Leveraging AI Algorithms for Electronic Warfare Data Processing

摘要
在现代军事行动中,实时快速处理和分析海量传感器数据的能力至关重要。这一点对于电子战(EW)系统而言尤为突出,该类系统严重依赖复杂算法进行信号分析。实现数据的实时处理与分析是一项重大挑战------传感器数据的复杂性和体量不断增加,常常导致瓶颈问题,阻碍及时决策并影响任务成功。传统数据处理方法在吞吐量、延迟和资源利用率方面存在不足,难以满足电子战系统的需求。
然而,更值得关注的是算法本身也正变得愈发庞大和复杂。许多工程团队缺乏应对这种复杂性的专业知识,这推动了对专注于算法加速/优化的专业人才的需求。
本白皮书探讨了算法优化的关键作用:通过为国防客户加速电子战算法,以更少的资源消耗实现更优性能,从而将原始数据实时转化为可操作的洞察。同时,本文还阐述了如何通过代码成熟化、性能提升和功耗降低来提高这些算法的技术成熟度等级(TRL),使其能够在更贴近实际应用的电子战硬件上运行,而非仅限于实验室环境。
系统架构师和设计工程师将通过本白皮书了解到:
- 军事领域对实时数据处理和传感器融合的需求如何推动创新;
- 军事网络中数据过载的挑战,以及确定性数据传输对任务关键型应用的重要性;
- 通过优化人工智能(AI)算法和先进处理技术增强电子战系统的实用解决方案;
- 算法优化的实际案例,这些案例展示了在性能和资源利用率方面的显著提升;
- 算法优化的优势,包括吞吐量提高、延迟降低和效率提升;
- 将研究级算法转化为高性能实时应用的流程。
算法与处理挑战
传统数据处理方法和算法在满足电子战系统对吞吐量、延迟和资源利用率的要求方面存在显著局限性。这些约束可能严重影响任务成功。传感器数据的复杂性和体量不断增加,进一步加剧了这些挑战,使得传统算法难以跟上节奏。
传统数据处理面临的挑战包括:
- 吞吐量:快速处理大量数据的能力往往不足,导致延迟;
- 延迟:数据处理和分析所需时间过长,阻碍实时决策;
- 资源利用率:计算资源利用效率低下,可能导致功耗增加和处理能力受限。
然而,最严峻的挑战在于算法开发。越来越多的计算复杂型算法需要将原始数据实时转化为可操作的洞察,许多具有潜力的算法尚未达到实时吞吐量和延迟要求。
这些算法涵盖从神经网络到统计建模的各类方法,往往耗时且消耗大量资源。许多仅处于研究阶段的算法虽在功能实现上经过优化,但速度和资源需求仍处于次要考虑地位。
算法开发人员可能缺乏将这些流程充分发挥潜力所需的工程专业知识,而他们的时间本可以更好地用于算法的进一步创新。工程团队能够对这些算法的软件实现进行优化,并将其移植到图形处理器(GPU)或现场可编程门阵列(FPGA)上,从而提高吞吐量、降低延迟,使其适用于实时应用场景。
为解决这些问题,迫切需要能够实现实时数据处理的改进型人工智能算法。对这些算法进行优化可以显著提高吞吐量、减少延迟并提升资源利用率。
算法分析与优化
第一步是深入理解算法。DornerWorks团队通过与算法开发人员合作,收集算法的基准性能数据,评估其当前的吞吐量、延迟和资源利用率。
随后,将使用测试数据验证算法经修改后的功能。确定实时实现所需的吞吐量和延迟要求,并明确目标硬件的规格以界定资源利用率要求(见图1)。
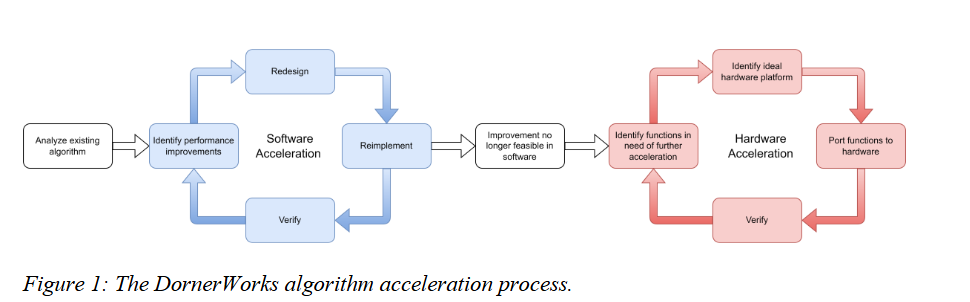
图1:DornerWorks算法加速流程
软件和硬件加速优化通过完善代码、提升性能和降低功耗实现。
软件加速
这是一个迭代过程。在尝试将算法移植到其他硬件平台之前,DornerWorks工程师会先在中央处理器(CPU)运行的软件中尽可能优化算法。由于算法中可能仅有部分需要进行硬件加速,因此确保算法其余部分在软件中具备最优性能至关重要。
如果算法尚未采用C或C++语言编写,将其转换为C++语言------这不仅因为C/C++语言比Python或MATLAB等其他语言运行速度更快,还因为它能更清晰地反映内存中的运行机制,便于后续加速。此外,C/C++代码更易于移植到高级综合(HLS)工具,从而缩短FPGA开发时间。
该迭代过程的第一步是识别算法中可提升性能的潜在空间,随后团队将重新设计算法架构以充分利用这些性能提升点。方案确定后,将根据新架构重新实现算法。最后阶段是验证性能提升效果,并与算法开发人员共同确认算法功能的完整性。
此过程不断重复,直至确定无法通过软件进一步实现算法加速。
硬件加速
硬件加速过程同样采用迭代方式。第一步是对算法进行性能分析,找出在中央处理器(CPU)上运行效率低下的函数。团队将检查这些运行不佳的代码,并确定最适合进一步加速的硬件平台------FPGA或GPU。
将相关代码段移植到选定的硬件平台后,需与原始算法开发人员再次验证算法功能,随后评估算法是否满足吞吐量和延迟要求。如果算法尚未实现实时运行,则重复该过程直至达到足够快的运行速度。
这种加速/优化过程能够提高算法的技术成熟度等级(TRL),使其适用于实际电子战硬件部署,而非仅局限于实验室环境。
实际应用案例
以下三个案例研究重点展示了DornerWorks优化流程的应用效果(客户名称已隐去)。
案例研究1:实时处理算法加速
- 原始实现:处理10秒数据需26分钟,占用24个CPU内核中的15.4个,运行145.2万亿条指令;
- 优化后实现:DornerWorks加速后的方案将处理时间缩短至7秒,仅占用24个CPU内核中的7.2个,运行5040亿条指令。该优化在显著提升性能的同时,降低了资源利用率。
案例研究2:CPU与GPU协同优化
- 原始实现:仅基于CPU的实现处理10秒数据需33分钟;
- 优化后实现:通过结合CPU和GPU,DornerWorks将处理时间缩短至9秒。这种混合方案证明了软件与硬件优化技术相结合的有效性。
案例研究3:基于现场可编程门阵列(FPGA)的功耗效率优化
- AI图像分类器:在英伟达RTX 3090 GPU上运行时功耗为332瓦;在AMD ZCU208 FPGA上运行相同算法时,功耗仅为15.5瓦,且帧率(FPS)性能相当。这一结果表明,通过FPGA优化可实现显著的功耗节省和效率提升。
利用现场可编程门阵列(FPGA)
在优化工作中,FPGA已成为CPU的有力替代方案。与GPU相比,FPGA功耗显著更低,非常适合电力资源有限的边缘计算场景(如上述案例研究3所示的功耗节省效果)。
其较低的功耗意味着发热量减少,这对于维持电子战系统的可靠性和使用寿命至关重要。
作为AMD高级合作伙伴,DornerWorks拥有丰富的FPGA开发经验,并利用AMD先进人工智能引擎(AIE)实现算法优化,以满足实时处理需求(见图2)。

图2:DornerWorks工程师可协助您将研究级算法转化为可部署的实时应用
未来方向与创新
算法优化为电子战系统设计人员带来了诸多优势,而DornerWorks认为还有更多潜力有待挖掘,主要包括以下几个方面:
先进人工智能与机器学习(ML)
先进人工智能和机器学习技术的融合将彻底改变电子战系统。这些技术能够增强信号处理、威胁检测和决策能力,针对不断演变的威胁提供更稳健、更具适应性的响应。DornerWorks正积极探索这些创新,以进一步优化电子战算法。
边缘计算
在军事应用中,边缘计算的重要性日益凸显------在数据源头附近进行处理可减少延迟,提高实时决策能力。FPGA凭借其功耗效率高、发热量低的特点,成为边缘计算的理想选择。DornerWorks专注于将FPGA应用于边缘场景,以提升电子战系统的性能和可靠性。
量子计算
尽管仍处于起步阶段,量子计算有望显著加速复杂计算和数据处理任务。DornerWorks正密切关注量子计算的发展动态,评估其在电子战系统和算法优化中的适用性。
跨域应用
为电子战系统开发的技术和方法可应用于其他军事领域,如网络安全、通信和自主系统。DornerWorks正探索这些跨域应用,以将优化算法的优势扩展到各类军事行动中。
持续研究与合作
与学术机构、行业合作伙伴和国防组织的持续研究与合作,对于保持技术领先地位至关重要。DornerWorks致力于持续的研究工作和合作关系,以推动创新并提升电子战系统的能力。
结论
DornerWorks凭借其在FPGA开发和算法优化方面的专业知识,在将研究级算法转化为高性能、可部署于任务关键型环境的实时应用方面发挥着关键作用。
成功加速复杂算法需要实时系统算法实现工程师与算法设计专家之间的协作。
DornerWorks将与您现有的团队合作,将您的应用加速转化为实时系统,为您的客户创造价值。如需了解更多信息,请访问www.DornerWorks.com。
专业术语表
| 英文术语 | 中文译法 | 说明 |
|---|---|---|
| Electronic Warfare (EW) | 电子战(EW) | 军事领域核心概念,指利用电磁频谱进行的对抗行动 |
| Algorithm Optimization | 算法优化 | 提升算法性能、降低资源消耗的技术过程 |
| Technology Readiness Level (TRL) | 技术成熟度等级(TRL) | 评估技术从概念到实际应用成熟度的标准 |
| Throughput | 吞吐量 | 单位时间内处理的数据量,衡量系统处理能力的关键指标 |
| Latency | 延迟 | 数据输入到结果输出之间的时间间隔 |
| Resource Utilization | 资源利用率 | 计算资源(如CPU、内存)的使用效率 |
| Graphics Processing Unit (GPU) | 图形处理器(GPU) | 擅长并行计算的硬件设备,常用于数据加速处理 |
| Field Programmable Gate Array (FPGA) | 现场可编程门阵列(FPGA) | 可重构硬件平台,兼具高性能与低功耗优势 |
| Central Processing Unit (CPU) | 中央处理器(CPU) | 计算机系统的核心运算单元 |
| High Level Synthesis (HLS) | 高级综合(HLS) | 将高级语言代码转换为硬件描述语言的工具/技术 |
| Sensor Data | 传感器数据 | 由各类传感器采集的原始数据 |
| Sensor Fusion | 传感器融合 | 整合多个传感器数据以提高信息可靠性的技术 |
| Deterministic Data Transmission | 确定性数据传输 | 保证数据传输延迟和抖动在预设范围内的传输方式 |
| Edge Computing | 边缘计算 | 在数据产生源头附近进行计算处理的架构 |
| Quantum Computing | 量子计算 | 基于量子力学原理的新型计算技术 |
| Cross-Domain Applications | 跨域应用 | 可在多个不同领域复用的技术或方法 |
| Artificial Intelligence (AI) | 人工智能(AI) | 模拟人类智能的计算机技术 |
| Machine Learning (ML) | 机器学习(ML) | 人工智能的分支,专注于让系统从数据中学习并改进 |
| AI Image Classifier | AI图像分类器 | 利用人工智能技术对图像进行类别识别的算法/系统 |
| Frames Per Second (FPS) | 帧率(FPS) | 单位时间内处理的图像帧数,衡量图像处理速度的指标 |
| Advanced AI Engines (AIEs) | 先进人工智能引擎(AIE) | AMD推出的用于加速AI任务的专用硬件模块 |