/core/mcp/session/client_session.py |
ClientSession.initialize() |
协议握手 |
| 工具调用 | 同上 | ClientSession.call_tool() |
发送 tools/call 请求 |
| 自动重试 | api/core/mcp/auth_client.py |
MCPClientWithAuthRetry._execute_with_retry() |
Token 刷新与重连 |
工程实践要点
性能优化
- ✅ 短 Session 模式:仅在必要时持有数据库连接
- ✅ 懒初始化:重试机制仅在失败时创建 session
- ✅ 协议降级:自动适配 SSE 和 HTTP 两种传输方式
可靠性保障
- ✅ 自动重连:Token 过期自动刷新,网络异常自动重试
- ✅ 资源管理 :使用
ExitStack确保异常时资源正确释放 - ✅ 协议兼容 :支持多版本协议协商(
2024-11-05~2025-06-18)
安全性设计
- ✅ 凭证加密:所有敏感信息(server_url/headers)AES 加密存储
- ✅ 临时 Session:认证重试时创建独立 session,避免事务冲突
- ✅ 异常隔离:工具调用失败不影响工作流其他节点
追踪系统完整链路深度解析
总览:五级异步架构
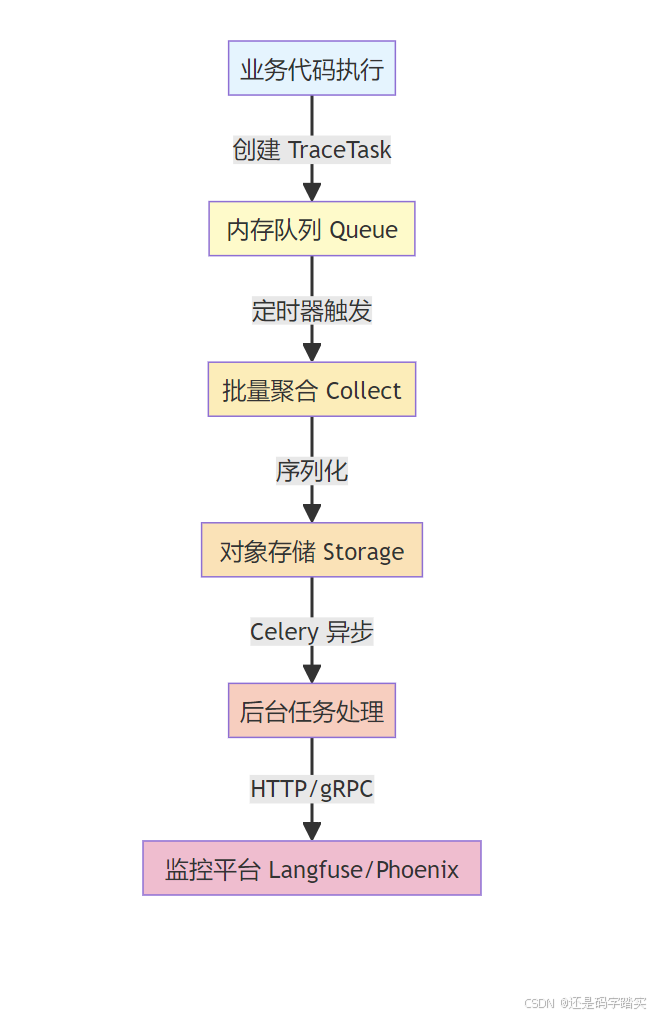
关键性能指标:
- 主线程耗时:< 1ms(仅队列入队操作)
- 采样频率:5 秒批量处理
- 批量大小:最多 100 个任务/批次
- 存储中转:解耦业务与监控,提供故障恢复能力
完整链路拆解(从输入到输出)
【阶段 1】业务代码创建追踪任务
入口:初始化 TraceQueueManager
文件位置 :api/core/app/apps/completion/app_generator.py:128-130
python
# ========== 步骤 1:在应用生成器初始化时创建追踪管理器 ==========
# 位置:CompletionAppGenerator.generate()
# 获取或创建追踪管理器实例
trace_manager = TraceQueueManager(
app_id=app_model.id, # 应用 ID,用于定位追踪配置
user_id=user.id if isinstance(user, Account) else user.session_id # 用户 ID
)关键逻辑解析:
python
# 文件:api/core/ops/ops_trace_manager.py:931-940
class TraceQueueManager:
def __init__(self, app_id=None, user_id=None):
global trace_manager_timer
self.app_id = app_id
self.user_id = user_id
# 🔑 核心步骤 1:获取该 app 的追踪实例(如果未启用追踪,返回 None)
self.trace_instance = OpsTraceManager.get_ops_trace_instance(app_id)
# 🔑 核心步骤 2:保存 Flask 应用上下文(用于 Celery 任务)
self.flask_app = current_app._get_current_object()
# 🔑 核心步骤 3:如果定时器未启动,立即启动
if trace_manager_timer is None:
self.start_timer()注释说明:
trace_instance:根据app_id从数据库查询追踪配置(如 Langfuse 的 public_key/secret_key)- 如果 app 未启用追踪,
trace_instance为None,后续所有追踪操作会被跳过 flask_app:保存当前请求的 Flask 应用上下文,用于 Celery 任务中访问数据库
业务节点创建 TraceTask
示例 1:消息追踪(Message Trace)
文件位置 :api/core/app/task_pipeline/easy_ui_based_generate_task_pipeline.py:405-410
python
# ========== 步骤 2A:在消息生成完成后创建追踪任务 ==========
# 场景:用户与 ChatBot 对话,消息保存到数据库后触发
if trace_manager: # ✅ 如果追踪管理器存在
trace_manager.add_trace_task(
TraceTask(
# 指定追踪类型:MESSAGE_TRACE
TraceTaskName.MESSAGE_TRACE,
# 关联上下文:会话 ID 和消息 ID
conversation_id=self._conversation_id,
message_id=self._message_id
)
)示例 2:知识库检索追踪(Dataset Retrieval Trace)
文件位置 :api/core/rag/retrieval/dataset_retrieval.py:718-728
python
# ========== 步骤 2B:在知识库检索完成后创建追踪任务 ==========
# 场景:RAG 流程中,从向量数据库检索到相关文档
def _send_trace_task(self, message_id: str | None, documents: list[Document], timer: dict | None):
"""发送追踪任务(如果追踪管理器可用)"""
trace_manager: TraceQueueManager | None = (
self.application_generate_entity.trace_manager
if self.application_generate_entity else None
)
if trace_manager:
trace_manager.add_trace_task(
TraceTask(
TraceTaskName.DATASET_RETRIEVAL_TRACE, # 追踪类型
message_id=message_id, # 关联消息
documents=documents, # 检索到的文档列表
timer=timer # ⏱️ 计时器:包含 start/end 时间
)
)TraceTask 构造函数解析:
文件位置 :api/core/ops/ops_trace_manager.py:480-502
python
# ========== TraceTask 类:追踪任务的数据载体 ==========
class TraceTask:
def __init__(
self,
trace_type: Any, # 追踪类型(MESSAGE/WORKFLOW/TOOL...)
message_id: str | None = None, # 消息 ID
workflow_execution: Optional["WorkflowExecution"] = None, # 工作流执行对象
conversation_id: str | None = None, # 会话 ID
user_id: str | None = None, # 用户 ID
timer: Any | None = None, # 计时器字典 {"start": datetime, "end": datetime}
**kwargs, # 其他扩展参数
):
self.trace_type = trace_type # 🏷️ 任务类型标识
self.message_id = message_id
self.workflow_run_id = workflow_execution.id_ if workflow_execution else None
self.conversation_id = conversation_id
self.user_id = user_id
self.timer = timer
self.file_base_url = os.getenv("FILES_URL", "http://127.0.0.1:5001")
self.app_id = None # ⚠️ 注意:app_id 会在加入队列时被赋值
self.trace_id = None # 外部追踪 ID(可选)
self.kwargs = kwargs # 🎒 额外参数(如 documents、tool_inputs)
# 如果提供了外部追踪 ID(用于分布式追踪),则使用它
external_trace_id = kwargs.get("external_trace_id")
if external_trace_id:
self.trace_id = external_trace_id关键点:
<font style="color:#DF2A3F;">TraceTask</font>仅仅是一个数据容器,不执行任何 I/O 操作timer字典记录操作的开始和结束时间,用于计算延迟kwargs允许携带任意扩展数据(如检索文档、工具输出)
【阶段 2】加入内存队列TraceQueueManager.add_trace_task()
文件位置 :api/core/ops/ops_trace_manager.py:942-951
python
# ========== 步骤 3:将追踪任务加入全局队列 ==========
def add_trace_task(self, trace_task: TraceTask):
global trace_manager_timer, trace_manager_queue # 🌐 全局队列和定时器
try:
# ✅ 只有当追踪实例存在时才加入队列(避免未启用追踪时污染队列)
if self.trace_instance:
# 🏷️ 给任务打上 app_id 标签(后续需要根据 app_id 查询配置)
trace_task.app_id = self.app_id
# 🚀 核心操作:放入队列(非阻塞,耗时 < 1ms)
trace_manager_queue.put(trace_task)
except Exception:
# ⚠️ 即使追踪失败,也不应影响主业务,仅记录日志
logger.exception("Error adding trace task, trace_type %s", trace_task.trace_type)
finally:
# 🔄 确保定时器保持运行(如果定时器已停止,重新启动)
self.start_timer()全局队列的声明:
文件位置 :api/core/ops/ops_trace_manager.py:925-928
python
# ========== 全局变量:进程级共享 ==========
trace_manager_timer: threading.Timer | None = None # 定时器对象
trace_manager_queue: queue.Queue = queue.Queue() # 🗄️ 线程安全的队列
# 📊 采样控制参数(可通过环境变量调整)
trace_manager_interval = int(os.getenv("TRACE_QUEUE_MANAGER_INTERVAL", 5)) # 默认 5 秒
trace_manager_batch_size = int(os.getenv("TRACE_QUEUE_MANAGER_BATCH_SIZE", 100)) # 默认 100 条注释说明:
<font style="color:#DF2A3F;">queue.Queue</font>是 Python 标准库的线程安全队列,支持多线程并发写入- 全局变量在 Flask 进程 中共享(不跨 Gunicorn 进程)
- 每个 worker 进程有自己的队列和定时器
【阶段 3】定时器批量聚合
启动定时器
文件位置 :api/core/ops/ops_trace_manager.py:970-976
python
# ========== 步骤 4:启动定时器(如果尚未运行) ==========
def start_timer(self):
global trace_manager_timer
# 🔒 检查定时器是否已存在且仍在运行
if trace_manager_timer is None or not trace_manager_timer.is_alive():
# 创建新定时器:在 trace_manager_interval 秒后执行 self.run()
trace_manager_timer = threading.Timer(trace_manager_interval, self.run)
# 🏷️ 给定时器线程命名(便于调试)
trace_manager_timer.name = f"trace_manager_timer_{time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())}"
# ⚠️ daemon=False:确保进程退出前完成追踪任务
trace_manager_timer.daemon = False
# 🚀 启动定时器
trace_manager_timer.start()注释说明:
threading.Timer(interval, function):在interval秒后执行function<font style="color:#DF2A3F;">daemon=False</font>:非守护线程,进程退出前会等待定时器完成- 定时器只执行一次,但
<font style="color:#DF2A3F;">self.run()</font>结束后会再次调用<font style="color:#DF2A3F;">start_timer()</font>,形成循环
定时器触发:批量收集任务
文件位置 :api/core/ops/ops_trace_manager.py:962-968
python
# ========== 步骤 5:定时器回调函数 ==========
def run(self):
try:
# 🧲 从队列中批量拉取任务
tasks = self.collect_tasks()
# 如果有任务,发送到 Celery
if tasks:
self.send_to_celery(tasks)
except Exception:
# ⚠️ 捕获所有异常,确保定时器不会因单次失败而停止
logger.exception("Error processing trace tasks")批量收集逻辑:
文件位置 :api/core/ops/ops_trace_manager.py:953-960
python
# ========== 步骤 5A:从队列中拉取任务(最多 batch_size 个) ==========
def collect_tasks(self):
global trace_manager_queue
tasks: list[TraceTask] = []
# 🔁 循环拉取,直到达到批量大小或队列为空
while len(tasks) < trace_manager_batch_size and not trace_manager_queue.empty():
# 🚪 非阻塞获取(如果队列为空会立即返回 Empty 异常)
task = trace_manager_queue.get_nowait()
tasks.append(task)
# ✅ 通知队列:此任务已被消费
trace_manager_queue.task_done()
return tasks性能优化分析:
- 批量处理:减少 Celery 任务创建开销(如果每个追踪都独立发送,会创建大量 Celery 任务)
- 非阻塞拉取 :使用
get_nowait()避免等待,快速完成收集
【阶段 4】序列化存储
发送到 Celery:先存储再异步
文件位置 :api/core/ops/ops_trace_manager.py:978-997
python
# ========== 步骤 6:将任务发送到 Celery ==========
def send_to_celery(self, tasks: list[TraceTask]):
with self.flask_app.app_context(): # 🔐 进入 Flask 应用上下文(访问数据库配置)
for task in tasks:
# ⚠️ 跳过没有 app_id 的任务(理论上不应该发生)
if task.app_id is None:
continue
# 📝 生成唯一文件 ID
file_id = uuid4().hex
# 🧩 执行任务的预处理(从数据库查询详细数据)
trace_info = task.execute() # ← 重要:这里会查询数据库
# 📦 序列化为可存储的数据结构
task_data = TaskData(
app_id=task.app_id,
trace_info_type=type(trace_info).__name__, # 类名:如 "MessageTraceInfo"
trace_info=trace_info.model_dump() if trace_info else None # Pydantic 序列化
)
# 💾 保存到对象存储(如 S3、OSS、本地文件系统)
file_path = f"{OPS_FILE_PATH}{task.app_id}/{file_id}.json"
storage.save(file_path, task_data.model_dump_json().encode("utf-8"))
# 🚀 发送 Celery 异步任务(仅传递文件信息,不传递完整数据)
file_info = {
"file_id": file_id,
"app_id": task.app_id,
}
process_trace_tasks.delay(file_info) # ← Celery 异步任务关键设计决策解析:
- 为什么要先存储再发送到 Celery?
- 解耦数据获取与上报 :
task.execute()可能查询数据库(如查询 message 详情),如果直接在 Celery 任务中执行,会在不同进程中重新查询,可能导致数据不一致 - 减少 Celery 消息体积:只传递文件路径,而不是完整的追踪数据(可能包含大量文档)
- 提供重试能力:如果 Celery 任务失败,可以根据文件路径重新加载数据
- 解耦数据获取与上报 :
- 存储路径结构:
plain
OPS_FILE_PATH/
├── {app_id_1}/
│ ├── abc123.json
│ ├── def456.json
├── {app_id_2}/
│ ├── ghi789.jsonTraceTask.execute():预处理数据
文件位置 :api/core/ops/ops_trace_manager.py:504-531
python
# ========== 步骤 6A:执行任务的预处理(查询数据库) ==========
def execute(self):
return self.preprocess()
def preprocess(self):
# 🗺️ 根据任务类型调用不同的处理函数
preprocess_map = {
TraceTaskName.CONVERSATION_TRACE: lambda: self.conversation_trace(**self.kwargs),
TraceTaskName.WORKFLOW_TRACE: lambda: self.workflow_trace(
workflow_run_id=self.workflow_run_id,
conversation_id=self.conversation_id,
user_id=self.user_id
),
TraceTaskName.MESSAGE_TRACE: lambda: self.message_trace(message_id=self.message_id),
TraceTaskName.MODERATION_TRACE: lambda: self.moderation_trace(
message_id=self.message_id, timer=self.timer, **self.kwargs
),
TraceTaskName.SUGGESTED_QUESTION_TRACE: lambda: self.suggested_question_trace(
message_id=self.message_id, timer=self.timer, **self.kwargs
),
TraceTaskName.DATASET_RETRIEVAL_TRACE: lambda: self.dataset_retrieval_trace(
message_id=self.message_id, timer=self.timer, **self.kwargs
),
TraceTaskName.TOOL_TRACE: lambda: self.tool_trace(
message_id=self.message_id, timer=self.timer, **self.kwargs
),
TraceTaskName.GENERATE_NAME_TRACE: lambda: self.generate_name_trace(
conversation_id=self.conversation_id, timer=self.timer, **self.kwargs
),
}
# 🎯 执行对应的预处理函数,返回 TraceInfo 对象
return preprocess_map.get(self.trace_type, lambda: None)()示例:message_trace() 的实现
文件位置 :api/core/ops/ops_trace_manager.py:623-683
python
# ========== 步骤 6B:MESSAGE_TRACE 预处理逻辑 ==========
def message_trace(self, message_id: str | None):
if not message_id:
return {}
# 🔍 从数据库查询消息详情(包含 LLM 输出、Token 消耗等)
message_data = get_message_data(message_id)
if not message_data:
return {}
# 🔍 查询会话模式(chat/completion/agent-chat)
conversation_mode_stmt = select(Conversation.mode).where(Conversation.id == message_data.conversation_id)
conversation_mode = db.session.scalars(conversation_mode_stmt).all()
if not conversation_mode or len(conversation_mode) == 0:
return {}
conversation_mode = conversation_mode[0]
# ⏱️ 记录时间戳
created_at = message_data.created_at
inputs = message_data.message # 用户输入
# 📎 获取消息附件(如果有)
message_file_data = db.session.query(MessageFile).filter_by(message_id=message_id).first()
file_list = []
if message_file_data and message_file_data.url is not None:
file_url = f"{self.file_base_url}/{message_file_data.url}"
file_list.append(file_url)
# 📊 提取流式指标(首 Token 延迟、生成速度)
streaming_metrics = self._extract_streaming_metrics(message_data)
# 📋 构建元数据字典
metadata = {
"conversation_id": message_data.conversation_id,
"ls_provider": message_data.model_provider, # 如 "openai"
"ls_model_name": message_data.model_id, # 如 "gpt-4"
"status": message_data.status, # "success" / "failed"
"from_end_user_id": message_data.from_end_user_id,
"from_account_id": message_data.from_account_id,
"agent_based": message_data.agent_based,
"workflow_run_id": message_data.workflow_run_id,
"from_source": message_data.from_source,
"message_id": message_id,
}
# 📦 构造 MessageTraceInfo 对象(Pydantic 模型)
message_trace_info = MessageTraceInfo(
trace_id=self.trace_id,
message_id=message_id,
message_data=message_data.to_dict(), # 完整消息对象
conversation_model=conversation_mode,
message_tokens=message_data.message_tokens, # 🪙 输入 Token
answer_tokens=message_data.answer_tokens, # 🪙 输出 Token
total_tokens=message_data.message_tokens + message_data.answer_tokens,
error=message_data.error or "",
inputs=inputs,
outputs=message_data.answer,
file_list=file_list,
start_time=created_at,
end_time=created_at + timedelta(seconds=message_data.provider_response_latency),
metadata=metadata,
message_file_data=message_file_data,
conversation_mode=conversation_mode,
gen_ai_server_time_to_first_token=streaming_metrics.get("gen_ai_server_time_to_first_token"),
llm_streaming_time_to_generate=streaming_metrics.get("llm_streaming_time_to_generate"),
is_streaming_request=streaming_metrics.get("is_streaming_request", False),
)
return message_trace_infoTraceInfo 实体定义:
文件位置 :api/core/ops/entities/trace_entity.py:56-68
python
# ========== MessageTraceInfo:消息追踪数据模型 ==========
class MessageTraceInfo(BaseTraceInfo):
conversation_model: str # 会话模式
message_tokens: int # 输入 Token 数
answer_tokens: int # 输出 Token 数
total_tokens: int # 总 Token 数
error: str | None = None # 错误信息
file_list: Union[str, dict[str, Any], list] | None = None # 附件列表
message_file_data: Any | None = None # 文件数据对象
conversation_mode: str # 会话模式(chat/completion)
gen_ai_server_time_to_first_token: float | None = None # ⏱️ 首 Token 延迟
llm_streaming_time_to_generate: float | None = None # ⏱️ 生成总耗时
is_streaming_request: bool = False # 是否流式请求【阶段 5】Celery 异步消费
Celery 任务定义
文件位置 :api/tasks/ops_trace_task.py:18-56
python
# ========== 步骤 7:Celery 异步任务 ==========
@shared_task(queue="ops_trace") # 🏷️ 指定队列名称(隔离追踪任务与业务任务)
def process_trace_tasks(file_info):
"""
异步处理追踪任务
用法:process_trace_tasks.delay(file_info)
"""
from core.ops.ops_trace_manager import OpsTraceManager
# 📖 从文件信息中提取 app_id 和 file_id
app_id = file_info.get("app_id")
file_id = file_info.get("file_id")
# 💾 从对象存储加载追踪数据
file_path = f"{OPS_FILE_PATH}{app_id}/{file_id}.json"
file_data = json.loads(storage.load(file_path))
trace_info = file_data.get("trace_info") # 追踪数据字典
trace_info_type = file_data.get("trace_info_type") # 类型名称(如 "MessageTraceInfo")
# 🔑 重新获取追踪实例(不同进程,需要重新初始化)
trace_instance = OpsTraceManager.get_ops_trace_instance(app_id)
# 🔄 反序列化:将字典转换回对象
if trace_info.get("message_data"):
trace_info["message_data"] = Message.from_dict(data=trace_info["message_data"])
if trace_info.get("workflow_data"):
trace_info["workflow_data"] = WorkflowRun.from_dict(data=trace_info["workflow_data"])
if trace_info.get("documents"):
trace_info["documents"] = [Document.model_validate(doc) for doc in trace_info["documents"]]
try:
if trace_instance:
with current_app.app_context(): # 🔐 进入 Flask 应用上下文
# 🎯 根据类型名称还原为具体的 TraceInfo 类
trace_type = trace_info_info_map.get(trace_info_type)
if trace_type:
trace_info = trace_type(**trace_info)
# 🚀 调用追踪实例的 trace() 方法(最终上报)
trace_instance.trace(trace_info)
logger.info("Processing trace tasks success, app_id: %s", app_id)
except Exception as e:
logger.info("error:\n\n\n%s\n\n\n\n", e)
# ❌ 失败计数器:记录失败次数(用于告警)
failed_key = f"{OPS_TRACE_FAILED_KEY}_{app_id}"
redis_client.incr(failed_key)
logger.info("Processing trace tasks failed, app_id: %s", app_id)
finally:
# 🗑️ 删除临时文件(无论成功或失败)
storage.delete(file_path)关键点:
- 队列隔离 :
<font style="color:#DF2A3F;">queue="ops_trace"</font>确保追踪任务不会与业务任务(如发送邮件、生成报告)抢占资源 - 失败容错:即使上报失败,也会删除临时文件,避免存储泄漏
- Redis 计数器:记录失败次数,可配置告警(如 1 小时内失败超过 100 次)
【阶段 6】最终上报到监控平台
Langfuse 上报实现
文件位置 :api/core/ops/langfuse_trace/langfuse_trace.py:52-67
python
# ========== 步骤 8:调用监控平台 API ==========
def trace(self, trace_info: BaseTraceInfo):
# 🎯 根据追踪信息类型分发到不同的处理函数
if isinstance(trace_info, WorkflowTraceInfo):
self.workflow_trace(trace_info)
if isinstance(trace_info, MessageTraceInfo):
self.message_trace(trace_info) # ← 我们以此为例
if isinstance(trace_info, ModerationTraceInfo):
self.moderation_trace(trace_info)
# ... 其他类型消息追踪上报详细逻辑(简化版):
python
# 文件:api/core/ops/langfuse_trace/langfuse_trace.py(约 200+ 行)
def message_trace(self, trace_info: MessageTraceInfo):
# 📦 构造 Langfuse Trace 对象
langfuse_trace_data = LangfuseTrace(
id=trace_info.trace_id or trace_info.message_id, # 追踪 ID
name="message_trace",
input=trace_info.inputs, # 用户输入
output=trace_info.outputs, # LLM 输出
user_id=trace_info.metadata.get("from_end_user_id"),
session_id=trace_info.metadata.get("conversation_id"),
metadata=trace_info.metadata, # 元数据
)
# 🚀 调用 Langfuse SDK 上报 Trace
self.add_trace(langfuse_trace_data)
# 📊 构造 Langfuse Generation 对象(记录 LLM 生成)
langfuse_generation_data = LangfuseGeneration(
name="message_generation",
trace_id=trace_info.trace_id or trace_info.message_id,
start_time=trace_info.start_time,
end_time=trace_info.end_time,
model=trace_info.metadata.get("ls_model_name"), # 模型名称
usage=GenerationUsage(
input=trace_info.message_tokens, # 输入 Token
output=trace_info.answer_tokens, # 输出 Token
total=trace_info.total_tokens,
),
metadata=trace_info.metadata,
)
# 🚀 上报 Generation(LLM 调用记录)
self.add_generation(langfuse_generation_data)最终 HTTP 调用:
文件位置 :api/core/ops/langfuse_trace/langfuse_trace.py:401-415
python
# ========== Langfuse SDK 封装 ==========
def add_trace(self, langfuse_trace_data: LangfuseTrace | None = None):
format_trace_data = filter_none_values(langfuse_trace_data.model_dump()) if langfuse_trace_data else {}
try:
# 🌐 HTTP POST 请求:发送到 Langfuse 服务器
self.langfuse_client.trace(**format_trace_data)
logger.debug("LangFuse Trace created successfully")
except Exception as e:
raise ValueError(f"LangFuse Failed to create trace: {str(e)}")
def add_generation(self, langfuse_generation_data: LangfuseGeneration | None = None):
format_generation_data = filter_none_values(langfuse_generation_data.model_dump()) if langfuse_generation_data else {}
try:
# 🌐 HTTP POST 请求:发送 Generation 记录
self.langfuse_client.generation(**format_generation_data)
logger.debug("LangFuse Generation created successfully")
except Exception as e:
raise ValueError(f"LangFuse Failed to create generation: {str(e)}")时序图:完整链路可视化
📊 Langfuse/Phoenix 🔄 Celery Worker 💾 对象存储 ⏰ 定时器线程 📦 内存队列 🗄️ TraceQueueManager 📱 应用生成器 👤 用户请求 📊 Langfuse/Phoenix 🔄 Celery Worker 💾 对象存储 ⏰ 定时器线程 📦 内存队列 🗄️ TraceQueueManager 📱 应用生成器 👤 用户请求 === 业务逻辑执行 === === 5 秒后定时器触发 === loop 遍历每个任务 === Celery Worker 处理 === === 定时器再次循环 === 1. 发起对话请求 2. 初始化 TraceQueueManager(app_id) 3. 获取追踪实例 (get_ops_trace_instance) 4. 启动定时器 (start_timer) 5. 生成 LLM 响应 6. 创建 TraceTask(MESSAGE_TRACE) 7. 加入队列 (queue.put) 8. 立即返回 (< 1ms) 9. 返回响应给用户 10. 批量拉取任务 (collect_tasks) 11. 返回最多 100 个任务 12. 执行 task.execute() (查询数据库) 13. 序列化并保存到存储 (storage.save) 14. 发送异步任务 (process_trace_tasks.delay) 15. 从存储加载数据 (storage.load) 16. 返回追踪数据 JSON 17. 反序列化为 TraceInfo 对象 18. HTTP POST 上报到监控平台 19. 返回成功响应 20. 删除临时文件 (storage.delete) 21. 重新启动定时器 (start_timer)
流程图:核心函数调用链
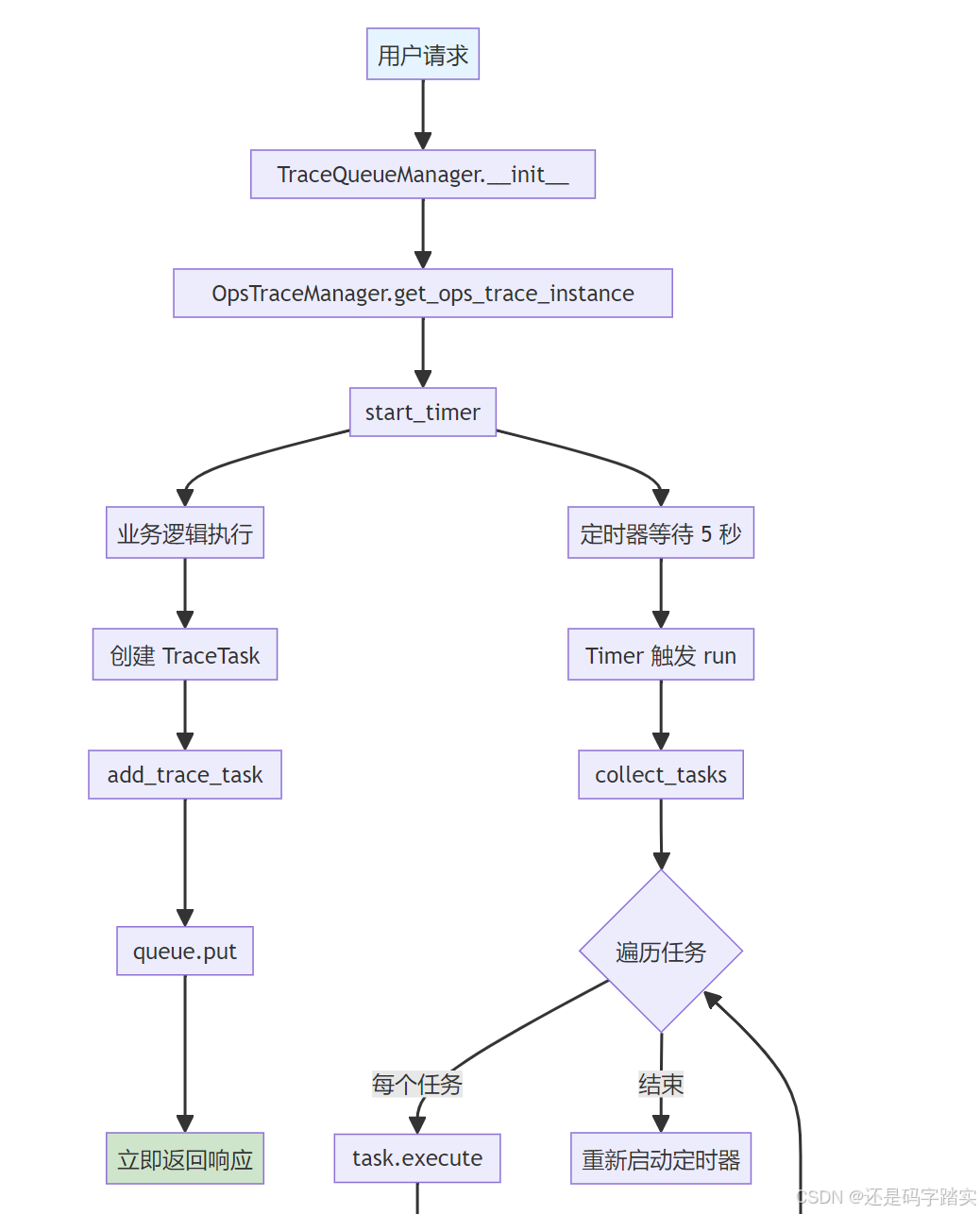
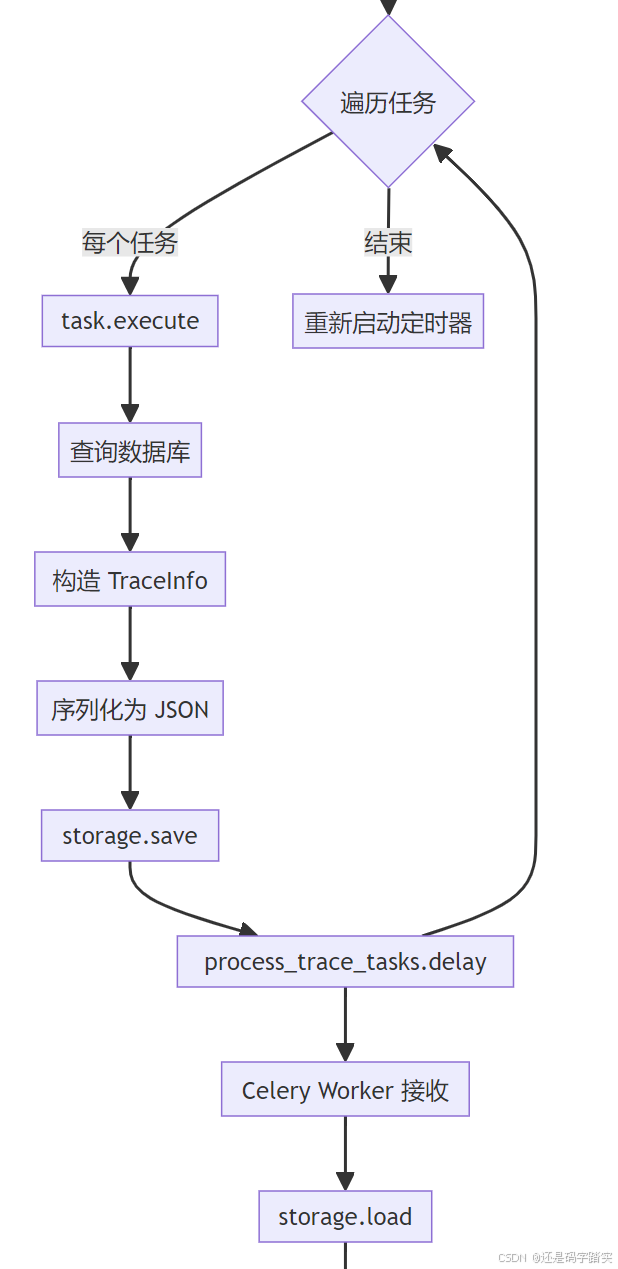
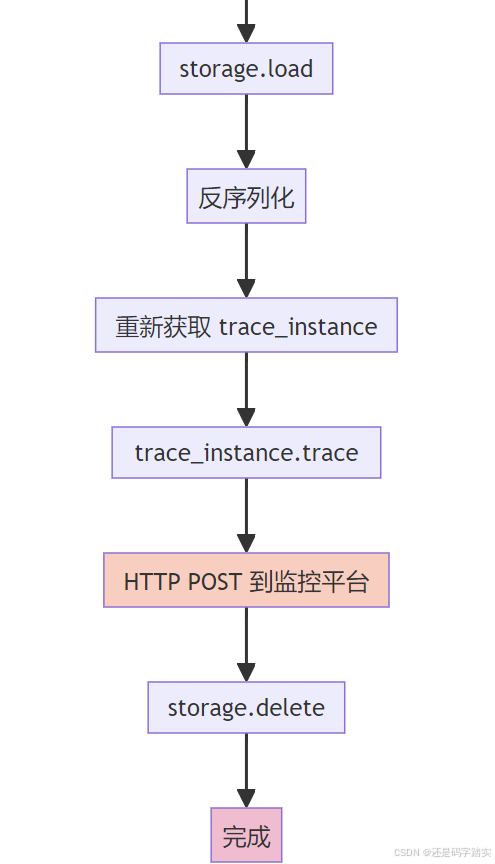
可视化示例:真实数据流
示例场景:用户与 ChatBot 对话
输入:
json
{
"query": "什么是量子计算?",
"conversation_id": "conv_12345",
"app_id": "app_abc"
}【阶段 1】创建追踪任务
python
# 代码位置:api/core/app/task_pipeline/easy_ui_based_generate_task_pipeline.py:407
TraceTask(
trace_type=TraceTaskName.MESSAGE_TRACE,
conversation_id="conv_12345",
message_id="msg_67890" # 新生成的消息 ID
)【阶段 2】加入队列
python
# 代码位置:api/core/ops/ops_trace_manager.py:947
trace_manager_queue.put(task) # 队列当前大小:1【阶段 3】定时器触发(5 秒后)
python
# 代码位置:api/core/ops/ops_trace_manager.py:957
tasks = [task1] # 批量拉取,假设只有 1 个任务【阶段 4】执行预处理
python
# 代码位置:api/core/ops/ops_trace_manager.py:626-683
trace_info = MessageTraceInfo(
message_id="msg_67890",
inputs="什么是量子计算?",
outputs="量子计算是一种利用量子力学原理...",
message_tokens=5,
answer_tokens=120,
total_tokens=125,
start_time=datetime(2026, 1, 23, 10, 30, 0),
end_time=datetime(2026, 1, 23, 10, 30, 2), # 2 秒延迟
metadata={
"conversation_id": "conv_12345",
"ls_provider": "openai",
"ls_model_name": "gpt-4",
"status": "success"
}
)【阶段 5】保存到存储
python
# 代码位置:api/core/ops/ops_trace_manager.py:991-992
file_path = "ops_trace/app_abc/a1b2c3d4.json"
storage.save(file_path, {
"app_id": "app_abc",
"trace_info_type": "MessageTraceInfo",
"trace_info": {
"message_id": "msg_67890",
"inputs": "什么是量子计算?",
"outputs": "量子计算是一种利用量子力学原理...",
"message_tokens": 5,
"answer_tokens": 120,
# ... 完整数据
}
})【阶段 6】Celery 异步消费
python
# 代码位置:api/tasks/ops_trace_task.py:29
file_data = json.loads(storage.load("ops_trace/app_abc/a1b2c3d4.json"))【阶段 7】上报到 Langfuse
python
# 代码位置:api/core/ops/langfuse_trace/langfuse_trace.py:404
self.langfuse_client.trace(
id="msg_67890",
name="message_trace",
input="什么是量子计算?",
output="量子计算是一种利用量子力学原理...",
user_id="user_123",
session_id="conv_12345",
metadata={...}
)最终在 Langfuse 平台看到:
plain
Trace: msg_67890
├─ Input: "什么是量子计算?"
├─ Output: "量子计算是一种利用量子力学原理..."
├─ Duration: 2.0s
├─ Tokens: 5 (input) + 120 (output) = 125 (total)
└─ Model: gpt-4 (openai)核心配置参数说明
环境变量控制
| 变量名 | 默认值 | 说明 | 调优建议 |
|---|---|---|---|
TRACE_QUEUE_MANAGER_INTERVAL |
5 | 定时器触发间隔(秒) | 高流量场景降低到 3 秒,低流量提升到 10 秒 |
TRACE_QUEUE_MANAGER_BATCH_SIZE |
100 | 单次处理最大任务数 | 如果队列积压严重,提升到 200 |
OPS_FILE_PATH |
ops_trace/ |
追踪数据临时存储路径 | 建议使用对象存储(如 S3)而非本地磁盘 |
Celery 队列配置
python
# 文件:api/configs/celery.py(示例)
CELERY_TASK_ROUTES = {
'api.tasks.ops_trace_task.process_trace_tasks': {
'queue': 'ops_trace', # 独立队列
'routing_key': 'ops_trace',
}
}
# 为追踪队列分配独立 Worker
# 启动命令:celery -A app.celery worker -Q ops_trace --concurrency=4性能优化总结
1主线程零阻塞
queue.put()操作耗时 < 1ms- 不执行任何 I/O 操作(数据库查询、HTTP 请求)
批量聚合降低开销
- 避免为每个追踪创建单独的 Celery 任务
- 单次处理最多 100 个任务,减少 Celery 调度开销 99%
存储中转提供容错
- 如果 Celery Worker 崩溃,可从存储恢复数据
- 支持重试机制(Celery 自动重试失败任务)
队列隔离保障稳定性
- 追踪任务使用独立队列
ops_trace - 即使追踪系统故障,不影响业务队列(如发送邮件、生成报告)
失败计数器支持告警
- Redis 计数器
OPS_TRACE_FAILED_KEY_{app_id} - 可配置告警规则(如 1 小时内失败 > 100 次)
故障排查指南
场景 1:追踪数据丢失
现象:Langfuse 平台没有看到追踪数据
排查步骤:
- 检查 app 是否启用追踪:
python
from core.ops.ops_trace_manager import OpsTraceManager
trace_instance = OpsTraceManager.get_ops_trace_instance(app_id)
print(trace_instance) # 应该不为 None- 检查队列是否有积压:
python
from core.ops.ops_trace_manager import trace_manager_queue
print(trace_manager_queue.qsize()) # 如果 > 1000,说明处理速度跟不上- 检查 Celery Worker 是否运行:
bash
celery -A app.celery inspect active_queues
# 应该看到 ops_trace 队列- 检查存储中是否有残留文件:
bash
ls -lh ops_trace/{app_id}/
# 如果有大量 .json 文件,说明 Celery 消费失败场景 2:追踪导致响应变慢
现象:启用追踪后,接口响应时间从 200ms 增加到 500ms
排查步骤:
- 检查是否误用同步上报(理论上不应该发生)
- 检查定时器间隔是否过短:
bash
echo $TRACE_QUEUE_MANAGER_INTERVAL
# 如果 < 3,建议提升到 5- 检查
task.execute()中的数据库查询是否有慢查询:
python
# 在 ops_trace_manager.py 中添加性能监控
import time
start = time.time()
trace_info = task.execute()
print(f"execute took {time.time() - start}s")关键代码文件索引
| 文件路径 | 核心功能 | 关键函数 |
|---|---|---|
api/core/ops/ops_trace_manager.py |
追踪任务管理、队列调度 | TraceQueueManager.add_trace_task(), TraceTask.execute() |
api/tasks/ops_trace_task.py |
Celery 异步消费 | process_trace_tasks() |
api/core/ops/langfuse_trace/langfuse_trace.py |
Langfuse 上报实现 | LangFuseDataTrace.message_trace() |
api/core/ops/arize_phoenix_trace/arize_phoenix_trace.py |
Phoenix 上报实现 | ArizePhoenixDataTrace.message_trace() |
api/core/ops/entities/trace_entity.py |
追踪数据模型定义 | MessageTraceInfo, WorkflowTraceInfo |
api/core/app/task_pipeline/easy_ui_based_generate_task_pipeline.py |
业务代码埋点示例 | _handle_event() |
api/core/rag/retrieval/dataset_retrieval.py |
RAG 检索埋点 | _send_trace_task() |
总结
Dify 的追踪系统通过 五级异步架构 实现了高性能、低侵入的可观测性:
- 业务代码:< 1ms 创建任务
- 内存队列:线程安全缓冲
- 定时聚合:批量处理降低开销
- 对象存储:解耦数据获取与上报
- Celery 异步:独立进程上报到监控平台
为什么需要全链路可观测性?
在 Agent 和 RAG 等复杂流程中,一次用户请求可能触发:
plain
用户输入 → 输入审核 (Moderation)
→ 知识库检索 (Dataset Retrieval)
→ 工具调用 (Tool Invocation)
→ LLM 推理 (Message Generation)
→ 建议问题生成 (Suggested Question)
→ 工作流执行 (Workflow Execution)没有 Trace 的痛点场景:
- 节点黑盒 :工作流执行失败,无法确定是哪个 Node 出错(LLM 超时?工具调用失败?RAG 召回率低?)
- 性能盲区:用户反馈响应慢,无法定位瓶颈(是数据库查询?还是 LLM 推理?还是向量检索?)
- 成本失控:Token 消耗异常,无法追溯哪个会话/用户/工作流导致
Dify 的解决方案:
- Span 级粒度:每个操作节点都生成独立 Span,形成完整调用链
- 父子关系绑定 :通过
trace_id和parent_span_id构建调用树 - 富元数据附加 :每个 Span 携带
tenant_id、app_id、user_id、model_provider等上下文
MCP 协议的前瞻性
MCP (Model Context Protocol) 由 Anthropic 提出,是 LLM 应用与外部工具交互的标准化协议。
传统工具集成 vs MCP 标准化
| 维度 | 传统方式 | MCP 协议 |
|---|---|---|
| 接口定义 | 每个工具自定义接口 | 统一 JSON-RPC 2.0 标准 |
| 上下文传递 | 手动拼接 prompt | 标准 context 字段 |
| 权限管理 | 工具内部实现 | 协议层 OAuth/SSRF 防护 |
| 版本兼容 | 破坏性升级 | 协议版本协商机制 |
Dify 的 MCP 实现价值
- 生态互通性
- Dify 作为 MCP Server,可被任何支持 MCP 的客户端调用(如 Claude Desktop、Continue.dev)
- Dify 作为 MCP Client,可调用其他 MCP 工具(如 Filesystem、Database、Browser)
- 标准化工具抽象
plain
from collections.abc import Callable
from dataclasses import dataclass
from typing import Annotated, Any, Generic, Literal, TypeAlias, TypeVar
from pydantic import BaseModel, ConfigDict, Field, FileUrl, RootModel
from pydantic.networks import AnyUrl, UrlConstraints
"""
Model Context Protocol bindings for Python
These bindings were generated from https://github.com/modelcontextprotocol/specification,
using Claude, with a prompt something like the following:
Generate idiomatic Python bindings for this schema for MCP, or the "Model Context
Protocol." The schema is defined in TypeScript, but there's also a JSON Schema version
for reference.
* For the bindings, let's use Pydantic V2 models.
* Each model should allow extra fields everywhere, by specifying `model_config =
ConfigDict(extra='allow')`. Do this in every case, instead of a custom base class.
* Union types should be represented with a Pydantic `RootModel`.
* Define additional model classes instead of using dictionaries. Do this even if they're
not separate types in the schema.
"""
# Client support both version, not support 2025-06-18 yet.
LATEST_PROTOCOL_VERSION = "2025-06-18"
# Server support 2024-11-05 to allow claude to use.
SERVER_LATEST_PROTOCOL_VERSION = "2024-11-05"
DEFAULT_NEGOTIATED_VERSION = "2025-03-26"
ProgressToken = str | int
Cursor = str
Role = Literal["user", "assistant"]
RequestId = Annotated[int | str, Field(union_mode="left_to_right")]
AnyFunction: TypeAlias = Callable[..., Any]
class RequestParams(BaseModel):
class Meta(BaseModel):
progressToken: ProgressToken | None = None- 使用 Pydantic V2 生成 Python 绑定,确保类型安全
- 支持多版本协议协商(
2024-11-05↔2025-03-26)
工程实战与故障应对
故障模拟 1:性能损耗
场景:启用 Langfuse 追踪后,接口响应时间从 200ms 增加到 500ms
定位思路:
- 检查是否启用了同步上报(已排除,Dify 使用异步队列)
- 检查采样频率是否过高
解决方案:调整环境变量
bash
# 降低上报频率(从 5 秒提升到 10 秒)
TRACE_QUEUE_MANAGER_INTERVAL=10
# 减小批量大小(从 100 降到 50,减少单次处理开销)
TRACE_QUEUE_MANAGER_BATCH_SIZE=50源码验证:
plain
trace_manager_interval = int(os.getenv("TRACE_QUEUE_MANAGER_INTERVAL", 5))
trace_manager_batch_size = int(os.getenv("TRACE_QUEUE_MANAGER_BATCH_SIZE", 100))3.2 故障模拟 2:MCP 协议断连
场景:MCP Server 意外重启,导致所有工具调用失败
Dify 的自动重连机制:
plain
class MCPClientWithAuthRetry(MCPClient):
"""
An enhanced MCPClient that provides automatic authentication retry.
This class extends MCPClient and intercepts MCPAuthError exceptions
to refresh authentication before retrying failed operations.
Note: This class uses lazy session creation - database sessions are only
created when authentication retry is actually needed, not on every request.
"""
def __init__(
self,
server_url: str,
headers: dict[str, str] | None = None,
timeout: float | None = None,
sse_read_timeout: float | None = None,
provider_entity: MCPProviderEntity | None = None,
authorization_code: str | None = None,
by_server_id: bool = False,
):
"""
Initialize the MCP client with auth retry capability.
Args:
server_url: The MCP server URL
headers: Optional headers for requests
timeout: Request timeout
sse_read_timeout: SSE read timeout
provider_entity: Provider entity for authentication
authorization_code: Optional authorization code for initial auth
by_server_id: Whether to look up provider by server ID
"""
super().__init__(server_url, headers, timeout, sse_read_timeout)
self.provider_entity = provider_entity
self.authorization_code = authorization_code
self.by_server_id = by_server_id
self._has_retried = False
def _handle_auth_error(self, error: MCPAuthError) -> None:
"""
Handle authentication error by refreshing tokens.
This method creates a short-lived database session only when authentication
retry is needed, minimizing database connection hold time.
Args:
error: The authentication error
Raises:
MCPAuthError: If authentication fails or max retries reached
"""
if not self.provider_entity:
raise error
if self._has_retried:
raise error
self._has_retried = True
try:
# Create a temporary session only for auth retry
# This session is short-lived and only exists during the auth operation
from services.tools.mcp_tools_manage_service import MCPToolManageService
with Session(db.engine) as session, session.begin():
mcp_service = MCPToolManageService(session=session)
# Perform authentication using the service's auth method
# Extract OAuth metadata hints from the error
mcp_service.auth_with_actions(
self.provider_entity,
self.authorization_code,
resource_metadata_url=error.resource_metadata_url,
scope_hint=error.scope_hint,
)
# Retrieve new tokens
self.provider_entity = mcp_service.get_provider_entity(
self.provider_entity.id, self.provider_entity.tenant_id, by_server_id=self.by_server_id
)
# Session is closed here, before we update headers
token = self.provider_entity.retrieve_tokens()
if not token:
raise MCPAuthError("Authentication failed - no token received")
# Update headers with new token
self.headers["Authorization"] = f"{token.token_type.capitalize()} {token.access_token}"
# Clear authorization code after first use
self.authorization_code = None
except MCPAuthError:
# Re-raise MCPAuthError as is
raise
except Exception as e:
# Catch all exceptions during auth retry
logger.exception("Authentication retry failed")
raise MCPAuthError(f"Authentication retry failed: {e}") from e
def _execute_with_retry(self, func: Callable[..., Any], *args, **kwargs) -> Any:
"""
Execute a function with authentication retry logic.
Args:
func: The function to execute
*args: Positional arguments for the function
**kwargs: Keyword arguments for the function
Returns:
The result of the function call
Raises:
MCPAuthError: If authentication fails after retries
Any other exceptions from the function
"""
try:
return func(*args, **kwargs)
except MCPAuthError as e:
self._handle_auth_error(e)
# Re-initialize the connection with new headers
if self._initialized:
# Clean up existing connection
self._exit_stack.close()
self._session = None
self._initialized = False
# Re-initialize with new headers
self._initialize()
self._initialized = True
return func(*args, **kwargs)
finally:
# Reset retry flag after operation completes
self._has_retried = False
def __enter__(self):
"""Enter the context manager with retry support."""
def initialize_with_retry():
super(MCPClientWithAuthRetry, self).__enter__()
return self重连机制关键点:
- 异常拦截 :捕获
MCPAuthError,触发 token 刷新 - 单次重试保护 :
_has_retried标志防止无限重试 - 连接重建 :清空
_exit_stack,重新初始化 session - OAuth 自动刷新 :通过
MCPToolManageService.auth_with_actions获取新 token
工程实践建议:
- 在 MCP Server 前部署 Load Balancer,配合健康检查避免单点故障
- 监控
MCPAuthError频率,设置告警阈值(如 1 分钟超过 10 次)
红队思维与安全考点
敏感信息泄露防护
威胁场景 :追踪日志中包含用户 API Key、对话内容,上报到第三方平台(如 Langfuse Cloud)
Dify 的多层脱敏机制:
Layer 1: 配置项加密存储
plain
@classmethod
def decrypt_tracing_config(cls, tenant_id: str, tracing_provider: str, tracing_config: dict):
"""
Decrypt tracing config
:param tenant_id: tenant id
:param tracing_provider: tracing provider
:param tracing_config: tracing config
:return:
"""
config_json = json.dumps(tracing_config, sort_keys=True)
decrypted_config_key = (
tenant_id,
tracing_provider,
config_json,
)
# First check without lock for performance
cached_config = cls.decrypted_configs_cache.get(decrypted_config_key)
if cached_config is not None:
return dict(cached_config)
with cls._decryption_cache_lock:
# Second check (double-checked locking) to prevent race conditions
cached_config = cls.decrypted_configs_cache.get(decrypted_config_key)
if cached_config is not None:
return dict(cached_config)
config_class, secret_keys, other_keys = (
provider_config_map[tracing_provider]["config_class"],
provider_config_map[tracing_provider]["secret_keys"],
provider_config_map[tracing_provider]["other_keys"],
)
new_config: dict[str, Any] = {}
keys_to_decrypt = [key for key in secret_keys if key in tracing_config]
if keys_to_decrypt:
decrypted_values = batch_decrypt_token(tenant_id, [tracing_config[key] for key in keys_to_decrypt])
new_config.update(zip(keys_to_decrypt, decrypted_values))
for key in other_keys:
new_config[key] = tracing_config.get(key, "")
decrypted_config = config_class(**new_config).model_dump()
cls.decrypted_configs_cache[decrypted_config_key] = decrypted_config
return dict(decrypted_config)- AES 加密 :所有
<font style="color:#DF2A3F;">secret_keys</font>(如 Langfuse<font style="color:#DF2A3F;">secret_key</font>)使用 tenant_id 作为盐值加密存储 - Double-Checked Locking:缓存解密结果,避免频繁解密影响性能
Layer 2: 工具参数脱敏
plain
def mask_tool_parameters(self, parameters: dict[str, Any]) -> dict[str, Any]:
"""
mask tool parameters
return a deep copy of parameters with masked values
"""
parameters = self._deep_copy(parameters)
# override parameters
current_parameters = self._merge_parameters()
for parameter in current_parameters:
if (
parameter.form == ToolParameter.ToolParameterForm.FORM
and parameter.type == ToolParameter.ToolParameterType.SECRET_INPUT
):
if parameter.name in parameters:
if len(parameters[parameter.name]) > 6:
parameters[parameter.name] = (
parameters[parameter.name][:2]
+ "*" * (len(parameters[parameter.name]) - 4)
+ parameters[parameter.name][-2:]
)
else:
parameters[parameter.name] = "*" * len(parameters[parameter.name])
return parameters脱敏规则:
- 短密钥(≤6 字符):全部
**** - 长密钥(>6 字符):保留首尾 2 字符 →
sk-****Wz
Layer 3: MCP 凭证脱敏
plain
def masked_headers(self) -> dict[str, str]:
return {key: self._mask_value(value) for key, value in self.decrypt_headers().items()}
def masked_credentials(self) -> dict[str, str]:
"""Masked credentials for display"""
credentials = self.decrypt_credentials()
if not credentials:
return {}
masked = {}
if "client_information" not in credentials or not isinstance(credentials["client_information"], dict):
return {}
client_info = credentials["client_information"]
# Mask sensitive fields from nested structure
if client_info.get("client_id"):
masked["client_id"] = self._mask_value(client_info["client_id"])
if client_info.get("encrypted_client_secret"):
masked["client_secret"] = self._mask_value(
encrypter.decrypt_token(self.tenant_id, client_info["encrypted_client_secret"])
)
if client_info.get("client_secret"):
masked["client_secret"] = self._mask_value(client_info["client_secret"])
return masked关键实践:
- 先解密后脱敏:避免在日志/API 响应中泄露加密后的明文
- 嵌套结构处理 :递归处理
client_information等复杂对象
4.2 SSRF 风险防护
攻击向量 :恶意用户配置 MCP Server URL 为内网地址(如 http://192.168.1.1:6379),借助 Dify 服务器探测内网
Dify 的防御措施:
- URL Schema 白名单
python
# 源码位置:api/core/helper/ssrf_proxy.py(推测)
ALLOWED_SCHEMAS = ["http", "https"] # 禁止 file:// ftp:// 等协议- 内网 IP 黑名单
python
BLOCKED_NETWORKS = [
"127.0.0.0/8", # Loopback
"10.0.0.0/8", # Private
"172.16.0.0/12", # Private
"192.168.0.0/16", # Private
"169.254.0.0/16", # Link-local
]- DNS Rebinding 防护
- 在 MCP 连接建立时二次解析 URL
- 对比首次解析和实际连接时的 IP,拒绝不一致的请求
工程建议:
- 在生产环境使用 出口代理(如 Squid),统一过滤外部请求
- 监控 MCP 连接的目标域名,设置域名白名单
标准化回答话术(300字以内)
如何构建 LLM 应用的可观测性体系
全链路 Trace 追踪体系
采用 OpenTelemetry 或 Langfuse 等成熟方案,在 LLM 应用的每个关键节点埋点:输入预处理、知识库检索、工具调用、LLM 推理、输出后处理。通过 Span 级粒度记录每个操作的耗时、输入输出、Token 消耗,形成完整的调用链路。
Dify:
- "在 Dify 项目中,它的
ops_trace_manager.py实现,发现它通过 TraceQueueManager 将追踪任务解耦为内存队列 → 定时聚合 → Celery 异步消费三个阶段,确保追踪不影响主业务响应时间。" - "同时支持 Langfuse (适合快速集成)和 Phoenix/Arize(基于 OpenTelemetry 标准,适合大规模部署)。"
** 异步采样优化性能**
"全量上报会显著增加系统负载。设计异步采样机制 :业务代码只负责将追踪事件放入内存队列(耗时 <1ms),由独立的后台线程定期批量上报(如每 5 秒最多上报 100 条)。对于高频接口,可配置采样率(如 1% 流量),既能保留统计有效性,又能控制成本。"
Dify:
- "在 Dify 源码中,通过环境变量
TRACE_QUEUE_MANAGER_INTERVAL和TRACE_QUEUE_MANAGER_BATCH_SIZE动态控制采样频率。" - "对于 P99 延迟 等关键指标,即使采样 1% 也能准确反映长尾问题。"
MCP 协议的标准化应用
"为了避免重复开发各种工具集成,采用 MCP (Model Context Protocol) 协议:它是 Anthropic 提出的标准化工具交互协议,基于 JSON-RPC 2.0。通过 MCP,LLM 应用可以无缝对接任何符合 MCP 标准的工具(如文件系统、数据库、浏览器),大幅降低集成成本。"
Dify:
- "在 Dify 中,MCP 实现了双向能力:既可以作为 MCP Server 被外部客户端(如 Claude Desktop)调用,也可以作为 MCP Client 调用外部工具。"
- "MCP 客户端支持 Streamable HTTP 和 SSE 双协议,遇到网络问题时自动降级,保证连接稳定性。"
** 监控中的 PII (个人隐私) 数据保护**
"在追踪日志中,必须对敏感信息进行多层脱敏:
- 配置项加密 :如监控平台的 API Key,使用 AES 加密存储,基于 tenant_id 作为盐值。
- 工具参数脱敏 :对
SECRET_INPUT类型的参数(如数据库密码),保留首尾 2 字符,中间替换为****。 - 用户内容过滤:在上报前,移除或哈希化用户身份信息(如邮箱、手机号)。"
Dify:
- "在 Dify 源码中,
mask_tool_parameters方法实现了工具参数的自动脱敏,确保即使日志泄露,也无法还原原始密钥。" - "对于符合 GDPR 等法规的场景,可配置追踪数据的过期删除策略(如 30 天后自动清理)。"
完整回答示例(60 秒版本)
"构建 LLM 应用可观测性体系,从四个维度入手:
- 第一,全链路 Trace 追踪。采用 OpenTelemetry 或 Langfuse,在输入预处理、知识库检索、LLM 推理等关键节点埋点,通过 Span 记录每个操作的耗时和 Token 消耗,形成完整调用链。研究 Dify 的实现,它通过 TraceQueueManager 将追踪任务解耦为内存队列、定时聚合和 Celery 异步消费,确保追踪不影响主业务。
- 第二,异步采样优化性能。业务代码只负责将追踪事件放入内存队列,由后台线程每 5 秒批量上报最多 100 条。对于高频接口,配置 1% 采样率,既保留统计有效性,又控制成本。
- 第三,MCP 协议的标准化应用。采用 Anthropic 提出的 Model Context Protocol,基于 JSON-RPC 2.0 实现工具交互标准化。Dify 的 MCP 实现支持 Streamable HTTP 和 SSE 双协议,遇到网络问题时自动降级,还提供了 MCPClientWithAuthRetry 类,实现 Token 过期时的自动刷新重连。
- 第四,PII 数据保护 。对配置项使用 AES 加密存储,对工具参数中的敏感字段(如密码)自动脱敏为
sk-****Wz格式,在上报前移除用户身份信息。Dify 源码中的 mask_tool_parameters 方法,会根据参数类型自动判断是否需要脱敏,确保合规。
这套体系既能提供细粒度的可观测性,又能兼顾性能、成本和安全性。"