一、GOP
1、含义
GOP 是视频编码中一个非常重要的概念,全称是 Group of Pictures(图片组)。
通俗理解:
整本书 = 整个视频
章节 = GOP(图片组)
页面 = 帧(Frame)
2、GOP的组成
一个GOP包含三种类型的帧:
1、I帧(关键帧) ---- Intra Frame
特点:完整独立的帧,不依赖其他帧
压缩率:低(占用空间大)
作用:随机访问的入口点
2、P帧(预测帧) ---- Predicted Frame特点:基于前一帧(I帧或P帧)进行预测编码
压缩率:中等
作用:提高压缩效率
3、B帧(双向预测帧) ---- Bi-directional Frame特点:基于前后帧进行预测
压缩率:高
作用:进一步提高压缩效率
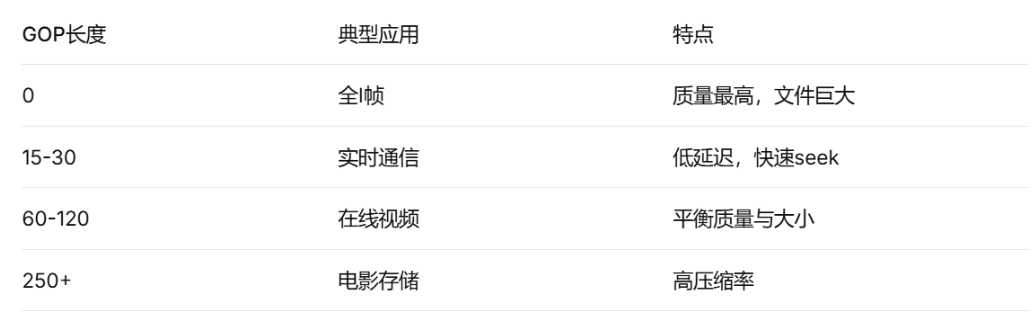
3、GOP的长度(gop_len)
短GOP(如:gop_len = 30)
含义:每30帧一个I帧优点:Seek快,容错性好
缺点: 文件体积大
应用: 直播、视频会议
长GOP(如:gop_len = 250)
含义:每250帧一个I帧优点: 压缩率高,文件小
缺点: Seek慢,容错性差
应用: 视频存储、点播
4、实际应用场景
二、YUV and RGB
1、两者对比
| 格式 | BGR (CV_8UC3) | NV12 (YUV420SP) |
|---|---|---|
| 数据类型 | 每像素 3 通道(8bit) | Y 分量 + UV 半分辨率交织 |
| 存储格式 | B,G,R 连续存储(3字节/像素) | Y 平面 + (UVUVUV...) |
| 颜色空间 | RGB 颜色空间 | YUV420(亮度+色度) |
| 内存占用 | 大(3 bytes/pixel) | 小(1.5 bytes/pixel) |
| 使用场景 | OpenCV内部处理、图像算法 | 视频编解码、视频传输、摄像头采集 |
绝大多数现代视频编码器都要求输入YUV格式(尤其是YUV420系列,如NV12),而不是直接处理BGR或RGB。
2、为什么视频编码器偏爱YUV(尤其是NV12)
这背后有三个核心原因:人类视觉系统、带宽效率和硬件优化。
a、人类视觉系统的特性(理论基础)
人眼对亮度的敏感度远高于对颜色的敏感度。
亮度 决定了图像的细节、轮廓和明暗对比。如果亮度信息丢失,图像会变得模糊不清。
色度 决定了图像的颜色。即使色度信息减少一半,人眼也很难察觉出明显的质量下降。
YUV格式的Y分量代表亮度,U和V代表色度,完美地契合了这一特性。因此,我们可以对色度信息进行"子采样"来压缩数据。
b、带宽和压缩效率(直接动力)
BGR格式每个像素需要3个字节。而NV12(属于YUV420) 通过色度子采样,平均每个像素仅需1.5个字节。
数据量的对比:
BGR/RGB: 宽度 × 高度 × 3 字节
NV12 (YUV420): 宽度 × 高度 × 1.5 字节
**结果:**在编码器开始其复杂的压缩算法(如H.264/HEVC)之前,仅仅通过转换到NV12格式,你就已经把数据量减少了50%! 这为后续的编码提供了更小的"原材料",极大地提高了压缩效率,是视频文件远小于图像序列的根本原因之一。
c、硬件和生态系统的支持(现实驱动)
**摄像头传感器:**绝大多数手机、摄像头和网络摄像头的传感器原生输出的就是YUV420格式的数据(通常是NV12或NV21)。直接使用这些数据避免了额外的转换开销。
硬件编码器:Intel Quick Sync、NVIDIA NVENC、AMD VCE以及移动芯片上的编码器,其设计输入就是YUV420格式。如果你强行输入BGR,驱动或编码库通常会在内部先将其转换为YUV,然后再进行编码,这反而会增加CPU负担和延迟。
**视频编码标准:**像H.264、H.265(HEVC)、VP9等主流编码标准,其算法和块结构都是基于YUV色彩空间设计的,特别是处理亮度和色度分离的方式。
结论:对于典型的视频应用,标准的工作流程是:
采集 (NV12/YUV) → 可选:转换为BGR进行处理 → 处理后再转回NV12 → 编码 (H.264/H.265等) → 传输/存储
NV12 → BGR: 当你从摄像头获取到NV12数据后,想用OpenCV显示或处理它,你需要调用cv::cvtColor(nv12_data, bgr_data, CV_YUV2BGR_NV12)。
BGR → NV12: 当你用OpenCV处理完一张图像,想用硬件编码器将其编码为H.264/H.265视频时,你需要先将其转换为NV12(或类似格式)。、
三、摄像头数据采集、处理流程
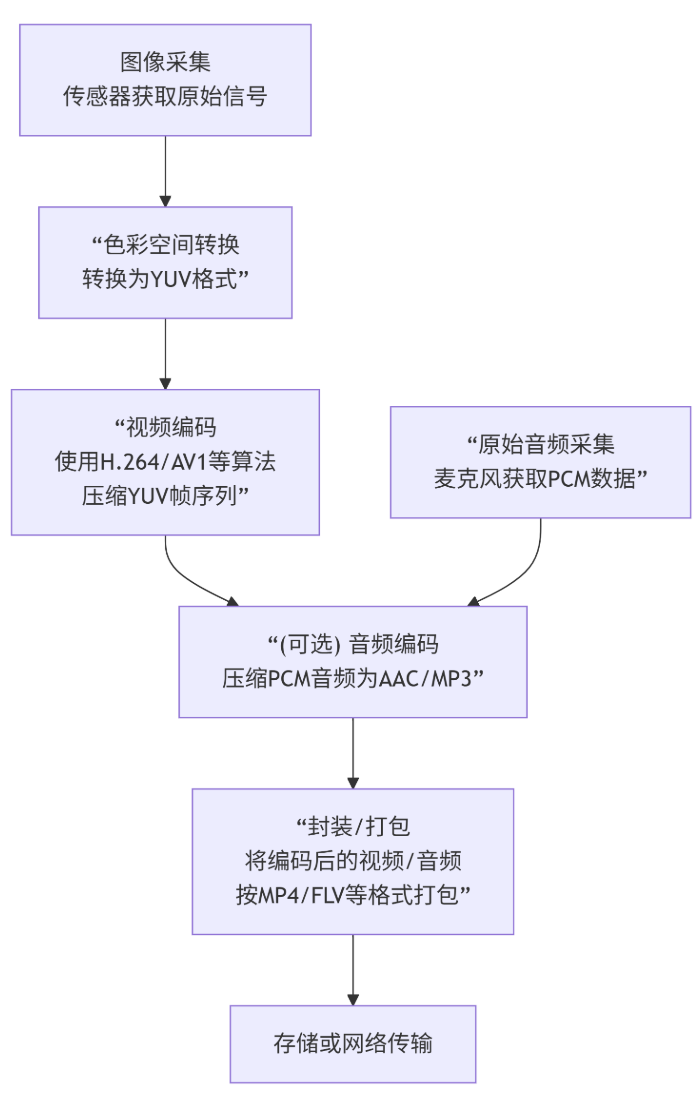
关键区分:
1、图像色彩格式 - "我们如何描述颜色?"
角色: 这是最底层的数据表示层。
**内容:**RGB、YUV就是这一层的概念。它定义了像素点的颜色是如何由几个分量(如R/G/B或Y/U/V)构成的。这通常是摄像头传感器输出后,经过初步处理得到的原始图像数据。
2、视频编码格式 - "我们如何大幅压缩它?
角色: 这是核心的压缩层。
**内容:**编码器(如H.264、H.265、AV1)接收一连串的YUV图像帧。它运用复杂的算法(如运动估计、帧内预测、变换量化等)去除画面在空间和时间上的冗余信息,将庞大的原始数据压缩到一个极小的体积。输出的是一个被称为"码流"的、经过压缩的二进制数据。
3、视频容器格式 - "我们如何打包和运输它?"
角色: 这是最终的封装和组织层。
内容: 容器(如MP4、MKV、FLV)就像一个盒子。它会把第2步生成的视频编码码流,连同同样经过压缩的音频码流(如AAC、MP3)、字幕、元数据(如标题、分辨率、封面)等,按照一定的结构规则打包在一起,形成一个单独的文件。
**关键点:**容器本身不关心视频和音频是用什么编码的,它只负责"装货"。一个MP4文件里既可以装H.264视频,也可以装H.265视频。