【论文总结】SAM 3D 是一个从单张图像重建 3D 物体的生成模型,可预测物体的几何形状、纹理和相机布局。包括:(1)数据构建方面,设计了"模型在环+人类在环"的标注流程,通过将渲染的 3D 模型合成到真实图像中创建半合成数据,让标注者从模型生成的候选结果中选择最佳 3D 模型并调整姿态,大规模获取视觉基础的 3D 标注数据;(2)训练策略采用三阶段渐进式框架:合成数据预训练建立形状纹理先验、半合成数据中期训练适应真实场景的光照和遮挡、真实数据后训练进行人类偏好对齐;(3)模型能够重建完整 3D 形状而非仅可见表面,支持任意视角重新渲染。有效解决了 3D 重建的数据稀缺问题,在自然场景的复杂遮挡和杂乱环境中表现优异。
ABSTRACT
We present SAM 3D, a generative model for visually grounded 3D object reconstruction, predicting geometry, texture, and layout from a single image. SAM 3D excels in natural images, where occlusion and scene clutter are common and visual recognition cues from context play a larger role. We achieve this with a human- and model-in-the-loop pipeline for annotating object shape, texture, and pose, providing visually grounded 3D reconstruction data at unprecedented scale. We learn from this data in a modern, multi-stage training framework that combines synthetic pretraining with real-world alignment, breaking the 3D "data barrier". We obtain significant gains over recent work, with at least a 5:1 win rate in human preference tests on real-world objects and scenes. We will release our code and model weights, an online demo, and a new challenging benchmark for in-the-wild 3D object reconstruction.
【翻译】我们提出了 SAM 3D,这是一个用于视觉基础 3D 物体重建的生成模型,可以从单张图像预测几何形状、纹理和布局。SAM 3D 在自然图像中表现出色,在这些图像中,遮挡和场景杂乱很常见,来自上下文的视觉识别线索发挥着更大的作用。我们通过人类和模型在环(human- and model-in-the-loop)的流程来标注物体形状、纹理和姿态,以前所未有的规模提供视觉基础的 3D 重建数据,从而实现了这一目标。我们在一个现代的多阶段训练框架中从这些数据中学习,该框架将合成预训练与真实世界对齐相结合,打破了 3D 的"数据壁垒"。与最近的工作相比,我们取得了显著的进步,在真实世界物体和场景的人类偏好测试中获得了至少 5:1 的胜率。我们将发布我们的代码和模型权重、在线演示以及一个新的具有挑战性的野外 3D 物体重建基准测试。
Figure 1 SAM 3D converts a single image into a composable 3D scene made of individual objects. Our method predicts per-object geometry, texture, and layout, enabling full scene reconstruction. Bottom: high-quality 3D assets recovered for each object.
【翻译】图 1 SAM 3D 将单张图像转换为由单个物体组成的可组合 3D 场景。我们的方法预测每个物体的几何形状、纹理和布局,实现完整的场景重建。底部:为每个物体恢复的高质量 3D 模型。
1 Introduction
In this paper (see Figure 1) we present SAM 3D, a generative neural network for 3D reconstruction from a single image. The model can reconstruct 3D shape and texture for any object, as well as its layout with respect to the camera, even in complex scenes with significant clutter and occlusion. As the reconstruction is of full 3D shape, not just of the visible 2.5D surface, one can then re-render the object from any desired viewpoint.
【翻译】在本文中(见图 1),我们提出了 SAM 3D,这是一个用于从单张图像进行 3D 重建的生成神经网络。该模型可以重建任何物体的 3D 形状和纹理,以及其相对于相机的布局,即使在具有显著杂乱和遮挡的复杂场景中也是如此。由于重建的是完整的 3D 形状,而不仅仅是可见的 2.5D 表面,因此可以从任何所需的视角重新渲染物体。
【解析】作者强调了单图像输入这一特点,这在实际应用中很重要,因为获取多视角图像往往成本高昂或不可行。模型的重建能力包括三个方面:形状(几何结构)、纹理(表面外观)和布局(物体在相机坐标系中的位置和姿态)。特别值得注意的是,即使在复杂场景中存在大量干扰物体和遮挡情况,模型依然能够工作。这里提到的 2.5D 表面指的是深度图或可见表面,只包含从某个视角能看到的部分,而完整的 3D 形状则包括物体的所有面,包括被遮挡的背面。完整重建使得后续可以从任意新视角渲染物体,这对于虚拟现实、增强现实和 3D 内容创作等应用场景具有重要价值。
Computer vision has traditionally focused on multi-view geometry as providing the primary signal for 3D shape. However psychologists (and artists before them) have long known that humans can perceive depth and shape from a single image, e.g. Koenderink et al. (1992) demonstrated this elegantly by showing that humans can estimate surface normals at probe points on an object's image, which can then be integrated to a full surface. In psychology textbooks these single image cues to 3D shape are called "pictorial cues", and include information such as in shading and texture patterns, but also recognition - the "familiar object" cue. In computer vision, this line of research dates back to Roberts (1963), who showed that once an image pattern was recognized as a known object, its 3D shape and pose could be recovered. The central insight is that recognition enables 3D reconstruction, an idea that has since resurfaced in different technical instantiations (Debevec et al., 2023; Cashman and Fitzgibbon, 2012; Kar et al., 2015; Gkioxari et al., 2019; Xiang et al., 2025). Note that this permits generalization to novel objects, because even if a specific object has not been seen before, it is made up of parts seen before.
【翻译】计算机视觉传统上专注于多视图几何作为 3D 形状的主要信号。然而,心理学家(以及在他们之前的艺术家)早就知道人类可以从单张图像感知深度和形状,例如 Koenderink 等人(1992)通过展示人类可以在物体图像上的探测点估计表面法线,然后将其积分为完整表面,优雅地证明了这一点。在心理学教科书中,这些从单张图像获得的 3D 形状线索被称为"图像线索",包括阴影和纹理模式等信息,还包括识别------"熟悉物体"线索。在计算机视觉中,这一研究方向可以追溯到 Roberts(1963),他表明一旦图像模式被识别为已知物体,就可以恢复其 3D 形状和姿态。核心见解是识别使 3D 重建成为可能,这一思想此后以不同的技术实例重新出现(Debevec 等人,2023;Cashman 和 Fitzgibbon,2012;Kar 等人,2015;Gkioxari 等人,2019;Xiang 等人,2025)。请注意,这允许泛化到新物体,因为即使以前没有见过特定物体,它也是由以前见过的部分组成的。
【解析】传统计算机视觉依赖多视图几何,通过三角测量等方法从多个视角的图像中恢复 3D 结构,这是一种基于几何约束的方法。但人类视觉系统展示了另一种可能性:即使只看一张照片,我们也能感知物体的三维形状。Koenderink 的研究通过实验证明,人类能够估计图像中各点的表面法线(垂直于表面的向量),这些局部法线信息可以通过积分重建出完整的表面形状。图像线索是心理学中的概念,指的是单张图像中包含的深度和形状信息,包括光照产生的阴影、表面纹理的透视变形、物体边缘的轮廓等。更重要的是"熟悉物体"线索,即通过识别物体的类别(比如认出这是一把椅子),我们就能推断出它的大致 3D 形状。Roberts 在 1963 年的开创性工作将这一思想引入计算机视觉,提出了基于识别的重建范式。这个核心思想是:如果系统能够识别出图像中的物体属于某个已知类别,就可以利用该类别的先验知识来推断其 3D 形状和在空间中的姿态。这种方法的优势在于泛化能力:即使遇到从未见过的具体物体实例,只要它由熟悉的部件组成(比如一个新款椅子由常见的椅背、椅面、椅腿组成),系统就能进行合理的重建。
A fundamental challenge for learning such models is the lack of data: specifically, natural images paired with 3D ground truth are difficult to obtain at scale. Recent work (Yang et al., 2024b; Xiang et al., 2025) has shown strong reconstruction from single images. However, these models are trained on isolated objects and struggle with objects in natural scenes, where they may be distant or heavily occluded. To add such images to the training set, we need to find a way to associate specific objects in such images with 3D shape models, acknowledging that generalist human annotators find it hard to do so (unlike, say, attaching a label like "cat" or marking its boundary). Two insights made this possible:
【翻译】学习此类模型的一个根本挑战是缺乏数据:具体来说,配对了 3D 真实标注的自然图像很难大规模获取。最近的工作(Yang 等人,2024b;Xiang 等人,2025)已经展示了从单张图像进行强大重建的能力。然而,这些模型是在孤立物体上训练的,在自然场景中的物体上表现不佳,这些物体可能很远或被严重遮挡。为了将此类图像添加到训练集中,我们需要找到一种方法将这些图像中的特定物体与 3D 形状模型关联起来,同时承认通用人类标注者很难做到这一点(不像给物体贴上"猫"这样的标签或标记其边界那么简单)。两个洞察使这成为可能:
【解析】指出了 3D 重建的困境:数据稀缺性问题。与 2D 视觉任务不同,3D 重建需要的不仅是图像,还需要对应的精确 3D 几何信息作为监督信号。在实验室环境中,可以通过多视角相机阵列、结构光扫描仪或激光雷达等设备获取物体的 3D 真值,但这些方法成本高昂且难以扩展到大规模数据集。更重要的是,这些方法通常只适用于孤立物体的采集,即物体被放置在受控环境中,背景干净,没有遮挡。虽然现有方法在这种理想条件下表现良好,但真实世界的场景要复杂得多。自然场景中的物体可能距离相机很远(导致分辨率低、细节缺失),或者被其他物体部分遮挡(只能看到物体的一小部分)。在这些情况下,即使是人类标注者也难以准确地为物体创建完整的 3D 模型。与简单的分类任务(给图像打标签)或分割任务(画出物体边界)不同,3D 标注需要标注者具备空间想象能力和 3D 建模技能,这对普通标注者来说门槛太高。因此,作者需要设计一种新的标注策略来解决这个问题。
• We can create synthetic scenes where 3D object models are rendered and pasted into images (inspired by Dosovitskiy et al. (2015)).
• While humans can't easily generate 3D shape models for objects, they can select the likely best 3D model from a set of proffered choices and align its pose to the image (or declare that none of the choices is good).
【翻译】• 我们可以创建合成场景,将 3D 物体模型渲染并粘贴到图像中(受 Dosovitskiy 等人(2015)的启发)。
【翻译】• 虽然人类不能轻易为物体生成 3D 形状模型,但他们可以从一组提供的选项中选择可能最好的 3D 模型,并将其姿态与图像对齐(或声明没有一个选项是好的)。
【解析】两个洞察。第一个洞察借鉴了数据增强的思想:既然难以获取真实场景的 3D 标注,那就创造半合成数据。具体做法是从现有的 3D 模型库中选取物体模型,通过渲染引擎生成该物体在不同视角、光照条件下的 2D 图像,然后将这些渲染结果合成到真实的背景图像中。这样做的好处是我们完全知道物体的 3D 真值(因为是从已知的 3D 模型渲染出来的),同时图像又具有一定的真实性(因为背景是真实照片)。这种方法可以快速生成大量训练数据,弥补真实标注数据的不足。第二个洞察则巧妙地降低了人类标注的难度。与其要求标注者从零开始创建 3D 模型,不如让模型先生成多个候选的 3D 重建结果,然后让标注者从中选择最接近真实情况的那个,并调整其在图像中的位置和朝向。
We design a training pipeline and data engine by adapting modern, multistage training recipes pioneered by LLMs (Minaee et al., 2025; Mo et al., 2025). As in recent works, we first train on a large collection of rendered synthetic objects. This is supervised pretraining: our model learns a rich vocabulary for object shape and texture, preparing it for real-world reconstruction. Next is mid-training with semi-synthetic data produced by pasting rendered models into natural images. Finally, post-training adapts the model to real images, using both a novel model-in-the-loop (MITL) pipeline and human 3D artists, and aligns it to human preference. We find that synthetic pretraining generalizes, given adequate post-training on natural images.
【翻译】我们通过改编大型语言模型(LLM)开创的现代多阶段训练方法(Minaee 等人,2025;Mo 等人,2025)来设计训练流程和数据引擎。与最近的工作一样,我们首先在大量渲染的合成物体上进行训练。这是有监督的预训练:我们的模型学习丰富的物体形状和纹理词汇表,为真实世界的重建做准备。接下来是中期训练,使用通过将渲染模型粘贴到自然图像中产生的半合成数据。最后,后训练使模型适应真实图像,同时使用新颖的模型在环(MITL)流程和专业 3D 建模师,并将其与人类偏好对齐。我们发现,只要在自然图像上进行充分的后训练,合成预训练就能很好地泛化。
【解析】作者借鉴了大语言模型训练的成功经验,设计了一个三阶段渐进式训练策略。从简单到复杂、从合成到真实逐步提升模型能力(其实和SAM的训练策略类似)。预训练阶段使用完全合成的数据,即纯粹由 3D 模型渲染生成的图像。这个阶段的目的是让模型建立对 3D 形状和纹理的基础理解,就像语言模型在预训练阶段学习语言的基本语法和词汇一样。由于合成数据可以大规模生成且具有完美的 3D 标注,模型可以在这个阶段学习到丰富的几何和外观先验知识。中期训练阶段引入半合成数据,这是连接合成世界和真实世界的桥梁。通过将渲染的 3D 模型合成到真实背景中,模型开始接触真实场景的复杂性,如真实的光照变化、背景杂乱、遮挡等情况,但仍然保留了准确的 3D 监督信号。这个阶段帮助模型逐步适应真实场景的视觉特征。后训练阶段是关键的对齐阶段,使用真实图像和真实的 3D 标注。这里引入了模型在环(MITL)机制:模型参与到数据标注过程中,生成候选的 3D 重建结果供人类选择和调整,人类的反馈又被用来进一步训练模型。这形成了一个正向循环:模型越好,生成的候选结果质量越高,人类标注越容易,获得的高质量标注数据越多,模型又能进一步提升。对于特别困难的样本,还会请专业 3D 艺术家介入,确保标注质量。渐进式训练策略的有效性:合成数据提供了充足的基础训练,而真实数据的后训练则确保模型在实际应用中的表现,两者相辅相成,共同克服 3D 数据稀缺的问题。
Our post-training data, obtained from our MITL data pipeline, is key to obtaining good performance in natural images. Generalist human annotators aren't capable of producing 3D shape ground truth; hence our annotators select and align 3D models to objects in images from the output of modules -- computational and retrieval-based -- that produce multiple initial 3D shape proposals. Human annotators select from these proposals, or route them to human artists for a subset of hard instances. The vetted annotations feed back into model training, and the improved model is reintegrated into the data engine to further boost annotation quality. This virtuous cycle steadily improves the quality of 3D annotations, labeling rates, and model performance.
【翻译】我们从 MITL 数据流程中获得的后训练数据是在自然图像上获得良好性能的关键。通用人类标注者无法生成 3D 形状真值;因此,我们的标注者从计算模块和检索模块的输出中选择并对齐 3D 模型到图像中的物体,这些模块会生成多个初始 3D 形状提案。人类标注者从这些提案中进行选择,或将其中一部分困难实例转交给专业 3D 艺术家处理。经过审核的标注反馈到模型训练中,改进后的模型重新集成到数据引擎中以进一步提升标注质量。这种良性循环稳步提高了 3D 标注的质量、标注速率和模型性能。
Due to the lack of prior benchmarks for real-world 3D reconstruction of object shape and layout, we propose a new evaluation set of 1000 image and 3D pairs: SAM 3D Artist Objects (SA-3DAO). The objects in our benchmark range from churches, ski lifts, and large structures to animals, everyday household items, and rare objects, and are paired with the real-world images in which they naturally appear. Professional 3D artists create 3D shapes from the input image, representing an expert human upper bound for visually grounded 3D reconstruction. We hope that contributing such an evaluation benchmark helps accelerate subsequent research iteration of real-world 3D reconstruction models.
【翻译】由于缺乏用于真实世界物体形状和布局 3D 重建的现有基准测试,我们提出了一个新的评估集,包含 1000 对图像和 3D 模型:SAM 3D Artist Objects (SA-3DAO)。我们基准测试中的物体范围从教堂、滑雪缆车和大型结构到动物、日常家居用品和稀有物体,并与它们自然出现的真实世界图像配对。专业 3D 艺术家根据输入图像创建 3D 形状,代表了视觉基础 3D 重建的专家人类上界。我们希望贡献这样一个评估基准测试能够帮助加速真实世界 3D 重建模型的后续研究迭代。
We summarize our contributions as follows:
• We introduce SAM 3D, a new foundation model for 3D that predicts object shape, texture, and pose from a single image. By releasing code, model weights, and a demo, we hope to stimulate further advancements in 3D reconstruction and downstream applications of 3D.
• We build a MITL pipeline for annotating shape, texture, and pose data, providing visually grounded 3D reconstruction data at unprecedented scale.
• We exploit this data via LLM-style pretraining and post-training in a novel framework for 3D reconstruction, combining synthetic pretraining with real-world alignment to overcome the orders of magnitude data gap between 3D and domains such as text, images, or video.
• We release a challenging benchmark for real-world 3D object reconstruction, SA-3DAO. Experiments show SAM 3D's significant gains via metrics and large-scale human preference.
【翻译】总结贡献如下:
【翻译】• 我们引入了 SAM 3D,这是一个新的 3D 基础模型,可以从单张图像预测物体的形状、纹理和姿态。通过发布代码、模型权重和演示,我们希望促进 3D 重建和 3D 下游应用的进一步发展。
【翻译】• 我们构建了一个 MITL 流程来标注形状、纹理和姿态数据,以前所未有的规模提供视觉基础的 3D 重建数据。
【翻译】• 我们通过类似 LLM 的预训练和后训练在一个新颖的 3D 重建框架中利用这些数据,将合成预训练与真实世界对齐相结合,以克服 3D 与文本、图像或视频等领域之间数量级的数据差距。
【翻译】• 我们发布了一个具有挑战性的真实世界 3D 物体重建基准测试 SA-3DAO。实验通过指标和大规模人类偏好显示了 SAM 3D 的显著提升。
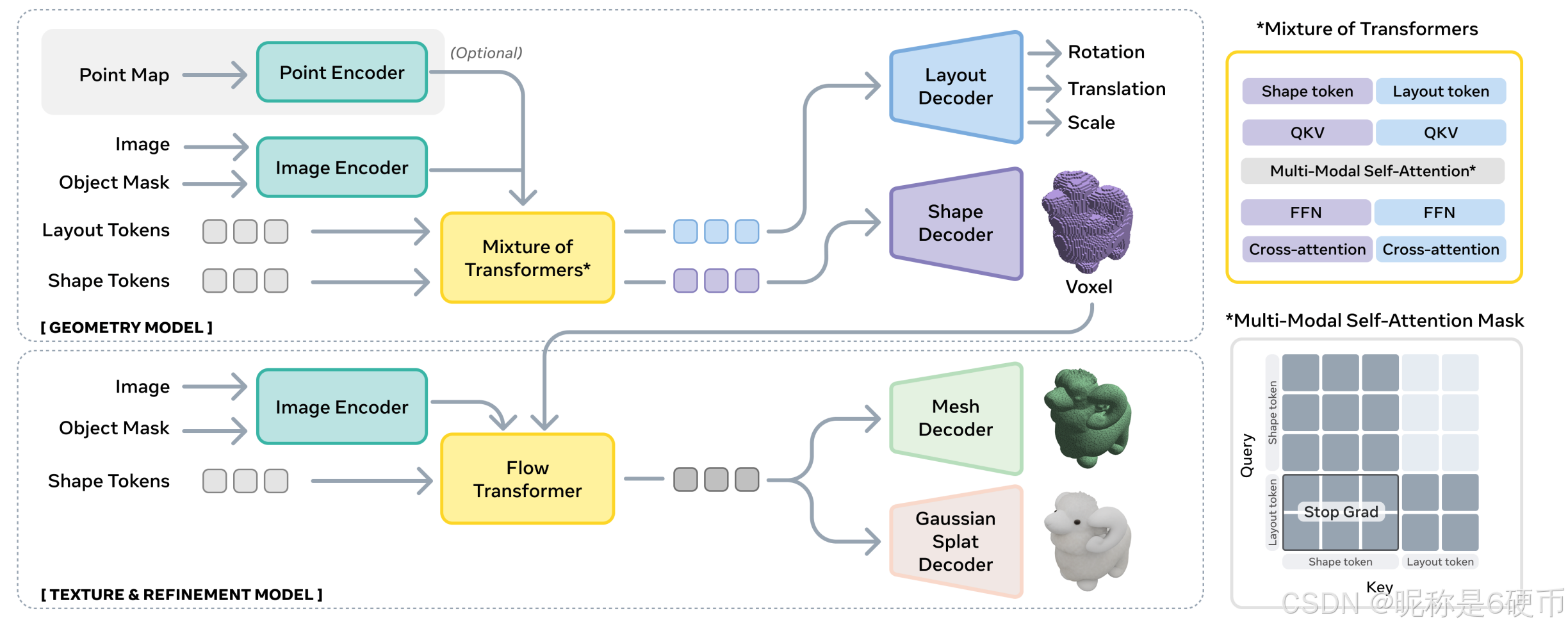
Figure 2 SAM 3D architecture. (top) SAM 3D first predicts coarse shape and layout with the
Geometry model; (right) the mixture of transformers architecture apply a two-stream approach
with information sharing in the multi-modal self-attention layer. (bottom) The voxels
predicted by the Geometry model are passed to the Texture & \& & Refinement model, which adds
higher resolution detail and textures.
【翻译】图 2 SAM 3D 架构。(顶部)SAM 3D 首先使用几何模型预测粗略形状和布局;(右侧)混合 Transformer 架构采用双流方法,在多模态自注意力层中进行信息共享。(底部)几何模型预测的体素被传递给纹理和细化模型,该模型添加更高分辨率的细节和纹理。
2 The SAM 3D Model
2.1 问题表述
The act of taking a photograph maps a 3D object to a set of 2D pixels, specified by a mask M M M in an image I I I . We seek to invert this map. Let the object have shape S S S , texture T T T , and rotation, translation and scale ( R , t , s ) (R,t,s) (R,t,s) in camera coordinates. Since the 3D to 2D map is lossy, we model the reconstruction problem as a conditional distribution p ( S , T , R , t , s ∣ I , M ) p(S,T,R,t,s|I,M) p(S,T,R,t,s∣I,M) . Our goal is to train a generative model q ( S , T , R , t , s ∣ I , M ) q(S,T,R,t,s|I,M) q(S,T,R,t,s∣I,M) that approximates p p p as closely as possible.
【翻译】拍摄照片的行为将 3D 物体映射到一组 2D 像素,由图像 I I I 中的掩码 M M M 指定。我们试图反转这个映射。设物体具有形状 S S S、纹理 T T T,以及在相机坐标系中的旋转、平移和缩放 ( R , t , s ) (R,t,s) (R,t,s)。由于 3D 到 2D 的映射是有损的,我们将重建问题建模为条件分布 p ( S , T , R , t , s ∣ I , M ) p(S,T,R,t,s|I,M) p(S,T,R,t,s∣I,M)。我们的目标是训练一个生成模型 q ( S , T , R , t , s ∣ I , M ) q(S,T,R,t,s|I,M) q(S,T,R,t,s∣I,M),使其尽可能接近 p p p。
【解析】这段话定义了单图像 3D 重建的核心数学框架。拍照本质上是一个降维过程:三维空间中的物体通过相机投影变成了二维图像上的像素集合。这个过程可用数学映射来描述,输入是完整的 3D 信息(形状 S S S、纹理 T T T、以及物体相对于相机的空间位置关系 ( R , t , s ) (R,t,s) (R,t,s),其中 R 表示旋转(Rotation)、t 表示平移(Translation)、s 表示缩放(Scale)),输出是 2D 图像 I I I 和对应的物体区域掩码 M M M。SAM 3D 要做的就是逆向这个过程:给定 2D 图像和掩码,恢复出原始的 3D 信息。但这个逆向过程面临的困难------信息丢失。从 3D 到 2D 的投影过程中,深度信息被压缩了,物体背面的信息消失了,光照、阴影、透视等因素引入了额外的复杂性。这说明从单张图像到 3D 重建不存在唯一解,同一张 2D 图像可能对应无数种可能的 3D 配置。因此,作者将问题重新表述为概率建模:不是寻找一个确定的答案,而是学习一个条件概率分布 p ( S , T , R , t , s ∣ I , M ) p(S,T,R,t,s|I,M) p(S,T,R,t,s∣I,M),这个分布描述了在给定图像 I I I 和掩码 M M M 的条件下,各种可能的 3D 配置 ( S , T , R , t , s ) (S,T,R,t,s) (S,T,R,t,s) 出现的概率。这个真实分布 p p p 反映了自然界中图像与 3D 物体之间的真实对应关系,但我们无法直接获得它。实际操作中,我们训练一个神经网络模型 q ( S , T , R , t , s ∣ I , M ) q(S,T,R,t,s|I,M) q(S,T,R,t,s∣I,M) 来近似这个真实分布。训练的目标是让模型分布 q q q 与真实分布 p p p 尽可能接近,这样模型就能生成符合真实世界规律的 3D 重建结果。这种概率建模方式的优势在于:允许模型在面对模糊情况时生成多种合理的候选结果;提供了一个可优化的数学框架,可以通过大量数据训练来逼近真实分布;能整合先验知识(通过预训练学到的形状和纹理规律)和观测证据(输入图像的视觉线索)来做出推断。这个概率框架也为后续的流匹配训练方法奠定了理论基础,模型学习的是如何从简单分布(如高斯噪声)逐步变换到目标分布 p ( S , T , R , t , s ∣ I , M ) p(S,T,R,t,s|I,M) p(S,T,R,t,s∣I,M) 的过程。
2.2 Architecture
We build upon recent SOTA two-stage latent flow matching architectures (Xiang et al., 2025). SAM 3D first jointly predicts object pose and coarse shape, then refines the shapes by integrating pictorial cues (see Figure 2). Unlike Xiang et al. (2025) that reconstructs isolated objects, SAM 3D predicts object layout, creating coherent multi-object scenes.
【翻译】我们基于最近的最先进的两阶段潜在流匹配架构(Xiang et al., 2025)。SAM 3D 首先联合预测物体姿态和粗略形状,然后通过整合图像线索来细化形状(见图 2)。与重建孤立物体的 Xiang et al. (2025) 不同,SAM 3D 预测物体布局,创建连贯的多物体场景。
【解析】SAM 3D 的架构设计采用了两阶段策略,第一阶段专注于建立物体的基本几何框架,包括物体在三维空间中的位置、朝向(姿态)以及大致的形状轮廓。这个阶段可以理解为先搭建骨架,确定物体的基本结构和空间关系。第二阶段则是精雕细琢的过程,模型会仔细分析输入图像中的视觉细节------纹理、光影、边缘等图像线索,用这些信息来完善第一阶段得到的粗糙形状,添加更精细的几何细节和表面纹理。两阶段设计的优势在于降低问题复杂度,第一阶段可以快速确定大致方向,避免在细节上浪费计算资源;第二阶段则可以专注于局部优化,在已有框架基础上精细调整。更重要的是,SAM 3D 相比前人工作有一个关键突破:它不仅能重建单个孤立的物体,还能预测物体在场景中的布局关系。这说明模型不是简单地将物体从背景中抠出来单独重建,而是理解物体与周围环境的空间关系,能够处理多个物体共存的复杂场景,生成的三维场景中各个物体的相对位置、大小比例都是合理的,形成了一个整体连贯的三维世界。这种能力对于实际应用至关重要,因为真实世界的图像往往包含多个物体,它们之间存在遮挡、接触等复杂的空间关系。
Input encoding. We use DINOv2 (Oquab et al., 2023) as an encoder to extract features from two pairs of images, resulting in 4 sets of conditioning tokens:
• Cropped object: We encode the cropped image I I I by mask M M M and its corresponding cropped binary mask, providing a focused, high-resolution view of the object.
• Full image: We encode the full image I I I and its full image binary mask, providing global scene context and recognition cues absent from the cropped view.
Optionally, the model supports conditioning on a coarse scene point map, P P P obtained via hardware sensors (e.g., LiDAR on an iPhone), or monocular depth estimation (Yang et al., 2024a; Wang et al., 2025a), enabling SAM 3D to integrate with other pipelines.
【翻译】输入编码。我们使用 DINOv2 (Oquab et al., 2023) 作为编码器从两对图像中提取特征,产生 4 组条件标记:
【翻译】• 裁剪物体:我们通过掩码 M M M 编码裁剪后的图像 I I I 及其对应的裁剪二值掩码,提供物体的聚焦高分辨率视图。
【翻译】• 完整图像:我们编码完整图像 I I I 及其完整图像二值掩码,提供裁剪视图中缺失的全局场景上下文和识别线索。
【翻译】可选地,模型支持对粗略场景点图 P P P 进行条件化,该点图通过硬件传感器(例如 iPhone 上的 LiDAR)或单目深度估计(Yang et al., 2024a; Wang et al., 2025a)获得,使 SAM 3D 能够与其他流程集成。
【解析】输入编码是模型理解图像的第一步,SAM 3D 采用了多视角编码策略来充分利用图像信息。DINOv2 是一个强大的视觉特征提取器,它通过自监督学习训练,能够捕捉图像中的语义信息和视觉模式。模型设计了四组不同的输入来提供互补的信息:第一组是裁剪物体及其掩码,这相当于给模型一个放大镜,让它专注观察目标物体的细节。裁剪操作去除了无关背景,提高了物体区域的像素分辨率,使模型能够更清晰地看到物体的纹理、边缘等局部特征。配套的二值掩码明确标识了哪些像素属于目标物体,哪些是背景,这为模型提供了精确的物体边界信息。第二组是完整图像及其掩码,这提供了宏观视角。完整图像保留了物体所在的环境上下文------物体周围有什么、物体在场景中的位置、场景的整体光照条件等。这些上下文信息对于理解物体的尺度、姿态和与环境的关系至关重要。例如,一个杯子在桌子上和在地板上,其尺寸和位置的推断会很不同。此外,模型还支持可选的深度信息输入 P P P,这是一个粗略的场景点云或深度图。这个信息可以来自硬件传感器(如 iPhone 的 LiDAR 激光雷达,能直接测量距离)或者单目深度估计算法(从单张图像推断深度)。深度信息直接提供了场景的三维几何线索,大大降低了从 2D 到 3D 重建的不确定性。这种可选设计使 SAM 3D 具有很好的灵活性,既可以在只有 RGB 图像的情况下工作,也可以在有额外深度信息时获得更好的性能,能够方便地集成到各种应用场景和数据处理流程中。
Figure 3 SAM 3D data, with a green outline around the target object, and the ground truth mesh shown in the bottom right. Samples are divided into four rows, based on type. Art-3DO meshes are untextured, while the rest may be textured or not, depending on the underlying asset (Iso-3DO, RP-3DO) or if the mesh was annotated for texture (MITL-3DO).
【翻译】图 3 SAM 3D 数据,目标物体周围有绿色轮廓,右下角显示真实网格。样本根据类型分为四行。Art-3DO 网格是无纹理的,而其余的可能有纹理也可能没有,取决于底层资产(Iso-3DO、RP-3DO)或网格是否标注了纹理(MITL-3DO)。
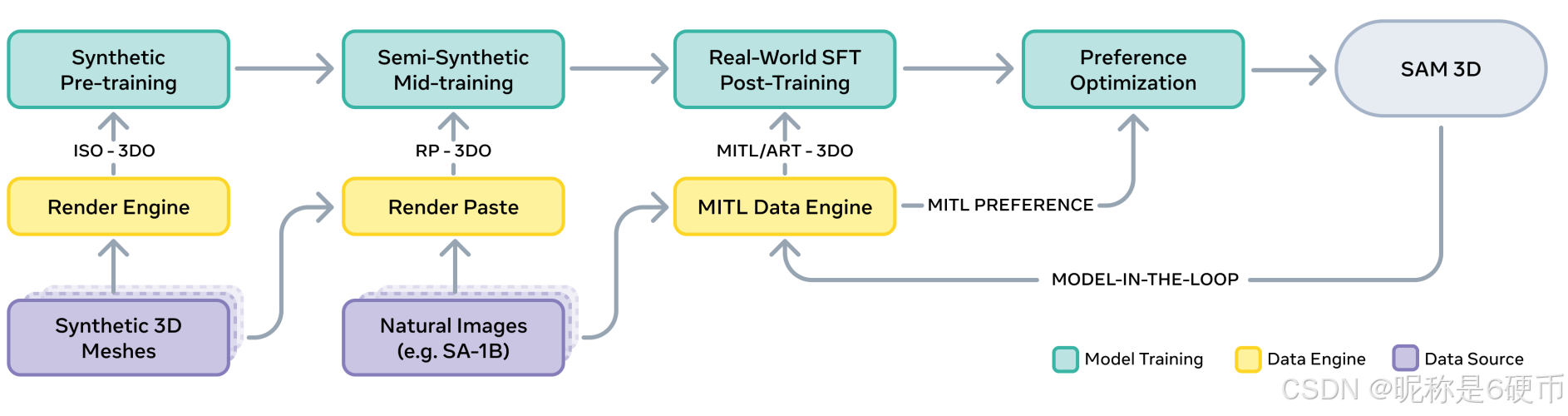
Figure 4 SAM 3D training paradigm. We employ a multi-stage pipeline incrementally exposing the model to increasingly complex data and modalities.
【翻译】图 4 SAM 3D 训练范式。我们采用多阶段流程,逐步让模型接触越来越复杂的数据和模态。
The Geometry Model models the conditional distribution p ( O , R , t , s ∣ I , M ) p(O,R,t,s|I,M) p(O,R,t,s∣I,M) , where O ∈ R 64 3 O\in\mathbb{R}^{64^{3}} O∈R643 is coarse shape, R ∈ R 6 R\in\mathbb{R}^{6} R∈R6 the 6D rotation (Zhou et al., 2019), t ∈ R 3 t\in\mathbb{R}^{3} t∈R3 the translation, and s ∈ R 3 s\in\mathbb{R}^{3} s∈R3 the scale. Conditioned on the input image and mask encodings, we employ a 1.2B parameter flow transformer with the Mixture-ofTransformers (MoT) architecture (Liang et al., 2025a; Deng et al., 2025), modeling geometry O O O and layout ( R , t , s ) (R,t,s) (R,t,s) using the attention mask in Figure 2. See Section C.1 for details.
【翻译】几何模型对条件分布 p ( O , R , t , s ∣ I , M ) p(O,R,t,s|I,M) p(O,R,t,s∣I,M) 进行建模,其中 O ∈ R 64 3 O\in\mathbb{R}^{64^{3}} O∈R643 是粗略形状, R ∈ R 6 R\in\mathbb{R}^{6} R∈R6 是 6D 旋转(Zhou et al., 2019), t ∈ R 3 t\in\mathbb{R}^{3} t∈R3 是平移, s ∈ R 3 s\in\mathbb{R}^{3} s∈R3 是缩放。以输入图像和掩码编码为条件,我们采用具有 1.2B 参数的流 Transformer,使用混合 Transformer(MoT)架构(Liang et al., 2025a; Deng et al., 2025),使用图 2 中的注意力掩码对几何 O O O 和布局 ( R , t , s ) (R,t,s) (R,t,s) 进行建模。详见 C.1 节。
【解析】几何模型是 SAM 3D 的第一阶段核心组件,负责从 2D 图像推断出物体的基本三维几何信息。模型的输出包含四个关键要素:粗略形状 O O O 用一个 64 × 64 × 64 64\times64\times64 64×64×64 的三维体素网格表示,每个体素可以理解为三维空间中的一个小立方体,标记该位置是否被物体占据。这个分辨率相对较低,所以称为"粗略"形状,它捕捉的是物体的大致轮廓和主体结构,而不是精细细节。旋转 R R R 用 6 维向量表示,这是一种连续且无奇异性的旋转表示方法,比传统的欧拉角或四元数更适合神经网络学习。它描述了物体相对于相机坐标系的朝向。平移 t t t 是三维向量,表示物体中心在相机坐标系中的位置。缩放 s s s 也是三维向量,表示物体在三个轴向上的尺寸大小。这四个输出共同定义了物体在三维空间中的完整几何配置。模型架构采用了流 Transformer,这是一种基于流匹配的生成模型,能够学习从简单分布(如噪声)到目标分布(真实几何配置)的连续变换过程。模型规模达到 12 亿参数,这个参数量使模型有足够的容量来学习复杂的 3D 先验知识和图像到几何的映射关系。混合 Transformer(MoT)架构是一个关键创新,它通过特殊设计的注意力掩码机制来控制不同类型 token 之间的交互模式。从图 2 可以看出,模型使用统一的 Transformer 架构同时处理条件 token(来自图像编码)和生成 token(几何 O O O 和布局 ( R , t , s ) (R,t,s) (R,t,s)),通过注意力掩码精确控制信息流动:几何 token 可以关注所有条件 token 来获取视觉线索,布局 token 可以关注条件 token 和几何 token 来确定物体的空间位置,而条件 token 之间可以自由交互以整合多尺度的图像信息。这种设计允许模型在单一架构内灵活地处理不同模态的信息,同时通过注意力掩码实现精细的跨模态信息融合控制。
The Texture & Refinement Model learns the conditional distribution p ( S , T ∣ I , M , O ) p(S,T|I,M,O) p(S,T∣I,M,O) . We first extract active voxels from the coarse shape O O O predicted by Geometry model. A 600M parameter sparse latent flow transformer (Xiang et al., 2025; Peebles and Xie, 2023) refines geometric details and synthesizes object texture.
【翻译】纹理和细化模型学习条件分布 p ( S , T ∣ I , M , O ) p(S,T|I,M,O) p(S,T∣I,M,O)。我们首先从几何模型预测的粗略形状 O O O 中提取活跃体素。一个 600M 参数的稀疏潜在流 Transformer(Xiang et al., 2025; Peebles and Xie, 2023)细化几何细节并合成物体纹理。
【解析】纹理和细化模型是 SAM 3D 的第二阶段,它接收第一阶段几何模型的输出作为输入,进一步完善三维重建结果。这个模型的任务是双重的:一方面要细化几何形状 S S S,将粗糙的 64 3 64^3 643 体素网格提升到更高分辨率,添加精细的几何细节如表面凹凸、边缘锐利度等;另一方面要生成纹理 T T T,为物体表面赋予颜色、材质等视觉属性。模型的输入除了原始图像 I I I 和掩码 M M M,还包括第一阶段预测的粗略形状 O O O,这个粗略形状提供了几何约束,确保细化后的结果与初步预测保持一致。处理流程首先进行体素提取,从 64 3 64^3 643 的体素网格中识别出"活跃"体素,即那些被物体占据的体素位置。这个提取过程实际上是一个稀疏化操作,因为大部分三维空间是空的,只有物体表面及内部的体素才是有意义的。通过只关注这些活跃体素,模型可以大幅减少计算量,将计算资源集中在真正需要细化的区域。模型采用稀疏潜在流 Transformer 架构,参数量为 6 亿。"稀疏"指的是模型只处理活跃体素,而不是整个三维空间,这使得在有限计算资源下处理高分辨率三维数据成为可能。"潜在"说明模型在压缩的潜在空间中工作,而不是直接操作原始的高维三维数据,这进一步提高了效率。流 Transformer 架构使模型能够逐步细化结果,从粗糙的几何逐渐演化到精细的带纹理的三维模型。这个阶段的关键挑战是如何从 2D 图像中推断出物体看不见部分的几何和纹理,模型需要利用在大规模数据上学到的先验知识来进行合理的补全和生成。
3D Decoders. The latent representations from the Texture & Refinement Model can be decoded to either mesh or 3D Gaussian splats via a pair of VAE decoders D m \mathcal{D}{m} Dm , D g \mathcal{D}{g} Dg . These separately-trained decoders share the same VAE encoder and hence the same structured latent space (Xiang et al., 2025). We also detail several improvements in Section C.6.
【翻译】3D 解码器。来自纹理和细化模型的潜在表示可以通过一对 VAE 解码器 D m \mathcal{D}{m} Dm、 D g \mathcal{D}{g} Dg 解码为网格或 3D 高斯点云。这些单独训练的解码器共享相同的 VAE 编码器,因此共享相同的结构化潜在空间(Xiang et al., 2025)。我们还在 C.6 节中详细介绍了几项改进。
【解析】3D 解码器是 SAM 3D 的最后一个组件,负责将模型内部的抽象表示转换为可用的三维输出格式。纹理和细化模型输出的是潜在表示,这是一种压缩的、抽象的数据格式,虽然包含了完整的三维信息,但不能直接用于渲染或其他下游应用。解码器的作用就是将这种潜在表示"翻译"成具体的三维数据格式。SAM 3D 提供了两种输出格式选项:网格(mesh)是传统的三维表示方法,由顶点、边和面组成,适合用于建模软件、游戏引擎等传统三维应用。3D 高斯点云(3D Gaussian splats)是一种三维表示方法,用一组带有位置、颜色、协方差等属性的高斯分布来表示三维场景,特别适合高质量的实时渲染。两个解码器 D m \mathcal{D}{m} Dm 和 D g \mathcal{D}{g} Dg 虽然是分别训练的,但它们共享同一个 VAE 编码器。VAE(变分自编码器)是一种生成模型,包含编码器和解码器两部分。这里的设计:编码器将三维数据(无论是网格还是高斯点云)映射到统一的潜在空间,两个解码器则分别从这个统一的潜在空间重建出不同格式的三维数据。这种共享潜在空间的设计带来了多个优势:首先,它确保了不同输出格式之间的一致性,同一个潜在表示解码出的网格和高斯点云描述的是同一个物体。其次,它提高了训练效率,编码器只需要训练一次,就能支持多种输出格式。最后,它使模型具有灵活性,用户可以根据应用需求选择合适的输出格式,而不需要重新训练模型。这种统一的潜在空间实际上学习到了一种与具体表示格式无关的三维物体的抽象表征,这是一种更本质、更通用的三维理解。
3 Training SAM 3D
SAM 3D breaks the 3D data barrier using a recipe that progresses from synthetic pretraining to natural post-training, adapting the playbook from LLMs, robotics, and other large generative models. We build capabilities by stacking different training strategies in pre- and mid-training, and then align the model to real data and human-preferred behaviors through a post-training data flywheel. SAM 3D uses the following approach:
【翻译】SAM 3D 使用一种从合成预训练到自然后训练的方法打破了 3D 数据障碍,借鉴了大语言模型、机器人和其他大型生成模型的策略。我们通过在预训练和中期训练中堆叠不同的训练策略来构建能力,然后通过后训练数据飞轮将模型与真实数据和人类偏好行为对齐。SAM 3D 使用以下方法:
Step 1: Pretraining. This phase builds foundational capabilities, such as shape generation, into a base model.
【翻译】步骤 1:预训练。此阶段将基础能力(如形状生成)构建到基础模型中。
Step 1.5: Mid-Training. Sometimes called continued pretraining, mid-training imparts general skills such as occlusion robustness, mask-following, and using visual cues.
Step 2: Post-Training. Post-training elicits target behavior, such as adapting the model from synthetic to real-world data or following human aesthetic preferences. We collect training samples ( I , M ) → ( S , T , R , t , s ) (I,M)\to(S,T,R,t,s) (I,M)→(S,T,R,t,s) and preference data from humans and use them in both supervised finetuning (SFT) and direct preference optimization (DPO) (Rafailov et al., 2023).
【翻译】步骤 2:后训练。后训练引出目标行为,例如将模型从合成数据适应到真实世界数据或遵循人类审美偏好。我们从人类收集训练样本 ( I , M ) → ( S , T , R , t , s ) (I,M)\to(S,T,R,t,s) (I,M)→(S,T,R,t,s) 和偏好数据,并在监督微调(SFT)和直接偏好优化(DPO)(Rafailov et al., 2023)中使用它们。
This alignment (step 2) can be repeated, first collecting data with the current model and then improving the model with the new data. This creates a virtuous cycle with humans providing the supervision. Figure 10b shows that as we run the data engine longer, model performance steadily improves; dataset generation emerges as a byproduct of this alignment.
The following sections detail the training objectives and data sources used in SAM 3D. We focus on the Geometry model; Texture & Refinement is trained similarly (details in Section C.5). Training hyper-parameters are in Section C.7.
【翻译】以下各节详细介绍了 SAM 3D 中使用的训练目标和数据源。我们重点关注几何模型;纹理和细化模型的训练方式类似(详见 C.5 节)。训练超参数见 C.7 节。
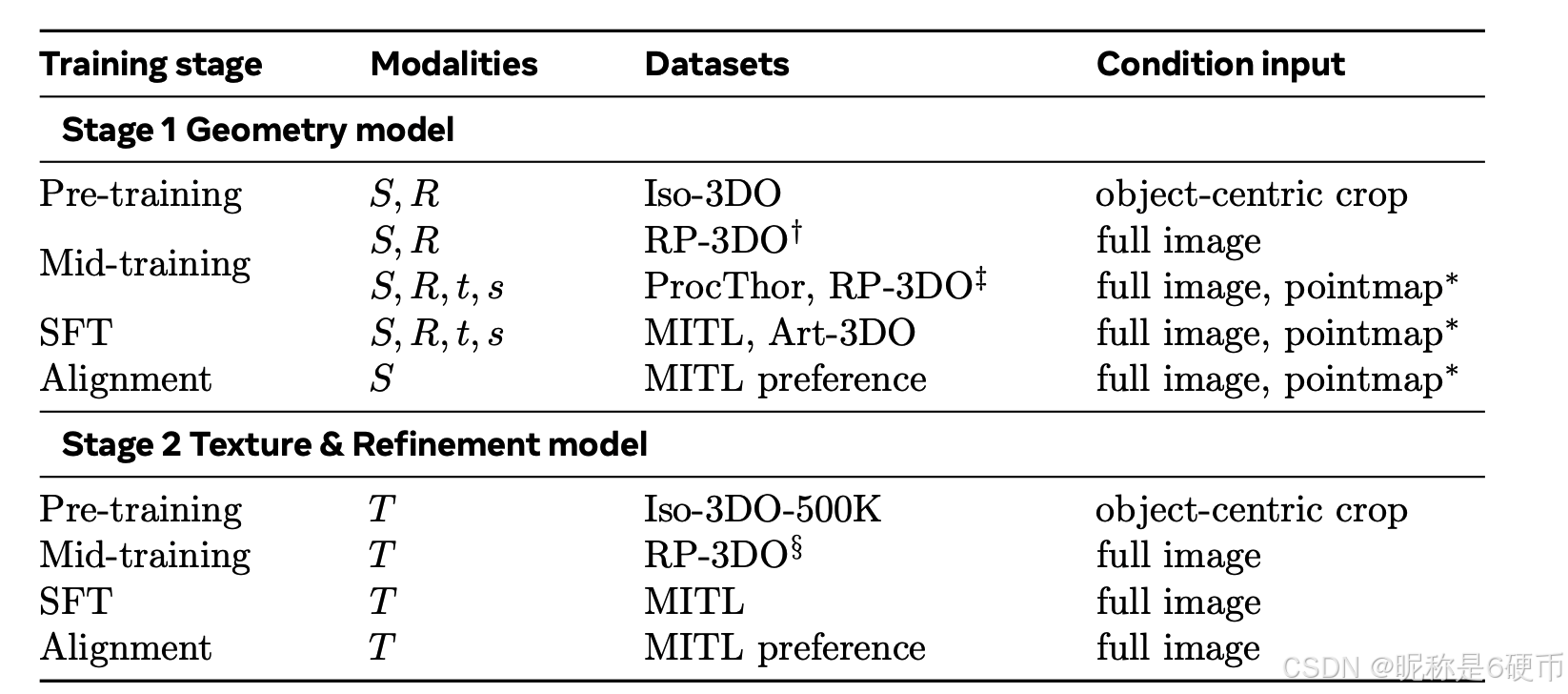
Table 1 SAM 3D training stages. †Flying Occlusion (FO) from RP-3DO. ‡Object Swap - Random (OS-R) from RP-3DO. §Object Swap - Annotated (OS-A) from RP-3DO. ∗optional. See Section B.2 for details.
【翻译】表 1 SAM 3D 训练阶段。†来自 RP-3DO 的飞行遮挡(FO)。‡来自 RP-3DO 的物体交换 - 随机(OS-R)。§来自 RP-3DO 的物体交换 - 标注(OS-A)。∗可选。详见 B.2 节。
3.1 预训练和中期训练:构建基础模型
Training begins with synthetic pretraining and mid-training, leveraging available large-scale datasets to learn strong priors for shape and texture, and skills such as mask-following, occlusion handling, and pose estimation. The rich features learned here drastically reduce the number of labeled real-world samples required in post-training (Hernandez et al., 2021), which generally incur acquisition costs. In pre- and mid-training, models are trained with rectified conditional flow matching (Liu et al., 2022) to generate multiple 3D modalities (see Section C.2).
【翻译】训练从合成预训练和中期训练开始,利用可用的大规模数据集来学习形状和纹理的强先验,以及掩码跟随、遮挡处理和姿态估计等技能。这里学到的丰富特征大幅减少了后训练中所需的标注真实世界样本数量(Hernandez et al., 2021),而这些样本通常会产生获取成本。在预训练和中期训练中,模型使用修正条件流匹配(Liu et al., 2022)进行训练,以生成多种 3D 模态(见 C.2 节)。
Pretraining trains the model to reconstruct accurate 3D shapes and textures from renders of isolated synthetic objects, following the successful recipes from (Xiang et al., 2025; Yang et al., 2024b; Wu et al., 2024). Specifically, we gather a set of image I I I , shape S S S , and texture T T T triplets, using 2.7 million object meshes from Objaverse-XL (Deitke et al., 2023) and licensed datasets, and render them from 24 viewpoints, each producing a high-resolution image of a single centered object; more detail in Section B.1. We call this dataset Iso-3DO and train for 2.5 trillion training tokens.
【翻译】预训练训练模型从孤立合成物体的渲染图中重建准确的 3D 形状和纹理,遵循 (Xiang et al., 2025; Yang et al., 2024b; Wu et al., 2024) 的成功方法。具体来说,我们收集一组图像 I I I、形状 S S S 和纹理 T T T 三元组,使用来自 Objaverse-XL (Deitke et al., 2023) 和授权数据集的 270 万个物体网格,并从 24 个视角渲染它们,每个视角生成一个单一居中物体的高分辨率图像;更多细节见 B.1 节。我们将此数据集称为 Iso-3DO,并使用 2.5 万亿训练 token 进行训练。
【解析】预训练阶段采用的是"孤立物体"训练策略,所谓孤立物体是指训练数据中的每张图像只包含一个物体,且该物体位于图像中心,背景通常是纯色或简单环境。这样简化了学习任务,让模型可以专注于理解物体本身的三维结构和表面纹理,而不需要同时处理复杂的场景理解、物体定位、遮挡关系等问题。训练数据的构建:通过渲染合成数据来获得完美的监督信号。研究者从 Objaverse-XL 数据集和其他授权数据集中收集了 270 万个三维网格模型,这些模型涵盖了各种类别的物体,从日常用品到复杂机械,提供了丰富的形状多样性。对于每个三维模型,系统会从 24 个不同的视角进行渲染,这个多视角设计很重要:它让模型能够学习到物体在不同观察角度下的外观变化规律,理解三维形状与二维投影之间的对应关系。24 这个数字是经过权衡的结果,既要保证视角的充分覆盖,又要控制数据量和计算成本。每次渲染都会生成一张高分辨率图像,同时保留对应的三维形状 S S S 和纹理 T T T 信息,形成 ( I , S , T ) (I, S, T) (I,S,T) 三元组。这种数据组织方式为监督学习提供了完整的输入输出对:输入是二维图像 I I I,输出是三维形状 S S S 和纹理 T T T。使用合成数据的最大优势在于可以获得完美的真值标注,因为三维模型本身就是已知的,不存在标注误差或歧义。这个数据集被命名为 Iso-3DO,其中"Iso"强调了孤立物体的特性,"3DO"表示三维物体数据集。训练规模达到 2.5 万亿 token,模型需要见到海量的图像-三维对应关系才能学会可靠的三维重建能力。大规模的训练使模型能够学习到丰富的三维先验知识:不同类别物体的典型形状、表面纹理的常见模式、光照与材质的交互效果等。这些在预训练阶段学到的知识为后续的中期训练和后训练奠定基础,使模型在面对真实世界图像时能够利用这些先验进行合理的三维推断。预训练阶段虽然只使用合成数据,但它建立的是模型理解三维世界的基本能力框架,这个框架在后续阶段会被逐步适配到真实场景中。
3.1.2 中期训练:半合成能力
Next, mid-training builds up foundational skills that will enable the model to handle objects in real-world images:
• Mask-following: We train the model to reconstruct a target object, defined by a binary mask on the input image.
• Occlusion robustness: The artificial occluders in our dataset incentivize learning shape completion.
• Layout estimation: We train the model to produce translation and scale in normalized camera coordinates.
We construct our data by rendering textured meshes into natural images using alpha compositing. This "render-paste" dataset contains one subset of occluder-occludee pairs, and another subset where we replace real objects with synthetic objects at similar location and scale, creating physically-plausible data with accurate 3D ground truth. We call this data R P ∼ 3 D O R P{\sim}3D O RP∼3DO ; it contains 61 million samples with 2.8 million unique meshes; Figure 3 shows examples. See Section B.2 for more details.
【翻译】我们通过使用 alpha 合成将带纹理的网格渲染到自然图像中来构建数据。这个"渲染-粘贴"数据集包含一个遮挡物-被遮挡物对的子集,以及另一个子集,其中我们在相似的位置和尺度上用合成物体替换真实物体,创建具有准确 3D 真值的物理上合理的数据。我们将这些数据称为 R P ∼ 3 D O RP{\sim}3DO RP∼3DO;它包含 6100 万个样本和 280 万个独特的网格;图 3 显示了示例。详见 B.2 节。
【解析】中期训练数据的构建采用了一种巧妙的半合成策略,称为"渲染-粘贴"方法。核心思想是将合成的三维物体渲染后融合到真实的自然图像中,从而创建既具有真实场景背景又有准确三维标注的训练数据。技术实现上使用 alpha 合成技术,每个像素都有一个 alpha 通道值,表示透明度。当将渲染的合成物体粘贴到真实图像上时,alpha 合成会根据透明度值平滑地混合两个图像层,使得合成物体的边缘与背景自然过渡,避免出现生硬的拼接痕迹,确保合成结果在视觉上的真实感。数据集包含两个重要的子集,每个子集服务于不同的训练目标。第一个子集是遮挡物-被遮挡物对,专门用于训练遮挡鲁棒性。这个子集中,研究者会在真实图像中添加合成的遮挡物,让它部分遮挡图像中的某个物体。由于遮挡物是合成的,我们知道它的确切三维形状和位置,同时也知道被遮挡物体的完整三维结构。这样模型就可以学习:给定一个被部分遮挡的物体,如何重建其完整的三维形状。第二个子集采用物体替换策略,将真实图像中的某个物体替换为合成物体。关键是这个替换要在相似的位置和尺度上进行,确保合成物体与周围环境在空间关系上保持一致。这种替换创建的数据在物理上是合理的,说明合成物体的大小、位置、朝向都符合场景的透视关系和物理约束,不会出现悬浮、穿透或尺度不匹配等不合理现象。同时,由于替换的物体是合成的,我们拥有其精确的三维真值标注,包括形状、纹理、位置、朝向和尺度等所有信息。这个数据集被命名为 R P ∼ 3 D O RP{\sim}3DO RP∼3DO,其中"RP"代表"渲染-粘贴","3DO"表示三维物体数据集,规模达到 6100 万个样本,使用了 280 万个不同的三维网格模型,大量不同的物体和场景组合为模型提供了充分的学习材料。半合成数据策略巧妙地结合了合成数据和真实数据的优势:从真实图像中获得自然的场景背景、光照条件和视觉复杂性,从合成物体中获得精确的三维标注。这种数据比纯合成数据更接近真实场景,比纯真实数据更容易获得准确标注,是连接预训练和后训练的重要桥梁。
After mid-training (2.7 trillion training tokens), the model has now been trained with all input and output modalities for visually grounded 3D reconstruction. However, all data used has been (semi-)synthetic; to both close the domain gap and fully leverage real-world cues, we need real images.
【翻译】在中期训练之后(2.7 万亿训练 token),模型现在已经使用所有输入和输出模态进行了视觉基础的 3D 重建训练。然而,使用的所有数据都是(半)合成的;为了弥合领域差距并充分利用真实世界的线索,我们需要真实图像。
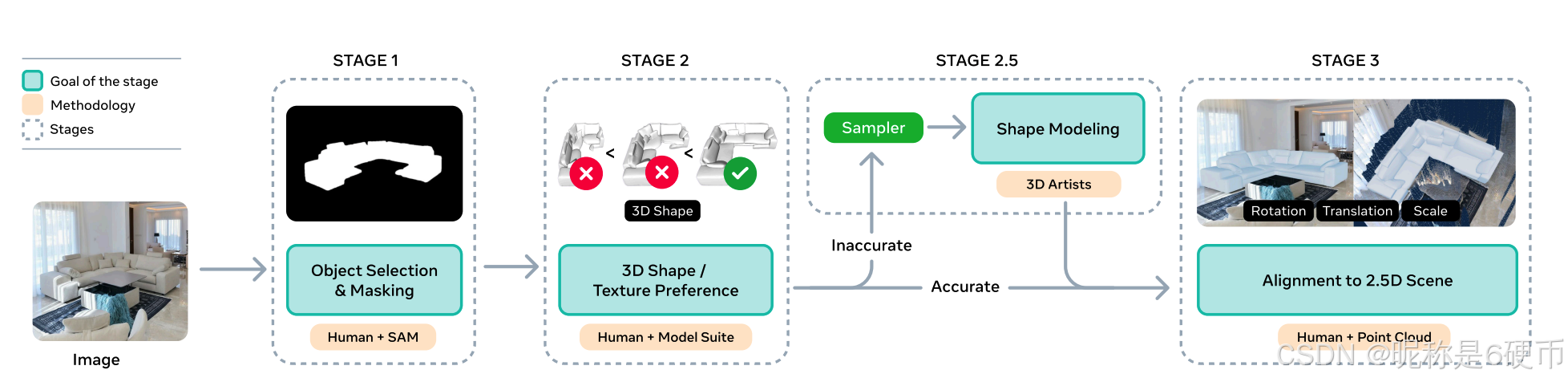
Figure 5 Life of an example going through the data collection pipeline. We streamline annotation by breaking it into subtasks: annotators first choose target objects (Stage 1); rank and select 3D model candidates (Stage 2); then pose these models within a 2.5 D 2.5\mathrm{D} 2.5D scene (Stage 3). Stages 2 and 3 use model-in-the-loop.
【翻译】图 5 一个示例在数据收集流程中的生命周期。我们通过将标注分解为子任务来简化流程:标注者首先选择目标物体(阶段 1);对 3D 模型候选进行排序和选择(阶段 2);然后在 2.5 D 2.5\mathrm{D} 2.5D 场景中对这些模型进行姿态调整(阶段 3)。阶段 2 和 3 使用模型在环。
3.2 后训练:真实世界对齐
In post-training, we have two goals. The first is to close the domain gap between (semi-)synthetic data and natural images. The second is to align with human preference for shape quality. We adapt the model by using our data engine iteratively; we first (i) collect training data with the current model, and then (ii) update our model using multi-stage post-training on this collected data. We then repeat.
【翻译】在后训练中,我们有两个目标。第一个是弥合(半)合成数据与自然图像之间的领域差距。第二个是与人类对形状质量的偏好对齐。我们通过迭代使用数据引擎来调整模型;我们首先 (i) 使用当前模型收集训练数据,然后 (ii) 使用在这些收集的数据上进行的多阶段后训练来更新我们的模型。然后我们重复这个过程。
3.2.1 后训练:数据收集步骤
The core challenge with collecting data for 3D visual grounding is that most people cannot create meshes directly; this requires skilled 3D artists, who even then can take multiple hours. This is different from the segmentation masks collected in SAM (Kirillov et al., 2023). However, given options, most people can choose which mesh resembles an object in the image most accurately. This fact forms the foundation of our data collection for SAM 3D. We convert preferences into training data as follows: sample from our post-trained model, ask annotators to choose the best candidate and then grade its overall quality according to a rubric which we define and update. If the quality meets the (evolving) bar, the candidate becomes a training sample.
【翻译】收集 3D 视觉定位数据的核心挑战在于大多数人无法直接创建网格;这需要熟练的 3D 艺术家,即使如此也需要花费数小时。这与 SAM (Kirillov et al., 2023) 中收集的分割掩码不同。然而,给定选项后,大多数人可以选择哪个网格最准确地类似于图像中的物体。这一事实构成了我们为 SAM 3D 收集数据的基础。我们将偏好转换为训练数据的方式如下:从我们的后训练模型中采样,要求标注者选择最佳候选,然后根据我们定义和更新的评分标准对其整体质量进行评分。如果质量达到(不断演变的)标准,该候选就成为训练样本。
Unfortunately at the first iteration, our initial model yields few high-quality candidates. This is because before the first collection step, very little real-world data for 3D visual grounding exists. We deal with this cold start problem by leveraging a suite of existing learned and retrieval-based models to produce candidates. In early stages, we draw mostly from the ensemble, but as training progresses our best model dominates, eventually producing about 80% of the annotated data seen by SAM 3D.
【翻译】不幸的是,在第一次迭代时,我们的初始模型产生的高质量候选很少。这是因为在第一次收集步骤之前,用于 3D 视觉定位的真实世界数据非常少。我们通过利用一套现有的学习型和检索型模型来生成候选,以应对这个冷启动问题。在早期阶段,我们主要从集成模型中抽取,但随着训练的进展,我们的最佳模型占据主导地位,最终产生了 SAM 3D 看到的约 80% 的标注数据。
Our annotation pipeline collects 3D object shape S S S , texture T T T , orientation R R R , 3D location t t t , and scale s s s from real-world images. We streamline the process by dividing into subtasks and leveraging existing appropriate models and human annotators within each (see Figure 5): identifying target objects, 3D model ranking and selection, and posing these within a 3D scene (relative to a point map). We outline each stage of the data engine below and present details in Section A. In total, we annotate almost 1 million images with 3.14 million untextured meshes and 100 textured meshes--unprecedented scale for 3D data paired with natural images.
【翻译】我们的标注流程从真实世界图像中收集 3D 物体形状 S S S、纹理 T T T、朝向 R R R、3D 位置 t t t 和尺度 s s s。我们通过划分为子任务并在每个子任务中利用现有的适当模型和人工标注者来简化流程(见图 5):识别目标物体、3D 模型排序和选择,以及在 3D 场景中对这些模型进行姿态调整(相对于点图)。我们在下面概述数据引擎的每个阶段,并在 A 节中提供详细信息。总共,我们标注了近 100 万张图像,包含 314 万个无纹理网格和 100 个带纹理网格------这是与自然图像配对的 3D 数据的空前规模。
【解析】标注流程需要收集完整的三维物体信息,包括几何形状 S S S、表面纹理 T T T、空间朝向 R R R、三维位置 t t t 和物体尺度 s s s。为了应对标注的复杂性,流程被分解为三个相对独立的子任务,每个子任务都结合了模型辅助和人工判断。第一阶段识别图像中需要重建的目标物体,第二阶段为该物体选择最合适的三维模型,第三阶段确定物体在场景中的精确位置和姿态。分解策略可降低单个任务的难度,使标注者可以专注于特定方面的判断。点图在第三阶段提供了场景的三维结构参考,帮助标注者准确放置物体。整个数据收集工作:近 100 万张真实图像被标注,生成了 314 万个无纹理网格模型。相比之下,带纹理的网格只有 100 个,这是因为纹理标注的成本和难度都远高于几何形状。
Stage 1: Choosing target objects ( I , M ) (I,M) (I,M) . The goal of this stage is to identify a large, diverse set of images I I I and object masks M M M to lift to 3D. To ensure generalization across objects and scenes, we sample images from several diverse real-world datasets, and utilize a 3D-oriented taxonomy to balance the object distribution. To obtain object segmentation masks, we use a combination of pre-existing annotations (Kirillov et al., 2023) and human labelers selecting objects of interest.
【翻译】阶段 1:选择目标物体 ( I , M ) (I,M) (I,M)。此阶段的目标是识别大量多样化的图像 I I I 和物体掩码 M M M 以提升到 3D。为了确保跨物体和场景的泛化,我们从多个不同的真实世界数据集中采样图像,并利用面向 3D 的分类法来平衡物体分布。为了获得物体分割掩码,我们结合使用预先存在的标注 (Kirillov et al., 2023) 和人工标注者选择感兴趣的物体。
【解析】第一阶段是构建输入数据对 ( I , M ) (I,M) (I,M),即图像和对应的物体掩码。研究者从多个真实世界数据集中采样,确保涵盖不同的场景类型、拍摄条件和物体类别。为了避免数据分布偏差,使用了面向三维重建的分类体系来指导采样,确保常见物体和罕见物体都有充分代表。物体掩码的获取采用混合策略:一部分直接使用现有的分割标注,特别是来自 SAM 项目的高质量掩码;另一部分由人工标注者根据三维重建的需求选择感兴趣的物体并标注掩码,保证掩码质量和任务相关性。
Stage 2: Object model ranking and selection ( S , T ) (S,T) (S,T) . The goal of this stage is to collect image-grounded 3D shape S S S and texture T T T . As described above, human annotators choose shape and texture candidates which best match the input image and mask. Annotators rate the example r r r and reject chosen examples that do not meet a predefined quality threshold, i.e. r < α r<\alpha r<α . Bad candidates also become negative examples for preference alignment.
【翻译】阶段 2:物体模型排序和选择 ( S , T ) (S,T) (S,T)。此阶段的目标是收集基于图像的 3D 形状 S S S 和纹理 T T T。如上所述,人工标注者选择最匹配输入图像和掩码的形状和纹理候选。标注者对示例进行评分 r r r,并拒绝不符合预定义质量阈值的选定示例,即 r < α r<\alpha r<α。差的候选也成为偏好对齐的负样本。
【解析】第二阶段聚焦于获取三维形状和纹理信息。标注者面对多个模型生成的候选结果,需要判断哪个最准确地反映了输入图像中的物体。选出最佳候选后,标注者还要给出质量评分 r r r,这个评分反映了重建结果与真实物体的匹配程度。只有评分超过阈值 α \alpha α 的候选才会被接受为训练样本。那些被拒绝的候选并非毫无价值,它们作为负样本被保留下来,用于后续的偏好对齐训练。这些负样本明确告诉模型哪些重建结果是不可接受的,帮助模型学习避免类似的错误。这种同时收集正负样本的策略为偏好学习提供了丰富的对比信号。
Our data engine maximizes the likelihood of a successful annotation, r > α r>\alpha r>α , by asking annotators to choose between N = 8 N=8 N=8 candidates from the ensemble; a form of best-of- N N N search (Ouyang et al., 2022) using humans. The expected quality of this best candidate improves with N N N , and we further increase N N N by first filtering using a model, and then filtering using the human (Anthony et al., 2017); we show results in Section A.7.
【翻译】我们的数据引擎通过要求标注者从集成模型的 N = 8 N=8 N=8 个候选中进行选择,来最大化成功标注的可能性 r > α r>\alpha r>α;这是一种使用人类的 best-of- N N N 搜索形式 (Ouyang et al., 2022)。这个最佳候选的预期质量随 N N N 提高,我们通过首先使用模型过滤,然后使用人工过滤 (Anthony et al., 2017) 来进一步增加 N N N;我们在 A.7 节中展示结果。
【解析】提高标注成功率的策略是增加候选数量 N N N。系统让标注者从 8 个候选中选择,这是一种人工参与的 best-of-N 搜索。统计上,候选越多,其中出现高质量结果的概率越大。但候选数量不能无限增加,因为会增加标注者的工作负担。研究者采用两级过滤策略来有效扩大候选池:首先用模型自动筛选出更多候选,然后只将其中质量较高的 8 个呈现给人工标注者。
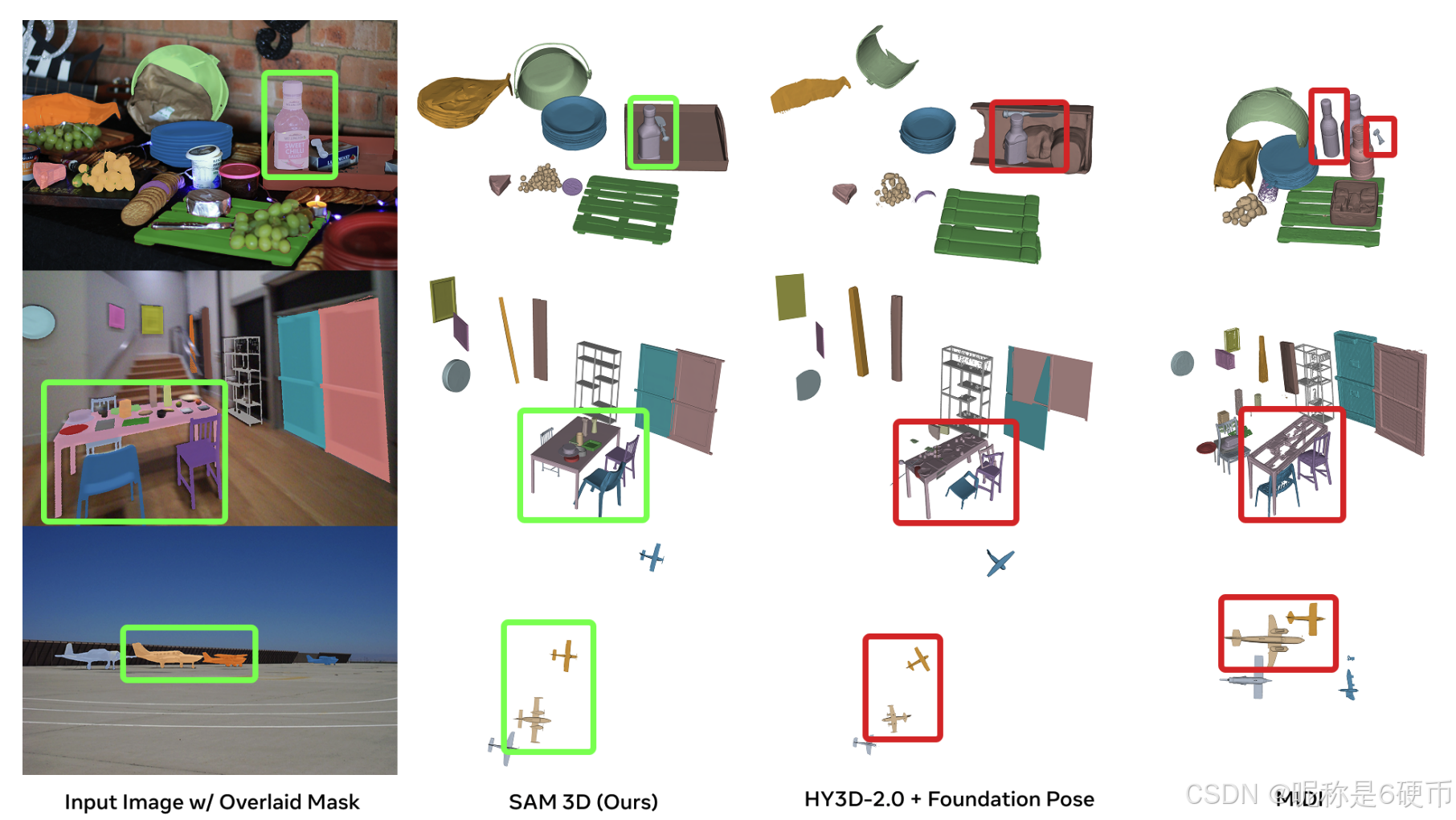
Figure 6 Qualitative comparison to competing image-to-3D asset methods. We compare to the recent Trellis (Xiang et al., 2025), Hunyuan3D-2.1 (Hunyuan3D et al., 2025), Direct3D-S2 (Wu et al., 2025) and Hi3DGen (Ye et al., 2025) on the artist-generated SA-3DAO for single shape reconstruction; we provide the 3D artist-created ground truth mesh as reference.
【翻译】图 6 与竞争的图像到 3D 资产方法的定性比较。我们在艺术家生成的 SA-3DAO 上与最近的 Trellis (Xiang et al., 2025)、Hunyuan3D-2.1 (Hunyuan3D et al., 2025)、Direct3D-S2 (Wu et al., 2025) 和 Hi3DGen (Ye et al., 2025) 进行单一形状重建的比较;我们提供 3D 艺术家创建的真值网格作为参考。
Stage 2.5: Hard example triage (Artists). When no model produces a reasonable object shape, our non-specialist annotators cannot correct the meshes, resulting in a lack of data precisely where the model needs it most. We route a small percentage of these hardest cases to professional 3D artists for direct annotation, and we denote this set A r t − 3 D O Art{-}3DO Art−3DO .
【翻译】阶段 2.5:困难样本分流(艺术家)。当没有模型产生合理的物体形状时,我们的非专业标注者无法修正网格,导致恰好在模型最需要的地方缺乏数据。我们将这些最困难案例的一小部分路由给专业 3D 艺术家进行直接标注,我们将这个集合表示为 A r t − 3 D O Art{-}3DO Art−3DO。
【解析】某些极具挑战性的案例中,所有模型生成的候选都质量不佳,普通标注者无法通过选择来获得合格的训练样本。这些困难案例往往涉及复杂形状、严重遮挡或罕见物体类别,恰恰是模型最需要学习的内容。为了填补这个数据空白,研究者将少量最困难的案例交给专业三维艺术家,由他们直接创建高质量的三维模型。虽然这种方式成本高昂,但对于提升模型在困难场景下的能力至关重要。这个由艺术家标注的数据集被命名为 A r t − 3 D O Art{-}3DO Art−3DO,它的规模虽小但质量极高,在后续训练中发挥着关键作用。
Stage 3: Aligning objects to 2.5D scene ( R , t , s ) (R,t,s) (R,t,s) . The previous stages produce a 3D shape for the object, but not its layout in the scene. For each stage 2 shape, annotators label the object pose by manipulating the 3D object's translation, rotation, and scale relative to a point cloud. We find that point clouds provide enough structure to enable consistent shape placement and orientation.
【翻译】阶段 3:将物体对齐到 2.5D 场景 ( R , t , s ) (R,t,s) (R,t,s)。前面的阶段为物体生成了 3D 形状,但没有生成其在场景中的布局。对于每个阶段 2 的形状,标注者通过相对于点云操纵 3D 物体的平移、旋转和缩放来标注物体姿态。我们发现点云提供了足够的结构来实现一致的形状放置和定向。
【解析】第三阶段解决物体在场景中的空间布局问题。前两个阶段已经确定了物体的形状和纹理,但还需要知道物体在三维空间中的具体位置、朝向和大小。标注者通过交互式界面调整三维模型的平移 t t t、旋转 R R R 和缩放 s s s 参数,使其与场景中的实际物体对齐。点云在这个过程中起到关键作用,它提供了场景的三维结构信息,包括地面、墙壁、其他物体等的空间位置。有了这些参考,标注者可以准确判断物体应该放在哪里、如何旋转、多大尺寸,确保重建结果在空间上的一致性和合理性。
In general, we can think of the data collection as an API that takes a current best model, q ( S , T , R , t , s ∣ I , M ) q(S,T,R,t,s\mid I,M) q(S,T,R,t,s∣I,M) , and returns (i) training samples D + = ( I , M , S , T , R , t , s ) D^{+}=(I,M,S,T,R,t,s) D+=(I,M,S,T,R,t,s) , (ii) a quality rating r ∈ 0 , 1 r\in0,1 r∈0,1 , and (iii) a set of less preferred candidates ( D − = ( I , M , S ′ , T ′ , R ′ , t ′ , s ′ ) , D^{-}=(I,M,S^{\prime},T^{\prime},R^{\prime},t^{\prime},s^{\prime}), D−=(I,M,S′,T′,R′,t′,s′), ) that are all worse than the training sample.
【翻译】一般来说,我们可以将数据收集视为一个 API,它接受当前最佳模型 q ( S , T , R , t , s ∣ I , M ) q(S,T,R,t,s\mid I,M) q(S,T,R,t,s∣I,M),并返回 (i) 训练样本 D + = ( I , M , S , T , R , t , s ) D^{+}=(I,M,S,T,R,t,s) D+=(I,M,S,T,R,t,s),(ii) 质量评分 r ∈ 0 , 1 r\in0,1 r∈0,1,以及 (iii) 一组较不受偏好的候选 ( D − = ( I , M , S ′ , T ′ , R ′ , t ′ , s ′ ) D^{-}=(I,M,S^{\prime},T^{\prime},R^{\prime},t^{\prime},s^{\prime}) D−=(I,M,S′,T′,R′,t′,s′)),它们都比训练样本差。
【解析】整个数据收集流程可以抽象为一个函数接口。输入是当前的最佳模型 q ( S , T , R , t , s ∣ I , M ) q(S,T,R,t,s\mid I,M) q(S,T,R,t,s∣I,M),它能够根据图像 I I I 和掩码 M M M 生成三维重建结果。输出包含三个部分:首先是高质量的正样本 D + D^{+} D+,包含完整的输入输出对;其次是质量评分 r r r,量化了重建质量;最后是负样本集合 D − D^{-} D−,包含那些质量不达标的候选。这种 API 式的抽象清晰地定义了数据引擎的输入输出关系,使得整个迭代训练流程可以自动化进行。每次迭代都用当前模型生成候选,通过人工标注筛选出高质量样本和负样本,然后用这些数据训练下一代模型,形成持续改进的循环。
3.2.2 后训练:模型改进步骤
The model improvement step in SAM 3D uses these training samples and preference results to update the base model through multiple stages of finetuning and preference alignment. Within each post-training iteration we aggregate data from all previous collection steps; keeping only samples where D + D^{+} D+ is above some quality threshold α \alpha α . As training progresses, α \alpha α can increase over time, similar to the cross-entropy method for optimization (de Boer et al., 2005). Our final post-training iteration uses 0.5 trillion training tokens.
【翻译】SAM 3D 中的模型改进步骤使用这些训练样本和偏好结果,通过多个阶段的微调和偏好对齐来更新基础模型。在每次后训练迭代中,我们聚合来自所有先前收集步骤的数据;仅保留 D + D^{+} D+ 高于某个质量阈值 α \alpha α 的样本。随着训练的进行, α \alpha α 可以随时间增加,类似于用于优化的交叉熵方法 (de Boer et al., 2005)。我们最终的后训练迭代使用了 0.5 万亿个训练标记。
Supervised Fine-Tuning (SFT). When post-training begins, the base model has only seen synthetic data. Due to the large domain gap between synthetic and real-world data, we begin by finetuning on our aligned meshes from Stage 3.
Figure 7 Qualitative comparison to competing scene reconstruction methods. We show SAM 3D's full 3D scene reconstructions versus alternatives (Wen et al., 2024; Huang et al., 2025).
【翻译】图 7 与竞争的场景重建方法的定性比较。我们展示了 SAM 3D 的完整 3D 场景重建与替代方法 (Wen et al., 2024; Huang et al., 2025) 的对比。
We begin SFT with the noisier non-expert labels (MITL-3DO), followed by the smaller, high-quality set from 3D artists (Art-3DO). The high quality Art-3DO data enhances model quality by aligning outputs with artists' aesthetic preferences. We find this helps suppress common failures, e.g. floaters, bottomless meshes, and missing symmetry.
【翻译】我们首先使用噪声较大的非专家标签 (MITL-3DO) 进行 SFT,然后使用来自 3D 艺术家的较小的高质量集合 (Art-3DO)。高质量的 Art-3DO 数据通过将输出与艺术家的审美偏好对齐来提升模型质量。我们发现这有助于抑制常见的失败情况,例如浮动物、无底网格和缺失对称性。
Preference optimization (alignment). After fine-tuning, the model can robustly generate shape and layout for diverse objects and real-world images. However, humans are sensitive to properties like symmetry, closure, etc. which are difficult to capture with generic objectives like flow matching. Thus, we follow SFT with a stage of direct preference optimization (DPO) (Rafailov et al., 2023), using D + / D − D+/D^{-} D+/D− pairs from Stage 2 of our data engine. We found this off-policy data was effective at eliminating undesirable model outputs, even after SFT on Art-3DO. DPO training details are in Section C.3.
【翻译】偏好优化(对齐)。微调后,模型可以为多样化的物体和真实世界图像稳健地生成形状和布局。然而,人类对对称性、封闭性等属性很敏感,这些属性很难用流匹配等通用目标捕获。因此,我们在 SFT 之后进行一个阶段的直接偏好优化 (DPO) (Rafailov et al., 2023),使用来自数据引擎阶段 2 的 D + / D − D+/D^{-} D+/D− 对。我们发现这种离策略数据在消除不良模型输出方面很有效,即使在 Art-3DO 上进行 SFT 之后也是如此。DPO 训练细节在 C.3 节中。
【解析】偏好优化是后训练的第二个关键阶段,目标是让模型输出更符合人类的主观偏好。经过监督微调后,模型已经具备了生成合理三维重建的能力,但仍然存在一些难以通过传统损失函数优化的问题。人类对三维物体的感知具有很强的主观性,特别关注对称性、结构完整性、表面光滑度等美学属性。这些属性很难用数学公式精确定义,传统的流匹配等生成模型目标函数主要关注数据分布的匹配,无法充分捕捉这些细微的质量差异。直接偏好优化提供了一种更直接的解决方案,它不需要显式定义什么是好的输出,而是通过学习人类的偏好排序来隐式地优化模型。训练数据来自数据引擎第二阶段收集的正负样本对 D + / D − D+/D^{-} D+/D−,其中 D + D+ D+ 是人类标注者选择的高质量结果, D − D^{-} D− 是被拒绝的低质量候选。DPO 算法通过最大化模型生成 D + D+ D+ 相对于 D − D^{-} D− 的概率比来训练,使模型学习到人类的偏好模式。这个方法的优势在于使用的是离策略数据,即数据是由之前版本的模型生成的,而不是当前模型,这提高了数据利用效率。实验表明,即使在高质量的 Art-3DO 数据上微调后,DPO 仍能进一步消除一些不符合人类偏好的输出,说明偏好学习捕捉到了监督学习难以学到的隐性知识。
Distillation. Finally, to enable sub-second shape and layout from the Geometry model, we finish a short distillation stage to reduce the number of function evaluations (NFE) required during inference from 25 → 4 25\rightarrow4 25→4. We adapt (Frans et al. ,2024) to our setting, and describe the details in Section C.4.
Dataset. To comprehensively evaluate the model capability under real-world scenarios, we carefully build a new benchmark SA-3DAO, consisting of 1K 3D artist-created meshes created from natural images. We also include ISO3D from 3D Arena (Ebert, 2025) for quantitatively evaluating shape and texture, and Aria Digital Twin (ADT) (Pan et al., 2023) for layout. We further conduct human preference evaluation on two curated sets for both scene-level and object-level reconstruction. The Pref Set uses real-world images from MetaCLIP (Xu et al., 2024) and SA-1B (Kirillov et al., 2023), as well as a set based on LVIS (Gupta et al., 2019). Refer to Section D for details on evaluation sets.
【翻译】数据集。为了全面评估模型在真实世界场景下的能力,我们精心构建了一个新的基准 SA-3DAO,包含 1K 个由 3D 艺术家从自然图像创建的网格。我们还包括来自 3D Arena (Ebert, 2025) 的 ISO3D 用于定量评估形状和纹理,以及 Aria Digital Twin (ADT) (Pan et al., 2023) 用于布局评估。我们进一步在两个精选集合上进行人类偏好评估,涵盖场景级和物体级重建。Pref Set 使用来自 MetaCLIP (Xu et al., 2024) 和 SA-1B (Kirillov et al., 2023) 的真实世界图像,以及基于 LVIS (Gupta et al., 2019) 的集合。有关评估集的详细信息请参见 D 节。
Settings. We conduct experiments with a Geometry model that is trained to condition on pointmaps. For datasets where pointmaps are unavailable, we estimate them with Wang et al. (2025a). We found that shape and texture quality do not depend on whether the model is trained with pointmap conditioning (see Section E.5), but layout (translation/scale) evaluation in Table 3 requires ground-truth depth/pointmap as reference.
【翻译】设置。我们使用训练为以点图为条件的几何模型进行实验。对于点图不可用的数据集,我们使用 Wang et al. (2025a) 进行估计。我们发现形状和纹理质量不依赖于模型是否使用点图条件进行训练(见 E.5 节),但表 3 中的布局(平移/缩放)评估需要真实深度/点图作为参考。
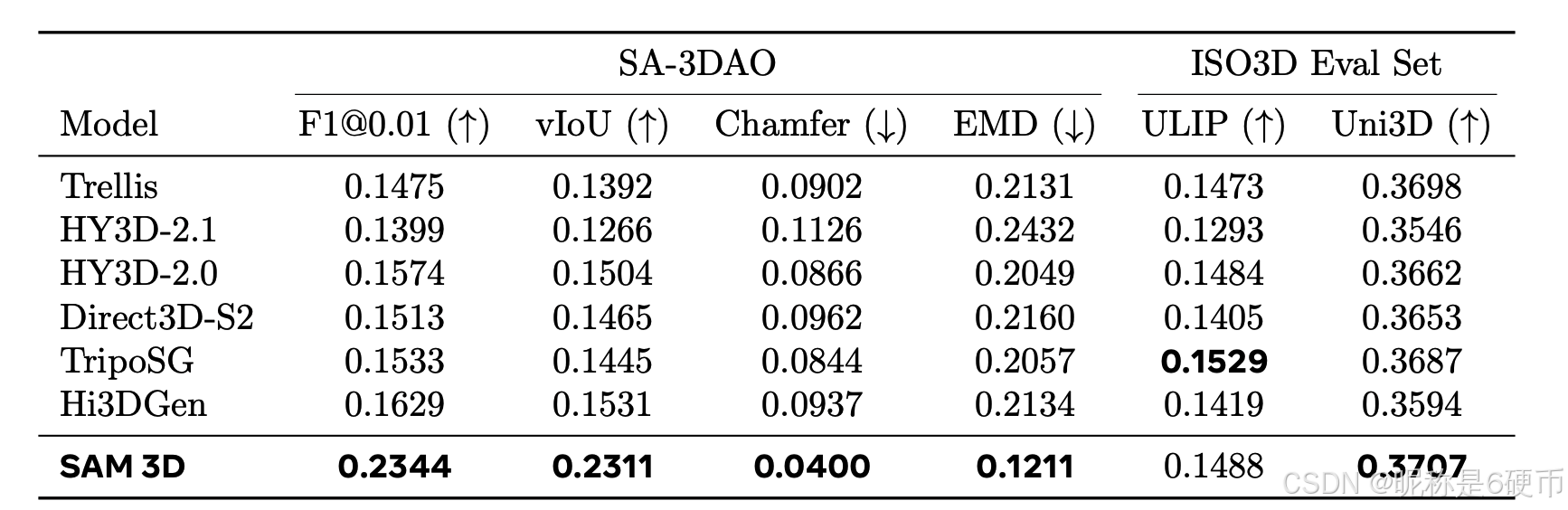
Table 2 3D shape quantitative comparison to competing image-to-3D methods, including Trellis (Xiang et al., 2025), HY3D-2.1 (Hunyuan3D et al., 2025), HY3D-2.0 (Team, 2025), Direct3D-S2 (Wu et al., 2025), TripoSG (Li et al., 2025), Hi3DGen (Ye et al., 2025). SA-3DAO shows metrics that measure accuracy against GT geometry; ISO3D (Ebert, 2025) has no geometric GT and so we show perceptual similarities between 3D and input images (ULIP (Xue et al., 2023) and Uni3D (Zhou et al., 2023)). TripoSG uses a significantly higher mesh resolution, which is rewarded in perceptual metrics.
【翻译】表 2 与竞争的图像到 3D 方法的 3D 形状定量比较,包括 Trellis (Xiang et al., 2025)、HY3D-2.1 (Hunyuan3D et al., 2025)、HY3D-2.0 (Team, 2025)、Direct3D-S2 (Wu et al., 2025)、TripoSG (Li et al., 2025)、Hi3DGen (Ye et al., 2025)。SA-3DAO 显示了衡量与真实几何精度的指标;ISO3D (Ebert, 2025) 没有几何真值,因此我们显示 3D 与输入图像之间的感知相似性(ULIP (Xue et al., 2023) 和 Uni3D (Zhou et al., 2023))。TripoSG 使用显著更高的网格分辨率,这在感知指标中得到了回报。
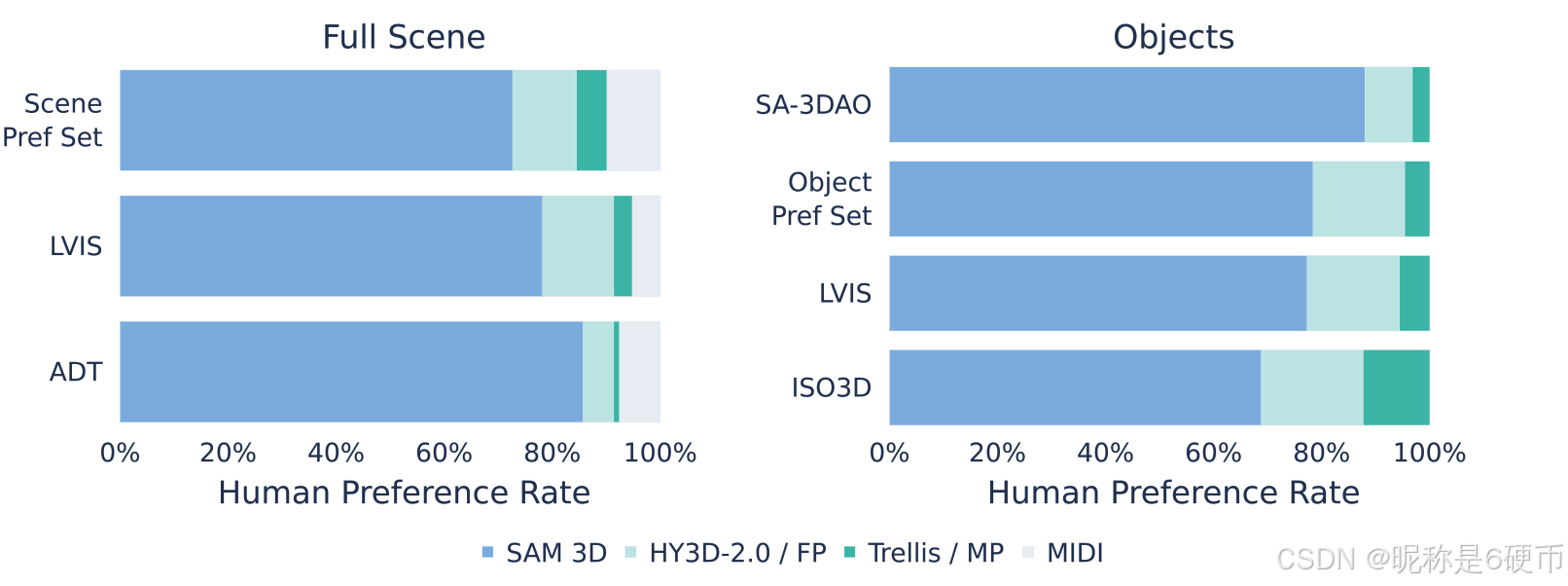
Figure 8 Preference comparison on scene-level and object-level reconstruction. Numbers indicate human preference rates. Objects comparisons are done on textured meshes. SAM 3D is significantly preferred over others on all fronts.
【翻译】图 8 场景级和物体级重建的偏好比较。数字表示人类偏好率。物体比较是在纹理网格上进行的。SAM 3D 在所有方面都明显优于其他方法。
4.1 与最先进方法的比较
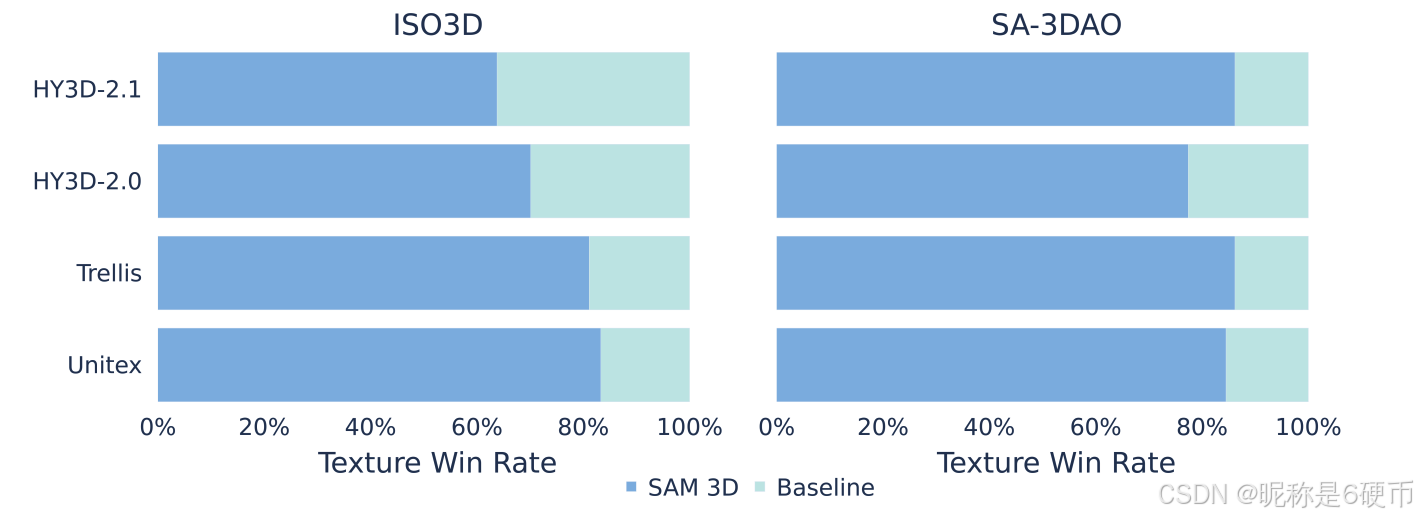
3D shape and texture. We evaluate single-object generation by comparing SAM 3D with prior state-of-the-art (SOTA) methods. In human preference studies, SAM 3D achieves an 5 : 1 head-to-head win rate on real images (see Figure 8). Table 2 presents quantitative evaluation on shape quality, where SAM 3D matches or exceeds previous SOTA performance on isolated object images (ISO3D), and significantly outperforms all baselines on challenging real-world inputs (SA-3DAO). Qualitative examples in Figure 6 further illustrate the model's strong generalization under heavy occlusion. In Figure 9, we compare SAM 3D texture vs. other texture models, given SAM 3D shapes (SAM 3D's improved shape actually benefits other methods in this eval). Annotators significantly prefer SAM 3D texture (details in Section E.2).
【翻译】3D 形状和纹理。我们通过将 SAM 3D 与先前的最先进 (SOTA) 方法进行比较来评估单物体生成。在人类偏好研究中,SAM 3D 在真实图像上实现了 5:1 的正面对比胜率(见图 8)。表 2 展示了形状质量的定量评估,其中 SAM 3D 在孤立物体图像 (ISO3D) 上达到或超过了先前的 SOTA 性能,并在具有挑战性的真实世界输入 (SA-3DAO) 上显著优于所有基线。图 6 中的定性示例进一步说明了模型在严重遮挡下的强大泛化能力。在图 9 中,我们比较了 SAM 3D 纹理与其他纹理模型,给定 SAM 3D 形状(SAM 3D 改进的形状实际上在此评估中使其他方法受益)。标注者明显更偏好 SAM 3D 纹理(详见 E.2 节)。
3D scene reconstruction. In preference tests on three evaluation sets, users prefer scene reconstructions from SAM 3D by 6 : 1 6:1 6:1 over prior SOTA (Figure 8). Figure 7 and Figure 20 in the appendix shows qualitative comparisons, while Table 3 shows quantitative metrics for object layout. On real-world data like SA-3DAO and ADT, the improvement is fairly stark and persists even when pipeline approaches use SAM 3D meshes. SAM 3D introduces a new real-world capability to generate shape and layout jointly (ADD-S a ◯ 0.12 % → 77 % \textcircled{\mathrm{a}}0.12\%\rightarrow77\% a◯0.12%→77% ), and a sample-then-optimize approach, as in the render-and-compare approaches (Labbé et al., 2022; Wen et al., 2024) can further improve performance (Section E.3). The strong results for layout and scene reconstruction demonstrate that SAM 3D can robustly handle both RGB-only inputs (e.g., SA-3DAO, LVIS, Pref Set) as well as provided pointmaps (e.g., ADT).
【翻译】3D 场景重建。在三个评估集的偏好测试中,用户对 SAM 3D 的场景重建的偏好比先前的 SOTA 高 6:1(图 8)。附录中的图 7 和图 20 显示了定性比较,而表 3 显示了物体布局的定量指标。在 SA-3DAO 和 ADT 等真实世界数据上,改进相当显著,即使流水线方法使用 SAM 3D 网格时也持续存在。SAM 3D 引入了一种新的真实世界能力,可以联合生成形状和布局(ADD-S a ◯ 0.12 % → 77 % \textcircled{\mathrm{a}}0.12\%\rightarrow77\% a◯0.12%→77%),并且采样后优化方法,如渲染和比较方法 (Labbé et al., 2022; Wen et al., 2024) 中的方法,可以进一步提高性能(E.3 节)。布局和场景重建的强大结果表明,SAM 3D 可以稳健地处理纯 RGB 输入(例如 SA-3DAO、LVIS、Pref Set)以及提供的点图(例如 ADT)。
Table 3 3D layout quantitative comparison to competing layout prediction methods on SA-3DAO and Aria Digital Twin (Pan et al., 2023). SAM 3D significantly outperforms both pipeline approaches used in robotics (Labbé et al., 2022; Wen et al., 2024) and joint generative models (MIDI (Huang et al., 2025)). Most SA-3DAO scenes only contain one object so we do not show MIDI results that require multi-object alignment. The metrics measure bounding box overlap, rotation error, and chamfer-like distances normalized by object diameter.
【翻译】表 3 在 SA-3DAO 和 Aria Digital Twin (Pan et al., 2023) 上与竞争的布局预测方法的 3D 布局定量比较。SAM 3D 显著优于机器人技术中使用的流水线方法 (Labbé et al., 2022; Wen et al., 2024) 和联合生成模型 (MIDI (Huang et al., 2025))。大多数 SA-3DAO 场景只包含一个物体,因此我们不显示需要多物体对齐的 MIDI 结果。这些指标衡量边界框重叠、旋转误差以及按物体直径归一化的类 chamfer 距离。
Figure 9 Preference comparison on texture. Since SAM 3D provides higher quality shape, we use the geometry results from SAM 3D and only perform texture generations for all methods. SAM 3D significantly outperforms others.
【翻译】图 9 纹理的偏好比较。由于 SAM 3D 提供更高质量的形状,我们使用 SAM 3D 的几何结果,并仅对所有方法执行纹理生成。SAM 3D 显著优于其他方法。
4.2 Analysis Studies
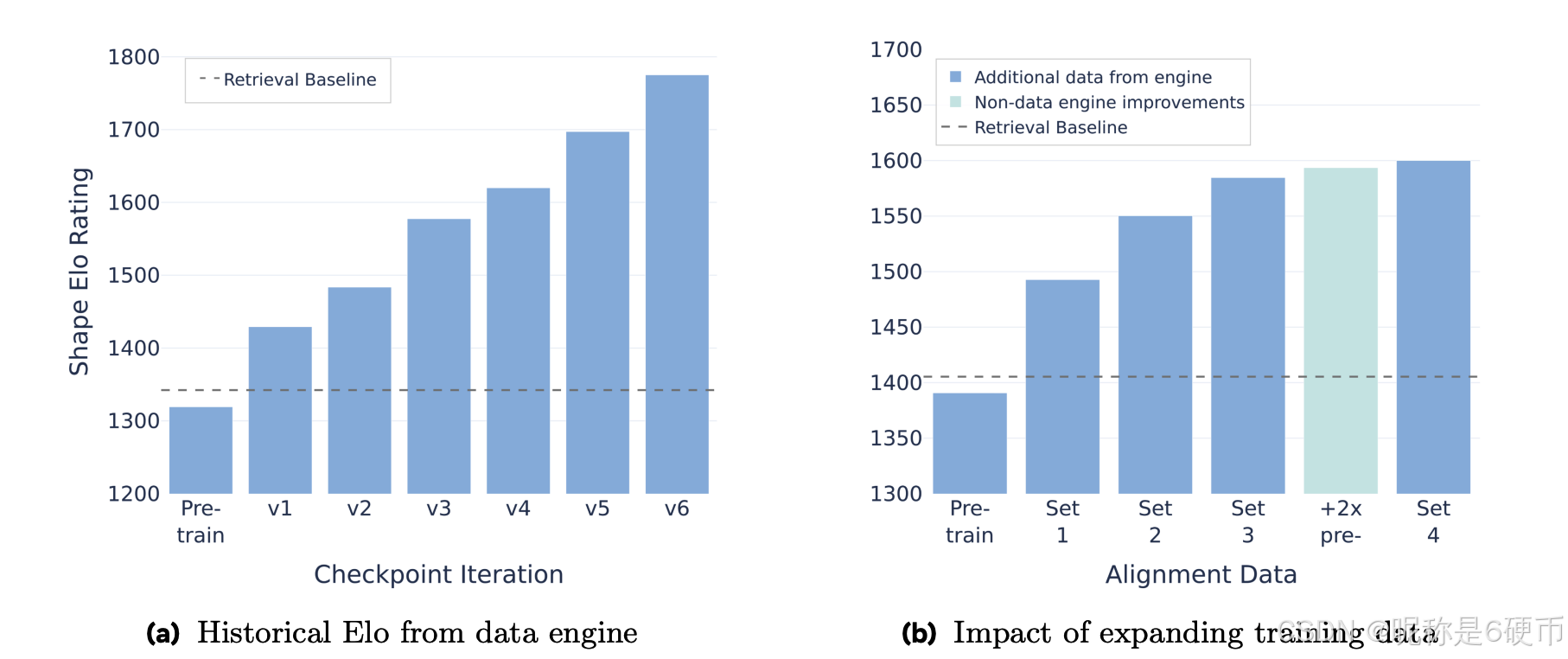
Post-training iterations steadily improve performance. We observed steady improvements as we ran the data engine for longer, with near-linear Elo scaling shown in the historical comparisons from Stage 2 of our data engine (Figure 10a). We found it important to scale all stages simultaneously. The cumulatively linear effect results from more data engine iterations, along with scaling up pretraining, mid-training, and adding new post-training stages. Figure 10b shows that iterating MITL-3DO data alone yields consistent improvements but with decreasing marginal impact.
【翻译】后训练迭代稳步提升性能。我们观察到随着数据引擎运行时间的延长,性能稳步提升,数据引擎第 2 阶段的历史比较显示了近乎线性的 Elo 评分增长(图 10a)。我们发现同时扩展所有阶段非常重要。累积的线性效应来自更多的数据引擎迭代,以及扩大预训练、中期训练和添加新的后训练阶段。图 10b 显示,仅迭代 MITL-3DO 数据就能产生一致的改进,但边际影响递减。
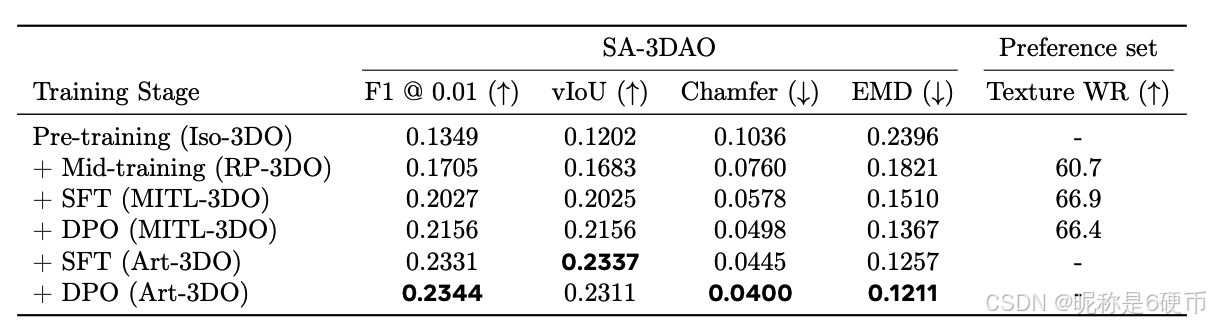
Multi-stage training improves performance. SAM 3D's real-world performance emerges through multi-stage training. Table 4 reveals near-monotonic 3D shape improvements as each training stage is added, validating the approach that leads to the final model (last row). In the appendix, Figure 17 shows similar results for texture and Table 7 shows the contribution of each individual real-world data stage, by knocking out the MITL-3DO, Art-3DO data, or DPO stages.
Other ablations. Please see the appendix for additional ablations on rotation representation (Section E.4), DPO (Section C.3), distillation (Section C.4), pointmaps (Section E.5), and scaling best-of- N N N in the data engine (Section A.7).
【翻译】其他消融实验。请参阅附录中关于旋转表示(E.4 节)、DPO(C.3 节)、蒸馏(C.4 节)、点图(E.5 节)以及数据引擎中 best-of- N N N 扩展(A.7 节)的额外消融实验。
5 Related Work
3D reconstruction has been a longstanding challenge in computer vision. Classical methods include binocular stereopsis (Wheatstone, 1838), structure-from-motion (Hartley and Zisserman, 2003; Szeliski, 2022; Scharstein and Szeliski, 2002; Torresani et al., 2008; Tomasi and Kanade, 1992), and SLAM (Smith et al., 1990; Castellanos et al., 1999). Other strategies reconstruct by analysis (e.g., silhouettes (Esteban and Schmitt, 2004)) or by synthesis via volume rendering (Kajiya and Von Herzen, 1984), using either implicit representations (Mildenhall et al., 2020) or explicit ones (Sitzmann et al., 2019; Liu et al., 2020). Supervised deep learning methods predict voxels (Xie et al., 2019; Wang et al., 2021), point clouds (Van Hoorick et al., 2022), or meshes (Worchel et al., 2022; Wen et al., 2019), or optimize implicit representations (Liu et al., 2024), e.g., signed distance functions (SDFs), often with high-quality output but requiring multiple views at inference. In contrast, we focus on the more restrictive setting of a single RGB image at test time.
【翻译】3D 重建一直是计算机视觉中的长期挑战。经典方法包括双目立体视觉 (Wheatstone, 1838)、运动恢复结构 (Hartley and Zisserman, 2003; Szeliski, 2022; Scharstein and Szeliski, 2002; Torresani et al., 2008; Tomasi and Kanade, 1992) 和 SLAM (Smith et al., 1990; Castellanos et al., 1999)。其他策略通过分析进行重建(例如轮廓 (Esteban and Schmitt, 2004))或通过体积渲染进行合成 (Kajiya and Von Herzen, 1984),使用隐式表示 (Mildenhall et al., 2020) 或显式表示 (Sitzmann et al., 2019; Liu et al., 2020)。监督深度学习方法预测体素 (Xie et al., 2019; Wang et al., 2021)、点云 (Van Hoorick et al., 2022) 或网格 (Worchel et al., 2022; Wen et al., 2019),或优化隐式表示 (Liu et al., 2024),例如有符号距离函数 (SDF),通常具有高质量输出但在推理时需要多个视图。相比之下,我们专注于测试时单个 RGB 图像这一更受限的设置。
Table 4 Cascading improvements from multi-stage training on 3D shape and texture. For texture, we report win rates (WR) between each row and the row above it.
【翻译】表 4 多阶段训练在 3D 形状和纹理上的级联改进。对于纹理,我们报告每行与其上一行之间的胜率 (WR)。
Figure 10 Data engine with additional iterations. The plots show Elo scores of different models; a 400 point Elo difference corresponds to 10:1 odds in a preference test. Models were (a) checkpoints around 3 weeks apart, indicating cumulative improvements as we scale and add different stages and (b) post-trained (SFT) using expanded training data.
【翻译】图 10 具有额外迭代的数据引擎。图表显示了不同模型的 Elo 评分;400 点 Elo 差异对应于偏好测试中 10:1 的胜率。模型为 (a) 间隔约 3 周的检查点,表明随着我们扩展和添加不同阶段的累积改进,以及 (b) 使用扩展训练数据进行后训练 (SFT)。
Single-view 3D reconstruction is considerably more difficult. A large body of work trains models with direct 3D supervision, predicting meshes (Xu et al., 2019; Kulkarni et al., 2022), voxels (Girdhar et al., 2016; Wu et al., 2017), point clouds (Fan et al., 2017; Mescheder et al., 2019), or CAD-aligned geometry (Wang et al., 2018; Gkioxari et al., 2019). A recent line of work (Zhang et al., 2023; Xiang et al., 2025; Ren et al., 2024) supervises with VAE (Kingma and Welling, 2013) latent representations. However, these methods are typically evaluated on simplified synthetic single-object benchmarks such as ShapeNet (Chang et al., 2015), Pix3D (Sun et al., 2018) or Objaverse (Deitke et al., 2023).
【翻译】单视图 3D 重建要困难得多。大量工作使用直接 3D 监督训练模型,预测网格 (Xu et al., 2019; Kulkarni et al., 2022)、体素 (Girdhar et al., 2016; Wu et al., 2017)、点云 (Fan et al., 2017; Mescheder et al., 2019) 或 CAD 对齐的几何 (Wang et al., 2018; Gkioxari et al., 2019)。最近的一系列工作 (Zhang et al., 2023; Xiang et al., 2025; Ren et al., 2024) 使用 VAE (Kingma and Welling, 2013) 潜在表示进行监督。然而,这些方法通常在简化的合成单物体基准上进行评估,例如 ShapeNet (Chang et al., 2015)、Pix3D (Sun et al., 2018) 或 Objaverse (Deitke et al., 2023)。
Layout estimation. A large body of work estimates object poses from a single image, for object shapes (Labbé et al., 2022; Wen et al., 2024; Shi et al., 2025; Geng et al., 2025; Huang et al., 2025) or detections (Brazil et al., 2023), but is typically restricted to tabletop robotics, streets, or indoor scenes where objects rest on a supporting surface. In contrast, our approach estimates both pose for a broad range of object types across diverse scenes.
【翻译】布局估计。大量工作从单个图像估计物体姿态,用于物体形状 (Labbé et al., 2022; Wen et al., 2024; Shi et al., 2025; Geng et al., 2025; Huang et al., 2025) 或检测 (Brazil et al., 2023),但通常仅限于桌面机器人、街道或物体放置在支撑表面上的室内场景。相比之下,我们的方法可以估计跨不同场景的广泛物体类型的姿态。
3D datasets. Sourcing 3D annotations is challenging: the modality itself is complex, and the specialized tools required are hard to master. Anecdotally, modeling a 3D mesh from a reference image can take an experienced artist hours (Section D). Instead, existing 3D datasets (e.g., ShapeNet (Chang et al., 2015), Objaverse-XL (Deitke et al., 2023)) primarily consist of single synthetic objects; without paired real-world images, models can only learn from rendered views. In the real-world domain, existing datasets are small and mostly indoors (Reizenstein et al., 2021; Khanna et al., 2024; Fu et al., 2021; Szot et al., 2021; Pan et al., 2023). Models trained on such constrained data struggle to generalize.
【翻译】3D 数据集。获取 3D 标注具有挑战性:模态本身很复杂,所需的专业工具难以掌握。据传闻,从参考图像建模 3D 网格可能需要经验丰富的艺术家花费数小时(D 节)。相反,现有的 3D 数据集(例如 ShapeNet (Chang et al., 2015)、Objaverse-XL (Deitke et al., 2023))主要由单个合成物体组成;没有配对的真实世界图像,模型只能从渲染视图中学习。在真实世界领域,现有数据集规模小且主要是室内场景 (Reizenstein et al., 2021; Khanna et al., 2024; Fu et al., 2021; Szot et al., 2021; Pan et al., 2023)。在这种受限数据上训练的模型难以泛化。
Post-training. While post-training began with a single supervised finetuning stage (Girshick et al., 2013; Wei et al., 2021), strong pretraining (Brown et al., 2020) made alignment much more data efficient (Hernandez et al., 2021), enabling iterative preference-based alignment like RLHF (Ouyang et al., 2022) and online DPO (Tang et al., 2024; Rafailov et al., 2023). When post-training must provide a strong steer, self-training methods offer denser supervision--leveraging the model itself to generate increasingly high-quality demonstrations, rather than relying solely on preference signals (Gulcehre et al., 2023; Anthony et al., 2017; Dong et al., 2023; Yuan et al., 2023). SAM 3D employs self-training to bridge the synthetic → \rightarrow → real domain gap and break the data barrier for 3D perception; most closely resembling RAFT (Dong et al., 2023), but also incorporating preference tuning.
【翻译】后训练。虽然后训练始于单个监督微调阶段 (Girshick et al., 2013; Wei et al., 2021),但强大的预训练 (Brown et al., 2020) 使对齐的数据效率大大提高 (Hernandez et al., 2021),实现了基于偏好的迭代对齐,如 RLHF (Ouyang et al., 2022) 和在线 DPO (Tang et al., 2024; Rafailov et al., 2023)。当后训练必须提供强大的引导时,自训练方法提供更密集的监督------利用模型本身生成越来越高质量的演示,而不是仅依赖偏好信号 (Gulcehre et al., 2023; Anthony et al., 2017; Dong et al., 2023; Yuan et al., 2023)。SAM 3D 采用自训练来弥合合成 → \rightarrow → 真实的领域差距,并打破 3D 感知的数据障碍;与 RAFT (Dong et al., 2023) 最为相似,但也结合了偏好调优。
Multi-stage pretraining. Modern pretraining increasingly employs multiple training stages. Early work on curriculum learning (Bengio et al., 2009) provided a basis for staged data mixing in pretraining, with higherquality data coming later (Grattafiori et al., 2024; OLMo et al., 2025). Li et al. (2023b); Abdin et al. (2024) show that mixing synthetic/web curricula can achieve strong performance at smaller scales. Increasingly, additional mid-training stages are used for capability injection, such as context extension (Grattafiori et al., 2024) or coding (Rozière et al., 2024), and recent work finds that mid-training significantly improves posttraining effectiveness (Lambert, 2025; Wang et al., 2025b). SAM 3D introduces synthetic pretraining and mid-training that can generalize for 3D.
【翻译】多阶段预训练。现代预训练越来越多地采用多个训练阶段。课程学习的早期工作 (Bengio et al., 2009) 为预训练中的分阶段数据混合提供了基础,更高质量的数据在后期出现 (Grattafiori et al., 2024; OLMo et al., 2025)。Li et al. (2023b); Abdin et al. (2024) 表明,混合合成/网络课程可以在较小规模上实现强大的性能。越来越多地,额外的中期训练阶段用于能力注入,例如上下文扩展 (Grattafiori et al., 2024) 或编码 (Rozière et al., 2024),最近的工作发现中期训练显著提高了后训练的有效性 (Lambert, 2025; Wang et al., 2025b)。SAM 3D 引入了可以泛化到 3D 的合成预训练和中期训练。
6 Conclusion
We share SAM 3D: a new foundation model for full reconstruction of 3D shape, texture, and layout of objects from natural images. SAM 3D's robustness on in-the-wild images, made possible by an innovative data engine and modern training recipe, represents a step change for 3D and an advance towards real-world 3D perception. With the release of our model, we expect SAM 3D to unlock new capabilities across diverse applications, such as robotics, AR/VR, gaming, film, and interactive media.
【翻译】我们分享 SAM 3D:一个用于从自然图像完整重建物体 3D 形状、纹理和布局的新基础模型。SAM 3D 在野外图像上的鲁棒性,通过创新的数据引擎和现代训练方法实现,代表了 3D 领域的重大变革和向真实世界 3D 感知的进步。随着我们模型的发布,我们期望 SAM 3D 能够在机器人、AR/VR、游戏、电影和交互媒体等各种应用中解锁新的能力。