【LangGraph】新篇章:LangGraph 持久化的三大应用能力*重点*
- 前言
-
- 一、什么是时间旅行?
- 二、为什么需要时间旅行?
- [三、核心前提:必须启用 Checkpointer](#三、核心前提:必须启用 Checkpointer)
- 四、时间旅行四步法详解
-
- [4.1 初始执行工作流:](#4.1 初始执行工作流:)
- [4.2 查看历史检查点:](#4.2 查看历史检查点:)
- [4.3 修改状态(创建分支):](#4.3 修改状态(创建分支):)
- [4.4 从检查点恢复执行:](#4.4 从检查点恢复执行:)
- 五、完整示例:AI笑话生成器的时间旅行调试
-
- [5.1 定义状态结构:](#5.1 定义状态结构:)
- [5.2 定义工作流节点:](#5.2 定义工作流节点:)
- [5.3 构建工作流图:](#5.3 构建工作流图:)
- [5.4 第一次执行:](#5.4 第一次执行:)
- [5.5 时间旅行调试案例:](#5.5 时间旅行调试案例:)
- 六、核心API速查表
- 七、总结
-
- [7.1 核心能力:](#7.1 核心能力:)
- [7.2 工作流示意图:](#7.2 工作流示意图:)
- [7.3 小细节:](#7.3 小细节:)
- [7.4 优势](#7.4 优势)
上一章-> 【LangGraph】持久化实现的三大能力------人机交互
前言
AI 工作流具有不确定性:同样的输入,大模型可能产生不同的结果
当复杂任务需要多个 AI 调用协同完成时,错误可能出现在任何步骤,定位问题变得非常困难
LangGraph 的 时间旅行(Time Travel) 能力 :
让你可以重放过去的每一次执行,检查和修改中间状态,甚至尝试不同的决策路径
本文带你掌握这项调试神器
一、什么是时间旅行?
LangGraph 的工作方式:每个节点执行后都会自动"存档",生成一个检查点(checkpoint)
时间旅行允许你:
- 查看历史上任意一个检查点的状态
- 从某个检查点恢复执行(重放)
- 修改某个检查点的状态,然后继续执行(分支探索)
这相当于给你的 AI 工作流装上了一台 "时光机"
二、为什么需要时间旅行?
| 场景 | 说明 |
|---|---|
| 分析推理过程 | 理解 AI 如何得出最终结果,学习成功的决策路径 |
| 定位和修复错误 | 精确找到错误发生的节点,测试修复方案而不影响原始流程 |
| 探索替代方案 | 尝试不同的输入或中间状态,比较不同路径的效果 |
举个例子:
假设你构建了一个三步 Agent:
先生成搜索关键词 → 调用搜索引擎 → 总结网页内容
最终答案不理想时,你无法直接知道是关键词生成出了问题,
还是搜索引擎返回了垃圾信息,还是总结模型跑偏了有了时间旅行,我们就可以回溯到第一步,查看生成的关键词
也可以回溯到第二步,查看搜索引擎的原始返回
甚至可以修改关键词后重新执行后两步,快速定位问题所在
三、核心前提:必须启用 Checkpointer
时间旅行依赖持久化机制。在编译图时,必须传入 checkpointer(如 InMemorySaver、PostgresSaver)
python
from langgraph.checkpoint.memory import InMemorySaver
graph = builder.compile(checkpointer=InMemorySaver())为什么必须要有 checkpointer?
因为 LangGraph 需要将每个节点执行后的状态自动保存到检查点中
没有 checkpointer,图不会记录任何历史状态,自然也就无法回溯或重放
四、时间旅行四步法详解
4.1 初始执行工作流:
python
import uuid
# 创建唯一线程ID确保执行隔离
config = {"configurable": {"thread_id": str(uuid.uuid4())}}
# 传入空字典作为初始状态,config包含线程配置
result = graph.invoke({}, config)4.2 查看历史检查点:
python
# 获取完整状态历史(按时间倒序排列)
states = list(graph.get_state_history(config))
for state in states:
print(f"检查点ID: {state.config['configurable']['checkpoint_id']}")
print(f"下⼀步节点: {state.next}")
print(f"当前状态: {state.values}")
print("-" * 50)举个例子:
【检查点 1/3】
ID: 1f0d4d2b-bdc2-6f06-8002-9b67bb1d3867
待执行节点: 流程结束
状态值: {'topic': '程序员', 'joke': '为什么程序员总是分不清万圣节和圣诞节?
因为 Oct 31 = Dec 25'}
【检查点 2/3】
ID: 1f0d4d2b-9506-6bf8-8001-6af0cdc2fea0
待执行节点: ('get_joke',)
状态值: {'topic': '程序员'}
4.3 修改状态(创建分支):
python
# 选择生成主题后的检查点(索引1)
target_state = states[1]
# 修改主题字段,创建新分支
new_config = graph.update_state(
target_state.config, # 原检查点配置
values={"topic": "程序员调试代码时的笑话"} # 新状态值
)
# 注意:原始检查点仍保留在历史记录中4.4 从检查点恢复执行:
python
# 从修改后的配置继续执行(传入None表示使用已有状态)
result = graph.invoke(None, new_config)
# 打印新生成的笑话
print("新笑话:", result["joke"])五、完整示例:AI笑话生成器的时间旅行调试
5.1 定义状态结构:
python
from typing import TypedDict
class State(TypedDict):
"""工作流状态定义"""
topic: str # 笑话主题
joke: str # 生成的笑话内容5.2 定义工作流节点:
python
from langchain.chat_models import init_chat_model
# 初始化模型(示例使用简化版GPT-4)
model = init_chat_model("gpt-4o-mini")
def generate_topic(state: State):
"""生成笑话主题节点"""
response = model.invoke("生成一个程序员相关的搞笑主题,要求六字以内")
return {"topic": response.content} # 去除可能的多余引号
def get_joke(state:State):
joke=model.invoke(f"说一个关于{state["topic"]}的笑话")
return {
"topic":joke.content
}5.3 构建工作流图:
python
from langgraph.graph import StateGraph, START, END
builder=StateGraph(State)
builder.add_node(get_topic)
builder.add_node(get_joke)
builder.add_edge(START,"get_topic")
builder.add_edge("get_topic","get_joke")
builder.add_edge("get_joke",END)
# 编译工作流(启用内存检查点)
graph=builder.compile(checkpointer=InMemorySaver())5.4 第一次执行:
python
config={"configurable":{"thread_id":"123"}}
# 步骤一:初始执⾏⼯作流
print(graph.invoke({}, config))5.5 时间旅行调试案例:
假设首次生成的主题过于宽泛:
python
# 获取历史状态
states = list(graph.get_state_history(config))
# 查看生成主题后的状态和相关配置
update=states[1]
print(update.values["topic"])
print(update.config)
# 修改为更具体的主题
new_config = update.update_state(
update[1].config,
values={"topic": "讲一个程序员笑话"}
)
# 从新主题继续执行
result = graph.invoke(None, new_config)
print("\n优化后结果:")
print(f"新主题:{result ['topic']}")
print(f"新笑话:{result ['joke']}")六、核心API速查表
| 方法 | 参数说明 | 返回值 | 典型用途 |
|---|---|---|---|
graph.get_state(config) |
thread_id必填 |
最新状态对象 | 获取当前进度 |
graph.get_state_history(config) |
thread_id必填 |
状态对象列表 | 审计/调试历史 |
graph.update_state(config, values) |
原配置+新值字典 | 新配置对象 | 创建分支版本 |
graph.invoke(None, config) |
检查点配置 | 最终状态 | 继续执行流程 |
关键参数说明:
thread_id:执行会话的唯一标识checkpoint_id:通过历史查询或update_state获取values:需要更新的状态字段字典
七、总结
7.1 核心能力:
| 功能 | 实现方式 | 典型应用场景 |
|---|---|---|
| 状态追溯 | get_state_history() |
调试异常流程 |
| 分支实验 | update_state()+invoke() |
A/B测试不同参数 |
| 流程修复 | 修改中间状态后重放 | 纠正模型偏差 |
| 交互调试 | 结合interrupt()机制 |
人工审核节点 |
7.2 工作流示意图:
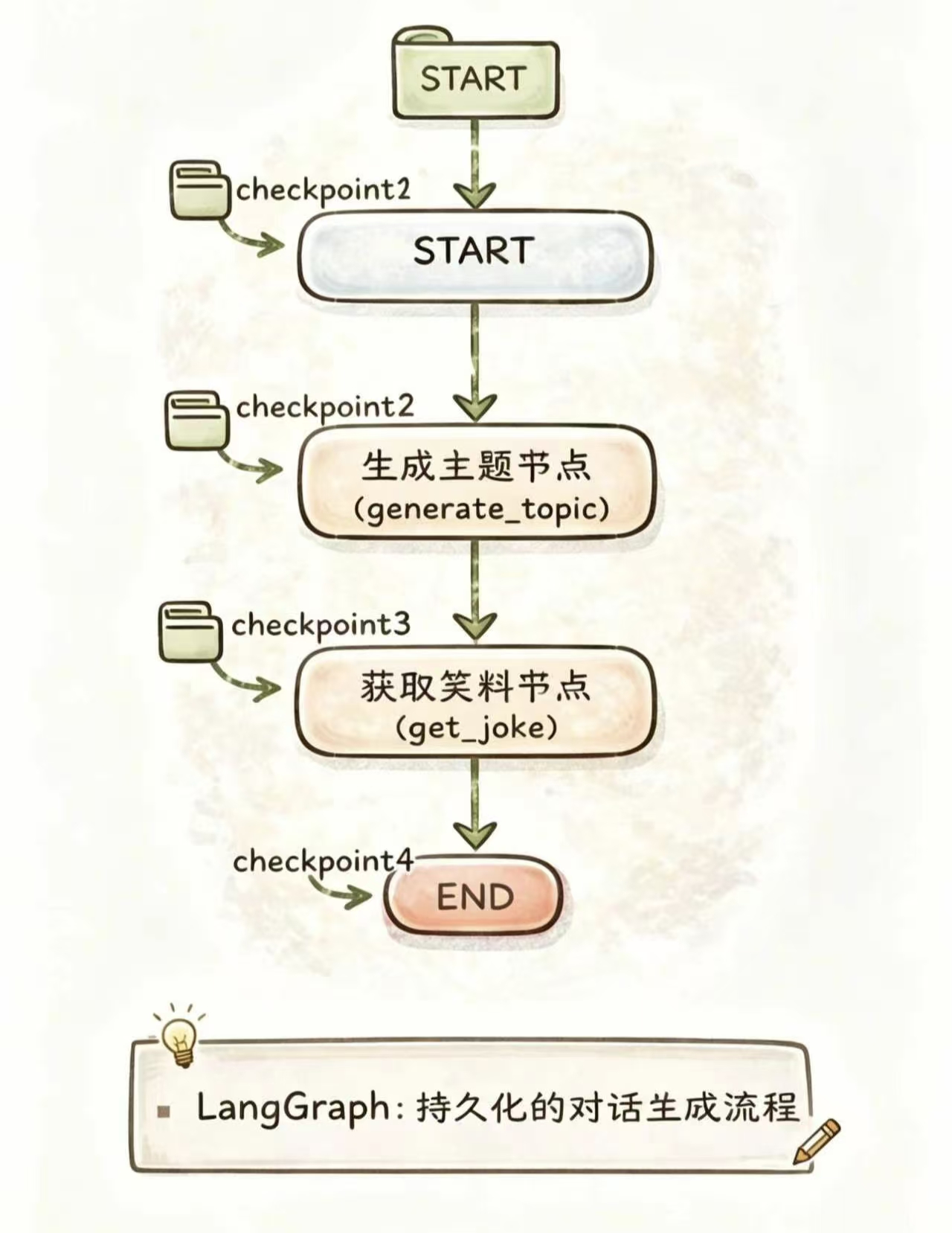
7.3 小细节:
- 检查点自动包含完整上下文,无需手动保存
- 修改状态会创建新分支,原始记录完整保留
- 通过
thread_id可管理多个独立会话,互不干扰 - 结合长期存储(Store)可实现跨会话记忆
7.4 优势
- 精准定位 AI 思维偏差节点
- 快速尝试不同生成路径
- 构建可解释的 AI 工作流
- 实现人机协同调试流程
掌握时间旅行能力,我们就能把 AI 工作流从"黑盒"变成"白盒"------可回溯、可修改、可分支、可复用!!!
本期分享就到这里了,下期再见~
