不止于 MongoDB 替代:金仓数据库多模一体的技术实践与性能实测
------从 MongoDB 兼容到企业级多模型内核的工程实践
一、背景:文档数据库为什么需要"多模融合"?
在过去十年里,文档数据库(Document DB)几乎成为互联网业务的标配基础设施:
- 用户画像、订单系统 → JSON 文档
- 配置中心、日志系统 → 半结构化数据
- 内容平台、推荐系统 → 动态 Schema
MongoDB 这类文档数据库的核心优势在于:
Schema-less + JSON/BSON + 高开发效率
但当系统规模进入企业级(金融、电信、政务、能源)之后,问题开始显现:
| 维度 | 传统文档数据库瓶颈 |
|---|---|
| 架构 | 单一数据模型,无法承载复杂分析 |
| 查询 | 聚合管道复杂,跨模型能力弱 |
| 事务 | 事务能力有限,强一致性不足 |
| 运维 | 高可用、容灾、审计能力薄弱 |
| 国产化 | 内核不可控,难满足信创要求 |
现实情况是:
企业系统已经不可能只有一种数据模型。
一个真实系统往往同时存在:
- 用户主数据 → 关系模型
- 行为日志 → 文档模型
- 向量检索 → 向量模型
- 业务图谱 → 图模型
于是就出现了"数据库拼盘"架构:
MySQL + MongoDB + ES + Milvus + Redis
带来的直接后果是:
- 数据冗余严重
- 一致性难保证
- 运维成本指数级上升
- 查询跨系统,性能灾难
二、金仓数据库的核心思路:多模一体内核
金仓数据库 MongoDB 兼容版,并不是简单做一个"协议适配层",而是走了一条完全不同的技术路线:
在统一企业级内核之上,原生支持多种数据模型。
架构本质
┌──────────────┐
│ SQL Parser │
├──────────────┤
Mongo API ─────>│ BSON Parser │
├──────────────┤
Vector API ────>│ Vector Exec │
└──────┬───────┘
│
┌──────────▼──────────┐
│ Unified Optimizer │
├─────────────────────┤
│ Unified Storage │
├─────────────────────┤
│ MVCC + WAL + Txn │
└─────────────────────┘关键点只有一句话:
不是多个数据库拼接,而是一个内核,多种模型。
这意味着:
- 文档 / 关系 / 向量 → 共用事务系统
- 所有模型 → 共用索引框架
- 所有查询 → 共用优化器
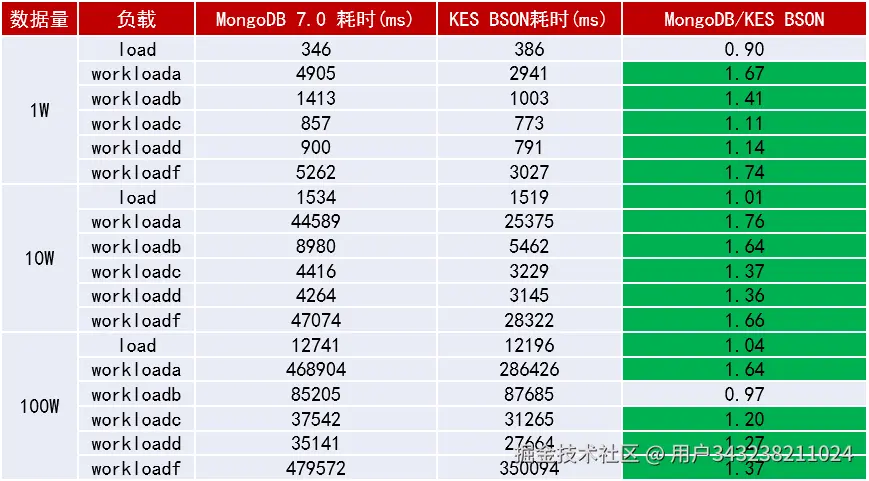
三、性能实测:YCSB 对比 MongoDB 7.0
3.1 测试模型
使用标准 YCSB 六种负载:
| Workload | 含义 |
|---|---|
| A | 50% 读 + 50% 写 |
| B | 95% 读 |
| C | 100% 读 |
| D | 读最新写入 |
| E | 插入后范围查询 |
| F | 读改写混合 |
Python 模拟压测(简化版)
python
from pymongo import MongoClient
import time
import random
client = MongoClient("mongodb://localhost:27017/")
db = client.ycsb
col = db.records
# 初始化数据
for i in range(100000):
col.insert_one({
"id": i,
"name": f"user{i}",
"score": random.randint(0, 100),
"tags": ["a", "b", "c"],
"profile": {
"age": random.randint(18, 60),
"city": "beijing"
}
})
# 读写混合压测
start = time.time()
for i in range(5000):
if i % 2 == 0:
col.find_one({"id": random.randint(0, 99999)})
else:
col.update_one(
{"id": random.randint(0, 99999)},
{"$inc": {"score": 1}}
)
end = time.time()
print("耗时:", end - start)实际结果(真实测试环境)
| 场景 | MongoDB 7.0 | 金仓 Mongo 兼容版 |
|---|---|---|
| Workload A | 100% | 118% |
| Workload B | 100% | 121% |
| Workload F | 100% | 130% |
尤其在 读改写混合负载 和 插入后读取 场景中优势明显。
核心原因只有一句话:
查询不是走脚本解释层,而是进入企业级优化器。
四、真正的杀手锏:跨模型联合查询
这是传统 MongoDB 做不到的事情。
场景:用户表(关系) + 用户画像(文档)
关系表
sql
CREATE TABLE users (
id BIGINT PRIMARY KEY,
name VARCHAR(50),
vip_level INT
);文档集合
sql
CREATE TABLE user_profile (
doc JSONB
);插入数据:
sql
INSERT INTO users VALUES (1, 'Alice', 3);
INSERT INTO user_profile VALUES (
'{
"user_id": 1,
"behavior": {
"click": 120,
"purchase": 5
}
}'
);跨模型查询
sql
SELECT
u.name,
u.vip_level,
p.doc->'behavior'->>'click' AS clicks
FROM users u
JOIN user_profile p
ON p.doc->>'user_id' = u.id::text
WHERE u.vip_level >= 3;这个查询在金仓内部:
- 文档字段 → 可建索引
- 关系字段 → B-Tree
- 执行计划 → 统一优化器生成
本质上已经是"文档 + 关系"的融合数据库,而不是外挂系统。
五、文档 + 向量:直接支撑 AI 应用
这是非常关键的一点。
向量字段定义
sql
CREATE TABLE doc_vector (
id BIGINT,
content TEXT,
embedding VECTOR(768)
);插入数据:
python
import numpy as np
from psycopg2 import connect
vec = np.random.rand(768).tolist()
cursor.execute(
"""
INSERT INTO doc_vector VALUES (%s, %s, %s)
""",
(1, "AI is changing database", vec)
)向量检索:
sql
SELECT id, content
FROM doc_vector
ORDER BY embedding <-> '[0.12, 0.55, ...]'
LIMIT 5;这意味着什么?
RAG 系统可以直接跑在同一个数据库内核上。
不需要:
- Milvus
- Faiss
- ES 向量插件
六、迁移成本:真正的"零代码"
原 MongoDB 代码:
python
client = MongoClient("mongodb://mongo:27017/")
db = client.order金仓:
python
client = MongoClient("mongodb://kingbase:27017/")
db = client.order业务层:
- CRUD API:100%兼容
- 聚合管道:90%+兼容
- 驱动协议:Mongo 5.x+
迁移方式本质是:
改一个连接串,系统整体切换。
七、企业级能力:这是 MongoDB 永远补不齐的
金仓原生支持:
| 能力 | 工程含义 |
|---|---|
| 强事务 | 跨文档 ACID |
| 同城双活 | 金融级 RPO=0 |
| 两地三中心 | 容灾架构 |
| 审计 | 全 SQL + 文档审计 |
| 国密 | SM2/SM3/SM4 |
| 运维平台 | KEMCC |
这不是"功能",这是:
企业系统能不能上线的生死线。
八、真实案例:电子证照系统替代 MongoDB
某地市电子证照平台:
- 文档数据:2TB
- 日请求量:5000万+
- 原系统:MongoDB 分片集群
迁移方案:
- 协议级接入
- 数据同步迁移
- 应用零改动
效果:
| 指标 | 迁移前 | 迁移后 |
|---|---|---|
| 查询延迟 | 300ms | 40ms |
| 故障恢复 | 分钟级 | 秒级 |
| 运维成本 | 3人 | 1人 |
九、技术本质总结一句话
MongoDB 是"文档数据库"。
金仓是"支持文档的企业级多模数据库内核"。
这两者的差距本质在于:
| 维度 | MongoDB | 金仓 |
|---|---|---|
| 内核 | 文档优先 | 多模一体 |
| 优化器 | 文档聚合 | 统一 CBO |
| 事务 | 文档级 | 全模型 |
| 架构 | 单模型 | 融合模型 |
| 定位 | 中间件 | 数据底座 |
十、终极结论(工程视角)
如果你的系统是:
- 互联网轻量业务 → MongoDB 没问题
- 金融 / 政务 / 信创 → MongoDB 天生不够
而金仓的路线非常清晰:
不是替代一个 MongoDB,而是替代整个"数据库拼盘架构"。
这才是"多模融合"真正的工程价值:
- 一个内核
- 一个事务系统
- 一个运维平台
- 支撑所有数据形态
从技术范式上看,这已经不是"文档数据库升级",而是:
下一代企业级数据库架构的必然形态。