文章目录
- [1 概要](#1 概要)
- [2 算子调试](#2 算子调试)
-
- [2.1 算子调试概述](#2.1 算子调试概述)
- [2.2 CPU域调试](#2.2 CPU域调试)
-
- [2.2.1 printf操作演示](#2.2.1 printf操作演示)
-
- [2.2.1.1 打印编号](#2.2.1.1 打印编号)
- [2.2.1.2 打印输入尺寸](#2.2.1.2 打印输入尺寸)
- [2.2.1.3 打印输入输入数值](#2.2.1.3 打印输入输入数值)
- [2.2.2 单步调试GDB](#2.2.2 单步调试GDB)
-
- [2.2.2.1 配置调试环境](#2.2.2.1 配置调试环境)
- [2.2 NPU域调试](#2.2 NPU域调试)
-
- [2.2.1 AscendC::printf()](#2.2.1 AscendC::printf())
- [2.2.2 DumpTensor()](#2.2.2 DumpTensor())
- [2.3 算子调试 - 内存检测 msSanitizer 功能介绍](#2.3 算子调试 - 内存检测 msSanitizer 功能介绍)
-
- [2.3.1 演示(内存检测)](#2.3.1 演示(内存检测))
- [3 算子调优](#3 算子调优)
- [3.1 msProf功能介绍](#3.1 msProf功能介绍)
-
-
- [3.1.1 演示](#3.1.1 演示)
-
- [3.1.1.1 上板调优](#3.1.1.1 上板调优)
- [3.1.1.2 仿真调优](#3.1.1.2 仿真调优)
-
- [3 总结](#3 总结)
1 概要
博主最近在学习华为昇腾的Ascend C的算子开发,在B站上根据教程一步步进行操作。
文章分为四个章节:
(1) 算子调试
(2) 矩阵编程 (高阶API)
(3) 融合算子
(4) 性能优化 (理论)
2 算子调试
2.1 算子调试概述
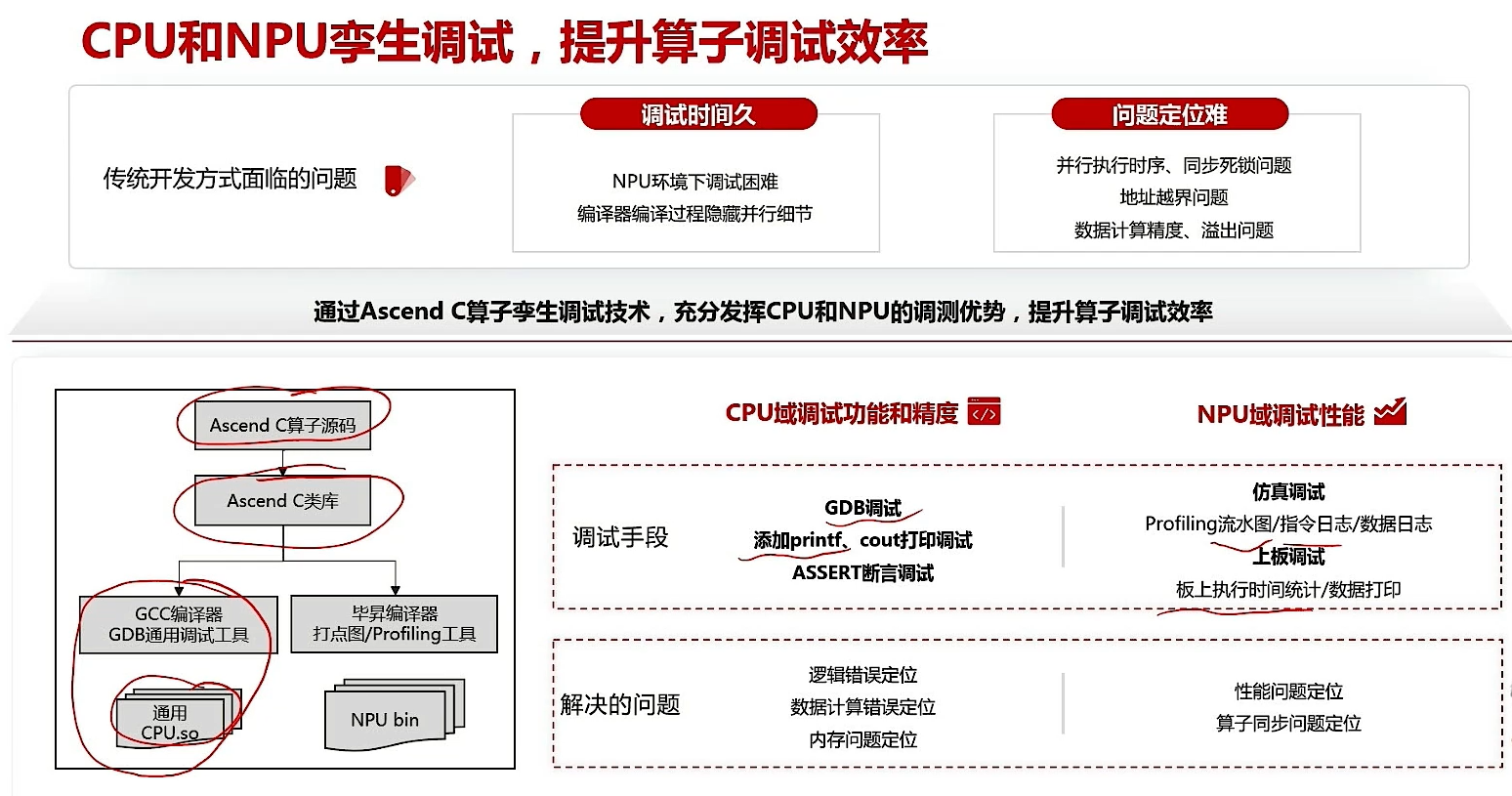
2.2 CPU域调试
2.2.1 printf操作演示

2.2.1.1 打印编号
(1) 首先下载华为官方提供的例程samples程序,并进入如下目录:
css
cd /home/lbh/samples/operator/AddCustomSample/KernelLaunch/AddKernelInvocationNeo
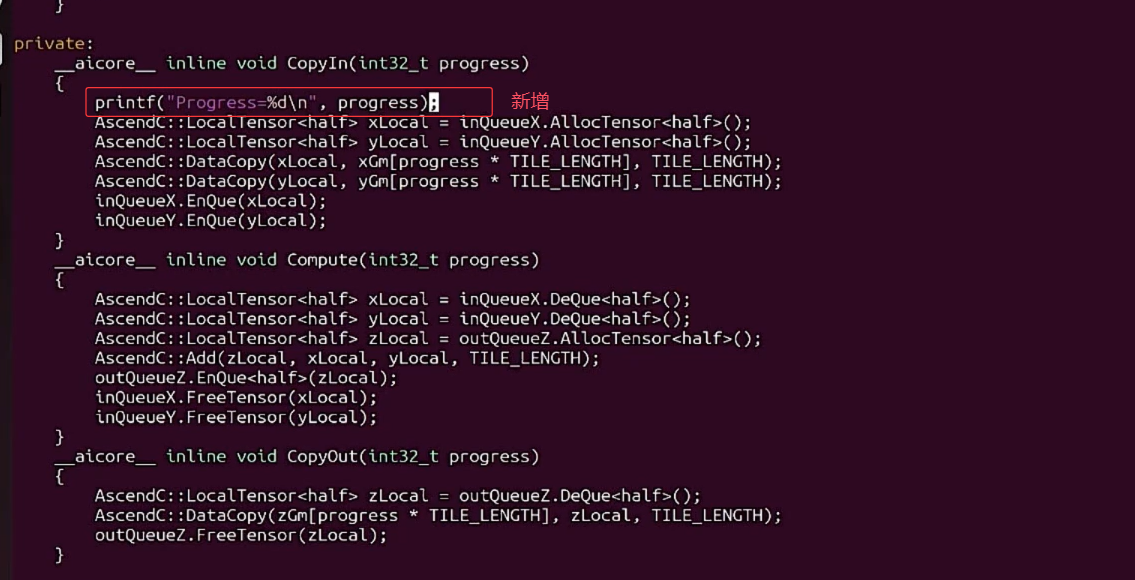
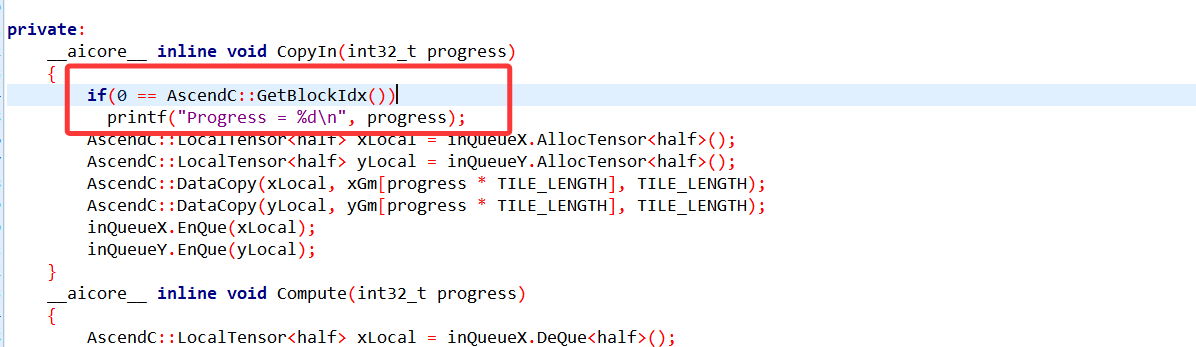
(2) 修改add_custom.cpp以打印相关的信息:
(3) 执行命令 bash run.sh -r cpu -v Ascend310B4, 输出如下
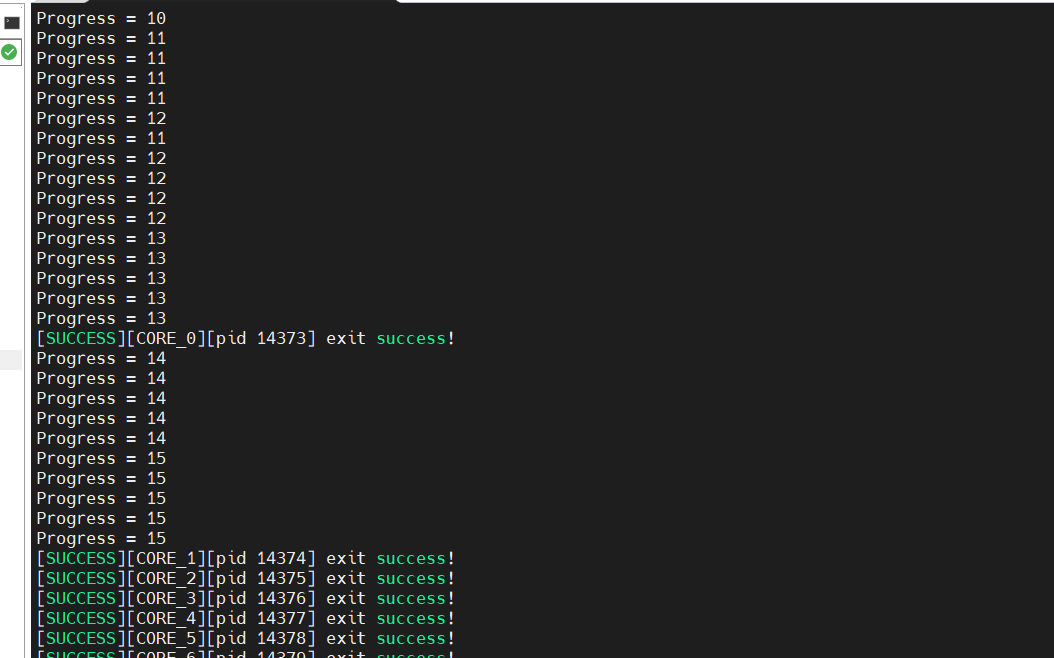
会发现输出很乱,是因为我们有8个核,多核运行相同的算子,每个核内部循环16次处理数据,因此会有8组重复的0-15。
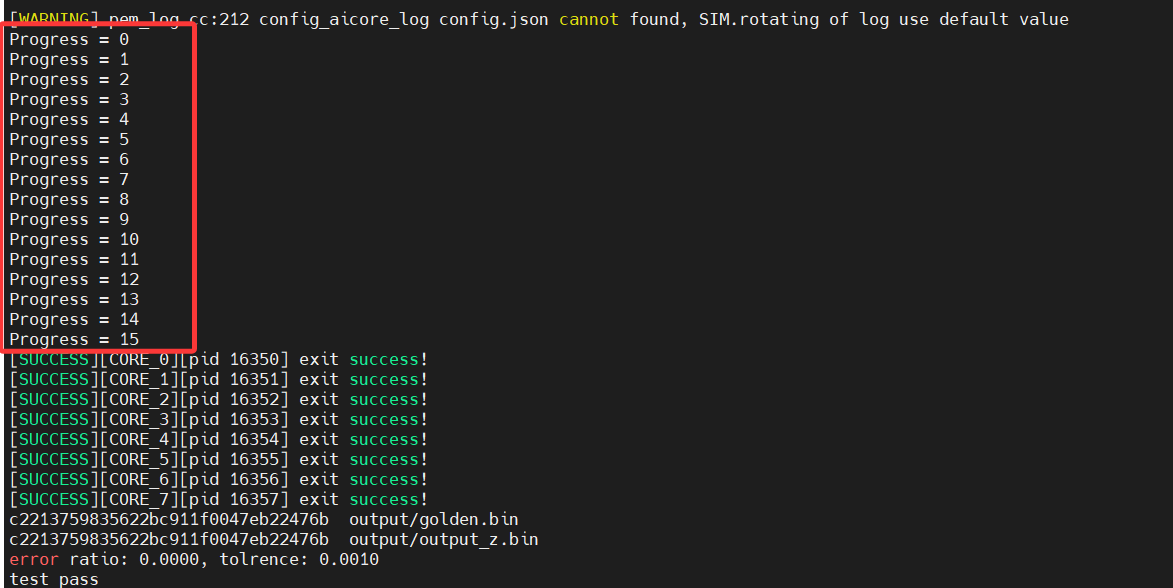
我们进行如下修改:
重新运行bash run.sh -r cpu -v Ascend310B4, 输出如下:
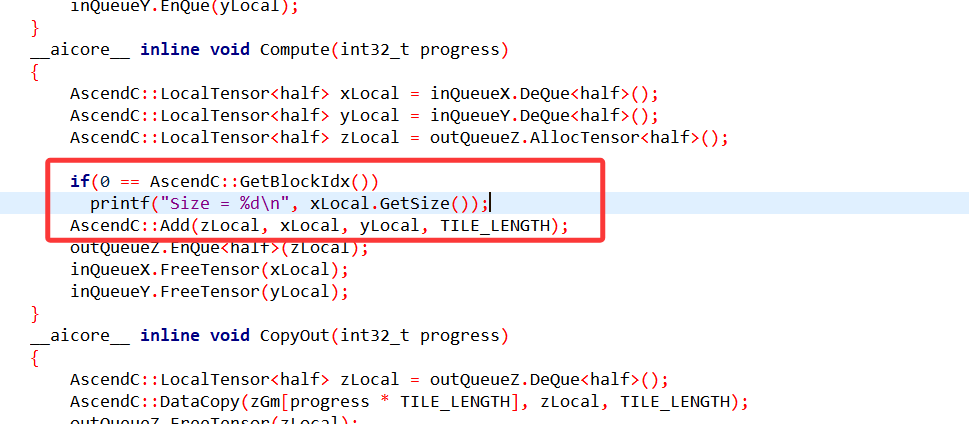
2.2.1.2 打印输入尺寸
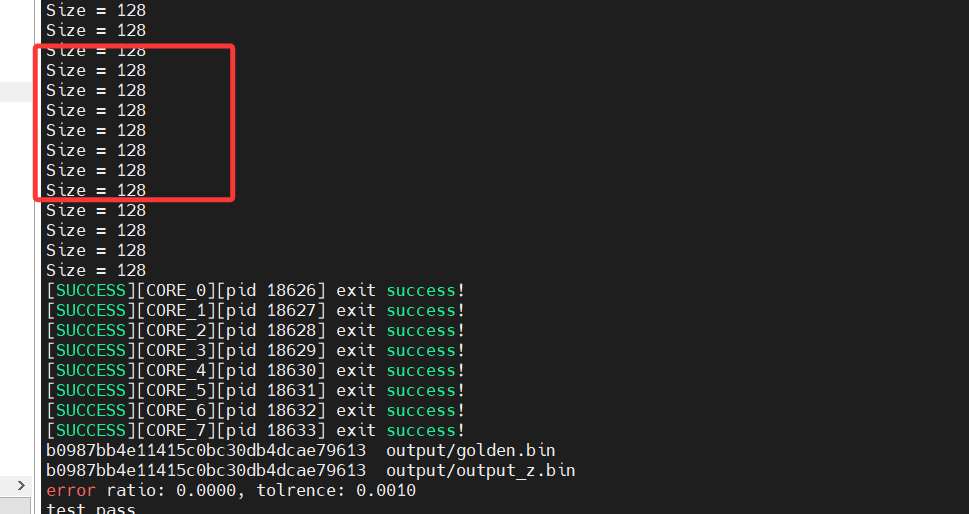
2.2.1.3 打印输入输入数值
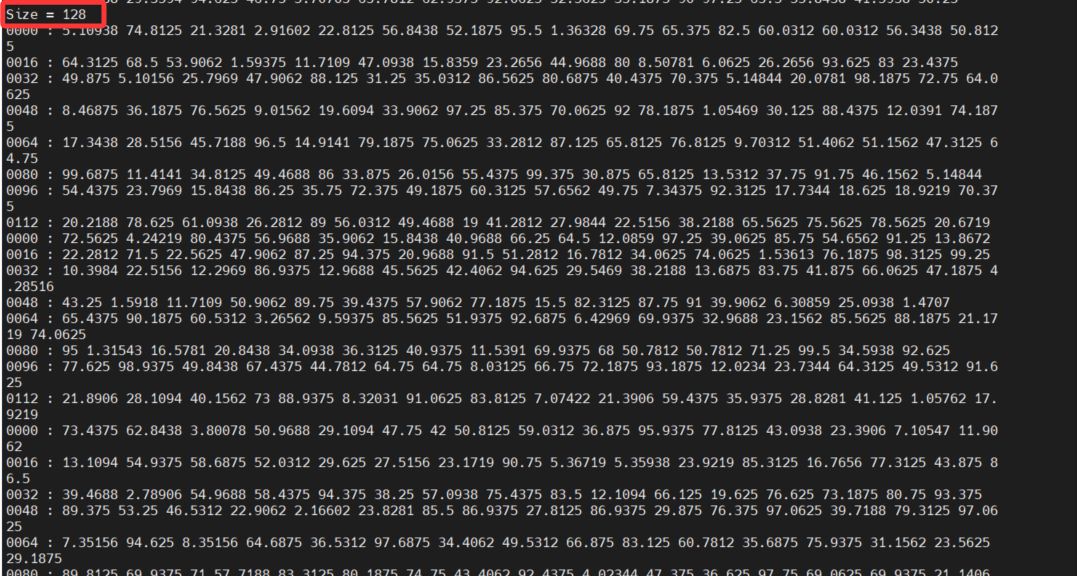
输出:
2.2.2 单步调试GDB

2.2.2.1 配置调试环境
(1) vim run.sh
122行修改如下
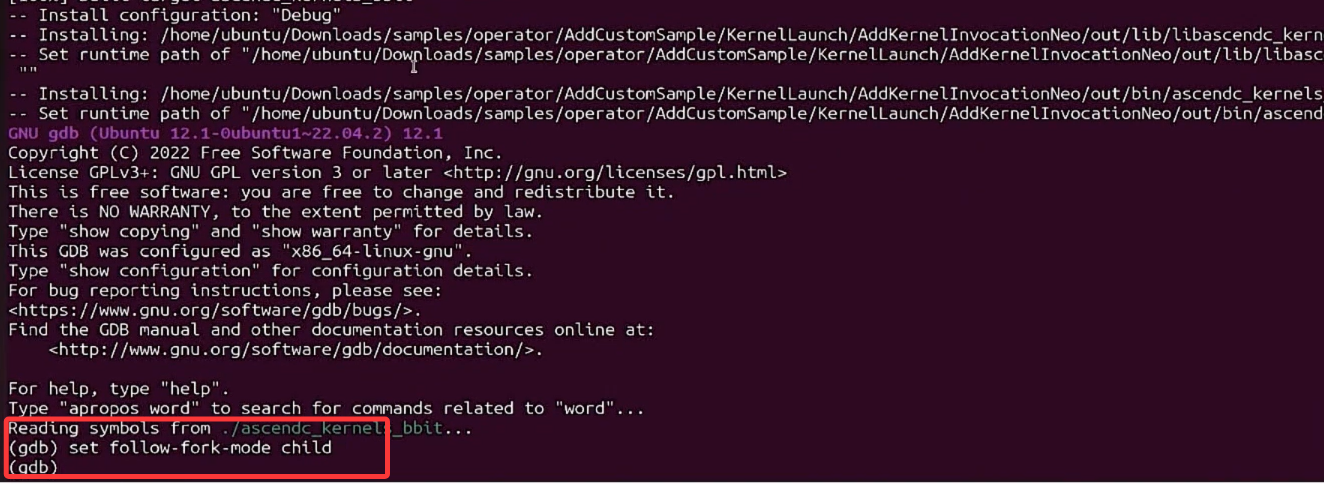
重新运行bash run.sh -r cpu -v Ascend310B4,之后会进入到调试程序中:
可执行如下命令进行调试:
gdb --args add_custom_cpu
set follow-fork-mode child #进入子进程
break add_custom.cpp:45 设置断点
run #执行到断点处
list #看上下代码
backtrace #看调用的栈
print i #打印i
break add_custom.cpp:56 #继续打断点
continue
display xLocal #输出对象的属性,非具体值
quit
2.2 NPU域调试


2.2.1 AscendC::printf()
(1) 首先下载华为官方提供的例程samples程序,并进入如下目录:
css
cd /home/lbh/samples/operator/AddCustomSample/KernelLaunch/AddKernelInvocationNeo(2) vi add_custom.cpp
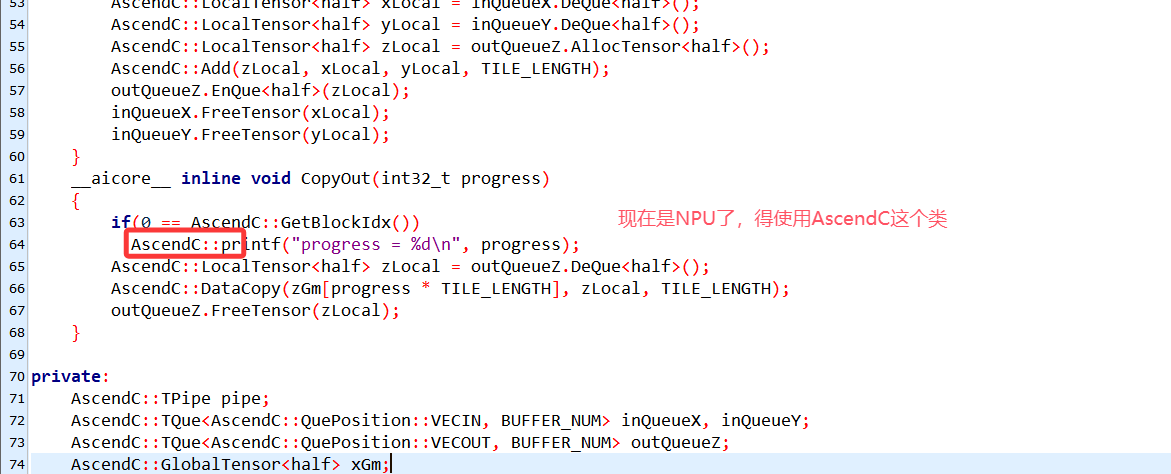
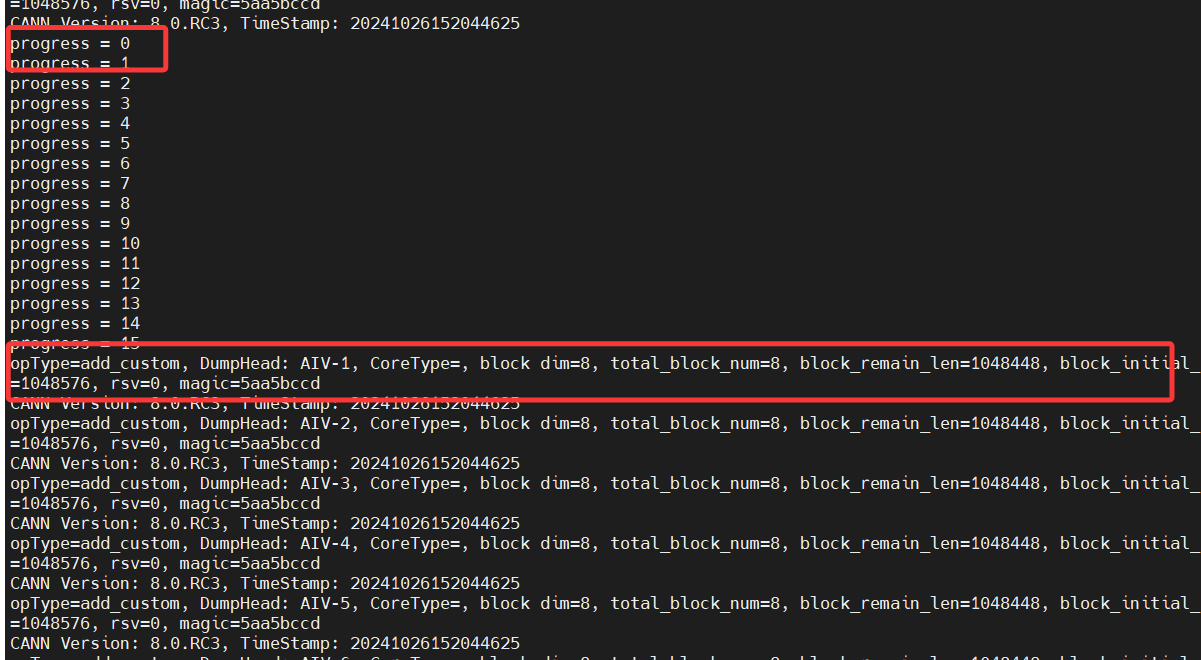
执行命令bash run.sh -r npu -v Ascend310B4,输出如下:
2.2.2 DumpTensor()
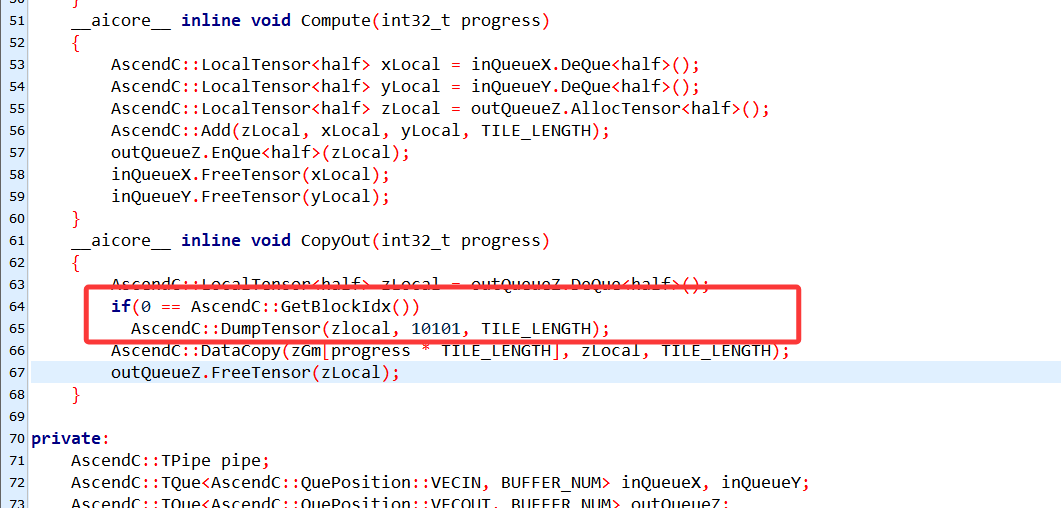
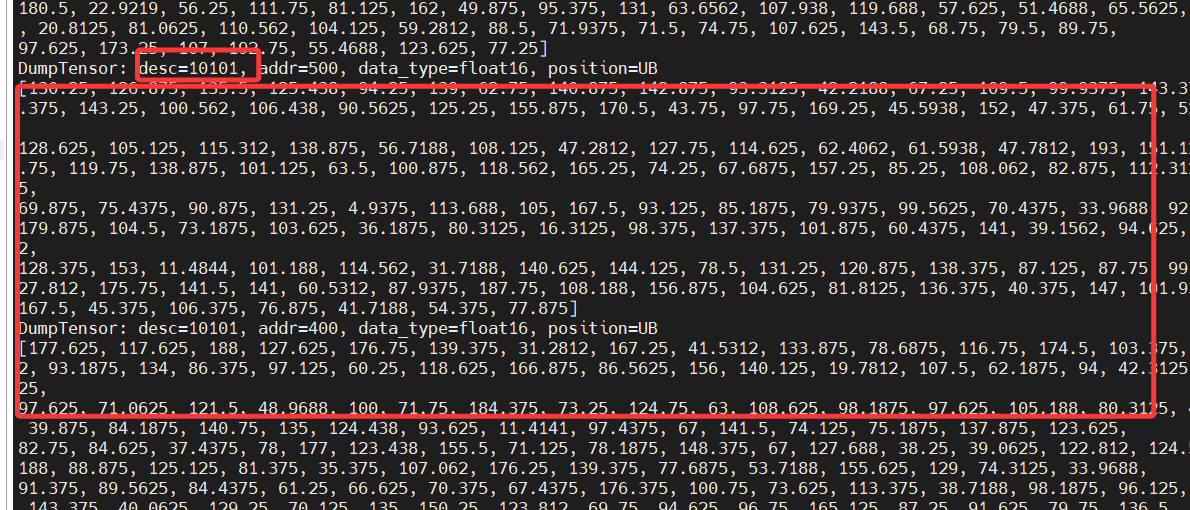
这次设置打印长度,只打印16个,修改如下:
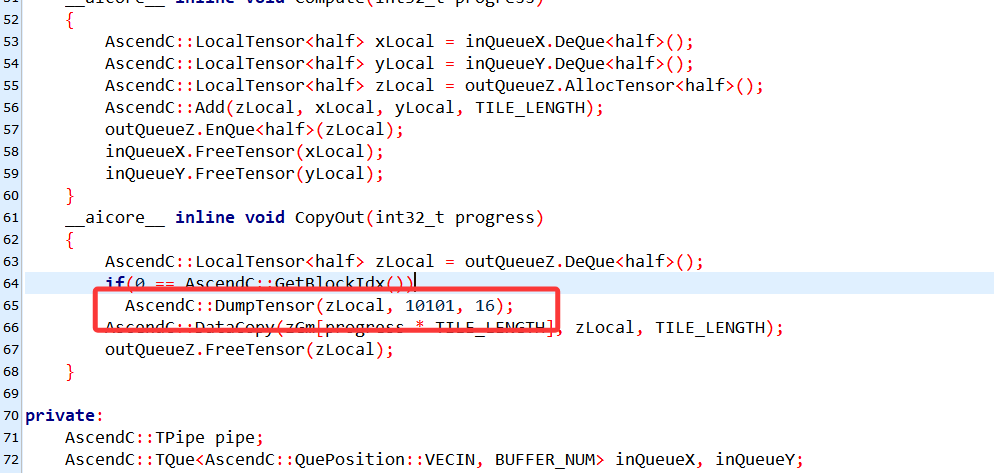
输出如下:
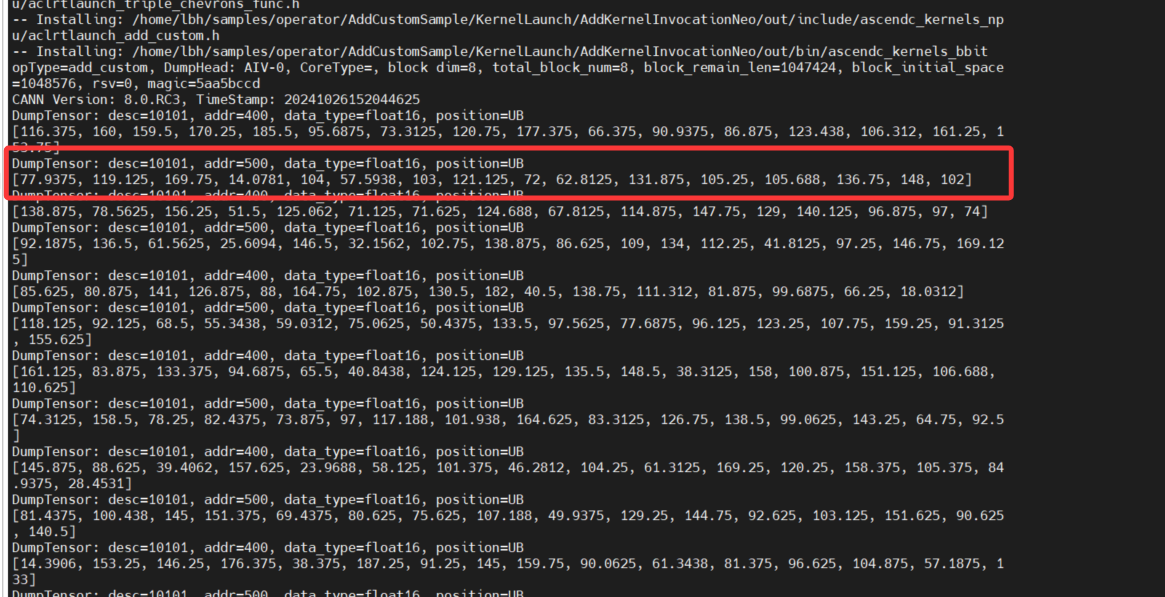
2.3 算子调试 - 内存检测 msSanitizer 功能介绍

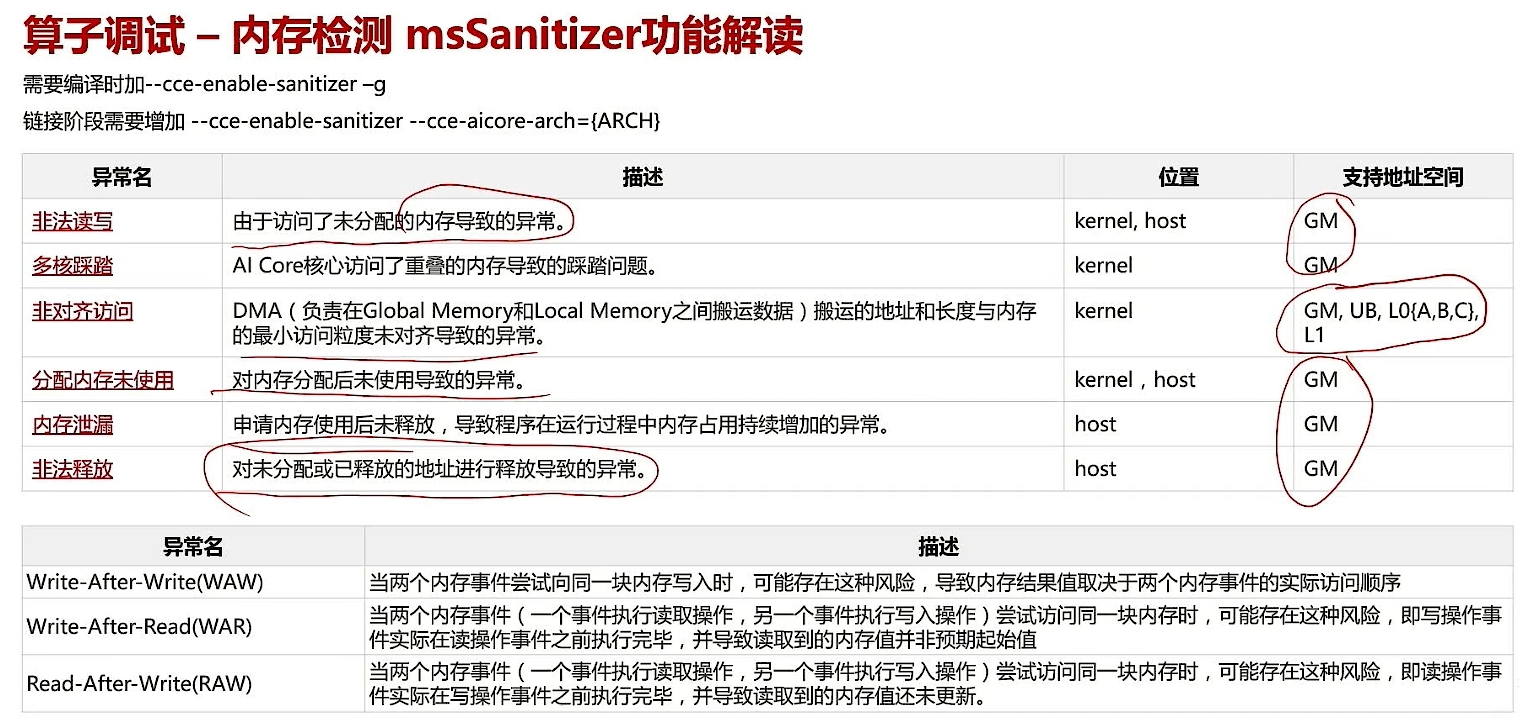
2.3.1 演示(内存检测)
(1) 首先下载华为官方提供的例程samples程序,并进入如下目录:
css
cd /home/lbh/samples/operator/AddCustomSample/FrameworkLaunch/AddCustom/op_kernel对CMakeLists.txt进行修改
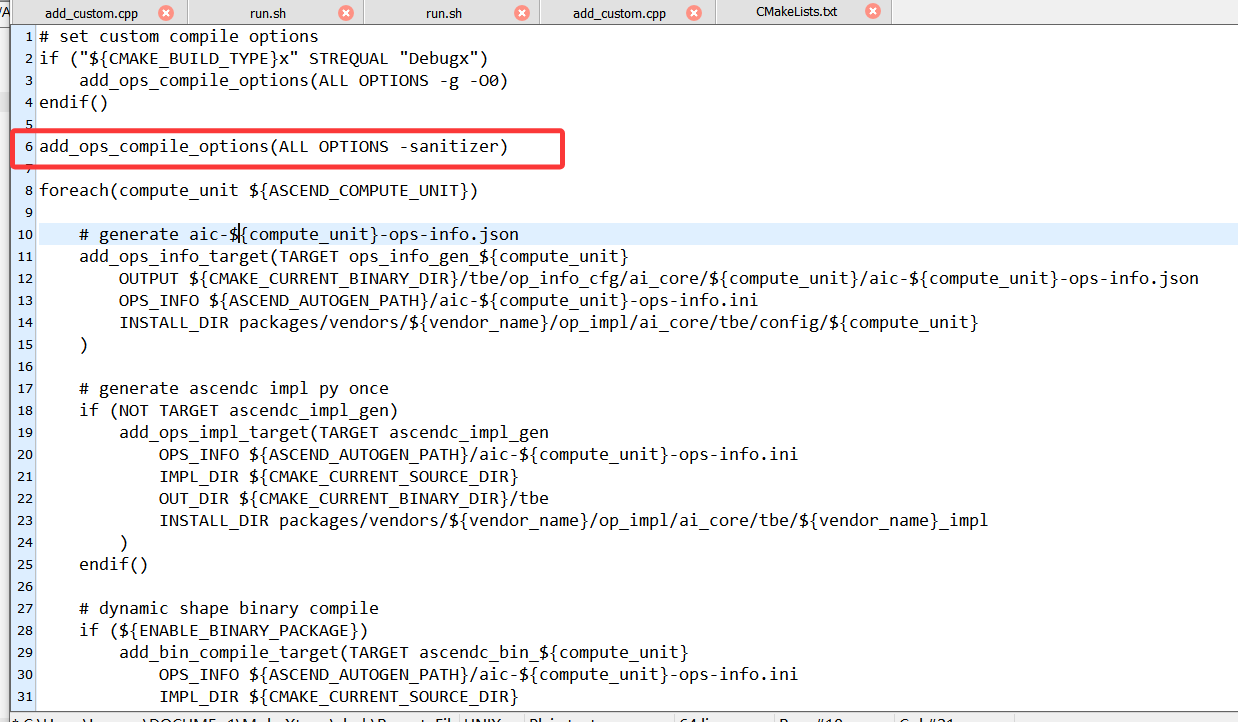
之后重新编译:
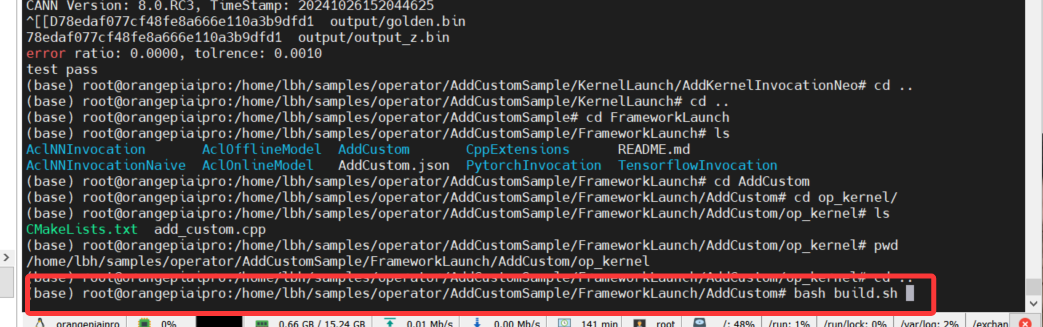
之后安装编译好得算子到环境中,即
cd build_out
./custom_opp_ubuntu_aarch64.run
公共安装后输出如下:
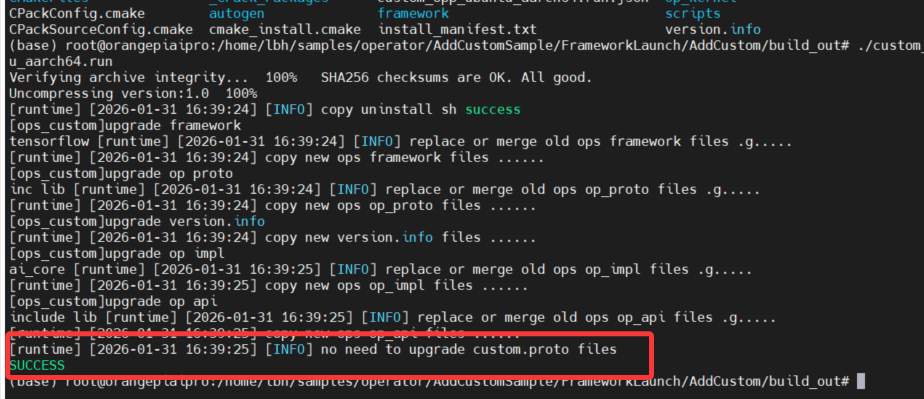
随后进入工程:
css
cd /home/lbh/samples/operator/AddCustomSample/FrameworkLaunch/AclNNInvocation之前的操作是安装了算子,现在进入的这个工程是运用之前安装的算子实现相应的计算。
之后在此工程中执行如下命令:
mssanitizer --tool=memcheck bash run.sh
--tool=racecheck #则为竞争检测
若程序存在问题会报如下类似错误:
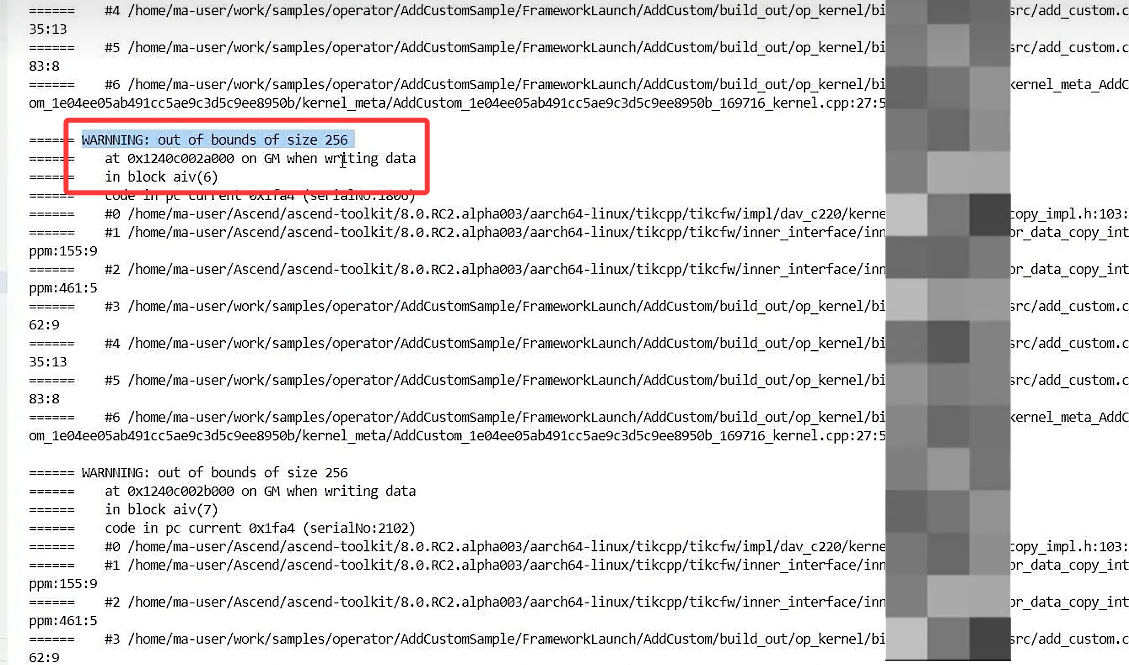
3 算子调优
3.1 msProf功能介绍
仿真调优可以在CPU上跑。
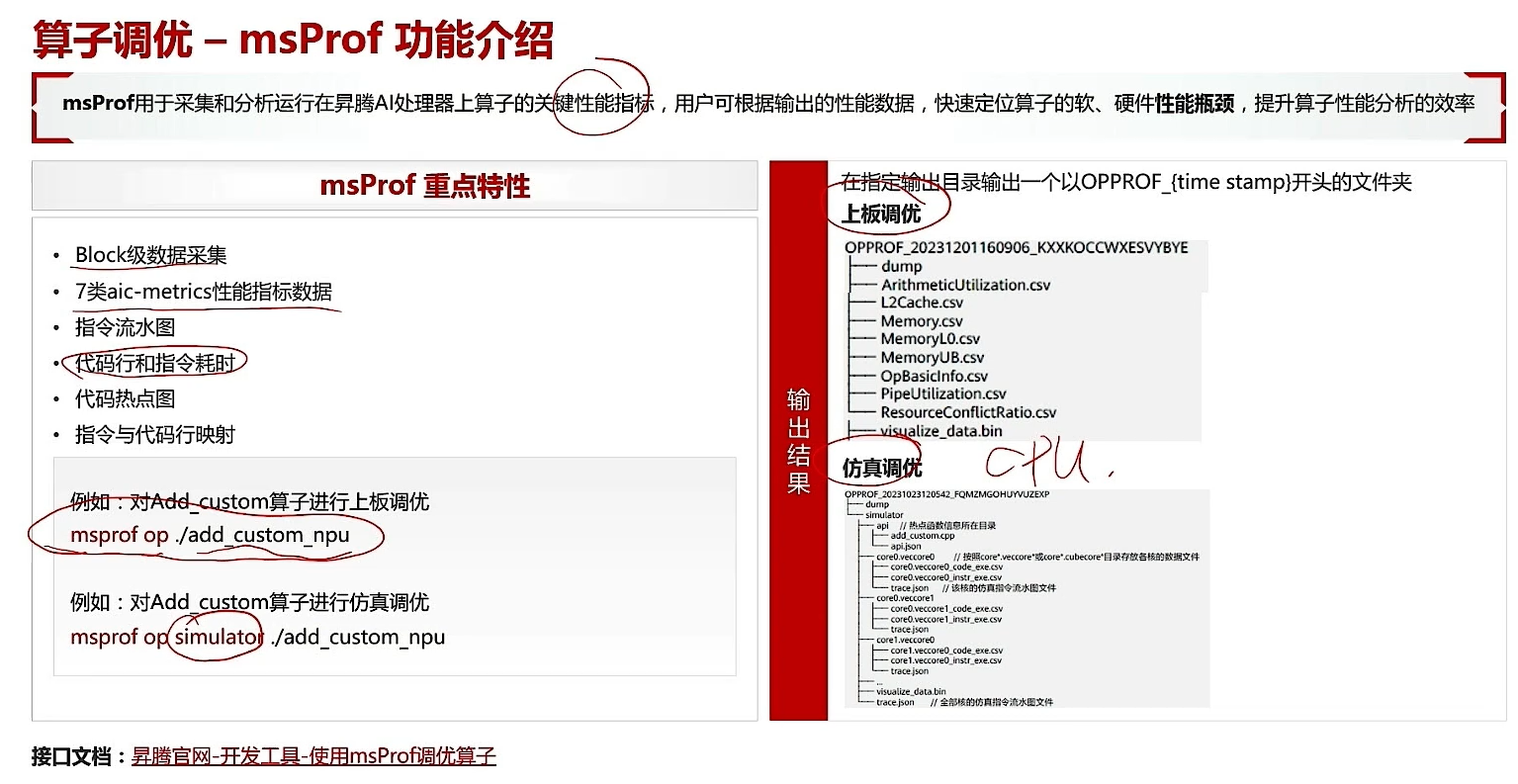
3.1.1 演示
(1) 首先下载华为官方提供的例程samples程序,并进入如下目录:
css
cd /home/lbh/samples/operator/AddCustomSample/KernelLaunch/AddKernelInvocationNeo首先修改CMakeLists.txt
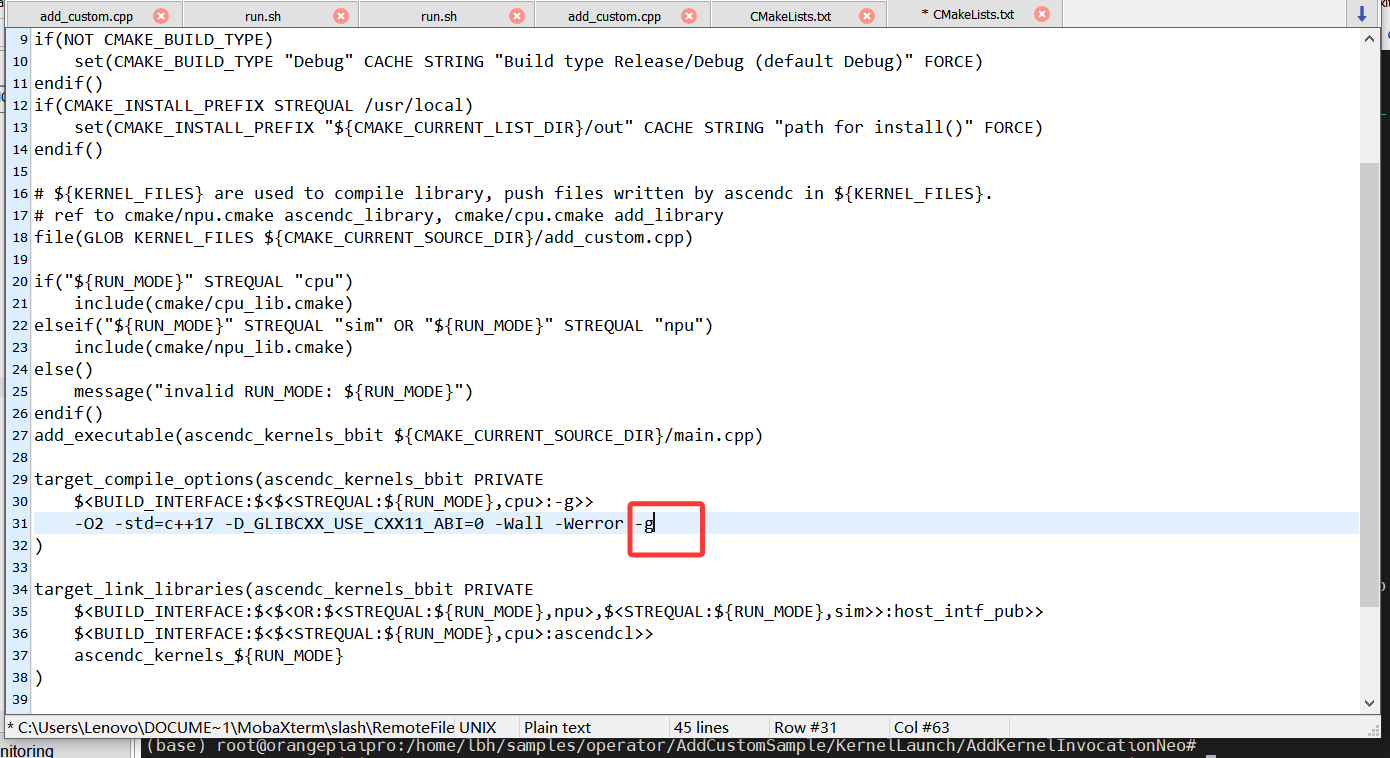
3.1.1.1 上板调优
修改完CMakeLists.txt之后修改run.sh脚本,修改如下:
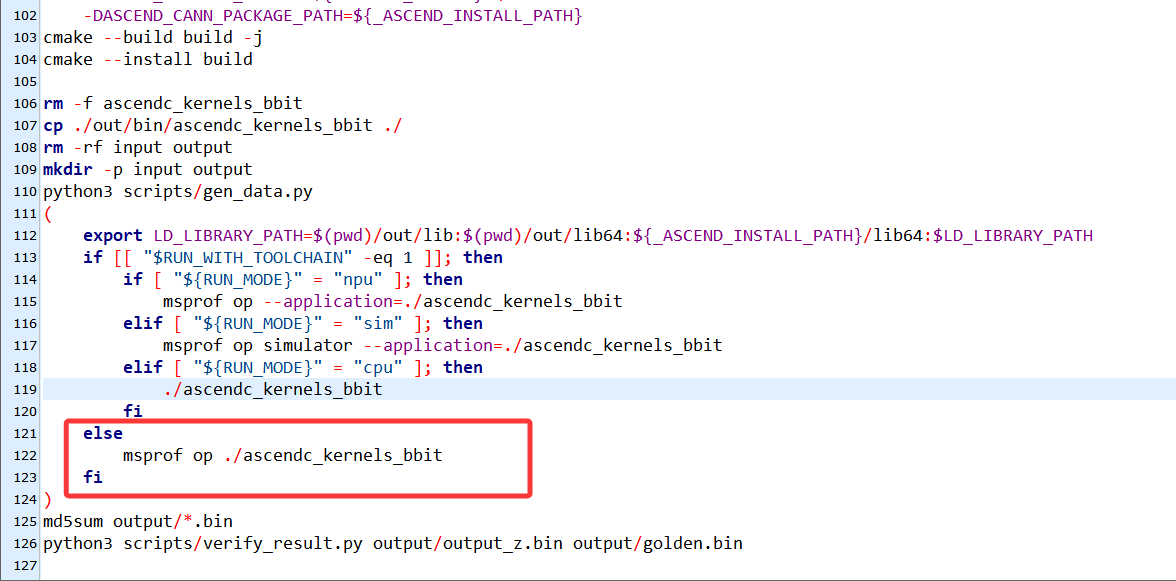
之后执行命令:
bash run.sh -r npu -v Ascend310B4
文件夹中会生成一个新的数据文件:
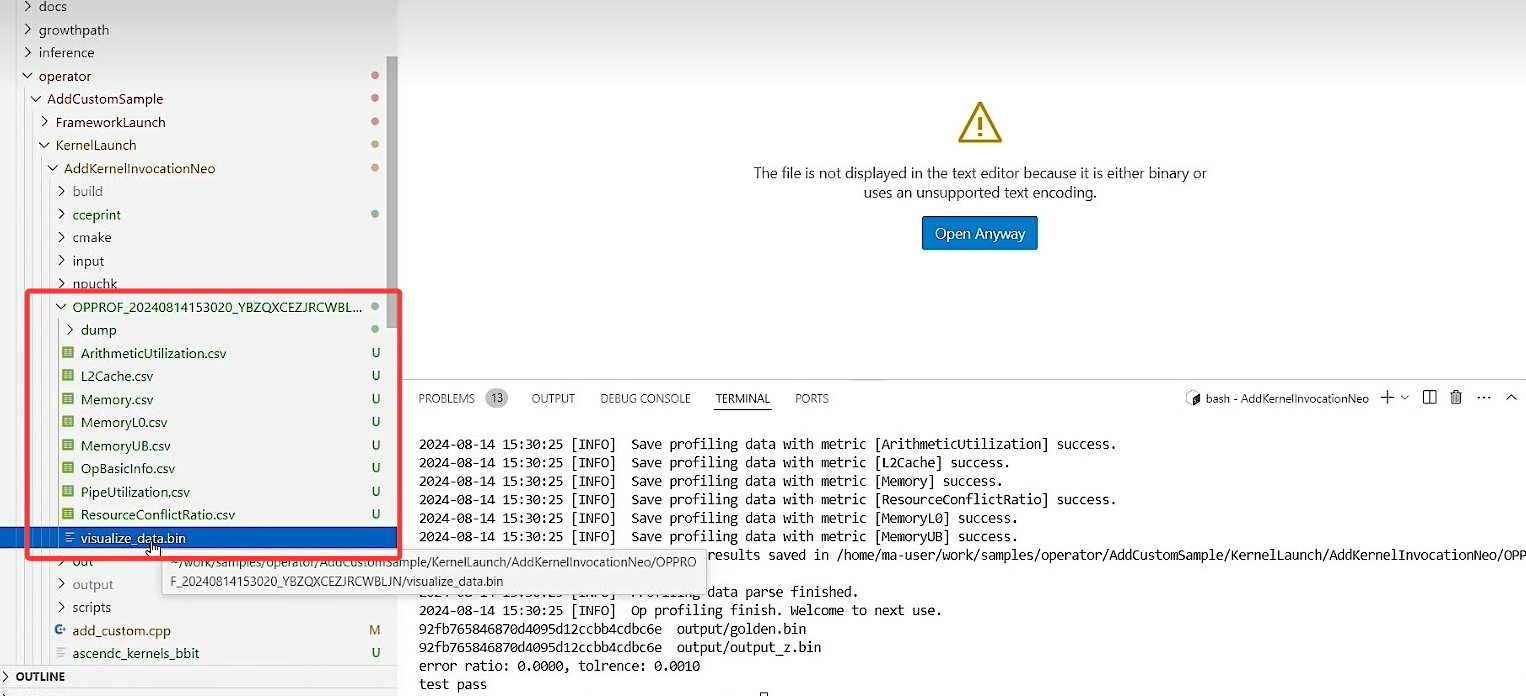
之后将visualize_data.bin下载下来,随后使用分析工具打开即可查看详细的信息。
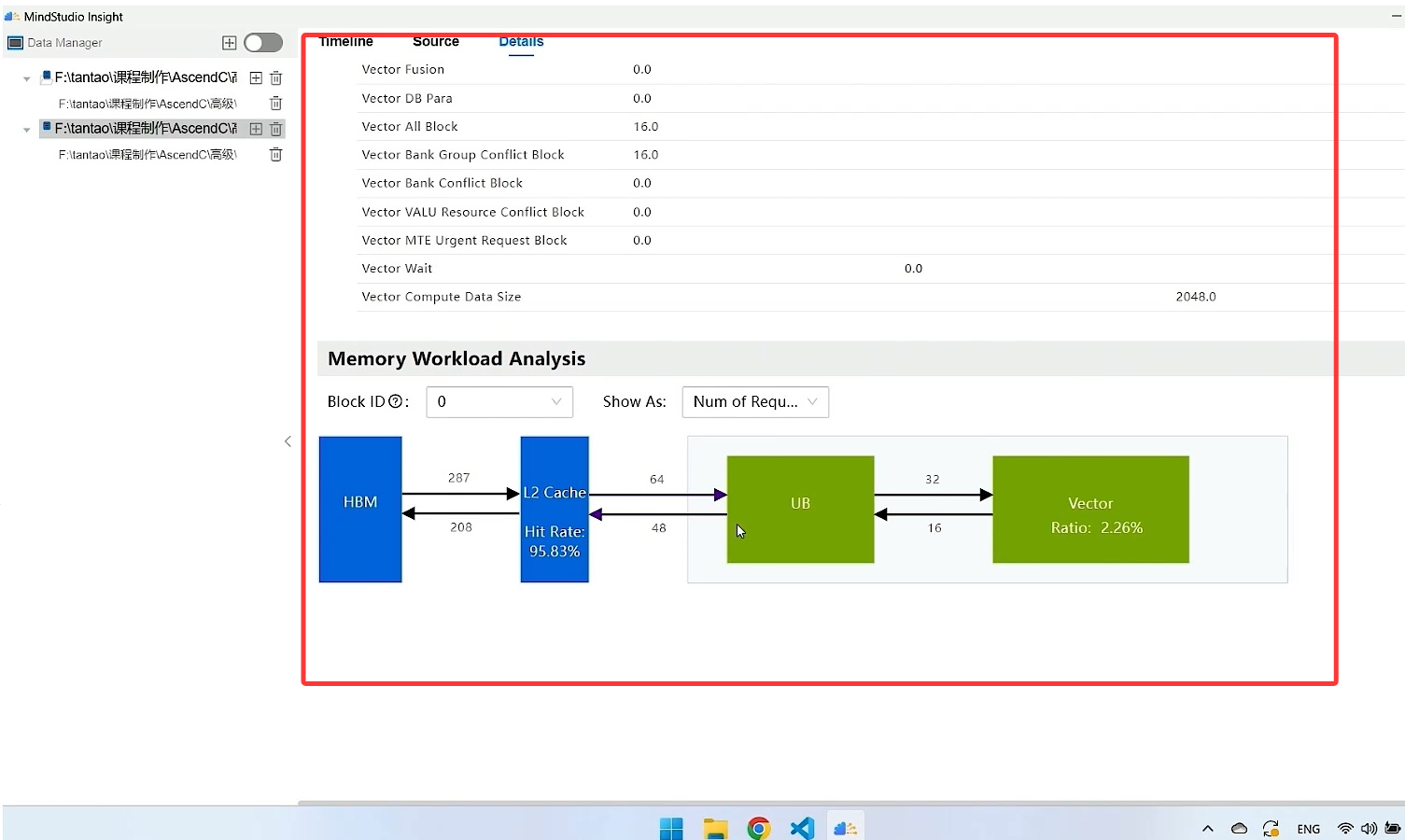
3.1.1.2 仿真调优
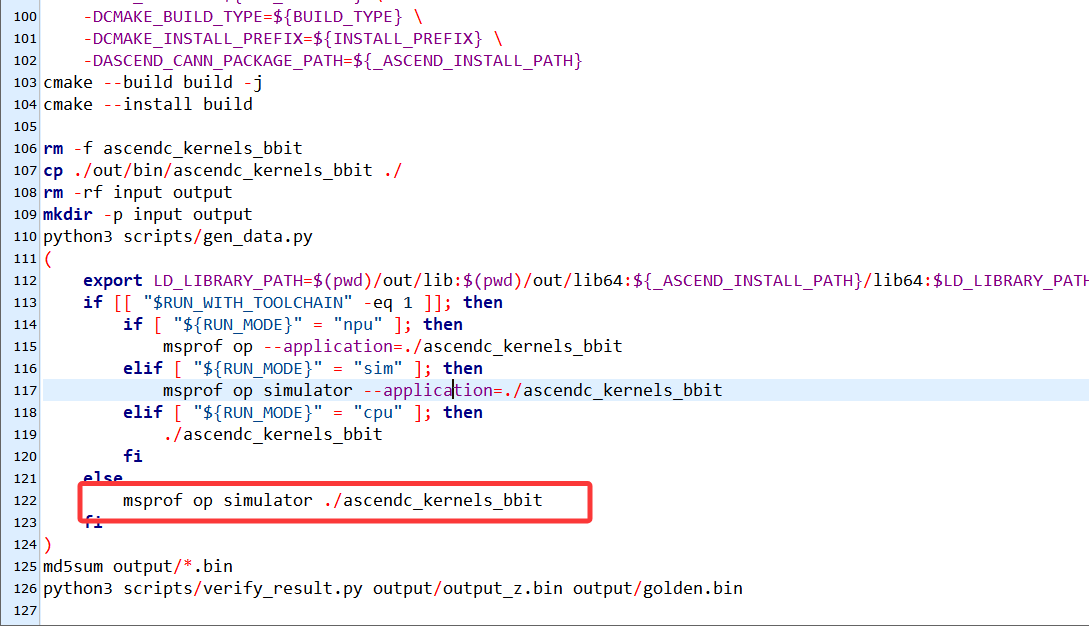
运行命令:bash run.sh -r sim -v Ascend310B4
bash run.sh -r sim -v Ascend310B4
每个内核中的运行情况可以查看
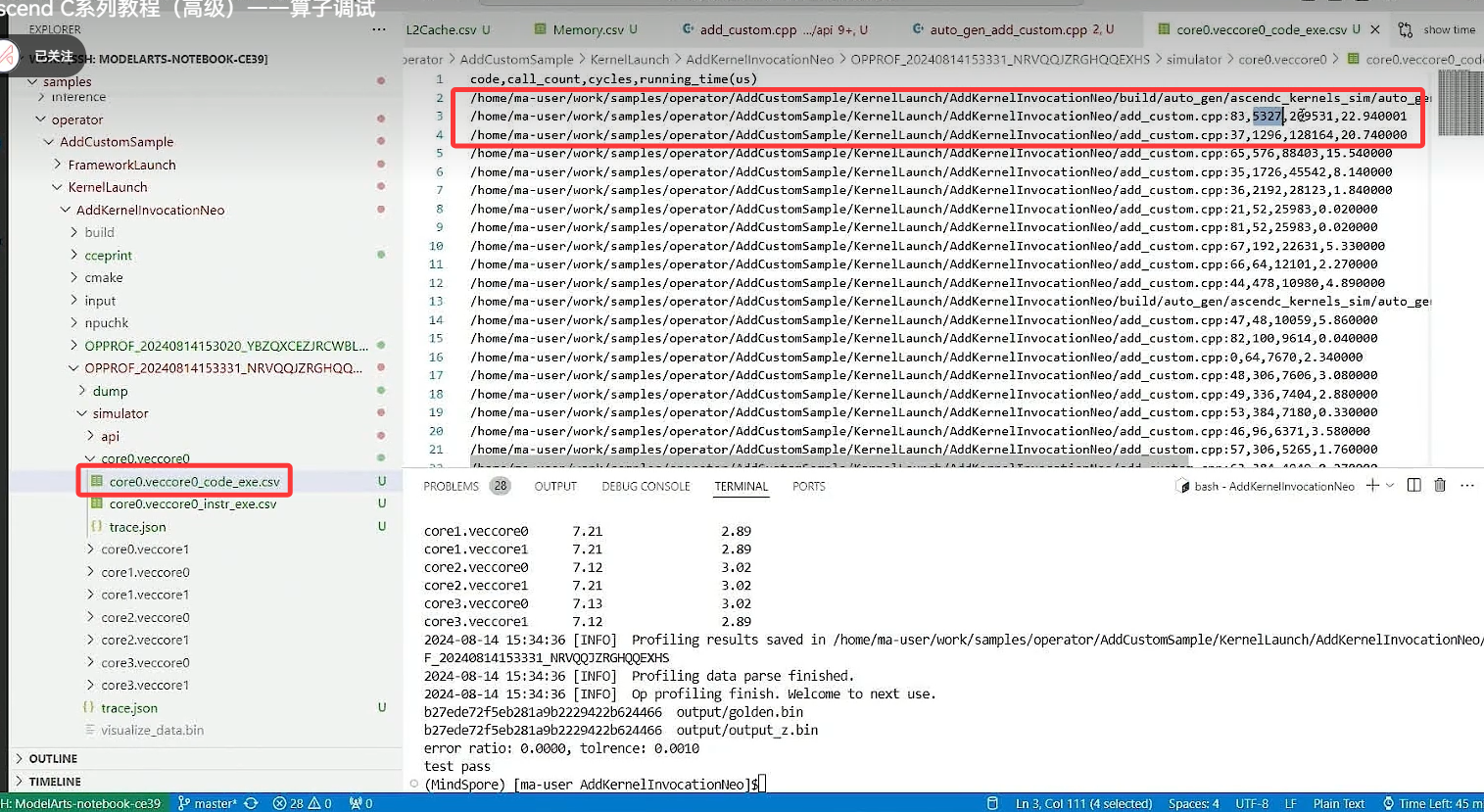
3 总结
本章节介绍了AscendC算子开发过程中的算子调试与调优。