1.物体检测和数据集
目标检测(Object Detection)
图片分类、目标检测和实例分割
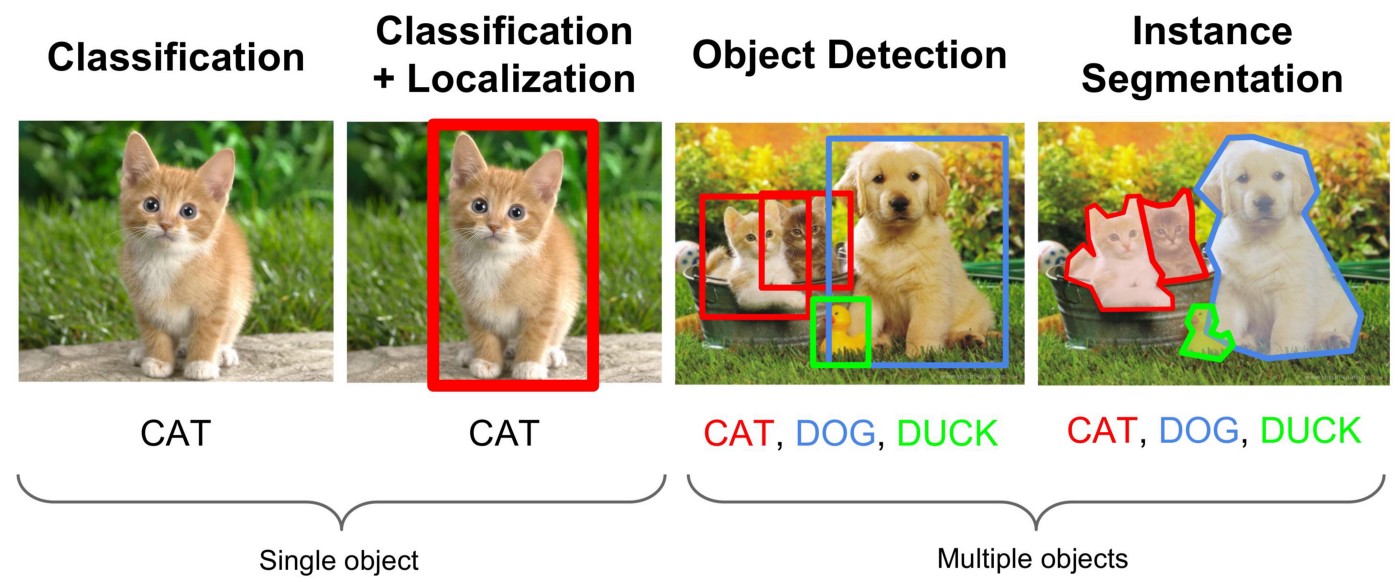
图像分类任务中,我们假设图像中只有一个主要物体对象,我们只关注如何识别其类别。 然而,很多时候图像里有多个我们感兴趣的目标,我们不仅想知道它们的类别,还想得到它们在图像中的具体位置。 在计算机视觉里,我们将这类任务称为目标检测(object detection)或目标识别(object recognition)。
深度学习物体检测,是让计算机在图片或视频中自动找出"物体在哪里",并判断"是什么"的技术
目标检测在多个领域中被广泛使用。 例如,在无人驾驶 里,我们需要通过识别拍摄到的视频图像里的车辆、行人、道路和障碍物的位置来规划行进线路。 机器人 也常通过该任务来检测感兴趣的目标。安防领域则需要检测异常目标,如歹徒或者炸弹。
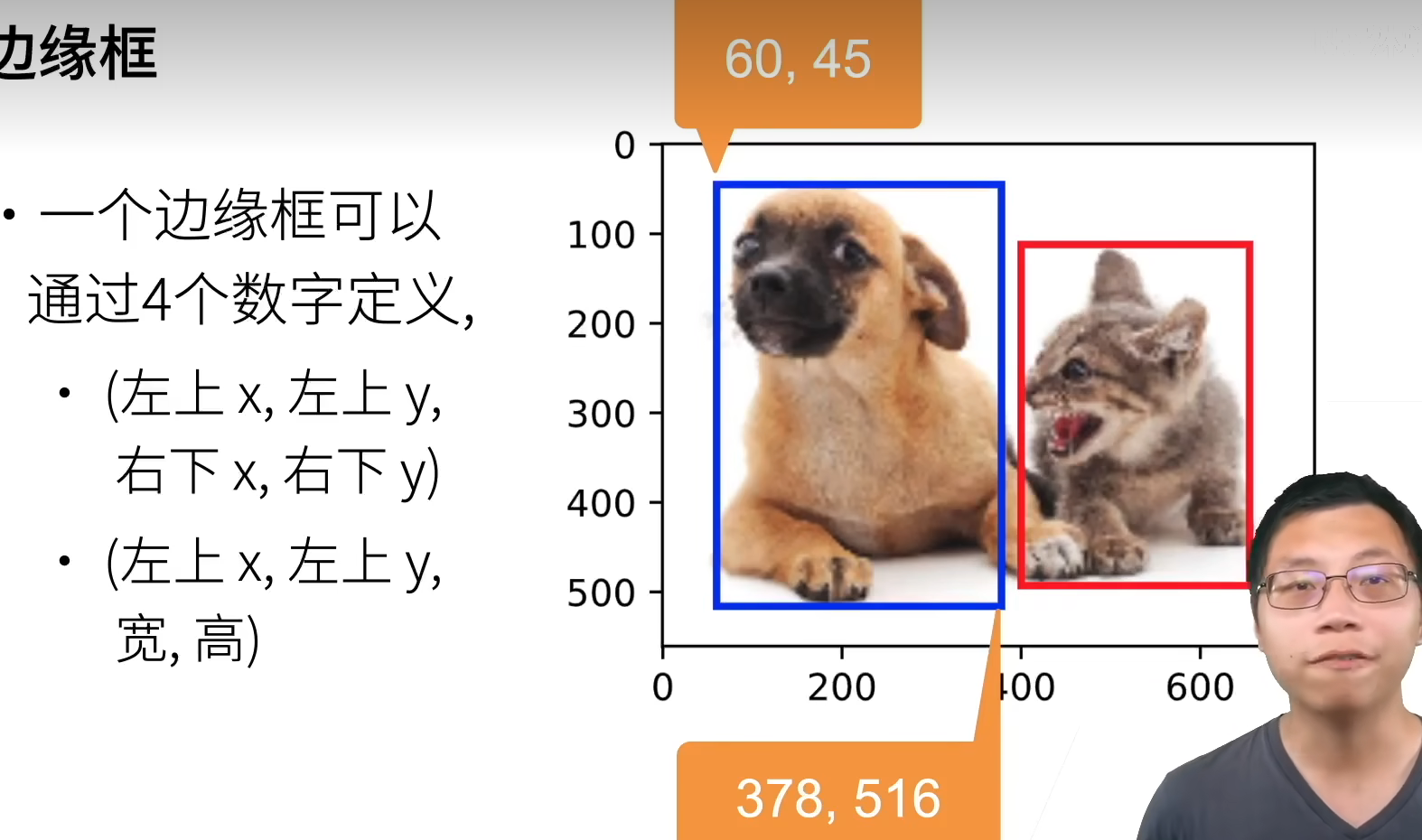
边界框(bounding box)
一个边界框可以用 4 个数字定义
- 左上 x,左上 y,右下 x,右下 y
- 左上 x,左上 y,宽,高
目标识别的数据集通常比图片分类的数据集小很多,因为标注成本高
目标检测数据集
- 每行表示一个物体,若一张图里有 n 个物体,则重复 n 行
如:
图片文件名,物体类别,边缘框(x1,y1,x2,y2)
- COCO(cocodataset.org)
80 类别,330K 图片,1.5M 物体
- 物体检测识别图片里的多个物体的类别和位置
- 位置通常用边缘框表示
代码实现
- 图像张量(image tensor):模型要看的"输入图片"(像素矩阵)。
- 标注张量(label tensor):告诉模型"物体是什么 + 在哪里"的信息。
先介绍图像张量:
python
batch[0].shape假设输出为:
plain
torch.Size([32, 3, 256, 256])这 4 个数字分别表示:
| 维度 | 含义 |
|---|---|
| 32 | 一个 batch 里有 32 张图片 |
| 3 | 每张图有 3 个通道(RGB) |
| 256 | 图像高度(像素) |
| 256 | 图像宽度(像素) |
所以:
图像张量就是把 32 张彩色图片排成一个 4D 张量,让神经网络一次性处理
标注张量:
python
batch[1].shape假设输出为:
plain
torch.Size([32, 1, 5])含义如下:
| 维度 | 含义 |
|---|---|
| 32 | 一个 batch 对应 32 张图 |
| 1 | 每张图只有 1 个目标(香蕉) |
| 5 | 1 个类标 + 4 个框坐标 |
这 5 个数是什么?
plain
[class_id, x_min, y_min, x_max, y_max]例如:
plain
tensor([0., 0.31, 0.15, 0.57, 0.62])表示:
- class_id = 0:类别是香蕉(只有一个类别)
- x_min = 0.31
- y_min = 0.15
- x_max = 0.57
- y_max = 0.62
坐标已经 归一化 到 [0,1] 范围(除以 256)。
python
%matplotlib inline
import torch
from d2l import torch as d2l
d2l.set_figsize()
img = d2l.plt.imread('/root/autodl-tmp/01_Data/03_catdog.jpg')
d2l.plt.imshow(img)
- 定义两种边界框表示函数
plain
假设你的 boxes 是一个形状:
[N, 4]
例如 N=3:
boxes =
tensor([
[10., 20., 30., 40.],
[50., 60., 70., 80.],
[15., 25., 35., 45.]
])
结果:
[ x1, y1, x2, y2 ]
中心格式 (cx, cy, w, h) 也是一样的逻辑
如果 boxes 是:[ cx, cy, w, h ]
那么:
cx = boxes[:,0] # 全部样本的 cx
cy = boxes[:,1] # 全部样本的 cy
w = boxes[:,2] # 全部宽度
h = boxes[:,3] # 全部高度
python
# 定义在这两种表示之间进行转换的函数
def box_corner_to_center(boxes):
"""从(左上,右下)转换到(中间,宽度,高度)"""
x1, y1, x2, y2 = boxes[:,0], boxes[:,1], boxes[:,2], boxes[:,3]
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
boxes = torch.stack((cx,cy,w,h),axis = -1)
return boxes
def box_center_to_corner(boxes):
"""从(中间,宽度,高度)转换到(左上,右下)"""
cx, cy, w, h = boxes[:,0], boxes[:,1], boxes[:,2], boxes[:,3]
x1 = cx - 0.5 * w
y1 = cy - 0.5 * h
x2 = cx + 0.5 * w
y2 = cy + 0.5 * h
boxes = torch.stack((x1,y1,x2,y2),axis = -1)
return boxes我们将根据坐标信息定义图像中狗和猫的边界框。 图像中坐标的原点是图像的左上角,向右的方向为 x 轴的正方向,向下的方向为 y 轴的正方向。
python
# 定义图像中狗和猫的边界框
dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0]
boxes = torch.tensor((dog_bbox,cat_bbox))
# boxes 转中间表示,再转回来,等于自己
box_center_to_corner(box_corner_to_center(boxes)) == boxes
输出:
tensor([[True, True, True, True],
[True, True, True, True]])- 画出边界框
python
# 将边界框在图中画出
def bbox_to_rect(bbox,color):
return d2l.plt.Rectangle(xy=(bbox[0],bbox[1]),width=bbox[2]-bbox[0],
height=bbox[3] - bbox[1], fill=False,
edgecolor=color,linewidth=2)
fig = d2l.plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox,'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox,'red'))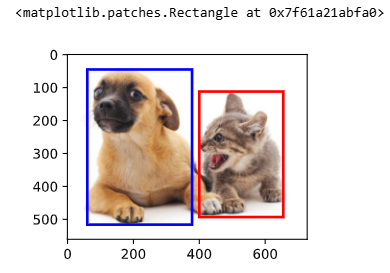
- 目标检测数据集
python
%matplotlib inline
import os
import pandas as pd
import torch
import torchvision
from d2l import torch as d2l
d2l.DATA_HUB['banana-detection'] = (d2l.DATA_URL + 'banana-detection.zip','5de25c8fce5ccdea9f91267273465dc968d20d72')
# 读取香蕉检测数据集
def read_data_bananas(is_train=True):
"""读取香蕉检测数据集中的图像和标签"""
data_dir = d2l.download_extract('banana-detection')
csv_fname = os.path.join(data_dir,
'bananas_train' if is_train else 'bananas_val',
'label.csv')
csv_data = pd.read_csv(csv_fname)
csv_data = csv_data.set_index('img_name')
images, targets = [], []
# 把图片、标号全部读到内存里面
for img_name, target in csv_data.iterrows():
images.append(torchvision.io.read_image(os.path.join(data_dir,'bananas_train' if is_train else 'bananas_val',
'images',f'{img_name}')))
targets.append(list(target))
print("len(targets):",len(targets))
print("len(targets[0]):",len(targets[0]))
print("targets[0][0]....targets[0][4]:",targets[0][0], targets[0][1], targets[0][2], targets[0][3], targets[0][4])
print("type(targets):",type(targets))
print("torch.tensor(targets).unsqueeze(1).shape:",torch.tensor(targets).unsqueeze(1).shape) # unsqueeze函数在指定位置加上维数为一的维度
print("len(torch.tensor(targets).unsqueeze(1) / 256):", len(torch.tensor(targets).unsqueeze(1) / 256))
print("type(torch.tensor(targets).unsqueeze(1) / 256):", type(torch.tensor(targets).unsqueeze(1) / 256))
return images, torch.tensor(targets).unsqueeze(1) / 256 # 归一化使得收敛更快- 创建自定义 Dataset 实例
python
# 创建一个自定义Dataset实例
class BananasDataset(torch.utils.data.Dataset):
"""一个用于加载香蕉检测数据集的自定义数据集"""
def __init__(self, is_train):
self.features, self.labels = read_data_bananas(is_train)
print('read ' + str(len(self.features)) + (f' training examples' if is_train else f'validation examples'))
def __getitem__(self, idx):
return (self.features[idx].float(), self.labels[idx])
def __len__(self):
return len(self.features)- 定义数据迭代器
python
# 为训练集和测试集返回两个数据加载器实例
def load_data_bananas(batch_size):
"""加载香蕉检测数据集"""
train_iter = torch.utils.data.DataLoader(BananasDataset(is_train=True),
batch_size, shuffle=True)
val_iter = torch.utils.data.DataLoader(BananasDataset(is_train=False),
batch_size)
return train_iter, val_iter- 测试
python
# 读取一个小批量,并打印其中的图像和标签的形状
batch_size, edge_size = 32, 256
train_iter, _ = load_data_bananas(batch_size)
batch = next(iter(train_iter))
# ([32,1,5]) 中的1是每张图片中有几种类别,这里只有一种香蕉要识别的类别
# 5是类别标号、框的四个参数
batch[0].shape, batch[1].shape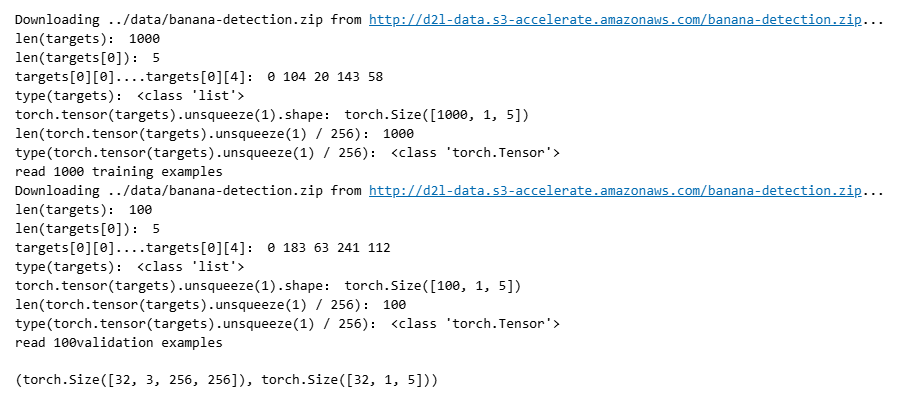
python
# 示例
# pytorch里permute是改变参数维度的函数,
# Dataset里读的img维度是[batch_size, RGB, h, w],
# 但是plt画图的时候要求是[h, w, RGB],所以要调整一下
# 做图片的时候,一般是会用一个ToTensor()将图片归一化到【0, 1】,这样收敛更快
print("原始图片:\n", batch[0][0])
print("原始图片:\n", (batch[0][0:10].permute(0,2,3,1)))
print("归一化后图片:\n", (batch[0][0:10].permute(0,2,3,1)) / 255 )
imgs = (batch[0][0:10].permute(0,2,3,1)) / 255
#imgs = (batch[0][0:10].permute(0,2,3,1))
# d2l.show_images输入的imgs图片参数是归一化后的图片
axes = d2l.show_images(imgs, 2, 5, scale=2)
for ax, label in zip(axes, batch[1][0:10]):
d2l.show_bboxes(ax, [label[0][1:5] * edge_size], colors=['w'])

2.锚框
锚框(Anchor Box)
目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边界从而更准确地预测目标的真实边界框(ground-truth bounding box)。
一类目标检测算法是基于锚框
- 提出多个被称为锚框的区域(边缘框)
- 预测每个锚框里是否含有关注的物体
- 如果是,预测从这个锚框到真实边缘框的偏移
- 调整位置,找到真实的边缘框
IoU - 交并比
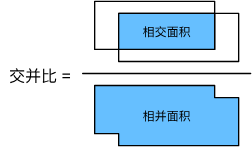
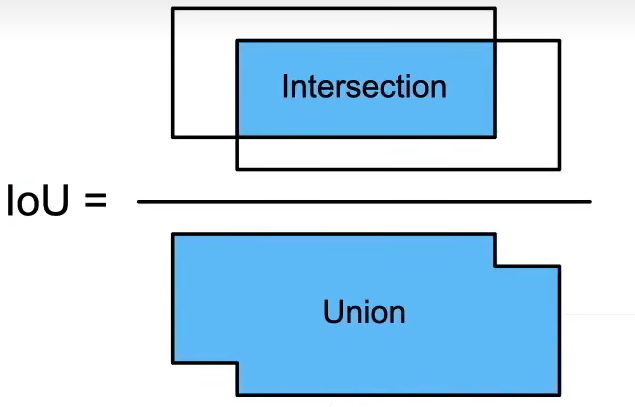
- IoU 用于对比两个锚框之间的相似度
- 0 表示无重叠,1 表示重合
- 这是 Jacquard 指数的一个特殊情况
- 给定两个集合 A 和 B
J(A,B)=∣A⋂B∣∣A⋃B∣J(A, B)={|A \bigcap B|\over|A \bigcup B|}J(A,B)=∣A⋃B∣∣A⋂B∣
赋予锚框标号(训练)
- 将每个锚框视为一个训练样本
- 将每个锚框,要么标注成背景,要么关联上一个真实边缘框
锚框组成:真实物体的标号(class) + 距离真实物体边界框的偏移(offset)
- 我们可能会生成大量的锚框(锚框多于边界框)
这会导致大量的负类样本(背景)
一般使用矩阵表示,其中列表示真实的边界框索引 (如下图所示,真实边界框为4个,一般为标注好的数据),行代表生成的锚框索引 (下图所示锚框为9个,一般为固定生成或根据图片生成),元素填充锚框与边界框的IoU值 。下图展示了如何赋予锚框标号的一种算法(IoU 表格):
每个真实框必须匹配一个 IoU 最大的锚框
图中每一格表示:
锚框 i 与 真实框 j 的 IoU 值 = xᵢⱼ
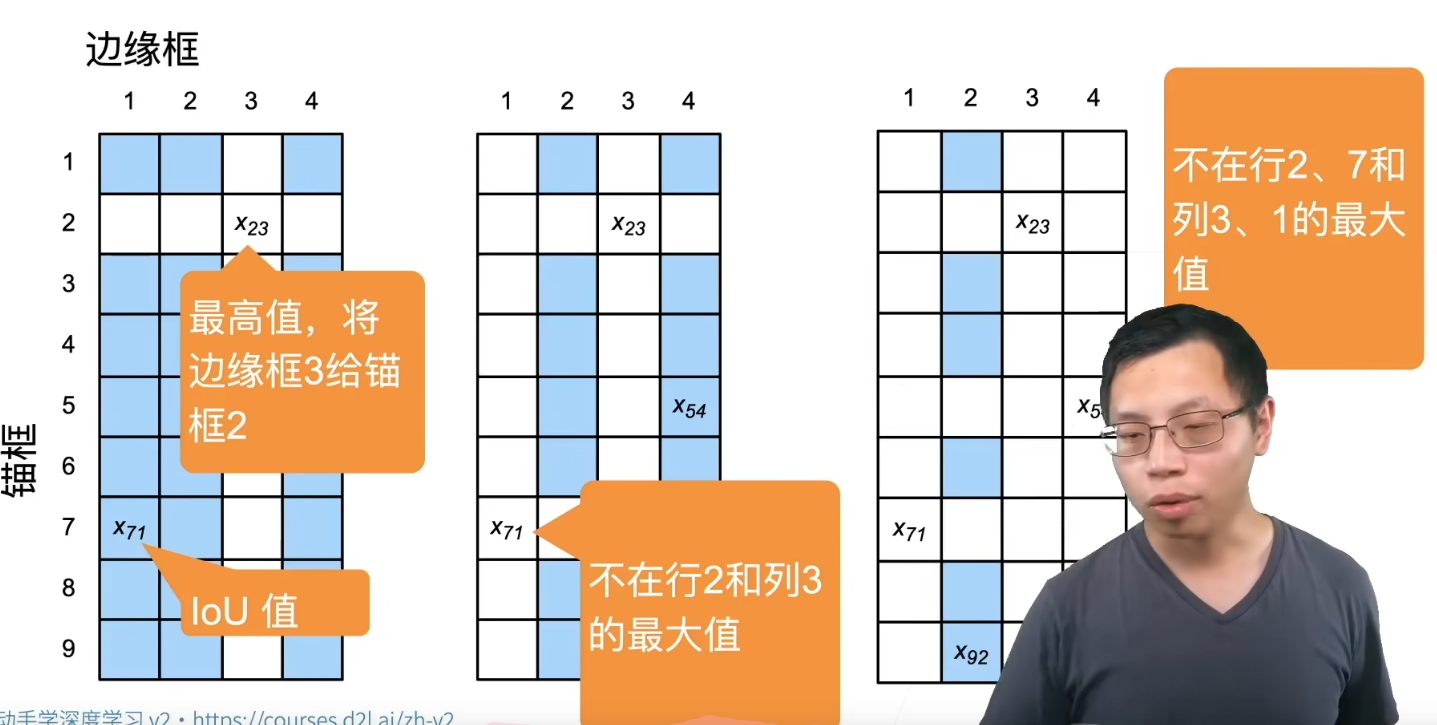
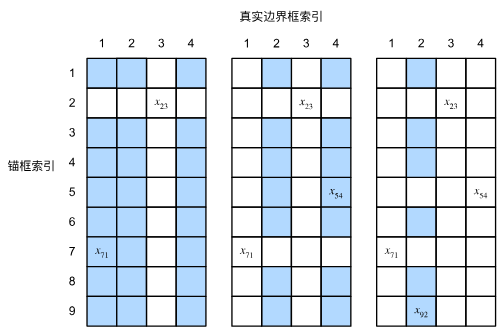
- 对上述矩阵取出最大值 (如左侧图所示,最大值为x23x_{23}x23),所在行对应的锚框则与该边界框关联(
锚框2与边界框3关联),并将该行与该列元素"抠除" - 在上步"抠除"后的矩阵内重复以上操作(如中图,找到最大值x71x_{71}x71,关联
锚框7与边界框1,继续抠除行7列1) - 继续重复上述步骤,直到所有边界框关联完毕,最后遍历剩下的锚框,然后根据阈值确定是否为它们分配真实边界框
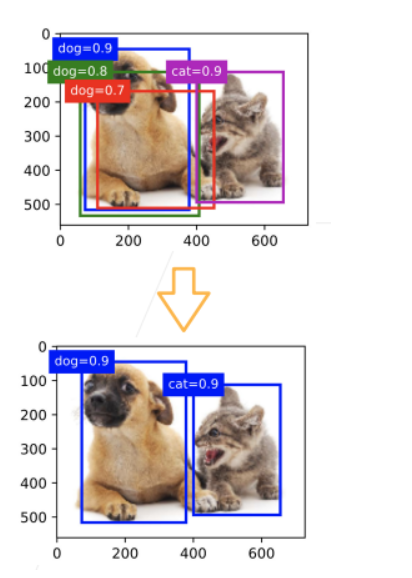
使用非极大值抑制(NMS)输出(预测)
- 每个锚框要预测一个边缘框
- NMS 可以合并相似的预测
- 对于非背景类的锚框,选中针对某一类别最大预测值(softmax)的锚框(如蓝色的
dog=0.9框) - 去掉所有其他和它 IoU 值大于阈值 \\theta 的预测锚框(如绿色、红色框)
- 重复上述过程直到所有预测要么被选中,要么被去掉
- 对于非背景类的锚框,选中针对某一类别最大预测值(softmax)的锚框(如蓝色的
总结
- 一类目标检测算法基于锚框来预测;
- 首先生成大量锚框。并赋予标号,每个锚框作为一个样本进行训练;
- 在预测时,使用 NMS 来去掉冗余的预测
代码实现
- 导入包
python
%matplotlib inline
import torch
from d2l import torch as d2l
torch.set_printoptions(2)- 定义像素的锚框
假设输入图像的高度 为 hhh,宽度 为 www。 我们以图像的每个像素为中心生成不同形状的锚框:锚框占图像的缩放比 为 s∈(0,1]s\in (0,1]s∈(0,1] ,锚框宽高比 为
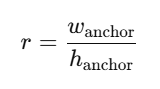 。则锚框的宽度和高度分别是wsrws\sqrt rwsr 和hs/rhs/\sqrt rhs/r 。
。则锚框的宽度和高度分别是wsrws\sqrt rwsr 和hs/rhs/\sqrt rhs/r 。
对于(h,w)(h,w)(h,w)的图片,有h×wh\times wh×w个像素,在乘以所有s,rs,rs,r的组合s×rs\times rs×r,就有h×w×s×rh\times w\times s\times rh×w×s×r个锚框。
只考虑组合:
(s1,r1),(s1,r2),...,(s1,rm),(s2,r1),(s3,r1),...,(sn,r1)(s_1,r_1),(s_1,r_2),...,(s_1,r_m),(s_2,r_1),(s_3,r_1),...,(s_n,r_1)(s1,r1),(s1,r2),...,(s1,rm),(s2,r1),(s3,r1),...,(sn,r1)
也就是s,rs,rs,r各自最合理的一个取值与其他的做匹配
python
def multibox_prior(data,sizes,ratios):
"""生成以每个像素为中心具有不同高宽度的锚框"""
# data.shape的最后两个元素为宽和高,第一个元素为通道数
in_height, in_width = data.shape[-2:]
# 数据对应的设备、锚框占比个数、锚框高宽比个数
device, num_sizes, num_ratios = data.device, len(sizes), len(ratios)
# 计算每个像素点对应的锚框数量
boxes_per_pixel = (num_sizes + num_ratios - 1)
# 将锚框占比列表转为张量并将其移动到指定设备
size_tensor = torch.tensor(sizes, device=device)
# 将宽高比列表转为张量并将其移动到指定设备
ratio_tensor = torch.tensor(ratios, device=device)
# 定义锚框中心偏移量
offset_h, offset_w = 0.5, 0.5
# 计算高度方向上的步长
steps_h = 1.0 / in_height
# 计算宽度方向上的步长
steps_w = 1.0 / in_width
# 生成归一化的高度和宽度方向上的像素点中心坐标
center_h = (torch.arange(in_height, device=device) + offset_h) * steps_h
center_w = (torch.arange(in_width, device=device) + offset_w) * steps_w
# 生成坐标网格
shift_y, shift_x = torch.meshgrid(center_h, center_w)
# 将坐标网格平铺为一维
shift_y, shift_x = shift_y.reshape(-1), shift_x.reshape(-1)
# 计算每个锚框的宽度和高度
w = torch.cat((size_tensor * torch.sqrt(ratio_tensor[0]),
sizes[0] * torch.sqrt(ratio_tensor[1:]))) \
* in_height / in_width
h = torch.cat((size_tensor / torch.sqrt(ratio_tensor[0]),
sizes[0] / torch.sqrt(ratio_tensor[1:])))
# 计算锚框的左上角和右下角坐标(相对于锚框中心的偏移量)
anchor_manipulations = torch.stack((-w, -h, w, h)).T.repeat(in_height * in_width, 1) / 2
# 计算所有锚框的中心坐标,每个像素对应boxes_per_pixel个锚框
out_grid = torch.stack([shift_x, shift_y, shift_x, shift_y], dim=1).repeat_interleave(boxes_per_pixel, dim=0)
# 通过中心坐标和偏移量计算所有锚框的左上角和右下角坐标
output = out_grid + anchor_manipulations
# 增加一个维度并返回结果
return output.unsqueeze(0) 有两个问题:
- 定义边框宽高的算法,以及 s 和 r 的定义;
- 图片的宽高必须是互质的,才能保证 x, y 在分配的时候不重复,这里的情况显然有重复,宽高的公约数是 4,所以重复了 4 倍,或者说锚框少了 4 倍。
- 按像素分块
python
# 返回锚框变量Y的形状
img = d2l.plt.imread('/root/autodl-tmp/01_Data/03_catdog.jpg')
print("img.shape:",img.shape) # 高561,宽72,3通道
h, w = img.shape[:2]
print(h,w)
X = torch.rand(size=(1,3,h,w)) # 批量大小为1,3通道
Y = multibox_prior(X, sizes=[0.75,0.5,0.25], ratios=[1,2,0.5]) # 占图片sizes尺寸的大小、高宽比ratios尺寸大小的锚框
print(Y.shape) # 1 是批量大小,2042040是一张图片生成的锚框数量,4个元素时每个锚框对应的位置
输出:
img.shape: (561, 728, 3)
561 728
torch.Size([1, 2042040, 4])
/root/miniconda3/lib/python3.8/site-packages/torch/functional.py:504: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:3483.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
python
# 访问以(250,250)为中心的第一个锚框
boxes = Y.reshape(h,w,5,4) # 上面的sizes×sizes=3×3,3+3-1=5,故每个像素为中心生成五个锚框
boxes[250,250,0,:] # 以250×250为中心的第一个锚框的坐标
输出:
tensor([0.06, 0.07, 0.63, 0.82])这里的分块只是把 5\\times4 的锚框分配到每个像素的位置,但并不是与像素索引准确映射,便于视察
绘制锚框
python
# 显示以图像中一个像素为中心的所有锚框
def show_bboxes(axes, bboxes, labels=None, colors=None):
"""显示所有边界框"""
def _make_list(obj, default_values=None):
# 如果obj为None,使用默认值;如果obj不是列表或元组,将其转换为列表
if obj is None:
obj = default_values
elif not isinstance(obj, (list, tuple)):
obj = [obj]
return obj
# 处理labels,确保其为列表形式
labels = _make_list(labels)
# 处理colors,确保其为列表形式
colors = _make_list(colors, ['b','g','r','m','c'])
# 遍历所有边界框
for i, bbox in enumerate(bboxes):
# 选择颜色
color = colors[i % len(colors)]
# 使用边界框和颜色生成矩形框
rect = d2l.bbox_to_rect(bbox.detach().numpy(),color)
# 在图像上添加矩形框
axes.add_patch(rect)
# 如果存在标签
if labels and len(labels) > i:
# 根据边界框的颜色选择标签的颜色
text_color = 'k' if color == 'w' else 'w'
# 在边界框上添加标签
axes.text(rect.xy[0], rect.xy[1], labels[i], va='center',
ha='center', fontsize=9, color=text_color,
bbox=dict(facecolor=color, lw=0))
# 设置图像大小
d2l.set_figsize()
# 创建一个张量来缩放边界框的尺寸
bbox_scale = torch.tensor((w,h,w,h))
# 在图像上显示图像
fig = d2l.plt.imshow(img)
print("fig.axes:",fig.axes)
# 在生成锚框的时候是0-1的值,进行缩放的话就可以省点乘法运算,因为最后输出并不需要显示所有锚框,所以可能会更快一点
print("boxes[250,250,:,:]:",boxes[250,250,:,:])
print("bbox_scale:", bbox_scale)
print("boxes[250,250,:,:] * bbox_scale:",boxes[250,250,:,:] * bbox_scale)
show_bboxes(fig.axes, boxes[250,250,:,:] * bbox_scale, ['s=0.75, r=1','s=0.5, r=1','s=0.25, r=1','s=0.75,r=2','s=0.75,r=0.5']) # 画出以250×250像素为中心的不同高宽比的五个锚框 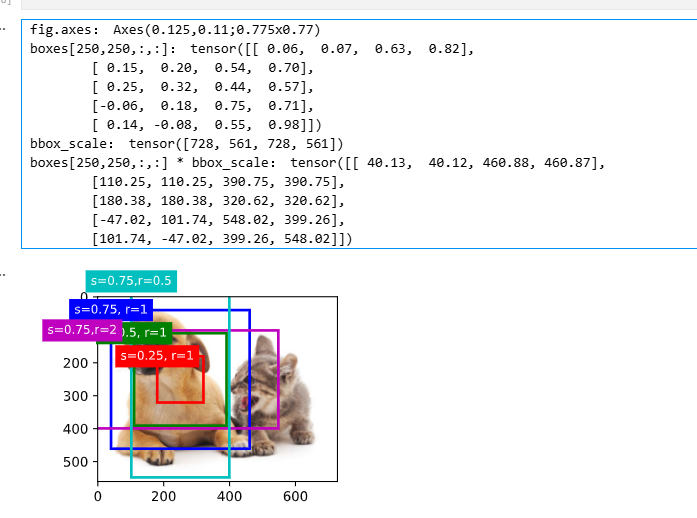
求 IoU
python
# 交并比(IoU)
def box_iou(boxes1,boxes2):
"""计算两个锚框或边界框列表中成对的交并比"""
# 定义一个lambda函数,计算一个锚框或边界框的面积
box_area = lambda boxes: ((boxes[:,2] - boxes[:,0]) *
(boxes[:,3] - boxes[:,1]))
# 计算boxes1中每个框的面积
areas1 = box_area(boxes1)
# 计算boxes2中每个框的面积
areas2 = box_area(boxes2)
# 计算交集区域的左上角坐标(对于每对框,取其左上角坐标的最大值)
inter_upperlefts = torch.max(boxes1[:,None,:2],boxes2[:,:2])
# 计算交集区域的右下角坐标(对于每对框,取其右下角坐标的最小值)
inter_lowerrights = torch.min(boxes1[:,None,2:],boxes2[:,2:])
# 计算交集区域的宽和高(如果交集不存在,宽和高为0)
inters = (inter_lowerrights - inter_upperlefts).clamp(min=0)
# 计算交集区域的面积
inter_areas = inters[:,:,0] * inters[:,:,1]
# 计算并集区域的面积(boxes1的面积 + boxes2的面积 - 交集的面积)
union_areas = areas1[:,None] + areas2 - inter_areas
# 返回交并比(交集的面积除以并集的面积)
return inter_areas / union_areas给边界框分配锚框
python
# 将真实边界框分配给锚框
def assign_anchor_to_bbox(ground_truth,anchors,device,iou_threshold=0.5):
"""将最接近的真实边界框分配给锚框"""
# 获取锚框和真实边界框的数量
num_anchors, num_gt_boxes = anchors.shape[0], ground_truth.shape[0]
# 计算所有的锚框和真实边缘框的IOU
jaccard = box_iou(anchors,ground_truth)
# 创建一个长度为num_anchors的张量,用-1填充,表示锚框到真实边界框的映射(初始时没有分配)
anchors_bbox_map = torch.full((num_anchors,), -1, dtype=torch.long, device=device)
# 对于每个锚框,找到与其IoU最大的真实边界框
max_ious, indices = torch.max(jaccard, dim=1)
# 找到IoU大于等于阈值(如0.5)的锚框,将这些锚框分配给对应的真实边界框
anc_i = torch.nonzero(max_ious >= 0.5).reshape(-1)
box_j = indices[max_ious >= 0.5]
anchors_bbox_map[anc_i] = box_j
# 初始化用于删除行和列的张量
col_discard = torch.full((num_anchors,),-1)
row_discard = torch.full((num_gt_boxes,),-1)
# 通过迭代找到IoU最大的锚框,并将其分配给对应的真实边界框
for _ in range(num_gt_boxes):
max_idx = torch.argmax(jaccard) # 找IOU最大的锚框
box_idx = (max_idx % num_gt_boxes).long() # 通过取余数操作,得到该元素对应的真实边界框的索引
anc_idx = (max_idx / num_gt_boxes).long() # 通过整除操作,得到该元素对应的锚框的索引
# 更新锚框到真实边界框的映射
anchors_bbox_map[anc_idx] = box_idx
# 在jaccard矩阵中删除已分配的锚框所在的行和列,以避免重复分配
jaccard[:,box_idx] = col_discard # 把最大Iou对应的锚框在 锚框-类别 矩阵中的一列删掉
jaccard[anc_idx,:] = row_discard # 把最大Iou对应的锚框在 锚框-类别 矩阵中的一行删掉
#函数返回一个张量anchors_bbox_map,它的长度与锚框的数量相同。
#这个张量用于存储每个锚框分配到的真实边界框的索引。
#如果某个锚框没有分配到真实边界框,那么在这个张量中对应的位置就会是-1。
#如果某个锚框分配到了真实边界框,那么在这个张量中对应的位置就会是分配到的真实边界框的索引。
#例如,如果我们有5个锚框和3个真实边界框,那么anchors_bbox_map可能会是这样的:[0, -1, 1, 2, -1]。这表示第1个锚框被分配到了第1个真实边界框,第2个锚框没有被分配到真实边界框,第3个锚框被分配到了第2个真实边界框,第4个锚框被分配到了第3个真实边界框,第5个锚框没有被分配到真实边界框。
return anchors_bbox_map在 for loop 之前的代码并没有实际用到,相当于一种补充算法,保证相关度有一个阈值,而且产生了一个bug------循环之前对所有锚框做了阈值映射,但在循环中重新映射的时候前面已经赋值的anchors_bbox_map没有被完全覆盖,所以对于同一个边界框,有不止一个锚框的映射。
锚框与边界框偏移拟合
做 Normalize,并且方差较大,分散样本,便于计算
假设一个锚框 A 被分配了一个真实边界框 B 。 一方面,锚框 A 的类别将被标记为与 B 相同。 另一方面,锚框 A 的偏移量将根据 B 和 A 中心坐标的相对位置以及这两个框的相对大小进行标记。 鉴于数据集内不同的框的位置和大小不同,我们可以对那些相对位置和大小应用变换,使其获得分布更均匀且易于拟合的偏移量。给定框 A 和 B ,中心坐标分别为 (xa,ya)(x_a,y_a)(xa,ya) 和 (xb,yb)(x_b,y_b)(xb,yb) ,宽度分别为 waw_awa 和 wbw_bwb ,高度分别为 hah_aha 和 hbh_bhb 。 我们可以将 A 的偏移量标记为:
(xb−xawa−μxσx,yb−yaha−μyσy,logwbwa−μwσw,loghbha−μhσh)\left({{x_b-x_a\over w_a}-\mu_x\over \sigma_x},{{y_b-y_a\over h_a}-\mu_y\over \sigma_y},{\log{w_b\over w_a}-\mu_w\over\sigma_w},{\log{h_b\over h_a}-\mu_h\over\sigma_h}\right)(σxwaxb−xa−μx,σyhayb−ya−μy,σwlogwawb−μw,σhloghahb−μh)
通常
μx=μy=μw=μh=0\mu_x=\mu_y=\mu_w=\mu_h=0μx=μy=μw=μh=0
σx=σy=0.1, σw=σh=0.2\sigma_x=\sigma_y=0.1,\ \sigma_w=\sigma_h=0.2σx=σy=0.1, σw=σh=0.2
python
def offset_boxes(anchors,assigned_bb,eps=1e-6):
"""对锚框偏移量的转换"""
# 将锚框从(左上角, 右下角)的形式转换为(中心点, 宽度, 高度)的形式
c_anc = d2l.box_corner_to_center(anchors)
# 将被分配的真实边界框从(左上角, 右下角)的形式转换为(中心点, 宽度, 高度)的形式
c_assigned_bb = d2l.box_corner_to_center(assigned_bb)
# 计算中心点的偏移量,并进行缩放
offset_xy = 10 * (c_assigned_bb[:,:2] - c_anc[:,:2] / c_anc[:,2:])
# 计算宽度和高度的偏移量,并进行缩放
offset_wh = 5 * torch.log(eps + c_assigned_bb[:,2:] / c_anc[:,2:])
# 将中心点和宽高的偏移量合并在一起
offset = torch.cat([offset_xy, offset_wh], axis=1)
# 返回计算得到的偏移量
return offset
# 标记锚框的类和偏移量
def multibox_target(anchors, labels):
"""使用真实边界框标记锚框"""
# 获取批量大小和锚框
batch_size, anchors = labels.shape[0], anchors.squeeze(0)
# 初始化偏移量、掩码和类别标签列表
batch_offset, batch_mask, batch_class_labels = [], [], []
# 获取设备和锚框数量
device, num_anchors = anchors.device, anchors.shape[0]
# 对于每个样本
for i in range(batch_size):
# 获取该样本的标签
label = labels[i,:,:]
# 将最接近的真实边界框分配给锚框
anchors_bbox_map = assign_anchor_to_bbox(label[:,1:],anchors,device)
# 生成锚框掩码,用于标记哪些锚框包含目标
bbox_mask = ((anchors_bbox_map >= 0).float().unsqueeze(-1)).repeat(1,4)
# 初始化类别标签
class_labels = torch.zeros(num_anchors, dtype=torch.long,device=device)
# 初始化被分配的边界框
assigned_bb = torch.zeros((num_anchors,4), dtype=torch.float32,device=device)
# 获取包含目标的锚框的索引
indices_true =torch.nonzero(anchors_bbox_map >= 0)
# 获取对应的真实边界框的索引
bb_idx = anchors_bbox_map[indices_true]
# 设置包含目标的锚框的类别标签
class_labels[indices_true] = label[bb_idx,0].long() + 1
# 设置被分配的边界框
assigned_bb[indices_true] = label[bb_idx, 1:]
# 计算锚框的偏移量,并通过掩码进行过滤
offset = offset_boxes(anchors, assigned_bb) * bbox_mask
# 将偏移量添加到列表中
batch_offset.append(offset.reshape(-1))
# 将掩码添加到列表中
batch_mask.append(bbox_mask.reshape(-1))
# 将类别标签添加到列表中
batch_class_labels.append(class_labels)
# 将所有偏移量堆叠在一起
bbox_offset = torch.stack(batch_offset)
# 将所有掩码堆叠在一起
bbox_mask = torch.stack(batch_mask)
# 将所有类别标签堆叠在一起
class_labels = torch.stack(batch_class_labels)
# 返回每一个锚框到真实标注框的offset偏移
# bbox_mask为0表示背景锚框,就不用了,为1表示对应真实的物体
# class_labels为锚框对应类的编号
# 返回偏移量、掩码和类别标签
return (bbox_offset, bbox_mask, class_labels) 栗子
python
# 在图像中绘制这些地面真相边界框和锚框
# 两个真实边缘框的位置信息
ground_truth = torch.tensor([[0,0.1,0.08,0.52,0.92],
[1,0.55,0.2,0.9,0.88]]) # 真实标注框的信息,包括类别标签(0代表狗,1代表猫)和位置信息(归一化的坐标)
# 五个锚框的位置信息
anchors = torch.tensor([[0,0.1,0.2,0.3],[0.15,0.2,0.4,0.4],
[0.63,0.05,0.88,0.98],[0.66,0.45,0.8,0.8],
[0.57,0.3,0.92,0.9]]) # 锚框的位置信息(归一化的坐标)
fig = d2l.plt.imshow(img)
# 在图像上画出真实的边界框,其中'k'代表黑色
show_bboxes(fig.axes,ground_truth[:,1:] * bbox_scale, ['dog','cat'],'k')
# 在图像上画出锚框,标注出锚框的索引号
show_bboxes(fig.axes,anchors * bbox_scale, ['0','1','2','3','4']) 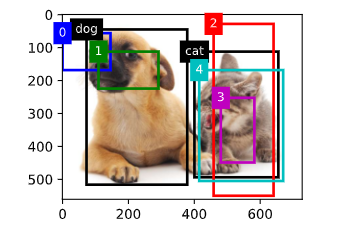
用最大抑制化简
python
# 应用逆偏移变换来返回预测的边界框坐标
def offset_inverse(anchors,offset_preds):
"""根据带有预测偏移量的锚框来预测边界框"""
# 将锚框从角点表示转换为中心-宽度表示
anc = d2l.box_corner_to_center(anchors)
# 利用预测的偏移量和原始锚框,计算预测边界框的中心坐标
pred_bbox_xy = (offset_preds[:,:2] * anc[:,2:] / 10) + anc[:,:2]
# 利用预测的偏移量和原始锚框,计算预测边界框的宽度和高度
pred_bbox_wh = torch.exp(offset_preds[:,2:] / 5) * anc[:, 2:]
# 将预测边界框的中心坐标和宽高组合在一起,得到预测边界框的中心-宽度表示
pred_bbox = torch.cat((pred_bbox_xy, pred_bbox_wh), axis=1)
# 将预测边界框从中心-宽度表示转换为角点表示
predicted_bbox = d2l.box_center_to_corner(pred_bbox)
# 返回预测的边界框
return predicted_bbox # 将锚框用偏移量进行偏移,得到预测的边界框
python
# 以下nms函数按降序对置信度进行排序并返回其索引
def nms(boxes, scores, iou_threshold):
"""对预测边界框的置信度进行排序"""
# 按照得分降序排列预测边界框的索引
B = torch.argsort(scores, dim = -1, descending=True)
# 创建一个空列表,用于存储保留下来的边界框索引
keep = []
# 当B中还有元素时,进行循环
while B.numel()>0: # 直到把所有框都访问过了,再退出循环
# 取B中得分最高的边界框索引
i = B[0] # B中的最大值,已经排好序了
# 将这个边界框索引添加到保留列表中
keep.append(i)
# 如果B中只有一个元素,那么结束循环
if B.numel() == 1: break
# 计算剩余的边界框与当前得分最高的边界框的IoU(交并比)
iou = box_iou(boxes[i,:].reshape(-1,4),
boxes[B[1:],:].reshape(-1,4)).reshape(-1)
# 找到所有与当前得分最高的边界框的IoU不大于阈值的边界框的索引
inds = torch.nonzero(iou <= iou_threshold).reshape(-1)
# 保留那些与当前得分最高的边界框的IoU不大于阈值的边界框
B = B[inds + 1]
# 返回保留下来的边界框索引
return torch.tensor(keep, device=boxes.device)
python
# 将非极大值抑制应用于预测边界框
def multibox_detection(cls_probs,offset_preds,anchors,nms_threshold=0.5,
pos_threshold=0.009999999):
"""使用非极大值抑制来预测边界框"""
# 获取设备类型和批次大小
device, batch_size = cls_probs.device, cls_probs.shape[0]
# 将锚框数据压缩到二维
anchors = anchors.squeeze(0)
# 获取类别数量和锚框数量
num_classes, num_anchors = cls_probs.shape[1], cls_probs.shape[2]
# 创建一个空列表,用于存储每个批次的预测结果
out = []
# 对每个批次进行循环
for i in range(batch_size):
# 获取类别概率和预测的偏移量
cls_prob, offset_pred = cls_probs[i], offset_preds[i].reshape(-1,4)
# 获取最大类别概率和对应的类别id
conf, class_id = torch.max(cls_prob[1:],0)
# 根据预测的偏移量和锚框得到预测的边界框
predicted_bb = offset_inverse(anchors,offset_pred) # 把预测框拿出来
# 对预测的边界框进行非极大值抑制,获取保留下来的边界框索引
keep = nms(predicted_bb, conf, nms_threshold)
# 获取所有的边界框索引
all_idx = torch.arange(num_anchors, dtype=torch.long, device=device)
# 将保留下来的边界框索引和所有的边界框索引拼接在一起
combined = torch.cat((keep,all_idx))
# 获取唯一的索引和对应的计数
uniques, counts = combined.unique(return_counts=True)
# 获取被丢弃的边界框索引
non_keep = uniques[counts==1]
# 将保留下来的边界框索引和被丢弃的边界框索引按顺序拼接在一起
all_id_sorted = torch.cat((keep, non_keep))
# 将被丢弃的边界框的类别id设为-1
class_id[non_keep] = -1
class_id = class_id[all_id_sorted]
# 根据索引获取对应的类别概率和预测的边界框
conf, predicted_bb = conf[all_id_sorted], predicted_bb[all_id_sorted]
# 找到类别概率低于阈值的边界框索引
below_min_idx = (conf < pos_threshold)
# 将类别概率低于阈值的边界框的类别id设为-1
class_id[below_min_idx] = -1
# 将类别概率低于阈值的边界框的类别概率设为1减去原来的值
conf[below_min_idx] = 1 - conf[below_min_idx]
# 将类别id,类别概率和预测的边界框拼接在一起,作为预测信息
pred_info = torch.cat((class_id.unsqueeze(1),conf.unsqueeze(1),predicted_bb),dim=1)
# 将每个批次的预测信息添加到结果列表中
out.append(pred_info)
# 将结果列表转为张量返回
return torch.stack(out)再一个栗子
我不太理解 cls_probs 第一行全零代表什么
python
# 将上述算法应用到一个带有四个锚框的具体示例中
# 四个锚框的坐标
anchors = torch.tensor([[0.1,0.08,0.52,0.92],[0.08,0.2,0.56,0.95],
[0.15,0.3,0.62,0.91],[0.55,0.2,0.9,0.88]])
# 偏移预测值,这里假设预测值全为0,即没有预测偏移
offset_preds = torch.tensor([0] * anchors.numel())
print("offset_preds:", offset_preds) # 打印偏移预测值
print("len(offset_preds):", len(offset_preds)) # 打印偏移预测值的长度
# 类别概率,每一列对应一个锚框,每一行对应一个类别,这里有三个类别:背景、猫、狗
cls_probs = torch.tensor([[0] * 4, # 背景类别概率
[0.9, 0.8, 0.7, 0.1], # 猫类别概率
[0.1, 0.2, 0.3, 0.9]]) # 狗类别概率
print("cls_probs:", cls_probs) # 四个锚框对背景、猫、狗这三个类的预测值,每一列为一个锚框 
python
# 在图像上绘制这些预测边界框和置信度
# 创建一个图像对象,并在图像上显示
fig = d2l.plt.imshow(img)
# 在图像上显示锚框,其中锚框的尺度需要进行转换以适应图像的尺度
# 每个锚框旁边的文本表示该锚框预测为某个类别的置信度
show_bboxes(fig.axes, anchors * bbox_scale, # 没有做NMS时,把四个锚框画出来
['dog=0.9','dog=0.8','dog=0.7','cat=0.9'])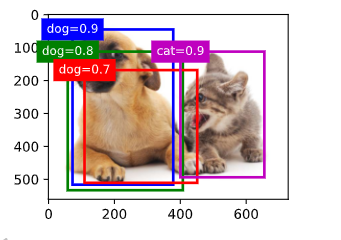
python
# 使用multibox_detection函数,输入类别预测概率、预测偏移量以及锚框,同时设置非极大值抑制的阈值为0.5
# 注意,这里需要先在输入数据的每个维度上添加一个维度(即批量大小的维度),然后才能传入函数
output = multibox_detection(cls_probs.unsqueeze(dim=0),
offset_preds.unsqueeze(dim=0),
anchors.unsqueeze(dim=0),nms_threshold=0.5)
# 打印输出结果,这里的输出结果包含了每个锚框的类别预测、置信度以及经过预测偏移调整后的锚框坐标
# output[0]表示批量中的第一张图片的预测结果
print("output:",output) #output[0]为批量大小中的第一个图片
python
# 输出由非极大值抑制保存的最终预测边界框
# 在图像上绘制通过非极大值抑制筛选后的预测边界框
fig = d2l.plt.imshow(img)
# 输出经过非极大值抑制后的预测结果
print("output[0]:", output[0])
# 遍历预测结果
for i in output[0].detach().numpy():
# 输出当前预测结果的详细信息
print(i)
# 判断如果预测结果的类别为-1,说明这个预测结果表示的是背景或在非极大值抑制中被移除了,所以我们直接跳过这个结果
if i[0] == -1: # 值-1表示背景或在非极大值抑制中被移除了
continue
# 打印预测的类别和置信度
print("int(i[0]):", int(i[0])) # i[0]=0表示狗,i[0]=1表示猫,即i的第一个元素表示框对应的类别
print("str(i[1]):", str(i[1])) # i的第二元素表示该类别的置信度
# 根据预测的类别和置信度生成标签
label = ('dog=', 'cat=')[int(i[0])] + str(i[1]) # 取('dog=', 'cat=')元组的第int(i[0]位置与str(i[1])进行拼接
print("label:",label)
# 在图像上绘制预测的边界框和标签
show_bboxes(fig.axes, [torch.tensor(i[2:]) * bbox_scale], label)
3.物体检测算法
准确说本课程是基于锚框的目标检测算法
| 方法 | 阶段 | 锚框来源 | 速度 | 精度 | 典型场景 |
|---|---|---|---|---|---|
| R-CNN | 两阶段 | 启发式 | 极慢 | 高 | 学术 |
| Fast R-CNN | 两阶段 | 启发式 | 中 | 高 | 过渡 |
| Faster R-CNN | 两阶段 | RPN | 中 | 很高 | 高精度 |
| Mask R-CNN | 两阶段 | RPN | 慢 | 极高 | 实例分割 |
| SSD | 单阶段 | 密集 anchor | 快 | 中 | 实时 |
| YOLO | 单阶段 | 网格 | 极快 | 中~高 | 实时系统 |
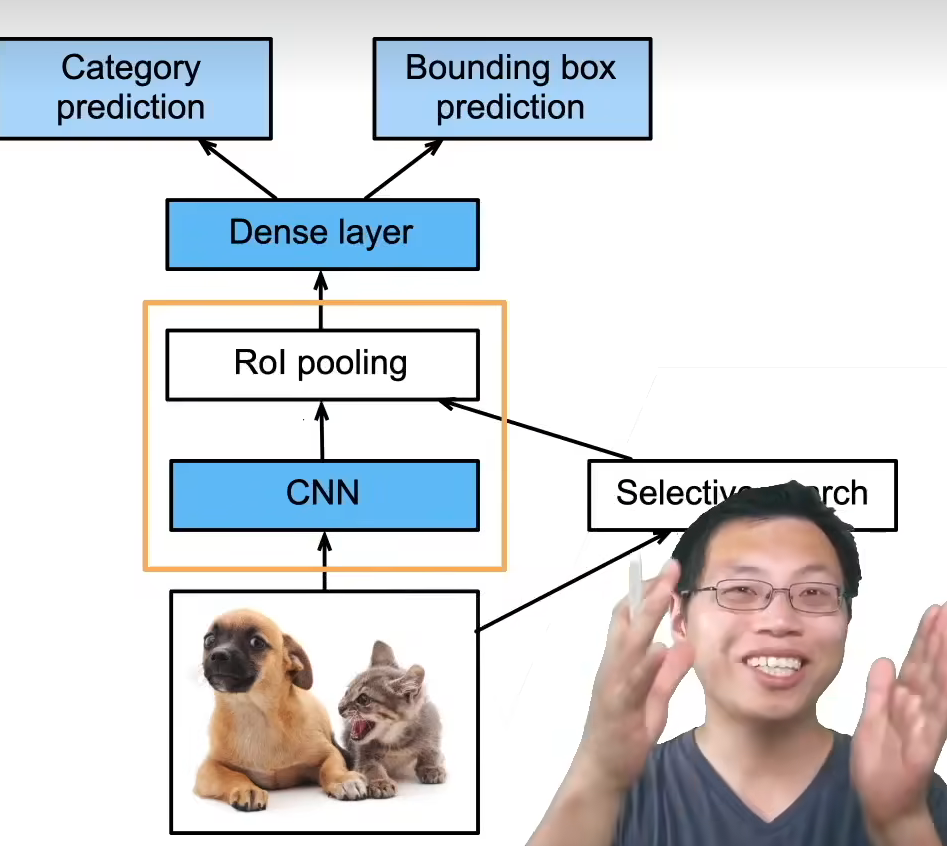
R-CNN(Region based CNN)
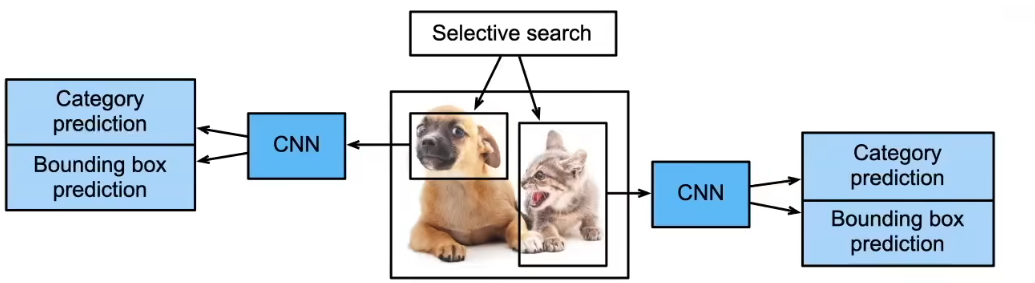
- 使用启发式搜索算法来选择锚框
- 使用预训练模型来对每个锚框提取特征
- 做两个预测
- 训练一个SVM来对类别分类预测
- 训练一个线性回归模型来预测边缘框偏移
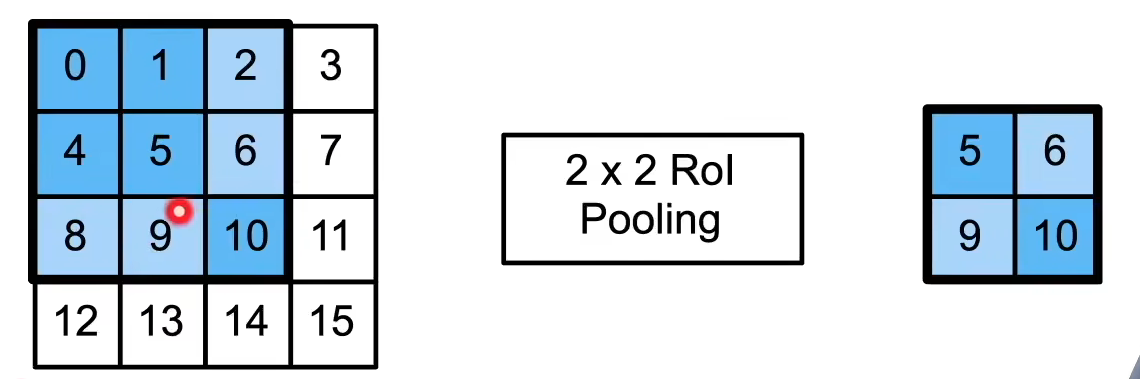
为了使大小不一的锚框可以成为统一规格,需要借助兴趣区域池化层(RoI Pooling)。
- 给定一个锚框,均匀分割 成 n×mn \times mn×m 块,输出每块里最大的值
- 不管锚框多大,总是输出 nmnmnm 个值。
核心思想
先"找可能是物体的区域",再"逐个区域分类和回归"。
流程
- 启发式搜索(Selective Search)
- 从图像中生成 ~2000 个候选区域(锚框 / RoI)
- 完全不是端到端、不可学习
- 每个锚框单独过 CNN
- 每个 RoI 都送进预训练 CNN(如 AlexNet)
- 极其慢(重复计算)
- 两个独立预测
- SVM:分类
- 线性回归:边框偏移
- RoI Pooling
- 解决"锚框大小不一"的问题
- 强制输出固定大小特征(如 7×77 \times 77×7)
Fast RCNN
- 使用CNN对图片本身抽取特征
- 用选择性搜索把锚框按比例映射到特征上
- 使用Rol池化层对每个锚框生成固定长度特征
- 对映射后的锚框进一步放缩特征
- 最终输出的锚框高度概括化
- 把锚框的特征传入全连接层进行类别和偏移预测
速度进步的本质是把CNN的对象从大批量锚框到该图片本身
python
图像 → CNN → 特征图
↓
RoI Pooling → 分类 + 回归流程变化
- 整张图片只过一次 CNN
- 得到共享的特征图(feature map)
- Selective Search 得到锚框
- 将锚框映射到特征图上(按比例缩放)
- RoI Pooling
- 从共享特征图中裁剪并池化
- 得到固定长度特征
- 全连接层
- 同时输出:
- 类别(Softmax)
- 边框回归(BBox regression)
- 同时输出:
仍然的问题
- 锚框仍然靠 启发式搜索
- 速度瓶颈还在「候选框生成」
Faster R-CNN:真正端到端
- 使用一个区域提议网络(Regional Proposal Network,本质还是一个神经网络)来替代启发式搜索来获得更好的锚框。
- 预测锚框是否识别物体,或者能否能偏移到边界框,经过NMS进一步优化锚框。
- 相当于一个简要的分类器
- 对精度特别关心的项目
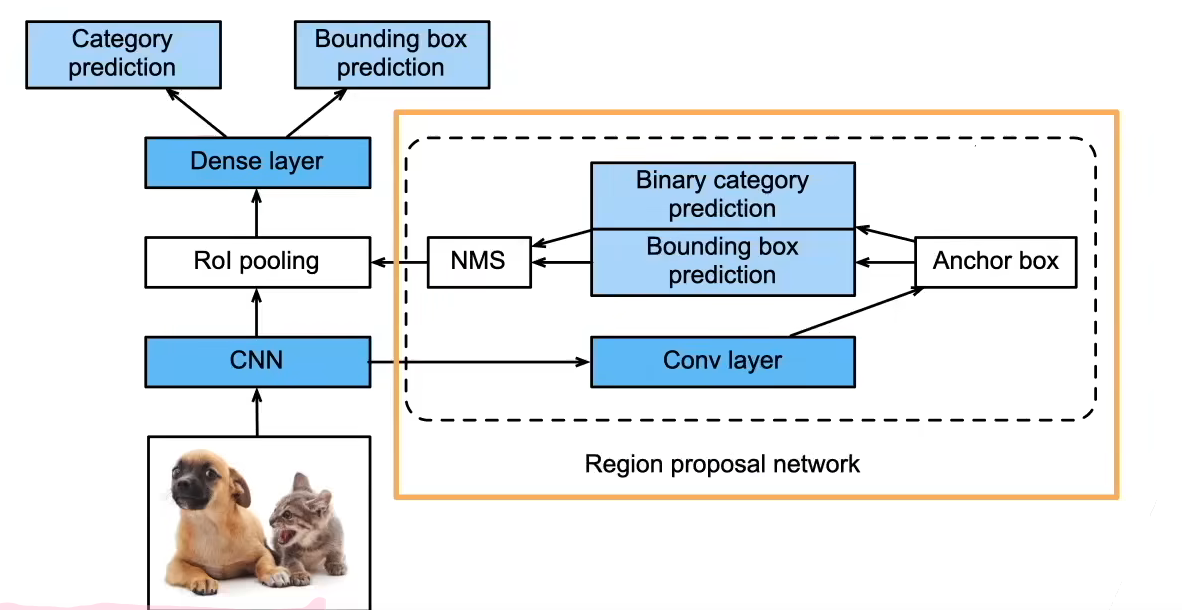
核心突破
用神经网络来"学会"生成锚框
结构
- CNN 主干共享
- 一个分支:RPN 生成候选框
- 一个分支:Fast R-CNN 做检测
区域提议网络(RPN)
- 在特征图上滑动窗口
- 对每个位置生成多个锚框
- 对每个锚框预测:
- 是否是前景(objectness)
- 边框偏移
再通过 NMS 筛选高质量锚框
优点
- 完全端到端
- 锚框质量更高
- 精度非常强
适合场景
- 对精度要求极高
- 速度不是第一目标(如自动驾驶、医学影像)
Mask R-CNN: 从"检测"到"实例分割"
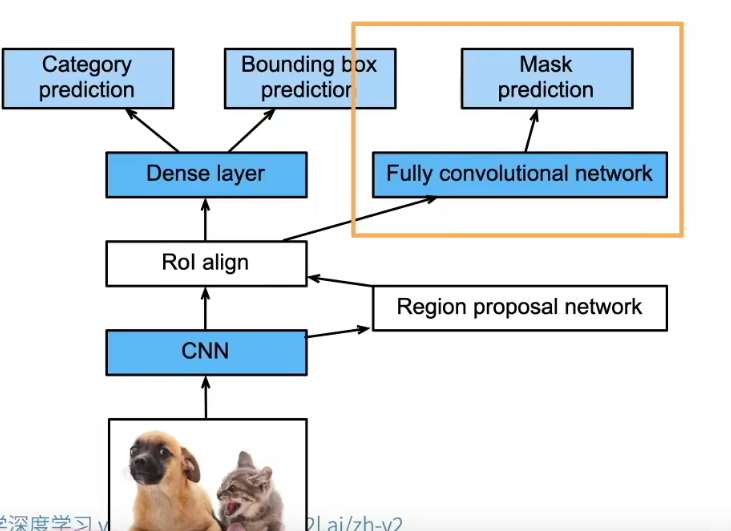
- 如果有像素级别 的标号,使用FCN (Fully convolutional network)来利用这些信息。
- 对于每个像素预测他的标号
- RoI是按照像素切(重组的时候会出现边界错位的误差),Mask可以把像素分割,用加权算法获得值
不只是"框住物体",还要"分出每个像素"
在 Faster R-CNN 上再加一条分支
- 分类
- 边框回归
- 像素级 Mask
关键改进
- RoI Pooling → RoI Align(消除量化误差)
- RoI Align
- 解决 RoI Pooling 中的量化误差
- 精确到像素级对齐
- Mask 分支
- 对每个 RoI,用 FCN 预测一个二值 mask
- 每个像素是否属于该实例
总结
- R-CNN是最早、也是最有名的一类基于锚框和CNN的目标检测算法
- Fast/Faster R-CNN持续提升性能
- Faster R-CNN和Mask R-CNN是在追求高精度场景下的常用算法
单发多框检测(SSD, Single Shot Detection) 速度优先
核心思想
- 在多尺度特征图上
- 用大量 密集 anchor
- 直接预测类别 + 偏移
生成锚框
- 对每个像素,生成多个以他为中心的锚框
- 给定 nnn 个大小 s1,...,sns_1,...,s_ns1,...,sn 和 mmm 个高宽比,那么生成 n+m−1n+m-1n+m−1 个锚框,其大小和高宽比分别为 (s1,r1),(s2,r1),...,(sn,r1),(s1,r2)(s1,r3),...,(s1,rm)(s_1,r_1),(s_2,r_1),...,(s_n,r_1),(s_1,r_2)(s_1,r_3),...,(s_1,r_m)(s1,r1),(s2,r1),...,(sn,r1),(s1,r2)(s1,r3),...,(s1,rm)

SSD模型
- 一个基础网络来抽取特征,然后多个卷积层块来减半高宽
- 在每段都生成锚框
- 底部段来拟合小物体,顶部段来拟合大物体
- 对每个锚框预测类别和边缘框
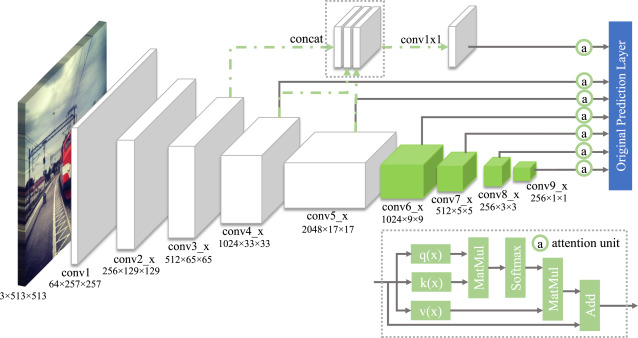
总结
- SSD通过单神经网络来检测模型
- 以每个像素为中心产生多个锚框
- 在多个段的输出上进行多尺度的检测
YOLO
- SSD中锚框大量重叠,因此浪费了很多计算
- YOLO将图片均匀分成 S×SS \times SS×S个锚框
- 每个锚框预测 BBB 个边缘框
- 后续版本(V2,V3,V4...)有持续改进
把目标检测当成一个回归问题
YOLO v1 的思想
- 图像划分为 S×SS×SS×S 网格
- 每个网格:
- 预测 BBB 个边框
- 预测类别概率
和 SSD 的关键区别
- SSD:锚框以"像素"为中心
- YOLO:锚框以"网格"为中心(更粗)
优势
- 极快(真正实时)
- 全局感受野强
- 重叠少,计算高效
不足(早期版本)
- 对小物体不友好
- 定位精度略弱
4.SSD的实现
多尺度目标检测实现
python
%matplotlib inline
import torch
from d2l import torch as d2l
img = d2l.plt.imread('/root/autodl-tmp/01_Data/03_catdog.jpg')
h, w = img.shape[:2]
print(h, w) # 打印导入图片的高、宽
print(img.shape) # 最后一个元素为通道数,通道数为3
python
# 在特征图(fmap)上生成锚框(anchors),每个单位(像素)作为锚框的中心
def display_anchors(fmap_w,fmap_h,s):
# 使用d2l库的set_figsize函数设置绘图的尺寸。
d2l.set_figsize()
# 创建一个全零的张量,形状为(1,10,fmap_h,fmap_w)。这里1是批量大小,10是通道数,fmap_h和fmap_w是特征图的高度和宽度。
fmap = torch.zeros((1,10,fmap_h,fmap_w)) # 批量大小为1,通道数为10
# 调用d2l库的multibox_prior函数,以特征图的每个像素为中心,生成多个形状和比例不同的锚框,并将结果赋值给anchors。
anchors = d2l.multibox_prior(fmap,sizes=s,ratios=[1,2,0.5]) # 生成以每个像素为中心的锚框
# 创建一个张量,内容为(w,h,w,h),用于将锚框的坐标从特征图的尺度转换到原始图片的尺度。
bbox_scale = torch.tensor((w,h,w,h))
# 使用d2l库的show_bboxes函数在原始图片上显示锚框。这里需要将锚框的坐标乘以bbox_scale进行尺度转换。因为批量大小为1,所以使用anchors[0]。
d2l.show_bboxes(d2l.plt.imshow(img).axes,anchors[0] * bbox_scale) # anchors[0]是因为这里的batchsize为1
python
# 探测小目标
# 调用display_anchors函数,输入参数是特征图的宽度(fmap_w=4)、高度(fmap_h=4)以及锚框的尺寸(s=[0.15])。
# 这行代码将在特征图上生成并显示锚框,特征图的尺寸是4x4,锚框的尺寸是0.15(相对于特征图的尺寸)。
# 对于每个特征图的像素,都会生成一个以该像素为中心,尺寸为0.15的锚框。
display_anchors(fmap_w=4,fmap_h=4,s=[0.15])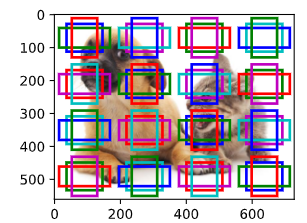
python
# 将特征图的高度和宽度减小一半,然后使用较大的锚框来检测较大的目标
display_anchors(fmap_w=2,fmap_h=2,s=[0.4])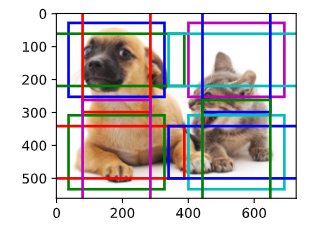
python
# 将特征图的高度和宽度较小一半,然后将锚框的尺度增加到0.8
display_anchors(fmap_w=1,fmap_h=1,s=[0.8])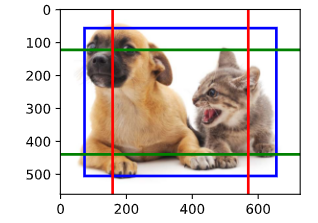
单发多框检测(SSD)
SSD 的代码本质只有一句话:
我在一张图上,提前放了很多"框模板",
模型只负责:
改一改框的位置,判断这个框里有没有东西
python
loc :告诉我,这个框要往哪挪
conf :告诉我,这个框是不是有东西
python
1. 定义 backbone(VGG / MobileNet)
2. 定义多尺度特征层
3. 生成 default boxes(anchors)
4. 预测:loc + conf
5. 计算 loss(匹配 + hard negative mining)
python
%matplotlib inline
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
# 类别预测层
# 定义一个函数cls_predictor,输入参数分别是输入通道数(num_inputs)、锚框数(num_anchors)以及类别数(num_classes)。
def cls_predictor(num_inputs, num_anchors, num_classes): # 输入通道数、多少个锚框、多少个类
# 每个锚框的输出通道数都为(num_classes + 1),加1为加的背景类
# 每一个锚框都要预测他的类别
# 返回一个卷积层,输入通道数是num_inputs,输出通道数是num_anchors * (num_classes + 1),
# 卷积核大小是3,填充大小是1。这里输出通道数乘以(num_classes + 1)的原因是,每个锚框需要预测num_classes + 1个类别的概率,
# 其中+1是因为增加了背景类(即没有检测到物体的情况)。
return nn.Conv2d(num_inputs, num_anchors * (num_classes + 1),
kernel_size=3, padding=1)
python
# 边界框预测层
# 定义一个函数bbox_predictor,输入参数分别是输入通道数(num_inputs)和锚框数(num_anchors)。
def bbox_predictor(num_inputs, num_anchors):
# 返回一个卷积层,输入通道数是num_inputs,输出通道数是num_anchors * 4,
# 卷积核大小是3,填充大小是1。这里输出通道数乘以4的原因是,每个锚框需要预测4个值(边界框的中心坐标和宽高)来确定边界框的位置。
return nn.Conv2d(num_inputs, num_anchors * 4, kernel_size=3, padding=1)
python
# 连接多尺度的预测
# 定义一个函数forward,输入参数是输入数据x和一个网络层block。
def forward(x, block):
# 返回通过网络层block处理输入数据x后的结果。
return block(x)
# 使用全0的输入数据和一个类别预测层,进行前向传播。这里输入数据的形状是(2,8,20,20),表示有2张图片,每张图片有8个通道,尺寸是20x20。
# 类别预测层的参数是8,5,10,表示输入通道数是8,锚框数是5,类别数是10。
Y1 = forward(torch.zeros((2,8,20,20)),cls_predictor(8,5,10))
# 使用另一个全0的输入数据和一个类别预测层,进行前向传播。这里输入数据的形状是(2,16,10,10),表示有2张图片,每张图片有16个通道,尺寸是10x10。
# 类别预测层的参数是16,3,10,表示输入通道数是16,锚框数是3,类别数是10。
Y2 = forward(torch.zeros((2,16,10,10)),cls_predictor(16,3,10))
# 打印Y1的形状,这里是(2, 55, 20, 20),表示有2张图片,每张图片有55个通道,尺寸是20x20。这里的55是因为每个锚框需要预测10+1个类别的概率,共有5个锚框,所以通道数是5*(10+1)=55。
print(Y1.shape) # 5 * (10 + 1) = 55, 55为每一个像素输出的所有锚框数对应的类别
print(Y2.shape) # 2为小批量里面有多少图片
python
# 定义一个函数flatten_pred,输入参数是预测结果pred。
def flatten_pred(pred):
# pred.permute(0,2,3,1)通道数放在最后
# start_dim=1把pred.permute(0,2,3,1)后面三个向量拉成一个向量,这样就变成一个2D矩阵
# 2D矩阵的高为批量大小,宽为每个图片的所有
# 如果pred.permute(0,2,3,1)不改的话,对于同一像素的类别预测flatten后会相隔较远
# 返回拉平后的预测结果。首先使用permute方法调整通道数的位置,然后使用flatten方法将除第一维(批量大小)之外的所有维度拉平。
return torch.flatten(pred.permute(0,2,3,1),start_dim=1)
# 定义一个函数concat_preds,输入参数是多个预测结果的列表preds。
def concat_preds(preds):
#[print(flatten_pred(p).shape) for p in preds]
# 返回连接后的预测结果。首先使用列表推导式和flatten_pred函数拉平每个预测结果,然后使用torch.cat方法在dim=1的维度上连接所有的预测结果。
return torch.cat([flatten_pred(p) for p in preds], dim=1)
# 打印连接后的预测结果的形状。这里输入的是两个预测结果Y1和Y2,输出的形状是(2, 35300),表示有2张图片,每张图片有25300个预测结果。
print(concat_preds([Y1, Y2]).shape)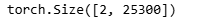
python
# 高和宽减半块
# 定义一个函数down_sample_blk,输入参数是输入通道数(in_channels)和输出通道数(out_channels)。
def down_sample_blk(in_channels, out_channels):
# 创建一个空列表blk,用于存储网络层。
blk = []
# 循环2次,每次添加2个卷积层、1个批量归一化层和1个ReLU激活函数。
for _ in range(2):
# 添加一个卷积层,输入通道数是in_channels,输出通道数是out_channels,卷积核大小是3,填充大小是1。
blk.append(nn.Conv2d(in_channels,out_channels,kernel_size=3,padding=1))
# 添加一个批量归一化层,输入通道数是out_channels。
blk.append(nn.BatchNorm2d(out_channels))
# 添加一个ReLU激活函数。
blk.append(nn.ReLU())
# 更新输入通道数为当前的输出通道数。
in_channels = out_channels
# 添加一个最大池化层,池化核大小是2,这可以将输入数据的高度和宽度减半。
blk.append(nn.MaxPool2d(2))
# 返回一个顺序容器,其中包含了所有的网络层。
return nn.Sequential(*blk)
# 打印通过下采样模块处理后的输出数据的形状。这里输入的是全0的数据,形状是(2,3,20,20),表示有2张图片,每张图片有3个通道,尺寸是20x20。
# 下采样模块的参数是3和10,表示输入通道数是3,输出通道数是10。输出的形状是(2,10,10,10),表示有2张图片,每张图片有10个通道,尺寸是10x10。
print(forward(torch.zeros((2,3,20,20)),down_sample_blk(3,10)).shape)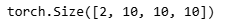
python
# 基本网络块
# 定义一个函数base_net,没有输入参数。
def base_net(): # 从原始图片抽特征,到第一次featuremao产生锚框,中间的那一截叫base_net
# 创建一个空列表blk,用于存储网络层。
blk = []
# 定义一个列表num_filters,表示每个下采样模块的输入通道数和输出通道数。
num_filters = [3,16,32,64] # 通道数由3到16,再到32,再到64
# 循环遍历num_filters列表,每次添加一个下采样模块。
for i in range(len(num_filters) - 1):
# 添加一个下采样模块,输入通道数是num_filters[i],输出通道数是num_filters[i+1]。
blk.append(down_sample_blk(num_filters[i],num_filters[i+1]))
# 返回一个顺序容器,其中包含了所有的网络层。
return nn.Sequential(*blk)
# 打印通过基础网络模块处理后的输出数据的形状。这里输入的是全0的数据,形状是(2,3,256,256),表示有2张图片,每张图片有3个通道,尺寸是256x256。
# 输出的形状是(2,64,32,32),表示有2张图片,每张图片有64个通道,尺寸是32x32。
print(forward(torch.zeros((2,3,256,256)),base_net()).shape)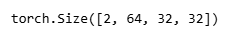
python
# 完整的单发多框检测模型由五个模块组成
# 定义一个函数get_blk,输入参数是一个整数i。
def get_blk(i):
# 如果i等于0,则返回基础网络模块。
if i == 0:
# 使得通道数变为64的featuremap
blk = base_net() # 使得通道数变为64的featuremap
# 如果i等于1,则返回一个下采样模块,输入通道数是64,输出通道数是128。
elif i == 1:
blk = down_sample_blk(64,128) # 通道数变为128
# 如果i等于4,则返回一个自适应最大池化层,输出尺寸是1x1。
elif i == 4:
blk = nn.AdaptiveMaxPool2d((1,1)) # 最后一层,把图片压缩到1×1
# 如果i等于其他值,则返回一个下采样模块,输入通道数是128,输出通道数也是128。
else:
blk = down_sample_blk(128, 128)
# 返回对应的网络模块。
return blk
python
# 为每个块定义前向计算
# 定义一个函数blk_forward,输入参数是输入数据X、网络模块blk、锚框大小size、纵横比ratio、类别预测器cls_predictor和边界框预测器bbox_predictor。
def blk_forward(X,blk,size,ratio,cls_predictor,bbox_predictor):
# 通过网络模块blk处理输入数据X,得到输出数据Y。
Y = blk(X)
# 在输出数据Y上生成锚框,锚框的大小是size,纵横比是ratio。
anchors = d2l.multibox_prior(Y,sizes=size,ratios=ratio)
# 使用类别预测器cls_predictor预测每个锚框的类别。
cls_preds = cls_predictor(Y)
# 使用边界框预测器bbox_predictor预测每个锚框的边界框。
bbox_preds = bbox_predictor(Y)
# 返回 卷积层输出、卷积层输出上生成的锚框、每一个锚框的类别的预测,每一个锚框到真实边缘框的预测
# 返回输出数据Y、生成的锚框、类别预测结果和边界框预测结果。
return (Y,anchors,cls_preds,bbox_preds)
python
# 超参数
# 小的size看小的特征,大的size看整个图片特征
# sizes 是一个二维列表,表示各个尺度下的锚框大小。数值越小,看的特征越小,数值越大,看的是整个图片的特征。
sizes = [[0.2,0.272],[0.37,0.447],[0.54,0.619],[0.71,0.79],[0.88,0.961]]
# ratios 是一个二维列表,表示各个尺度下的锚框纵横比。这里每个尺度下的锚框纵横比都是 [1,2,0.5]。
ratios = [[1,2,0.5]] * 5
# num_anchors 是一个整数,表示每个尺度下的锚框数量。这里的计算方法是:每个尺度下的大小数量 + 每个尺度下的纵横比数量 - 1。
num_anchors = len(sizes[0]) + len(ratios[0]) - 1
python
# 定义完整的模型
# TinySSD 是 PyTorch 的一个自定义模型类,继承自 nn.Module 类。
class TinySSD(nn.Module):
# 构造函数,输入参数是分类的数量 num_classes 和其他命名参数。
def __init__(self, num_classes, **kwargs):
# 调用父类 nn.Module 的构造函数。
super(TinySSD,self).__init__(**kwargs)
# 保存分类的数量。
self.num_classes = num_classes
# 定义一个列表,表示每个模块的输入通道数。
idx_to_in_channels = [64,128,128,128,128]
# 对于每个模块:
for i in range(5):
# setattr是给对象的属性赋值
# 创建模块,并保存到 self 的属性中。
setattr(self,f'blk_{i}',get_blk(i))
# 创建类别预测器,并保存到 self 的属性中。
setattr(self,f'cls_{i}',cls_predictor(idx_to_in_channels[i],num_anchors,num_classes))
# 创建边界框预测器,并保存到 self 的属性中。
setattr(self,f'bbox_{i}',bbox_predictor(idx_to_in_channels[i],num_anchors))
# 定义前向传播函数,输入参数是输入数据 X。
def forward(self,X):
# 初始化锚框、类别预测和边界框预测的列表。
anchors, cls_preds, bbox_preds = [None] * 5, [None] * 5, [None] * 5
# 对于每个模块:
for i in range(5):
X, anchors[i], cls_preds[i], bbox_preds[i] = blk_forward(
X, getattr(self, f'blk_{i}'), sizes[i], ratios[i],
getattr(self, f'cls_{i}'), getattr(self, f'bbox_{i}'))
# 进行前向计算,并获取输出数据、锚框、类别预测和边界框预测。
# 将所有模块的锚框沿着第一个维度(索引从 0 开始)拼接起来。
anchors = torch.cat(anchors, dim=1) # 把所有的anchors并在一起
# 将所有模块的类别预测结果拼接起来。
cls_preds = concat_preds(cls_preds)
# 将类别预测结果重塑为三维张量,第一维度是批量大小,第二维度是 -1 表示自动计算,第三维度是类别数量+1。
cls_preds = cls_preds.reshape(cls_preds.shape[0],-1,self.num_classes+1)
# 将所有模块的边界框预测结果拼接起来。
bbox_preds = concat_preds(bbox_preds)
# 返回锚框、类别预测结果和边界框预测结果。
return anchors, cls_preds, bbox_preds
python
# 创建一个模型实例,然后使用它执行前向计算
# 创建一个 TinySSD 类的实例,类别数量为 1。
net = TinySSD(num_classes=1)
# 创建一个全零张量,形状为(32,3,256,256),代表有 32 张 3 通道的 256x256 图像。
X = torch.zeros((32,3,256,256))
# 使用模型进行前向计算,输入是创建的全零张量,输出是锚框、类别预测和边界框预测。
anchors, cls_preds, bbox_preds = net(X)
# 打印锚框的形状,每一张图片都有5444个锚框。
print('output anchors:',anchors.shape)
# 打印类别预测的形状,32为批量大小,2为类别1加上背景为2。
print('output class preds:',cls_preds.shape)
# 打印边界框预测的形状,每张图片有5444个锚框,每个锚框有4个坐标,所以是5444*4=21776。
print('output bbox preds:',bbox_preds.shape) 
python
# 读取香蕉检测数据集
# 设置批量大小为32。
batch_size = 32
# 使用 d2l 的 load_data_bananas 函数加载香蕉检测数据集,只使用训练数据集(train_iter)。
# "_" 是一个常用的占位符,表示我们不关心的变量(在这里,我们不关心测试数据集)。
train_iter, _ = d2l.load_data_bananas(batch_size)
python
# 初始化其参数并定义优化算法
# 选择一个可用的设备进行计算(优先选择 GPU),并创建一个 TinySSD 类的实例,类别数量为1。
device, net = d2l.try_gpu(), TinySSD(num_classes=1)
# 使用随机梯度下降(SGD)优化器,学习率设置为 0.2,权重衰减为 5e-4。optimizer 的参数是模型的所有参数。
trainer = torch.optim.SGD(net.parameters(),lr=0.2,weight_decay=5e-4)
python
# 定义损失函数和评价函数
# 交叉熵损失用于类别预测。reduction 参数设置为 'none' 表示保留每个元素的损失。
cls_loss = nn.CrossEntropyLoss(reduction='none')
# L1 损失用于边界框预测。reduction 参数设置为 'none' 表示保留每个元素的损失。
bbox_loss = nn.L1Loss(reduction='none')
# 定义损失计算函数
# cls_preds 和 cls_labels 是类别预测和标签。
# bbox_preds 和 bbox_labels 是边界框预测和标签。
# bbox_masks 是用于过滤无关的负类样本的掩码。
# 函数返回总损失,即类别损失和边界框损失的和。
def calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels, bbox_masks):
batch_size, num_classes = cls_preds.shape[0], cls_preds.shape[2]
# 计算类别损失,然后调整形状,以便每个样本有一个损失值。
cls = cls_loss(cls_preds.reshape(-1,num_classes),cls_labels.reshape(-1)).reshape(batch_size,-1).mean(dim=1)
# 计算边界框损失,只考虑非背景的预测。
# mask使得锚框为背景框时为0,就不预测偏移,否则为1,才预测锚框的偏移。
bbox = bbox_loss(bbox_preds * bbox_masks, bbox_labels * bbox_masks).mean(dim=1)
# 返回总损失。
return cls + bbox
# 定义评价函数
# 计算类别预测的准确性。函数返回正确预测的数量。
def cls_eval(cls_preds,cls_labels):
return float((cls_preds.argmax(dim=-1).type(cls_labels.dtype)==cls_labels).sum())
# 计算边界框预测的准确性。函数返回所有边界框预测和标签之间的绝对差的和。
def bbox_eval(bbox_preds,bbox_labels,bbox_masks):
return float((torch.abs((bbox_labels - bbox_preds) * bbox_masks)).sum())
python
# 训练模型
# 设置训练周期数和计时器
num_epochs, timer = 20, d2l.Timer()
# 创建一个动画对象,用于动态显示训练过程中的类别错误和边界框的平均绝对误差
animator = d2l.Animator(xlabel='epoch',xlim=[1,num_epochs],
legend=['class error','bbox mae'])
# 将网络移动到相应的设备(如GPU)
net = net.to(device)
# 开始训练周期
for epoch in range(num_epochs):
# 创建一个累加器用于存储训练过程中的指标
metric = d2l.Accumulator(4)
# 设置网络为训练模式
net.train()
# 遍历训练数据
for features, target in train_iter:
# 计时开始
timer.start()
# 清零梯度
trainer.zero_grad()
# 将特征和目标移动到相应的设备
X, Y = features.to(device), target.to(device)
# 前向传播,得到锚框、类别预测和边界框预测
anchors, cls_preds, bbox_preds = net(X)
# 获取边界框标签、掩码和类别标签
bbox_labels, bbox_masks, cls_labels = d2l.multibox_target(anchors, Y)
# 计算损失
l = calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels, bbox_masks)
# 反向传播,计算梯度
l.mean().backward()
# 更新参数
trainer.step()
# 更新指标
metric.add(cls_eval(cls_preds,cls_labels),cls_labels.numel(),
bbox_eval(bbox_preds,bbox_labels,bbox_masks),
bbox_labels.numel())
# 计算类别错误率和边界框平均绝对误差
cls_err, bbox_mae = 1 - metric[0] / metric[1], metric[2] / metric[3]
# 更新动画
animator.add(epoch + 1, (cls_err, bbox_mae))
# 打印最后的类别错误率和边界框平均绝对误差
print(f'class err {cls_err:.2e}, bbox mae {bbox_mae:.2e}')
# 打印训练速度和设备信息
print(f'{len(train_iter.dataset) / timer.stop():.1f} examples/sec on'
f'{str(device)}')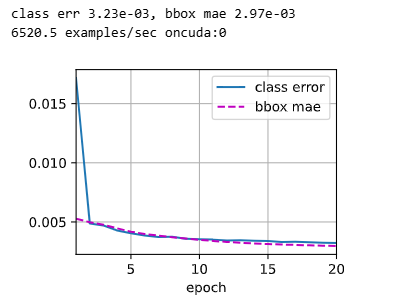
python
# 预测目标
# 读取待预测的图片,并将其转换为浮点型张量
X = torchvision.io.read_image('/root/autodl-tmp/01_Data/04_banana.jpg').unsqueeze(0).float()
# 从四维张量中移除单维条目,然后调整各维度的顺序,最后转换为长整型张量
img = X.squeeze(0).permute(1,2,0).long()
# 定义预测函数
def predict(X):
# 将网络设置为评估模式
net.eval()
# 前向传播,得到锚框、类别预测和边界框预测
anchors, cls_preds, bbox_preds = net(X.to(device))
# 对类别预测进行softmax操作,得到类别概率,然后调整各维度的顺序
cls_probs = F.softmax(cls_preds,dim=2).permute(0,2,1) # softmax使得变成概率
# 调用多框检测函数,得到预测结果
output = d2l.multibox_detection(cls_probs, bbox_preds, anchors) # 里面调用了NMS
# 获取置信度不为-1的预测结果的索引
idx = [i for i, row in enumerate(output[0]) if row[0] != -1]
# 返回置信度最大的预测结果
return output[0, idx] # 只要置信度最大的框
# 对图片进行预测
output = predict(X)置信度 = 模型有多相信"这个锚框里真的有某一类目标"
python
# 筛选所有置信度不低于0.9的边界框,做为最终输出
# 定义显示边界框的函数
def display(img, output, threshold):
# 设置图像大小
d2l.set_figsize((5,5))
# 展示图像
fig = d2l.plt.imshow(img)
# 遍历预测结果
for row in output:
# 获取置信度
score = float(row[1])
# 如果置信度低于阈值,则忽略该预测结果
if score < threshold:
continue
# 获取图像的高度和宽度
h, w = img.shape[0:2]
# 获取预测的边界框,并将其转换为实际像素坐标
bbox = [row[2:6] * torch.tensor((w, h, w, h), device=row.device)]
# 显示边界框
d2l.show_bboxes(fig.axes,bbox,'%.2f' % score,'w')
# 显示置信度不低于0.9的边界框
display(img,output.cpu(),threshold=0.9)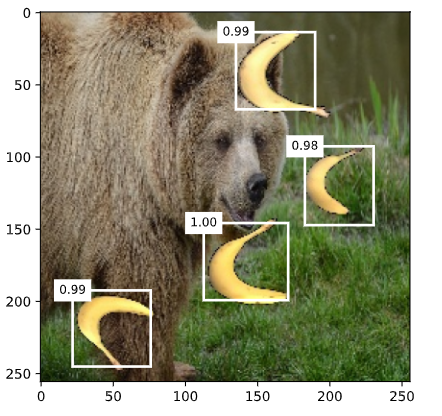
python
# 定义平滑L1损失函数
def smooth_11(data, scalar):
out = []
# 遍历输入数据
for i in data:
# 对于绝对值小于1/scalar^2的数据,采用平方损失
if abs(i) < 1 / (scalar**2):
out.append(((scalar * i)**2) / 2)
# 对于绝对值大于1/scalar^2的数据,采用绝对值损失
else:
out.append(abs(i) - 0.5 / (scalar**2))
# 返回平滑L1损失
return torch.tensor(out)
# 定义不同的sigma值
sigmas = [10, 1, 0.5]
# 定义不同的线型
lines = ['-','--','-.']
# 定义x值范围
x = torch.arange(-2,2,0.1)
# 设置图像大小
d2l.set_figsize()
# 遍历不同的sigma值
for l, s in zip(lines,sigmas):
# 计算平滑L1损失
y = smooth_11(x,scalar=s)
# 绘制损失函数曲线
d2l.plt.plot(x,y,l,label='sigma=%.1f' % s)
# 显示图例
d2l.plt.legend()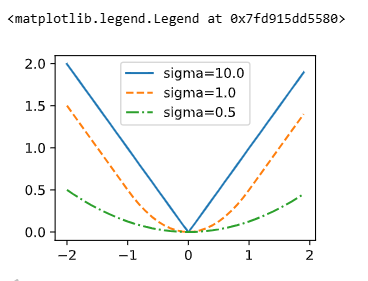
python
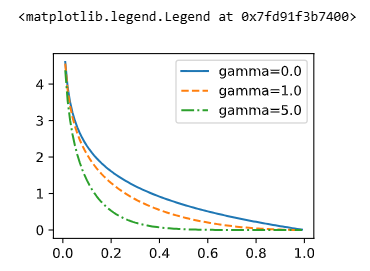
# 定义焦点损失函数
def focal_loss(gamma, x):
# 根据公式计算焦点损失
return -(1 - x)**gamma * torch.log(x)
# 定义x值范围
x = torch.arange(0.01, 1, 0.01)
# 遍历不同的gamma值
for l, gamma in zip(lines, [0, 1, 5]):
# 计算焦点损失
y = d2l.plt.plot(x, focal_loss(gamma, x), l, label='gamma=%.1f' % gamma)
# 显示图例
d2l.plt.legend()