目录
满足我们日常需求的网络程序都是在应用层。
1、协议
TCP是面向字节流的协议,它能保证数据的可靠传输,但不理解字节背后的"数据边界"和"数据含义"。这就带来了几个关键问题,当客户端发送一个数据后,服务器如何确保读取到的是完整数据?即便读到完整数据,又该如何解析其含义?当客户端连续发送多条数据时,服务器又如何准确区分每条数据、避免解析混乱?要解决这些问题,就必须定制应用层协议。
注:我们之前调用的write和read,本质是用户缓冲区与内核缓冲区之间的数据拷贝接口,并不负责数据的实际发送和接收。真正决定数据"什么时候发、发多少、出错了怎么办"的核心是TCP协议------作为传输控制协议,它的核心价值就是解决传输层的可靠性问题。不过接下来并不讲TCP协议,关于TCP协议在下一部分会进行展开。
1.1、序列化和反序列化
协议的本质是一种"约定"。在之前的网络编程中,读写数据时多采用"原始字符串(无固定结构)"的方式,但实际开发中,我们常需要传输"结构化数据"(比如包含多个用户信息、带操作数和运算符的计算请求等)。要让结构化数据能在网络中传输并被正确解析,就必须依赖序列化和反序列化技术。
关于序列化和反序列化,我们可以自己手动去写,也可以选择一些现成的方案,比如适合轻量场景的JSON、兼顾性能与兼容性的Protobuf等,下面先简单的介绍一下应用广泛的JSON方案。
想要使用JSON,需要下载第三方库,在Ubuntu上可以使用如下命令进行下载:
bash
sudo apt install -y libjsoncpp-dev下载完成后,下载的头文件如下图所示:
其中jsoncpp/json 是头文件所在的目录,其中最常用的头文件就是json.h。
下面举个例子简单的使用一下JSON,例如:
cpp
#include <iostream>
#include <jsoncpp/json/json.h>
#include <unistd.h>
int main()
{
// 序列化
Json::Value part1;
part1["haha"] = "haha";
part1["hehe"] = "hehe";
Json::Value root;
root["x"] = 100;
root["y"] = 200;
root["op"] = '+';
root["desc"] = "this is a + oper";
root["test"] = part1;
Json::FastWriter w;
std::string res1 = w.write(root);
std::cout << res1 << std::endl;
Json::StyledWriter l; // 使用这种方式可读性会比较好
std::string res2 = l.write(root);
std::cout << res2 << std::endl;
sleep(3);
// 反序列化
Json::Value v;
Json::Reader r;
r.parse(res1, v);
int x = v["x"].asInt();
int y = v["y"].asInt();
char op = v["op"].asInt();
std::string desc = v["desc"].asString();
std::cout << x << std::endl;
std::cout << op << std::endl;
std::cout << y << std::endl;
std::cout << desc << std::endl;
return 0;
}运行结果为:
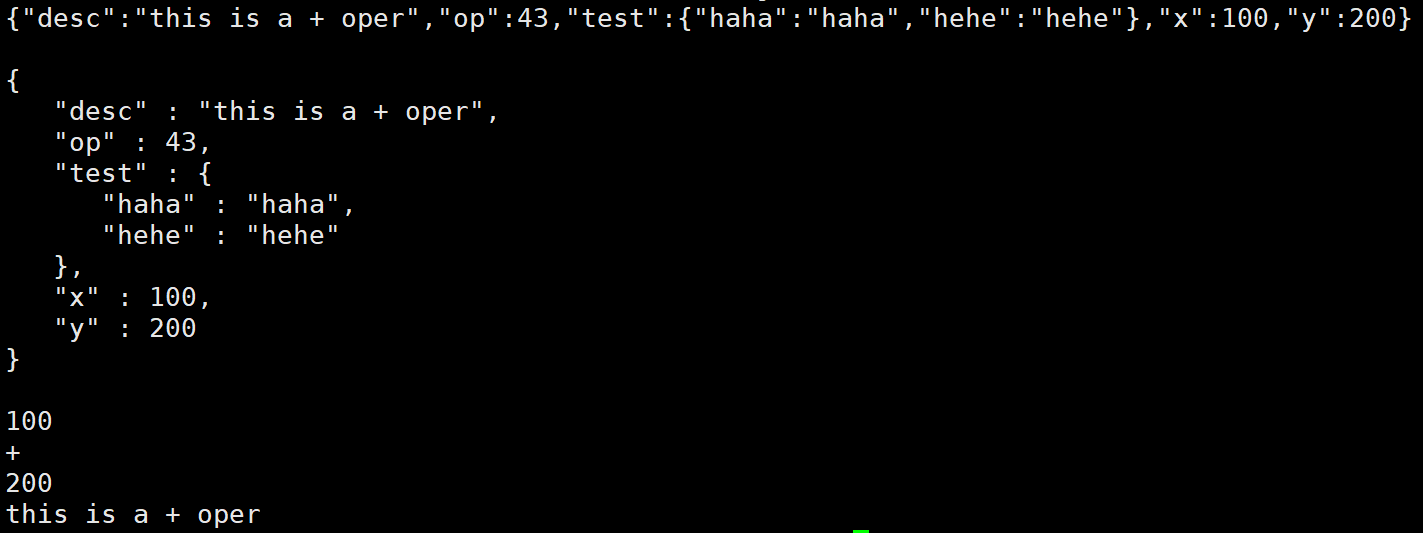
注意:在编译JSON的代码的时候别忘记加上-l jsoncpp选项指明第三方库。
1.2、网络版计算器
我们以"服务器版简单计算器"为例,理解协议的作用,客户端需要将计算任务传递给服务器,服务器计算后返回结果。这个过程中,核心需求是"客户端构造的计算请求,服务器能准确解析;服务器返回的结果,客户端也能正确识别"。
TcpServer.hpp:
cpp
#pragma once
#include "Socket.hpp"
#include "Log.hpp"
#include <signal.h>
#include <functional>
using func_t = std::function<std::string(std::string& package)>;
class TcpServer
{
public:
TcpServer(uint16_t port, func_t calback): port_(port), calback_(calback)
{}
bool InitServer()
{
listensock_.Socket();
listensock_.Bind(port_);
listensock_.Listen();
lg(Info, "init server ... done");
return true;
}
void Start()
{
signal(SIGCHLD, SIG_IGN);
signal(SIGPIPE, SIG_IGN);
while(true)
{
std::string clientip;
uint16_t clientport;
int sockfd = listensock_.Accept(&clientip, &clientport);
if(sockfd < 0) continue;
lg(Info, "accept a new link, sockfd: %d, clientip: %s, clientport: %d", sockfd, clientip.c_str(), clientport);
// 提供服务
if(fork() == 0)
{
// 子进程
listensock_.Close(); // 关闭监听套接字
std::string inbuffer_stream;
while(true)
{
char buffer[128];
ssize_t n = read(sockfd, buffer, sizeof(buffer));
if(n > 0)
{
buffer[n] = 0;
inbuffer_stream += buffer;
lg(Debug, "debug:\n%s", inbuffer_stream.c_str());
while(true)
{
std::string info = calback_(inbuffer_stream);
if(info.empty()) break;
write(sockfd, info.c_str(), info.size());
}
}
else if(n == 0) break;
else break;
}
exit(0);
}
// 父进程
close(sockfd); // 关闭文件accept返回的文件描述符
}
}
~TcpServer()
{}
private:
Sock listensock_; // 监听套接字
uint16_t port_; // 端口号
func_t calback_; // 回调函数
};Socket.hpp:
cpp
#pragma once
#include <unistd.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include "Log.hpp"
#include <cstring>
#include <string>
enum { SocketErr = 2, BindErr, ListenErr };
const int backlog = 10;
class Sock
{
public:
Sock() {}
~Sock() {}
public:
void Socket()
{
sockfd_ = socket(AF_INET, SOCK_STREAM, 0);
if(sockfd_ < 0)
{
lg(Fatal, "socket error, %s: %d", strerror(errno), errno);
exit(SocketErr);
}
}
void Bind(uint16_t port)
{
struct sockaddr_in local;
memset(&local, 0, sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(port);
local.sin_addr.s_addr = INADDR_ANY;
if(bind(sockfd_, (struct sockaddr*)&local, sizeof(local)) < 0)
{
lg(Fatal, "bind error, %s: %d", strerror(errno), errno);
exit(BindErr);
}
}
void Listen()
{
if(listen(sockfd_, backlog) < 0)
{
lg(Fatal, "listen error, %s: %d", strerror(errno), errno);
exit(ListenErr);
}
}
int Accept(std::string* clientip, uint16_t* clientport)
{
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
int newfd = accept(sockfd_, (struct sockaddr*)&peer, &len);
if(newfd < 0)
{
lg(Warning, "accept error, %s: %d", strerror(errno), errno);
return -1;
}
char ipstr[64];
inet_ntop(AF_INET, &peer.sin_addr, ipstr, sizeof(ipstr));
*clientip = ipstr;
*clientport = ntohs(peer.sin_port);
return newfd;
}
bool Connect(const std::string& ip, const uint16_t& port)
{
struct sockaddr_in peer;
memset(&peer, 0, sizeof(peer));
peer.sin_family = AF_INET;
peer.sin_port = htons(port);
inet_pton(AF_INET, ip.c_str(), &(peer.sin_addr));
int n = connect(sockfd_, (const struct sockaddr*)&peer, sizeof(peer));
if(n == -1)
{
std::cerr << "connect to " << ip << ":" << port << " error" << std::endl;
return false;
}
return true;
}
void Close() // 关闭监听套接字
{
close(sockfd_);
}
int Fd()
{
return sockfd_;
}
private:
int sockfd_; // 监听套接字
};ServerCal.hpp:
cpp
#pragma once
#include "Protocol.hpp"
#include <iostream>
enum { Div_Zero = 1, Mod_Zero, Other_Oper };
class ServerCal // 计算器
{
public:
ServerCal()
{}
Response CalculatorHelper(const Request& req)
{
Response resp(0, 0);
switch (req.op)
{
case '+':
resp.result = req.x + req.y;
break;
case '-':
resp.result = req.x - req.y;
break;
case '*':
resp.result = req.x * req.y;
break;
case '/':
{
if(req.y == 0) resp.code = Div_Zero;
else resp.result = req.x / req.y;
}
break;
case '%':
{
if(req.y == 0) resp.code = Mod_Zero;
else resp.result = req.x % req.y;
}
break;
default:
resp.code = Other_Oper;
break;
}
return resp;
}
std::string Calculator(std::string& package)
{
std::string content;
bool r = Decode(package, &content);
if(!r) return "";
Request req;
r = req.Deserialize(content);
if(!r) return "";
content = "";
Response resp = CalculatorHelper(req);
resp.Serialize(&content);
content = Encode(content);
return content;
}
~ServerCal()
{}
};
cpp
#include "TcpServer.hpp"
#include "ServerCal.hpp"
#include <iostream>
#include <unistd.h>
static void Usage(const std::string& proc)
{
std::cout << "\nUsage: " << proc << " port\n" << std::endl;
}
int main(int argc, char* argv[])
{
if(argc != 2)
{
Usage(argv[0]);
exit(0);
}
uint16_t port = std::stoi(argv[1]);
ServerCal cal;
TcpServer* tsvp = new TcpServer(port, std::bind(&ServerCal::Calculator, &cal, std::placeholders::_1));
tsvp->InitServer();
daemon(0, 0); // 守护进程化
tsvp->Start();
return 0;
}Protocol.hpp:
cpp
#pragma once
/*
* 协议
*/
#include <iostream>
#include <string>
#include <jsoncpp/json/json.h>
const std::string blank_space_sep = " "; // 空格分隔符
const std::string protocol_sep = "\n"; // 换行分割符
std::string Encode(std::string& content) // 封装上内容的大小
{
std::string package = std::to_string(content.size());
package += protocol_sep;
package += content;
package += protocol_sep;
return package;
}
// "len"\n"x op y"\n
bool Decode(std::string& package, std::string* content) // 解包获取内容
{
size_t pos = package.find(protocol_sep);
if(pos == std::string::npos) return false;
std::string len_str = package.substr(0, pos);
size_t len = std::stoi(len_str);
size_t total_len = len_str.size() + len + 2;
if(package.size() < total_len) return false;
*content = package.substr(pos + 1, len);
package.erase(0, total_len);
return true;
}
class Request // 请求
{
public:
Request()
{}
Request(int data1, int data2, char oper):x(data1), y(data2), op(oper)
{}
public:
bool Serialize(std::string* out) // 对请求进行序列化
{
#ifdef MySelf
// "x op y"
std::string s = std::to_string(x);
s += blank_space_sep;
s += op;
s += blank_space_sep;
s += std::to_string(y);
*out = s;
return true;
#else
Json::Value root;
root["x"] = x;
root["y"] = y;
root["op"] = op;
//Json::FastWriter w;
Json::StyledWriter w;
*out = w.write(root);
return true;
#endif
}
// "x op y"
bool Deserialize(const std::string& in) // 对请求进行反序列化
{
#ifdef MySelf
size_t left = in.find(blank_space_sep);
if(left == std::string::npos) return false;
std::string part_x = in.substr(0, left);
size_t right = in.rfind(blank_space_sep);
if(right == std::string::npos) return false;
std::string part_y = in.substr(right + 1);
if(left + 2 != right) return false;
op = in[left + 1];
x = std::stoi(part_x);
y = std::stoi(part_y);
return true;
#else
Json::Value root;
Json::Reader r;
r.parse(in, root);
x = root["x"].asInt();
y = root["y"].asInt();
op = root["op"].asInt();
return true;
#endif
}
void DebugPrint()
{
std::cout << "新请求构建: " << x << " " << op << " " << y << std::endl;
}
public:
int x;
int y;
char op; // + - * / %
};
class Response // 应答
{
public:
Response()
{}
Response(int res, int c):result(res), code(c)
{}
public:
bool Serialize(std::string* out) // 序列化
{
#ifdef MySelf
// "result code"
std::string s = std::to_string(result);
s += blank_space_sep;
s += std::to_string(code);
*out = s;
return true;
#else
Json::Value root;
root["result"] = result;
root["code"] = code;
//Json::FastWriter w;
Json::StyledWriter w;
*out = w.write(root);
return true;
#endif
}
// "result code"
bool Deserialize(const std::string& in) // 反序列化
{
#ifdef MySelf
size_t pos = in.find(blank_space_sep);
if(pos == std::string::npos) return false;
std::string part_left = in.substr(0, pos);
std::string part_right = in.substr(pos + 1);
result = std::stoi(part_left);
code = std::stoi(part_right);
return true;
#else
Json::Value root;
Json::Reader r;
r.parse(in, root);
result = root["result"].asInt();
code = root["code"].asInt();
return true;
#endif
}
void DebugPrint()
{
std::cout << "响应完成: " << result << " " << code << std::endl;
}
public:
int result;
int code; // 0表示可信,非零的具体数值表明错误原因
};Log.hpp:
cpp
#pragma once
#include <iostream>
#include <stdarg.h> // 使用可变参数列表需要用到这个头文件
#include <ctime>
#include <cstdlib>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#define Info 0
#define Debug 1
#define Warning 2
#define Error 3
#define Fatal 4
#define SIZE 1024
#define Screen 1
#define Onefile 2
#define Classfile 3
#define LogFile "log.txt"
class Log
{
public:
Log()
{
printMethod = Screen; // 默认为屏幕打印
path = "./log/";
}
void Enable(int method) // 更换日志的打印方式
{
printMethod = method;
}
std::string levelToString(int level) // 返回日志等级的字符串
{
switch (level)
{
case Info:
return "Info";
case Debug:
return "Debug";
case Warning:
return "Warning";
case Error:
return "Error";
case Fatal:
return "Fatal";
default:
return "None";
}
}
void printLog(int level, const std::string &logtxt) // 日志打印
{
switch (printMethod)
{
case Screen:
std::cout << logtxt << std::endl;
break;
case Onefile:
printOneFile(LogFile, logtxt);
break;
case Classfile:
printClassFile(level, logtxt);
break;
default:
break;
}
}
void printOneFile(const std::string &logname, const std::string &logtxt) // 打印到一个文件中
{
std::string _logname = path + logname;
int fd = open(_logname.c_str(), O_WRONLY | O_CREAT | O_APPEND, 0666);
if (fd < 0)
{
return;
}
write(fd, logtxt.c_str(), logtxt.size());
close(fd);
}
void printClassFile(int level, const std::string &logtxt) // 分类打印到对应的文件
{
std::string filename = LogFile;
filename += '.';
filename += levelToString(level);
printOneFile(filename, logtxt);
}
~Log()
{}
void operator()(int level, const char *format, ...)
{
char leftbuffer[1024]; // 一条日志左边的格式信息,包括日志等级和时间。
time_t t = time(nullptr); // 返回值是时间戳
struct tm *ctime = localtime(&t); // 该函数可以将时间戳转换成一个struct tm 结构。
// 下面的\是续行符,加不加都行。
snprintf(leftbuffer, sizeof(leftbuffer), "[%s][%d-%d-%d %d:%d:%d]", levelToString(level).c_str(),\
ctime->tm_year + 1900, ctime->tm_mon + 1, ctime->tm_mday,\
ctime->tm_hour, ctime->tm_min, ctime->tm_sec);
va_list s;
va_start(s, format);
char rightbuffer[SIZE]; // 一条日志右边日志内容
vsnprintf(rightbuffer, sizeof(rightbuffer), format, s);
va_end(s);
char logtxt[SIZE * 2]; // 合成一条日志信息
snprintf(logtxt, sizeof(logtxt), "%s %s", leftbuffer, rightbuffer);
// printf("%s", logtxt);
printLog(level, logtxt); // 打印
}
private:
int printMethod; // 日志打印的方式
std::string path; // 日志打印路径
};
Log lg;
cpp
#include "Socket.hpp"
#include "Protocol.hpp"
#include <iostream>
#include <ctime>
#include <cassert>
#include <unistd.h>
static void Usage(const std::string& proc)
{
std::cout << "\nUsage: " << proc << " serverip serverport\n" << std::endl;
}
int main(int argc, char* argv[])
{
if(argc != 3)
{
Usage(argv[0]);
exit(0);
}
std::string serverip = argv[1];
uint16_t serverport = std::stoi(argv[2]);
Sock sockfd;
sockfd.Socket();
bool r = sockfd.Connect(serverip, serverport);
if(!r) return 1;
srand(time(nullptr) ^ getpid());
int cnt = 1;
const std::string opers = "+-*/%=^&";
std::string inbuffer_stream;
while(cnt <= 10)
{
std::cout << "=========================\ntest number: " << cnt << std::endl;
int x = rand() % 100 + 1;
usleep(1234);
int y = rand() % 100;
usleep(4321);
char oper = opers[rand() % opers.size()];
Request req(x, y, oper);
req.DebugPrint();
std::string package;
req.Serialize(&package);
package = Encode(package);
write(sockfd.Fd(), package.c_str(), package.size());
char buffer[128];
ssize_t n = read(sockfd.Fd(), buffer, sizeof(buffer));
if(n > 0)
{
buffer[n] = 0;
inbuffer_stream += buffer;
std::string content;
bool r = Decode(inbuffer_stream, &content);
assert(r);
Response resp;
r = resp.Deserialize(content);
assert(r);
resp.DebugPrint();
}
sleep(1);
cnt++;
}
sockfd.Close();
return 0;
}简单来说无论我们采用什么样的协议,只要保证,一端发送时构造的数据,在另一端能够正确的进行解析,该协议就是可行的,这就是应用层协议。
2、HTTP协议
虽然说,应用层协议是自己定的,但实际上,已经有了一些现成的、又非常好用的应用层协议,供我们直接使用,HTTP就是其中之一,HTTP就是超文本传输协议。
2.1、URL
平时我们俗称的 "网址" 其实就是说的URL,URL(统一资源定位符)的核心格式如下:
diff
http://username:password@www.example:8080/admin/dashboard.html?lang=en&theme=dark#section1其中http是指协议类型,表示使用HTTP协议;username是指用户名,password是指密码,不过这两个已经不常用了,一般的网址都不带这两个;
再然后就是域名www.example.com,域名本质其实就是服务器的地址(可带端口号,如上图中的8080),域名经过解析就是IP地址(注:域名需要向域名注册服务商申请并付费注册后才能获得)。
后面的/admin/dashboard.html指服务器内资源的路径,用/分隔层级,该部分如果没有的话,默认为/,即web根目录(这个/并不是Linux中的根目录,而是该服务资源所处的目录);
lang=en和theme=dark是指查询参数,向服务器传递额外信息,以?开头,参数间用&分隔;最后的section1是锚点,定位页面内具体位置,以#开头,不发送给服务器,这个锚点也是比较少见的;
注:HTTP的端口一般默认为80,HTTPS一般的默认端口为443。
2.2、URL特殊符号
像**/ ? : # & =**等这样的字符,已经被URL当做特殊意义理解了,因此这些字符不能随意出现在URL中,比如,某个参数中需要带有这些特殊字符,就必须先对这样的特殊字符进行转义。
转义规则:
1、把要转义的字符(比如?、/、=)先转换成对应的 ASCII 码(比如?的 ASCII 码是 63,/ 是 47)。
2、再把 ASCII 码转换成两位十六进制数(比如 63 转成 3F,47 转成 2F)。
3、最后在十六进制数前面加个%,就是转义后的结果(比如?→%3F,/→%2F)。
注:在浏览器中输入URL后,对于特殊字符,浏览器会自动的进行转义,不需要我们自己进行转义。
2.3、HTTP协议格式
2.3.1、HTTP请求
完整的HTTP请求的格式如下图所示:
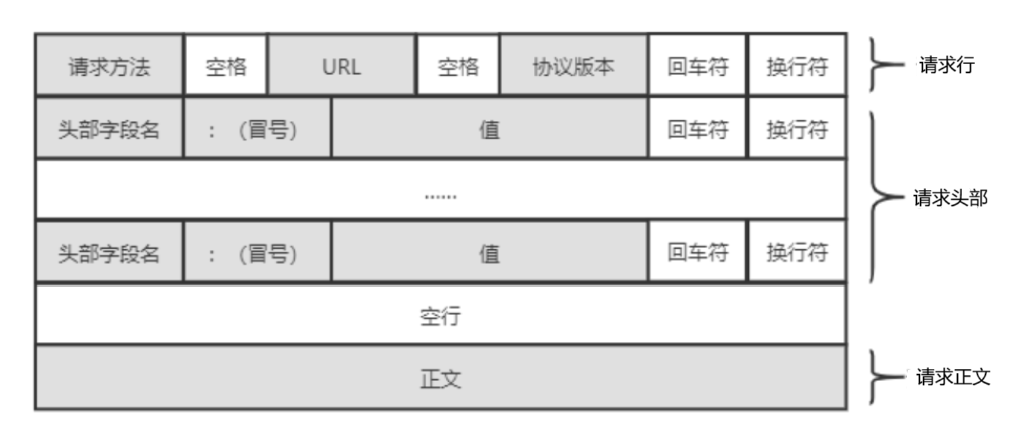
请求行:请求方法 + url + 版本。(其中的url中一般只含有资源路径和查询参数)
请求头部:请求的属性,为冒号分割的键值对,冒号后有一个空格,遇到空行表示请求头部结束,该部分是可以没有的。
空行:空行是必须要有的,空行本质上就是\r\n。
请求正文:空行后面的内容都是请求正文,允许为空字符串,如果请求正文存在,则在请求头部中会有一个Content-Length属性来标识请求正文的长度。
注意:实际上,在接收和发送缓冲区中上图仅仅只是一行,也就是一个大的字符串,只是为了方便观察,变成了多行进行展示。
另外就是请求行和空行是必须要有的。例如:我们可以构造一个最简单的请求
cpp
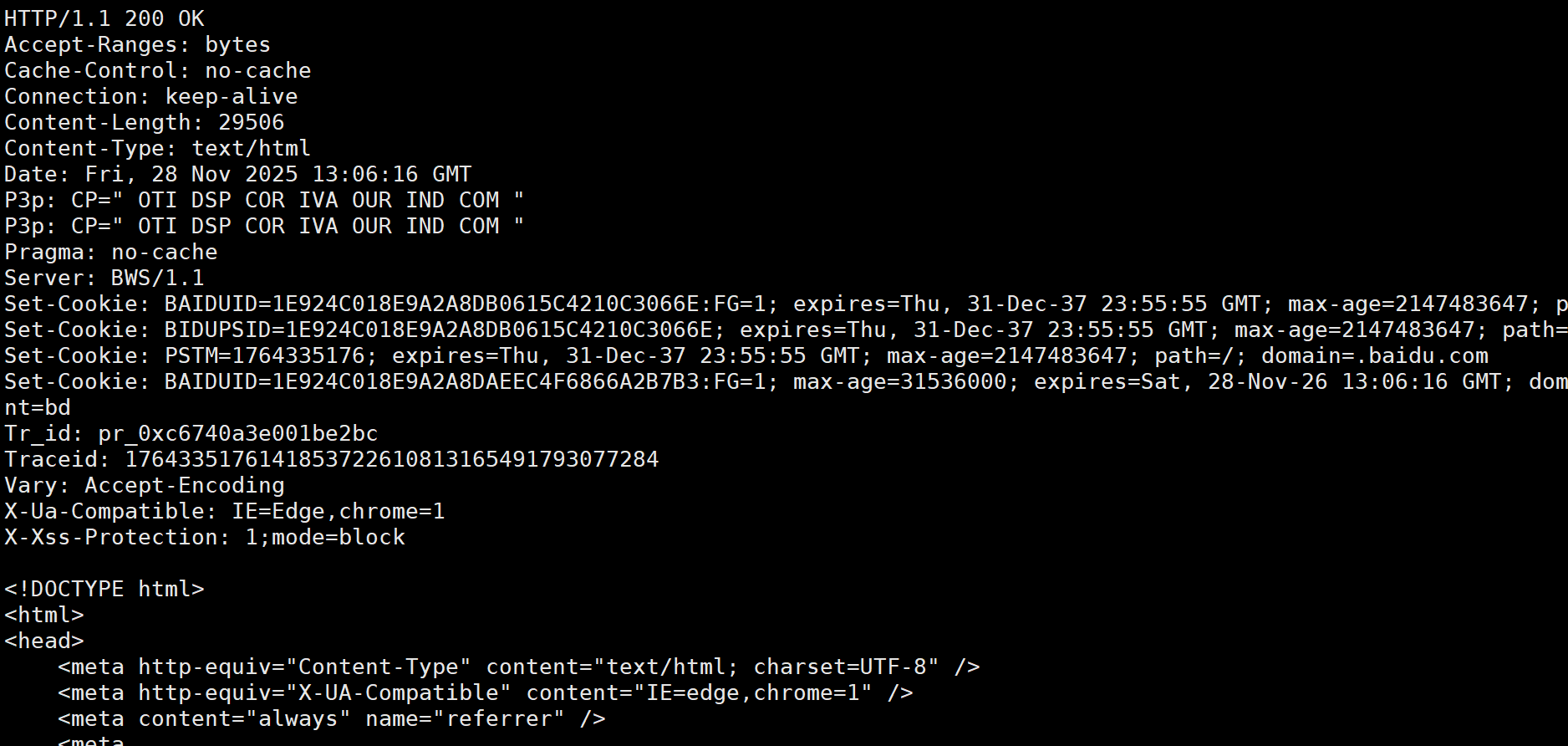
telnet www.baidu.com 80使用上面的命令后,输入如下内容:只要输入GET / HTTP/1.1按两次enter键即可。
bash
GET / HTTP/1.1响应结果为:仅仅只截取了一部分响应结果,关于响应的格式,可以看下面的HTTP响应部分
2.3.2、HTTP响应
完整的HTTP响应的格式如下图所示:
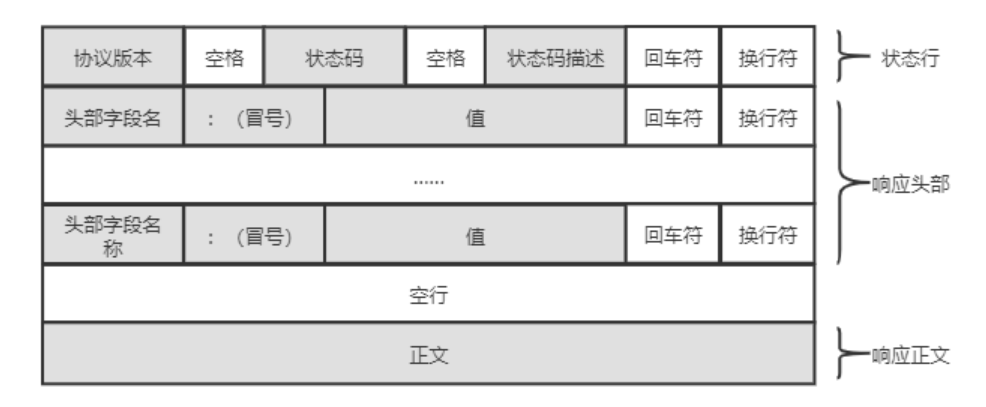
状态行:版本号 + 状态码 + 状态码解释。
响应头部:请求的属性,冒号分割的键值对,冒号后有一个空格,遇到空行表示响应头部结束。
空行:空行是必须要有的,本质上就是\r\n。
响应正文:空行后面的内容都是响应正文,允许为空字符串,如果响应正文存在,则在响应头部中会有一个Content-Length属性来标识响应正文的长度,如果服务器返回了一个html页面,那么html页面内容就是在响应正文中。
注意:与HTTP响应一样,在接收和发送缓冲区中上图仅仅只是一行,也就是一个大的字符串,只是为了方便观察,变成了多行进行展示。
2.4、方法和状态码以及属性
2.4.1、HTTP请求方法
其中HTTP的请求方法如下图所示:
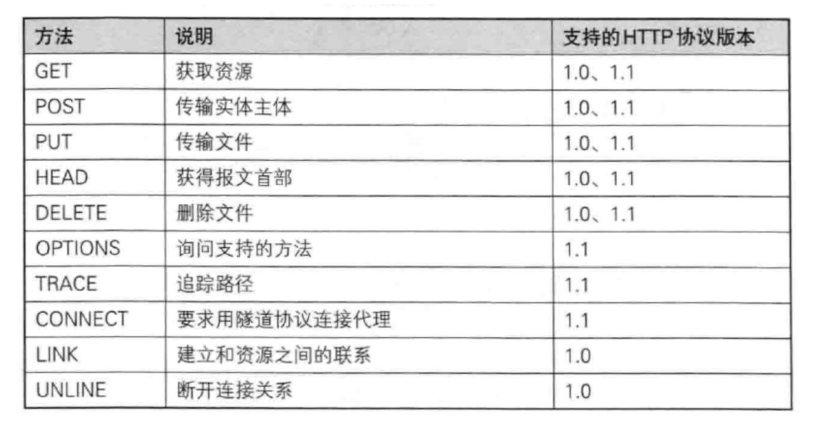
注:其中最常用的就是GET方法,再然后就是POST方法。网络一般就两种行为,一个是获取资源,另一个就是把资源传上去。
当我们需要获取资源时,一般用的就是GET方法,当想要提交一些数据时,就可以使用POST方法。数据是通过表单进行提交的,关于表单可以去看HTML的文章。当然并不是说使用GET方法就不可以提交数据,POST方法就不可以获取数据,如果我们提交数据给服务器使用GET方法,那我们的数据是通过URL进行提交的,提交的内容会回显在URL中(也就是查询参数)。POST方法的提交,是通过请求正文进行提交的,因此使用POST会更私密一些,另外就是使用GET提交的数据量不能太大。
2.4.2、HTTP状态码
其中状态码如下图所示:
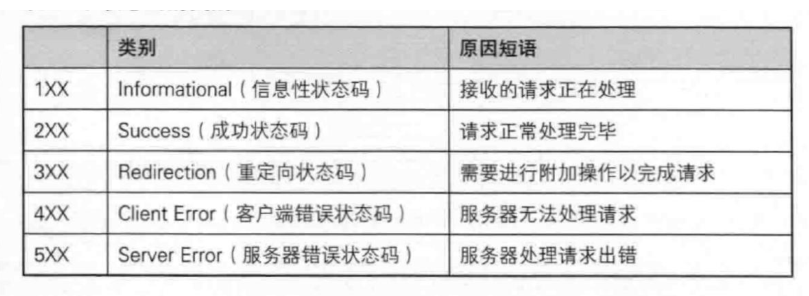
注:1XX的相关状态码很少见,不再多说。常见的状态码,比如:200表示OK,404表示Not Found。
下面主要说一下3XX相关的重定向状态码,重定向就是你访问 A 地址,服务器告诉你 "A 地址不行 或者换地方了,你去 B 地址找吧",然后浏览器会自动跳转到 B 地址,整个过程你可能只看到 "页面加载了一下",甚至没感觉。重定向有两种:一种是临时重定向(302)、一种是永久重定向(301)。
临时重定向是指 A 地址暂时不能用,这次先去 B 地址,下次访问还是可以试 A 地址。特点就是浏览器不缓存,每次访问 A 地址,都会先问服务器,再按服务器的指示跳 B 地址。典型的场景就是用户登录后跳转到一个页面。
永久重定向是指 A 地址永久作废,所有请求都要转到 B 地址。特点就是浏览器会缓存这个重定向规则,下次你再访问 A 地址,浏览器直接跳 B 地址,根本不向服务器发请求。
2.4.3、HTTP属性
其中,HTTP的常见请求的属性有:
Host:客户端告知服务器,所请求的资源是在哪个主机的哪个端口上。
User-Agent:告知服务器客户端的操作系统和浏览器版本信息。
Connection:是否在双方通信时使用长链接。简单来说,就是决定 "一次请求后,连接要不要断开"。如果值为Keep-Alive表示长链接,如果是Close表示短链接。
注:简单来说,一次请求响应一个资源,然后关闭链接这种就是短链接。建立一个链接,发送和返回多个请求和响应这种就是长链接。HTTP/1.0默认支持的就是短链接,HTTP/1.1默认支持的就是长链接,因为过去网页的资源比较少,现在的网页资源比较多,所以想要获取一个网络页面需要多次请求。
Content-Length:请求正文的长度,单位是字节。
Content-Type:告诉服务器我给你传的数据是什么格式。例如:Content-Type: text/html; charset=utf-8(返回 HTML 页面,编码 UTF-8)。
Accept:告诉服务器客户端能接收什么格式的数据。
Accept-Encoding:告知服务器客户端支持的数据压缩格式。
Accept-Language:告知服务器客户端偏好的语言类型。
Cookie:用于在客户端存储少量信息,通常用于实现会话的功能。比如:第一次登录网站,提交用户名和密码;服务器验证通过后,会生成一个随机唯一的会话标识(比如 Session ID);服务器通过响应属性Set-Cookie,把这个会话标识发给浏览器;浏览器把会话标识保存(两种方式:文件级保存,关闭浏览器或者电脑也不失效;内存级保存,关闭浏览器就失效);之后再访问这个网站,浏览器会自动在请求头Cookie里带上这个会话标识;服务器读取会话标识,通过它在数据库中找到对应的用户信息,认出你是 "已登录用户",直接返回你的个人页面,无需再次登录。
Referer:当前页面是从哪个页面跳转过来的。
Cache-Control:告知服务器客户端的缓存策略。
HTTP常见的响应属性有:
Server:标识服务器的软件类型和版本。
Connection:与请求头的Connection对应,告知客户端连接的类型,Connection: Keep-Alive表示服务器希望保持长连接,Connection: Close表示服务器会在响应后断开连接;
Content-Length:告知客户端响应正文的字节长度,方便客户端判断正文是否接收完整。
Content-Type:告知客户端响应正文的格式和编码方式,客户端据此解析正文。
Set-Cookie:服务器给客户端 "设置 Cookie"。
Cache-Control:告知客户端响应数据的缓存策略。
Location:重定向专用,重定向时,告诉客户端接下来要去哪里访问。
2.5、HTTP服务器
下面简单的实现一个HTTP服务器,例如:
运行该服务器,如下图所示:

在浏览器中输入IP:port就可以访问(部分浏览器可能还要在前面带上协议,也就是http)。此处我们使用19000端口号启动了HTTP服务器,虽然HTTP服务器一般使用80端口,但这只是一个通用的习惯,并不是说HTTP服务器就不能使用其他的端口号。
另外再介绍一个东西就是网页的小图标,使用浏览器测试我们的服务器时,可以看到服务器打出的请求中还有一个GET /favicon.ico HTTP/1.1 这样的请求,favicon.ico 就是网站的 "小图标",打开浏览器标签页时,标题左边那个小小的图标(比如百度标签页的 "熊掌" 图标、知乎的 "知" 字图标),本质就是这个文件。
注:如果感兴趣的话或者真的想要做一个很不错的HTTP服务器,可以去找一些HTTP的库,这样的话可以避免造太多轮子,稳定性也会更好,开发的效率也快。
另外介绍一个命令wget,核心功能是通过 HTTP/HTTPS 等协议从网络上下载文件,命令格式为:
bash
wget 下载链接例如:下载百度首页
bash
wget https://www.baidu.com下载后,文件会保存在当前目录。还可以使用-O选项,指定保存的文件名,例如:
bash
wget -O baidu_home.html https://www.baidu.com3、HTTPS协议
HTTPS也是一个应用层协议,是在HTTP协议的基础上多了一个加密。而HTTP协议内容都是按照文本的方式明文传输的,这就可能导致在传输过程中出现信息泄漏的情况。
3.1、加密与解密
加密 就是把明文(要传输的信息)进行一系列变换,生成密文 。解密 就是把密文再进行一系列变换,还原成明文 。在这个加密和解密的过程中,往往需要一个或者多个中间的数据,辅助进行这个过程,这样的数据称为密钥。
注:攻破的成本大于攻破后的收益,一般来说我们就认为是安全的。加密解密到如今已经发展成一个独立的学科,也就是密码学。
3.1.1、为什么要加密
由于我们通过网络传输的任何的数据都会经过很多运营商的网络设备(路由器,交换机等),如果不加密的话,那么运营商的网络设备就可以解析出你传输的数据内容,并进行篡改。
因为http的内容是明文传输的,明文数据会经过路由器、wifi热点、通信服务 、运营商、代理服务器等多个物理节点,如果信息在传输过程中被劫持,传输的内容就完全暴露了。劫持者还可以篡改传输的信息且不被双方察觉,这就是中间人攻击,所以需要对信息进行加密。
不止运营商可以劫持,其他的黑客也可以用类似的手段进行劫持,来窃取用户隐私信息,或者篡改内容。在互联网上,明文传输是比较危险的事情,HTTPS就是在HTTP的基础上进行了加密,进一步的来保证用户的信息安全。
3.1.2、常见的加密方式
3.1.2.1、对称加密
简单来说就是同一个密钥可以同时用作信息的加密和解密,这种加密方法称为对称加密 ,也称为单密钥加密,特征是加密和解密所用的密钥是相同的。
常见对称加密算法:DES、3DES、AES、TDEA、Blowfish、RC2等。
优势:算法公开透明、计算量小、加密解密速度快、效率高,适合处理大批量数据。
局限:密钥需严格保密,且密钥分发、保管难度大(密钥在传输或共享过程中易被劫持)。
例如:举一个简单的例子

3.1.2.2、非对称加密
非对称加密需要两个密钥来进行加密和解密,这两个密钥是公开密钥 (简称公钥 )和私有密钥 (简称私钥),公钥和私钥是配对的。
通过公钥对明文加密,变成密文;通过私钥对密文解密,变成明文。也可以反着用,通过私钥对明文加密,变成密文;通过公钥对密文解密,变成明文。
常见非对称加密算法:RSA,DSA,ECDSA。
特点:算法复杂而使得加密解密速度没有对称加密解密的速度快,效率比较差。
注:一般两个密钥是要公开一个的,这个公开的密钥叫公钥,不公开的叫私钥。用公钥加密只有拥有私钥才能解密。非对称加密的数学原理比较复杂,涉及到一些数论相关的知识。
3.1.3、数据摘要
数据摘要 ,也叫数据指纹,其基本原理是利用Hash函数对信息进行运算,生成一串固定长度的字符串,这个字符串就是数字摘要。数据摘要并不是一种加密机制,但可以用来判断数据有没有被篡改。
数据摘要常见算法:有MD5、SHA1、SHA256、SHA512等。
特点:无法通过摘要反推原始数据;原始数据只要有一点点的修改,生成的摘要就会有很大的差别;无论原始数据大小,摘要长度一致;计算速度快,适合校验数据完整性。
数据摘要经过非对称加密,就得到数字签名(后面细说)。
3.2、HTTPS加密方式
既然要保证数据安全,就需要进行"加密",网络传输中不再直接传输明文了,而是加密之后的"密文"。下面我们首先来看看各种加密方式的特点。
3.2.1、各种加密方式
方案1:只使用对称加密。
如果通信双方都各自持有同一个密钥X,且没有别人知道,这两方的通信安全当然是可以被保证的,除非密钥被破解。
引入对称加密之后,即使数据被截获,由于黑客不知道密钥是啥,因此就无法进行解密,也就不知道请求的真实内容是啥了。
但事情没这么简单,对称加密的密钥必须严格保密,但如果通信双方不在同一物理环境下,密钥就需要通过网络传输给对方。而传输过程中没有更安全的加密手段保护密钥本身,密钥只能以明文的方式传递,极易被中间人劫持。如下图所示:
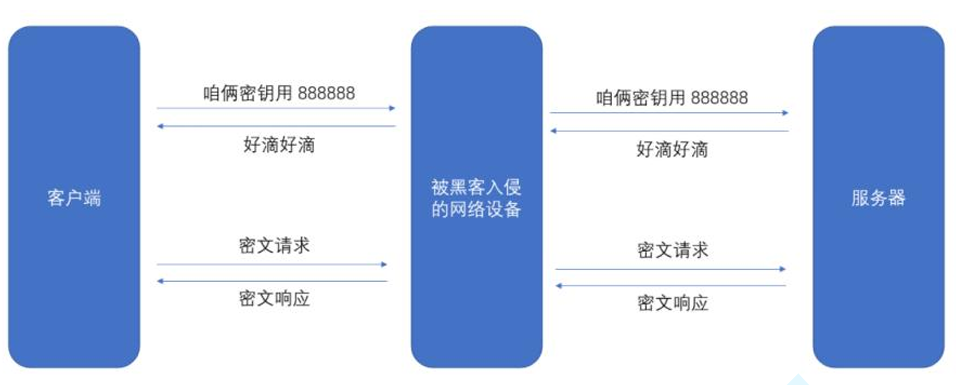
但是如果直接把密钥明文传输,那么黑客也就能获得密钥了, 因此密钥的传输也必须加密传输,但是要想对密钥进行对称加密,就仍然需要先协商确定一个"密钥的密钥",这就成了"先有鸡还是先有蛋"的问题了,此时密钥的传输再用对称加密就行不通了。
方案2:只使用非对称加密
鉴于非对称加密的机制,如果服务器先把公钥以明文方式传输给浏览器,之后浏览器向服务器传数据前都先用这个公钥加密好再传,从客户端到服务器信道似乎是安全的 ,因为只有服务器有相应的私钥能解开公钥加密的数据。
但是服务器到浏览器的这条信息传输的路径怎么保障安全呢?如果服务器用它的私钥加密数据传给浏览器,那么浏览器用公钥可以解密它,而这个公钥是一开始通过明文传输给浏览器的,若这个公钥被中间人劫持到了,那他也能用该公钥解密服务器传来的信息了。
方案3:双方都使用非对称加密
1、服务端拥有公钥S与对应的私钥S',客户端拥有公钥C与对应的私钥C'。
2、客户和服务端交换公钥。
3、客户端给服务端发信息:先用S对数据加密,再发送,只能由服务器解密,因为只有服务器有私钥S'。
4、服务端给客户端发信息:先用C对数据加密,再发送,只能由客户端解密,因为只有客户端有私钥C'
这样种方式貌似是可行的,但是效率太低,也有还是有问题(下面提到)。
方案4:非对称加密和对称加密混合使用
1、服务端具有非对称公钥S和私钥S'
2、客户端发起请求,获取服务端公钥S
3、客户端在本地生成对称密钥C,通过公钥S加密,发送给服务器。
4、由于中间的网络设备没有私钥,即使截获了数据,也无法还原出内部的原文,也就无法获取到对称密钥。
5、服务器通过私钥S'解密,还原出客户端发送的对称密钥C,并且使用这个对称密钥加密给客户端返回的响应数据。
6、后续客户端和服务器的通信都只用对称加密即可,由于该密钥只有客户端和服务器两个主机知道,其他主机或设备不知道该密钥,即使截获数据也没有意义。
注:由于对称加密的效率比非对称加密高很多,在上面的过程中只是在开始阶段协商密钥的时候使用非对称加密,后续的传输仍然使用对称加密,保证了效率。
虽然上面已经比较接近实际的加密方案了,但是依旧有安全问题,方案2,方案3,方案4都存在一个问题,如果最开始,中间人就已经开始攻击了呢?
中间人攻击,针对上面的场景:
Man-in-the-Middle Attack,简称"MITM攻击",在方案4中,客户端获取到公钥S之后,对客户端形成的对称秘钥X用服务端给客户端的公钥S进行加密,中间人即使窃取到了数据,此时中间人确实无法解出客户端形成的密钥X,因为只有服务器有私钥S' ,但是中间人的攻击,如果在最开始协商加密的时候就进行了,那就不一定了。
1、服务器具有非对称加密算法的公钥S,私钥S'
2、中间人具有非对称加密算法的公钥M,私钥M'
3、客户端向服务器发起请求,服务器明文传送公钥S给客户端。
4、中间人劫持数据,提取公钥S并保存好,然后将被劫持报文中的公钥S替换成为自己的公钥M,并将伪造的数据发给客户端。
5、客户端收到报文,提取公钥M,自己形成对称秘钥X,用公钥M加密X,形成报文发送给服务器。
6、中间人劫持后,直接用自己的私钥M'进行解密,得到通信秘钥X,再用曾经保存的服务端公钥S加密后,将数据推送给服务器。
7、服务器拿到报文,用自己的私钥S'解密,得到通信秘钥X。
8、双方开始采用X进行对称加密,进行通信。
但是一切都在中间人的掌握中,劫持数据,进行窃听甚至修改,都是可以的。上面的攻击方案,同样适用于方案2,方案3,问题本质出在哪里了呢?客户端无法确定收到的含有公钥的数据报文,就是目标服务器发送过来的。
3.2.2、证书与CA认证
引入证书,CA认证:服务端在使用HTTPS前,需要向CA机构申领一份证书,证书里含有证书申请者信息、公钥信息等。服务器把证书传输给浏览器,浏览器从证书里获取服务器的公钥就行了,证书就如身份证,证明服务端公钥的权威性。
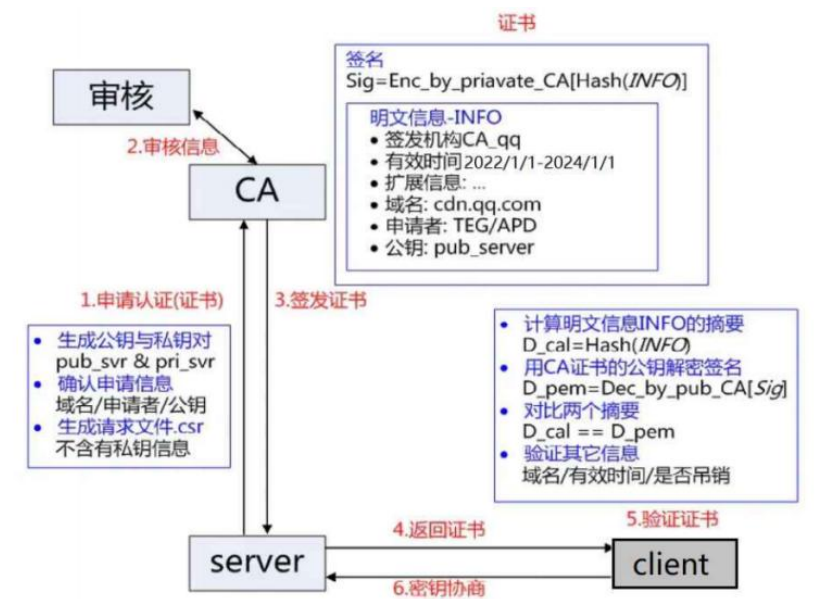
注:其中的公钥和私钥对就是指的服务器端的公钥和私钥;签发的证书是要安装在服务器上的,这个证书可以理解成是一个结构化的字符串,里面包含了以下信息:证书发布机构、证书有效期、服务器的公钥、证书所有者、数字签名等等(不包括服务器的私钥)
是有一些线上的CSR文件生成的网站的,如下:
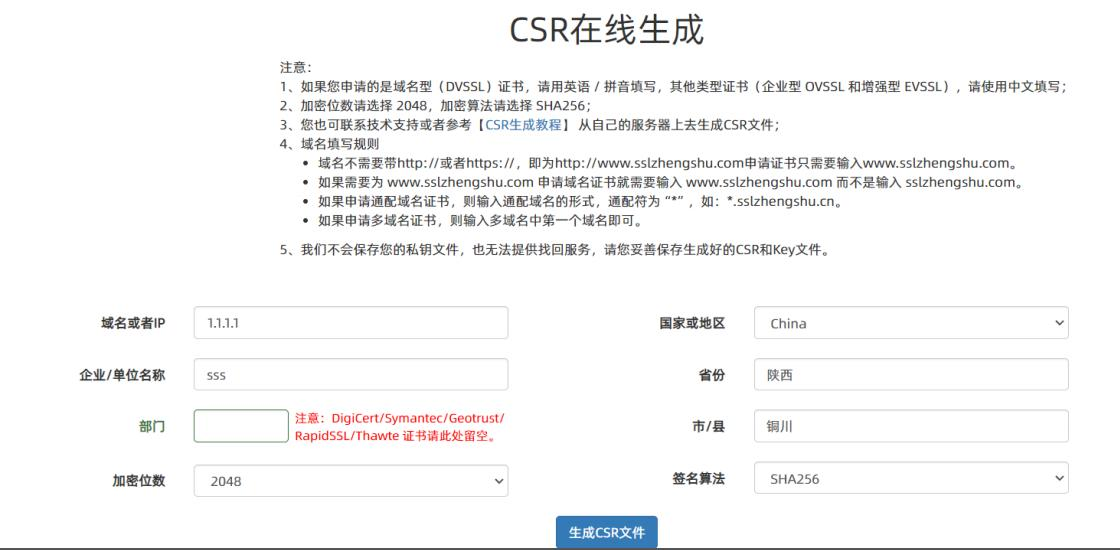
生成的结果如下图所示:

形成CSR文件之后,后续就是向CA进行申请认证,不过一般认证过程很繁琐,网络上也提供各种证书申请的服务商,一般真的需要,直接找这些服务商解决即可。
3.2.3、数字签名
对数据进行Hash后形数据摘要(也就是一个定长字符串),然后对形成的数据摘要进行非对称加密变形成了数字签名,数字签名的形成是基于非对称加密算法的。
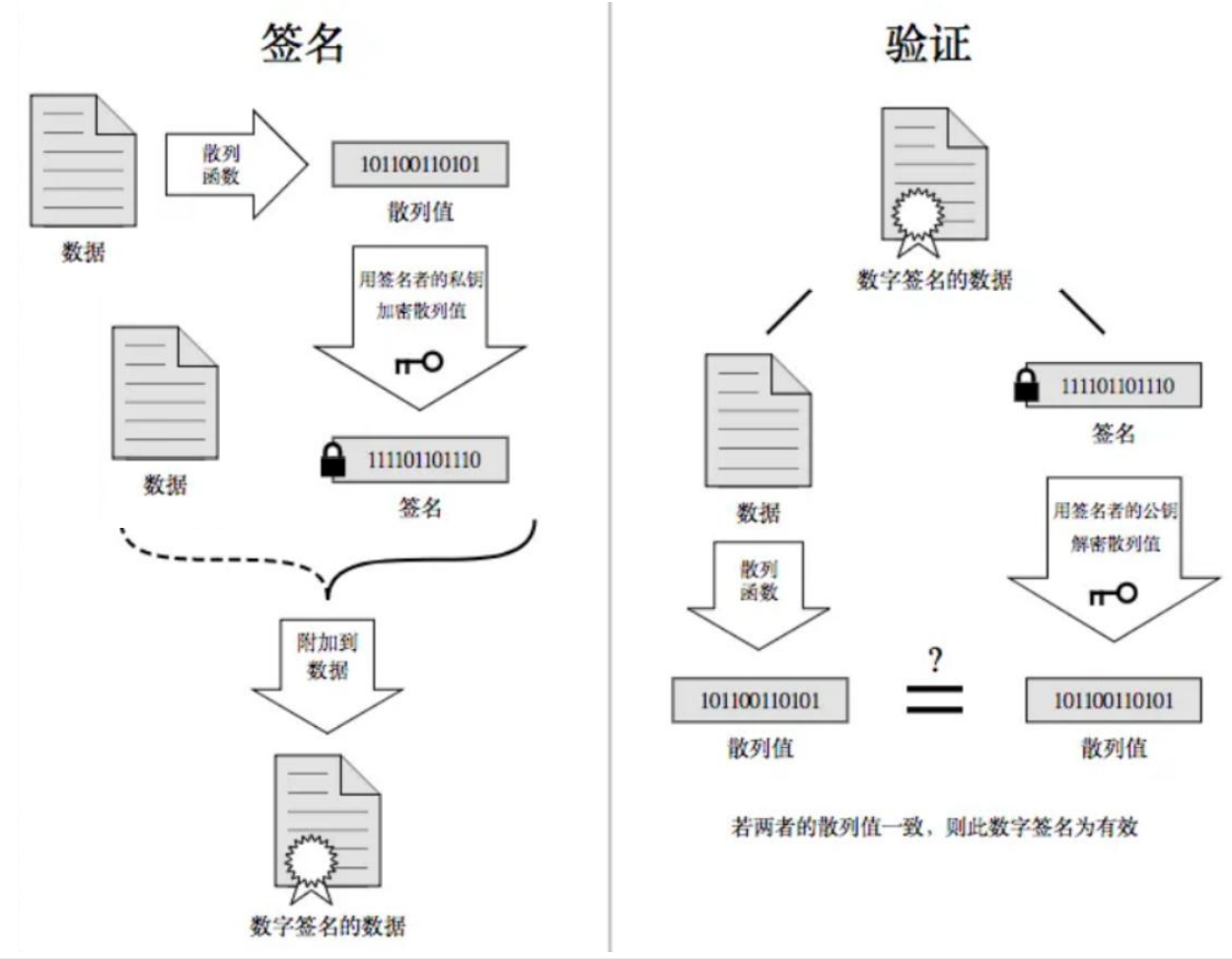
当服务端申请CA证书的时候,CA机构会对该服务端进行审核,并形成数字签名,过程如下:
1、CA机构拥有非对称加密的私钥A和公钥A'。
2、CA机构对服务端申请的证书明文数据进行hash,形成数据摘要。
3、然后对数据摘要用CA的私钥A'加密,得到数字签名S。
服务端申请的证书明文和数字签名S共同组成了证书,这样一份证书就可以颁发给服务端了。
3.2.4、最终加密方案
非对称加密与对称加密和证书认证:在客户端和服务器刚一建立连接的时候,服务器给客户端返回一个证书,证书包含了服务端的公钥,也包含了网站的身份信息等。
当客户端获取到这个证书之后,会对证书进行校验,防止证书是伪造的。
1、判定证书的有效期是否过期。
2、判定证书的发布机构是否受信任(操作系统中或者浏览器中已内置的受信任的证书发布机构)。
3、再然后验证证书是否被篡改,从系统或浏览器中拿到该证书发布机构的公钥,对证书中的数字签名解密,得到一个hash值(称为数据摘要),该哈希值设为hash1,然后使用相同的hash方法计算证书内容的hash值,设为hash2,对比hash1和hash2是否相等,如果相等,则说明证书是没有被篡改过的。
中间人有没有可能篡改该证书?若中间人仅篡改了证书的明文,由于他没有CA机构的私钥,所以无法对明文hash之后用私钥加密形成数字签名,那么也就没办法对篡改后的证书形成匹配的数字签名,如果强行篡改,客户端收到该证书后就会发现明文hash后的结果和签名解密后的值不一致,则说明证书已被篡改,证书不可信,从而终止向服务器传输信息,防止信息泄露给中间人。若中间人对数字签名和明文都进行了修改或者中间人仅对数字签名进行了修改安全性同样也是可以保证的。
中间人整个掉包证书?因为中间人没有CA私钥,所以无法制作假的证书,所以中间人只能向CA申请真证书,然后用自己申请的证书进行掉包,但是,证书明文中包含了域名等服务端认证信息,如果整体掉包,客户端依旧能够识别出来。
注:中间人没有CA私钥,所以对任何证书都无法进行合法修改,包括自己的证书。
例如:查看浏览器的受信任证书,打开 Edge,点击右上角「⋯」→「设置」;左侧选「隐私、搜索和服务」,右侧下滑到「安全性」,点击「管理证书」;弹出的「证书管理器」窗口,如下图所示:
再点击「查看从Windows导入的本地证书」,如下图所示:
总结:HTTPS工作过程中涉及到的密钥有三组
第一组(非对称加密,CA私钥以及客户端内置的CA公钥):用于校验证书是否被篡改,客户端持有CA公钥(操作系统包含了可信任的CA认证机构有哪些,同时持有对应的公钥),服务器在客户端请求时,返回证书,客户端通过这个公钥进行证书验证,保证证书的合法性,进一步保证证书中携带的服务端生成的公钥的权威性。
第⼆组(非对称加密):用于协商生成对称加密的密钥,客户端用收到的CA证书中的公钥 (也就是服务端生成的公钥)给随机生成的对称加密的密钥加密,传输给服务器,服务器通过生成的私钥解密获取到对称加密密钥。
第三组(对称加密):客户端和服务器后续传输的数据都通过这个对称密钥加密解密。
注:其实一切的关键都是围绕这个对称加密的密钥,其他的机制都是辅助这个密钥工作的,第⼆组非对称加密的密钥是为了让客户端把这个对称密钥传给服务器,第一组非对称加密的密钥是为了让客户端拿到第⼆组非对称加密的公钥。