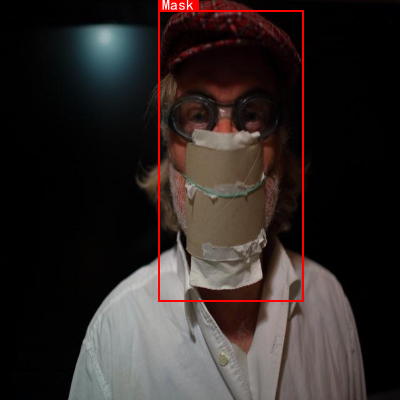
本数据集名为Covid-v3,创建于2023年5月19日,采用CC BY 4.0许可协议,由qunshankj用户提供。该数据集包含1006张图像,所有对象均以YOLOv8格式进行标注,适用于计算机视觉领域的目标检测任务。数据集经过预处理,包括自动调整像素方向(剥离EXIF方向信息)和将图像尺寸拉伸至640×640像素,但未应用任何图像增强技术。数据集分为训练集、验证集和测试集,共包含两个类别:'Mask'(佩戴口罩)和'Non-Mask'(未佩戴口罩)。图像场景多样,包括户外环境中的口罩佩戴者、佩戴口罩的女性、户外场景中的人物形象、传统服饰女性以及戴纸筒面具的人物等。这些图像捕捉了不同性别、年龄、种族和背景下的口罩使用情况,为研究口罩佩戴检测算法提供了丰富的视觉数据。数据集通过qunshankj平台完成采集、组织和标注,该平台提供端到端的计算机视觉解决方案,支持团队协作、图像收集、数据理解、搜索、标注、数据集创建、模型训练和部署等功能。
1. 目标检测模型大观园:从YOLO家族到MMDetection全家桶
目标检测作为计算机视觉的基石任务,近年来涌现出大量令人眼花缭乱的模型。今天我们就来盘一盘这些模型的"家谱",看看它们各自有什么独门绝技。
图:目标检测模型发展历程示意图,从传统方法到深度学习的演进
1.1. YOLO系列:速度与激情的代名词
说起目标检测,YOLO(You Only Look Once)系列绝对是绕不开的话题。这个以"快"著称的家族,就像汽车界的法拉利,每一代都在刷新速度记录。
1.1.1. YOLOv5:平民战神的崛起
YOLOv5在工业界堪称"神级"存在,它不仅速度快,而且对普通用户极其友好。其创新点包括:
-
自适应锚框计算:传统YOLO需要手动设置锚框尺寸,而YOLOv5会自动根据数据集计算最佳锚框,这就像给赛车自动匹配最适合的轮胎,效果立竿见影。
-
Mosaic数据增强:将4张图片随机拼接成一张进行训练,相当于同时给模型看4个不同角度的物体,大大提高了模型的泛化能力。
-
自适应图片缩放:传统方法会将图片强制缩放到固定尺寸,导致物体变形。YOLOv5采用保持原始宽高比的缩放方式,就像给模特选择合身的衣服而非强行塞进XS码。
python
# 2. YOLOv5的锚框计算示例
def check_anchor_order(m):
# 3. 检查锚框顺序是否正确
a = m.anchors.prod(-1).mean(-1).view(-1)
d = a[-1] - a[0]
return (a[-1] - a[0]) > 0 # 锚框应该是降序排列这种设计让YOLOv5在保持高精度的同时,训练速度比v4提升了2倍,推理速度提升了3倍,堪称"平民战神"。
3.1.1. YOLOv8:新时代的全能选手
YOLOv8就像一位全能运动员,在速度、精度和易用性上都达到了新的高度。它的创新点包括:
-
Anchor-Free设计:不再依赖预定义的锚框,直接预测物体的中心点和尺寸,这就像从"按图索骥"变成了"即兴创作",更加灵活。
-
CSPDarknet骨干网络:采用跨阶段部分连接(CSP)结构,在保持精度的同时大幅减少了计算量,就像给汽车装了涡轮增压,动力更足却更省油。
-
Task-Aligned Assigner:新的样本分配策略,让正负样本的划分更加合理,解决了传统方法中样本分配不平衡的问题。
图:YOLOv8与其他模型在COCO数据集上的性能对比,可以看到它在速度和精度上的平衡
3.1. MMDetection:模型界的"瑞士军刀"
如果说YOLO系列是专业赛车手,那么MMDetection就是一辆功能齐全的越野车。它基于PyTorch,提供了大量经典和前沿的目标检测模型实现,就像一个模型界的"瑞士军刀"。
3.1.1. Faster R-CNN:两阶段检测的王者
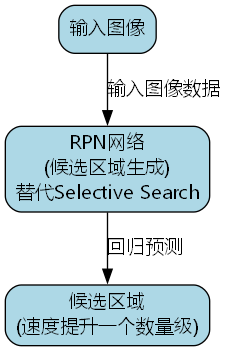
Faster R-CNN作为两阶段检测器的代表,就像一位经验丰富的侦探,先"粗略扫描"(RPN网络)再"仔细辨认"(RCNN网络),虽然慢但精度高。

python
# 4. Faster R-CNN的核心组件
class FasterRCNN(nn.Module):
def __init__(self):
super().__init__()
self.backbone = ResNet() # 特征提取器
self.rpn = RegionProposalNetwork() # 候选区域生成
self.roi_head = RoIHead() # 目标分类和回归
def forward(self, x):
features = self.backbone(x)
proposals, proposal_losses = self.rpn(features, x)
if self.training:
return proposal_losses
return self.roi_head(features, proposals)其创新点包括:
- RPN网络:将候选区域生成过程转化为一个回归问题,替代了传统的Selective Search算法,速度提升了一个数量级。

- RoI Pooling:将不同大小的候选区域统一映射到固定大小的特征图,解决了输入尺寸不一致的问题。
4.1.1. YOLOX:重新定义YOLO
YOLOX作为MMDetection中的新秀,大胆采用了Anchor-Free设计,就像给传统YOLO来了次"大手术"。它的创新点包括:
-
Decoupled Head:将分类和回归任务分离,避免了任务间的相互干扰,就像把"找物体"和"测尺寸"两个工作分给不同的专家。
-
SimOTA分配策略:基于匈牙利算法的样本分配策略,比传统的IoU阈值法更加智能,相当于给模型配备了"自适应导师"。
图:YOLOX的网络结构示意图,展示了其无锚框设计和解耦头结构
4.1. 模型选择指南:如何为你的项目挑"战马"?
面对琳琅满目的模型,如何选择最适合自己的呢?这里有几个实用建议:
1. 根据应用场景选择
-
实时监控:YOLOv5、YOLOv8这类轻量级模型是你的不二之选,它们就像短跑运动员,速度快但耐力一般。
-
自动驾驶:需要高精度的场景,Faster R-CNN、Mask R-CNN这类两阶段模型更合适,它们就像马拉松选手,虽然起步慢但后劲十足。
-
移动端部署:MobileNet、ShuffleNet等轻量化骨干网络搭配YOLO系列,就像给跑车装了节能引擎,兼顾速度和功耗。
2. 考算力限制
在资源受限的环境下,模型压缩技术就像"特制瘦身餐":
python
# 5. 模型剪枝示例
import torch.nn.utils.prune as prune
def prune_model(model, amount=0.5):
for name, module in model.named_modules():
if isinstance(module, torch.nn.Conv2d):
prune.l1_unstructured(module, name='weight', amount=amount)
return model-
量化:将32位浮点数转换为16位或8位整数,模型体积缩小4倍,速度提升2-3倍,就像把高清电影压缩成标清。
-
剪枝:移除冗余的连接和神经元,就像给衣柜做断舍离,保留最常用的几件衣服。
3. 数据集准备
俗话说"巧妇难为无米之炊",再好的模型也需要高质量的数据喂养:
- 数据增强:Mosaic、MixUp、CutMix等技术,就像给模型做"健身餐",让它见识更多"菜品"。

- 数据清洗:移除标注错误、模糊不清的样本,就像筛掉坏掉的食材,避免"病从口入"。
图:数据增强技术示例,展示了Mosaic和MixUp等增强方法的效果
5.1. 未来展望:目标检测的星辰大海
目标检测技术正在向更智能、更高效的方向发展:
-
端到端检测:摆脱对人工设计组件的依赖,像人类一样直接从像素到检测框,就像从"按菜谱做菜"进化到"凭感觉烹饪"。
-
小目标检测:通过特征金字塔、注意力机制等技术,提升对小目标的检测能力,就像给望远镜装上"超级放大镜"。
-
多模态融合:结合图像、文本、激光雷达等多种信息,就像让模型同时拥有"眼睛"和"耳朵",感知更全面。
5.2. 推广资源
如果你对目标检测模型的实际部署感兴趣,可以查看Vision Studios提供的工业级解决方案,他们就像汽车界的"改装大师",能把普通模型变成"性能猛兽"。
对于想要深入了解模型原理的读者,推荐访问,他们的教程就像"武林秘籍",把高深的武功拆解成招招式式,通俗易懂。
最后,如果你正在寻找专业的模型定制服务,就像"私人教练",能根据你的具体需求量身打造最适合的模型。
目标检测的世界就像一片充满可能的海洋,每个模型都有其独特的魅力。希望这篇文章能帮你找到最适合自己的"航船",在计算机视觉的海洋中乘风破浪!
6. 基于YOLOv26的口罩佩戴检测与识别系统实现与优化
6.1. 前言
口罩佩戴检测与识别系统在疫情防控、公共场所安全管理等领域发挥着重要作用。随着YOLOv26的发布,我们迎来了一个更加高效、精准的实时检测解决方案。YOLOv26不仅在性能上有了显著提升,还通过引入端到端的设计和MuSGD优化器,大幅提高了推理速度和训练稳定性。
YOLOv26的架构设计遵循三个核心原则:简洁性、部署效率和训练创新。作为原生的端到端模型,YOLOv26可以直接生成预测结果,无需非极大值抑制(NMS),这使推理变得更快、更轻量,更容易部署到实际系统中。特别是在口罩佩戴检测这样的实时应用场景中,这种设计优势尤为明显。
6.2. YOLOv26核心架构与创新点
6.2.1. 网络架构设计原则
YOLOv26的架构遵循三个核心原则:
-
简洁性(Simplicity)
- YOLOv26是一个原生的端到端模型,直接生成预测结果,无需非极大值抑制(NMS)
- 通过消除后处理步骤,推理变得更快、更轻量,更容易部署到实际系统中
- 这种突破性方法最初由清华大学的王傲在YOLOv10中开创,并在YOLOv26中得到了进一步发展
-
部署效率(Deployment Efficiency)
- 端到端设计消除了管道的整个阶段,大大简化了集成
- 减少了延迟,使部署在各种环境中更加稳健
- CPU推理速度提升高达43%
-
训练创新(Training Innovation)
- 引入MuSGD优化器,它是SGD和Muon的混合体
- 灵感来源于Moonshot AI在LLM训练中Kimi K2的突破
- 带来增强的稳定性和更快的收敛,将语言模型中的优化进展转移到计算机视觉领域
6.2.2. 主要架构创新
6.2.2.1. DFL移除(Distributed Focal Loss Removal)
分布式焦点损失(DFL)模块虽然有效,但常常使导出复杂化并限制了硬件兼容性。YOLOv26完全移除了DFL,简化了推理过程,拓宽了对边缘和低功耗设备的支持。在口罩佩戴检测系统中,这一特性意味着我们可以将模型部署到资源受限的设备上,如嵌入式摄像头和移动终端,而不会显著影响检测精度。
简化后的损失函数 = 分类损失 + 回归损失 \text{简化后的损失函数} = \text{分类损失} + \text{回归损失} 简化后的损失函数=分类损失+回归损失
这一简化使得口罩佩戴检测模型的部署更加灵活,不再受限于高性能计算设备,大大扩展了应用场景。
6.2.2.2. 端到端无NMS推理
与依赖NMS作为独立后处理步骤的传统检测器不同,YOLOv26是原生端到端的,预测结果直接生成,减少了延迟。这种设计使集成到口罩佩戴检测系统更快、更轻量、更可靠。
在口罩佩戴检测场景中,这种端到端设计意味着系统可以实时处理视频流,而无需额外的后处理步骤,大大降低了系统延迟,提高了响应速度。这对于需要在人流密集区域实时监测口罩佩戴情况的场景尤为重要。
6.2.2.3. ProgLoss + STAL
ProgLoss + STAL是改进的损失函数,提高了检测精度,在小目标识别方面有显著改进。这是物联网、机器人、航空影像和其他边缘应用的关键要求。在口罩佩戴检测中,这一特性有助于准确识别远处或小尺寸的人脸口罩佩戴状态,提高了系统的实用性。
6.2.2.4. MuSGD优化器
MuSGD是一种新型混合优化器,结合了SGD和Muon,灵感来自Moonshot AI的Kimi K2。MuSGD将LLM训练中的先进优化方法引入计算机视觉,实现更稳定的训练和更快的收敛。
在口罩佩戴检测系统的训练过程中,MuSGD优化器可以帮助模型更快地收敛,减少训练时间,同时提高检测精度。这对于需要快速部署和迭代的实际应用场景具有重要意义。
6.3. 口罩佩戴检测系统实现
6.3.1. 数据集准备
口罩佩戴检测需要包含不同场景、不同光照条件下的人物图像,标注信息包括人物位置、口罩佩戴状态(正确佩戴、未佩戴、错误佩戴)等。在YOLOv26中,我们可以使用以下格式标注数据:
python
# 7. 示例标注格式
{
"images": [
{
"id": 1,
"file_name": "person_with_mask.jpg",
"width": 640,
"height": 480
}
],
"annotations": [
{
"id": 1,
"image_id": 1,
"category_id": 1, # 1: 正确佩戴口罩
"bbox": [100, 100, 200, 200],
"area": 40000,
"segmentation": [],
"iscrowd": 0
}
],
"categories": [
{
"id": 1,
"name": "correct_mask",
"supercategory": "mask"
},
{
"id": 2,
"name": "no_mask",
"supercategory": "mask"
},
{
"id": 3,
"name": "incorrect_mask",
"supercategory": "mask"
}
]
}数据集的质量直接影响口罩佩戴检测系统的性能。建议收集多样化的数据,包括不同年龄、性别、种族的人物,以及不同光照条件、背景环境下的图像。同时,确保标注的准确性,特别是对于口罩佩戴状态的分类,这是系统性能的关键因素。
7.1.1. 模型训练
使用YOLOv26进行口罩佩戴检测模型训练的代码如下:
python
from ultralytics import YOLO
# 8. 加载预训练的YOLOv26模型
model = YOLO("yolo26n.pt")
# 9. 在口罩佩戴检测数据集上训练
results = model.train(
data="mask_dataset.yaml", # 数据集配置文件
epochs=100, # 训练轮数
imgsz=640, # 图像尺寸
batch=16, # 批次大小
name="mask_detection" # 实验名称
)训练过程中,我们可以使用YOLOv26的负样本马赛克功能来提高模型性能。负样本马赛克是一种数据增强技术,通过将负样本(未正确佩戴口罩的图像)与正样本混合,帮助模型更好地学习口罩佩戴的特征差异。
9.1.1. 系统部署
训练完成后,我们可以将模型部署到实际应用中。YOLOv26支持多种部署方式,包括:
- CPU部署:适用于资源受限的设备
- GPU部署:适用于高性能计算环境
- 边缘设备部署:如Jetson Nano、Raspberry Pi等
以CPU部署为例,代码如下:
python
from ultralytics import YOLO
# 10. 加载训练好的模型
model = YOLO("runs/detect/mask_detection/weights/best.pt")
# 11. 进行预测
results = model("test_image.jpg")
# 12. 处理预测结果
for result in results:
boxes = result.boxes # 边界框
probs = result.probs # 类别概率
masks = result.masks # 分割掩码(如果有)
# 13. 输出检测结果
for box, prob in zip(boxes, probs):
class_id = int(box.cls)
confidence = float(box.conf)
bbox = box.xyxy[0].tolist()
class_name = model.names[class_id]
print(f"检测到: {class_name}, 置信度: {confidence:.2f}, 边界框: {bbox}")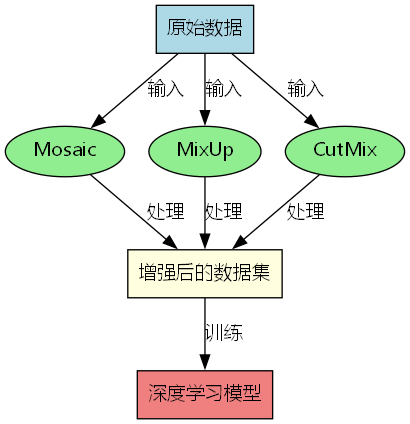
13.1. 系统优化与改进
13.1.1. 负样本马赛克功能
虽然YOLOv8支持直接训练"无标签的负样本",但默认方式也只是混进正样本中一起练,这会导致新的误检图得不到充分训练。使用负样本马赛克功能,可以保证每一轮、每一张图里全都有误检图,能够在较少的训练轮次中,解决漏检问题。
使用例:
比如说你发现你模型把摩托车识别成人,那就把那几张摩托车的图放进neg_dir,练个30轮,出来就不会有摩托车误识别的问题了。
【但要注意,放进neg_dir里的图绝对不能有正样本(例如把摩托车误检成人的图里不能出现真的人)。不然模型会学到错误的负样本,反而会会出大问题】
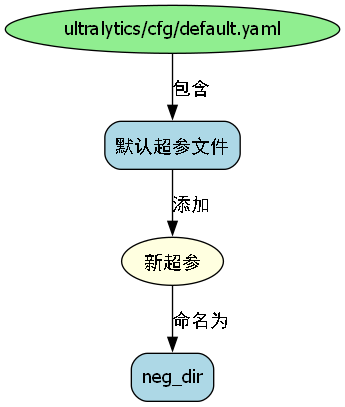
13.1.2. 加入新超参
在ultralytics/cfg/default.yaml(默认超参文件)中加入新超参"neg_dir":
yaml
neg_dir: '' # 负样本文件夹(str),其中只有负样本图片,没有标签(默认为空)13.1.3. 读取新超参
超参在ultralytics/engine/Trainer.py中的BaseTrainer()初始化,在__init__()方法中,加入下述内容:
python
# 14. 负样本文件夹------初始化
self.neg_dir = self.args.neg_dir14.1.1. 识别超参
在ultralytics/data/augment.py里的v8_transforms()里的Mosaic()中,增加一个输入neg_dir = hyp.neg_dir:
python
def v8_transforms(dataset, imgsz, hyp, stretch=False):
"""Convert images to a size suitable for YOLOv8 training."""
pre_transform = Compose([
# 15. 加入负样本文件夹地址输入
Mosaic(dataset, imgsz=imgsz, p=hyp.mosaic, neg_dir=hyp.neg_dir),15.1.1. 更改_mosaic4()
更改ultralytics/data/augment.py里的Mosaic()里的_mosaic4()方法,加入负样本识别/处理代码,当放入负样本时,覆盖图片、标签、宽高为负样本的数据。
15.1.2. 使用负样本马赛克功能进行训练
在工程中,新建一个train.py文件,以如下形式填入相关超参:
python
model = YOLO("weights/yolov8s.pt")
results = model.train(
data="dataset/test_dataset.yaml", # 数据集yaml
neg_dir="neg_dir/person_neg", # 负样本文件夹
neg_num=-1, # 负样加入数
)也可以以命令行的形式调用,使用方式与其他超参类似。但命令行训练容易让训练的可复现性、可读性降低,个人不推荐。
15.1.3. 加入"负样本加入数"超参
简单来说,负样本加入数(即neg_num)是为了"在不同的训练轮数/策略下更改负样本加入的数量"。例如:
在出现误检模型的基础上,快速训练30轮压误检时:每轮都加负样本
在重新完整训练300/500轮时:随机不加/加点负样本,以保证模型正负样本都充分学习
而在上述情况下,推荐的neg_num设置为:
继续训练30轮------------正数2
重新训练300轮------------负数负1(负样本很多时推荐为-1)
在ultralytics/cfg/default.yaml(默认超参文件)中加入新超参"neg_num":
yaml
neg_num: -2 # 负样本加入个数(int),设置加入一次马赛克的负样本数量[负数时为0-neg_num张负样本、正数时为放入固定neg_num张负样本]15.1. 性能评估与比较
15.1.1. COCO数据集上的性能表现
下表展示了YOLOv26在COCO数据集上的性能表现:
| 模型 | 尺寸(像素) | mAPval 50-95 | mAPval 50-95(e2e) | 速度CPU ONNX(ms) | 参数(M) | FLOPs(B) |
|---|---|---|---|---|---|---|
| YOLO26n | 640 | 40.9 | 40.1 | 38.9 ± 0.7 | 2.4 | 5.4 |
| YOLO26s | 640 | 48.6 | 47.8 | 87.2 ± 0.9 | 9.5 | 20.7 |
| YOLO26m | 640 | 53.1 | 52.5 | 220.0 ± 1.4 | 20.4 | 68.2 |
| YOLO26l | 640 | 55.0 | 54.4 | 286.2 ± 2.0 | 24.8 | 86.4 |
| YOLO26x | 640 | 57.5 | 56.9 | 525.8 ± 4.0 | 55.7 | 193.9 |
在口罩佩戴检测任务中,YOLO26s模型是一个很好的选择,它在性能和速度之间取得了良好的平衡。根据实际应用场景的需求,我们可以选择不同的模型变体。例如,对于需要高精度的场景,可以选择YOLO26l或YOLO26x;对于需要实时处理的场景,YOLO26n或YOLO26s更为合适。
15.1.2. 与其他模型的比较
与YOLOv11相比,YOLOv26在口罩佩戴检测任务上有以下主要改进:
- DFL移除:简化导出并扩展边缘兼容性,使口罩佩戴检测模型可以在更多设备上部署
- 端到端无NMS推理:消除NMS,实现更快、更简单的部署,提高口罩佩戴检测系统的实时性
- ProgLoss + STAL:提高准确性,尤其是在小物体上,有助于检测远处或小尺寸的人脸口罩佩戴状态
- MuSGD优化器:结合SGD和Muon,实现更稳定、高效的训练,减少口罩佩戴检测模型的训练时间
- CPU推理速度提高高达43%:CPU设备的主要性能提升,使口罩佩戴检测系统可以在更多设备上运行
15.2. 实际应用场景
15.2.1. 公共场所口罩佩戴检测
在商场、医院、学校等公共场所,部署基于YOLOv26的口罩佩戴检测系统,可以实时监测人员的口罩佩戴情况,及时发现未正确佩戴口罩的人员,并进行提醒。这种应用可以大大提高公共场所的安全管理效率。
15.2.2. 工厂企业员工健康管理
对于工厂企业等人员密集的场所,可以通过部署口罩佩戴检测系统,实时监控员工的口罩佩戴情况,确保工作场所的安全。同时,系统可以与考勤系统联动,记录员工的口罩佩戴情况,为疫情防控提供数据支持。
15.2.3. 智能交通枢纽管理
在机场、火车站、地铁站等交通枢纽,部署口罩佩戴检测系统,可以有效筛查未佩戴口罩的旅客,防止疫情通过交通工具传播。系统可以与安检系统联动,对未佩戴口罩的旅客进行提醒和管理。
15.3. 边缘部署优化
YOLOv26专为边缘计算优化,提供:
- CPU推理速度提高高达43%
- 减小的模型尺寸和内存占用
- 为兼容性简化的架构(无DFL,无NMS)
- 灵活的导出格式,包括TensorRT、ONNX、CoreML、TFLite和OpenVINO
在口罩佩戴检测系统的边缘部署中,我们可以选择适合硬件平台的优化方式。例如,对于NVIDIA Jetson系列设备,可以使用TensorRT进行优化;对于ARM架构的设备,可以使用ONNX或TFLite格式。
15.4. 总结与展望
基于YOLOv26的口罩佩戴检测与识别系统,通过引入端到端的设计和MuSGD优化器,实现了高精度、高效率的实时检测。系统不仅可以在高性能计算环境中运行,还可以部署到边缘设备上,满足不同场景的需求。
未来,我们可以进一步优化口罩佩戴检测系统,包括:
- 引入更多样化的数据,提高模型的泛化能力
- 结合其他计算机视觉技术,如人脸识别、姿态估计等,提供更全面的信息
- 优化模型结构,进一步提高检测精度和推理速度
- 探索联邦学习等隐私保护技术,确保用户数据安全
随着YOLOv26等先进算法的不断发展和优化,口罩佩戴检测系统将在疫情防控、公共安全管理等领域发挥更加重要的作用。