AI大模型微调(三)------Qwen3模型Lora微调(使用Llamafactory)
文章目录
- AI大模型微调(三)------Qwen3模型Lora微调(使用Llamafactory)
- 一、安装LLaMA-Factory&开发环境
- 二、数据集
- 三、LoRA指令微调
- 四、可视化/零代码微调
- 五、可能出现的问题
-
- 1.CUDA未找到
- [2.ValueError: Your setup doesn't support bf16/gpu.](#2.ValueError: Your setup doesn't support bf16/gpu.)
- 总结
一、安装LLaMA-Factory&开发环境
开源项目地址:https://github.com/hiyouga/LLaMA-Factory
文档:https://llamafactory.readthedocs.io/zh-cn/latest/
python
# 创建新开发环境
conda create -n llama_factory_Qwen3 python=3.11 -y
conda activate llama_factory_Qwen3
(llama_factory_Qwen3) C:\Users\Administrator>D:
# 下载项目 & 安装
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"在git失败时,清理DNS缓存,然后继续:
python
ipconfig/flushdns二、数据集
dataset_info.json 包含了所有经过预处理的本地数据集 ,以及在线数据集 。如果您希望使用自定义数据集,请务必在 dataset_info.json 文件中添加对数据集及其内容的定义。目前项目支持 Alpaca 格式和 ShareGPT 格式的数据集。以本实践任务关注的微调数据集为例:
1.Alpaca
指令监督微调 (Instruct Tuning) 通过让模型学习详细的指令以及对应的回答来优化模型在特定指令下的表现。instruction 列对应的内容为人类指令,input 列对应的内容为人类输入,output 列对应的内容为模型回答。下面是一个例子:
javascript
{
"instruction": "计算这些物品的总费用。",
"input": "输入:汽车 - $3000,衣服 - $100,书 - $20。",
"output": "汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。"
}在进行指令监督微调时,instruction 列对应的内容会与 input 列对应的内容拼接后作为最终的人类输入,即人类输入为 instruction\ninput 。而 output 列对应的内容为模型回答。在上面的例子中,人类的最终输入是:
python
计算这些物品的总费用。
输入:汽车 - $3000,衣服 - $100,书 - $20。模型的回答是:
python
汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。如果指定 system 列对应的内容将被作为系统提示词。history 列是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。注意在指令监督微调时,历史消息中的回答内容也会被用于模型学习。
指令监督微调数据集的最终 格式要求 如下:
javascript
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]下面提供一个Alpaca 格式多轮 对话的例子,对于单轮对话只需省略history列:
javascript
[
{
"instruction": "今天的天气怎么样?",
"input": "",
"output": "今天的天气不错,是晴天。",
"history": [
[
"今天会下雨吗?",
"今天不会下雨,是个好天气。"
],
[
"今天适合出去玩吗?",
"非常适合,空气质量很好。"
]
]
}
]对于上述格式的数据,dataset_info.json 中的数据集描述应为:
javascript
"数据集名称": {
"file_name": "data.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system",
"history": "history"
}
}2.ShareGPT
相比 alpaca 格式的数据集,sharegpt 格式支持更多的角色种类,例如 human、gpt、observation、function 等等。它们构成一个对象列表呈现在 conversations 列中。
下面是 sharegpt 格式的一个例子:
javascript
{
"conversations": [
{
"from": "human",
"value": "你好,我出生于1990年5月15日。你能告诉我今天几岁了吗?"
},
{
"from": "function_call",
"value": "{\"name\": \"calculate_age\", \"arguments\": {\"birthdate\": \"1990-05-15\"}}"
},
{
"from": "observation",
"value": "{\"age\": 31}"
},
{
"from": "gpt",
"value": "根据我的计算,你今天31岁了。"
}
],
"tools": "[{\"name\": \"calculate_age\", \"description\": \"根据出生日期计算年龄\", \"parameters\": {\"type\": \"object\"}}"
}注意:其中 human 和 observation 必须出现在奇数位置,gpt 和 function 必须出现在偶数位置。
javascript
[
{
"conversations": [
{
"from": "human",
"value": "人类指令"
},
{
"from": "function_call",
"value": "工具参数"
},
{
"from": "observation",
"value": "工具结果"
},
{
"from": "gpt",
"value": "模型回答"
}
],
"system": "系统提示词(选填)",
"tools": "工具描述(选填)"
}
]对于上述格式的数据,dataset_info.json 中的数据集描述应为:
javascript
"数据集名称": {
"file_name": "data.json",
"formatter": "sharegpt",
"columns": {
"messages": "conversations",
"system": "system",
"tools": "tools"
}
}3.自定义数据集
我们用于训练的数据也转换成 Alpaca 格式,然后在 data/dataset_info.json 中进行注册(如果不做字段名转换,则需要在注册的时候在 columns 字段中做两个数据的映射配置)。接下来,我们使用一个具体的例子来说明数据集的使用。该数据集是商品文案生成数据集,原始格式如下,很明显,训练目标是输入 content(也就是 prompt),输出 summary(对应 response)。
javascript
{
"content": "类型#裤*版型#宽松*风格#性感*图案#线条*裤型#阔腿裤",
"summary": "宽松的阔腿裤这两年真的吸粉不少,明星时尚达人的心头爱。毕竟好穿时尚,谁都能穿出腿长2米的效果宽松的裤腿,当然是遮肉小能手啊。上身便..."
}想将该自定义数据集放到我们的系统中使用,则需要进行如下两步操作:
复制该数据集到 data 目录下
修改 data/dataset_info.json 新加内容完成注册,该注册同时完成了 3 件事:
- 自定义数据集的名称为 my_local,后续训练的时候就使用这个名称来找到该数据集
- 指定了数据集具体文件位置
- 定义了原数据集的输入输出和我们所需要的格式之间的映射关系
javascript
{
...
"adgen_local": {
"file_name": "AdvertiseGen/train.json",
"columns": {
"prompt": "content",
"response": "summary"
}
}
...
}三、LoRA指令微调
在准备好数据集之后,我们就可以开始准备训练了,我们的目标就是让原来的 LLaMA 模型能够学会我们定义的 "你是谁",同时学会我们希望的商品文案的一些生成。
这里我们先使用命令行版本来训练,从命令行更容易学习相关的原理。
javascript
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train `
--stage sft ` # 当前训练的阶段,枚举值,有"sft","pt","rm","ppo"等,代表了训练的不同阶段,这里我们是有监督指令微调
--do_train ` # 是否是训练模式
--model_name_or_path <local_model_path> `
--dataset alpaca_gpt4_zh,identity,adgen_local ` # 使用的数据集列表,所有字段都需要按上文在data_info.json里注册,多个数据集用逗号分隔
--dataset_dir ./data ` # 数据集所在目录,这里是 data,也就是项目自带的data目录
--template qwen3 `
--finetuning_type lora ` # 微调训练的类型,枚举值,有"lora","full","freeze"等,这里使用lora
--output_dir <local_lora_save_path> ` # 训练结果保存的位置
--overwrite_cache `
--overwrite_output_dir `
--cutoff_len 1024 ` # 训练数据集的长度截断
--preprocessing_num_workers 16 `
--per_device_train_batch_size 2 ` # 每个设备上的batch size,最小是1,如果GPU显存大,可以适当增加
--per_device_eval_batch_size 1 `
--gradient_accumulation_steps 8 `
--lr_scheduler_type cosine `
--logging_steps 50 `
--warmup_steps 20 `
--save_steps 100 `
--eval_steps 50 `
--evaluation_strategy steps `
--load_best_model_at_end `
--learning_rate 5e-5 `
--num_train_epochs 5.0 `
--max_samples 1000 ` # 每个数据集采样多少数据
--val_size 0.1 ` # 随机从数据集中抽取多少比例的数据作为验证集
--plot_loss `
--fp16 # 使用半精度混合精度训练训练完后就可以在设置的output_dir下看到如下内容,主要包含 3 部分:
- adapter开头的就是 LoRA 保存的结果了,后续用于模型推理融合
- training_loss和trainer_log等记录了训练的过程指标
- 其他是训练时各种参数的备份
四、可视化/零代码微调
python
# 开启可视化操作界面
# set这种方法是临时的
(llama_factory_Qwen3) D:\LLaMA-Factory>set CUDA_VISIBLE_DEVICES=0
# 开启
(llama_factory_Qwen3) D:\LLaMA-Factory>llamafactory-cli webui1.模型下载源
因为选择huggingface整不了,选择了modelscope
2.微调方法
根据需要选择,这里选择的是LORA
3.Train-数据集
根据需要,可以选择LLamaFactory自带的,也可以用自己的数据集,
4.Train-计算类型
根据自己的显卡选
5.模型名称
选模型要根据自己显卡档次选,太大可能加载失败
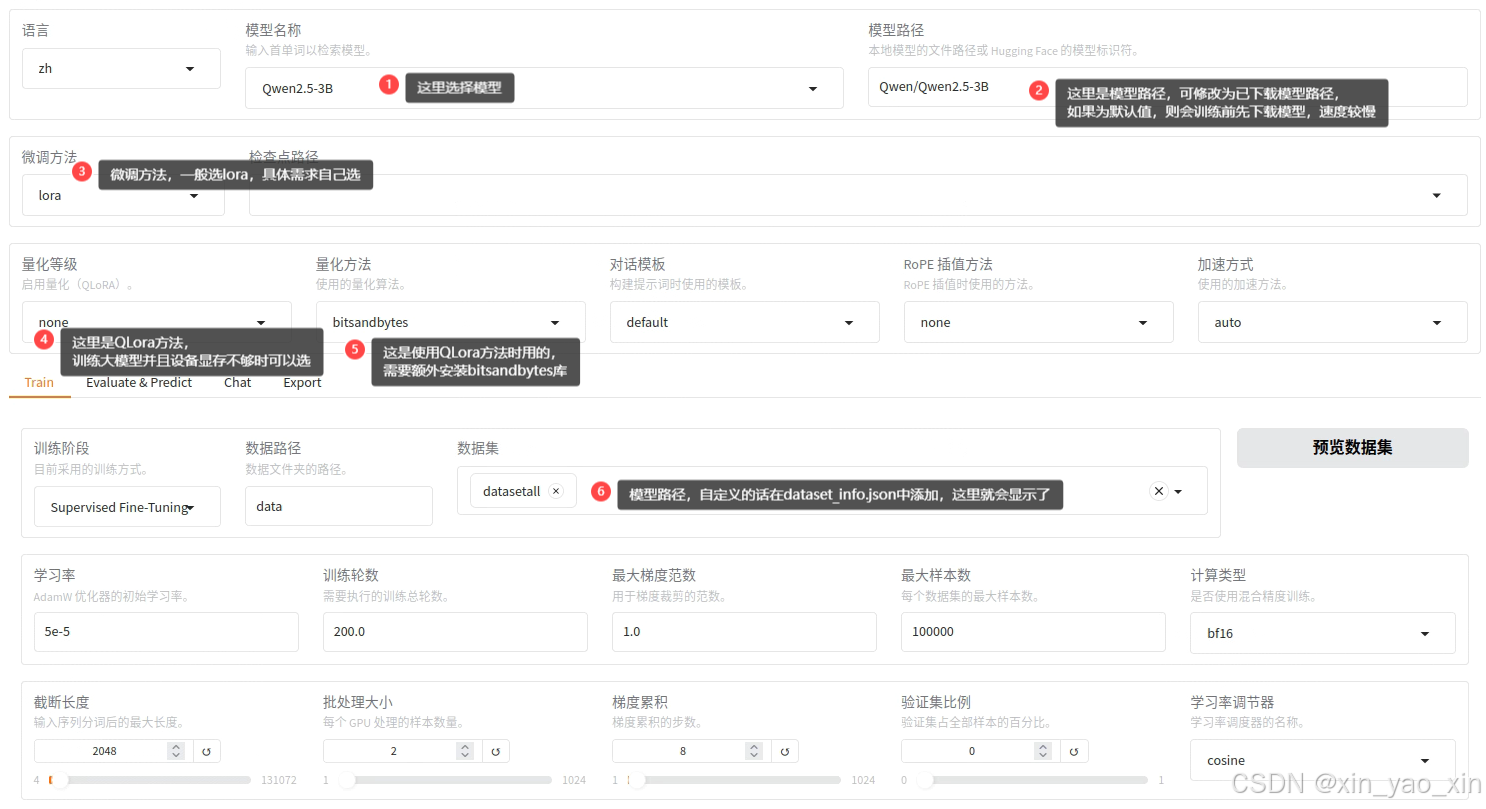
6.导出微调过的模型
先创建个文件夹,然后把绝对路径放Export部分导出目录,最上边检查点路径选要合并的那一个
五、可能出现的问题
1.CUDA未找到
解决方法:在自己创的环境里换跟自己CUDA版本匹配的Pytorch版本
链接:Pytorch官网
下的不成功,就换个下载源
2.ValueError: Your setup doesn't support bf16/gpu.
这个错误是因为你的 GPU 不支持 bf16(bfloat16)格式。这很常见,大多数消费级 NVIDIA 显卡都不支持 bf16(只有 RTX 30/40 系列部分型号支持)。换个适合的,直接在UI界面改
总结
记得关注么么叽