V3.0 新一代架构突破------从 "集中汇总" 到 "分布式协同"
KaiwuDB V2.x 版本中的分布式执行引擎传统架构采用的是"管理节点(Master Engine,即 ME)--- 执行节点(TS Engine)"二级架构的集中式设计:
• 通信链路:ME 向各执行节点下发 Flowspec 任务,执行节点间无直接通信链路,所有交互均通过 ME 中转。
• 计算汇总:所有执行节点计算结果需全量回传至 ME,由 ME 承担二次汇总计算职责。
为了减少冗余编解码的操作以及传输与计算的开销,进一步提升分布式执行的性能,KaiwuDB 在 V3.0 中将新一代架构通过四项核心改造实现架构层面的突破性升级,其关键组件与数据流转逻辑如下。
1. 基于 Pipeline 架构:释放并行潜力,提升扩展弹性
支撑高并发查询调度,满足 AP 场景横向扩展需求。采用 Pipeline 流式执行架构,通过任务拆分与流水线化执行,实现单设备高效并行;引入优先级调度机制,支持资源弹性分配与高优先级任务倾斜。
查询并发承载能力大幅提升,架构扩展性适配从百级到万级查询的弹性需求,资源利用率显著提高。
2. 统一编码:强化效率与兼容性,提速大数据处理
统一编码标准,提升大规模数据集传输与处理效率。标准化采用 DataChunk 作为默认执行编码,依托其统一规范与高效的序列化 / 反序列化特性,单机处理 160 万行结果集场景下可提速 3 秒。整体消除编码层面性能损耗,为 TB 级数据分析提供高效、兼容的编码支撑,数据处理吞吐量显著提升。
3. 执行节点间 BRPC 传输:优化分布式协同,降低传输开销
实现节点间低延迟、高可靠数据传输,减少资源占用。采用 BRPC 作为执行节点间核心传输协议,依托其原生 C++ 接口与高效通信机制,简化传输链路、减少冗余开销;内置统一 Shuffle 机制,保障数据分发有序性。使得分布式传输延迟与网络带宽占用显著降低,节点间协同效率提升,支撑大规模分布式查询稳定执行。
4. 算子全下推与能力升级:完善算力支撑,适配复杂场景
提升算子性能与功能覆盖度,支撑大规模、复杂计算需求。推进算子全下推架构,减少数据回传开销;新增 Join 算子完善跨模计算能力,为 Hash Agg 算子适配落盘机制规避内存溢出,优化 Sort 算子执行逻辑提升大规模数据排序性能。算子层功能与性能双升级,可高效支撑复杂查询、高基数聚合、TB 级数据排序等重负载任务,适配 AP 场景多样化计算需求。
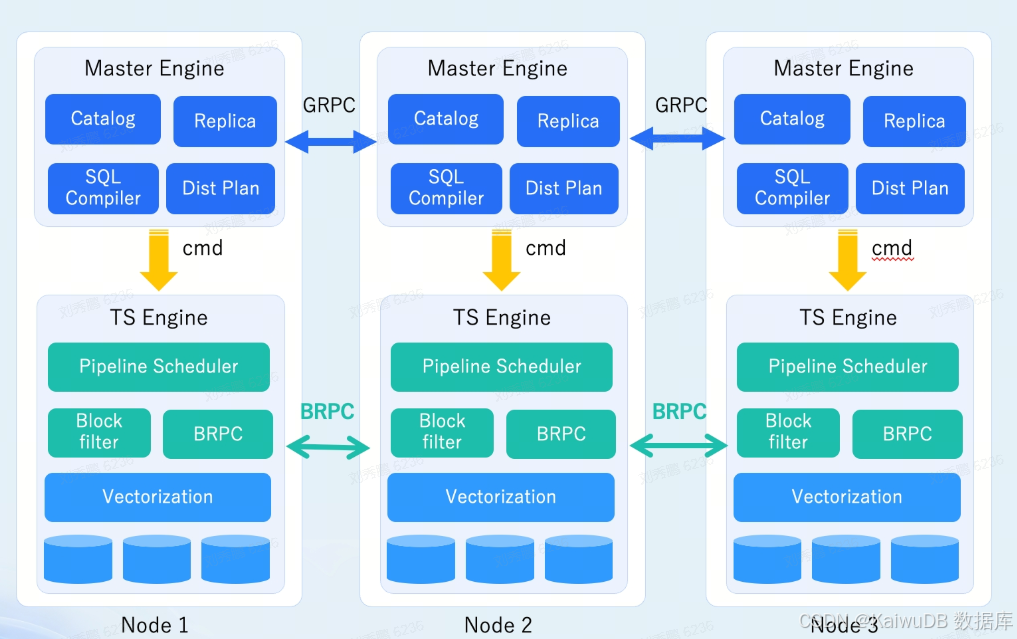
KaiwuDB 3.0 分布式执行架构
上述四项核心改造的具体作用机制如下:
✅BRPC 通信层改造:在执行节点节点间构建专用通信链路,采用与本地算子同源的数据格式传输中间结果,彻底消除节点间的数据转换开销。
✅全算子下推执行改造:将所有计算算子从 ME 迁移至执行节点部署执行,仅由 Root 执行节点承担最终结果汇总职责,其余执行节点仅向 ME 反馈执行状态,数据传输量降幅超 90%。
✅Block Filter 机制引入:将数据过滤规则下推至存储层,存储节点基于 Block 元数据统计信息预过滤无效数据,显著降低计算层的输入数据量,提升计算效率。
✅Pipeline 流水线调度改造:基于 Pipeline 模型对查询任务进行拆分与并行化编排,实现任务高效并行处理,其核心架构与数据流转逻辑如下:
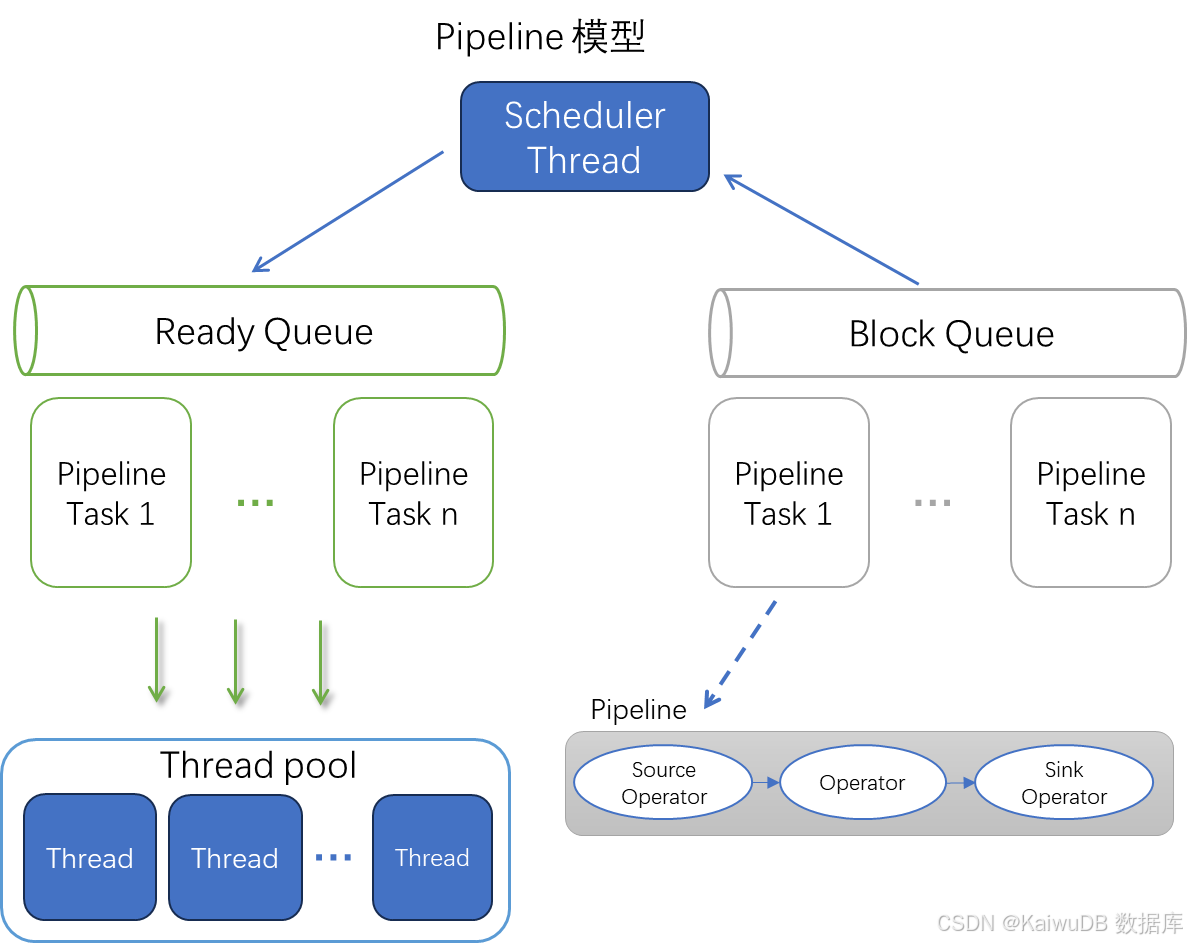
Pipeline 模型
Pipeline 模型沿用传统数据处理的流水线设计范式,将复杂查询任务解耦为若干细粒度、可并行调度的子任务;各子任务被编排为多个 Pipeline Stage(流水线阶段),每个 Stage 由一组 Operator(算子)构成协同处理单元。数据在算子间遵循流水线机制逐阶段流转处理,最终达成查询任务的高效执行目标。
分布式执行调度流程
调度层承担逻辑执行计划的分布式改写职责,将其解耦为执行节点级计划片段(Flowspec),并对各片段的执行时序与并发度进行精细化编排,保障多模分布式执行结果的一致性与准确性。
针对时序数据查询,分布式执行调度层会将所有算子全量下推至执行节点端执行,以下为全新执行架构的调度流程示例(以具体 SQL 查询为例):
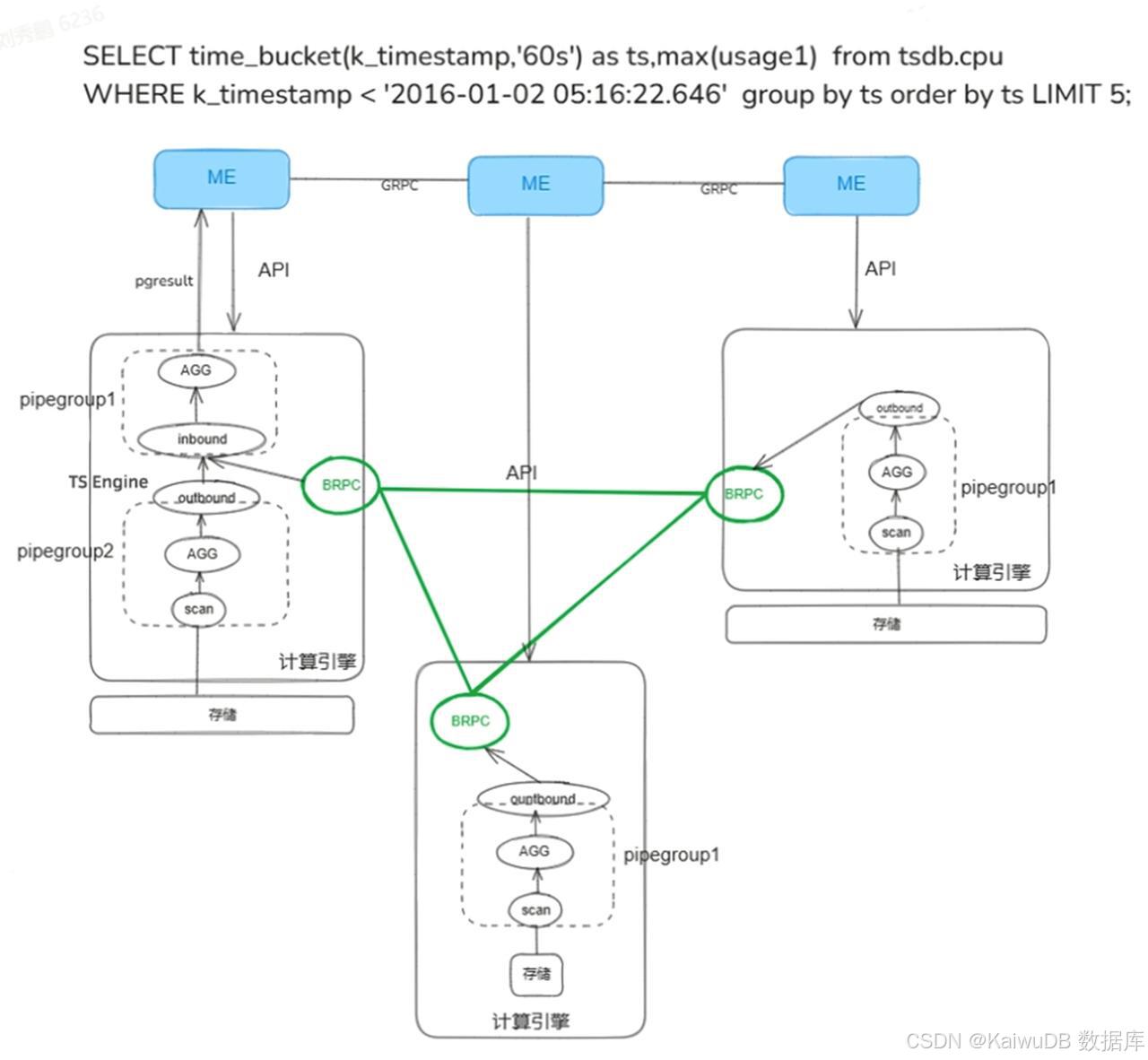
KaiwuDB 3.0 分布式执行流程
总结与展望
综上,KaiwuDB 分布式执行引擎通过一系列核心优化举措,系统性破解了传统架构的多重瓶颈,构建起高效、稳定、可扩展的分布式执行体系,为高并发、大规模时序数据及多模数据分析业务提供了坚实的技术支撑。
- 统一引擎架构适配 AP 场景
通过全算子下推、BRPC 统一通信及 Pipeline 标准化调度机制,有效突破传统架构的性能与扩展性约束,可稳定支撑未来高并发、大规模分析型处理 AP 场景的查询负载需求。
- 核心性能实现跨越式提升
依托计算全量下推、统一编码规范及 BRPC 零转换传输技术,显著降低冗余数据传输及编解码开销;借助 Block Filter 预过滤机制,进一步提升海量数据处理效率与 CPU 资源利用率,优化系统资源配置。
- 降低系统复杂度
明确管理节点(ME)的调度职责、根执行节点的结果汇总职责及普通执行节点的计算职责边界,降低模块间耦合度,可快速定位问题节点及流水线阶段(Stage),提升 Debug 的效率与精准性。
- 分布式处理能力全面升级
以 Pipeline 流水线调度与 Block Filter 预过滤机制保障核心性能输出,依托统一架构设计提升系统可维护性与可扩展性,通过算子落盘优化策略改善存储 I/O 资源利用率,全面支撑复杂大规模业务场景的稳定运行需求。
未来,KaiwuDB 将基于现有架构持续深化技术迭代,聚焦复杂业务场景的功能完善,推动引擎向更智能、更可靠、更贴合用户核心业务需求的方向演进,助力业务实现数据价值的高效挖掘与转化。