提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 一、前言
- 二、YOLOv12的核心创新:高效注意力机制的革命
-
-
- 区域注意力(Area Attention,A2)机制
-
- 残差高效层聚合网络(R-ELAN)
-
- 架构级优化
-
- 三、YOLOv12性能基准
- 四、环境搭建(windows版本)
-
- **1、基础环境搭建**
- **2. requirements.txt安装**
- **3. 安装flash-attention**
- **4. 环境验证**
- 五、量化流程
-
-
- 在上述环境中安装量化依赖库
-
提示:以下是本篇文章正文内容,下面案例可供参考
一、前言
YOLO12于2025年初发布,引入了一种以注意力为中心的架构,这与之前YOLO模型中使用的传统基于CNN的方法不同,但仍保持了许多应用所需的实时推理速度。该模型通过注意力机制和整体网络架构中的新颖方法创新,实现了高目标检测准确性,同时保持了实时性能。
本文将深入解析YOLOv12的架构创新,重点介绍其区域注意力模块(A2)和R-ELAN结构,然后详细展示如何将YOLOv12模型通过PNNX转换并部署到NCNN框架,实现高性能目标检测与分割。相比YOLOv11,YOLOv12在保持实时性的同时,精度提升显著,本文将通过完整流程展示其部署优势。
YOLO12代码仓库: https://github.com/sunsmarterjie/yolov12
ncnn-android-yolov12: https://github.com/LeeeFu/ncnn-android-yolov12
二、YOLOv12的核心创新:高效注意力机制的革命
1. 区域注意力(Area Attention,A2)机制
在计算机视觉领域,传统自注意力机制(如Transformer中的标准注意力)面临根本性瓶颈:计算复杂度随特征图尺寸呈二次方增长(O(n²)),且内存访问模式低效,导致实时应用难以落地。YOLOv12通过引入区域注意力(Area Attention, A2) 机制来解决这个问题。该机制将特征图划分为L个相等的部分,默认为4部分,从而将计算复杂度降低至O((H/L)²W²)或O(H²(W/L)²),有效降低了计算成本。此外,这种分割方式避免了复杂的窗口划分过程,简化了操作流程,同时保持了较大的感受野,使得模型可以在不牺牲性能的前提下实现高效的计算。与传统方法相比,区域注意力不仅显著降低了计算负担,还提升了内存访问效率,特别是在结合FlashAttention技术后,通过优化I/O减少了内存访问次数,进一步提高了计算效率。
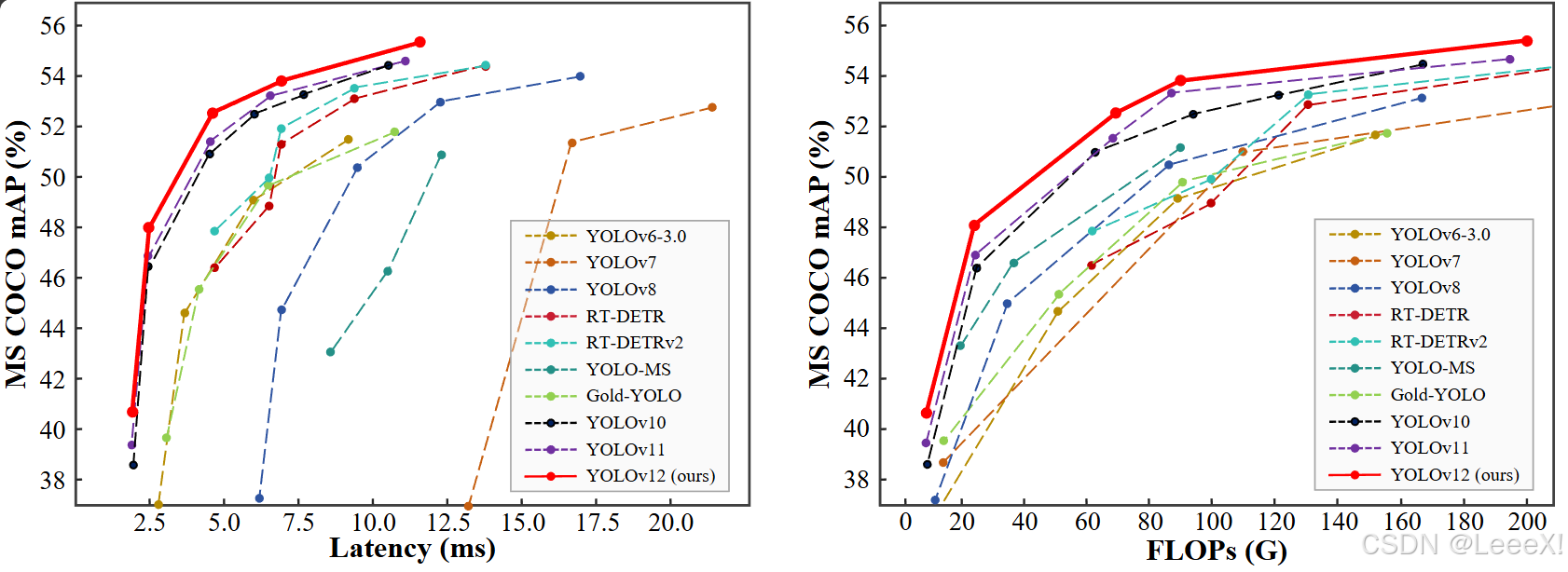
在COCO数据集上,YOLOv12-N(Nano版本)实现40.6% mAP与1.64ms推理延迟(RTX 3080) ,较YOLOv11的250fps降至180fps(因感受野扩大导致速度微降,但精度提升显著)。关键优势在于与FlashAttention的协同优化 :A2通过减少内存访问次数(利用GPU内存层次结构),使注意力操作在Turing/Ampere/Hopper架构GPU上加速0.3--0.4ms。对比竞品,YOLOv12-S比RT-DETR-R18快42%,计算量(FLOPs)与参数量(Params)分别降低36%与45%,证明A2在精度-效率平衡上实现质的飞跃。
2. 残差高效层聚合网络(R-ELAN)
原始的ELAN架构在处理大规模模型时容易出现梯度阻断和训练不稳定的问题,这主要是因为缺乏有效的输入到输出的残差连接 。为了解决这些问题,YOLOv12引入了残差高效层聚合网络(R-ELAN) ,通过添加块级残差连接和缩放因子(默认值为0.01)来增强模型的稳定性。这种方法不仅能缓解梯度消失问题,还能提高训练过程中的收敛速度。另外,R-ELAN重新设计了特征聚合的方法,创建了一个类似瓶颈的结构,这样既能有效地减少计算量,又能确保信息流的顺畅传递。
R-ELAN的应用带来了显著的性能改善:参数量减少了18%,FLOPs降低了24%,这表明模型变得更加轻量化且计算效率更高。尤其是在处理较大规模的数据集时,R-ELAN展现出了更好的稳定性和更高的准确性。与前代产品相比,这种架构优化不仅增强了模型的鲁棒性,还在一定程度上缩短了训练时间,使得YOLOv12能够在各种应用场景中更加灵活地部署。
3. 架构级优化
YOLOv12的架构级优化摒弃了YOLOv11的冗余设计,通过系统性精简实现效率最大化:
- MLP比例动态调整:将Transformer中MLP扩展比例从4降至2,平衡注意力层(O(n²))与前馈层(O(n))计算量,避免MLP成为性能瓶颈;
- 位置编码隐式化:移除显式位置编码,代之以7×7深度可分离卷积(DSConv) 作为"位置感知器",利用卷积的局部性隐式建模空间信息,减少额外参数(位置编码占模型3.2%参数);
- 结构深度压缩:将堆叠块数量从YOLOv11的3组精简至1组,通过瓶颈结构(Bottleneck)降低深度,加速特征融合;
- 卷积算子集成:在关键层(如特征融合层)保留高效卷积操作,替代部分自注意力,减少参数量(卷积占比提升至68%)。通过计算流重构(如MLP比例与DSConv协同)实现系统级效率提升,彻底打破YOLOv11"模块堆砌"模式。
三、YOLOv12性能基准
了解架构革新后,我整理了官方YOLO11和YOLO12的测试数据,做成下面这个对比表。下表基于COCO val2017数据集,在相同硬件配置下对比YOLO11与YOLO12各尺寸模型的性能表现:
| Model | size(pixels) | mAPval(50-95) | Speed T4(ms) | params(M) | FLOPs(B) |
|---|---|---|---|---|---|
| YOLO11n | 640 | 39.5 | 1.50 | 2.6 | 6.5 |
| YOLO12n | 640 | 40.4 | 1.60 | 2.5 | 6.0 |
| YOLO11s | 640 | 47.0 | 2.50 | 9.4 | 21.5 |
| YOLO12s | 640 | 47.6 | 2.42 | 9.1 | 19.4 |
| YOLO11m | 640 | 51.5 | 4.70 | 20.1 | 68.0 |
| YOLO12m | 640 | 52.5 | 4.27 | 19.6 | 59.8 |
| YOLO11l | 640 | 53.4 | 6.20 | 25.3 | 86.9 |
| YOLO12l | 640 | 53.8 | 5.83 | 26.5 | 82.4 |
| YOLO11x | 640 | 54.7 | 11.30 | 56.9 | 194.9 |
| YOLO12x | 640 | 55.4 | 10.38 | 59.3 | 184.6 |
几个关键发现:
YOLOv12-N比YOLOv10-N高2.1% mAP,比YOLOv11-N高1.2% mAP,速度相当。 可视化分析显示YOLOv12产生更清晰的物体轮廓和更精确的前景激活。在工业检测等应用中,YOLOv12显示出更准确的缺陷定位能力。
与竞品的对比 与同类模型相比,YOLOv12展现出显著优势,与YOLO系列前代比较相比YOLOv10/v11,Nano版本mAP提升显著(2.1%/1.2%),且保持实时性能。 训练曲线更稳定,可完成完整600轮训练,而YOLOv8通常在200轮后因性能提升有限而早停。
与RT-DETR系列比较,YOLOv12-S比RT-DETR-R18/RT-DETRv2-R18快42%,计算量和参数减少36%/45%。在相同硬件上,mAP提高1.5%/0.1%。
YOLO12能够高效支持以下多种计算机视觉任务:
- 目标检测:在图像或视频帧中识别并定位多个物体。
- 实例分割:对物体进行像素级的精确轮廓划分。
- 图像分类:将整幅图像归入相应的类别或标签。
四、环境搭建(windows版本)
注:利用Anaconda来搭建windows基础环境,YOLO12推荐**python3.11、pyTorch 2.4.1、torchvision 0.19.1、torchaudio 2.4.1、ultralytics 8.3.63 **
1、基础环境搭建
bash
#1. 创建虚拟环境
conda create -n yolov12 python=3.11
#2. 进入虚拟环境
conda activate yolov12
#3. 下载YOLO12源码
git clone https://github.com/sunsmarterjie/yolov12.git
# 4. 下载预训练环境
wget https://github.com/sunsmarterjie/yolov12/releases/download/v1.0/yolov12n.pt
wget https://github.com/sunsmarterjie/yolov12/releases/download/v1.0/yolov12s.pt
wget https://github.com/sunsmarterjie/yolov12/releases/download/seg/yolov12n-seg.pt
wget https://github.com/sunsmarterjie/yolov12/releases/download/v1.0/yolov12s.pt
# 5. 安装pytorch(GPU)通常外网下载比较慢,可以科学上网下载后,离线安装
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu1242. requirements.txt安装
进入yolov12-main 这个文件夹,将前三行给注释掉,因为torch相关的我们已经手动完成安装,以及flash_attn组件是linux版本,我们windows上的需要手动安装。

之后进行安装
bash
pip install -r requirements.txt
pip install -e .
python
#torch==2.2.2
#torchvision==0.17.2
#flash_attn-2.7.3+cu11torch2.2cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
timm==1.0.14
albumentations==2.0.4
onnx==1.14.0
onnxruntime==1.15.1
pycocotools==2.0.7
PyYAML==6.0.1
scipy==1.13.0
onnxslim==0.1.31
onnxruntime-gpu==1.18.0
gradio==4.44.1
opencv-python==4.9.0.80
psutil==5.9.8
py-cpuinfo==9.0.0
huggingface-hub==0.23.2
safetensors==0.4.3
numpy==1.26.43. 安装flash-attention
进入flash-attention,选中相对应版本,下载完成之后需要本地安装,复制到yolov12-main文件夹中,cd到yolov12-main文件夹后,进行安装。
bash
pip install flash_attn-2.7.0.post2+cu124torch2.4.1cxx11abiFALSE-cp311-cp311-win_amd64.whl4. 环境验证
在yolov12-main文件夹中创建一个infer.py脚本,加载检测和分割的预训练权重,确保环境没有问题
python
from ultralytics import YOLO
model = YOLO('yolov12n/yolov12{n/n-seg}.pt')
model.predict(source='bus.jpg',save=True)

五、量化流程
1. 在上述环境中安装量化依赖库
python
pip install -U pnnx ncnn待更新--260126--
🌷🌷🍀🍀🌾🌾🍓🍓🍂🍂🙋🙋🐸🐸🙋🙋💖💖🍌🍌🔔🔔🍉🍉🍭🍭🍋🍋🍇🍇🏆🏆📸📸⛵⛵⭐⭐🍎🍎👍👍🌷🌷