一.一维数组
数组是一些相同类型元素的集合,数组中存放的是一个或者多个数据,但是数组元素个数不可为0。数组中存放的多个数据,类型是相同的。数组分为一维数组和多维数组,多维数组常见的是二维数组。下面让我们介绍一下一维数组的相关知识:

上面的图片就是一维数组的逻辑图片
1.一维数组的创建
一维数组创建的语法形式如下:
cpp
type arr_name[常量值];
- type指的是数组内部元素的数据类型,不仅可以是内置类型,也可以是自定义类型。
- arr_name指的是该数组的数组名,数组名应该像变量一样,起名时应有意义。
- 常量值指的是数组的长度,在创建数组时,需要告诉系统数组需要开辟多大的空间。
比如:现在需要存储全班20人的数学成绩,我们就可以创建一个数组将,数学成绩这种类型相同的数集中管理起来。具体操作如下:
cpp
int math[20];
//或者
const int N = 20;
int math[N];上述两种创建数组的方式其实是一样的,只不过第二种创建方法需要首先创建一个只读变量(不可修改),这个变量具有常量属性,不可以被修改,将其作为数组的大小符合逻辑。
2.数组的初始化
在数组创建完之后,就需要进行数组的初始化,类似于变量一样。不及时对数组进行初始化,容易造成意想不到的严重后果。所以在数组创建之后,需要给定一些初始值。数组的初始化一般使用大括号,将初始化的数据放在大括号内。
cpp
//完全初始化,数据会依次放⼊数组
int arr[5] = {1,2,3,4,5};
//不完全初始化
int arr2[6] = {1};//第⼀个元素初始化为1,剩余的元素默认初始化为0
//错误的初始化 - 初始化项太多
int arr3[3] = {1, 2, 3, 4};数组的初始化分为完全初始化和不完全初始化。
- 完全初始化指的是对数组的所有元素均进行了初始化。
- 不完全初始化指的是只对数组的前某些元素进行初始化,则剩余元素会默认初始化为0。
- 在数组进行初始化时,初始化的元素数量不能超过数组本身的容量。否则就是错误初始化。
3.数组元素的访问
数组在创建之后,少不了之后对数据的具体管理,所以数组还需要进行调用的方法。于是C/C++语言就提供了数组元素访问的方法。具体请看下方数组:
cpp
int arr[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
上述图片看完可以得出结论:数组每个元素都会对应一个下标。数组第一个元素的下标为0,以此类推......当数组元素个数为n时,最后一个元素的下标为n-1。有了下标离访问数组元素又进一步,这时我再介绍一下下标访问操作符,就可以通过这个操作符获取数组的元素。
数组的访问提供了一个操作符: ,这个操作符叫做下标访问操作符。有了下标访问操作符,我们就可以轻松的访问到数组的元素了。请看下方代码:
cpp
#include <iostream>
using namespace std;
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
cout << arr[7] << endl; // 8
cout << arr[3] << endl; // 4
return 0;
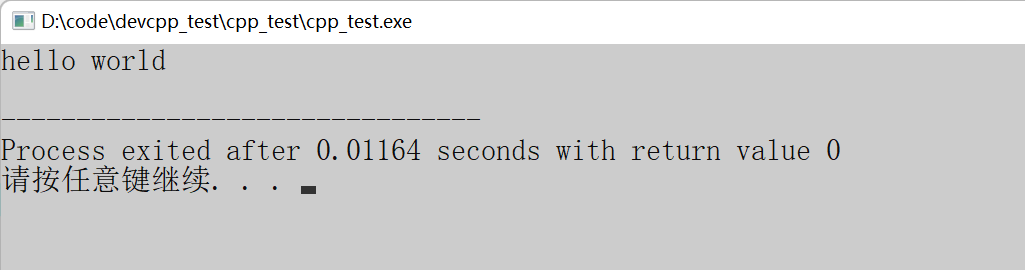
}
根据上述代码可以得出:下标访问操作符内写出数组的下标就可以访问对应位置的数组元素。有了下标访问操作符,就可以进行任意数组元素的访问。
4.数组元素的打印
通过上述知识点的学习,我们知道访问数组某一元素,需要用到下标访问操作符。那么当我们需要访问整个数组该怎么办呢?
这时我们就需要利用循环语句,先产生所有的数组下标,在循环内部将数组每个元素进行访问即可。
注意:如果通过循环语句产生的下标超过了有效下标的范围,比如:使用负数作为下标,或者超出了下标的最大值,再使用下标访问操作符进行访问,就会造成数组的越界访问。这种问题代码编译不会报错,但是运行时会出现严重的问题的。
(1)数组和sizeof关键字
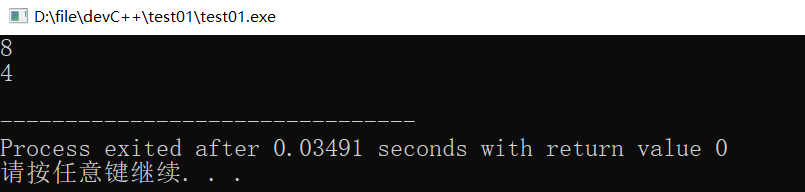
sizeof(数组名):计算数组的总大小,单位是字节。要想求出数组元素的个数就需要:sizeof(数组名)/sizeof(第一个元素)。详细请看下方代码:
cpp
#include <iostream>
using namespace std;
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
cout << sizeof(arr) << endl;
cout << sizeof(arr) / sizeof(arr[0]) << endl;
return 0;
}
(2)打印的具体实现
通过上述知识的学习,我们就可以打印出数组的所有元素,详细请看下方代码:
cpp
#include <iostream>
using namespace std;
int main()
{
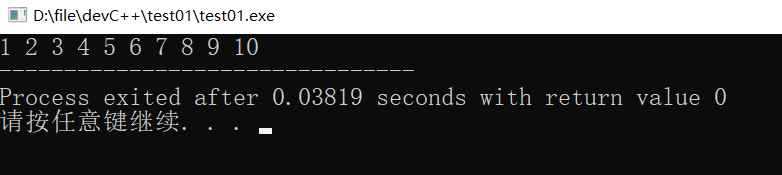
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int i = 0;
for(i = 0; i < sizeof(arr)/sizeof(arr[0]); i++)
{
cout << arr[i] << " ";
}
return 0;
}
5.范围for循环
打印数组元除了可以使用上面之前讲的三种循环的方法外,还有一个更加简便的方法,使用范围for。范围for是C++11标准引用的。如果编译器不支持C++11,就需要相关操作才能使用。
(1)相关配置
在使用DevC++的过程中,有时候一旦出现较新的语法就编译不过,可能是编译器不支持,提示的错误如下所示:
cpp
#include <iostream>
#include<string>
using namespace std;
int main()
{
string s = "abc";
cout << "s:" << s << endl;
//尾删
s.pop_back();
cout << "s:" << s << endl;
//尾删
s.pop_back();
cout << "s:" << s << endl;
return 0;
}
解决方法如下:
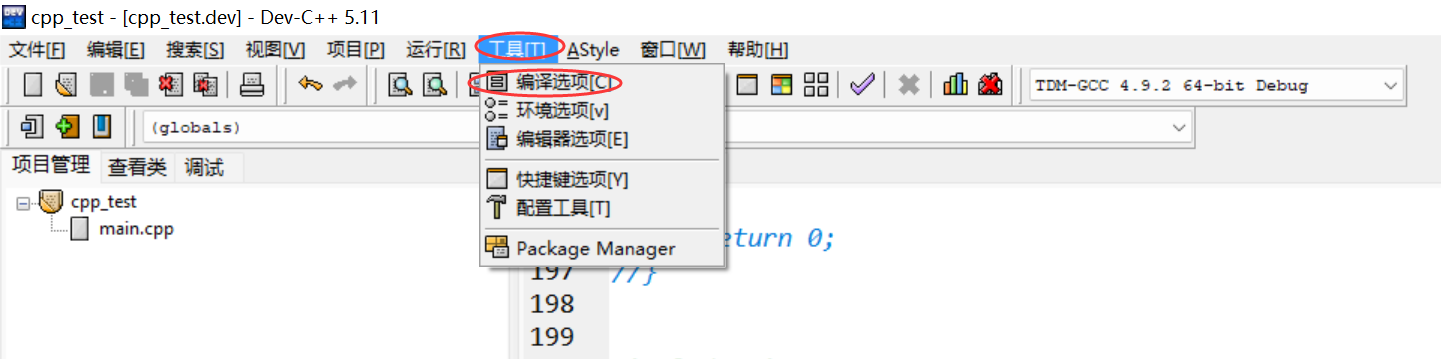
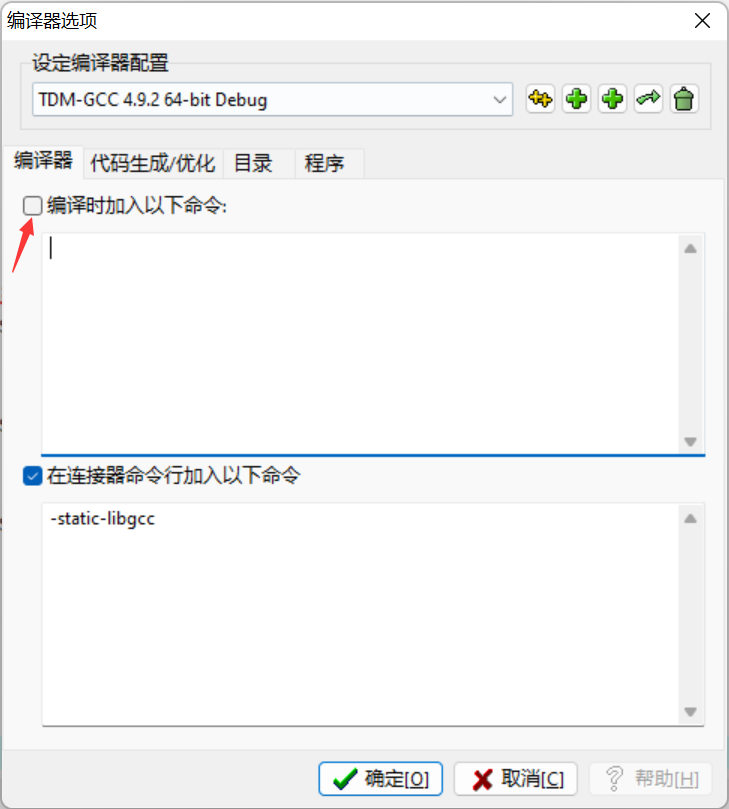
出现上述窗口时,勾选【编译时加入以下命令】,然后在下方的编译框加上:-std=c++11即可解决此类问题。
(2)范围for语法
下面是范围for语句的相关语法,看语法不如看例子,紧接着给出相关示例:
cpp
for ( 类型 变量名 : 数组名 )
语句 //多条语句需要加⼤括号
cpp
#include <iostream>
using namespace std;
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
for (int e : arr)
{
cout << e << " ";
}
return 0;
}上述代码的for就是范围for,代码的意思是将arr数组中的元素,依次放在e变量中,然后打印e,直接遍历完整个数组的元素。这里的e是一个单独的变量,不是数组的元素,所有情况下对e的修改,不会影响数组元素的变化。但是范围for语法要谨慎使用,范围for是对数组中所有元素进行遍历的,但是我们实际情况下,可能只需要遍历指定元素。
(3)auto关键字
该关键字主要的作用是:让编译器自动推导出变量的类型的。比如:
cpp
#include <iostream>
using namespace std;
int main()
{
auto a = 3.14;
auto b = 100;
auto c = 'x';
return 0;
}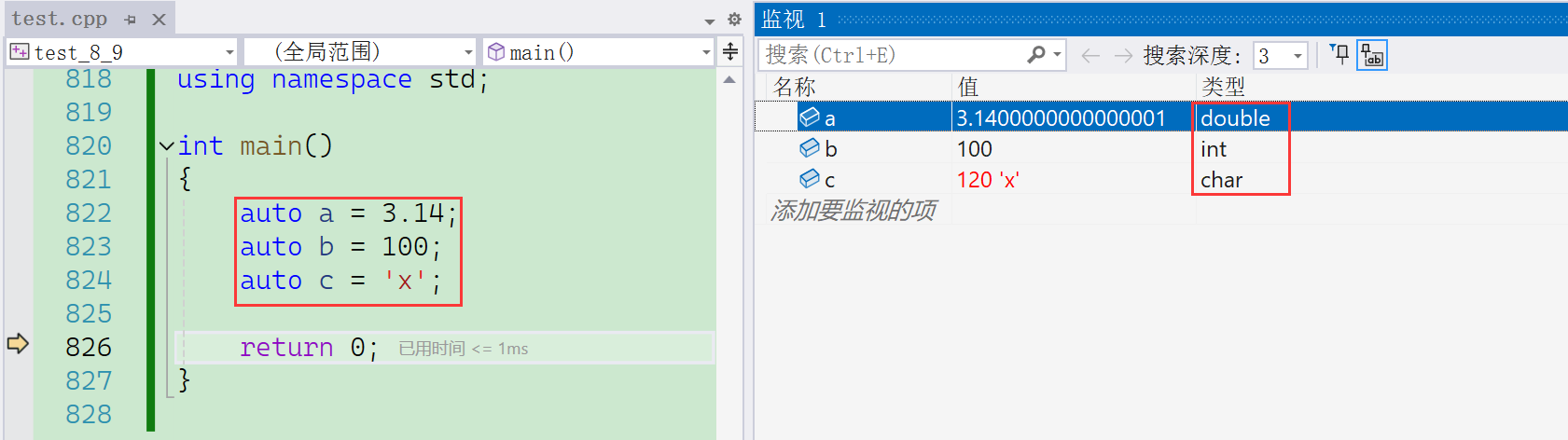
根据上面的图片可以得出auto关键字可以让编译器推导出变量的数据类型,有着这样作用的关键字可以与范围for结合起来使用。
cpp
#include <iostream>
using namespace std;
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
for (auto e : arr) //auto能够⾃动推导数组中每个元素的数据类型,在数组范围内遍历
打印元素
{
cout << e << " ";
}
return 0;
}范围for语句中的e类型可以是auto,当我们不知道数组中存放什么类型的数据时,可以使用auto关键字作为数组内元素的类型,auto关键字在范围for语句中,很常用。当然如果明确知道数组元素的类型,就可以将auto关键字换成已知的类型。
6.memset函数
(1)函数介绍
cpp
void * memset ( void * ptr, int value, size_t num );该函数的作用是:将内存中的值以字节的单位设置成想要的内容。需要包含<cstring>头文件
参数解释:
- ptr指针:指向了要设置数组的内存块的起始位置。
- value:指的是需要数组需要设置的值。
- num:需要设置的字节数
(2)函数的应用
cpp
#include <iostream>
#include <cstring>
using namespace std;
int main ()
{
char str[] = "hello world";
memset(str, 'x', 6);
cout << str << endl;
int arr[] = {1,2,3,4,5};
memset(arr, 0, sizeof(arr));//这⾥数组的⼤⼩也可以⾃⼰计算
for(auto i : arr)
{
cout << i << " ";
}
cout << endl;
return 0;
}
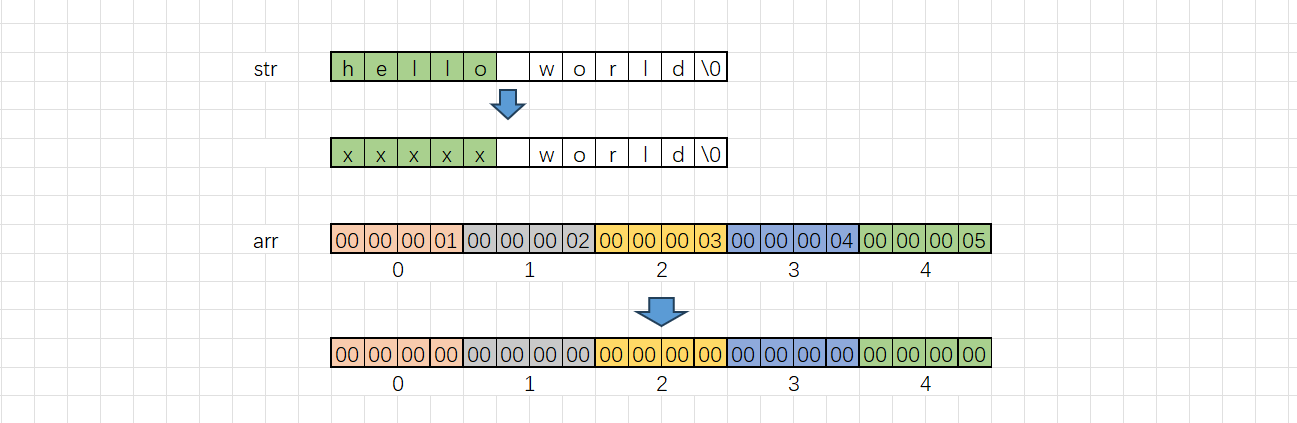
上述代码的具体解释:利用memset函数将数组的前6个字节变成x字符。随后利用范围for语句将改变后的数组打印在屏幕上。
(3)错误使用
cpp
#include <iostream>
using namespace std;
int main ()
{
int arr[] = {1,2,3,4,5};
memset(arr, 1, 4 * sizeof(int));
for(auto e : arr)
{
cout << e << " ";
}
cout << endl;
return 0;
}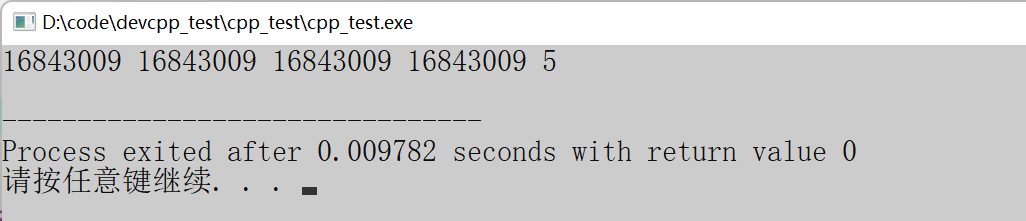
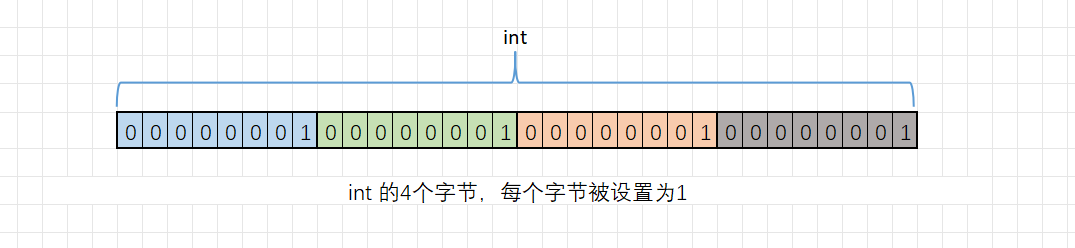
从上面打印的结果可以看出,当value设置为1或者其他数字时,打印结果并不符合预期。主要原因是:memset函数是给每个字节设置value值,单位是字节。而一个整形元素占用4个字节,且这个整形元素是以二进制的补码形式存储的,将该变量内存存储的二进制序列的每一位均换成value值,结果是一定不符合预期的。如下图所示:
7.memcpy函数
(1)函数介绍
在使用数组时,难免会出现目前有数组a,需要给数组b赋值的情况。那么直接赋值不可以吗?当然不可以,数组不是变量不可以直接相互赋值。
cpp
int a[10] = {1,2,3,4,5,6,7,8,9,10};
int b[10] = {0};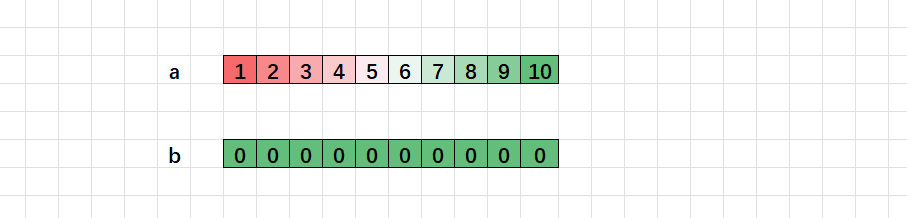
在C++中有库函数memcpy可以作数组内容的拷贝,当然该函数其实是用来做内存块的拷贝的,当然用来做数组内容的拷贝也没有任何问题。但是需要正确包含头文件<cstring>。函数原型如下:
cpp
void * memcpy ( void * destination, const void * source, size_t num );
//destination -- ⽬标空间的起始地址
//source -- 源数据空间的起始地址
//num -- 拷⻉的数据的字节个数
- destination:赋值目标数组的起始地址
- source:被赋值数组的起始地址
- num:拷贝数据的字节个数
(2)函数的应用
cpp
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
int a[10] = {1,2,3,4,5,6,7,8,9,10};
int b[10] = {0};
memcpy(b, a, 10 * sizeof(int));
for(int e: b)
{
cout << e << " ";
}
return 0;
}上述代码利用了memcpy函数,将数组a拷贝给了数组b。在拷贝的过程中需要给目标数组留足够的空间,否则函数就没办法正确地进行数组拷贝。
二.二维数组
1.二维数组的概念
前面学习的数组被称为一维数组,数组的元素都是内置类型的,如果将一维数组作为数组的元素,我们就会得到二维数组。二维数组作为数组的元素的数组被称为三维数组,二维数组以上的数组被称为多维数组。因为二维数组是多维数组中最常见的,所以接下来我们讲解二维数组:
2.二维数组的创建
cpp
type arr_name[常量值1][常量值2];
//例如
int arr[3][5];
double data[2][8];下面解释一下上述代码的细节:
- 3表示数组有三行。
- 5表示数组一行有五个元素。
- int表示数组的每个元素是整型类型
- arr是数组名,可以根据自己的想法起有意义的名字。
3.二维数组的初始化
在创建二维数组之后,与一维数组一样的。均需要对数组进行初始化,一维数组和二维数组一样均要用到大括号将需要初始化的数据括起来。
cpp
//不完全初始化
int arr1[3][5] = {1,2};
int arr2[3][5] = {0};
//完全初始化
int arr3[3][5] = {1,2,3,4,5, 2,3,4,5,6, 3,4,5,6,7};
//按⾏初始化
int arr4[3][5] = {{1,2},{3,4},{5,6}};
//如果数组初始化了,数组在指定⼤⼩的时候可以省略⾏,⽽不能省略列
int arr5[][5] = {1,2,3};
int arr6[][5] = {1,2,3,4,5,6,7};
int arr7[][5] = {{1,2}, {3,4}, {5,6}};二维数组的初始化分为不完全初始化和完全初始化和按行初始化。
- 不完全初始化:只将部分数组元素进行初始化,留了一部分元素没有进行初始化。这些留下没有被初始化的会被默认初始化为0。
- 完全初始化:将二维数组的所有元素都进行了相应的初始化。
- 按行初始化:将每一行的元素额外用大括号括起来进行初始化,每一行元素初始化时,可完全初始化,也可不完全初始化。一行留下没被初始化的会默认初始化为0。
注意:如果数组初始化了,可以在中括号内省略行,但是不能省略列。因为省略行依然可以得出数组的大概结构,省略列之后数组的结构就不再确定,不利于后续数组元素的管理。
4.二维数组的下标
当我们掌握了二维数组的创建和初始化,接下来使用二维数组就离不开二维数组的下标。二维数组是有行和列的区分的,只要锁定了行和列就能唯一锁定二维数组的元素。C/C++语言规定,二维数组的行和列是从0开始的。如下图所示:
cpp
int arr[3][5] = {1,2,3,4,5, 2,3,4,5,6, 3,4,5,6,7};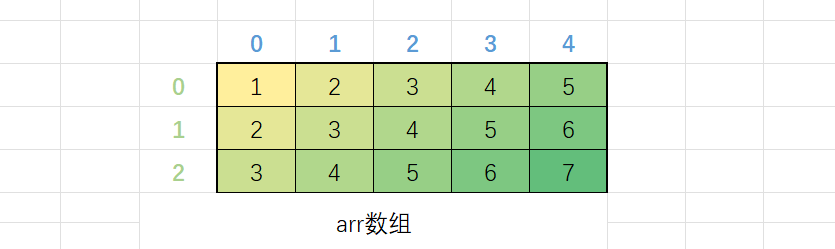
图中最左侧的数字表示行号,第一行蓝色的数字表示列号,两者都是从0开始的。
cpp
#include <iostream>
using namespace std;
int main()
{
int arr[3][5] = {1,2,3,4,5, 2,3,4,5,6, 3,4,5,6,7};
cout << arr[2][4] << endl;
return 0;
}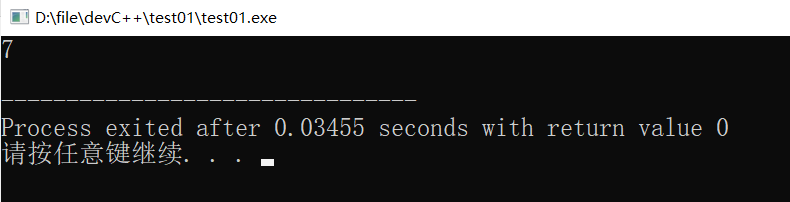
上述代码中,打印的是数组的第3行第四列的元素。行的下标是3,列的下标是4。
5.二维数组的打印
cpp
#include <iostream>
using namespace std;
int main()
{
int arr[3][5] = { 1,2,3,4,5, 2,3,4,5,6, 3,4,5,6,7 };
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 5; j++)
{
cout << arr[i][j] << " ";
}
cout << endl;
}
return 0;
}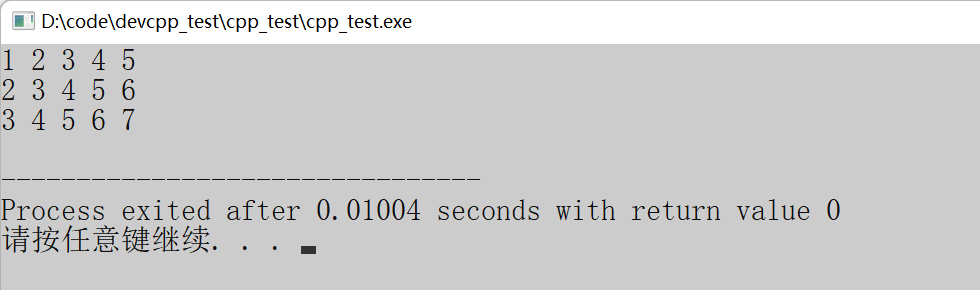
一维数组的打印需要用到一层循环遍历一维数组的下标。所以二维数组就需要二层循环获取二维数组的下标,在循环中利用数组的下标访问操作符得到数组对应的元素。
6.memset函数
memset函数是用来设置内存的,将内存中的值以字节的单位设置成想要的内容,下面演示两个例子:使用memset函数设置二维数组的内容:
cpp
#include<iostream>
using namespace std;
int main()
{
int a[10][10];
memset(a, 0, sizeof(a)); //将⼆维整型数组中每个字节都设置为0
for(int i = 0; i < 10; i++)
{
for(int j = 0; j < 10; j++)
{
cout << a[i][j] << " ";
}
cout << endl;
}
return 0;
}
cpp
#include<iostream>
using namespace std;
int main()
{
char a[10][10];
memset(a, 'a', sizeof(a)); //将⼆维字符数组中每个字节都设置为字符a
for(int i = 0; i < 10; i++)
{
for(int j = 0; j < 10; j++)
{
cout << a[i][j] << " ";
}
cout << endl;
}
return 0;
}根据上面的两个例子可以发现二维数组运用memset函数和一维数组的用法是一样的。这里两种数组都需要注意该函数设置内容的单位是字节。
三.字符数组
1.字符数组的介绍
数组的元素是字符类型时,这种数组就叫做字符数组。字符数组可以是一维数组,也可以是多维数组。接下来主要讨论一维字符数组的情况,下面是字符数组的创建:
cpp
char arr1[5]; //⼀维数组
char arr2[3][5];//⼆维数组 C语言中使用双括号括起来一串字符表示字符串,这种表示形式在C++语言中同样支持,但是一般我们会将这种字符串称为C语言风格字符串。如果需要将一个C语言风格的字符串存储起来,就可以是字符数组。
(1)字符数组的初始化
cpp
char a[10]; //字符数组的创建 字符数组的创建和一维数组的创建是一样的形式,在这里就不赘述了。字符数组初始化的形式有两种,如下:
cpp
//⽅式1
char ch1[10] = "abcdef";
char ch2[] = "abcdef";//如果数组初始化的时候,数组的⼤⼩可以省略不写,数组⼤⼩会根据初
始化内容来确定
//⽅式2
char ch3[10] = {'a', 'b', 'c', 'd', 'e', 'f'};
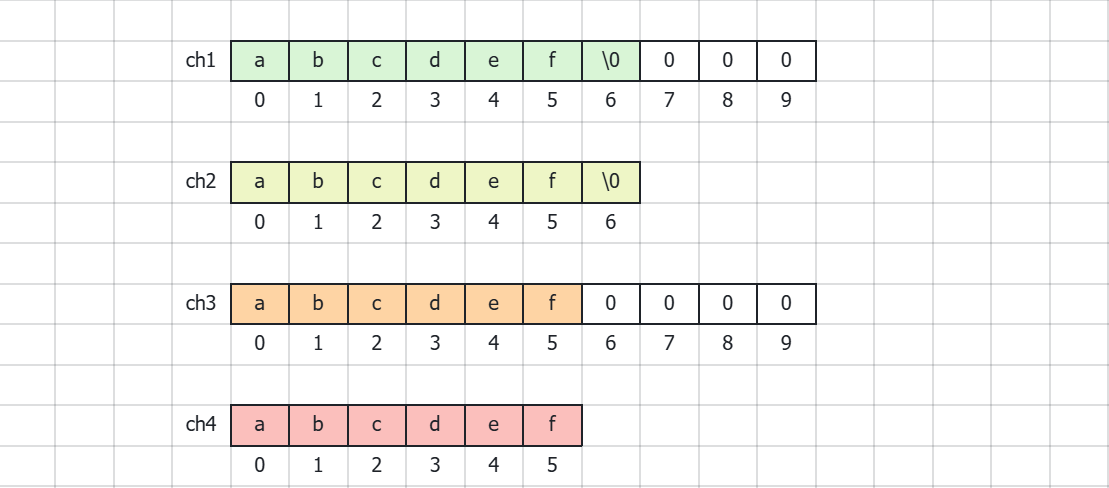
char ch4[] = {'a', 'b', 'c', 'd', 'e', 'f'};上述两种方式是字符数组初始化的不同情况。如果调试查看ch2和ch4的数组内容,我们会发现数组ch2后面多了一个'\0'字符,这是因为字符串的末尾会隐藏一个'\0'字符。这个'\0'字符是字符串结束的标志。在打印字符串时遇到'\0'字符时会使打印结束。当我们把字符串存放在一维数组中时,可以把字符数组当作字符串。具体请看下方图片:
(2)字符串长度
字符数组中存放着的字符串,这个字符数组有属于自己的长度,也就是数组的元素个数,这个可以使用sizeof计算,那数组中存放的字符串长度是多少?该怎样计算呢?
其实C/C++语言有一个库函数叫做strlen,可以求出字符串的长度,strlen计算字符串的工作原理就是计算字符串'\0'之前的字符个数。该库函数需要包含头文件:<cstring>。下面是该函数的声明:
cpp
size_t strlen ( const char * str );
//str - 指针,存放的是字符串的起始地址,从这个地址开始计算字符串的⻓度 str:指的是需要计算的字符串的首地址
cpp
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char arr[20] = "abcdef";
cout << "数组的⻓度:" << sizeof(arr)/sizeof(arr[0]) << endl;
cout << "字符串的⻓度:" << strlen(arr) << endl;
return 0;
}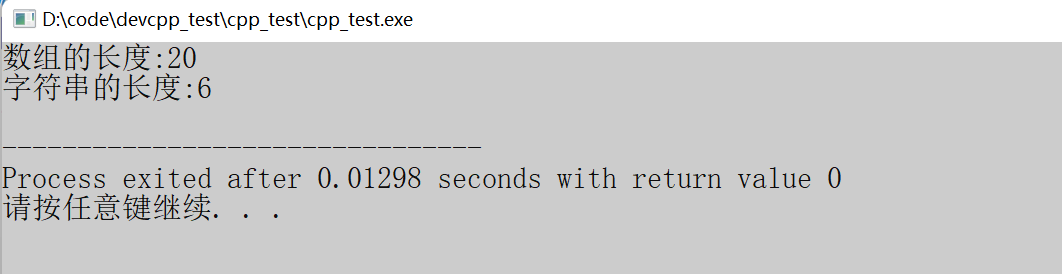
上述代码分别使用了sizeof和strlen求出了数组的大小和字符串长度。数组的大小是创建数组时,中括号内的数字;而字符串的长度用strlen函数求,求的是字符串末尾标志'\0'之前的字符数。
2.字符数组的输入
(1)输入没有空格字符串
使用scanf函数和字符数组来实现:
cpp
#include <cstdio>
int main()
{
char arr[20] = { 0 };
//输⼊
scanf("%s", arr);
//输出
printf("%s", arr);
return 0;
}上述代码的具体解释:首先创建一个字符数组,将其不完全初始化为0。随后利用scanf函数的格式控制符%s来输入字符串。这里的具体原理:函数通过格式控制符读取字符串时,会从输入缓冲流读取字符,直到遇到空白字符为止,读取完之后自动在末尾加上字符串的末尾标志'\0'。
使用cin函数和字符数组实现:
cpp
#include <iostream>
using namespace std;
int main()
{
char arr[20] = { 0 };
//输⼊
cin >> arr;
//输出
cout << arr << endl;
return 0;
}cin函数和scanf函数一样,在读取字符串时会跳过空白字符,读取完后会在字符串末尾加上字符串末尾的标志 '\0'。
上面的两个代码都是将字符串读取之后从数组的起始位置开始存放的,当然也可以指定位置进行存放,比如从数组的第二个元素的位置开始存放,如下代码:
cpp
#include <iostream>
using namespace std;
int main()
{
char arr[20] = { 0 };
//输⼊
cin >> arr + 1;//arr表⽰数组的起始位置,+1意思是跳过⼀个元素,就是第⼆个元素的位置
//可以通过调试观察⼀下arr的内容
cout << arr + 1;
return 0;
}那么从第n个元素开始存放,就应该是cin >> arr + n;;使用scanf函数也是一样的道理。下面是相关代码演示:
cpp
#include <cstdio>
int main()
{
char arr[20] = { 0 };
//输⼊
scanf("%s", arr+2);//从arr+2的位置开始存放
//输出
printf("%s", arr+2);//从arr+2的位置开始打印
return 0;
}(2)输入有空格的字符串
<1>发现问题
前面我们讲解了scanf和cin函数读取字符串时,会跳过空白字符。那么当字符串内本来就有空白字符需要我们读取又该怎么办呢?
<2>scanf函数实现方法
cpp
#include <cstdio>
int main()
{
char arr[20] = {0};
//输⼊
scanf("%s", arr);
//输出
printf("%s", arr);
return 0;
}上述代码中:当输入有空白字符的字符串时,因为scanf函数的相关性质,会导致只能读取到字符串空白字符之前的字符串。如下输入输出情况:

占位符%s,不能简单等同于字符串。它的底层逻辑是:从当前第一个非空白字符开始读取,直到遇到空白字符为止。因为占位符%s的读取不会包含空白字符,所以无法用来读取含有空白字符的字符串。除非多个%s连用,可是我们怎么知道字符串中空白字符的个数呢?所以这就意味着scanf函数不适合读取可能包含空白字符的字符串。同时,scanf函数将字符串读入字符数组时,不会检测字符串是否超出了数组长度。所以储存字符串时,该函数可能会导致数组越界,从而导致意想不到的后果。为了防止这一情况的发生,在使用%s格式控制符时,可以指定读入字符串的最长长度,即写成:%ms,其中的m是一个整数,表示读取字符串的最大长度,后面的字符会自动忽视掉。下面请看代码演示:
cpp
#include <cstdio>
int main()
{
char name[11];
scanf("%10s", name);
return 0;
}上述代码中,scanf函数利用格式控制符的性质规定最大读取10个字符长度的字符串,多余的字符自动忽略。这样就不会有数组溢出的风险了。
<3>cin函数实现方式
cpp
#include <iostream>
using namespace std;
int main()
{
char arr[20] = { 0 };
//输⼊
cin >> arr;
//输出
cout << arr << endl;
return 0;
}
根据上面的运行结果可以得出:cin函数和scanf函数一样,都会在读取字符串的时候忽略掉空白字符。读取范围是第一个非空白字符到空白字符为止。同时会在已经读取完毕的字符串末尾加上字符串末尾的标志。
<4>解决问题
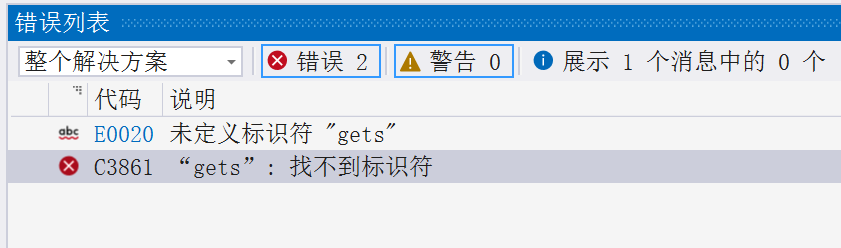
a.gets函数和fgets函数
使用gets函数的方式,可以解决上述的问题,但是gets存在安全问题,在C++11标准取消了gets,给出了更加安全的函数:fgets函数。下面是两个函数的具体解释:
cpp
char * gets ( char * str );
char * fgets ( char * str, int num, FILE * stream );
- gets函数是从第一个字符开始读取,一直读到\n为止,但是不会读取到\n,也就是读取到的内容中不包含\n,但是会在读取到的内容后自动加上'\0'
- fgets函数也是从第一个字符开始读取,最多读取num-1个字符,最后一个位置留给'\0'作为字符串末尾标志的位置。如果num的长度远大于输入的字符串长度,就会读取到\n停止,并且会读取到 \n,将其作为读取的一部分,同时在\n的后面加上\0。
cpp
#include <cstdio>
//⽅案1
int main()
{
char arr[10] = {0};
gets(arr);
printf("%s\n", arr);
return 0;
}
//替代⽅案-⽅法2
#include <cstdio>
int main()
{
char arr[10] = {0};
fgets(arr, sizeof(arr), stdin);
printf("%s\n", arr);
return 0;
}上述两种程序在控制台上输入abc def后按回车,差异如下: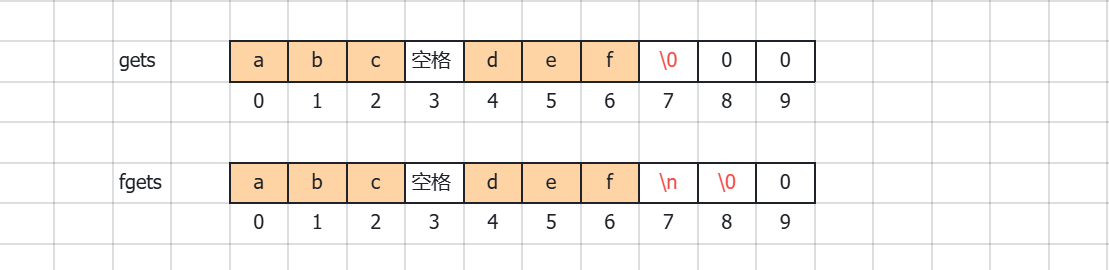
上述代码使用了不同的两个函数。gets函数在读取字符串时,在末尾加上\0即可。fgets函数在读取字符串时分两种情况,当num小于数组字符串的字符数时,会在末尾加上\0;当num大于需要读取字符串的字符数时,会将\n读取在内,之后在\n后加上\0。
虽然在DevC++上使用gets函数没有报错,但是该函数在VS2022中会报以下错误,所以尽量减少gets函数的使用:
b.scanf函数
当然C语言的scanf函数也可以做到读取带空白字符的字符串,只是不常见而已。方式就是将%s改成%\^\\ns,其中在%和s之间加上了\^\\n,意思是一直读取,直到遇到\n。这样即使遇到空格也不会结束读取了。这种读取方式不会将\n读取到,但是会在末尾加上\0。下面是相关代码的演示:
cpp
#include <cstdio>
int main()
{
char arr[10] = "xxxxxxxx";
scanf("%[^\n]s", arr);
printf("%s\n", arr);
return 0;
}c.getchar函数
当然也可以使用getchar函数进行逐个字符的读取,也是可以读取到一个含有空白字符的子字符串的。下面是代码演示:
cpp
#include <cstdio>
int main()
{
char arr[10] = { 0 };
int ch = 0;
int i = 0;
while ((ch = getchar()) != '\n')
{
arr[i++] = ch;
}
printf("%s\n", arr);
return 0;
}上述代码的意思是:利用getchar函数逐个读取字符串,从而达到读取含有空白字符的字符串。利用while循环,当读取的字符不是\n就进入循环读取,如果碰到\n就停止读取字符。
3.字符数组的输出
C语言中可以在printf函数中使用%s格式控制符的方式,打印字符数组的字符串。C++语言可以利用cout函数直接打印字符数组的字符串内容。当然也可以通过循环的方式逐个字符打印字符串的内容。下面是三种输出方式的代码演示:
cpp
//⽅法1
#include <iostream>
#include <cstdio>
using namespace std;
int main()
{
char a[] = "hello world";
cout << a << endl;
printf("%s\n", a);
return 0;
}
cpp
//⽅法2
//单个字符的打印,直到\0字符,\0不打印
#include <iostream>
using namespace std;
int main()
{
char a[] = "hello world";
int i = 0;
while (a[i] != '\0')
{
cout << a[i];
i++;
}
cout << endl;
return 0;
}
cpp
//⽅法3
//单个字符打印,根据字符串⻓度来逐个打印
//strlen可以求出字符串的⻓度,不包含\0
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char a[] = "hello world";
int i = 0;
for (i = 0; i < strlen(a); i++)
{
cout << a[i];
}
cout << endl;
return 0;
}4.strcpy和strcat函数
(1)strcpy函数
使用字符数组可以存放字符串,但是字符数组能否直接进行赋值呢?比如:
cpp
char arr1[] = "abcdef";
char arr2[20] = {0};
arr2 = arr1;//这样这节赋值可以吗? 像上述代码的写法是不行的,不可以达到赋值的效果。需要字符串的赋值需要strcpy函数来完成。下面是该函数的介绍:
cpp
char * strcpy ( char * destination, const char * source );
//destination - 是⽬标空间的地址
//source - 是源头空间的地址
//需要的头⽂件 <cstring>
- destination:指的是目标字符串的地址
- source:指的是被拷贝的字符串的地址
下面是函数使用的代码演示:
cpp
#include <cstdio>
#include <cstring>
int main()
{
char arr1[] = "abcdef";
char arr2[20] = {0};
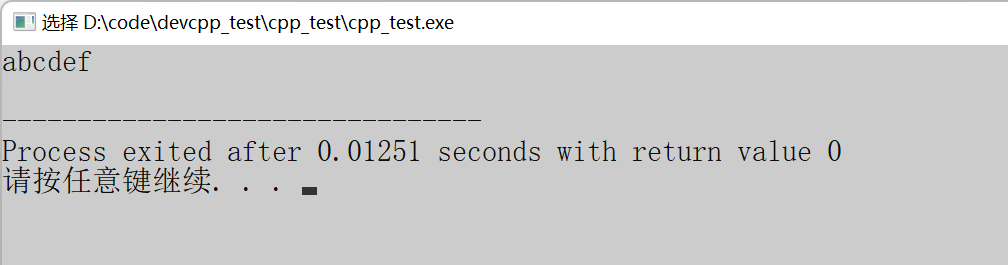
strcpy(arr2, arr1);
printf("%s\n", arr2);
return 0;
}
(2)strcat函数
有时候需要在一个字符串的末尾再加上一个字符串,该如何追加呢?比如:
cpp
char arr1[20] = "hello ";
char arr2[] = "world";
arr1 += arr2;//这样也是不⾏的 像上面的写法,显然不能达到目标。但是C/C++语言有strcat函数可以完成这个操作,下面是函数的具体介绍:
cpp
char * strcat ( char * destination, const char * source );
//destination - 是⽬标空间的地址
//source - 是源头空间的地址
//需要的头⽂件 <cstring>
- destination:指的是目标字符串的地址
- source:指的是被追加的字符串地址
下面是该函数实现追加字符串的具体代码演示:
cpp
#include <cstdio>
#include <cstring>
int main()
{
char arr1[20] = "hello ";
char arr2[] = "world";
strcat(arr1, arr2);
printf("%s\n", arr1);
return 0;
}