1. 核心原理:配置优先级 (Configuration Precedence)
Spark 的配置加载遵循严格的覆盖(Override)机制。当同一个参数在多个地方被设置时,Spark 会按照以下顺序生效(由高到低):
| 优先级 | 配置方式 | 典型来源 | 说明 |
|---|---|---|---|
| 1 (最高) | 代码显式配置 | SparkConf.set() / SQL SET |
硬编码。在代码运行时刻动态设置,覆盖所有外部配置。不推荐在生产代码中写死资源参数(如内存大小)。 |
| 2 | 提交命令参数 | spark-submit --conf / Flags |
动态传参。生产环境标准方式,运维人员可通过命令行灵活调整资源,不侵入代码。 |
| 3 | 配置文件 | spark-defaults.conf |
全局默认 。位于 $SPARK_HOME/conf。集群管理员设置的"底线"或通用配置。 |
| 4 (最低) | 系统/源码默认 | Spark 源码 / spark-env.sh |
系统兜底。若以上均未配置,则使用源码中的默认值(如 executor 默认 1g)。 |
官方文档依据
-
文档地址 : Apache Spark Configuration - Dynamically Loading Spark Properties
-
原文引用:
"Properties set directly on the SparkConf take highest precedence, then flags passed to spark-submit or spark-shell, then options in the spark-defaults.conf file."

2. 部署模式差异:YARN vs Standalone
虽然优先级规则通用,但不同资源管理器(Cluster Manager)下的资源表现不同。
2.1 YARN 模式 (企业最常用)
Spark 客户端向 YARN ResourceManager 申请容器(Container),YARN 负责调度。
-
资源限制 : 配置的资源(Memory/Cores)绝对不能超过 YARN 容器的最大允许值(由
yarn-site.xml中的yarn.scheduler.maximum-allocation-mb等决定)。否则任务无法启动。 -
核心参数:
-
--num-executors: 明确申请多少个容器(若开启动态分配spark.dynamicAllocation.enabled则此参数可能被忽略)。 -
--executor-memory: 每个容器的 JVM 堆内存大小。 -
--executor-cores: 每个容器的 CPU 核数(建议 2-5 核,避免过大导致 GC 压力)。
-
内存计算公式 (防坑指南) : YARN 实际扣除的资源量并非仅仅是 executor-memory,而是包含了堆外内存:
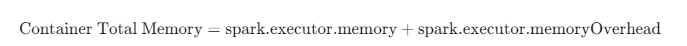
-
Overhead (堆外内存) : 默认为
executor-memory的 10%,且最小值为 384MB。 -
风险: 如果不预留 overhead,任务可能会因物理内存超标被 YARN 直接 Kill。
2.2 Standalone 模式 (独立集群)
Spark 自带的调度器,资源管理较为粗犷,具有**"贪婪"**特性。
贪婪机制 : 默认情况下,Standalone 模式下的应用会尽可能占用集群中所有 Worker 的所有空闲 Core,导致后续任务无法提交。
核心参数:
-
spark.cores.max(或--total-executor-cores): 必须设置。限制当前应用在整个集群能使用的总核数。 -
spark.executor.cores: 定义单个 Executor 占用的核数。
- Executor 数量计算:
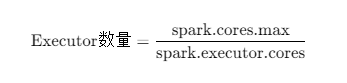
- Worker 限制 : 物理节点上限由
spark-env.sh中的SPARK_WORKER_CORES和SPARK_WORKER_MEMORY决定。
2.3 模式对比总结
| 特性 | YARN 模式 | Standalone 模式 |
|---|---|---|
| 资源管理者 | YARN ResourceManager | Spark Master |
| 总核数控制 | num-executors * executor-cores |
必须显式设置 spark.cores.max,否则贪婪占用 |
| 单体核数 | --executor-cores |
--executor-cores (若不设则占用单节点所有核) |
| 内存管理 | 严格限制 (Heap + Overhead),超用即 Kill | 相对宽松,主要受限于 Worker 总内存 |
| Driver 资源 | Cluster模式下需预先申请 | 运行在提交节点,受机器物理资源限制 |
3. 测试与验证方案
以下脚本用于验证优先级规则及运行时行为。请在安装了 Spark 客户端的网关机上运行。
3.1 验证一:代码优先级 > 命令行参数 (Python)
目的: 证明即使命令行指定了 1 核,代码中写死的 4 核依然胜出。
脚本 resource_priority_test.py:
python
from pyspark import SparkConf, SparkContext
import time
# 1. 在代码中"硬编码"配置:强制指定 Executor 核数为 4
conf = SparkConf() \
.setAppName("Resource_Priority_Test") \
.set("spark.executor.cores", "4")
sc = SparkContext(conf=conf)
# 2. 获取实际生效的配置
actual_cores = sc.getConf().get("spark.executor.cores")
actual_memory = sc.getConf().get("spark.executor.memory", "Default (1g)")
print("\n" + "="*50)
print(f"【测试结果验证】")
print(f"代码中设置的 Core 数: 4")
print(f"命令行传入的 Core 数: (见提交命令)")
print(f"实际生效的 Core 数: {actual_cores} (预期: 4)")
print(f"实际生效的 Memory: {actual_memory}")
print("="*50 + "\n")
# 3. 保持运行 60秒,以便在 Spark UI 查看
time.sleep(60)
sc.stop()
提交命令 (制造冲突):
bash
# 故意在命令行指定 executor-cores 为 1
/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark/bin/spark-submit \
--master yarn \
--deploy-mode client \
--executor-cores 1 \
--executor-memory 2g \
resource_priority_test.py
-
终端打印的 实际生效的 Core 数 应该是 4 (代码胜出)。
-
终端打印的 实际生效的 Memory 应该是 2g (代码没设,命令行生效)。
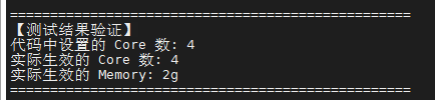
Yarn集群上验证如下:
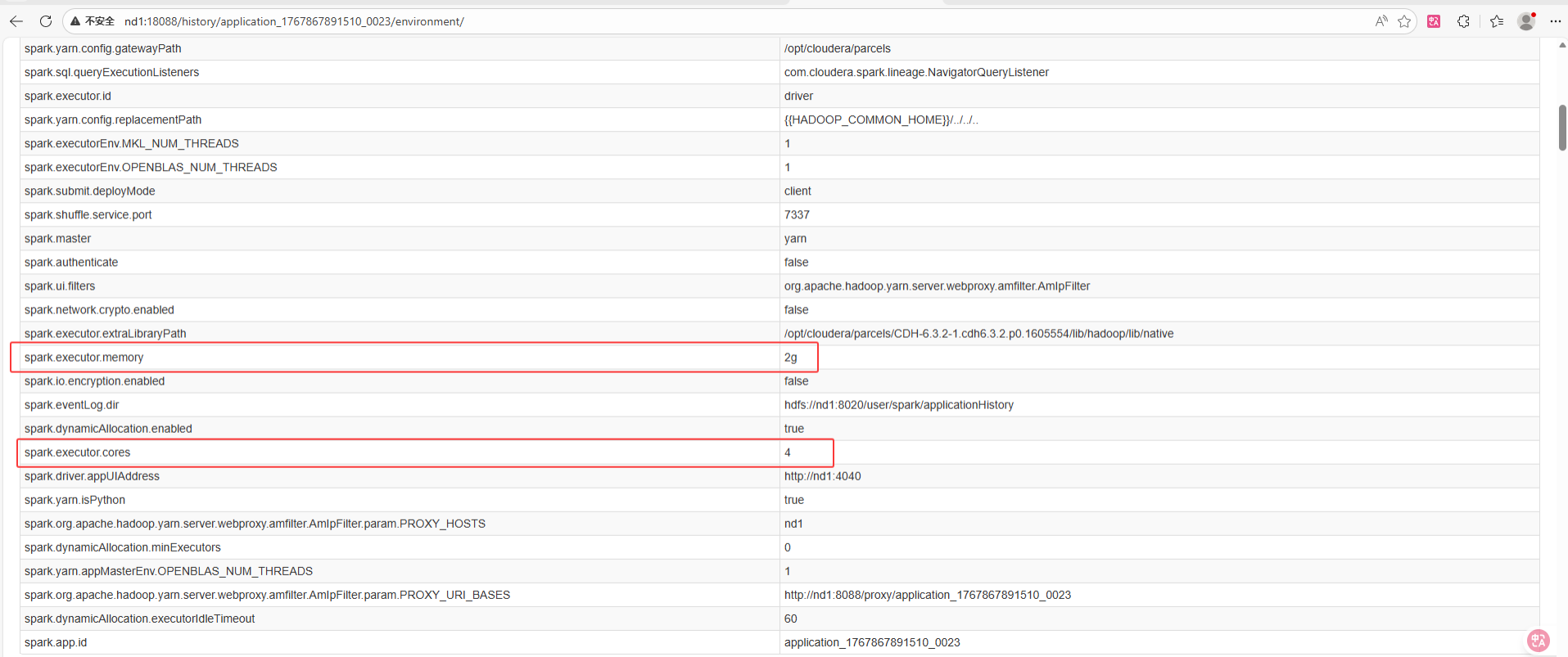
-
现象解读:
-
Core 数:代码中 set("spark.executor.cores", "4") 覆盖了命令行中的 --executor-cores 1。最终 YARN 分配的 Container 是 4 核。
-
Memory:代码中未指定内存,所以 spark-submit 命令行中的 --executor-memory 2g 生效了(这是一种"补缺"或"继承"机制)。
-
-
底层原理:
-
Spark 在启动时,首先解析 spark-submit 的参数构建一个基础 SparkConf。
-
然后执行你的 Python 代码,当代码执行到 new SparkConf().set(...) 时,这些键值对会覆盖 或合并进之前的配置中。
-
最后,使用合并后的配置去初始化 SparkContext 并向 YARN ResourceManager 申请资源。一旦 SparkContext 初始化完成,Container 的规格(Core/Memory)就固定了。
-
补充提示(Driver 资源的特殊情况): 你使用的是 --deploy-mode client。 如果使用的是 --deploy-mode cluster:
-
Executor 配置:依然遵循"代码 > 命令行"。
-
Driver 配置 :命令行优先级更高(或者说代码配置无效)。
- 原因 :在 Cluster 模式下,Driver 是在 AM(ApplicationMaster)中启动的。YARN 必须在运行你的 Python/Java 代码之前就先申请好 Driver 的资源启动它。所以,代码里写的 set("spark.driver.memory", ...) 在 Cluster 模式下通常来不及生效(除非是 Spark 内部参数,而非资源申请参数)。
3.2 测试二:静态资源锁定与动态参数 (Spark Shell)
模拟类似 Flink SQL Client 或 JDBC 长连接的场景。由于CDH 6.3.2环境中未安装 spark-sql CLI 工具,我们使用 spark-shell 调用 SQL API 进行等效验证。
核心验证点:
-
动态参数(如 Shuffle 分区)可以在会话中即时修改生效。
-
静态资源(如 Executor 内存)在 Session 启动后即被锁定,后续的 SET 命令无法改变物理资源。
1. 启动命令:
bash
# 启动 Spark Shell,指定初始资源为 1g
/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark/bin/spark-shell \
--master yarn \
--name "MySparkSQLSession" \
--num-executors 2 \
--executor-memory 1g \
--executor-cores 2 \
--conf spark.sql.shuffle.partitions=200
2. 交互验证 (Scala 模式):
在 scala> 命令行中输入以下代码,模拟 SQL 配置修改:
bash
// 1. 查看当前配置 (应为启动时指定的 1g)
spark.sql("SET spark.executor.memory").show(false)
// 2. 尝试修改动态参数 (Shuffle 分区数),立即生效
spark.sql("SET spark.sql.shuffle.partitions=10")
spark.sql("SET spark.sql.shuffle.partitions").show(false)
// 3. 尝试修改静态资源参数 (虽然命令成功,但物理资源无效)
spark.sql("SET spark.executor.memory=4g")
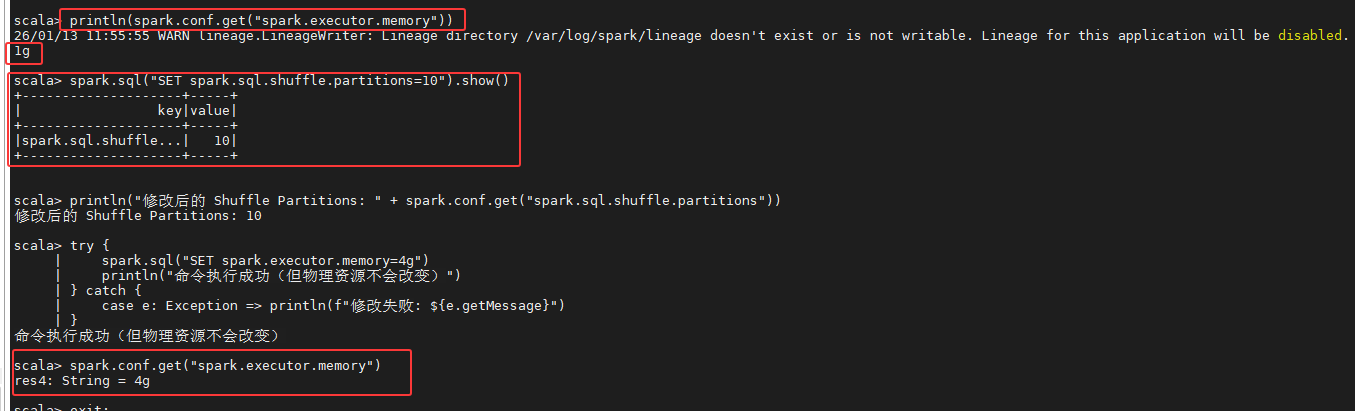
spark.sql("SET spark.executor.memory").show(false)3. 结果验证:
- Spark UI (Environment 页) : 虽然代码通过
SET命令将配置值更新为了4g,但在 Spark UI 的 Executors 标签页中,正在运行的 Executor 内存依然是 1g。
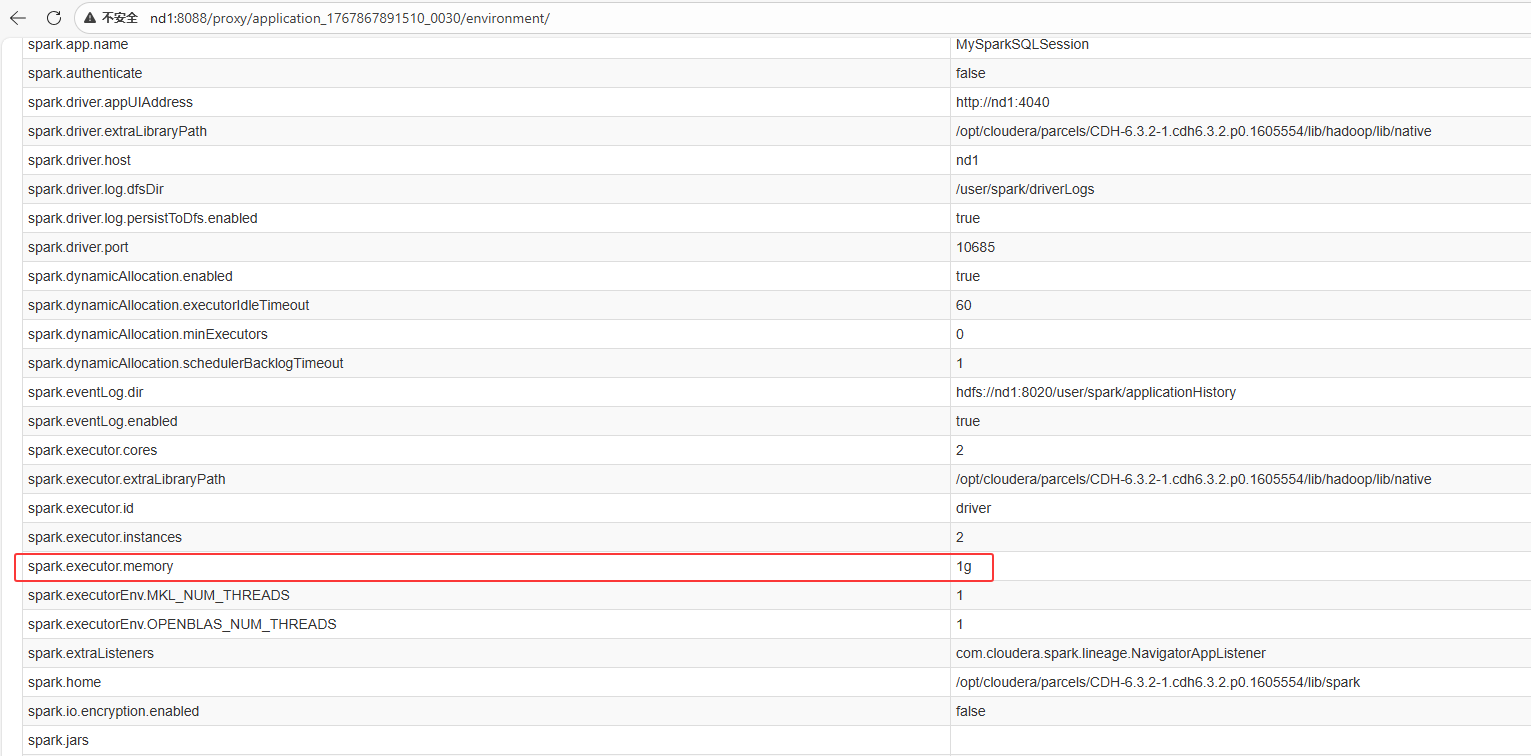
- YARN 资源监控: YARN 上的 Container 规格依然保持启动时的申请值。
4. 现象解读与底层原理:
-
Runtime Config (运行时配置):
-
例如
spark.sql.shuffle.partitions。 -
这类参数控制的是 Driver 端 DAGScheduler 如何划分 Stage 和 Task,不涉及向 YARN 申请物理硬件,因此支持热更新,修改后对后续作业立即生效。
-
-
Static Config (静态配置):
-
例如
spark.executor.memory、spark.executor.cores。 -
原理 :在 YARN 模式下,Executor 本质上是一个运行在 Container 里的 JVM 进程。JVM 的堆内存大小(
-Xmx)是在进程启动的那一刻由启动命令写死的。 -
结论:如果不重启 SparkContext(即重启会话),无法动态扩容单个 Executor 的物理内存。即使开启了动态资源分配(Dynamic Allocation),新增加的 Executor 也是严格按照启动时定义的"模板"来申请的。
-
补充提示(Flink vs Spark 的区别):
-
Flink Session:Flink 的 JobManager 是一个长期服务。提交新 Job 时,可以为该 Job 单独申请新的 Slot 资源,灵活性略高。
-
Spark Session :SparkContext 初始化后,Executor 的规格(单体大小)就被锁定了。虽然可以通过动态分配增加 Executor 的数量 ,但无法改变单个 Executor 的大小。
3.3 测试三:Standalone 资源分配 (Python)
3.3.1 环境准备 (所有节点)
由于 Spark 3.5.7 不再支持 Python 21,你需要确保三台机器(10.x.xx.206, 209, 210)都安装了Python 3。
在每台机器上执行:
bash
sudo yum install -y python3
# 验证安装
python3 --version3.3.2 准备脚本(PriorityTest.py)
在主节点10.x.xx.206 的/home/bigdata/目录下重新创建脚本。为了避免Python 2/3的混合干扰,建议使用纯英文注释或在首行声明编码。
代码内容:
python
# -*- coding: utf-8 -*-
from pyspark import SparkConf, SparkContext
import time
def run_test():
conf = SparkConf()
# Priority 1 (Highest): Code Configuration
# We set cores to 2, which should override 4 (submit) and 6 (conf file)
conf.setAppName("Priority-Test-App-Code-Level")
conf.set("spark.cores.max", "2")
sc = SparkContext(conf=conf)
print("\n" + "="*50)
print("TEST RESULT:")
print("Application ID: " + str(sc.applicationId))
# Get actual effective configuration
actual_cores = sc.getConf().get("spark.cores.max")
print("spark.cores.max (Actual): " + str(actual_cores))
if str(actual_cores) == "2":
print(">>> SUCCESS: Code configuration (Value=2) won!")
else:
print(">>> FAILED: The effective value is " + str(actual_cores))
print("="*50 + "\n")
# Keep running for 60s to check Web UI
print("Wait 60s for Web UI check...")
time.sleep(60)
sc.stop()
if __name__ == "__main__":
run_test()3.3.3 设置配置文件优先级(最低优先级)
编辑主节点 10.x.xx.206 上的$SPARK_HOME/conf/spark-defaults.conf(若没有则从模板中复制cp spark-defaults.conf.template spark-defaults.conf) :
bash
# 【优先级 3:配置文件】 - 设置为 6 核
spark.cores.max 6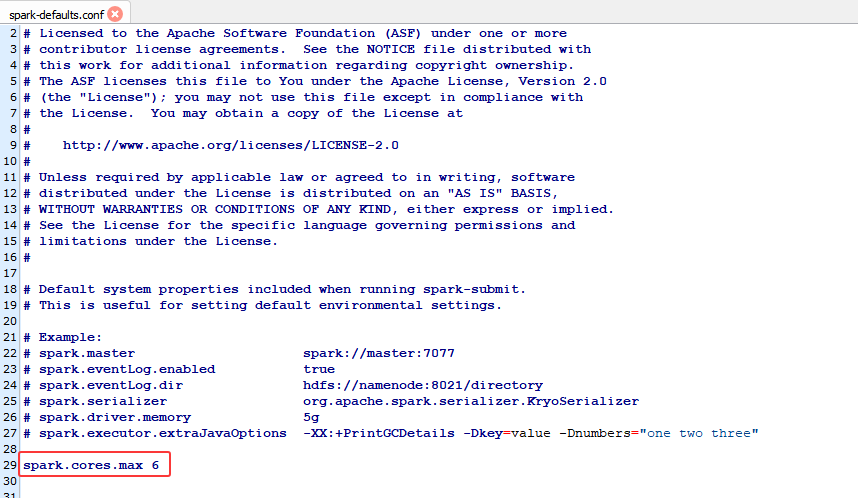
3.3.4 执行提交命令(中等优先级)
在主节点执行以下命令。请注意:
-
指定Python3:通过环境变量强制Spark使用Python 33。
-
Master地址 :使用
7077端口进行通信。 -
提交参数 :设置
--conf spark.cores.max=4。
bash
# 设置 Python3 环境变量
export PYSPARK_PYTHON=/usr/bin/python3
export PYSPARK_DRIVER_PYTHON=/usr/bin/python3
# 提交任务
$SPARK_HOME/bin/spark-submit \
--master spark://10.x.xx.206:7077 \
--conf spark.cores.max=4 \
--name "Priority-Test-Submit-Level" \
/home/bigdata/PriorityTest.py
3.3.5 验证结果
-
结局查看 :脚本会直接打印
spark.cores.max (Actual): 2。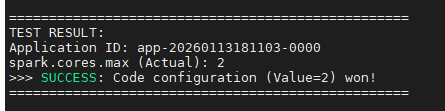
-
网页界面查看:
-
访问
http://10.x.xx.206:8085(根据你的配置,Web UI端口为8085)。 -
找到名为
Priority-Test-App-Code-Level的应用程序。 -
查看Cores 列:如果显示为2 ,则完整验证了优先级顺序:代码 (2) > 提交命令 (4) > 配置文件 (6)。
-

排错提示 :如果 Worker 节点启动任务失败,请检查 Worker 节点的日志,确保每个 Worker 节点也能通过/usr/bin/python3找到 Python 3 解释器。
3.3.6 验证 Standalone 资源计算公式
提交命令:
bash
# 假设集群足够大
/home/bigdata/spark-3.5.7-bin-hadoop3/bin/spark-submit \
--master spark://10.8.16.206:7077 \
--conf spark.cores.max=12 \
--executor-cores 4 \
--class org.apache.spark.examples.SparkPi \
./examples/jars/spark-examples_2.12-3.5.7.jar \
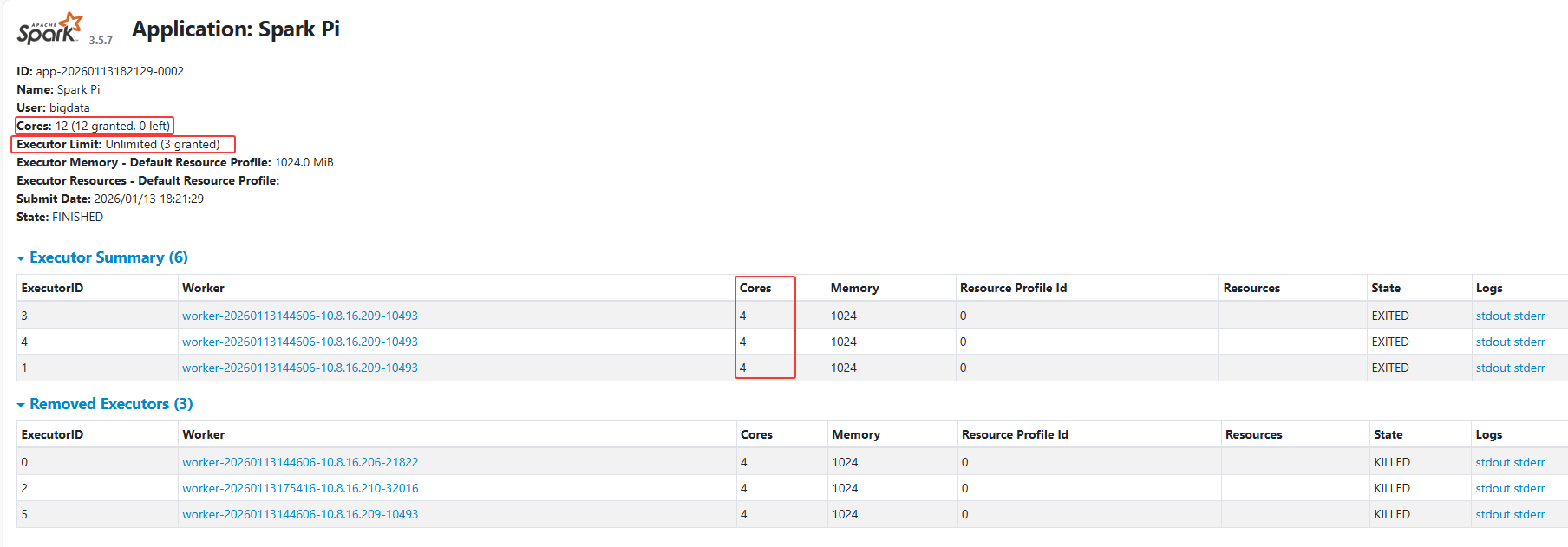
100验证方式:
-
打开 Standalone Master UI (
http://master-ip:8080)。 -
查看 Running Applications。
-
预期该任务会启动 3 个 Executor (12 / 4 = 3)。
4. 进阶:特殊场景说明
4.1Driver 资源的特殊性 (Client vs Cluster)
-
Client 模式 : Driver 运行在提交命令的机器上。
spark-submit命令行中的--driver-memory有效,但代码中的set("spark.driver.memory")无效(因为 JVM 已经启动了)。 -
Cluster 模式 : Driver 运行在集群的 AM 中。
spark-submit命令行的参数用于向 YARN 申请启动 AM 的资源。代码中的配置同样来不及生效。- 结论 : Driver 资源务必在命令行 或配置文件中指定。
4.2 静态配置 vs 运行时配置
-
Static Config (静态) : 如
executor.memory。JVM 启动即固定,Session 期间不可变。 -
Runtime Config (动态) : 如
spark.sql.shuffle.partitions。控制 DAG 生成逻辑,支持 SQLSET热更新。
5. 最佳实践总结
-
避免代码硬编码:
-
错误: conf.set("spark.executor.memory", "4g")。这会导致运维人员无法在不重新编译/修改代码的情况下调整资源。
-
正确: 资源参数应完全剥离,仅在 spark-submit 脚本或调度系统(如 Airflow/DolphinScheduler)中指定。
-
-
YARN 模式规范:
- 明确指定 num-executors、executor-cores (推荐 2-4 核) 和 executor-memory。
-
Standalone 模式防贪婪:
- 务必在 spark-submit 中设置 --total-executor-cores (即 spark.cores.max),防止测试任务挤占生产集群所有资源。
-
SQL 开发: 在 SQL 文件头部使用 SET 命令可以控制 Shuffle 并行度等运行时参数,但基础资源建议在提交脚本中定义。
-
排查工具:
- Spark Web UI -> Environment: 这是检验配置来源的唯一真理。查看 "Resource Profile" 或 "Spark Properties" 表格,可以追溯某个参数到底是来自代码、命令行还是默认文件。