9.6 爬虫实例
9.6.1 获取时光网某个年度电影数据
通过打开网址:http://film.mtime.com/search/movies/movies?type=year\&word=1987可以看到1987年度所有的电影数据。
py
url = 'http://film.mtime.com/search/movies/movies?type=year&word=1987'
r = requests.get(url=url)
r.encoding = r.apparent_encoding
print(r.text)通过以上代码并不能获取到网页数据。
于是进行以下操作:
1、打开谷歌浏览器,按f12进入到开发调试模式,一般会在浏览器的下方弹出调试操作界面。
2、在调试操作界面中,点击网络选项卡,点击清除按钮,清除掉之前录制的网络日志。
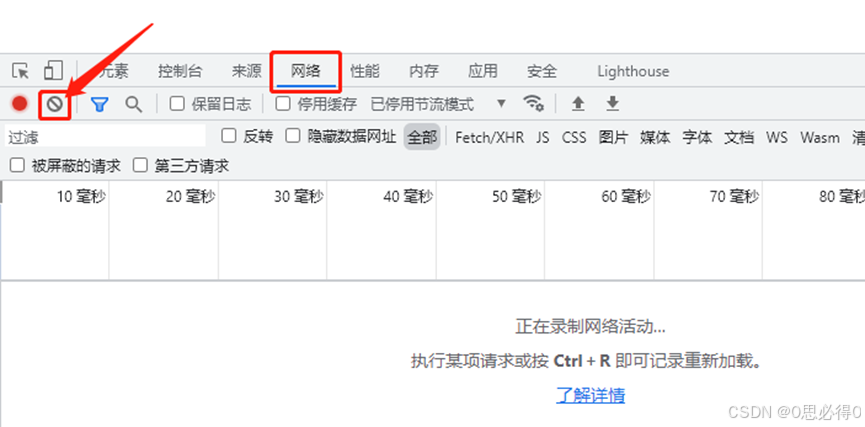
3、将要打开的网址输入到地址栏中,接下来会自动录制网络日志显示在调试操作界面的下方。
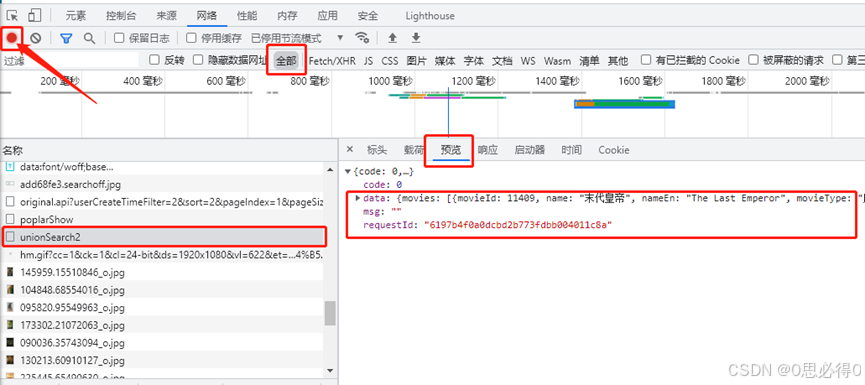
4、待网页内容完全加载完毕,点击调试操作界面左上角的红色圆点以停止录制网络日志。此时红色圆点会变成灰色。之后点击中部的全部按钮(如果后续的记录太多,可以点击全部右边的Fetch/XHR进行筛选),再右下方切换到预览选项卡,之后在左下方名称模块,通过鼠标点击或者键盘上下选择记录,当预览处能看到要获取到的数据时为止。
5、从预览切换到标头,此时在常规处可以看到请求的网址,这个就是接下来爬虫需要访问的网址。标头选项卡下方还有个请求标头,有些网址爬虫还需要带上这里的参数。比如:User-Agent、Host,这些参数都是包含在headers中的。
例如:
py
net_headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'}
r = requests.get(url=url, headers= net_headers)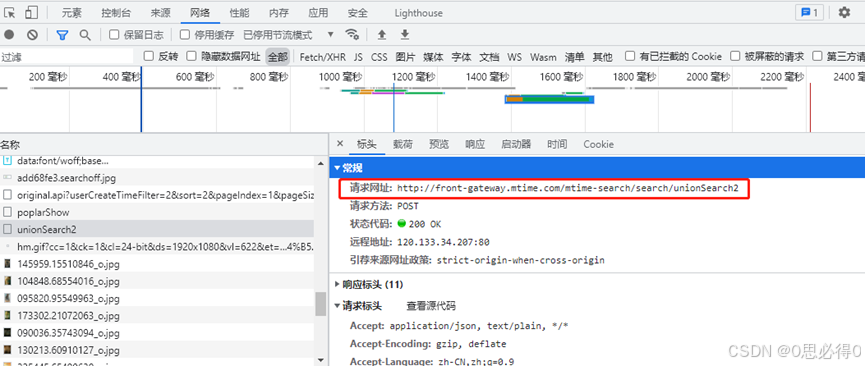
6、此时如果能通过下面的代码获取到data内容,则表明已成功爬取数据。接下来就是通过eval函数或者json将文本类型的data转换成可以被python识别的数据类型,在进行编辑、整理和持久化即可。
py
r = requests.get(url=url, headers= net_headers)
r.encoding = r.apparent_encoding
print(r.text)7、如果第6步无法获取到data内容,则有可能还需要添加参数。切换到载荷,可以看到表单数据,接下来可以将表单数据打包成参数(关键参数即可,不需要所有的参数),传给request即可。
py
params = {'year': '2017'}
r = requests.get(url=url, params=params)
r.encoding = r.apparent_encoding
print(r.text)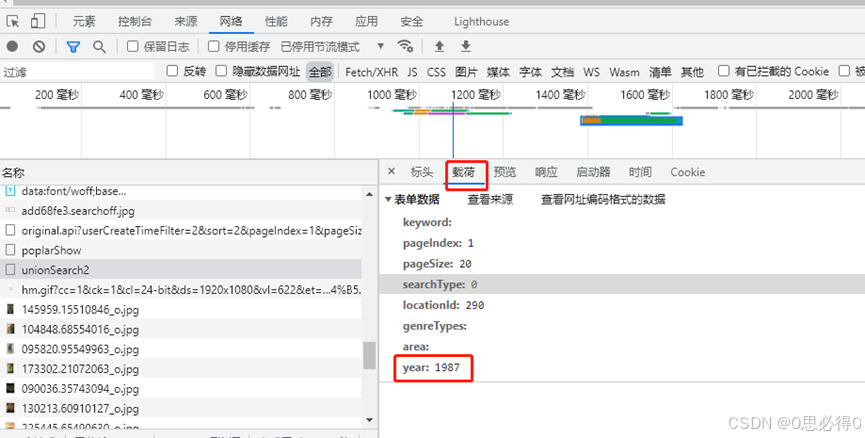
当然,如果是Post请求,那么载荷这里就是Json数据:
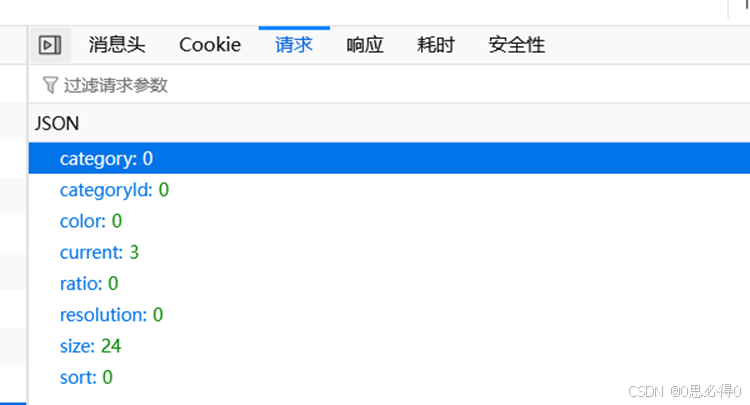
py
url = 'https://api.zzzmh.cn/v2/bz/v3/getData'
params = {
'category': 0,
'categoryId': 0,
'color': 0,
'current': page,
'ratio': 0,
'resolution': 0,
'size': 24,
'sort': 0,
}
r = requests.get (Headers=headers, Url=url, Json=params, Verify=True)