前言
大语言模型(LLM)虽然能力强大,但存在 "知识截止期"、"幻觉"(编造不存在的信息)、"无法精准回答私有数据问题" 等痛点。而 RAG(Retrieval-Augmented Generation,检索增强生成)正是解决这些问题的核心方案 ------ 它先从私有知识库中检索相关信息,再让 LLM 基于检索结果生成回答,既保留了 LLM 的生成能力,又保证了回答的准确性和时效性。
本文会从 RAG 的产生原因、核心模块、完整代码实现三个维度,带你从零理解 RAG,文末附可直接运行的完整代码(基于 LangChain1.0+轻量化的Chroma + 通义千问 Embedding + DeepSeek-chat)。
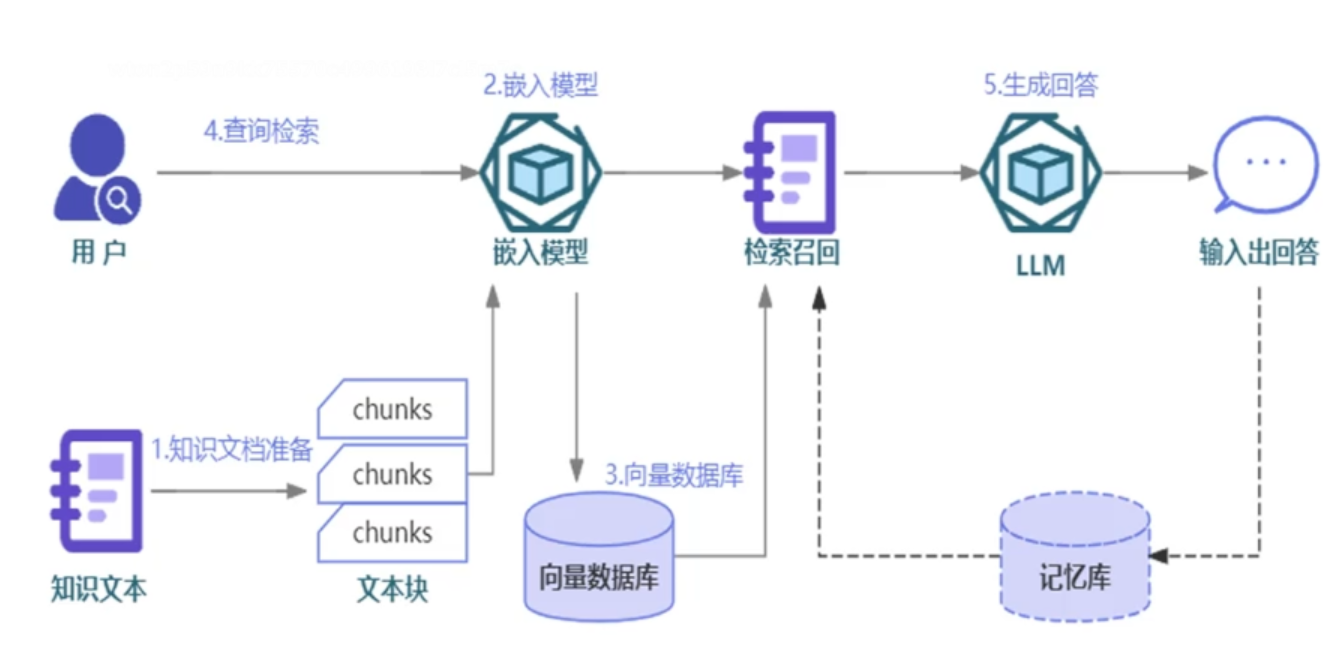
文档的处理
文档的分块
本博客文章仅仅处理的是pdf文档,实际的项目可能包含excel、ppt、word、csv、html、txt文档。下列代码就是对所有的pdf进行加载。
python
loaders=[]
for filename in os.listdir(PDF_PATH):
if filename.endswith('.pdf'):
pdf_path=os.path.join(PDF_PATH,filename)
loader=PyPDFLoader(pdf_path)
loaders.append(loader)
documents=[]
for loader in loaders:
documents.extend(loader.load())对于文档的预处理,一般是分块操作。分块的大小(chunk_size)一般设置为1000,重叠(overlap)设置为200,设置一定量的重叠是为了确保上下文的一致性。
此外由于大语言模型和嵌入模型对于输入长度有一定的限制,比如32k 或者128k token,无法支持整本pdf的输入。
python
text_spliter=RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len
)具体情况
实际上并不能这么做,理由是书籍千变万化,这么做只是非常粗糙的做法,我以动手学习深度学习为例,下面的图片中包括:图片,文字,标题,代码,公式,代码。如此复杂的情况仅仅使用1000token且重复200token是无法达到较好的RAG检索效果。
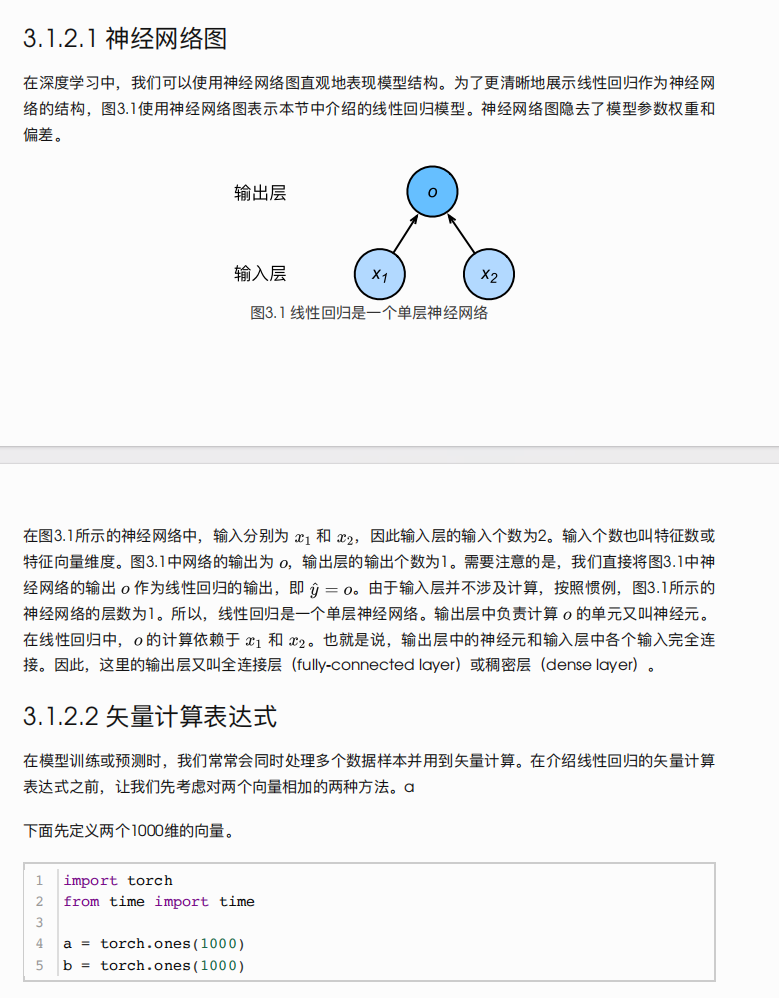
为了解决这种问题,我们可以根据文档内容特点来调整实际的分块逻辑,因为使用统一的分块逻辑往往效果差。且不同的文档类型还需要兼容不同的分块逻辑,这些都需要在实际中慢慢摸索。
比如,对于动手学习深度学习这本书,可以按照标题(1级,2级,3级等)、数学公式、代码等来分块。
下面这段Python 代码实现了对文档内容按章 - 节 - 小节层级的结构化拆分。代码首先定义正则表达式匹配 1、1.1、1.1.1 格式的章节标题,通过 defaultdict 构建嵌套字典存储结构。执行时先将文档按行拆分,跳过以 "目录" 开头的内容,直到匹配到第一章标题后开始解析。
它会识别标题的层级(章 / 节 / 小节),记录当前层级并将后续文本内容归入对应层级,最后将各层级下的多行文本合并为完整字符串,最终返回包含各章节标题和对应内容的嵌套字典,实现了文档内容的层级化提取与整理。
python
import re
from collections import defaultdict
def split_by_chapter(content):
"""按章-节-小节拆分文档,跳过目录"""
# 章节匹配正则(支持1、1.1、1.1.1格式)
chapter_pattern = r'(\d+(?:\.\d+)*)\s+([^\n]+)'
sections = defaultdict(dict) # 存储结构:{章: {节: {小节: 内容}}}
current_chapter = None
current_section = None
current_subsection = None
content_lines = content.split('\n')
# 跳过目录(假设目录以"目录"开头,以正文第一章结束)
skip目录 = True
for line in content_lines:
line = line.strip()
if not line:
continue
# 退出目录判断(当匹配到第一章时)
if re.match(r'^1\s+', line):
skip目录 = False
if skip目录:
continue
# 匹配章节
match = re.match(chapter_pattern, line)
if match:
level = len(match.group(1).split('.'))
title = match.group(2)
if level == 1: # 章
current_chapter = match.group(1)
current_section = None
current_subsection = None
sections[current_chapter]['title'] = title
sections[current_chapter]['content'] = []
sections[current_chapter]['sections'] = defaultdict(dict)
elif level == 2: # 节
current_section = match.group(1)
current_subsection = None
sections[current_chapter]['sections'][current_section]['title'] = title
sections[current_chapter]['sections'][current_section]['content'] = []
sections[current_chapter]['sections'][current_section]['subsections'] = defaultdict(dict)
elif level == 3: # 小节
current_subsection = match.group(1)
sections[current_chapter]['sections'][current_section]['subsections'][current_subsection]['title'] = title
sections[current_chapter]['sections'][current_section]['subsections'][current_subsection]['content'] = []
else:
# 向当前层级添加内容
if current_subsection:
sections[current_chapter]['sections'][current_section]['subsections'][current_subsection]['content'].append(line)
elif current_section:
sections[current_chapter]['sections'][current_section]['content'].append(line)
elif current_chapter:
sections[current_chapter]['content'].append(line)
# 合并内容为字符串
for chapter in sections:
sections[chapter]['content'] = '\n'.join(sections[chapter]['content'])
for section in sections[chapter]['sections']:
sections[chapter]['sections'][section]['content'] = '\n'.join(sections[chapter]['sections'][section]['content'])
for subsection in sections[chapter]['sections'][section]['subsections']:
sections[chapter]['sections'][section]['subsections'][subsection]['content'] = '\n'.join(
sections[chapter]['sections'][section]['subsections'][subsection]['content']
)
return sections嵌入模型
什么是嵌入模型
由于程序无法理解文本,所以需要把文本转化为数字,这就是嵌入模型的简单理解。实际上是把非结构化的文本转化为****高维的稠密限量。
这种转化不是简单的文字映射,而是把语义更加相邻的文本放到一起。越相似的语义,在高维空间中越相近。实际的高维空间可能到了1024维,因为少量的维度是无法表示丰富的语义信息。
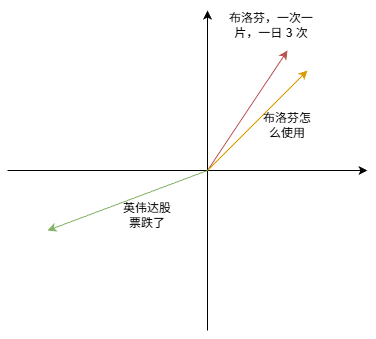
下图是一个演示(维度仅仅为2,因为到了四维及以上,无法绘制),布洛芬用法和体温靠近,但是和英伟达股票信息无关。
常见的嵌入模型
一般来讲,嵌入模型分为通用的嵌入模型和垂直嵌入模型。
通用嵌入模型
- OpenAI
text-embedding-ada-002:效果稳定,API 调用便捷,适合快速开发; - 通义千问
text-embedding-v1:阿里云开源模型,国内访问友好,免费易用; - Sentence-BERT:轻量级开源模型,支持本地化部署,可微调适配特定场景;
- GLM-Embedding:智谱 AI 推出的模型,兼顾效果与速度,适合中文场景
垂直嵌入模型
对于医疗领域,有PubmedBERT/BioBERT,能精准把握医疗的核心词汇,是医疗RAG的首选。
对于金融领域,有FinBERT,适用于金融的期刊的,书籍等。
上述仅仅举例,实在没有,自己也可以微调一个BERT,然后放到项目中。
阿里云的百炼平台提供了诸多嵌入模型,本简易演示使用的最便宜、通用的'text-embedding-v1'。下面是直达链接,可以访问:大模型服务平台百炼控制台
向量数据库
什么是向量数据库
向量数据库是专门存储、增加、删除、检索****高位稠密向量的数据库
传统的MySQL、PostgreSQL数据库存储结构化或者半结构化的数据,数据是按行、列、字段等组织存在,有明确的语义信息。
而向量数据库存储的是高维向量,不具备直接的语义信息,但是可以捕捉文本、图像、音频的语义关系。检索时是按照相似度来检索,支持最近似最近邻搜索算法(Approximately Nearest Neighborhood)。
这个算法在查询一个向量时,会返回和他最相邻的向量,此外使用Chroma是还可以指定,检索器就会返回,对应的最相邻的
个高维向量。
python
db = Chroma.from_documents(
documents=split_docs,
embedding=embeddings,
persist_directory=CHROMA_DB_PATH
)
retriever = db.as_retriever(search_kwargs={"k": 4})两个高纬度空间中的稠密向量有多相近,可以参考余弦相似度公式:
什么是元数据
元数据(metadate)是在每个嵌入(embedding)或者文档中添加的附加信息,可以用于描述、过滤、检索该条目。元数据本身不参与向量计算,但是可以参与过滤或者混合检索。
下面是一个元数据的简易演示的例子。
python
import chromadb
from chromadb.utils import embedding_functions
# 1. 初始化客户端(使用内存模式)
client = chromadb.Client()
# 2. 创建一个集合(collection)
collection = client.create_collection(
name="demo_collection",
# 可选:指定嵌入函数(这里用默认的,也可以用 SentenceTransformer 等)
embedding_function=embedding_functions.SentenceTransformerEmbeddingFunction(model_name="all-MiniLM-L6-v2")
)
# 3. 添加带元数据的文档
collection.add(
documents=[
"苹果是一种水果。",
"特斯拉是一家电动汽车公司。",
"Python 是一种编程语言。"
],
metadatas=[
{"category": "food", "language": "zh"},
{"category": "tech", "company": "Tesla", "industry": "automotive"},
{"category": "tech", "language": "en", "topic": "programming"}
],
ids=["doc1", "doc2", "doc3"]
)
# 4. 查询时使用元数据过滤
results = collection.query(
query_texts=["和编程有关的内容"],
n_results=2,
where={"category": "tech"} # 仅返回 category 为 'tech' 的结果
)
print("查询结果(带元数据过滤):")
for doc, meta, dist in zip(results['documents'][0], results['metadatas'][0], results['distances'][0]):
print(f"- 文本: {doc}")
print(f" 元数据: {meta}")
print(f" 距离: {dist:.4f}\n")向量数据库分类
FAISS
FAISS向量数据库的核心定位是高性能向量检索库,底层采用C++代码,提供python的接口。
FAISS支持多种索引,包括IVF、HNSW、PQ 等,适合多种场景。
但是FAISS数据库只支持单机,扩展性较差;
此外FAISS不支持元数据。
Chroma
Chroma向量数据库的核心定位是**轻量的,专门为LLM设计(如RAG检索)**的向量数据库。
Chroma支持元数据,在检索时可以采取向量相似度和元数据的混合检索。
Chroma支持单机和小集群(2~5个电脑),相对FAISS扩展性更加强。
Chroma不支持多种索引。
Milvus
Milvus向量数据库的核心定位是企业级、分布式、云原生的向量数据库。
Milvus支持超大规模的向量,具备高并发,低延迟的特点。
Milvus支持多种索引类型,如HNSW、IVF_FLAT、ANNOY,适合多种的场景。
Milvus还兼容混合检索,包括向量和标量的检索。支持元数据检索。
环境依赖
API KEY的配置
在项目的根目录下创建一个.env文件,可以用来配置下列的api_key
bash
DEEPSEEK_API_KEY=你的DeepSeek API KEY
DEEPSEEK_BASE_URL="https://api.deepseek.com"
DASHSCOPE_API_KEY=你的dashscope API KEYPython package的安装
python
# 安装所需依赖
pip install langchain langchain-openai langchain-community langchain-text-splitters chromadb python-dotenv pypdf dashscopepdf的上传
在当前工作目录下创建新文件夹,命名为pdf_folder,然后放入你的pdf文件
代码
在完成了上述的环境配置之后,就可以直接运行代码了。
python
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_classic.chains import RetrievalQA
import os
load_dotenv()
CHROMA_DB_PATH='./chroma_db'
PDF_PATH='./pdf_folder'
embeddings=DashScopeEmbeddings(
model='text-embedding-v1',
dashscope_api_key=os.getenv("DASHSCOPE_API_KEY")
)
llm=ChatOpenAI(
model='deepseek-chat',
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url=os.getenv("DEEPSEEK_BASE_URL"),
temperature=0.1,
max_tokens=500
)
if not os.path.exists(CHROMA_DB_PATH):
loaders=[]
for filename in os.listdir(PDF_PATH):
if filename.endswith('.pdf'):
pdf_path=os.path.join(PDF_PATH,filename)
loader=PyPDFLoader(pdf_path)
loaders.append(loader)
documents=[]
for loader in loaders:
documents.extend(loader.load())
text_spliter=RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
documents=text_spliter.split_documents(documents)
print(f"it is building a vector database")
chroma_db=Chroma.from_documents(
documents=documents,
embedding=embeddings,
persist_directory=CHROMA_DB_PATH
)
else:
print(f"load a pre-existing vector database")
chroma_db=Chroma(
embedding_function=embeddings,
persist_directory=CHROMA_DB_PATH
)
retriever=chroma_db.as_retriever(search_args={"k":4})
qa_chain=RetrievalQA.from_chain_type(
llm=llm,
chain_type='stuff',
retriever=retriever,
return_source_documents=True
)
def ask_question(question):
result=qa_chain.invoke({"query":question})
print(f"回答如下:{result['result']}")
print(f"\n检索来源")
for line in result['source_documents']:
print(f"来源于{line.metadata['source']}{line.metadata['page']} 页码")
return result
while True:
user_question=input('请输入你的问题,没有请输入q,表示退出\n')
if user_question.lower()=='q':
break
ask_question(user_question)