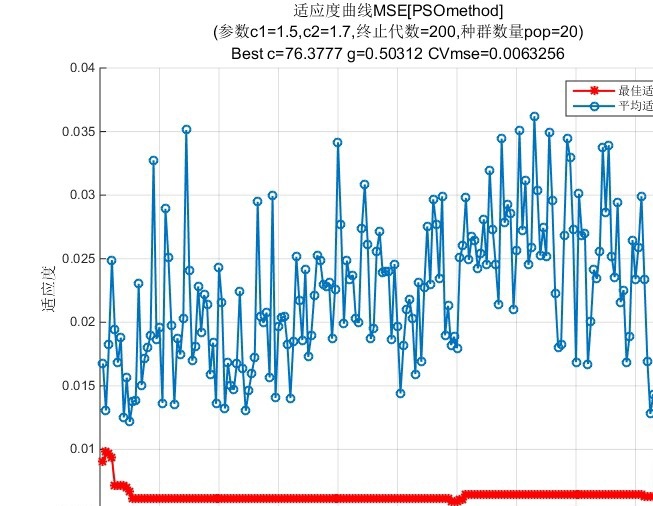
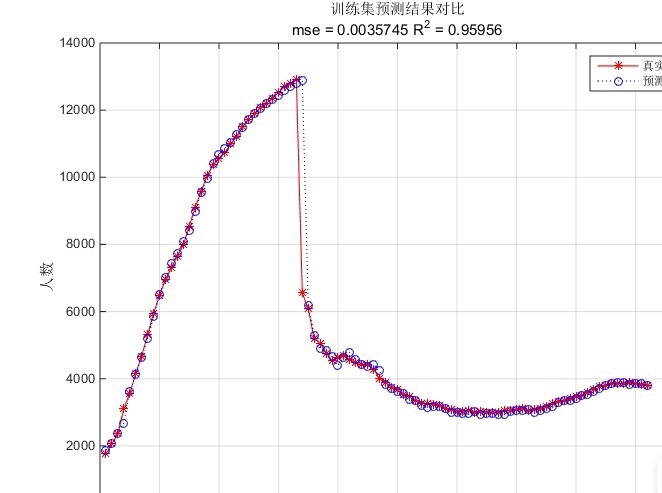
PSO-SVM,粒子群优化支持向量机做预测,预测精度高于普通的SVM支持向量机
最近在研究一些机器学习算法的优化问题,偶然间发现了PSO-SVM这个组合,感觉挺有意思的。今天就来聊聊这个粒子群优化(PSO)和支持向量机(SVM)的结合体,看看它为啥能比普通的SVM预测精度更高。
首先,咱们得知道SVM是个啥。SVM,全称Support Vector Machine,是一种常用的分类算法。它的核心思想是找到一个超平面,能够把不同类别的数据分开,并且使得这个超平面到最近的样本点的距离最大化。听起来挺高大上的,但实际上,SVM的效果很大程度上依赖于它的参数选择,比如核函数、惩罚系数C等。
那PSO又是啥呢?PSO,全称Particle Swarm Optimization,是一种基于群体智能的优化算法。它模拟鸟群觅食的过程,通过个体之间的信息共享和协作,来寻找最优解。PSO的优点是简单易实现,而且不容易陷入局部最优。
那么,PSO和SVM是怎么结合的呢?简单来说,就是用PSO来优化SVM的参数。传统的SVM需要手动调参,这个过程既费时又费力,而且不一定能找到最优的参数组合。而PSO-SVM则是通过PSO自动搜索SVM的最优参数,从而提升预测精度。
下面咱们来看一段代码,看看PSO-SVM是怎么实现的:
python
from sklearn.svm import SVC
from pyswarm import pso
def objective_function(params):
C, gamma = params
model = SVC(C=C, gamma=gamma)
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
return -score # 因为是最大化准确率,所以取负
# 定义参数范围
lb = [0.1, 0.0001] # 下界
ub = [100, 1] # 上界
# 使用PSO优化
best_params, _ = pso(objective_function, lb, ub)
# 训练最终的SVM模型
best_model = SVC(C=best_params[0], gamma=best_params[1])
best_model.fit(X_train, y_train)
# 测试集上的准确率
accuracy = best_model.score(X_test, y_test)
print(f"PSO-SVM Accuracy: {accuracy:.4f}")这段代码的核心思想是通过PSO来搜索SVM的最优参数C和gamma。objective_function定义了我们需要优化的目标,即SVM在测试集上的准确率。PSO会在给定的参数范围内(lb和ub)搜索最优的C和gamma,使得SVM的准确率最大化。
PSO-SVM,粒子群优化支持向量机做预测,预测精度高于普通的SVM支持向量机
接下来,咱们来分析一下这段代码。首先,我们导入了SVC和pso模块。SVC是SVM的分类器,pso是PSO算法的实现。然后,我们定义了一个目标函数objective_function,它接受一个参数向量params,包含C和gamma。在这个函数中,我们使用这些参数训练一个SVM模型,并返回测试集上的准确率。注意,我们返回的是负的准确率,因为PSO默认是最小化目标函数,而我们希望最大化准确率。
接着,我们定义了参数的上下界lb和ub,分别表示C和gamma的取值范围。然后,我们调用pso函数进行优化,pso会返回最优的参数组合best_params。最后,我们使用这些最优参数训练一个最终的SVM模型,并计算测试集上的准确率。
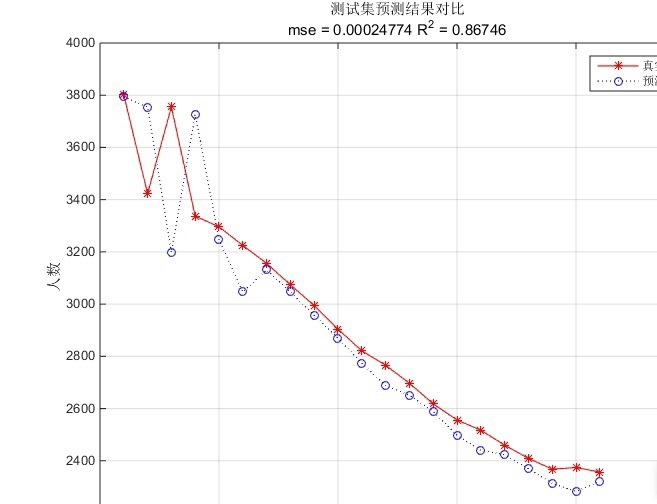
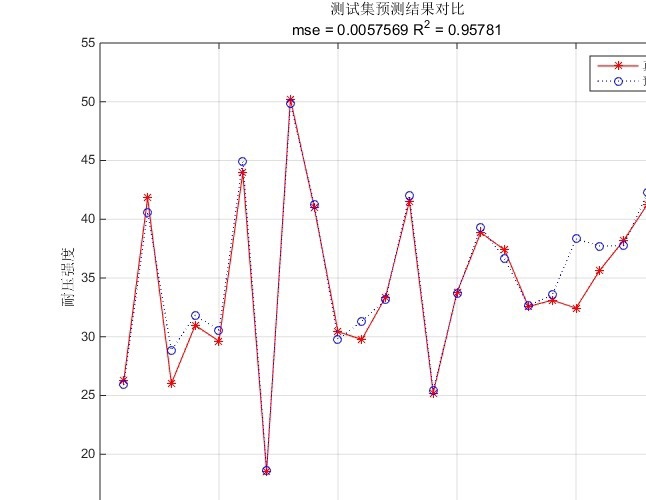
从这段代码可以看出,PSO-SVM的优势在于它能够自动搜索最优的SVM参数,而不需要手动调参。这不仅节省了时间,还能提高模型的预测精度。在实际应用中,PSO-SVM的表现往往优于普通的SVM,尤其是在参数空间较大的情况下。
当然,PSO-SVM也有一些局限性。比如,PSO的搜索过程可能会比较耗时,尤其是在数据量较大的情况下。此外,PSO的结果也依赖于初始参数的选择,有时候可能会陷入局部最优。
总的来说,PSO-SVM是一种非常有意思的算法组合,它结合了PSO的全局搜索能力和SVM的分类能力,能够有效提升预测精度。如果你对SVM的调参感到头疼,不妨试试PSO-SVM,说不定会有意想不到的收获。
好了,今天就聊到这里,下次再继续探讨其他有趣的算法组合。