项目简介
本项目是一个基于 PaddleOCR-json 的桌面工具------Umi-OCR 智能重命名助手 。
它通过对两组图片(A 组、B 组)进行 OCR 文字识别与相似度匹配,将 B 组图片自动重命名为 A 组对应的图片名称,适用于:
- 批量图片归档:如教材截图、试卷、文档扫描件等
- 截图整理:自动按页面标题、章节名等文字内容进行匹配命名
- 多来源图片比对:不同来源的同一组图片(例如手机拍照 vs 扫描仪)进行统一命名
识别核心由 PaddleOCR-json_v1.4.1/PaddleOCR-json.exe 提供,本项目的 Python 程序 main.py 负责:
- 启动和管理 OCR 引擎进程
- 并发执行图片 OCR 识别
- 对识别文本进行相似度匹配
- 通过 PySide6 提供现代简约风格的图形界面
项目构成
主要文件与目录
-
main.py- 整个应用的主入口,包含:
OCRController:负责启动、管理PaddleOCR-json.exe子进程,并对单张图片进行 OCR。OCRWorker(继承自QThread):在后台线程中批量执行 OCR 并通过信号实时更新界面。ImageCard:单张图片在界面中的卡片组件,展示缩略图、文件名、尺寸、OCR 摘要、匹配状态等。- 其他 UI 相关类与逻辑:窗口布局、按钮交互、进度条、日志输出、结果预览等。
- 架构分层:
- 表现层:PySide6 图形化界面(窗口、小部件、卡片网格等)
- 业务逻辑层:图片列表管理、任务调度、重命名策略与匹配逻辑
- 核心服务层 :通过
OCRController调用PaddleOCR-json.exe完成文字识别
- 整个应用的主入口,包含:
-
PaddleOCR-json_v1.4.1/PaddleOCR-json.exe:本地 OCR 引擎(无需联网)models/:各语言的 OCR 模型与配置、字典文件ch_PP-OCRv3_det_infer/:中文文本检测模型ch_PP-OCRv3_rec_infer/:中文文本识别模型ch_ppocr_mobile_v2.0_cls_infer/:方向/分类模型- 其他语言模型(英文、日文、韩文、繁体中文、俄文等)
dict_*.txt:对应语言的字符字典config_*.txt:对应语言/配置的识别参数
- 运行依赖 DLL:如
paddle_inference.dll,onnxruntime.dll,opencv_world4100.dll等。
-
__pycache__/- Python 运行时自动生成的缓存目录,可忽略。
核心依赖与运行环境
- 操作系统:Windows 10 / 11(本项目当前主要针对 Windows 平台)
- Python:建议 Python 3.8 及以上
- 主要依赖库 :
- PySide6:用于图形界面(窗口、按钮、列表、卡片等)
- Pillow (PIL) :用于图片读取和格式转换(例如将
avif/heic等不支持格式转为 PNG) - fuzzywuzzy (可选):用于更精确、灵活的文本相似度匹配
- 如果未安装,将自动回退使用
difflib进行备选匹配(控制台会提示警告)。
- 如果未安装,将自动回退使用
- 标准库 :
os,sys,time,tempfile,pathlib,subprocess,json, 等。
说明 :请根据你当前环境,将实际使用到的第三方库加入
requirements.txt(若你计划分享或部署此项目)。
功能概述
-
双文件夹智能重命名
- 选择 A 组文件夹:一般为"标准命名"的图片集合,名称已正确或代表目标命名方式。
- 选择 B 组文件夹:名称混乱或无意义(如随机截图名)的图片集合。
- 程序通过 OCR 分别识别 A、B 两组图片中的文字内容,计算文本相似度,将 B 组图片重命名为与最相似的 A 组图片名称。
-
OCR 智能识别
- 基于 PaddleOCR 模型,支持多语言文字识别。
- 对不被原生支持的图片格式(如
.avif,.heic,.heif)尝试自动转换为 PNG 后再识别。 - 每张图片识别完成后,界面会实时更新 进度状态 与 文字摘要。
-
现代化图形界面(PySide6)
- 窗口布局采用现代简约风格,提供卡片式图片展示。
- 每张图片对应一张
ImageCard:- 顶部带有删除按钮,可快速从任务中移除该图片。
- 中间显示统一大小的图片缩略图。
- 底部显示文件名、尺寸信息与少量 OCR 文本摘要。
- 还支持显示匹配状态的小角标(例如匹配成功/失败)。
-
多线程与实时进度显示
- 使用
OCRWorker(QThread)在后台进行识别,避免阻塞界面。 - 主线程通过 Qt 的
Signal/Slot将每张图片的进度、状态同步到界面:- "正在识别 x/y"
- "识别完成 √"
- "识别失败 ✗" 等。
- 使用
-
识别结果管理与重命名
- 为每张图片记录 OCR 文本结果。
- 对 A/B 两组图片的文本结果进行相似度计算(优先使用
fuzzywuzzy,否则用difflib)。 - 自动生成重命名方案并在界面中展示,用户可以检查后执行(具体交互细节以实际 UI 为准)。
使用说明
以下为典型使用流程示例,具体按钮名称与布局请以实际界面为准。
1. 启动程序
在项目根目录下执行:
bash
python main.py如果使用虚拟环境,请先激活对应虚拟环境,再运行上述命令。
程序启动后会弹出主窗口,界面左/右侧分别用于 A 组、B 组文件夹或图片列表展示。
2. 选择图片文件夹
-
选择 A 组文件夹
- 点击界面中类似"选择 A 组文件夹"/"选择参考图片目录"的按钮。
- 在系统文件对话框中选中对应的文件夹。
- 成功后,A 组图片会以
ImageCard形式加载到界面中。
-
选择 B 组文件夹
- 点击类似"选择 B 组文件夹"/"选择待重命名目录"的按钮。
- 选中包含待重命名图片的目录。
- B 组图片同样以卡片形式显示。
某些版本可能支持拖拽图片/文件夹到窗口中,请根据实际界面提示操作。
3. 启动 OCR 识别
- 在 A 组图片加载完成后,点击类似"开始识别 A 组"或"一键识别"的按钮即可。
- 程序将:
- 启动或复用
PaddleOCR-json.exe进程; - 逐张图片发送识别请求;
- 在界面底部或侧边栏实时显示识别进度。
- 启动或复用
对 B 组同理,可以分别或统一触发识别。
4. 检查识别结果与匹配关系
- 在每张图片对应的
ImageCard上可以看到:- 缩略图
- 文件名
- OCR 文本摘要(前若干字符)
- 匹配状态角标(若已完成匹配/对齐)
- 在主界面中,通常会有 列表/表格 显示匹配结果,例如:
A组图片名↔B组图片名(建议新名称)↔相似度分数
- 建议在执行真正的重命名前,浏览一遍匹配结果,确认是否符合预期。
5. 执行重命名
- 当你对匹配方案满意后,可以点击类似"应用重命名"/"开始重命名"的按钮。
- 程序会按照匹配关系将 B 组图片的文件名改为 A 组对应图片名(可能附加序号或保留扩展名等,视实际实现而定)。
- 完成后,界面会提示重命名结果。
注意:重命名操作具有不可逆性,建议事先备份重要文件,或在测试目录中先尝试。
内部工作原理(简述)
1. OCR 引擎调用流程
-
程序使用
subprocess.Popen启动PaddleOCR-json.exe:stdin、stdout管道用于与引擎通信。- 工作目录设置为
PaddleOCR-json_v1.4.1,保证模型、DLL 能正常加载。 - 在 Windows 上通过
STARTUPINFO隐藏命令行窗口。
-
启动后,程序会等待标准输出中出现
"OCR init completed."或"初始化完成"这类提示,确保引擎就绪。 -
对每张待识别图片:
- 先通过
convert_image_if_needed判断是否需要格式转换(如.avif,.heic等)。 - 将图片路径打包为 JSON:
{"image_path": "实际路径"},写入引擎的 stdin。 - 读取 stdout 的一行 JSON 结果,解析
code字段与data中的text字段,组合成最终文本。 - 对临时转换出的 PNG 文件,使用完后尝试删除,避免缓存堆积。
- 先通过
2. 多线程识别与 UI 更新
-
OCRWorker继承自QThread:- 在其
run()方法中遍历图片列表:- 每处理一张图片,会通过
progress信号向主线程发送:- 当前图片路径
- OCR 文本(或空字符串表示"正在识别中")
- 状态描述(如"正在识别 A 组: 1/10 ...")
- 每处理一张图片,会通过
- 完成全部图片后通过
finished信号通知主界面。 - 支持中途中断(例如窗口关闭时)通过
isInterruptionRequested()安全退出。
- 在其
-
主线程中,相关槽函数会:
- 更新
ImageCard显示的文本摘要与状态。 - 刷新整体进度条、日志面板等。
- 更新
3. 模糊匹配逻辑
- 优先尝试导入
fuzzywuzzy库并将FUZZYWUZZY_AVAILABLE置为 True。 - 如果导入失败,则打印一条警告信息,并使用 Python 标准库中的
difflib作为备选方案。 - 在 A/B 两组图片都识别完成后:
- 对每张 B 组图片的 OCR 文本,与所有 A 组文本计算相似度得分。
- 选取分数最高且(可能)高于某个阈值的 A 组作为匹配对象。
- 将该 A 组图片名作为 B 组图片的目标新名称。
常见问题与排查
-
Q:程序提示找不到
PaddleOCR-json.exe或模型文件?- A :请确认:
PaddleOCR-json_v1.4.1目录完整存在于项目根目录;- 其中包含
PaddleOCR-json.exe与models文件夹; - 没有随意移动/改名这些文件和目录。
- A :请确认:
-
Q:识别结果为空或乱码?
- A :
- 确认图片是否清晰、分辨率是否过低、文字是否过小或倾斜严重;
- 检查是否使用了正确的语言模型和配置(中文 vs 其他语言);
- 查看控制台输出,确认 OCR 引擎是否报错。
- A :
-
Q:界面卡顿或无响应?
- A :
- 理论上,OCR 放在 QThread 中执行,主界面不应被阻塞;
- 如果仍感觉卡顿,可能是:
- 同步更新 UI 的频率过高;
- 一次性加载的图片数量非常大;
- 可尝试减少同时识别的图片数量或优化图片尺寸。
- A :
-
Q:重命名后文件丢失?
- A :一般是被移动/重命名到同一目录下的新文件名,请在文件夹中按时间/名称排序查找。
- 建议重要文件先备份,在测试目录验证流程无误后再大规模使用。
- A :一般是被移动/重命名到同一目录下的新文件名,请在文件夹中按时间/名称排序查找。
许可证与致谢
- 本项目代码:你可以根据自己意愿选择合适的开源协议(例如 MIT、Apache-2.0 等),并在此处进行说明。
- PaddleOCR-json 与模型文件 :
- 来自 PaddleOCR 相关项目及其衍生工具,遵循各自的开源协议。
- 使用时请遵守上游项目的授权条款与使用规范。
如需二次开发或集成到你的其他项目中,建议:
- 抽离 OCR 调用逻辑 (
OCRController等)为独立模块; - 将 UI 层与业务层适当解耦,方便替换前端或接入其他系统;
- 充分测试在不同分辨率、不同语言、不同图片质量下的识别效果与匹配准确率。
效果
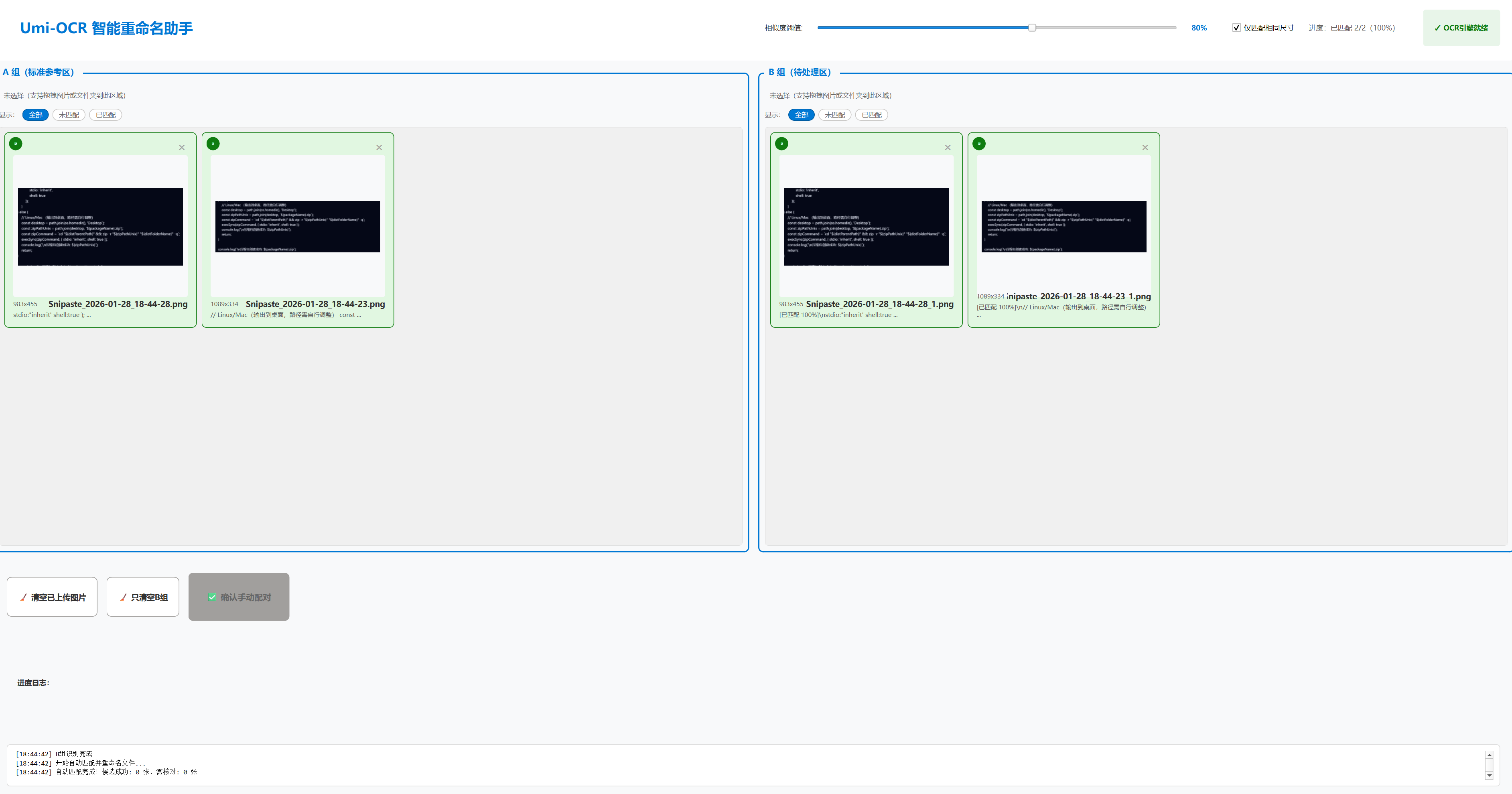
分为ab组,识别文字,匹配上则b组对应图片重命名为a组图片名称