JVM 垃圾回收机制(GC)
文章目录
- [JVM 垃圾回收机制(GC)](#JVM 垃圾回收机制(GC))
- 观前须知
- [1. 第二步:释放垃圾](#1. 第二步:释放垃圾)
-
- [1.1 标记-清除](#1.1 标记-清除)
- [1.2 复制算法](#1.2 复制算法)
-
- [缺点 & 总结:](#缺点 & 总结:)
- [1.3 标记-整理](#1.3 标记-整理)
-
- [缺点 & 总结](#缺点 & 总结)
- [1.4 分代回收(重点)](#1.4 分代回收(重点))
-
- [新生代 与 老年代](#新生代 与 老年代)
- [GC 根据对象年龄,做出调整](#GC 根据对象年龄,做出调整)
- [新生代:伊甸区 & 幸存区](#新生代:伊甸区 & 幸存区)
- 分代回收的思路(:star:重点)
- [疑问:为什么新生代区用 复制算法,老年代区用 标记-整理?](#疑问:为什么新生代区用 复制算法,老年代区用 标记-整理?)
- [举例理解 分代回收 机制](#举例理解 分代回收 机制)
- 特殊情况
- 分代回收总结(★)
- [1.5 总结](#1.5 总结)
观前须知
如果你是第一次点击这篇博客的,你需要先看我的这篇博客:
JVM 垃圾回收机制(GC),再过来看这篇博客。
垃圾回收机制(GC),如今并不是 Java 才有的,很多语言都有这个机制。
但是,GC 的确是 Java 带头引起了潮流。
垃圾回收机制(GC),至于它的叫法,我有时会使用 GC 来称呼,有时用 垃圾回收 来称呼,有时候就是全称了,你知道它们都表示 垃圾回收机制 就可以了。
下面的博客,我们会介绍 垃圾回收机制 -- 释放垃圾 的原理。
1. 第二步:释放垃圾
垃圾回收的工作过程,分为两个大步骤:
- 找到 垃圾(不再使用的对象)
- 释放 垃圾(对应的内存释放掉)
我们有两种方案,来找到垃圾:
- 引入计数(Python,PHP 采用的方案)
- 可达性分析(Java 采用了这个方案,重点了解)
目前,垃圾找到了,那么我们该怎么释放这些垃圾呢?
释放垃圾,我们有四种方案:
- 标记-清除
- 复制算法
- 标记-整理
- 分代回收 (Java 采用的方案,重点了解)
接下来,我们分别进行介绍。
1.1 标记-清除
标记-清除 :把垃圾对象的内存 ,直接进行释放。
这样的做法,会产生一个问题:内存碎片
缺点:内存碎片
假如,我们有这么一块内存:

当前,2,4,6,8 存储的对象,是垃圾,需要回收。
采用 标记-清除 的做法,释放垃圾之后,这块内存就长这样了:
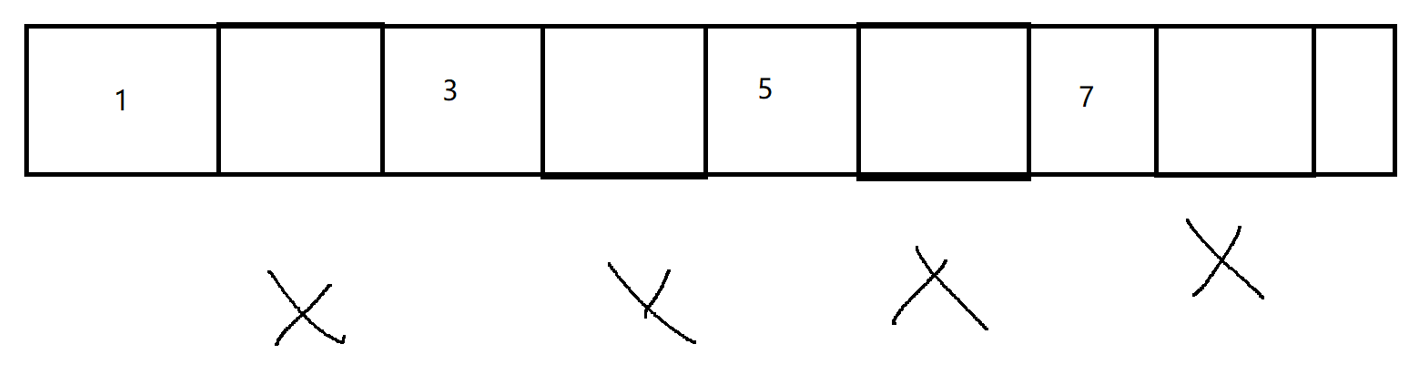
虽然,垃圾被回收了,内存空间空闲出来了,但是,这些空间是不连续的 !!!
这样的内存空间,就是一个典型的内存碎片问题。
我们申请内存,都是申请连续的内存空间(全是空闲的) 。
比如申请 1M 的内存空间,必须是连续的,不能是多个部分拼接到一起。
如果内存碎片非常多,虽然总的空闲空间很大,但是但凡想申请一个稍微大一点的内存,都会失败。
总的空闲空间是 4G ,此时,内存碎片非常多 ,就会使得申请 1G 空间都可能失败。
就比如:
你想买一台 IPhone17 pro max,你总的钱是够的,但是,你的钱是 微信 + 支付宝 + 多张银行卡 凑够的钱。
此时,你想一次性支付,购买 IPhone17 pro max,是不行的。
这种情况,仅和上述 内存碎片 的场景,进行关联举例。
当然,现实生活中,你可以通过很多种方式解决,借钱啊,分期付款啊,都行。
总结:
标记-清除,直接释放垃圾 ,简单粗暴,但是会产生 内存碎片 的问题。
1.2 复制算法
复制算法 的思路:
申请的内存空间,存储对象的时候,只会使用一半 。
需要进行垃圾释放 时,把不是垃圾的对象,拷贝(复制)到另一半内存空间 ,然后把这一侧的空间,全部释放掉。
用图片来演示一下:
申请的内存空间,存储对象

经过一轮 GC,发现2,4,6 存储的对象是垃圾,需要释放
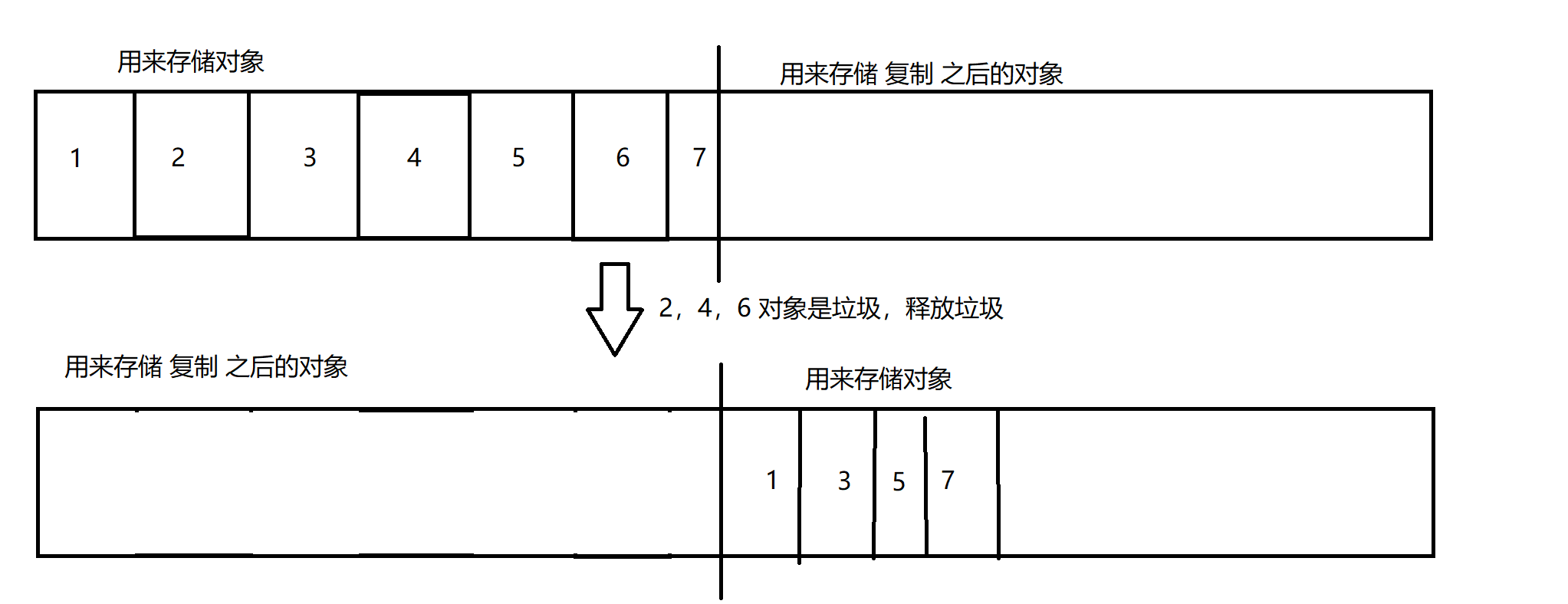
在右边的内存空间,存放新的对象
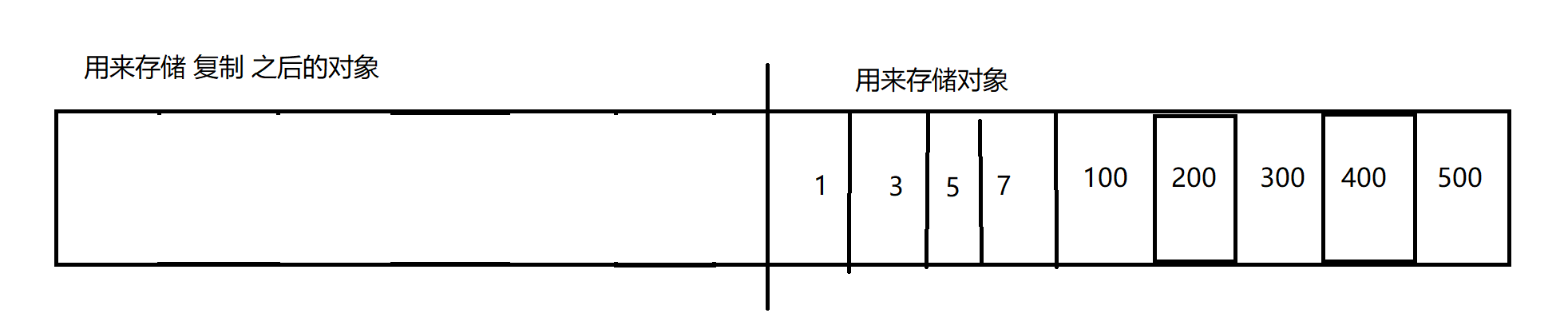
又经过一轮 GC,发现 100,300,500 存储的对象是垃圾,需要释放
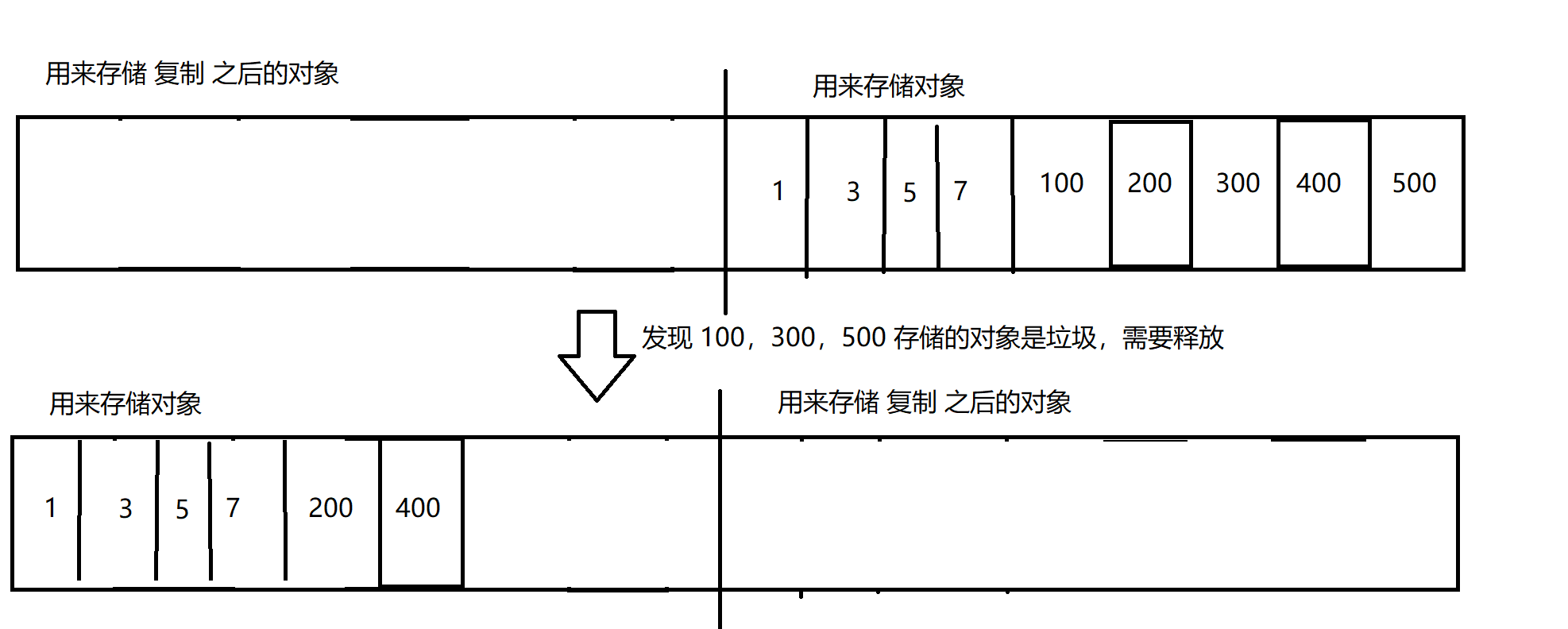
之后,就是按照这样的方式,释放垃圾。
此时,就可以确保,空闲的内存,不会出现 内存碎片 的问题了。
缺点 & 总结:
复制算法,虽然解决了 内存碎片 的问题,但是,这种释放垃圾的方式,它又有新的缺点。
缺点:
- 内存的空间利用率,是很低的 (浪费一半的内存空间,2G 变 1G)
- 一旦不是垃圾的对象(还需要使用的对象)很多,复制的成本,就会很高 (尤其是一个内存空间占用很大的对象)
1.3 标记-整理
标记-整理 的思路:
发现垃圾后,把不是垃圾的对象(还需要使用的对象),统统往前移动 。
移动完成,把剩余的对象,全部删除。
我们仍然以图片的方式,进行演示:
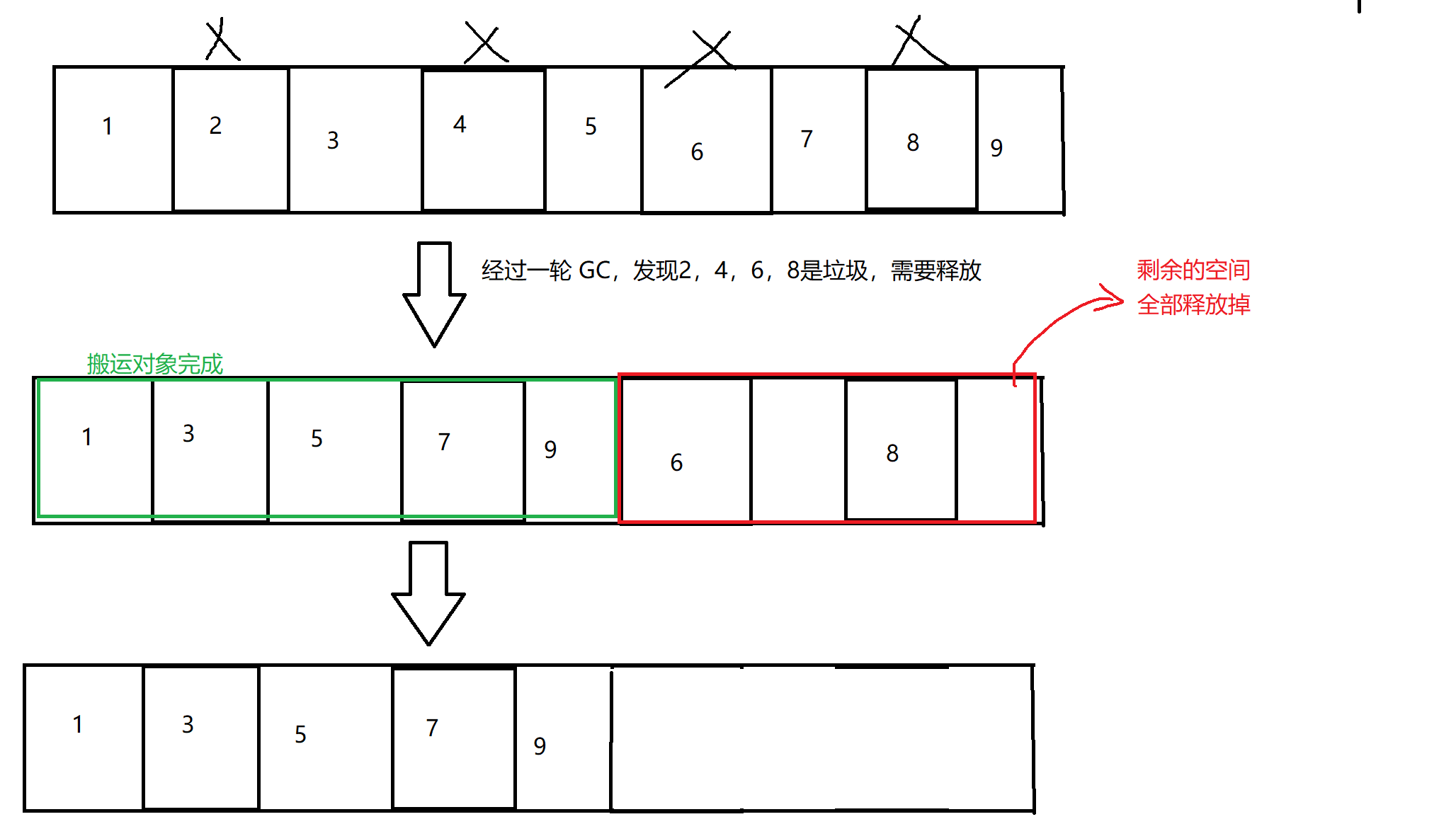
这个搬运过程,类似于数据结构中的 顺序表 的数据搬运,后面的数据,覆盖掉前面的数据。
缺点 & 总结
标记-整理 ,它的优点 是:解决内存碎片问题 & 保证了内存的利用率
但是,它仍然是有缺点的:
内存搬运数据的操作,开销是挺大的 。
一旦不是垃圾的对象(还需要使用的对象)很多,搬运的成本,就很高,尤其是这样的对象,是一个很大的对象。
所以,标记-整理,只是解决了 内存空间利用率 的问题 ,没有解决复制成本的问题。
1.4 分代回收(重点)
上述三种方案,是释放垃圾的基本思想 ,那么,分代回收,是结合了 2,3 方案,扬长避短。
分代 中的 "代" ,指的是 "对象的年龄" ,这里的年龄,指的是 GC的轮次。
某一个对象,经历一轮 GC 的可达性分析之后,是 "可达" 的,不是垃圾 ,此时,这个对象的年龄就会 + 1 。
一个对象的年龄,初始就是 0;
新生代 与 老年代
分代回收,根据对象年龄的大小,把 堆 上的内存空间,分为两个部分:
- 新生代区 (年龄小的对象放这里)
- 老年代区 (年龄大的对象 放这里)

因为不同年龄的对象,特点是不同的 :
如果某一个对象的年龄,比较大 ,说明,这个对象经过多轮 GC 的可达性分析之后,仍然在使用 ,之后,大概率还是会继续存在 的。
如果某一个对象的年龄,比较小 ,说明,这个对象有可能快速挂掉。
上述特点分析,我们可以举一个生活中的例子:
老虎,一般是独居动物,狮子,是群居动物。
老虎幼仔 刚生出来的时候,是需要老虎妈妈亲自带大的,幼仔一般是很脆弱的,无法独立觅食,容易饿死。(对象年龄小)
一个成年老虎 ,能够一直存活 ,说明它是身强体壮,猎食能力优秀的,之后,它还是继续存活。(对象年龄大)
再举一个例子:
C语言,已经存在 50年 ,但是,目前仍是计算机入门语言的首选 ,说明,C语言是有它的特点之处的。(对象年龄大)
并且,C语言,未来 50年,还会继续持续存在,仍是计算机入门语言的首选 。
和 C语言 同一个时期诞生出来的语言,都死的差不多了。(对象年龄小)
总结一句话就是 :一个东西,要死早死了 ,之所以一直没死 ,肯定是这个东西,有特殊之后,有用处,之后,大概率还是会继续存在的。
经验规律总结:
新生代区 :存放的是 新生代的对象(对象年龄小 ),可能很快速就挂掉了
老年代区 :存放的是 老年代的对象(对象年龄大 ),可能会持续存在
GC 根据对象年龄,做出调整
针对不同年龄的对象,采取不同的策略。
根据上述经验规律,GC 就会做出调整:
老年代区的对象,GC 的频次会降低
新生代区的对象,GC 的频次会升高
老年代区的对象,之后会持续存在 ,就没必要对它进行过多的 GC可达性分析 了,可以省一点资源 。
新生代区的对象 ,可能会快速挂掉 ,就需要对他们,采取更高频次的 GC可达性分析。
新生代:伊甸区 & 幸存区
新生代区域 ,根据年龄,又做出了不同的划分,分为:
- 伊甸区(1块大区域)
- 幸存区(2块相同的小区域)
具体的分块是这样的:
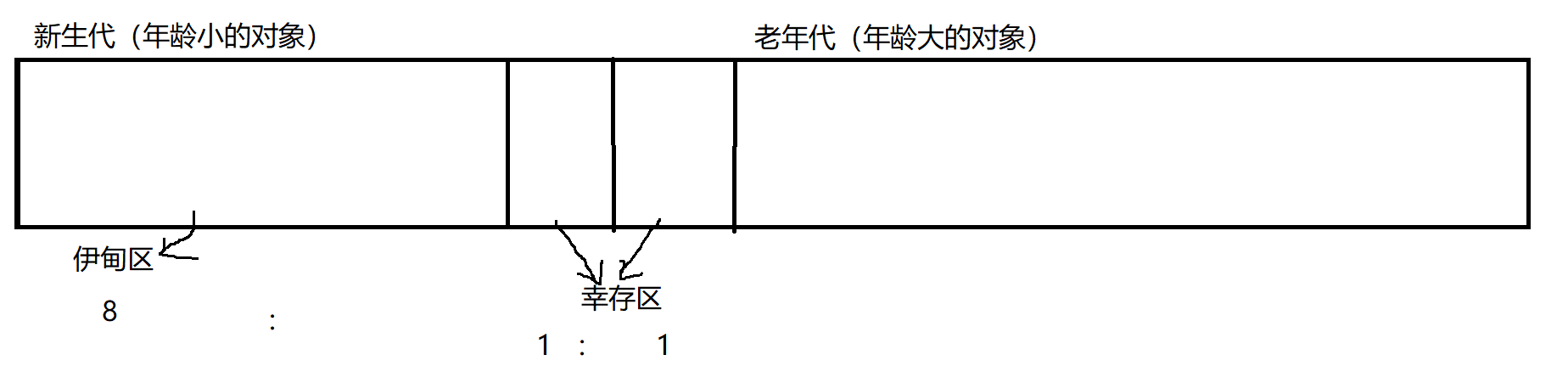
伊甸区和幸存区的内存占比为:8 : 1 : 1
至于,为什么名字是这样命名的,主要是来自于 《圣经》。
你们不用了解,记住这两块区域叫什么名字就行。
分代回收的思路(⭐️重点)
伊甸区:存放新创建的对象
绝大部分的 新对象,都活不过第一轮的 GC。
可能 10个新对象,第一轮 GC 之后,只剩下一个了(具体代码,具体分析,这里随口一说)。
分代回收的具体思路:
-
新对象,撑过第一轮 GC 之后,就会使用 复制算法,复制到 幸存区。(伊甸区 => 幸存区:复制算法)
所以,幸存区的空间 比 伊甸区的空间 小很多。
伊甸区 => 幸存区 使用 复制算法 ,这里的复制的对象的规模,是很少的,开销是比较小的。
-
幸存区中的对象 ,也要经历 GC 的扫描 (即可达性分析),每一轮,也会消灭一大部分的对象,剩余的对象再次通过 复制算法,复制到 另一个幸存区。
由于 幸存区 占用的空间,是比较少 的,虽然这里存放的对象,也比较少 ,但是,这样的空间利用率,还是可以接受的。
幸存区中的对象 会经过,多次 GC扫描 ,释放垃圾时,使用 复制算法,在两个幸存区中不断移动。
-
幸存区中的某一个对象 ,经历了多次 GC扫描 之后,多次复制,都存活下来 了,此时,这个对象的年龄就大了,就会使用 复制算法 复制到 老年代区
-
处于 老年代区 的对象 ,GC 扫描 后,发现垃圾,会使用 标记-整理 的方式,释放垃圾。
老年代区的对象,数量本身就是很少的 ,采用 标记-整理 的方式,释放垃圾,搬运对象的成本,就小了很多。
疑问:为什么新生代区用 复制算法,老年代区用 标记-整理?
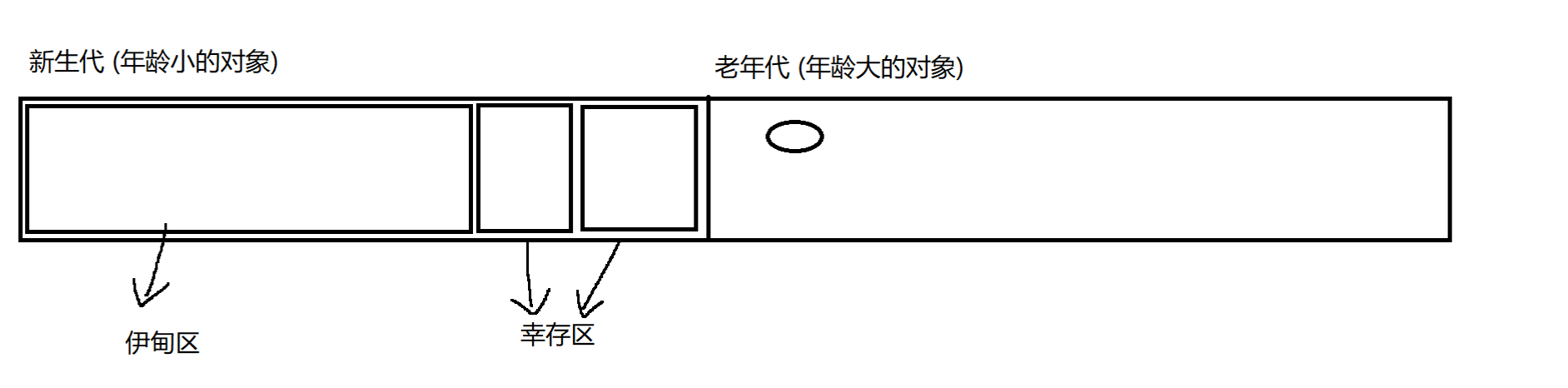
我们重新看一下,堆 上的内存空间 ,是被分为这样的:
复制算法,我们是将内存空间划为两份:
一半用来存对象 ,一半用来存储 复制 之后的对象 。
符合新生代区中,伊甸区和幸存区的划分方式。
标记-整理 ,我们仅使用一块内存空间 :
符合老年代区 中,仅划分 一块的内存区域 的方式。
举例理解 分代回收 机制
分代回收 是将 复制算法和标记-整理 两种基本的垃圾释放思想,结合到一起 ,大家可能不好直接就理解了,但是,我们举一个生活中的例子:
面试进公司,公司年度考核
伊甸区:公司会收到大量的简历(新对象)
绝大部分会被筛选掉,只有少数能够进入到笔试面试环节
幸存区:进入笔试面试
笔试:基本是 一轮
面试:基本都是 多轮 面试,少则 2-3 轮,多则 6-7 轮。
如果经过多轮面试,你都通过了,拿到 offer,就正式进入到老年代区,成为正式员工
老年代区 :进入公司,半年一度的绩效考核,一年一度的年度考核(周期很长)
根据考核结果,进行末尾淘汰。
特殊情况
分代回收也有一种很特殊的情况 :如果某个对象特别大,会直接进入老年代区,不会进入伊甸区和幸存区 。
原因是:复制成本高
这就相当于,有人可以不同面试,直接进公司。
比如:这个公司,是他爸爸开的。
所以,这个特殊情况,出现的概率,很小很小。
分代回收总结(★)
我们画一张草图,总结一下,分代回收的工作方式:

对象会在伊甸区,幸存区 中,经历多次 GC 扫描,垃圾的释放,使用 复制算法(复制成本小)
老年代区的对象 ,GC扫描的频次,会少很多 ,垃圾的释放,使用 标记-整理 (搬运对象成本小)
新生代区 中的对象,大多数的对象会快速消亡 ,使得每次 复制的对象少,复制的开销少,可控 。
老年代区 中的对象 ,数量很少 且 大部分的生命周期较长,使得每次需要搬运的对象少,搬运的开销少,可控。
1.5 总结
释放垃圾,我们有四种方案:
- 标记-清除 :简单粗暴,直接释放内存空间 ,但是会产生 内存碎片 的问题。
- 复制算法 :内存的空间利用率很低,复制的成本不可控
- 标记-整理 :内存搬运数据的操作,开销不可控
- 分代回收 :把 复制算法和标记-整理 两种基本的垃圾释放思想,结合到一起 ,扬长避短,使得 复制的成本和搬运对象的成本 都是可控的
分代回收,是 JVM 释放对象,采用的综合性策略
看到这里,你可以点击这篇博客:JVM 垃圾回收机制(GC),回去看完关于 JVM垃圾回收机制 的介绍。
最后,如果这篇博客能帮到你的,请你点点赞,有写错了,写的不好的,欢迎评论指出,谢谢!