文章目录
-
- 引言:为何迁移?从"问题词"看迁移动因
- 一、迁移前的核心挑战:兼容性与成本分析
-
- [1.1 语法与语义差异带来的兼容性障碍](#1.1 语法与语义差异带来的兼容性障碍)
- [1.2 数据类型与字符集陷阱](#1.2 数据类型与字符集陷阱)
- [1.3 迁移成本的隐性构成](#1.3 迁移成本的隐性构成)
- [二、迁移策略:离线 vs 在线,工具选型与流程设计](#二、迁移策略:离线 vs 在线,工具选型与流程设计)
-
- [2.1 离线迁移:适用于可停机场景](#2.1 离线迁移:适用于可停机场景)
- [2.2 在线迁移:零停机方案](#2.2 在线迁移:零停机方案)
- 三、关键配置:提升迁移效率与成功率
-
- [3.1 KingbaseES Oracle兼容参数设置](#3.1 KingbaseES Oracle兼容参数设置)
- [3.2 性能调优参数(针对大数据量)](#3.2 性能调优参数(针对大数据量))
- 四、应用层适配:从驱动到SQL的平滑过渡
-
- [4.1 连接驱动替换](#4.1 连接驱动替换)
- [4.2 SQL语句微调](#4.2 SQL语句微调)
- 五、测试与验证:确保迁移质量
-
- [5.1 数据一致性校验](#5.1 数据一致性校验)
- [5.2 性能回归测试](#5.2 性能回归测试)
- 六、数据迁移
- 结语:迁移不是终点,而是新起点
引言:为何迁移?从"问题词"看迁移动因
在当前国产化替代和信创生态加速发展的背景下,越来越多的企业开始将核心业务系统从国外数据库(如Oracle)向国产数据库迁移。这一趋势背后,既有政策引导的推动,也有企业自身对技术自主可控、成本优化及安全合规的迫切需求。
然而,在实际操作中,"Oracle迁移"这一关键词常伴随着一系列"问题词":
- 兼容性差:PL/SQL语法、内置函数、数据类型不一致;
- 迁移成本高:需重写大量存储过程、触发器、包体;
- 停机时间长:传统迁移方式要求业务中断,影响连续性;
- 性能下降:迁移后查询变慢、事务处理能力不足;
- 工具缺失:缺乏成熟、稳定、自动化的迁移辅助手段。
这些痛点不仅增加了项目风险,也延长了交付周期。因此,如何高效、低风险地完成从Oracle到国产数据库的平滑过渡,成为众多IT团队亟需解决的核心课题。
本文将以KingbaseES(金仓数据库)为例,深入剖析Oracle迁移过程中的关键挑战,并提供一套系统化、可落地的迁移策略与最佳实践。

一、迁移前的核心挑战:兼容性与成本分析
1.1 语法与语义差异带来的兼容性障碍
尽管KingbaseES在设计上高度兼容Oracle的SQL和PL/SQL语法,但仍存在若干关键差异点:
| 特性 | Oracle | KingbaseES | 兼容情况 |
|---|---|---|---|
ROWID 伪列 |
支持 | 使用 OID 伪列替代 |
需配置 default_with_oids = true |
NVL() 函数 |
支持 | 使用 COALESCE() 或启用Oracle兼容模式 |
可通过参数开启兼容 |
| 匿名块执行 | 直接支持 | 需包裹在 DO $$ ... $$ 中 |
需代码调整 |
| 包(Package) | 支持同名函数/过程 | 不允许同名同参 | 需重命名 |
| 对象方法链式调用 | 支持 obj.method1().method2() |
不支持 | 需拆分为多步赋值 |
示例:对象方法调用不兼容
sql
-- Oracle 写法(合法)
result := obj.getA().getB().getC();
-- KingbaseES 必须改写为:
temp1 := obj.getA();
temp2 := temp1.getB();
result := temp2.getC();此类差异虽小,但在大型系统中可能遍布成千上万处,若无自动化工具识别,人工排查成本极高。
1.2 数据类型与字符集陷阱
Oracle默认使用 BYTE 语义定义 CHAR/VARCHAR2 长度,而KingbaseES默认为 CHAR 语义。若未统一设置,可能导致:
- 字段截断(如
VARCHAR2(10 BYTE)在中文环境下仅存5个汉字); - 索引失效(因实际存储长度不一致);
- 应用层报错(如JDBC驱动返回长度不符)。
解决方案:在KingbaseES中显式设置会话参数:
sql
SET nls_length_semantics = 'BYTE';或在初始化时全局配置 postgresql.conf。
此外,字符集不匹配也是常见问题。例如Oracle使用 ZHS16GBK,而KingbaseES默认为 UTF8。若未正确转换,将导致中文乱码。
检查Oracle字符集命令:
sql
SELECT userenv('language') FROM dual;
-- 返回:SIMPLIFIED CHINESE_CHINA.ZHS16GBK迁移前必须确保目标库字符集一致,或通过工具进行转码处理。
1.3 迁移成本的隐性构成
迁移成本不仅包括人力投入,还涉及:
- 停机窗口成本:业务中断每小时损失可达数十万元;
- 回退风险成本:若迁移失败,需快速回滚至原系统;
- 长期维护成本:新系统是否易于运维、监控、扩展。
因此,理想的迁移方案应具备:
- 最小停机时间(支持在线迁移);
- 可逆性(支持双向同步或快照回退);
- 自动化程度高(减少人工干预)。
二、迁移策略:离线 vs 在线,工具选型与流程设计
KingbaseES官方提供了两类核心工具:
- KDTS(Kingbase Data Transfer Service):适用于结构+数据的批量迁移;
- KFS(Kingbase FlySync):基于日志解析的实时数据同步工具。
根据业务连续性要求,可选择不同策略:
2.1 离线迁移:适用于可停机场景
适用条件:
- 业务允许数小时至数天停机;
- 数据量中等(< 1TB);
- 无复杂依赖或外部系统耦合。
流程:
- 停止源Oracle写入;
- 使用KDTS全量导出结构与数据;
- 导入KingbaseES;
- 验证一致性后切换应用连接。
KDTS SHELL配置示例(datasource-oracle.yml):
yaml
source:
url: jdbc:oracle:thin:@192.168.1.10:1521:ORCL
driver-class-name: oracle.jdbc.OracleDriver
username: scott
password: tiger
target:
url: jdbc:kingbase8://192.168.1.20:54321/ORCL
driver-class-name: com.kingbase8.Driver
username: scott
password: kingbase
migration:
schemas: [SCOTT]
include-tables: ["EMP", "DEPT"]
drop-existing-object: true
write-batch-size: 1000
use-kdms: true # 启用PL/SQL对象转换提示 :
use-kdms: true可自动转换存储过程、函数等PL/SQL对象。
2.2 在线迁移:零停机方案
适用条件:
- 7×24小时业务系统;
- 数据量大(> 1TB);
- 要求RPO≈0。
核心思路 :
存量 + 增量 = 完整数据
步骤:
-
获取一致点SCN :
sqlALTER SYSTEM CHECKPOINT; SELECT checkpoint_change# FROM v$database; -- 假设返回 200725471 -
导出快照(带SCN) :
bashexpdp scott/tiger schemas=SCOTT flashback_scn=200725471 dumpfile=full.dmp -
导入中间库 → KDTS迁至KingbaseES;
-
启动KFS,从SCN=200725471开始捕获增量 :
bashfsrepctl -service oracle online -from-event ora:200725471
此方案确保业务不停写,数据最终一致。
三、关键配置:提升迁移效率与成功率
3.1 KingbaseES Oracle兼容参数设置
在 kingbase.conf 中建议开启以下参数:
ini
# 兼容Oracle行为
ora_input_emptystr_isnull = on
ora_date_style = on
default_with_oids = on
# 字符语义
nls_length_semantics = 'BYTE'
# 模式搜索路径
search_path = '"$user", public, SCOTT'3.2 性能调优参数(针对大数据量)
| 参数 | 建议值 | 说明 |
|---|---|---|
shared_buffers |
物理内存的25% | 提升缓存命中率 |
work_mem |
256MB~1GB | 加速排序、哈希操作 |
maintenance_work_mem |
2GB | 加快索引创建 |
checkpoint_segments |
32 | 减少I/O抖动 |
max_connections |
≥100 | 满足KDTS并发需求 |
注意:迁移完成后应恢复生产级配置,避免资源浪费。
四、应用层适配:从驱动到SQL的平滑过渡
4.1 连接驱动替换
| 原Oracle驱动 | KingbaseES替代方案 |
|---|---|
ojdbc8.jar |
kingbase8-9.4.0.jar |
| ODBC (Oracle) | KingbaseES ODBC Driver |
| OCI | DCI(KingbaseES兼容OCI接口) |
JDBC连接串变更示例:
java
// Oracle
String url = "jdbc:oracle:thin:@localhost:1521:ORCL";
// KingbaseES
String url = "jdbc:kingbase8://localhost:54321/ORCL";4.2 SQL语句微调
常见需修改的语句:
| Oracle | KingbaseES |
|---|---|
TO_DATE('2023-01-01', 'YYYY-MM-DD') |
直接 '2023-01-01'::DATE |
SYSDATE |
CURRENT_TIMESTAMP |
ROWNUM <= 10 |
LIMIT 10 |
CONNECT BY |
使用递归CTE(WITH RECURSIVE) |
提示 :KingbaseES支持
ROWNUM伪列(需开启兼容模式),但推荐使用标准SQL。
五、测试与验证:确保迁移质量
5.1 数据一致性校验
使用KDTS生成的迁移报告,重点检查:
- 表行数是否一致;
- 主键/唯一约束是否冲突;
- LOB字段是否完整(尤其图片、文档)。
手动校验脚本示例:
sql
-- 行数对比
SELECT 'EMP', COUNT(*) FROM EMP;
-- 校验和(适用于小表)
SELECT SUM(HASH(empno || ename)) FROM EMP;5.2 性能回归测试
使用TPC-C或真实业务SQL进行压测,对比:
- 平均响应时间;
- TPS(每秒事务数);
- 锁等待时间。
若性能下降 > 20%,需进行:
- 执行计划分析(
EXPLAIN ANALYZE); - 索引优化;
- 统计信息更新(
ANALYZE)。
六、数据迁移
数据迁移
Oracle 向 KingbaseES进行数据迁移需使用以下工具:
- KingbaseES 数据迁移工具 KDTS 动态加载待迁移的数据库访问接口,方便用户按照需求指定和使用。异构数据源之间的数据迁移:支持Oracle9i、10g、11g、12c、19c到KingbaseES的数据迁移。
- KingbaseES 数据同步工具 KFS 支持同、异构数据源之间的数据迁移。KingbaseES 数据同步工具 KFS 支持结构迁移、支持全量数据迁移、支持列名映射,支持数据迁移过滤,在配置数据任务时,可以对迁移的表配置where条件、通过匹配的where条件过滤需要迁移的数据。
一般而言,不同的迁移方式需要用到不同的迁移工具:
- 离线迁移,使用 KDTS 即可完成 Oracle 的完整迁移。
- 在线迁移,需要先使用 KDTS 完成历史状态迁移,然后使用 KFS 完成数据的在线追平。
下述分别介绍使用离线迁移方式和在线迁移方式迁移数据的步骤:
- 离线迁移
用户可使用KDTS进行数据的离线迁移,KDTS提供了两种形态(WEB、SHELL),用户可根据需要进行选择,以下章节将分别介绍WEB、SHELL版本进行oracle迁移的具体步骤。
WEB迁移步骤
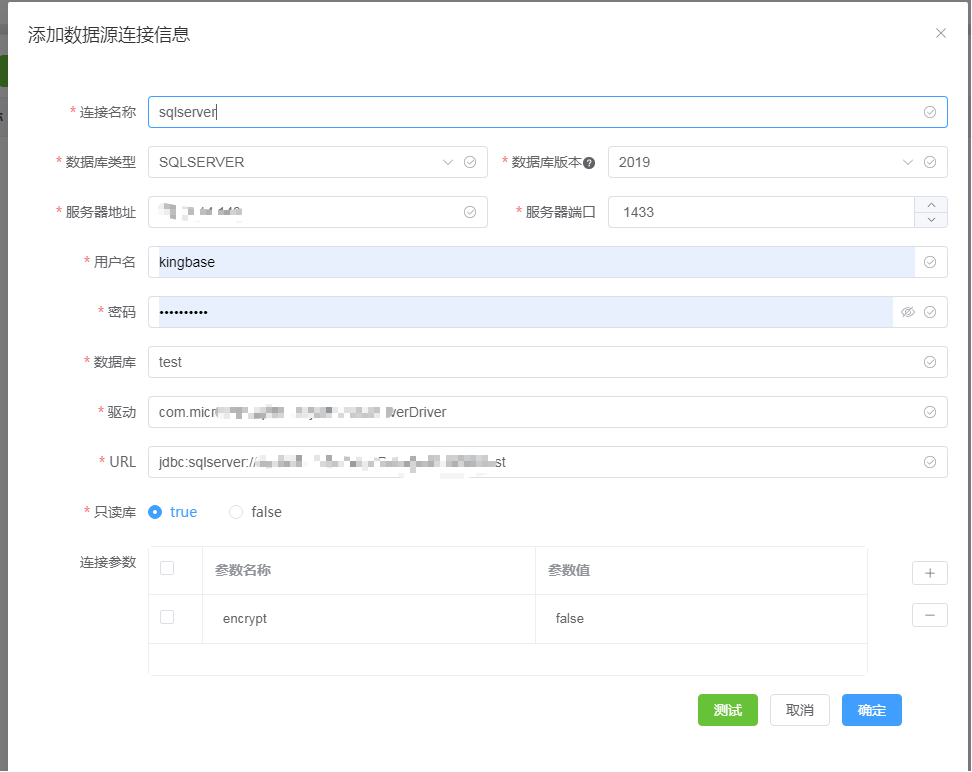
创建源数据库连接 ,创建数据库连接界面如下,填写数据源信息,包括: "连接名称"、"数据库类型"、"数据库版本"、"服务器地址"、"端口"、"用户名"、"密码"、"数据库"、"连接参数"。
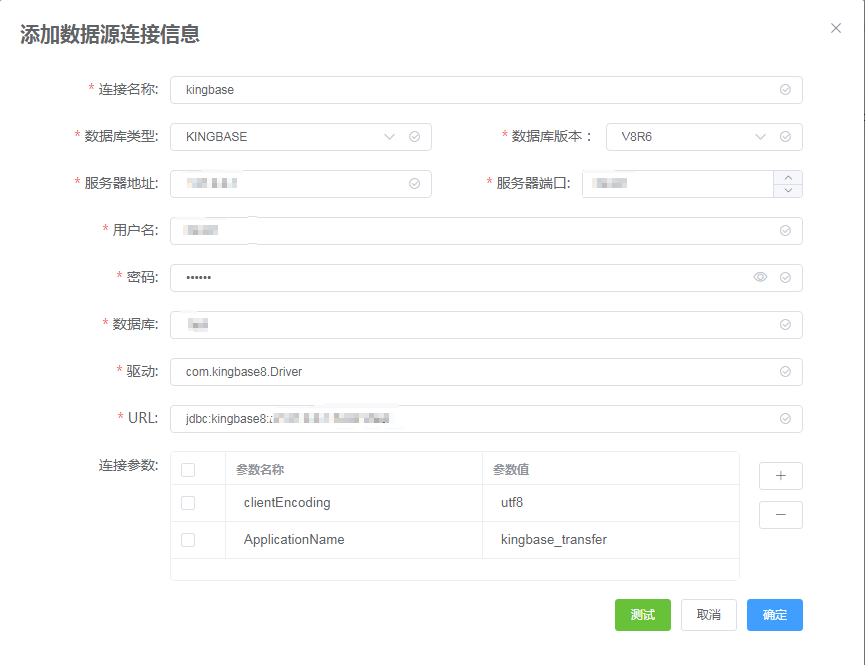
创建目标数据库连接 ,创建数据库连接界面如下,填写数据源信息,包括: "连接名称"、"数据库类型"、"数据库版本"、"服务器地址"、"端口"、"用户名"、"密码"、"数据库"、"驱动"、"URL"、"连接参数"。
新建迁移任务
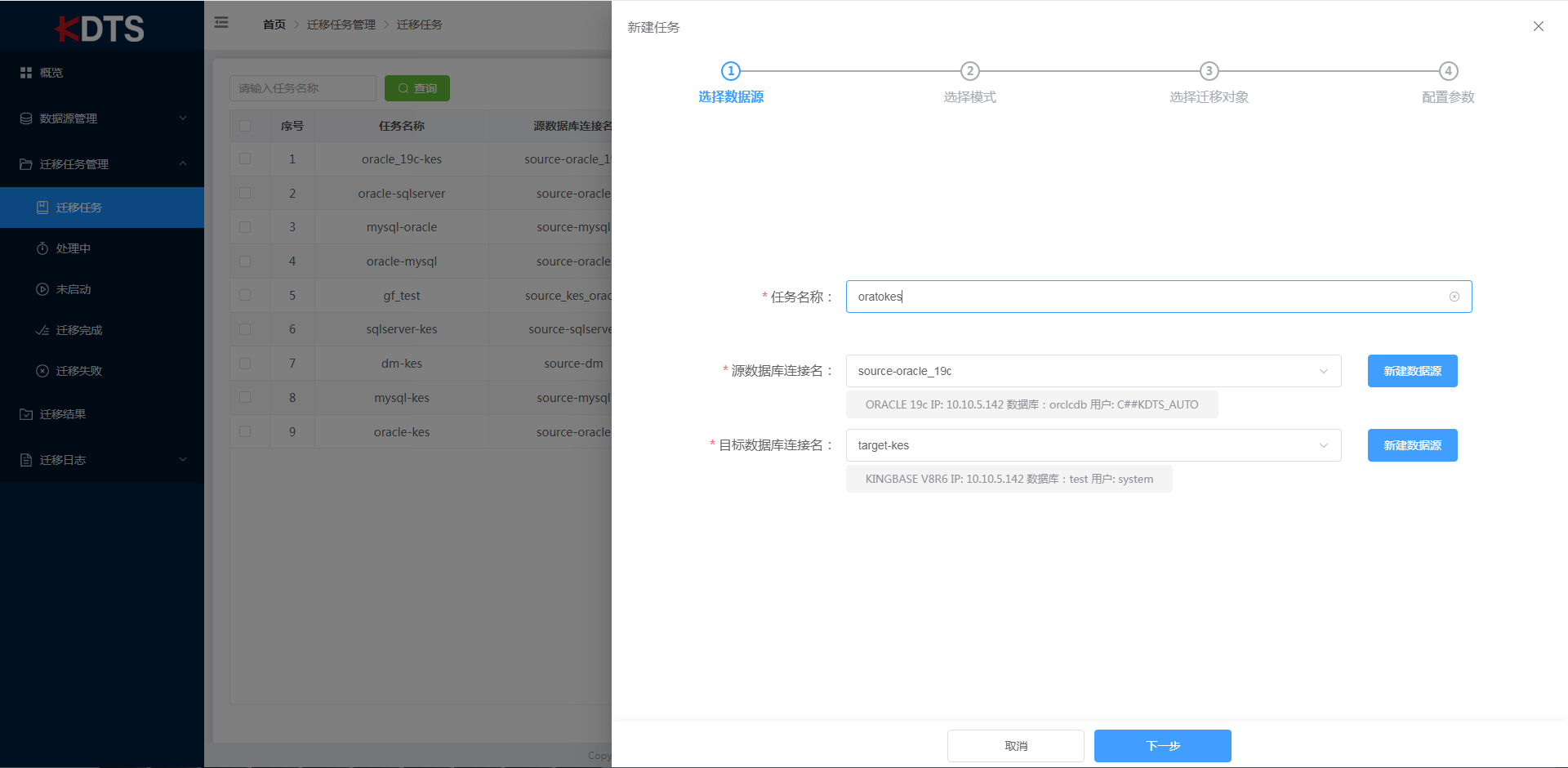
,KDTS采用向导页的方式指导用户新建迁移任务,简单易用,用户依次配置"选择数据源"-"选择模式"-"选择迁移对象"-"配置参数",即可快速配置一个迁移任务。
- 选择数据源
填写自定义任务名称(任务名称不能重复),选择"源数据库"和"目标数据库",或者选择"新建数据源"后使用。
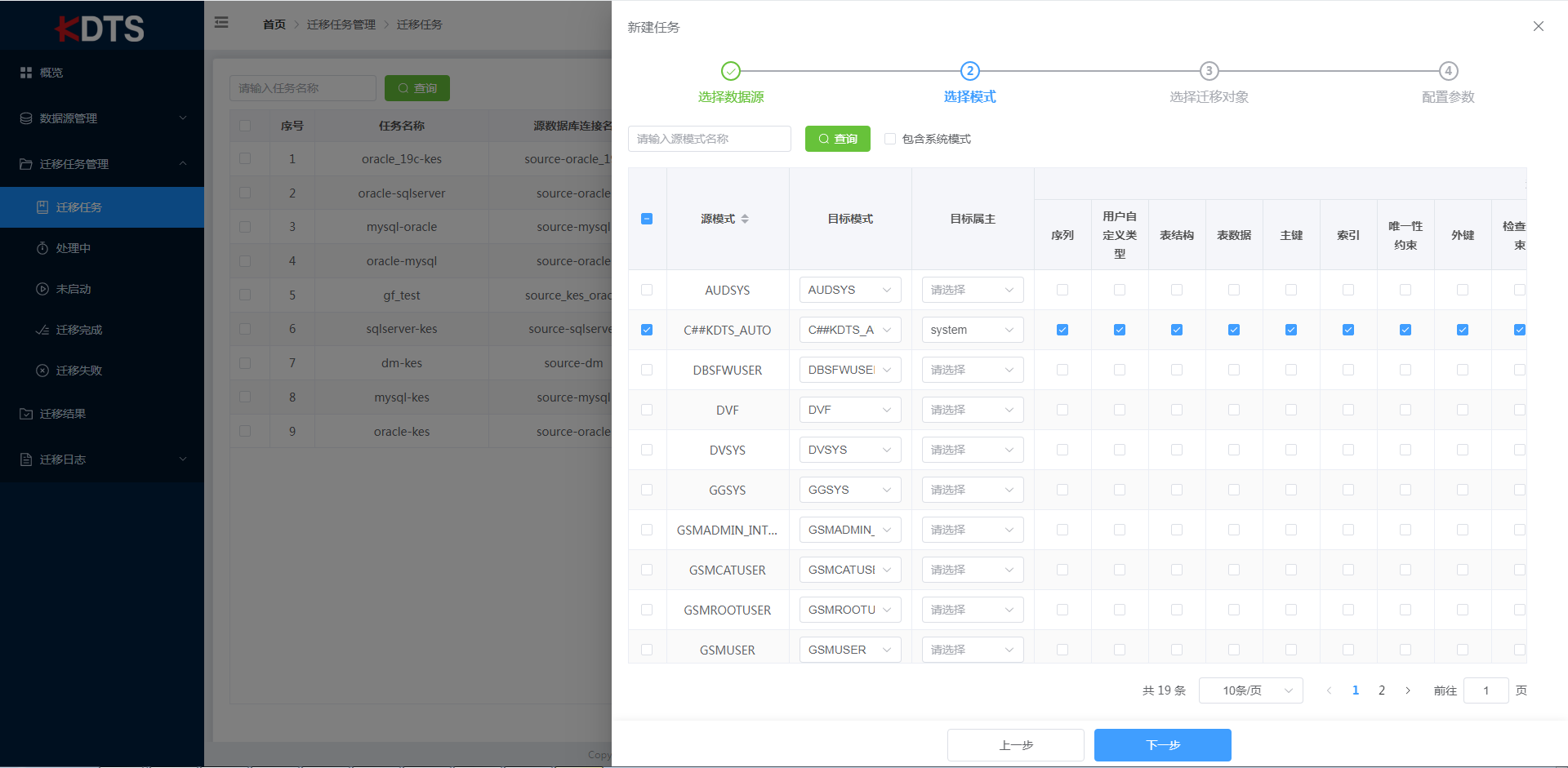
- 选择模式
选择需迁移的模式(如需选择模式在系统模式中可选中"包含系统模式"复选框)的表、视图、序列、函数、存储过程、程序包、同义词。当模式较多时也可以通过左上方的查询框进行检索。 请至少选择一种模式,否则将收到错误提示,以至于不能完成新建任务。
- 选择迁移对象
通过已选模式选择需要迁移数据的表,模式较多时可在已选模式搜索框内输入模式名关键字进行快速检索。
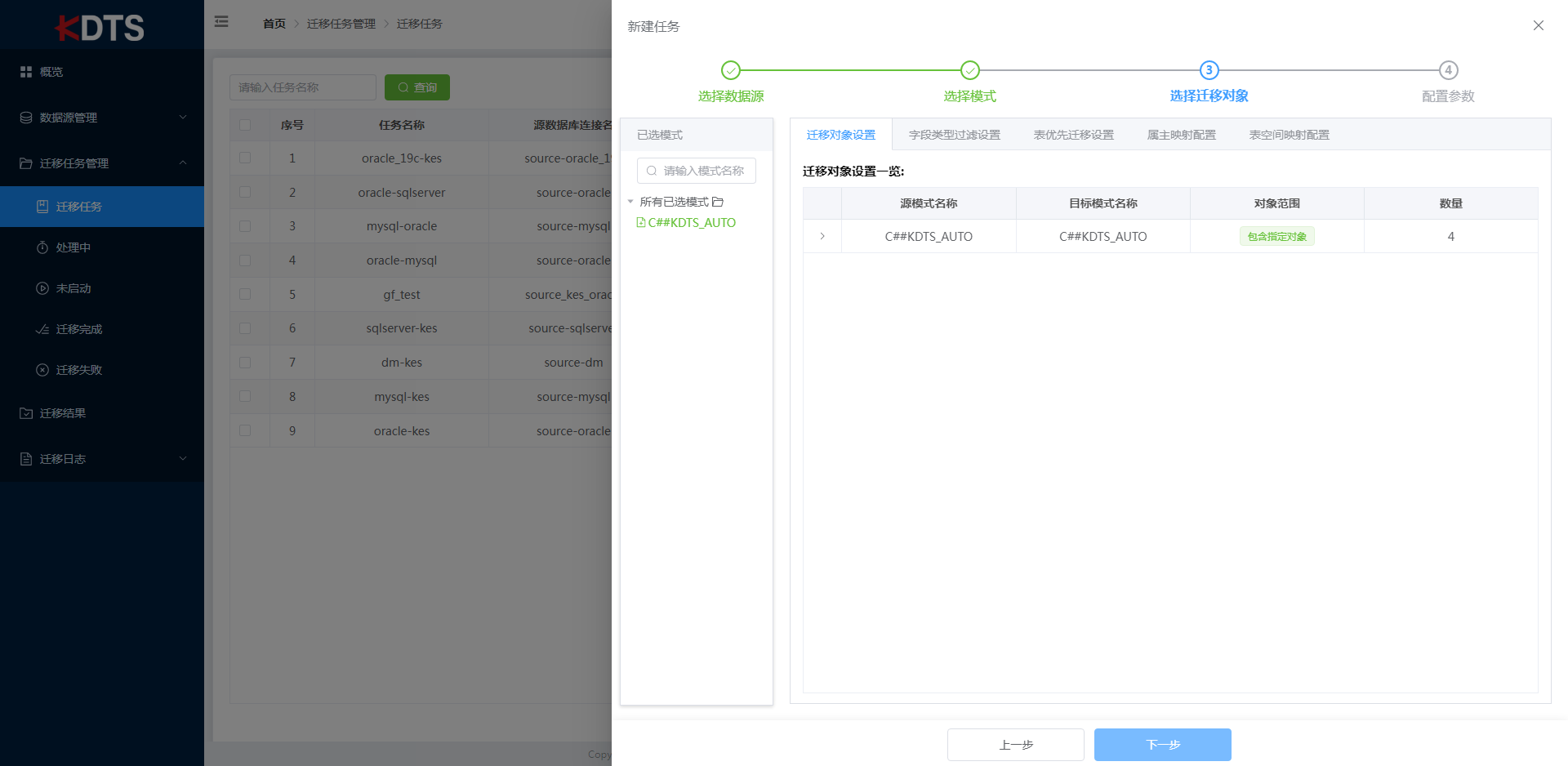
可迁移此模式下全部表,也可以指定或排除部份表,当选择"包含指定表"或"排除指定表"时,请通过"从列表选择"、"从文件导入"或者在输入框内输入表名将数据添加到包含列表中,若未添加数据,则会提示错误导致无法进行下一步并完成新建任务。
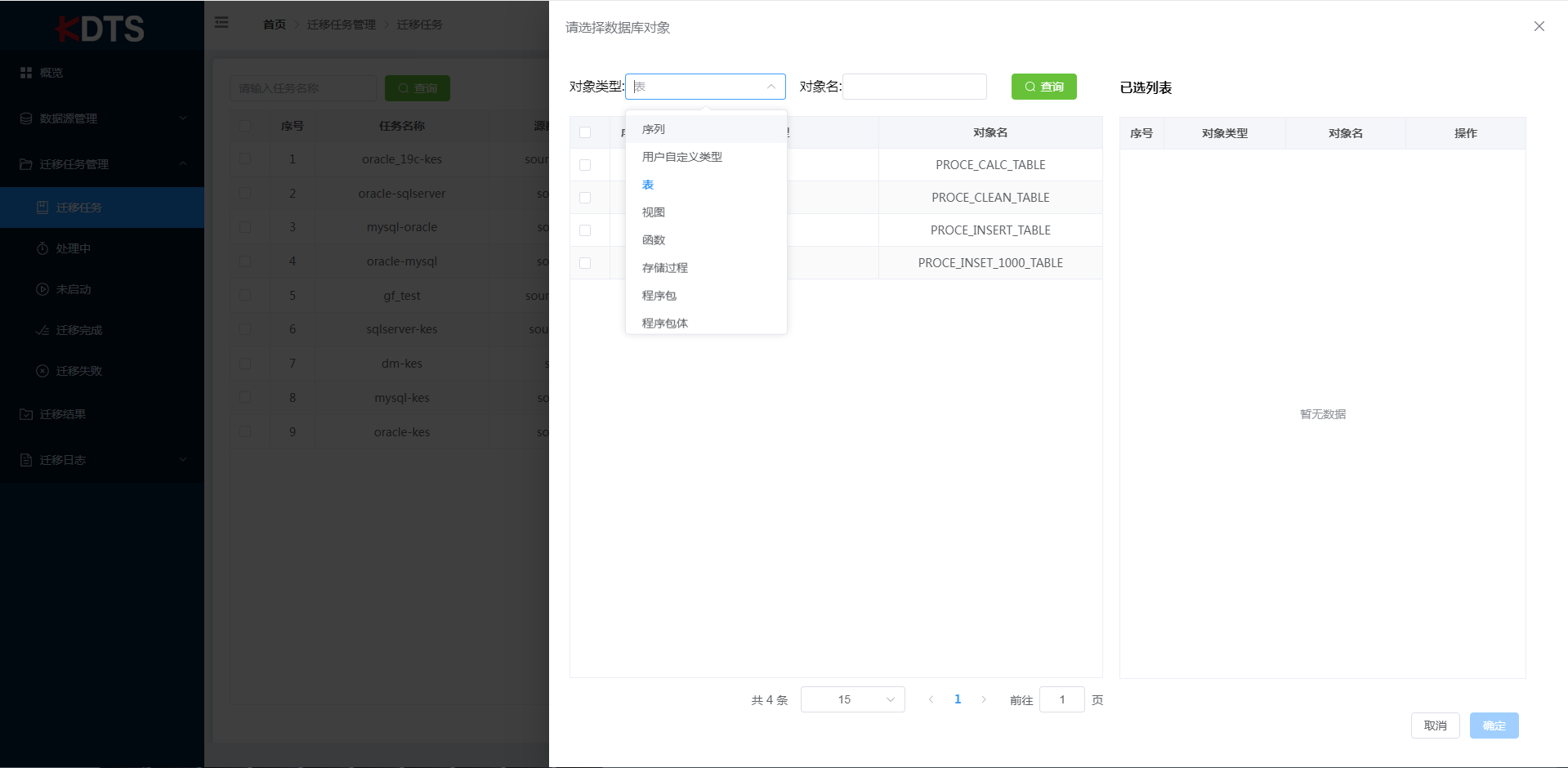
点击"包含指定表"时也可选择多种方式。可直接在输入框内填写表名,多个表用","分割,回车确认;"从列表选择"可在模式中选择指定表;若需"从文件导入",可点击"下载导入模板",根据导入模板规则填写,然后从文件导入该模板。当需要"排除指定表"时,同指定部份表相同操作,但结果相反。
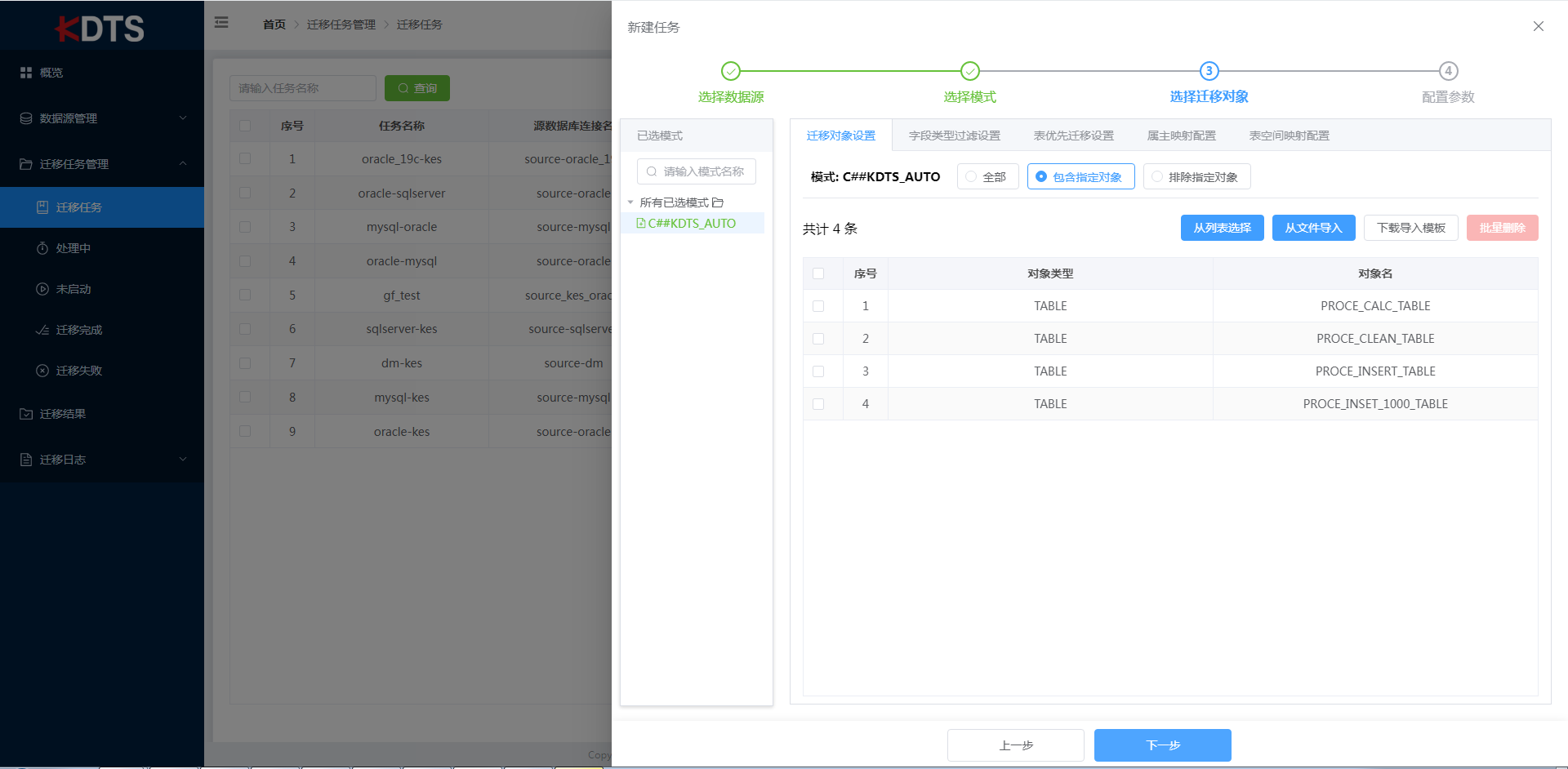
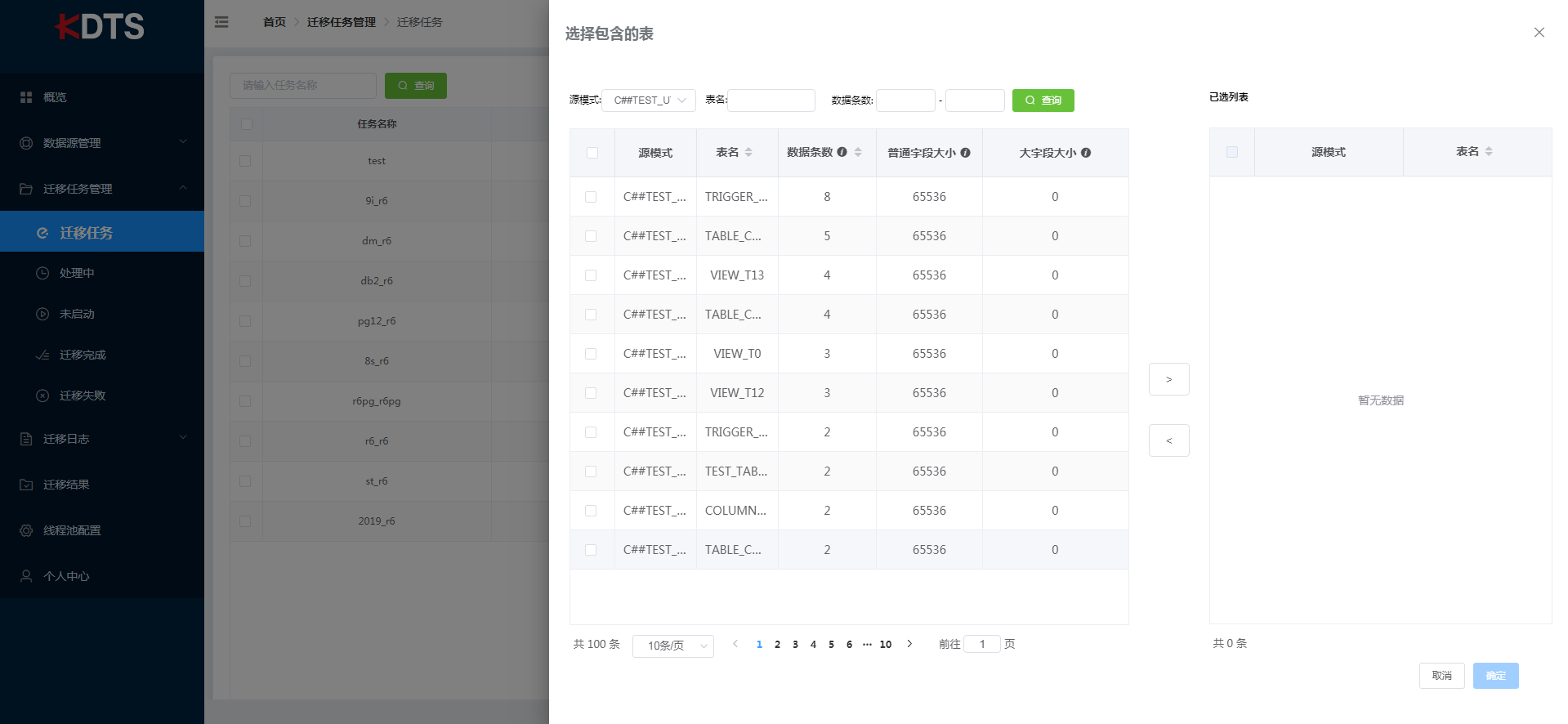
从列表选择表时,可选择对应模式、检索表名关键字、数据条数限制进行快速检索对应的表。点击"添加"按钮后加入到已选列表,当想要移除部份表时可以选择对应的表点击"移除"按钮取消表。选择完成后点击确定。
- 配置参数
迁移工具提供了一系列配置参数用于迁移方案的个性化配置,满足多种迁移场景。配置参数分为"迁移配置"、"数据类型映射"、"线程配置"三个方面。以下以迁移配置为例,介绍各参数的含义。其他配置项请参考工具-迁移工具章节描述。
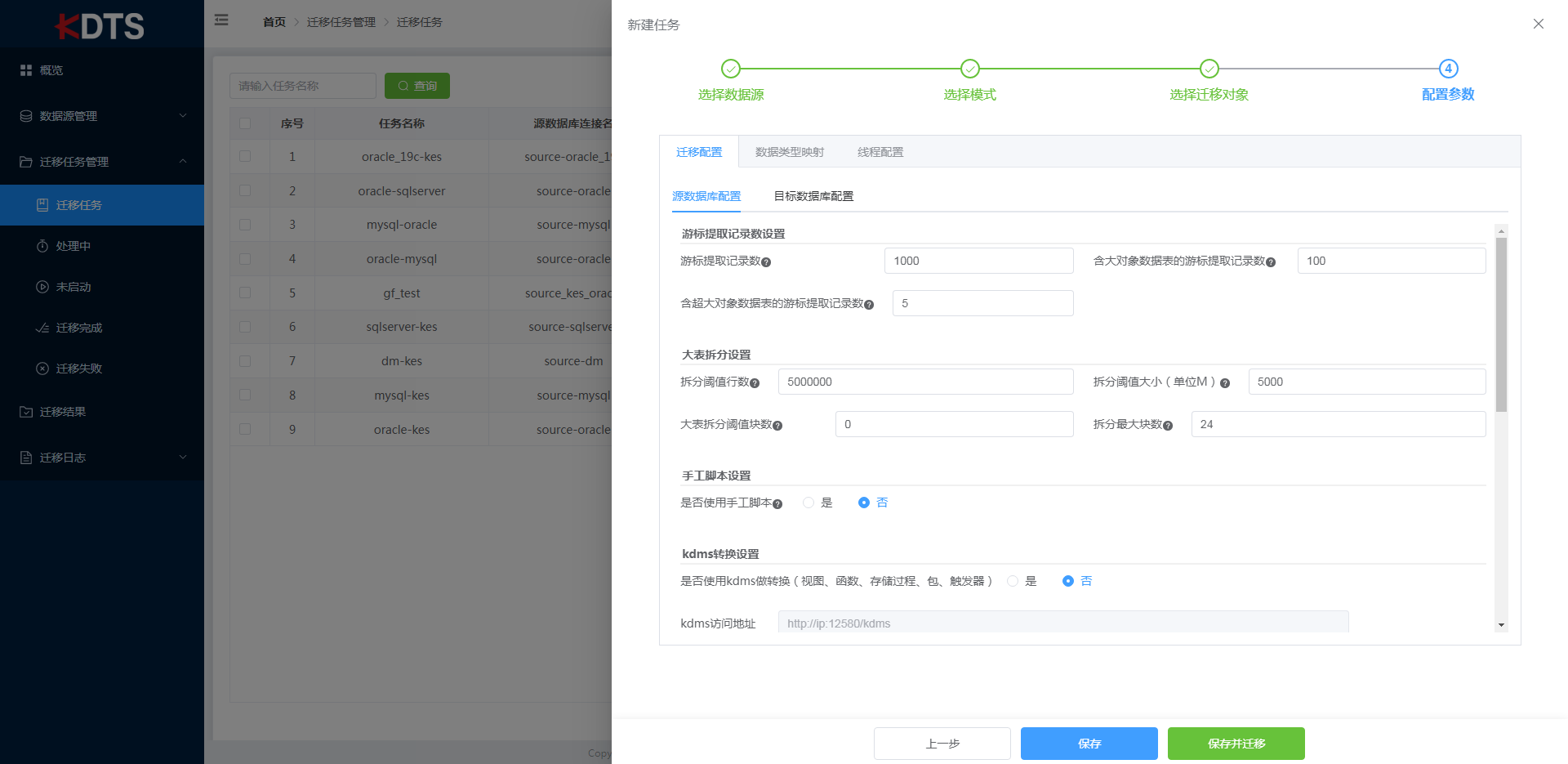
- 表默认处理方式,包括两个复选框项("建表/重建表"、"导入数据"),迁移到KingbaseES数据库是否需要建表或者重建表,以及是否只迁移表结构而不迁移数据的选择,根据实际需求选择合适的选项(默认是全选)。
- 表排序依据,对迁移的表进行排序,可通过"按行数和大字段大小交替"、"行数"、"大小进行排序"(默认是按行数和大字段大小交替)。
- 表数据读取和写入,对表数据的读取和写入制定规则,可操作项包括"源库游标读取记录数"(默认是100)、"批量写入目标库记录数"(默认是1000)、"每次批量提交大小"(默认是100MB)、"LOB字段预读取大小"(默认是4000Byte)。
- 大表拆分阈值依据,对大表进行拆分迁移,设置拆分界限。
- 非对象设置包含"主键"、"检查约束"、"唯一约束"、"外键"、"索引"、"触发器"、"自动转换对象名",可以根据自己的需求选择是否迁移这些非对象数据(默认是全选)。
- 数据库连接数设置,可以限制迁移程序对源数据库和目标数据库的最大连接数(默认是100)。
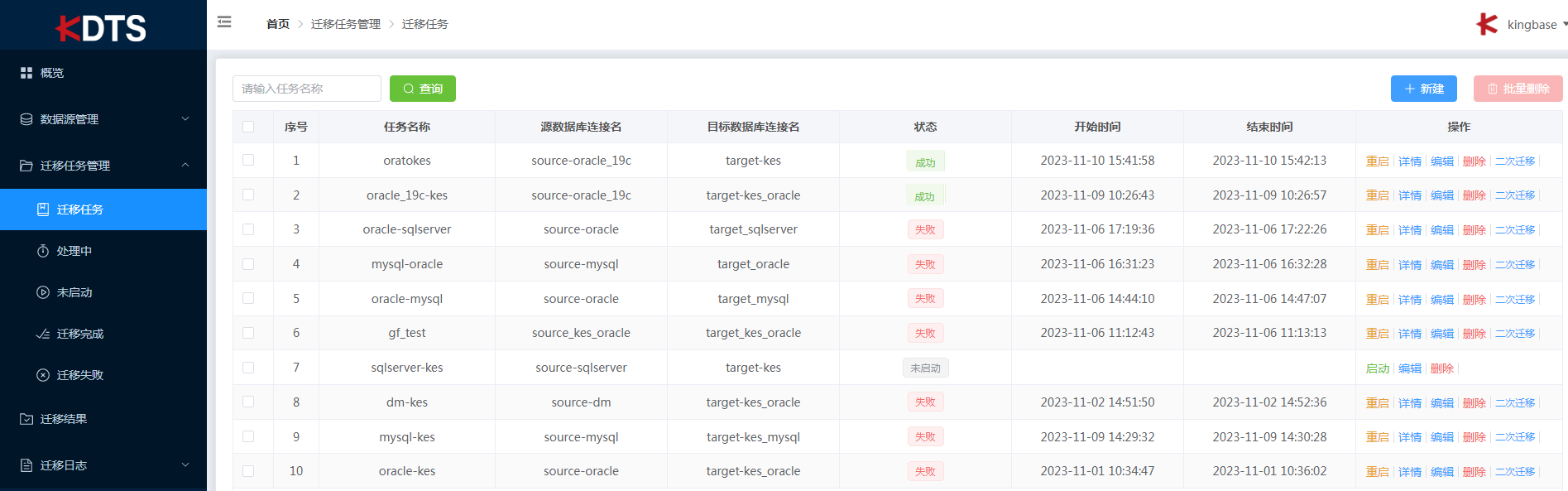
执行迁移任务
,可将此任务作为预迁移任务点击"保存",或者作为执行任务点击"保存并迁移"。迁移完成后任务状态将变成:
- 迁移完成,迁移结束"状态"栏显示"成功",则迁移任务成功。
- 迁移失败,迁移结束"状态"栏显示"失败",则迁移任务失败。失败后可点击详情查看日志有助于解决问题。
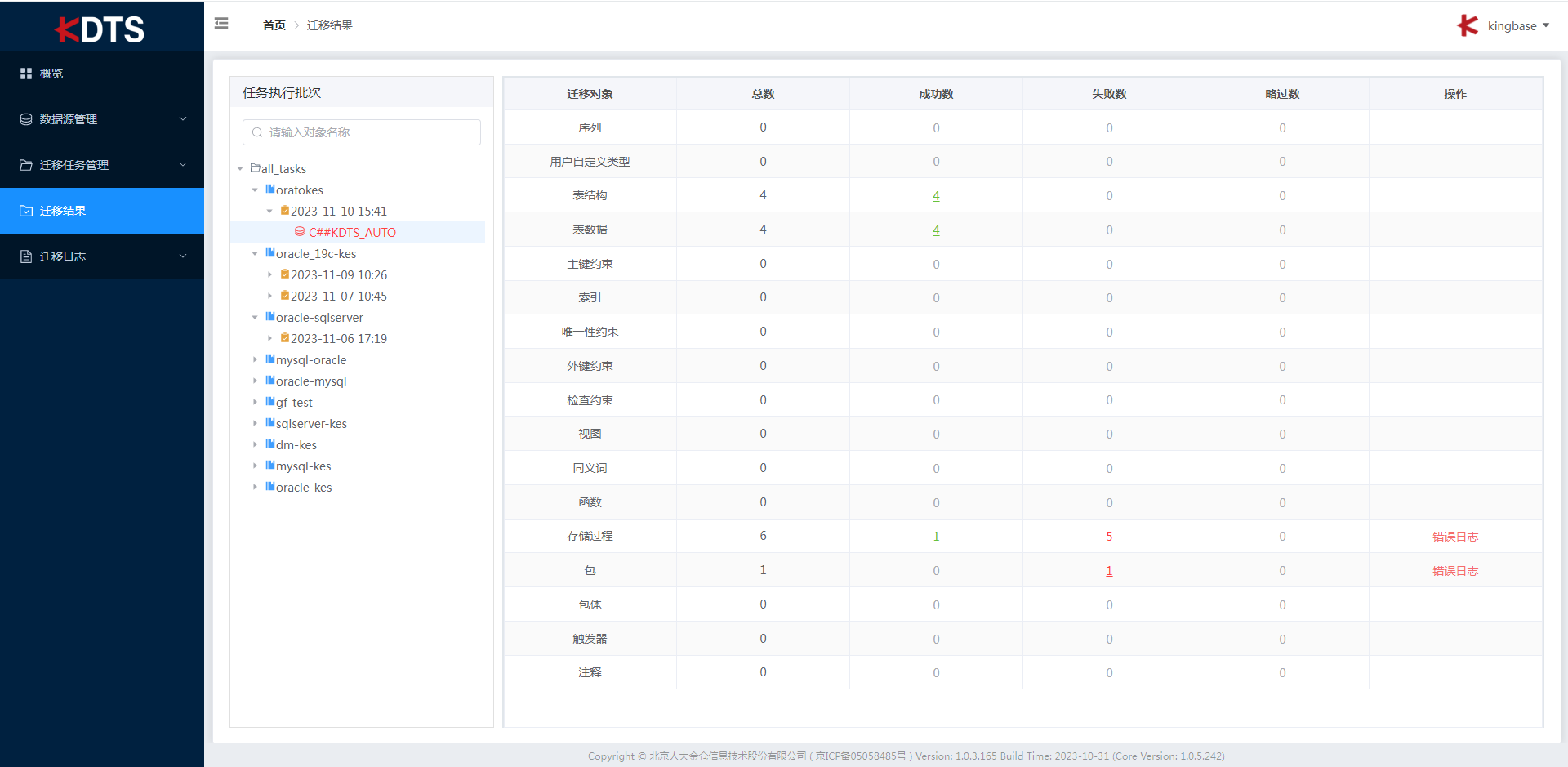
查看迁移报告及问题处理
,迁移完成后,需要确认执行结果,包括迁移数据量,是否有错误发生,可以通过迁移日志和迁移结果进行查看。
"迁移日志"打印迁移任务执行后的日志,具体可分为"系统日志"、"Error日志"、"Info日志"。
"迁移结果"功能的工作区包括"任务执行批次"、"迁移对象"、"总数"、"成功数"、"失败数"、"略过数"、"操作",可以查看历史迁移任务执行的每次记录,以及每次迁移的对象、成功数、失败数、查看失败任务的错误日志。
SHELL迁移步骤
工程目录说明 ,使用SHELL方式进行迁移需要对工程文件有一定了解:
- bin: 启动脚本
- conf: 配置文件
- doc: 帮助文档
- drivers: 数据库连接驱动(注意不同版本驱动的存放目录差别,详见readme.md)
- jdk: jdk
- kdms: kdms程序
- lib: 程序包
- logs: 日志
- result: 迁移报告
JDK安装 ,下载与KDTS安装服务器相匹配的JDK(需要匹配操作系统和CPU架构,如Liunx/AArch64、Linux/x64、Windows/x64等),版本选择JDK 11或更高。下载地址: https://jdk.java.net/archive/, 将下载的JDK解压到KDTS-CLI/jdk目录下即可。
备注
- 请使用解压版本的JDK,以免安装JDK影响服务器上的其它应用。
- 不要把当前的JDK加入系统环境变量,以免影响服务器上的其他应用。
- 如果需要使用服务器上已有的JDK,配置bin/startup.sh(Windows平台为startup.bat)中的JAVA_PATH即可。
配置数据库连接信息,配置步骤分为3步:激活配置文件、配置数据库连接、配置相关参数。
1)进入KDTS-CLI/conf目录下,打开application.yml文件,根据源库类型设置当前激活的源库配置(active: oracle),如下所示:

在正确设置application.yml中的active项后,打开对应配置文件(datasource-oracle.yml),按实际运行环境进行配置即可。
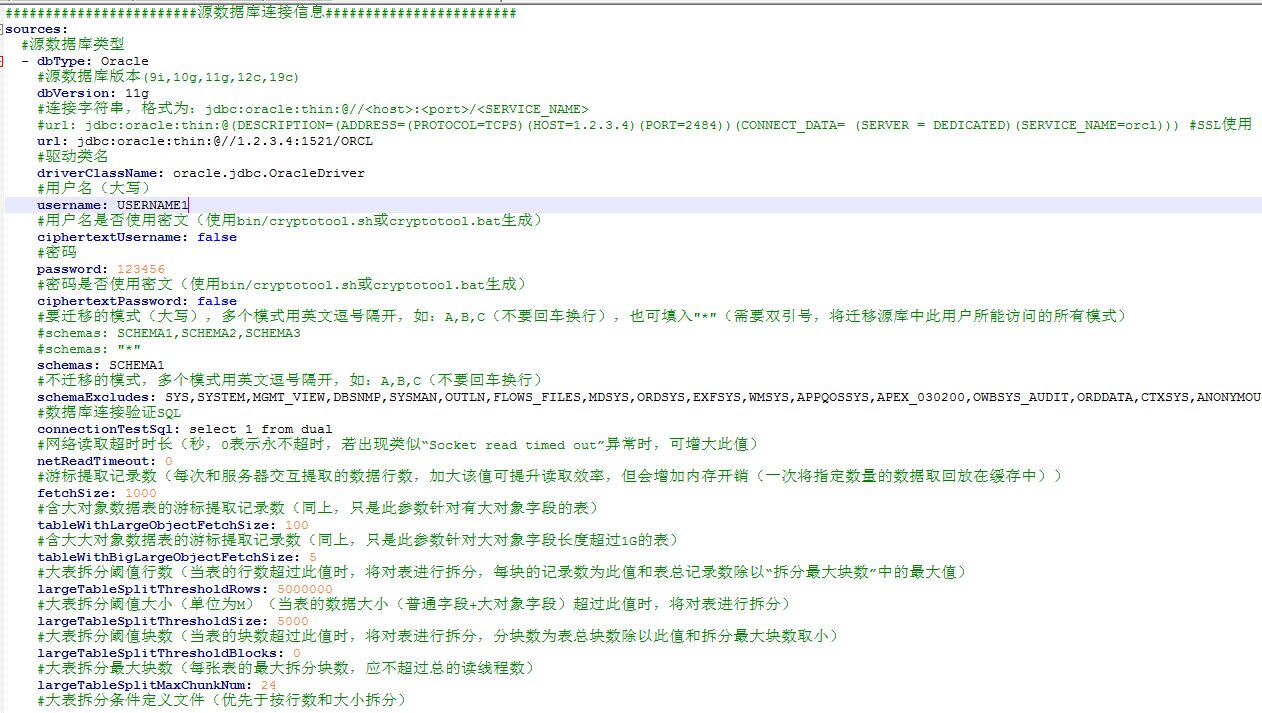
2)配置源端数据库连接信息、目标数据库连接信息。编辑conf/datasource-oracle.yml文件,编辑源端和目标端连接信息,包括url、driver-class-name、username、password信息,如下图所示:

3) 配置要迁移的源库模式,数据库对象,涉及到的参数见下图:


4) 迁移配置参数说明
编辑conf/datasource-oracle.yml文件有多个配置参数,可灵活使用。以下列举常用的配置参数。
- fetch-size,源数据库游标读取记录数,在一定范围内增加该值可提升读取效率,但会增加内存开销。
- table-with-large-object-fetch-size,源数据库含大对象数据表的游标读取记录数,此参数针对有大对象字段的表。
- large-table-split-threshold-rows,大表拆分阈值行数(当表的行数超过此值时,将对表进行拆分,每块的记录数为此值和表总记录数除以"拆分最大块数"中的最大值)。
- large-table-split-threshold-size,大表拆分阈值大小(单位为M),当表的数据大小(普通字段+大对象字段)超过此值时,将对表进行拆分。
- large-table-split-condition-file,大表拆分条件定义文件,优先于按行数和大小拆分。
- table-data-filter-condition-file,表数据过滤条件定义文件。
- use-kdms,是否使用kdms做转换(视图、函数、存储过程、包、触发器)。
- kdms-url,kdms访问地址,前提是use-kdms: true。
- write-batch-size,目标数据库表数据批量提交记录数.
- write-batch-size-big-lob,目标数据库表数据批量提交记录数,特指大对象数据。
- drop-existing-object,是否默认删除目标库中已存在的对象(如表、视图等)。
- truncate-table,是否默认清空目标库中已存在的表数据。
- rename-object,目标数据库对象重命名,除表名、列名外的其他对象: pk、fk、constraint、unique constraint、index 等。
- useDbmsStats,是否使用数据库系统统计信息(如表的记录数、大小等)。
- useManualScript,是否使用手工脚本。
- useKdms,是否使用kdms做转换(视图、函数、存储过程、包、触发器)。
- kdmsUrl,kdms访问地址。
- kdmsSourceDbType,kdms源数据库类型。
- kdmsTargetDbType,kdms目标数据库类型。
- readDataTimeout,读数据超时时长(单位毫秒,0表示永不超时)。
- maxRetries,最大重试次数。
- retryInterval,重试间隔(毫秒)。
- readDataCanResume,读数据(中断后)能否恢复。
- characterNeedDecoding,字符是否需要解码,处理类似Oracle字符集为US7ASCII、WE8ISO8859P1等时迁移中文乱码的问题。
- encodingCharset,编码字符集(字符集为US7ASCII、WE8ISO8859P1设置为"ISO-8859-1")。
- decodingCharset,解码字符集(字符集为US7ASCII、WE8ISO8859P1设置为"GB18030")。
- decodingBytes,是否解码字节(字符集为US7ASCII时设为true)。
- dataCompareBufferSize,源端数据对比缓冲区大小(行数)。
- dataCompareAlgorithm,数据对比摘要算法。
- maximumPoolSize,源数据库最大连接数。
线程相关设置
可根据实际服务器配置按比例调整,如果与目标数据库运行在同一服务器上,应将绝大部分资源分配给数据库。
进入 KDTS-CLI/conf目录下,打开:kb-thread-config.xml,如下图所示:

数据迁移属于IO密集型操作,涉及网络络IO和磁盘IO的交互,一旦发生IO,线程就会处于等待状态,当IO结束,数据准备好后,线程才会继续执行。为提升数据迁移的效率可以多设置⼀些线程池中线程的数量,避免任务等待,线程可以去做更多的迁移任务,提高并发处理效率。但不是线程数设置的越高,效率就越高,线程上下文切换是有代价的。 对于对于IO密集型线程数的设置公式为:线程数 = CPU核心数/(1-阻塞系数) ,其中阻塞系数一般为0.8~0.9之间,取0.9则:
双核CPU: 2/(1-0.9) = 20
64核2路CPU: 64*2/(1-0.9) = 1280
启动脚本 ,进入 KDTS-CLI/bin 目录下,编辑: startup.sh:
- 检查JDK的路径是否正确
JAVA_PATH=${BASE_PATH}/jdk
- 设置JVM内存
系统默认自动获取JVM内存参数,若需手动调整JVM参数:
<font style="color:rgb(68, 73, 80);background-color:rgb(246, 247, 248);">JAVA_OPT="-server -Dfile.encoding=UTF-8 -Dconfig.path=$\{CONFIG_DIR\} -Xmx16g -Xms16g"</font> 主要是: <font style="color:rgb(68, 73, 80);background-color:rgb(246, 247, 248);">-Xmx16g -Xms16g</font> 参数
- 启动运行脚本
进入 KDTS-CLI/bin目录,执行: ./startup.sh 。
查看迁移报告及问题处理
,可以在运行日志(kdts_plus_***.log)中查看到迁移整个过程的信息,包括任务启动、迁移进程、结果汇总。
可查看result下的迁移结果(在形如"result/2021-12-02_15-15-15/Sehcma1"目录下)
- index.html--报告主页面
- detail_XXX.html--XXX详细信息(如表结构、表数据、表主键等)
- FailedScript--失败脚本目录
- IgnoredScript--略过脚本目录
- SuccessScript--成功脚本目录
在迁移过程中一旦某个对象创建失败,KDTS会将该对象的创建sql保留到本次迁移任务文件夹下的FailedScript目录下*.sql文件,用户可以手动修改后通过Ksql或者KStudio工具手动执行。
- 在线迁移
在线迁移过程中,为保障异构数据库数据同步且客户业务不停机,需要一个中间数据库(与源端数据库版本相同的单实例数据库)做媒介迁移存量数据。操作的过程分两部分。
- 先将存量数据迁移至中间数据库上,然后KDTS迁移工具进行初始数据搬迁或通过ETL进行初始数据搬迁至异构数据库(目标数据库)中。
- 待上一步操作完成,从指定断点开始启动KFS源端,正常启动目标端的KFS程序(在已经有KFS运行的情况下,可能需要重置KFS)。
备注
在迁移源库存量数据时避免做以下操作:
1). 运行大型批处理操作会降低复制速率。
2). 备份时执行DDL操作将导致DML和DDL之间存在锁问题
源端数据库备份
- 获取当前数据库一致性scn号
plain
alter system checkpoint global;
select checkpoint_change# from v$database;
假设获取的值为200725471,该scn号将用作启动KFS起始的scn号。- 创建备份目录(需要sysdba权限)
plain
create directory dump_dir as 'd:/dump_dir';
grant read,write on directory dump_dir to kfs_user;- 完整备份数据库
在单实例oracle数据库服务器上执行(导出用户kfs_user的内容):
plain
expdp kfs_user/123456 schemas=kfs_user directory=dump_dir flashback_scn=200725471 dumpfile=DBNAME_20220511.dump存量数据迁移
- 在中间库中创建备份目录(需要sysdba权限)
plain
create directory dump_dir as 'E:/dump_dir';
grant read,write on directory dump_dir to kfs_user;- 将源端备份的数据文件拷贝至E:/dump_dir目录下
- 将备份的数据还原至中间库
plain
impdp kfs_user_new/123456 directory= dump_dir remap_schema=kfs_user:kfs_user_new table_exists_action=replace dumpfile= DBNAME_20220511.dump- 使用数据迁移工具(KDTS)将中间库的数据搬迁至目标数据库。
启动KFS完成数据追平
备注
若KFS之前已经部署运行,则源端和目标端需要先执行重置命令fsrepctl --service XXX reset -all --y,确认中间表、kufl文件等被清除。 KFS部署参考《Kingbase FlySync 安装部署手册》。
源端操作 ,先启动KFS到offline状态,replicator start offline。再使用ONLINE命令,将源端的KFS完全启起来,执行ONLINE命令时需要指定-from-event参数,参数值为备份数据库时查询的scn值。
plain
replicator start offline
fsrepctl -service oracle online -from-event ora:200725471: 200725471目标端操作 ,启动目标端KFS,等待数据追平。
提示
追平的判断方法:
[hes@h1-105](mailto:hes@h1-105) \~$ fsrepctl services Processing services command... NAME VALUE ---- -----appliedLastSeqno: 3 //若源端无新数据产生,则源端和目标端相同 appliedLatency : 0.297 //若源端无新数据产生,延迟时间为0 role : master serviceName : postgresql serviceType : local started : true state : ONLINE Finished services command...
多次迁移
若项目开发过程中,需要定期从一个指定的源数据库迁移到目的数据库中, 那么根据迁移时源数据库和应用的状态,决定离线迁移还是在线迁移。
同时,由于是多次迁移,需要考虑每次迁移时数据库对象的定义是否需要迁移, 若不需要,则只迁移数据就可以,使用 KDTS 和 KFS 都支持只迁移数据; 若每次迁移时需要迁移对象定义,则:
1)对于定义发生变更的表,选择迁移定义和数据。可使用 KDTS的"迁移部分表"功能完成,详细步骤可参考 迁移工具 。
2)对于定义没有发生变更的表,只同步数据即可。可使用 KDTS的"按条件迁移"功能完成,详细步骤可参考 迁移工具 。
应用代码迁移
服务器应用代码迁移
数据迁移后,需要迁移应用系统中用到的服务器应用代码,例如 PL/SQL。
KDTS 已经完成了存储过程,函数,包等 PL/SQL对象的迁移, 只需要关注应用代码中用到的匿名块的代码的迁移。KingbaseES 的 plsql 语言和Oracle的plsql高度兼容, 需要关注如下2点:
- package中Oracle 允许存在同名同参数的存储过程和函数,KingbaseES 不支持,需要重命名为不同名字。
- KingbaseES 不支持 Object type的方法的连续调用,例如不支持 方法1.方法2.方法3, 需要改写为
plain
var1 := 方法1;
var2 := var1.方法2;
var3 := var2.方法3;客户端应用代码迁移
在应用编程接口方面,KingbaseES与Oracle兼容程度较高,所以,一般情况下,应用程序迁移比较容易。应用程序迁移通常应和迁移后的系统测试同时进行。这样可及时修改测试过程中发现的问题。
通常,在应用程序可采用API方式访问和操纵数据库:
该方式通过数据库厂商提供的各种标准应用编程接口在应用程序中与数据库进行交互。常用的应用编程接口如JDBC和ODBC等。目前,大多数数据库厂商均提供很多标准的数据库API及其驱动程序。
在实际应用中,应首先加载驱动程序。加载成功后,利用API函数与数据库交互并完成对数据库数据的操作。
ODBC
对于使用ODBC的应用程序,应创建 KingbaseES ODBC 数据源,然后修改应用程序中连接数据库的用户名、密码等。此外,在Windows系统下对于OLEDB、ADO和NDP,则不需创建数据源。
- Windows数据源配置
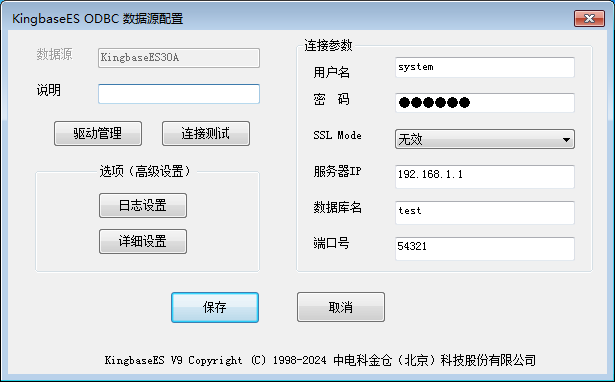
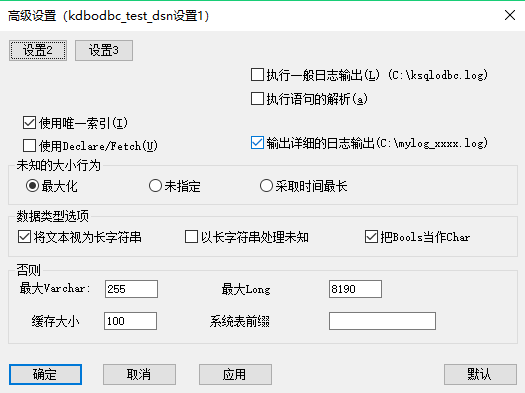
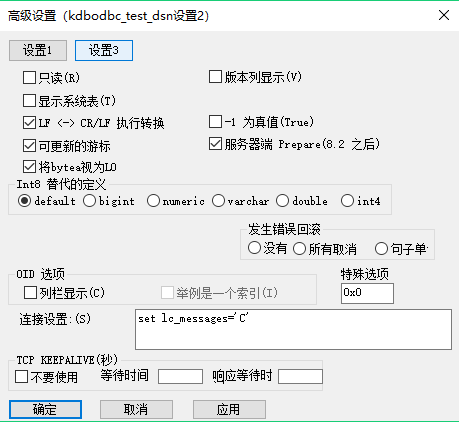
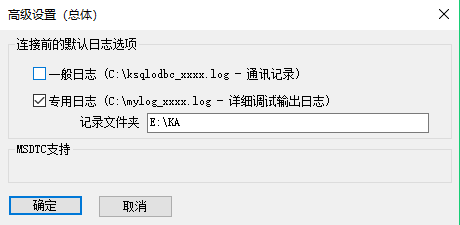
具体配置参数解释请参考 KingbaseES客户端编程接口指南-ODBC 。
- Linux数据源配置
首先检查 ODBC Driver 是否已经安装。在系统中找到 odbcinst.ini 文件,和/usr/bin/odbcinst 对应的 odbcinst.ini 在 /etc 目录下,和 /usr/local/bin/odbcinst 对应的 odbcinst.ini 在 /usr/local/etc 目录下。在odbcinst.ini 文件中查找 KingbaseES 9 ODBC Driver 这一项。
如果没有,则参考增加如下内容:
plain
[KingbaseES 9 ODBC Driver]
Description = KingbaseES 9 ODBC Driver for Linux
Driver = /opt/Kingbase/Odbc/lib/kdbodbcw.so
增加odbc.ini文件,内容如下:
[kingbase]
Description = KingbaseES
Driver = KingbaseES 9 ODBC Driver
Servername = 127.0.0.1
Port = 54321
Username = SYSTEM
Password = MANAGER
Database = TEST具体配置参数解释请参考 KingbaseES客户端编程接口指南-ODBC 。
移植Oracle OCI应用程序
KingbaseES支持OCI的大部分常用接口。
具体参见手册 KingbaseES客户端编程接口指南-DCI 。
其它应用框架
其它应用框架的使用,请参照客户端编程开发框架的使用指南。如无说明,请及时联系KingbaseES支持工程师。
测试与调试迁移后的系统
任何一个成熟的应用系统如果代码、尤其是关键代码变动后,则应进行全面细致的测试。类似的,更换新的后台数据库系统以后,也应对迁移后的数据库系统进行全面的功能和性能测试。
功能测试和排错
功能测试是指对迁移后的数据库系统的每一个模块和功能进行全面的系统回归测试,用以确保新系统各个功能的正确性。
因此,完成数据库对象和应用程序迁移后,应对迁移后的系统进行全面的功能测试,并对测出问题及时分析、排查和修改。对那些很难定位的问题,请及时联系KingbaseES支持工程师。
性能测试和调优
迁移后的系统性能测试和调优是在完成迁移得系统功能测试后和系统上线前,在实际或模拟生产数据上,对迁移后的系统进行的性能测试和调优。
迁移后的系统性能测试和调优的主要步骤如下:
- 构造测试数据:若条件允许的话,建议构造与实际生产数据规模相同的数据,并模拟构造未来一年、两年、五年或更长生命周期的数据进行测试。
- 部署测试软硬件环境:根据测试数据规模的大小,配置适当的测试软硬件环境。
- 性能测试:既可采用手动方式,也可利用TPCC测试工具、LoadRunner等工具对迁移后的系统进行自动测试。
- 性能调优:对未达到性能指标的功能模块及其SQL语句进行优化并给出相关建议。
通常,性能测试效果与测试数据规模、软硬件配置等因素密切相关。因此,建议性能测试时,测试数据规模、软硬件配置应尽量与将来的实际生产环境一致。必要时,在未来一年、两年、五年等不同模拟数据规模场景下,应分别测试迁移后的系统的性能指标,用以保证钱以后的系统未来仍能具有良好的性能表现。
结语:迁移不是终点,而是新起点
从Oracle到KingbaseES的迁移,本质上是一次架构演进而非简单替换。它要求团队不仅掌握工具使用,更要理解两种数据库的内核差异、应用耦合方式及运维体系。
通过科学的评估、合理的工具选型、精细的配置调优和全面的测试验证,完全可以实现低成本、低风险、高成功率的迁移目标。更重要的是,这一过程将推动企业构建更自主、更安全、更具弹性的数据基础设施,为未来数字化转型奠定坚实基础。