切分方式,是 RAG 系统里最早、也最难回头的选择
在 RAG 项目里,切分方式通常是最早被确定的部分之一:
- 文档进来
- 切一切
- 建向量
- 后面再慢慢调
而且在当时,这个选择往往显得并不重要:
"反正后面还有 embedding、TopK、rerank、模型兜底。"
但你只要做过一两个完整项目,就会慢慢意识到一件事:
切分方式不是一个"前处理细节",
而是整个系统如何理解世界的第一步。
尤其是在 语义切分 和 结构切分 之间,
它们的差异,远远不只是"切得聪不聪明"。
先给一个非常明确的结论(一定要先看)
在展开之前,我先把这篇文章最重要的一句话写出来:
语义切分和结构切分的差异,
不在"切得准不准",
而在"谁在为理解负责"。
如果你只用"召回效果"来比较这两种方式,
你一定会选错。
第一层:两种切分方式,到底在做什么(先对齐认知)
我们先不用任何评价,只说事实。
基于结构的切分
结构切分依赖的是:
- 标题
- 段落
- 列表
- HTML / Markdown 结构
- 文档层级
它的核心假设是:
文档作者已经帮你做过一次"语义组织"。
切分做的事情是:
- 尊重原始组织方式
- 不跨越结构边界
- 尽量保持上下文完整性
基于语义的切分
语义切分依赖的是:
- embedding 相似度
- 语义边界检测
- 内容相似性聚类
它的核心假设是:
模型比文档结构更懂"哪里该断"。
切分做的事情是:
- 打破原始结构
- 按"语义连续性"重新分块
- 追求 chunk 内语义一致
结构切分 vs 语义切分 示意
第二层:语义切分的"聪明",来自哪里
先说清楚语义切分为什么这么吸引人。
在很多 demo 或小样本测试中,语义切分往往表现得非常好:
- chunk 内主题集中
- 相似问题召回更稳定
- Top1 看起来"更准"
这是因为语义切分擅长做一件事:
把"看起来相关的内容",
紧密地绑在一起。
在以下场景中,它非常有优势:
- FAQ
- 知识点型文档
- 概念解释类内容
你会明显感觉到:
"模型好像更懂了。"
但这个"懂",是有前提条件的。
第三层:结构切分的"笨",其实是一种约束
结构切分经常被嫌弃:
- chunk 里内容不够集中
- 有些地方看起来"多余"
- 召回结果不如语义切分"干净"
但这些"缺点",其实来自它的一个核心特性:
它不替你重新组织意义。
结构切分选择的是:
- 保留作者的表达顺序
- 保留条件、例外、上下文
- 哪怕它们看起来"不够语义纯净"
这意味着:
结构切分,把"理解责任",
明确地留给了模型和系统。
而不是提前在切分阶段"替模型做决定"。
第四层:真正的分水岭------"责任转移"发生在切分阶段
这是很多人没意识到的关键点。
当你选择 语义切分 时,你其实在做一件事:
把"哪些内容应该被放在一起"的判断,
提前交给了 embedding 模型。
这意味着:
- 切分阶段已经做了一次"隐式理解"
- 后续系统默认这个理解是对的
而当你选择 结构切分 时:
你刻意避免在切分阶段做理解判断。
你说的是:
- "我尊重原文"
- "理解发生在后面"
这两种选择,决定了后面系统犯错的方式完全不同。
第五层:语义切分,如何系统性放大"适用范围错误"
这是语义切分在工程中最危险的地方。
语义切分往往会:
- 把相似主题的内容合并
- 把"规则 + 例外"拆散
- 或把"条件语句"与上下文分离
结果是:
- chunk 内语义一致
- 但逻辑条件丢失
模型面对的是:
一个"看起来完整,但缺乏边界"的知识块。
于是模型很容易:
- 把局部规则当成全局规则
- 把"在某些情况下成立"
当成"普遍成立"
这类错误往往:
- 不明显
- 不好评估
- 非常像"模型理解错误"
但实际上:
理解已经在切分阶段被误导了。
第六层:结构切分,如何把风险"暴露"出来
相比之下,结构切分更容易产生的问题是:
- 信息看起来分散
- 需要多个 chunk 才能拼出结论
- 模型更容易说"不知道"
但从风险角度看,这是一个更健康的失败模式。
因为:
- 模型能感知信息不足
- 证据缺失更容易被察觉
- TopK 的问题更容易定位
换句话说:
结构切分更容易失败,
但失败得更诚实。
第七层:TopK 介入后,两种切分方式的差异被进一步放大
TopK 的作用是:
从"候选世界"里选 K 个最相关 chunk。
但它不会:
- 判断 chunk 内部是否自洽
- 判断 chunk 之间是否冲突
在语义切分下:
- TopK 往往召回多个
"语义高度相似的大块" - 冲突被掩盖
- 模型更敢综合
在结构切分下:
- TopK 更像是
"上下文片段集合" - 冲突和缺失更容易显现
这意味着:
TopK 在语义切分中是"放大器",
在结构切分中更像"探照灯"。
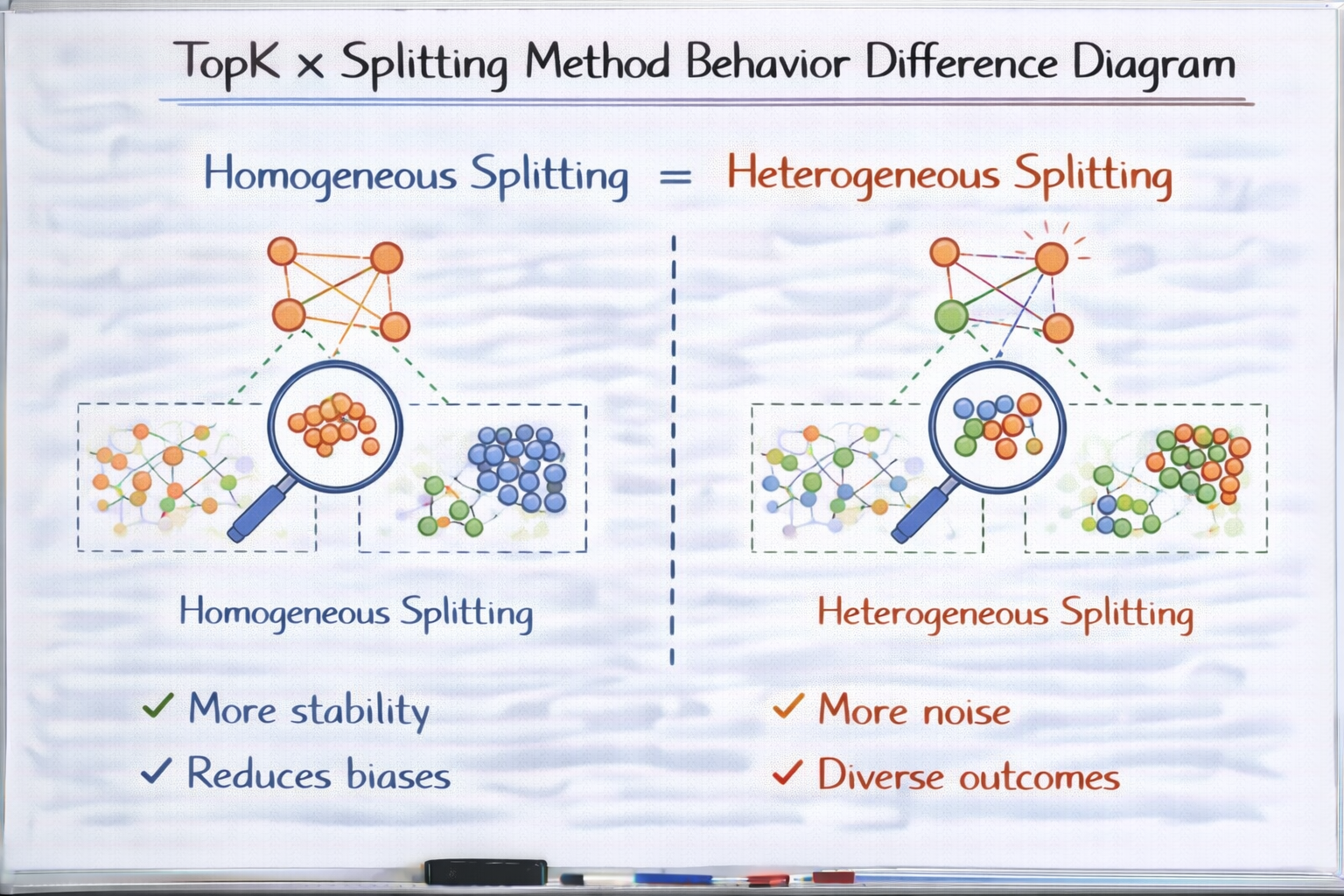
TopK × 切分方式 行为差异
第八层:一个极简伪代码,看责任是怎么被提前决定的
python
# 语义切分
chunks = semantic_split(document)
# chunk 已被 embedding 判定"语义完整"
# 结构切分
chunks = structural_split(document)
# chunk 只是原文片段这两行代码的差异在于:
-
第一种:
chunk 本身就带着"理解假设"
-
第二种:
chunk 只是原始材料
后面你再怎么 rerank、再怎么 prompt,
都已经是在这个前提之上修修补补。
第九层:什么时候语义切分是"更合理的选择"
说清楚风险,不代表否定它。
语义切分在以下场景中,往往是合适的:
- 知识点高度独立
- 文档结构本身混乱
- 内容天然是"平铺式"的
- 错误成本相对低
一句话总结:
当"适用范围错误"不是主要风险时,
语义切分可以提高效率。
第十层:什么时候结构切分是"更安全的选择"
结构切分更适合:
- 强规则文档
- 有大量条件、例外
- 法规、流程、说明书
- 错误成本高的场景
因为它的核心优势是:
不替你理解,
也不替你犯错。
一个非常实用的判断问题(强烈建议)
在你决定用哪种切分方式前,可以问自己一句话:
如果模型答错了,
我更希望错误来自
"没看到",
还是
"看错了"?
- "没看到" → 结构切分
- "看错了" → 语义切分风险更大
这个问题,比任何指标都重要。
很多团队在 RAG 项目中选择语义切分,是因为它在早期 demo 中更"好看",但长期风险往往被低估。用LLaMA-Factory online对比不同切分策略下的模型输出,更容易判断:你的系统是在"提前理解",还是在"诚实暴露不确定性"。
总结:切分方式,决定系统将以什么方式犯错
我用一句话,把这篇文章彻底收住:
语义切分和结构切分的区别,
不在于谁更聪明,
而在于:
谁替你做了决定。
当你开始:
- 把切分当成"责任分配"
- 而不是"文本处理"
- 在系统早期就思考"错误形态"
你才真正开始工程化地设计 RAG 系统。