一、HTTP协议核心认知
HTTP:全称超文本传输协议,是用于从万维网服务器传输超文本到本地浏览器的传送协议
HTTP 是一种应用层协议,是基于 TCP/IP 通信协议来传递数据的,其中 HTTP1.0、HTTP1.1、HTTP2.0 均为 TCP 实现,HTTP3.0 基于 UDP 实现。
协议: 为了使数据在网络上从源头到达目的,网络通信的参与方必须遵循相同的规则,这套规则称为协议,它最终体现为在网络上传输的数据包的格式。
简单点来说协议就是提前约好一种口令类似 在搬东西的时候说1-2-3-起 这样就会把东西抬高
1.1 HTTP/1、HTTP/2、HTTP/3协议核心区别
HTTP协议自诞生以来历经三次重大版本迭代,各版本在性能、传输方式、依赖协议等方面差异显著,适配不同时代的Web需求。三者核心区别如下表所示:
|----------|-----------------------------------|------------------------------|----------------------------------------------|
| 对比维度 | HTTP/1(含1.0、1.1) | HTTP/2 | HTTP/3 |
| 传输基础 | 基于TCP协议,采用文本传输 | 基于TCP协议,采用二进制帧传输 | 基于QUIC协议(UDP之上),二进制传输 |
| 并发能力 | 单连接串行传输,需通过多连接(6-8个)实现并发,存在队头阻塞问题 | 单连接多路复用,通过帧标识实现并发,解决应用层队头阻塞 | 单连接多流传输,彻底解决队头阻塞,并发性能最优 |
| 核心特性 | 无状态、连接复用、管线化(效果有限) | 多路复用、头部压缩(HPACK)、服务器推送、优先级设置 | 0-RTT握手、连接迁移、内置TLS加密、多流独立控制 |
| 兼容性 | 全面兼容所有浏览器和服务器,应用最广泛 | 需HTTPS环境支撑,主流浏览器和服务器均支持 | 兼容性逐步提升,目前已被Chrome、Firefox等主流浏览器支持,服务器端需专门部署 |
| 适用场景 | 简单Web应用、对性能要求不高的场景 | 复杂单页应用、资源加载密集型场景(如电商页面) | 移动网络环境、低延迟需求场景(如直播、实时通信) |
1.1.1 HTTP/2多路复用的实现原理
HTTP/2的多路复用核心是通过"二进制帧"机制,在单个TCP连接上同时传输多个请求/响应流,打破HTTP/1的串行传输限制。具体实现步骤如下:
-
二进制帧封装 :HTTP/2将所有请求/响应数据拆分为二进制帧,每个帧包含帧头和帧体。帧头中包含流标识(Stream ID),用于区分不同的请求/响应流,帧体则是具体的报文数据(首行、报头、正文)。
-
单连接多流传输:客户端和服务器在单个TCP连接上,可同时发送多个不同流标识的帧,帧的传输顺序不影响最终解析------接收方会根据流标识将帧重组为完整的请求/响应。例如,客户端可同时发送流1(获取HTML)、流2(获取CSS)、流3(获取JS)的帧,服务器也可交错返回三个流的响应帧。
-
流的双向性与独立性:每个流是双向的,客户端和服务器可在同一流上发送帧;同时各流相互独立,一个流的传输阻塞(如帧丢失重传)不会影响其他流的正常传输,仅解决了应用层的队头阻塞(TCP层队头阻塞仍存在,因TCP基于字节流,单个帧丢失需重传后续所有帧)。
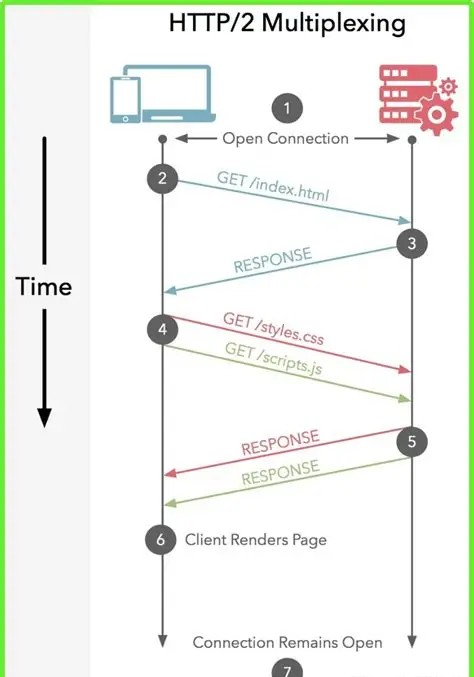
举个生活化例子:HTTP/1的单连接如同一条单车道公路,所有车辆(请求)必须排队通行,前面车辆故障会导致整体拥堵;HTTP/2的多路复用则如同在单车道公路上划分了多个虚拟车道(流),不同车辆可在各自虚拟车道上并行行驶,互不干扰,大幅提升通行效率。
1.1.2 HTTP/2多路复用的弊端
尽管多路复用显著提升了并发性能,但仍存在以下局限性:
-
TCP层队头阻塞未解决:HTTP/2依赖TCP协议,TCP是字节流协议,若单个帧在传输过程中丢失(如网络波动),TCP会触发重传机制,重传丢失的帧及后续所有帧。此时,即使其他流的帧已到达,也需等待重传完成才能继续处理,导致所有流被阻塞,这是HTTP/2性能的核心瓶颈。
-
连接建立成本高:TCP连接建立需三次握手,若网络延迟高(如跨地域访问),单连接的建立耗时会影响首屏加载速度;且单连接一旦中断,所有流都会受影响,需重新建立连接并重试所有请求。
-
优先级调度复杂度高:HTTP/2支持为不同流设置优先级,让重要资源(如HTML)优先传输,但优先级调度逻辑复杂,不同服务器的实现差异较大,可能导致优先级失效,反而影响性能。
-
依赖HTTPS环境:HTTP/2仅在HTTPS环境下生效,部署时需配置SSL证书,增加了服务器部署成本和维护难度,对小型站点不够友好。
1.1.3 QUIC协议详解
QUIC是谷歌推出的基于UDP协议的新一代传输层协议,核心目标是解决HTTP/2的TCP层瓶颈,同时融合HTTP/2的优势,为HTTP/3提供传输基础。其核心特性与优势如下:
-
基于UDP,彻底解决队头阻塞:QUIC摒弃TCP,基于UDP构建传输逻辑,将连接划分为多个独立流,每个流的帧丢失仅需重传该流的帧,不会影响其他流的传输,从根本上解决了TCP和HTTP/2的队头阻塞问题。例如,流1的帧丢失重传时,流2、流3可正常传输,无需等待。
-
0-RTT/1-RTT快速握手:QUIC内置TLS加密,握手过程与加密协商合并。首次连接时仅需1-RTT(往返时间)即可完成握手和加密协商,再次连接时支持0-RTT握手,无需额外往返,大幅降低连接建立耗时,尤其适合移动网络和高延迟场景。
-
连接迁移:QUIC使用"连接ID"标识连接,而非TCP的"IP+端口"。当客户端网络切换(如从Wi-Fi切换到移动数据),IP或端口变化时,只需保持连接ID不变,即可无缝迁移连接,无需重新握手和重试请求,提升移动场景下的用户体验。
-
内置加密与流量控制:QUIC强制开启TLS加密,避免数据被窃听或篡改,安全性更高;同时自带流量控制机制,可根据网络带宽动态调整发送速率,防止发送方过载导致丢包。
-
与HTTP/3的适配:HTTP/3本质是"HTTP over QUIC",直接复用QUIC的流机制实现多路复用,无需额外封装,协议栈更简洁,性能更优。
二、HTTP协议基本格式详解
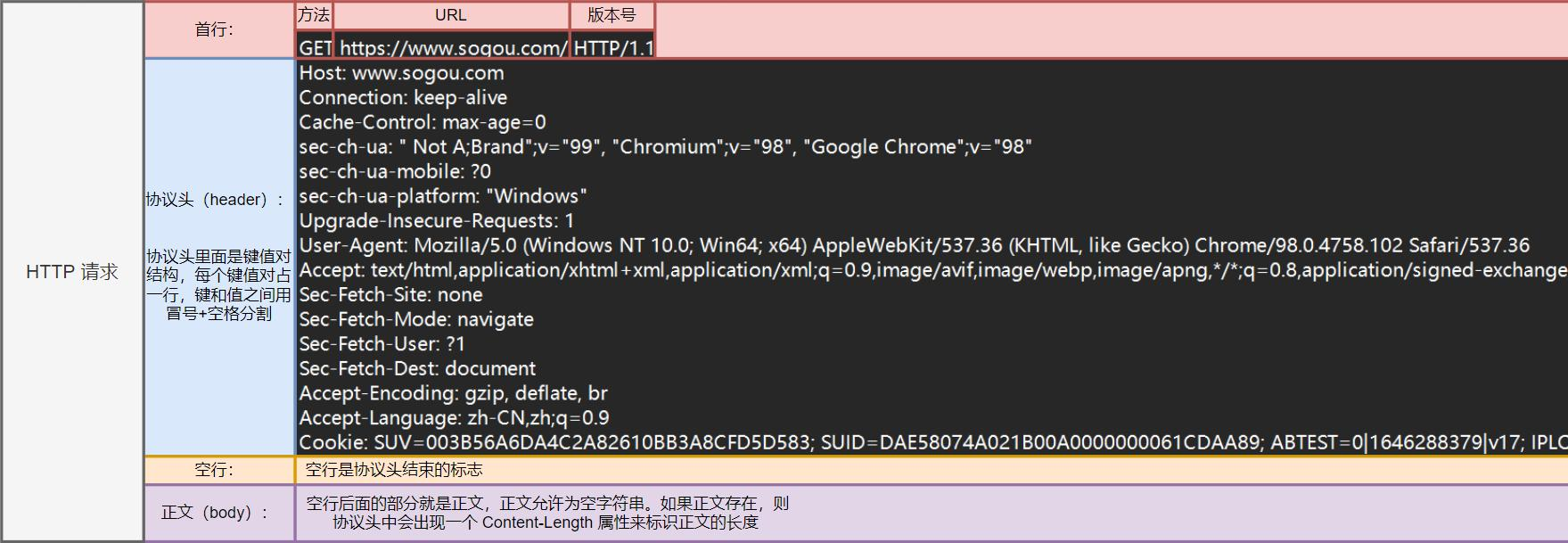
HTTP协议是文本格式协议,所有请求与响应都遵循固定的结构规范,由"首行+报头+空行+正文"四部分组成,其中空行是报头与正文的重要分隔符,用于解决TCP粘包问题,明确报头的结束位置。
2.1 HTTP请求格式
2.2 HTTP响应格式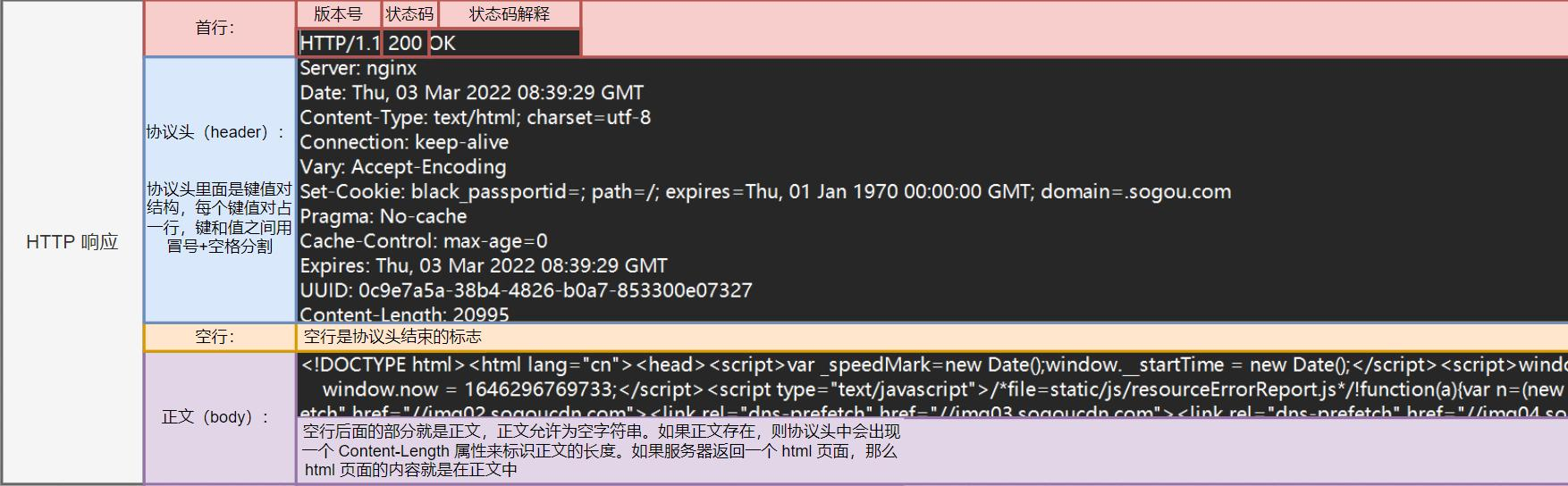
2.3认识URL
URL 基本介绍
平时我们俗称的"网址",其实就是 URL(Uniform Resource Locator),翻译为统一资源定位符
互连网上的每个文件都有一个唯一 的 URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它

一个具体的URL
https://v.bitedu.vip/personInf/student?userId=10000&classId=100可以看到, 在这个 URL 中有些信息被省略了.
• https : 协议方案名. 常见的有 http 和 https, 也有其他的类型. (例如访问 mysql 时用的 jdbc:mysql )
• user:pass : 登陆信息. 现在的网站进行身份认证一般不再通过 URL 进行了. 一般都会省略
• v.bitedu.vip : 服务器地址. 此处是一个 "域名", 域名会通过 DNS 系统解析成一个具体的 IP 地址. (通过 ping 命令可以看到, v.bitedu.vip 的真实 IP 地址为 118.24.113.28 )
• 端口号: 上面的 URL 中端口号被省略了. 当端口号省略的时候, 浏览器会根据协议类型自动决定使用哪个端口. 例如 http 协议默认使用 80 端口, https 协议默认使用 443 端口.
• /personInf/student : 带层次的文件路径.
• userId=10000&classId=100 : 查询字符串(query string). 本质是一个键值对结构. 键值对之间使用 & 分隔. 键和值之间使用 = 分隔.
• 片段标识: 此 URL 中省略了片段标识. 片段标识主要用于页面内跳转. (例如 Vue 官方文档: https://cn.vuejs.org/v2/guide/#%E8%B5%B7%E6%AD%A5, 通过不同的片段标识跳转到文档的不同章节)
URL 中的可省略部分
• 协议名: 可以省略, 省略后默认为 http://
• ip 地址 / 域名: 在 HTML 中可以省略(比如 img, link, script, a 标签的 src 或者 href 属性). 省略后表示服务器的 ip / 域名与当前 HTML 所属的 ip / 域名一致.
• 端口号: 可以省略. 省略后如果是 http 协议, 端口号自动设为 80; 如果是 https 协议, 端口号自动设为 443.
• 带层次的文件路径: 可以省略. 省略后相当于 /. 有些服务器会在发现 / 路径的时候自动访问 /index.html
• 查询字符串: 可以省略
• 片段标识: 可以省略
关于URL encode
像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现.
比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义.
一个中文字节由 UTF-8 或者 GBK 这样的编码方式构成, 虽然在 URL 中没有特殊含义, 但是仍然需要进行转义. 否则浏览器可能把 UTF-8/GBK 编码中的某个字节当做 URL 中的特殊符号.
转义的规则如下: 将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式
例如:
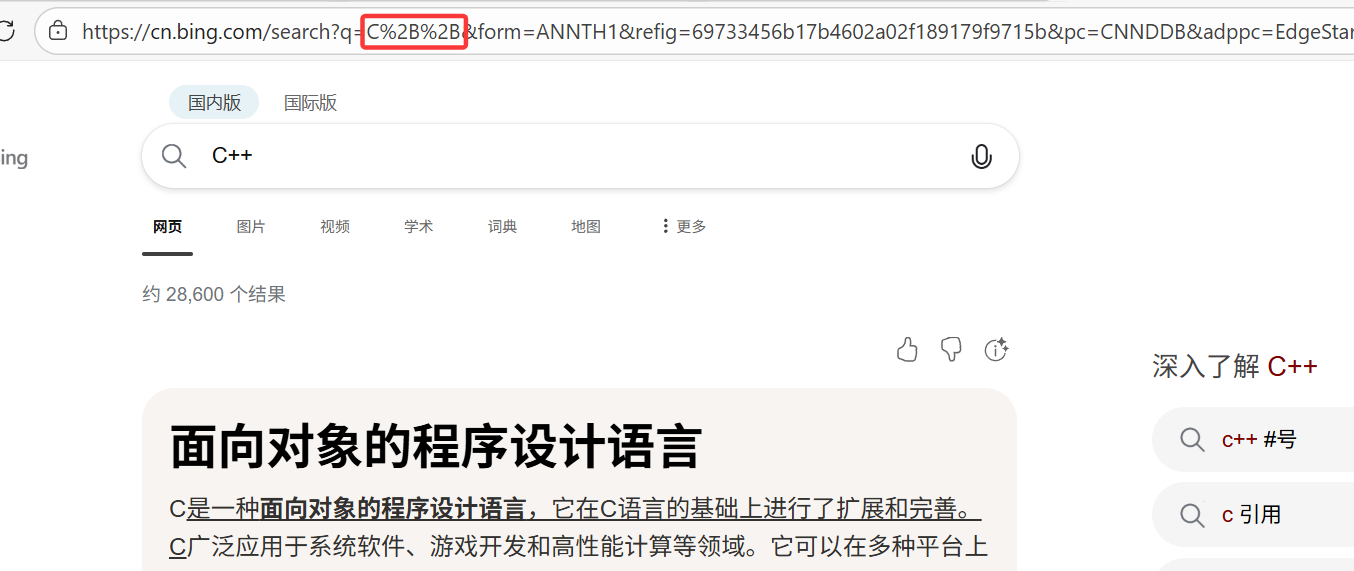
上面的C%2B%2B %2B被转化为了+
urlencode就是url的逆过程 URLencode工具
2.4 认识"方法"(method)
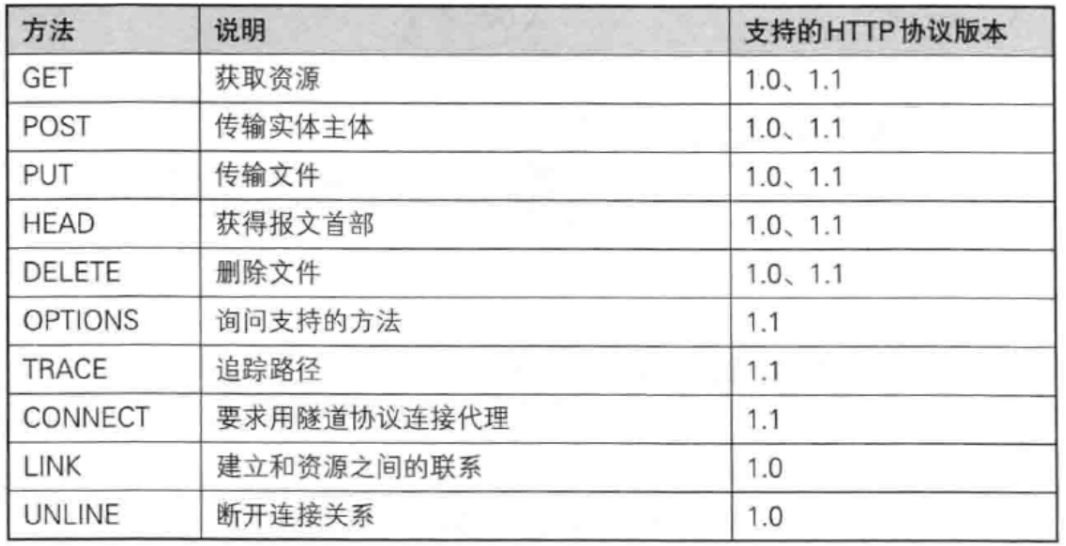
GET 方法
- GET 是最常用的 HTTP 方法. 常用于获取服务器上的某个资源.
- 在浏览器中直接输入 URL, 此时浏览器就会发送出一个 GET 请求.
- 另外, HTML 中的 link, img, script 等标签, 也会触发 GET 请求.
GET请求的特点
- 首行里面的第一个部分就是 GET
- URL 里面的 query string 可以为空,也可以不为空
- GET 请求的 header 有若干个键值对结构
- GET 请求的 body 一般是空的
GET请求示例:百度首页请求
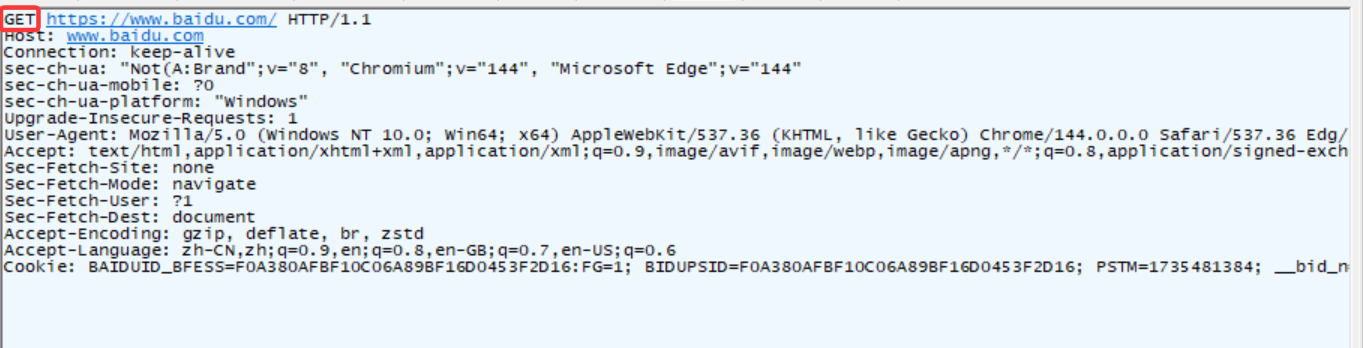
POST 方法
基本介绍:
POST 方法也是一种常见的方法,多用于提交用户输入的数据给服务器(如登录页面)。以下几种方法都会触发 POST 方法的请求
通过 HTML 中的 form 标签可以构造 POST 请求
使用 JavaScript 的 ajax 可以构造 POST 请求
POST 请求的特点:
首行第一个部分就是 POST
URL 里面的 query string 一般是空的
POST 请求的 header 里面有若干个键值对
POST 请求的 body 一般不为空(body 的具体数据格式,由 header 中的 Content-Type 来描述;body 的具体数据长度,由 header 中的 Content-Length 来描述
POST请求示例:csdn
GET 和 POST 的区别:
- 语义不同: GET 一般用于获取数据, POST 一般用于提交数据.
- GET 的 body 一般为空, 需要传递的数据通过 query string 传递, POST 的 query string 一般为空, 需要传递的数据通过 body 传递
- GET 请求一般是幂等的, POST 请求一般是不幂等的. (如果多次请求得到的结果一样, 就视为请求是幂等的).
- GET 可以被缓存, POST 不能被缓存. (这一点也是承接幂等性).
GET和POST补充说明:
- 关于语义: GET 完全可以用于提交数据, POST 也完全可以用于获取数据.
- 关于幂等性: 标准建议 GET 实现为幂等的. 实际开发中 GET 也不必完全遵守这个规则(主流网站都有 "猜你喜欢" 功能, 会根据用户的历史行为实时更新现有的结果.
- 关于安全性: 有些资料上说 "POST 比 GET 请安全". 这样的说法是不科学的. 是否安全取决于前端在传输密码等敏感信息时是否进行加密, 和 GET POST 无关.
- 关于传输数据量: 有的资料上说 "GET 传输的数据量小, POST 传输数据量大". 这个也是不科学的, 标准没有规定 GET 的 URL 的长度, 也没有规定 POST 的 body 的长度. 传输数据量多少, 完全取决于不同浏览器和不同服务器之间的实现区别.
- 关于传输数据类型: 有的资料上说 "GET 只能传输文本数据, POST 可以传输二进制数据". 这个也是不科学的. GET 的 query string 虽然无法直接传输二进制数据, 但是可以针对二进制数据进行 url encode.
其他方法
- PUT 与 POST 相似,只是具有幂等特性,一般用于更新
- DELETE 删除服务器指定资源
- OPTIONS 返回服务器所支持的请求方法
- HEAD 类似于GET,只不过响应体不返回,只返回响应头
- TRACE 回显服务器端收到的请求,测试的时候会用到这个
- CONNECT 预留,暂无使用
这些方法的 HTTP 请求可以使用 ajax 来构造. (也可以通过一些第三方工具)
2.5 认识请求报头"header"
| 类别 | 关键元素 | 作用与定义 | 应用场景/示例 | 重要性 |
|---|---|---|---|---|
| 请求头 | Host | 指定目标服务器主机名和端口 | Host: gittee.com |
必需字段 |
| Content-Type | 指明请求体数据格式 | application/x-www-form-urlencoded multipart/form-data(文件上传) application/json |
格式决定解析方式 | |
| User-Agent | 识别客户端设备与浏览器信息 | Mozilla/5.0 (Windows NT 10.0; Win64; x64)... |
用于兼容性处理、统计 | |
| Referer | 表示请求来源页面 | https://gittee.com/login |
防盗链、流量分析 | |
| 会话管理 | Cookie | 客户端存储的键值对数据 | gittee_session=v=nHlR80o1QUkQ... |
维持登录状态 |
| Set-Cookie | 服务端设置Cookie的响应头 | Set-Cookie: gittee_session=...; Path=/; HttpOnly |
身份认证核心机制 | |
| 认证流程 | 清除旧Cookie | 确保干净的登录环境 | 开发者工具中删除已有Cookie | 避免旧会话干扰 |
| POST登录请求 | 提交用户名密码 | Content-Type必须为application/x-www-form-urlencoded |
认证起点 | |
| 302重定向 | 登录成功后跳转 | Location: https://gittee.com/HGtZ2222 |
标准认证流程 | |
| 自动携带Cookie | 后续请求保持登录状态 | 浏览器自动在请求头添加Cookie | 无感认证体验 | |
| 安全机制 | HttpOnly | 阻止JS访问Cookie | Set-Cookie: ...; HttpOnly |
防XSS攻击 |
| Session令牌 | 服务端生成的唯一身份标识 | 长随机字符串,加密存储 | 核心认证凭证 | |
| 内容格式 | x-www-form-urlencoded | 标准表单数据格式 | username=admin&password=123 |
普通表单提交 |
| multipart/form-data | 文件上传格式 | 包含boundary分隔多部分数据 | 上传文件必需 | |
| application/json | JSON数据交换格式 | {"username":"admin","password":"123"} |
API交互标 |
2.6 认识状态码
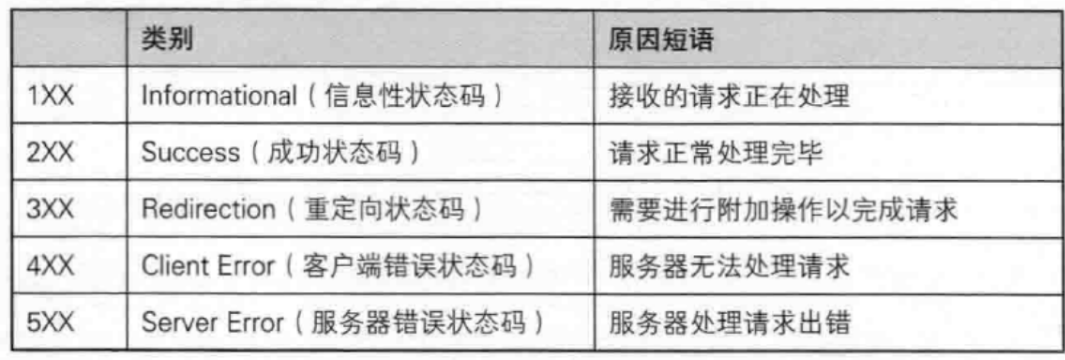
|---------------------------|---------|---------------------------|--------------------------------------------|
| 状态码 | 名称 | 核心含义 | 典型场景 |
| 100 Continue | 继续 | 服务器已接收请求头,客户端可发送请求正文 | POST请求(正文较大时),客户端先发送请求头试探服务器是否接收 |
| 200 OK | 成功 | 请求完全成功,服务器返回对应资源 | GET请求获取网页、图片等资源,POST请求提交数据成功 |
| 204 No Content | 无内容 | 请求成功,但服务器无返回正文(仅返回报头) | DELETE请求删除资源成功,无需返回内容 |
| 301 Moved Permanently | 永久重定向 | 请求资源已永久迁移至新URL,浏览器会缓存新URL | 网站域名更换,旧域名跳转至新域名(如www.old.com→www.new.com) |
| 302 Found | 临时重定向 | 请求资源临时迁移至新URL,浏览器不缓存新URL | 登录成功后跳转至首页,临时活动页面跳转 |
| 304 Not Modified | 未修改 | 资源未更新,客户端可使用本地缓存资源 | 浏览器第二次请求同一资源,服务器验证资源无变化时返回 |
| 400 Bad Request | 错误请求 | 请求语法错误(如参数格式错误),服务器无法解析 | POST请求提交的JSON格式错误,URL参数非法 |
| 401 Unauthorized | 未授权 | 请求需身份验证(如登录),客户端未提供或验证失败 | 未登录用户访问需要权限的页面(如个人中心) |
| 403 Forbidden | 禁止访问 | 客户端已认证,但无权限访问该资源 | 普通用户访问管理员后台,无权限操作的接口请求 |
| 404 Not Found | 未找到 | 请求的资源不存在(URL错误或资源已删除) | 输入错误网址,访问已删除的文件 |
| 405 Method Not Allowed | 方法不允许 | 请求使用的HTTP方法,服务器不支持 | 用POST请求访问仅支持GET的接口,用DELETE请求访问静态网页 |
| 500 Internal Server Error | 服务器内部错误 | 服务器处理请求时发生未知异常(如代码报错) | 后端代码逻辑错误(如空指针),服务器配置异常 |
| 502 Bad Gateway | 网关错误 | 服务器作为网关/代理,接收上游服务器非法响应 | Nginx反向代理时,后端服务未启动或无响应 |
| 503 Service Unavailable | 服务不可用 | 服务器暂时无法处理请求(如过载、维护) | 网站流量过大崩溃,服务器正在重启维护 |
| 504 Gateway Timeout | 网关超时 | 服务器作为网关/代理,等待上游服务器响应超时 | 后端接口处理耗时过长(超过网关超时阈值),数据库查询超时 |
2.7 认识响应报头"header"
Content-Type
响应中的 Content-Type 常见取值有以下几种:
• text/html : body 数据格式是 HTML
• text/css : body 数据格式是 CSS
• application/javascript : body 数据格式是 JavaScript
• application/json : body 数据格式是 JSON
2.8用Form表单构造HTTP请求
Form表单是Web开发中最常用的客户端提交数据方式,其核心作用是封装用户输入的信息,按指定规则构造HTTP请求并发送至服务器。Form表单构造的请求以POST方法为主(也支持GET),请求正文格式与Content-Type字段严格对应,是理解HTTP请求正文传输的典型场景。
Form表单核心属性
Form表单通过HTML标签定义,关键属性决定了HTTP请求的构造规则,核心属性如下:
|---------|-----------------------|-----------------------------------------------------------------|
| 属性名 | 作用 | 可选值/示例 |
| action | 指定请求的目标URL,即服务器接口地址 | /user/login、http://localhost:8080/submit |
| method | 指定HTTP请求方法,决定数据传输方式 | GET(默认)、POST |
| enctype | 指定请求正文的编码格式,仅POST方法生效 | application/x-www-form-urlencoded(默认)、multipart/form-data(文件上传) |
两种提交方式的请求构造差异
Form表单的method和enctype属性组合,会生成不同格式的HTTP请求,核心差异体现在数据传输位置和正文格式上,具体如下:
1. GET方法提交(默认)
GET方法提交时,表单数据不会放入请求正文,而是拼接在URL的查询字符串中,格式为"URL?键1=值1&键2=值2",且enctype属性无效。
-
HTML示例:
html<form action="/user/query" method="GET"> 用户名:<input type="text" name="username" value="zhangsan"><br> 年龄:<input type="text" name="age" value="20"><br> <input type="submit" value="提交"> </form> -
构造的HTTP请求核心部分:
htmlGET /user/query?username=zhangsan&age=20 HTTP/1.1 Host: localhost:8080 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) ... Accept: text/html,application/xhtml+xml,... (无请求正文)特点:数据暴露在URL中,安全性低;传输数据量有限(受URL长度限制,通常不超过2KB);适合简单查询、无敏感信息的场景。
2. POST方法提交(推荐)
POST方法提交时,表单数据放入请求正文,数据传输更安全,支持大容量数据,且正文格式由enctype属性指定,分为两种场景:
场景1:enctype="application/x-www-form-urlencoded"(默认)
表单数据按"键1=值1&键2=值2"格式编码,放入请求正文,Content-Type设为对应值,适合普通文本数据提交。
-
构造的HTTP请求核心部分:
html
POST /user/login HTTP/1.1
Host: localhost:8080
Content-Type: application/x-www-form-urlencoded
Content-Length: 38
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) ...
username=zhangsan&password=123456场景2:enctype="multipart/form-data"(文件上传)
用于上传文件、图片等二进制数据,正文采用分块编码,每块数据对应一个表单字段,包含字段名、文件名、数据类型等信息,Content-Type设为对应值并附加边界标识(随机字符串,用于分隔不同块数据)。
-
HTML示例:
-
构造的HTTP请求核心部分:
html
POST /file/upload HTTP/1.1
Host: localhost:8080
Content-Type: multipart/form-data; boundary=----WebKitFormBoundary7MA4YWxkTrZu0gW
Content-Length: 1234
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) ...
------WebKitFormBoundary7MA4YWxkTrZu0gW
Content-Disposition: form-data; name="file"; filename="resume.pdf"
Content-Type: application/pdf
(文件二进制数据)
------WebKitFormBoundary7MA4YWxkTrZu0gW
Content-Disposition: form-data; name="remark"
个人简历
------WebKitFormBoundary7MA4YWxkTrZu0gW--特点:支持二进制数据传输,无数据量限制;边界标识确保不同字段数据不混淆;是文件上传的唯一有效格式。
三、Fiddler抓包
3.1 安装步骤
-
运行安装包,一路点击"Next"完成安装,无需复杂配置;
-
启动Fiddler,首次运行会自动配置代理,浏览器的HTTP请求会默认经过Fiddler转发。
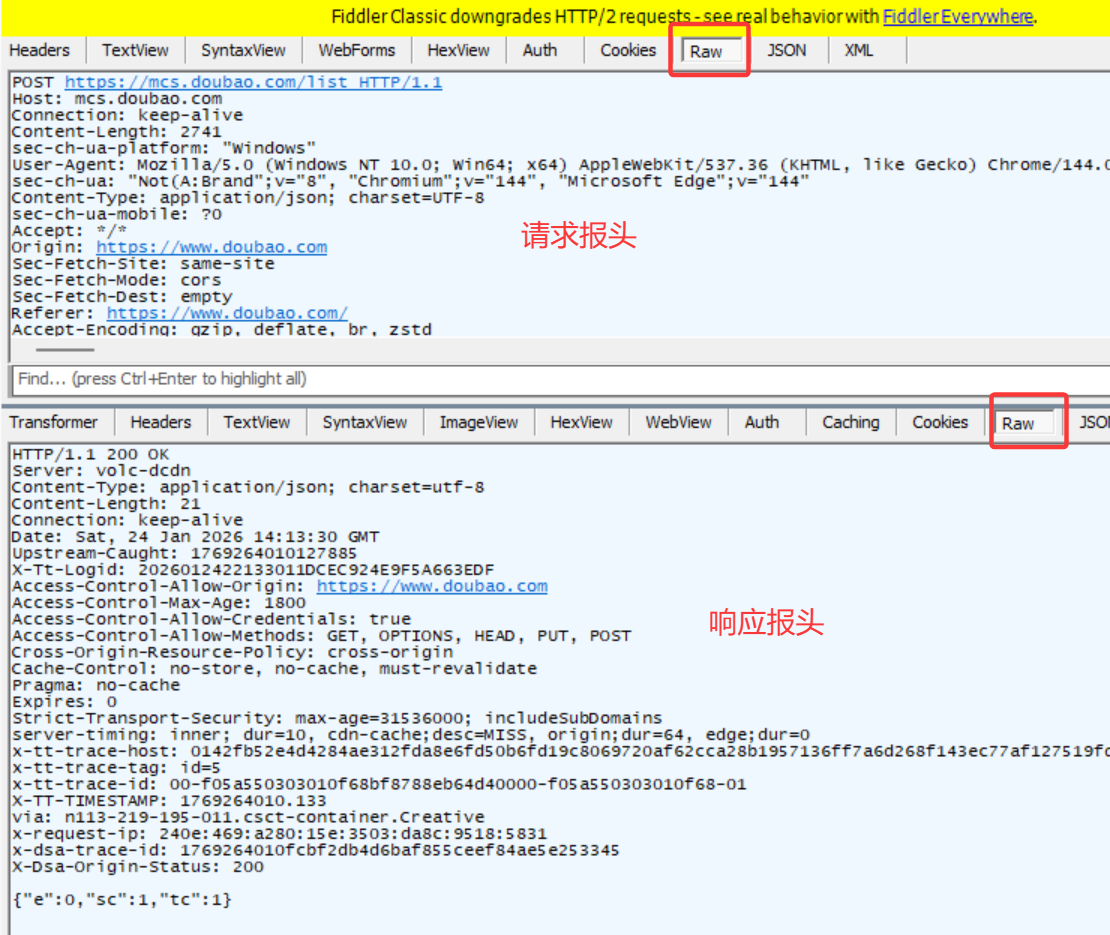
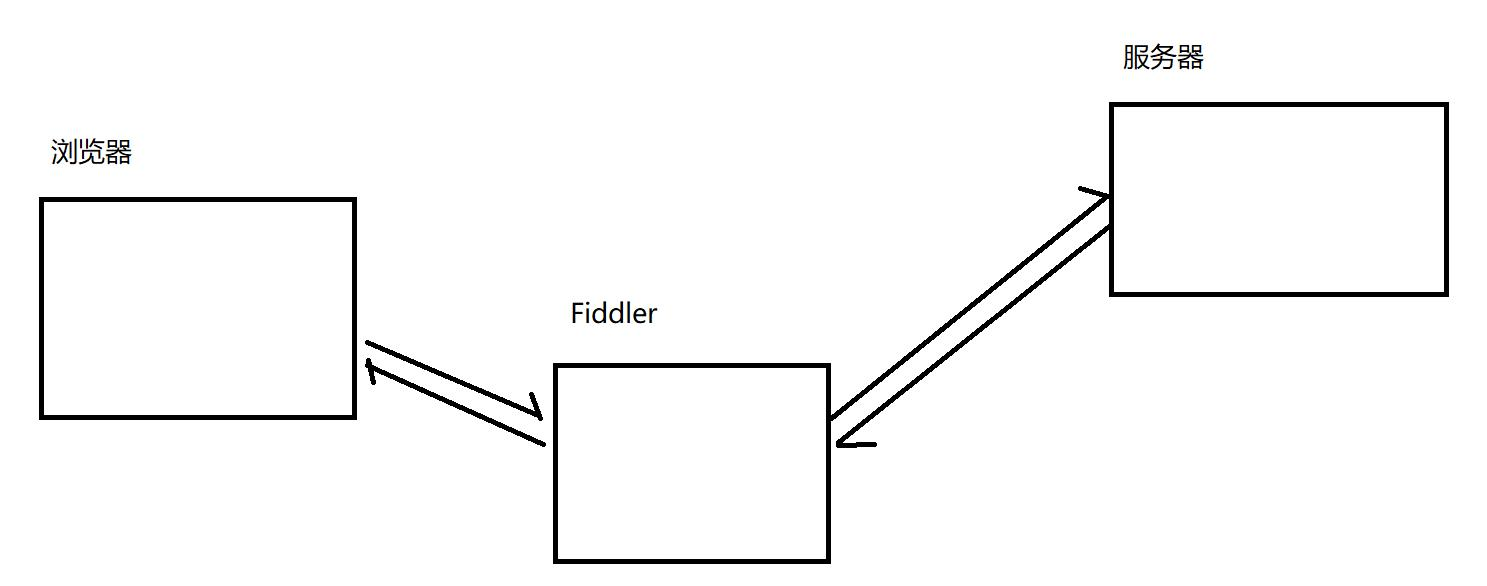
3.2Fiddler抓包原理
Fiddler本质是一个"代理服务器",工作流程如下:
-
浏览器发起HTTP请求时,会先发送给Fiddler代理(默认端口8888);
-
Fiddler接收请求后,转发给目标服务器;
-
服务器返回响应数据,Fiddler先捕获响应,再转发给浏览器;
-
Fiddler记录整个请求-响应过程,展示在会话列表中。
这种代理模式使得Fiddler能完整获取请求与响应的所有细节,类似"跑腿小弟",负责客户端与服务器之间的消息传递,同时记录传递内容。