文章:Segment and Matte Anything in a Unified Model
代码:暂无
单位:沃尔玛全球科技
一、问题背景:分割与抠图的"两难困境"
-
SAM的短板:SAM凭借10亿级掩码训练数据,支持点、框、文本等多种交互提示,零样本泛化能力超强,但输出掩码的边界精度不足,缺乏亚像素级细节,无法直接用于精细抠图。
-
现有改进方案的局限:后续的HQ-SAM、DIS-SAM等模型虽提升了分割精度,但需要额外后处理或人工交互,实用性打折扣;而MatAny、MAM等SAM衍生抠图模型,要么依赖额外重模型,要么无法兼顾分割性能。
-
核心矛盾:分割需要全局物体信息,抠图需要局部边界细节,二者存在强关联性,但此前缺乏能将二者统一、且轻量化的框架。
二、方法创新:SAMA的"三合一"核心设计
研究者提出的Segment And Matte Anything(SAMA),作为SAM的轻量化扩展,仅增加1.8%参数量,就实现了"分割+抠图"一体化,核心创新有三点:
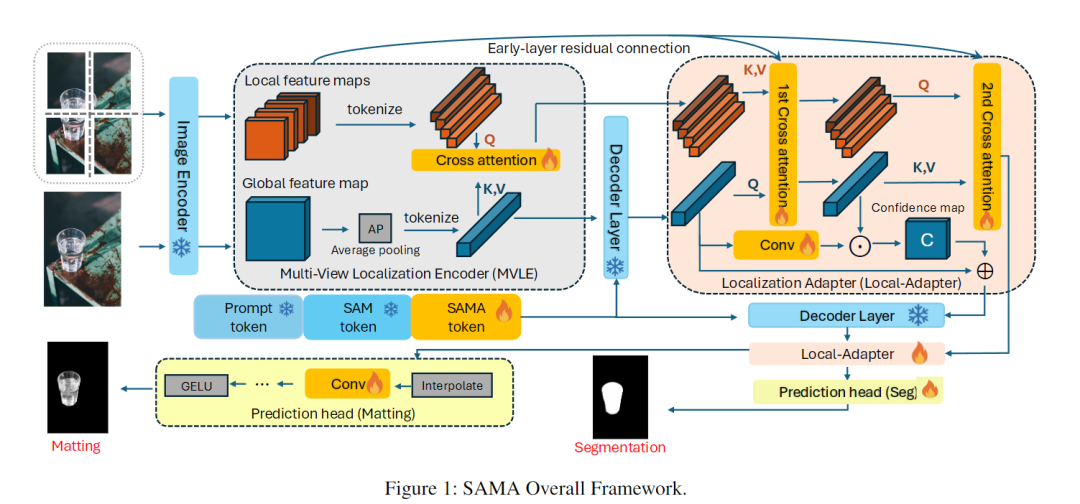
1. 多视角定位编码器(MVLE):捕捉细节不遗漏
借鉴人类"远看全局、近看细节"的视觉逻辑,SAMA将输入图像分成4个不重叠的局部补丁,每个补丁放大后与原图一起输入编码器。通过跨注意力机制对齐局部细节和全局信息,解决了SAM仅靠全局特征无法捕捉精细结构的问题。
2. 定位适配器(Local-Adapter):细化边界更精准
在SAM解码器中插入专属模块,通过两轮交叉注意力融合全局上下文和局部特征。同时引入"置信度图",既保留SAM的零样本泛化能力,又能精准修复物体边界,让分割和抠图的边缘更锐利。
3. 双任务预测头:一键输出双结果
设计两个轻量化预测头,分别对应分割和抠图任务。通过上采样和卷积层协同优化,实现一次输入同时输出高精度分割掩码和细腻alpha抠图,无需额外切换模型。
关键是,SAMA训练时冻结了SAM的全部参数,仅微调新增模块,既保证了数据效率,又不会丢失SAM的核心优势。
三、实验结果:多项 benchmark 刷新纪录
在分割和抠图两大任务的标准数据集上,SAMA表现亮眼:
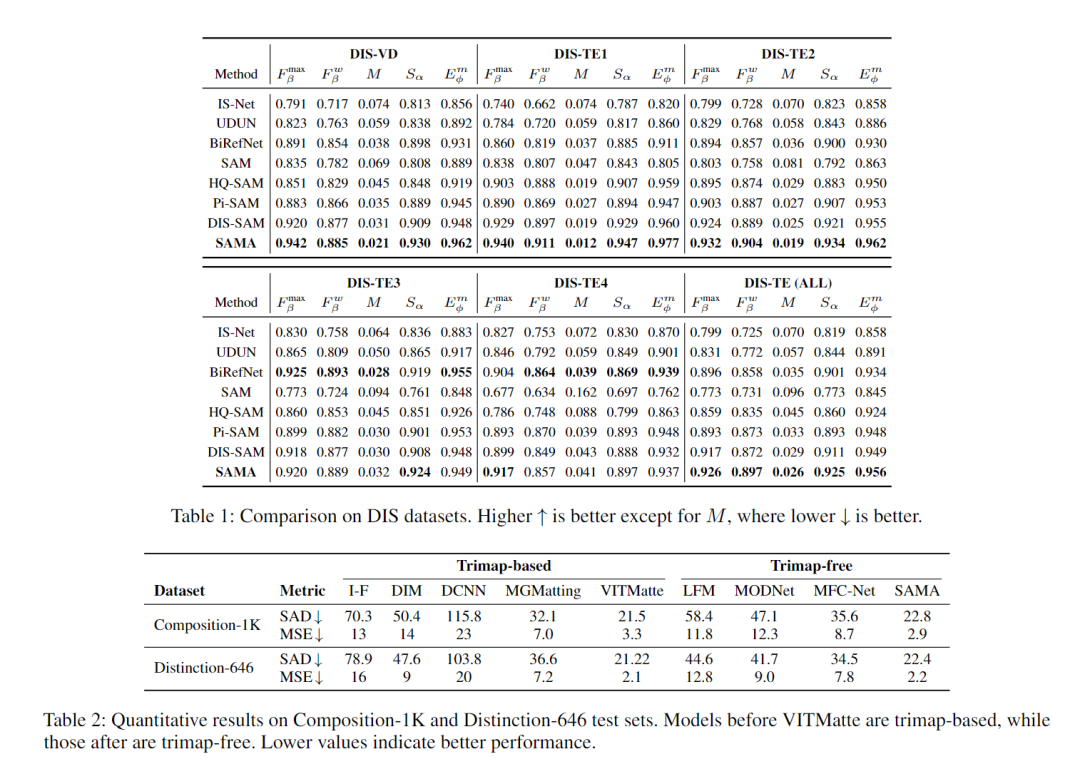
1. 分割任务:细节碾压同类模型
在精细分割数据集DIS-5K上,SAMA的最大F值达到0.942,显著超过SAM(0.835)、HQ-SAM(0.851)等模型;即使面对形状复杂的物体(如铁丝网),也能精准分割出细微结构。在零样本分割数据集COIFT上,仅用1-5个点提示,SAMA的mIoU分数也远超同类模型。
2. 抠图任务:无需Trimap也能赢
在Composition-1K、Distinction-646等抠图基准上,SAMA作为无Trimap模型,SAD(误差指标)低至22.4,媲美甚至超过需要Trimap辅助的VITMatte等模型。视觉效果上,能清晰抠出头发丝、透明玻璃的通透质感,解决了传统模型"抠不干净"的痛点。
3. 效率不打折
尽管新增了双任务能力,SAMA的推理速度(FPS)仅比SAM轻微下降,参数量仅增加1.8%,在普通GPU上也能流畅运行,兼顾性能与实用性。
四、优势与局限
核心优势
-
一体化高效:一个模型搞定分割+抠图,无需分步操作,大幅降低使用成本;
-
高精度+高灵活:既保留SAM的点、框、文本等交互提示能力,又实现亚像素级边界精度;
-
轻量化易部署:新增参数少,推理速度快,无需高端硬件即可落地。
现存局限
-
仅支持静态图像:目前只能处理单张图片,无法应用于视频分割与抠图;
-
硬件要求较高:依赖SAM backbone,推理仍需≥10GB显存的GPU,普通设备难以运行;
-
不支持文本直接提示:暂时需要框、点等交互提示,未接入文本-图像关联能力。
五、一句话总结
SAMA以轻量化设计实现了分割与抠图的统一,既继承了SAM的灵活交互与泛化能力,又补齐了精细边界处理的短板,为图像编辑、自动驾驶感知等场景提供了更高效的解决方案。