Spring Framework
Spring是一种轻量级框架,旨在提高开发人员的开发效率以及系统的可维护性。
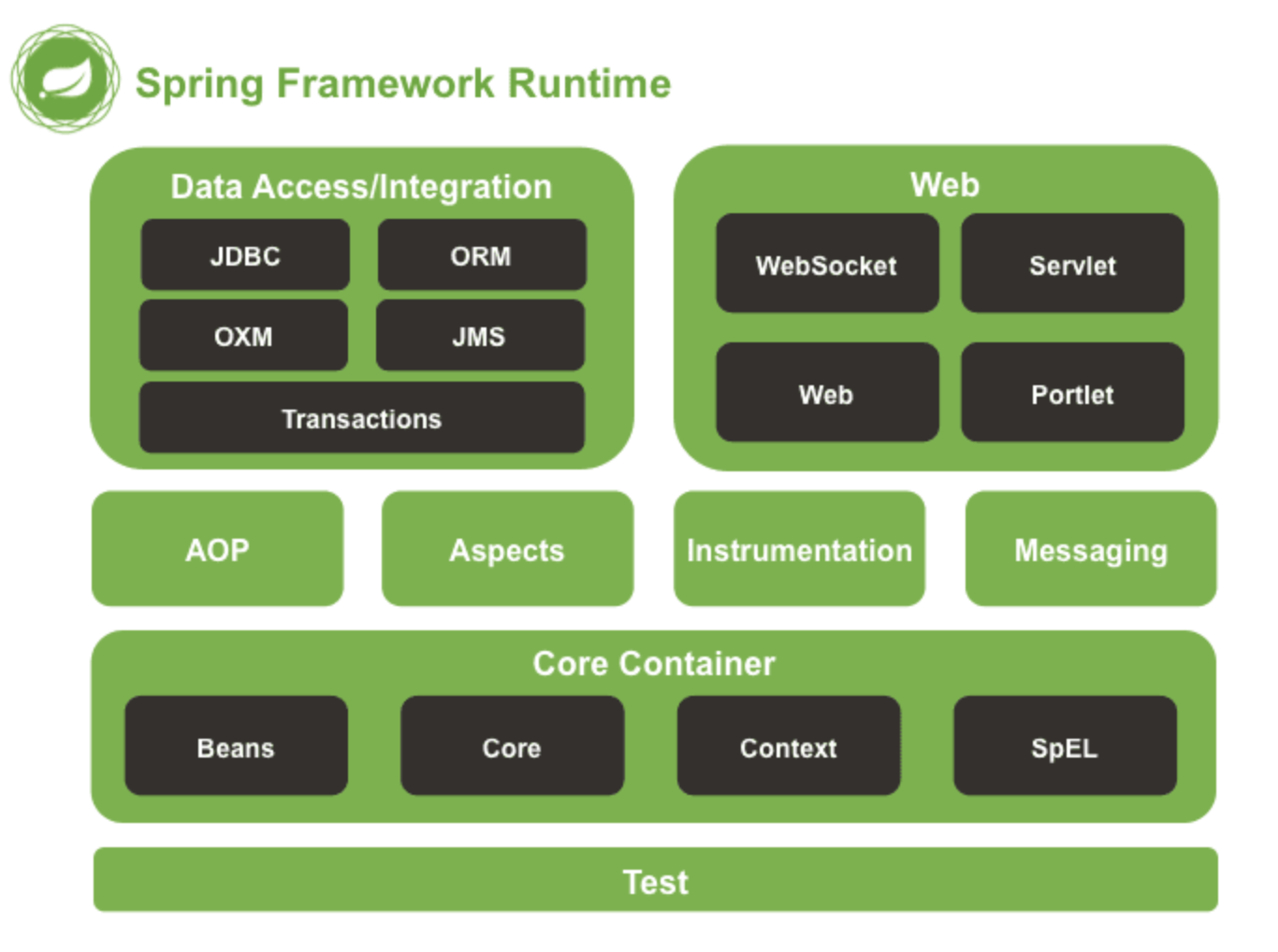
我们一般说的Spring框架就是Spring Framework,它是很多模块的集合,使用这些模块可以很方便地协助我们进行开发。这些模块是核心容器、数据访问/集成、Web、AOP(面向切面编程)、工具、消息和测试模块。比如Core Container中的Core组件是Spring所有组件的核心,Beans组件和Context组件是实现IOC和DI的基础,AOP组件用来实现面向切面编程。
Spring官网列出的Spring的6个特征:
- 核心技术:依赖注入(DI),AOP,事件(Events),资源,i18n,验证,数据绑定,类型转换,SpEL。
- 测试:模拟对象,TestContext框架,Spring MVC测试,WebTestClient。
- 数据访问:事务,DAO支持,JDBC,ORM,编组XML。
- Web支持:Spring MVC和Spring WebFlux Web框架。
- 集成:远程处理,JMS,JCA,JMX,电子邮件,任务,调度,缓存。
- 语言:Kotlin,Groovy,动态语言。
下图对应的是Spring 4.x的版本,目前最新的5.x版本中Web模块的Portlet组件已经被废弃掉,同时增加了用于异步响应式处理的WebFlux组件。
- Spring Core:基础,可以说Spring其他所有的功能都依赖于该类库。主要提供IOC和DI功能。
- Spring Aspects:该模块为与AspectJ的集成提供支持。
- Spring AOP:提供面向切面的编程实现。
- Spring JDBC:Java数据库连接。
- Spring JMS:Java消息服务。
- Spring ORM:用于支持Hibernate等ORM工具。
- Spring Web:为创建Web应用程序提供支持。
IoC(Inversion of Control,控制反转)
1. 核心思想:从"主动索取"到"被动接受"
在传统开发中,如果 A 类依赖 B 类,A 必须亲自 new B()。这意味着 A 必须知道 B 的构造细节,两者产生了硬编码耦合。
-
控制反转 (IoC) :将对象的创建、组装、生命周期管理的权利 移交给第三方容器(Spring)。
-
依赖注入 (DI) :IoC 的具体实现手段。容器在运行时动态地将依赖对象注入到组件中。
底层哲学:好莱坞原则(Don't call us, we'll call you)。你只需要声明"我需要什么",至于什么时候给、怎么给,由容器说了算。
2. 核心模型
要实现 IoC,Spring 抽象出了两个极其关键的模型:
A. BeanDefinition
Spring 不会直接操作 .class 文件,而是先将其扫描并解析成 BeanDefinition 对象。
- 它记录了 Bean 的所有元数据:类名、作用域(Scope)、是否懒加载、构造函数参数、属性值、初始化方法名等。
B. BeanFactory 与 ApplicationContext
-
BeanFactory :这是 IoC 的底层引擎(根接口),负责最基础的 Bean 实例化和依赖注入,采用延迟加载。
-
ApplicationContext :是 BeanFactory 的子接口,增加了国际化、事件广播、资源加载等高级功能,并在启动时预加载所有单例 Bean。
BeanFactory 与 ApplicationContext 的底层区别
| 特性 | BeanFactory | ApplicationContext |
|---|---|---|
| 加载时机 | 懒加载 。只有在调用 getBean 时才创建 Bean。 |
预加载。启动时就创建所有非懒加载的单例 Bean。 |
| 扩展功能 | 仅提供基础的 IoC/DI 支持。 | 继承了 BeanFactory,提供国际化、AOP 集成、事件传播。 |
| 底层实现 | 它是 IoC 的底层引擎,轻量级。 | 内部持有 DefaultListableBeanFactory 的引用,功能更全面。 |
ApplicationContext提供了一种解析文本消息的方法,一种加载文件资源(如图像)的通用方法,它们可以将事件发布到注册为侦听器的bean。
底层原理
Spring IoC 的核心本质可以概括为:将配置元数据(XML/注解)转化为内部数据结构(BeanDefinition),再通过反射机制和设计模式(工厂)驱动对象的全生命周期。
1. 核心基石:BeanDefinition (元数据建模)
在 Spring 内部,你写的每一个 class 并不是直接丢进 Map 里的。Spring 首先会将类信息"抽象化"为一个 BeanDefinition 对象。
-
它存了什么? 类的全路径、是否单例、是否懒加载、依赖的对象、初始化/销毁方法、构造函数参数等。
-
为什么要这一层? 它是解耦的关键。有了
BeanDefinition,Spring 就不再依赖具体的类,而是依赖这套"说明书"。
2. 核心引擎:DefaultListableBeanFactory
如果你去翻源码,你会发现 ApplicationContext 只是个"空壳",它内部真正干活的对象是 DefaultListableBeanFactory。
它内部维护了几个核心集合(数据结构):
-
beanDefinitionMap: 一个ConcurrentHashMap,存放所有的BeanDefinition。 -
singletonObjects: 一级缓存,存放已经创建好的、完整的单例 Bean。 -
beanDefinitionNames: 一个List,记录 Bean 注册的顺序。
3. 运行过程
IoC 的运行过程可以高度概括为三个阶段:解析、注册、实例化。
第一阶段:解析与注册 (Loading & Registration)
-
Resource 定位 :通过
ResourceLoader找到 XML 或扫描@Component路径。 -
解析 :BeanDefinitionReader 读取资源,将其解析为 BeanDefinition 。
-
注册 :调用
BeanDefinitionRegistry.registerBeanDefinition,把"说明书"存入 beanDefinitionMap 中。
第二阶段:预处理 (BeanFactoryPostProcessor)
在 Bean 还没实例化之前,Spring 允许你修改这些"说明书"。
- 典型案例 :
PropertyPlaceholderConfigurer。它会扫描BeanDefinition,把里面的${db.url}占位符替换成真实的配置文件内容。
第三阶段:实例化与依赖注入 (The Lifecycle)
当调用 getBean() 时,触发以下流程:
-
实例化 (Instantiation):
- 默认使用 CGLIB 或 JDK 反射 调用构造函数创建原始对象。
-
属性填充 (Populate Bean):
- 这一步处理 DI (依赖注入) 。Spring 会递归地调用
getBean来获取依赖项,并通过反射 设置字段值。
- 这一步处理 DI (依赖注入) 。Spring 会递归地调用
-
初始化 (Initialization):
-
Aware 接口回调 :注入
BeanName、BeanFactory等环境信息。 -
BeanPostProcessor (前置) :执行
postProcessBeforeInitialization。 -
自定义 Init 方法 :执行
@PostConstruct或InitializingBean.afterPropertiesSet。 -
BeanPostProcessor (后置) :AOP 动态代理通常就在这一步发生 ,它会返回一个代理后的对象。
-
Bean的生命周期
大概的流程模型是这样:
-
实例化 (Constructor)
-
属性填充 (DI)
-
Aware 接口回调
-
BeanPostProcessor 前置处理 (处理
@PostConstruct) -
初始化 (InitializingBean / init-method)
-
BeanPostProcessor 后置处理 (AOP 的切入点)
-
销毁 (DisposableBean / destroy-method)
第一阶段:实例化前后的扩展 (Instantiation)
这是对象从"说明书"(BeanDefinition)变成"内存对象"的过程。
-
InstantiationAwareBeanPostProcessor.postProcessBeforeInstantiation()
-
作用:在调用构造函数之前触发。
-
高级技巧 :这里是短路点。如果你在这里返回了一个代理对象,Spring 将不再走后续流程,直接进入初始化后的阶段。
-
-
实例化(Bean 的构造)
- 通过反射调用构造函数。
-
MergedBeanDefinitionPostProcessor.postProcessMergedBeanDefinition()
- 作用 :处理
@Autowired、@Value等注解的元数据采集。
- 作用 :处理
-
InstantiationAwareBeanPostProcessor.postProcessAfterInstantiation()
- 作用 :实例化后,属性填充前。如果返回
false,则跳过后续属性填充流程。
- 作用 :实例化后,属性填充前。如果返回
第二阶段:属性赋值与依赖注入 (Populate)
-
InstantiationAwareBeanPostProcessor.postProcessProperties()
- 核心逻辑 :真正处理
@Autowired、@Resource等注解,完成依赖注入。
- 核心逻辑 :真正处理
-
属性填充
- 如果是 XML 配置,这里会执行具体的 Setter 注入。
第三阶段:初始化阶段 (Initialization) ------ 核心扩展点
这是程序员最常干预的阶段。
1. Aware 接口回调
Spring 会按顺序调用各种 Aware 接口,让 Bean 感知到容器的存在:
-
BeanNameAware:获取 Bean 的名称。 -
BeanFactoryAware:获取当前 BeanFactory。 -
ApplicationContextAware:获取整个应用上下文。
2. BeanPostProcessor.postProcessBeforeInitialization()
- 关键点 :处理
@PostConstruct注解。它由CommonAnnotationBeanPostProcessor实现。
3. 初始化
-
InitializingBean.afterPropertiesSet():实现该接口自定义逻辑。
-
Custom init-method :在 XML 或
@Bean(initMethod = "...")中定义的初始化方法。
4. BeanPostProcessor.postProcessAfterInitialization() ------ AOP 的发生地
-
核心原理 :这是生命周期中最强大的扩展点。Spring 的 AOP 代理对象通常就在这里生成。
-
注意:这里返回的对象会替换掉原始的 Bean,最终存入单例池。
第四阶段:使用与销毁 (Usage & Destruction)
-
Bean 准备就绪
- 此时 Bean 已经放入单例池,可以被业务代码使用了。
-
销毁前扩展
@PreDestroy:在销毁动作开始前执行。
-
销毁回调
-
DisposableBean.destroy():实现该接口。 -
Custom destroy-method:自定义的销毁方法。
-
Bean的作用域
在 Spring 中,作用域(Scope) 决定了容器如何创建 Bean 实例,以及这个实例在什么时候、什么范围内被共享。
Spring 核心作用域(最常用)
这是所有 Spring 应用(包括非 Web 应用)都通用的作用域。
Singleton(单例 - 默认)
-
定义 :在整个 Spring IoC 容器中,该 Bean 只有一个实例。
-
加载时机 :默认在容器启动、预初始化时创建。
-
线程安全 :不是线程安全的 。因为多个线程共享同一个实例,如果 Bean 内部有成员变量(有状态),并发修改会导致数据混乱。
-
场景:无状态的服务类(Service)、数据访问类(DAO)、工具类(Utils)。
Prototype(多例/原型)
-
定义 :每次通过 getBean() 获取时,容器都会创建一个新的实例。
-
加载时机 :延迟加载,只有在用到时才创建。
-
生命周期 :Spring 不管"售后" 。容器负责创建并初始化实例交给客户端,但之后不再管理它的生命周期,也不会调用其
destroy销毁方法。 -
场景:有状态的 Bean、非线程安全的对象。
Web 相关作用域
这些作用域仅在 Web 环境下(如 Spring MVC)有效。
| 作用域 | 范围 | 生命周期描述 |
|---|---|---|
| Request | HTTP 请求 | 每次 HTTP 请求创建一个实例,请求结束,Bean 销毁。 |
| Session | HTTP 会话 | 同一个 Session 共享一个实例,Session 过期,Bean 销毁。 |
| Application | ServletContext | 整个 Web 应用生命周期内只有一个实例(类似全局单例)。 |
| WebSocket | WebSocket 会话 | 在一次完整的 WebSocket 会话中共享一个实例。 |
作用域失效问题(Scope Breakdown)
如果在一个单例(Singleton)Bean里 注入了一个多例(Prototype)Bean,会发生什么?
想象你有两个类:
-
ServiceA(Singleton):单例,全公司只有一台复印机。 -
TaskB(Prototype):多例,每次复印需要的纸张。
java
@Component
@Scope("singleton")
public class ServiceA {
@Autowired
private TaskB taskB; // 注入多例 Bean
public void doWork() {
System.out.println("ServiceA 使用了: " + taskB);
}
}
@Component
@Scope("prototype")
public class TaskB {
// 每次创建都会有一个新的对象地址
}预期的结果: 每次调用 serviceA.doWork(),打印出的 taskB 地址都不一样(因为taskB是多例)。
真实的结果: 无论调用多少次,打印出的 taskB 永远是同一个对象( 这个多例 Bean 表现得像单例一样**)**。
问题的根源在于 "依赖注入只发生一次"。
-
容器启动 :Spring 扫描到
ServiceA是单例,开始创建它。 -
寻找依赖 :Spring 发现
ServiceA依赖TaskB。 -
创建依赖 :Spring 去容器里找
TaskB,发现是Prototype,于是 "嘭" 地一声创建了一个全新的TaskB实例。 -
完成注入 :Spring 把这个全新的
TaskB塞进了ServiceA的成员变量里。 -
结束 :
ServiceA组装完成,进入单例池。
关键点: 因为 ServiceA 是单例,它只会被组装一次 。一旦组装完成,它肚子里的那个 TaskB 就被"焊死"了。以后你再怎么调用 ServiceA,它都不会再去向 Spring 容器要新的 TaskB。
如何解决?
如果你确实需要每次都拿到新的多例 Bean,有三种常见的方法:
@Lookup 注解(推荐)
这是最优雅的方式。Spring 会动态拦截这个方法的调用,每次都去容器里重新找一次 TaskB。Spring 会动态生成子类重写该方法,确保每次调用都返回新实例。
放弃注入,手动获取 :每次用的时候调用 applicationContext.getBean()(不推荐,侵入性强)。
使用 ScopedProxy:通过 AOP 代理,在每次访问该属性时,由代理对象去容器里找一个新的目标实例。
Bean的线程安全问题
Spring 框架本身并没有对 Bean 进行任何多线程封装,也没有提供线程安全的保证。
Bean 是否线程安全,完全取决于 Bean 的作用域(Scope) 以及 它是"有状态"还是"无状态"的。
Singleton(单例)------ 有风险
由于单例 Bean 在整个容器中只有一个实例,所有的线程都会共享这个对象。
-
如果这个 Bean 是**无状态(Stateless)**的(如典型的 Service、DAO、Controller),它是逻辑上"线程安全"的。
-
如果这个 Bean 是有状态(Stateful)的(即内部有可以被修改的成员变量),那它就是线程不安全的。
Prototype(多例)------ 相对安全
每次获取都会创建一个新实例,不涉及线程间的共享,因此不存在竞态条件。但如果这个多例 Bean 被注入到了一个单例 Bean 中,或者被传递给了其他线程,依然需要开发者自己保证安全
"有状态" vs "无状态"
这是判断线程安全最务实的标准:
-
无状态(Stateless) :类中没有成员变量,或者成员变量只 读(如通过 IoC 注入的其他 Service)。
-
例子 :大多数
UserService、UserMapper。 -
结论 :安全。
-
-
有状态(Stateful) :类中定义了可以被改变的成员变量 (如
private int count;或private List list;),用于存储中间业务数据。-
例子:一个用来统计访问次数的单例 Controller。
-
结论 :不安全。
-
为什么 Controller 和 Service 通常不需要考虑线程安全?
在典型的 Spring Boot 场景中,虽然 Controller 是单例,但我们几乎不在其中定义"业务相关的成员变量"。
-
局部变量 :所有业务逻辑的数据都存在于方法内部的局部变量中。每个线程调用方法时,局部变量会存放在各自线程的虚拟机栈中,彼此隔离。
-
只读注入 :注入的
Mapper或Service也是无状态单例,这种"只读"链条是安全的。
如果你必须在单例 Bean 中存储某种"状态",请参考以下资深工程师的解决方案:
方案 A:使用 ThreadLocal (最推荐)
ThreadLocal 为每个线程提供了一个独立的变量副本。这在处理"当前登录用户"、"数据库连接"或"事务上下文"时非常有用。
- 原理:将变量绑定到当前线程,实现线程隔离。
方案 B:使用并发容器或原子类
如果确实需要跨线程累计数据,使用 AtomicInteger、ConcurrentHashMap 等。
方案 C:改变作用域
将 Scope 设置为 prototype、request 或 session。但要注意之前讨论过的"作用域失效"注入问题。
方案 D:避免成员变量
尽量将状态通过方法参数传递,或者封装到专门的 Request DTO 对象中,随方法栈生灭。
循环依赖
简单来说,循环依赖就是:A 对象的创建依赖于 B,而 B 对象的创建又依赖于 A。
循环依赖的两种形态
在 Spring 中,循环依赖通常表现为以下两种形式:
A. 直接循环依赖(双向依赖)
这是最常见的场景:Bean A 注入了 Bean B,同时 Bean B 也注入了 Bean A。
A <---> B
B. 间接循环依赖(环形依赖)
涉及三个或更多的 Bean 形成一个闭环。
A ---> B ---> C ---> A
要理解为什么循环依赖棘手,我们需要回到我们之前聊过的 Bean 生命周期:
-
Spring 尝试创建 Bean A。
-
实例化 A:在堆里开辟内存,拿到 A 的原始引用(此时 A 还是个空壳)。
-
属性填充 A:Spring 发现 A 需要 B,于是去容器里找 B。
-
创建 Bean B:容器里没有 B,开始创建 B。
-
实例化 B:拿到 B 的原始引用。
-
属性填充 B:Spring 发现 B 需要 A,于是又去容器里找 A。
-
死锁点 :此时 A 还没创建完(还在第 3 步),如果没有任何机制,Spring 就会在这里无限套娃,最终抛出
BeanCurrentlyInCreationException。
循环依赖的分类与 Spring 的处理能力
| 依赖类型 | 作用域 | 是否能解决 | 理由 |
|---|---|---|---|
| Setter 注入 | Singleton | 是 | Spring 利用三级缓存,通过提前暴露"半成品"对象来打破循环。 |
| 构造器注入 | Singleton | 否 | 实例化需要调用构造函数,构造函数需要参数。如果参数还没实例化,连"半成品"都生不出来。 |
| Setter 注入 | Prototype | 否 | 多例 Bean 不入缓存,Spring 无法找到之前创建过的半成品。 |
如何规避循环依赖?
虽然 Spring 的单例池能帮我们解决大部分 Setter 循环依赖,但从架构设计 的角度来看,循环依赖通常意味着组件职责划分不清。
-
业务重构:尝试提取出第三个 Bean C,让 A 和 B 都依赖 C,从而将环拆开。
-
延迟加载 (@Lazy) :在其中一个注入点加上
@Lazy。Spring 会先注入一个代理对象(Proxy),等真正用到时再从容器获取。 -
使用 Setter 注入代替构造器注入:虽然不推荐,但确实能让 Spring 的缓存机制生效。
Spring三层缓存
在源码中,它们的定义如下:
| 缓存级别 | 变量名 | 存储的内容 | 作用 |
|---|---|---|---|
| 第一级缓存 | singletonObjects |
完整的 Bean | 存放已经完全初始化好的单例 Bean 。我们平时 getBean 拿到的就是它。 |
| 第二级缓存 | earlySingletonObjects |
半成品 Bean | 存放已经实例化(new 了),但还没填充属性的 Bean。用于解决重复提取。 |
| 第三级缓存 | singletonFactories |
Bean 工厂 | 存放 ObjectFactory。用于在需要时提前创建代理对象 (AOP)。 |
假设 ServiceA 和 ServiceB 互相依赖。我们看 Spring 是如何运作的:
-
实例化 A :Spring 通过反射
new出 A 的原始对象。 -
加入三级缓存 :Spring 把一个能获取 A 的"工厂"丢进 singletonFactories。
-
属性填充 A :发现需要 B,于是去
getBean(B)。 -
实例化 B :
new出 B 的原始对象。 -
加入三级缓存 :把 B 的工厂丢进 singletonFactories。
-
属性填充 B:发现需要 A。
-
惊险时刻 (查询 A):
-
查一级缓存:没有。
-
查二级缓存:没有。
-
查三级缓存:找到了 A 的工厂!
-
-
执行工厂 (获取 A) :通过 A 的工厂拿到 A 的引用。如果 A 需要 AOP,这里拿到的就是 A 的代理对象。
-
转移缓存 :把 A 从三级缓存移到二级缓存 。
-
完成 B :B 顺利注入了 A,完成初始化,进入一级缓存 。
-
回溯 A :A 拿到 B 的引用,也完成初始化,进入一级缓存 。
为什么一定要有"第三级"?
如果我只用两级缓存(即只有原始对象和完整对象),行不行?
如果不涉及 AOP,两级缓存确实够了。但如果要处理 AOP,必须有第三级。
为什么?
-
Bean 的原则 :Spring 默认是在 Bean 完全初始化后的最后一步(
BeanPostProcessor)才创建代理对象的。 -
循环依赖的矛盾:如果发生了循环依赖,A 必须在还没初始化完时,就得把自己的代理对象给 B。
-
解决方案 :第三级缓存不直接存对象,而是存一个工厂。
-
如果没有循环依赖,这个工厂永远不会被触发,代理对象依然在最后一步创建。
-
如果发生了循环依赖,B 通过这个工厂提前触发 AOP 逻辑,拿到 A 的代理对象,从而保证了 B 注入的是增强后的 A,而不是原始的 A。
-
结论 :三级缓存的本质是为了延迟处理 AOP。它保证了即便在循环依赖这种极端情况下,AOP 的代理逻辑依然能正确介入。
DI(Dependency Injection,依赖注入)
如果说 IoC(控制反转)是一套哲学思想 ,那么 DI 就是这套思想的具体技术实现。在 Spring 生态中,DI 是让整个应用"活"起来的血液。
底层实现原理
DI 的运行高度依赖 Java 的反射(Reflection)机制和 元数据(Metadata)。
A. 元数据解析
Spring 启动时,通过扫描注解(如 @Autowired)或读取 XML,将依赖关系记录在 BeanDefinition 中。
B. 依赖查找(Dependency Resolution)
当 Spring 创建 Bean A 时,它会检查 A 的 BeanDefinition:
-
发现 A 依赖 B。
-
去单例池(一级缓存)中查找 B。
-
如果没找到,则递归触发 B 的创建流程。
C. 注入操作(Injection Logic)
一旦依赖对象准备好,Spring 会通过以下底层方式完成注入:
-
反射字段赋值 :利用
Field.set(Object obj, Object value)强制设置私有属性。 -
反射方法调用 :利用
Method.invoke(Object obj, Object... args)调用 Setter 方法。 -
反射构造调用 :利用
Constructor.newInstance(Object... initargs)创建实例。
三种主要的 DI 实现方式
| 方式 | 代码示例 | 优点 | 缺点 |
|---|---|---|---|
| 构造器注入 | public A(B b) { this.b = b; } |
官方推荐 。保证依赖不为空,支持 final 字段,方便单测。 |
参数过多时构造函数显得臃肿。 |
| Setter 注入 | public void setB(B b) { this.b = b; } |
允许可选依赖,可以在对象创建后重新注入。 | 无法保证对象在使用前已完全初始化。 |
| 字段注入 | @Autowired private B b; |
代码最简洁,可读性高。 | 不推荐 。强耦合容器,无法使用 final,隐藏了类的真实依赖。 |
@Autowired和@Resource的区别
| 特性 | @Autowired | @Resource |
|---|---|---|
| 来源 | Spring 框架 (org.springframework...) |
Java 标准 (JSR-250, javax 或 jakarta) |
| 默认注入方式 | 按类型 (By Type) | 按名称 (By Name) |
| 支持的注入位置 | 构造器、字段、Setter 方法、配置方法 | 字段、Setter 方法(不支持构造器) |
| 是否支持可选 | 支持 (required = false) |
不支持 |
| 多实现处理 | 配合 @Qualifier 使用 |
通过 name 属性指定 |
@Autowired 的逻辑流转
-
按类型查找 :去容器里找类型匹配的 Bean。
-
唯一性检查:
-
如果只找到一个,直接注入。
-
如果找到多个,则触发按名称查找(找变量名和 Bean ID 一致的)。
-
如果没有匹配名称,抛出异常(除非设置了
required = false)。
-
@Resource 的逻辑流转
-
按名称查找 :默认取变量名 作为
name去容器找。 -
按类型回退:
-
如果指定了
name且没找到,直接报错。 -
如果没有指定
name且按名称没找到,则回退到按类型查找。
-
来源与生态
-
@Autowired是 Spring 特有的。如果你的项目未来要脱离 Spring(虽然概率极低),这些注解会失效。 -
@Resource是 Java 定义的标准规范(JSR-250)。它具有更好的通用性,理论上在其他支持 CDI 的容器中也能运行。
注入位置的差异
-
@Autowired支持构造器注入 。这是 Spring 目前官方推荐的方式,因为构造器注入能保证依赖不为空,且方便编写单元测试。 -
@Resource不支持构造器注入 。如果你坚持使用构造器注入,就只能用@Autowired或者@Inject(另一个 Java 标准注解)。
处理多实现类(Bean 冲突)
当你一个接口有多个实现类(比如 SmsService 和 EmailService 继承自 MessageService)时:
-
使用
@Autowiredjava@Autowired @Qualifier("smsService") // 必须显式配合 @Qualifier private MessageService messageService; -
使用
@Resource:java@Resource(name = "smsService") // 语义更清晰,一个注解搞定 private MessageService messageService;
@Component和@Bean的区别
| 特性 | @Component | @Bean |
|---|---|---|
| 作用位置 | 类(Class)级别 | 方法(Method)级别 |
| 注册方式 | 配合**组件扫描(Component Scan)**自动注册 | 在配置类中通过方法调用手动注册 |
| 适用范围 | 适用于你自己编写的源代码类 | 适用于第三方库的类,或需要复杂逻辑创建的对象 |
| 灵活性 | 较低(类上打注解即可) | 极高(可以在方法内写逻辑、设参数) |
| 侵入性 | 强(需要在业务类上加注解) | 无(业务类可以是一个纯净的 POJO) |
Lite 模式 vs Full 模式
-
Full 模式(@Configuration + @Bean) :Spring 会使用 CGLIB 对配置类进行代理。这样当你在一个
@Bean方法中调用另一个@Bean方法时,Spring 会拦截该调用,直接从容器中找现有的单例,确保单例一致性。 -
Lite 模式(仅在普通类中使用 @Bean) :Spring 不会生成 CGLIB 代理。如果你在一个方法里调用另一个方法,它会像普通 Java 调用一样直接
new一个新对象,这可能会破坏 Bean 的单例属性。
在实际的企业级项目开发中,我们遵循以下原则:
-
项目内部业务类 :优先使用
@Component/@Service。这样代码整洁,符合"约定大于配置"。 -
第三方依赖、中间件配置、跨模块共享组件 :必须使用
@Configuration+@Bean。这便于集中管理,且能利用@Bean提供的initMethod和destroyMethod属性。 -
需要解耦时 :如果你不希望业务代码里出现任何 Spring 的注解(保持 POJO 纯净),请使用
@Bean。
AOP(Aspect-Oriented Programming,面向切面编程)
动态代理
在深入探讨 Spring AOP 时,JDK 动态代理 与 CGLIB 是绕不开的两座大山。
简单来说:JDK 动态代理是基于"接口"的,而 CGLIB 是基于"继承"的。
JDK 动态代理:基于接口的"协议"代理
JDK 动态代理利用了 Java 的反射机制。它要求目标类必须实现至少一个接口。
实现原理
-
生成代理类 :在运行时,JVM 会在内存中动态生成一个名为 Proxy(或类似名称)的类。
-
继承关系 :这个生成的代理类会继承 java.lang.reflect.Proxy 并实现目标类的所有接口 。
-
分发请求 :当你调用代理对象的方法时,它统一转发给
InvocationHandler.invoke(),在该方法内部通过反射调用目标对象的真实方法。
CGLIB 代理:基于继承的"暴力"重写
CGLIB (Code Generation Library) 是一个强大的高性能字节码生成库 。它不需要接口,而是通过创建目标类的子类来实现代理。
实现原理
-
字节码生成 :CGLIB 底层使用了 ASM 框架,直接操作字节码。
-
继承关系 :它会动态生成一个目标类的子类。
-
方法拦截 :子类会重写(Override)父类的所有非 final 方法。当你调用方法时,它会通过
MethodInterceptor进行拦截。 -
FastClass 机制 :CGLIB 不使用反射 ,而是为代理类和目标类各生成一个 FastClass,通过索引直接调用方法,效率高于反射。
Spring 到底用哪一个?
这是面试的高频坑点。Spring AOP 的决策逻辑如下:
-
如果目标对象实现了接口 ,默认采用 JDK 动态代理。
-
如果目标对象没有实现接口 ,采用 CGLIB。
-
强制切换 :你可以通过配置
proxy-target-class="true"强制 Spring 全部使用 CGLIB。
注意: 在 Spring Boot 2.x 之后,为了减少由于"接口缺失"导致的注入失败,Spring Boot 默认将
spring.aop.proxy-target-class设为了true,即默认倾向于使用 CGLIB。
AOP
为什么需要 AOP?(痛点分析)
如果说 IoC 是为了解耦对象 ,那么 AOP 就是为了解耦逻辑 。,AOP 并不是要取代 OOP(面向对象编程),而是作为 OOP 的一种补充,用来处理那些散落在系统各处、与业务主逻辑无关的"横向关注点"。
在没有 AOP 的时代,如果我们想给所有的 Service 方法加上日志记录、权限校验或事务控制,那么就会发生:
-
代码重复 (Code Scattering):同样的逻辑出现在几十个甚至上百个方法中。
-
侵入性强 (Code Tangling):核心业务逻辑被淹没在系统级服务代码中,维护困难。
设计思想:横向切分 (Cross-cutting Concerns)
AOP 的核心思想是 "将系统中的非业务代码抽离出来,形成独立的切面"。
-
OOP(纵向):封装业务实体,通过继承和多态建立纵向的层次结构。
-
AOP(横向):像手术刀一样,横向切入系统执行流,在不修改原始代码的前提下,动态地注入逻辑。
为了描述这个"切入"过程,Spring 定义了一套术语:
-
JoinPoint(连接点) :程序执行过程中的某个点,在 Spring AOP 中,这通常指一个方法执行。
-
Pointcut(切点) :一个表达式,用来定义哪些方法需要被增强(解决"在哪干"的问题)。
-
Advice(通知):增强的代码逻辑(解决"干什么"和"什么时候干"的问题,如 Before, After, Around)。
-
Aspect(切面) :切点 + 通知。一个完整的模块,既定义了逻辑,也定义了位置。
-
Target(目标对象):被代理的原始业务对象。
底层实现原理:代理机制 + 拦截器链
Spring AOP 的底层实现可以分为两个关键阶段:代理生成 和 链式调用。
A. 代理的生成
正如我们之前讨论的,Spring 会根据目标对象是否实现接口,决定使用 JDK 动态代理 还是 CGLIB 。在容器启动时,AnnotationAwareAspectJAutoProxyCreator(一个 BeanPostProcessor)会扫描所有的 Aspect,并为匹配的 Target 生成一个代理对象存入容器。
B. 拦截器链与递归调用 (The Chain)
当代理对象的方法被调用时,它并不会直接跳转到通知代码,而是维护了一个 MethodInterceptor 拦截器链。
-
Spring 将所有的 Advice 包装成
MethodInterceptor。 -
核心类
ReflectiveMethodInvocation负责控制链条的执行。 -
它通过一个索引
currentInterceptorIndex递归地调用proceed()方法。
AOP 的典型使用场景
-
声明式事务管理 (@Transactional) :这是 AOP 最成功的应用,通过
TransactionInterceptor实现。 -
日志记录:记录接口的入参、出参、执行耗时,用于排查问题。
-
权限校验 (Spring Security):在进入 Controller 前验证用户的权限标记。
-
缓存处理 :通过
@Cacheable注解,先查 Redis,命中则直接返回,不命中则执行方法。 -
幂等性检查:通过自定义注解防止表单重复提交。
-
异常统一处理:捕获特定切面下的异常,转化为统一的响应格式。
Spring AOP vs AspectJ
Spring AOP :基于动态代理 。仅支持方法级别的连接点,是在运行时生成的代理对象。优点是易用,不需要特殊的编译器。
- AspectJ :基于静态织入 (Weaving) 。支持构造函数、字段访问 等所有点。它在编译期、类加载期通过修改字节码来实现。优点是性能更高、功能更全,但门槛也更高。
切点(Pointcut)、通知(Advice)与通知链的执行顺序是什么
切点与通知的关系:Where vs When & What
-
切点 (Pointcut) :定义了"在哪里"增强。它是一个表达式,本质上是在众多的连接点(Join Points)中进行过滤。
-
通知 (Advice) :定义了"什么时候 "干"什么事"。
-
通知链 (Advice Chain) :当一个方法被多个通知增强时,Spring 会将这些通知封装成一个个
MethodInterceptor,并组织成一个有序的链条。
单个切面(Aspect)内通知的执行顺序
在 Spring 5.2.7 之后,为了与 AspectJ 的原生标准保持一致,执行顺序进行了微调。这是目前主流的执行路径:
正常流程:
-
@Around(环绕通知前部分代码) -
@Before(前置通知) -
Target Method (目标方法执行)
-
@AfterReturning (返回通知)
-
@After(后置通知,类似 finally) -
@Around(环绕通知后部分代码)
异常流程:
-
@Around(前部分) -
@Before -
Target Method (抛出异常)
-
@AfterThrowing (异常通知)
-
@After(后置通知) -
@Around(后部分,通常在 catch 块之后或不执行,取决于环绕通知内部的 try-catch 逻辑)
多个切面(Multiple Aspects)的执行顺序
当同一个方法被 Aspect A 和 Aspect B 同时拦截时,顺序由 优先级(Order) 决定。
-
如何指定顺序:
-
实现
Ordered接口。 -
使用
@Order注解。
-
-
规则 :数值越小,优先级越高,越先进入,越后退出。(类似于"剥洋葱"模型)
执行顺序:
-
Aspect A (
@Order(1)) -> 进入(Before / Around 开始) -
Aspect B (
@Order(2)) -> 进入(Before / Around 开始) -
Target Method 执行
-
Aspect B -> 退出(After / AfterReturning / Around 结束)
-
Aspect A -> 退出(After / AfterReturning / Around 结束)
核心原理:通知链的递归调用
Spring AOP 并没有使用简单的 for 循环来执行这些通知,而是使用了 "责任链模式 + 递归"。
-
Spring 将所有通知包装成
MethodInterceptor。Spring 并不直接执行你的@Before或@After。在 AOP 代理生成后,Spring 会把所有通知(Advice)都适配成MethodInterceptor接口。】-
BeforeAdviceAdapter :把
@Before包装成一个拦截器,逻辑是:先执行增强逻辑,再执行mi.proceed()。 -
AfterReturningAdviceAdapter :把
@AfterReturning包装成拦截器,逻辑是:先执行mi.proceed(),拿到结果后再执行增强逻辑。
-
-
核心执行器是
ReflectiveMethodInvocation。内部有两个核心属性:-
List<MethodInterceptor> interceptors:一个有序的拦截器列表(即通知链)。 -
int currentInterceptorIndex:一个指针,记录当前执行到第几个拦截器 ,初始值为 -1。
-
-
每个拦截器都会调用 mi.proceed()。当我们调用代理对象的方法时,实际上是在调用
mi.proceed()。-
如果还有下一个拦截器,就继续递归。
-
如果没有了,说明已经到了链条末尾,执行目标方法(
invokeJoinpoint)。
-
-
随着递归的"回溯" ,后续的
After和Around后半部分逻辑会被依次执行。
-
职责链 :每个拦截器只负责自己的那部分逻辑,且知道如何交给下一个(调用
proceed())。 -
递归 :利用了 Java 方法调用的 栈(Stack) 特性。
-
往下走(压栈) :实现
@Before的语义。 -
往回走(弹栈/回溯) :实现
@After的语义。
-
这套设计的精妙之处在于:它让"环绕"和"后置"通知能够极其方便地捕获到目标方法的返回值或异常,因为它们就在同一个方法的调用上下文里。
为什么必须用递归,而不用 for 循环?
这是高级工程师必须看透的一点:因为 @Around 和 @After 逻辑需要等待"后序结果"。
-
for循环的局限 :它是一维的,只能按顺序走完。它很难实现"先执行 A 的前半部分,再执行 B 的前半部分,再执行业务,最后执行 B 的后半部分和 A 的后半部分"。 -
递归的优势 :递归自带 "压栈" 和 "出栈"。
-
压栈过程 :处理所有
@Before和@Around的前半段。 -
出栈过程 :处理所有
@AfterReturning、@After和@Around的后半段。
-
这完美契合了"洋葱模型"或者"套娃模型"。
设计模式
Spring 框架之所以被公认为 Java 领域的工业级艺术品,正是因为它几乎集成了 23 种设计模式 中的精髓。
1. 工厂模式 (Factory Pattern)
这是 Spring 最基础的模式。Spring 并不直接通过 new 创建对象,而是通过工厂来管理。
-
实用例子 :
BeanFactory和ApplicationContext。 -
解构:
-
BeanFactory是一个底层工厂,它根据BeanDefinition(配置说明书)来生产 Bean。 -
优点:使用者不需要关心对象是怎么创建出来的、用了哪个构造函数,实现了对象创建逻辑与业务逻辑的彻底分离。
-
2. 单例模式 (Singleton Pattern)
Spring 中的 Bean 默认都是单例的,但注意:Spring 的单例和 GOF 提到的传统单例有所不同。
-
实用例子 :Bean Scopes (默认作用域)。
-
解构:
-
传统单例是每个 ClassLoader 只有一个实例,而 Spring 单例是每个 IoC 容器中只有一个实例。
-
Spring 通过
ConcurrentHashMap实现了一个"单例池",确保在容器运行期间,相同的 Bean 只被实例化一次。 -
优点:极大地减少了频繁创建和销毁对象带来的内存开销和 GC 压力。
-
3. 代理模式 (Proxy Pattern) ------ AOP 的灵魂
这是 Spring 中最强大的模式,没有它就没有声明式事务。
-
实用例子 :
@Transactional事务管理。 -
解构:
-
当你给一个方法加上
@Transactional时,Spring 并不是直接运行你的代码,而是为你生成一个代理对象。 -
代理对象会在方法开始前开启事务,结束后提交事务,报错时回滚事务。
-
实现:JDK 动态代理(基于接口)或 CGLIB(基于继承)。
-
4. 模板方法模式 (Template Method Pattern)
Spring 极大地减少了 JDBC 或 JMS 等底层操作的样板代码(Boilerplate Code),靠的就是这个模式。
-
实用例子 :
JdbcTemplate、RestTemplate。 -
解构:
-
父类定义了算法的骨架 (如:获取连接 -> 开启事务 -> 执行 SQL -> 关闭连接)。
-
具体的 "执行 SQL" 这一步留给开发者通过回调函数(Callback)去实现。
-
优点:开发者只需要关心核心业务 SQL,所有繁琐的资源关闭和异常处理都由框架统一负责。
-
5. 策略模式 (Strategy Pattern)
Spring 处理资源加载或实例化时,经常会根据不同情况选择不同的算法。
-
实用例子 :
Resource接口。 -
解构:
-
当你访问资源时,Spring 定义了
Resource接口,但具体实现有很多:ClassPathResource、FileSystemResource、UrlResource。 -
Spring 会根据你的路径前缀(
classpath:或file:)自动选择最合适的策略去加载资源。 -
优点:统一了资源访问方式,且具备极强的扩展性。
-
6. 观察者模式 (Observer Pattern) ------ 异步解耦
Spring 的事件驱动模型是典型的观察者模式实现。
-
实用例子 :
ApplicationEvent和ApplicationListener。 -
解构:
-
当某个动作发生时(如容器启动完成
ContextRefreshedEvent),容器会向所有注册的监听器广播这个事件。 -
优点:实现了解耦。比如你可以在用户注册成功后,发布一个"用户注册事件",由短信模块和邮件模块分别监听并执行,而注册代码本身不需要知道这些模块的存在。
-
7. 适配器模式 (Adapter Pattern)
在 Spring MVC 中,适配器模式让 DispatcherServlet 能够调用各种不同类型的处理器。
-
实用例子 :
HandlerAdapter。 -
解构:
-
Spring MVC 的 Controller 可以是实现接口的类,也可以是标注了
@RequestMapping的普通方法。 -
DispatcherServlet不需要知道这些 Controller 的具体结构,它只调用HandlerAdapter。适配器负责把请求转换成 Controller 能听懂的话。 -
优点:让系统能够兼容各种不同形式的处理器,提高了框架的灵活性。
-
8. 责任链模式(Chain of Responsibility)
将多个处理器(Handler)连接成一条链,请求沿着链条传递,每个处理器都有机会处理该请求或将其传递给下一个处理器。
Spring AOP:拦截器链 (MethodInterceptor)
Spring AOP 的底层核心------通知(Advice)的执行,就是标准的责任链模式实现。
-
核心组件 :
ReflectiveMethodInvocation。 -
工作机制 : Spring 将一个方法上的所有通知(Before, After, Around 等)都封装成
MethodInterceptor,并放入一个 List 中。 -
执行逻辑 : 它维护了一个指针
currentInterceptorIndex。当调用proceed()方法时,指针后移,获取下一个拦截器。每个拦截器内部又会调用invocation.proceed(),从而形成递归调用。这种设计允许通知在目标方法执行前后"环绕"执行。
Spring MVC
Spring MVC是一个基于 Servlet API 构建的原始 Web 框架,采用了经典的 MVC(Model-View-Controller) 设计模式。Spring MVC下我们一般把后端项目分为Service层(处理业务)、Dao层(数据库操作)、Entity层(实体类)、Controller层(控制层,返回数据给前台页面)。
核心设计思想:前端控制器模式 (Front Controller)
在没有 Spring MVC 的原生 Servlet 开发时代,我们需要在 web.xml 中配置成百上千个 Servlet 来对应不同的 URL。这导致了配置臃肿、代码重复且难以维护。
Spring MVC 引入了 DispatcherServlet 作为统一的入口。
-
集中处理:所有的 HTTP 请求都会先经过这个"大管家"。
-
逻辑分发:由大管家根据配置,将请求分发给具体的业务处理器(Controller)。
-
解耦:将请求接收、参数解析、业务逻辑执行、视图渲染等流程彻底解耦。
Spring MVC 的核心组件(六大金刚)
要理解 Spring MVC 的底层,必须掌握这六个核心组件:
| 组件名称 | 核心职责 |
|---|---|
| DispatcherServlet | 前端控制器。负责统一接收请求、协调各组件并分发响应。 |
| HandlerMapping | 处理器映射器 。负责根据 URL 找到对应的 Handler(控制器方法)。 |
| HandlerAdapter | 处理器适配器 。负责调用具体的 Handler,解决不同形态 Controller 的执行问题。 |
| Handler (Controller) | 业务处理器。由开发者编写,处理核心业务逻辑。 |
| ModelAndView | 数据与视图模型。封装了业务执行后的数据(Model)和要跳转的页面路径(View)。 |
| ViewResolver | 视图解析器。负责将逻辑视图名(如 "index")解析为真实的物理视图(如 "/WEB-INF/jsp/index.jsp")。 |
请求处理全流程
当一个请求打到服务器,Spring MVC 会经历以下步骤:
-
请求到达 :用户向服务器发送 HTTP 请求,请求首先被 DispatcherServlet(前端控制器)拦截。
-
寻找处理器 :DispatcherServlet 询问 HandlerMapping,映射器根据请求的 URL、方法等信息,寻找匹配的处理器。
-
返回执行链 :HandlerMapping 返回一个 HandlerExecutionChain 对象。这个对象包含了具体的 Handler (控制器方法)以及该方法关联的所有 Interceptors(拦截器)。
-
获取适配器 :DispatcherServlet 根据 Handler 的类型,向 HandlerAdapter(处理器适配器)发起询问,确认哪个适配器可以执行该处理器。
-
拦截器前置处理 :在真正执行 Controller 之前,按顺序执行拦截器的
preHandle()方法。如果返回false,请求在此中断。 -
执行逻辑 :适配器调用真正的 Controller 方法。
-
返回结果 :控制器方法处理完业务逻辑后,返回一个 ModelAndView 对象(包含数据模型和逻辑视图名)。
-
拦截器后置处理 :执行拦截器
postHandle方法。此时可以对模型数据或视图进行最后的加工。 -
视图解析 :DispatcherServlet 将逻辑视图名(如
"user_list")交给 ViewResolver ,解析成真实的 View 对象(如 JSP、Thymeleaf 模板)。 -
渲染数据:View 对象将 Model 数据填充到模板中(如 JSP、Thymeleaf)。
-
响应返回:DispatcherServlet 将最终生成的 HTML 或 JSON 返回给客户端。
提示 :在现代的 RESTful 开发中,我们通常使用
@RestController:
不再返回 ModelAndView:Controller 直接返回 Java 对象(POJO、List 等)。
HttpMessageConverter 介入 :跳过视图解析和渲染阶段。Spring 会调用
HttpMessageConverter(如 Jackson 库)直接将对象转为 JSON 或 XML 字符串,并写入 HTTP Response 的 Body 中。
常用注解
控制器定义注解
-
@Controller:标识一个类为 Spring MVC 的控制器。通常用于传统的 Web 开发,配合视图解析器返回 HTML 页面。 -
@RestController:最常用 。它是@Controller和@ResponseBody的组合。标志着该控制器下的所有方法默认都会将返回值直接写入 HTTP 响应体(通常是 JSON),非常适合前后端分离的架构。
请求映射注解 (Routing)
现在推荐使用具体的语义化注解,而不是通用的 @RequestMapping。
-
@GetMapping:用于查询操作。 -
@PostMapping:用于新增操作。 -
@PutMapping:用于更新操作(覆盖式更新)。 -
@DeleteMapping:用于删除操作。 -
@PatchMapping:用于部分更新。 -
@RequestMapping:通常定义在类级别,用于指定基础路径(Base Path),实现请求地址的层级管理。
数据绑定与入参处理 (Data Binding)
这是处理 HTTP 请求参数的核心:
-
@PathVariable:处理 RESTful 风格的路径变量。例如/users/{id}中的{id}。 -
@RequestParam:处理 Query String(查询字符串)或表单参数。支持设置defaultValue和required。 -
@RequestBody:极其重要 。将 HTTP 请求体中的 JSON 字符串反序列化为 Java 对象 。它底层依赖HttpMessageConverter(如 Jackson)。 -
@RequestHeader:用于获取请求头信息(如Authorization,User-Agent)。 -
@CookieValue:用于直接获取 Cookie 中的值。 -
@ModelAttribute:用于从 Model 中获取数据或将请求参数绑定到一个复杂的对象上(多用于 Form 表单提交)。
响应处理注解
-
@ResponseBody:将方法返回值自动转为 JSON/XML 写入响应体。如果使用了@RestController,则无需手动加在方法上。 -
@ResponseStatus:用于指定方法执行成功后返回的 HTTP 状态码(如201 Created或204 No Content)。
Spring Data & Transaction ( 数据持久化 )
事务
Spring 事务是 Spring 框架中一项核心功能,它通过简洁的抽象,让开发者能轻松管理数据库操作的一致性。Spring事务的本质是对数据库事务的抽象和封装 。真正的数据库事务提交和回滚是通过数据库的binlog 或redo log 实现的。
实现原理
Spring 事务的实现原理核心在于通过 AOP(面向切面编程) 和动态代理技术,将复杂的事务管理逻辑透明地织入业务方法中,从而简化开发。
-
代理对象的创建 :当你在一个类或方法上使用
@Transactional注解 时,Spring 在容器启动阶段(Bean 初始化时)会为这个 Bean 创建一个代理对象 。这个代理对象并非原始的 Bean 实例,而是一个增强了事务管理逻辑的包装器。 -
方法拦截 :当你的代码调用被
@Transactional注解的方法时,实际上调用的是代理对象 的方法 。代理对象会拦截这次调用,并将控制权交给一个名为 TransactionInterceptor 的关键组件 。 -
事务管理器的调度 :
TransactionInterceptor会解析@Transactional注解中定义的属性(如传播行为、隔离级别等),然后调用 PlatformTransactionManager (平台事务管理器)来执行具体的事务操作,如开启、提交、回滚 。
Spring 事务抽象出三个核心接口,各司其职,共同完成了事务的管理 :
| 核心组件 | 职责说明 | |
|---|---|---|
**PlatformTransactionManager** (事务管理器) |
事务管理的**"总指挥"**。它定义了事务的基本操作:获取事务状态、提交、回滚。Spring 为不同数据访问技术(JDBC, JPA, Hibernate 等)提供了相应的实现 。 | |
**TransactionDefinition** (事务定义) |
定义了事务的**"属性规则"** ,包括传播行为、隔离级别、超时时间、是否只读等。@Transactional注解的属性就是其具体体现 。 |
|
**TransactionStatus** (事务状态) |
代表了事务在运行过程中的**"当前状态"**,如是否是新事务、是否已被标记为回滚、是否有保存点等。事务管理器根据状态进行操作 。 |
事务能够正确运作的关键在于事务上下文与当前线程的绑定。
-
事务拦截与执行流程 :当我们调用被代理的业务方法时,调用首先会被
TransactionInterceptor 拦截。其核心方法invokeWithinTransaction会按以下步骤执行 :-
解析事务属性 :从
@Transactional注解中提取出传播行为、隔离级别等配置信息。 -
获取事务 :根据传播行为(例如
PROPAGATION_REQUIRED表示如果当前没有事务就创建一个,有则加入),通过PlatformTransactionManager获取或创建事务,并得到一个TransactionStatus对象。 -
绑定资源 :最关键的一步是获取与当前事务关联的数据库连接(Connection),并将其通过 ThreadLocal 绑定到当前线程 。这意味着在同一个事务的上下文中,后续的所有数据库操作都会获取到同一个 Connection,从而保证了数据操作的原子性。
-
执行业务逻辑:在事务上下文中调用原始目标方法。
-
提交/回滚:如果方法正常执行完毕,则提交事务;如果抛出了异常,则根据规则(默认只回滚运行时异常和 Error)决定是否回滚事务。
-
清理资源 :最后,解除
ThreadLocal中绑定的资源。
-
-
ThreadLocal的核心作用 :Spring 使用ThreadLocal来确保一个事务内的所有数据库操作都能获取到同一个 Connection ,这是实现事务的基石 。TransactionSynchronizationManager是这个机制的管理者,它内部维护了多个ThreadLocal变量,用来存储当前线程的事务资源(如 DataSource、Connection)和同步状态。-
Spring事务管理的核心挑战在于,如何让一个事务(通常开始于Service层的一个方法)内部调用的所有数据库操作(可能跨越多个DAO方法)共享同一个数据库连接。
ThreadLocal通过以下流程完美解决了这个问题-
事务拦截 :当执行到被
@Transactional注解标记的方法时,Spring的AOP代理(通常是TransactionInterceptor)会拦截该方法调用。 -
资源绑定 :事务管理器(如
DataSourceTransactionManager)会从事务相关的数据源获取一个数据库连接,并通过TransactionSynchronizationManager将这个连接绑定到当前线程的 ThreadLocal变量中。 -
连接传递 :在该事务后续执行过程中,任何需要数据库连接的地方(例如,通过
JdbcTemplate执行SQL),Spring都会自动从当前线程的ThreadLocal中获取之前绑定的那个连接,而不是新建一个。 -
事务结束与清理 :当事务方法执行完毕(成功提交或异常回滚)后,事务管理器会提交或回滚事务,并最关键的一步 :将连接从
ThreadLocal中解绑并释放回连接池。这确保了资源被正确清理,防止内存泄漏。
-
-
隔离级别
Spring 框架定义了五种标准的事务隔离级别,用于控制并发事务之间的可见性,平衡数据一致性和系统性能。
| 隔离级别 | 核心特性 | 能解决的并发问题 | 性能影响 | 典型应用场景 |
|---|---|---|---|---|
**READ_UNCOMMITTED** (读未提交) |
允许读取其他事务未提交的更改。 | 无 | 并发性能最高,但数据一致性风险最大。 | 对数据一致性要求极低的场景,如非关键的统计估算。 |
**READ_COMMITTED** (读已提交) |
只允许读取其他事务已提交的更改。 | 防止脏读。 | 平衡点,性能较好。 | 绝大多数Web应用的默认选择,如用户会话更新。 |
**REPEATABLE_READ** (可重复读) |
保证在同一事务中,多次读取同一数据的结果一致。 | 防止脏读、不可重复读。 | 并发性能有所下降。 | 需要事务内数据视图稳定的场景,如报表生成。 |
**SERIALIZABLE** (串行化) |
最高隔离级别,事务完全串行执行。 | 防止脏读、不可重复读、幻读。 | 并发性能最低,可能导致大量锁等待和超时。 | 对数据一致性有严苛要求的核心业务,如金融交易。 |
**DEFAULT** (默认) |
使用所连接数据库的默认隔离级别。 | 取决于数据库 | 取决于数据库 | 追求配置简便或希望行为与数据库默认设置一致时。 |
选择策略
-
优先从
READ_COMMITTED开始:它在避免脏读和保持性能之间取得了良好平衡,是许多数据库(如Oracle、PostgreSQL)和应用的默认选择。 -
需要时升级到
REPEATABLE_READ:当业务逻辑要求在一个事务内多次读取的数据必须绝对一致时(例如,先查询后依据结果更新),可考虑此级别。 -
极端情况才使用
SERIALIZABLE:由于其严重的性能损耗,仅在对数据一致性有零容忍要求且其他方法无法满足时使用。 -
了解数据库差异 :不同数据库对隔离级别的实现有差异。例如,MySQL的
REPEATABLE_READ通过MVCC机制在一定程度上缓解了幻读,而其他数据库可能不同。选择DEFAULT时,务必清楚当前数据库的默认行为。
当你在 Spring 的 @Transactional注解中显式设置了与 MySQL 当前会话不同的隔离级别时,Spring 会在事务启动前向数据库发送一条设置指令。
底层发生的事:
-
当方法被调用时,Spring 的事务拦截器会先获取一个数据库连接。
-
随后,它会通过 JDBC 在该连接上执行一条类似
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED的 SQL 语句,临时修改了当前数据库会话的隔离级别 。 -
然后才执行业务 SQL。
-
方法执行完毕后,事务结束,这个连接被归还到连接池,其隔离级别设置可能会被重置(取决于连接池配置)。
因此,在此事务的生命周期内,生效的是 Spring 所设置的 READ_COMMITTED 级别,覆盖了 MySQL 实例的默认 REPEATABLE READ 设置 。
在生产环境中,建议在 Spring 代码中显式地指定所需的隔离级别 ,而不是依赖 DEFAULT。这能使代码的意图更清晰,避免因数据库默认配置的不同(例如,从 MySQL 迁移到 PostgreSQL)而引入难以察觉的行为变化 。
传播行为
Spring 事务传播行为定义了当多个事务方法相互调用时,事务应该如何传播和交互。这解决了业务方法相互调用时,是应该共用同一个事务,还是开启新事务,或者干脆不用事务等核心问题。
支持当前事务的情况:
1. REQUIRED(必需)
这是 Spring 默认的传播行为,适用于绝大多数场景。
-
工作方式 :如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新事务。
-
场景示例 :一个下单方法
placeOrder()调用了扣减库存deductStock()和创建订单createOrder()等方法。这些方法通常应该在同一事务中,要么全部成功,要么全部失败。将它们都设置为REQUIRED可以保证这一点。 -
核心价值:保证多个关联操作的事务统一性。
2. SUPPORTS(支持)
行为较为随和,对事务的存在与否没有强制要求。
-
工作方式 :如果当前存在事务,则加入;如果当前没有事务,则以非事务方式执行。
-
场景示例 :一个查询方法
getUserInfo()。如果它在某个更新事务中被调用(例如先查询后更新),则加入事务以保证数据一致性;如果被单独调用,则无需开启事务,提升性能。 -
核心价值:灵活适应调用方的事务状态,特别适用于查询操作。
3. MANDATORY(强制)
要求必须在已有事务中运行,否则会抛出异常。
-
工作方式 :强制要求当前必须存在事务,否则抛出 IllegalTransactionStateException异常。
-
场景示例 :一个资金结算方法
settleAccount()。此操作至关重要,绝不能在没有事务保护的情况下执行。使用MANDATORY可以确保它只能被其他事务方法调用,避免误用。 -
核心价值:用于强制保证某些关键操作的事务安全性。
不支持当前事务的情况:
4. REQUIRES_NEW(新建)
会启动一个全新的、独立的事务,并挂起当前事务(如果存在)。
-
工作方式 :无论当前是否存在事务,都会创建一个新事务。如果当前有事务,则将其挂起。
-
场景示例 :日志记录。即使在核心业务事务(如下单)中需要记录操作日志,也希望日志记录能成功保存,即使后续业务失败回滚。将日志方法设置为
REQUIRES_NEW,可使日志事务独立提交,不受主事务影响。 -
核心价值:实现事务的完全独立,避免内外事务相互干扰。
5. NOT_SUPPORTED(不支持)
明确不在事务中执行,并挂起当前事务。
-
工作方式 :以非事务方式执行。如果当前存在事务,则将其挂起,待方法执行完毕后再恢复。
-
场景示例:执行一些与核心业务数据一致性无关,但可能比较耗时的操作,例如发送短信/邮件通知。这样可以避免长时间占用数据库连接,影响主事务性能。
-
核心价值:让特定操作脱离事务环境,提高效率或避免不必要的资源锁定。
6. NEVER(从不)
强制要求不能在事务中执行。
-
工作方式 :强制要求当前必须没有事务,否则抛出异常。
-
场景示例:一些数据校验方法。你可能希望这些校验是纯粹的内存操作,快速且不涉及数据库事务,以确保校验逻辑的绝对清晰。
-
核心价值 :强制保证方法在非事务环境下运行,是
MANDATORY的反向操作。
7. NESTED(嵌套)
这是一个特殊且强大的传播行为,它在一个已存在的事务中创建一个"嵌套事务"。
-
工作方式 :如果当前存在事务,则在嵌套事务内执行(基于数据库的保存点,Savepoint 机制)。如果当前没有事务,则其行为同 REQUIRED。
-
场景示例:处理一个包含多个子项的订单。你可以在主事务中保存订单主信息,然后在一个嵌套事务中处理每个子项。如果某个子项处理失败,你可以回滚到保存点,只撤销该子项的操作,而不影响已保存的订单主信息和之前成功的子项,然后可以选择重试或跳过该子项,继续处理后续子项。
-
核心价值 :允许部分回滚,提供了更精细的事务控制粒度。需要注意的是,此行为依赖于底层数据库对保存点的支持。
事务失效
1. 内部调用(自调用问题)
这是最常见的失效原因。在同一个类中,一个无事务的方法调用另一个有 @Transactional 注解的方法。
-
失效原因 :Spring 事务是基于 AOP 代理 的。当你通过 this.method() 调用时,走的是目标对象原生的方法,绕过了代理对象,事务增强逻辑根本没机会执行。
-
解决方案:
-
将方法拆分到不同的 Service 类中。
-
通过
AopContext.currentProxy()获取当前代理对象调用。 -
注入自己(自我注入,注意循环依赖)。
-
2. 访问权限问题(非 public 方法)
如果你把 @Transactional 注解写在 private、protected 或 default 作用域的方法上,事务会失效。
-
失效原因 :Spring 的 TransactionInterceptor 在拦截方法前会检查方法的修饰符。出于设计考虑,它只处理 public 方法。此外,如果使用 JDK 动态代理,它只能代理接口定义的方法。
-
解决方案 :确保注解方法是
public的。
3. 异常被"吃掉"了(Try-Catch 处理不当)
在 Service 层手动 try-catch 了异常,且没有在 catch 块中手动抛出。
-
失效原因 :Spring 事务感知的信号是 异常 。如果异常在方法内部被捕获且消化了,代理对象认为方法执行成功,依然会提交事务。
-
解决方案:
-
在
catch块中重新抛出RuntimeException。 -
手动调用
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly()。
-
4. 异常类型匹配错误
Spring 默认只在捕获到 RuntimeException 或 Error 时回滚。
-
失效原因 :如果你抛出的是 Checked Exception (受检异常,如
IOException、SQLException),事务默认不会回滚。 -
解决方案 :显式指定回滚类型:
@Transactional(rollbackFor = Exception.class)。
5. 数据库引擎不支持事务
这是一个基础设施层面的问题。
-
失效原因 :如果你的 MySQL 表使用了 MyISAM 存储引擎,它是没有事务日志的,Spring 无论怎么发
rollback命令,数据库都不会有反应。 -
解决方案 :将表引擎修改为 InnoDB。
6. Bean 没有被 Spring 管理
如果你通过 new 关键字手动创建了 Service 实例,而不是从 Spring 容器中获取。
-
失效原因 :Spring 只能拦截容器内的 Bean。手动
new的对象不具备代理特性,事务自然失效。 -
解决方案 :使用
@Autowired或@Resource注入 Bean。
7. 多线程调用
在事务方法内部开启新线程执行异步任务。
-
失效原因 :Spring 的事务信息(连接、状态等)是存储在 ThreadLocal 中的。新开启的线程无法获取主线程的事务上下文,它们不在同一个连接里。
-
解决方案:异步任务通常需要独立的事务控制,或者通过消息队列解耦。
8. 错误的传播行为(Propagation)
配置了不支持事务的传播属性。
-
失效原因 :如果设置了
Propagation.NOT_SUPPORTED(挂起当前事务,以非事务运行)或Propagation.NEVER(如果存在事务则抛异常),则不会有事务保障。 -
解决方案 :根据业务选择正确的传播行为(通常默认
REQUIRED即可)。
| 失效类型 | 检查点 | 核心原理 |
|---|---|---|
| 代理失效 | 是否是 this.xxx() 调用?是否是 private? |
AOP 代理增强失效 |
| 异常失效 | 是否 try-catch 没抛出?异常类型是否对? |
信号捕获失败 |
| 环境失效 | 数据库引擎是否是 InnoDB?Bean 是否受管? | 基础设施不支持 |
| 范围失效 | 是否在多线程中使用事务? | ThreadLocal 变量隔离 |
Spring Boot
为什么要使用Spring Boot?
1. 告别配置地狱:起步依赖 (Starter POMs)
在没有 Spring Boot 之前,如果你想搭建一个 Web 项目,你需要手动管理几十个 Jar 包的版本冲突。
-
痛点 :版本不一致导致的
NoSuchMethodError是家常便饭。 -
Spring Boot 的解法 :它引入了 Starter 概念。你只需要引入 spring-boot-starter-web,它就会自动帮你把 Spring MVC、Jackson、Tomcat 等所有必要的依赖打包进来,并保证它们的版本是兼容的 。
2. 约定优于配置 (Convention over Configuration)
这是 Spring Boot 的灵魂。
-
传统 Spring :你需要手动配置
DispatcherServlet、视图解析器、事务管理器、组件扫描路径......即使每个项目的配置都大同小异。 -
Spring Boot 的解法 :它通过 自动配置 (Auto-configuration) 机制,在项目启动时扫描 Classpath。如果你引入了 MySQL 驱动,它就自动帮你配好
DataSource;如果你引入了 Redis,它就自动配好RedisTemplate。 -
关键点 :它提供的是默认配置。如果你有特殊需求,随时可以覆盖。
3. 内嵌服务器:让部署变得简单 (Embedded Server)
-
传统方式:你需要安装 Tomcat,打包成 WAR 包,拷贝到 Tomcat 的 webapps 目录下。
-
Spring Boot 方式 :它直接将 Tomcat(或 Jetty、Undertow)内嵌 在 Jar 包里。
-
优势 :你的应用就是一个独立的、可执行的 Jar 包。通过
java -jar app.jar即可启动,这为 Docker 容器化 和 微服务云原生部署 扫清了最后的障碍。
4. 生产级特性:监控与管理 (Actuator)
Spring Boot 不仅仅关注开发过程,还关注运维阶段。
-
Actuator 组件 :只需一行配置,就能暴露
/health(健康检查)、/metrics(性能指标)、/env(环境变量)等端点。 -
价值:这让 Spring Boot 应用能完美对接 Prometheus、Grafana 等现代监控系统,实现了真正的"生产就绪"。
约定优于配置
"约定优于配置"(Convention over Configuration,简称 CoC )的出现,本质上是为了减少开发人员需要做出的决定数量,从而在不失灵活性的前提下,极大地提高开发效率。
在 Java EE 早期(如 EJB 时代)或 Spring 3.x 以前,配置信息的膨胀让项目变得极其臃肿:
-
配置地狱:配置文件比业务代码还长。
-
重复劳动:每个项目都要配数据库连接、配视图解析器、配组件扫描,而这些配置在 90% 的场景下是一模一样的。
-
学习曲线陡峭:新手不得不先掌握复杂的配置逻辑,才能写出第一个 "Hello World"。
核心定义:什么是"约定"?
简单来说:"如果你没有指定配置,那么我们就按照默认的套路来;如果你指定了,就以你的为准。"
-
传统开发模式:每一步都需要显式告诉框架该怎么做(Explicit Configuration)。
-
约定优于配置:框架预设了一套"标准答案"。如果你的需求符合标准,你一句话都不用说,框架自动帮你接好线。
Spring Boot 是如何落地这一思想的?
Spring Boot 是 CoC 思想的集大成者,主要体现在以下三个层面:
A. 标准的项目结构 (Maven/Gradle)
Spring Boot 约定了源代码必须放在 src/main/java,资源文件必须放在 src/main/resources。只要你遵守这个约定,构建工具就能自动找到编译路径,无需手动配置。
B. 自动配置 (Auto-Configuration) ------ 最核心的实现
Spring Boot 会根据你 Classpath 下引入的 Jar 包,自动推断你的意图。
-
例子 :你在
pom.xml里引入了spring-boot-starter-data-jpa。 -
约定 :Spring Boot 认为你肯定要连数据库。它会自动检测路径下有没有 MySQL 驱动,如果有,它就自动为你配置一个
DataSource、EntityManager和事务管理器。你只需要在application.properties里填上地址就行。
C. 条件装配机制 (@Conditional)
底层原理是大量的 @ConditionalOnClass 和 @ConditionalOnMissingBean 注解。
- 逻辑 :只有当你没有手动定义某个 Bean 时,Spring Boot 的默认 Bean 才会生效。这完美契合了"约定为主,自定义覆盖"的逻辑。
自动装配
在 Spring Boot 中,自动装配(Auto-Configuration) 是实现"约定优于配置"的核心技术。它能根据类路径(Classpath)下的 Jar 包、定义的 Bean 以及各种属性设置,自动推断并配置 Spring 容器所需的 Bean。
1. @SpringBootApplication为应用启动类上的一个复合注解,它主要由三个关键注解组成:
-
@SpringBootConfiguration:本质就是@Configuration,标志这是一个配置类。 -
@ComponentScan:启用组件扫描,默认扫描当前包及其子包。 -
@EnableAutoConfiguration :这是自动装配的真正开启者。
@EnableAutoConfiguration利用了 Spring 的 @Import 机制,导入了 AutoConfigurationImportSelector 类。这个类的职责是:在容器启动时,决定哪些配置类应该被加载到容器中。
- Spring Boot 会扫描类路径下的特定文件来寻找候选配置类。
-
旧版本(2.7 以前) :读取 META-INF/spring.factories 文件 中以
EnableAutoConfiguration为 Key 的类。 -
新版本(2.7 及 3.x) :读取
META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports文件。
这些文件中列出了成百上千个配置类(如 DataSourceAutoConfiguration、RedisAutoConfiguration)。
- Spring 并不会加载文件里列出的所有类,而是通过 @Conditional 及其派生注解进行筛选:
-
@ConditionalOnClass:类路径下存在某个类时(比如存在Druid.class),才加载该配置。 -
@ConditionalOnMissingBean:容器中没有用户自定义的同名 Bean 时,才加载默认 Bean(这是实现"自定义覆盖约定"的关键)。 -
@ConditionalOnProperty:配置文件中存在某个属性且值为特定值时,才开启配置。
启动流程
流程始于 SpringApplication.run(Application.class, args)这行代码。
第一阶段:初始化阶段
当你调用 new SpringApplication(...) 时,Spring 并没有立即启动:
-
判定 Web 应用类型 : Spring 通过检查 Classpath 下是否存在特定的类(如
DispatcherServlet或DispatcherHandler)判定是REACTIVE(WebFlux)、SERVLET(MVC)还是NONE(普通 Java 应用)。 -
加载初始化器 (
ApplicationContextInitializer) : 利用 SPI 机制 (从META-INF/spring.factories或spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports)读取所有的初始化器。 -
加载监听器 (
ApplicationListener): 同样通过 SPI 机制,加载所有感兴趣的事件监听器(如日志系统初始化监听器)。 -
推断主类 (Main Class) : 通过堆栈追踪(Stack Trace)找到那个包含
main方法的类
@SpringBootApplication启动类上的这个注解是一个复合注解,它是以下三个注解的集合体 :
- @Configuration:标记该类是一个配置类,其内部可以使用 @Bean注解定义 Bean。
- @ComponentScan:自动扫描当前包及其子包下的组件(如 @Component, @Service, @Controller),并将它们注册为 Bean。
- @EnableAutoConfiguration:这是 Spring Boot 自动配置的开关,是整个框架"约定优于配置"理念的核心 。
第二阶段:执行 run() 方法
1. 启动监听器与环境构建
-
启动计时器 (
StopWatch):记录启动耗时。 -
获取运行监听器 (
getRunListeners) :获取SpringApplicationRunListeners。它负责在启动的各个节点发布事件。 -
准备环境 (prepareEnvironment):
-
创建一个
ConfigurableEnvironment。 -
配置属性源 (configurePropertySources) :加载命令行参数、YAML、Properties、环境变量等。
-
发布环境就绪事件 :触发一系列监听器(如日志系统的初始化)。
-
2. 容器创建与预处理
-
创建上下文 (createApplicationContext) :根据推断的 Web 类型,使用策略模式 创建对应的容器。
- 例如:
AnnotationConfigServletWebServerApplicationContext。
- 例如:
-
容器预处理 (
prepareContext):-
关联环境 :将刚才准备好的
Environment塞进容器。 -
应用初始化器 (
applyInitializers) :依次调用构造阶段加载的ApplicationContextInitializer。 -
单例注入 :将
args参数和Banner注册为单例 Bean。 -
加载 Bean 定义 :最重要的动作------将启动类(
PrimarySource)加载到容器中,为后续的注解扫描(@ComponentScan)做准备。
-
第三阶段:刷新容器
这是最硬核的部分。refreshContext 底层调用的是 Spring 核心方法 AbstractApplicationContext.refresh()。
1. 激活工厂后置处理器 (invokeBeanFactoryPostProcessors)
这是 自动装配 (Auto-configuration) 发生的时刻。
-
ConfigurationClassPostProcessor :它会解析 @Configuration 注解,执行 @ComponentScan,并读取 spring.factories 中的自动配置类。
-
条件评估 :此时会触发 @ConditionalOnClass 等逻辑,决定哪些 Bean 应该进入候选名单。
2. 初始化内嵌 Web 容器 (onRefresh)
这是 Spring Boot 与传统 Spring 的最大区别。
-
在 Web 环境下,
onRefresh会触发createWebServer()。 -
根据配置(如
spring-boot-starter-tomcat),它会实例化 Tomcat 、Jetty 或 Undertow。
3. 完成单例 Bean 的实例化 (finishBeanFactoryInitialization)
-
Spring 会冻结 Bean 定义,开始根据依赖关系实例化所有的单例 Bean。
-
此时发生 DI(依赖注入) 、BeanPostProcessor 拦截、以及 AOP 代理 的生成。
4. 发布就绪与运行 Runners
-
发布完成事件:容器完全启动。
-
执行 Runner :遍历执行所有的 CommandLineRunner 和 ApplicationRunner。这通常用于执行系统的"预热"逻辑(如加载缓存、检查配置)。
如何自定义编写一个starter?
Starter(起步依赖) 是 Spring Boot 的核心"开箱即用"机制。它是一组预先打包好的 Maven 或 Gradle 依赖描述符,旨在简化开发者的依赖配置。
在没有 Starter 之前,如果你想开发一个 Web 项目,你可能需要手动在 pom.xml 中引入 Spring MVC、Tomcat、Jackson、Logback 等十几个依赖,还得小心翼翼地处理它们之间的版本冲突。
从技术实现上看,一个 Starter 主要包含两部分:
-
依赖清单(Dependency List) :它利用了 Maven 的传递依赖 特性。你只需引入一个
spring-boot-starter-web,它就会自动拉取 Web 开发所需的所有 Jar 包。 -
自动配置逻辑(Auto-configuration):这是 Starter 的灵魂。它包含了一组特殊的代码,当检测到类路径(Classpath)下存在特定的类时,会自动在 Spring 容器中创建并配置对应的 Bean。
starter 解决了什么问题?
-
版本管理地狱 :Spring Boot 通过
spring-boot-dependencies(BOM) 统一管理了所有 Starter 的版本。你不再需要为每个 Jar 包手动写<version>,从而避免了版本不兼容引发的NoSuchMethodError。 -
配置冗余 :它遵循"约定优于配置"。例如,只要你引入了
spring-boot-starter-jdbc,它就假设你需要数据库连接,并自动为你寻找数据源配置。 -
快速起步:开发者只需关注业务功能(如:我要做 Web、我要用 Redis、我要连 JPA),通过引入对应的"全家桶"即可秒级搭建环境。
常见的核心 Starter 举例
| Starter 名称 | 应用场景 | 包含的核心技术 |
|---|---|---|
| spring-boot-starter-web | 构建 Web 应用(含 RESTful) | Spring MVC, Tomcat, Jackson |
| spring-boot-starter-test | 单元测试与集成测试 | JUnit, AssertJ, Mockito |
| spring-boot-starter-data-jpa | 数据库持久化(JPA) | Hibernate, Spring Data JPA, JDBC |
| spring-boot-starter-aop | 面向切面编程 | Spring AOP, AspectJ |
| spring-boot-starter-actuator | 应用监控与管理 | 健康检查、度量指标、审计 |
当你引入一个 Starter 时,背后的执行逻辑如下:
-
引入依赖:Maven 将 Starter 及其下挂的所有 Jar 包下载到类路径下。
-
触发扫描 :Spring Boot 启动时,扫描
META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports文件。 -
条件装配 :配置类通过
@ConditionalOnClass等注解检查类路径。如果发现了 Starter 带来的特定类(如RedisTemplate.class),则激活该配置。 -
注入 Bean :将配置好的 Bean 注入 IoC 容器,供你直接
@Autowired使用
1. 项目命名与依赖配置
首先,创建一个 Maven 项目。根据官方约定,自定义 Starter 的命名格式建议为 {name}-spring-boot-starter。
核心依赖: 你需要引入 spring-boot-autoconfigure,这是实现自动配置逻辑的基础。
XML
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-autoconfigure</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
</dependencies>2. 编写业务功能类 (The Feature)
这是你想要"启动"的核心功能。比如我们写一个简单的 WeatherService,根据配置返回天气信息。
java
public class WeatherService {
private String unit; // 摄氏度或华氏度
public WeatherService(String unit) {
this.unit = unit;
}
public String getSchema() {
return "Current unit is: " + unit;
}
}3. 定义配置属性类 (Properties)
利用 @ConfigurationProperties 将 application.yml 中的配置映射到 Java 对象中。这体现了"外部化配置"的思想(将散落在配置文件中的设置,集中、类型安全地映射到一个 Java 对象中,方便在程序里使用。)。
java
// 请自动将配置文件中所有以 weather为前缀的属性,找出来并绑定到这个类的字段上
@ConfigurationProperties(prefix = "weather")
public class WeatherProperties {
private String unit = "Celsius"; // 默认值
public String getUnit() { return unit; }
public void setUnit(String unit) { this.unit = unit; }
}-
使用
application.properties文件时:XML# 设置温度单位为华氏度 weather.unit=Fahrenheit -
使用
application.yml文件时(更常用,层次更清晰):XMLweather: unit: Fahrenheit
4. 编写自动配置类 (Auto-Configuration)
这个类决定了你的 Bean 在什么情况下会被创建 。这里需要大量使用 @Conditional 系列注解来实现"条件装配"。
java
@Configuration
@EnableConfigurationProperties(WeatherProperties.class) // 启用属性绑定
@ConditionalOnClass(WeatherService.class) // 当类路径下存在这个类时才触发
public class WeatherAutoConfiguration {
@Bean
@ConditionalOnMissingBean // 只有当用户没有自定义 WeatherService 时,才创建默认的
@ConditionalOnProperty(prefix = "weather", name = "enabled", havingValue = "true") // 只有配置了 enabled=true 才开启
public WeatherService weatherService(WeatherProperties properties) {
return new WeatherService(properties.getUnit());
}
}5. 注册自动配置 (SPI 发现)
Spring Boot 不会自动扫描你 Jar 包里的 @Configuration。你必须通过 SPI (Service Provider Interface) 机制明确告诉它。
-
路径 :在
src/main/resources/下创建目录META-INF/spring/。 -
文件名 :创建文件
org.springframework.boot.autoconfigure.AutoConfiguration.imports。 -
内容:填入自动配置类的全限定名。
常用注释
1. 核心启动与配置类
这类注解定义了 Spring Boot 应用的入口和基础行为。
-
@SpringBootApplication: 这是最核心的复合注解。它包含了:-
@SpringBootConfiguration:标识为配置类。 -
@EnableAutoConfiguration:开启自动装配魔法。 -
@ComponentScan:默认扫描当前包及其子包下的 Bean。
-
-
@Configuration:标识一个类为配置类,内部通常包含@Bean方法。 -
@Bean:手动声明一个 Bean 实例,交给 IoC 容器管理。
2. 条件装配类
这些注解是实现"按需加载"的关键,通常出现在自动配置类(Auto-configuration)或自定义 Starter 中。
| 注解 | 触发条件 |
|---|---|
@ConditionalOnClass |
当类路径(Classpath)下存在指定的类时生效。 |
@ConditionalOnMissingBean |
当容器中没有指定类型的 Bean 时生效(常用于提供默认实现)。 |
@ConditionalOnProperty |
当配置文件(yml/properties)中存在特定属性且符合值时生效。 |
@ConditionalOnBean |
当容器中存在指定的 Bean 时生效。 |
@ConditionalOnExpression |
基于 SpEL 表达式的逻辑判断。 |
3. 配置属性绑定类
Spring Boot 强调"外部化配置 ",以下注解负责将配置文件与 Java 对象解耦。
-
@ConfigurationProperties: 最推荐。将配置文件中指定前缀(prefix)的属性批量绑定到一个 POJO 类上。支持松散绑定(Relaxed Binding)和嵌套属性。 -
@EnableConfigurationProperties: 在配置类上开启对指定@ConfigurationProperties类的支持。 -
@Value: 用于注入单个属性值。不支持松散绑定,通常用于注入简单的配置项或环境变量。
4. Web 与集成开发常用类
虽然部分注解属于 Spring MVC,但在 Spring Boot 项目中几乎是必用的。
-
@RestController:@Controller+@ResponseBody的结合体,返回 JSON 数据。 -
@RequestMapping家族:@GetMapping、@PostMapping、@PutMapping、@DeleteMapping。
-
@RestControllerAdvice:全局异常处理和数据增强。 -
@RequestBody:接收并解析 HTTP 请求体中的 JSON 数据。 -
@PathVariable:获取 RESTful URL 中的路径参数。
将yml中的配置项注入到类中
在Spring Boot中,将YAML配置文件中的设置应用到代码里主要有三种核心方法。
| 方法 | 核心注解 | 适用场景 | 关键特点 |
|---|---|---|---|
| 类型安全的批量绑定 | @ConfigurationProperties |
注入一组具有层级结构的配置(如数据库、第三方服务配置) | 支持复杂数据类型(List, Map, 嵌套对象)、类型安全、松散绑定、校验 |
| 单个配置项注入 | @Value |
注入少量独立的配置项 | 简单灵活,支持SpEL表达式和默认值,但不易管理大量相关配置 |
| 编程式动态获取 | Environment接口 |
需要在运行时根据条件动态读取配置 | 编程方式灵活,可在非Bean组件中使用,但需手动处理类型转换 |
@ConfigurationProperties
这是Spring Boot推荐的方式,尤其适合将一组相关的配置(如整个数据库连接信息)一次性映射到一个JavaBean中,从而实现类型安全的配置管理 。
1. 创建配置类
首先,你需要创建一个普通的Java类,并使用 @ConfigurationProperties 注解,通过其 prefix属性指定配置在YAML文件中的共同前缀 。
XML
# application.yml
app:
name: "MyApplication"
server:
host: "192.168.1.100"
port: 8080
services:
- "user-service"
- "order-service"
java
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
import java.util.List;
@Component // 将该类声明为Spring管理的组件(Bean)
@ConfigurationProperties(prefix = "app") // 绑定所有以'app'开头的配置
public class AppConfig {
private String name;
private Server server; // 嵌套对象
private List<String> services; // 集合
// 静态内部类,对应YAML中的`server`嵌套结构
public static class Server {
private String host;
private int port;
// 必须提供getter和setter方法
public String getHost() { return host; }
public void setHost(String host) { this.host = host; }
public int getPort() { return port; }
public void setPort(int port) { this.port = port; }
}
// 必须为所有需要绑定的字段提供getter和setter方法
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public Server getServer() { return server; }
public void setServer(Server server) { this.server = server; }
public List<String> getServices() { return services; }
public void setServices(List<String> services) { this.services = services; }
}2. 启用配置绑定
为了让Spring识别并处理 @ConfigurationProperties注解,你需要通过以下两种方式之一启用它:
-
在配置类上添加
@Component等注解,让组件扫描能发现它(如上例所示)。 -
在一个
@Configuration类上使用@EnableConfigurationProperties(YourConfigClass.class)进行显式启用 。
3. 在业务类中注入使用
配置类本身已经是一个Spring Bean,你可以像注入其他服务一样在Controller或Service中使用它
其他配置注入方式
使用 @Value注解
适用于注入单个、零散的配置值 。
java
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
@Component
public class MyService {
// 直接注入单个值
@Value("${app.name}")
private String appName;
// 可以设置默认值,当`app.description`不存在时使用冒号后的值
@Value("${app.description:Default Description}")
private String appDescription;
}使用 Environment接口
提供了一种编程式的、更灵活的方式来获取属性,尤其适合在非Bean组件中或需要动态获取配置的场景 。
java
import org.springframework.core.env.Environment;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class MyComponent {
@Autowired
private Environment environment;
public void someMethod() {
// 通过getProperty方法获取配置
String appName = environment.getProperty("app.name");
Integer serverPort = environment.getProperty("app.server.port", Integer.class); // 指定类型
String someValue = environment.getProperty("some.key", "Default Value"); // 带默认值
}
}定时任务
在 Spring Boot 中编写定时任务非常方便,它提供了一套清晰的注解和配置方式。
1. 启用定时任务支持
在主启动类上添加 @EnableScheduling注解,这是告诉 Spring Boot 开启定时任务功能的开关。
java
@SpringBootApplication
@EnableScheduling // 核心注解,启用定时任务功能
public class MyApplication {
public static void main(String[] args) {
SpringApplication.run(MyApplication.class, args);
}
}2. 创建定时任务类并编写方法
在一个被 Spring 管理的 Bean(例如添加了 @Component注解的类)中,编写你的任务方法,并在方法上使用 @Scheduled注解来定义执行规则。
java
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
@Component // 将类声明为Spring管理的组件
public class MyScheduledTasks {
// 此方法每5秒执行一次
@Scheduled(fixedRate = 5000)
public void taskWithFixedRate() {
System.out.println("固定频率任务执行,当前时间:" + System.currentTimeMillis());
// 在这里写入你的业务逻辑,比如清理临时文件、发送心跳包等
}
}@Scheduled注解提供了多种参数来满足不同的调度需求:
| 调度策略 | 关键字 / 示例 | 核心特点与适用场景 |
|---|---|---|
| 固定频率 | @Scheduled(fixedRate = 5000) |
从上一次开始 时间计算,每隔5秒执行一次。适合执行时间短且稳定的任务。 |
| 固定延迟 | @Scheduled(fixedDelay = 5000) |
从上一次结束 时间计算,延迟5秒后再执行下一次。适合执行时间不确定的任务,避免重叠。 |
| Cron表达式 | @Scheduled(cron = "0 0 12 * * ?") |
功能最强大,可实现复杂时间规则(如每天中午12点执行)。适合需要精确日历控制的任务。 |
| 初始延迟 | @Scheduled(initialDelay = 10000, fixedRate = 5000) |
常与上述策略结合,让应用启动后先延迟10秒 ,再开始按固定频率执行。适合避免应用启动时资源竞争。 |
Cron 表达式
Cron 表达式由6-7个字段组成,格式为:秒 分 时 日 月 周 年(可选)。
- *表示任意值。
- ?用于不关心的字段(通常用于日和周的冲突避免)。
- -表示范围,如 10-20。
- /表示间隔,如 0/5表示从0秒开始,每5秒。
常用示例:
-
0 0/5 * * * ?:每5分钟执行一次。 -
0 0 9-18 * * MON-FRI:工作日早9点到晚6点整点执行。 -
0 0 10 L * ?:每月最后一天上午10点执行。
SpringBoot如何自定义线程池并且应用到实际的场景
配置自定义线程池
创建配置类是定义线程池的第一步,以下是两种主流方式:
1. 基础配置方式
直接使用 @Bean注解创建 ThreadPoolTaskExecutor实例,这是最常用的方法 。
java
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.ThreadPoolExecutor;
@Configuration
@EnableAsync // 关键注解:启用异步支持
public class ThreadPoolConfig {
@Bean(name = "customTaskExecutor")
public ThreadPoolTaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// 核心线程数,默认为1
executor.setCorePoolSize(10);
// 最大线程数,默认为Integer.MAX_VALUE
executor.setMaxPoolSize(20);
// 队列容量,默认为Integer.MAX_VALUE
executor.setQueueCapacity(100);
// 非核心线程空闲存活时间(秒)
executor.setKeepAliveSeconds(60);
// 线程名称前缀,便于日志追踪
executor.setThreadNamePrefix("CustomExecutor-");
// 拒绝策略:当池和队列都满时,由调用者线程直接执行任务
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
// 等待所有任务结束后再关闭线程池
executor.setWaitForTasksToCompleteOnShutdown(true);
// 关闭前的等待时间(秒)
executor.setAwaitTerminationSeconds(60);
// 初始化
executor.initialize();
return executor;
}
}2. 基于配置文件的动态配置
通过 application.yml管理参数,提升灵活性
XML
# application.yml
task:
pool:
corePoolSize: 10
maxPoolSize: 20
keepAliveSeconds: 60
queueCapacity: 100
java
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
@Data
@Component
@ConfigurationProperties(prefix = "task.pool") // 绑定配置
public class TaskThreadPoolConfig {
private int corePoolSize;
private int maxPoolSize;
private int keepAliveSeconds;
private int queueCapacity;
}
@Configuration
@EnableAsync
public class AsyncConfig {
@Autowired
private TaskThreadPoolConfig config;
@Bean(name = "customTaskExecutor")
public ThreadPoolTaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// 使用配置文件中的值
executor.setCorePoolSize(config.getCorePoolSize());
executor.setMaxPoolSize(config.getMaxPoolSize());
executor.setKeepAliveSeconds(config.getKeepAliveSeconds());
executor.setQueueCapacity(config.getQueueCapacity());
executor.setThreadNamePrefix("CustomExecutor-");
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
executor.initialize();
return executor;
}
}线程池的应用
配置好线程池后,可以通过以下方式在业务代码中使用。
1. 结合 @Async注解实现异步执行
在方法上添加 @Async并指定线程池名称,该方法便会异步执行 。
java
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Service;
@Service
public class OrderService {
// 指定使用自定义的线程池
@Async("customTaskExecutor")
public void processOrder(Order order) {
// 模拟耗时操作,如订单处理、日志记录等
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
System.out.println("订单处理完成,线程: " + Thread.currentThread().getName());
}
}@Async
在 Spring 框架中,@Async注解是一个强大的工具,它能让你轻松地将方法调用变为异步执行,从而提升应用的响应速度和并发处理能力。
@Async的核心价值在于实现 "异步调用 "。这意味着,当你调用一个标记了 @Async的方法时,该方法不会在调用者的线程中立即执行,而是由 Spring 将其提交到一个独立的线程池中运行。调用者的线程在发起调用后立即返回,不会被这个耗时任务阻塞。
工作原理:AOP 与动态代理
@Async的功能并非由注解本身实现,而是依赖于 Spring 强大的 AOP 和动态代理机制。
-
启用与扫描 :当你在配置类或启动类上添加
@EnableAsync注解后,Spring 会开启异步功能支持。 -
代理创建 :Spring 容器在初始化 Bean 时,如果发现某个 Bean 的类或方法上标有 @Async,就会通过一个后置处理器为其创建一个代理对象。这个代理对象包装了原始的 Bean。
-
调用拦截 :当你的代码(例如 Controller)通过 Spring 容器注入并调用这个 Bean 的方法时,实际上调用的是代理对象 的方法。
-
异步执行 :代理对象的方法被调用时,会被一个特殊的拦截器(如 AsyncExecutionInterceptor )捕获。该拦截器不会直接执行你的业务方法,而是从注解中解析出需要使用的线程池,然后将你的业务方法封装为一个 Callable任务,提交给线程池去执行 。提交完成后,拦截器立即返回,从而使调用者线程得以继续。
常见"坑"与最佳实践
-
自调用失效 :在同一个类中,一个方法A直接调用另一个被
@Async标记的方法B,异步是无效的 。因为自调用绕过了 Spring 的代理对象,直接调用了原始方法。解决方案是将异步方法抽取到另一个 Service 中。 -
方法必须为
public:@Async注解只能应用于public方法上,对private,protected方法无效。 -
异常处理 :异步方法内部的异常默认不会 传播到调用者。如果方法返回
Future,异常会在调用future.get()时抛出。对于返回void的方法,需要实现AsyncUncaughtExceptionHandler接口来全局处理未捕获的异常。 -
避免循环依赖 :如果两个 Service 相互注入,并且都包含
@Async方法,可能在启动时因代理创建顺序问题导致循环依赖。建议使用构造函数注入来避免。
2. 编程式使用 CompletableFuture
对于需要处理返回结果或组合多个异步任务的场景,CompletableFuture更合适 。
java
@Service
public class DataProcessService {
@Autowired
private ThreadPoolTaskExecutor customTaskExecutor; // 直接注入线程池
public CompletableFuture<String> processDataAsync(String data) {
// 使用 supplyAsync 并指定线程池
return CompletableFuture.supplyAsync(() -> {
// 模拟数据处理
return "处理后的数据: " + data.toUpperCase();
}, customTaskExecutor);
}
}
// 在调用处,可以等待所有任务完成
@GetMapping("/process-batch")
public String processBatch() {
List<String> dataList = Arrays.asList("data1", "data2", "data3");
CompletableFuture<?>[] futures = dataList.stream()
.map(dataProcessService::processDataAsync)
.toArray(CompletableFuture[]::new);
// 等待所有任务完成
CompletableFuture.allOf(futures).join();
return "批量处理完成";
}异常处理
整个异常处理流程的起点在 Spring MVC 的核心------DispatcherServlet 。当 Controller中的方法抛出异常时,会被 DispatcherServlet的 doDispatch方法捕获 。随后,它进入异常解决流程,核心目标是找到一个能够处理该异常的组件 。
-
局部优先:
@ExceptionHandler首先,Spring 会查找抛出异常的那个 Controller内部是否定义了用 @ExceptionHandler注解的方法 。如果找到了匹配的异常类型,就由这个局部处理器方法直接处理并生成响应 。这是最精确、优先级最高的处理方式 。
-
@ExceptionHandler注解的源码非常简单,其主要作用是指定该方法可以处理的异常类型(Class<? extends Throwable>\[\] value())。这些异常类型就是后续匹配的关键。
-
ExceptionHandlerMethodResolver :这个类是幕后功臣。它在应用启动时(例如,当某个Controller类被加载时),会扫描该类中所有被
@ExceptionHandler标记的方法。它会解析出每个方法能处理的异常类型 ,并建立一个内部的 映射表(Map) ,其键(Key)是异常类型,值(Value)是对应的 Method对象。这个映射关系是后续快速匹配的基础。 -
当异常发生时,Spring并不是简单地按顺序尝试所有方法。它会使用一个叫做 ExceptionDepthComparator的比较器 ,从所有可能匹配的异常类型中(包括异常本身及其所有父类),找出与抛出异常继承关系最直接、最具体 的那个类型。这就保证了
NullPointerException会优先由处理NullPointerException的方法处理,而不是由处理其父类RuntimeException的方法处理。
-
-
全局兜底:
@ControllerAdvice如果
Controller内部没有合适的处理器,Spring 会转而查找由 @ControllerAdvice注解的全局异常处理类 。这些类中定义的@ExceptionHandler方法能够处理所有Controller抛出的指定异常,实现了异常的集中管理 。其背后的核心技术是ExceptionHandlerExceptionResolver,它负责在应用启动时扫描和缓存这些处理方法,并在异常发生时执行精确的匹配逻辑 。-
Spring在容器启动时,会通过
ControllerAdviceBean类扫描所有被@ControllerAdvice注解的类 ,并将它们收集起来。随后,ExceptionHandlerExceptionResolver会为每一个这样的类创建一个ExceptionHandlerMethodResolver实例,用于解析其内部的@ExceptionHandler方法,并将这些解析器缓存起来,形成全局的异常处理能力。 -
@ControllerAdvice的强大之处在于它可以通过注解属性(如 basePackages, assignableTypes, annotations)来限制其生效的Controller范围。例如,@ControllerAdvice(basePackages = "com.example.api")只会处理指定包下Controller的异常。这是通过一个 HandlerTypePredicate组件在匹配阶段进行判断的。
-
当存在多个
@ControllerAdvice类时,可以通过 @Order注解或实现 Ordered接口来定义它们的优先级。数值越小,优先级越高。这在处理模块化应用的异常时非常有用。 -
推荐使用
@RestControllerAdvice:对于现代RESTful应用,直接使用@RestControllerAdvice代替@ControllerAdvice更为方便,因为它本身组合了@ControllerAdvice和@ResponseBody注解,可以确保你的@ExceptionHandler方法返回值直接序列化为JSON/XML,而无需额外注解
-
Spring Boot 的默认兜底机制
当异常未被任何 @ExceptionHandler(无论是局部的还是全局的)捕获时,Spring Boot 的默认机制才会登场,这是它相较于 Spring MVC 提供的一大便利。
-
统一入口:
ErrorPageCustomizerSpring Boot 通过自动配置类
ErrorMvcAutoConfiguration注册了一个ErrorPageCustomizer。这个组件的作用是:当容器(如 Tomcat)监测到异常发生时,自动将请求转发到配置的/error路径 。这个路径默认为/error,但可以通过server.error.path配置项自定义 。 -
请求处理:
BasicErrorController请求被转发到
/error后,由BasicErrorController处理。它的一个精妙之处在于能自动适配客户端类型 :-
对于浏览器 ,它的
errorHtml()方法会被调用,返回一个 HTML 错误页面。 -
对于机器客户端 (如 Postman、移动应用),它的
error()方法会被调用,返回 JSON 格式的错误信息。
-
-
数据与视图解析
-
错误属性:
DefaultErrorAttributes无论返回 HTML 还是 JSON,
BasicErrorController都会使用DefaultErrorAttributes工具来从请求中获取详细的错误信息,如状态码、异常信息、请求路径等,并将其封装在一个Map中供视图或响应体使用 。 -
视图解析:
DefaultErrorViewResolver当需要返回 HTML 页面时,会使用
DefaultErrorViewResolver。它会按照一套清晰的优先级规则去解析自定义错误视图 :-
精确匹配:
templates/error/404.html -
模糊匹配:
templates/error/4xx.html -
静态资源:
static/error/404.html -
如果以上都未找到,最终会使用内置的 "Whitelabel" 错误页面。
-
-
Spring Cloud
微服务
单体架构(Monolith):最初的美好与必然的崩塌
每个伟大的系统几乎都始于单体。在项目初期,单体是完美的:开发快、部署简单、测试容易、性能损耗极低(全是内存调用,没有网络开销)。
单体的弊端:
随着业务膨胀,单体逐渐变成了"大泥球":
-
发布流水线拥堵:哪怕改一行代码,也要重新编译部署整个几百MB甚至数GB的 Jar 包。一个人的错误会让全公司的发布停摆。
-
扩展性差:如果系统里只有"图片处理"模块耗内存,你必须水平扩展整个单体应用,极度浪费资源。
-
技术债累积:想把旧的 Struts2 换成 Spring Boot?对不起,全局重构,没人敢动。
-
故障蔓延(Blast Radius):一个模块的内存泄漏或死循环,会拖垮整台服务器,导致全站崩溃。
微服务的本质是 "分而治之" 。它将单体拆分为多个独立自治的服务,每个服务运行在自己的进程中。但这带来了一个致命的问题:原本简单的内存调用,变成了不可靠的网络调用。 为了解决这些"网络带来的混乱",微服务组件才应运而生。每个组件的出现,都是为了填补分布式系统的一个坑。
Spring Cloud 并不是一个具体的、单一的框架,而是一个全家桶(Umbrella Project) 。它集合了一系列子项目,旨在为开发者提供一套快速构建分布式系统(即微服务)的工具集。在微服务架构中,你会遇到很多单体架构不曾有的麻烦(比如:服务怎么找、配置怎么改、挂了怎么办)。Spring Cloud 的出现,就是为了屏蔽分布式环境下的复杂性,提供一套标准化的解决方案。
Spring Boot 负责"从 0 到 1"创建一个应用,而 Spring Cloud 负责"从 1 到 N"协调这些应用如何像一个整体一样工作。
五大核心组件(架构视角)
一个完整的微服务系统,通常需要这五类功能的支撑。目前市面上最流行的是 Spring Cloud Alibaba 体系,下表展示了功能与对应组件的映射:
| 核心功能 | 解决什么问题? | 主流实现 (Alibaba/原生) | 早期实现 (Netflix/停更) |
|---|---|---|---|
| 服务发现与注册 | 自动记录和查找服务的 IP 和端口。 | Nacos / Consul | Eureka |
| 集中配置中心 | 统一管理所有服务的配置文件。 | Nacos / Spring Cloud Config | Config |
| 智能路由网关 | 系统的统一入口,负责鉴权、限流、转发。 | Spring Cloud Gateway | Zuul |
| 熔断与降级 | 防止某个服务挂掉导致全站雪崩。 | Sentinel / Resilience4j | Hystrix |
| 负载均衡 | 将请求平均分配到多个服务实例上。 | LoadBalancer | Ribbon |
-
注册中心:服务 A 和 B 启动后,把自己的地址报给 Nacos。
-
配置中心:服务从 Nacos 实时读取自己的数据库连接等配置。
-
网关:用户的请求打到 Gateway,Gateway 问 Nacos :"服务 A 在哪?",然后转发过去。
-
容错处理:如果服务 B 响应慢,Sentinel 立即介入,防止请求堆积。
注册中心(Registry Center)
1. 核心作用:它解决了什么问题?
注册中心的核心职责是实现服务实例的自动化管理,具体解决了三个痛点:
-
解耦 IP 与服务名 :调用者(Consumer)不再需要记住成百上千个具体的 IP 地址,只需要记住服务逻辑名(如
order-service)。 -
动态扩缩容:当流量高峰期你新增了 10 台机器,注册中心会自动把这 10 台机器的 IP 告知调用者,无需人工修改配置。
-
健康检查(熔断的前提):如果某台机器宕机,注册中心通过心跳机制发现它"失联"了,会立即将其从通讯录中剔除,防止请求打到死节点上。
2. 运行机制:服务的一生
注册中心的工作流程可以概括为以下四个关键环节:
-
服务注册(Service Register) :服务提供者在启动时 ,将**自己的服务名、IP、端口、元数据(版本、权重等)**上报给注册中心。
-
服务续约(Service Renew / Heartbeat) :提供者每隔几秒(默认通常 30s)发一次"心跳"给注册中心,证明自己还活着。
-
服务发现(Service Discovery) :消费者在需要调用接口时,去注册中心拉取(Fetch)一份最新的提供者名单,并缓存在本地。
-
服务剔除(Service Evict) :如果注册中心长时间没收到某实例的心跳,就会认为它挂了,将其从注册表中抹除,并通知所有消费者更新缓存。
3. 底层原理:CAP 定理的权衡
注册中心作为分布式系统,必须在 CAP(一致性、可用性、分区容错性) 中做取舍。目前主流注册中心分为两大派系:
AP 架构(可用性优先)------ 代表:Eureka、Nacos(默认)
-
理念 :在分布式环境下,即便数据短时间不一致(比如某个 IP 已经挂了但还没被剔除),也比整个注册中心瘫痪强。
-
特点:每个节点都是平等的,即使只剩一个节点也能提供服务。适合服务规模大、对可用性要求极高的场景。
CP 架构(一致性优先)------ 代表:Zookeeper、Consul、Nacos(通过配置)
-
理念 :注册中心里的数据必须是绝对正确的。如果发生网络分区导致无法选出 Leader,整个注册中心宁可拒绝服务。
-
特点 :利用 Raft 或 ZAB 协议保证强一致性。适合对数据准确性要求极高的场景。
在服务发现领域,AP 通常优于 CP。因为即使拿到了一个稍微过时的 IP,也可以通过客户端负载均衡和重试机制解决;但如果注册中心挂了,整个微服务集群都会瞬间"失联"。
| 特性 | Eureka | Zookeeper | Nacos (推荐) | Consul |
|---|---|---|---|---|
| 开发者/背景 | Netflix | Apache | Alibaba | HashiCorp |
| CAP 模式 | AP | CP | AP/CP 可切换 | CP |
| 一致性协议 | HTTP 最终一致性 | ZAB | Raft / Distro | Raft |
| 健康检查 | TTL (心跳) | TCP 连接 (临时节点) | TCP/HTTP/MySQL | HTTP/TCP/gRPC |
| 功能丰富度 | 仅注册中心 | 通用分布式协调 | 注册中心 + 配置中心 | 注册中心 + 配置中心 |
| 现状 | 维护状态,不再更新 | 成熟稳定 | 国内主流,生态活跃 | 强大,支持 Service Mesh |
配置中心(Configuration Center)
实现配置的集中化管理、动态更新、环境隔离、版本控制与安全审计
1. 核心作用:为什么需要它?
在单体时代,配置通常写在 application.yml 里。但在微服务架构下,这种做法会引发以下问题:
-
配置散乱:几百个微服务,每个都有自己的配置文件,修改一个公共参数(如数据库连接池大小)需要手动改几百次。
-
无法热更新:传统的配置修改必须重启服务才能生效。在生产环境下,重启意味着业务中断或风险。
-
环境不隔离:开发、测试、生产环境的配置容易混淆,手动切换极易出错。
-
缺乏安全性与审计:谁在什么时候改了什么配置?能不能回滚?明文密码是否泄露?单体配置无法回答这些问题。
2. 核心机制:它是如何工作的?
配置中心的运作遵循"一处修改,到处生效 "的原则,通常采用 C/S(客户端/服务器)架构。
-
管理后台(Dashboard):运维或开发在 UI 界面修改配置并保存。
-
持久化存储:配置中心 Server 将变更存入数据库(如 MySQL)或版本库(如 Git)。
-
配置下发/拉取:Server 通知客户端(微服务)有更新,或者客户端定期询问 Server。
-
本地缓存与刷新 :客户端获取新配置后,更新本地缓存,并通过 Spring 的容器机制 (如
@RefreshScope)重新注入到 Bean 中。
3. 底层原理:推(Push)还是拉(Pull)?
这是配置中心设计的核心技术点。目前主流框架通常采用 "长轮询(Long Polling)" 机制,兼顾了实时性和系统压力。
-
长轮询机制(以 Nacos 为例):
-
客户端发起请求询问:"我的配置变了吗?"
-
Server 不会立即返回,而是把请求"挂起"一段时间(如 30s)。
-
如果在挂起期间配置变了 :Server 立即返回新内容。
-
如果到期了配置还没变 :Server 返回空,客户端立即再次发起请求。
-
优点:比简单的"拉"更实时,比纯粹的"推"更可靠(不会因为网络闪断导致丢失通知)。
-
-
动态刷新原理 : 在 Spring 生态中,当配置中心通知变更时,Spring 会发布一个
EnvironmentChangeEvent。标注了@RefreshScope的 Bean 会被销毁并重新创建,从而加载最新的配置值,实现无感更新。
| 特性 | Apollo (阿波罗) | Nacos (推荐) | Spring Cloud Config |
|---|---|---|---|
| 开发者/背景 | 携程 (Ctrip) | 阿里巴巴 | Spring 官方 |
| 配置持久化 | MySQL | MySQL / Raft | Git / SVN / 本地文件 |
| 热更新支持 | 极佳 (毫秒级) | 极佳 (长轮询) | 需配合 Bus (消息总线) |
| 权限/审核 | 非常严谨(多级审核) | 较简单 | 基本没有 UI,需自研 |
| 部署难度 | 较高(组件多) | 非常简单(一个包) | 中等 |
| 选型建议 | 大型企业级,对权限要求极严。 | 中小型及主流项目,简单好用。 | 极简主义,深度依赖 Git。 |
典型使用场景
-
数据库/中间件切换:在不停机的情况下,将流量从主库切换到从库,或修改 Redis 集群地址。
-
业务开关(Feature Toggle):通过一个布尔值动态开启或关闭某个新功能(如:大促期间关闭不重要的非核心业务逻辑)。
-
灰度发布控制:动态调整网关的权重配置,实现 10% 的用户访问新版本。
-
日志级别动态调整 :线上出 Bug 时,临时将日志级别从
INFO改为DEBUG,排查完再改回来,无需重启。
网关(API Gateway)
统一接入、安全防护、流量治理、业务解耦。
核心作用:为什么它不可或缺?
在没有网关的时代,客户端(手机、网页)需要直接和几十个微服务通信。这简直是灾难:
-
鉴权混乱:难道每个微服务都要写一遍登录校验逻辑吗?
-
跨域控制:每个服务都要配置一遍 CORS,维护成本极高。
-
安全风险:微服务的 IP 直接暴露在公网,等于裸奔。
-
客户端复杂:客户端需要维护大量的服务端地址,一旦服务拆分或合并,客户端就得跟着改代码。
三大核心概念
在 Spring Cloud Gateway 中,理解了这三个词,你就理解了它的工作逻辑:
-
路由(Route):网关的基本模块。它由 ID、目标 URI、一组谓词和一组过滤器组成。
-
谓词(Predicate) :"匹配规则" 。它是 Java 8 的
java.util.function.Predicate。简单说,就是判断当前的请求是否符合这个路由。比如:路径是不是以/order/开头? -
过滤器(Filter) :"加工环节"。在请求发送到下游服务之前(pre)或之后(post)对请求进行修改。比如:增加一个请求头,或者统计耗时。
为什么 Spring Cloud Gateway 淘汰了经典的 Zuul 1.x?
Zuul 1.x 的局限(Servlet 模式)
Zuul 1.x 基于 Servlet 2.5,采用的是阻塞式 I/O 。每一个请求都会占用一个线程,直到请求结束。在高并发场景下,线程池很快就会被耗尽,导致系统瘫痪。
Gateway 的底层(Reactive 模式)
Spring Cloud Gateway 是基于 Spring 5、Project Reactor 和 Netty 构建的。
-
非阻塞/事件驱动 :它运行在 Netty 之上,不需要为每个请求分配一个线程。一个少量的线程池就能处理数万个并发连接。
-
性能:在高并发、高长连接(如 WebSocket)场景下,性能远超 Zuul 1.x。
4. 核心工作流程
-
请求到达 :
DispatcherHandler接收请求。 -
查找路由 :
RoutePredicateHandlerMapping根据 Predicate 找到匹配的路由。 -
过滤链执行 :
FilteringWebHandler获取该路由的 Filter 链。 -
转发与响应:请求经过 Pre 过滤器 -> 转发到后端服务 -> 获取响应 -> 经过 Post 过滤器 -> 返回客户端。
| 特性 | Spring Cloud Gateway | Netflix Zuul 2.x | Nginx / OpenResty |
|---|---|---|---|
| 底层基础 | Netty / Project Reactor | Netty | C / Lua |
| 编程模型 | 响应式 (Reactive) | 响应式 (Reactive) | 事件驱动 |
| 动态路由 | 支持较好 | 支持 | 需要 Reload 或 Lua |
| 开发难度 | Java 开发者上手极快 | 较复杂 | 需要熟悉 Nginx/Lua |
| 适用场景 | Java 微服务生态首选 | Netflix 体系 | 高性能静态资源/边缘负载 |
典型使用场景
-
统一鉴权:在网关层校验 JWT 或 Session,合法的请求才下发到业务模块。
-
流量监控 & 限流:利用 Redis + Lua 脚本实现令牌桶或漏桶算法,保护下游服务不被压垮。
-
黑白名单:封禁恶意爬虫的 IP。
-
灰度发布:通过自定义 Predicate,将 10% 的流量引导至新版本的 Service B。
-
协议转换:外部是 HTTP 请求,网关内部转为 Dubbo 或 gRPC 调用。
熔断(Circuit Breaker)和降级(Fallback)
核心作用:为什么要当"保险丝"?
在微服务环境中,请求往往需要跨越多个服务(A -> B -> C)。如果服务 C 响应极慢或宕机,会导致服务 B 的线程大量积压,进而拖垮服务 A,最终引发全站崩溃,这就是所谓的**"雪崩效应(Cascading Failure)"**。
-
熔断的作用 :当检测到下游服务异常(超时、报错率高)时,及时切断调用鏈,直接返回错误,保护调用方不被拖死。
-
降级的作用 :当主逻辑走不通时(熔断、限流或报错),提供一个"备选方案"(如返回默认值、缓存数据或友好提示),保证业务流程不断掉,只是功能有所损耗。
核心机制:熔断器的"三态"转换
熔断器的设计灵感完全来自于物理电表箱。它有三种标准状态,通过状态机进行切换:
A. 关闭状态 (Closed)
-
逻辑:这是正常状态。请求可以自由通过。
-
动作:熔断器会统计请求的成功率和错误率。
-
切换 :当错误率达到设定的阈值(如最近 10 次请求有 50% 失败),熔断器会跳到"开启"状态。
B. 开启状态 (Open)
-
逻辑:这是保护状态。所有请求直接被拦截,不再去调下游服务。
-
动作 :直接执行 Fallback(降级逻辑)。
-
切换 :开启一段时间(冷却时间,如 5s)后,会自动切换到"半开"状态。
C. 半开状态 (Half-Open)
-
逻辑 :这是尝试状态。允许少量 请求通过,去测试下游服务是否恢复。
-
切换:
-
如果请求全部成功,说明下游好了,回到"关闭"状态。
-
如果请求依然失败 ,说明下游没好,滚回"开启"状态,继续冷静。
-
目前主流框架(如 Sentinel 或 Resilience4j)通常采用以下两种维度进行判定:
-
慢调用比例:如果请求响应时间超过 X 毫秒的比例达到阈值,触发熔断。这在解决"拖慢系统"的问题上非常有效。
-
异常比例/异常数:如果请求报错的比例(如 1 分钟内失败率 > 50%)达到阈值,触发熔断。
底层支撑:通常使用滑动时间窗口(Sliding Window)算法。它将时间切成小格,动态统计最近一段时间内的请求数据,保证统计的时效性和准确性。
| 特性 | Hystrix (已停更) | Sentinel (推荐) | Resilience4j |
|---|---|---|---|
| 背景 | Netflix | 阿里巴巴 | Spring 官方推荐 |
| 隔离策略 | 线程池隔离 / 信号量隔离 | 信号量隔离 (性能更高) | 信号量隔离 |
| 熔断判定 | 基于异常比例 | 异常比例/异常数/慢调用 | 基于异常比例/慢调用 |
| 控制台 | 较弱 (Hystrix Dashboard) | 非常强大 (实时监控/动态规则) | 无原生控制台 |
| 动态规则 | 不支持(需重启或复杂配置) | 支持 (配合 Nacos 实时下发) | 支持 |
典型使用场景
-
外部接口依赖:调用第三方支付、地图或物流接口。这些接口不可控,必须加熔断,防止对方宕机拖死我方系统。
-
核心与非核心业务剥离:在大促(如双 11)期间,手动或自动降级掉"评价"、"猜你喜欢"等非核心逻辑,把资源留给"下单"、"支付"。
-
缓存失效补偿:当从 Redis 读不到数据或 Redis 挂了时,降级逻辑可以去读一个备份的本地缓存或内存数据。
负载均衡(Load Balancing)
1. 核心作用:它解决了什么问题?
它是为了解决分布式系统的三大生存问题:
-
高可用性(High Availability):如果某个实例挂了,负载均衡器能瞬间感知并绕过它,保证业务不中断。
-
水平扩展(Scalability):当流量翻倍时,你只需多开几台机器,负载均衡器会自动把新流量分过去。
-
低延迟与高性能:通过将请求分摊,避免单个节点由于 CPU 或内存过载而导致的
2. 核心机制:服务器端 vs 客户端
这是理解 Spring Cloud 负载均衡的关键。负载均衡主要分为两大流派:
A. 服务器端负载均衡 (Server-side LB)
-
硬件代表:F5。
-
软件代表:Nginx、LVS、阿里云 SLB。
-
机制 :客户端只知道网关或负载均衡器的地址 。负载均衡器接收请求后,根据内部配置转发给后端的某台机器。
-
特点:客户端是"盲目"的,它不知道后面到底有多少台机器。
B. 客户端负载均衡 (Client-side LB)
-
代表组件 :Spring Cloud LoadBalancer (取代了已停更的 Netflix Ribbon)。
-
机制 :客户端(调用者)自己去注册中心(如 Nacos)拉取一份完整的服务清单,然后自己在本地根据算法选出一台机器进行调用。
-
特点:调用者"心中有数",减少了一次额外的网络跳转(不需要经过中间代理),性能更高,灵活性更强。
负载均衡器的大脑就是它的算法。常见的算法包括:
| 算法名称 | 逻辑描述 | 适用场景 |
|---|---|---|
| 轮询 (Round Robin) | 像发牌一样,按顺序给每个实例发一个请求。 | 实例硬件配置基本一致。 |
| 随机 (Random) | 随便抓一个。 | 简单场景,概率上基本平均。 |
| 加权 (Weight) | 给性能好的机器多发点,给老旧机器少发点。 | 异构服务器(新老机器混搭)。 |
| 最小连接数 (Least Connections) | 谁现在手里的活儿最少就给谁。 | 请求处理耗时差异较大的场景。 |
| 源地址哈希 (Source IP Hash) | 同一个 IP 的请求永远发到同一台机器。 | 需要实现 Session 保持 或本地缓存。 |
| 一致性哈希 (Consistent Hash) | 即使节点增减,也能最大限度保证请求分布的稳定性。 | 分布式缓存、有状态服务。 |
3. 底层原理:它是如何运作的?
在 Spring Cloud 环境下,负载均衡的运作通常包含以下三个关键步骤:
-
服务列表获取 :通过与注册中心通信,实时维护一份
ServiceList。 -
健康检查(Ping):持续监测列表中的实例是否还活着。
-
选择策略执行 :在发起
RestTemplate或Feign调用时,通过拦截器(Interceptor)拦截请求,修改 URL(将服务名替换为具体 IP),然后发送。
Spring Cloud LoadBalancer 是基于 Reactive 响应式编程构建的,相比于 Ribbon 的阻塞式逻辑,它更适配 Spring 5+ 的异步环境。
典型使用场景
-
网关接入层:Nginx 接收外部公网流量,分发给多个网关集群节点。
-
微服务间调用:Service A 通过 Feign 调用 Service B,在 A 内部执行负载均衡逻辑。
-
有状态连接:在 WebSocket 场景下,利用 IP Hash 确保长连接不中断。
-
灰度/蓝绿发布 :通过自定义负载均衡策略,将特定的用户流量(如 Header 里带
version=v2的)定向到新版本实例。
动态代理是如何将接口转化为 HTTP 请求的?
1. 启动阶段
当你开启**@EnableFeignClients** 时,Spring Boot 会启动扫描机制。
-
解析元数据 :
FeignClientRegistrar会找到所有标注了@FeignClient的接口,并解析其属性(服务名、URL、配置等)。 -
注册 BeanDefinition :Spring 并不会直接实例化这个接口,而是注册一个
FeignClientFactoryBean。 -
创建 JDK 动态代理 :当你真正
@Autowired这个接口时,FactoryBean会通过Feign.builder()构造出一个 JDK 动态代理对象 (即Proxy.newProxyInstance)。
2. InvocationHandler 的分发
当你调用接口方法(如 userClient.getUser(1))时,由于它是个代理对象,请求会被拦截并转发给 FeignInvocationHandler。
-
内部结构 :这个 Handler 内部持有一个
Map<Method, MethodHandler>。 -
路由寻址 :它会根据你调用的 Method,从 Map 中找到对应的 SynchronousMethodHandler 。每一个方法都有自己专属的处理器,里面记录了该方法的注解信息。
3. 转化过程:将方法"翻译"成模板
这是最关键的一步。SynchronousMethodHandler 会通过以下步骤完成转化:
-
RequestTemplate 生成 :利用 Contract(契约)解析器。它会读取方法上的 @GetMapping、@PathVariable、@RequestBody 等注解。
-
参数填充 :它将你传入的实参(如 id=1)填入 URL 模板中。
GET /users/{id}\\rightarrowGET /users/1
-
构造 Request 对象 :最终生成一个包含 URL、Method、Header、Body 的****Request 对象。
4. 运行时执行:从逻辑请求到物理请求
有了 Request 对象后,Feign 会进入最后的发射阶段:
-
负载均衡 (Load Balancer) :如果你的 URL 是服务名(如
http://user-service/),Feign 会拦截请求,询问LoadBalancer(如 Spring Cloud LoadBalancer),根据策略选出一个真实的物理 IP。 -
执行客户端 (Client):
-
默认是
HttpURLConnection(性能较差,不推荐)。 -
可以配置为 OkHttp 或 Apache HttpClient。
-
-
编解码 (Encoder/Decoder):
-
Encoder:将 Java 对象转为 JSON(通过 Jackson)。
-
Decoder:将 HTTP 响应的 JSON 转回 Java 对象。
-
当网络出现抖动时,Feign 是如何配合"重试机制 (Retryer)"和"超时配置"来保证请求的可靠性的?
网络抖动(Jitter)是微服务架构中的"幽灵",它不一定会让服务直接宕机,但会通过延迟波动和偶发性丢包,把系统的脆弱性放大。
1. 超时配置:划定容忍的底线
在进行网络调用时,Feign 主要受两个超时参数控制。如果这两个参数设置不当,网络抖动就会演变成大面积的线程积压。
-
ConnectTimeout(连接超时) :指从建立 TCP 连接到连接成功的最大等待时间。在网络抖动时,如果握手包丢失,这个设置能防止线程死等。
-
ReadTimeout(读取超时) :指连接建立后,从服务器读取到可用数据的最大等待时间。这是应对"慢接口"和"网络丢包"的关键。
默认情况下,Feign 的超时时间非常慷慨(甚至可能是无穷大,取决于底层 HttpClient 的实现)。在生产环境,必须显式设置。 建议 ReadTimeout 设为下游接口平均响应时间的 2~3 倍。
2. 重试机制 (Retryer):给予第二次机会
当 Feign 发现请求失败时(触发了 RetryableException ),它不会立即放弃,而是询问 Retryer:我还能再试一次吗?
Feign 默认重试策略的工作逻辑:
-
捕获异常 :只有特定的异常(如超时、连接拒绝)会被封装成
RetryableException。 -
计算间隔 :
Retryer会根据当前重试次数,计算下一次重试需要等待的时间。 -
判断限制 :检查是否达到了最大重试次数(
maxAttempts)。
Feign 内部重试 vs Spring Cloud 重试
作为高级开发,你必须分清这两套重试机制。这是最容易出错的地方:
-
Feign 原生重试 :由
feign.Retryer实现。默认是关闭 的(NEVER_RETRY)。 -
Spring Cloud 负载均衡重试 :这是通过
Spring Cloud LoadBalancer(或早期的 Ribbon)实现的。
在现代 Spring Cloud 环境中,我们通常禁用 Feign 的原生重试,而使用 Spring Cloud LoadBalancer 的重试机制。
- 原因:LoadBalancer 的重试更高级,它可以在请求失败后,**换一台服务器实例(Next Server)**进行重试,这能有效避开由于单台机器故障导致的持续失败。
Spring Security
Spring Security是一套由 Servlet Filter 组成的强大过滤器链,配合 AOP 实现的方法拦截体系。
过滤器链(Security Filter Chain)
Servlet 规范定义了 Filter,但 Servlet 容器(如 Tomcat)并不认识 Spring 容器里的 Bean。为了让 Spring 定义的安全逻辑生效,Spring 设计了一套"套娃"机制:
-
DelegatingFilterProxy:这是一个标准的 Servlet 过滤器,部署在 Tomcat 中。它不干活,只负责找人。它会去 Spring 容器里找一个名为springSecurityFilterChain的 Bean。 -
FilterChainProxy:这就是那个被找的人,它是 Spring Security 的总司令部 。它持有并管理着一个或多个SecurityFilterChain。
当我们说"过滤器链"时,通常指的是 DefaultSecurityFilterChain。它内部维护了一个 List<Filter>。在一个标准的 Web 安全配置中,过滤器通常按以下顺序排列:
| 顺序 | 过滤器名称 | 职责 (Responsibility) |
|---|---|---|
| 1 | ChannelProcessingFilter |
检查协议(HTTP vs HTTPS)。 |
| 2 | WebAsyncManagerIntegrationFilter |
整合异步请求上下文。 |
| 3 | SecurityContextPersistenceFilter |
极其重要。在请求开始时从 Session 加载上下文,结束时存回 Session。 |
| 4 | HeaderWriterFilter |
向响应中添加安全头部(如 X-Frame-Options)。 |
| 5 | LogoutFilter |
处理登出请求。 |
| 6 | UsernamePasswordAuthenticationFilter |
认证核心。处理表单登录。 |
| 7 | DefaultLoginPageGeneratingFilter |
生成默认登录页面。 |
| 8 | ExceptionTranslationFilter |
异常翻译官。捕获后续滤器抛出的安全异常,决定是去登录还是报 403。 |
| 9 | FilterSecurityInterceptor |
授权终点。最终判定用户是否有权访问该 URL。 |
过滤器链的执行并不是简单的 for 循环,而是基于 职责链模式(Chain of Responsibility) 的递归调用。
java
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) {
if (currentFilterIndex < filters.size()) {
Filter filter = filters.get(currentFilterIndex++);
// 过滤器处理完自己的逻辑后,必须调用 chain.doFilter 才能继续往下走
filter.doFilter(request, response, this);
} else {
// 所有过滤器都走完了,进入真正的 Controller(Servlet)
targetServlet.service(request, response);
}
}-
前进(Pre-processing):请求从第 1 个过滤器一直走到第 N 个,每一步都在做检查或提取信息。
-
回溯(Post-processing):Controller 执行完后,响应会逆序经过每个过滤器。这让过滤器有机会修改响应头或处理异常。
这种机制带来了极高的灵活性 和解耦性:
-
按需插拔 :如果你想搞 JWT 认证,只需要写一个
JwtAuthenticationFilter插入到链中即可。 -
短路机制 :如果第 6 个过滤器发现用户没登录,它可以直接返回响应,而不调用
chain.doFilter(),请求根本打不到 Controller,保护了业务系统。 -
职责单一:每个过滤器只管一件事(有的管 Session,有的管密码,有的管 CSRF),代码极其清晰。
认证(Authentication)和授权(Authorization)
在任何应用中,安全主要归结为两个最基本的问题:
-
认证(Authentication):你是谁?(用户名/密码、验证码、指纹、三方登录)。
-
授权(Authorization):你能干什么?(普通用户只能看,管理员能删)。
一、 Authentication(认证)内部流程
认证流程的核心是将用户提供的凭证(如用户名密码)转化为一个已认证的身份对象。
1. 核心组件
-
Authentication:认证令牌,包含用户信息、权限列表、是否已认证的状态。 -
AuthenticationManager:认证入口,通常实现类是ProviderManager。 -
AuthenticationProvider:具体的认证逻辑实现(如处理用户名密码、短信验证码、OAuth2 等)。 -
UserDetailsService:负责从数据库或内存加载用户信息。 -
PasswordEncoder:负责密码的加密与匹配。
2. 执行步骤
-
请求拦截 :用户提交登录请求,被
UsernamePasswordAuthenticationFilter拦截。 -
创建未认证令牌 :过滤器从请求中提取用户名和密码,封装成一个
UsernamePasswordAuthenticationToken(此时isAuthenticated = false)。 -
提交认证 :过滤器将该令牌交给
AuthenticationManager。 -
委派 Provider :
ProviderManager遍历其持有的AuthenticationProvider列表,找到能处理该令牌的 Provider(如DaoAuthenticationProvider)。 -
加载用户信息 :Provider 调用
UserDetailsService.loadUserByUsername()获取数据库中的用户信息(UserDetails)。 -
校验凭证 :Provider 使用
PasswordEncoder比对用户输入的密码与数据库中的加密密码。 -
认证成功 :校验通过后,Provider 会创建一个新的、已认证的
Authentication对象,其中包含用户的权限信息(Authorities),并将isAuthenticated设为true。 -
存储上下文 :认证信息被返回给过滤器,过滤器将其放入
SecurityContextHolder中(底层是ThreadLocal),供后续流程使用。
二、 Authorization(授权)内部流程
授权流程发生在认证之后,当用户尝试访问受保护的资源(如 URL 或方法)时触发。
1. 核心组件
-
SecurityContextHolder:授权时从中获取已认证的身份信息。 -
FilterSecurityInterceptor:负责 Web 资源授权的拦截器。 -
MethodSecurityInterceptor:负责方法级别授权的拦截器。 -
AccessDecisionManager:访问决策管理器,决定是否放行。 -
AccessDecisionVoter:投票器,根据用户权限和资源要求进行投票。
2. 执行步骤
-
资源拦截 :用户访问 URL(如
/admin/delete),被FilterSecurityInterceptor拦截。 -
获取权限要求 :拦截器根据配置(如
.hasRole("ADMIN"))获取访问该资源所需的权限信息(ConfigAttribute)。 -
提取当前身份 :从
SecurityContextHolder中获取当前登录用户的Authentication对象。 -
发起决策请求 :拦截器将"当前用户信息"、"请求资源"、"资源权限要求"三者交给
AccessDecisionManager。 -
内部投票 :
AccessDecisionManager轮询其持有的AccessDecisionVoter列表。每个投票器根据自己的逻辑(如角色匹配、表达式计算)投出:ACCESS_GRANTED(赞成)、ACCESS_DENIED(反对)或ACCESS_ABSTAIN(弃权)。 -
统计结果:
-
一票通过制(默认):只要有一个赞成,就放行。
-
一票否决制:只要有一个反对,就拒绝。
-
多数服从制:赞成票多于反对票则放行。
-
-
最终处理:
-
通过:请求继续向后执行(进入 Controller)。
-
拒绝 :抛出
AccessDeniedException,由异常处理过滤器(ExceptionTranslationFilter)处理,通常返回 403 错误。
-
结合 OAuth2 和 JWT 实现"单点登录(SSO)"和"无状态认证"
在微服务架构中,传统的 Session 模式由于需要服务器端存储且难以跨域共享,已经不再适用。
Spring Security + OAuth2 + JWT 的组合,实质上是将"身份验证"与"资源保护"进行了解耦。OAuth2 提供了协议标准 ,JWT 提供了数据载体 ,而 Spring Security 则负责逻辑拦截。
1. 核心架构角色
在微服务环境中,这套体系通常分为三个关键角色:
-
认证服务器 (Authorization Server) :负责用户的登录校验、发放 JWT 令牌。它是整个系统的"护照办"。
-
资源服务器 (Resource Server) :各个具体的微服务 。它们不负责登录,只负责校验 JWT 是否合法,并根据其中的权限信息决定是否放行。
-
网关 (API Gateway) :**系统的统一入口。**它通常负责"令牌转发 (Token Relay)"和初步的鉴权。
2. "单点登录 (SSO)" 的实现逻辑
SSO 的核心是:用户只需要在认证服务器登录一次,就能获得访问所有微服务的通行证。
内部流程:
-
引导登录:用户访问任一子服务或网关,Spring Security 发现无权访问,将其重定向到认证服务器。
-
统一认证 :用户在认证服务器输入账号密码。此时,认证服务器会建立自己的 Session (通常是基于 Cookie 的)。
-
发放令牌 :认证成功后,根据 OAuth2 协议(通常是 Authorization Code 模式),认证服务器生成一个 JWT 返回给客户端。
-
后续访问 :当用户访问第二个子服务时,再次被重定向到认证服务器。由于认证服务器已有该用户的 Session,它会直接静默发放新的令牌,用户感知不到第二次登录。
3. "无状态认证 (Stateless)" 的实现原理
微服务的横向扩展要求服务必须是无状态 的。JWT(JSON Web Token) 是实现这一点的绝佳工具。
为什么是无状态的?
-
自包含性 :JWT 内部包含了用户信息(如
user_id,user_name)和权限列表(authorities)。 -
自验证性 :JWT 使用非对称加密算法(如 RSA)。
-
认证服务器 使用私钥对令牌签名。
-
各微服务 只需持有公钥,即可在本地校验令牌的完整性和合法性。
-
底层逻辑 :微服务在接收到请求时,Spring Security 的拦截器会提取 Header 中的 JWT,利用本地公钥解密校验。由于不需要查数据库,也不需要查 Session,这个过程是完全无状态且高性能的。
-
令牌刷新 (Refresh Token) :JWT 通常过期时间较短(如 30 分钟)。为了不让用户频繁登录,需要使用 OAuth2 的
refresh_token机制来动态置换新的 JWT。 -
令牌撤回 (Revocation):JWT 一旦发出,除非过期,否则无法撤回。
- 高级方案 :在 Redis 中维护一个"黑名单",记录已注销或被踢出的令牌 ID(jti)。微服务校验 JWT 时需额外查一次 Redis。
-
敏感信息:不要在 JWT 的 Payload 里存放密码等敏感信息,因为 Base64 编码是可以通过工具轻松解密的。
在微服务节点内部,Spring Security 做了以下工作:
-
配置资源服务器 :通过
oauth2ResourceServer()将自己定义为资源服务器。 -
JWT 转换 (Converter) :将解密后的 JWT Claims 转化为 Spring Security 认识的
GrantedAuthority权限对象。 -
上下文传播 :在请求执行期间,将用户信息存入 SecurityContextHolder,让业务代码可以像单体应用一样方便地获取当前用户。
服务 A 调用服务 B 时,令牌如何传递?
-
Feign 拦截器 :我们通常会编写一个
RequestInterceptor。它的任务是从当前线程的 SecurityContext 中取出 JWT,并将其塞入 Feign 调用的 Header 中。 -
网关透传 :Spring Cloud Gateway 会通过
TokenRelayGatewayFilterFactory自动将前端传来的 Token 转发给下游服务,确保认证信息在链路中不丢失。