PageIndex:基于推理的文档索引系统
在处理长篇专业文档时,传统的向量数据库检索常常无法满足用户需求。PageIndex作为一款创新的文档索引系统,以其基于推理的检索技术脱颖而出,致力于提升对复杂文档的理解与处理效率。
什么是PageIndex?
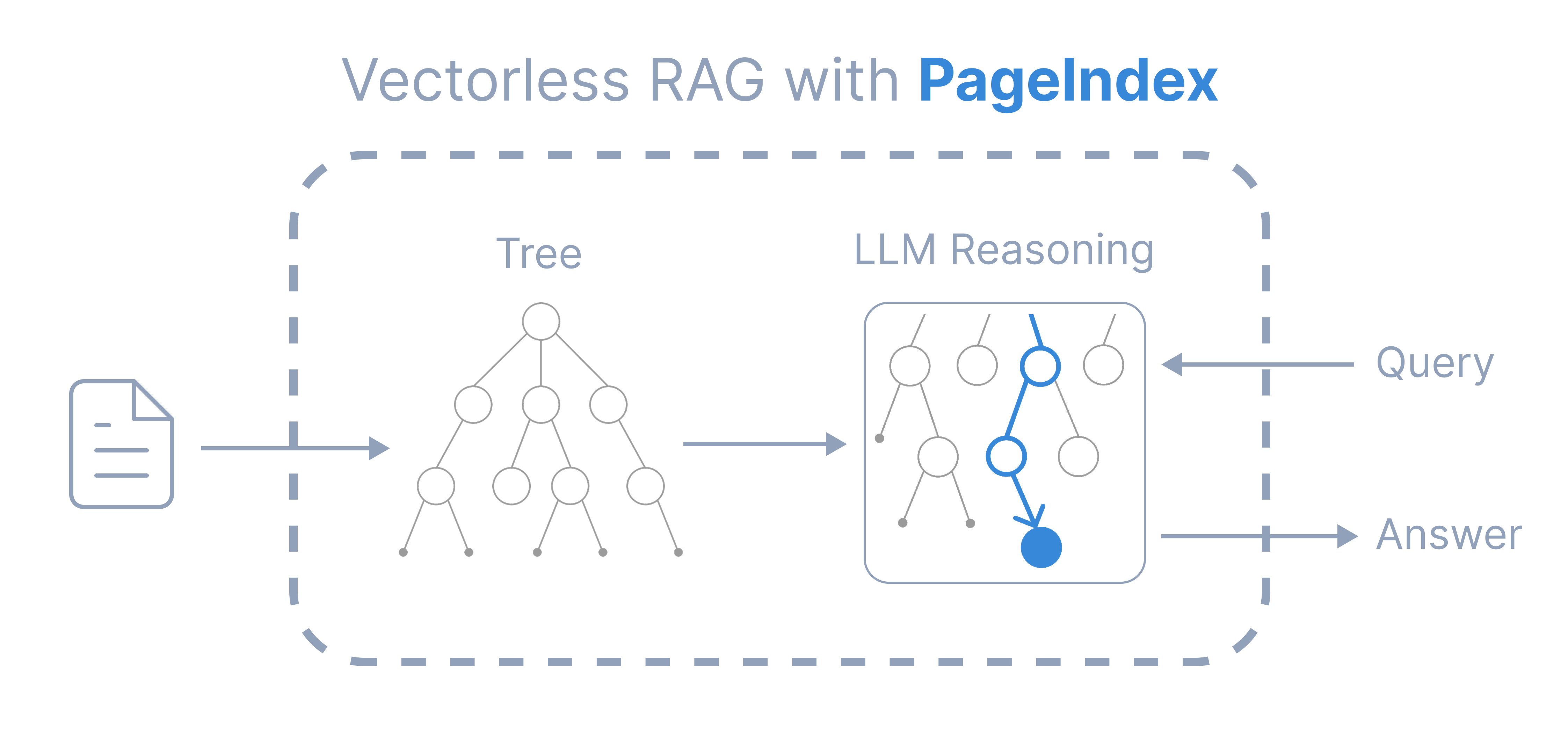
PageIndex是一个无向量 、基于推理的RAG (Retrieval Augmented Generation)系统。它通过构建文档的层次树索引 ,使大型语言模型(LLMs)能够基于该索引进行推理,从而实现上下文感知的检索。这种方式模拟了人类专家在处理复杂文档时的思维过程,避免了依赖语义相似度的局限性。
核心功能
与传统向量基础的RAG相比,PageIndex的主要优势包括:
- 无向量数据库:利用文档结构和LLM的推理能力进行检索,而不是向量相似度搜索。
- 无切块处理:文档以自然段落组织,而非人为切分。
- 类人检索:模拟人类在复杂文档中提取知识的过程。
- 更好的可解释性和追溯性:基于推理的检索结果可追溯,提供相应的页面和章节引用。
应用场景
PageIndex特别适合需要多步推理的专业领域,如:
- 金融报告:如SEC文件和财务披露,可以精确提取关键信息。
- 法律文件:提供对法律文书的深入分析。
- 学术书籍:帮助学术研究人员快速获取所需信息。
以下是PageIndex生成的文档树结构示例,展示了如何将长篇PDF转换为语义树结构,以便大型语言模型高效处理。
jsonc
{
"title": "Financial Stability",
"node_id": "0006",
"start_index": 21,
"end_index": 22,
"summary": "The Federal Reserve ...",
"nodes": [
{
"title": "Monitoring Financial Vulnerabilities",
"node_id": "0007",
"start_index": 22,
"end_index": 28,
"summary": "The Federal Reserve's monitoring ..."
},
{
"title": "Domestic and International Cooperation and Coordination",
"node_id": "0008",
"start_index": 28,
"end_index": 31,
"summary": "In 2023, the Federal Reserve collaborated ..."
}
]
}
使用方法
要使用PageIndex生成文档的树结构,请按照以下步骤:
1. 安装依赖
bash
pip3 install --upgrade -r requirements.txt2. 设置OpenAI API密钥
在根目录创建.env文件,并添加你的API密钥:
bash
CHATGPT_API_KEY=your_openai_key_here3. 运行PageIndex处理PDF
bash
python3 run_pageindex.py --pdf_path /path/to/your/document.pdf可选参数:
--model OpenAI model to use (default: gpt-4o-2024-11-20)
--toc-check-pages Pages to check for table of contents (default: 20)
--max-pages-per-node Max pages per node (default: 10)
--max-tokens-per-node Max tokens per node (default: 20000)
--if-add-node-id Add node ID (yes/no, default: yes)
--if-add-node-summary Add node summary (yes/no, default: yes)
--if-add-doc-description Add doc description (yes/no, default: yes)对于Markdown文件的支持,你可以使用-md_path标志生成树结构:
bash
python3 run_pageindex.py --md_path /path/to/your/document.md实践案例
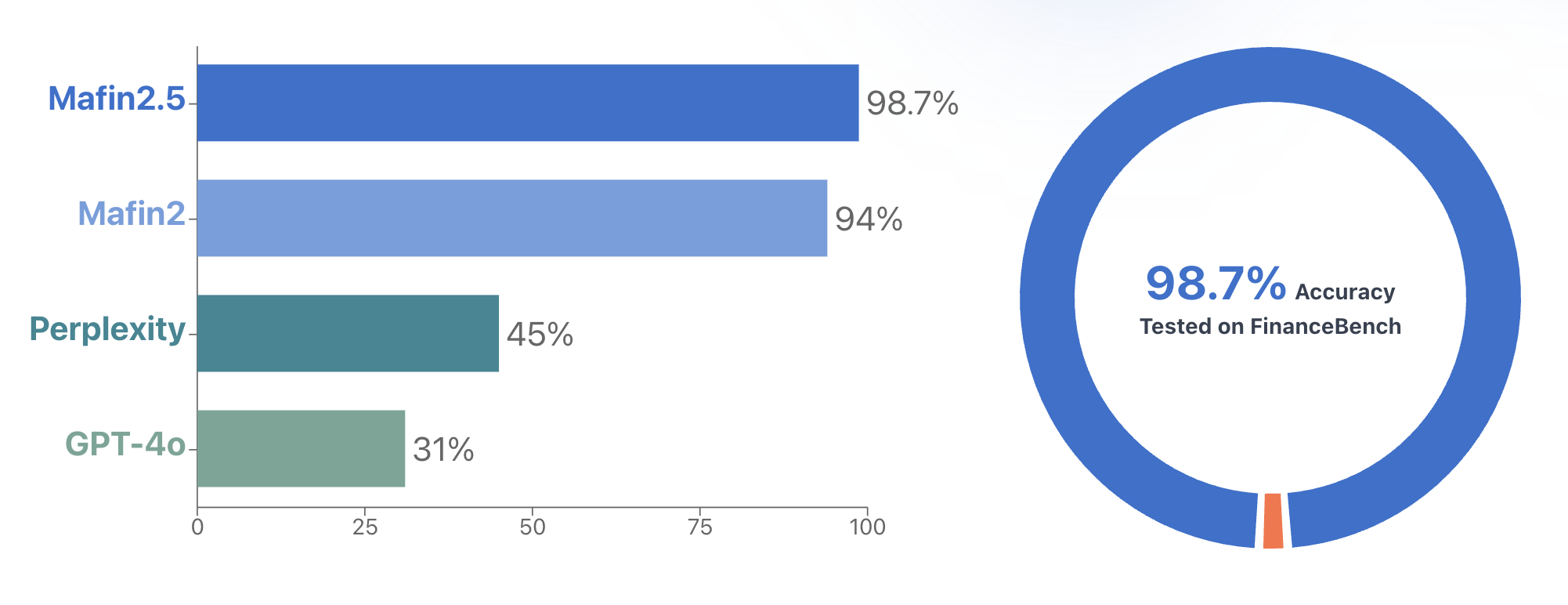
PageIndex在金融文档分析方面表现尤为突出,其推理基础的RAG系统Mafin 2.5在FinanceBench基准测试中达到**98.7%**的准确度,显著超越传统的基于向量的RAG系统。通过层次索引和推理驱动的检索,PageIndex使得复杂金融报告的精确导航和关键信息提取成为可能。
部署选项
资源和学习
- Cookbooks:提供实用的示例和高级用例。
- Tutorials:包含文档搜索和树搜索的实用指南。
- Blog:技术文章、研究见解和产品更新。
同类项目
从功能和特点上来看,PageIndex与其他开源项目,如Haystack和Langchain,存在一定的差异。Haystack强调集成检索与生成能力,适合多种文档类型,而Langchain则专注于串联大型语言模型的应用场景,具有高灵活性和适应性。然而,PageIndex独特的推理基础和无向量检索系统,使其在金融和法律文档分析上表现出更优的效果,尤其适用于需要多步骤推理的复杂文档处理。