解释器模式(interpreter),给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。
需求
- O表示音阶'O 1'表示低音阶,'O 2'表示中音阶,'O 3'表示高音阶;
- 'P '表示休止符,
- 'C D E F G A B '表示'Do-Re-Mi-Fa-So-La-Ti';
- 音符长度 1表示一拍,2表示二拍,0.5表示半拍,0.25表示四分之一拍,以此类推;
注意:所有的字母和数字都要用半角空格分开。例如上海滩的歌曲第一句,'浪奔',可以写成'O 2 E 0.5 G 0.5 A 3 '表示中音开始,演奏的是mi so la。
为了只关注设计模式编程,而不是具体的播放实现,你只需要用控制台根据事先编写的语句解释成简谱就成了。
代码
业务类
c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct Expression {
void (*interpret)(struct Expression *, char **);
void (*excecute)(char, double);
} Expression;
void ExpressionInterpret(Expression *obj, char **plainText) {
int n = strlen(*plainText);
if(n == 0) {
return;
}
else {
char playKey = (*plainText)[0];
int cur = 2;
while(cur < n ) {
if((*plainText)[cur] == ' ') {
break;
}
cur++;
}
char value[4];
strncpy(value, *plainText+2, cur-2);
value[cur-2] = '\0';
double playValue;
sscanf(value, "%lf", &playValue);
obj->excecute(playKey, playValue);
*plainText += cur+1;
}
}
// 音阶
typedef struct Note {
Expression base;
} Note;
void NoteExcecute(char key, double value) {
char note;
if(key >= 'C' && key <= 'G') {
note = key-'C'+'1';
}
else if(key >= 'A' && key <= 'B') {
note = key-'A'+'6';
}
printf("%c ", note);
}
Expression *InitNote() {
Note *obj = (Note *)malloc(sizeof(Note));
obj->base.excecute = NoteExcecute;
obj->base.interpret = ExpressionInterpret;
return (Expression *)obj;
}
// 音阶
typedef struct Scale {
Expression base;
} Scale;
void ScaleExcecute(char key, double value) {
char *scale = NULL;
int v = (int)value;
switch (v)
{
case 1:
scale = "低音";
break;
case 2:
scale = "中音";
break;
case 3:
scale = "高音";
break;
default:
break;
}
printf("%s ", scale);
}
Expression *InitScale() {
Scale *obj = (Scale *)malloc(sizeof(Scale));
obj->base.excecute = ScaleExcecute;
obj->base.interpret = ExpressionInterpret;
return (Expression *)obj;
}客户端
c
int main() {
char *text = "O 2 E 0.5 G 0.5 A 3 E 0.5 G 0.5 D 3 E 0.5 G 0.5 A 0.5 O 3 C 1 O 2 A 0.5 G 1 C 0.5 E 0.5 D 3";
int n = strlen(text);
Expression *exp = NULL;
char *tmp = text;
while(tmp-text < n) {
switch (tmp[0])
{
case 'O':
exp = InitScale();
break;
case 'C':
case 'D':
case 'E':
case 'F':
case 'G':
case 'A':
case 'B':
exp = InitNote();
break;
default:
break;
}
exp->interpret(exp, &tmp);
free(exp);
}
printf("\n");
return 0;
}UML图
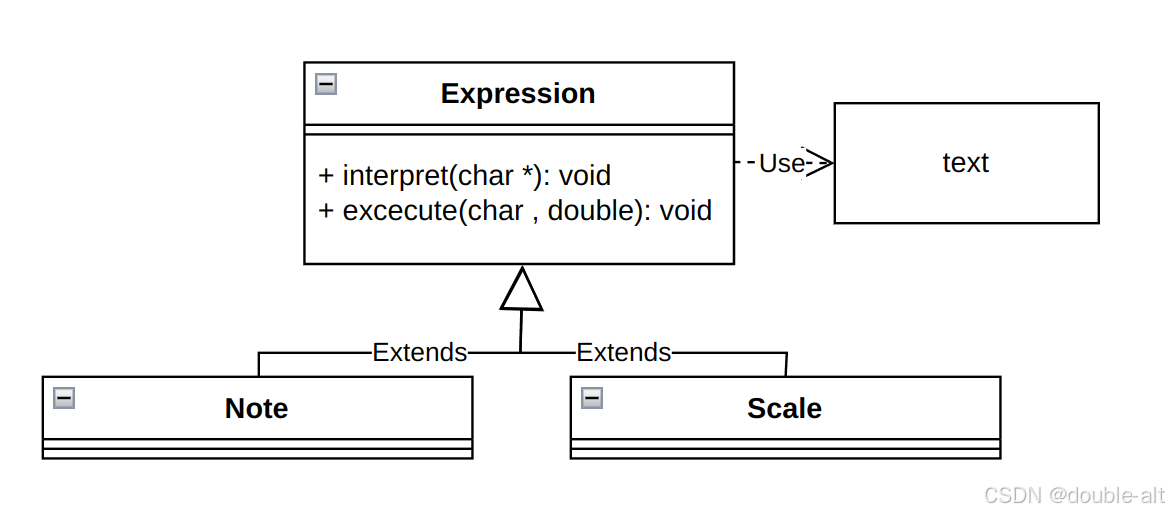
总结
-
解释器模式使用场景?
如果一种特定类型的问题发生的频率足够高,那么可能就值得将该问题的各个实例表述为一个简单语言中的句子。这样就可以构建一个解释器,该解释器通过解释这些句子来解决该问题。
如当有一个语言需要解释执行,并且你可将该语言中的句子表示为一个抽象语法树时,可使用解释器模式。
-
解释器模式的优点?
用了解释器模式,就意味着可以很容易地改变和扩展文法,因为该模式使用类来表示文法规则,你可使用继承来改变或扩展该文法。也比较容易实现文法,因为定义抽象语法树中各个节点的类的实现大体类似,这些类都易于直接编写。
-
解释器模式的缺点?
解释器模式为文法中的每一条规则至少定义了一个类,因此包含许多规则的文法可能难以管理和维护。建议当文法非常复杂时,使用其他的技术如语法分析程序或编译器生成器来处理。
正则表达式就是解释器模式思想的一个实际使用场景。