从JDK 7 到 JDK 21:JVM 内存架构的四大区域进化成了什么模样?
作者:Weisian
日期:2026年1月30日

十年前,你的Java程序还在"永久代"里艰难喘息;如今,它已在"元空间"的浩瀚中自由驰骋。
从JDK 7到JDK 21,JVM的内存架构经历了一场悄无声息却翻天覆地的重构------曾经臃肿的永久代被彻底移除,堆外内存管理焕然一新,垃圾回收器从"Stop-the-World"的噩梦走向毫秒级停顿的优雅......
这不是简单的版本升级,而是一场围绕性能、稳定与可扩展性的深度进化。今天,就让我们拨开字节码的迷雾,一探JVM内存四大区域在这十四年间究竟经历了怎样的蜕变。
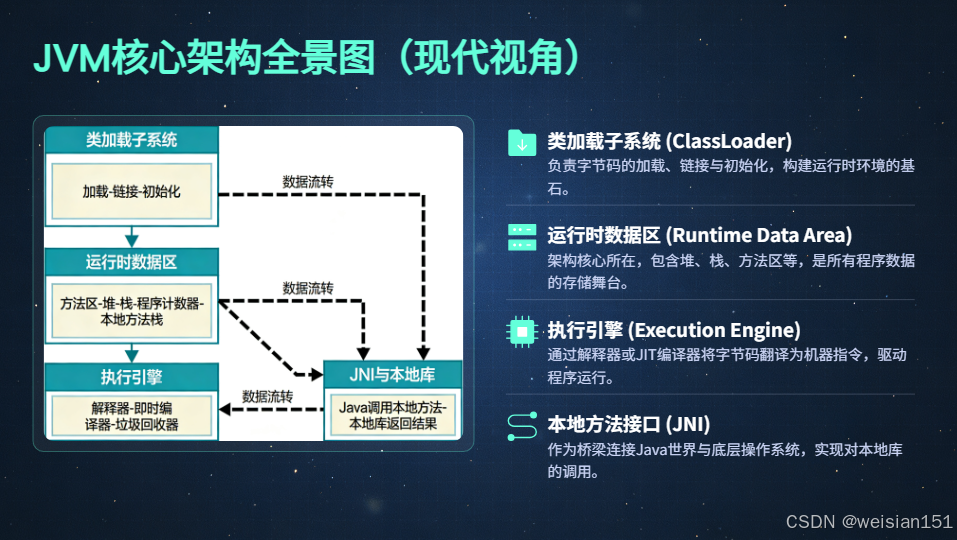
一、开篇:先建立宏观认知------JVM 的四大内存区域
要理解 JVM 在 JDK 7 到 JDK 21 之间的演进,首先得站在"上帝视角"俯瞰它的整体架构。现代 JVM 并非一个黑盒,而是一个高度模块化、协同运作的运行时引擎。其中,运行时数据区(Runtime Data Areas) 是一切内存行为的核心舞台,它被清晰划分为 线程共享 与 线程私有 两大阵营,共包含四大关键区域:
- 堆(Heap):对象实例的家园,垃圾回收的主战场
- 方法区(Method Area):类元数据的仓库,从"永久代"蜕变为"元空间"
- Java 虚拟机栈(VM Stack):方法调用的执行上下文,每个线程独享
- 程序计数器(PC Register)与本地方法栈(Native Stack):支撑字节码执行与 JNI 调用的底层设施
下面这张架构图,展示了现代 JVM 核心组件关系:
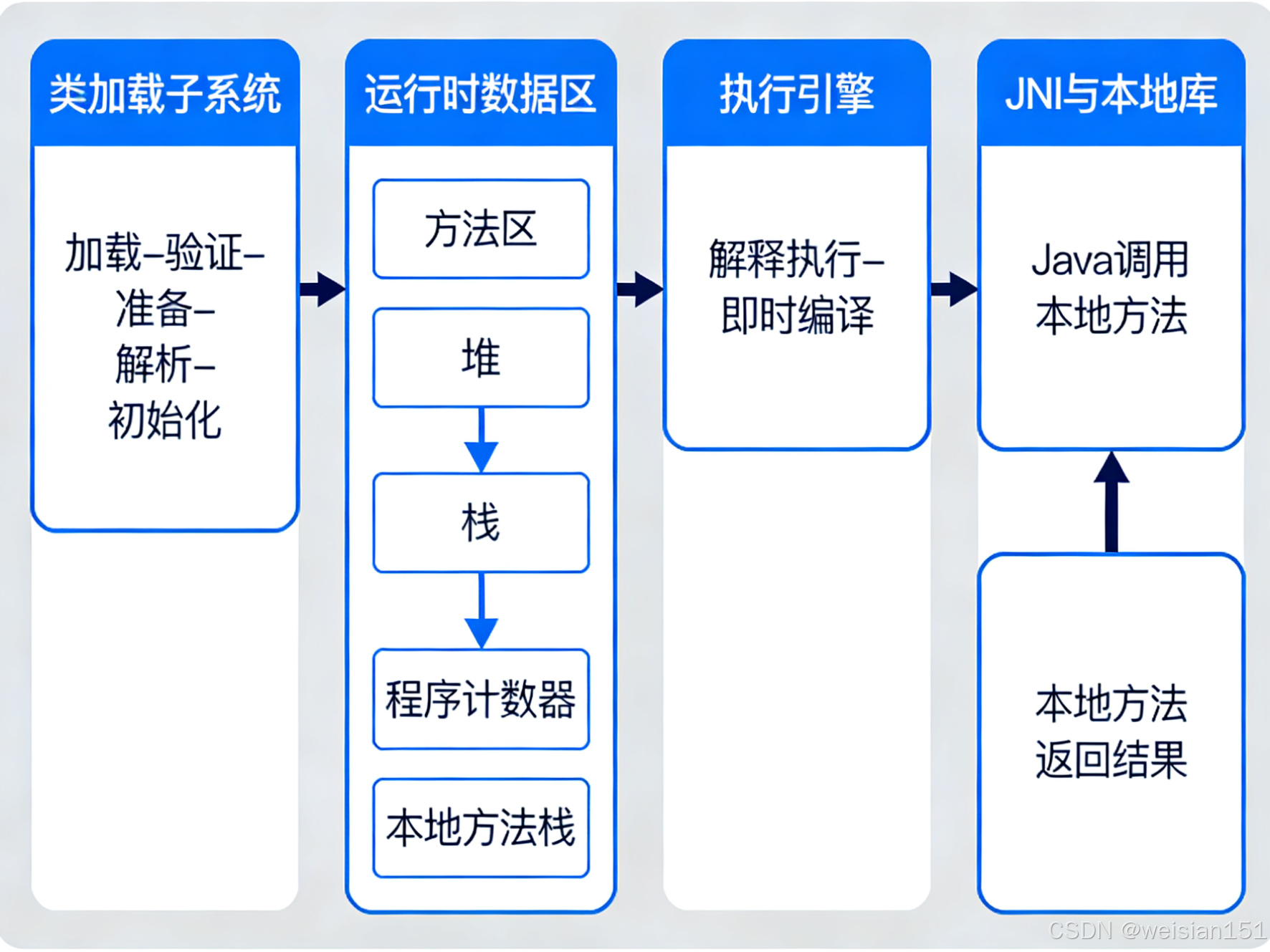
关键洞察 :在这张看似稳定的架构图中,方法区、垃圾回收器、JIT 编译器 恰恰是过去十五年变化最剧烈的三大模块。
它们如同工厂的"智能控制系统"------表面不动声色,内里却经历了从机械齿轮到 AI 调度的跃迁。
比如:
- 方法区 从 JDK 7 的"永久代(PermGen)"彻底迁移到 JDK 8+ 的"元空间(Metaspace)",摆脱了固定大小限制;
- 垃圾回收器 从 CMS、G1 的探索,进化到 ZGC、Shenandoah 的亚毫秒级停顿;
- JIT 编译器 从 C1/C2 分层编译,迈向 GraalVM 与 JITWatch 支持下的动态优化新范式。
二、核心模块1:类加载子系统------内存加载的"入口管家"
如果把JVM比作一座高效运转的智能工厂,那么类加载子系统 就是工厂的"大门安检与物料入库专员"------它负责将外部的.class字节码文件(原材料),经过一系列严格的校验、转换、初始化流程,最终规整地存入JVM的运行时数据区(仓库),为后续执行引擎(生产车间)提供可直接使用的类信息与数据。
它不仅是Java程序运行的第一道门槛,更是实现Java"跨平台"、"类隔离"、"动态加载"的核心支撑,而其运行过程全程与方法区、堆内存紧密绑定,也是JDK7到JDK21期间,伴随模块化、虚拟线程等特性迭代而持续优化的核心模块。
2.1 核心定位:不止是"加载class",更是内存的"前置管理者"
类加载子系统的核心职责并非简单地"读取.class文件",而是完成**"字节流→内存结构化数据→可用类模板"**的全链路转换,其核心价值体现在三点:
- 隔离性:通过不同类加载器划分命名空间,避免不同来源(核心类库/第三方框架/用户代码)的类冲突,保护JVM核心内存结构不被恶意或错误代码破坏;
- 懒加载性:遵循"按需加载"原则,类不会在JVM启动时全部加载,而是在首次被使用(如创建实例、调用静态方法)时才触发加载,减少初始化阶段的内存占用;
- 内存绑定性 :加载流程的最终产物直接落地到运行时数据区------类元数据(结构信息、常量、静态变量)存入方法区,
java.lang.Class对象(类的访问入口)存入堆内存,为后续程序执行提供内存支撑。
简单来说:没有类加载子系统的"前置处理",堆和方法区就没有可操作的"数据原料",整个JVM将无法执行任何指令。
2.2 核心执行流程(五步法,不可逆且全程安全校验)
类的加载流程是一个严格有序、不可逆的线性过程,从字节流进入JVM到类可用,共分为"加载→验证→准备→解析→初始化"五个步骤,其中前四个步骤由JVM自动完成,只有第五步"初始化"会执行用户编写的静态代码。
1. 加载(Loading):获取字节流,生成初步内存结构
这是类加载的"入口步骤",核心任务是**"找到并读取字节流,转换为方法区的初步类结构"**,具体执行三件事:
- 根据类的全限定名 (如
java.lang.String、com.example.User),定位并获取该类的.class字节流(来源多样:本地磁盘class文件、jar包、网络传输(如RMI)、动态生成(如ASM框架、反射动态代理)、数据库存储等); - 将字节流中的二进制数据,转换为JVM方法区可识别的运行时类数据结构(包含类的版本、字段、方法、常量池等信息,格式由JVM规范定义);
- 在堆内存中生成一个对应的
java.lang.Class对象,作为该类在方法区中元数据的访问入口(后续程序通过反射操作类时,本质就是操作这个Class对象)。
示例 :当你在代码中写User user = new User();时,JVM首先会通过应用类加载器,根据com.example.User的全限定名,在项目的target/classes目录下找到User.class文件,读取其字节流,然后在方法区存入User类的结构信息,同时在堆中创建Class<User>对象。

2. 验证(Verification):字节码"安检",防止破坏内存
这是JVM的"安全守门步骤",核心任务是校验字节流的合法性与安全性,防止恶意或不符合JVM规范的字节码文件被加载,从而破坏JVM的内存结构或引发运行时异常。该步骤是保证JVM稳定运行的关键,分为四个子校验环节,层层递进:
- 文件格式验证 :校验字节流是否符合
.class文件格式规范(如是否以魔数0xCAFEBABE开头、版本号是否在JVM支持范围内、常量池格式是否合法等),这一步校验失败会直接抛出java.lang.ClassFormatError; - 元数据验证 :校验类的元数据信息是否符合Java语言规范(如是否有父类(除
java.lang.Object外)、是否继承了不可被继承的类(如final修饰的类)、字段和方法的定义是否合法等),这一步校验失败会抛出java.lang.NoClassDefFoundError或java.lang.IncompatibleClassChangeError; - 字节码验证 :校验类的字节码指令是否符合JVM执行规范(如指令操作数类型是否匹配、跳转指令是否指向合法的代码行、是否会出现非法的内存访问等),这一步是验证环节的核心,校验失败会抛出
java.lang.VerifyError; - 符号引用验证 :校验类中的符号引用(如引用的其他类、字段、方法)是否真实存在且可访问(如是否有权限访问引用的类、方法是否存在等),这一步为后续"解析"步骤做准备,校验失败会抛出
java.lang.NoSuchMethodError或java.lang.NoClassDefFoundError。
示例 :如果你手动修改User.class文件的魔数(将0xCAFEBABE改为其他值),当JVM加载该类时,文件格式验证会直接失败,抛出java.lang.ClassFormatError: Invalid magic number in class file com/example/User,类加载流程直接终止。

3. 准备(Preparation):为静态变量分配内存,设置默认初始值
这是类加载的"内存分配步骤",核心任务是为类变量(static修饰)在方法区分配内存,并设置默认初始值,注意两个关键细节:
- 仅处理类变量(static修饰变量):实例变量的内存分配是在对象创建时(堆内存中)完成的,不属于该步骤的职责;
- 设置默认初始值 (而非显式赋值):默认初始值是JVM为每种基本数据类型定义的"零值",不会执行代码中的显式赋值语句(如
public static int a = 10;,该步骤会将a设为0,而非10)。
| 数据类型 | 默认初始值 | 数据类型 | 默认初始值 |
|---|---|---|---|
| int | 0 | boolean | false |
| long | 0L | char | '\u0000'(空字符) |
| float | 0.0f | 所有引用类型 | null |
| double | 0.0d | short | 0 |
特殊示例 :被final修饰的静态变量(常量),会在该步骤直接设置为显式赋值的值 ,而非默认初始值。例如public static final int b = 20;,在准备阶段,b会被直接赋值为20,而非0。原因是final常量的值在编译期就已确定,会被写入字节码的ConstantValue属性中,JVM在准备阶段直接读取该属性完成赋值,这也是"常量"无法被修改的底层原因。

4. 解析(Resolution):符号引用→直接引用,绑定内存地址
这是类加载的"地址绑定步骤",核心任务是将方法区运行时常量池中的"符号引用",转换为"直接引用",完成类、字段、方法的内存地址绑定。
先明确两个关键概念,用通俗的比喻理解:
- 符号引用 :就是"一个名字",是编译期生成的、用字符串表示的引用目标(如
com.example.User、user.getName()),不涉及具体的内存地址,仅表示"要引用什么",在编译期即可确定; - 直接引用:就是"内存地址",是可以直接指向目标的指针、偏移量或句柄,对应着方法区中类元数据的具体内存位置,仅在运行期才能确定(因为内存地址是JVM加载类时动态分配的)。
示例 :在编译User user = new User();时,编译器并不知道User类会被加载到方法区的哪个内存地址,也不知道User的构造方法在哪里,因此会生成一个符号引用(如Lcom/example/User;<init>())存入常量池;而在"解析"步骤,JVM会根据这个符号引用,找到方法区中User类的构造方法对应的内存地址,将符号引用替换为这个内存地址(直接引用),后续调用构造方法时,就能直接通过该地址找到对应的指令。
注意:解析步骤并非必须紧跟在准备步骤之后,可以延迟到"初始化"之后、首次调用该引用时再执行(如动态绑定场景:多态、反射),这是JVM为了优化内存和执行效率而做的灵活调整。

5. 初始化(Initialization):执行用户静态代码,完成类的最终初始化
这是类加载流程的最后一步,也是唯一执行用户编写代码的步骤 ,核心任务是执行类构造器<clinit>()方法,完成类变量的显式赋值和静态代码块的执行。
关于<clinit>()方法,有几个关键细节必须掌握:
- 自动生成 :
<clinit>()方法不是由用户编写的,而是由JVM编译器自动收集类中的静态变量赋值语句 和静态代码块(static{}),按代码书写顺序合并生成的; - 父类优先 :JVM会保证在执行子类的
<clinit>()方法前,先执行父类的<clinit>()方法(因此java.lang.Object的<clinit>()方法会最先执行); - 仅执行一次 :一个类的
<clinit>()方法只会被执行一次,由JVM保证线程安全(避免多线程同时初始化一个类导致的静态变量赋值混乱); - 无返回值 :
<clinit>()方法没有参数、没有返回值,也不能被用户直接调用; - 可选性 :如果一个类中没有静态变量赋值语句,也没有静态代码块,那么JVM不会为该类生成
<clinit>()方法。
完整代码示例(演示初始化流程):
java
package com.example;
public class ClassLoadDemo {
// 静态变量(准备阶段设为0,初始化阶段赋值为10)
public static int a = 10;
// 静态代码块(初始化阶段按顺序执行)
static {
a = 20;
System.out.println("父类静态代码块执行,a = " + a);
}
// 构造方法(不属于类加载流程,属于对象创建流程)
public ClassLoadDemo() {
a = 30;
System.out.println("父类构造方法执行,a = " + a);
}
public static void main(String[] args) {
// 首次使用子类,触发子类加载与初始化
ChildDemo child = new ChildDemo();
// 输出最终的a值
System.out.println("最终a值 = " + ChildDemo.a);
}
}
class ChildDemo extends ClassLoadDemo {
// 子类静态变量
public static int b = 100;
// 子类静态代码块
static {
b = 200;
System.out.println("子类静态代码块执行,b = " + b);
}
// 子类构造方法
public ChildDemo() {
b = 300;
System.out.println("子类构造方法执行,b = " + b);
}
}运行结果(对应初始化流程):
父类静态代码块执行,a = 20
子类静态代码块执行,b = 200
父类构造方法执行,a = 30
子类构造方法执行,b = 300
最终a值 = 30结果解析:
- 运行
main方法时,首次使用ChildDemo,触发子类加载; - 类加载流程中,初始化阶段先执行父类
ClassLoadDemo的<clinit>()方法(静态变量a赋值10→静态代码块修改为20),输出父类静态代码块内容; - 再执行子类
ChildDemo的<clinit>()方法(静态变量b赋值100→静态代码块修改为200),输出子类静态代码块内容; - 类初始化完成后,创建
ChildDemo实例,触发父类构造方法执行(a改为30),再触发子类构造方法执行(b改为300); - 最终输出
a的值为30(构造方法修改后的值)。

2.3 核心组成:类加载器+加载模型,支撑内存隔离与安全
类加载子系统的核心组成分为"类加载器(执行者) "和"类加载模型(规则)",两者配合完成类的加载与隔离,是保证JVM内存安全的核心支撑。
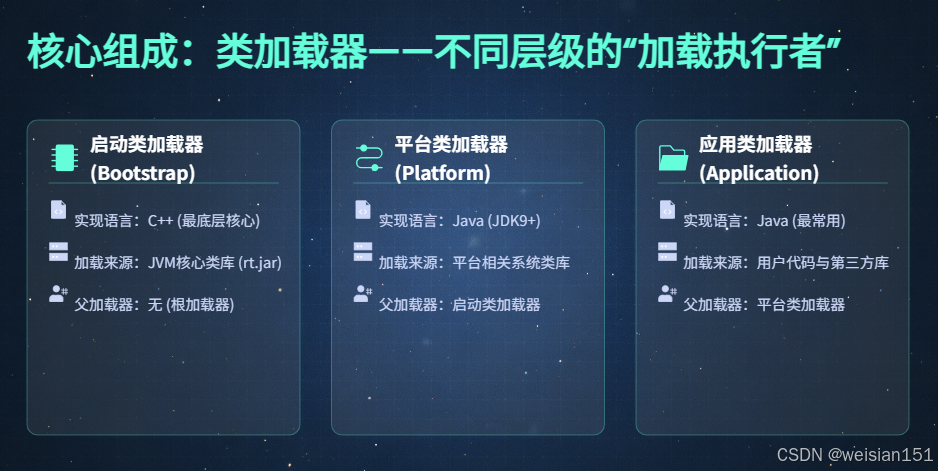
1. 类加载器:不同层级的"加载执行者"
类加载器是实现"加载"步骤的具体载体,JVM默认提供3种核心类加载器(JDK9前后有调整),不同类加载器负责加载不同来源的类,形成层级结构,避免类冲突。
| 类加载器类型 | 实现语言 | 加载来源 | 父加载器 | JDK支持情况 |
|---|---|---|---|---|
| 启动类加载器(Bootstrap) | C++ | JVM核心类库(如rt.jar、java.base模块) |
无(顶级加载器) | JDK7+全支持 |
| 扩展类加载器(Extension) | Java | JRE扩展目录(jre/lib/ext)下的jar包 |
启动类加载器 | JDK7-JDK8(已移除) |
| 平台类加载器(Platform) | Java | 平台核心模块、第三方模块化jar、系统类库 | 启动类加载器 | JDK9+全支持 |
| 应用类加载器(Application) | Java | 用户项目代码、第三方非模块化jar(如Maven依赖) | 扩展/平台类加载器 | JDK7+全支持 |
补充说明:
- 启动类加载器(Bootstrap)是唯一由C++实现的类加载器,不属于Java类(无法通过
getClassLoader()获取,返回null),其加载的核心类库存放在JVM的核心目录中,具有最高权限; - 除启动类加载器外,其他类加载器均由Java实现,且继承自
java.lang.ClassLoader类,支持用户自定义扩展(如Tomcat的WebAppClassLoader,实现不同Web应用的类隔离)。
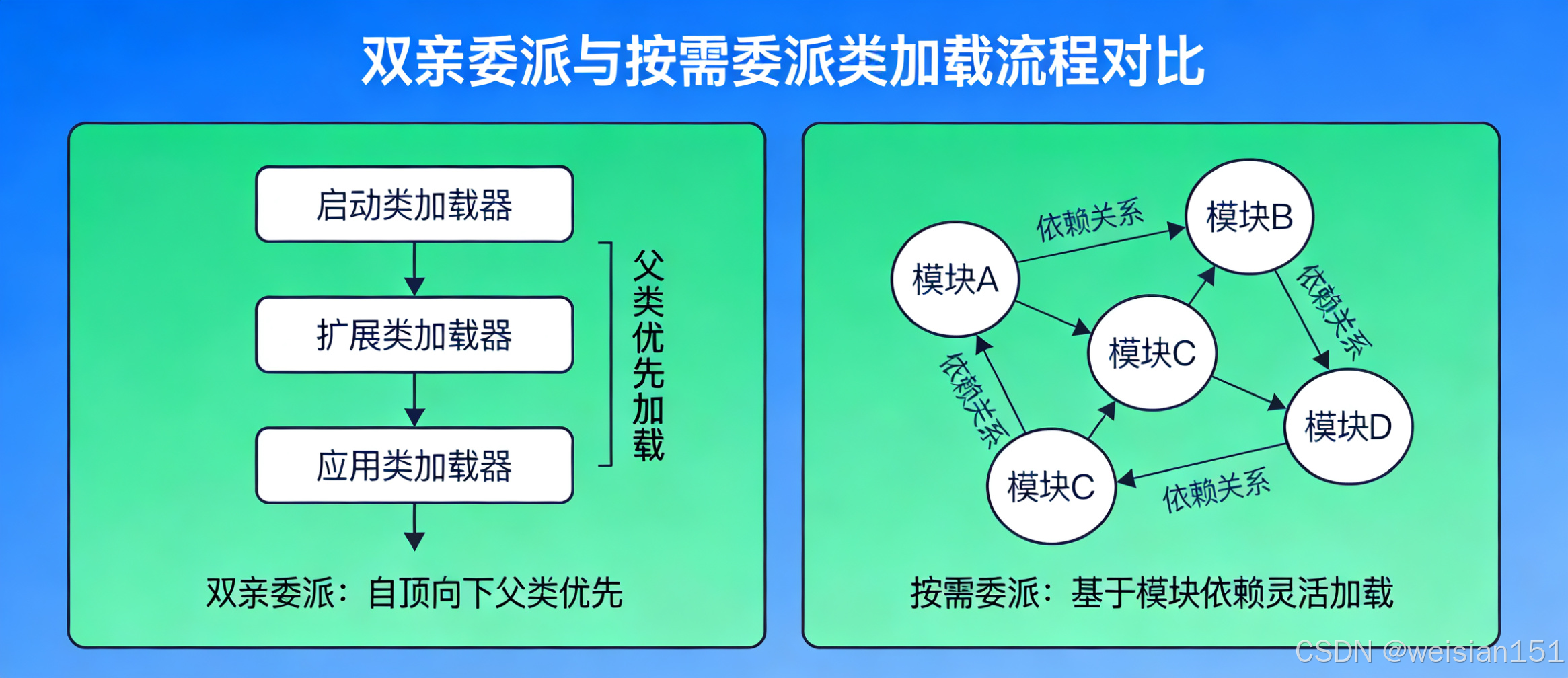
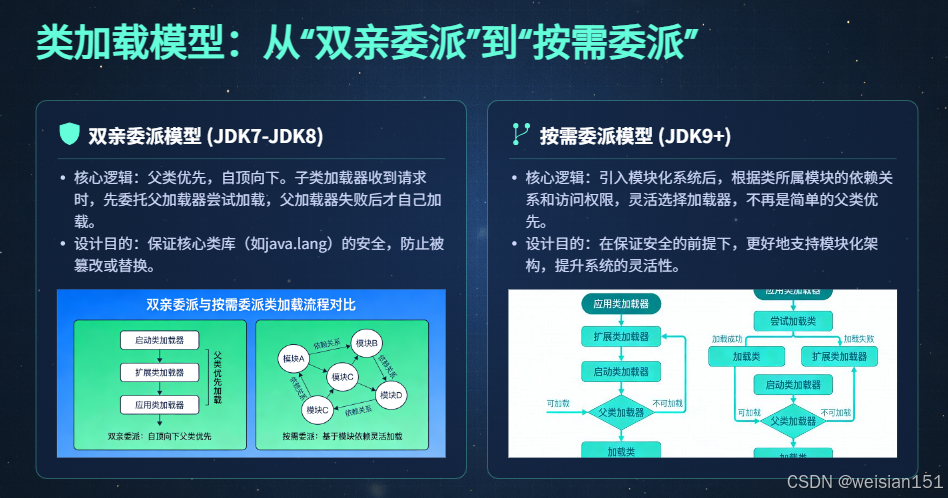
2. 类加载模型:从"双亲委派"到"按需委派",优化内存与权限控制
类加载模型是类加载器的"运行规则",规定了类加载器的调用顺序,核心目标是**"保证核心类库的安全性,避免类重复加载"**,从JDK7到JDK21,经历了"双亲委派模型→按需委派模型"的升级。
(1)JDK7-JDK8:严格的双亲委派模型
这是经典的类加载模型,核心规则是**"子类加载器在加载类时,会先委托父类加载器尝试加载,只有父类加载器无法加载时,子类加载器才会自己尝试加载"**,具体流程如下:
- 当应用类加载器收到类加载请求时,首先将请求委托给其父类加载器(扩展类加载器);
- 扩展类加载器收到请求后,再委托给其父类加载器(启动类加载器);
- 启动类加载器检查是否能加载该类(是否在核心类库范围内),如果能,则直接加载,返回Class对象;
- 如果启动类加载器无法加载,扩展类加载器会尝试自己加载(是否在扩展目录范围内),如果能,返回Class对象;
- 如果扩展类加载器也无法加载,应用类加载器会尝试自己加载(是否在用户项目代码范围内),如果能,返回Class对象;
- 如果所有类加载器都无法加载,抛出
java.lang.ClassNotFoundException。
核心价值 :防止核心类库被恶意篡改。例如,用户无法自定义一个java.lang.String类并被加载------因为当加载java.lang.String时,会委托给启动类加载器,而启动类加载器已经加载了核心类库中的java.lang.String,用户自定义的类永远不会被加载,从而保护了JVM核心内存结构的安全。
(2)JDK9+:按需委派模型(双亲委派的升级版本)
JDK9引入模块化系统(Jigsaw)后,传统的双亲委派模型无法满足模块化的访问控制需求,因此升级为**"按需委派模型(也称模块委派模型)",核心规则是"根据类的模块归属和访问权限,灵活选择类加载器,而非严格的父类优先"**,具体优化点:
- 移除扩展类加载器,替换为平台类加载器,简化类加载器层级;
- 类加载的优先级不再是"父类优先",而是"模块优先+权限优先"------先判断类所属的模块是否被当前模块授权访问,再根据模块的归属选择对应的类加载器;
- 支持模块化jar的"按需加载",只有模块被依赖时才会触发加载,减少内存占用;
- 保留双亲委派的核心思想(保护核心类库),对非模块化类仍遵循父类优先的加载规则。
核心价值:适配模块化系统,提升类加载的灵活性和安全性,减少不必要的内存占用,同时兼容传统非模块化代码。
2.4 JDK7-JDK21关键演进
类加载子系统的演进主要围绕"模块化支持 "、"性能优化 "、"安全增强 "、"高并发适配"展开,核心变更集中在JDK9(模块化)和JDK21(虚拟线程适配),具体演进节点如下:
1. JDK7:基础稳定,严格双亲委派,无模块化
- 核心状态:类加载器层级为"Bootstrap→Extension→Application",严格遵循双亲委派模型,无任何模块化设计;
- 核心特点 :核心类库打包为
rt.jar(约数百MB),JVM启动时会加载该jar包中的大部分核心类,内存占用较高; - 存在问题 :
- 扩展类加载器的加载目录(
jre/lib/ext)使用场景有限,且容易引发第三方jar包冲突; - 无模块化隔离,用户代码可能通过反射访问核心类库的内部方法,存在安全风险;
- 核心类库整体加载,初始化阶段内存占用高,启动速度较慢;
- 扩展类加载器的加载目录(
- 典型异常:用户自定义类与核心类库重名时,会被双亲委派模型拦截,抛出类冲突异常(保护核心内存安全)。
2. JDK9:模块化革命(Jigsaw),重构类加载器与委派模型
这是类加载子系统最具颠覆性的版本,核心围绕"模块化"展开,具体变更如下:
- 移除扩展类加载器,新增平台类加载器:将扩展类加载器的职责合并到平台类加载器中,简化类加载器层级为"Bootstrap→Platform→Application";
- 核心类库模块化拆分 :将传统的
rt.jar、tools.jar等拆分为数十个核心模块(如java.base、java.lang、java.util),每个模块仅包含必要的类,且模块间有明确的访问控制; - 双亲委派模型升级为按需委派模型:适配模块化场景,支持"模块优先"加载,同时保留对非模块化代码的兼容;
- 新增模块访问权限校验 :模块通过
module-info.java文件声明对外暴露的包和方法,未暴露的内部类和方法无法被其他模块访问,即使通过反射也无法突破(默认情况下),大幅提升内存中类信息的安全性; - 优化类加载内存占用 :模块化支持"按需加载",只有被依赖的模块才会被加载,JVM启动时仅需加载
java.base等核心模块,内存占用大幅降低,启动速度提升; - 具体示例(模块化声明) :
在JDK9+中,创建模块化项目时,需要在src/main/java下创建module-info.java文件,声明模块名称和对外暴露的包:
java
// 声明模块名称:com.example.demo
module com.example.demo {
// 对外暴露com.example包(其他模块可访问该包下的类)
exports com.example;
// 依赖java.base模块(默认自动依赖,可省略)
requires java.base;
// 依赖第三方模块化jar(如Gson)
requires com.google.gson;
}3. JDK17:模块化稳定化,强化安全与兼容性
JDK17作为长期支持(LTS)版本,主要对JDK9引入的模块化类加载机制进行稳定化和安全增强,具体变更:
- 固化模块化类加载流程,修复JDK9-JDK16中模块化加载的兼容性问题(如第三方框架与模块化核心类库的适配问题);
- 强化模块访问权限校验,默认禁止反射访问模块内部类,即使通过
setAccessible(true)也无法突破(需通过JVM参数--add-opens显式授权),进一步封堵安全漏洞; - 优化模块化类的缓存机制,将频繁访问的类元数据缓存到方法区的专用区域,减少重复加载带来的内存开销;
- 典型场景:Spring Boot 3.x及以上版本适配JDK17模块化,通过
module-info.java声明依赖,避免类加载冲突,提升运行时内存稳定性。
4. JDK21:适配虚拟线程,优化高并发类加载性能
JDK21作为最新LTS版本,类加载子系统的演进主要围绕**"虚拟线程高并发场景"**进行优化,具体变更:
- 优化类加载的线程安全机制 :传统类加载的
<clinit>()方法通过重量级锁保证线程安全,在虚拟线程高并发场景下(数万甚至数十万虚拟线程同时触发类加载),容易引发锁竞争,JDK21将该锁优化为轻量级锁,减少锁竞争带来的内存开销和性能损耗; - 优化模块化类的动态加载/卸载逻辑:支持虚拟线程场景下的类动态加载与卸载,当某个模块不再被使用时,JVM可以快速回收其在方法区中的类元数据,减少内存泄漏的风险;
- 优化类加载的缓存策略:新增"虚拟线程专属类缓存",将频繁被虚拟线程访问的类缓存到就近内存区域,减少跨线程内存访问的开销,提升高并发场景下的类加载速度;
- 典型场景:在基于JDK21虚拟线程的Web服务中(如Spring Boot 3.2+),数万虚拟线程同时调用同一个用户自定义类时,类加载器不会出现锁阻塞,类初始化的内存开销更低,服务响应速度更快。

总结
- 类加载子系统的核心是完成「字节流→内存结构化数据」的转换,最终产物落地到堆(Class对象)和方法区(类元数据),是JVM内存使用的前置环节。
- 类加载五步法不可逆,其中仅初始化阶段执行用户静态代码,
<clinit>()方法的执行顺序和线程安全性是理解类加载的关键。 - JDK7到JDK21的核心演进脉络是「无模块化→模块化→模块化稳定→虚拟线程适配」,委派模型从严格双亲委派升级为按需委派,核心优化方向是减少内存占用、提升安全性和高并发性能。
- 线程私有区域(程序计数器、虚拟机栈)基本无架构变更,而方法区、堆的演进与类加载子系统的优化紧密相关。
三、核心模块2:运行时数据区------JVM的"核心内存仓库"(含TLAB关键细节)
如果说类加载子系统是JVM的"物料入库专员",那么运行时数据区就是JVM的"核心立体仓库"------所有Java程序运行时产生的对象、指令、变量、常量数据,最终都会存储在这里,它是程序执行的"数据地基",也是执行引擎(尤其是垃圾回收器GC)唯一的核心操作区域。
这片内存仓库的设计逻辑,始终围绕"线程归属"划分,分为线程私有区 和线程共享区 :前者是每个线程的"专属小隔间",随线程生死而存亡,无需GC操心;后者是所有线程的"公共大仓库",存储核心业务对象,是GC日夜"打扫清理"的主战场。而堆内存中的TLAB(线程本地分配缓冲区),则是JVM为提升高并发对象分配效率设计的"专属快速通道",也是理解现代JVM内存优化的关键细节。
3.1 线程私有区(无需GC,线程独立分配,无共享冲突)
核心特点:线程创建时自动分配,线程销毁时自动释放,内存的分配与释放由JVM底层直接管控,无需垃圾回收器介入,也不存在线程安全冲突(每个线程独享一份)。该区域的异常多为栈深度超限或内存分配不足,与GC无关。

3.1.1 程序计数器:JVM指令执行的"导航仪"
-
核心定位 :一块体积极小的内存区域,专门用于记录当前线程正在执行的字节码指令的行号偏移量 ,相当于线程执行指令的"导航坐标"。
补充说明:如果当前线程执行的是Java方法,程序计数器记录的是字节码指令的行号;如果执行的是Native方法(C/C++实现),程序计数器的值为null(未定义)。 -
核心功能 :
- 线程切换恢复:JVM是多线程并发执行的,同一时间一个CPU核心只能执行一个线程的指令,当线程被挂起(如时间片用完)时,程序计数器会记录当前执行到的指令位置,当线程再次被唤醒时,就能通过该计数器恢复到之前的执行位置,不会出现指令执行错乱。
- 支持流程控制:为分支、循环、跳转、异常处理、方法返回等操作提供指令定位支撑,例如循环执行时,计数器会指向循环体的起始指令行,保证循环能够重复执行。
-
内存特性 :
- 是JVM规范中唯一不会抛出
OutOfMemoryError(OOM,内存溢出)的区域,因为它的内存大小是固定的(仅需存储指令行号偏移量),与线程数量无关,也不会随程序运行动态扩容。 - 占用内存极小,几乎可以忽略不计,每个线程都有一个独立的程序计数器,彼此隔离,互不干扰。
- 是JVM规范中唯一不会抛出
-
代码示例(直观理解) :
javapublic class ProgramCounterDemo { public static void main(String[] args) { int a = 1; int b = 2; int c = a + b; // 程序计数器会记录该指令的行号 System.out.println(c); } }当该程序运行时,主线程的程序计数器会依次记录"定义a"、"定义b"、"计算c"、"输出c"对应的字节码指令行号,即使中途有其他线程抢占CPU,主线程被挂起,再次唤醒时也能通过计数器准确回到未执行完成的指令位置,继续完成计算和输出。
-
版本演进 :JDK7-JDK21无核心架构改造,仅做底层适配性优化
- JDK7-JDK18:传统实现,仅支持重量级线程的指令记录,指令切换的内存开销略高。
- JDK21:适配虚拟线程的轻量级指令切换,优化了指令记录的存储格式,减少虚拟线程频繁切换时的计数器内存开销,提升高并发场景下的线程切换效率(虚拟线程数量可达数万甚至数十万,该优化尤为重要)。

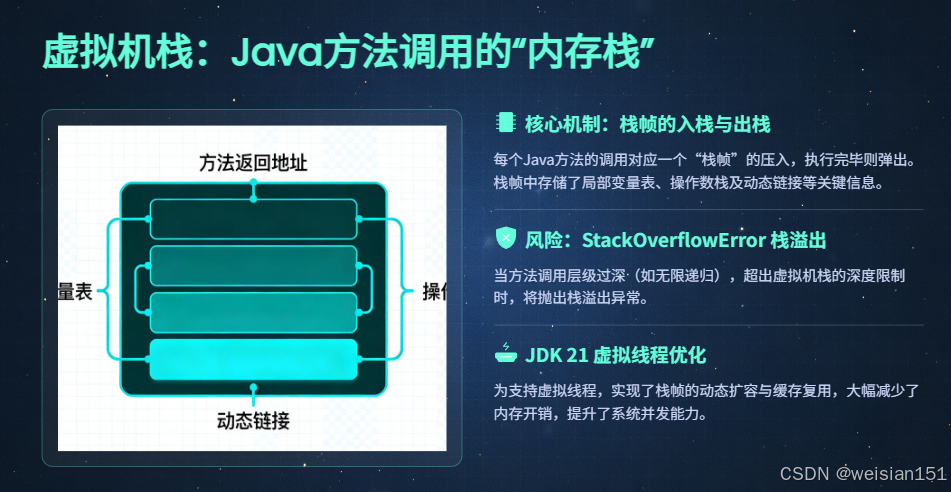
3.1.2 虚拟机栈:Java方法调用的"内存栈"
-
核心定位 :专门存储Java方法调用过程中的栈帧(Stack Frame),是方法执行、结束的内存载体,每个Java方法的执行过程,对应着一个栈帧的"入栈"(方法开始执行)和"出栈"(方法执行完成)过程。
-
核心组成 :虚拟机栈的核心单元是栈帧 ,一个栈帧对应一个正在执行的Java方法,栈帧中包含四大核心数据区域,所有数据均为线程私有,不存在共享冲突:
- 局部变量表 :
- 存储方法内的局部变量 (非static、非实例变量)和方法参数 (如
main方法的args参数)。 - 仅存储编译期可知的基本数据类型(
byte、short、int、long、float、double、char、boolean)和对象引用类型(存储对象在堆中的内存地址或句柄,并非对象本身)。 - 内存大小在编译期确定,运行时不会动态扩容,方法执行完成后,局部变量表随栈帧出栈释放。
- 特殊说明:局部变量表中的变量没有默认初始值,必须显式赋值后才能使用(与类变量的准备阶段不同)。
- 存储方法内的局部变量 (非static、非实例变量)和方法参数 (如
- 操作数栈 :
- 一个临时的数据存储栈,用于执行字节码指令时的操作数入栈、出栈和计算,相当于方法执行的"临时工作台"。
- 例如执行
int c = a + b;时,会先将a、b的值压入操作数栈,然后执行加法指令,将栈顶的两个值弹出相加,再将结果压回操作数栈,最后将结果存入局部变量表的c中。
- 动态链接 :
- 指向方法区中运行时常量池的方法引用,用于将符号引用(编译期生成的方法名)转换为直接引用(方法在内存中的实际地址)。
- 与类加载的"解析"步骤关联,大部分符号引用在解析阶段转换为直接引用,少数动态绑定场景(如多态、反射)会在方法执行时(运行时)通过动态链接完成转换。
- 方法返回地址 :
- 记录方法执行完成后,需要返回到的父方法(调用当前方法的方法)的指令位置,保证方法执行完成后,父方法能够继续执行后续指令。
- 例如
main方法调用add()方法,add()方法的返回地址就是main方法中调用add()之后的指令行号。
- 局部变量表 :
-
内存特性 :
- 栈的深度可通过JVM参数
-Xss配置(默认值约1M,不同JVM版本略有差异),例如-Xss2m表示将每个线程的虚拟机栈大小设置为2M。 - 当方法调用层级过深(如无限递归),导致栈帧入栈数量超过虚拟机栈的最大深度时,会抛出
StackOverflowError异常。 - 当JVM无法为虚拟机栈分配足够的内存(如创建大量线程,每个线程都需要分配虚拟机栈内存)时,会抛出
OutOfMemoryError异常。 - 内存分配是**后进先出(LIFO)**的栈结构,栈帧的入栈、出栈操作效率极高,无需GC介入。
- 栈的深度可通过JVM参数
-
代码示例(演示栈帧入栈/出栈与
StackOverflowError) :javapublic class VMStackDemo { // 用于记录递归调用次数 private static int count = 0; public static void recursiveMethod() { count++; // 无限递归调用,导致栈帧不断入栈 recursiveMethod(); } public static void main(String[] args) { try { recursiveMethod(); } catch (StackOverflowError e) { System.out.println("递归调用次数:" + count); System.out.println("异常信息:" + e.getMessage()); } } }运行结果 :
递归调用次数:11428 异常信息:null结果解析 :
main方法执行时,一个栈帧入栈;main方法调用recursiveMethod(),recursiveMethod()的栈帧入栈。recursiveMethod()无限递归调用自身,每次调用都会产生一个新的栈帧入栈,虚拟机栈的深度不断增加。- 当栈帧数量超过
-Xss配置的栈最大深度时,抛出StackOverflowError异常,程序终止。 - 该示例清晰展示了虚拟机栈的栈帧入栈逻辑,以及无限递归导致的栈溢出问题。
-
版本演进 :核心优化围绕虚拟线程的轻量级栈帧展开
- JDK7-JDK18:固定栈帧大小,每个重量级线程对应一个独立的虚拟机栈,栈帧内存一旦分配,大小固定,无法动态调整,适配传统重量级线程(数量通常在数百至数千级别)。
- JDK19-JDK21:为虚拟线程 实现轻量级栈帧 ,带来三大核心优化:
- 动态扩容/缩容:虚拟线程的栈帧大小不再固定,而是根据方法执行的需要动态调整,避免内存浪费(例如简单方法仅需少量栈内存,无需分配1M默认栈空间)。
- 栈折叠(Stack Folding):当虚拟线程被挂起(如等待I/O操作)时,JVM会将其栈帧折叠压缩,减少栈内存占用,提升内存利用率。
- 栈缓存复用:虚拟线程销毁时,其栈帧内存不会立即释放,而是缓存起来供其他新建的虚拟线程使用,减少高并发场景下的栈内存分配开销(虚拟线程数量可达数万,该优化大幅提升性能)。
- 补充:虚拟线程的栈内存默认按需分配,无需手动配置
-Xss参数,JVM会自动根据场景优化调整。
3.1.3 本地方法栈:Native方法的"专属栈"
-
核心定位 :与虚拟机栈的架构、功能基本一致,唯一的区别是专门为Native方法(由C/C++实现,被Java方法调用)提供栈帧支持,是JVM调用本地方法的内存载体。
-
核心关联:与**本地方法接口(JNI,Java Native Interface)**强耦合,Java方法通过JNI调用Native方法时,JVM会在本地方法栈中为该Native方法分配一个栈帧;Native方法执行完成后,栈帧出栈,内存释放。
-
内存特性 :
- 与虚拟机栈类似,会抛出
StackOverflowError(Native方法调用层级过深)和OutOfMemoryError(无法分配足够的栈内存)异常。 - 部分JVM实现(如HotSpot虚拟机)将虚拟机栈和本地方法栈合并为一个统一的栈区域,不再做严格区分,简化内存管理逻辑。
- 内存分配与释放由JVM和操作系统共同管控,无需GC介入,线程私有,无共享冲突。
- 与虚拟机栈类似,会抛出
-
代码示例(演示JNI与本地方法栈使用) :
(注:该示例需要编写C/C++本地代码,此处仅展示Java端代码,直观理解本地方法调用)javapublic class NativeStackDemo { // 声明本地方法(由C/C++实现) public native void sayHello(); // 加载本地库(包含Native方法的实现) static { System.loadLibrary("NativeDemo"); // 本地库名称为NativeDemo(对应Windows下的NativeDemo.dll,Linux下的libNativeDemo.so) } public static void main(String[] args) { NativeStackDemo demo = new NativeStackDemo(); // 调用本地方法,触发本地方法栈帧入栈 demo.sayHello(); } }执行说明 :
- 运行该Java程序时,
static代码块会加载本地库NativeDemo。 main方法调用sayHello()本地方法,JVM会在本地方法栈中为sayHello()分配一个栈帧。sayHello()方法(C/C++实现)执行完成后,栈帧出栈,本地方法栈内存释放。- 整个过程中,本地方法的执行数据存储在本地方法栈中,与虚拟机栈隔离,互不干扰。
- 运行该Java程序时,
-
版本演进 :逐步优化Native方法调用的内存开销,适配虚拟线程
- JDK7-JDK11:基础栈帧设计,仅支持重量级线程的Native方法调用,JVM与操作系统之间的内存交互开销略高,Native方法执行时的栈内存无法复用。
- JDK11+:优化Native方法栈的内存分配逻辑,减少JVM与操作系统的内存交互次数,提升Native方法的执行效率;新增本地方法栈的缓存机制,减少重复调用同一Native方法的栈帧分配开销。
- JDK21:适配虚拟线程的Native方法调用,核心优化是支持虚拟线程在执行Native方法时的栈挂起/恢复 :
- 虚拟线程执行Native方法时,若需要等待I/O操作,其本地方法栈帧会被安全挂起,不会占用CPU资源。
- 当Native方法执行完成(或等待条件满足)时,栈帧能够快速恢复,继续执行后续逻辑,保证高并发场景下的内存稳定性和执行效率。

3.2 线程共享区(GC核心操作区域,全线程共用,存储核心对象)
核心特点:JVM启动时分配,JVM关闭时释放 ,内存占用大(通常占JVM总内存的80%以上),是Java对象的主要存储区域,也是所有线程共用的内存区域,存在线程安全冲突。该区域是执行引擎(GC)的核心操作对象,所有垃圾回收器均针对该区域的不同子分区设计,子分区的架构改造直接驱动了GC回收器的迭代升级(如G1、ZGC、Shenandoah的出现)。

3.2.1 Java堆:GC主战场,对象存储的"核心粮仓"(含TLAB)
- 核心定位 :JVM中最大的一块内存区域,专门用于存储所有Java对象实例和数组对象,是对象创建的唯一内存区域(逃逸分析优化后的"栈上分配"和"标量替换"除外,属于小众优化场景)。同时,它也是垃圾回收器(GC)回收的主战场,绝大多数GC操作都集中在Java堆中,因此Java堆也被称为"GC堆"。
- 内存特性 :
- 可通过JVM参数
-Xms(初始堆大小)和-Xmx(最大堆大小)配置,例如-Xms512m -Xmx2g表示堆的初始大小为512M,最大大小为2G。 - 为了提升GC效率,通常建议将
-Xms和-Xmx设置为相同值,避免JVM运行过程中动态调整堆大小带来的性能开销。 - 当Java堆无法为新创建的对象分配足够的内存,且GC无法回收足够的空闲内存时,会抛出
OutOfMemoryError异常(这是Java开发中最常见的OOM异常之一)。 - 堆内存是线程共享的,多个线程同时在堆中分配对象时,存在锁竞争问题(TLAB优化就是为了解决该问题)。
- 可通过JVM参数
(1)经典分代划分(GC分代回收的基础,JDK7-JDK21通用逻辑)
分代划分是JVM内存管理的核心思想,其核心依据 是:Java程序运行过程中,对象的存活时间存在明显差异------大部分对象是"朝生夕死"的(如方法内的局部对象,方法执行完成后就不再被引用),仅占少数对象会长期存活(如应用程序的全局对象、缓存对象)。
基于这一特性,将Java堆划分为不同的"代",对不同存活时间的对象采用不同的GC回收策略和算法,能够大幅提升GC回收效率,减少GC停顿时间(STW)。JDK7-JDK21始终保留分代回收的核心逻辑,仅对存储结构做了优化(从固定物理分代到动态Region分代)。
经典的Java堆分为新生代 和老年代两大区域,部分场景下还包含"大对象区"(隐性分区)。
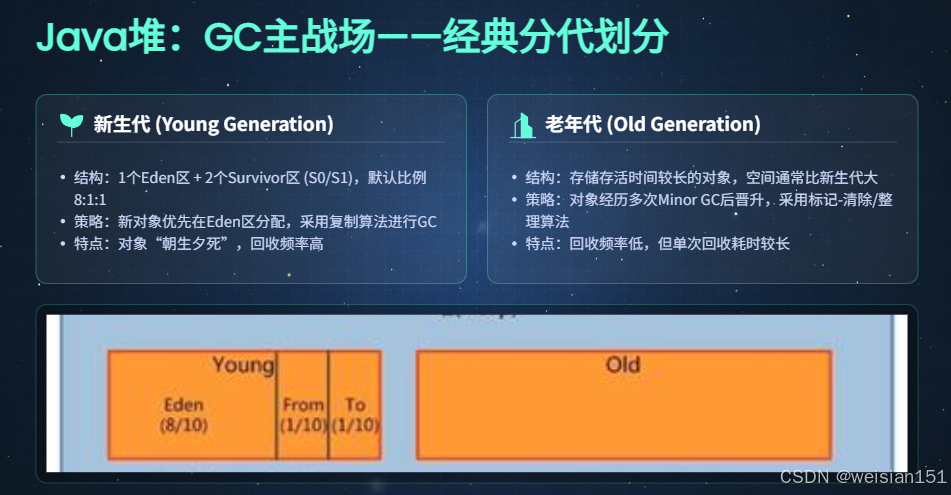
1. 新生代:存放"朝生夕死"的新对象,GC回收频率最高
- 核心定位:专门存放新创建的对象(除大对象外),对象的存活时间极短,回收频率极高(通常每秒可达数次)。
- 内存占比 :默认占整个Java堆内存的1/3左右,可通过JVM参数
-XX:NewRatio配置(-XX:NewRatio=2表示老年代内存大小:新生代内存大小=2:1,即新生代占1/3,老年代占2/3)。 - 细分区域 :新生代内部进一步细分为3个小区域,比例默认为8:1:1 (可通过JVM参数
-XX:SurvivorRatio配置,-XX:SurvivorRatio=8表示Eden区:Survivor区=8:1):
- Eden区(伊甸园):占新生代的8/10,是对象分配的主要区域,新创建的对象(除大对象外)优先在Eden区分配内存。
- Survivor 0区(S0,又称From Survivor):占新生代的1/10,用于存储Minor GC后存活的对象。
- Survivor 1区(S1,又称To Survivor):占新生代的1/10,与S0区功能相同,两者始终有一个区域是空的,用于交替存储存活对象(复制算法的核心)。
- 内存特性与GC流程:
- 对象分配 :新对象优先在Eden区分配,Eden区有足够空闲内存时,直接分配;Eden区满时,触发Minor GC(新生代GC,又称Young GC)。
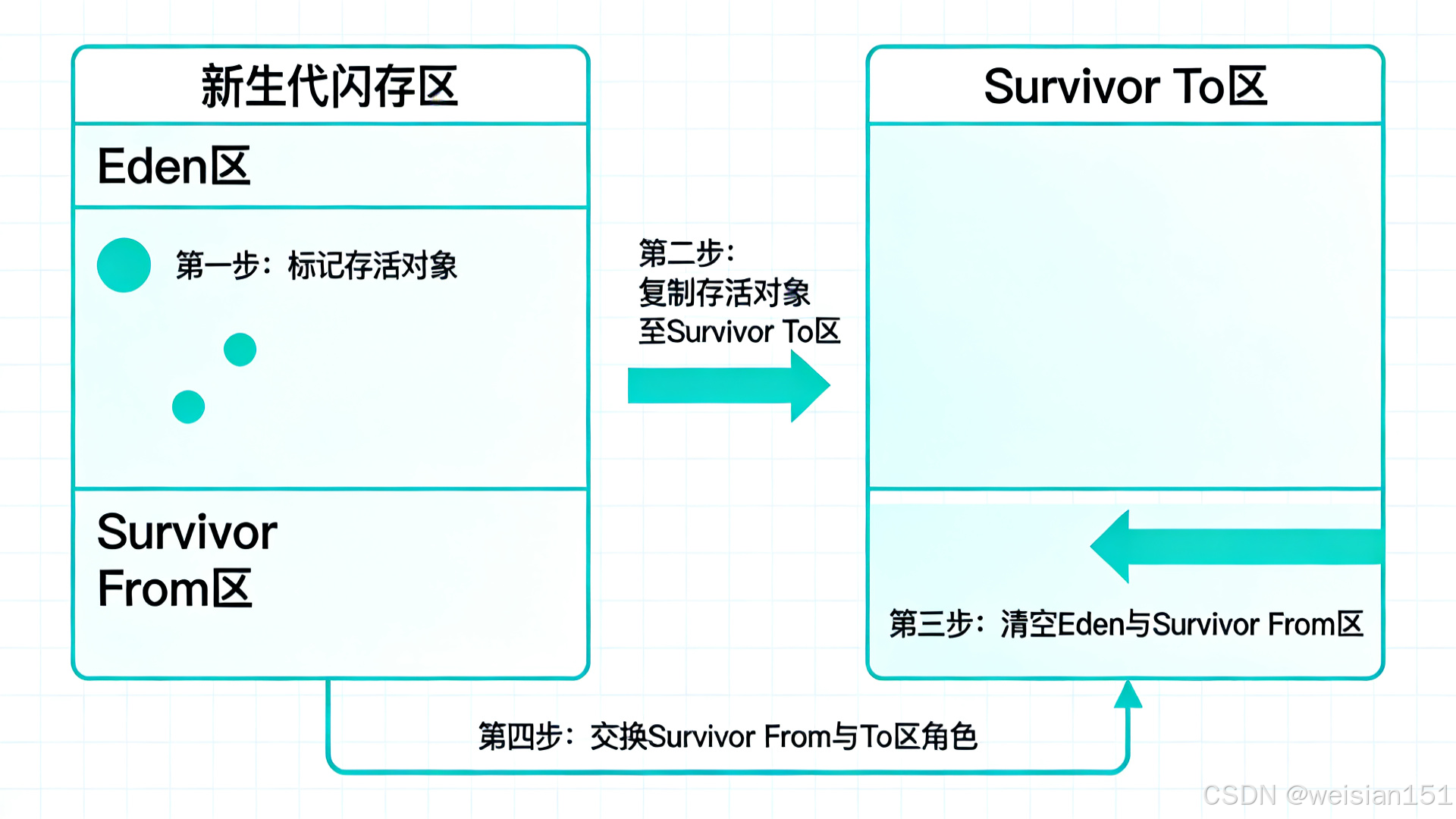
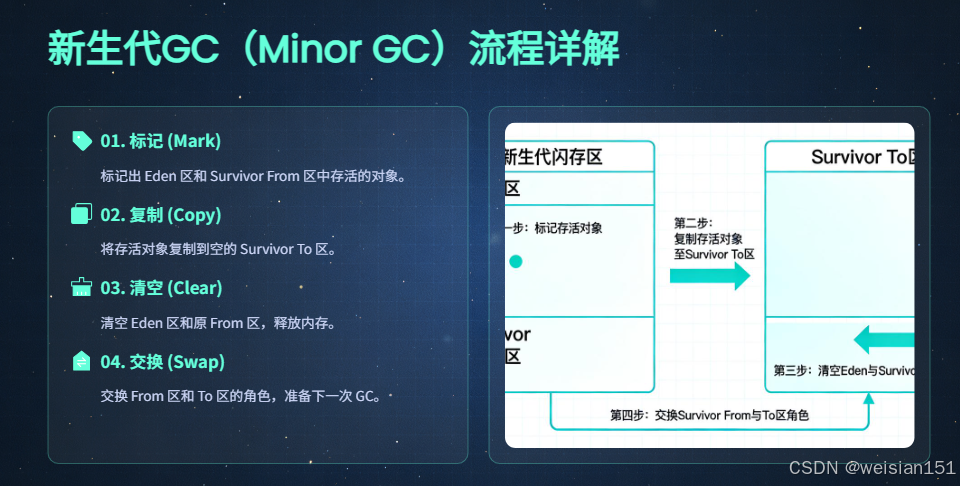
- Minor GC 回收逻辑 :采用复制算法 (高效回收短存活对象),具体流程如下:
- 第一步:标记Eden区和S0区中存活的对象(被引用的对象)。
- 第二步:将存活的对象复制到空的S1区中,同时为对象分配新的内存地址,并更新对象的引用。
- 第三步:清空Eden区和S0区的所有对象,释放内存。
- 第四步:交换S0区和S1区的角色(原来的S0区变为空,原来的S1区变为新的S0区),为下一次Minor GC做准备。
- 对象晋升 :每个对象都有一个"年龄计数器",每次Minor GC后对象存活,年龄计数器加1;当对象的年龄达到指定阈值(默认15,可通过
-XX:MaxTenuringThreshold配置)时,会被"晋升"到老年代,成为长期存活对象。 - Minor GC 特点:回收速度快(复制算法,仅处理短存活对象),停顿时间短(STW时间短),回收频率高。
-
代码示例(直观理解新生代对象分配与Minor GC) :
javaimport java.util.ArrayList; import java.util.List; public class YoungGenDemo { // 每个对象占用1KB内存 private static final int OBJECT_SIZE = 1024; public static void main(String[] args) { List<byte[]> list = new ArrayList<>(); try { // 循环创建对象,填充Eden区 while (true) { list.add(new byte[OBJECT_SIZE]); } } catch (OutOfMemoryError e) { System.out.println("新生代内存不足,抛出OOM异常"); e.printStackTrace(); } } }执行说明(配置JVM参数:
-Xms10m -Xmx10m -XX:NewRatio=2 -XX:+PrintGCDetails) :- 堆总大小为10M,新生代占约3.3M,老年代占约6.7M。
- 循环创建1KB大小的字节数组对象,对象优先分配在Eden区(约2.64M)。
- 当Eden区被填满时,触发Minor GC,采用复制算法回收未被
list引用的对象(此处所有对象都被list引用,无法回收)。 - 多次Minor GC后,对象年龄达到15,晋升到老年代,老年代也被填满。
- 最终堆内存不足,抛出
OutOfMemoryError异常,同时控制台会打印GC详细日志,展示新生代的回收过程。
2. 老年代:存放"长命百岁"的对象,GC回收频率低
- 核心定位:专门存放存活时间长的对象,包括:多次Minor GC后仍存活的对象、直接分配的大对象、需要长期存储的全局对象/缓存对象。
- 内存占比 :默认占整个Java堆内存的2/3左右,可通过
-XX:NewRatio配置。 - 内存特性与GC流程:
- 对象进入方式 :
- 新生代对象年龄达到阈值(默认15)后,晋升进入老年代。
- 大对象(超过指定大小)直接进入老年代(避免在新生代频繁复制)。
- 新生代Survivor区空间不足时,部分存活对象会直接晋升到老年代(空间分配担保)。
- GC触发条件 :当老年代内存不足时,触发Major GC (老年代GC),若Major GC仍无法回收足够的内存,会触发Full GC(全堆GC,回收新生代+老年代+方法区)。
- 回收算法 :早期采用标记-清除算法 或标记-整理算法 (针对长存活对象,复制算法效率低):
- 标记-清除算法:先标记存活对象,再清除未被标记的对象,优点是无需移动对象,缺点是会产生内存碎片。
- 标记-整理算法:先标记存活对象,再将存活对象移动到内存的一端,然后清除另一端的所有对象,优点是无内存碎片,缺点是需要移动对象,开销较大。
- Major GC/Full GC 特点:回收速度慢(处理长存活对象,对象数量多),停顿时间长(STW时间长),回收频率低(通常几分钟甚至几小时一次)。
- 补充说明:Full GC是JVM尽量避免的GC操作,因为其停顿时间长,会严重影响应用程序的性能(尤其是高并发场景)。现代JVM(如JDK17+的ZGC)通过优化回收算法,大幅减少了Full GC的发生概率和停顿时间。
3. 大对象区(隐性分区):存放"超大尺寸"对象
-
核心定位:专门存放超过指定大小的"大对象"(如大数组、大字符串),是一个隐性分区(不单独划分物理区域,本质上属于老年代的一部分)。
-
配置参数 :可通过JVM参数
-XX:PretenureSizeThreshold配置大对象的阈值(默认值因JVM版本而异,通常为32K或64K),例如-XX:PretenureSizeThreshold=65536表示超过64K的对象为大对象。 -
核心目的:避免大对象在新生代的Eden区和Survivor区之间频繁复制(大对象复制开销大,且容易耗尽新生代内存),直接将大对象分配到老年代,提升GC效率,减少内存碎片。
-
代码示例(演示大对象直接进入老年代) :
javapublic class LargeObjectDemo { // 定义大对象大小为100KB(超过默认阈值) private static final int LARGE_OBJECT_SIZE = 1024 * 100; public static void main(String[] args) { // 创建大对象,直接进入老年代 byte[] largeObject = new byte[LARGE_OBJECT_SIZE]; System.out.println("大对象创建完成"); } }执行说明(配置JVM参数:
-Xms10m -Xmx10m -XX:PretenureSizeThreshold=65536 -XX:+PrintGCDetails) :- 配置大对象阈值为64K,创建的100KB字节数组超过该阈值,属于大对象。
- 运行程序后,查看GC详细日志,可发现该大对象直接被分配到老年代,未进入新生代的Eden区。
(2)核心优化:TLAB(线程本地分配缓冲区)------ 高并发对象分配的"快速通道"
TLAB(Thread Local Allocation Buffer)是JVM为提升高并发场景下对象分配效率而设计的核心优化,也是现代JVM的默认开启特性。
设计背景:解决堆内存的锁竞争问题
Java堆是线程共享区域,当多个线程同时在新生代Eden区分配对象时,需要竞争堆的全局锁(保证对象分配的线程安全),这会导致以下问题:
- 高并发场景下(如数万线程同时创建对象),锁竞争激烈,对象分配效率大幅下降。
- 频繁的锁竞争会带来额外的性能开销,影响应用程序的整体响应速度。
为了解决这一问题,JVM引入了TLAB机制,为每个线程分配一块独立的"私有缓冲区",让线程在自己的缓冲区中分配对象,无需竞争全局锁。
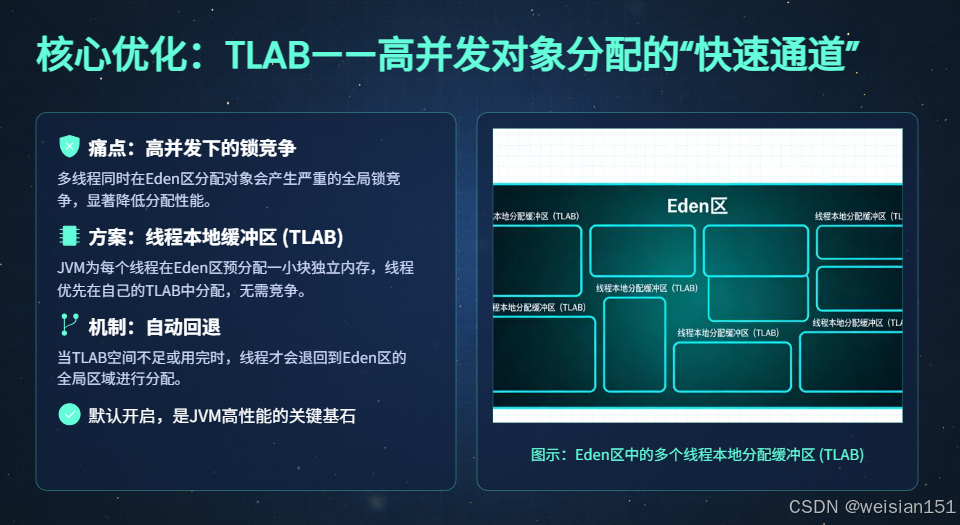
1. 核心定义
TLAB是JVM在新生代Eden区为每个线程预先分配的一块独立的小型内存缓冲区,线程创建对象时,优先在自己的TLAB中分配内存,无需竞争堆的全局锁,从而大幅提升高并发场景下的对象分配效率。
关键补充 :TLAB并非独立于Java堆的内存区域,它本质上是新生代Eden区的一部分,只是被划分为多个小块,分别分配给不同的线程,作为线程的"专属分配区域"。
2. 核心特性
-
归属与配置:
-
归属:新生代Eden区,不属于老年代,也不是独立内存区域。
-
大小配置:可通过JVM参数
-XX:TLABSize手动配置TLAB的大小(如-XX:TLABSize=16k),默认情况下由JVM自动计算(根据线程的对象分配频率、堆大小等动态调整)。 -
空闲空间配置:可通过
-XX:TLABWasteTargetPercent配置TLAB空闲空间的最大比例(默认1%),用于平衡对象分配效率和内存利用率。 -
对象分配逻辑(核心流程):
线程创建对象
↓
检查当前线程的TLAB是否有足够空闲内存
↓ 是
直接在TLAB中分配对象(无需竞争全局锁,效率高)
↓ 否
检查对象大小是否超过TLAB的最大容量
↓ 是(大对象)
直接切换至Eden区全局分配(需竞争全局锁)
↓ 否(TLAB不足,但对象不大)
JVM自动为线程重新分配一块新的TLAB(从Eden区中划分)
↓
在新的TLAB中分配对象
关键补充:TLAB"不足"分为两种情况------一是TLAB的空闲内存不足以容纳当前对象,二是TLAB的空闲内存虽能容纳对象,但剩余空间过小(低于TLABWasteTargetPercent配置的比例),为了避免内存浪费,JVM会选择重新分配新的TLAB。
-
回收逻辑:
-
TLAB没有独立的回收机制,随新生代Eden区一起被Minor GC回收,无需单独处理。
-
Minor GC执行时,JVM会标记TLAB中存活的对象(被引用的对象),并将其复制到Survivor区;同时,清空所有TLAB的空闲内存。
-
Minor GC完成后,JVM会为仍存活的线程重新分配新的TLAB,保证后续对象分配的效率。
-
开关配置:
-
默认开启(
-XX:+UseTLAB),这是JVM的最优默认配置,适用于绝大多数场景(尤其是高并发场景)。 -
低并发场景下(如单线程、少量线程),锁竞争不激烈,TLAB的优化收益不明显,可手动关闭(
-XX:-UseTLAB),但通常不建议这样做(无明显性能提升,反而可能带来额外开销)。 -
可视化流程(辅助理解) :
【新生代Eden区】 ┌─────────────────────────────────────────────────┐ │ TLAB-线程1 │ TLAB-线程2 │ TLAB-线程3 │ 全局区域 │ │ (线程1专属) │ (线程2专属) │ (线程3专属) │ (竞争分配) │ └─────────────────────────────────────────────────┘
3. 版本演进:从固定大小到缓存复用,持续优化效率与内存利用率
- JDK7 :基础TLAB实现,支持固定大小TLAB分配。
- 特点:每个线程的TLAB大小固定,分配逻辑简单,对象分配效率有明显提升。
- 不足:存在少量内存浪费------TLAB未用完的空闲空间会被标记为"不可用",无法被其他线程使用,只能等待Minor GC时回收。
- JDK8 :TLAB核心优化版本,支持动态大小调整。
- 核心优化1:JVM根据线程的对象分配频率,动态调整TLAB的大小(对象分配频繁的线程,TLAB调大;分配不频繁的线程,TLAB调小),减少内存浪费。
- 核心优化2:新增
-XX:TLABWasteTargetPercent参数,配置TLAB空闲空间的最大比例(默认1%),当TLAB的空闲空间超过该比例时,JVM会选择重新分配TLAB,平衡对象分配效率与内存利用率。 - 核心优化3:优化TLAB的分配算法,减少TLAB创建时的内存开销,提升高并发场景下的TLAB分配速度。
- JDK9+:适配动态Region分代,优化大堆场景下的TLAB。
- 核心优化1:TLAB在Region内部分配(堆被划分为多个Region),适配G1收集器的动态分代结构,提升大堆场景(如几十G、上百G堆内存)下的对象分配效率。
- 核心优化2:支持TLAB的"预分配"机制,JVM会提前为即将创建的线程分配TLAB,减少线程创建时的TLAB分配开销,提升线程启动速度。
- 核心优化3:优化TLAB的内存对齐,减少内存碎片,提升CPU缓存命中率。
- JDK21 :为虚拟线程优化TLAB,实现轻量级TLAB缓存复用。
- 核心优化1:虚拟线程销毁时,其TLAB不会立即被回收(若TLAB还有较多空闲内存),而是被缓存到JVM的TLAB缓存池中,供其他新建的虚拟线程复用。
- 核心优化2:减少虚拟线程高并发场景下的TLAB分配开销(虚拟线程数量可达数万,TLAB复用大幅提升效率),同时减少内存浪费,提升堆内存利用率。
- 核心优化3:适配虚拟线程的动态栈帧,优化TLAB与虚拟线程的内存关联,减少虚拟线程挂起/恢复时的TLAB内存开销。
(3)Region存储结构(JDK9+,低延迟GC适配)------ 动态分代替代固定物理分代
随着JVM堆内存的不断增大(从早期的几G到现在的几十G、上百G),传统的"固定物理分代"(新生代、老年代划分为固定的物理区域)已经无法满足低延迟GC的需求(大堆场景下,固定分代的GC停顿时间过长)。
因此,JDK9+引入了Region存储结构(G1收集器默认采用,ZGC、Shenandoah收集器进一步优化),替代传统的固定物理分代,实现堆内存的动态分代。
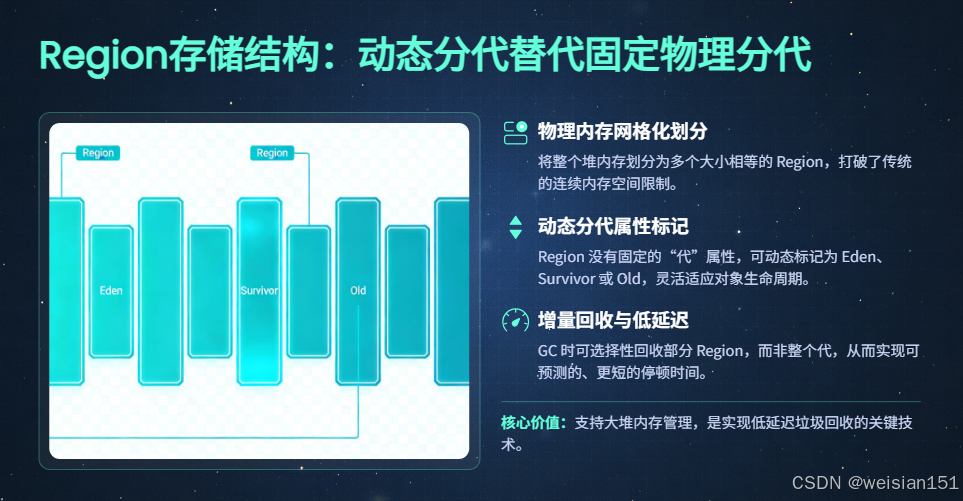
1. 核心定义
将整个Java堆划分为多个大小相等、独立的内存块(Region),Region的大小默认在1M~32M之间(根据堆的总大小自动调整,且必须是2的幂次方),例如堆总大小为16G时,Region大小可能为16M。
每个Region没有固定的"代"属性,而是可以动态标记为不同的类型,包括:
- Eden区Region(E):对应传统新生代的Eden区。
- Survivor区Region(S):对应传统新生代的Survivor区。
- 老年代Region(O):对应传统老年代。
- 大对象Region(H):专门存储超过一个Region大小的大对象(Humongous Region)。
2. 核心特性
- 动态分代:Region的"代"属性可以动态变化,例如一个Eden区Region在Minor GC后,可被重新标记为Survivor区Region或老年代Region,实现堆内存的灵活复用。
- 按需回收:GC回收器可以只回收部分Region(而非整个新生代或老年代),减少GC停顿时间,提升低延迟性能(这是G1、ZGC、Shenandoah收集器的核心优势)。
- TLAB适配:TLAB在Region内部分配,每个Region可以划分为多个TLAB,供不同线程使用,提升大堆场景下的对象分配效率。
- 无内存碎片:Region的大小固定,且支持动态标记与复用,能够有效减少内存碎片,提升堆内存利用率。
3. 核心优势(对比传统固定物理分代)
- 适配大堆场景(几十G、上百G),大幅减少GC停顿时间,满足低延迟应用的需求(如金融、电商核心系统)。
- 堆内存复用效率更高,减少内存浪费。
- 支持更灵活的GC回收策略,提升GC效率。
(4)Java堆版本演进:从固定分代到动态Region,适配低延迟GC
- JDK7:传统物理分代(新生代+老年代),堆中包含永久代(方法区的物理实现)。
- 核心特点:新生代划分为Eden+S0+S1(8:1:1),老年代为固定物理区域,永久代属于堆的一部分(容易出现
PermGen spaceOOM)。 - 核心优化:字符串常量池从永久代迁移至Java堆,减少永久代的内存压力。
- TLAB:基础实现,支持固定大小TLAB分配,存在少量内存浪费。
- 配套GC:默认采用Parallel GC(并行收集器),专注于吞吐量,停顿时间较长。
- JDK8:彻底移除永久代,堆仅保留新生代+老年代,物理分代不变。
- 核心特点:移除永久代,方法区由元空间(Metaspace)替代(基于本地内存实现,不再属于Java堆),Java堆的结构更简洁。
- 核心优化:优化新生代Eden区的对象分配逻辑,减少锁竞争;TLAB支持动态大小调整,新增
TLABWasteTargetPercent参数,平衡效率与内存利用率。 - 配套GC:默认仍为Parallel GC,G1 GC逐渐成熟(可通过
-XX:+UseG1GC开启)。 - JDK9:引入Region动态分代,G1收集器成为默认GC。
- 核心特点:将堆划分为多个大小相等的Region,替代传统固定物理分代,实现动态分代,为低延迟GC铺路。
- 核心优化:TLAB适配Region结构,在Region内部分配,提升大堆场景下的对象分配效率;优化新生代的Minor GC流程,减少停顿时间。
- 配套GC:G1 GC成为默认收集器,支持部分Region回收,大幅提升大堆场景下的性能。
- JDK17:ZGC收集器转正(LTS版本),Region结构进一步优化。
- 核心特点:ZGC收集器成为正式特性,基于Region结构实现,支持超大堆(上百G、上千G),GC停顿时间控制在毫秒级。
- 核心优化:Region大小支持动态调整(根据对象大小自适应),优化大对象的存储与回收;TLAB适配ZGC的Region结构,提升超高并发场景下的对象分配效率。
- 配套GC:ZGC、Shenandoah GC成熟稳定,支持低延迟、大堆场景。
- JDK21:为虚拟线程优化堆内存,ZGC支持分代回收。
- 核心特点:优化堆内存的对象分配逻辑,适配虚拟线程的高并发场景;ZGC引入分代回收,进一步提升GC效率,减少停顿时间。
- 核心优化:实现TLAB缓存复用,减少虚拟线程创建对象时的内存锁竞争;优化Region的动态标记与复用,提升堆内存利用率。
- 配套GC:ZGC分代回收成为默认特性,兼顾吞吐量与低延迟,适配虚拟线程的高并发、大堆场景。
3.2.2 方法区:类元数据的"存储仓库"(从永久代到元空间)
- 核心定位 :JVM规范中的一个逻辑区域 ,专门用于存储已被类加载子系统加载的类元数据、运行时常量池、静态变量、即时编译器(JIT)编译后的代码缓存等数据,是类加载子系统的核心存储区域,也是类信息的"持久化仓库"。
- 内存特性 :
- 属于Java堆的逻辑分区(JDK7前为物理分区,JDK8后为独立的本地内存区域,逻辑上仍属于运行时数据区)。
- 内存不足时,会抛出
OutOfMemoryError异常(JDK7前为PermGen space,JDK8后为Metaspace)。 - GC仅回收"无用的类元数据"(类卸载)和过期的常量,回收条件极为严格,远不如Java堆的回收频繁。
- 线程共享,多个线程可同时访问方法区中的类元数据,存在线程安全冲突(类加载子系统通过锁机制保证类元数据的线程安全)。
- 核心子区域:运行时常量池 :
-
核心定位 :方法区的核心组成部分,专门用于存储字面量 和符号引用 ,是类加载完成后,从
.class文件常量池加载而来的内存区域。 -
存储内容 :
- 字面量:直接量,包括字符串字面量(如
"hello world")、基本数据类型的常量(如100、true)。 - 符号引用:编译期生成的引用,包括类的全限定名、方法的名称与参数类型、字段的名称与类型等(对应类加载"解析"步骤的输入)。
- 字面量:直接量,包括字符串字面量(如
-
核心特性 :
- 运行时常量池是动态的 ,并非只能存储编译期生成的常量,运行时也可以向其中添加常量(如
String.intern()方法,可将字符串字面量添加到运行时常量池中)。 - 随类的卸载而销毁,当一个类被卸载时,其对应的运行时常量池也会被回收。
- 运行时常量池是动态的 ,并非只能存储编译期生成的常量,运行时也可以向其中添加常量(如
-
代码示例(演示运行时常量池的动态性) :
javapublic class RuntimeConstantPoolDemo { public static void main(String[] args) { String s1 = "hello"; String s2 = "hello"; String s3 = new String("hello"); String s4 = s3.intern(); // s1和s2指向运行时常量池中的同一个字符串对象 System.out.println("s1 == s2: " + (s1 == s2)); // s3指向堆中的字符串对象,s4指向运行时常量池中的字符串对象 System.out.println("s3 == s4: " + (s3 == s4)); System.out.println("s1 == s4: " + (s1 == s4)); } }运行结果 :
s1 == s2: true s3 == s4: false s1 == s4: true结果解析 :
s1和s2直接赋值为"hello",编译期"hello"被存入.class文件常量池,类加载后加载到运行时常量池中,s1和s2均指向运行时常量池中的同一个对象,因此s1 == s2为true。s3通过new String()创建,对象存储在Java堆中,s3指向堆中的对象。s3.intern()方法将堆中的"hello"字符串添加到运行时常量池中(若不存在),并返回运行时常量池中的字符串对象引用,s4指向该引用,因此s1 == s4为true,s3 == s4为false。- 该示例清晰展示了运行时常量池的动态性,以及字符串字面量在运行时常量池与堆中的存储差异。
-

方法区版本演进(核心改造:JDK7-JDK8,从永久代到元空间)
方法区的演进核心是存储载体的变更------从JDK7及以前的"永久代(PermGen)"(Java堆内部),变更为JDK8及以后的"元空间(Metaspace)"(本地内存),这一变更解决了永久代的内存溢出问题,大幅提升了方法区的内存灵活性。
1. JDK7:永久代(PermGen)------ 方法区的物理实现(Java堆内部)
- 核心实现 :在HotSpot虚拟机中,方法区的物理实现为永久代(PermGen),属于Java堆的一部分,与新生代、老年代共存于Java堆内存中。
- 配置参数:可通过JVM参数配置永久代的大小:
-XX:PermSize:永久代初始大小(默认值因JVM版本而异)。-XX:MaxPermSize:永久代最大大小(默认值通常为64M或128M)。- 存储内容:类元数据、运行时常量池、静态变量、字符串常量池(JDK7早期,后期迁移至Java堆)、JIT编译后的代码缓存。
- 核心问题:
- 容易出现
OutOfMemoryError: PermGen space异常 :永久代的大小是固定的(受MaxPermSize限制),当应用程序加载的类数量过多(如大型框架、动态生成类),或静态变量、常量过多时,容易耗尽永久代内存,抛出OOM异常。 - 内存管理复杂:永久代属于Java堆,需要与新生代、老年代共享堆内存,GC回收逻辑复杂,类卸载困难,容易产生内存碎片。
- 不灵活:永久代的大小需要手动配置,若配置过小,容易出现OOM;若配置过大,会浪费堆内存,影响新生代、老年代的内存分配。
- 关键变更 :JDK7中,将字符串常量池从永久代迁移至Java堆,这是永久代移除的铺垫,目的是减少永久代的内存压力,降低OOM异常的发生概率。
2. JDK8:元空间(Metaspace)------ 方法区的新实现(本地内存)
- 核心实现 :彻底移除永久代(PermGen),方法区的物理实现变更为元空间(Metaspace),元空间基于**本地内存(Native Memory)**实现(即操作系统的直接内存,不属于Java堆内存)。
- 配置参数:可通过JVM参数配置元空间的大小:
-XX:MetaspaceSize:元空间初始大小(触发元空间GC的阈值,默认值约21M)。-XX:MaxMetaspaceSize:元空间最大大小(默认无上限,可占用整个本地内存)。-XX:MinMetaspaceFreeRatio:元空间空闲内存的最小比例,用于控制元空间的扩容。-XX:MaxMetaspaceFreeRatio:元空间空闲内存的最大比例,用于控制元空间的缩容。- 存储内容:类元数据、运行时常量池、静态变量、JIT编译后的代码缓存(字符串常量池已迁移至Java堆,不再存储于元空间)。
- 核心优势:
- 解决了永久代的OOM问题 :元空间基于本地内存实现,默认无内存上限(可通过
MaxMetaspaceSize限制),大幅减少了OutOfMemoryError异常的发生概率。 - 内存管理更灵活:元空间的大小可根据应用程序的需要动态扩容/缩容,无需手动配置(除非有特殊限制),提升了内存利用率。
- GC回收效率更高:元空间的GC与Java堆的GC解耦,仅在元空间内存不足时触发单独的元空间GC,减少了Full GC的发生概率,提升了应用程序的性能。
- 类卸载更简单:元空间的类元数据存储结构更简洁,类卸载的条件更易满足,减少了内存碎片的产生。
- 关键补充 :虽然元空间默认无内存上限,但并非无限大------本地内存的大小受操作系统的内存限制(如物理内存、交换分区),若应用程序加载的类数量过多,仍可能耗尽本地内存,抛出
OutOfMemoryError: Metaspace异常。

3. JDK9:元空间优化,适配模块化系统
- 核心优化:
- 优化类元数据的存储结构,适配JDK9引入的模块化系统(Jigsaw),提升模块化类的元数据存储效率和访问速度。
- 支持类元数据的并发卸载,减少元空间GC的停顿时间(STW),提升应用程序的并发性能。
- 优化元空间的扩容/缩容逻辑,减少元空间与操作系统之间的内存交互开销,提升内存利用率。
- 将JIT编译后的代码缓存从元空间迁移至独立的"代码缓存"区域,进一步简化元空间的内存管理逻辑。
4. JDK17:元空间稳定化,与Full GC完全解耦
- 核心优化:
- 固化元空间的内存管理逻辑,修复JDK9-JDK16中模块化类元数据存储的兼容性问题,提升元空间的稳定性。
- 元空间的GC与Full GC完全解耦,仅在元空间内存不足时触发单独的元空间GC,不再触发Full GC,大幅减少了Full GC的发生概率,提升了应用程序的低延迟性能。
- 强化类元数据的访问权限校验,默认禁止反射访问模块化类的内部元数据,提升了元空间的安全性。
- 优化元空间的内存碎片整理逻辑,减少元空间的内存碎片,提升内存利用率。
5. JDK21:元空间优化,适配虚拟线程的高并发类加载
- 核心优化:
- 优化元空间的类元数据分配逻辑,适配虚拟线程的高并发类加载场景,减少类加载时的元空间锁竞争,提升类加载效率。
- 支持类元数据的轻量级缓存复用,将频繁访问的类元数据缓存到元空间的专用缓存区域,减少类元数据的重复加载开销,提升高并发场景下的类访问速度。
- 优化元空间的缩容逻辑,当应用程序的类加载数量减少时,元空间能够快速缩容,释放本地内存,提升系统的整体内存利用率。
- 适配虚拟线程的动态类加载/卸载场景,减少类卸载时的内存开销,降低内存泄漏的风险。
3.3 运行时数据区与GC的核心关联(详细对照表)
| 运行时数据区 | 是否被GC回收 | 核心回收策略 | 关联核心GC回收器 | 回收特点与补充说明 |
|---|---|---|---|---|
| 程序计数器 | 否 | 无 | 无 | 内存大小固定,随线程销毁释放,无需GC介入,无OOM风险。 |
| 虚拟机栈 | 否 | 无 | 无 | 栈帧随方法执行入栈/出栈,线程销毁时释放,无需GC介入,可能抛出StackOverflowError和OOM。 |
| 本地方法栈 | 否 | 无 | 无 | 与虚拟机栈类似,为Native方法服务,无需GC介入,部分JVM实现与虚拟机栈合并。 |
| 堆-新生代(含TLAB) | 是 | 复制算法(高效回收短存活对象,无内存碎片,需预留空闲空间) | SerialGC、ParallelGC、G1、ZGC、Shenandoah | 回收频率高,停顿时间短(Minor GC),TLAB随新生代一起回收,无单独回收逻辑。 |
| 堆-老年代 | 是 | 标记-清除算法(无需移动对象,有内存碎片)、标记-整理算法(无内存碎片,需移动对象) | SerialOld、ParallelOld、G1、ZGC、Shenandoah | 回收频率低,停顿时间长(Major GC/Full GC),现代GC(ZGC)采用更高效的回收算法,减少停顿。 |
| 堆-大对象区(隐性) | 是 | 标记-整理算法(避免大对象移动带来的开销,减少内存碎片) | G1、ZGC、Shenandoah | 本质属于老年代,直接分配大对象,回收逻辑与老年代一致,减少新生代频繁复制的开销。 |
| 方法区(元空间)-类元数据 | 是(类卸载) | 标记-清除算法(类元数据存储分散,移动开销大,允许少量内存碎片) | 所有GC回收器 | 回收条件严格(类实例、类加载器、Class对象均无引用),回收频率极低,与Full GC解耦(JDK17+)。 |
| 方法区(元空间)-运行时常量池 | 是(常量回收) | 标记-清除算法(过期常量直接清除,无需移动) | 所有GC回收器 | 动态添加常量,回收过期无引用的常量,随类卸载或元空间GC一起回收,回收频率较低。 |
| 代码缓存(JIT编译代码) | 是 | 标记-清除算法(代码缓存存储分散,移动开销大) | G1、ZGC、Shenandoah | 回收过期的JIT编译代码,仅在代码缓存不足时触发,回收频率极低。 |

总结
- 运行时数据区按线程归属分为私有区和共享区,私有区无需GC、随线程生死存亡,共享区是GC主战场、存储核心对象。
- 新生代的TLAB是高并发对象分配的核心优化,本质是Eden区专属缓冲区,JDK21针对虚拟线程实现了TLAB缓存复用,进一步提升效率。
- Java堆的演进脉络是「固定物理分代→动态Region分代」,适配大堆和低延迟GC场景;方法区的核心变迁是「永久代→元空间」,解决了固定内存上限的OOM问题。
- 不同区域的GC回收策略与对象存活时间匹配,新生代用复制算法、老年代用标记-整理/清除算法,核心目标是平衡回收效率与停顿时间。
3.4 【深度补充】为什么只有方法区改用本地内存(元空间),其他JVM内存区域不采用本地内存?
从JDK7永久代(PermGen,属于Java堆)到JDK8元空间(Metaspace,使用本地内存Native Memory),是JVM内存架构一次极其精准的针对性改造 ,而不是"全局把所有区域都换成本地内存"。背后不是技术做不到,而是内存用途、生命周期、GC管理、OS约束、性能模型完全不同,只有方法区/类元数据这一类数据,适合、且必须放到本地内存。
下面从「为什么方法区必须改本地内存」+「为什么堆、栈、PC、本地方法栈不能/不需要用本地内存」两个维度,把原理讲透。

1、先明确:本地内存 vs JVM托管内存(堆/栈)的核心差异
在讲原因前,先统一两个概念的边界:
-
JVM托管内存(Heap/Stack等)
- 由JVM向OS一次性申请一大块内存,内部自己管理划分、分配、回收。
- GC全权负责对象生命周期、内存整理、碎片合并。
- 受
-Xmx、-Xms、-Xss等参数硬限制,大小可控、边界清晰。 - 所有内存访问、对象布局、指针格式由JVM自己定义,便于优化(TLAB、指针压缩、逃逸分析、分代回收等)。
-
本地内存(Native Memory / Direct Memory)
- 由JVM通过OS系统调用(
malloc/mmap等)按需分配、按需释放。 - 不受JVM GC托管,不会被Minor GC / Full GC自动扫描、移动、整理。
- 大小默认只受操作系统物理内存+交换分区限制。
- 结构通常是简单的"块分配",不支持复杂GC对象模型、对象移动、压缩指针。
- 由JVM通过OS系统调用(
一句话总结:
本地内存 = 不受GC管理、OS直接管理、适合长生命周期、结构简单的数据
JVM托管内存 = GC全权管理、适合大量短生命周期对象、支持复杂内存优化
2、为什么唯独「方法区/类元数据」适合改用本地内存?
永久代(PermGen)当年最大的痛点,本质是:类元数据的生命周期、大小特征,和Java堆里的普通对象完全相反,强行塞进堆里,和GC分代模型严重冲突。
1. 类元数据的特征,天生适合本地内存
-
生命周期极长,几乎"一次加载、长期甚至全程存活"
- 应用启动时加载类,运行期间很少卸载,只有容器热部署、动态大量生成类才会卸载。
- 这种"长命数据"放在堆里,会长期占用老年代,拉高Full GC频率,却几乎没什么可回收的。
- 放到本地内存:不需要GC频繁扫描、移动,只在类真正卸载时才释放,完全匹配生命周期。
-
数据结构简单、规整,不需要GC复杂算法
- 类元数据:类名、父类、接口、字段描述符、方法字节码、常量池入口等。
- 结构是"一块一块的固定结构元数据",没有复杂对象引用网、没有跨代引用、不需要复制、不需要分代。
- 本地内存用简单的
malloc/free式内存池管理就足够,不需要复制算法、标记-整理、对象移动。
-
数量不可预估,堆的固定上限极易OOM
- 大型应用、框架(Spring/MyBatis)、动态代理、ASM生成类,会在运行时产生大量类。
- 永久代用
-XX:MaxPermSize硬上限,一旦类多就OOM;调大又挤占堆空间。 - 本地内存默认几乎无上限(受OS限制),可以动态膨胀,从根源解决
PermGen space。
-
与类加载器强绑定,而非与GC分代绑定
- 类元数据的生命周期 ≡ 类加载器生命周期。
- 只要类加载器存活,它加载的所有类就不能卸载。
- 这种"按加载器批量管理、批量释放"的模式,和GC"按对象可达性分析、逐代回收"完全不匹配,放在本地内存按加载器维度管理更自然。
-
结论:方法区改元空间,是"把不适合堆的数据搬出堆"
类元数据不是GC友好型数据,却被强行塞进堆里十几年。JDK8把它移到本地内存,本质是:
让堆专心管「大量、短命、复杂引用关系」的Java对象;
让本地内存专心管「少量、长命、结构简单」的类元数据。
这是一次职责分离,而不是盲目扩大本地内存使用范围。
3、为什么 JVM 其他内存区域 不适合、也不应该 改用本地内存?
我们逐个区域说明:堆、虚拟机栈、本地方法栈、程序计数器,每一个都有明确理由不能/不需要换成本地内存。
1. Java 堆(Heap):绝对不能改用本地内存
堆是JVM最核心、最复杂、优化最多的区域,一旦改用本地内存,整套GC体系、对象模型、性能优化全部作废。
-
对象生命周期极度两极化,必须GC精细管理
- 绝大多数对象朝生夕死,必须靠Minor GC复制算法快速回收。
- 本地内存无GC,这些短命对象会瞬间撑爆内存,无法自动清理。
-
堆依赖大量JVM专属优化,本地内存不支持
- TLAB(线程本地分配缓冲区):堆内细粒度划分,线程无锁分配。本地内存无法高效做这种细粒度、高并发池化。
- 指针压缩(UseCompressedOops):JVM把64位指针压成32位,节省内存、提升缓存命中率。本地内存由OS管理,无法统一做指针压缩。
- 对象移动与压缩:GC做对象移动、整理碎片,保证连续空间。本地内存一旦分配,很难安全移动(C/C++指针到处乱指,移动会导致全部野指针)。
- 分代、Region、卡表、写屏障:整套低延迟GC(G1/ZGC/Shenandoah)都建立在"JVM完全掌控内存布局"之上,换成本地内存直接失效。
-
OOM诊断完全失控
- 堆OOM可以通过堆dump分析对象、定位泄漏。
- 本地内存泄漏只能看OS层面内存增长,无法dump、无法定位具体对象,排查难度指数上升。
结论 :
堆是为「亿万级短命Java对象、高并发分配、精细GC」设计的,本地内存完全无法承载这套模型,不可能替换。
2. 虚拟机栈 / 本地方法栈:不需要、也不能用本地内存
栈区域的设计哲学是:极快分配释放、线程独享、结构严格LIFO、无碎片。
-
栈的分配/释放是纯粹"栈指针移动",速度远超malloc
- 方法进入:栈顶指针+=帧大小
- 方法退出:栈顶指针-=帧大小
- 这是计算机体系结构里最快的内存管理方式,比OS系统调用
malloc/free快几个数量级。 - 改用本地内存(malloc),每次方法调用都走系统调用,性能会暴跌。
-
栈必须和线程强绑定、随线程销毁整体释放
- 线程消亡 → 整个栈直接废弃,不需要逐块释放。
- 本地内存是按块独立分配,线程退出时要遍历逐一free,既慢又容易漏,引发Native内存泄漏。
-
HotSpot 本身就把栈放在OS原生线程栈上
- 虚拟机栈/本地方法栈,底层本来就用的是OS线程的本地栈空间,本质已经是Native Memory范畴。
- JVM只是在这块OS已分配的内存上,定义自己的栈帧格式,并没有再额外用malloc去申请"托管栈"。
- 你看到的
-Xss,本质是限制OS线程栈的大小,不是JVM再申请一块内存。
结论 :
栈区域已经在使用本地内存体系,只是由OS线程模型统一管理,JVM不再重复封装。不存在"改成本地内存"的空间和收益。
3. 程序计数器(PC):极小、寄存器级,完全没必要
- 只存一个指令偏移量/行号,宽度就是一个机器字(32/64位)。
- 很多JVM实现会直接把PC映射到CPU寄存器,或线程TCB(线程控制块)中,连内存都不占用。
- 体积小到可以忽略,生命周期严格等于线程,无分配、无释放、无OOM。
- 用本地内存纯属多此一举,没有任何收益,还增加一次间接访问开销。
结论 :
程序计数器是JVM中最轻量的部件,不存在"用不用本地内存"的问题,连正经内存区域都算不上。
4、总结
可以用一句话总结JVM内存区域的选择哲学:
- 短命、复杂、高并发、需要精细GC优化的对象(业务对象、数组) → 必须留在JVM堆,由GC全权托管,享受TLAB、指针压缩、分代回收、低延迟GC等全套优化;
- 长命、结构简单、数量不可预估、与类加载器绑定的数据(类元数据) → 适合放到本地内存(元空间),摆脱堆大小上限,避免无效GC扫描,从根源解决PermGen OOM;
- 栈、PC 这类线程私有的控制流区域 → 本身就依托OS本地线程栈,结构简单、生命周期与线程一致,既不需要GC,也不需要额外堆空间,天然最优。
所以JDK8只把方法区改为元空间使用本地内存,不是"其他区域不能改",而是"只有方法区这一类数据,改了才有巨大收益,且没有副作用"。其他区域一旦改用本地内存,性能、稳定性、可维护性都会全面倒退。
四、核心模块3:执行引擎------字节码执行者+GC内存回收者
4.1 核心定位
作为JVM的**"核心动力总成"**,执行引擎承担着两大不可替代的核心职责,是JVM能够实现"跨平台运行"和"自动内存管理"的核心支撑:
- 字节码执行职责:将.class文件中存储的、与平台无关的Java字节码,翻译为当前操作系统CPU可直接执行的本地机器指令,驱动硬件完成程序逻辑运行,是连接Java高级语言与底层硬件的"翻译官+执行者"。
- 内存回收职责 :作为自动内存管理的核心,对运行时数据区的线程共享区域(堆、方法区)进行无用内存识别与回收,释放不再被引用的对象所占用的内存空间,实现内存自动复用,从根源上避免手动管理内存带来的内存泄漏和
OutOfMemoryError(OOM)异常。
简单来说,执行引擎是JVM连接**"内存数据"与"硬件执行"、"内存分配"与"内存回收"**的核心桥梁,没有它,Java程序只能是存储在磁盘上的静态字节码文件,无法落地运行,且会快速耗尽内存资源。

4.2 核心组成(三大组件,职责明确、协同工作)
执行引擎的三大核心组件(解释器、JIT编译器、垃圾回收器)并非孤立运行,而是相互协同、优势互补,共同实现"启动快、运行高效、内存安全"的目标:解释器保障快速启动,JIT编译器提升长期运行性能,GC保障内存自动复用,三者形成一个完整的执行与内存管理闭环。
4.2.1 解释器:字节码的"逐行翻译官"
- 核心定位 :采用"逐行解释、逐行执行"的模式,将Java字节码指令逐条翻译为本地机器指令并立即执行,无需提前编译整个方法或程序,核心优势是启动速度快、内存占用低、对冷门代码友好,核心劣势是运行效率低(同一字节码被多次执行时,会重复翻译,产生大量冗余开销)。
- 核心实现 :JDK7+默认采用模板解释器(Template Interpreter) ,替代了早期的"字节码解释器(Bytecode Interpreter)",实现了效率的大幅提升:
- 传统字节码解释器:先将字节码翻译为中间指令,再将中间指令翻译为机器指令,存在"二次翻译"的开销,效率较低。
- 模板解释器:为每一条Java字节码指令预先绑定一个对应的"机器指令模板"(一组优化后的本地机器指令),解释执行时,直接加载对应的机器指令模板并执行,省去了中间指令转换的步骤,大幅提升了解释执行的效率,同时保持了逐行执行的灵活性。
- 内存关联:解释执行过程中,直接操作虚拟机栈的栈帧(创建、入栈、出栈、修改局部变量表/操作数栈),通过栈帧中的对象引用访问堆中的对象实例,无需额外占用大量内存(不存储编译后的机器码,仅占用少量栈内存用于维护执行状态),对内存受限的场景(如嵌入式设备)非常友好。
- 工作场景:主要用于程序启动阶段、冷门代码执行阶段(仅被执行1-2次的代码)、动态生成的临时代码执行阶段,为JIT编译器的"热点代码编译"争取时间,同时保障程序能够快速落地运行,避免"编译等待"导致的启动延迟。
- 版本演进 :JDK7引入模板解释器后,核心架构趋于稳定,JDK8-JDK21仅做小幅效率优化,无核心架构改造:
- JDK7-JDK18:模板解释器成熟稳定,针对不同CPU架构(x86、ARM)优化机器指令模板,提升跨平台的解释执行效率。
- JDK21:为虚拟线程适配轻量级指令执行逻辑,优化了解释执行时的栈帧操作(减少栈帧的创建/销毁开销、支持栈帧折叠复用),降低虚拟线程高并发场景下的栈内存开销,同时保持了解释器的快速启动特性,适配虚拟线程"大量创建、快速启停"的场景。
4.2.2 JIT编译器:热点代码的"一次性编译器"
JIT(Just-In-Time,即时编译器),与解释器的"逐行翻译"不同,它采用"一次性编译、多次执行"的模式,是提升Java程序长期运行性能的核心组件。
-
核心定位 :通过JVM内置的"热点探测器"识别出热点代码 (频繁执行的方法、循环体,通常认为被执行次数达到一定阈值的代码为热点代码),将其一次性编译为优化后的本地机器码,存储在本地内存的"代码缓存"中,后续该热点代码被调用时,直接跳过解释执行步骤,调用已编译好的机器码执行,核心优势是运行效率极高(消除重复翻译开销,且支持大量代码优化),核心劣势是启动阶段无收益、编译过程占用CPU和内存资源。
-
核心实现 :HotSpot虚拟机提供了三款编译器,适配不同的应用场景,三者可按需切换:
- C1编译器(客户端编译器,Client Compiler) :
- 核心定位:侧重快速编译、低编译开销、保障程序启动速度,编译优化的力度较浅,不追求极致的运行性能。
- 适配场景:桌面应用、客户端应用、嵌入式设备(追求快速启动,对长期运行性能要求不高)。
- 核心优化:简单的常量传播、方法内联(仅内联小型方法)、循环展开(浅层次)等,编译速度快,生成的机器码体积较小。
- C2编译器(服务端编译器,Server Compiler) :
- 核心定位:侧重极致的运行性能、深度优化,编译开销较大,编译时间较长,适合长期运行的服务端程序。
- 适配场景:微服务、分布式系统、后台管理系统等服务端应用(追求高吞吐量、低延迟,对启动速度要求相对较低)。
- 核心优化:深度的常量传播、全局代码优化、大规模方法内联、循环重排序、锁优化等,生成的机器码执行效率极高,能够接近C/C++程序的运行性能。
- Graal编译器(JDK9+引入,Graal Compiler) :
- 核心定位:新一代高性能编译器,支持JIT即时编译 和AOT提前编译(Ahead-Of-Time),兼具C1的编译速度和C2的运行性能,同时支持跨语言编译、动态优化,是JVM编译器的未来发展方向。
- 适配场景:服务端应用、云原生应用、需要兼顾启动速度和运行性能的场景,JDK21后成为默认可选编译器。
- 核心优势:基于"中间表示(IR)"的深度优化,支持模块化编译、自适应优化,能够根据运行时数据动态调整优化策略,同时AOT编译可将字节码提前编译为机器码,进一步提升程序启动速度。
- C1编译器(客户端编译器,Client Compiler) :
-
核心编译优化手段 :JIT编译器的高性能,核心来源于一系列强大的编译优化手段,这些优化能够大幅减少内存访问次数、消除冗余操作、提升CPU缓存命中率,从而提升执行效率,其中最核心的优化包括:
- 逃逸分析(Escape Analysis):分析对象的作用域,判断对象是否"逃逸"出方法(是否被方法外部引用)。如果对象未逃逸出方法,可进行后续的标量替换、栈上分配等优化,减少堆内存分配和GC开销。
- 标量替换(Scalar Replacement) :将一个复杂的对象(聚合量)拆分为多个基本数据类型(标量,如
int、long),这些标量可以直接存储在虚拟机栈的局部变量表中,无需在堆中创建对象,从而减少堆内存压力和GC开销。 - 栈上分配(Stack Allocation):基于逃逸分析的结果,对于未逃逸的对象,直接在虚拟机栈上分配内存(而非堆内存),对象随栈帧出栈而自动释放,无需GC回收,大幅提升内存分配和释放效率。
- 锁消除(Lock Elimination):分析代码中的锁对象,判断锁是否为"无用锁"(如对象仅在方法内部创建和使用,无多线程共享,不存在线程安全问题),自动消除该锁,减少锁竞争带来的开销。
- 锁粗化(Lock Coarsening) :将多个连续的、细粒度的锁操作(如循环内的
synchronized锁)合并为一个粗粒度的锁操作,减少锁的获取和释放次数,降低锁竞争开销。 - 循环优化:包括循环展开、循环重排序、循环不变量提取等,减少循环的分支判断和冗余操作,提升CPU执行效率,充分利用CPU的流水线特性。
-
核心执行模式 :JDK7+默认采用分层编译(Tiered Compilation) ,融合了解释器、C1编译器、C2编译器的优势,兼顾程序的启动速度和长期运行性能,避免了"纯解释执行"的低效和"纯C2编译"的启动延迟:
- 分层编译将代码执行分为5个层级,核心逻辑是"从低层级到高层级,逐步优化热点代码":
- 层级0:纯解释执行(模板解释器),快速启动,无编译开销。
- 层级1:C1编译器轻量级编译(简单优化),编译速度快,提升热点代码执行效率。
- 层级2:C1编译器中等优化,进一步提升性能,编译开销适中。
- 层级3:C1编译器全量优化,接近C2编译器的性能,编译开销较大。
- 层级4:C2编译器深度优化(极致性能),针对高频热点代码,生成最优机器码。
- 工作流程:程序启动后先以层级0解释执行,热点探测器实时监控代码执行次数,当代码达到最低热点阈值时,触发层级1编译,后续随着执行次数增加,逐步升级到更高层级编译,最终高频热点代码会被编译为层级4的最优机器码,实现"启动快、运行越来越快"的效果。
-
内存关联 :
- 编译过程中:操作虚拟机栈(获取方法执行信息)、堆(获取对象引用关系)、方法区(获取类元数据、运行时常量池),占用一定的CPU和堆内存资源用于完成编译优化。
- 编译完成后:将生成的机器码存储在**代码缓存(Code Cache)**中,代码缓存属于本地内存(Native Memory),不受JVM堆内存限制,可通过以下JVM参数配置:
-XX:InitialCodeCacheSize:代码缓存初始大小(默认约2M)。-XX:ReservedCodeCacheSize:代码缓存最大预留大小(默认约240M)。-XX:CodeCacheExpansionSize:代码缓存扩容步长。
- 执行过程中:直接调用代码缓存中的机器码,无需再访问字节码和解释器,大幅提升执行效率,代码缓存中的机器码会被GC定期回收(仅回收过期的、不再被执行的机器码)。
-
版本演进 :JIT编译器的演进核心是"提升编译效率、优化生成代码性能、支持新特性(如虚拟线程、AOT编译)":
- JDK7:引入分层编译(从实验特性转正为正式特性),实现C1/C2编译器的协同工作,兼顾启动速度和运行性能,成为默认执行模式。
- JDK8:优化C2编译器的深度优化逻辑,提升方法内联和循环优化的效果,减少生成机器码的体积,同时优化代码缓存的管理,减少内存浪费。
- JDK9:引入Graal编译器(实验特性),支持AOT提前编译(
jaotc工具),允许将字节码提前编译为机器码,进一步提升程序启动速度,同时优化分层编译的切换逻辑,减少编译开销。 - JDK11:Graal编译器优化跨平台支持,提升ARM架构下的编译性能,同时支持JDK11的模块化系统,优化模块化类的编译效率。
- JDK17:Graal编译器成熟度大幅提升,标记为稳定特性,优化其JIT编译的速度和生成代码的性能,接近C2编译器的水平。
- JDK21:Graal编译器成为默认可选编译器,与C2编译器并列,同时适配虚拟线程的热点代码编译,优化虚拟线程高并发场景下的编译开销,支持虚拟线程栈帧的编译优化,进一步提升高并发场景下的运行性能。

4.2.3 垃圾回收器(GC):内存的"自动清洁工"
垃圾回收器(Garbage Collector,GC)是执行引擎的核心组成部分,也是Java语言的核心优势之一,它实现了"自动内存管理",让开发者无需手动分配和释放内存,大幅降低了内存泄漏和OOM异常的发生概率。
- 核心定位 :专门负责回收运行时数据区共享区域(堆、方法区)的无用内存(即不再被任何引用指向的对象、类元数据、常量),释放内存空间并实现自动复用,避免内存资源耗尽,是JVM自动内存管理的核心。
- 核心设计依据 :
- 基于堆的分代划分/Region分区结构:不同回收器针对堆的不同区域(新生代、老年代、Region)设计,采用适配的回收算法,提升回收效率。
- 基于对象存活特性:利用"大部分对象朝生夕死、少数对象长期存活"的特性,采用分代回收策略,对新生代和老年代使用不同的回收算法和回收频率。
- 基于应用场景需求:不同应用场景对GC的要求不同(如服务端应用追求高吞吐量,金融应用追求低延迟),因此设计了多种不同特性的GC回收器,供开发者按需选择。
- 核心术语铺垫 :在了解GC回收器之前,先明确几个核心术语,便于理解后续内容:
- STW(Stop The World):GC回收过程中,暂停所有用户线程的执行,仅保留GC线程运行,目的是避免用户线程修改对象引用关系,保证GC回收的准确性。STW时间是衡量GC性能的核心指标之一,现代GC的核心优化方向就是"减少STW时间"。
- 吞吐量(Throughput):指CPU用于执行用户程序的时间占总时间的比例(吞吐量=用户程序执行时间/(用户程序执行时间+GC时间)),高吞吐量意味着GC开销小,适合后台计算、批处理等对延迟不敏感的场景。
- 低延迟(Low Latency):指GC回收过程中的STW时间极短(通常在毫秒级甚至亚毫秒级),避免用户程序出现长时间停顿,适合金融交易、实时通信、电商核心系统等对延迟敏感的场景。
- 并发回收(Concurrent Collection):GC线程与用户线程同时运行,仅在少数关键步骤触发短暂STW,大幅减少整体停顿时间,是低延迟GC的核心特性。
- 并行回收(Parallel Collection):多个GC线程同时运行,加快GC回收速度,减少单次GC的STW时间,但用户线程仍需全程暂停,适合追求高吞吐量的场景。
GC回收器分类与特性(HotSpot实现,按特性分类)
以下表格详细梳理了HotSpot虚拟机中主流GC回收器的核心特性,清晰展示各回收器的适用场景和优劣:
| 回收器类型 | 核心回收区域 | 核心回收算法 | 引入版本 | 转正/默认版本 | 淘汰版本 | 核心回收模式 | 关键特性 | 适用场景 |
|---|---|---|---|---|---|---|---|---|
| SerialGC(串行GC) | 新生代 | 复制算法 | JDK初始版本 | JDK7前客户端默认 | 未淘汰(仍可用) | 单线程、串行 | 1. 单线程回收,实现简单,内存占用低; 2. STW时间长(回收速度慢); 3. 吞吐量低,无并发/并行优化。 | 嵌入式设备、内存极小(<1G)的场景、客户端应用(JDK7前),现代应用极少使用。 |
| SerialOldGC | 老年代 | 标记-整理算法 | JDK初始版本 | JDK7前客户端默认 | 未淘汰(仍可用) | 单线程、串行 | 1. 单线程回收,配合SerialGC使用,形成完整分代回收; 2. STW时间长,回收速度慢; 3. 无内存碎片,适合小堆场景。 | 仅作为SerialGC的老年代回收器,配合使用,现代应用极少使用。 |
| ParallelGC(并行GC) | 新生代 | 复制算法 | JDK1.4.1 | JDK7+服务端默认 | 未淘汰(仍可用) | 多线程、并行 | 1. 多线程并行回收,回收速度快,STW时间短于SerialGC; 2. 高吞吐量,注重减少GC总开销; 3. 无并发回收,用户线程全程暂停。 | 后台计算、批处理、数据挖掘等对延迟不敏感、追求高吞吐量的服务端场景。 |
| ParallelOldGC | 老年代 | 标记-整理算法 | JDK6 | JDK7+服务端默认 | 未淘汰(仍可用) | 多线程、并行 | 1. 多线程并行回收,配合ParallelGC使用,提升老年代回收效率; 2. 高吞吐量,无内存碎片; 3. STW时间仍较长,不适合低延迟场景。 | 配合ParallelGC,用于高吞吐量场景,作为G1GC普及前的主流服务端回收器。 |
| CMSGC(并发标记清除) | 老年代 | 标记-清除算法 | JDK1.5 | JDK8 | JDK14(彻底淘汰) | 多线程、并发 | 1. 并发回收(标记/清除阶段与用户线程并行),STW时间极短(仅初始标记和重新标记阶段); 2. 低延迟,适合对停顿敏感的场景; 3. 产生内存碎片,可能触发频繁Full GC; 4. CPU开销大,吞吐量较低。 | (已淘汰)JDK8之前的低延迟服务端场景,如电商、金融系统,现被G1/ZGC替代。 |
| G1GC(Garbage-First) | 全堆(Region分区) | 复制算法+标记-整理算法 | JDK7(实验) | JDK9+默认 | 未淘汰(主流) | 多线程、并发+并行 | 1. 全堆Region分区,支持可预测停顿(通过-XX:MaxGCPauseMillis配置目标停顿时间); 2. 兼顾吞吐量与低延迟,平衡两者需求; 3. 无内存碎片,支持大堆场景(几十G); 4. 新生代与老年代动态划分,灵活回收。 |
现代主流服务端场景,微服务、分布式系统、电商后台等,兼顾吞吐量和低延迟,是JDK9-JDK17的默认回收器。 |
| ZGC(低延迟GC) | 全堆(Region分区) | 复制算法+标记-整理算法(彩色指针+读屏障) | JDK10(实验) | JDK11(转正) | 未淘汰(主流) | 多线程、并发 | 1. 亚毫秒级STW(停顿时间<10ms,几乎可忽略),支持超低延迟; 2. 支持超大堆场景(4TB~16TB),适合海量内存应用; 3. 彩色指针+读屏障技术,实现无停顿并发回收; 4. 无内存碎片,CPU开销适中,吞吐量优秀。 | 对延迟要求极高的场景,如金融交易、实时通信、超大堆服务端应用,JDK21+默认分代ZGC。 |
| ShenandoahGC(低延迟GC) | 全堆(Region分区) | 复制算法+标记-整理算法(并发压缩) | JDK12(实验) | JDK14(转正) | 未淘汰(可选) | 多线程、并发 | 1. 亚毫秒级STW,支持超低延迟,与ZGC性能相当; 2. 支持并发压缩,无内存碎片,回收效率高; 3. 不依赖特定CPU架构,跨平台兼容性更好; 4. 适合大堆场景,吞吐量优秀。 | 对延迟要求极高、跨平台部署的场景,如云原生应用、分布式大数据系统,作为ZGC的优秀替代方案。 |

GC版本演进(与内存区改造强绑定,核心趋势:低延迟、大堆、兼顾吞吐量)
GC回收器的演进与运行时数据区的改造(如永久代→元空间、固定分代→Region分区)强绑定,核心趋势是"从单线程到多线程、从并行到并发、从高吞吐量到低延迟、从小堆到大堆、从分代到动态分代",逐步满足现代应用对内存和性能的更高要求:
-
JDK7:
- 核心默认回收器:
ParallelGC + ParallelOldGC(高吞吐量),是服务端应用的主流选择,兼顾回收效率和内存利用率。 - 可选回收器:CMSGC(低延迟),优化了并发标记逻辑,减少了STW时间,但仍存在内存碎片问题。
- 重要进展:G1GC作为实验特性引入,采用Region分区结构,为后续低延迟GC铺路;优化新生代TLAB分配,提升对象分配效率。
- 核心默认回收器:
-
JDK8:
- 核心优化:优化CMSGC的并发标记和重新标记逻辑,减少停顿时间,同时优化CMSGC的内存碎片处理(引入碎片整理机制),降低Full GC发生概率。
- G1GC优化:仍为实验特性,优化其Region回收策略和可预测停顿目标,提升大堆场景下的性能,逐步成熟。
- 内存关联优化:彻底移除永久代,引入元空间(本地内存),新增元空间GC回收机制,与Full GC解耦,减少Full GC的发生频率。
-
JDK9:
- 核心变更:G1GC正式转正为默认回收器,替代
ParallelGC + ParallelOldGC,标志着JVM GC从"追求高吞吐量"向"兼顾吞吐量与低延迟"转型。 - 重要进展:ZGC作为实验特性引入,采用彩色指针+读屏障技术,支持超大堆场景,亚毫秒级STW,为超低延迟GC奠定基础。
- 优化:优化元空间的并发类卸载,减少元空间GC的STW时间,提升模块化类的卸载效率;优化G1GC的Region动态划分,提升回收灵活性。
- 核心变更:G1GC正式转正为默认回收器,替代
-
JDK11:
- 核心变更:ZGC正式转正(LTS版本),标志着JVM支持超大堆、超低延迟场景;CMSGC标记为废弃,不再推荐使用。
- G1GC优化:引入自适应停顿调整,支持动态调整GC停顿目标,根据应用运行状态优化回收策略,减少Full GC发生概率;优化新生代Minor GC的并行回收,提升回收速度。
- 其他优化:优化代码缓存的GC回收,减少本地内存浪费。
-
JDK14:
- 核心变更:ShenandoahGC正式转正,实现亚毫秒级STW和并发压缩,无内存碎片,跨平台兼容性更好;CMSGC彻底淘汰,从HotSpot虚拟机中移除。
- ZGC优化:支持并发内存压缩,解决ZGC早期版本的内存碎片问题,提升超大堆场景下的内存利用率;优化ZGC的CPU开销,提升吞吐量。
- G1GC优化:引入NUMA架构支持,提升多节点服务器上的回收效率;优化老年代Major GC的并行回收,减少STW时间。
-
JDK17:
- 核心优化:优化ZGC/ShenandoahGC的CPU开销,减少并发回收时对用户线程的影响,提升大堆场景下的吞吐量,使低延迟GC同时兼顾高吞吐量。
- G1GC优化:引入并行Full GC,替代传统的串行Full GC,大幅减少Full GC的STW时间;优化Region的内存碎片整理,提升堆内存利用率。
- 其他优化:适配模块化系统,优化类元数据的回收效率,减少元空间内存泄漏的风险。
-
JDK21:
- 核心变更:ZGC分代回收正式转正(默认开启),融合了分代回收的高吞吐量和ZGC的低延迟,实现"鱼与熊掌兼得":新生代采用快速复制回收,老年代采用并发低延迟回收,大幅提升GC效率,减少STW时间。
- ShenandoahGC优化:优化并发压缩策略,适配虚拟线程高并发场景,减少虚拟线程创建对象时的GC开销;优化Region的回收优先级,提升可预测停顿的准确性。
- 其他优化:为虚拟线程优化堆内存分配和TLAB缓存复用,减少高并发场景下的GC压力;优化G1GC的分代回收逻辑,提升与虚拟线程的兼容性。

总结
- 执行引擎承担两大核心职责:字节码翻译执行、无用内存自动回收,三大组件(解释器、JIT编译器、GC)协同工作,兼顾启动速度、运行性能和内存安全。
- 解释器保障快速启动,JIT编译器通过分层编译和深度优化提升长期运行性能,二者形成"解释+编译"的混合执行模式,是Java程序高效运行的核心。
- GC回收器的演进趋势是「高吞吐量→兼顾低延迟→超低延迟+超大堆」,ZGC分代回收(JDK21)实现了低延迟与高吞吐量的平衡,成为现代大堆应用的首选。
- GC的发展与内存区改造强绑定,Region分区支撑了低延迟GC,元空间解决了永久代OOM问题,二者共同推动JVM适应现代高并发、大内存的应用场景。
五、核心模块4:本地方法接口(JNI)------跨内存的"交互桥梁"
5.1 核心定位
本地方法接口(Java Native Interface,JNI)是JVM定义的一套跨语言、跨内存的标准化交互规范,并非具体的实现代码,它搭建起了Java程序与本地代码(C/C++/汇编等)之间的通信桥梁。
其核心价值在于:突破Java语言的跨平台抽象层限制,让Java程序能够调用本地方法、访问操作系统底层硬件与资源(如物理内存、磁盘文件、网络套接字、显卡驱动等),同时也支持本地代码反向调用Java方法,最终实现JVM托管内存(堆、虚拟机栈)与操作系统本地内存(Native Memory)、Java运行时与本地程序运行时的数据互通和逻辑协同。
简单来说,JNI是Java"既保持跨平台简洁性,又能触及底层操作"的关键支撑,是Java语言实现"上层易用、底层可控"的重要基石。

5.2 核心作用
JNI的核心作用围绕"打通Java运行时与本地运行时的壁垒"展开,具体分为三大核心场景,覆盖数据交互、环境支撑和底层访问:
-
为Native方法提供完整执行环境
- 负责参数转换与传递 :将Java层传递的参数(基本数据类型、对象引用)转换为本地代码可识别的数据类型(如
jint对应Java的int、jobject对应Java的对象引用),并将参数从虚拟机栈传递至本地方法栈。 - 负责栈帧管理与上下文切换:Native方法执行时,为其在本地方法栈中分配专属栈帧,存储本地方法的局部变量、临时数据和返回地址;方法执行完毕后,销毁对应栈帧,完成虚拟机栈与本地方法栈的上下文切换,同时将本地方法的返回值转换为Java数据类型并返回至Java层。
- 负责异常传递与处理 :捕获本地代码执行过程中抛出的原生异常(如C/C++的
segfault),转换为Java层可识别的Exception(如UnsatisfiedLinkError、NullPointerException),并传递至Java运行时进行后续处理,保证异常链路的完整性。
- 负责参数转换与传递 :将Java层传递的参数(基本数据类型、对象引用)转换为本地代码可识别的数据类型(如
-
实现跨内存的数据安全交互
- Java层访问本地内存:Java程序通过JNI提供的API,读取或修改本地内存中存储的数据(如C/C++分配的数组、结构体),无需将本地数据完整拷贝至JVM堆,减少内存拷贝开销。
- 本地层操作JVM托管内存:本地代码通过JNI提供的引用(本地引用、全局引用、弱全局引用),安全访问和修改JVM堆中的Java对象(如修改对象的成员变量、调用对象的方法),且遵循JVM的内存管理规范,避免干扰GC的可达性分析。
- 核心保障:通过JNI的引用管理机制,防止本地代码操作的Java对象被GC错误回收,同时也避免无效引用导致的堆内存泄漏,实现跨内存数据交互的安全性和可靠性。
-
弥补Java语言底层操作能力的不足
- 调用操作系统底层API:Java语言为了实现跨平台,屏蔽了不同操作系统的底层差异,因此无法直接调用操作系统的原生API(如Windows的
Win32 API、Linux的posix API)。JNI允许Java程序通过本地代码调用这些底层API,实现内存分配、线程创建、文件IO、网络通信、硬件驱动交互等底层操作。 - 复用成熟的本地库资源:大量行业成熟库(如图像处理库OpenCV、加密库OpenSSL、科学计算库BLAS)均以C/C++形式实现,JNI允许Java程序直接复用这些库的功能,无需重新用Java实现,提升开发效率和程序性能。
- 优化性能关键路径:对于程序中性能要求极高的核心路径(如高频数据解析、实时渲染),可通过C/C++实现并通过JNI调用,利用本地代码的执行效率优势,弥补Java解释执行/即时编译在极端场景下的性能短板。
- 调用操作系统底层API:Java语言为了实现跨平台,屏蔽了不同操作系统的底层差异,因此无法直接调用操作系统的原生API(如Windows的
5.3 核心内存关联
JNI的交互过程本质是跨内存空间的操作,涉及JVM托管内存和操作系统本地内存两大区域,各内存区域的职责和交互规则清晰明确,任何违规操作都可能导致内存泄漏、程序崩溃等问题:
-
操作本地方法栈(JVM托管内存范畴)
- 本地方法栈是JVM为每个线程分配的专属内存区域,专门用于支撑Native方法的执行,遵循后进先出(LIFO)的栈帧管理规则。
- JNI在Native方法执行前,会在当前线程的本地方法栈中创建一个专属栈帧,用于存储:本地方法的局部变量表、方法参数、临时计算结果、返回地址(指向Java层调用该Native方法的指令位置)。
- Native方法执行完毕后,JNI会自动销毁该栈帧,释放本地方法栈的内存空间,栈帧中的数据随栈帧销毁而自动失效,无需手动管理,不存在内存泄漏风险。
- 关联参数:可通过
-Xss参数(与虚拟机栈共享配置)限制本地方法栈的最大大小,若Native方法递归过深或局部变量过多,会抛出StackOverflowError异常。
-
操作JVM堆(JVM托管内存核心范畴)
- JVM堆是所有线程共享的内存区域,存储Java对象实例,由GC全权负责回收和内存整理,JNI访问堆内存必须通过JNI引用,不可直接操作堆内存地址,否则会破坏GC的可达性分析。
- JNI提供三种核心引用类型,用于管理堆对象的生命周期,满足不同场景的需求:
- 本地引用(Local Reference):默认引用类型,仅在当前Native方法执行期间有效,方法执行完毕后,由JNI自动回收,不会阻止GC回收对应的Java对象,适合临时访问堆对象(如方法参数、局部创建的对象)。
- 全局引用(Global Reference) :由开发者手动创建(
NewGlobalRef())和销毁(DeleteGlobalRef()),在整个JVM运行期间有效,会阻止GC回收对应的Java对象,适合长期复用的堆对象(如全局配置对象),若忘记销毁会导致堆内存泄漏。 - 弱全局引用(Weak Global Reference) :由开发者手动创建(
NewWeakGlobalRef())和销毁(DeleteWeakGlobalRef()),在整个JVM运行期间有效,但不会阻止GC回收对应的Java对象,适合需要长期持有但不影响对象回收的场景(如缓存对象),GC回收对象后,引用会变为无效。
- 核心约束:本地代码不可缓存
jobject等引用的直接内存地址,因为GC可能会移动堆对象(如标记-整理算法、ZGC的并发压缩),导致缓存的地址失效,引发程序崩溃。
-
占用与操作本地内存(操作系统托管范畴)
- Native方法执行过程中,通过C/C++的
malloc()、calloc()或操作系统的mmap()等接口分配的内存,属于本地内存(Native Memory),不受JVM托管,GC无法识别和回收这些内存。 - 本地内存的特点:
- 大小仅受操作系统物理内存+交换分区限制,不受
-Xmx等JVM堆参数约束; - 需由开发者手动调用
free()等接口释放,若忘记释放,会导致本地内存泄漏,长期运行会耗尽系统内存,引发OutOfMemoryError(本地内存不足); - 本地内存中的数据与JVM堆数据独立,数据交互需通过JNI提供的拷贝接口(如
GetByteArrayElements()、ReleaseByteArrayElements()),避免直接跨内存访问。
- 大小仅受操作系统物理内存+交换分区限制,不受
- 常见本地内存占用场景:Native方法分配的缓冲区、C/C++全局变量、第三方本地库的内部缓存、JNI的代码缓存(与JIT编译器共享),这些内存的使用情况无法通过JVM堆dump排查,需借助操作系统工具(如
top、pmap、Process Explorer)分析。
- Native方法执行过程中,通过C/C++的

5.4 JDK7-JDK21关键演进(核心趋势:简化使用、提升性能、增强安全、适配新特性)
JNI的演进始终围绕"降低使用门槛、减少内存泄漏风险、提升交互性能、增强内存安全性、适配JVM新特性(如虚拟线程)"展开,从JDK7到JDK21,JNI的成熟度和易用性大幅提升,同时也更好地支撑了现代Java应用的需求:
-
JDK7:基础JNI规范成熟稳定
- 提供完整的基础JNI API,支持基本的参数转换、对象访问、本地方法调用和异常处理,满足大部分常规场景的需求。
- 存在明显短板:本地引用管理繁琐,需手动调用
DeleteLocalRef()释放大量临时本地引用,否则易导致本地引用表溢出;堆内存与本地内存的交互拷贝开销较大;缺乏严格的内存访问校验,本地代码可能非法访问JVM堆内存。 - 补充:引入
InvokeDynamic指令,为后续JNI的动态方法调用优化铺路,同时优化了JNI对java.nio直接缓冲区(Direct Buffer)的支持,减少数据拷贝开销。
-
JDK8:优化交互性能,减少拷贝开销
- 核心优化:优化JNI的对象引用转换逻辑,减少
jobject与本地指针之间的转换开销,提升Native方法的调用效率。 - 内存交互优化:增强对直接缓冲区(
java.nio.ByteBuffer)的支持,允许本地代码直接访问直接缓冲区的底层本地内存,无需将数据拷贝至JVM堆,大幅减少跨内存数据交互的拷贝开销,提升IO密集型场景的性能。 - 其他优化:优化JNI调用的栈帧切换逻辑,减少虚拟机栈与本地方法栈之间的上下文切换开销,提升高频次本地方法调用的执行效率;完善JNI的异常处理机制,提供更详细的异常信息,便于问题排查。
- 核心优化:优化JNI的对象引用转换逻辑,减少
-
JDK11:简化引用管理,降低内存泄漏风险
- 核心优化:优化JNI的本地引用管理器,实现无用本地引用的自动回收 ,对于大量临时创建的本地引用,无需开发者手动调用
DeleteLocalRef()释放,由JVM在Native方法执行期间定期清理或方法执行完毕后批量清理,大幅降低了本地引用导致的内存泄漏风险和开发门槛。 - 性能优化:优化JNI调用的栈帧复用逻辑,对于频繁调用的Native方法,复用其栈帧结构,减少栈帧创建与销毁的开销;优化全局引用的查询效率,提升长期持有全局引用场景下的交互性能。
- 安全增强:引入基础的JNI调用权限校验,限制未授权的类调用敏感本地方法,提升程序的安全性;同时优化JNI的日志输出,便于跟踪本地方法的调用链路和内存使用情况。
- 核心优化:优化JNI的本地引用管理器,实现无用本地引用的自动回收 ,对于大量临时创建的本地引用,无需开发者手动调用
-
JDK17:增强内存安全性,禁止非法内存访问
- 核心优化:增加JNI的严格内存访问校验(Strict Memory Access),默认开启相关校验机制,禁止Native方法通过非法引用、无效指针访问JVM堆内存,防止本地代码破坏JVM的内存布局,引发程序崩溃或内存泄露。
- 安全增强:强化JNI的类访问权限控制,遵循Java模块系统(JPMS)的访问规则,禁止本地代码访问模块中未导出的类和方法,提升模块化应用的安全性;同时禁止JNI手动修改堆对象的元数据(如类信息、字段描述),防止破坏Java的类型安全。
- 其他优化:优化JNI对大内存直接缓冲区的支持,提升超大块数据跨内存交互的性能;完善JNI的内存泄漏检测机制,在JVM退出时输出未释放的全局引用和本地内存信息,便于问题排查。
-
JDK21:适配虚拟线程,支撑高并发场景
- 核心优化:全面适配虚拟线程(Virtual Threads),解决传统JNI调用对虚拟线程的阻塞问题:支持虚拟线程执行Native方法时的栈挂起/恢复,保证虚拟线程在调用耗时本地方法(如磁盘IO、网络调用)时,不会阻塞对应的内核线程(Carrier Thread),让内核线程可以去调度其他虚拟线程,充分发挥虚拟线程"高并发、轻量级"的优势。
- 内存优化:优化虚拟线程与JNI的内存交互,减少虚拟线程执行Native方法时的本地内存占用,实现虚拟线程本地方法栈的轻量化管理;同时优化虚拟线程的TLAB缓存与JNI的协同工作,减少高并发场景下跨内存数据交互的开销。
- 其他优化:优化JNI的并发调用性能,提升多虚拟线程同时调用Native方法时的吞吐量;完善虚拟线程场景下的JNI异常传递机制,保证异常链路的完整性和可追溯性。

总结
- JNI是Java程序与本地代码的标准化交互桥梁,核心价值是打通JVM托管内存与操作系统本地内存,弥补Java底层操作能力的不足。
- JNI的核心作用包括提供Native方法执行环境、实现跨内存数据交互、调用操作系统底层API,其内存交互需遵循严格的引用管理规则,避免内存泄漏。
- JNI的演进趋势是「简化使用→提升性能→增强安全→适配虚拟线程」,从JDK7到JDK21,逐步降低内存泄漏风险,提升交互效率,更好地支撑现代高并发应用场景。
- 使用JNI时需注意:合理管理全局引用、手动释放本地内存、避免非法访问JVM堆,同时尽量减少JNI调用的频率,降低跨内存交互的开销。
六、核心总结
-
架构归属明确:垃圾回收器(GC)并非独立体系,而是执行引擎的核心组成部分,与解释器、JIT编译器协同工作,完成字节码执行与内存回收;
-
TLAB核心价值:TLAB是新生代Eden区的线程私有缓冲区,是高并发场景下对象分配的核心优化,JDK7-JDK21的演进围绕"效率提升+内存节约+虚拟线程适配"展开;
-
演进核心逻辑:从解决内存溢出(永久代→元空间),到优化内存分配(TLAB迭代),再到适配大堆/高并发(Region动态分代),最终支撑虚拟线程极致并发,内存区的改造直接驱动执行引擎(GC)的迭代;
-
自动内存管理支撑:TLAB提升对象分配效率,GC保证内存复用,两者协同支撑JVM的自动内存管理,是Java程序无需手动管理内存的核心保障。
结语
回顾JVM从JDK7到JDK21的演进,就像观看一部技术史诗:
2011年的JDK7 是位稳重的中年工程师:
-
经验丰富但稍显保守
-
工具齐全但不够智能
-
能完成任务但不够优雅
2023年的JDK21 已成为全能的AI助手:
-
智能预测你的需求(JIT优化)
-
几乎无感知地完成工作(ZGC)
-
同时处理海量任务(虚拟线程)
-
自我学习和优化(Graal编译器)
最关键的变化 不仅仅是性能提升,而是架构哲学的根本转变:
-
从"一刀切"配置 → 自适应智能调整
-
从"停顿不可避免" → "停顿几乎消失"
-
从"资源粗放使用" → 精细化弹性管理

最后留个思考题:如果你的应用还停留在JDK8,你错过的不仅仅是性能提升,而是整个软件架构范式的进化。升级JDK版本,本质上是为你的应用"更换一个更先进的操作系统"。