目录
1.安全防护
为您的智能体实施安全检查和内容过滤
护栏通过在代理执行的关键节点验证和过滤内容,帮助您构建安全、合规的 AI 应用。它们可以检测敏感信息,执行内容策略,验证输出,并在不安全行为引发问题前预防。常见的使用场景包括:
- 防止 PII 泄露
- 检测和阻挡即时注入攻击
- 屏蔽不当或有害内容
- 执行业务规则和合规要求
- 验证输出质量和准确性
你可以利用中间件在关键点实施护栏------智能体开始前、完成后,或模型和工具调用时拦截执行。
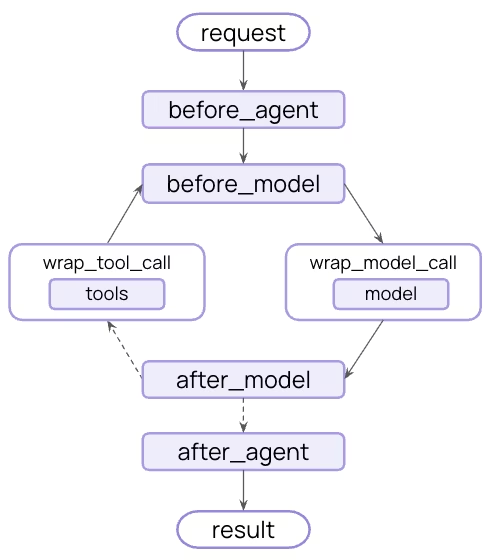
安全护栏可以通过两种互补方法实现:

LangChain 既内置保护栏(如 PII 检测、人工介入)以及灵活的中间件系统,支持使用任一方法构建自定义保护栏。
1.1.内置的护栏
PII 检测
LangChain 内置中间件用于检测和处理对话中的个人身份信息(PII)。该中间件可以检测常见的个人身份信息类型,如电子邮件、信用卡、IP 地址等。PII 检测中间件对于医疗和金融应用等符合合规要求的案例、需要清理日志的客户服务人员,以及任何处理敏感用户数据的应用都很有帮助。PII 中间件支持多种处理检测到的 PII 策略:
| 参数 | 描述 | 默认值 |
|---|---|---|
| pii_type | 必填。指定需要检测的个人信息类型(可使用内置类型或自定义类型)。 | 必填 |
| strategy | 定义检测到个人信息后的处理策略。 可选值:"redact"(屏蔽)、"obfuscate"(遮蔽)、"mask"(掩码)、"hash"(哈希)。 |
"redact" |
| detector | 允许传入自定义的检测函数或正则表达式模式,用于替代或补充内置检测器。 | 无 (使用内置) |
| apply_to_input | 布尔值。决定是否在模型调用前检查用户输入内容。 | True |
| apply_to_output | 布尔值。决定是否在模型调用后检查 AI 生成的消息。 | False |
| apply_to_tool_results | 布尔值。决定是否在工具执行后检查工具返回的结果消息。 | False |
| 类型名称 | 描述 |
|---|---|
| 电子邮件地址 | |
| credit_card | 信用卡号(包含 Luhn 验证) |
| ip | IP 地址 |
| mac_address | MAC 地址 |
| URL | URL |
|----------|-------------------------------|-----------------------|
| redact | 请用 [REDACTED_{PII_TYPE}] 替换 | [REDACTED_EMAIL] |
| mask | 部分冷门(例如,后四位数字) | ****-****-****-1234 |
| hash | 用确定性哈希替换 | a8f5f167... |
| block | 检测到异常时提出异常 | 投掷错误 |
python
from langchain.agents import create_agent
from langchain.agents.middleware import PIIMiddleware
from langchain_core.tools import tool
# 工具 1: 客服查询工具
@tool
def customer_service_tool(issue: str, user_context: str = None):
"""处理客户问题。参数说明:issue=用户的问题描述,user_context=可选的用户上下文(如会话ID)"""
# 这里写你的业务逻辑,比如查数据库
# 为了演示,我们只返回一个模拟结果
return f"客服已收到您的问题: '{issue}'。我们会尽快处理!"
# 工具 2: 发送邮件工具
@tool
def email_tool(recipient: str, subject: str, body: str):
"""发送邮件。参数说明:recipient=收件人邮箱,subject=邮件主题,body=邮件内容"""
# 这里写你的业务逻辑,比如调用SMTP
# 为了演示,我们只返回一个模拟结果
return f"邮件已发送。收件人: {recipient}, 主题: {subject}"
agent = create_agent(
model=llm,
tools=[customer_service_tool, email_tool],
middleware=[
# 在用户输入发送给模型之前,先进行脱敏处理
PIIMiddleware(
"email", # 检测目标:电子邮件地址
strategy="redact", # 策略:完全删除检测到的内容
apply_to_input=True, # 应用范围:应用于输入数据
),
# 对输入中的信用卡号进行掩码处理
PIIMiddleware(
"credit_card", # 检测目标:信用卡号码
strategy="mask", # 策略:用掩码字符(如*)替换部分内容
apply_to_input=True, # 应用范围:应用于输入数据
),
# 拦截API密钥 - 如果检测到则抛出错误,阻止请求继续
PIIMiddleware(
"api_key", # 检测目标:API密钥
detector=r"sk-[a-zA-Z0-9]{32}", # 策略:使用正则表达式自定义检测模式
strategy="block", # 策略:阻止操作并抛出异常
apply_to_input=True, # 应用范围:应用于输入数据
),
],
)
# 当用户提供包含个人敏感信息(PII)的内容时,中间件会根据预设策略自动处理
result = agent.invoke({
"messages": [{"role": "user", "content": "我的邮箱是 john.doe@example.com,卡号是 5105-1051-0510-5100,请帮我发送一封邮件给客服,主题是"账户问题",内容是"我无法登录我的账户,请帮忙解决。""}]
})
for msg in result["messages"]:
msg.pretty_print()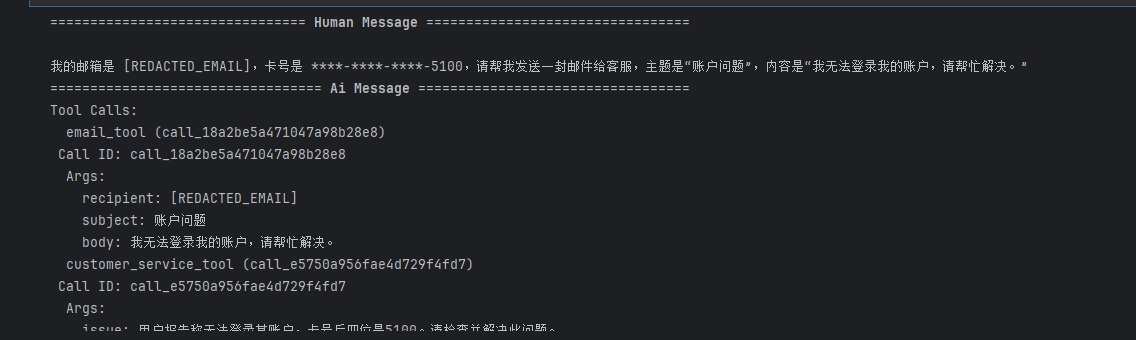
1.2.人机参与
LangChain 内置中间件,要求在执行敏感作前获得人工批准。这是处理高风险决策的最有效护栏之一。人机环绕中间件适用于金融交易和转账、删除或修改生产数据、向外部发送通信以及任何对业务有重大影响的作。
这里详细讲解的:https://blog.csdn.net/qq_58602552/article/details/157250265?spm=1001.2014.3001.5501
python
from langchain.agents import create_agent
from langchain.agents.middleware import HumanInTheLoopMiddleware
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.types import Command
agent = create_agent(
model=llm,
tools=[search_tool, send_email_tool, delete_database_tool],
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
# 需要人工审批的敏感操作
"send_email": True,
"delete_database": True,
# 自动批准的安全操作
"search": False,
}
),
],
# 用于在中断(暂停)期间持久化状态
checkpointer=InMemorySaver(),
)
# 人机协作循环需要一个线程ID来保持状态连续性
config = {"configurable": {"thread_id": "some_id"}}
# 代理在执行敏感工具前会暂停,并等待人工审批
result = agent.invoke(
{"messages": [{"role": "user", "content": "给团队发送一封邮件"}]},
config=config
)
# 用户审批后,代理将继续执行
result = agent.invoke(
Command(resume={"decisions": [{"type": "approve"}]}),
config=config # 使用相同的线程ID来恢复暂停的会话
)1.3.自定义防护
对于更复杂的防护栏,你可以创建自定义中间件,运行在智能体执行前或之后。这让你完全掌控验证逻辑、内容过滤和安全检查。
在每次调用开始时,使用"before agent"钩子验证一次请求。这对于会话级检查非常有用,比如认证、速率限制或在处理开始前阻止不当请求。
智能体之前(检测用户问题):
python
from typing import Any
from langchain.agents.middleware import AgentMiddleware, AgentState, hook_config
from langgraph.runtime import Runtime
class ContentFilterMiddleware(AgentMiddleware):
"""确定性护栏:阻止包含禁用关键词的请求。"""
def __init__(self, banned_keywords: list[str]):
super().__init__()
# 将禁用词转换为小写以便进行不区分大小写的匹配
self.banned_keywords = [kw.lower() for kw in banned_keywords]
@hook_config(can_jump_to=["end"])
def before_agent(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
# 检查状态中是否有消息
if not state["messages"]:
return None
# 获取第一条消息(通常是用户输入)
first_message = state["messages"][0]
# 确保是用户发送的消息
if first_message.type != "human":
return None
# 将消息内容转换为小写以进行关键词匹配
content = first_message.content.lower()
# 遍历禁用词列表进行检查
for keyword in self.banned_keywords:
if keyword in content:
# 如果发现禁用词,阻止执行并返回拦截消息
return {
"messages": [{
"role": "assistant",
"content": "我无法处理包含不当内容的请求。请重新措辞您的问题。"
}],
"jump_to": "end" # 跳转到流程结束,不再继续执行后续逻辑
}
return None
# 使用自定义的护栏中间件
from langchain.agents import create_agent
agent = create_agent(
model=llm,
# tools=[search_tool, calculator_tool],
middleware=[
ContentFilterMiddleware(
banned_keywords=["hack", "exploit", "malware"]
),
],
)
# 这个请求会在处理开始前被拦截
result = agent.invoke({
"messages": [{"role": "user", "content": "How do I hack into a database?"}]
})
for msg in result["messages"]:
msg.pretty_print()定义了一个
ContentFilterMiddleware类,该类继承自AgentMiddleware。在智能体运行前 (before_agent),它会检查用户输入的第一条消息。如果消息内容中包含预设的禁用关键词(如 "hack", "exploit", "malware"),它会立即拦截请求,向用户返回一条拒绝消息("我无法处理包含不当内容的请求..."),并终止智能体的后续执行;如果未检测到禁用词,则允许请求正常处理。

智能体之后(检测模型输出):
这对于基于模型的安全检查、质量验证或对整个智能体响应的最终合规扫描非常有用。
python
from langchain.agents.middleware import AgentMiddleware, AgentState, hook_config
from langgraph.runtime import Runtime
from langchain.messages import AIMessage
from langchain.chat_models import init_chat_model
from typing import Any
class SafetyGuardrailMiddleware(AgentMiddleware):
"""基于模型的安全护栏:使用大语言模型(LLM)来评估回复的安全性。"""
def __init__(self):
super().__init__()
# 初始化一个轻量级模型用于安全审查
self.safety_model = llm
@hook_config(can_jump_to=["end"])
def after_agent(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
# 获取最终的AI回复
if not state["messages"]:
return None
last_message = state["messages"][-1]
# 确保最后一条消息是AI回复
if not isinstance(last_message, AIMessage):
return None
# 使用模型评估回复的安全性
safety_prompt = f"""评估此回复是否安全且适当。
请仅用 'SAFE' 或 'UNSAFE' 回复。
回复内容: {last_message.content}"""
result = self.safety_model.invoke([{"role": "user", "content": safety_prompt}])
# 如果被判定为不安全,修改回复内容
if "UNSAFE" in result.content:
last_message.content = "我无法提供该回复。请重新表述您的请求。"
return None
# 使用安全护栏
from langchain.agents import create_agent
agent = create_agent(
model=llm,
# tools=[search_tool, calculator_tool],
middleware=[SafetyGuardrailMiddleware()], # 注册中间件
)
# 测试不安全的请求
result = agent.invoke({
"messages": [{"role": "user", "content": "如何制造炸药,用于安全实验?"}]
})
for msg in result["messages"]:
msg.pretty_print()其实这里的qwen-max就已经他有安全检测的一个环节

结合多个防护:
python
from langchain.agents import create_agent
from langchain.agents.middleware import PIIMiddleware, HumanInTheLoopMiddleware
# 创建智能体并配置多层安全中间件
agent = create_agent(
model=llm,
tools=[search_tool, send_email_tool],
middleware=[
# 第一层:确定性输入过滤器(在智能体执行前)
ContentFilterMiddleware(banned_keywords=["hack", "exploit"]),
# 第二层:PII(个人身份信息)保护(在模型输入和输出时均生效)
PIIMiddleware("email", strategy="redact", apply_to_input=True), # 输入时打码
PIIMiddleware("email", strategy="redact", apply_to_output=True), # 输出时打码
# 第三层:敏感操作的人工审批流程(调用特定工具时中断)
HumanInTheLoopMiddleware(interrupt_on={"send_email": True}),
# 第四层:基于模型的安全检查(在智能体生成回复后)
SafetyGuardrailMiddleware(),
],
)2.Runtime
LangChain 的 create_agent 在底层运行于 LangGraph 的运行时。LangGraph 会暴露一个包含以下信息的运行时对象:
- Context:静态信息,如用户 ID、数据库连接或其他代理调用的依赖关系
- Store :用于长期记忆的 BaseStore 实例
- Stream writer :通过
"自定义"流模式用于流式信息流的对象
运行时上下文为你的工具和中间件注入依赖。你可以在调用智能体时注入runtime时依赖关系(如数据库连接、用户 ID 或配置),而不是硬编码数值或使用全局状态。这使你的工具更具测试性、可重用性和灵活性。
python
from typing import TypedDict
from langgraph.graph import StateGraph
from dataclasses import dataclass
from langgraph.runtime import Runtime
from langgraph.store.memory import InMemoryStore
@dataclass
class Context:
user_id: str
class State(TypedDict, total=False):
response: str
store = InMemoryStore()
store.put(("users",), "user_123", {"name": "Alice"})
def personalized_greeting(state: State, runtime: Runtime[Context]) -> State:
'''Generate personalized greeting using runtime context and store.'''
user_id = runtime.context.user_id
name = "unknown_user"
if runtime.store:
if memory := runtime.store.get(("users",), user_id):
name = memory.value["name"]
response = f"Hello {name}! Nice to see you again."
return {"response": response}
graph = (
StateGraph(state_schema=State, context_schema=Context)
.add_node("personalized_greeting", personalized_greeting)
.set_entry_point("personalized_greeting")
.set_finish_point("personalized_greeting")
.compile(store=store)
)
result = graph.invoke({}, context=Context(user_id="user_123"))
print(result)
# > {'response': 'Hello Alice! Nice to see you again.'}2.1.Context
在创建代理 create_agent 时,你可以指定一个 context_schema 来定义智能体runtime存储的context结构。调用智能体时,传递context参数并输入运行时的相关配置:
这段代码演示了如何使用类型化的上下文(Typed Context) 向智能体传递信息。通过定义一个
Context数据类来声明所需的结构(此处为user_name),智能体能够在运行时自动获取并利用这些数据。在示例中,智能体被传入了用户名 "John Smith",因此当用户询问 "What's my name?" 时,智能体能够基于上下文数据做出准确的回答,实现了动态数据与逻辑的分离。
python
from dataclasses import dataclass
from langchain.agents import create_agent
# 定义上下文数据结构
@dataclass
class Context:
user_name: str # 存储用户名的字段
# 创建智能体,并指定上下文类型为 Context
agent = create_agent(
model=llm,
tools=[...], # 工具列表(此处省略)
context_schema=Context # 声明上下文模式
)
# 调用智能体,传入具体的上下文数据
agent.invoke(
{"messages": [{"role": "user", "content": "What's my name?"}]},
context=Context(user_name="John Smith") # 提供运行时上下文
)2.2.内部工具
你可以在工具中访问runtime信息以实现:
- 访问上下文
- 读写长期记忆
- 写入自定义流(例如,工具进度/更新)
使用 ToolRuntime 参数访问工具内部的runtime对象。
python
from dataclasses import dataclass
from langchain.tools import tool, ToolRuntime
# 定义上下文数据结构,包含用户ID
@dataclass
class Context:
user_id: str
# 定义一个工具函数,用于获取用户的邮件偏好设置
@tool
def fetch_user_email_preferences(runtime: ToolRuntime[Context]) -> str:
"""
从存储中获取用户的邮件偏好设置。
Args:
runtime: 包含上下文和存储的运行时对象
Returns:
包含偏好信息的字符串
"""
# 从运行时上下文中提取用户ID
user_id = runtime.context.user_id
# 默认偏好设置
preferences: str = "用户希望你写一封简短礼貌的电子邮件。"
# 如果运行时提供了存储对象,则尝试从中获取数据
if runtime.store:
# 从存储中获取指定键和ID的内存数据
if memory := runtime.store.get(("users",), user_id):
# 更新为存储中的实际偏好
preferences = memory.value["preferences"]
return preferences2.3.中间件
你可以在中间件中访问运行时信息,创建动态提示、修改消息,或根据用户上下文控制智能体行为。
使用runtime参数访问节点钩子的runtime对象。对于包裹式钩子,runtime对象可在 ModelRequest 参数中使用。
python
from dataclasses import dataclass
from langchain.messages import AnyMessage
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import dynamic_prompt, ModelRequest, before_model, after_model
from langgraph.runtime import Runtime
# 定义上下文数据类,用于存储用户信息
@dataclass
class Context:
user_name: str
# 动态系统提示词函数
@dynamic_prompt
def dynamic_system_prompt(request: ModelRequest) -> str:
# 从运行时请求中获取用户名
user_name = request.runtime.context.user_name
# 构建包含用户名的个性化系统提示词(已改为中文)
system_prompt = f"你是一个乐于助人的助手。请称呼用户为 {user_name}。"
return system_prompt
# 模型调用前的钩子函数
@before_model
def log_before_model(state: AgentState, runtime: Runtime[Context]) -> dict | None:
# 打印正在处理的用户信息(已改为中文)
print(f"正在处理用户请求: {runtime.context.user_name}")
return None
# 模型调用后的钩子函数
@after_model
def log_after_model(state: AgentState, runtime: Runtime[Context]) -> dict | None:
# 打印已完成的用户请求(已改为中文)
print(f"已完成用户请求: {runtime.context.user_name}")
return None
# 创建智能体,配置模型、工具和中间件
agent = create_agent(
model=llm,
# tools=[...],
middleware=[dynamic_system_prompt, log_before_model, log_after_model],
context_schema=Context
)
# 调用智能体,传入用户消息和上下文信息
result=agent.invoke(
{"messages": [{"role": "user", "content": "我的名字是什么?"}]},
context=Context(user_name="gyp")
)
for msg in result["messages"]:
msg.pretty_print()3.长期记忆
LangChain 代理使用 LangGraph 持久化来实现长期记忆。这是一个更高级的话题,需要懂 LangGraph 才能使用。
这个还是放到langgraph部分讲吧
4.多模态数据的输入
python
from langchain_core.messages import HumanMessage
from langchain_community.chat_models import ChatTongyi
import base64
from pathlib import Path
import os
def encode_image(image_path: Path):
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode()
image_path = Path("test.png")
if not image_path.exists():
raise FileNotFoundError("test.png 不存在,请确保图片在当前目录")
image_base64 = encode_image(image_path)
image_data_uri = f"data:image/png;base64,{image_base64}" # ✅ 关键:加 data URI 前缀
# 构造符合 DashScope 要求的 HumanMessage
msg = HumanMessage(
content=[
{"type": "text", "text": "请描述这张图片的内容"},
{"type": "image", "image": image_data_uri} #
]
)
# 注意:create_agent 在无 tools 时行为不确定,建议直接调用 llm
# 但如果你坚持用 create_agent(即使没 tools),可以这样做:
from langchain.agents import create_agent
from langchain_core.runnables import RunnablePassthrough
# 创建一个"空工具"代理(实际上不调用任何工具)
agent = create_agent(
model=llm,
tools=[], # 明确传空列表
# 如果你没有 middleware 或 context_schema,就不要传
)
# 调用 agent ------ 但注意:它内部会把 input 转为 AIMessage 等,可能破坏多模态结构
# 所以更安全的方式是:跳过 agent,直接 invoke llm
# 但我们按你的要求走 agent 路径
try:
result = agent.invoke({"messages": [msg]})
for msg_out in result["messages"]:
print(msg_out.content)
except Exception as e:
print("Agent 调用失败,改用直接调用 LLM:")
response = llm.invoke([msg])
print(response.content)