Hi,大家好,我是半亩花海。在上节说明了最简单的深度迁移--Finetune(微调) 之后,本文主要将介绍迁移学习的深度迁移学习 ------深度神经网络的可迁移性。本文探讨了深度神经网络的可迁移性,重点分析了不同网络层次的特征迁移能力。研究表明:1)网络前3层主要学习通用特征,迁移效果最佳;2)加入微调(fine-tune)能显著提升迁移性能;3)深度迁移比随机初始化效果更好;4)层次迁移能加速网络优化。实验发现,随着迁移层数增加,性能会下降,但前3层始终具有较好的可迁移性。
目录
一、引入------深度神经网络
随着 AlexNet Krizhevsky et al., 2012 在 2012 年的 ImageNet 大赛上获得冠军,深度学习开始在机器学习的研究和应用领域大放异彩。尽管取得了很好的结果,但是神经网络本身就像一个黑箱子,看得见,摸不着,解释性不好 。由于神经网络具有良好的层次结构, 很自然地就有人开始关注,能否通过这些层次结构来很好地解释网络?于是,有了我们熟知的例子:假设一个网络要识别一只猫,那么一开始它只能检测到一些边边角角的东西,和猫根本没有关系;然后可能会检测到一些线条和圆形;慢慢地,可以检测到有猫的区域;接着是猫腿、猫脸等等。图 1是一个简单的示例。
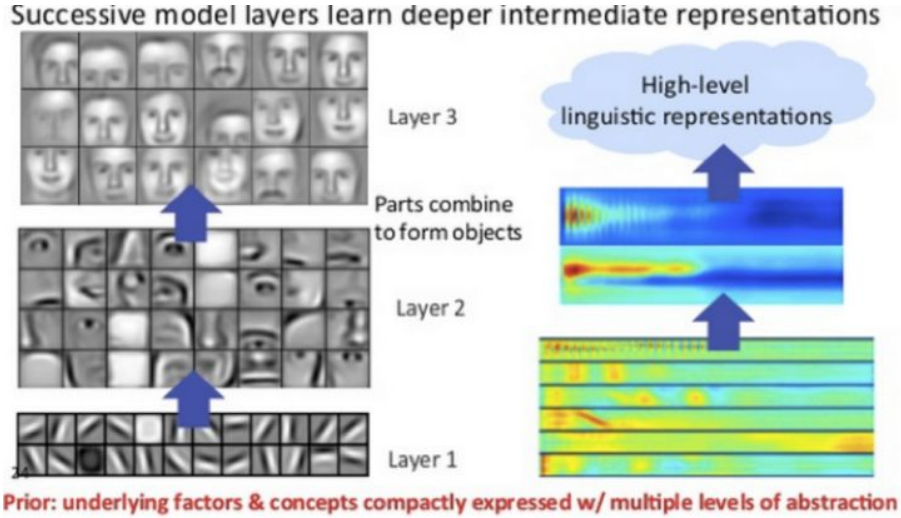 图 1:深度神经网络进行特征提取到分类的简单示例
图 1:深度神经网络进行特征提取到分类的简单示例
这表达了一个什么事实呢?概括来说就是:前面几层都学习到的是通用的特征(general feature);随着网络层次的加深,后面的网络更偏重于学习任务特定的特征(specific feature)。 这非常好理解,我们也都很好接受。那么问题来了:如何得知哪些层能够学习到 general feature,哪些层能够学习到 specific feature 。更进一步:如果应用于迁移学习,如何决定该迁移哪些层、固定哪些层?
这个问题对于理解神经网络以及深度迁移学习都有着非常重要的意义。
二、深度神经网络可迁移性
来自康奈尔大学的 Jason Yosinski 等人 Yosinski et al., 2014 率先进行了深度神经网络可迁移性的研究,将成果发表在 2014 年机器学习领域顶级会议 NIPS 上并做了口头汇报。 该论文是一篇实验性质的文章(通篇没有一个公式)。其++目的就是要探究上面我们提到的几个关键性问题++ 。因此,文章的全部贡献都来自于实验及其结果:
在 ImageNet 的 1000 类上,作者把 1000 类分成两份( 和
),每份 500 个类别。然后,分别对
和
基于 Caffe 训练了一个 AlexNet 网络。一个 AlexNet 网络一共有 8 层, 除去第 8 层是类别相关的网络无法迁移以外,作者在 1 到 7 这 7 层上逐层进行 finetune 实 验,探索网络的可迁移性。
为了更好地说明 finetune 的结果,作者提出了有趣的概念: 和
。
迁移 网络的前
层到
(
)vs 固定 B 网络的前 n 层(
)
- 简单说一下什么叫
:(所有实验都是针对数据
- 相应地,有
**三、**深度网络迁移实验结果
实验结果如下图 (图 2) :
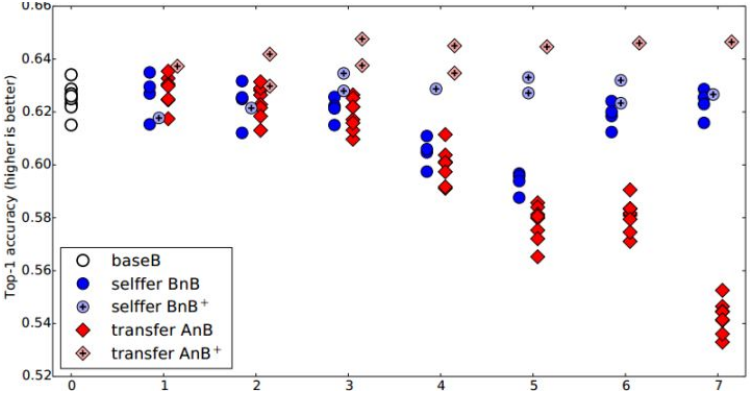 图 2:深度网络迁移实验结果 1
图 2:深度网络迁移实验结果 1
这个图说明了什么呢?我们先看蓝色的 和
(就是
加上 finetune)。对
而言,原训练好的
模型的前 3 层直接拿来就可以用而不会对模型精度有什么损失。 到了第 4 和第 5 层,精度略有下降,不过还是可以接受。然而到了第 6 第第 7 层,精度居然奇迹般地回升了!这是为什么?原因如下:对于一开始精度下降的第 4 第 5 层来说,确实是到了这一步,feature 变得越来越 specific,所以下降了。那对于第 6 第 7 层为什么精度又不变了?那是因为,整个网络就 8 层,我们固定了第 6 第 7 层,这个网络还能学什么呢?所以很自然地,精度和原来的
网络几乎一致!
对 来说,结果基本上都保持不变。说明 finetune 对模型结果有着很好的促进作用!
我们重点关注 和
。对 AnB 来说,直接将
网络的前 3 层迁移到
,貌似不会有什么影响,再一次说明,网络的前 3 层学到的几乎都是 general feature!往后,到了第 4 第 5 层的时候,精度开始下降,我们直接说:一定是 feature 不 general 了! 然而, 到了第 6 第 7 层,精度出现了小小的提升后又下降,这又是为什么?作者在这里提出两点: co-adaptation 和 feature representation。就是说,第 4 第 5 层精度下降的时候,主要是由于 A 和 B 两个数据集的差异比较大,所以会下降;到了第 6 第 7 层,由于网络几乎不迭代了,学习能力太差,此时 feature 学不到,所以精度下降得更厉害。
再看 。加入了 finetune 以后,
的表现对于所有的
几乎都非常好,甚至比
(最初的
)还要好一些!这说明:finetune 对于深度迁移有着非常好的促进作用!
把上面的结果合并就得到了下面一张图 (图 3):
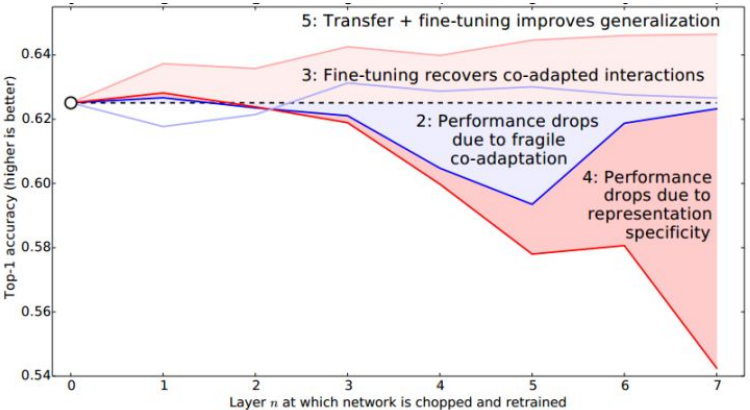 图 3:深度网络迁移实验结果 2
图 3:深度网络迁移实验结果 2
至此, 和
基本完成。作者又想,是不是我分
和
数据的时候,里面存在一些比较相似的类使结果好了?比如说
里有猫,
里有狮子,所以结果会好?为了排除这些影响,作者又分了一下数据集,这次使得
和
里几乎没有相似的类别。在这个条件下再做
,与原来精度比较(0% 为基准)得到了下图 (图 4):
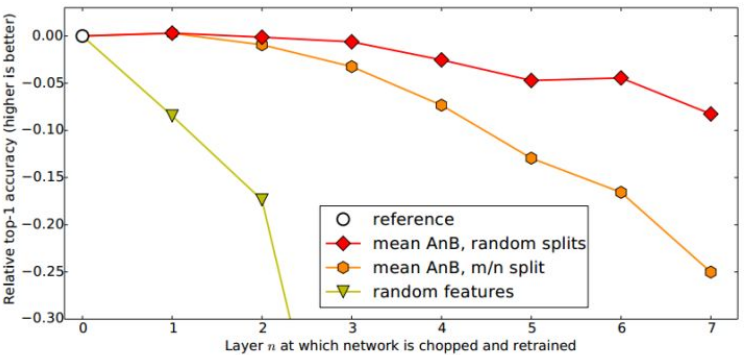 图 4:深度网络迁移实验结果 3
图 4:深度网络迁移实验结果 3
这个图说明了什么呢?简单:随着可迁移层数的增加,模型性能下降。但是,前 3 层仍 然还是可以迁移的!同时,与随机初始化所有权重比较,迁移学习的精度是很高的!
四、实验结论
虽然该论文并没有提出一个创新方法,但是通过实验得到了以下几个结论,对以后的深 度学习和深度迁移学习都有着非常高的指导意义:
- 神经网络的前 3 层基本都是 general feature,进行迁移的效果会比较好;
- 深度迁移网络中加入 fine-tune,效果会提升比较大,可能会比原网络效果还好;
- Fine-tune 可以比较好地克服数据之间的差异性;
- 深度迁移网络要比随机初始化权重效果好;
- 网络层数的迁移可以加速网络的学习和优化。
五、参考资料
1. 王晋东《迁移学习简明手册》(PDF版) https://www.labxing.com/files/lab_publications/615-1533737180-LiEa0mQe.pdf#page=82&zoom=100,120,392
2. 《迁移学习简明手册》发布啦! https://zhuanlan.zhihu.com/p/35352154