提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
你想知道在MSVC编译器中,如何脱离/utf-8这个组合选项,分别单独配置源字符集(source-charset) 和执行字符集(execution-charset),明确各自的配置写法和适用场景。
一、核心参数定义(先理清两个参数的本质)
在MSVC编译器中,这两个参数是完全独立的,作用边界清晰:
| 参数 | 核心作用 | 通俗理解 |
|---|---|---|
/source-charset:<编码> |
指定编译器解析源文件字节流的编码(解决"编译器怎么读源文件里的汉字") | 告诉编译器"源文件是XX编码" |
/execution-charset:<编码> |
指定字符串字面量编译到程序后的内存编码(解决"程序里的字符串是XX编码") | 告诉编译器"把字符串转成XX编码存" |
二、分别配置的具体写法(MSVC编译器)
方式1:VS图形界面配置(推荐,可视化操作)
- 右键Qt项目 → 「属性」→ 「配置属性」→ 「C/C++」→ 「命令行」;
- 在「附加选项」输入框中,按需求组合以下参数 (替换
<编码>为实际值); - 确保"配置"选「所有配置」、"平台"选「所有平台」,避免只改单个配置。
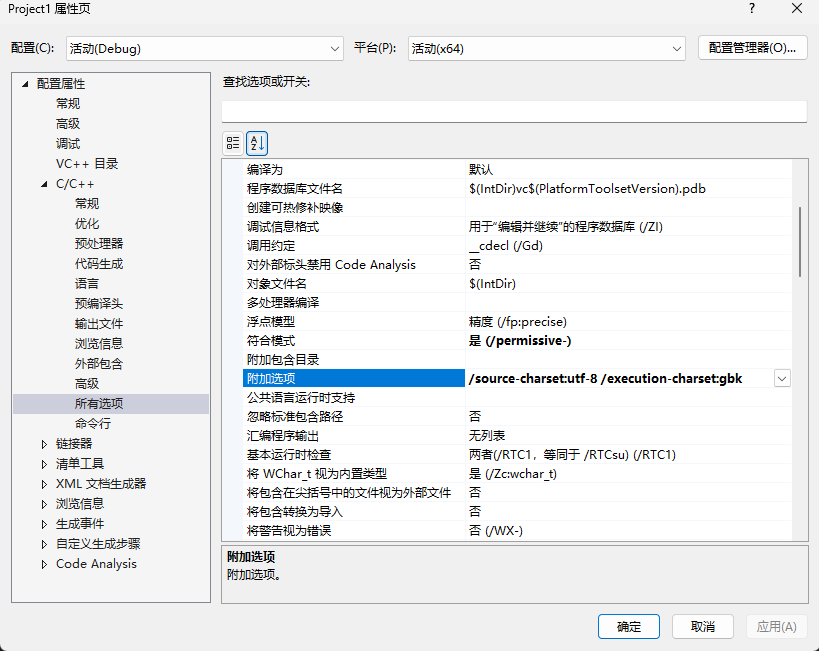
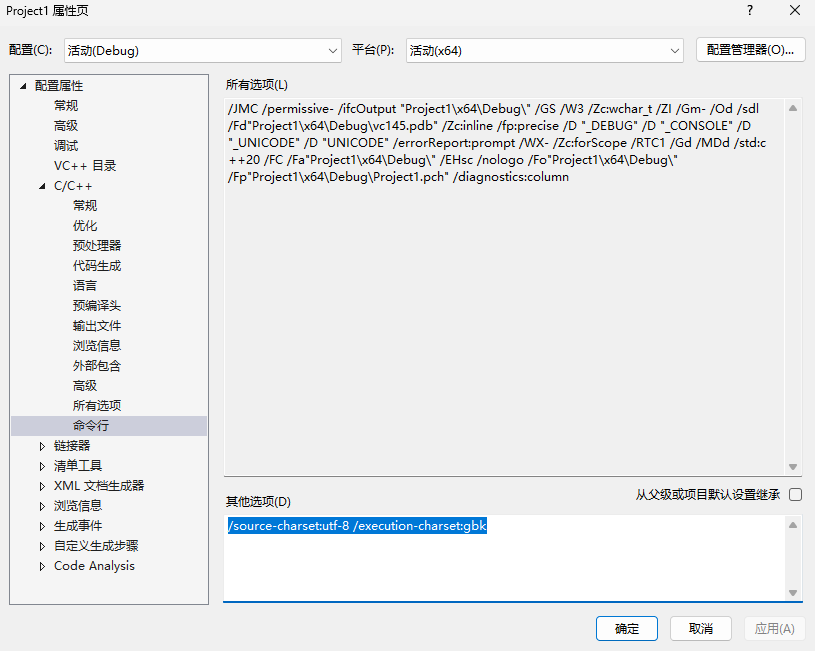
方式2:直接写编译命令/CMake/qmake(适合脚本化)
-
编译命令行中直接追加参数:
bash# 示例:cl.exe 你的代码.cpp /source-charset:utf-8 /execution-charset:gbk cl.exe main.cpp /source-charset:utf-8 /execution-charset:gbk -I D:\Qt\include /link Qt5Core.lib -
CMakeLists.txt中配置(Qt项目常用):
cmake# 给MSVC编译器添加编译选项 if(MSVC) # 分别指定源字符集和执行字符集 add_compile_options(/source-charset:utf-8) add_compile_options(/execution-charset:gbk) endif() -
qmake的.pro文件中配置:
pro# 仅对MSVC生效 win32-msvc* { QMAKE_CXXFLAGS += /source-charset:utf-8 QMAKE_CXXFLAGS += /execution-charset:gbk }
三、常用配置示例(覆盖实际场景)
示例1:源文件是GBK,执行字符集要UTF-8(Windows老项目常见)
/source-charset:gbk /execution-charset:utf-8- 场景:源文件由记事本保存为GBK编码(Windows默认),但程序需要UTF-8编码的字符串(Qt推荐);
- 说明:编译器按GBK解析源文件里的汉字,再转成UTF-8存到程序中,
QStringLiteral("大傻瓜")可正常编译。
示例2:源文件是UTF-8(无BOM),执行字符集要GBK(特殊兼容场景)
/source-charset:utf-8 /execution-charset:gbk- 场景:源文件是UTF-8(Qt Creator默认),但需要兼容老系统的GBK字符串;
- 说明:编译器按UTF-8读源文件,转成GBK存到程序中。
示例3:等价于/utf-8(两者都设为UTF-8,推荐通用场景)
/source-charset:utf-8 /execution-charset:utf-8- 这就是
/utf-8的完整写法,也是最推荐的配置(统一编码无兼容问题)。
四、关键注意事项
- 编码名称规范 :MSVC识别的编码名需用官方值,常见的:
- UTF-8:
utf-8(小写,无空格); - GBK/GB2312:
gbk或cp936(cp936是Windows对GBK的代码页编号,更通用); - 简体中文:
chinese-simplified(等价于cp936)。
- UTF-8:
- 优先级 :单独配置的
/source-charset和/execution-charset,优先级高于/utf-8(若同时写,以单独配置为准); - 与QStringLiteral的配合 :只要
/source-charset匹配源文件编码,QStringLiteral("汉字")就不会报"Illegal byte sequence"错误------因为编译器能正确解析源文件的字节序列了。
总结
- 单独配置的核心格式:
/source-charset:<编码>(解析源文件) +execution-charset:<编码>(编译后存储); - 编码名用MSVC规范值(如utf-8、cp936),按需组合即可适配不同源文件/执行场景;
- 通用推荐配置:
/source-charset:utf-8 /execution-charset:utf-8(等价于/utf-8),能解决QStringLiteral("汉字")的编译报错问题。