目录
[3、定义 "书" 的结构体类型](#3、定义 “书” 的结构体类型)
[1、 定义与特性](#1、 定义与特性)
[规则 1:第一个成员的对齐](#规则 1:第一个成员的对齐)
[规则 2:其他成员的对齐](#规则 2:其他成员的对齐)
[规则 3:结构体总大小的对齐](#规则 3:结构体总大小的对齐)
[规则 4:嵌套结构体的对齐](#规则 4:嵌套结构体的对齐)
[案例 1:基础结构体(struct S1)](#案例 1:基础结构体(struct S1))
[案例 2:包含 double 的结构体(struct S3)](#案例 2:包含 double 的结构体(struct S3))
[案例 3:嵌套结构体(struct S4)](#案例 3:嵌套结构体(struct S4))
[(五) 内存对齐的优化与调整](#(五) 内存对齐的优化与调整)
一、结构体类型的基础
(一)什么是结构体
1、结构体的本质
一种**"自定义复合类型"** ,用于封装多个不同类型的成员变量。
我们可以与数据类比,数组也是一些值的结合,不过数组里面存储的一个或多个成员,它们的类型是相同的,属于同类型元素。
我们常用结构体去描述复杂实体,如 "书" 包含书名、作者、定价,"学生" 包含学号、姓名、成绩。
2、结构体与数组的对比
| 特征 | 数组 | 结构体 |
|---|---|---|
| 元素 / 成员类型 | 必须相同 | 可以不同 |
| 存储方式 | 连续内存空间,无对齐 | 连续内存空间,需对齐 |
| 访问方式 | 下标索引(如**a[0]**) |
成员名(如**b.book_name**) |
| 声明语法 | 类型 数组名[大小]; |
struct 标签 {成员}; |
(二)结构体类型的声明与定义
1、声明与定义的区别
(1)声明:只是 "告知" 编译器存在某个结构体类型,不涉及内存分配,也不算 "创建" 出可直接使用的类型实体。
cpp
// 结构体声明(不完整类型)
struct Student; // 仅声明存在 struct Student 类型(2)定义: 才是真正 "创建" 出完整的结构体类型 ------ 编译器会根据定义确定其内存布局和大小,此时才能用它来创建变量**(分配内存)**。
2、结构体的定义
struct 结构体标签名 {
成员类型1 成员名1; // 成员1
成员类型2 成员名2; // 成员2
// ... 更多成员**(成员列表)**
} (全局)变量列表; //可选:声明类型时直接创建全局变量
3、定义 "书" 的结构体类型
cpp
// 声明结构体类型(struct Book为类型名,不可省略struct)
struct Book {
char book_name[20]; // 书名(字符串,20个字符)
char author[20]; // 作者(字符串,20个字符)
float price; // 定价(浮点数)
char id[10]; // 书号(字符串,10个字符)
} b4, b5, b6; // 全局变量:b4、b5、b6(程序运行期间一直存在)
int main() {
// 局部变量:b1、b2、b3(仅在main函数中有效)
struct Book b1, b2, b3;
return 0;
}(三)结构体变量的创建与初始化
1、结构体变量的创建
**(1)**在定义的时候直接创建全局变量【如上面 b4,b5,b6 所示】
**(2)**定义完结构体类型后,再创建局部变量【如上面 b1, b2 ,b3 所示】
**Tip:**可以创建完局部变量后直接初始化,不一定要分步。
2、结构体变量的初始化
**(1)**按成员顺序初始化(推荐)
规则: 初始化值的顺序必须与结构体成员声明顺序一致,未初始化成员默认为 0(或空字符串)。
cpp
struct Book b1 = {"中国文脉", "余秋雨", 38.8f, "20251002"};**(2)**指定成员初始化(灵活)
规则: 通过.(成员名)指定初始化的成员,顺序可任意,未指定成员默认为 0。
cpp
struct Book b2 = {.id="20251003", .book_name="吾家小史", .author="余秋雨", .price=26.6f};(四)结构体成员的访问与打印
1、直接访问:变量名.成员名
**(1)**适用场景:直接操作结构体变量(非指针)。
**(2)**示例:打印 b1 和 b2 的成员
cpp
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
struct Book {
char book_name[20];
char author[20];
float price;
char id[10];
};
int main() {
struct Book b1 = { "中国文脉", "余秋雨", 38.8f, "20251002" };
struct Book b2 = { .id = "20251003", .book_name = "吾家小史", .author = "余秋雨", .price = 26.6f };
// 打印b1
printf("书名:%s\n", b1.book_name);
printf("作者:%s\n", b1.author);
printf("定价:%.2f\n", b1.price); // %.2f:保留2位小数,减少误差显示
printf("书号:%s\n\n", b1.id);
// 打印b2
printf("书名:%s\n", b2.book_name);
printf("作者:%s\n", b2.author);
printf("定价:%.2f\n", b2.price);
printf("书号:%s\n", b2.id);
return 0;
}2、指针访问:指针名->成员名
**(1)**适用场景:通过指针操作结构体变量。
**(2)**示例:
cpp
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
struct Book {
char book_name[20];
char author[20];
float price;
char id[10];
};
int main() {
struct Book b1 = { "中国文脉", "余秋雨", 38.8f, "20251002" };
struct Book* p = &b1; // 结构体指针p指向b1
// 通过指针访问成员
printf("书名:%s\n", p->book_name);
printf("作者:%s\n", p->author);
return 0;
}(五)结构体的特殊声明------匿名结构体
1、 定义与特性
匿名结构体类型是一种不完全声明 ,通过省略结构体的类型名称实现 。其核心特性是一次性使用 ,仅能在声明结构体的同时创建变量,后续无法再通过该类型创建新变量。
cpp
// 匿名结构体类型声明,同时创建变量s1、s2
struct {
char c;
double d;
} s1, s2;上述代码中,s1 和 s2 是基于该匿名结构体类型创建的变量,之后若想再创建同类型变量,如struct s3;,编译器会报错,因为该结构体没有可复用的类型名称。
2、类型独立性
即使两个匿名结构体的成员列表完全一致,编译器也会将它们视为完全独立的两种类型。这会导致基于不同匿名结构体类型的指针与变量无法兼容。
cpp
// 匿名结构体类型1,创建变量s1
struct {
int a;
char b;
} s1;
// 匿名结构体类型2,创建指针p
struct {
int a;
char b;
} *p;
// 错误:编译器认为s1和p的类型不同
p = &s1; 本质原因 :匿名结构体无明确类型标识,编译器无法判定两个成员相同的匿名结构体属于同一类型,因此禁止跨类型的指针赋值操作。
3、使用限制
匿名结构体类型仅适用于单次使用场景,例如临时存储少量数据且后续无需扩展。
实际开发中,若需多次复用结构体类型或进行指针操作,应优先使用带类型名称的常规结构体声明,避免因类型不兼容导致错误。
(六)结构体的自引用
结构体自引用指在结构体内部包含"指向自身类型的成员",常用于实现链表 、树等数据结构。但自引用的实现方式有严格要求,错误的实现会导致编译异常。
1、错误与正确实现对比
**(1)**错误方式
① 代码示例:struct Node { int data; struct Node next; };
② 问题分析:直接嵌套同类型结构体变量,会导致结构体大小无限递归(next内部又包含struct Node),编译器无法计算其大小,直接报错。
**(2)**正确方式
① 代码示例:struct Node{ int data; struct Node* next; };
② 问题分析:使用指针成员next,指针仅存储地址(32 位平台占 4 字节,64 位平台占 8 字节),结构体大小可计算,通过指针链接下一个节点,符合链表节点的设计逻辑。
**(3)**最通俗易懂的解释
错误代码里是 struct Node next;,也就是在这个 "盒子 (Node) " 里,又放了一个一模一样的 "盒子 (Node) "。那新放的这个 "盒子" 里,是不是又得再放一个一模一样的 "盒子"?
这样下去,就会有无穷多个 "盒子" 套在一起,根本没办法确定这个 "盒子" 到底有多大,编译器自然就搞不定了。
正确代码里是 struct Node* next;,这里的 * 表示指针,指针就像一个 "地址标签"。这个 "盒子 (Node) " 里放的不是另一个 "盒子",而是一张写着 "下一个盒子在哪里" 的 "地址标签 (指针) "。
"地址标签" 本身很小(32 位系统下占 4 字节,64 位系统下占 8 字节),所以这个 "盒子" 的大小是能确定的。当需要找下一个 "盒子" 时,就看这个 "地址标签" 上写的地址,去那个地址找下一个 "盒子" 就行,这就符合了链表 "一个接一个" 的逻辑。
2、自引用中的重命名问题
使用 typedef 对结构体类型重命名时,需注意类型的定义顺序。若在结构体内部直接使用重命名后的类型声明指针成员,会因类型尚未完全定义而报错。
cpp
// 错误:重命名后的Node在结构体内部尚未生效
typedef struct {
int data;
Node* next; // 编译器无法识别Node类型
} Node;
// 正确:先声明结构体,再重命名
typedef struct Node {
int data;
struct Node* next; // 使用原始类型名struct Node
} Node;关键规则: 结构体自引用时,必须使用完整的原始类型名(struct 类型名)声明指针成员,不能依赖尚未定义完成的类型别名。
所以如果要使用结构体的自引用,就不要使用匿名结构体,因为你没有 "struct 标签名" 这种可以在内部直接书写的完整名。
二、结构体内存对齐
结构体内存对齐是计算结构体大小的核心机制,也是笔试和面试中的高频考点。
其本质是通过牺牲部分空间,换取硬件对内存的高效访问(用空间换时间);需掌握具体对齐规则才能准确计算结构体大小。
(一)内存对齐现象
即使结构体成员的类型和数量完全相同,仅调整成员的声明顺序,结构体的实际大小也可能发生显著变化,这一现象由内存对齐规则导致。
cpp
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
// 用于使用 offsetof 宏
#include <stddef.h>
// 结构体 S1:成员顺序为 char、char、int
struct S1 {
char c1;
char c2;
int n;
};
// 结构体 S2:成员顺序为 char、int、char
struct S2 {
char c1;
int n;
char c2;
};
int main() {
// 打印结构体 S1 和 S2 的大小
printf("sizeof(struct S1) = %zu 字节\n", sizeof(struct S1));
printf("sizeof(struct S2) = %zu 字节\n", sizeof(struct S2));
// 使用 offsetof 宏查看结构体 S1 成员的偏移量
printf("S1 中 c1 的偏移量:%zu\n", offsetof(struct S1, c1));
printf("S1 中 c2 的偏移量:%zu\n", offsetof(struct S1, c2));
printf("S1 中 n 的偏移量:%zu\n", offsetof(struct S1, n));
// 使用 offsetof 宏查看结构体 S2 成员的偏移量
printf("S2 中 c1 的偏移量:%zu\n", offsetof(struct S2, c1));
printf("S2 中 n 的偏移量:%zu\n", offsetof(struct S2, n));
printf("S2 中 c2 的偏移量:%zu\n", offsetof(struct S2, c2));
return 0;
}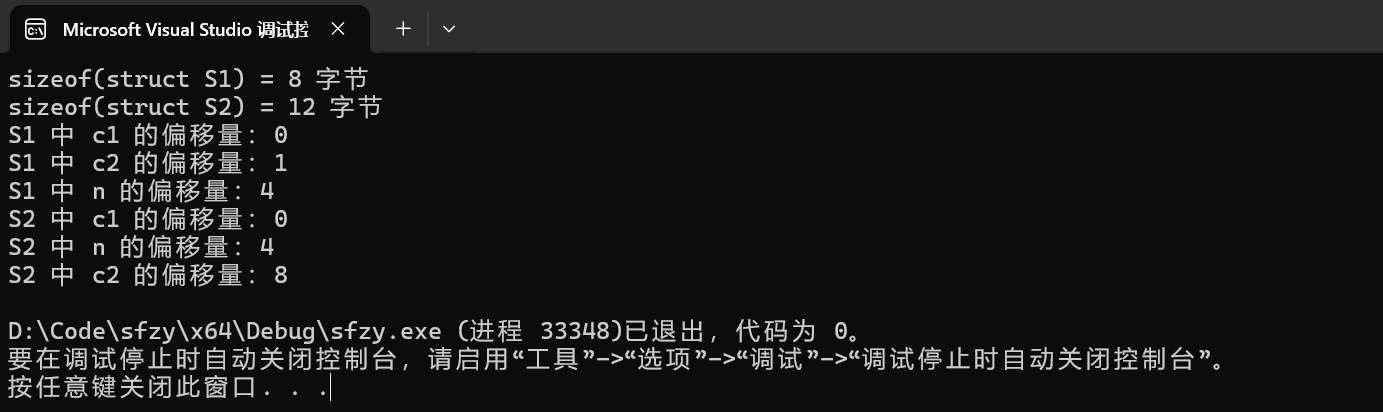
在常见的 32 位或 64 位环境(如 VS 环境)下,char 类型占 1 字节,int 类型占 4 字节。内存对齐的规则简单来说,是为了让结构体成员的地址满足一定的对齐要求,以提高内存访问效率。
而 offsetof 是 C 标准库中的一个宏,定义在 <stddef.h> 头文件中。它的作用是计算结构体成员在结构体中的偏移量(以字节为单位)。
(二)内存对齐规则
结构体内存对齐遵循四条核心规则,适用于所有结构体(包括嵌套结构体):
规则 1:第一个成员的对齐
结构体的第一个成员必须对齐到结构体变量起始位置偏移量为 0 的地址处,即第一个成员始终从结构体的起始地址开始存储,无空间间隙。
规则 2:其他成员的对齐
除第一个成员外,其他成员需对齐到「对齐数」的整数倍地址处。
**对齐数计算:**编译器默认对齐数与该成员自身大小的较小值。
① VS 环境:默认对齐数为 8
② Linux(gcc)环境:无默认对齐数,对齐数即成员自身大小
例如,VS 环境下int类型成员的对齐数为min(8, 4) = 4。8 这是 VS 环境的默认对齐数 ,4这是int 类型的自身大小,所以最后两者之间选择小的那个为 4.
因此int成员必须从偏移量为 4、8、12 等 4 的倍数地址开始存储。
规则 3:结构体总大小的对齐
结构体的总大小必须是所有成员中**"最大对齐数"**的整数倍。若当前计算的总大小不满足该条件,需自动填充字节至最大对齐数的整数倍。
规则 4:嵌套结构体的对齐
如果嵌套了结构体的情况,嵌套的结构体成员对齐到自己的成员中最大对齐数的整数倍处,而非外部结构体的对齐数。
结构体的整体大小就是所有最大对齐数(含嵌套结构体中成员的对齐数)的整数倍。
(三)对齐规则实例计算
案例 1:基础结构体(struct S1)
cpp
struct S1 {
char c1; // 1字节,对齐数1,偏移0
char c2; // 1字节,对齐数1,偏移1
int n; // 4字节,对齐数4,需从4的倍数地址开始,偏移4-7
};**成员存储:**c1(0)、c2(1)、n(4-7)
**总大小计算:**当前占用 8 字节,最大对齐数为 4(int 的对齐数),8 是 4 的整数倍,因此总大小为 8 字节(浪费 2-3 字节)。
案例 2:包含 double 的结构体(struct S3)
cpp
struct S3 {
double d; // 8字节,对齐数8,偏移0-7
char c; // 1字节,对齐数1,偏移8
int i; // 4字节,对齐数4,需从12开始(跳过9-11),偏移12-15
};**成员存储:**d(0-7)、c(8)、i(12-15)
**总大小计算:**当前占用 16 字节,最大对齐数为 8(double的对齐数),16 是 8 的整数倍,总大小为 16 字节(浪费 9-11 字节)。
案例 3:嵌套结构体(struct S4)
cpp
// 嵌套的结构体S3,内部最大对齐数为8
struct S3 {
double d;
char c;
int i;
};
struct S4 {
char c1; // 1字节,对齐数1,偏移0
struct S3 s3; // 嵌套结构体,需对齐到自身最大对齐数8,偏移8-23(16字节)
double d; // 8字节,对齐数8,偏移24-31
};**成员存储:**c1(0)、s3(8-23)、d(24-31)
**总大小计算:**当前占用 32 字节,最大对齐数为 8(s3和d的对齐数),32 是 8 的整数倍,总大小为 32 字节(浪费 1-7 字节)。
(四)内存对齐的原因
内存对齐并非语法限制,而是由硬件平台特性和性能需求决定,主要包括两个核心原因:
1、平台原因(兼容性)
并非所有硬件平台都能访问任意地址上的任意类型数据。
部分硬件平台(如早期嵌入式处理器)仅能在特定地址处访问特定类型数据,例如要求整型数据必须从 4 的倍数地址开始读取,否则会抛出硬件异常。内存对齐可确保数据存储符合硬件访问规则,避免程序崩溃。
2、性能原因(效率)
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。
原因在于,处理器访问内存时,通常以 "块" 为单位。如 32 位处理器一次读取 4 字节,64 位处理器一次读取 8 字节。若数据未对齐,可能需要两次内存访问才能获取完整数据;而对齐的数据仅需一次访问即可。
**未对齐场景:**int 成员从偏移量 1 开始存储,需先读取 0-3 字节(获取该int的前 3 字节),再读取 4-7 字节(获取后 1 字节),共两次操作。
**对齐场景:**int 成员从偏移量 4 开始存储,一次读取 4-7 字节即可获取完整数据,效率显著提升。
本质:内存对齐是 **"空间换时间"**的优化策略,通过少量空间浪费换取内存访问效率的提升。
(五) 内存对齐的优化与调整
1、成员顺序优化
通过调整结构体成员的声明顺序,将空间较小的成员集中存放,可减少因对齐产生的空间浪费。例如:
cpp
//优化前
struct S1
{
char c1;
int i;
char c2;
};
//优化后
struct S2
{
char c1;
char c2;
int i;
};两者成员完全相同,但优化后节省 4 字节空间,原因是两个 char 成员集中存放,减少了空间碎片(减少了内存对齐导致的 "填充空间")。
2、修改默认对齐数
编译器支持通过**"#pragma pack(n)"** 指令修改默认对齐数(n通常为 2 的幂次方,如 1、2、4、8),使用**"#pragma pack()"**可恢复默认对齐设置。
cpp
// 设置默认对齐数为1(取消对齐,成员紧密排列)
#pragma pack(1)
struct S {
char c1;
int n;
char c2;
};
// 恢复默认对齐
#pragma pack()
// 此时sizeof(struct S) = 6字节(1+4+1),无空间浪费注意:修改默认对齐数需谨慎,仅在对内存占用要求极高(如嵌入式开发)且明确硬件支持的场景下使用,否则可能导致性能下降或兼容性问题。
三、结构体传参
结构体传参有两种方式:传值调用 和传址调用,两者在空间占用 、性能 和功能上存在显著差异,实际开发中需优先选择传址调用。以下是实际案例:
cpp
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
struct S
{
int data[1000];
int num;
};
// 结构体传参
void print1(struct S s)
{
printf("%d\n", s.num);
}
// 结构体地址传参
void print2(struct S* ps)
{
printf("%d\n", ps->num);
}
int main()
{
struct S s = { {1,2,3,4}, 100 };
print1(s); // 传结构体
print2(&s); // 传地址
return 0;
}(一)传参方式对比
1、传值调用
(1)实现原理:创建结构体参数的副本(形参),函数内操作副本
(2)空间占用:复制整个结构体,若结构体较大(如包含 1000 元素的数组),空间浪费严重
(3)功能限制:无法修改实参,仅能读取数据
(4)适用场景:结构体较小且无需修改实参的场景
2、传址调用
(1)实现原理:传递结构体变量的地址(指针),函数内通过指针访问实参
(2)空间占用:仅占用指针大小(4/8 字节),空间占用固定
(3)功能限制:可修改实参,功能灵活
(4)适用场景:结构体较大、需高效传参或修改实参的场景
函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。如果传递一个结构体对象的时候,结构体过大,参数压栈的的系统开销比较大,所以会导致性能的下降。
(二)常见错误与解决
1、错误案例:类型未定义
cpp
// 错误:使用结构体前未定义类型
void print1(struct S s) {
// 打印成员...
}
struct S {
int a;
char b;
};
int main() {
struct S s = {10, 'a'};
print1(s);
return 0;
}(1)错误原因 :编译器按代码顺序编译,调用 print1时 struct S 尚未定义,无法识别参数类型。
(2)解决方法 :将结构体类型定义移至函数声明之前,确保编译器编译函数时已知晓结构体类型。
(三)传址调用的优势与安全性
传址调用的核心优势是高效,无论结构体多大,仅需传递 4/8 字节的地址,避免了大量数据拷贝的时间和空间开销。
若需防止函数意外修改实参,可在指针参数前添加限定符,确保实参只读:
cpp
// const限定:函数仅能读取s指向的结构体,无法修改
void print2(const struct S* s) {
printf("%d %c\n", s->a, s->b);
}
int main() {
struct S s = {10, 'a'};
print2(&s); // 传地址,高效且安全
return 0;
}结论 :结构体传参优先选择传址调用,结合 const 可兼顾效率与安全性。
四、结构体实现位段
位段是结构体的扩展特性,通过精确控制成员占用的比特位数,实现内存的精细化管理,适用于成员取值范围有限的场景(如状态标志、协议字段)。
(一)位段的定义与语法
位段的声明与结构体相似,但有两个关键区别:
1、成员类型限制
位段成员必须是int、unsigned int或signed int(C99 后支持char等其他整型类型)。
2、比特位指定
成员名后需添加冒号(:)和数字,指定该成员占用的比特位数。
cpp
// 变量前面可以有下划线,但是不能以数字开头
// 位段类型声明:_a占2bit,_b占5bit,_c占10bit,_d占30bit
struct A {
int _a : 2;
int _b : 5;
int _c : 10;
int _d : 30;
};**注意:**单个成员的比特位数不能超过其类型的总比特数( 如int类型最大支持 32 比特,因此_d:30合法,_d:33非法 )。
(二)位段的空间优势
位段的核心价值是节省内存 。当成员的取值范围有限时,无需分配完整的字节(如int占 4 字节),仅需分配足够表示取值的比特位即可。
例如:表示 0-3 的状态(共 4 种取值),仅需 2 比特(_a:2),相比int的 4 字节(32 比特),空间节省 93.75%。
**★实测:**上面的 struct A 的大小为 8 字节(2+5+10+30=47 比特,需 6 字节,但因对齐规则分配 8 字节),而若用普通结构体(4 个int),大小为 16 字节,空间节省 50%。
(三)位段的内存分配规则 (★)
位段的内存分配以**"成员类型的字节大小"**为单位,按需开辟空间,具体规则如下:
若成员类型为int(4 字节):每次开辟 4 字节(32 比特),用完后再开辟新的 4 字节。若成员类型为char(1 字节):每次开辟 1 字节(8 比特),用完后再开辟新的 1 字节。
以下面代码为例:
cpp
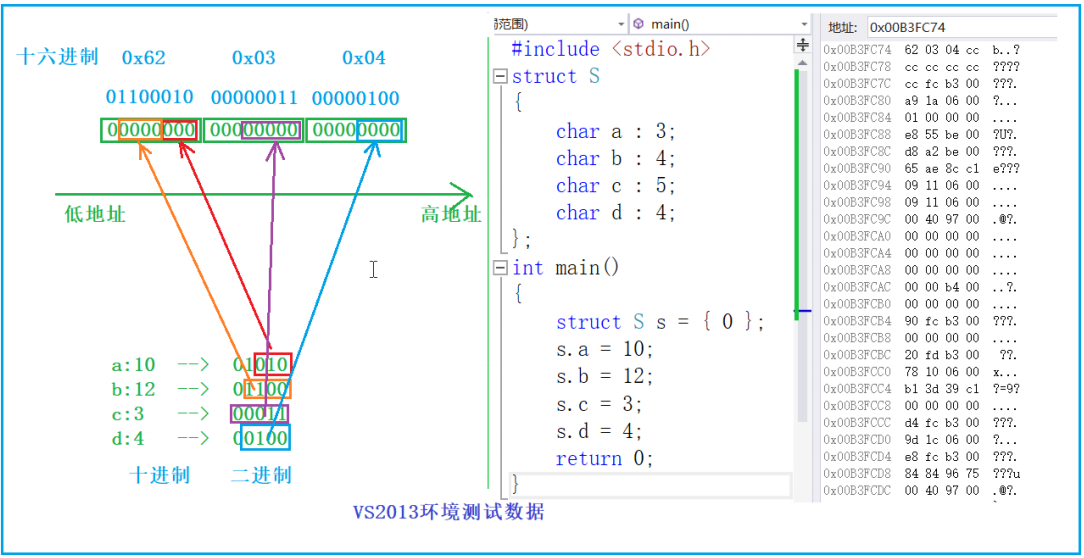
struct B {
char _a : 3; // 3bit
char _b : 4; // 4bit
char _c : 5; // 5bit
char _d : 4; // 4bit
};
struct B b = {0};
s.a = 10;
s.b = 12;
s.c = 3;
s.d = 4;**第一步:**开辟 1 字节 (8 比特),存储_a(3bit) 和 _b(4bit),剩余 1 比特 (不足存储 _c 的 5bit,浪费)。
**第二步:**开辟第 2 字节 (8 比特),存储_c(5bit),剩余 3 比特 (不足存储 _d 的 4bit,浪费) 。
**第三步:**开辟第 3 字节(8 比特),存储_d(4bit),剩余 4 比特。
**总大小:**3 字节(符合char类型的分配规则)。
(四)位段的跨平台问题
位段的实现依赖编译器,存在显著的跨平台兼容性问题,主要体现在以下四点:
1、符号性不确定
int类型的位段可能被编译器视为有符号或无符号,若最高位为 1,有符号位段会被解析为负数,无符号则为正数。
2、最大位数不确定
16 位平台的int为 2 字节(16 比特),32 位平台为 4 字节(32 比特),若位段成员指定 30 比特,在 16 位平台会报错。
3、存储顺序不确定
编译器可能从字节的高位向低位存储位段成员,也可能从低位向高位存储(如_a:3可能占用字节的 0-2 比特,也可能占用 5-7 比特)。
4、剩余空间处理不确定
当字节剩余空间不足存储下一个位段成员时,编译器可能浪费剩余空间并开辟新字节,也可能复用其他字节的剩余空间。
**结论:**位段适用于对内存敏感且无需跨平台的场景(如嵌入式硬件寄存器映射、网络协议封装),注重可移植性的程序应避免使用。
(五)位段的应用
下图是网络协议中,IP数据报的格式,我们可以看到其中很多的属性只需要几个 bit 位就能描述,这里使用位段,能够实现想要的效果,也节省了空间,这样网络传输的数据报大小也会较小一些,对网络的畅通是有帮助的。

(六)位段的使用注意事项
1、禁止取地址操作
位段成员可能共用同一字节 ,而内存中仅对字节分配地址 ,字节内部的比特位无独立地址。因此,无法对位段成员使用取址运算符(&),也不能通过scanf直接输入值到位段成员。
cpp
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
struct A {
int _a : 2;
int _b : 5;
int _c : 10;
int _d : 30;
};
int main()
{
struct A sa = { 0 };
scanf("%d", &sa._b);//这是错误的
//正确的⽰范
int b = 0;
scanf("%d", &b);
sa._b = b;
return 0;
}2、取值范围限制
位段成员的取值范围由其占用的比特位数决定,超出范围的值会被自动截断,仅保留低位。
_a:2 的取值范围为 0-3(2 比特最多表示 4 种状态),若赋值为 10(二进制1010),实际存储为010(十进制 2)。
以上即为 自定义类型:结构体 的全部内容,麻烦三连支持一下呗~
