文章目录
-
- [1. 引言:Redis 慢,真的慢吗?](#1. 引言:Redis 慢,真的慢吗?)
- [2. Redis Pipeline:减少 RTT 的利器](#2. Redis Pipeline:减少 RTT 的利器)
-
- [2.1 什么是 Pipeline](#2.1 什么是 Pipeline)
- [2.2 Pipeline 的工作原理](#2.2 Pipeline 的工作原理)
- [2.3 Pipeline 示例(Java)](#2.3 Pipeline 示例(Java))
- [2.4 Pipeline 的优点与局限](#2.4 Pipeline 的优点与局限)
- [3. Redis Lua 脚本:原子操作的终极方案](#3. Redis Lua 脚本:原子操作的终极方案)
-
- [3.1 什么是 Lua 脚本](#3.1 什么是 Lua 脚本)
- [3.2 Lua 脚本的执行特性](#3.2 Lua 脚本的执行特性)
- [3.3 Lua 脚本示例:库存扣减](#3.3 Lua 脚本示例:库存扣减)
- [3.4 Lua 脚本的优点与代价](#3.4 Lua 脚本的优点与代价)
- [4. Pipeline vs Lua 脚本:核心对比](#4. Pipeline vs Lua 脚本:核心对比)
- [5. Pipeline + Lua:可以一起用吗?](#5. Pipeline + Lua:可以一起用吗?)
- [6. 常见应用场景对比](#6. 常见应用场景对比)
-
- [Pipeline 适合:](#Pipeline 适合:)
- [Lua 脚本适合:](#Lua 脚本适合:)
- [7. 为什么不用事务(MULTI / EXEC)?](#7. 为什么不用事务(MULTI / EXEC)?)
- [8. 实战建议](#8. 实战建议)
- [9. 一个常见误区](#9. 一个常见误区)
- [10. 总结](#10. 总结)
- 参考

1. 引言:Redis 慢,真的慢吗?
很多人在使用 Redis 时会抱怨:
"Redis 明明是内存数据库,为什么还是感觉慢?"
但真正的问题往往不在 Redis 本身,而在于:
- 网络 RTT(往返延迟)
- 多次请求 / 响应
- 非原子操作带来的并发问题
一个 Redis 命令的执行可以简化为以下 4 步:
- 发送命令;
- 命令排队;
- 命令执行;
- 返回结果。
其中,第 1 步和第 4 步耗费时间之和称为 Round Trip Time(RTT,往返时间),也就是数据在网络上传输的时间。
Redis 为此提供了两种重要机制:
- Pipeline(管道)
- Lua 脚本
它们分别从 性能 和 一致性 两个维度解决问题。
2. Redis Pipeline:减少 RTT 的利器
2.1 什么是 Pipeline
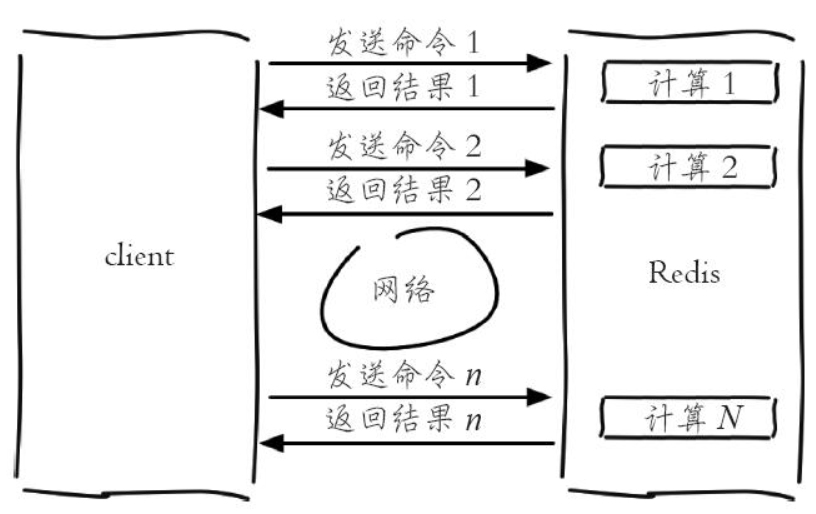
Redis 是典型的请求-响应模型:
plain
Client → Command → Redis → Response → Client如果你需要执行 1000 条命令:
- 1000 次网络往返
- RTT 成本远大于命令执行时间
没有pipeline的话,执行n次指令如下。
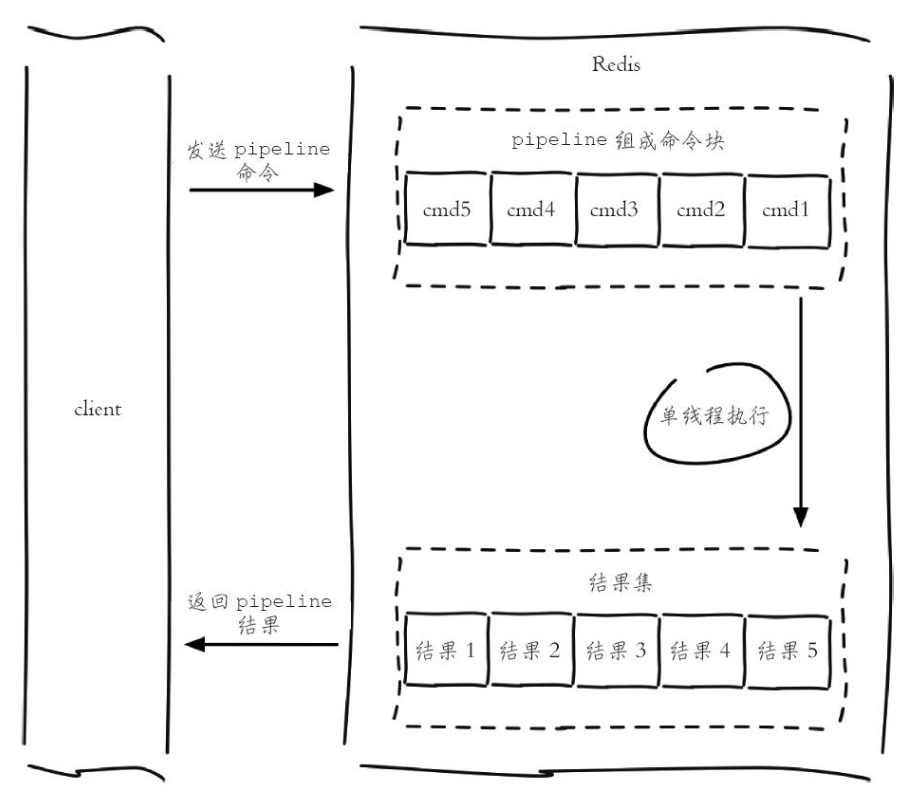
Pipeline 的核心思想是:
一次性发送多条命令,批量接收结果。
使用pipeline后如下
2.2 Pipeline 的工作原理
plain
Client → cmd1, cmd2, cmd3, ... → Redis
Client ← res1, res2, res3, ... ← Redis特点:
- Redis 仍然顺序执行命令
- 只是减少了网络交互次数
2.3 Pipeline 示例(Java)
java
List<Object> result = redisTemplate.executePipelined(
(RedisCallback<Object>) connection -> {
for (int i = 0; i < 1000; i++) {
connection.incr(("key:" + i).getBytes());
}
return null;
}
);2.4 Pipeline 的优点与局限
优点:
- 大幅减少 RTT
- 提升吞吐量
- 实现简单
局限:
- ❌ 不保证原子性
- ❌ 过程中无法获取中间结果
- ❌ 单个 Pipeline 过大会占用大量内存
最佳实践:
Pipeline虽然好用,但是每次Pipeline组装的命令个数不能没有节制,否则一次组装Pipeline数据量过大,一方面会增加客户端的等待时间,另一方面会造成一定的网络阻塞,可以将一次包含大量命令的Pipeline拆分成多次较小的Pipeline来完成。
3. Redis Lua 脚本:原子操作的终极方案
3.1 什么是 Lua 脚本
Redis 支持通过 Lua 脚本:
bash
EVAL script numkeys key1 key2 ... arg1 arg2 ...Redis 保证:
Lua 脚本在执行期间是原子性的。
3.2 Lua 脚本的执行特性
- 单线程执行
- 执行期间不会被其他命令打断
- 可以读写多个 key
这使得 Lua 非常适合:
- 复杂逻辑
- 原子操作
- 高并发控制
3.3 Lua 脚本示例:库存扣减
lua
local stock = redis.call("GET", KEYS[1])
if tonumber(stock) <= 0 then
return -1
end
redis.call("DECR", KEYS[1])
return 1执行:
bash
EVAL script 1 stock_key3.4 Lua 脚本的优点与代价
优点:
- 原子性保证
- 减少网络交互
- 逻辑集中在 Redis
代价:
- Lua 调试成本高
- 脚本过长可能阻塞 Redis
- 不适合复杂业务逻辑
4. Pipeline vs Lua 脚本:核心对比
| 维度 | Pipeline | Lua 脚本 |
|---|---|---|
| 主要目标 | 提升性能 | 保证原子性 |
| 网络交互 | 批量 | 单次 |
| 原子性 | ❌ | ✅ |
| 适合场景 | 批量读写 | 复杂事务 |
| 风险点 | 内存占用 | 阻塞 Redis |
5. Pipeline + Lua:可以一起用吗?
答案是:可以,但意义不大。
原因:
- Lua 本身就是一次请求
- Pipeline 对 Lua 的收益有限
但在某些场景下,可以:
- Pipeline 批量执行多个 Lua(谨慎)
6. 常见应用场景对比
Pipeline 适合:
- 批量缓存预热
- 批量统计更新
- 离线数据同步
Lua 脚本适合:
- 秒杀库存扣减
- 分布式锁
- 计数器限制
- 幂等校验
7. 为什么不用事务(MULTI / EXEC)?
Redis 事务:
- 不支持回滚
- 不保证隔离级别
- 性能不如 Lua
因此在工程实践中:
Lua > Transaction > Pipeline
8. 实战建议
- 性能问题先考虑 Pipeline
- 一致性问题优先 Lua
- Lua 脚本要短小、可控
- Pipeline 分批提交,避免 OOM
- 脚本尽量使用
EVALSHA
9. 一个常见误区
Pipeline 能提高性能,但不能解决并发一致性问题。
10. 总结
Redis 提供的 Pipeline 和 Lua 脚本,本质上解决的是两类问题:
- Pipeline:减少网络 RTT,提高吞吐
- Lua:保证原子性,承载复杂逻辑
要快用 Pipeline,要准用 Lua。
参考
Redis 管道、事务、Lua 脚本对比Redis 提供三种将客户端多条命令打包发送给服务端执行的方式: Pipelin - 掘金