目录
- [1 目标定位](#1 目标定位)
- [2 特征点检测](#2 特征点检测)
- [3 目标检测](#3 目标检测)
- [4 卷积的滑动窗口实现](#4 卷积的滑动窗口实现)
- [5 Bounding Box预测](#5 Bounding Box预测)
- [6 交并比](#6 交并比)
- [7 非极大值抑制](#7 非极大值抑制)
- [8 Anchor Boxes](#8 Anchor Boxes)
- [9 YOLO算法](#9 YOLO算法)
- [10 候选区域](#10 候选区域)
1 目标定位
下面,我们来学习目标检测,它是计算机视觉系统中一个新兴的应用方向,相比前两年,它的性能越来越好,在构建目标检测之前,我们先了解一下目标定位,首先,看看它的定义。

图像分类任务我们已经很熟悉了,就是用算法遍历图片,判断其中的对象是不是汽车,这就是图像分类。下面我们要学习构建神经网络的另一个问题,即定位分类问题。这意味着我们不仅要用算法判断图片中是不是一辆汽车,还要在图像中标记出它的位置,用边框或者红色方框把汽车圈起来,这就是定位分类问题,其中"定位"的意思是判断汽车在图片中的具体位置,后面我们再讲讲当图片中有多个对象的时候应该如何检测他们并确定出位置。比如,你正在做一个自动驾驶的程序,程序不但要检测其他车辆,还要检测其他对象,如行人、摩托车等等。本章我们要研究的定位分类问题通常只有一个较大的对象位于图片的中间位置,我们要对它进行识别和定位,而在对象检测问题中,图片可以含有多个对象,甚至单张图像中会有多个不同分类的对象,因此,图像分类的思路可以帮助学习分类定位,而目标定位的思路又有助于学习目标检测,我们首先从分类和定位开始讲起。
2 特征点检测
神经网络可以通过输出图片上的特征点的 (x, y) 坐标来实现对目标特征的识别,下面我们一起看几个例子。

上面是一个人脸识别和人体姿态检测的例子,假如我们要标注人脸的一些特征信息,比如人脸的左眼的两个眼角的坐标和右眼的两个眼角的坐标等等,我们可以定义一个目标标签,标签向量的第一个元素表示图像中是否含有人脸,后面的标签表示脸部的所有的特征点坐标的x,y值,当然这些特征点元素的数量由自己决定。利用人工标注的大量人脸图像和标签数据一起丢入网络中训练,就可以达到特征点识别的目的。
3 目标检测
如何通过卷积神经网络进行目标检测呢?采用的是基于滑动窗口的目标检测算法。

我们可以先输入一些适当剪切后的汽车识别的正负样本,然后把他们丢进卷积神经网络中进行训练,从而得到一个训练好的网络。下面我们就可以利用这个网络去实现滑动窗口目标检测。

网络训练好后,我们就可以进行滑动窗口检测了,可以分别采用不同大小的步幅或者窗口进行在待识别图像上进行边滑动边检测,直到检测出相应目标。
当然,这种方法存在一些缺点,就是计算成本太高,如果采用细粒度或者小步幅,检测性能可能会提高,但是由于要进行卷积处理的窗口数量太多,计算成本会很高,如果采用粗粒度或者大步幅,计算成本可能会下降,但是检测性能肯定会有所降低。
4 卷积的滑动窗口实现
下面我们看看如何在卷积层上应用滑动窗口检测算法,为了构建滑动窗口的卷积应用,首先要知道如何把神经网络的全连接层转化层卷积层。

所谓将全连接层转换为卷积层就是利用和图像大小相同的卷积核进行卷积操作,最后适当的 1x1xn 特征图像,这也就对应了全连接层的向量,最后通过 1x1 的卷积核进行softmax操作。
下面我们就看看如何通过卷积实现滑动窗口检测算法。
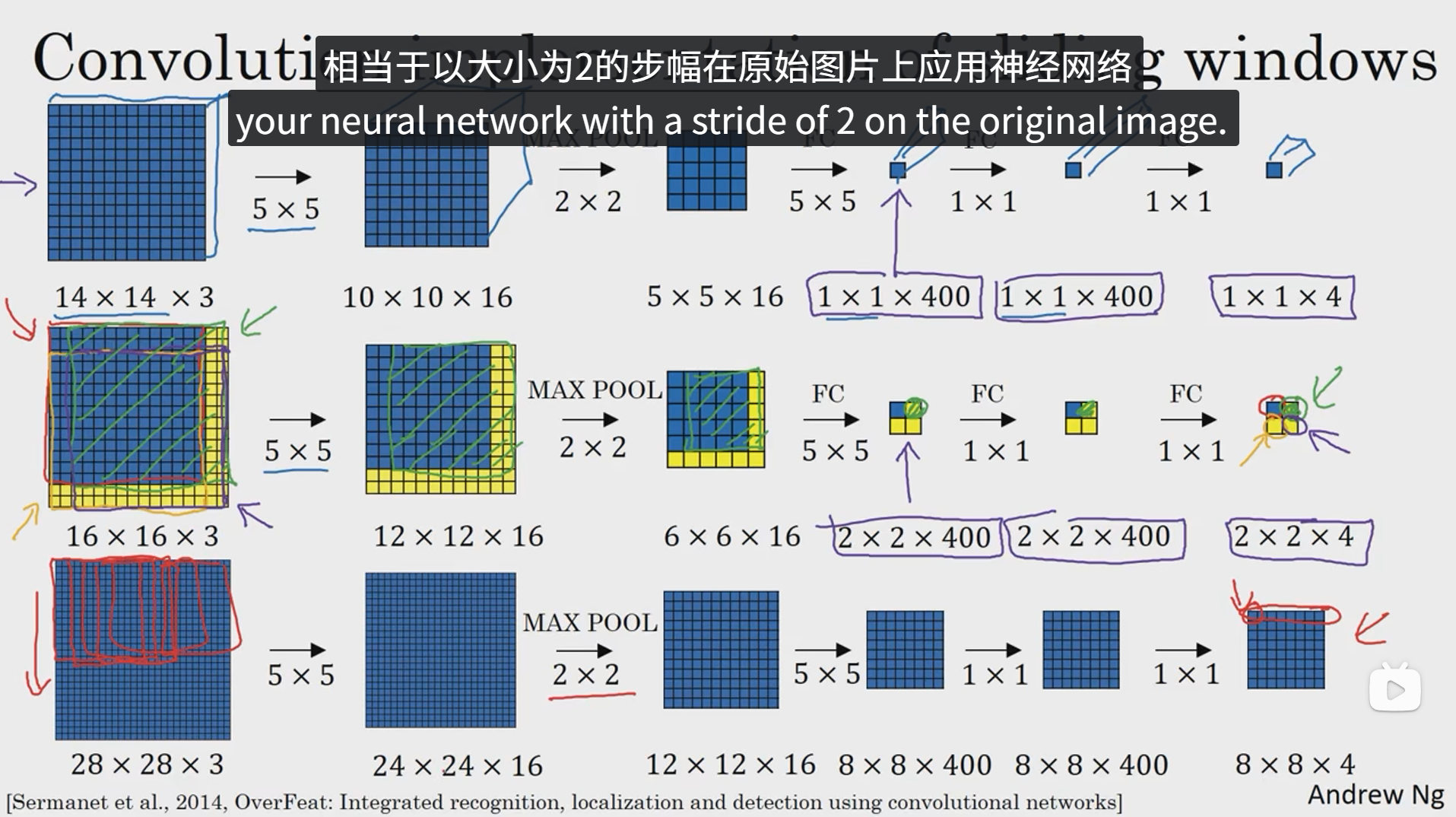
如上图,如果对一张图像单独剪切图像的一部分进行卷积操作,然后重复此过程,可能会导致很多公共区域重复计算,所以我们就索性直接对整张图片进行卷积操作,然后对每部分该剪切下来的图像进行分块映射,最终可以在输出结果中找到每块窗口对应的输出值,这样就能省去很多重复计算,这就是卷积的滑动窗口实现。这样可以大大提高滑动窗口的效率。
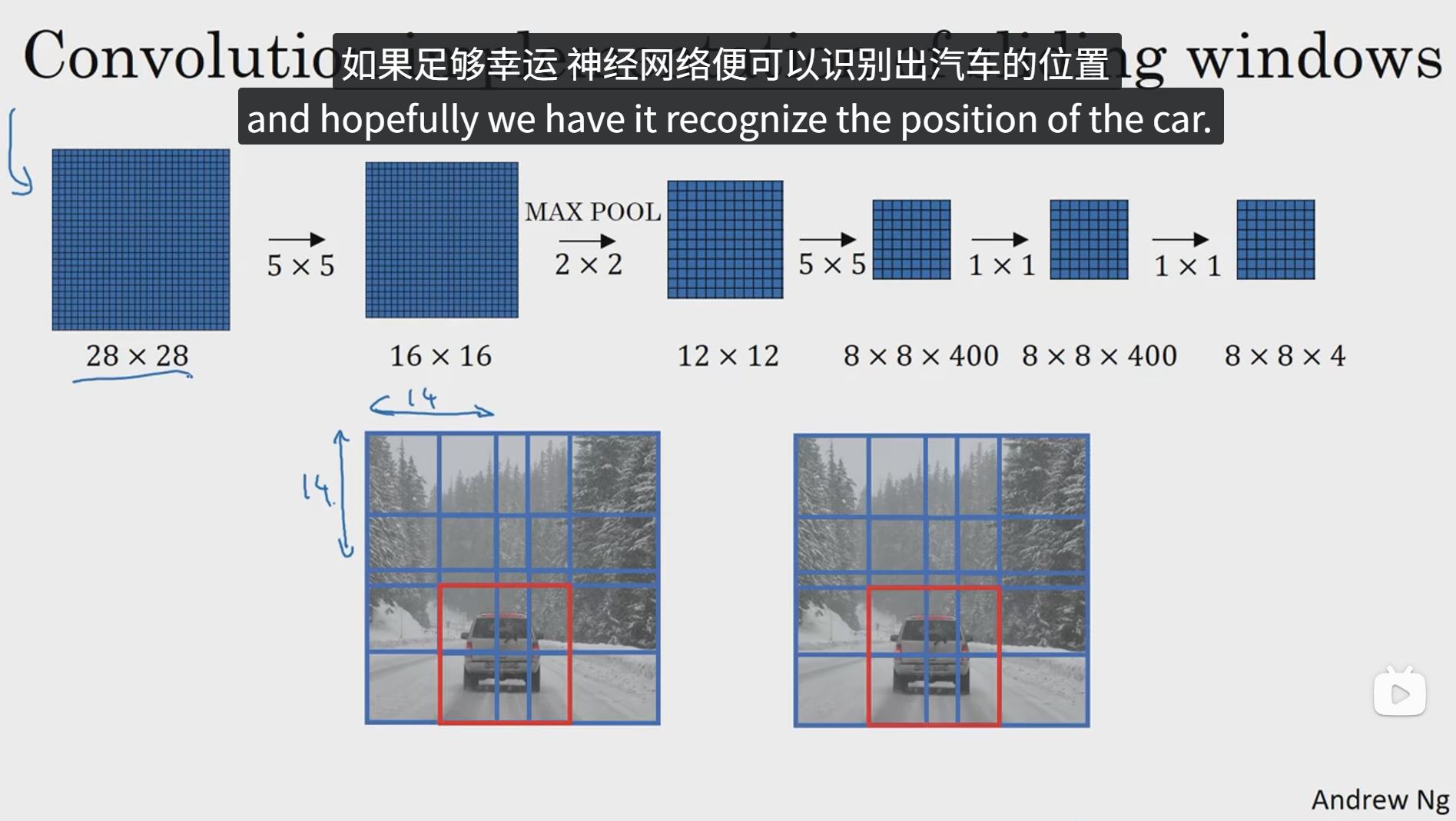
不过这总算法存在一个缺点,就是边界框的位置可能不够准确,下面我们将学习如何解决这个问题。
5 Bounding Box预测
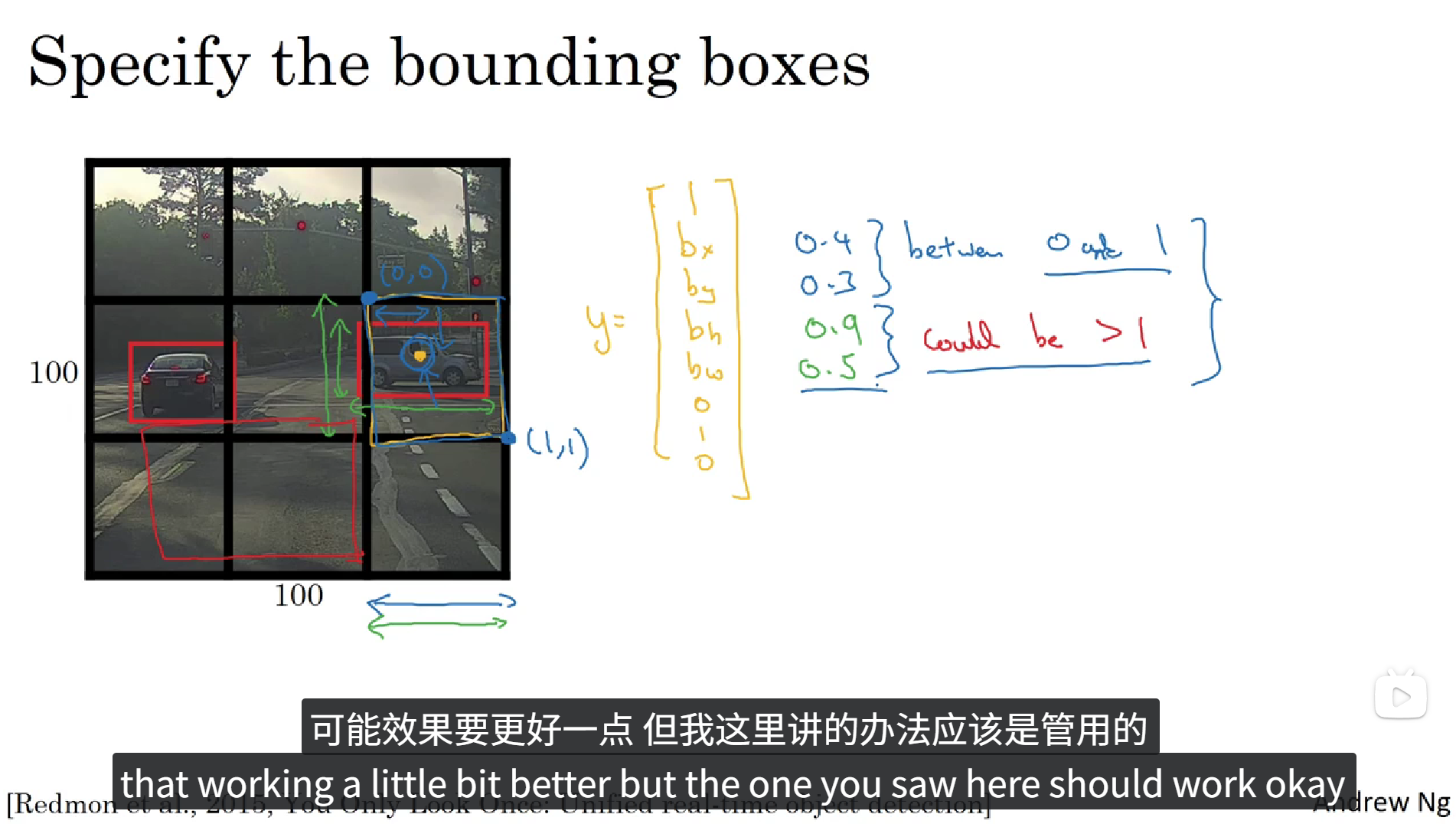
滑动窗口的卷积实现,这个算法的效率很高,但仍然存在问题。不能输出最精准的边界框,下面,我们看看如何得到更精准的边界框。

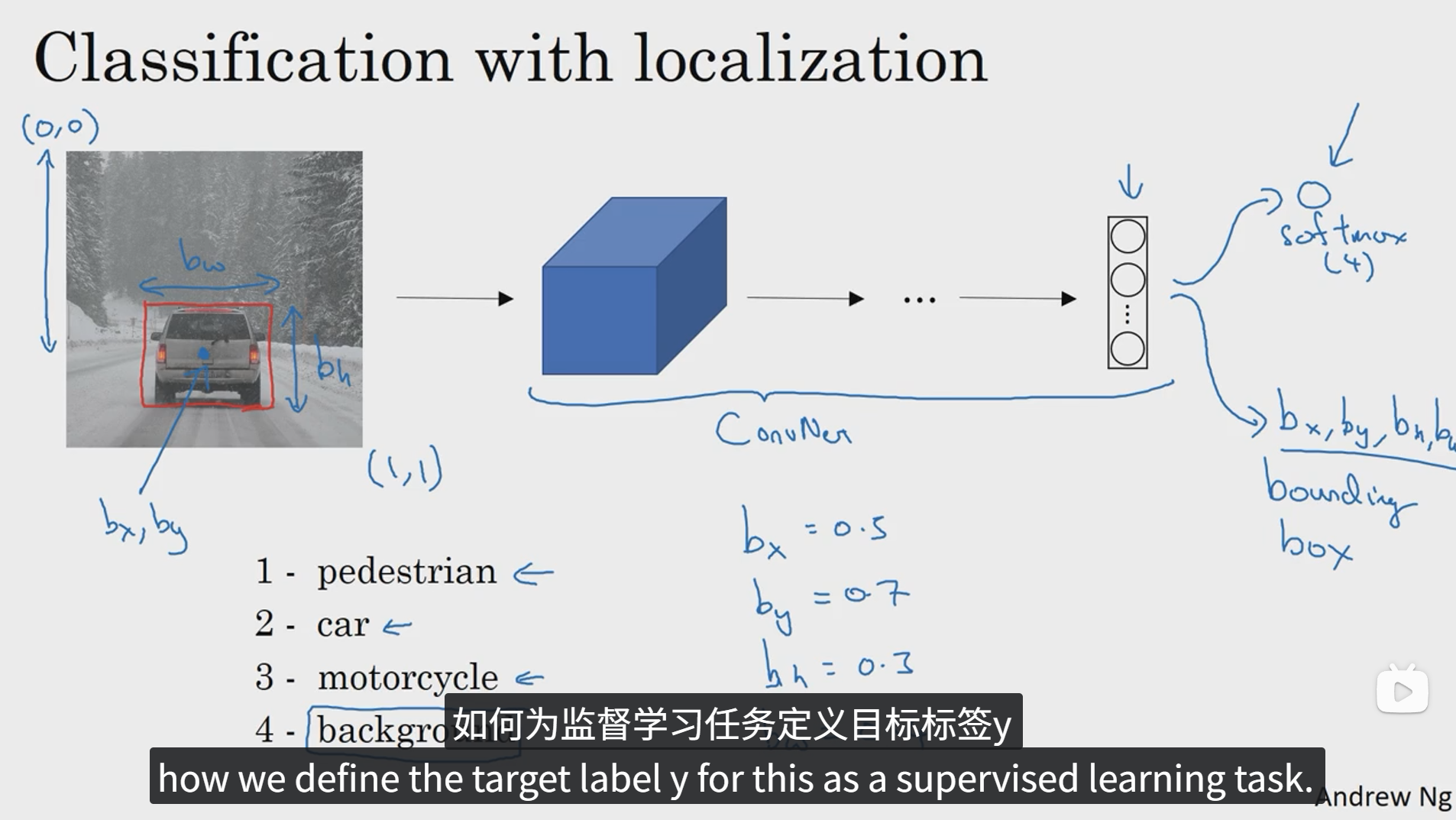
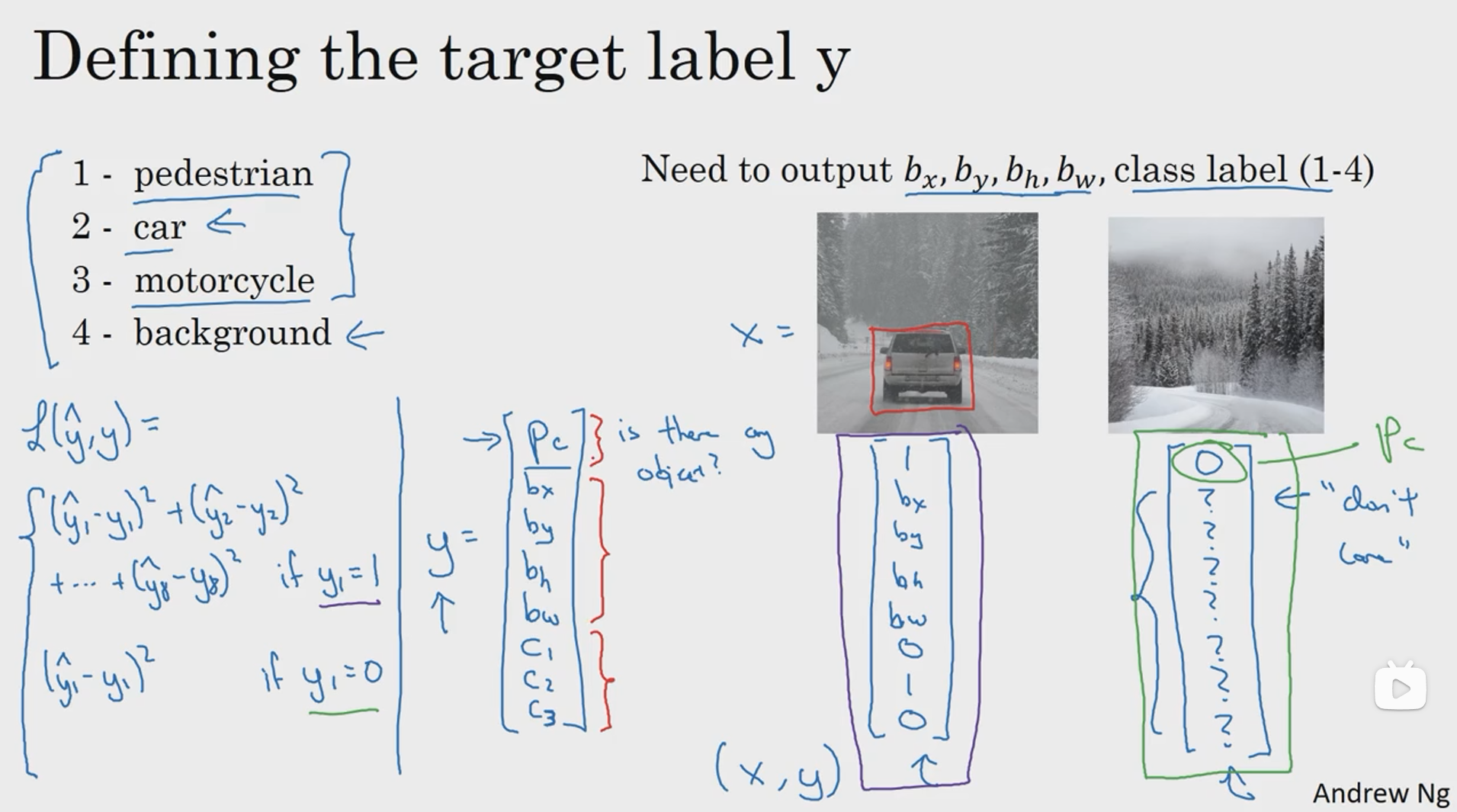
如以上图片,滑动窗口算法在目标检测的过程中可能会只框到目标物体的一部分,这样就会造成检测的不准确,那如何才能精准的检测到物体并且得到更加精准的边界框呢?答案是YOLO算法,YOLO的意思是你只看一次。
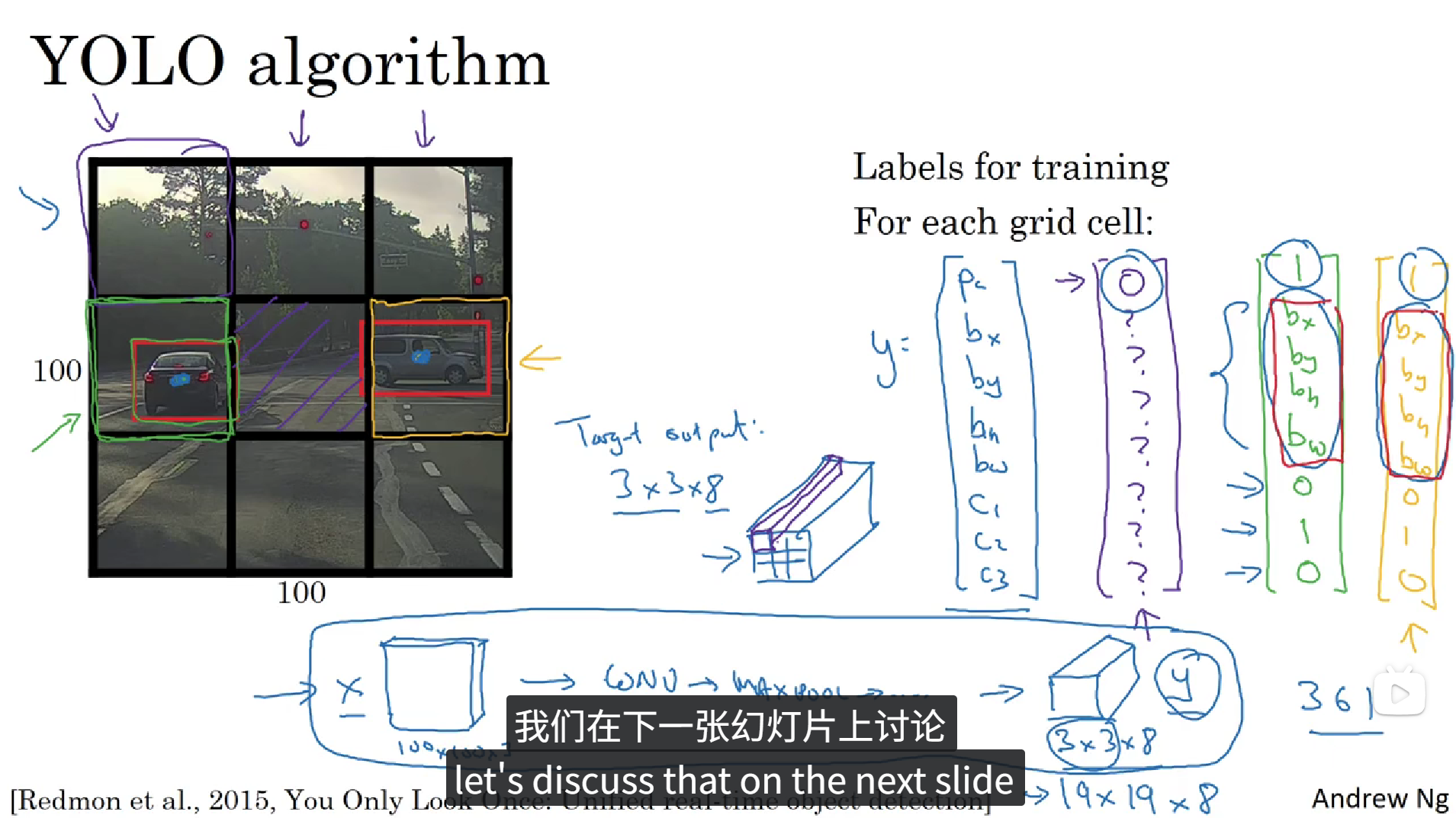
正如上面所说,YOLO算法会先将图像分为N个格子,上面的图中我们把它分成了9个格子,然后将整张图像丢入卷积神经网络,利用相同的卷积核只跑一次,预测标签和之前的相似,Pc为置信度,bx, by, bh, bw分别为待识别物体相对于本个格子的相对坐标和大小,每个格子具有一个这样的标签,所以卷积最终的输出的大小就是 3x3x8。这种算法会大大提高边框的准确性。
6 交并比
如何判断目标检测算法运作良好呢?下面我们介绍一下交并比函数,可以用来评价对象检测算法。

在目标检测算法中,你希望能够同时定位对象,所以如果实际边界框是这样的,你的算法给出这个紫色的边界框,那么这个结果是好还是坏,所以交并比(IoU)函数做的是计算两个边界框交集和并集之比。那么交并比就是计算交集的大小,即这个橙色阴影面积,然后除以绿色阴影的并集的面积。一般约定,在计算机检测任务中,如果IoU大于或者等于0.5就说明检测正确,如果预测器和实际边界框完美重叠,则IoU就是1,因为交集就等于并集。但一般来说,只要IoU大于等于0.5,那么结果就是可以被接受的,一般约定0.5是阈值,IoU越高,预测越准确。除此之外,这个阈值是人为设定的,可以由你来设定,如果你想对精确性要求严格一点,可以适当进行提高。
7 非极大值抑制
到目前为止,我们学到的目标检测中的一个问题是我们的算法可能对同一个对象作出多次检测,所以算法不是对某个对象检测出一次,而是检测出多次,非极大值抑制这个方法可以确保你的算法对每个对象只检测一次,现在我们举个例子。

图中画出了三个不同的目标框,每个框都有自己的pc(预测值),先选取预测值最大的那个框(即亮框),然后再将这个框周围的那些与这个框交并比较高且pc值较小的目标框进行抑制(即暗框)。这就是非极大值抑制,你只需要输出概率最大的分类结果。

这是一个非极大值抑制的例子,大概过程是这样的,首先,我们先去除 pc <= 0.6 的边界框,然后逐一检测剩余的边界框,首先在剩下的边界框中挑选出 pc 最大的,然后对于除了这个框之外的和这个框的 IoU > 0.5 的边界框再次进行去除,重复上述过程,知道只剩下 pc 最大的边界框,这就是非极大值抑制的大致过程。
8 Anchor Boxes
到目前位置,目标检测中存在的一个问题是每个格子只能检测出一个目标,如果你想让一个格子检测出多个对象,你可以这么做,就是使用 anchor box 这个概念,下面我们看一个例子。
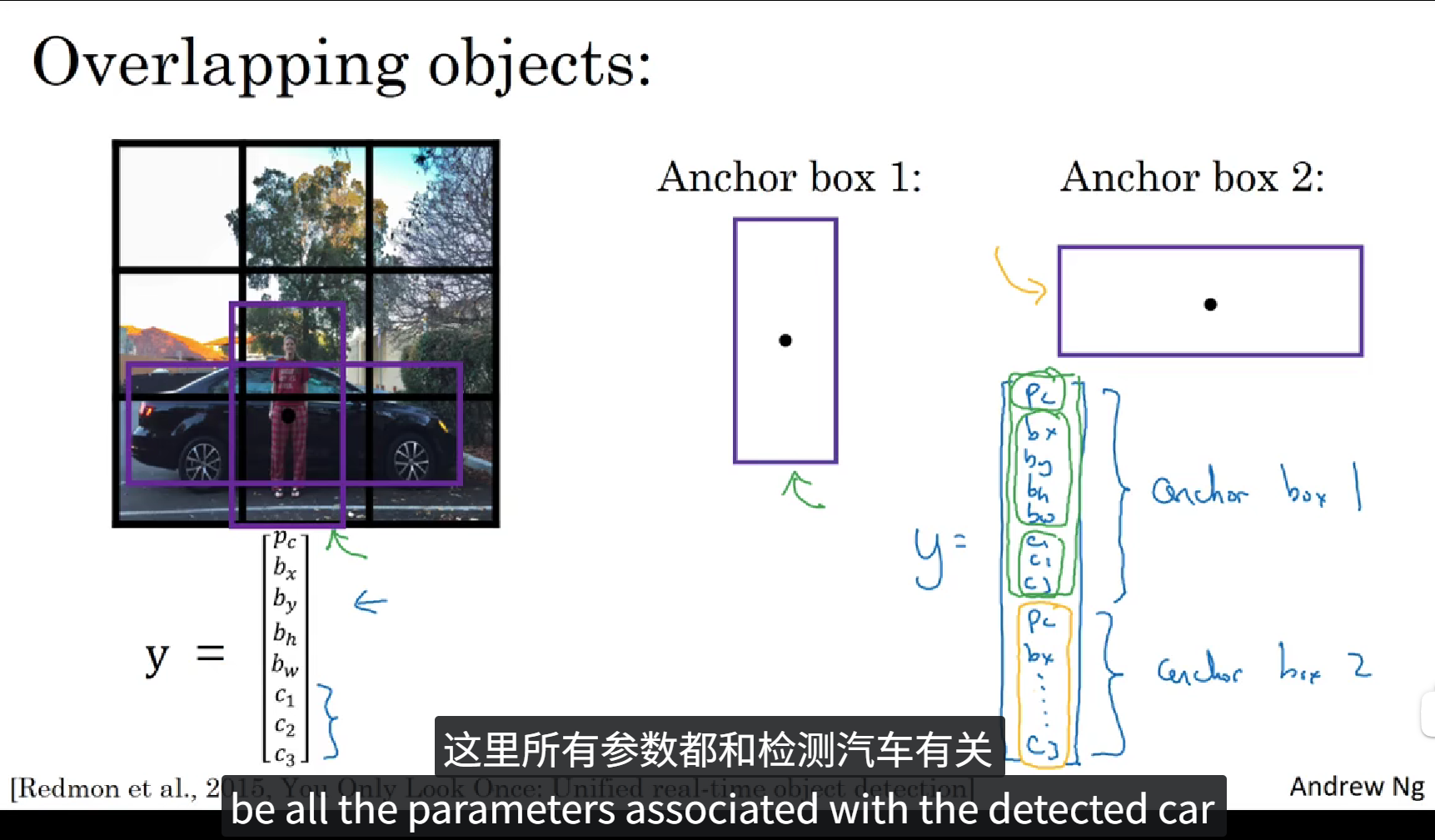
当图像中存在两个对象重叠在一起的时候,由于中心坐标的重合,我们无法判断究竟框选哪个对象,所以我们可以提前定义两个形状的 Anchor box ,如上图所示,Anchor box1表示人, Anchor box2 表示车,同时训练标签中元素的数量也由8个扩充为16个,这些元素一共分为两组,一组表示 Anchor box1,另一组表示 Anchor box2。

下面我们看一个具体的例子。
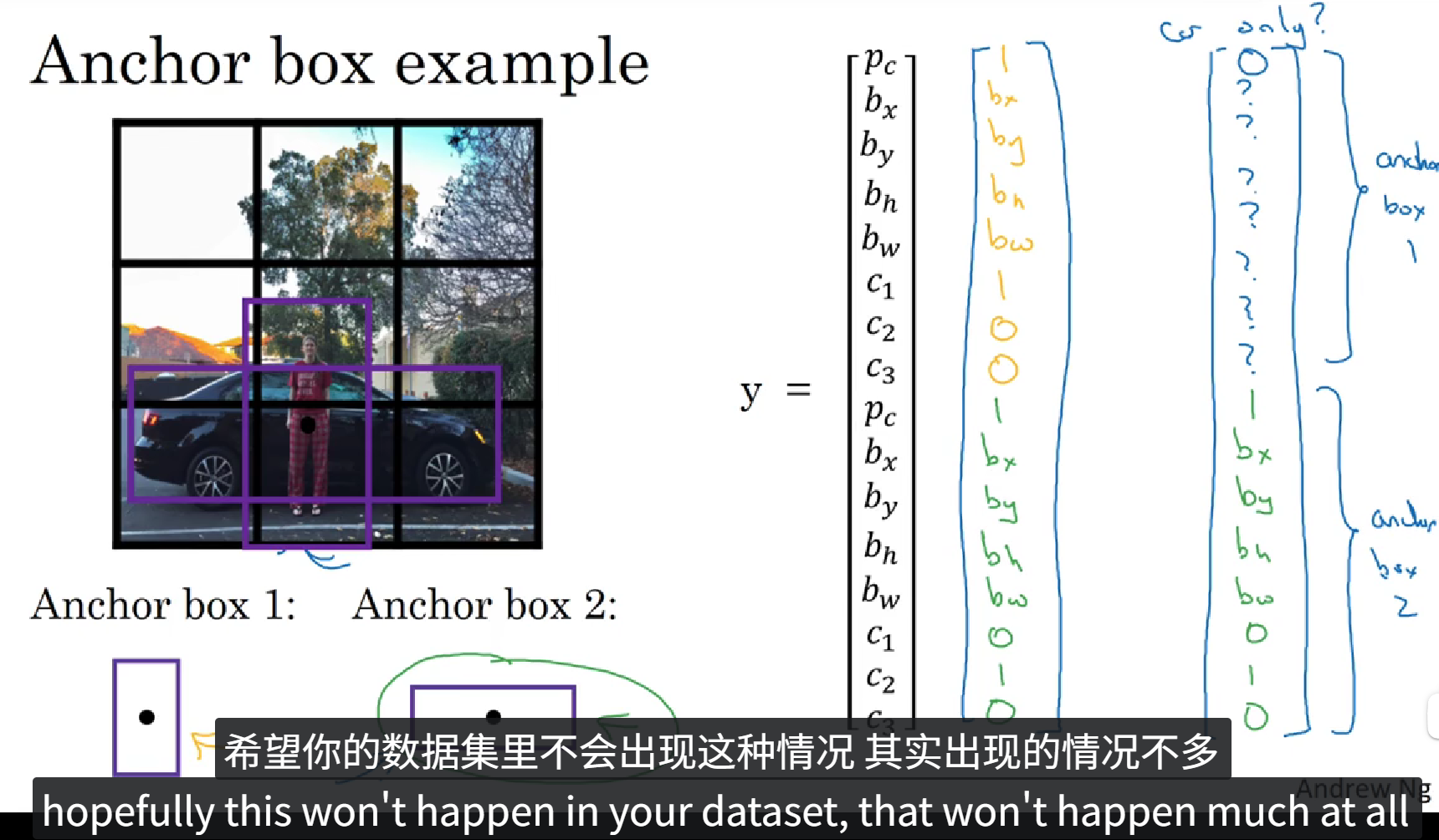
上面的PPT中定义了一个含有16个元素的训练标签,前8个元素表示 Anchor box1,后8个元素表示 Anchor box2,在图像中包含重叠的一个人和一辆车,我们根据物体的实际值框选范围和 Anchor box 的 IoU 判断出来哪个框属于哪个Anchor box,最后填充训练标签。这就是 Anchor boxes 的大致流程。当然 Anchor box 也不止两个,可以由图像中物体种类的多少自定义,当然,当目标种类越多的时候,Anchor box 的种类也就越多,同时训练标签的维度也就更高。
9 YOLO算法
这一节,我们综合之前所学的所有东西,去构建YOLO目标检测算法。
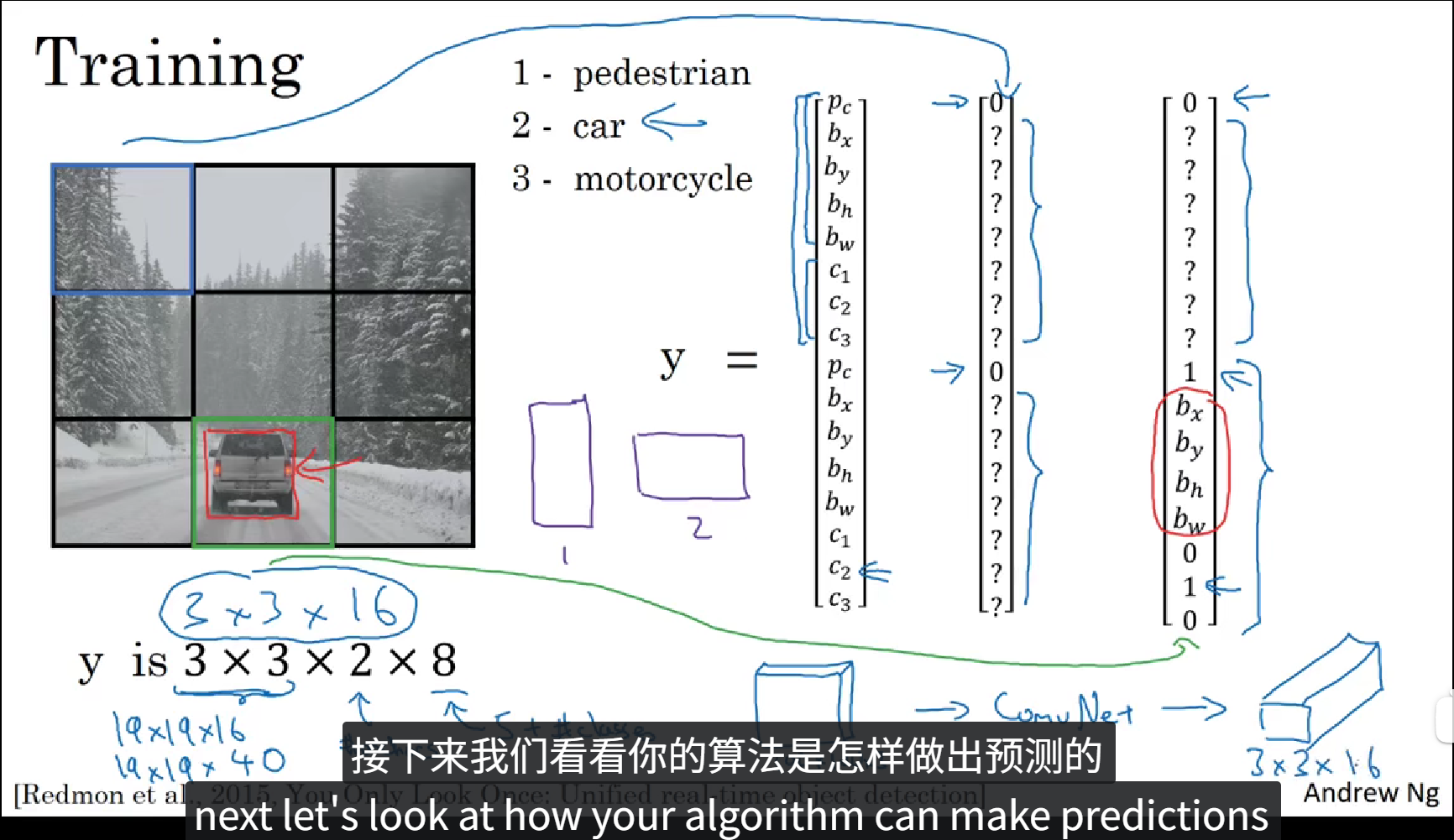
以上是 YOLO算法 的训练过程。
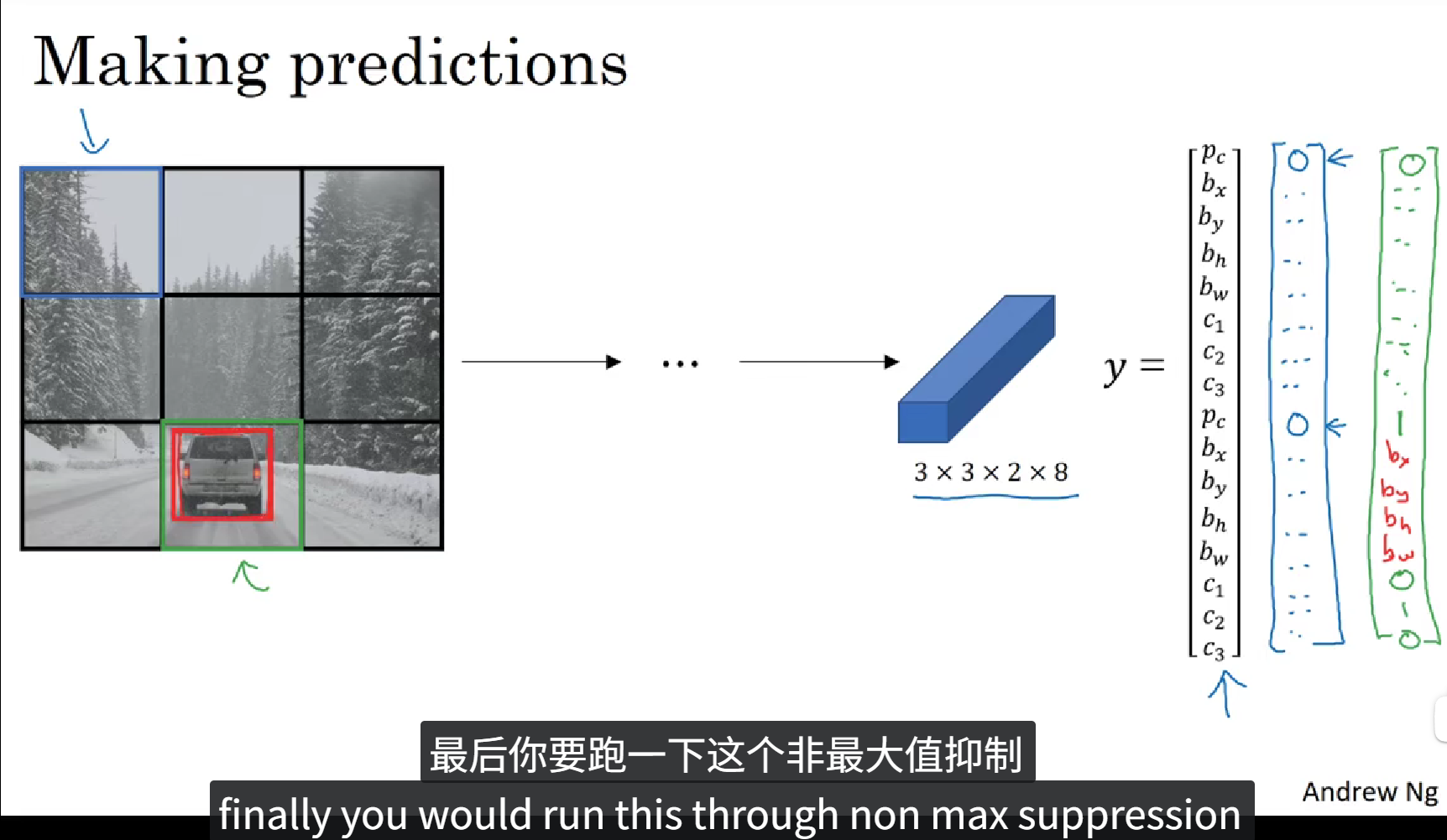
以上是 YOLO算法 的预测过程。

以上是 YOLO算法 的非极大值抑制的过程。
10 候选区域
如果我们阅读一下对象检测的文献,可能会看到一组概念,就是所谓的候选区域,这是个在计算机视觉领域是非常由影响力的概念。

所谓候选区域,就是先用图像分割算法先分割出一些目标色块,然后在目标色块周围运行分类器,这就减少了分类器对整个图像进行扫描,这样的扫描经常会扫描到一些没有目标的区域,从而造成资源浪费,性能降低。这个操作也叫做 R-CNN(区域卷积)。