ollama + kag 完全本地化运行向量化和大模型
| 💡 关于ollama是一个可以本地运行的大模型软件,通过将大模型下载到本地的方式来运行大模型,也可以提供api访问,可切换和下载不同大模型,支持windows、macos、linux。kag是一个可本地部署的知识库应用,可对接到本地的大模型,可通过docker部署。通过二者的配合,实现完全本地化的知识库。本教程是在windows系统下,其他系统应该大同小异。 |
|---|
大纲
1、安装所需依赖
1.1、安装docker
1.2、安装ollama
1.3、安装kag
2、ollama + kag 整合
2.1 在ollama中安装向量模型
2.2 在ollama中安装文本大模型
2.3 配置kag
3、测试效果
4、使用ollama提供的api能力,以及在claude code中接入ollama写代码
4.1 用ollama提供的api能力
4.2 在claude code中接入ollama写代码
正文
1、安装所需依赖
1.1、安装docker
docekr官网下载:https://www.docker.com/
不同操作系统下载不同版本即可。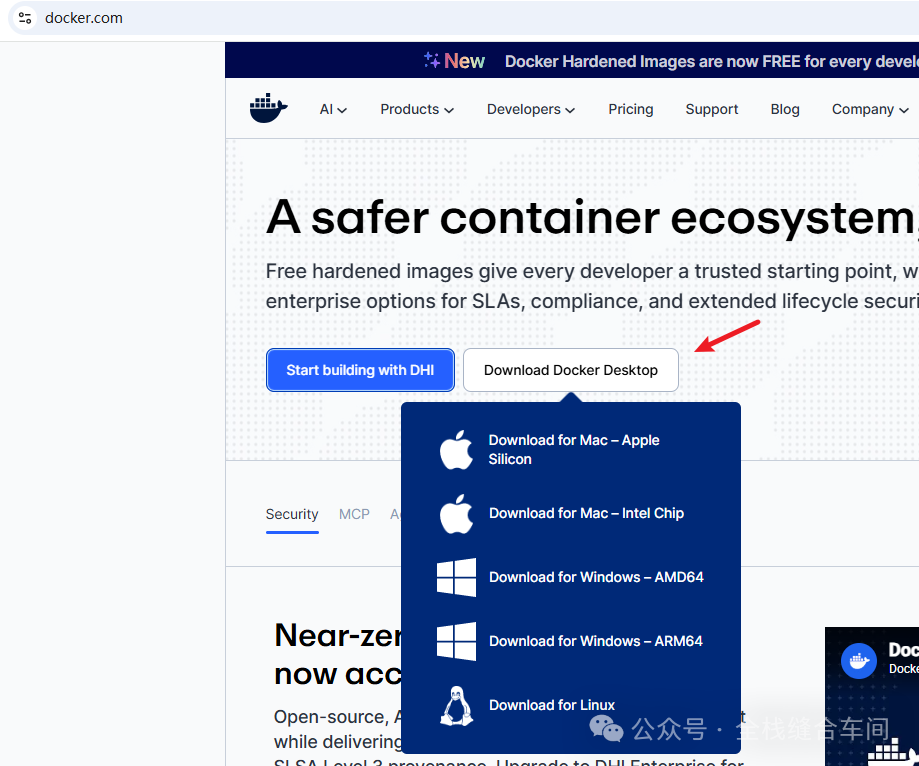
安装好之后打开是这样的(我已经安装了,且下载了一些镜像):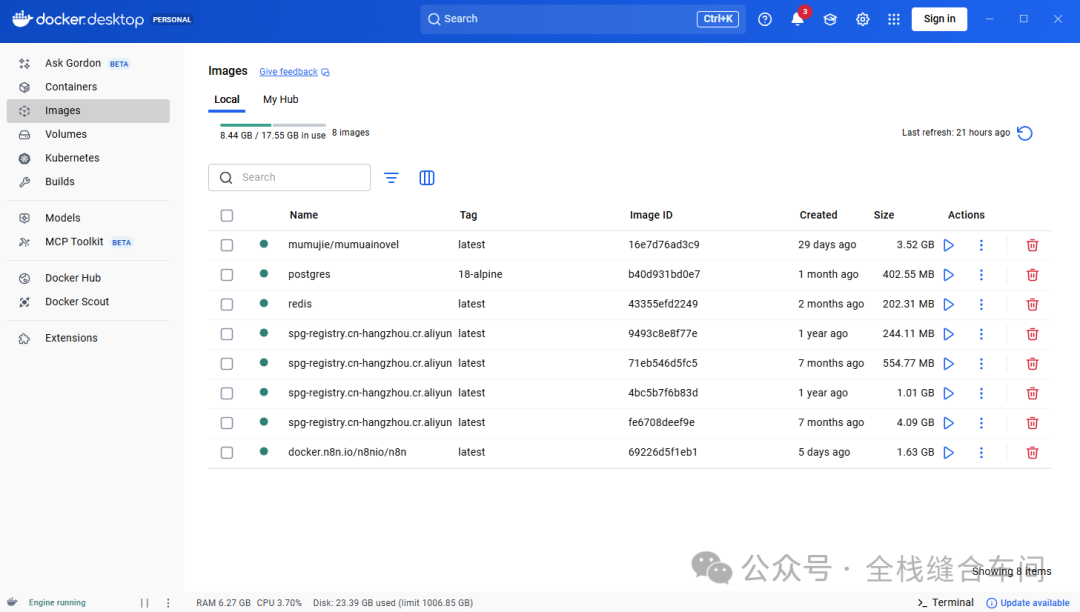
1.2、安装ollama
关于ollama,我之前的文章也有介绍,详见:使用ollama安装本地大模型,可安装其他大模型
打开ollama的官网进行下载: https://ollama.com/download
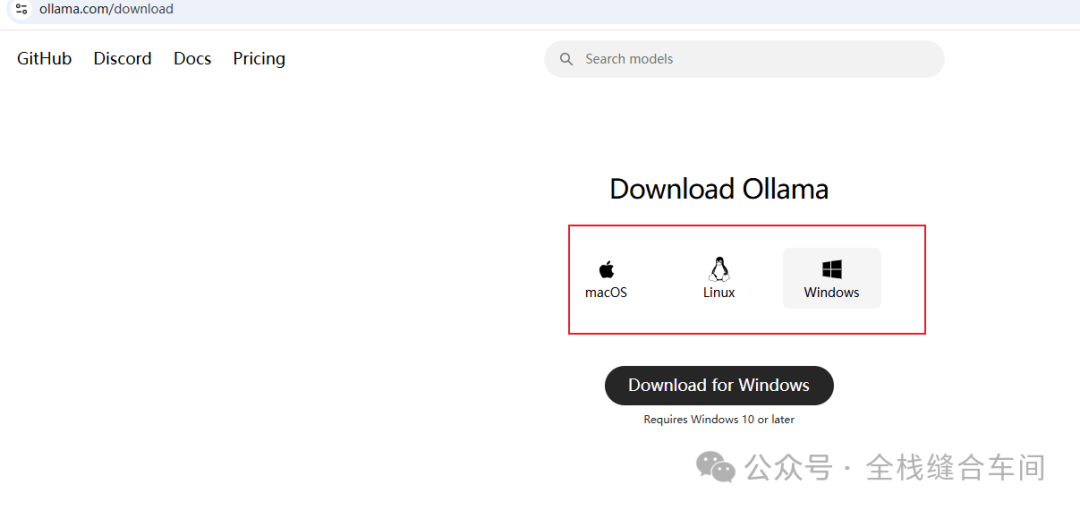 ollama下载到本地后先别急着安装,因为直接安装的话是默认安装到C盘的,模型下载也是下载到C盘,我们需要改为其他盘(如果C盘空间足够也可以忽略本步骤):
ollama下载到本地后先别急着安装,因为直接安装的话是默认安装到C盘的,模型下载也是下载到C盘,我们需要改为其他盘(如果C盘空间足够也可以忽略本步骤):
我们可以通过以下命令行更改安装目录,这里我指定让ollama安装到D盘的专门装软件的一个文件夹下:
OllamaSetup.exe /DIR="D:\soft\ollama"在OllamaSetup.exe 安装文件下打开cmd: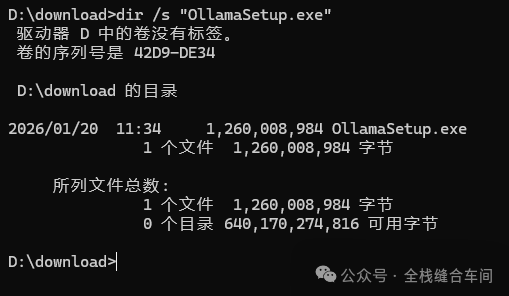 开始安装到D盘指定的文件夹下:
开始安装到D盘指定的文件夹下: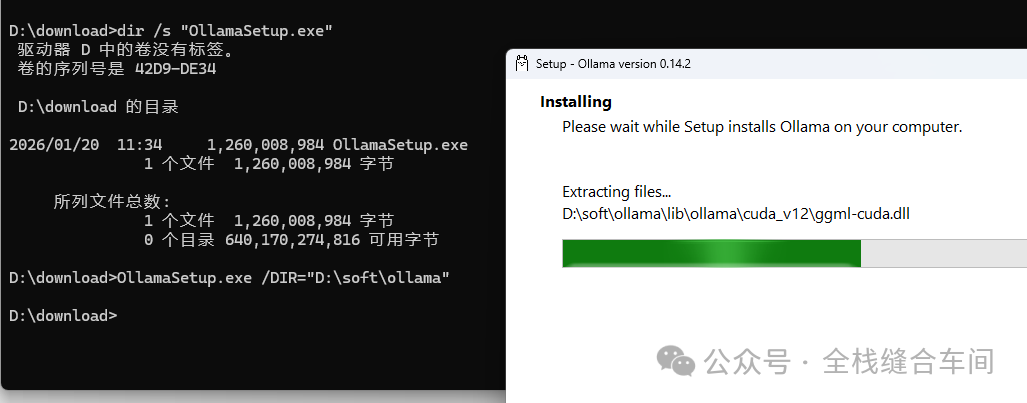 等待安装完成。
等待安装完成。
安装完成后,会自动打开ollama: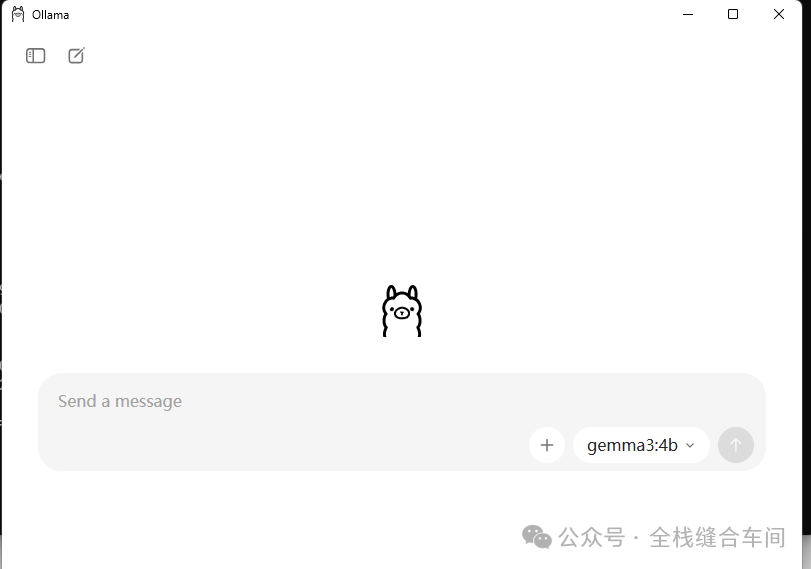
再设置models下载的位置: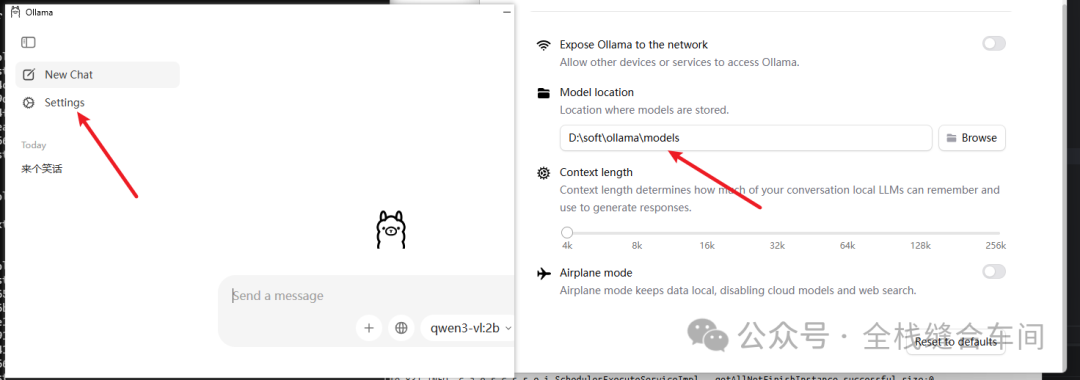
1.3、安装kag
这是kag的github说明文档:https://github.com/OpenSPG/KAG/blob/master/README_cn.md 系统版本和软件要求:
打开一个cmd,分别执行下面两行命令:
curl -sSL https://raw.githubusercontent.com/OpenSPG/openspg/refs/heads/master/dev/release/docker-compose.yml -o docker-compose.ymldocker compose -f docker-compose.yml up -d因为我之前安装过了,所以安装过程就不复现了,安装完成后的docker容器是这样的: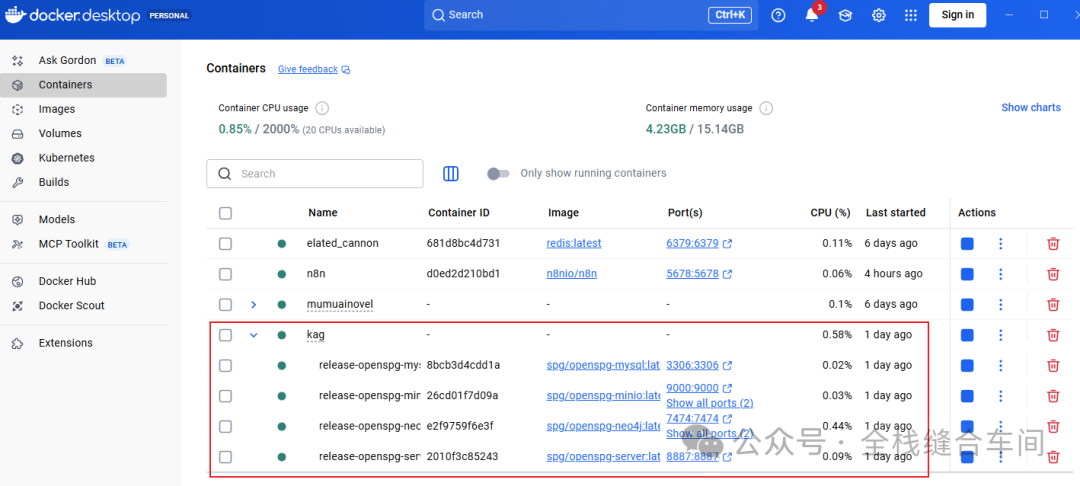
2、ollama + kag 整合
2.1 在ollama中安装文本大模型
ollama支持的模型如下: https://ollama.com/search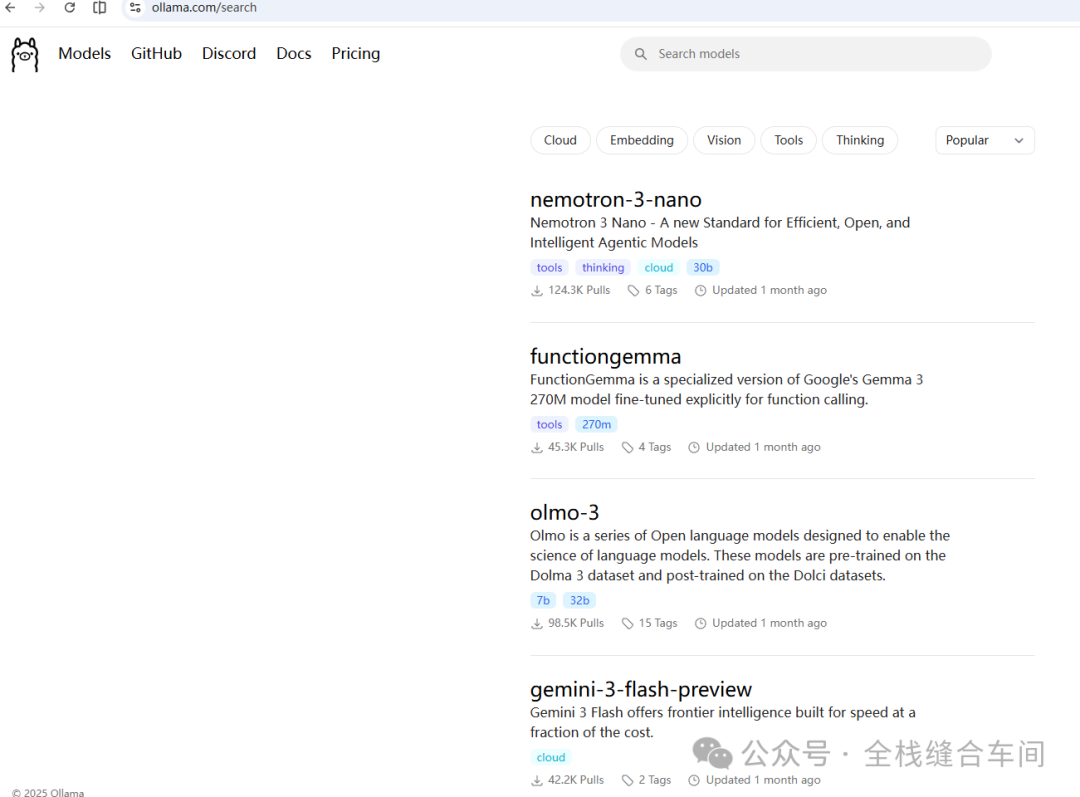
有两种方式:
1、直接在ollama软件内下载,直接点击下载即可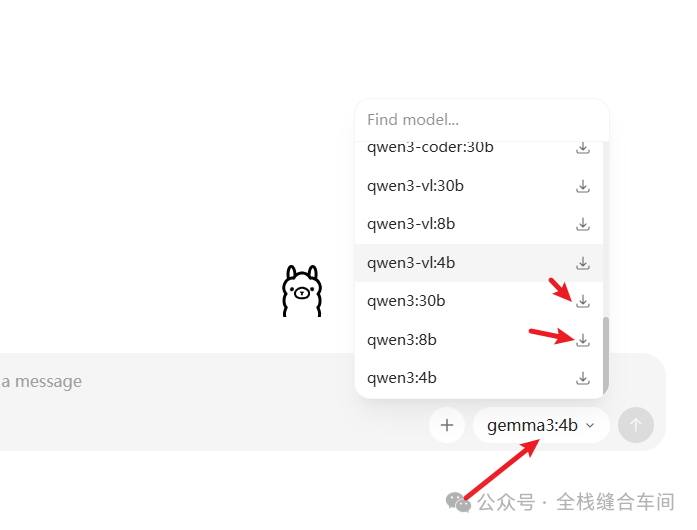
2、命令行的方式下载, 我这里下载一个小一点的模型,这个qwen3-vl: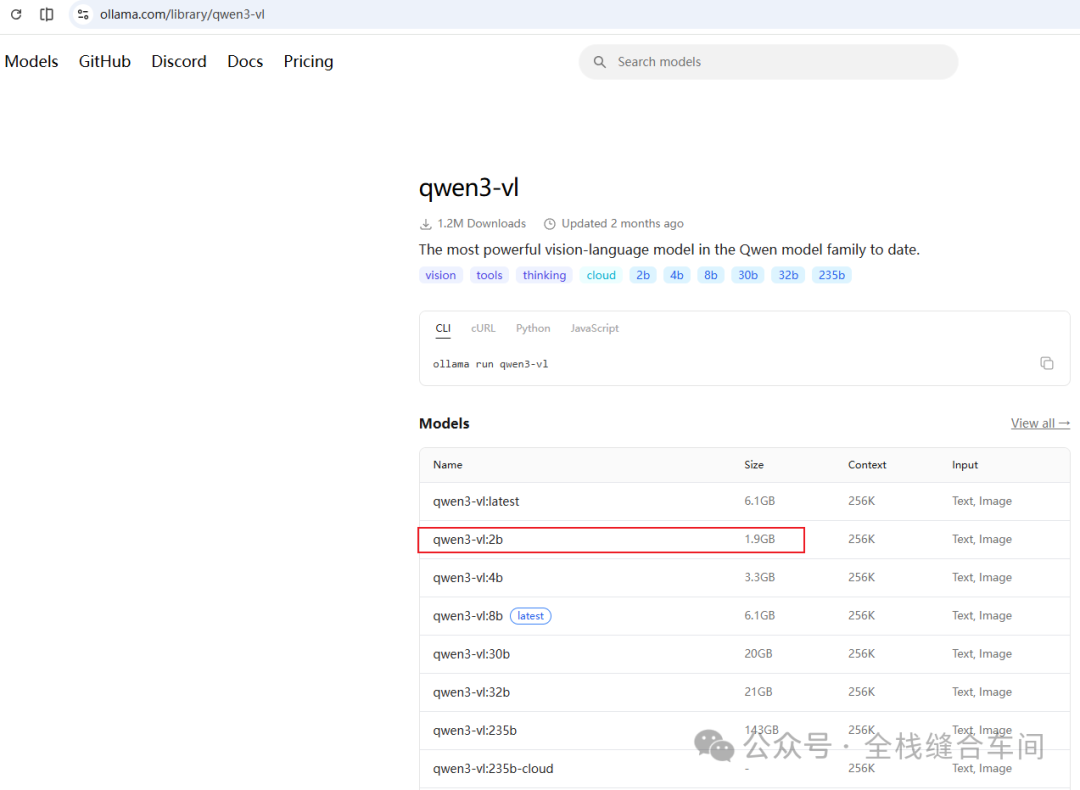
ollama run qwen3-vl:2b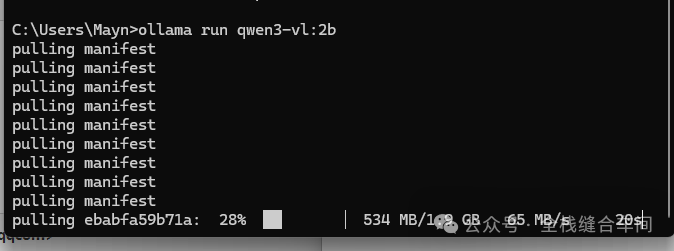 等待下载完成。
等待下载完成。
安装完成后会自动开始对话: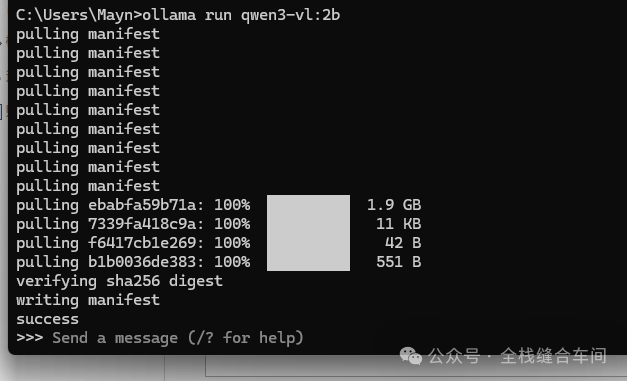 我们问一下他是谁,还有挺长的思考过程:
我们问一下他是谁,还有挺长的思考过程:
在ollama软件里对话:
输出速度还是可以的:
在api模式下使用: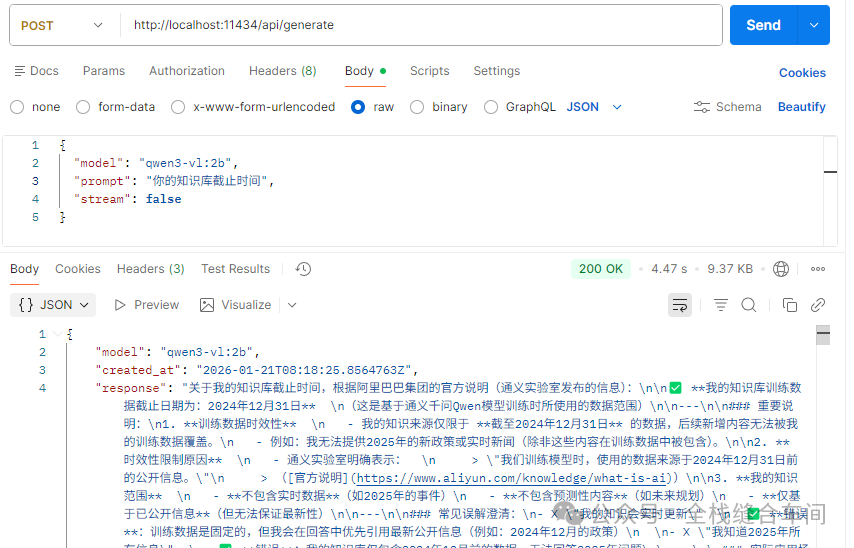
ollama的本地端口是11434.
curl:
curl --location 'http://localhost:11434/api/generate' \--header 'Content-Type: application/json' \--data '{ "model": "qwen3-vl:2b", "prompt": "你的知识库截止时间", "stream": false}'2.2 在ollama中安装向量模型
我们进到ollama的向量模型列表:https://ollama.com/search?c=embedding
向量模型我选择下载这个下载量高的: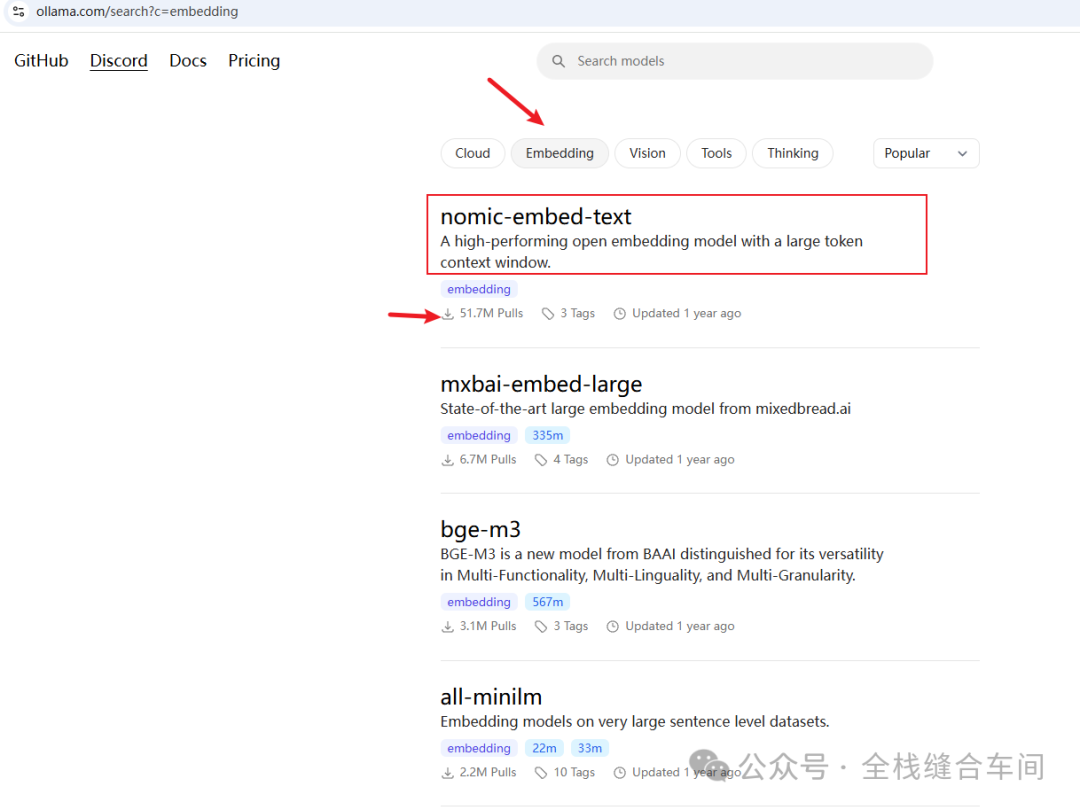
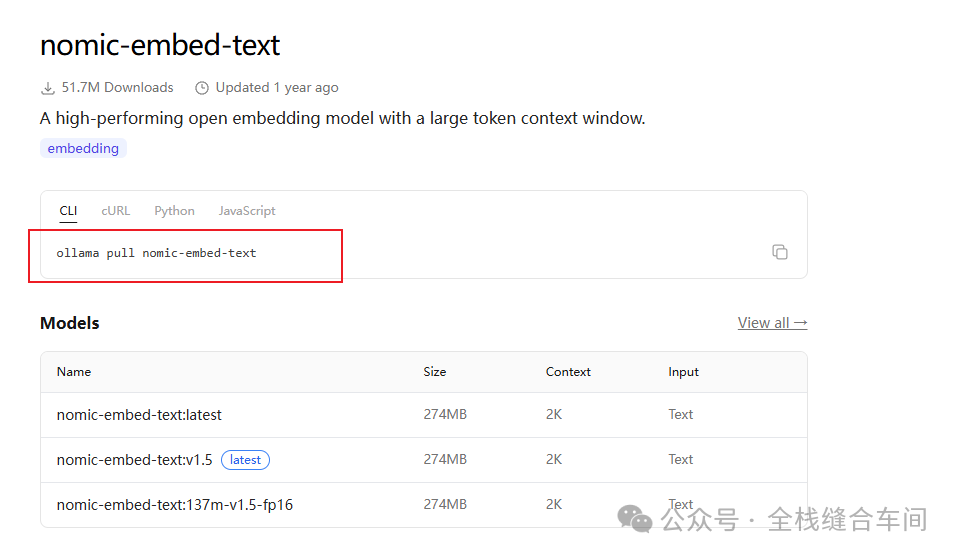
打开一个cmd命令行窗口,执行下面命令安装向量模型:
ollama pull nomic-embed-text向量模型下载完就不会自动进入对话了: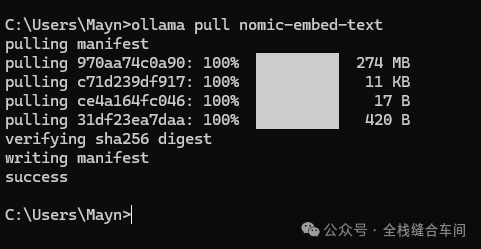
我们可以试试通过api方式调用向量模型返回什么: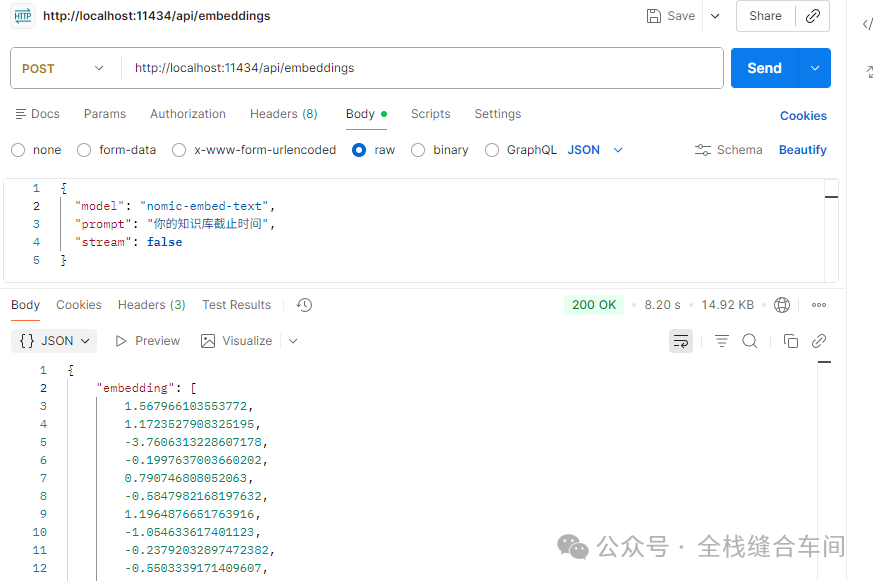
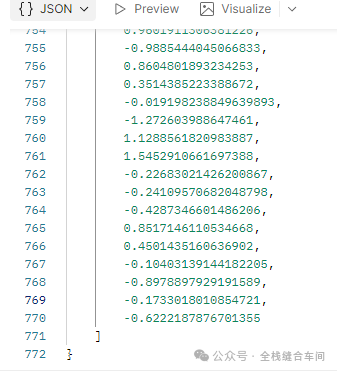 向量维度为768维,算是低维度了。
向量维度为768维,算是低维度了。
调用向量模型的curl:
curl --location 'http://localhost:11434/api/embeddings' \--header 'Content-Type: application/json' \--data '{ "model": "nomic-embed-text", "prompt": "你的知识库截止时间", "stream": false}'2.3 配置kag
使用docekr安装好kag后,我们打开:http://localhost:8887: 默认账号密码分别为:openspg、openspg@kag
默认账号密码分别为:openspg、openspg@kag
登录进来后我们配置一下模型: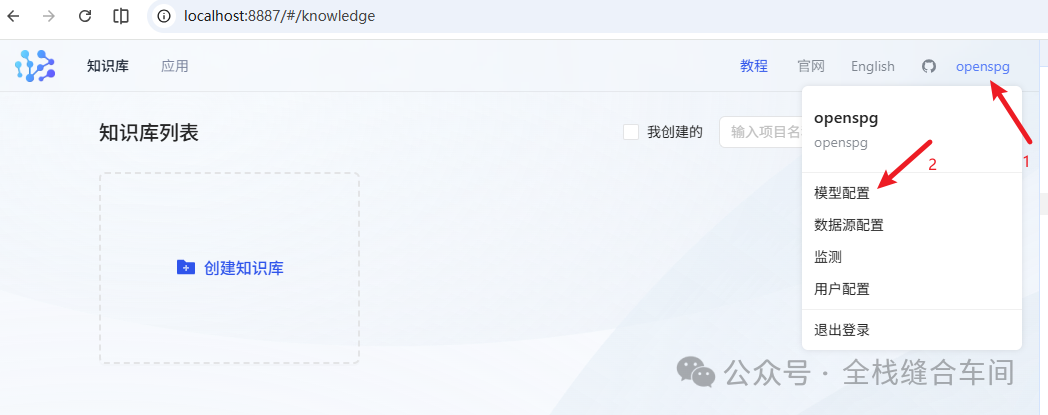
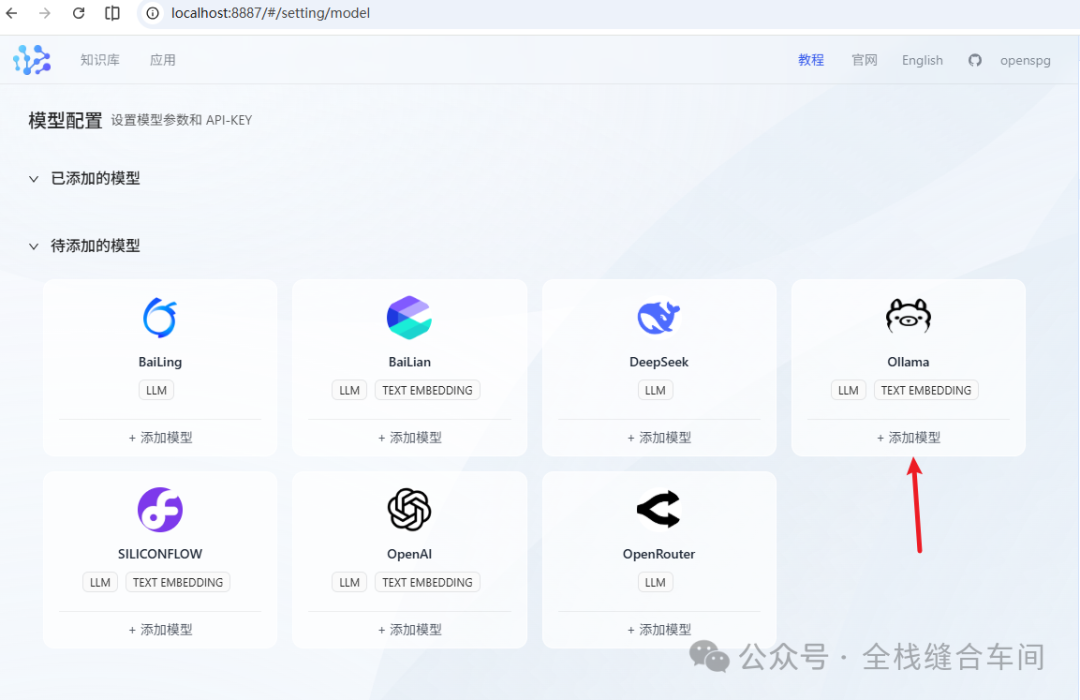
先填好文本大模型,这个大模型是我们之前安装好的: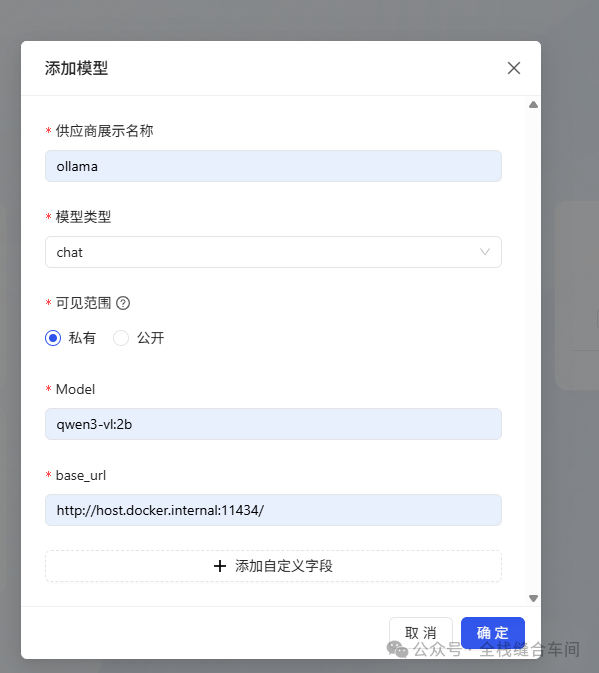 base_url为:http://host.docker.internal:11434/ 点击确定。
base_url为:http://host.docker.internal:11434/ 点击确定。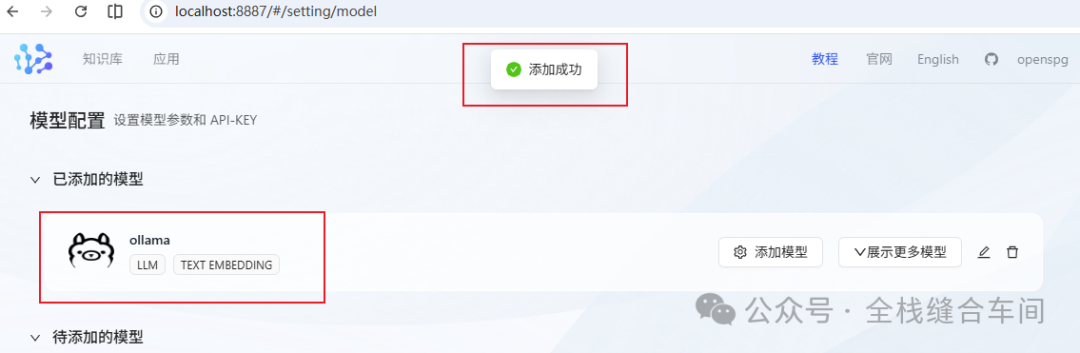 文本模型添加好后,我们继续添加向量模型:
文本模型添加好后,我们继续添加向量模型: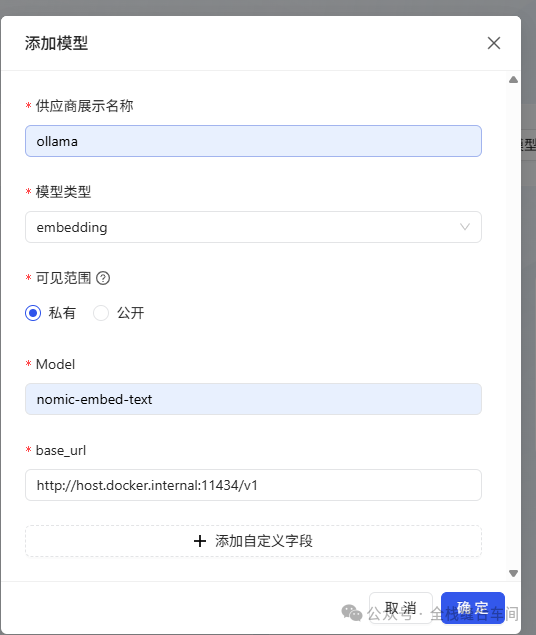 base_url为:http://host.docker.internal:11434/v1 这个向量模型也是我们之前安装好的。
base_url为:http://host.docker.internal:11434/v1 这个向量模型也是我们之前安装好的。
确认文本和向量化的模型都加好了: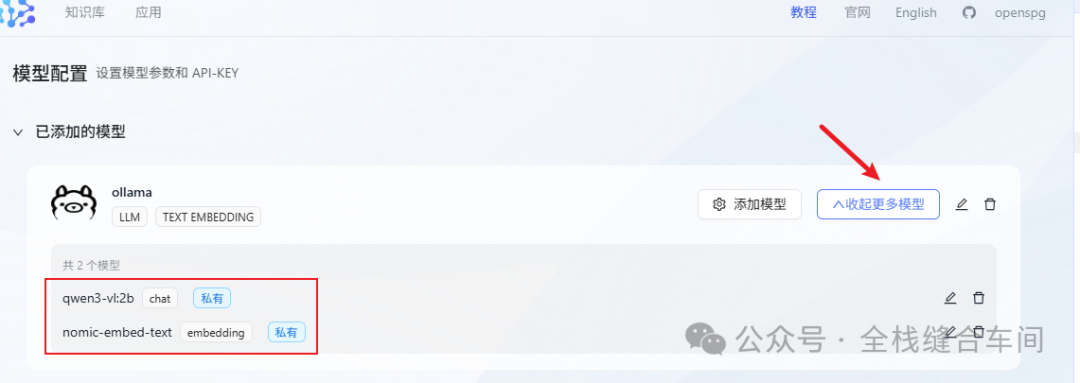
创建知识库
我们回到首页,点击新建知识库: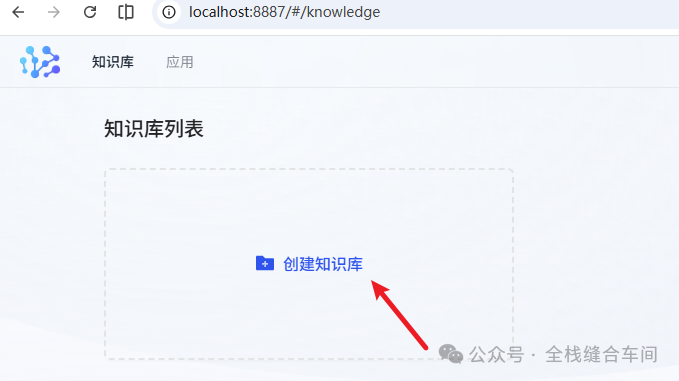
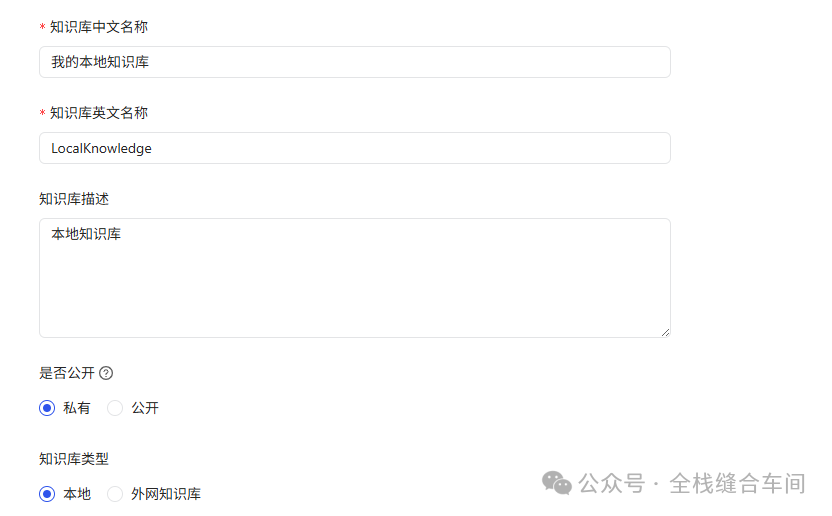
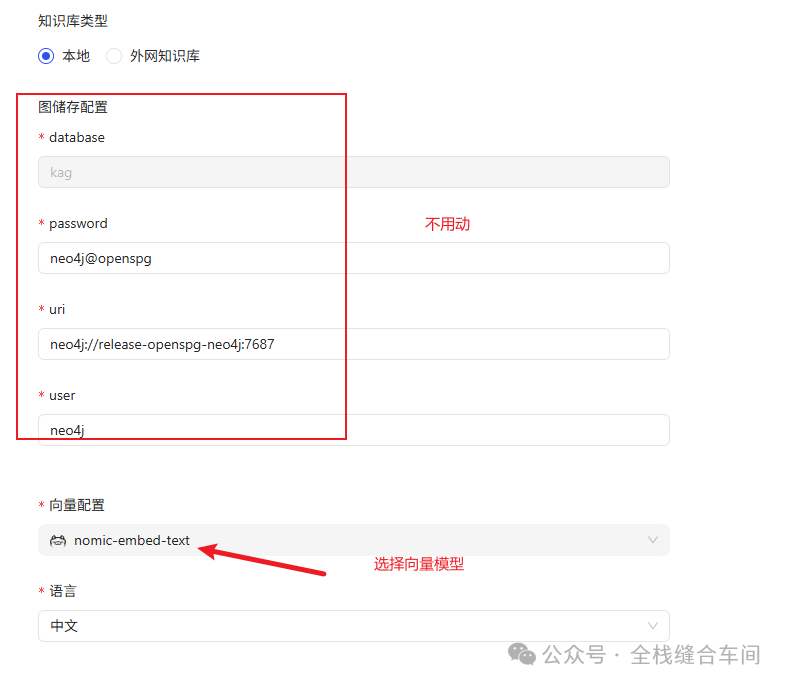 知识库创建成功:
知识库创建成功: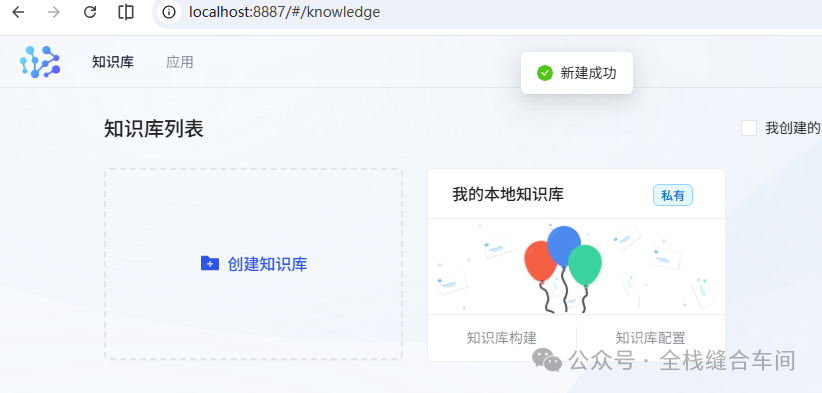
我们点击知识库进来,再点击创建任务: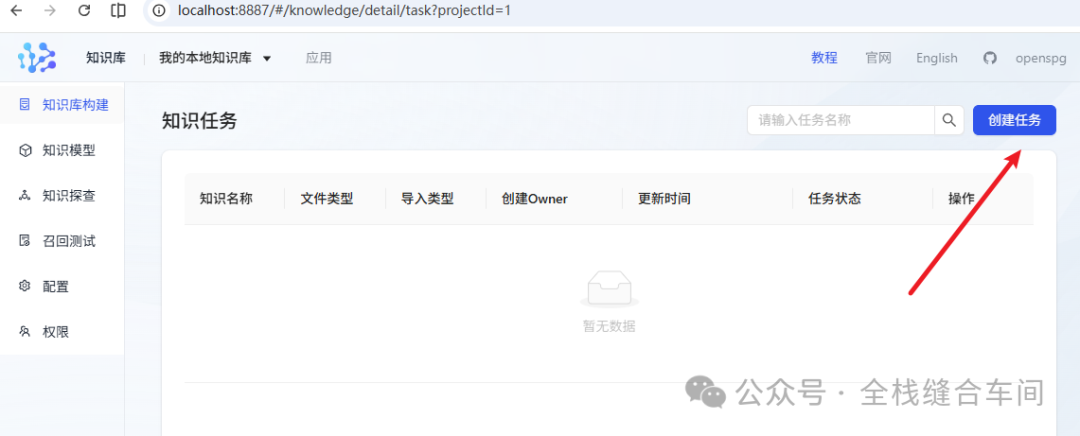 我就拿这本:《凡人修仙传》为例:
我就拿这本:《凡人修仙传》为例: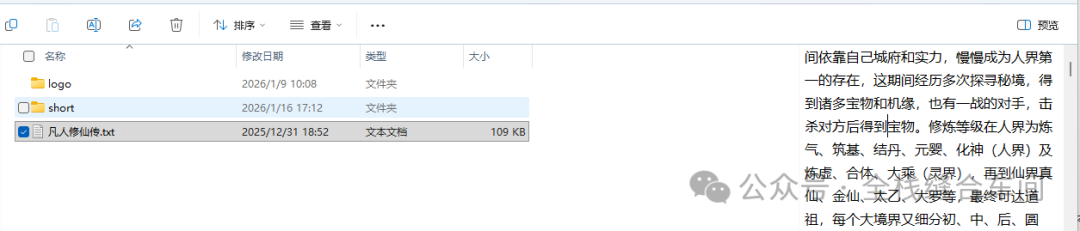
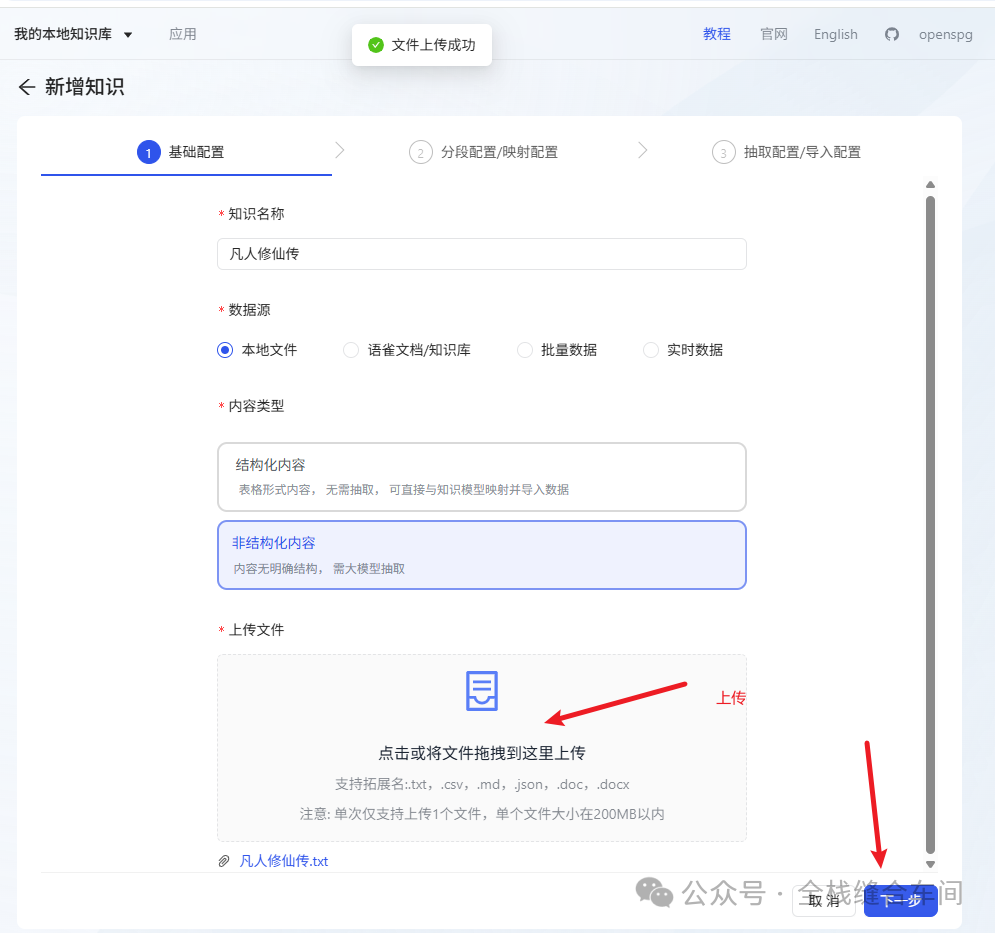 上传成功后,点击下一步:
上传成功后,点击下一步: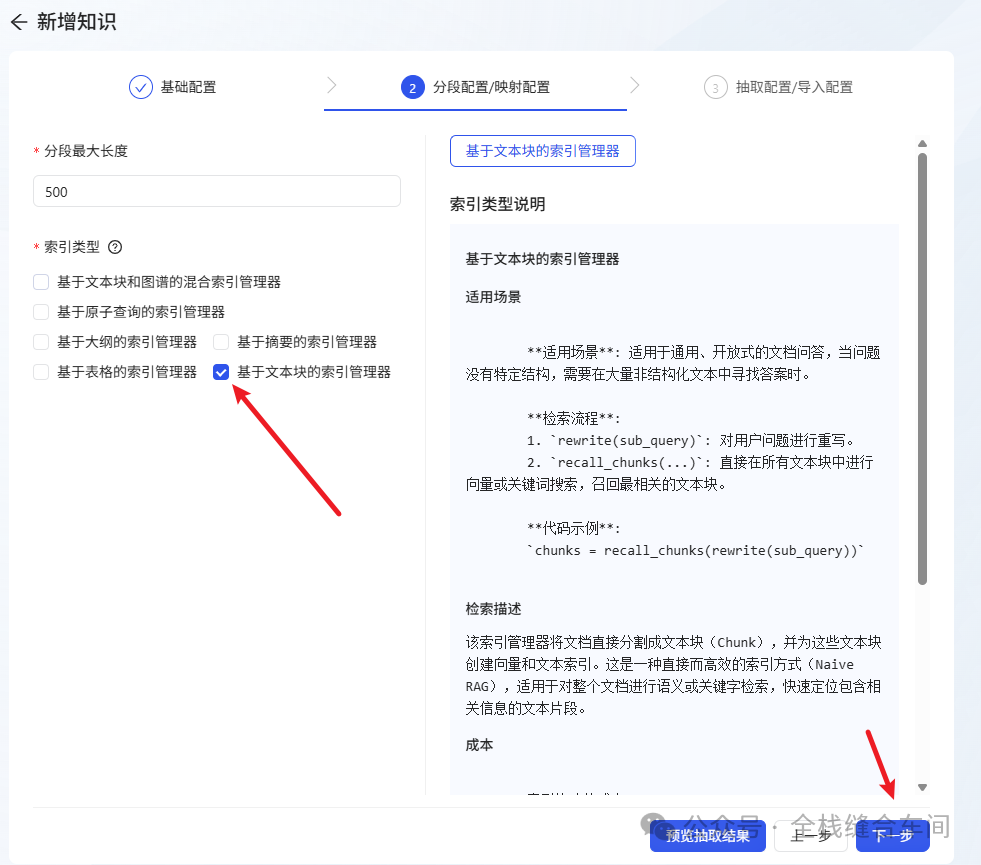 再下一步:
再下一步: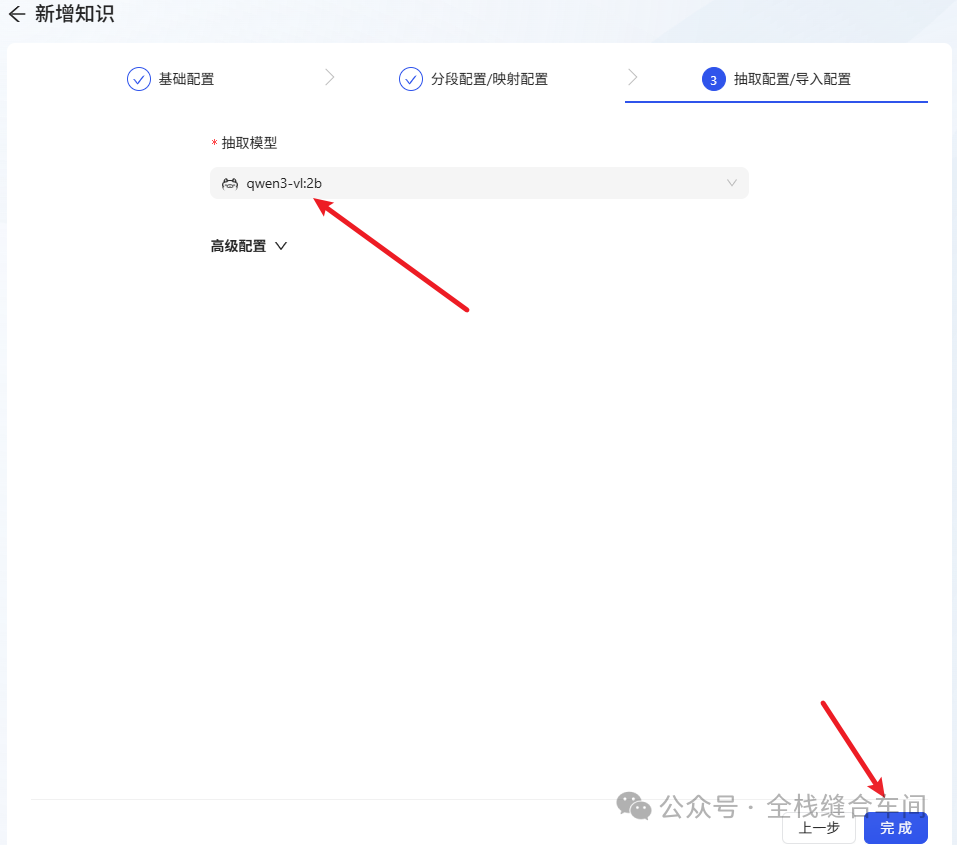 选择之前的文本大模型。
选择之前的文本大模型。
等待执行完成,就是解析文本并向量化的过程: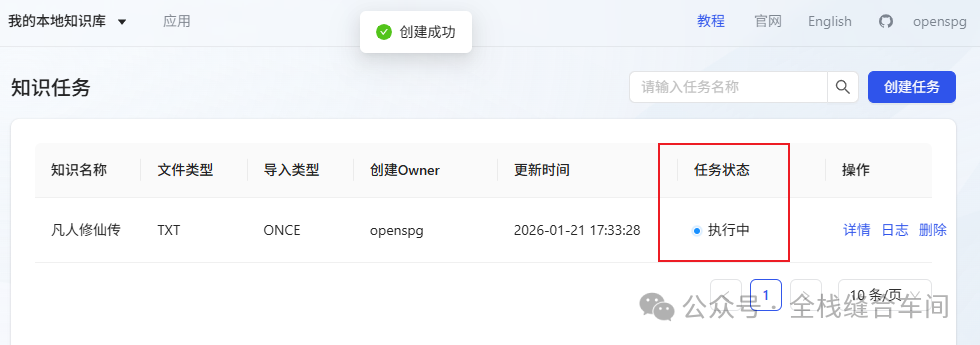
我们可以点击详情看看具体是如何分块额度: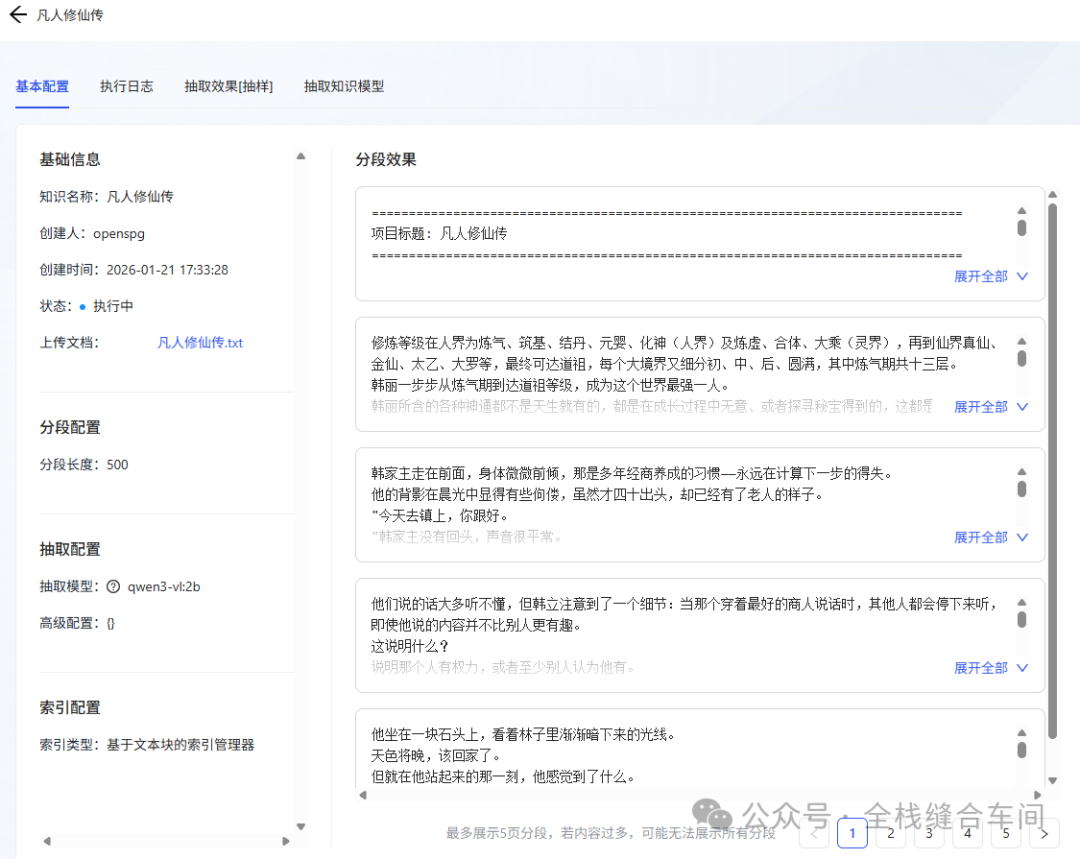 完成了:
完成了: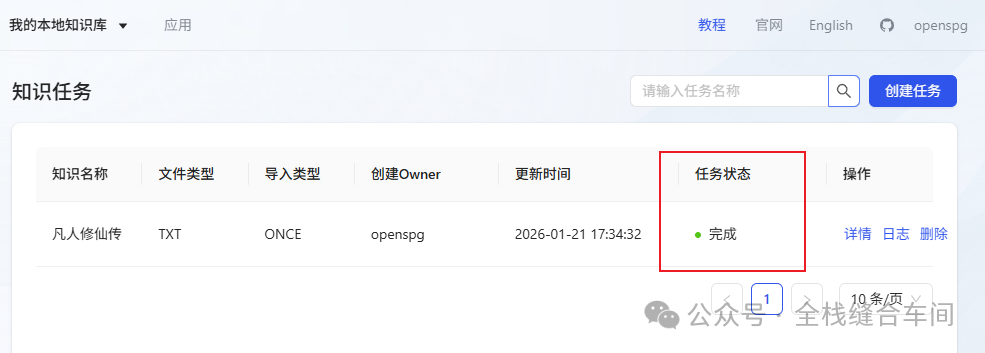
创建应用
我们再创建一下应用: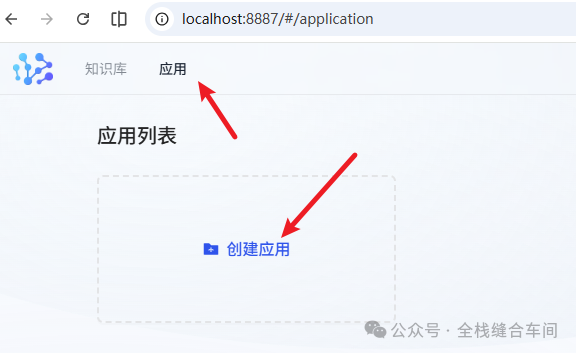
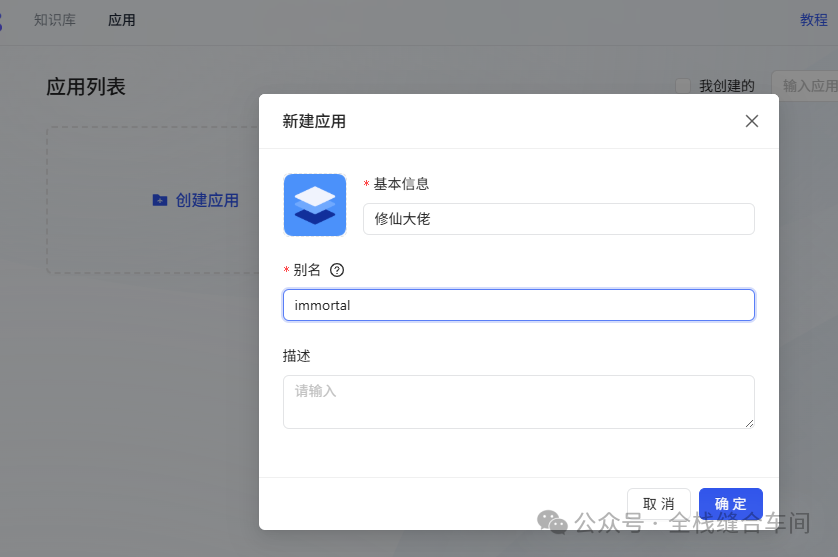 点击确定。
点击确定。
选择一个知识库: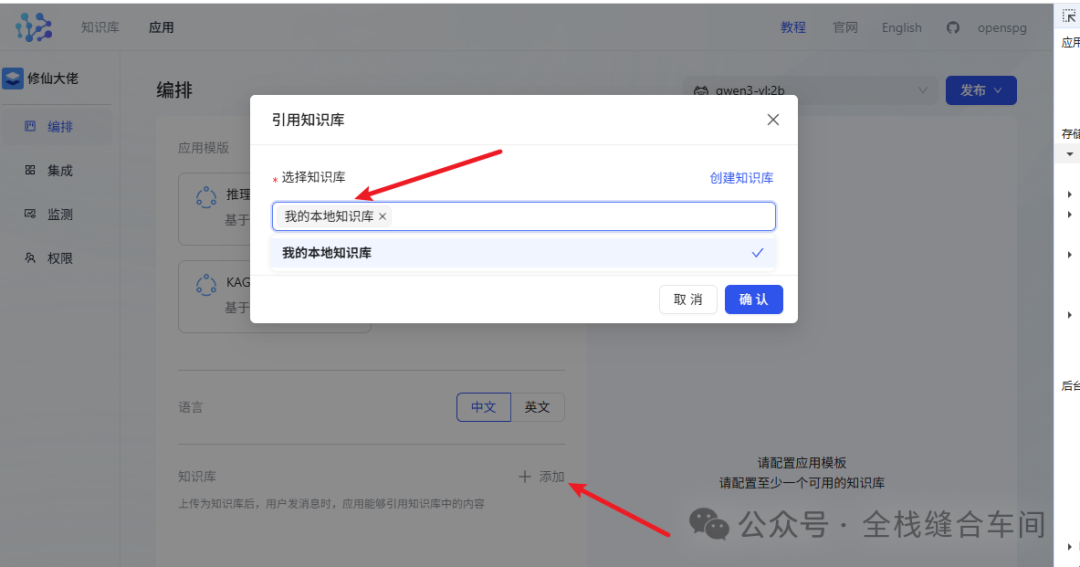 确认。
确认。
3、测试效果
我们尝试下问个问题: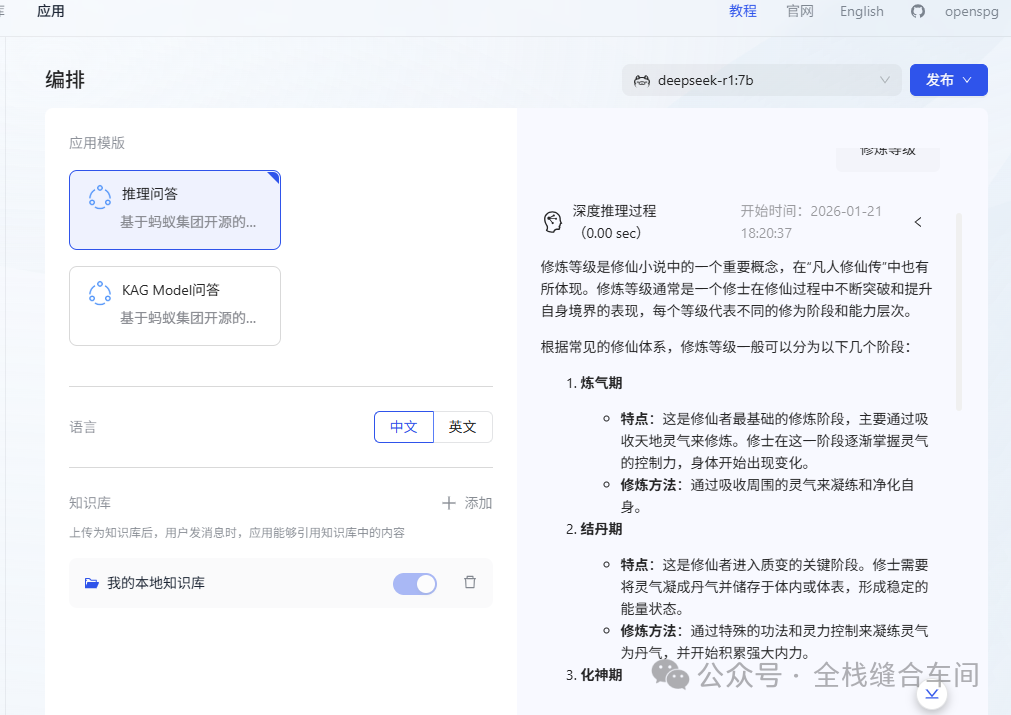
等级都返回了。
发布应用: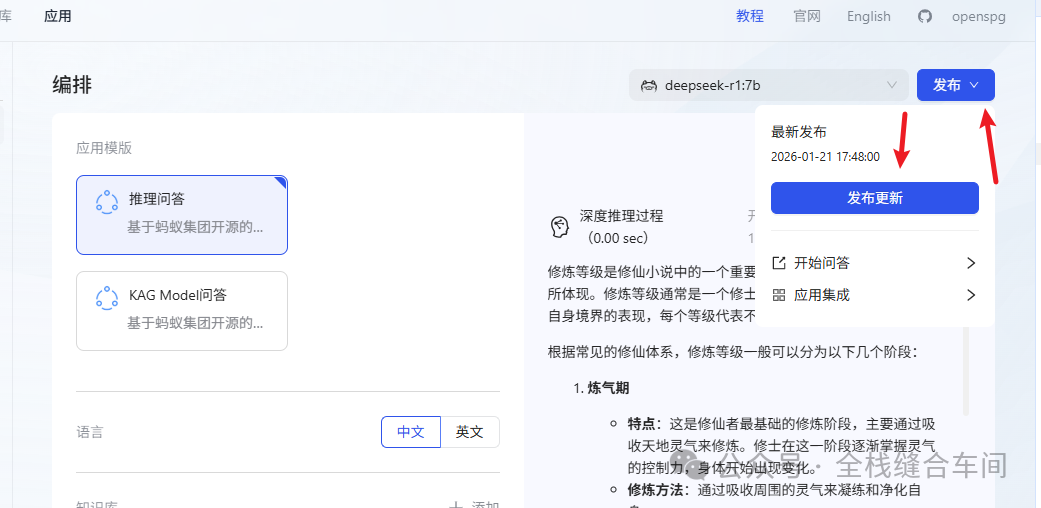
点击开始问答: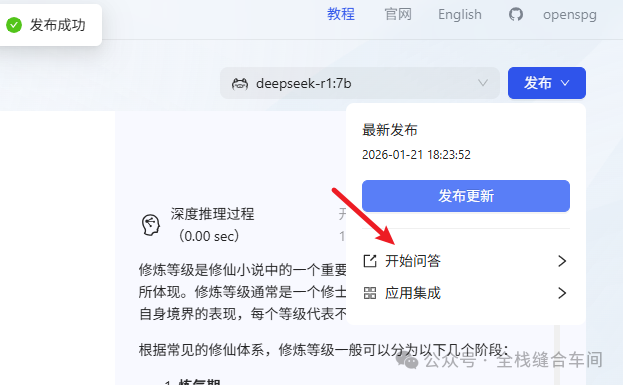
就是一个类似于chatgpt的聊天对话界面了,支持分组: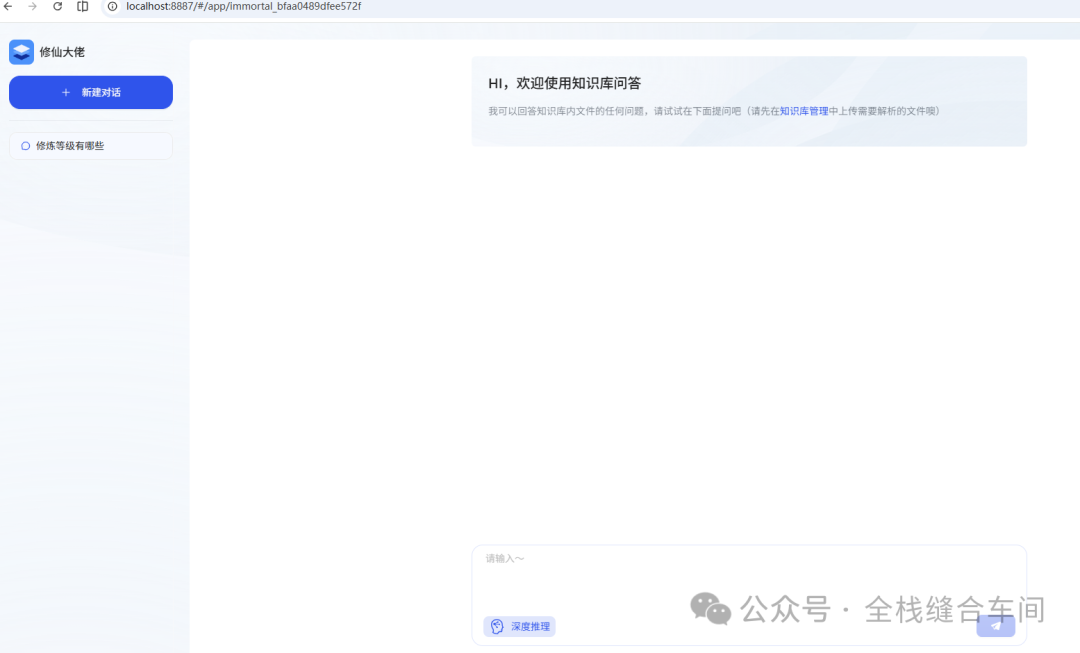
4、使用ollama提供的api能力,以及在claude code中接入ollama写代码
4.1 用ollama提供的api能力
这是还是用qwen2.5:7b这个模型做演示: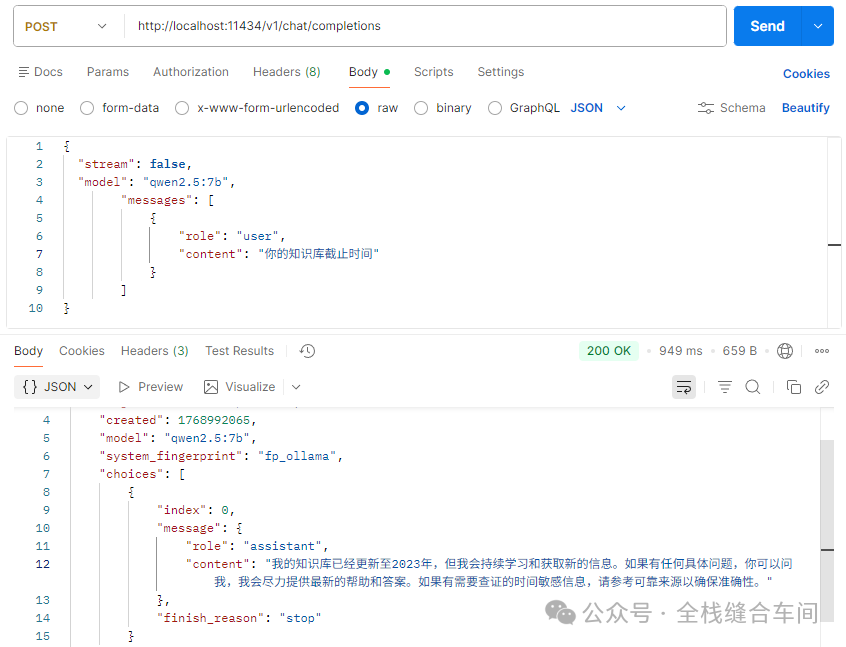
curl:
curl --location 'http://localhost:11434/v1/chat/completions' \--header 'Content-Type: application/json' \--data '{ "stream": false, "model": "qwen2.5:7b", "messages": [ { "role": "user", "content": "你的知识库截止时间" } ]}'4.2 在claude code中接入ollama写代码
需要用到qwen2.5:7b这个模型,因为有些模型不支持工具调用,需要先下载这个模型:
ollama run qwen2.5:7b打开cmd,输入命令:
set ANTHROPIC_AUTH_TOKEN=ollamaset ANTHROPIC_BASE_URL=http://localhost:11434# 指定模型claude --model qwen2.5:7b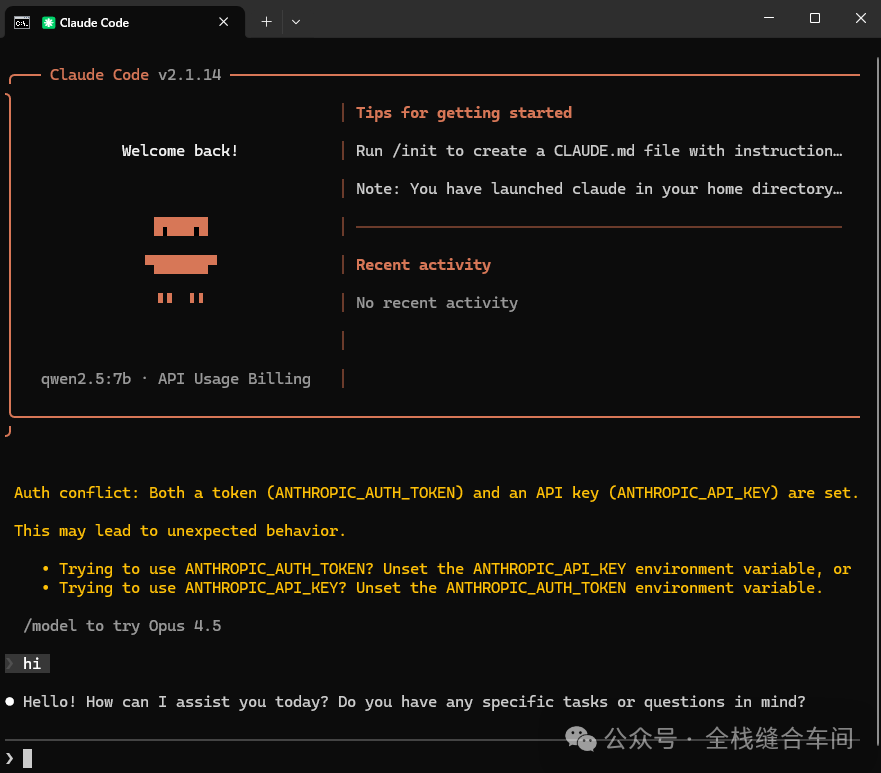 这下就可以在本地使用大模型了,不用花钱。
这下就可以在本地使用大模型了,不用花钱。